
Reliable Semantic Communication System Enabled by Knowledge Graph

 , , , and
, , , and
Abstract
:1. Introduction
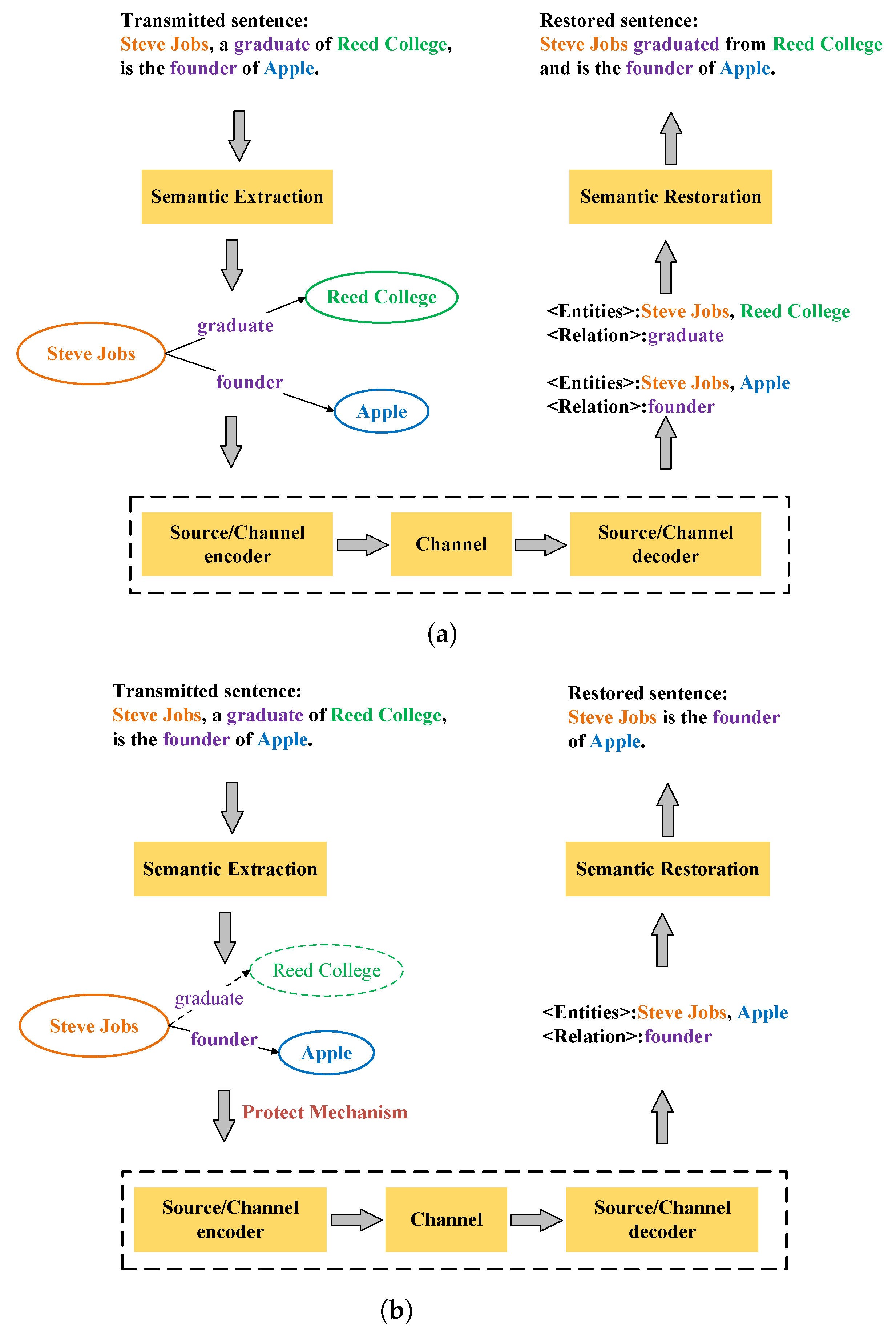
- A semantic extraction method is proposed to extract triplets from transmitted text to represent its core semantic information, reducing the information redundancy of the transmitted text.
- A semantic restoration method based on text generation from the knowledge graph is proposed, which completes the semantic restoration process by reconstructing the text structure between entities and relations.
- A novel semantic communication system was developed, which can sort triplets based on semantic importance and adaptively adjust the transmitted contents according to the channel quality.
2. Related Work
2.1. Semantic Communication Development
2.2. Performance Metrics
2.2.1. BLEU Score
2.2.2. METEOR Score
2.2.3. Semantic Similarity Score
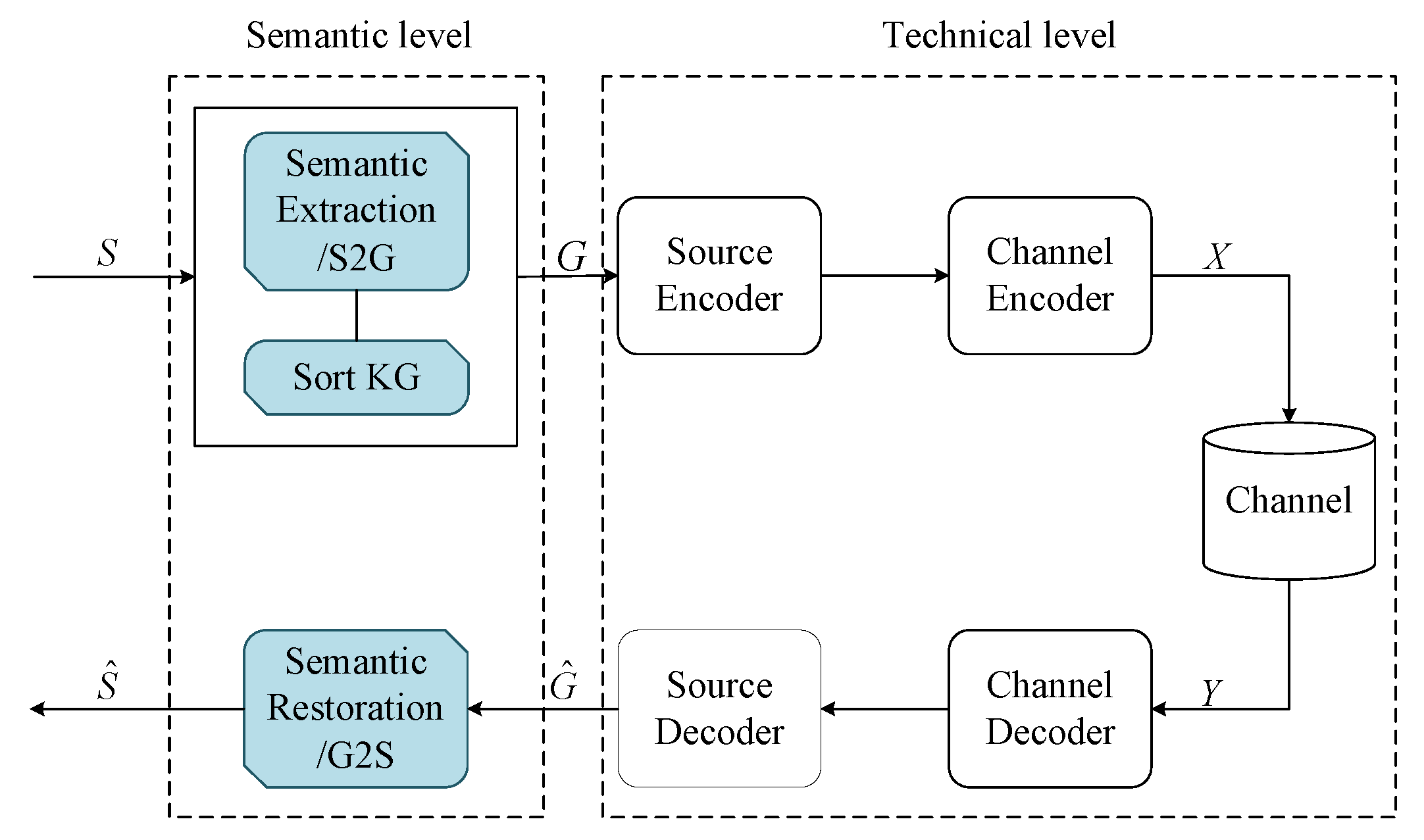
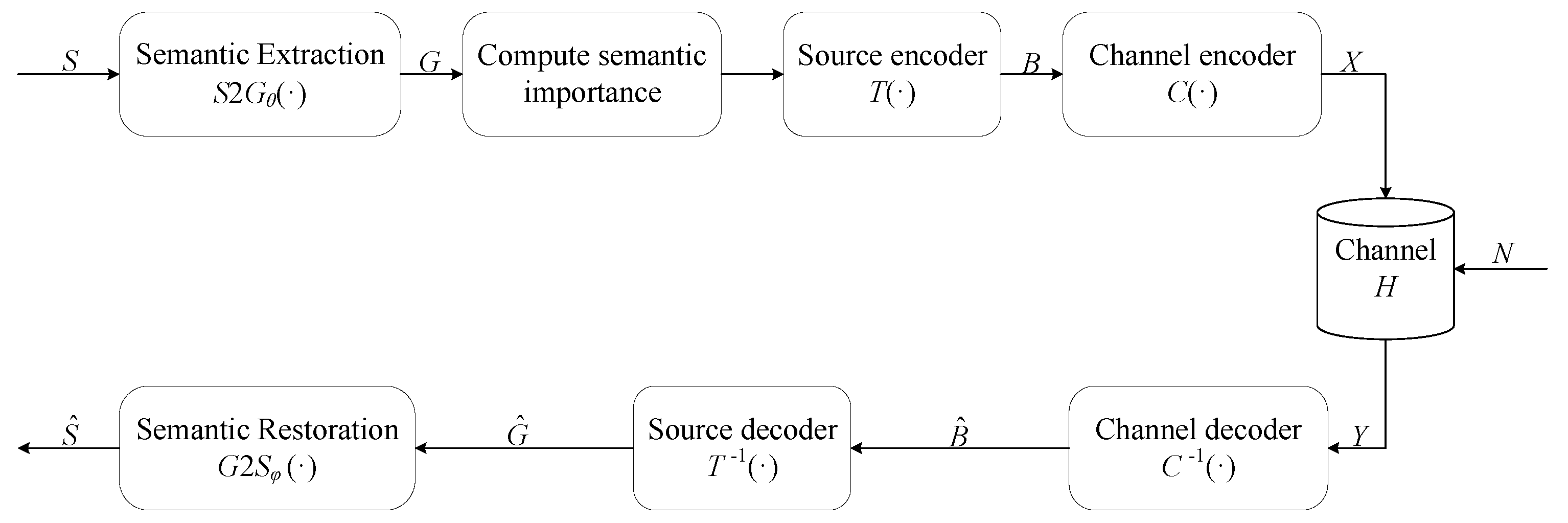
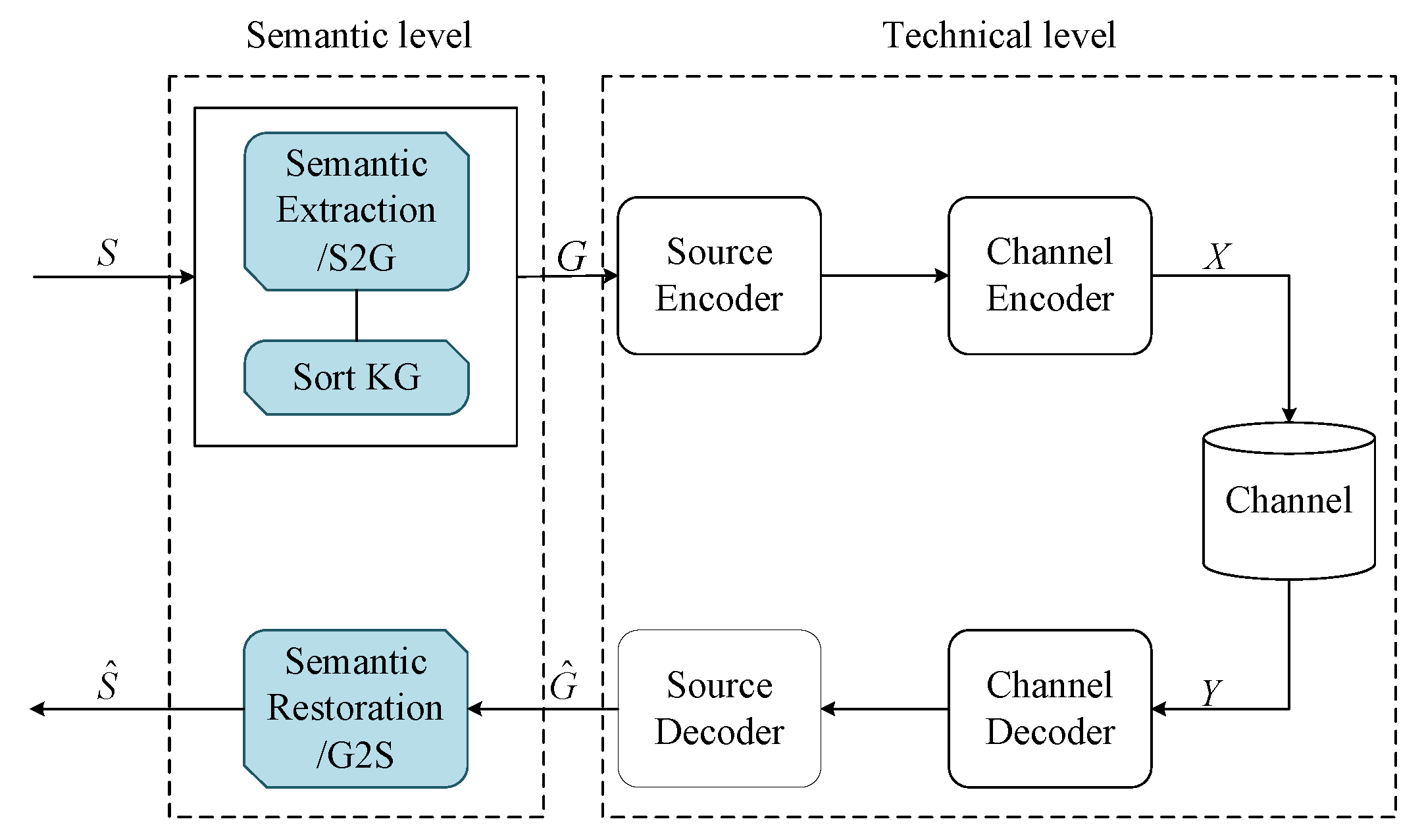
3. System Model
3.1. Semantic Extraction Method
| Algorithm 1 The proposed semantic extraction method |
| Input: the transmitted sentence S |
| Output: The knowledge graph G |
3.2. Semantic Restoration Method
| Algorithm 2 The proposed semantic restoration method |
| Input: the received knowledge graph |
| Output: the knowledge graph |
3.3. System Process
| Algorithm 3 Process of the proposed semantic communication system. |
| Input: The transmitted sentence S |
|
| Output: The restored sentence |
4. Experimental Results
4.1. Experimental Settings
4.2. Experimental Result Analysis
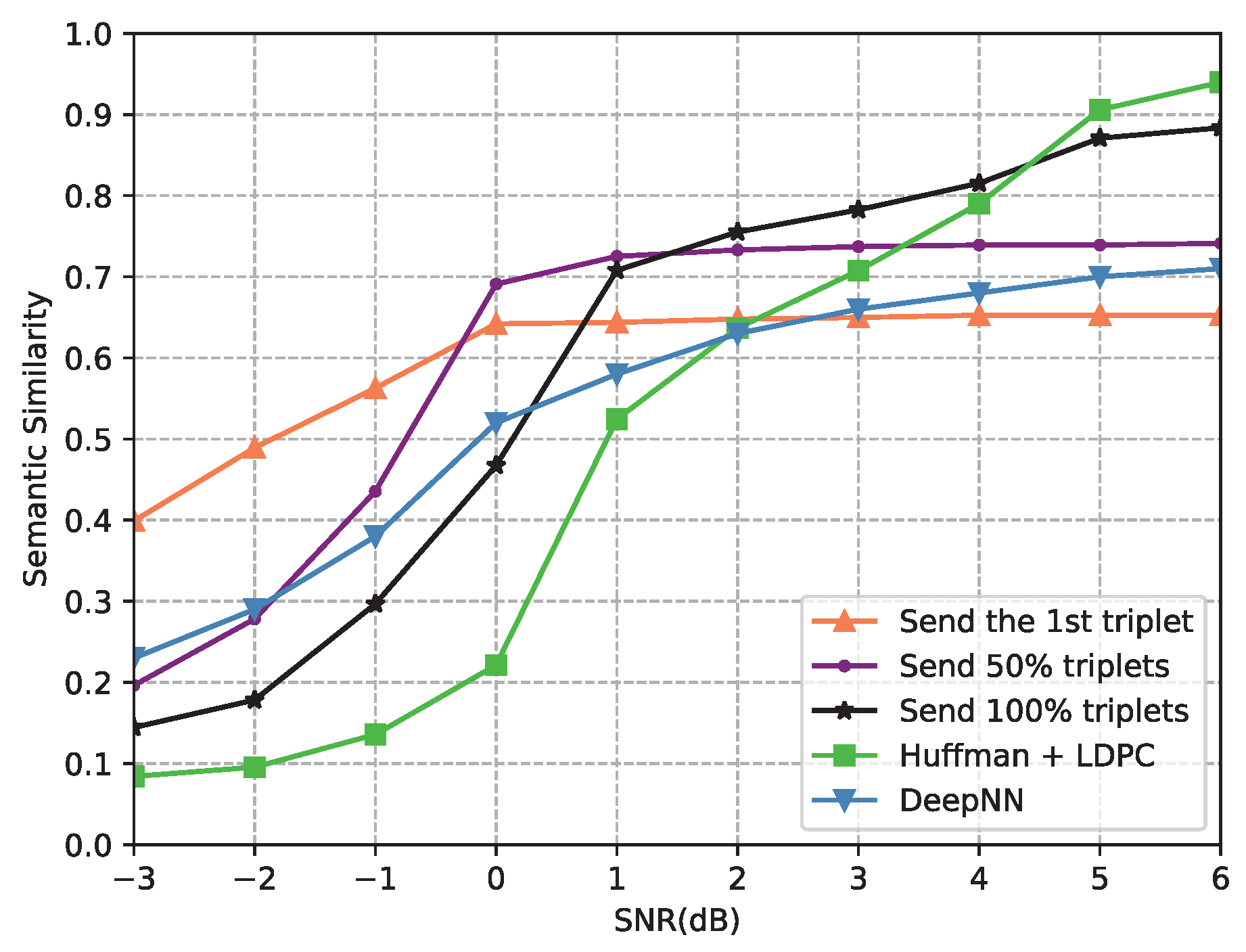
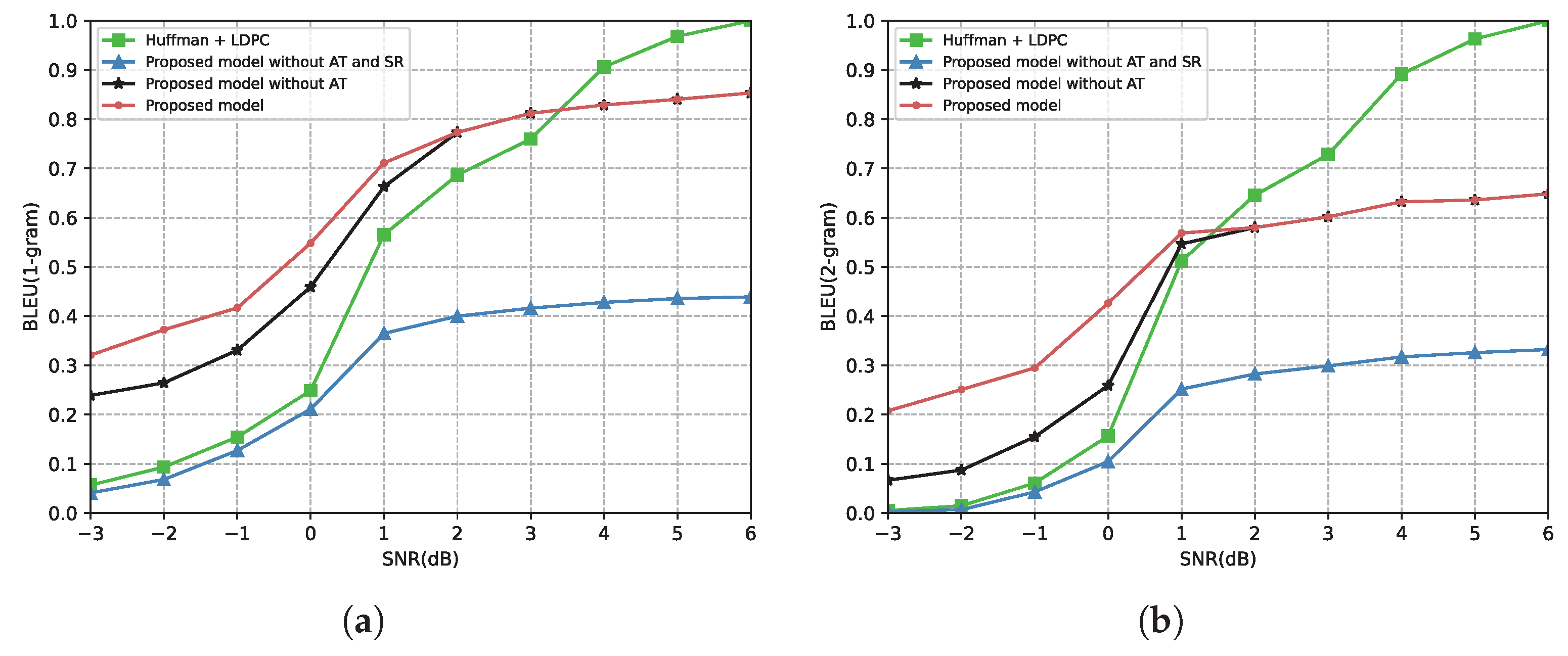
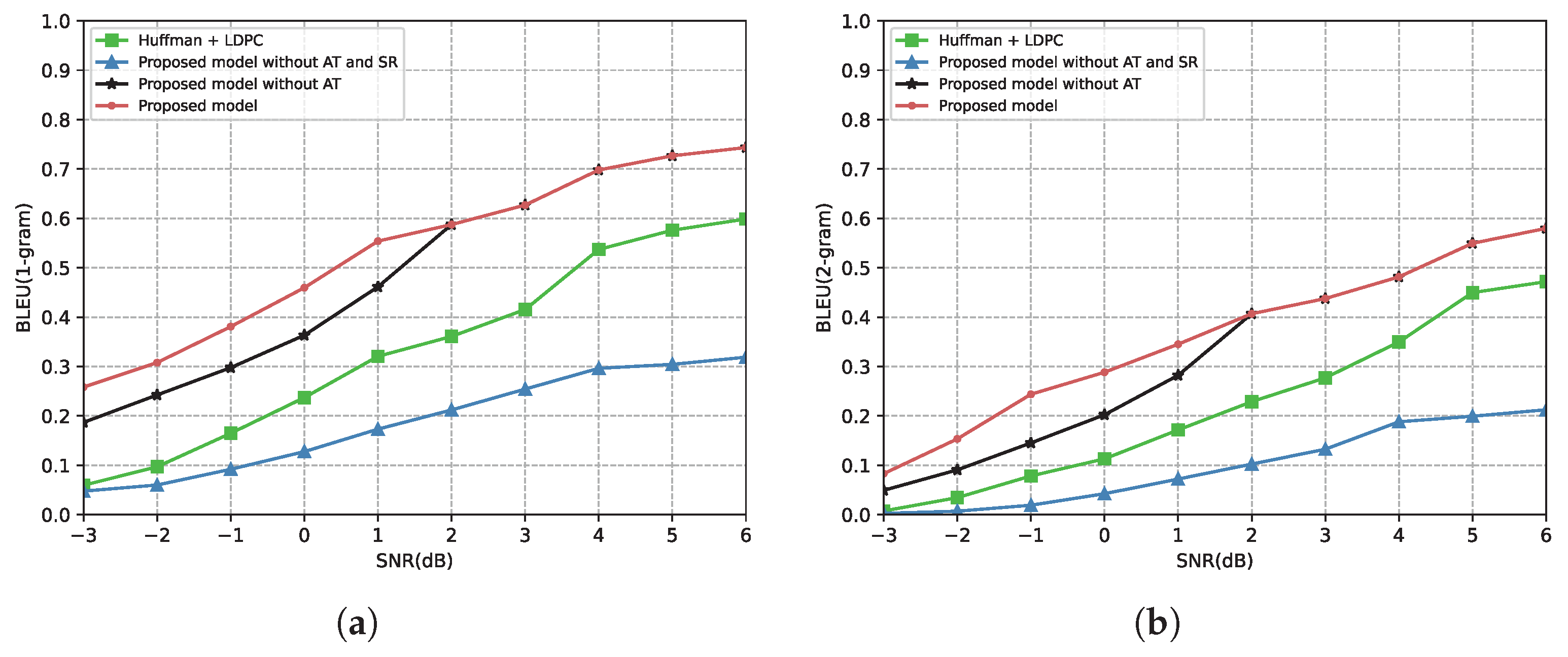
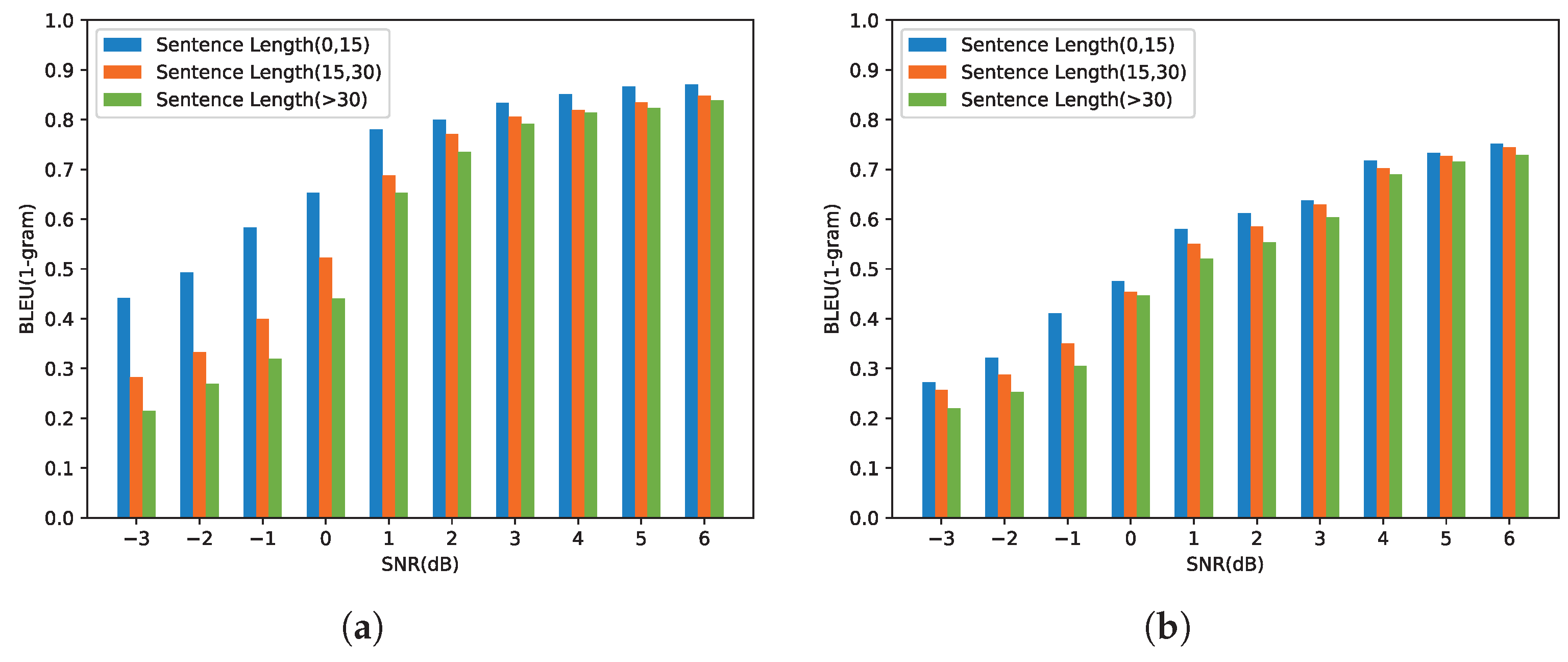
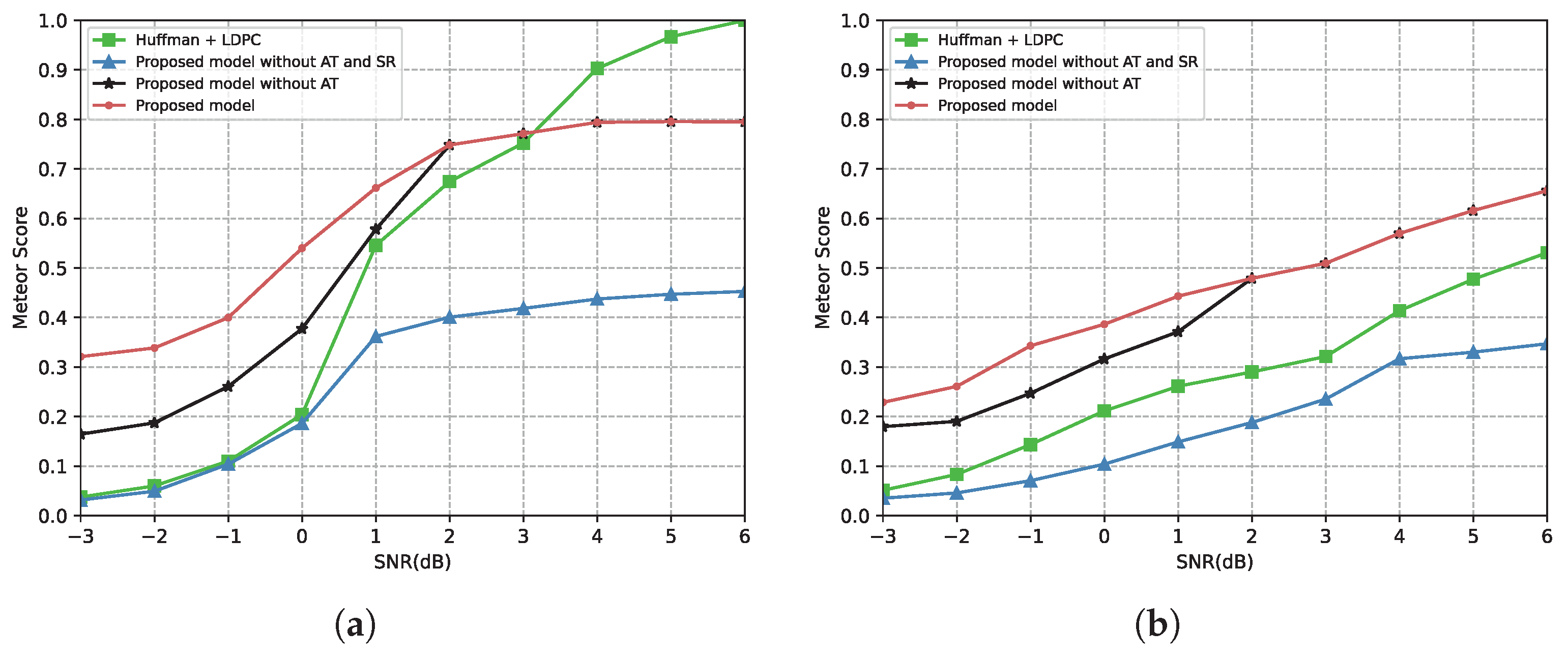
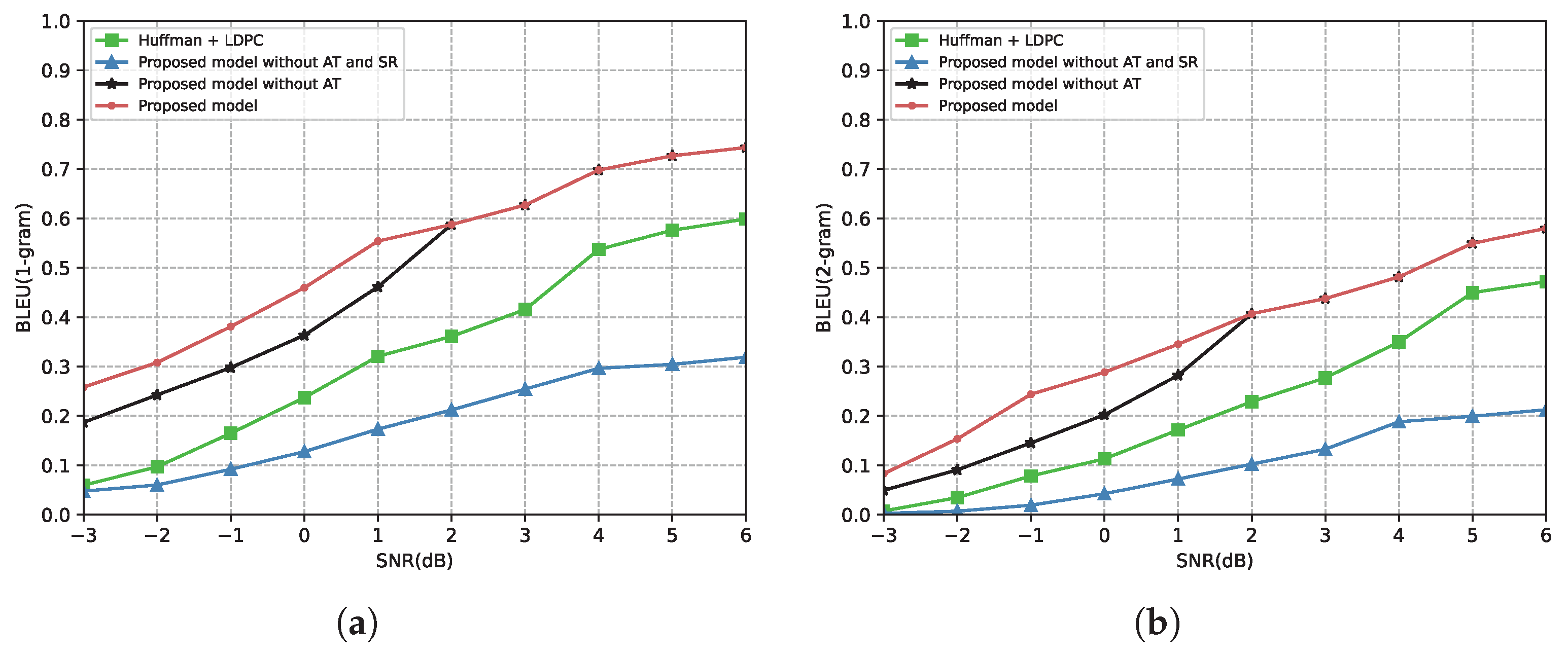
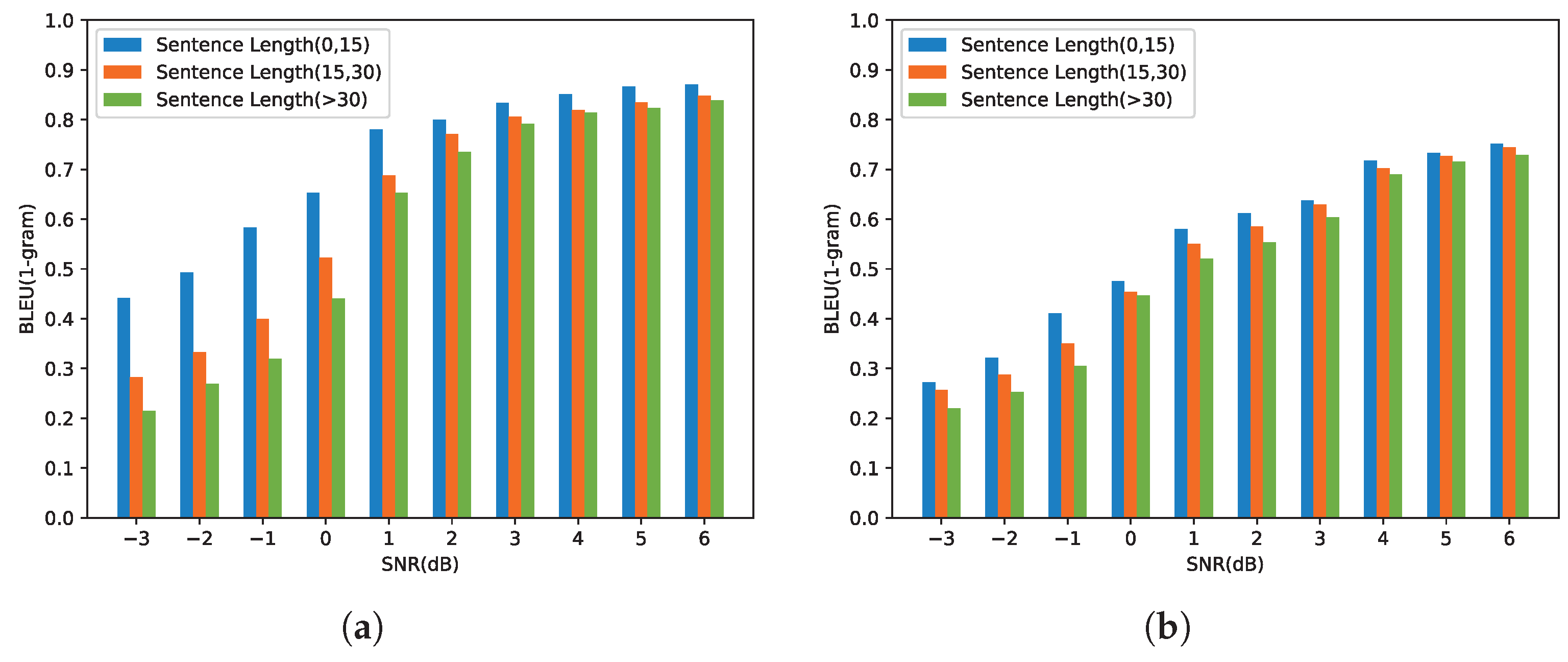
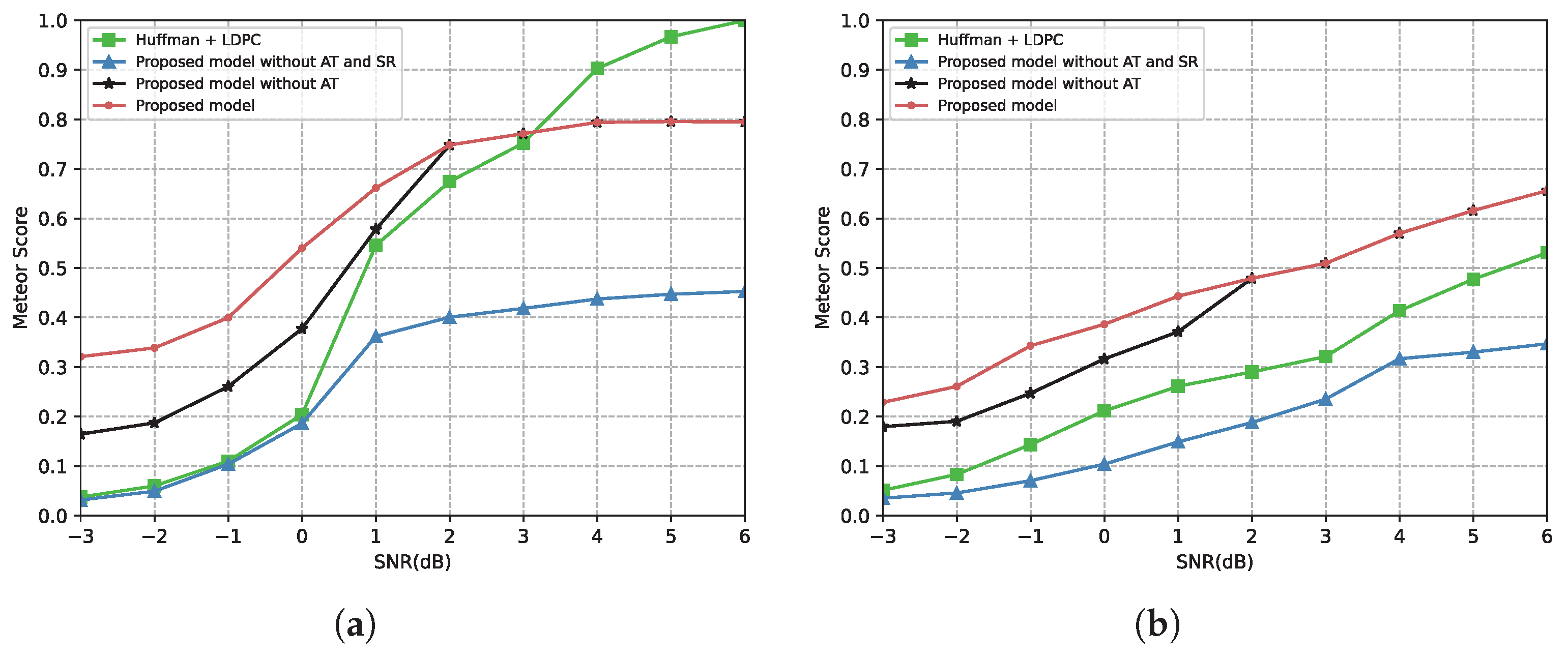
4.2.1. Performance of the Proposed Semantic Communication System
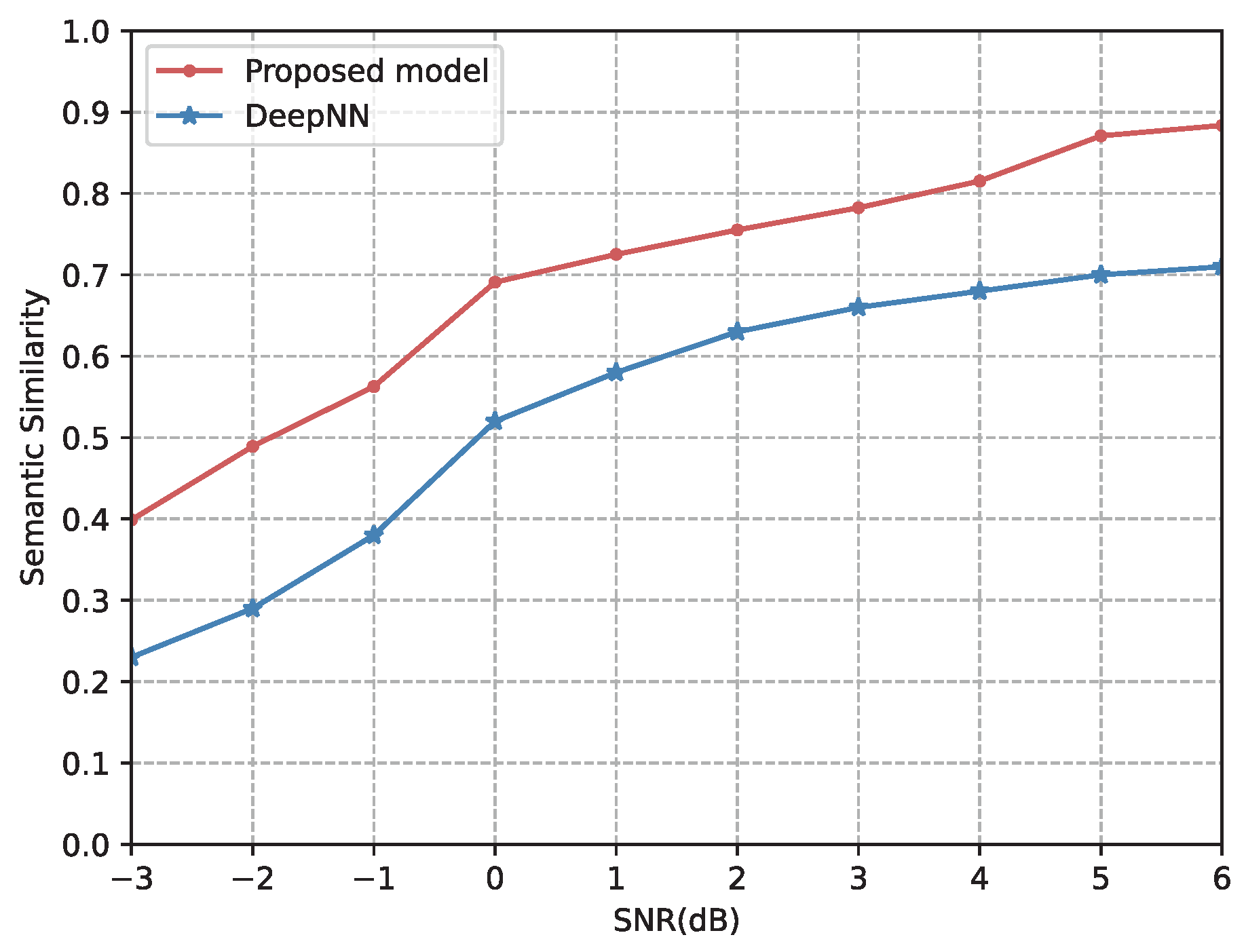
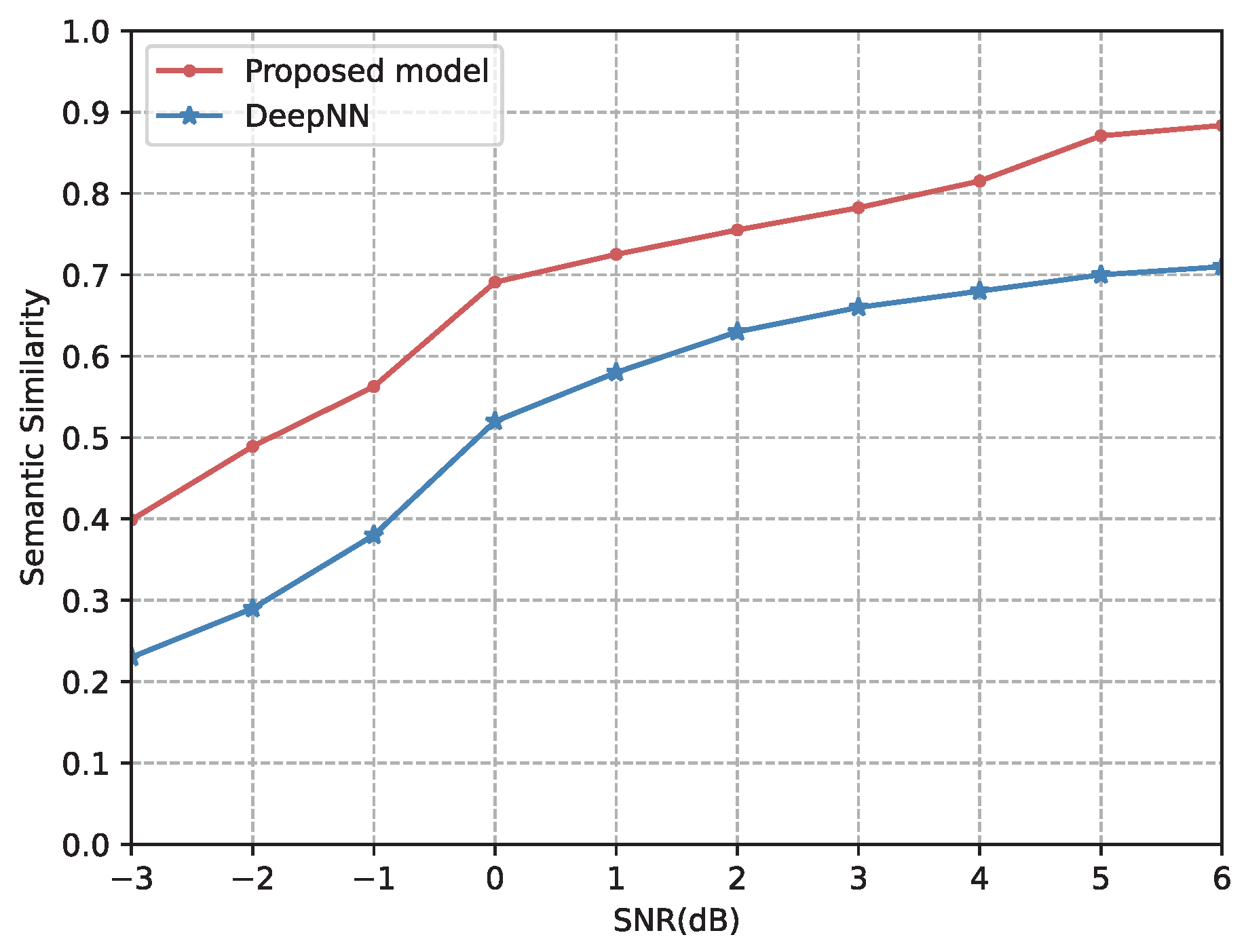
4.2.2. Comparison with Other Semantic Communication Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sah, D.K.; Kumar, D.P.; Shivalingagowda, C.; Jayasree, P.V.Y. 5G applications and architectures. In 5G Enabled Secure Wireless Networks; Jayakody, D., Srinivasan, K., Sharma, V., Eds.; Springer: Cham, Switzerland, 2019; pp. 45–68. [Google Scholar]
- Zhang, Y.; Zhang, P.; Wei, J. Semantic communication for intelligent devices: Architectures and a paradigm. Sci. Sin. Inform. 2022, 52, 907–921. [Google Scholar] [CrossRef]
- International Telecommunication Union. Report on the Implementation of the Strategic Plan and the Activities of the Union for 2019–2020; ITU: Geneva, Switzerland, 2020. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Pencheva, E.; Atanasov, I.; Asenov, I. Toward network intellectualization in 6G. In Proceedings of the 2020 XI National Conference with International Participation (ELECTRONICA), Sofia, Bulgaria, 23–24 July 2020; pp. 1–4. [Google Scholar]
- Khan, L.U.; Saad, W.; Niyato, D.; Han, Z.; Hong, C.S. Digital-Twin-Enabled 6G: Vision, architectural trends, and future directions. IEEE Commun. Mag. 2022, 60, 74–80. [Google Scholar] [CrossRef]
- Zhang, P.; Xu, W.J.; Gao, H.; Niu, K.; Xu, X.D.; Qin, X.Q.; Yuan, C.X.; Qin, Z.J.; Zhao, H.T.; Wei, J.B.; et al. Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks. Engineering 2021, 8, 60–73. [Google Scholar] [CrossRef]
- Shi, G.M.; Gao, D.H.; Song, X.D.; Chai, J.X.; Yang, M.X.; Xie, X.M.; Li, L.D.; Li, X.Y. A new communication paradigm: From bit accuracy to semantic fidelity. arXiv 2021, arXiv:2101.12649. [Google Scholar]
- Weaver, W. Recent contributions to the mathematical theory of communication. ETC: Rev. Gen. Semant. 1953, 10, 261–281. [Google Scholar]
- Güler, B.; Yener, A.; Swami, A. The semantic communication game. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 787–802. [Google Scholar] [CrossRef]
- Popovski, P.; Simeone, O.; Boccardi, F.; Gündüz, D.; Sahin, O. Semantic-effectiveness filtering and control for post-5G wireless connectivity. J. Indian Inst. Sci. 2020, 100, 435–443. [Google Scholar] [CrossRef]
- Weng, Z.Z.; Qin, Z.J.; Li, G.Y. Semantic communications for speech signals. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021. [Google Scholar]
- Ji, S.X.; Pan, S.R.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open research knowledge graph: Next generation infrastructure for semantic scholarly knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Marina del Rey, CA, USA, 19–21 November 2019; pp. 243–246. [Google Scholar]
- Atef Mosa, M. Predicting semantic categories in text based on knowledge graph combined with machine learning techniques. Appl. Artif. Intell. 2021, 35, 933–951. [Google Scholar] [CrossRef]
- Zhou, F.H.; Li, Y.H.; Zhang, X.Y.; Wu, Q.H.; Lei, X.F.; Hu, R.Q. Cognitive semantic communication systems driven by knowledge graph. arXiv 2022, arXiv:2022.11958v1. [Google Scholar]
- Shi, G.M.; Xiao, Y.; Li, Y.Y.; Xie, X.M. From semantic communication to semantic-aware networking: Model, architecture, and open problems. IEEE Commun. Mag. 2021, 59, 44–50. [Google Scholar] [CrossRef]
- Rudolf, C.; Bar-Hillel, Y. An outline of a theory of semantic information. J. Symb. Log. 1954, 19, 230–232. [Google Scholar]
- Floridi, L. Outline of a theory of strongly semantic information. Minds Mach. 2004, 14, 197–221. [Google Scholar] [CrossRef] [Green Version]
- Bao, J.; Basu, P.; Dean, M.; Partridge, C.; Swami, A.; Leland, W.; Hendler, J. Towards a theory of semantic communication. In Proceedings of the IEEE Network Science Workshop, West Point, NY, USA, 22–24 June 2011; pp. 110–117. [Google Scholar]
- Basu, P.; Bao, J.; Dean, M.; Hendler, J. Preserving quality of information by using semantic relationships. In Proceedings of the 2012 IEEE International Conference on Pervasive Computing and Communications Workshops, Lugano, Switzerland, 19–23 March 2012; pp. 58–63. [Google Scholar]
- Lan, Q.; Wen, D.; Zhang, Z.; Zeng, Q.; Chen, X.; Popovski, P.; Huang, K. What is semantic communication? A view on conveying meaning in the era of machine intelligence. arXiv 2021, arXiv:2110.00196. [Google Scholar]
- Farsad, N.; Rao, M.; Goldsmith, A. Deep learning for joint source-channel coding of text. In Proceedings of the 2018 IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2326–2330. [Google Scholar]
- Rao, M.; Farsad, N.; Goldsmith, A. Variable length joint source-channel coding of text using deep neural networks. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018. [Google Scholar]
- Liu, Y.L.; Zhang, Y.Z.; Luo, P.; Jiang, S.T.; Cao, K.; Zhao, H.T.; Wei, J.B. Enhancing communication reliability from the semantic level under low SNR. Electronics 2022, 11, 1358. [Google Scholar] [CrossRef]
- Xie, H.Q.; Qin, Z.J.; Li, G.Y.; Juang, B.H. Deep learning enabled semantic communication systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Xie, H.Q.; Qin, Z.J. A lite distributed semantic communication system for Internet of Things. IEEE J. Sel. Areas Commun. 2021, 39, 142–153. [Google Scholar] [CrossRef]
- Lu, K.; Li, R.P.; Chen, X.F.; Zhao, Z.F.; Zhang, H.G. Reinforcement learning-powered semantic communication via semantic similarity. arXiv 2021, arXiv:2108.12121. [Google Scholar]
- Weng, Z.Z.; Qin, Z.J. Semantic communication systems for speech transmission. IEEE J. Sel. Areas Commun. 2021, 39, 2434–2444. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, G.; Qin, Z.; Cai, Y.; Yu, G. Robust semantic communications against semantic noise. arXiv 2022, arXiv:2202.03338v1. [Google Scholar]
- Xie, H.Q.; Qin, Z.J.; Li, G.Y. Task-oriented multi-user semantic communications for VQA task. arXiv 2021, arXiv:2108.07357. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Li, R.P.; Zhao, Z.F.; Peng, C.H.; Zhang, H.G. Semantic communication with adaptive universal transformer. IEEE Wirel. Commun. Le. 2022, 11, 453–457. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; pp. 228–231. [Google Scholar]
- Agirre, E.; Banea, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Mihalcea, R.; Rigau, G.; Wiebe, J. SemEval-2016 Task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 497–511. [Google Scholar]
- Mathur, N.; Baldwin, T.; Cohn, T. Tangled up in BLEU: Reevaluating the evaluation of automatic machine translation evaluation metrics. arXiv 2020, arXiv:2006.06264. [Google Scholar]
- Kilgarriff, A.; Fellbaum, C. WordNet: An electronic lexical database. Language 2000, 76, 706–708. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Qi, R.; Zhang, Y.H.; Zhang, Y.H.; Bolton, J.; Manning, C.D. Stanza: A python natural language processing toolkit for many human languages. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; pp. 101–108. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Gallager, R. Low-density parity-check codes. IRE Trans. Inf. Theory 1962, 8, 21–28. [Google Scholar] [CrossRef] [Green Version]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating training corpora for NLG micro-planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 179–188. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentence | Triplets of Knowledge Graph | Semantic Similarity |
|---|---|---|
| Steve Jobs, a graduate of Reed | Steve Jobs – graduate-Reed College | 0.56 |
| College, is the founder of Apple | Steve Jobs – founder-Apple | 0.73 |
| Model | General Features | Technical Methods |
|---|---|---|
| SCKG | (1) Adding the semantic extraction module and semantic restoration module into traditional communication architecture. (2) Using triplets as semantic basic symbols for semantic extraction and restoration. | (1) Semantic extraction—network structure using NER + LSTM. (2) Semantic restoration—network structure using GAT + RNN + ATTENTION. |
| Huffman [43] + LDPC [44] | (1) Using the traditional communication architecture from Shannon’s information theory. (2) Using Huffman coding as source coding and using LDPC coding as channel coding. | (1) Convert transmitted sentences to bit sequences by using Huffman coding. (2) Using LDPC coding to combat channel distortion. |
| DeepNN [23] | (1) Using the deep neural network for source-channel joint coding. (2) Replacing source encoding and channel encoding with the encoder of the deep neural network. (3) Replacing source decoding and channel decoding with the decoder of the deep neural network. | (1) Encoder—network structure using BILSTM. (2) Decoder—network structure using LSTM. |
| Type | Parameters for Semantic Extraction Method | Parameters for Semantic Restoration Method |
|---|---|---|
| Epochs | 50 | 50 |
| Batch size | 32 | 32 |
| Optimizer | Adam | Adam |
| Learning rate | ||
| Drop | 0 | 0.1 |
| Strategies | Time Complexity/s |
|---|---|
| Huffman + LDPC | 2.7324 |
| Proposed model without AT and SR | 3.1638 |
| Proposed model without AT | 3.7742 |
| Proposed model | 3.8539 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Liu, Y.; Zhang, Y.; Luo, P.; Cao, K.; Xiong, J.; Zhao, H.; Wei, J. Reliable Semantic Communication System Enabled by Knowledge Graph. Entropy 2022, 24, 846. https://doi.org/10.3390/e24060846
Jiang S, Liu Y, Zhang Y, Luo P, Cao K, Xiong J, Zhao H, Wei J. Reliable Semantic Communication System Enabled by Knowledge Graph. Entropy. 2022; 24(6):846. https://doi.org/10.3390/e24060846
Chicago/Turabian StyleJiang, Shengteng, Yueling Liu, Yichi Zhang, Peng Luo, Kuo Cao, Jun Xiong, Haitao Zhao, and Jibo Wei. 2022. "Reliable Semantic Communication System Enabled by Knowledge Graph" Entropy 24, no. 6: 846. https://doi.org/10.3390/e24060846
APA StyleJiang, S., Liu, Y., Zhang, Y., Luo, P., Cao, K., Xiong, J., Zhao, H., & Wei, J. (2022). Reliable Semantic Communication System Enabled by Knowledge Graph. Entropy, 24(6), 846. https://doi.org/10.3390/e24060846