Abstract
Encrypting pictures quickly and securely is required to secure image transmission over the internet and local networks. This may be accomplished by employing a chaotic scheme with ideal properties such as unpredictability and non-periodicity. However, practically every modern-day system is a real-time system, for which time is a critical aspect for achieving the availability of the encrypted picture at the proper moment. From there, we must improve encryption’s performance and efficiency. For these goals, we adopted the distributed parallel programming model, namely, the message passing interface (MPI), in this study. Using the message passing interface, we created a novel parallel crypto-system. The suggested approach outperforms other models by 1.5 times. The suggested parallel encryption technique is applicable.
1. Introduction
The fast advancement of communication technology and the exchange of information across the internet, utilizing a transfer control protocol as plain text, necessitates the use of encryption to safeguard sensitive data during the transition. The term “crypto” is derived from the Greek word “kryptos”, which means “hidden or secret” [1,2]. Indeed, the use of encryption initially arose as the art of communication itself in 1900 B.C. Furthermore, encryption was designed to change a communication into an unreadable form in order to safeguard it surreptitiously while it was sent from one location to another. After many years of development, cryptography and cybersecurity have evolved in ways of encryption to add aspects to sensitive data such as secrecy, integrity, and authenticity, as is recognized by the CIA [3,4,5]. At present, cryptography includes three aspects, namely, symmetric, asymmetric, and procedural aspects [6,7,8]. From ancient times until 1976, the majority of encryption techniques were symmetric, meaning they utilized the same key for encryption and decryption. Encryption is the process of converting plain text (text that can be read) to unreadable text (written information that cannot be read; ciphertext). Decryption, on the other hand, is a process that turns unreadable text (ciphertext) into readable plain text [9]. Diffie, Hellman, and Merkle introduced asymmetric cryptography in 1976 [10]. In asymmetric cryptography, there are two keys: a public key for encryption and a private key for decryption, according to [11]. The public key may be used by anybody to encrypt data; however, the private key can only be used by the authorized individual to decode the data. Stream and block ciphers are included in symmetric ciphers [12,13]. The stream cipher algorithm encrypts bits one-by-one [14]. It appears to be tiny, speedy, and widespread in embedded devices such as GSM phones. Block ciphers, on the other hand, encrypt the entire block (several bits) which are mostly used and common in internet applications [15]. Encryption is now used in several areas, including biology, math, and physics, to secure private information during network transmission. Text and images are two examples of data types that may be sent via a network. Currently, photos are commonly used; hence, encryption is necessary to make these images safe and confidential [16]. However, one of the most difficult aspects of transferring data through a network is ensuring its security and speed. To address the first issue, a plain picture must be transformed into an encrypted image during the transition to keep the image safe from unwanted users. Picture encryption is a practical method of ensuring image confidentiality, integrity, and availability, since it encrypts digital images before storing them for transmission. The receiver cannot distinguish the original information from the encrypted picture information, and only genuine receivers or users with private cipher keys can decrypt it accurately and successfully. The classical and traditional encryption algorithms cannot achieve this level of security for images, and they also have a low security level when used for image encryption. However, chaos theory, which was used in physics, mathematics, biology, and engineering until the 1980s, and which became the foundation of cryptographic applications, was regarded as a good and, in fact, the best choice to permute each pixel in the image and convert it to a scrambled image that can resist statistical attacks [17]. The development of fifth-generation (5G) wireless networks is gaining traction, with the goal of connecting practically all parts of life via a network with substantially faster speed, very low latency, and pervasive connections. Because of its importance in our lives, the network must protect its users, components, and services [18]. The sensitivity to beginning circumstances, ergodicity, pseudo-randomness, unpredictability, topological transitivity, and parameter changes contribute to the strength of chaos encryption. However, this sort of security takes a long time to process and send pictures over a network [19]. In order to accomplish speed, increase efficiency, provide time gain, and minimize transaction costs, strong hardware architectures are used by leveraging parallelism as an alternate approach to process data. Speed, particularly in information technology, has now become a crucial component affecting many facets of our lives, even in this period dubbed “the age of speed”. As is well-known, the chaos encryption process is the greatest way to ensure security, particularly for images; yet, the sophisticated structure of chaos, as well as the enormous number of iterations and rounds inside its internal states, makes it slower than other encryption algorithms as a result of the preceding and of the critical requirement for an efficient system that can be utilized to encrypt pictures and video. In this research, we suggested a new parallel encryption system based on chaotic maps and the message passing interface to efficiently encrypt pictures and video. This system may be designed to achieve a high level of security while still providing great encryption performance. The remainder of this work is structured as follows. Section 2 examines some of the linked literature. Some parallel programming approaches are shown in Section 3. Section 4 puts the experimental results to the test. Section 5 examines the performance of a novel algorithm. Finally, in Section 6, we will go through the findings.
2. Related Work
Encryption algorithms are mathematical procedures that are used to conduct encryption by utilizing two inputs: plain text and a secret key. Effective encryption techniques are required to secure sensitive data and keep them private. Following are several algorithms and publications that are typically related.
2.1. Stream Ciphers Algorithms
Many stream cipher algorithms, such as Salsa 20, Rabbit, and HC-128, have been studied in the literature. Salsa20/r is one of Daniel J. Bernstein’s stream encryption algorithms, where r = 8, 12, or 20, which is the number of iterations of the round function. The Salsa algorithm may employ cryptographic keys of 128, 192, and 256 bits, according to [20]. To create 512 internal states, a 64-bit nonce (unique message number), a 64-bit counter, and four 32-bit constants are utilized. A keystream output of 512 bits is considered. Each output block comprises a unique combination of the key, nonce, and counter. Because there is no chaining between blocks, Salsa20/r operates in the same way as a block cipher in counter mode. Salsa20/r generates keystreams with a maximum length of 270 bits. Rabbit, on the other hand, is a stream cipher that was invented in 2004. It is thought to be one of the most effective and sophisticated algorithms. It requires a 64-bit nonce and a 128-bit key as input. After each repetition, it produces a 128-bit result. Its encryption comprises of 513 internal state variables, eight 32-bit counters, and one counter carry bit [21]. It is resistant to a wide range of attacks, including algebraic, correlation, and statistical attacks. Differential fault attacks, on the other hand, were found in 2009. The HC-128 stream cipher algorithm has a 128-bit key and a 128-bit instantiation vector (IV). Its internal state is divided into two tables, each of which includes 512 registers of 32-bit length, and one of which is created by a nonlinear output function; each register is updated in 1024 steps [22]. The HC-265 variant has a 256-bit key length and varies from the HC-128 in that the table size is 1024 32-bit elements rather than 512 32-bit elements.
2.2. Related Papers
Abutaha explains and presents a stream cipher method based on chaos theory in his paper [23]. He creates a new chaotic stream generator [24] with the goal of generating a keystream in order to use the key as the primary component of the encryption technique. His chaos generator structure is made up of an instantiation vector, a key setup, nonvolatile memory, and an internal state that creates the output function as the keystream. Its internal state consists of two recursive cells, each of which includes one of two chaotic maps based on mathematical equations such as the skew tent map (ST) and the piecewise linear chaotic map (PWLC), as well as a linear feedback shift register as a perturbation approach. In addition, he implements this generator in a sequential version and a parallel model based on a shard memory architecture using the Pthread library, but his results show that using a shared parallel model with Pthread is only suitable for large datasets, whereas small datasets are not suitable for Pthread. In his paper [25], Dariusz describes a parallel technique based on OpenMP that parallelizes a block cipher based on a spatiotemporal chaotic system and a chaotic neural network. He demonstrates that the use of a multicore and multiprocessor may minimize the encryption and decryption times; moreover, his experimental results suggest that time-consuming loops inside the function can be parallelizable. In their paper [26], with a chaos-based encryption scheme based on the logistic map and Fibonacci sequence that is used to convert the logistic map into an integer value, Lui et al. demonstrate the chaos algorithm in both sequential and parallel versions depending on the message passing interface (MPI) using a master/slave communication model through using the master to initialize the parameter, logistic map, and Fibonacci sequence. This methodology is appropriate for the encryption and decryption of sensitive data or multimedia. Ünal Çavuşoğlu et al., in their paper [27], developed a new random number generator (RNG) and a chaos-based parallel encryption algorithm for increasing both the security and speed; they used a parallel data encryption model by dividing an image into the number of used threads and encrypting each part with a separate thread. The partitioning process is computed according to a different number of threads for an image with the size of m columns and m rows, and the rows are divided by the number of threads to obtain n parts of equal size for processing in each thread. The keyspace size of their generated algorithm is in the parallel version, instead of in the sequential version, according to the use of different initial conditions for each thread. Amany Elrefaey et al. [28] demonstrate a parallel implementation of chaotic-based picture encryption that is dependent on two phases required for chaotic-based image encryption processes: replacement and diffusion. They established a parallelization notion on the Baker method by employing a vectorization form and approach, rather than a loop in the sequential version, by generating a map table just once that maps the new pixel position to the previous pixel position. This table remains the same during all replacement iterations. They accomplished parallelization in the diffusion idea by developing a modified method that divides the picture into n similar-sized divisions and executes the encryption operation on each component individually in parallel, utilizing multiple processor cores. Massod et al. [13] suggested a new system that is computationally less costly and provides a greater degree of security. The system is built on a shuffling process, using fractals as the key as well as a three-dimensional Lorenz chaotic map. The shuffling procedure applied the confusion attribute and jumbled the pixels of the standard picture. A three-dimensional Lorenz chaotic map is utilized for a diffusion process that distorts all of the image’s pixels.
Massod et al. [29] suggested a lightweight cryptosystem to encrypt medical pictures with enhanced security based on a Henon chaotic map, Brownian motion, and Chen’s chaotic system.
In the next part, we will look at several parallel programming paradigms and multiprocessor architectures.
3. Parallel Programming Models and Techniques
In the 1980s, CPU manufacturers such as Intel and AMD enhanced the speed of their computers by expanding the hardware design and increasing the number of transistors for each processor, in order to achieve high performance. This transitional period lasted until the mid-1990s and the beginning of the 2000s. When the clock rate increases, they approach a physical limit created by inhibiting the CPU’s ability to cool itself. Manufacturers boost performance by designing a new CPU architecture with several cores that can accept various instructions and data streams (MIMD). The concept of existing multi-core architecture is based on the idea of utilizing all of these cores by employing parallel programming techniques. The parallel programming paradigms are determined by the hardware architecture, which is either shared memory or distributed memory. Both architectures share the same concept of breaking work down into such units and assigning these units to each core to process individually. All control units (CU) and processing units (PU) are shared with a single memory in a shared memory architecture. In distributed memory, however, each processing unit and control unit has its own local memory that is totally connected via the interconnection network. The need for high speed and high performance of hardware systems, in many aspects, such as artificial intelligence, IoT, real-time applications, video conferencing, and video-on-demand, has led programmers to search for and rely on another way of programming that paved the way to solving problems that concurrent programming encountered consistently. Parallel programming is an alternate option that interfaces directly with hardware to give the required application with great speed and efficiency. Parallel programming appears to be the greatest technique to fully utilize all available resources and processors in order to provide high-speed performance. This style of programming may be used to address mathematical problems in many scientific fields. Parallel programming models and techniques are divided into two categories: shared memory and distributed memory. OpenMP and Pthread are examples of shared memory models, whereas message passing interfaces are examples of distributed memory models. OpenMP is a Fortran and C/C++ application program interface (API). It takes a user program and breaks it down into threads that run on a shared memory basis. OpenMP is a cross-platform program that may operate on any operating system, including UNIX, Linux, and Windows [30]. OpenMP is made up of compiler directives, runtime libraries, and environmental libraries. Pthread, on the other hand, is a library that can be linked with the C/C++ programming languages. It is not a programming language in the same way that Python or Java are. It was sometimes referred to as a POSIX thread [31]. A standardized extension exists for Posix threads (IEEE Std 1003.1c-1995). Thread management-creating, joining threads, and so on, are some of the numerous processes performed by POSIX threads. Mutexes, condition variables, and thread synchronize through read/write locks and barriers, unlike MPI, which stands for message passing interface [32]. MPI communicates with other languages such as C/C++ and FORTRAN. MPI is widely regarded as one of the most essential programming languages for utilizing distributed memory architecture. It is almost as though another language has its own data type and function. To communicate between two processors, the first executes a send operation, while the second receives an operation. MPI has several implementations, including MPICH, MPICH2, and OpenMPI. MPI is now binding to other languages by enclosing MPI implementations in other languages such as Java, MATLAB, and Python. In this work, we concentrate on a parallel distributing model based on a message passing interface model, since it has a better capacity to accelerate performance when compared to other parallel models.
4. Proposed Parallel Chaos Crypto System
The new technique is heavily reliant on two non-recursive filters (skew tent map and PWLC map), which provide randomization and non-periodicity. Because chaos is sensitive to beginning circumstances, increasing the unpredictability will increase the randomness. The beginning circumstances of our algorithm are drastically modified in each iteration. In order to improve a chaotic generator’s efficiency and computing performance, we use MPI for each cell of the non-recursive filter, which allows each cell to function in its own memory space, separate from the others, as seen in Figure 1 and Figure 2. Each process will execute each cell individually, as shown in Algorithm 1 and Figure 2. The system begins by taking a clear image as an input and then converts it into bytes by splitting the image into divisions of four bytes. We add padding if we are unable to split the picture into four-byte chunks. The MPI environment was set up to apply MPI to each recursive cell in order to achieve the required parallel suggested system by distributing the amount of processors and cores evenly to the PWLC and skew tent chaotic maps by calling them concurrently. The result of the two maps is then XOR together to form four bytes. These procedures are continued until the number of created keystream sequences equals the amount of plain image bytes. Finally, encryption is performed for every four produced sequences, with each sequence containing four bytes of keystreams. Those 16 bytes of keystream will XOR with the plain image’s 16 bytes. This technique is continued until the entire image is encrypted. Because the stream cipher is a symmetric encryption technique, decryption follows the same steps as encryption. First, we construct the four bytes’ combination of the encrypted picture. The chaotic generator is then used to produce the same key streams using the same secret key. Finally, the picture is decrypted by XORing the four-byte combinations with the key streams.
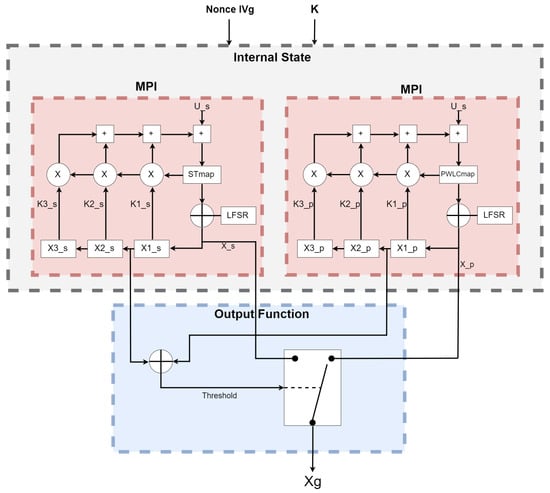
Figure 1.
Proposed parallel chaos generator.
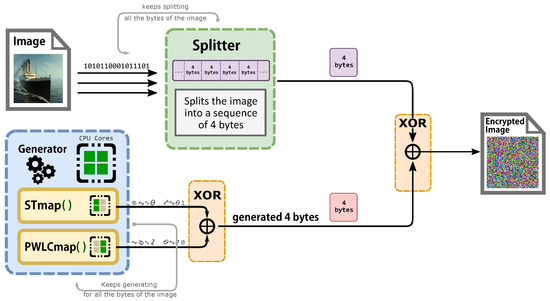
Figure 2.
Description of the architecture of the parallel proposed cryptosystem.
The equations of the discrete skew tent and the discrete PWLCM maps are, respectively, given by [24]:
Discrete Skew Tent Map:
Discrete PWLCM map:
The values produced by the recursive cells in the internal state are entered to the output function. Then, the output sequence is obtained by XORing and , as clarified in Equation (3):
| Algorithm 1 PARALLEL IMAGE CHAOS ENCRYPTION ALGORITHM |
| Input: clear image Output: Scrambled Encrypted image
|
Based only on the process ID, the MPI system advises each process on which portion of the global problem they should be working on. Large amounts of data, as well as load balancing across processors, need the usage of both point-to-point and group communication. The goal behind employing point-to-point communication is to distribute data over two or more processors in accordance with the computer and workstation specifications. Rather than concentrating all processing power and labor in one location, as indicated in Figure 3, the message contents are transferred to a system-controlled block of memory. Process 0 continues to perform additional tasks without pause. When process 1 is finished, it reads the message from the remote system buffer and puts it in the proper memory address. The suggested approach divides the burden of bits over several cores utilizing MPI, which will raise the average bit rate and lower the number of cycles per byte of data. In general, there are two distinct techniques for using ILP. The first technique depends on hardware to assist, detect, and utilize parallelism dynamically, whereas the second, as in our proposed research, focuses on software technology to find parallelism statically at the compile time. The suggested parallel chaos cryptosystem intends to eliminate reliance on data, names, and controls. We can eliminate data reliance by changing the code and reordering or scheduling the instruction with worries that ordering does not have an effect, resulting in unwanted outcome. We handle this problem by utilizing distinct objects, rather than relying on a single common item, according to the naming dependence.
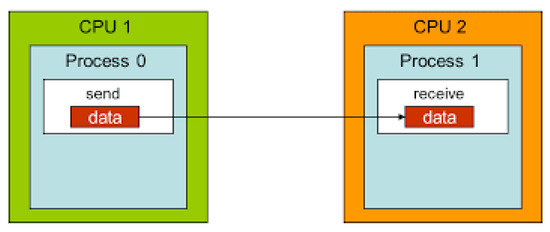
Figure 3.
Point-to-point communication.
5. Performance Computation of Proposed Parallel Computing
We conduct various tests on two computers to calculate and assess the performance of the proposed parallel cryptosystem based on MPI. The first features an Intel Core i3 (TM) processor running at 1800 GHz and 4 GB of RAM, while the second has an Intel Core i5 (TM) processor running at 2400 GHz and 4 GB of RAM. As a trustworthy Linux version, we operate the parallel cryptosystem on Ubuntu 18.04. In these tests, three metrics are taken into account: the number of cycles required to create one byte (cycle/byte), the generation time in microseconds, and the rate at which bits are transported in megabits per second (Mbit/s), as clarified in Table 1, Table 2, Table 3 and Table 4.

Table 1.
NCpB for sequential, Pthread, and MPI implementation on two cores.
Table 2.
Generation time for sequential, Pthread, and MPI implementation on two cores.
Table 3.
Performance results comparison of the stream cipher algorithms.
Table 4.
Bit rate for sequential, Pthread, and MPI implementation on two cores.
As seen in Table 1, the number of cycles per byte decreases quicker in MPI as compared to sequential and parallel implementations because MPI uses all parallelisms. Cores can handle both tiny and big amounts of data by distributing and balancing the load evenly among all processors. As indicated in Table 1, NCBP is 44.9 when the data size is modest, such as 2048 bytes in MPI, but 155.9 and 82,950 in sequential and Pthread. When using MPI on huge data sets such as 3,145,278 bytes, the NCPB in MPI is 22.2, whereas the NCPB in seq and parallel is 32.0 and 36.3, respectively. As a consequence of the results, we believe that employing MPI in our cryptosystem is the quickest model in small and large image sizes. In contrast to Table 1, which indicates the number of cycles, Table 2 gives the average time of the chaos generator in both sequential and parallel modes. According to the findings, the average time of a parallel chaos generator based on MPI implementation is less than that of a sequential chaos generator and a parallel chaos generator based on a shared memory architecture (Pthread implementation). That is, MPI uses all of its core parallelism by distributing memory to each core, which works independently of the others. When tiny data is entered into the generator, such as 128 in MPI, the average encryption duration is 11 cycles, whereas the sequential and Pthread versions take 38 and 1389 cycles, respectively. However, when huge amounts of data are entered into the cryptosystem, such as 3,145,728 bytes, the average generation time in MPI is 119,640, but the average generation time in sequential and Pthread is 162,322 and 133,493 microseconds, respectively. As is well-known these days, time is a significant component in determining the efficiency and availability of software programs; so, employing MPI as a parallel model is the ideal option for reducing time and increasing availability by encrypting pictures. As shown in Table 4, which illustrates the result of bit rate, which is the number of bits processed in a unit of time, the bit rate in MPI is 862.32 when the data is 512, while the bit rate in sequential and Pthread implementation is 156.04 and 14.95, respectively. When the size is increased to 3,145,728, the bit rate is 864.79, whereas the bit rate in sequential and Pthread implementation is 620.14 and 754.07, respectively. Why is the bit rate being increased? When compared to other implementations, MPI has a good communication system that allows the processors to communicate and transmit data among themselves, allowing MPI to have the greatest encryption bit rate in both small and huge data.
Nonetheless, when the data is 3,145,278 bytes, the NCpB in MPI is 13.2 and in Pthread is 19.2 and 16.7, respectively as shown in Table 5.
Table 5.
NCpB for sequential, Pthread, and MPI implementation on four cores.
When applying generation time results on a computer that has four cores, the result, as reported in Table 6, demonstrates that the generation time decreases proportionally with an increasing number of processors. The generation time In MPI is 13, in contrast to the sequential and Pthread implementations, for which the generation times are 40 and 1143, respectively, when the data contains 256 bytes. However, when the data contains 3,145,728 bytes, the generation time is 69,631, but the generation time in sequential and Pthread is 97,584 and 80,568, respectively. As noted from Table 7, which reported the result of the bitrate on a computer that has four cores, that experimental result shows that the bitrate is increasing proportionally with an increasing number of processors on a workstation. The bitrate in MPI is 1103.5 when the data is 4096 bytes, in contrast to the sequential and parallel implementation, whose bit rates are 341.33 and 16.32, respectively. For 196,608-byte data, the bit rate in MPI is 1434.06. However, in Pthread and sequential, the bit rates are 1077.63 and 366.88, respectively. As illustrated in Table 3, this demonstrates a performance comparison result between the stream cipher algorithms and our proposed algorithm. We implement this data by encrypting the Lena image three times, each time with a different size. The result shows that the performance increases in MPI, compared to the others, with an increase in the size of data. Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9 show the curves that depict the NCpB, generation time, and bit rate measurements either in two or four cores for the sequential, Pthread, and MPI implementations.
Table 6.
Generation time for sequential, Pthread, and MPI implementation on four cores.
Table 7.
Bit rate for sequential, Pthread, and MPI implementation on four cores.
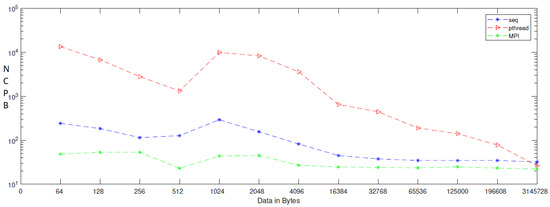
Figure 4.
NCPB for sequential, Pthread, and MPI implementation on two cores.
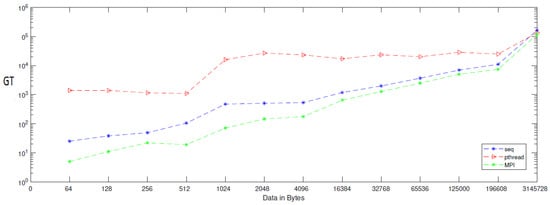
Figure 5.
Generation time for sequential, Pthread, and MPI implementation on two cores.
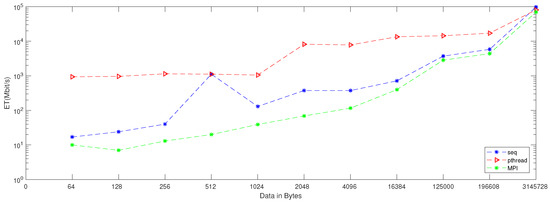
Figure 6.
Bit rate for sequential, Pthread, and MPI implementation on two cores.
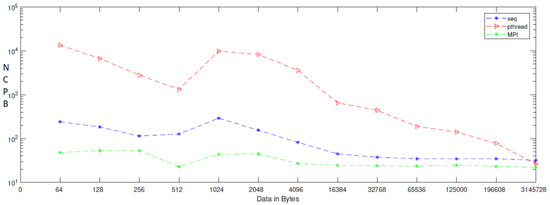
Figure 7.
NCpB for sequential, Pthread, and MPI implementation on four cores.
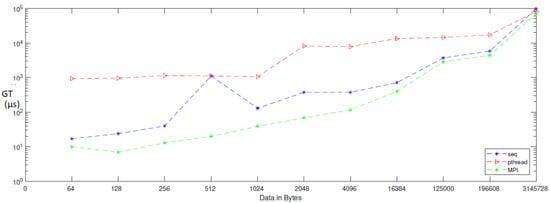
Figure 8.
Generation time for sequential, Pthread, and MPI implementation on four cores.
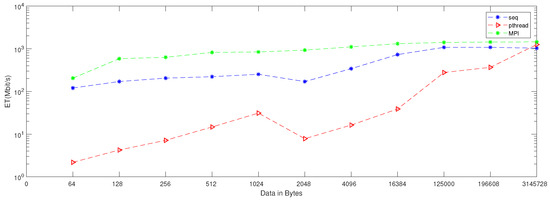
Figure 9.
Bit rate for sequential, Pthread, and MPI implementation on four cores.
5.1. Speed-Up Calculations
The term ”speed-up” refers to the measuring of parallel code in terms of how much quicker it executes in parallel. Assuming that the time to execute code on one processor is time_seq and the time to run code on N processors is time_parallel, the speed-up is provided in Equation (4) [33]:
For assessing bit rate enhancement, divide the bit rate in parallel by the bit_rate in sequential, as shown in Equation (5):
The enhancement of a number of cycles per byte can be given as shown in Equation (6):
Our results are for the performance shown in Figure 10. The Figures clarified that the performance is better when we applied our algorithm in four cores.
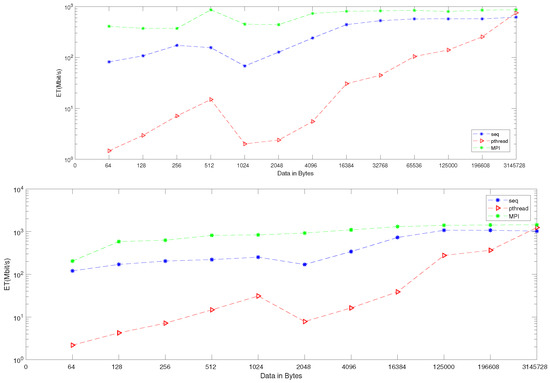
Figure 10.
Bit rate enhancement on two and four cores: the upper figure represents two cores, and the lower figure represents the four-core enhancement.
5.2. Amdahl’s Law
Amdahl’s law is used to compute an upper bound on the speed-up of an application without actually writing any concurrent code. Each uses the percentage of (proposed) parallel execution time (pctPar), serial execution time (1-pctPar), and the number of threads/cores (p). A simple formulation of Amdahl’s law to estimate the speed-up of a parallel application on p cores is given here [34]:
In our case, we expect 45% of a serial application’s run time could be executed in parallel on four cores; the estimated speed-up, according to Amdahl’s Law, could be as much as (1/(0.55 + 0.45/4) = 1.50943396226). We expect an increase in overhead with an increasing number of cores that will appear, especially, when the number of processors is more than eight.
6. Security
In this section, we will discuss the security analysis of the parallel proposed cryptosystem against cryptanalytic and statistical attacks.
6.1. Keyspace
As we know in encryption, the larger keyspace algorithm has a strong ability to resist a brute-force attack, in contrast to algorithms that have a small keyspace and that suffer from a lack of sequence randomness. The proposed cryptosystem has a different keyspace according to the selected delay. The keyspace in delay = 1 is nearly 299 bits; however, in delay = 3, the keyspace reaches 555 bits. This numerous keyspace makes the proposed cryptosystem immune to brute-force attacks. Table 8 lists the size of the keyspace of similar chaotic algorithms. As clarified in Table 8, our algorithm’s keyspace in delay 3 is 555 bits; it seems to be the largest one, compared to the listed algorithms.
Table 8.
Keyspace comparison of similar algorithms.
6.2. Key Security and Sensitivity Attack
To test the key sensitivity of our proposed cryptosystem, we use two important measurements: the number of pixel change rate (NPCR) and the unified average changing intensity (UACI). These show that the proposed cryptosystem is very sensitive to a one-bit change that occurs when we encrypt the “Lena” image more than 100 times with 100 secret keys that differ in the LSB bit.
where:
and the UACI that is used to measure the average intensity difference between the two ciphered images can be defined as follows:
In the prior Equations (11)–(13), L, C, and P are the height, width, and plane sizes of the image, respectively. i, j, and p are the rows, columns, and plane indexes, respectively. As the results in Table 9 show, the NPCR and UACI values of the proposed cryptosystem are close to the optimal NPCR and UACI values, 99.61 and 33.46, respectively [40].
Table 9.
NPCR and UACI measurements.
6.3. Information Entropy
The entropy E(X) is statistical measure of uncertainty in information theory [50]. It is defined as follows:
where X is a random variable and is the probability of the gray value . Let us consider that there are 256 states of the information source in red, green, and blue colors of the image, with the same probability. We can obtain the ideal E(X) = 8, corresponding to a truly random source. As noted from Table 10, the information entropy of some ciphered images, such as Titanic, Photographer, Manhattan, Cameraman, Lena, and Boat, is closer to 8. The entropy of all ciphers is closer to 8, which proves that the ciphered image is a random dataset of pixels.
Table 10.
Information entropy of some ciphered images.
Table 11 provides the contrast data with other advanced schemes by comparing the information entropy in our proposed scheme with other advanced algorithms. The result has shown that our proposed scheme has greater superiority in information entropy, compared to the other algorithms.
Table 11.
Information entropy comparison.
7. Statistical Analysis
7.1. NIST Test
The NIST statistical test suite, which is proposed by the National Institute of Standards and Technology, includes 15 tests that concentrate on different types of non-randomness that could be in a sequence. These tests are cumulative sums (forward), the longest run of ones, cumulative sums (reverse, non-overlapping templates, block-frequency, frequency (mono bit), runs, rank, FFT, overlapping templates, random excursions variant, approximate entropy, serial 1, serial 2, and universal. In order to investigate the randomness of binary data, we apply NIST [51] to many ciphered texts, and the results show that the ciphertext has a high rate of randomness, as shown in Figure 11 and Table 12 [52].
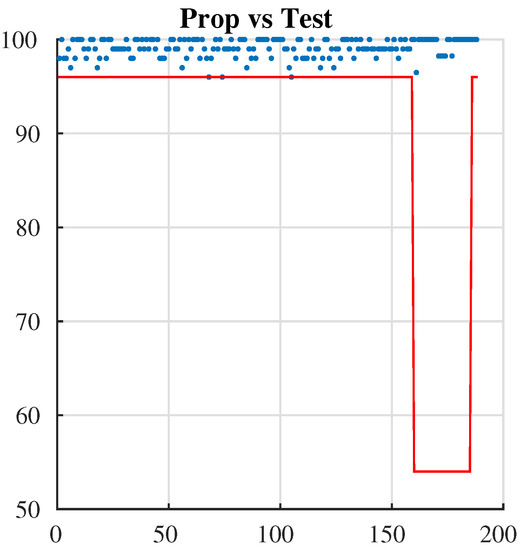
Figure 11.
NIST test.
Table 12.
Nist test values.
7.2. Chi-Square Test and Histogram
In order to resist potential and statistical attacks, we apply a histogram, which represents the distribution of pixels in specific images. It is a measure to test the uniformity of a ciphered image. Whenever the histogram in a ciphered image is uniform, the image has more immunity against statistical attacks. For this purpose, we apply the histogram for many pictures and, as seen from Figure 12 and Figure 13, the histogram of the ciphered image is uniform, compared with its plain image.
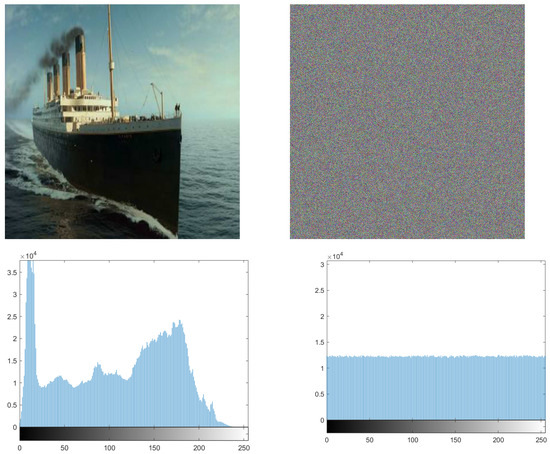
Figure 12.
Histogram of the Titanic plain image and its ciphered image.
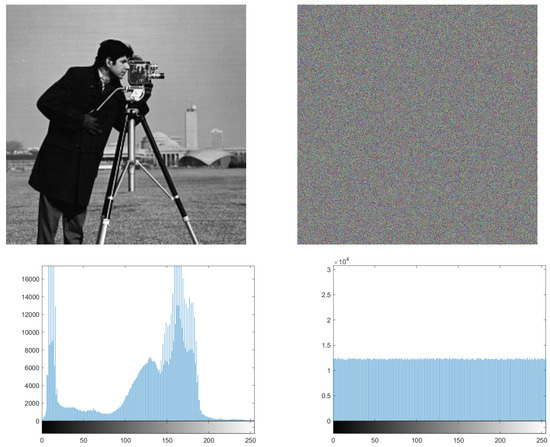
Figure 13.
Histogram of the Photographer plain image and its ciphered image.
Equation (10) is used to perform the Chi test, where K is the number of levels (here ), Oi is the observed occurrence frequency of each color level (0–255) on the histogram of the ciphered image, and Ei is the expected occurrence frequency of the uniform distribution, given here by . For a secure cryptosystem, the experimental chi-square value must be less than the theoretical chi-square one, which is 293 in the case of and K = 256. In Figure 12 and Figure 13, we give the histograms for the plain/ciphered images for Lena, Boat, Cameraman, and Peppers in size . As we can see, the histogram of the ciphered image seems to be uniform. To assess the uniformity, we performed the chi-square test. The experimental value obtained is less than the theoretical one at 293. This means that the histograms are uniform (see Table 13).
Table 13.
Chi-square value of histograms for different ciphered/plain images with different sizes.
8. Correlation Analysis
The correlation test is an important test, especially in the encryption field, owing to the importance of hiding information from an attacker, and keeping the attacker from deciphering plain-text information from the ciphered text. Thus, in order to achieve security, the correlation of the proposed cryptosystem should be as low as possible. We apply this test by taking 10,000 adjacent pixels from the plain image and the ciphered image, and use them as inputs in Equations (13)–(15).
In the previous equations, is the correlation coefficient of two sequences x and y. xi and yi are the values of x and y, respectively. For proving that the ciphered image is completely different from the original image, we used a correlation analysis of adjacent pixels for both the ciphered and original image. As the result clarified in Figure 14 shows, adjacent pixels in the plain image are redundant and correlated; however, adjacent pixels in the ciphered image are nearly completely different, and seem to have redundancy and correlation as low as possible (Figure 15). This is more proof that shows that our proposed system has immunity against statistical attacks.
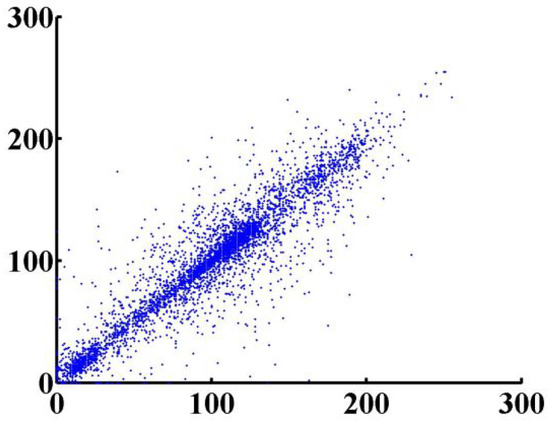
Figure 14.
Adjacent pixels for plain image.
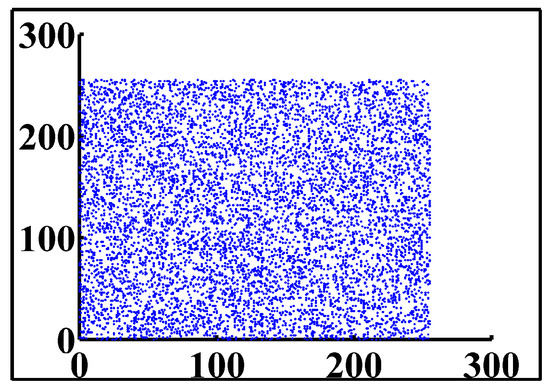
Figure 15.
Adjacent pixels for ciphered image.
The correlation coefficient values for all previously tested plain/ciphered images are given in Table 14. As we expected, these results conform to those found in the literature.
Table 14.
Correlation coefficient values for the previous plain/ciphered images.
9. Conclusions
We created a parallel chaos generator based on the message passing interface that we consider to be the fastest chaotic stream encryption model due to its generic, random, and non-periodic structure. The proposed system is quicker than previous parallel systems that rely on Pthread or sequential systems. Furthermore, we use a variety of tests on the cryptosystem to assess its efficiency, speed, and security, including the Chi-square and histogram, NIST, correlation analysis, and information entropy tests. All of the tests demonstrated that the proposed cryptosystem is resistant to brute-force and statistical attacks. In addition to the previously mentioned traits and benefits, the results demonstrate that the sequence created by the proposed parallel cryptosystem has a significant degree of unpredictability or uncertainty. Finally, we completed the research objectives by developing a system that combines security and performance. We can adapt our approach to be utilized in video encryption in the future.
Author Contributions
Methodology, M.A.; Project administration, M.A.; Resources, S.A.; Software, I.A.; Supervision, M.A. and S.A.; Validation, S.A.; Writing—review & editing, S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
The authors are grateful to the Deanship of Scientific Research at King Saud University for funding this work through the Vice Deanship of Scientific Research Chairs: Research Chair of New Emerging Technologies and 5G Networks and Beyond.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Venkateswaran, R.; Sundaram, V. Information Security: Text Encryption and Decryption with poly substitution method and combining the features of Cryptography. Int. J. Comput. Appl. 2010, 3, 28–31. [Google Scholar] [CrossRef]
- Damico, T.M. A brief history of cryptography. Inq. J. 2009, 1, 1/1. [Google Scholar]
- AbuTaha, M.; Farajallah, M.; Tahboub, R.; Odeh, M. Survey Paper: Cryptography Is the Science of Information Security. 2011. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.227.7620&rep=rep1&type=pdf (accessed on 10 December 2021).
- Apampa, K.M.; Wills, G.; Argles, D. Towards security goals in summative e-assessment security. In Proceedings of the 2009 International Conference for Internet Technology and Secured Transactions, (ICITST), London, UK, 9–12 November 2009; pp. 1–5. [Google Scholar]
- Sumra, I.A.; Hasbullah, H.B.; AbManan, J.B. Attacks on security goals (confidentiality, integrity, availability) in VANET: A survey. In Vehicular Ad-Hoc Networks for Smart Cities; Springer: Berlin/Heidelberg, Germany, 2015; pp. 51–61. [Google Scholar]
- Carter, B.A.; Kassin, A.; Magoc, T. Asymetric Cryptosystems. 2007. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.131.6626&rep=rep1&type=pdf (accessed on 20 January 2022).
- Fujisaki, E.; Okamoto, T. Secure integration of asymmetric and symmetric encryption schemes. In Annual International Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 1999; pp. 537–554. [Google Scholar]
- Brandt, F. Efficient cryptographic protocol design based on distributed El Gamal encryption. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2005; pp. 32–47. [Google Scholar]
- Agrawal, E.; Pal, P.R. A Secure and Fast Approach for Encryption and Decryption of Message Communication. Int. J. Eng. Sci. 2017, 7, 11481. [Google Scholar]
- Forouzan, B.A. Cryptography & Network Security; McGraw-Hill, Inc.: New York, NY, USA, 2007. [Google Scholar]
- Khan, A.G.; Basharat, S.; Riaz, M.U. Analysis of asymmetric cryptography in information security based on computational study to ensure confidentiality during information exchange. Int. J. Sci. Eng. Res. 2018, 9, 992–999. [Google Scholar]
- Chandra, S.; Bhattacharyya, S.; Paira, S.; Alam, S.S. A study and analysis on symmetric cryptography. In Proceedings of the 2014 International Conference on Science Engineering and Management Research (ICSEMR), Chennai, India, 27–29 November 2014; pp. 1–8. [Google Scholar]
- Masood, F.; Ahmad, J.; Shah, S.A.; Jamal, S.S.; Hussain, I. A novel hybrid secure image encryption based on julia set of fractals and 3D Lorenz chaotic map. Entropy 2020, 22, 274. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manifavas, C.; Hatzivasilis, G.; Fysarakis, K.; Papaefstathiou, Y. A survey of lightweight stream ciphers for embedded systems. Secur. Commun. Netw. 2016, 9, 1226–1246. [Google Scholar] [CrossRef] [Green Version]
- Rezaeipour, D.; Rushdan Md Said, M. The block cipher algorithm-properties, encryption efficiency analysis and security evaluation. JOurnal Adv. Appl. Math. Sci. 2010, 4, 129–137. [Google Scholar]
- Kumar, M.; Aggarwal, A.; Garg, A. A review on various digital image encryption techniques and security criteria. Int. J. Comput. Appl. 2014, 96. [Google Scholar] [CrossRef]
- Avasare, M.G.; Kelkar, V.V. Image encryption using chaos theory. In Proceedings of the 2015 International Conference on Communication, Information & Computing Technology (ICCICT), Mumbai, India, 15–17 January 2015; pp. 1–6. [Google Scholar]
- Ahmad, I.; Shahabuddin, S.; Kumar, T.; Okwuibe, J.; Gurtov, A.; Ylianttila, M. Security for 5G and beyond. IEEE Commun. Surv. Tutor. 2019, 21, 3682–3722. [Google Scholar] [CrossRef]
- Misra, A.; Gupta, A.; Rai, D. Analysing the parameters of chaos based image encryption schemes. World Appl. Program. 2011, 1, 294–299. [Google Scholar]
- Bernstein, D.J. The Salsa20 Family of Stream Ciphers, New Stream Cipher Designs: The eSTREAM Finalists; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Boesgaard, M.; Vesterager, M.; Zenner, E. The Rabbit stream cipher. In New Stream Cipher Designs; Springer: Berlin/Heidelberg, Germany, 2008; pp. 69–83. [Google Scholar]
- Jolfaei, A.; Vizandan, A.; Mirghadri, A. Image encryption using HC-128 and HC-256 stream ciphers. Int. J. Electron. Secur. Digit. Forensics 2012, 4, 19–42. [Google Scholar] [CrossRef]
- Taha, M.A.; Assad, S.E.; Queudet, A.; Deforges, O. Design and efficient implementation of a chaos-based stream cipher. Int. J. Internet Technol. Secur. Trans. 2017, 7, 89–114. [Google Scholar] [CrossRef]
- Abutaha, M.; El Assad, S.; Jallouli, O.; Queudet, A.; Deforges, O. Design of a pseudo-chaotic number generator as a random number generator. In Proceedings of the 2016 International Conference on Communications (COMM), Bucharest, Romania, 9–10 June 2016; pp. 401–404. [Google Scholar]
- Burak, D. Parallelization of an encryption algorithm based on a spatiotemporal chaotic system and a chaotic neural network. Procedia Comput. Sci. 2015, 51, 2888–2892. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Song, D.; Xu, Y. A parallel encryption algorithm for dual-core processor based on chaotic map. In Fourth International Conference on Machine Vision (ICMV 2011): Computer Vision and Image Analysis; Pattern Recognition and Basic Technologies; International Society for Optics and Photonics: Bellingham, WA, USA, 2012; Volume 8350, p. 83500B. [Google Scholar]
- Çavuşoğlu, Ü.; Kaçar, S. A novel parallel image encryption algorithm based on chaos. Clust. Comput. 2019, 22, 1211–1223. [Google Scholar] [CrossRef]
- Elrefaey, A.; Sarhan, A.; El-Shennawy, N.M. Improving the speed of chaotic-maps-based image encryption using parallelization. In Proceedings of the 2017 13th International Computer Engineering Conference (ICENCO), Giza, Egypt, 27–28 December 2017; pp. 61–66. [Google Scholar]
- Masood, F.; Driss, M.; Boulila, W.; Ahmad, J.; Rehman, S.U.; Jan, S.U.; Qayyum, A.; Buchanan, W.J. A lightweight chaos-based medical image encryption scheme using random shuffling and XOR operations. Wirel. Pers. Commun. 2021, 1–28. [Google Scholar] [CrossRef]
- Chandra, R.; Dagum, L.; Kohr, D.; Menon, R.; Maydan, D.; McDonald, J. Parallel Programming in OpenMP; Morgan Kaufmann: Burlington, MA, USA, 2001. [Google Scholar]
- Lewis, B.; Berg, D.J. PThreads Primer; Sun Microsystems Inc.: Santa Clara, CA, USA, 1996. [Google Scholar]
- Pacheco, P. An Introduction to Parallel Programming; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Grama, A.; Kumar, V.; Gupta, A.; Karypis, G. Introduction to Parallel Computing; Pearson Education: London, UK, 2003. [Google Scholar]
- Shi, Y. Reevaluating Amdahl’s Law and Gustafson’s Law; (MS: 38-24); Computer Sciences Department, Temple University: Philadelphia, PA, USA, 1996. [Google Scholar]
- Wang, X.; Zhu, X.; Wu, X.; Zhang, Y. Image encryption algorithm based on multiple mixed hash functions and cyclic shift. Opt. Lasers Eng. 2018, 107, 370–379. [Google Scholar] [CrossRef]
- Guesmi, R.; Farah, M.A.B.; Kachouri, A.; Samet, M. A novel chaos-based image encryption using DNA sequence operation and Secure Hash Algorithm SHA-2. Nonlinear Dyn. 2016, 83, 1123–1136. [Google Scholar] [CrossRef]
- Curiac, D.I.; Volosencu, C. Chaotic trajectory design for monitoring an arbitrary number of specified locations using points of interest. Math. Probl. Eng. 2012, 2012, 940276. [Google Scholar] [CrossRef]
- Curiac, D.I.; Iercan, D.; Dranga, O.; Dragan, F.; Banias, O. Chaos-based cryptography: End of the road? In Proceedings of the The International Conference on Emerging Security Information, Systems, and Technologies (SECUREWARE 2007), Valencia, Spain, 14–20 October 2007; pp. 71–76. [Google Scholar]
- Zhu, S.; Zhu, C.; Wang, W. A new image encryption algorithm based on chaos and secure hash SHA-256. Entropy 2018, 20, 716. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Noonan, J.P.; Agaian, S. NPCR and UACI randomness tests for image encryption. Cyber J. Multidiscip. J. Sci. Technol. J. Sel. Areas Telecommun. (JSAT) 2011, 1, 31–38. [Google Scholar]
- Liao, X.; Kulsoom, A.; Ullah, S. A modified (Dual) fusion technique for image encryption using SHA-256 hash and multiple chaotic maps. Multimed. Tools Appl. 2016, 75, 11241–11266. [Google Scholar]
- Chen, G.; Mao, Y.; Chui, C.K. A symmetric image encryption scheme based on 3D chaotic cat maps. Chaos Solitons Fractals 2004, 21, 749–761. [Google Scholar] [CrossRef]
- Belazi, A.; Abd El-Latif, A.A.; Belghith, S. A novel image encryption scheme based on substitution-permutation network and chaos. Signal Process. 2016, 128, 155–170. [Google Scholar] [CrossRef]
- Song, C.Y.; Qiao, Y.L.; Zhang, X.Z. An image encryption scheme based on new spatiotemporal chaos. Opt.-Int. J. Light Electron Opt. 2013, 124, 3329–3334. [Google Scholar] [CrossRef]
- Hua, Z.; Zhou, Y. Image encryption using 2D Logistic-adjusted-Sine map. Inf. Sci. 2016, 339, 237–253. [Google Scholar] [CrossRef]
- Ahmad, J.; Hwang, S.O. A secure image encryption scheme based on chaotic maps and affine transformation. Multimed. Tools Appl. 2016, 75, 13951–13976. [Google Scholar] [CrossRef]
- Ghazvini, M.; Mirzadi, M.; Parvar, N. A modified method for image encryption based on chaotic map and genetic algorithm. Multimed. Tools Appl. 2020, 79, 26927–26950. [Google Scholar] [CrossRef]
- Xiao, S.; Yu, Z.; Deng, Y. Design and analysis of a novel chaos-based image encryption algorithm via switch control mechanism. Secur. Commun. Netw. 2020, 2020, 7913061. [Google Scholar] [CrossRef] [Green Version]
- You, L.; Yang, E.; Wang, G. A novel parallel image encryption algorithm based on hybrid chaotic maps with OpenCL implementation. Soft Comput. 2020, 24, 12413–12427. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Barker, E.B.; Kelsey, J.M. Recommendation for Random Number Generation Using Deterministic Random Bit Generators (Revised); US Department of Commerce, Technology Administration, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2007.
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; Technical report; Booz-Allen and Hamilton Inc.: McLean, VA, USA, 2001. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).