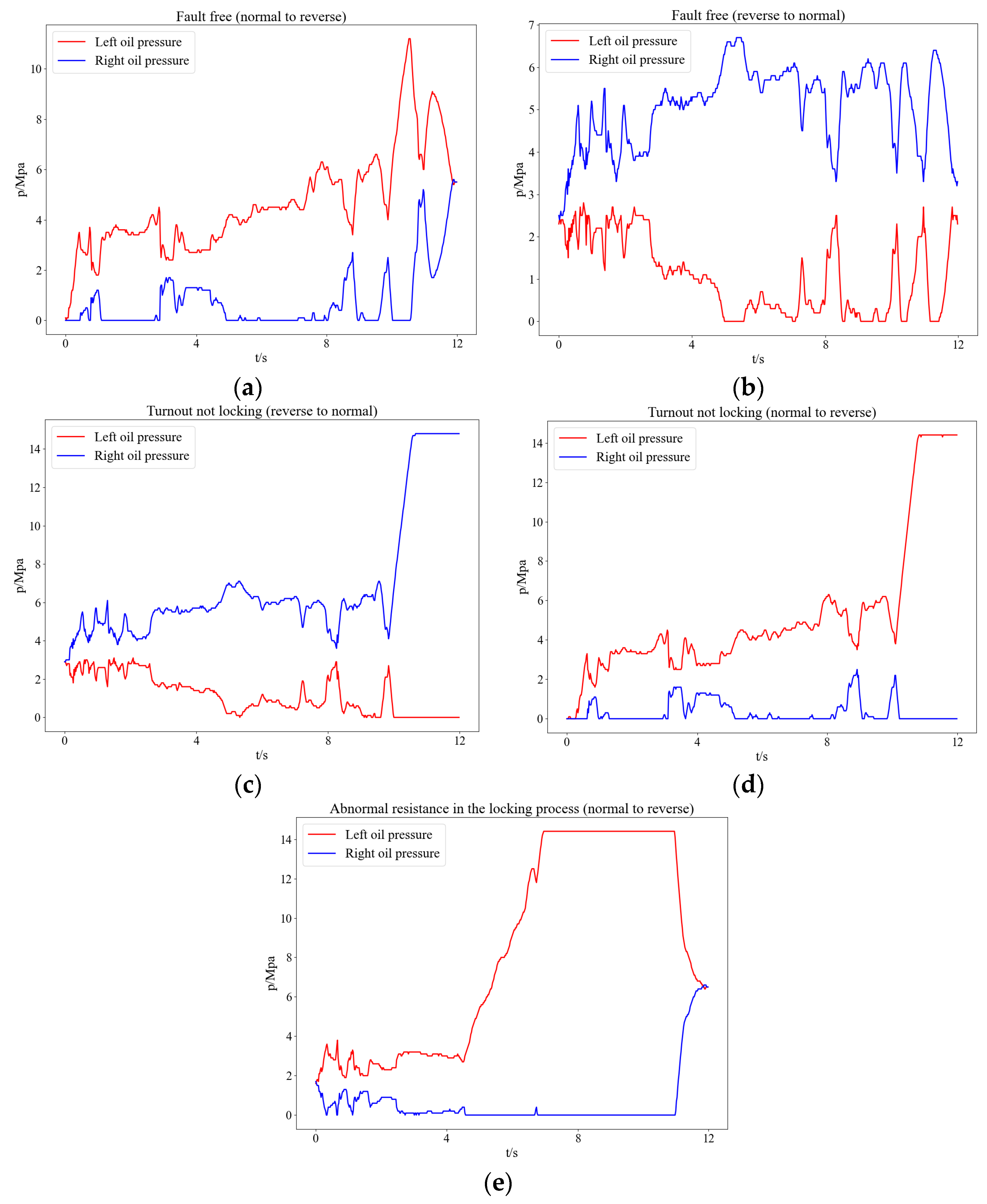
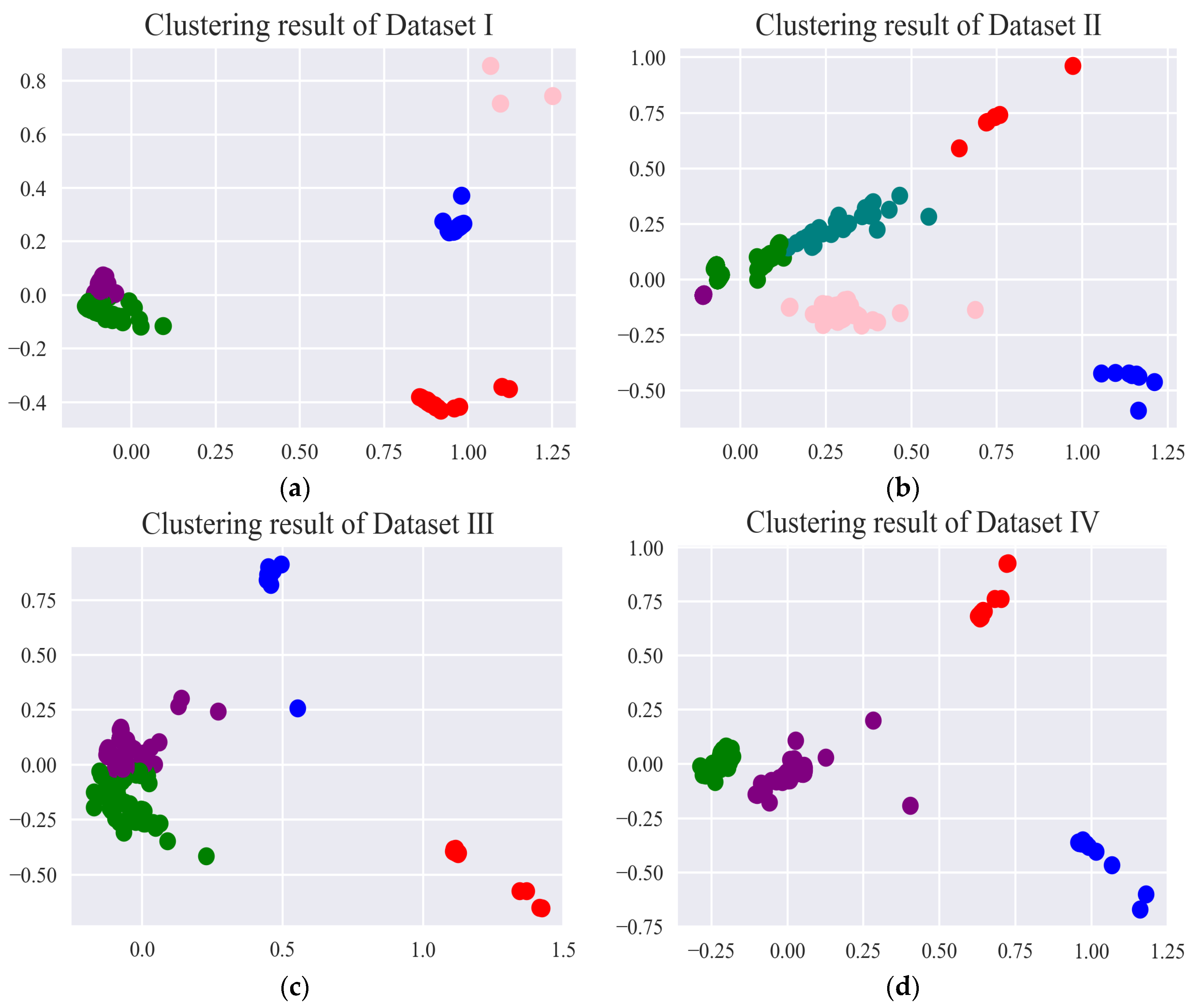
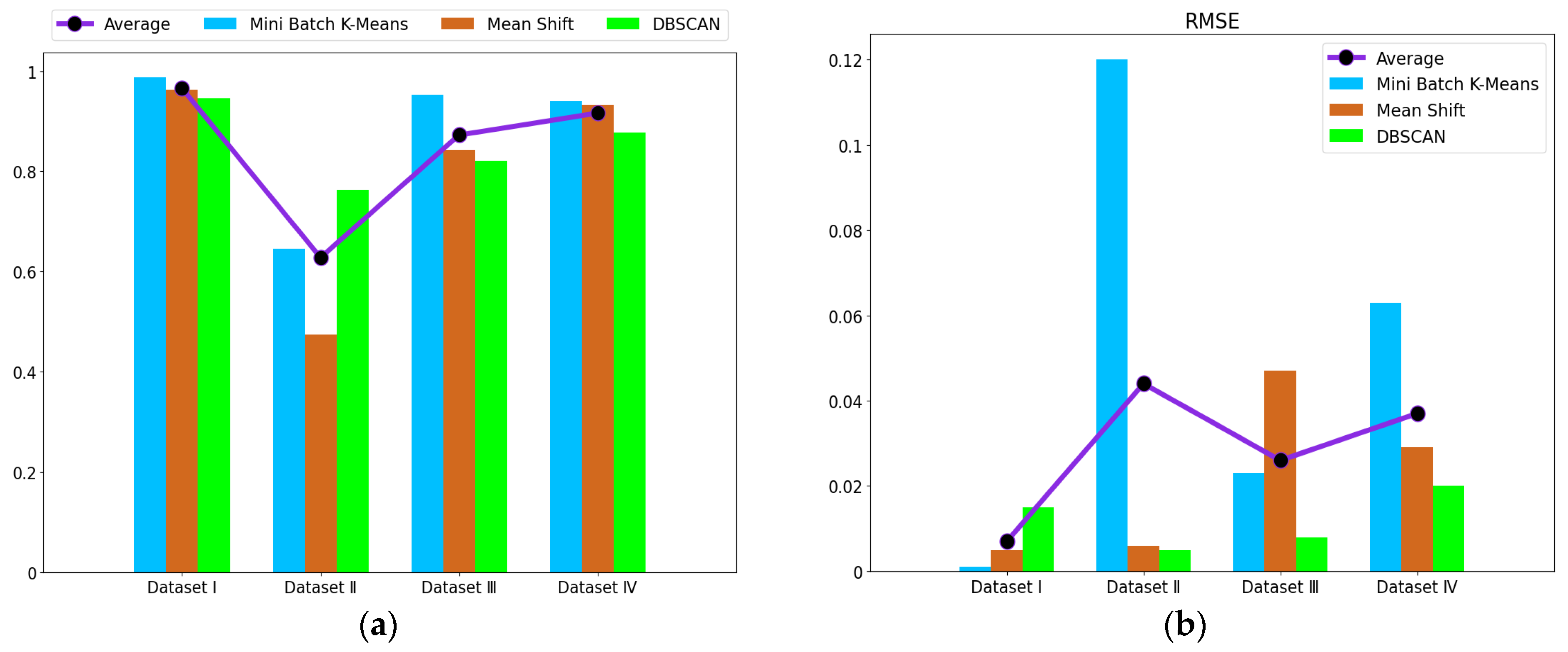
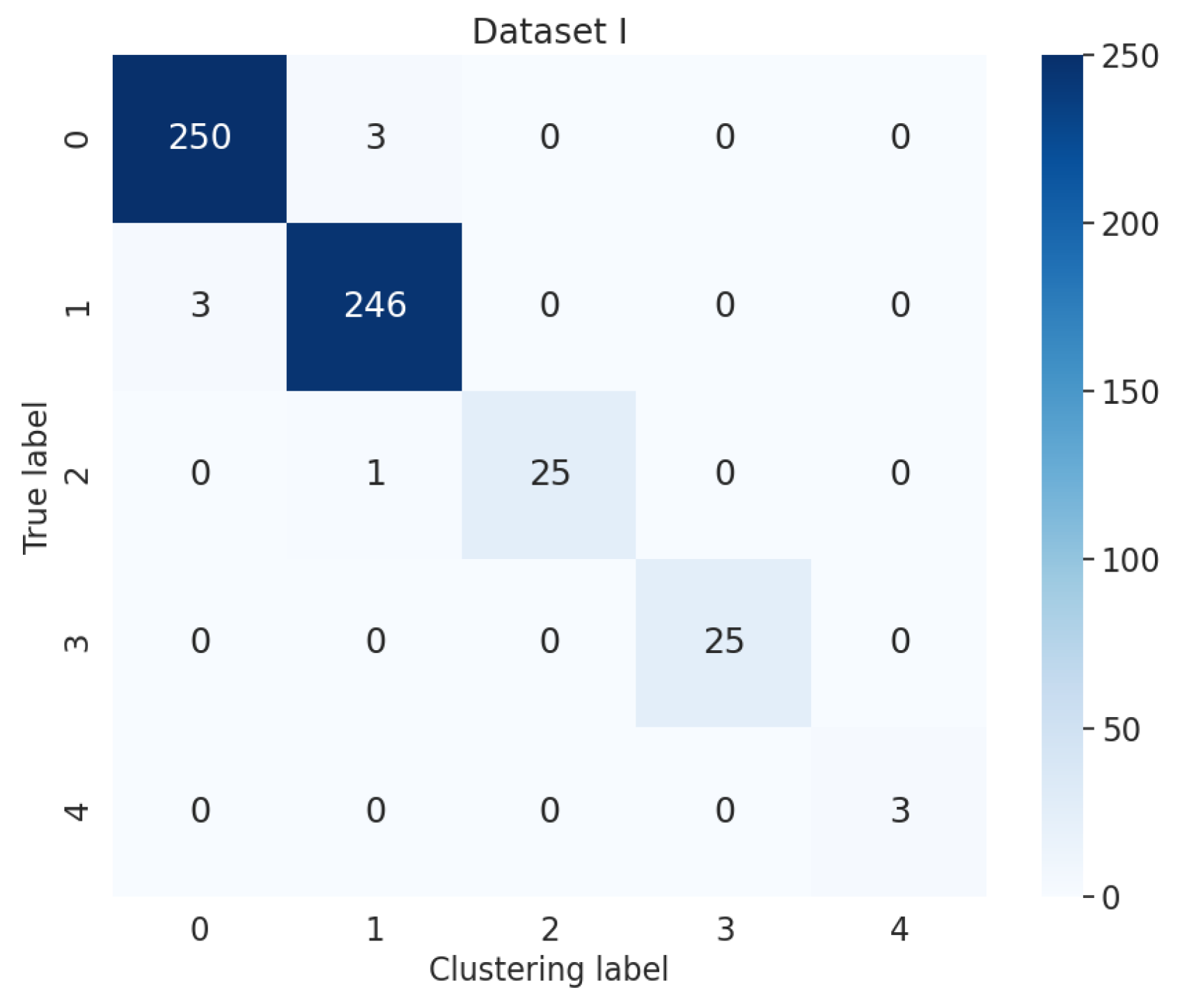
1. Introduction
In a railway, a switch machine is track switch equipment that makes train transfer from one track to another, and it is an important signal device to ensure the train operation safety. A switch machine is often eroded under a poor working environment with high intensity and heavy load, which leads to fault occurrence. The fault of switch machines may cause serious accidents, such as train derailment and capsizing, resulting in heavy casualties and property losses. Fault detection of switch machines is very important for railway transportation safety. However, for a long time, the fault detection of switch machines mainly depends on the expert knowledge and experience of railway workers, or adopts a simple threshold setting method, which not only are inefficient but also bring a heavy workload to railway workers, which often leads to misjudgment.
Recently, many fault diagnosis methods combining a support vector machine (SVM), fuzzy logic system, artificial neural network (ANN), and others have been constantly appearing. Asada [
1] proposed an effective approach for accurately classifying several fault modes combined with a wavelet transform and support vector machines to detect faults of an AC point machine. In [
2], support vector machines with a Gaussian kernel were used to diagnose a fault of an electric switch machine, which verified the features obtained with principal components analysis (PCA) getting better results than the existing features. Moreover, an SVM-based fault detection approach was proposed to identify the fault states of a switch machine based on the electric current curve, and the envelope and morpheme match algorithm were applied to predict the fault of a switch machine in this approach [
3]. The type-1 and singleton fuzzy logic system trained by the conjugate gradient method was proposed by de Aguiar [
4] to realize fault diagnosis by different classifiers based on the current signal of an electric switch machine, which could offer a higher convergence rate and performance. Further, de Aguiar [
5] used the set-membership concept derived from the adaptive filter theory in the type-1 and singleton/nonsingleton fuzzy logic systems so that the model convergence speed was improved and computation complexity was reduced, and then he demonstrated that the upper and lower singleton type-2 fuzzy logic system was a more effective classifier for an electric switch machine fault [
6]. The long- and short-term memory (LSTM) and the deep wavelet scattering transform (DWST) were explored for classifying various switch degradations, and the feasibility of a dataset captured under the service conditions was demonstrated in [
7]. A hybrid fault diagnosis (HFD) method was adopted to identify a fault based on the current curves of a railway switch machine in [
8]. A locally connected autoencoder was employed to automatically capture high-order features in order to solve the fault diagnosis problem with no training steps based on the current signal of an electric point machine [
9]. DAG-SVMs were applied to intelligently detect a fault after extracting characteristics based on the action current signal of an electric switch machine, and the experiment showed that the accuracy of classification after Kalman filter pretreatment was better than that of direct classification in [
10]. The artificial intelligent methods, such as RNN (recurrent neural network), CNN (convolutional neural network), autoencoder, and other deep learning methods, were adopted for feature extraction and fault diagnosis in industrial fields [
11,
12,
13]. More and more intelligent fault diagnosis methods were applied in various engineering areas, which could achieve diagnosis accurately. Additionally, the methods provided a reliable basis for fault detection of the switch machine.
The intelligent fault diagnosis methods were also applied to some special electric switch machines, such as ZD6 and S700K. The similarity function was defined by the Fréchet distance, action current template curves were built, and the fault diagnosis method according to the greatest curve similarity was constructed for a ZD6 switch machine in [
14]. In [
15], the railway turnout intelligent fault detection algorithm was proposed based on a BP neural network by analyzing the characteristics of action current curves for a ZD6 switch machine. A senior Bayesian model based on rough set theory was applied to detect the fault of an S700K switch machine, which effectively enhanced the speed and accuracy of fault diagnosis [
16]. The wavelet packet energy entropy was used for switch machine fault detection based on the three-phase alternating current of an S700K switch machine [
17]. Grey correlation analysis and a neural network were combined to obtain better detection results based on power curves of an S700K electric switch machine [
18]. A fuzzy clustering analysis method based on the action power curve was proposed to achieve the fault detection of an S700K switch machine, which could accurately extract fault features and support simultaneous detection of multiple faults [
19]. In [
20], ensemble empirical mode decomposition (EEMD) based on the power curve of an S700K switch machine was proposed to decompose a signal, and the fuzzy clustering analysis algorithm was used to realize fault classification, which were more fully characterized fault signals. Variational mode decomposition (VMD) and the kernel fuzzy c-means (KFCM) clustering algorithm were employed to classify the fault types of an S700K switch machine based on the power curve, whose better classification results were obtained by adding kernel functions [
21]. FCM and hidden semi-Markov models (HSMMs) were combined to quickly and accurately identify the health status based on the power data of an S700K switch machine [
22].
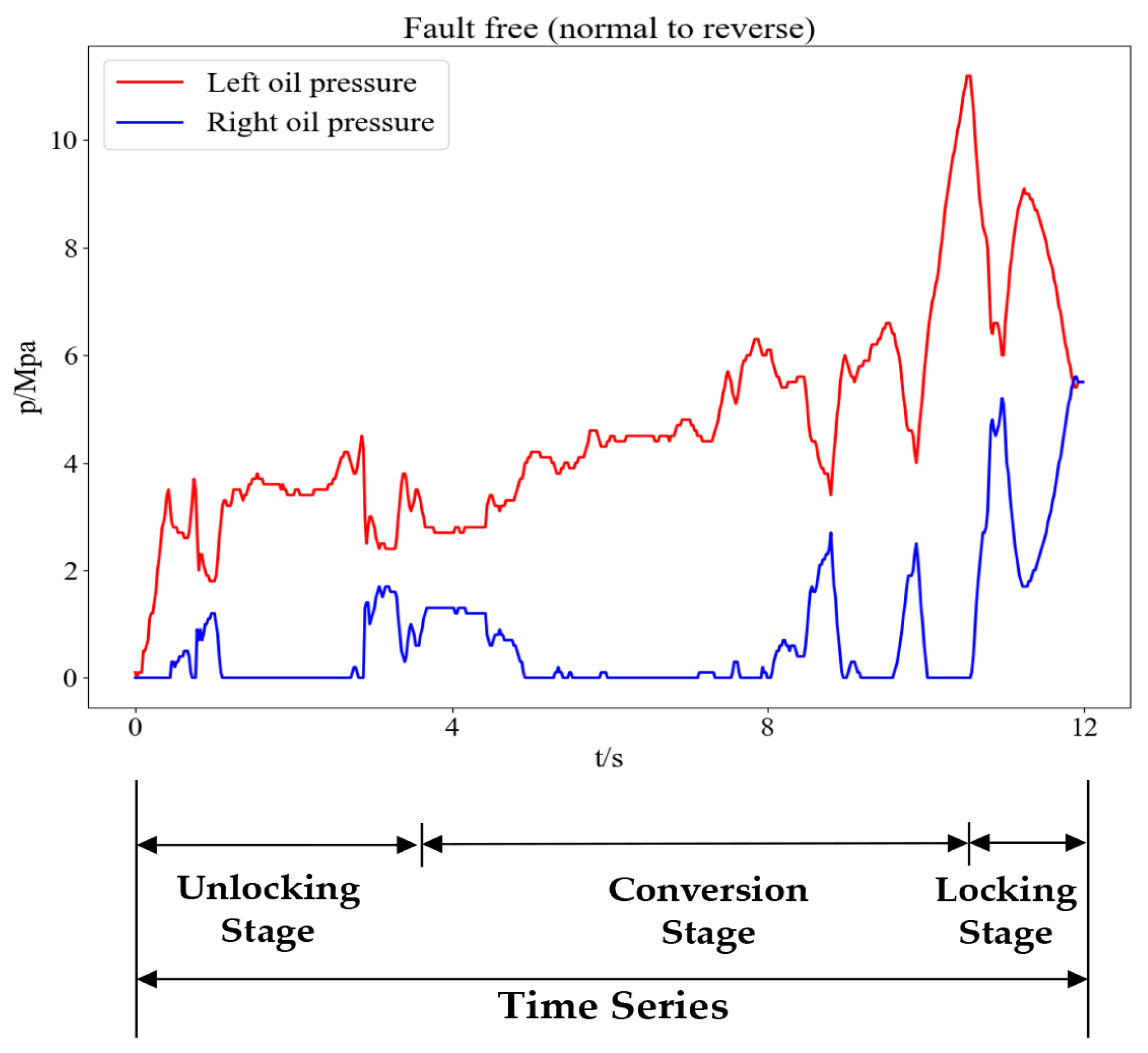
However, there are other types of switch machine, which are applied in different railway passenger stations, freight stations, and marshalling stations. An electrohydraulic switch machine is a new type of switch machine that has appeared in China since the 1980s, which is suitable for the development trend of a high-speed railway. An electrohydraulic switch machine uses hydraulic transmission, and hydraulic oil is generally utilized as a working medium. Additionally, the oil pressure signal contains a lot of useful information about operation and the fault status of an electrohydraulic switch machine. Zhou [
23] applied grey correlation theory to the intelligent fault detection of turnouts based on the oil pressure signal of a ZYJ7 electrohydraulic switch machine. For the existing fault detection, the expert system [
24] is hard for acquiring knowledge and needs a lot of prior knowledge of railway staff; the Kalman filtering method [
25] can only be successful in a part of the dataset; a reliable and reasonable prior probability has to be provided for a Bayesian network [
26], in which determination is very difficult; a support vector machine [
3] is a binary classifier in principle, which is very sensitive to feature selection; and a neural network [
7] needs numerous samples for training to avoid misdetection. However, unsupervised clustering methods can support multiple fault detections and effectively improve performance, which do not need to be trained and be provided with many prior parameters. Most of the literature has focused on the fault detection of electric switch machines based on the current or power signal. However, there is a pressing need for feature extraction and fault detection research works for electrohydraulic switch machines with more application and promotion of speed-up turnouts in the future. The features from oil pressure signal time series can effectively provide information reflecting the fault status and obtain a better detection effect for an electrohydraulic switch machine. However, the oil pressure signal of an electrohydraulic switch machine includes plenty of fault characteristics, which is nonstationary and difficult to extract. Besides, existing methods of extracting a feature directly from the whole signal and sectionalizing averagely a feature extraction are not able to extract effective feature information from the signal.
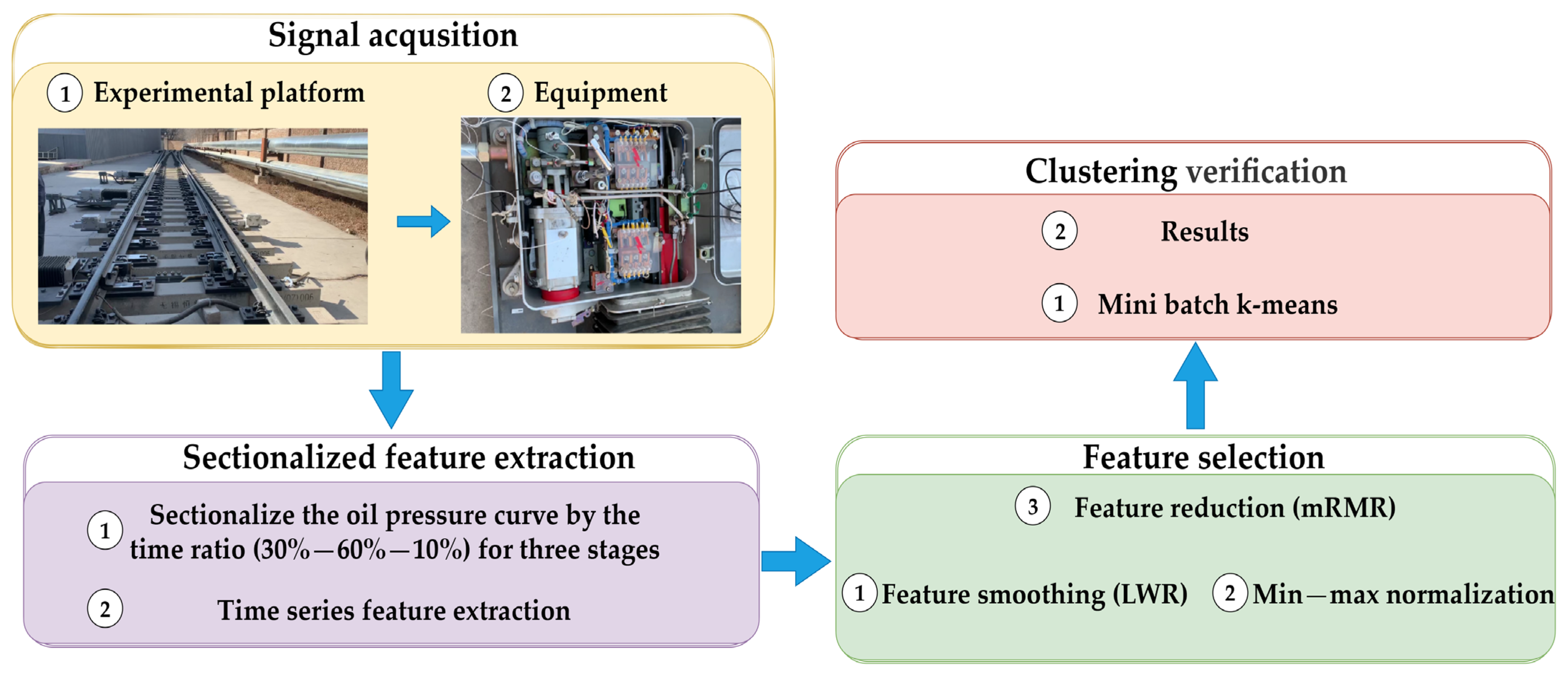
For the above reasons, a novel fault detection method for an electrohydraulic switch machine based on the sectionalized feature extraction according to the best time ratio from the oil pressure signal is proposed in this paper. The rest of the paper is organized as follows:
Section 2 describes the principles and the framework of the proposed approach. The effectiveness and accuracy of the fault detection method based on sectionalized feature extraction are illustrated by experiments in
Section 3. Finally, some conclusions are summarized in
Section 4.
4. Conclusions
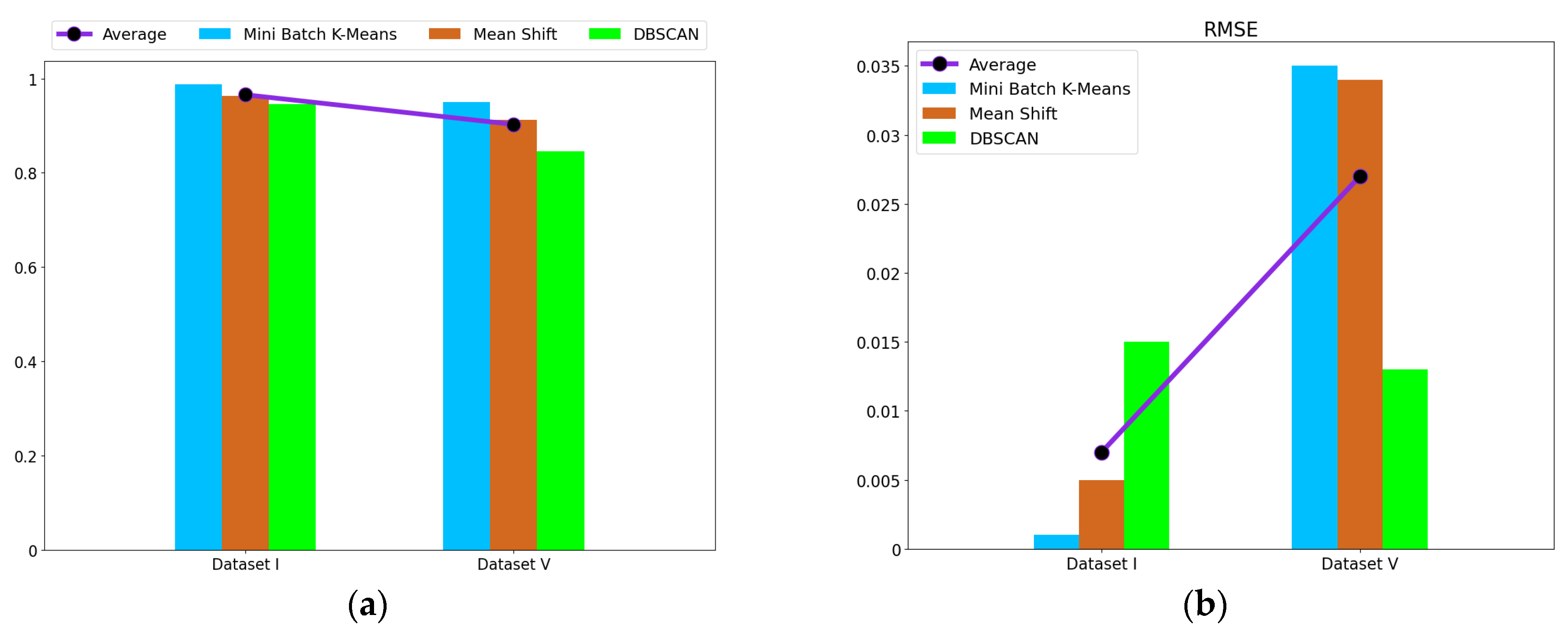
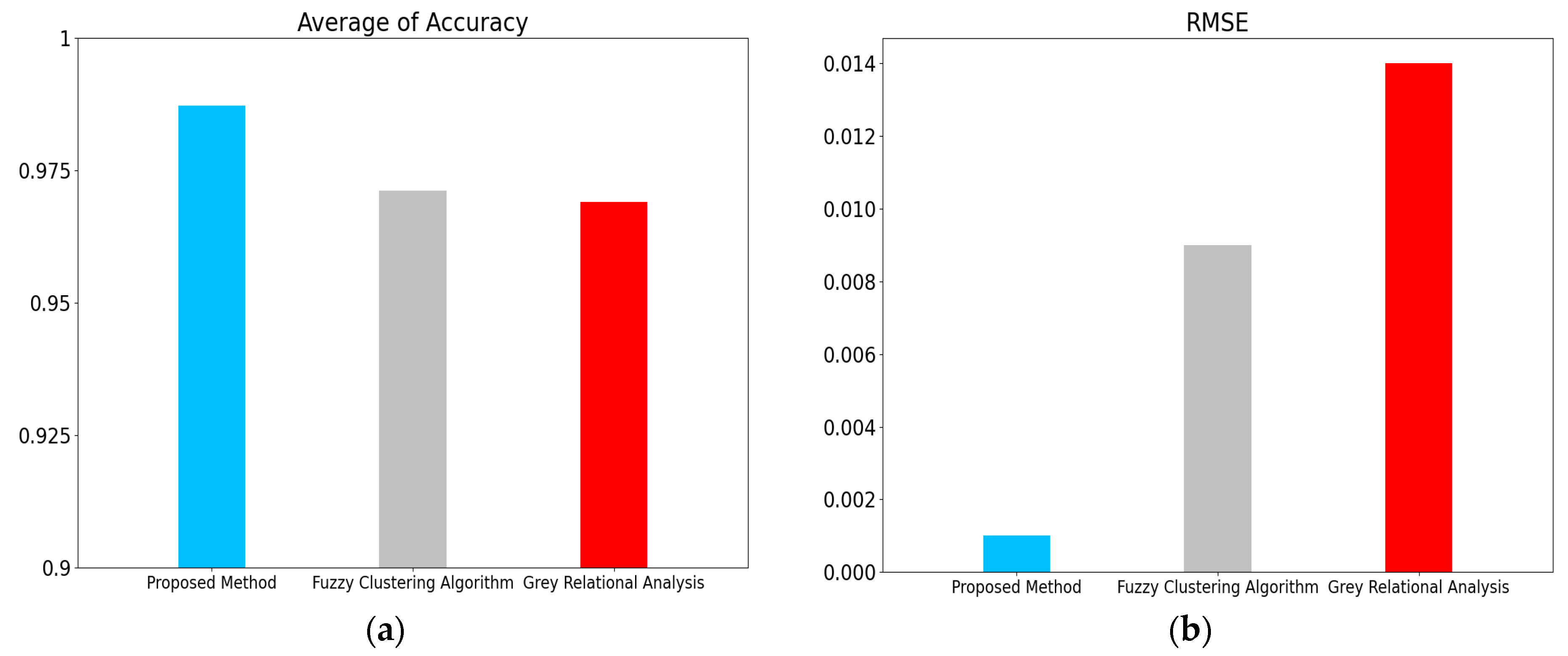
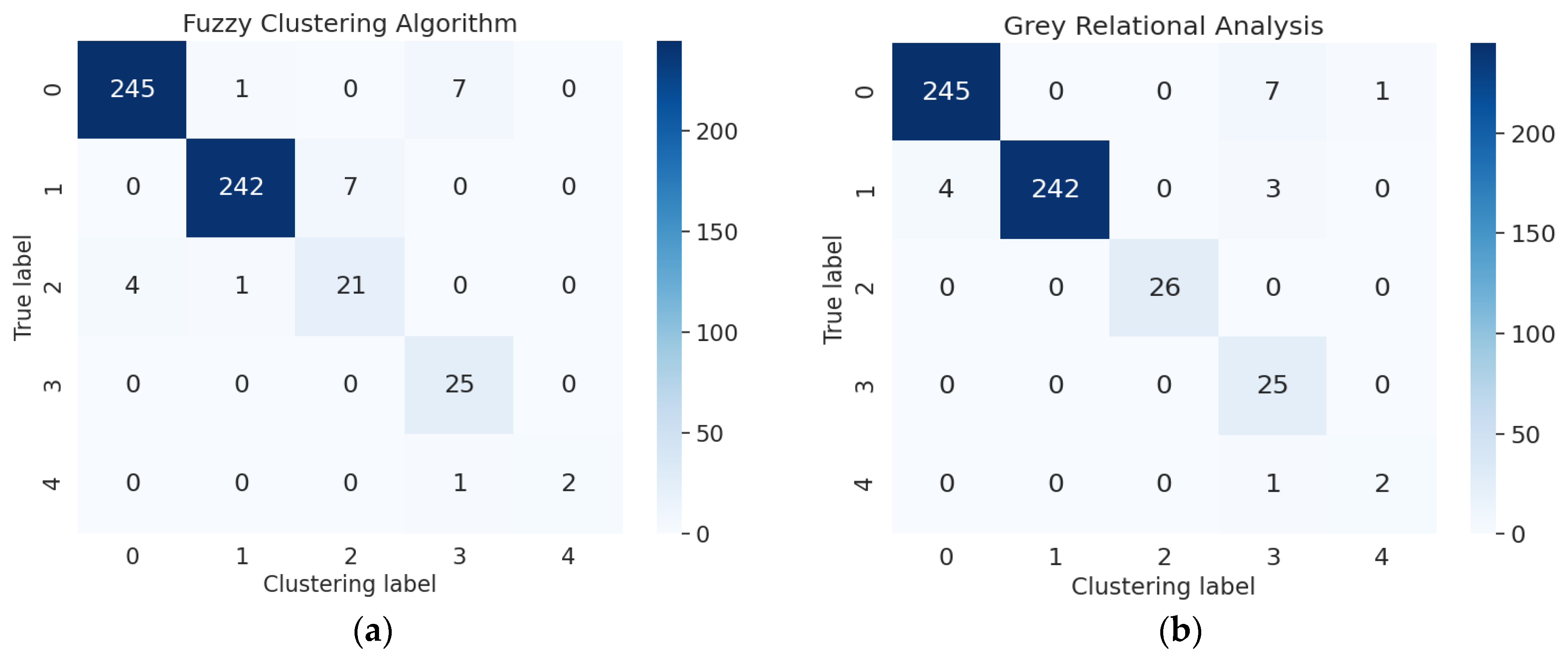
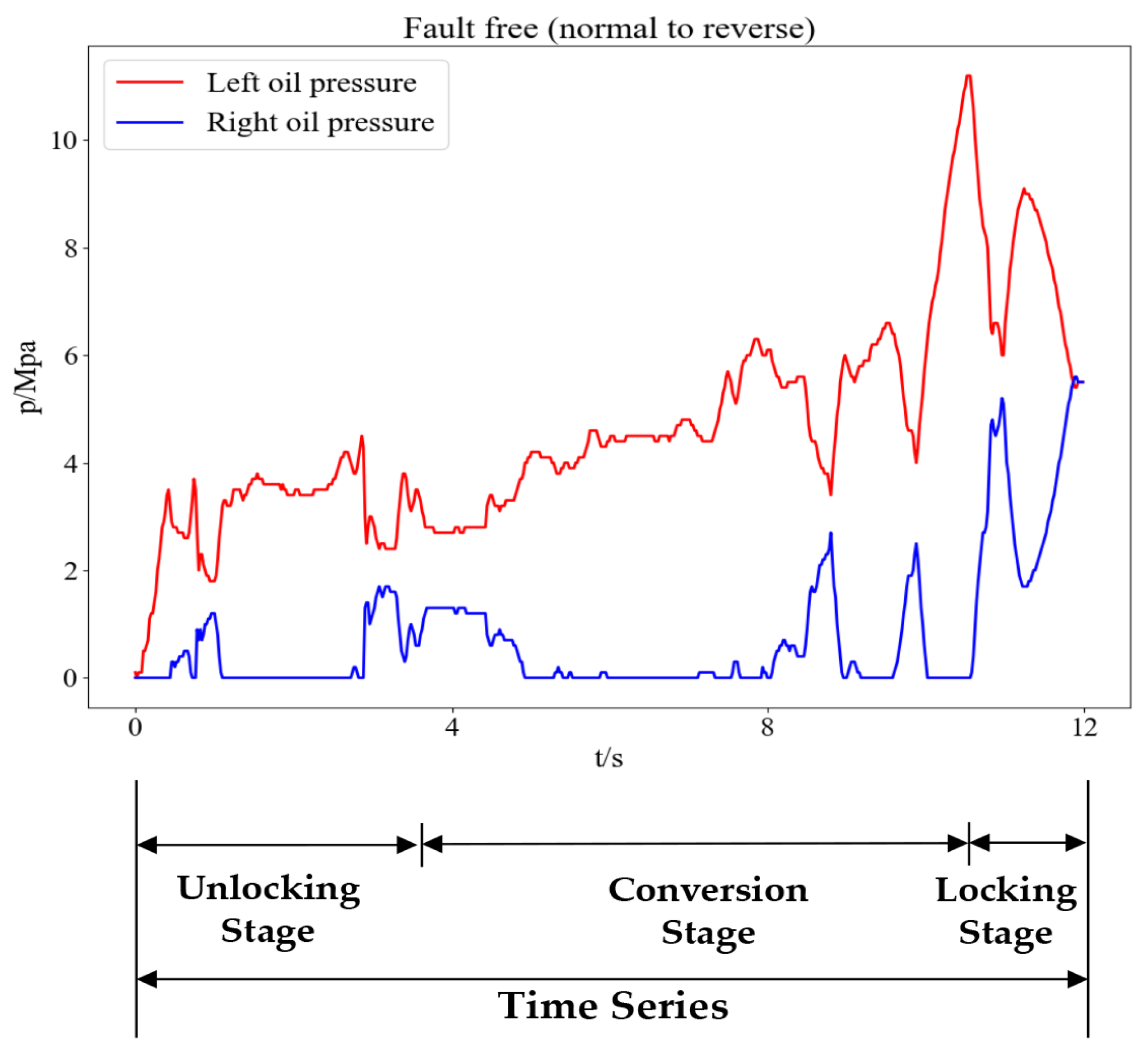
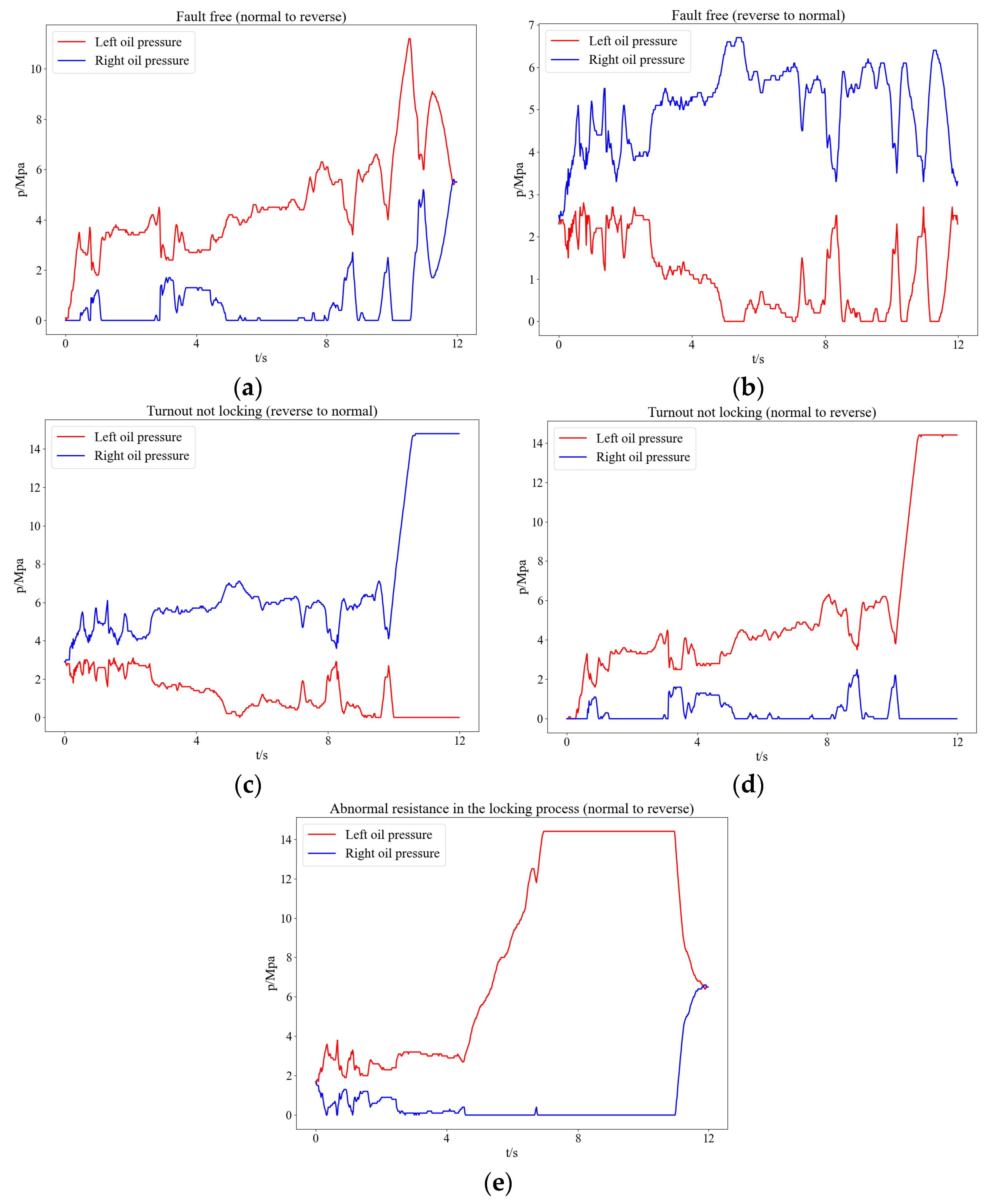
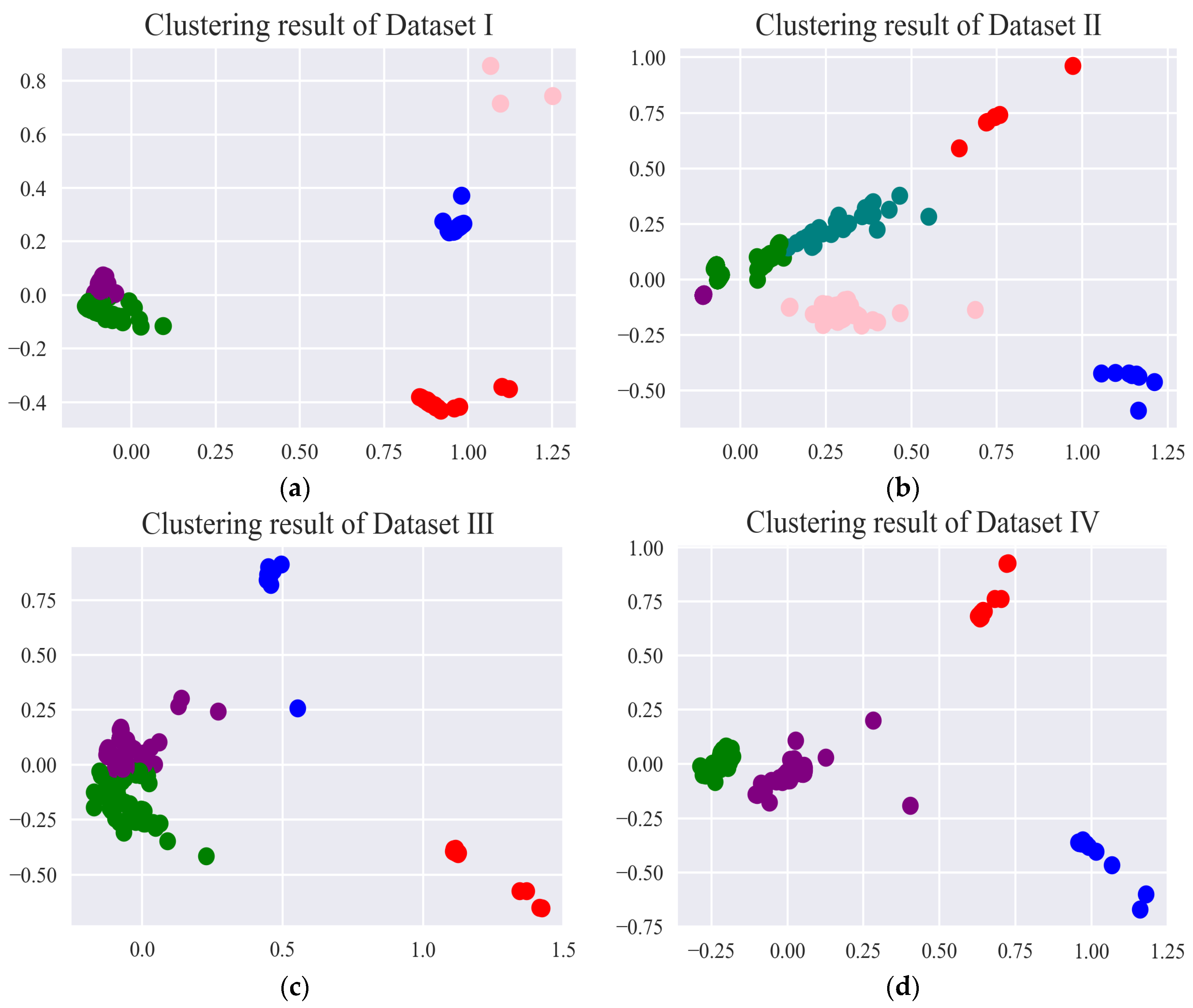
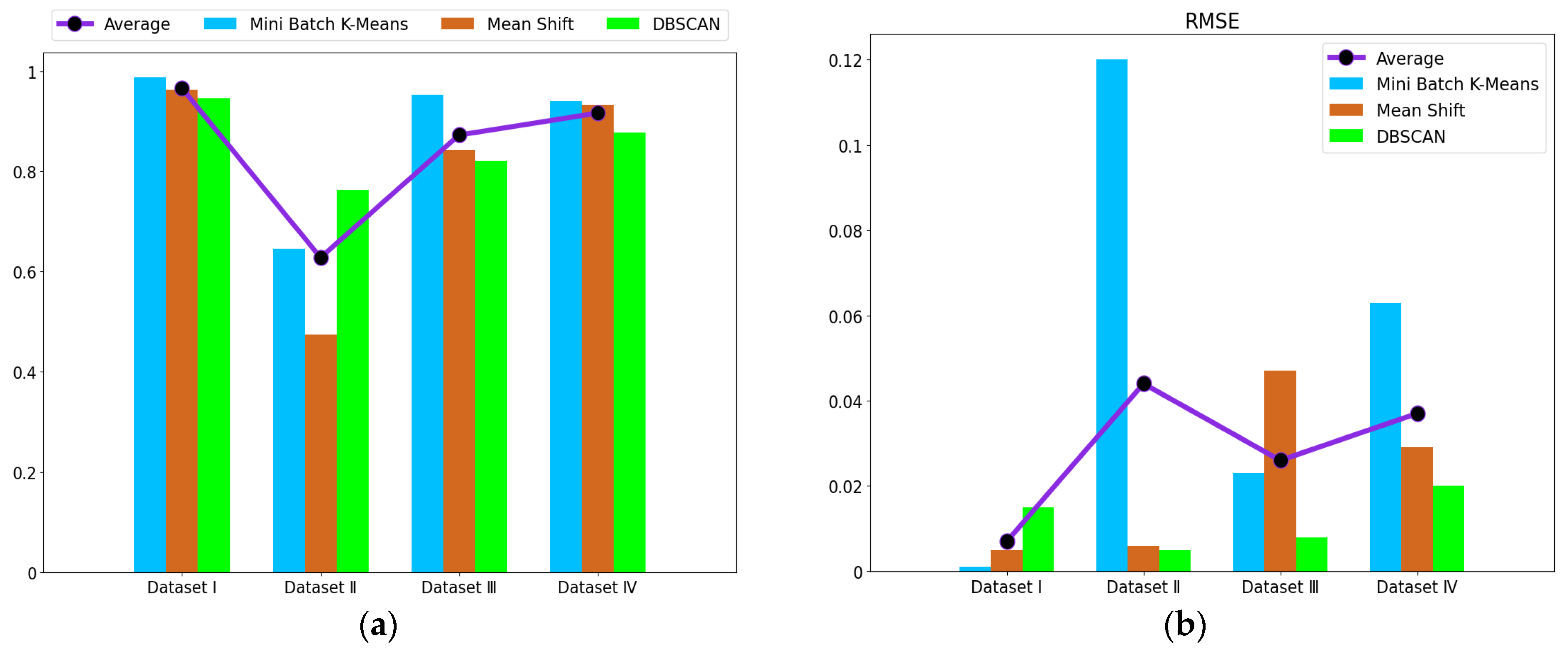
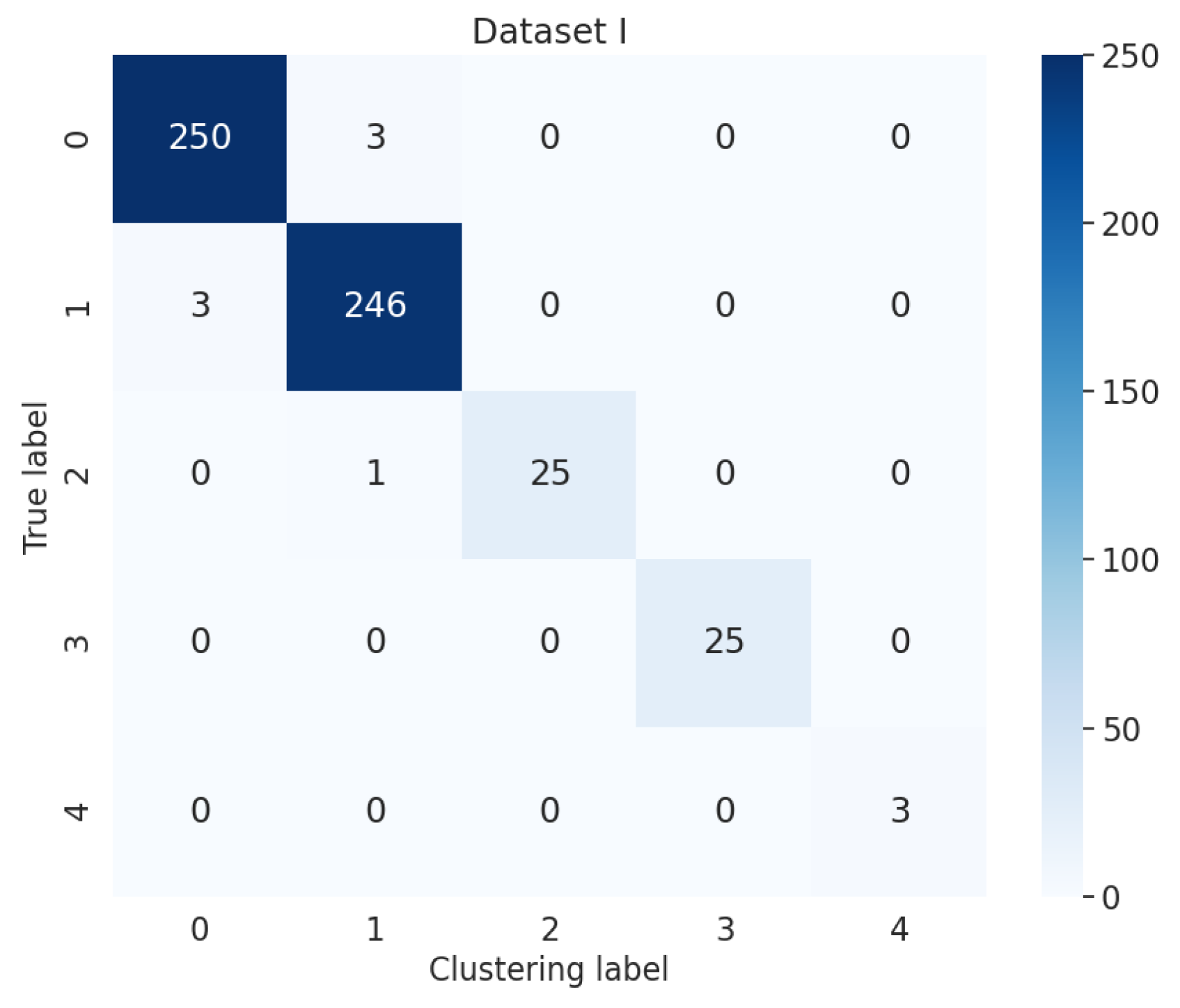
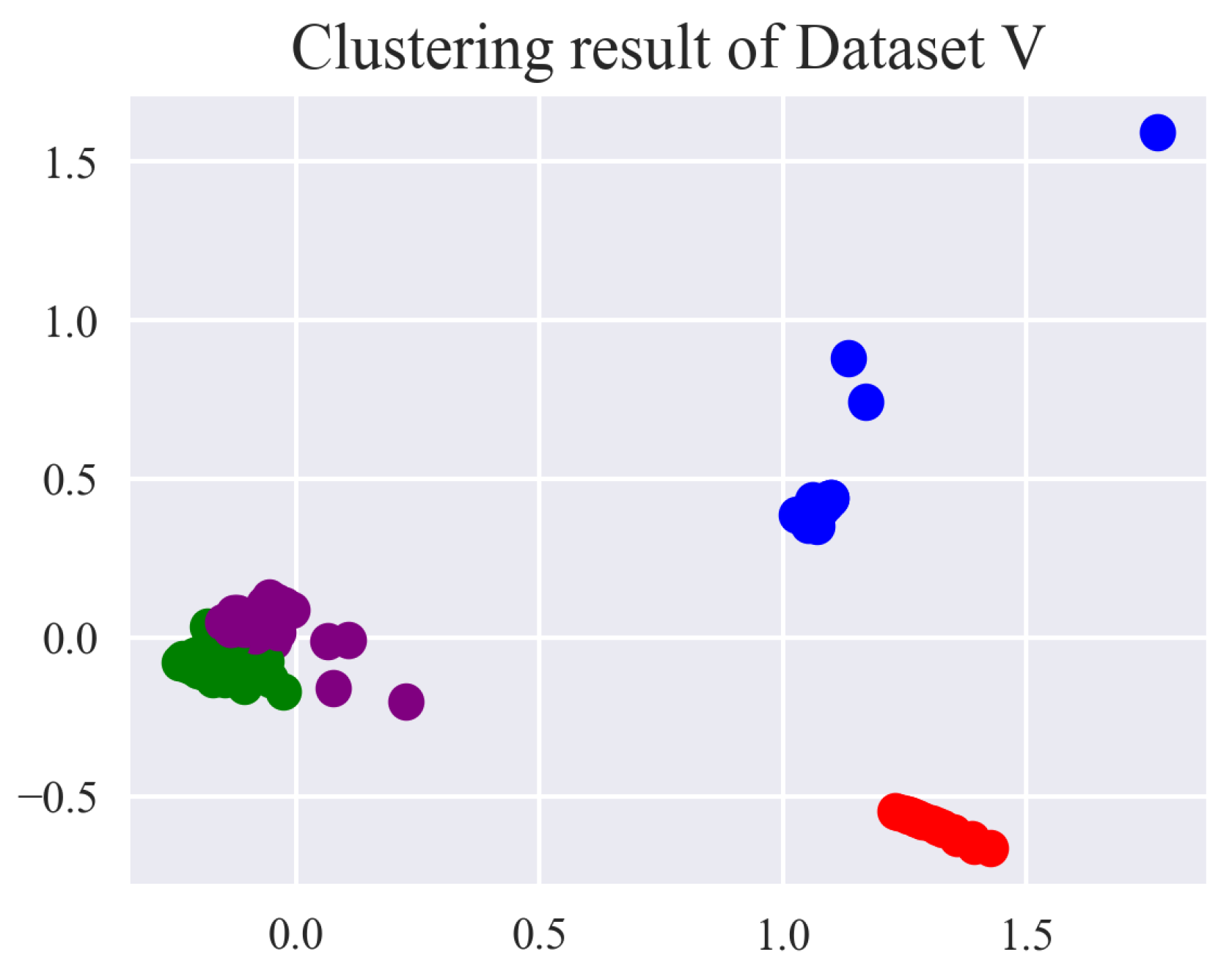
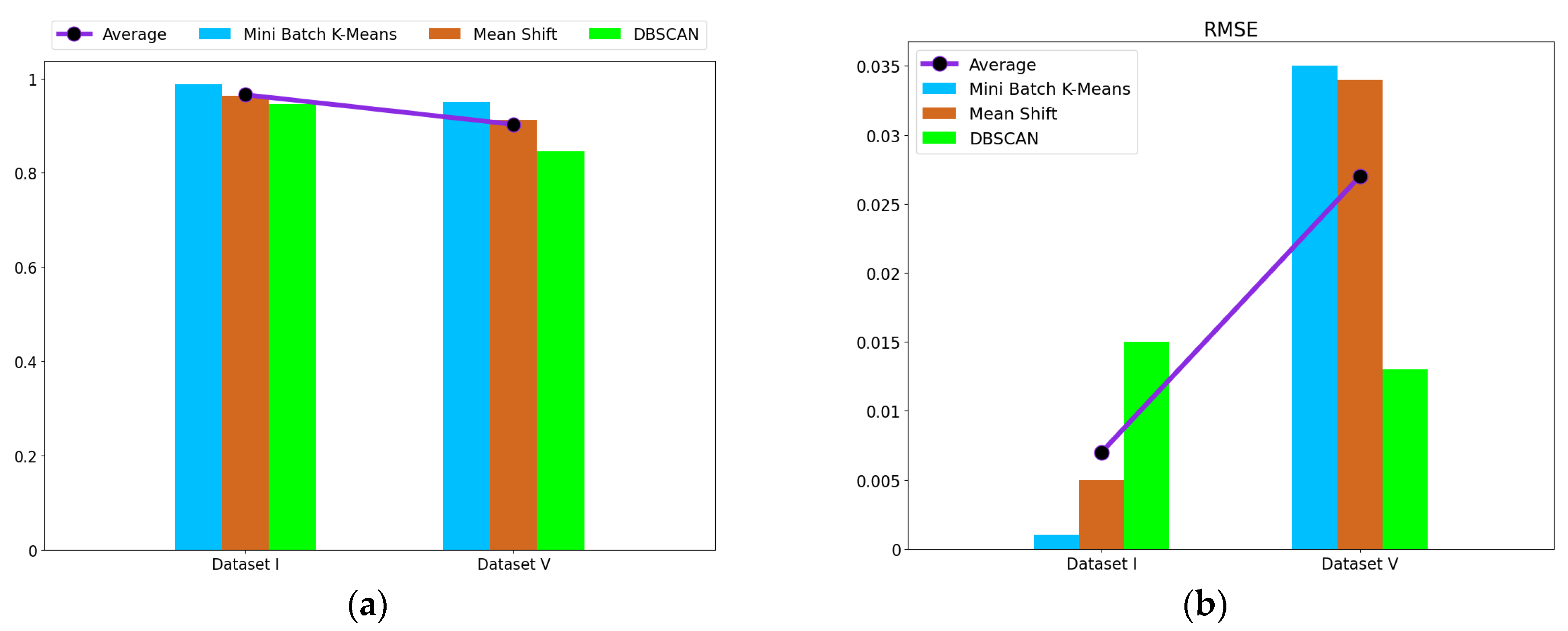
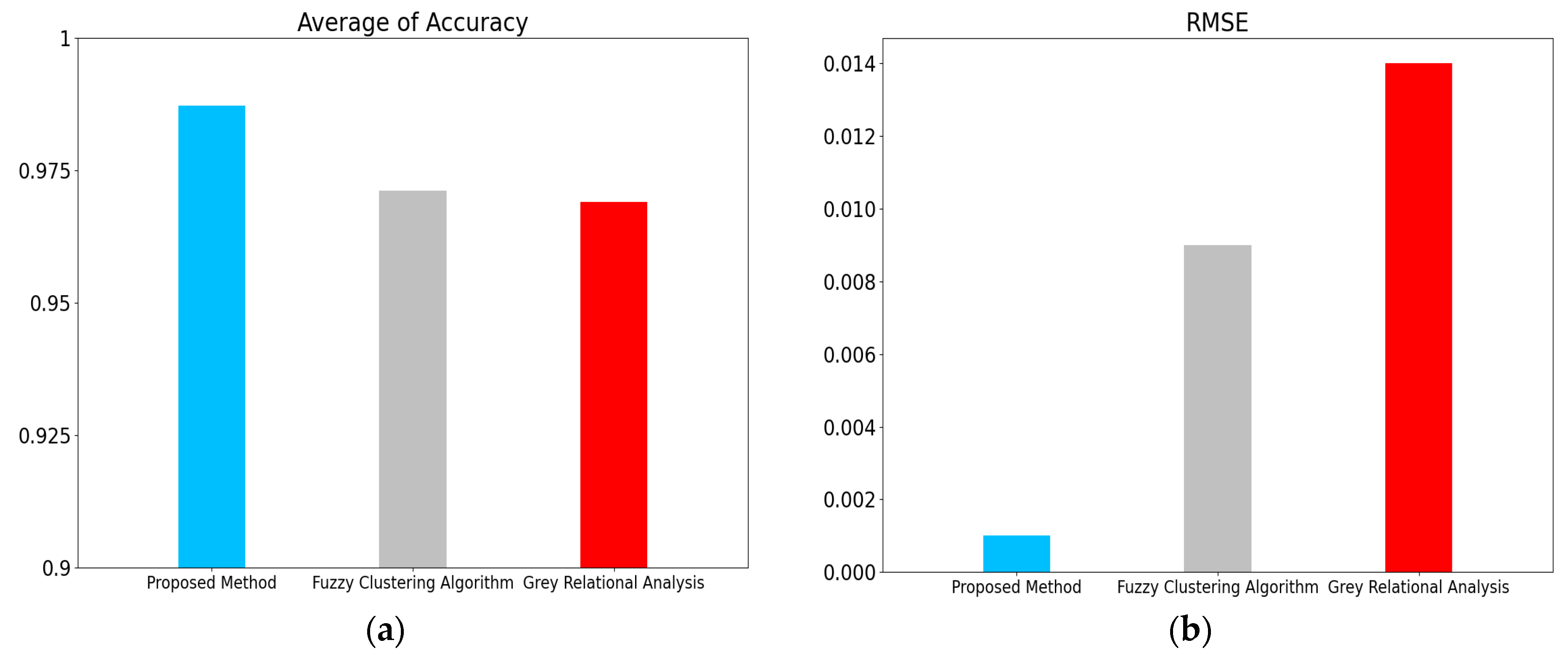
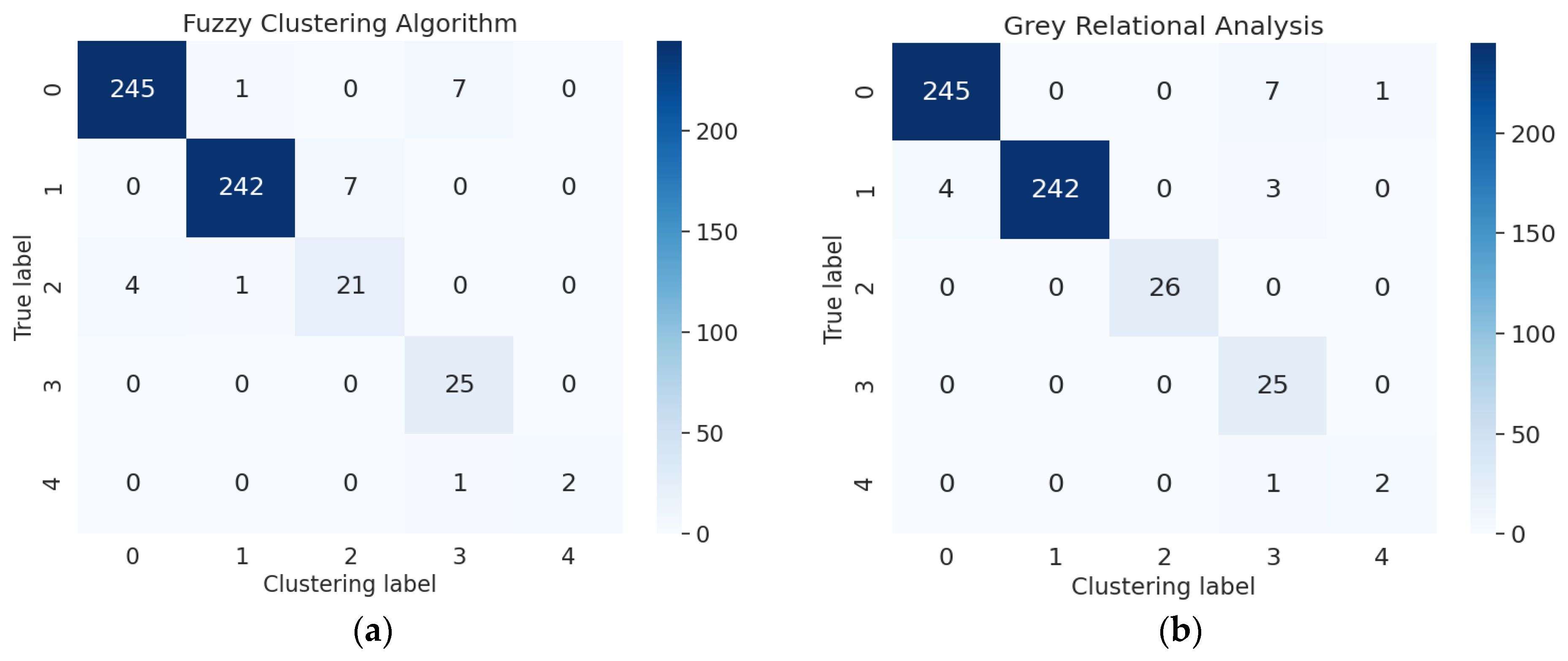
The fault detection of the electrohydraulic switch machine based on sectionalized feature extraction from the oil pressure signal during the working process was proposed in this paper. The fault detection framework for the electrohydraulic switch machine was established. First, the whole oil pressure signal was divided into three stages with the sectionalization time ratio (30%–60%–10%) according to the switching process. Five features of each stage of the oil pressure signal were computed, and the features were smoothed and normalized. Then, the mRMR algorithm was used to eliminate redundant features and derive the optimal feature set. The mini batch k-means clustering method was applied to achieve the fault detection of the electrohydraulic switch machine. The contrastive experiments verified the effectiveness and accuracy of the proposed method.
We came to the conclusion that (1) the mean, peak-to-average ratio (PAR), and impulse (IM) of the oil pressure signal interval stage were superior to other types of features for the fault identification of an electrohydraulic switch machine, whereas kurtosis (Ku) and variance (Var) did not perform as well in terms of fault clustering. (2) Moreover, the features extracted from the unlocking and locking stages outnumbered those of the conversion stage, which meant the different fault information in each stage. (3) The fault detection method proposed in this paper, which was based on the unsupervised algorithm, can realize free-label fault detection in high recognition. The proposed method can provide support for railway staff without the cost of massive sample data. The experiments verified that the proposed diagnosis method could accurately identify faults of electrohydraulic switch machines and reduce economic costs. Due to the limited fault sample data collected in this paper, we will acquire more comprehensive fault sample data as much as possible in the next step to further increase the accuracy of the method. In the future, we will improve the method to fully meet the needs of practical engineering application.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}