
Community Detection in Semantic Networks: A Multi-View Approach


Abstract
:1. Introduction
- (1)
- We propose to extract features of the network from multiple perspectives for community detection. The approach efficiently utilizes semantic information in social networks at various granularities. Compared with single-view community detection, multi-view community detection has better performance in modularity, accuracy, and F-score.
- (2)
- We propose an approach for reconstructing social networks. The approach utilizes a data matrix to describe the connections between user attributes in each perspective, which can subsequently be utilized to capture the intrinsic correlations across multiple views using matrix fusion. On the other hand, the method can avoid errors caused by the absence of data and relationships.
- (3)
- We present a multi-view community detection method based on the adaptive loss function. The method can decrease the impact of outlier points on community segmentation. Experiments show that the method is not only applicable to real social networks, but also outperforms traditional community detection methods when coping with other types of data.
2. Semantic Feature Representation of Nodes
2.1. Word Frequency
2.2. Keywords
2.3. Topic
3. Reconstruction of Social Networks
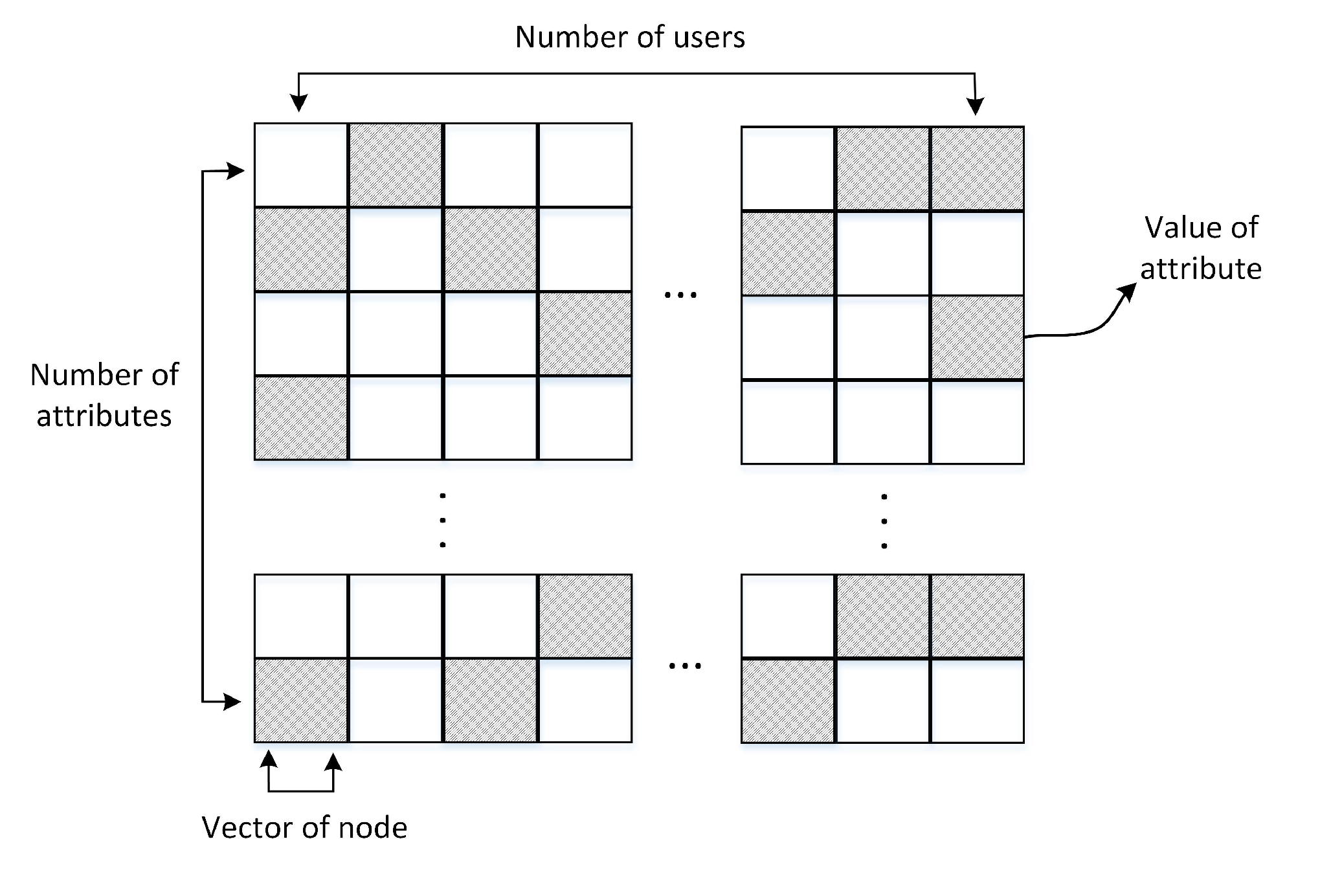
3.1. Node Representation
3.2. Node Similarity Calculation
4. Community Detection
4.1. Adaptive Loss Function
4.2. Multi-View Community Detection Based on Adaptive Loss Function
4.3. Algorithm Optimization
| Algorithm 1 Multi-view community detection based on adaptive loss function (ALMV) |
|
| Algorithm 2 Multi-view community analysis method of social networks |
|
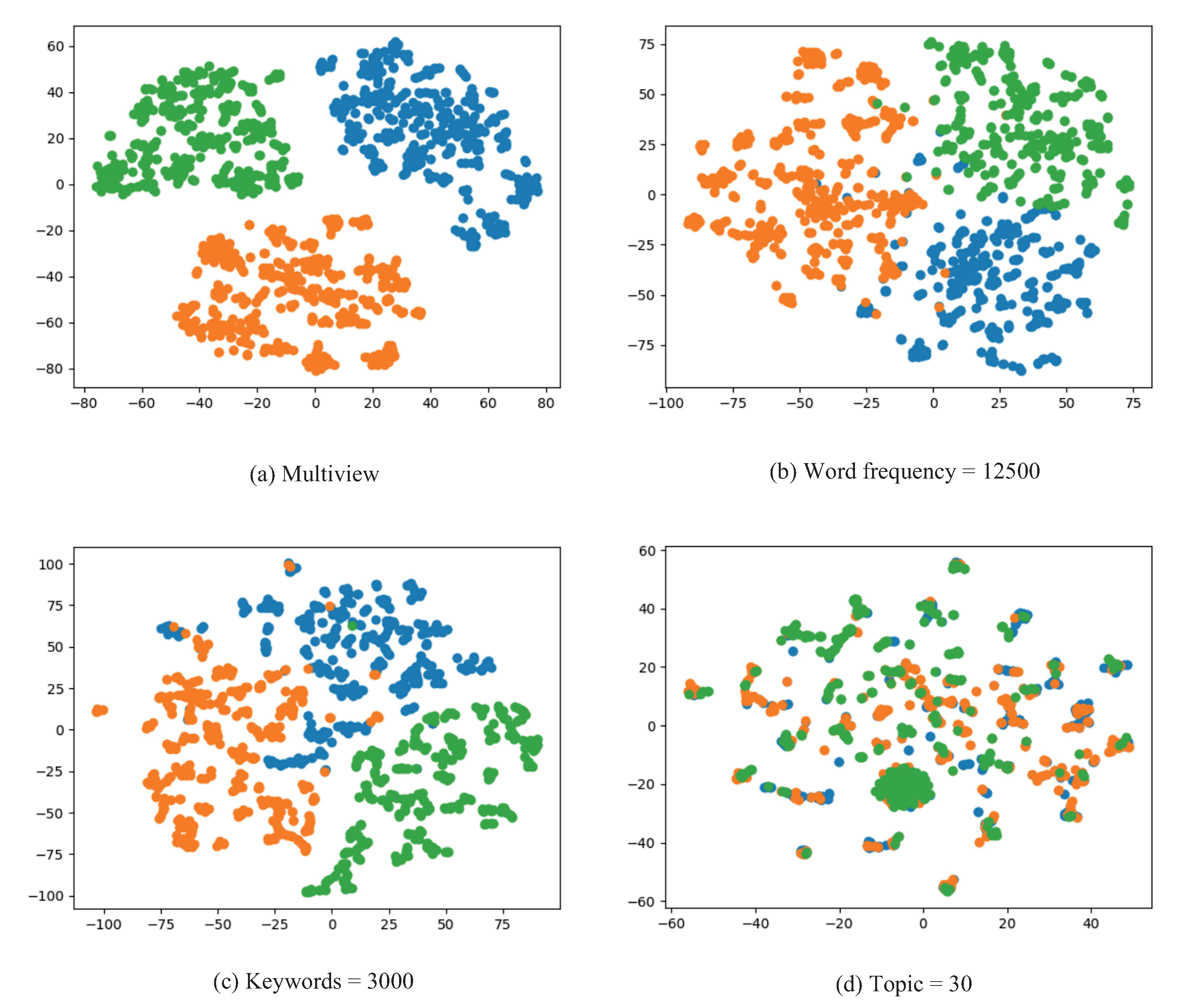
5. Experiments
5.1. Evaluation Index
- Accuracy (AC). Given data , let and represent the correct community and the predicted community, respectively. AC is defined as:Here, n is , the total number of data. If , then the function is equal to 1, otherwise it is equal to 0.
- Normalized Mutual Information (NMI). NMI represents the shared statistical information between the predicted and true categories. Given the correct category group and the predicted category group of the dataset G, let and denote the data points in categories and , respectively, and denote the data points that are both in and , the normalized mutual information of and is defined as:
- Adjusted Rand coefficient (AR). AR is an optimized indicator based on the Rand coefficient (RI). Its formula is:where is the expected value of the Rand coefficient; a is a data point object that belongs to the same class in , and also belongs to the same class in ; b is a data point object that belongs to the same class in and does not belong to the same class in ; c is a data point object that does not belong to the same class in , and belongs to the same class in ; d is a data point object that does not belong to the same class in , and also does not belong to the same class in .
- F-score. A comprehensive evaluation index that balances the impact of Accuracy and Recall. First, we introduce several basic concepts. TP (True positives): positive classes are judged as positive classes; FP (False positives): negative classes are judged as negative classes; FN (False negatives): positive classes are judged as negative classes; TN (True negatives): negative classes are judged as negative classes. F-score is defined as:where , .
- Modularity (Q): Newman et al. [45] introduced modularity to assess the quality of community structure, which is defined as follows:where is the sum of the degrees of all nodes in the network G; is the Similarity matrix of the G; is the degree of node ; and is the Kronecker function, which is 1 if and are in the same community and 0 otherwise.
5.2. Experiment on Real Social Networks
5.2.1. Experiment Preparation
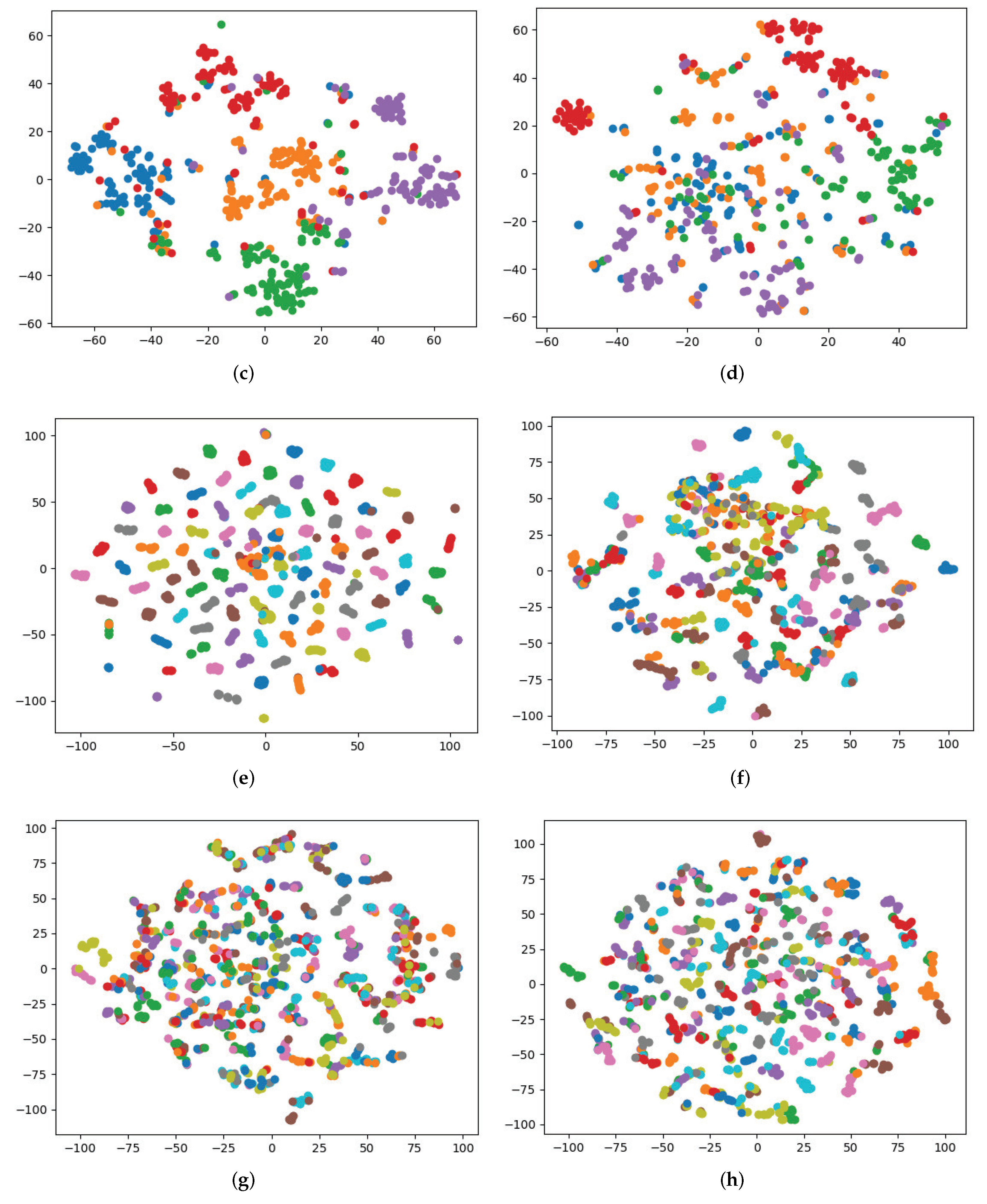
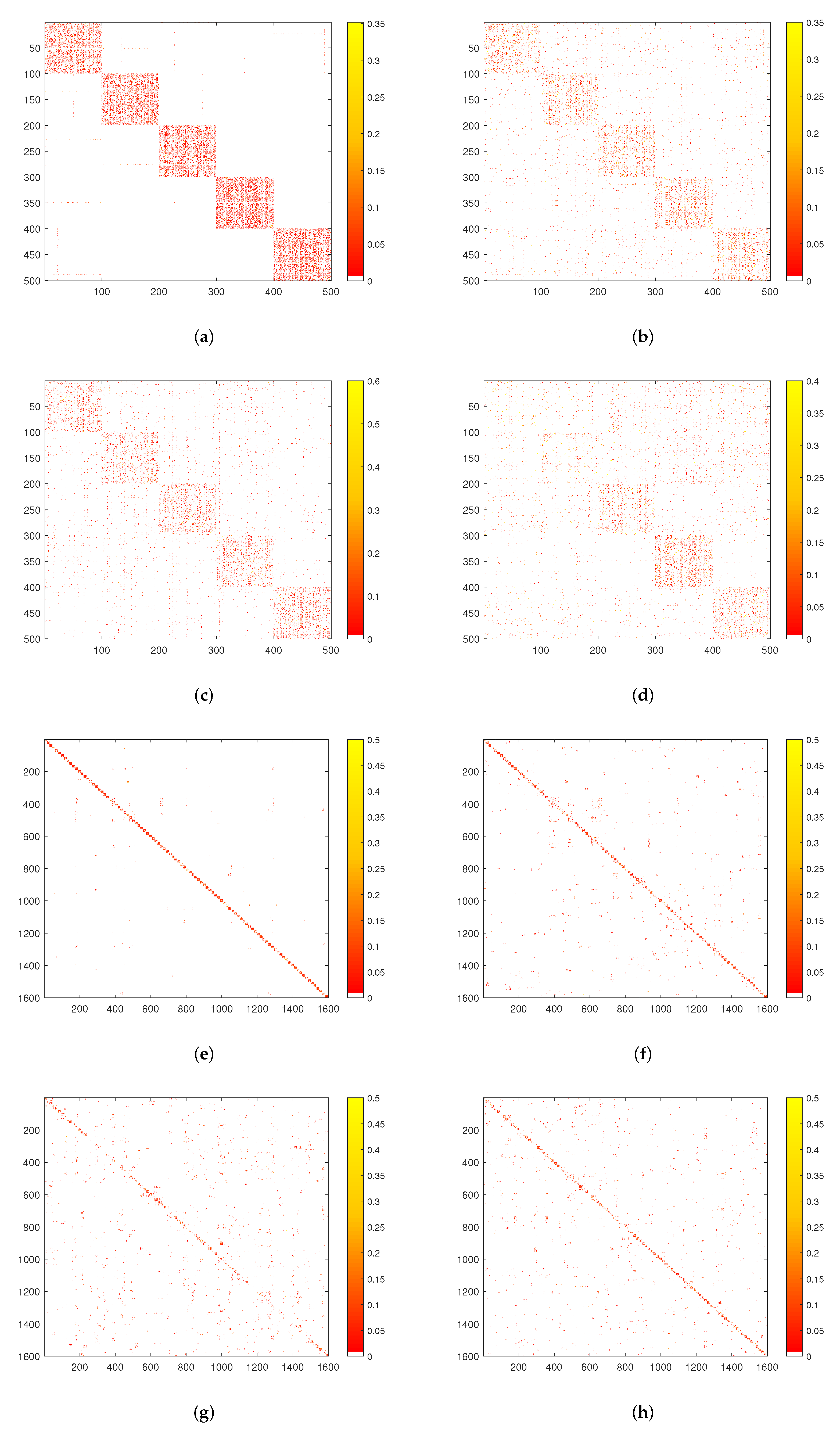
5.2.2. Experimental Results
5.3. Experiment on the Public Dataset
5.3.1. Dataset
- WebKB dataset (http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/ accessed on 14 August 2022) (WebKB) [46]: This dataset consists of 203 pages in four categories collected by the Department of Computer Science at Cornell University. One page consists of three views: the page text content of the page, the anchor text on the link, and the text in the title.
- BBC dataset (http://mlg.ucd.ie/datasets/segment.html accessed on 14 August 2022) (BBC): This dataset comes from 250 BBC news sites, which correspond to five topics (business, entertainment, sports, science and technology, politics). It consists of 685 instances, each of which is divided into four parts, namely, four perspectives.
- BBC Sport dataset (http://mlg.ucd.ie/datasets/segment.html accessed on 14 August 2022) (BBCSports) [47]: This dataset is a documentation dataset consisting of sports news articles on five topics (track and field, football, tennis, rugby, and cricket) on the BBC Sports website from 2004 to 2005. Each article will extract two different types of features. It contains 685 samples with feature dimensions of 3183 and 333 from different perspectives.
- 20 Newsgroups dataset (http://lig-membres.imag.fr/grimal/data.html accessed on 14 August 2022) (20NGs): The dataset consists of 20 different collections of newsgroup documents. It contains 500 different instances, each of which is preprocessed in three different ways.
- 3Sources dataset (http://mlg.ucd.ie/datasets/3sources.html accessed on 14 August 2022) (3Sources): The dataset was collected from three online news organizations, the BBC, Reuters, and the Guardian, from February to April 2009. These three organizations reported 169 stories on one of six topics (entertainment, health, politics, business, sports, science, and technology).
- Wikipedia articles dataset (http://www.svcl.ucsd.edu/projects/crossmodal/ accessed on 14 August 2022) (Wikipedia) [48,49]: This dataset is a selection of files from a collection of Wikipedia featured articles. Each article has 2 perspectives and 10 categories; 693 instances are selected as experimental datasets.
- One-hundred plant species leaves dataset (https://archive.ics.uci.edu/ml/datasets/One-hundred+plant+species+leaves+data+set accessed on 14 August 2022) (100leaves) [50]: The dataset consists of 1600 samples from three perspectives, each of which is one of 100 species.
- Handwritten digit 2 source dataset (https://cs.nyu.edu/~roweis/data.html accessed on 14 August 2022) (HW2sources): The dataset was collected from 2000 samples from two sources: MNIST handwritten digits (0–9) and USPS handwritten digits (0–9).
5.3.2. Baseline Method
- Normalized cut (Ncut) [14]: Ncut is a typical graphics-based method, which is used in each perspective of each dataset to select the best performance perspective as the result. The parameters in the algorithm are set according to the author’s recommendations.
- Fast unfolding algorithm (Louvain) [16]: Louvain is a modularity-based community detection algorithm that discovers hierarchical community structures with the objective of maximizing the modularity of the entire graph’s attribute structure. In this paper, we construct the weight matrix by Gaussian kernel function and run the algorithm in a recursive manner.
- Clustering with Adaptive Neighbors (CAN) [51]: CAN is an algorithm that learns both data similarity matrix and clustering structure. It assigns an adaptive and optimal neighbor to each data point based on the local distance to learn the data similarity matrix. The number of iterations and parameters of this algorithm run in this paper are the default values set by the author.
- Smooth Representation (SMR) [52]: This method deeply analyzes the grouping effect of representation-based methods, and then sub-spatial clustering is performed by the grouping effect. When experimenting on datasets with this method, the parameters are set to and .
- Multi-View Deep Matrix Factorization (DMF) [53]: DMF can discover hidden hierarchical geometry structures and have better performance in clustering and classification. In this paper, the model is set into two layers, with the first layer having 50 implicit attributes.
- Co-regularized Spectral Clustering (CRSC) [24]: This method achieves multi-view clustering by co-regularizing the clustering hypothesis, which is a typical multi-view clustering method based on spectral clustering and kernel learning. It uses the default parameters set by the author.
- Multi-view Clustering with Graph Learning (MVGL) [54]: This is a multi-view clustering method based on graphics learning, which learns initial diagrams from data points of different views and further optimizes the initial diagrams using rank constraints of Laplace matrices.We set the number of neighbors to the default value of 10 for our experiment.
- Proximity-based Multi-View NMF (PMVNMF) [55]: It exploits the local and global structure of the data space to deal with sparsity in real multimedia (text and image) data and by transferring probability matrices as first-order and second-order approximation matrices to reveal their respective underlying local and global geometric structures. This method uses the default parameters set by the author.
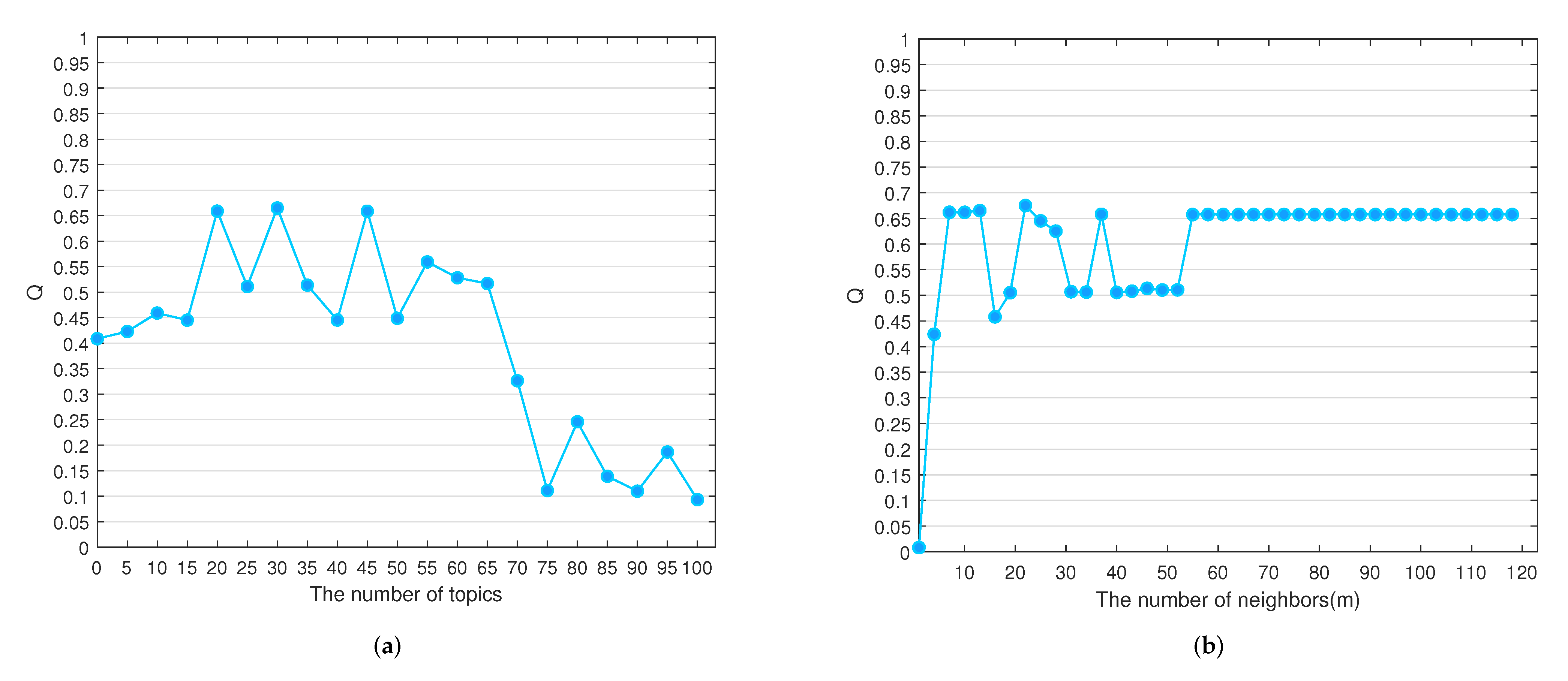
5.3.3. Parameter Analysis
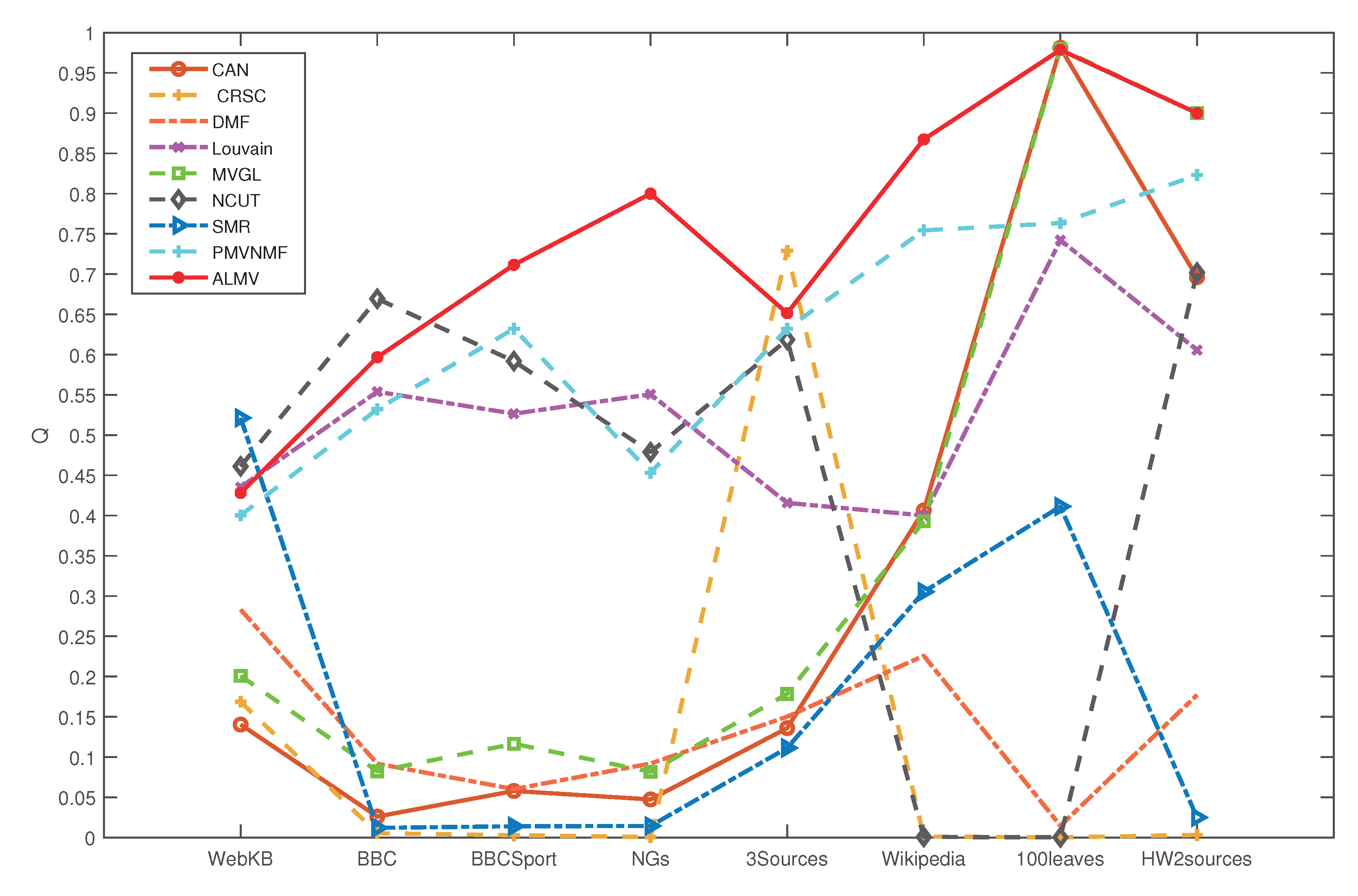
5.3.4. Experimental Result on Public Dataset
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dakiche, N.; Tayeb, F.B.S.; Slimani, Y.; Benatchba, K. Tracking community evolution in social networks: A survey. Inf. Process. Manag. 2019, 56, 1084–1102. [Google Scholar] [CrossRef]
- Li, L.; He, J.; Wang, M.; Wu, X. Trust agent-based behavior induction in social networks. IEEE Intell. Syst. 2016, 31, 24–30. [Google Scholar] [CrossRef]
- Abdelsadek, Y.; Chelghoum, K.; Herrmann, F.; Kacem, I.; Otjacques, B. Community extraction and visualization in social networks applied to Twitter. Inf. Sci. 2018, 424, 204–223. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Ma, T.; Liu, Q.; Cao, J.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. LGIEM: Global and local node influence based community detection. Future Gener. Comput. Syst. 2020, 105, 533–546. [Google Scholar] [CrossRef]
- Chunaev, P. Community detection in node-attributed social networks: A survey. Comput. Sci. Rev. 2020, 37, 100286. [Google Scholar] [CrossRef]
- Sharma, K.K.; Seal, A. Outlier-robust multi-view clustering for uncertain data. Knowl.-Based Syst. 2021, 211, 106567. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Y.; Liu, B. GMC: Graph-based multi-view clustering. IEEE Trans. Knowl. Data Eng. 2019, 32, 1116–1129. [Google Scholar] [CrossRef]
- Wu, J.; Xie, X.; Nie, L.; Lin, Z.; Zha, H. Unified Graph and Low-Rank Tensor Learning for Multi-View Clustering. Proc. AAAI Conf. Artif. Intell. 2020, 34, 6388–6395. [Google Scholar] [CrossRef]
- Newman, M.E. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef]
- Donetti, L.; Munoz, M.A. Detecting network communities: A new systematic and efficient algorithm. J. Stat. Mech. Theory Exp. 2004, 2004, P10012. [Google Scholar] [CrossRef]
- Mitrović, M.; Tadić, B. Spectral and dynamical properties in classes of sparse networks with mesoscopic inhomogeneities. Phys. Rev. E 2009, 80, 026123. [Google Scholar] [CrossRef]
- Cour, T.; Benezit, F.; Shi, J. Spectral segmentation with multiscale graph decomposition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 2, pp. 1124–1131. [Google Scholar]
- Guimera, R.; Amaral, L.A.N. Functional cartography of complex metabolic networks. Nature 2005, 433, 895–900. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Arenas, A.; Duch, J.; Fernández, A.; Gómez, S. Size reduction of complex networks preserving modularity. New J. Phys. 2007, 9, 176. [Google Scholar] [CrossRef]
- Newman, M.E. Analysis of weighted networks. Phys. Rev. E 2004, 70, 056131. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, H.; Chen, Z.; Lu, H.; Tao, L.; Ma, W.Y. Recom: Reinforcement clustering of multi-type interrelated data objects. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 274–281. [Google Scholar]
- Bickel, S.; Scheffer, T. Multi-view clustering. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; pp. 19–26. [Google Scholar] [CrossRef]
- Kailing, K.; Kriegel, H.P.; Pryakhin, A.; Schubert, M. Clustering multi-represented objects with noise. Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 394–403. [Google Scholar]
- Jiang, Y.; Liu, J.; Li, Z.; Lu, H. Collaborative PLSA for multi-view clustering. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; IEEE: New York, NY, USA, 2012; pp. 2997–3000. [Google Scholar]
- Ghassany, M.; Grozavu, N.; Bennani, Y. Collaborative multi-view clustering. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; IEEE: New York, NY, USA, 2013; pp. 1–8. [Google Scholar]
- Kumar, A.; Rai, P.; Daume, H. Co-regularized multi-view spectral clustering. Adv. Neural Inf. Process. Syst. 2011, 24, 1413–1421. [Google Scholar]
- Liu, X.; Zhu, X.; Li, M.; Wang, L.; Zhu, E.; Liu, T.; Kloft, M.; Shen, D.; Yin, J.; Gao, W. Multiple kernel k k-means with incomplete kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1191–1204. [Google Scholar] [CrossRef]
- Nie, F.; Li, J.; Li, X. Parameter-free auto-weighted multiple graph learning: A framework for multiview clustering and semi-supervised classification. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; pp. 1881–1887. [Google Scholar]
- Wang, Y.; Lin, X.; Wu, L.; Zhang, W.; Zhang, Q. Exploiting correlation consensus: Towards subspace clustering for multi-modal data. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 981–984. [Google Scholar]
- Kuang, D.; Ding, C.; Park, H. Symmetric nonnegative matrix factorization for graph clustering. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 April 2012; SIAM: Philadelphia, PA, USA, 2012; pp. 106–117. [Google Scholar]
- Rajput, N.K.; Ahuja, B.; Riyal, M.K. A statistical probe into the word frequency and length distributions prevalent in the translations of Bhagavad Gita. Pramana 2019, 92, 1–6. [Google Scholar] [CrossRef]
- Liu, J.; Yang, T. Word Frequency Data Analysis in Virtual Reality Technology Industrialization. J. Physics Conf. Ser. 2021, 1813, 012044. [Google Scholar] [CrossRef]
- Rajput, N.K.; Grover, B.A.; Rathi, V.K. Word frequency and sentiment analysis of twitter messages during coronavirus pandemic. arXiv 2020, arXiv:2004.03925. [Google Scholar]
- Yang, L.; Li, K.; Huang, H. A new network model for extracting text keywords. Scientometrics 2018, 116, 339–361. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Nie, F.; Wang, X.; Jordan, M.; Huang, H. The Constrained Laplacian Rank Algorithm for Graph-Based Clustering. Proc. AAAI Conf. Artif. Intell. 2016, 30. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 210–227. [Google Scholar] [CrossRef]
- Zhang, R.; Nie, F.; Guo, M.; Wei, X.; Li, X. Joint learning of fuzzy k-means and nonnegative spectral clustering with side information. IEEE Trans. Image Process. 2018, 28, 2152–2162. [Google Scholar] [CrossRef]
- Oellermann, O.R.; Schwenk, A.J. The Laplacian Spectrum of Graphs; University of Manitoba: Winnipeg, MB, USA, 1991. [Google Scholar]
- Fan, K. On a theorem of Weyl concerning eigenvalues of linear transformations: II. Proc. Natl. Acad. Sci. USA 1950, 36, 31. [Google Scholar] [CrossRef]
- Nie, F.; Wang, H.; Huang, H.; Ding, C. Adaptive loss minimization for semi-supervised elastic embedding. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Cai, D.; He, X.; Han, J. Document clustering using locality preserving indexing. IEEE Trans. Knowl. Data Eng. 2005, 17, 1624–1637. [Google Scholar] [CrossRef]
- Hu, J.; Li, T.; Luo, C.; Fujita, H.; Yang, Y. Incremental fuzzy cluster ensemble learning based on rough set theory. Knowl.-Based Syst. 2017, 132, 144–155. [Google Scholar] [CrossRef]
- Santos, J.M.; Embrechts, M. On the use of the adjusted rand index as a metric for evaluating supervised classification. In Proceedings of the International Conference on Artificial Neural Networks, Limassol, Cyprus, 14–17 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 175–184. [Google Scholar]
- Lovász, L.; Plummer, M.D. Matching Theory; American Mathematical Society: Providence, RI, USA, 2009; Volume 367. [Google Scholar]
- Newman, M.E.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef]
- Getoor, L. Link-based classification. In Advanced Methods for Knowledge Discovery from Complex Data; Springer: Berlin/Heidelberg, Germany, 2005; pp. 189–207. [Google Scholar]
- Greene, D.; Cunningham, P. Practical solutions to the problem of diagonal dominance in kernel document clustering. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 377–384. [Google Scholar]
- Pereira, J.C.; Coviello, E.; Doyle, G.; Rasiwasia, N.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. On the role of correlation and abstraction in cross-modal multimedia retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 521–535. [Google Scholar] [CrossRef]
- Rasiwasia, N.; Costa Pereira, J.; Coviello, E.; Doyle, G.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia retrieval. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 251–260. [Google Scholar]
- Mallah, C.; Cope, J.; Orwell, J. Plant leaf classification using probabilistic integration of shape, texture and margin features. Signal Process. Pattern Recognit. Appl. 2013, 5, 45–54. [Google Scholar]
- Nie, F.; Wang, X.; Huang, H. Clustering and projected clustering with adaptive neighbors. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24 –27 August 2014; pp. 977–986. [Google Scholar]
- Hu, H.; Lin, Z.; Feng, J.; Zhou, J. Smooth representation clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3834–3841. [Google Scholar]
- Zhao, H.; Ding, Z.; Fu, Y. Multi-view clustering via deep matrix factorization. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Zhan, K.; Zhang, C.; Guan, J.; Wang, J. Graph learning for multiview clustering. IEEE Trans. Cybern. 2017, 48, 2887–2895. [Google Scholar] [CrossRef]
- Bansal, M.; Sharma, D. A novel multi-view clustering approach via proximity-based factorization targeting structural maintenance and sparsity challenges for text and image categorization. Inf. Process. Manag. 2021, 58, 102546. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| G | Social network |
| I | Identity matrix |
| Column vector with all 1 element | |
| C | Connected matrix |
| S | Consensus matrix |
| The weight of single-view | |
| k | The number of communities |
| V | The number of analysis views |
| Trace of matrix X | |
| Frobenius norm of matrix X | |
| i-norm of matrix X | |
| i-norm of matrix x |
| Word Frequency | Modularity Q |
|---|---|
| 2500 | 0.5342 |
| 5000 | 0.6663 |
| 7500 | 0.6701 |
| 10,000 | 0.7024 |
| 11,000 | 0.7392 |
| 12,500 | 0.7441 |
| 14,000 | 0.7172 |
| 15,000 | 0.7263 |
| 20,000 | 0.6972 |
| Keywords | Modularity Q |
|---|---|
| 250 | 0.6195 |
| 500 | 0.6421 |
| 1000 | 0.6376 |
| 1500 | 0.6710 |
| 2000 | 0.7001 |
| 2500 | 0.6986 |
| 3000 | 0.7165 |
| 4000 | 0.6781 |
| 5000 | 0.6734 |
| Dataset | Categories | View | Samples | Features |
|---|---|---|---|---|
| WebKB | 4 | 3 | 203 | 1703/230/230 |
| BBC | 5 | 4 | 685 | 4659/4633/4665/4684 |
| BBCSport | 5 | 2 | 544 | 3183/3203 |
| 20NGs | 5 | 3 | 500 | 2000/2000/2000 |
| 3Sources | 6 | 3 | 169 | 3560/3631/3068 |
| Wikipedia | 10 | 2 | 693 | 128/10 |
| 100leaves | 100 | 3 | 1600 | 64/64/64 |
| HW2sources | 10 | 2 | 2000 | 784/256 |
| Dataset | Index | Ncut | Louvain | CAN | SMR | DMF | CRSC | MVGL | PMVNMF | ALMV |
|---|---|---|---|---|---|---|---|---|---|---|
| WebKB | AC(%) | 72.41 | 48.77 | 56.16 | 65.52 | 64.04 | 70.44 | 30.18 | 71.23 | 76.85 |
| NMI(%) | 28.73 | 38.23 | 9.24 | 34.51 | 25.29 | 27.18 | 10.90 | 39.22 | 43.51 | |
| AR(%) | 36.03 | 35.82 | 5.08 | 37.49 | 31.46 | 34.49 | 3.61 | 31.56 | 43.97 | |
| F-score(%) | 64.04 | 54.12 | 56.29 | 62.47 | 57.19 | 61.54 | 33.92 | 69.23 | 70.04 | |
| BBC | AC(%) | 32.56 | 21.31 | 34.16 | 48.91 | 28.38 | 33.14 | 34.74 | 48.53 | 69.34 |
| NMI(%) | 2.66 | 41.41 | 4.40 | 36.57 | 7.42 | 1.88 | 6.40 | 40.56 | 56.28 | |
| AR(%) | 0.07 | 10.07 | 0.59 | 17.10 | 3.65 | 0.23 | 0.15 | 44.87 | 47.89 | |
| F-score(%) | 37.70 | 13.71 | 38.07 | 40.27 | 25.39 | 37.93 | 37.46 | 50.63 | 63.33 | |
| BBCSports | AC(%) | 35.66 | 20.04 | 36.58 | 71.51 | 32.54 | 35.85 | 40.07 | 73.52 | 80.88 |
| NMI(%) | 1.29 | 48.56 | 4.36 | 56.06 | 6.24 | 1.81 | 14.24 | 63.21 | 76.35 | |
| AR(%) | 0.23 | 10.69 | 0.48 | 46.24 | 3.63 | 0.26 | 4.02 | 52.90 | 72.78 | |
| F-score(%) | 38.36 | 14.09 | 38.48 | 61.55 | 26.02 | 38.43 | 40.08 | 66.71 | 79.88 | |
| 20NGs | AC(%) | 21.20 | 25.60 | 23.00 | 46.60 | 36.80 | 21.80 | 22.80 | 34.64 | 97.80 |
| NMI(%) | 2.11 | 47.40 | 6.98 | 32.61 | 10.97 | 2.96 | 77.51 | 47.65 | 92.87 | |
| AR(%) | 0 | 15.67 | 0.31 | 17.16 | 7.95 | 0.06 | 0.23 | 13.98 | 94.57 | |
| F-score(%) | 38.36 | 14.09 | 38.48 | 61.55 | 26.02 | 38.43 | 40.08 | 37.78 | 95.65 | |
| 3Sources | AC(%) | 33.14 | 49.11 | 35.50 | 49.11 | 37.22 | 31.36 | 22.80 | 56.82 | 75.74 |
| NMI(%) | 4.20 | 62.55 | 10.74 | 41.62 | 23.78 | 7.92 | 7.51 | 46.95 | 67.05 | |
| AR(%) | −0.21 | 39.91 | 0.04 | 22.84 | 10.4 | 3.55 | 0.23 | 40.31 | 53.70 | |
| F-score(%) | 29.12 | 47.84 | 36.36 | 42.77 | 30.86 | 28.34 | 32.78 | 55.12 | 66.55 | |
| Wikipedia | AC(%) | 52.81 | 19.63 | 53.82 | 58.30 | 50.79 | 51.37 | 24.39 | 43.34 | 61.18 |
| NMI(%) | 50.19 | 5.52 | 55.57 | 55.23 | 51.76 | 40.20 | 20.33 | 52.58 | 56.25 | |
| AR(%) | 35.32 | 1.73 | 31.46 | 41.45 | 33.98 | 33.42 | 0.73 | 36.60 | 45.27 | |
| F-score(%) | 43.09 | 14.78 | 40.88 | 48.42 | 41.57 | 40.50 | 19.10 | 44.12 | 51.80 | |
| 100leaves | AC(%) | 47.63 | 57.19 | 63.69 | 33.75 | 23.87 | 75.06 | 76.56 | 71.32 | 82.56 |
| NMI(%) | 72.36 | 81.59 | 83.62 | 65.86 | 54.68 | 90.39 | 89.29 | 83.75 | 93.25 | |
| AR(%) | 31.15 | 42.18 | 42.94 | 20.99 | 9.39 | 69.41 | 50.62 | 57.12 | 54.58 | |
| F-score(%) | 31.97 | 42.89 | 43.65 | 22.12 | 10.31 | 69.73 | 51.25 | 51.76 | 55.17 | |
| HW2sources | AC(%) | 11.90 | 53.40 | 48.25 | 46.15 | 40.71 | 68.35 | 98.45 | 96.32 | 99.05 |
| NMI(%) | 1.33 | 57.33 | 60.45 | 43.27 | 36.78 | 61.01 | 96.20 | 95.32 | 97.61 | |
| AR(%) | 0 | 40.46 | 30.88 | 29.31 | 22.68 | 53.15 | 96.59 | 92.61 | 97.90 | |
| F-score(%) | 16.01 | 46.24 | 41.25 | 36.93 | 30.50 | 57.86 | 96.93 | 96.73 | 98.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Liu, Q.; Zhang, J.; Ding, X.; Chen, C.; Wang, L. Community Detection in Semantic Networks: A Multi-View Approach. Entropy 2022, 24, 1141. https://doi.org/10.3390/e24081141
Yang H, Liu Q, Zhang J, Ding X, Chen C, Wang L. Community Detection in Semantic Networks: A Multi-View Approach. Entropy. 2022; 24(8):1141. https://doi.org/10.3390/e24081141
Chicago/Turabian StyleYang, Hailu, Qian Liu, Jin Zhang, Xiaoyu Ding, Chen Chen, and Lili Wang. 2022. "Community Detection in Semantic Networks: A Multi-View Approach" Entropy 24, no. 8: 1141. https://doi.org/10.3390/e24081141
APA StyleYang, H., Liu, Q., Zhang, J., Ding, X., Chen, C., & Wang, L. (2022). Community Detection in Semantic Networks: A Multi-View Approach. Entropy, 24(8), 1141. https://doi.org/10.3390/e24081141