Abstract
Differential privacy (DP) has become a de facto standard to achieve data privacy. However, the utility of DP solutions with the premise of privacy priority is often unacceptable in real-world applications. In this paper, we propose the best-effort differential privacy (B-DP) to promise the preference for utility first and design two new metrics including the point belief degree and the regional average belief degree to evaluate its privacy from a new perspective of preference for privacy. Therein, the preference for privacy and utility is referred to as expected privacy protection (EPP) and expected data utility (EDU), respectively. We also investigate how to realize B-DP with an existing DP mechanism (KRR) and a newly constructed mechanism (EXP) in the dynamic check-in data collection and publishing. Extensive experiments on two real-world check-in datasets verify the effectiveness of the concept of B-DP. Our newly constructed EXP can also satisfy a better B-DP than KRR to provide a good trade-off between privacy and utility.
1. Introduction
The explosive progress of mobile Internet and location technology, LBS (Location Based Service) applications, including Brightkite, Gowalla, Facebook and other social network platforms, generate a large number of check-in data every day. Check-in data generally include information such as time, locations, PoI (Points of Interest) attributes, mood and comments, and hence the check-in data has become a carrier of a user’s life trajectory and interest tendency [1,2,3,4]. However, a data analyst’s mining and analysis of the check-in data may directly or indirectly expose the sensitive information of a data provider [5,6,7,8,9]. There have been many privacy protection methods [10,11,12,13,14,15,16]. Some of them [10,11] rely on specific attack assumptions and background knowledge, and some methods [12,13,14,15] are based on differential privacy (DP) [17]. DP provides provable privacy protection, which is independent of the background knowledge and computational power of an attacker. The protection level of DP is evaluated by privacy budget [17]. When the privacy budget is relatively small, it has strong privacy protection, but the utility is often poor [17]. With the gradual integration of DP on practical applications, utility has become the bottleneck of its development and popularization.
In general, there is a contradiction between privacy and utility and it is necessary to be a trade-off [18,19]. In [19], the authors discussed a monotone trade-off in the semi-honest model. Therein, when the utility becomes worse, the privacy protection becomes stronger, and on the other hand, when the utility gets better, the privacy protection gets weaker. In many other DP theoretical studies, including strict -DP [17] and relaxed -DP [20], they often provide privacy priority and then make data more available or the best available, which is a kind of trade-off with satisfying utility as much as possible under the privacy guarantee. Unfortunately, the applications of DP in real-world do not seem to follow this principle completely. One of the best examples is the four applications in Apple’s MacOS Sierra (version 10.12), i.e., Emojis, New words, Deeplinks and Lookup Hints. When they collect the data, the privacy budget is set to only 1 or 2 per each datum, but the overall privacy budget for the four applications is as high as 16 per day [21]. Furthermore, Apple renews the available privacy budget every day, which would result in a potential privacy loss of 16 times the number of days that a user participated in DP data collection for the four applications [21]. It is far beyond the reasonable protection scope of DP [22].
Based on the above facts, when there exists a contradiction between privacy and utility, privacy is no longer a priority as suggested in the DP theoretical studies, but the most desirable way is to balance the preference for privacy and utility, where the preference for privacy and utility is referred to as expected privacy protection (EPP) and expected data utility (EDU), respectively. However, few researchers have proposed solutions to reasonably balance EPP and EDU except the authors in [23]. They proposed an adaptive DP and its mechanisms in a rational model, which can achieve a balance between the approximate EDU and the EPP by adding conditional filtering noise [23]. If the privacy protection intensity under the balance of the approximate EDU that is satisfied by the data analyst is not the expectation of the data provider, then it still cannot meet the EPP of the data provider. In addition, the absolute value range of the conditional filtering noise belongs to (0.5,1.5), which makes it easy to be attacked by background knowledge. Therefore, best-effort differential privacy (B-DP) is proposed to make the EDU satisfied first and then the EPP satisfied as much as possible in this paper. We face the following two basic challenges at least.
- If the EDU is to be satisfied first, then privacy protection may be no longer to be guaranteed by DP, how does it evaluate the guarantee degree of satisfying EPP as much as possible under B-DP?
- If there is a reasonable metric for the guarantee degree of satisfying EPP as much as possible under B-DP, does it exist an implementation mechanism (or algorithm) to realize B-DP?
With the challenges of B-DP above, this paper explores a typical application with dynamic collection and publishing of continuous check-in data, where the check-in scenario is a semi-honest model with an honest but curious data collector. Each check-in user visiting a POI generates a check-in state and perturbs his check-in state to a POI Center for his privacy protection, where the POI Center is a data collector. The frequency of check-in users are calculated by POI Center according to the received check-in states, which is approximately the check-in data distribution and used for publishing to data analysts. We assume that one check-in state is perturbed to only one check-in state and each publishing is required to satisfy the EDU first and then satisfy EPP as much as possible in the dynamic publishing, and moreover, the privacy to be protected is the check-in state of a user and the utility to be realized is the distribution of the check-in data with relative error as its metrics (see Section 4.1 for more details). In fact, since the relative error is used as a metric of the published distribution, it needs a distribution dependent privacy protection mechanism (or implementation) in order to satisfy the EPP as much as possible under the constraint of EDU. In addition, since each publishing is required to satisfy the EDU first and then satisfy EPP as much as possible in the dynamic publishing, it needs a algorithm to make the privacy protection under the constraint of EDU to be satisfied continuously as much as possible in the process of dynamic publishing. Therefore, this mechanism or algorithm will be proposed from a new perspective, which is different from the existing methods in literature.
1.1. Our Contributions
The main contributions of this paper are concluded as follows.
- A privacy protection concept of B-DP and two metrics of privacy guarantee degree are put forward. B-DP discussed in this paper is an expansion of the concept of DP, which can satisfy the EDU first and then provide the EPP as much as possible to be usefull for real-world applications. It uses two new metrics including the point belief degree (see Definition 4) and the regional average belief degree (see Definition 5) to quantify the degree of privacy protection for any expected privacy budget (see Section 4.2), rather than for DP itself by the privacy budget to evaluate only one EPP with the expected privacy budget equal to . In addition, the regional average belief degree can be used as the average guarantee degree of the EPP in a region including multiple expected privacy budgets. To the best of our knowledge, it is a new discussion and definition of B-DP that is different from the existing literature, and it uses two new metrics to explore and analyze the performance of privacy from a new perspective of the preference for privacy.
- An EXP mechanism is proposed (see Definition 10). The newly constructed EXP mechanism can be used to the categorical data for privacy protection, which smartly alters the privacy budget based on its probability in the data distribution to make itself to realize a better B-DP compared to the existing KRR mechanism [24,25]. Thereby, it also verifies that B-DP can be better realized to provide a good trade-off between privacy and utility.
- The dynamic algorithm with the implementation algorithms of two perturbation mechanisms is proposed to realize the dynamic collection and publishing of continuous check-in data and meanwhile to satisfy B-DP. The two perturbation mechanisms include the newly constructed EXP and a classical DP mechanism KRR [25,26] (a simple local differential privacy (LDP) mechanism). We take KRR as an example to show how to realize B-DP based on the existing DP mechanisms for the categorical data. Moreover, the number of domain values of both KRR and EXP is more than 2 and both the randomized algorithms based on them only take one value as input and one value as output. In addition, the dynamic algorithm can also be used to other applications of social behavior except check-in data.
1.2. Outline
The remainder of this paper is organized as follows: Section 2 summarizes the related work on the trade-off methods, utility metrics of relative error and LDP mechanisms. Section 3 presents conceptual background of DP and details of KRR mechanism and utility metrics. Section 4 introduces the system model, the relevant definitions of B-DP, including two metrics of the guarantee degree, etc., and model symbolization of the check-in data. Section 5 introduces the design and implementation of B-DP mechanisms and Section 6 describes the design of B-DP mechanism algorithm in the dynamic collection and publishing. Section 7 provides the experimental evaluation of the dynamic collection and publishing algorithm based on both two B-DP mechanisms. Finally, we provide a discussion and conclusion in Section 8.
2. Related Work
DP has become a research hotspot in the field of privacy protection since Dwork [12] proposed it in 2006. The model of DP starts from the traditional centralization [15,18], gradually grows to be distributed [27], and develops to be localization [24,28] and even to be personalized localization [29] and so on. It is not only the evolution process of DP technique, but also the comprehensive embodiment of the gradual integration of DP technique with real-world applications. However, no matter how it evolves, the two themes running through DP are privacy and utility [18], which is also focused by this paper. Table 1 summarizes the mainly related work from the pespective of privacy and utility priority as well as their metrics, the used privacy mechanism and the focusing problem with EPP and EDU. It will be divided into three categories to show its details.

Table 1.
Comparison of existing literature with the method proposed in this paper.
- Trade-off model with utility first. The majority of DP research is based on the trade-off model with privacy first, while there are few relevant ones on the trade-off model with utility first. Therein, Katrina et al. [30] proposed a generalized “noise reduction” framework based on the modified “Above Threshold” algorithm [33] to minimize the empirical risk of privacy (ERM) on the premise of utility priority, but the scheme is only applicable to the framework that minimizes the empirical risk of privacy, where the privacy minimized may not be able to meet the EPP. Liu et al. proposed firstly that DP satisfies the monotonic trade-off between privacy and utility and its associated bounded monotone trade-off under the semi-honest model. They showed that there is no trade-off under the rational model, while unilateral trade-off could lead to utility disaster or privacy disaster [18,23,34]. They also presented an adaptive DP and its mechanisms under the rational model, which can realize the trade-off between approximately EDU and EPP by adding conditional filtering noise [23], but the mechanisms are probably not able to meet the expectation of data provider for privacy protection and are easily attacked by background knowledge because of the adding conditional filtering noise. Most importantly, the above two utility-first research [23,30] do not provide a quantitative metrics of the unmet privacy protection or the unmet degree of EPP, whereas this paper presents two detailed quantitative metrics including the point belief degree and the regional average belief degree to evaluate the privacy from a new perspective of preference for privacy.
- Utility metrics of relative error. Maryam et al. [31] presented DP in real-world applications, which discussed how to add Laplace [12] noise from a view of utility. They studied the relationship between the cumulative probability of noise and the privacy level in Laplace mechanism and combined with the relative error metrics to discuss how to use a DP mechanism reasonably without losing the established utility. However, the literature does not delve into the details that how the guarantee degree of privacy protection will be changed when utility is satisfied. Xiao et al. [18] presented a DP publishing algorithm on a batch query using resampling technique of correlation noise to reduce noise added and improve data utility. When the algorithm picks the priority items each time, it is based on the intermediate results with noise, and the intermediate results with noise are not enough to reflect the original order of data. In this way, there is a bias in adjusting the privacy budget allocation, which may cause the query items that should be optimized to be not optimized, thus affecting the utility of published data. However, the literature is a classical example of optimizing utility with privacy first, which runs counter to the theme of this paper. In addition, the above two schemes are essentially based on the central DP and use continuous Laplace mechanism, which are different from the LDP (discrete) data statistics and release required by the check-in application in this paper. Therefore, these schemes cannot be directly applied to the applications this paper considers.
- LDP mechanisms. In 1965, Warner first proposed the randomized response technique (W-RR) to collect statistical data on sensitive topics and keep the sensitive data of contributing individuals confidential [35]. Although W-RR can strictly satisfy -LDP [25] in one survey statistics, multiple collections on the same survey individuals will weaken the privacy protection intensity [12]. Therefore, Erlingsson et al. [28] used a double perturbation scheme combining permanent randomized response with instantaneous randomized response, namely, RAPPOR, to expand the application of W-RR, and it has been used by Google in Chrome browser to collect users’ behavior data. In addition, RAPPOR also uses Bloom Filter technology [36] as the encoding method, which maps the statistical attributes into a binary vector. Finally, the mapping relation and Lasso regression method [37] are combined to reconstruct the frequency statistics corresponding to the original attribute string. Due to the high communication cost of RAPPOR, Bassily et al. [32] proposed the S-Hist method. In the method, each user first encodes his attributes, then randomly selects one of the bits and uses the randomized response technique to perturb it, and finally sends the result of the perturbation to the data collector, so as to reduce the communication cost. Chen et al. [29] proposed a PCEP mechanism and designed a PLDP (personalized LDP) applied to spatial data with it, aiming to protect the users’ location information and count the number of users in the area. Therein, the privacy budget of the scheme is determined by the users’ personalization, and hence the utility depends on the users’ individual behavior settings. In addition, the mechanism combines the S-Hist [32] method and adopts the random projection technique [38]. Although it can greatly reduce the communication cost, it still has the problem of unstable query precision. Based on the check-in application with multiple check-in spots in this paper, the KRR mechanism [24,25] just easily fits this application with no prior data distribution knowledge, but it is not very good for B-DP. In addition, DP has already been studied in these applications, such as social networks [39,40], recommender systems [41], data publishing [42,43,44], deep learning [45], reinforcement learning [46] and federated learning [47].
3. Preliminaries
In this section, the key notations used in this paper are given in Table 2.
Table 2.
Notations.
3.1. Differential Privacy (DP)
Differential privacy (DP), broadly speaking, is a privacy protection technique that does not depend on an attacker’s background knowledge and computational power [17,20,48]. It can be generally divided into central DP and LDP depending on whether it is based on a trusted data collector [33]. The formal definitions of these two types of DP are given as follows.
Definition 1
(()-(Central) DP [17,20]). A randomized algorithm M and a set S of all possible outputs of M, for a given dataset D and any adjacent dataset that differ on at most one record, if M satisfies the following inequality, then it is said that M satisfies -(central) DP.
where represents the risk of privacy disclosure and is controlled by the randomness of algorithm M, the parameter ϵ is called privacy budget that represents the level of privacy protection, and δ represents the probability of failure to satisfy ϵ-(central) DP. When , M satisfies the ϵ-(central) DP.
Definition 2
(-LDP [25,26]). A randomized algorithm , for a given dataset χ, any and any , is said to satisfy -LDP if satisfies
where and δ have the similar meanings as above in Definition 1.
In the check-in application of this paper, the POI Center is an honest and curious data collector, even if the POI Center or other attackers can obtain the check-in state submitted by a user, they cannot conclusively infer the original check-in state of the user. If can satisfy -LDP to protect the check-in state of the user, then it needs to meet the following definition.
Definition 3
(Check-in state of -LDP). A user u generates a check-in in a POI, whose check-in state variable is denoted as with . Assume that the original check-in state of u is or for . Moreover, and generate the same check-in state for after being perturbed by a randomized algorithm , respectively, and the perturbed check-in state variable is with . If there exists an such that satisfies the following constraints for ,
where, and are the perturbation probabilities of the original check-in states and to the check-in state , respectively, then will enable the check-in state to satisfy -LDP. When , satisfies ϵ-LDP.
Property 1
(Parallel composition [49]). Assume that randomized algorithms are and their privacy budgets are , respectively, then for the disjoint datasets , an algorithm provides max-(local) DP, and the level of privacy protection it provides depends on the largest privacy budget.
3.2. KRR Mechanism
KRR is a LDP mechanism [24,25], which satisfies the following probability distribution,
where and
KRR is a more general form of the randomized response mechanism of W-RR, that is, when , KRR degenerates into W-RR.
3.3. Utility Metrics
In this paper, the worst relative error of POIs in check-in statistics will be used to measure the overall utility of the check-in application, where the calculation formula of the relative error of is as follows,
where is the estimated result of check-in statistics after LDP protection, is the real check-in result of the , and the parameter is a constant to avoid the situations that causes the denominator to be 0 or is too small [18,50,51]. For the convenience of analysis, this paper will use the relative root mean square error for the utility metrics approximately, the specific formula is as follows,
where is the expectation of the mean square error between the real statistical result and the statistical estimate result after LDP protection, and the parameter is defined as above. Then, the formula for calculating the maximum relative error of n POIs is as follows,
As above, not only can represent data distribution, but also can represent frequency or counts.
4. Problem Formulations
4.1. System Model
As shown in Figure 1, there are three types of participants, namely, check-in users (data providers), POI Center (data collector), and data analysts (for example, POI managers) in the check-in model. Each check-in user visiting a POI generates a check-in state and sends it to POI Center through a terminal with the check-in APP, where each check-in state corresponds to a count and the check-in state belongs to catagory data. POI Center calculates the counts and frequency of check-in users’ visiting POIs according to the received check-in states, where frequency is approximately the check-in data distribution and used for publishing to data analysts. In addition, it is assumed that each check-in user is independent of each other and only one check-in state is submitted by a check-in user in one publishing. It is also assumed that the check-in scenario is a semi-honest model, in which the POI Center is an honest but curious data collector, and the check-in state of a user is sensitive. Hence, a user will adopt a perturbation mechanism (for example, LDP mechanism) to perturb his check-in state for his privacy protection, and then sends it to the POI Center. Therein, it is assumed that one check-in state is perturbed to only one check-in state.
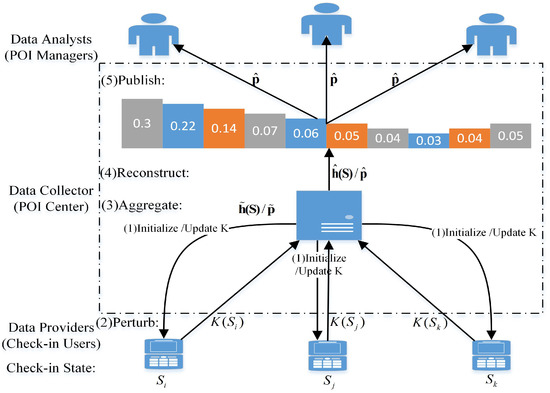
Figure 1.
POI check-in model. Therein, and represent check-in states. and represent the check-in counts and the check-in frequency (data distribution) in perturbation phase, respectively, while and represent the check-in counts and the check-in frequency (data distribution) in construction phase, respectively. K represents a perturbation mechanism. The more details can also be seen in Section 4.3.
In this paper, we focus on the dynamic collection and publishing of continuous check-in data with both privacy and utility requirements, where the privacy to be protected is the check-in state of a user and the utility to be realized is the distribution of the check-in data with relative error as its metrics. Therein, the privacy refers to EPP, which is the preference for privacy of a user, and the utility refers to EDU, which is the preference for utility of a data analyst. Moreover, each publishing is required to satisfy the EDU first and then satisfy EPP as much as possible in the dynamic publishing. Thereby, we adopt B-DP based on the LDP model including perturbation, aggregation, reconstruction and publishing, and we also need to have the process of initializing or updating the perturbation mechanism K at least to make every publishing to satisfy the EPP as much as possible under the EDU satisfied first in the dynamic publishing, as shown in Figure 1.
4.2. The Related Concepts of B-DP
In the concept of best-effort differential privacy (B-DP), there is an expected privacy protection (EPP) and an expected data utility (EDU), respectively. When the two cannot be satisfied simultaneously, the EDU should be satisfied first and the EPP should be satisfied as much as possible. Since the protection level of DP is evaluated by privacy budget [17], the preference for privacy also refers to the preference for the privacy budget in the B-DP. Hence, the EPP refers to a data provider’s preference for the privacy budget and we define this privacy budget as the expected privacy budget symbolized as . We use to symbolize the expected privacy protection region, which refers to a data provider’s preference for a region including multiple expected privacy budgets.
We use to symbolize the EDU. In this paper, the expectation of the maximum relative error of Formula (7) is used to measure data utility. When the expectation of the maximum relative error of Formula (7) is less than or equal to , it means that the EDU is satisfied; when equal, it means that the EDU is just satisfied. The privacy budget of a DP mechanism that just satisfies the EDU is symbolized as .
Definition 4
(-Point belief degree). It defines the guarantee degree of EPP under the expected privacy budget , which can be provided by the -DP mechanism, as the point belief degree, and the symbol is denoted as . Moreover, , where n represents the number of POIs in check-in application, represents the probability of perturbed by -DP mechanism, represents the actual privacy budget of , and represents an indicator function for whether the EPP is satisfied, which is defined as follows,
Definition 5
(-Regional average belief degree). The average guarantee degree of the EPP under the expected privacy protection region , which can be provided by the -DP mechanism, is defined as the regional average belief degree, and the symbol is denoted as . When and for , it defines
where can refer the definition of point belief degree.
Definition 6
(-B-DP). The DP mechanism that just satisfies the EDU η with the point belief degree of the expected privacy budget is defined as -B-DP. Therein, the -B-DP, where the point belief degree is maximum, is defined as -Best-B-DP.
Definition 7
(-B-DP). The DP mechanism that just satisfies the EDU η with the regional average belief degree of the expected privacy protection region is defined as -B-DP. Therein, the -B-DP, where the regional average belief degree is maximum, is defined as -Best-B-DP.
Note that, generally, B-DP includes both central B-DP and local B-DP, which depends on whether it is based on a trusted data collector the same as the DP. This paper focuses on local B-DP.
4.3. Model Symbolization
Let with represent n POIs in check-in scenario, and the check-in state space is where is the check-in state of . Let be variables of the original check-in state, the perturbed check-in state and the estimated check-in state of the user u, respectively. Let and be the probability distributions of the original check-ins, the perturbed check-ins and the estimated check-ins, respectively, where , and . Assume that it is the same probability distribution law for all the users, that is, , and for any and u. , and represent the original check-in counts vector, the perturbed check-in counts vector and the estimated check-in counts vector with users, respectively.
Definition 8
(Random perturbation and perturbation probability matrix Q). The process for any user u to change check-in state from to with a certain perturbation probability is called random perturbation, and the perturbation probability is denoted as with . The matrix composed of for any is called the perturbation probability matrix Q, where and for any .
Therefore, the perturbed probability distribution , the original probability distribution and the perturbation probability matrix Q have the following relationship
From Equation (10), it can be seen that for any . Obviously, and are not always equal, and hence the result of the perturbation is biased. Assume that Q is always reversible and its inverse matrix is defined as . Therefore, it can get the following theorem.
Theorem 1.
The check-in counts vector is perturbed by the perturbation probability matrix Q to obtain the perturbed check-in counts vector and then it is corrected by the inverse matrix R. The estimated check-in counts vector satisfies .
Proof.
Since , and , it has . Therefore, the result follows. □
Theorem 1 states that the estimated check-in counts vector obtained after the correction of the inverse matrix R is an unbiased estimate of the original check-in counts vector .
Here, the relative root mean square error of the original check-in counts and the estimated check-in counts for n POIs and m users on can be calculated as follows,
where and can be calculated as follows,
Theorem 2.
The relative root mean square error between the original probability of check-ins and the estimated probability of check-ins is , where
Proof.
The relative root mean square error between the original probability of check-ins and estimated probability of check-ins can be represented as follows,
Therefore, , where □
If means that the EDU is just satisfied, then Q should satisfy the following constraints according to B-DP.
Assume that there is a randomized algorithm with a perturbation probability matrix Q, which can provide the expected privacy budget with the point belief degree . Then, if wants to satisfy -Best-B-DP, it should still need to maximize . Therefore, should satisfy the following optimization problem.
Similarly, it is assumed that can provide the expected privacy protection region with the regional average belief degree , where is the point belief degree of the expected privacy budget . Then, if wants to satisfy -Best-B-DP, it should still need to maximize . Therefore, should satisfy the following optimization problem.
From the above optimization Equations (15) and (16), in each optimization problem, it can be concluded that the perturbation probability matrix Q contains unknown variables, inequality constraints, n equality constraints and one EDU constraint. Therefore, directly solving the optimization problem is a huge challenge, especially in the case of a large domain size n. Therefore, two simplified models are considered in this paper and we will present the details one by one in the following section.
5. Design and Implementation of B-DP Mechanism
This section includes the design of two B-DP mechanisms and their implementation algorithms. One is based on a classical LDP mechanism KRR, and the other is based on the newly constructed mechanism EXP in this paper. The number of domain values of both two mechanisms is more than 2. Moreover, we combine three data distributions with the typical non-uniformity and two B-DP mechanisms to directly show and analyze the two metrics proposed in this paper, including the point belief degree and the regional average belief degree.
5.1. B-DP Mechanism Based on KRR
Without prior knowledge of the data distribution, we assume that it is uniform. Setting for and , then it has , and . Therefore, the privacy budget of KRR here is not arbitrary, which is constrained by the EDU of .
Definition 9
(-KRR). KRR that just meets the EDU η is called -KRR.
Here, it can also derive the following theorem.
Theorem 3.
If there exists -KRR, then it satisfies -LDP. Moreover, the point belief degree of -KRR is
Proof.
If there exists -KRR, then it has . Since , it satisfies -LDP. According to , when , , it has ; when , , it has . Hence, the result follows. □
Thus, it is impossible for -KRR to provide the EPP , or provide the EPP with a 100% satisfaction. Therefore, what KRR can achieve is two distinct jumps of EPP with or without guarantee, that is, it is not a good B-DP mechanism.
5.2. B-DP Mechanism Based on EXP
Since relative error is used as utility metrics about the check-in data distribution in this paper, and a privacy budget of DP usually determines absolute error which is the numerator of relative error, thus the privacy budget of every POI should vary with its probability in the distribution of check-ins, that is, the value of the privacy budget should be reduced when the corresponding probability in the data distribution becomes larger, and increased when the corresponding probability in the data distribution becomes smaller. In this way, the small amounts of check-ins can also satisfy the EDU, while the large amounts of check-ins can also satisfy the EPP in priority, so as to better realize B-DP. It defines the following perturbation mechanism EXP.
Definition 10
(Perturbation mechanism EXP). Given the data distribution , where . Call the randomized algorithm with Q as perturbation mechanism EXP if Q satisfies , where is the probability that the check-in state is perturbed from to for and is the privacy setting parameter, where satisfies Formulas (18)–(20), and is the parameter of privacy protection intensity change point.
When ,
When ,
When ,
Theorem 4.
In perturbation mechanism EXP, its Q satisfies the following properties.
When and the normalized factor perturbing from to a POI is for ,
When and the normalized factor perturbing from to a POI is for ,
When and the normalized factor perturbing from to a POI is for ,
Proof.
According to Definition 10, it can be seen that is the probability that the check-in state of is perturbed to that of for . Moreover, since , it is easy to obtain the result of Theorem 4. □
Definition 11.
(-EXP) EXP that just satisfies the EPU η is called -EXP where and is the actual privacy budget for each , that is, for .
Theorem 5.
Based on the definition of -EXP,
(1) if there exists -EXP, then it satisfies -LDP;
(2) when is fixed and the point belief degree of -EXP is , where is the actual privacy budget for each , -EXP is the approximately optimal -Best-B-DP, where the indicator function is
(3) if there exists -EXP and its point belief degree is , then it satisfies -LDP.
Proof.
See Appendix A. □
5.3. Implementation of B-DP Machanism
For the check-ins scenario, two B-DP mechanisms based on KRR and EXP are proposed and realized in this paper. KRR is one of the classical mechanisms of LDP, but it cannot well realize B-DP. EXP is newly proposed in this paper, which can not only provide the protection of approximately optimal -Best-B-DP, but also provides the protection of relaxed -LDP to satisfy the EDU. The pseudo codes of the two B-DP mechanisms are given in Algorithms 1 and 2, respectively.
| Algorithm 1 B-DP machanism based on KRR. |
| Input: Probability distribution , sample size m and expected data utility (EDU) |
| Output: Privacy budget and perturbation probability matrix Q |
|
| Algorithm 2 B-DP mechanism based on EXP. |
| Input: Probability distribution , sample size m, expected data utility (EDU) , expected privacy budget (or expected privacy protection region with ) |
| Output: Privacy setting parameter , the parameter of privacy protection intensity change point , perturbation probability matrix Q and actual privacy budget of for |
|
5.4. Case Analysis of Point Belief Degree and Regional Average Beleif Degree
The above description theoretically analyzes two metrics, including the point belief degree and the regional average belief degree, on the two B-DP mechanisms based on KRR and EXP. In order to show the two metrics more clearly, the following of this section will use three data distributions with typical non-uniformity for analysis. For simplicity, in the following of this section, the KRR-based B-DP mechanism is represented by KRR and the EXP-based B-DP mechanism is represented by EXP, including the diagram descriptions.
(1) Three data distributions with typical non-uniformity.
The data distribution in this section is set as Pareto distribution, where the discrete case of Pareto distribution satisfies for and . Three data distributions of , 1.55, 1.17 and 0.52 are shown in Figure 2 and are, respectively, denoted as , and , where . Figure 2 shows both ordered and disordered cases of Pareto distribution, where the disordered case illustrates that the identification of scenic spots is independent of the order of probability. It also shows the corresponding Gini coefficient of , and , which is calculated according to the method of Gini mean difference [52]. Gini coefficient is used to indicate the degree of unevenness of data distribution. There exists a quantitative relationship between Pareto distribution parameter and Gini coefficient in Table 3. As shown in Figure 2, the data distribution of is pretty uneven, and the data distribution of is relatively reasonably uneven, while the data distribution of is relatively even.
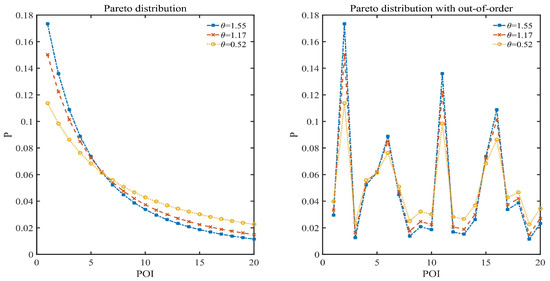
Figure 2.
Pareto distribution.
Table 3.
Gini coefficient VS. Pareto parameter of .
(2) Point belief degree
In the point belief degree in KRR, let ( is used as the expected privacy budget or used as a basis for division of the expected privacy protection region, just for better comparison between KRR and EXP) determined by -KRR (see definition of -KRR and Algorithm 1 for details), which equals the -coordinate of the jump point shown by the dotted line in Figure 3. It is also combined with the same and to determine the perturbation probability and related parameters with EXP (see Algorithm 2 for details). For example, when the EDU , the point belief degree of KRR and EXP is shown in Figure 3.
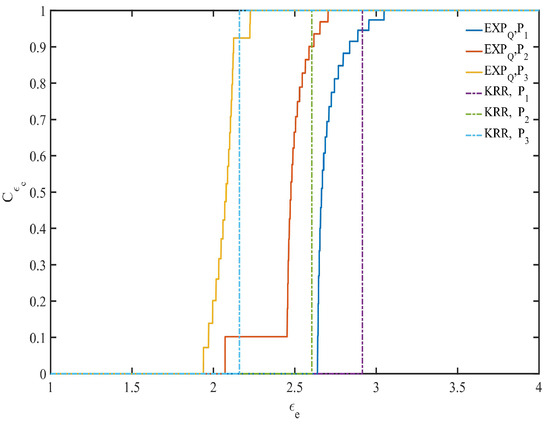
Figure 3.
Point belief degree with .
From Figure 3, it can be seen that under the same EDU, if the expected privacy budget of any data provider is , KRR can provide -DP with belief degree of 1. On the other hand, if the expected privacy budget of any data provider is , its belief degree is 0. However, in EXP, if the expected privacy budget of any data provider is , it indicates that it cannot satisfy the EPP when is closer to , and when is large enough, it can also provide -DP with belief degree of 1. Conversely, if the expected privacy budget of all data providers is , it indicates that it can satisfy the EPP when is closer to , and the degree of providing -DP is greater when is closer to . Therefore, in the case of EDU first, EXP can provide a privacy guarantee degree between 0 and 1 for the EPP, while KRR can only provide either 0 or 1. Moreover, EXP can provide more privacy protection than KRR, especially when the EDU and the EPP are contradictory, and when the EPP of all data providers is not fully (partially) satisfied.
(3) Regional average belief degree
In the regional average belief degree in KRR, maximizing equals to maximize , and hence it is the same as Algorithm 1. According to the approximately optimal expected privacy budget under satisfying the EDU , the data provider’s expected privacy protection region can be roughly divided into three categories: , , and .
Similarly, EXP can provide different levels of optimal privacy protection for the three categories of expected privacy protection region (see Algorithm 2 for details). Generally speaking, the regional average privacy protection degree of EXP in region is less than or equal to that of KRR. However, the regional average privacy protection degree of EXP in region is greater than or equal to that of KRR. For region , it may exist the situation where there is a contradiction between the EPP and the EDU. As shown in Figure 4, there is the regional average belief degree of both mechanisms with and the data distributions , and , respectively, where is determined by -KRR with (see the dotted line in Figure 4 where the value of whose is the first non-zero value is equal to ).
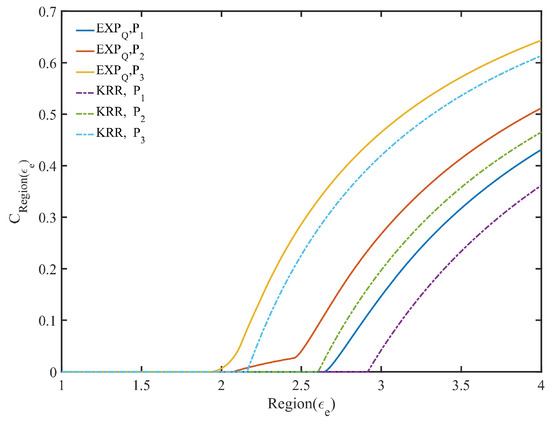
Figure 4.
Regional average belief degree with .
As can be seen from Figure 4, under the same EDU and the same expected privacy protection region, EXP is more capable of offering data providers with a certain degree of privacy protection than KRR.
6. B-DP Dynamic Collection and Publishing Algorithm Design
Algorithms 1 and 2 are implemented with KRR and EXP under the known data distribution, and moreover, the point belief degree and the regional average belief degree under B-DP are analyzed. In real-world, there is often no prior data distribution at the beginning or accurate prior data distribution cannot be obtained. This means the implementation of two B-DP mechanisms of Algorithms 1 and 2 cannot be directly applied to the collection and publishing of continuous check-in data with relative error as utility metrics. Therefore, this paper designs an iterative update algorithm to adaptively update the data distribution in order to realize the two B-DP mechanisms, so as to adaptively realize B-DP dynamic collection and publishing of continuous check-in data. See pseudo codes of Algorithm 3 for more details. Therein, Algorithms 1 or 2 is a main part of Algorithm 3.
| Algorithm 3 B-DP dynamic collection and publishing of check-in data algorithm—(KRR/EXP). |
|
Since the original data distribution is assumed to be uniform during initialization, it is possible to calculate the privacy setting parameter or with a closed-form expression that satisfies the EDU , as shown in the example with EXP below. According to Corollary A1 of Appendix A, in the case of uniform data distribution, EXP degenerates into KRR. Let , the probability of Q be calculated as follows, where is that makes true.
Let , and the inverse matrix R of Q can be expressed as
Therefore, p, q and that satisfy the EDU can be calculated. Since , it has and . Hence, , and .
7. Experimental Evaluation of B-DP Dynamic Collection and Publishing Algorithm
In this paper, the check-in data uses relative error as its utility metrics and the implementation of the two B-DP mechanisms based on KRR and EXP needs to rely on the data distribution. Therein, the number of domain values of both KRR and EXP is more than 2, and moverover, both the randomized algorithms based on them only take one value as input and one value as output. Thereby, KRR and EXP are fit for the check-in perturbation model we consider in this paper. In this section, we evaluate the performance of the dynamic algorithm based on the two B-DP mechanisms in terms of validity and robustness as well as privacy and utility. For simplicity, in the following of this section, we use KRR and EXP to represent B-DP mechanism based on KRR and B-DP mechanism based on EXP in the dynamic algorithm, respectively, including the diagram descriptions.
7.1. Experimental Settings
(1) Datasets
Two datasets with real-world data from location-based social networking platforms are used to verify the algorithms.
Brightkite [6]: It contains 4,491,143 check-ins over the period of April 2008–October 2010. In this paper, we used the check-ins of June 2008–September 2008, September 2009–December 2009 and January 2010—April 2010 from Brightkite to construct three types of check-in distributions with different uniformity degree according to the unified longitude and latitude division method, which are, respectively, abbreviated as B1, B2 and B3, and the number of regions is 12.
Gowalla [6]: It contains 6,442,890 check-ins over the period of Feburary 2009–October 2010. We used the check-ins of January 2010–April 2010 of Gowalla to construct three types of check-in distributions with different uniformity degree according to different partitioning methods of longitude and latitude, which are, respectively, abbreviated as G1, G2 and G3, and the number of regions is 25, respectively.
The average data distribution and the corresponding Gini coefficient of the data are shown in Figure 5 and Table 4, respectively. Therein, Gini coefficient is used to indicate the degree of unevenness of data distribution, which is calculated according to the method of Gini mean difference [52].
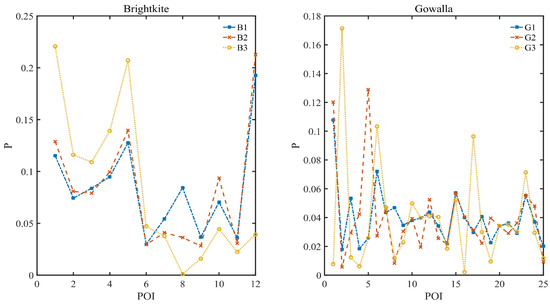
Figure 5.
The average data distribution of Brightkite VS. Gowalla.
Table 4.
Gini coefficient of data in Brightkite and Gowalla.
Figure 5 and Table 4 both show that the daily check-in data in two datasets fluctuates greatly, meaning a high diveristy. We verify the effectiveness of our algorithms on these real-world datasets in our experiment.
(2) Utility/Privacy Metrics
Utility Metrics: The utility uses the maximum relative error as its metrics (see Section 3.3 for details). In this paper, it uses the mean and deviation of the maximum relative error to evaluate the same EDU between KRR and EXP in the dynamic algorithm.
Privacy Metrics: The privacy uses two new metrics including the point belief degree and the regional average belief degree (see Defintions 4 and 5 for details). In this paper, it needs to compare the privacy gurantee degree about the expected privacy protection (EPP) under the same expected data utility (EDU) using these two privacy metrics between KRR and EXP in the dynamic algorithm.
(3) Parameter Settings
We evaluate our solutions through experiments using two real-world datasets. The experiments are performed on an Intel Core CPU 2.50-GHz Windows 10 machine equipped with 8 GB of main memory by matlab. In the experiments, the total check-in amount of statistical validity is . Three kinds of EDU are , and . The expected privacy protection region is or . The modified estimate parameter w is set as Table 5. The update threshold parameter is , and the remaining relevant parameters and are set to 0.5 and 0.005, respectively.
Table 5.
All kinds of modified estimate parameter w used in the dynamic algorithm.
7.2. Validity and Robustness Evaluation
The performance of validity and robustness of the corresponding dynamic algorithm with KRR and EXP is examined through the dynamic statistics process with two real-world datasets.
Figure 6 and Figure 7 show the mean values and deviations of the maximum relative error under the three kinds of EDU (, and ), which are shown by the statistics of the corresponding data subsets under B1, B2, B3, G1, G2 and G3 according to the frequency of once a day. Moreover, the frequency of each day is different and each result is repeated 10 times. In both Figure 6 and Figure 7, the horizontal axis of each graph represents the number of time slices in continuously, and the vertical axis represents the maximum relative error between the original data distribution and the estimated data distribution for any . As can be seen from the left small graphs of Figure 6 and Figure 7, the corresponding dynamic algorithm with KRR and EXP can converge quickly and maintain the corresponding unified convergence stable state under different data distributions of B1, B2, B3, G1, G2 and G3. This verifies that the dynamic algorithm has a good validity and robustness.

Figure 6.
The mean and deviation of on B1, B2 and B3 subsets of Brightkite. Three settings of EDU, including , and , are compared. (a) B1; (b) B2; (c) B3.

Figure 7.
The mean and deviation of on G1, G2 and G3 subsets of Gowalla. Three settings of EDU, including , and , are compared. (a) G1; (b) G2; (c) G3.
7.3. Utility and Privacy Evaluation
The performance of utility and privacy of the corresponding dynamic algorithm with two B-DP mechanisms based on KRR and EXP is also examined through the dynamic statistics process with two real-world datasets. As can also be seen from the right small graphs of Figure 6 and Figure 7, a part of the left small graphs of Figure 6 and Figure 7, it shows clearly that the dynamic algorithm can satisfy the utility even during the dynamic process.
In addition, Figure 8 and Figure 9 show the point belief degree and the regional average belief degree of each subset of two datasets under the three kinds of EDU (, and ). In Figure 8 and Figure 9, the horizontal axis of each graph represents the EPP with different expected privacy buget and the vertical axis represents the gurantee degree of the EPP satisfied. It shows that the gurantee degree of the EPP satisfied varies with the data distribution and EDU. For example, from the point belief degree of all small graphs in the left of Figure 8 and Figure 9, the gurantee degree of the EPP satisfied becomes better until its value up to 1 when the expected privacy buget becomes bigger, and the more evener distribution can support the EPP with the smaller to provide a better privacy protection in the same EDU (as Figure 10 shown). The smaller value of EDU, i.e., the lower utility, can generally support the EPP with the smaller to provide a better privacy protection in the same data distribution (as Figure 11 shown).
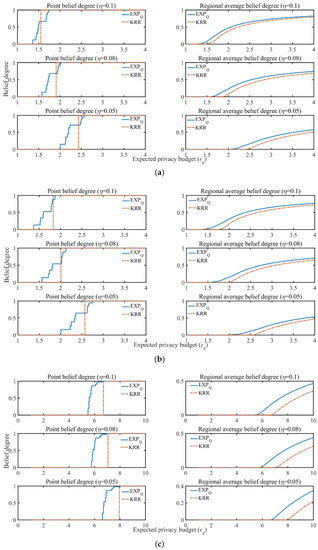
Figure 8.
The belief degree on B1, B2 and B3 subsets of Brightkite, where the belief degree includes the point belief degree and the regional average belief degree. (a) B1; (b) B2; (c) B3.
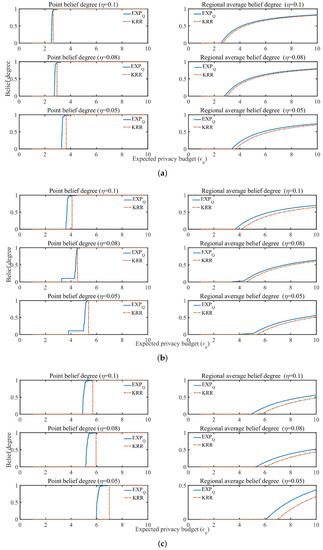
Figure 9.
The belief degree on G1, G2 and G3 subsets of Gowalla, where the belief degree includes the point belief degree and the regional average belief degree. (a) G1; (b) G2; (c) G3.

Figure 10.
The minimum with based on the same EDU () and different data distributions, where is the point belief degree on the EPP of , and moreover, , and represent three kinds of EDU.
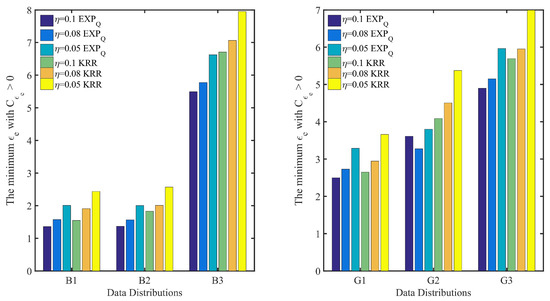
Figure 11.
The minimum with based on the same data distribution and different EDU (), where is the point belief degree on the EPP of , and moreover, , and represent three kinds of EDU.
In Figure 10, for EXP on G1, G2 and G3 with the given EDU (such as ), it shows clearly that the minimum with is the smallest on G1 and the largest on G3. According to Table 4, G3 is pretty uneven, while G1 is relatively even. It is the same for EXP on B1, B2 and B3, KRR on B1, B2 and B3 as well as on G1, G2 and G3. In Figure 11, for EXP on G1, G2 and G3 with the given data distribution (such as G1), it also shows clearly that the minimum with is the smallest on the EDU with and the largest on the EDU with . Similar trends can be observed for EXP on B1, B2 and B3, KRR on B1, B2 and B3 as well as on G1, G2 and G3.
For the regional average belief degree, the similar results can be concluded from all small graphs in the right of Figure 8 and Figure 9. Moreover, in Figure 12, it shows the maximum difference of in EXP minus in KRR with different on each subset. It shows that the more unevener the data distribution is, the more bigger the maximum difference is. It means that EXP is more adapt to the unevener data distribution than KRR.
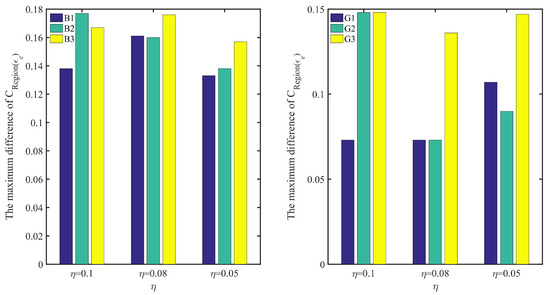
Figure 12.
The maximum difference of in EXP minus in KRR with different , where is the regional average belief degree on the region of or , and , and represents three kinds of EDU.
Furthermore, in order to be more objective evaluation of the privacy performance of KRR and EXP, it extends to use the privacy metrics of DP to compare the on each subset shown in Table 6, where refers to the privacy budget of a DP mechanism that just satisfies the EDU . As can be seen from Table 6, except for and on B3, all the of EXP is a little greater than those of KRR, which means that EXP provides a little worse DP than KRR. However, EXP could provide better B-DP from a new perspective of preference for privacy and utility than KRR to provide a good trade-off between them.
Table 6.
on each subset, where , and represent three kinds of EDU.
8. Discussions and Conclusions
This paper proposes a concept of best-effort differential privacy (B-DP) with the expected data utility (EDU) satisfied first and then with the expected privacy protection (EPP) satisfied as much as possible, and designs two new metrics including point belief degree and regional average belief degree to measure the guarantee degree of satisfying the EPP. Moreover, we also provide implementation algorithms, including the corresponding dynamic algorithm of two B-DP mechanisms based on KRR and a newly constructed mechanism EXP. Extensive experiments on two real-world check-in datasets verify the effectiveness of the concept of B-DP. It also verifies that the dynamic algorithm has a good validity and robustness, and can satisfy the utility even during the dynamic process. Besides, EXP is more adapt to the unevener data distribution and satisfies a better B-DP than KRR to provide a good trade-off between privacy and utility.
Specifically, the point belief degree measures the guarantee degree of privacy protection for any one expected privacy budget, and the regional average belief degree measures the average guarantee degree of the EPP in a region including multiple expected privacy budgets. Compared with the ()-DP, the latter can measure only one EPP with the expected privacy budget equal to and cannot directly measure the average guarantee degree of the EPP, that is, the ()-DP can only measure the guarantee degree of the EPP when , i.e., . In addition, many real-world applications can only provide an approximate value of as their EPP, and hence a neighborhood interval with can be regarded as their EPP. Therefore, the regional average belief degree introduced in this paper is very necessary.
Moreover, two B-DP mechanisms based on KRR and newly constructed EXP in this paper are applied to the dynamic collection and publishing of check-in data with relative error as its utility metrics. Therein, KRR itself does not depend on the data distribution, but the dynamic collection and publishing algorithm with B-DP mechanism based on KRR needs to, where the privacy setting parameter has to be adjusted with the influence of data distribution to realize the utility guaranteed firstly in real time. In addition, EXP itself is dependent on the data distribution to realize some of its outputs having strong privacy protection and some having weak privacy protection, which is different from KRR to provide consistent privacy protection intensity. Thus, the dynamic collection and publishing algorithm based on these two B-DP mechanisms needs to depend on the data distribution, and then it has to face the challenges of algorithm validity and robustness with unknown data distribution. Fortunately, the experimental results have already verified that the algorithm can solve both challenges and is promising for the typical application of check-in data.
Besides, if the scenic spots use EXP for privacy protection, the data provider may be more inclined to visit these scenic spots with a large number of visitors, because the regions where these scenic spots are located may have a stronger privacy protection. Compared with the algorithms based on the existing DP mechanisms with consistent privacy protection intensity to realize B-DP, such as KRR in this paper, they maybe do not achieve the EPP at all, but the algorithm based on EXP newly proposed in this paper can achieve the EPP partly at least, that is, EXP can satisfy a better B-DP to provide a good trade-off between privacy and utility.
In a word, although the B-DP dynamic collection and publishing algorithm based on KRR or EXP is not necessarily perfect, it fully proves the feasibility of the concept of B-DP in this paper. It is not only a great step forward for the basic theory of DP, but also provides two feasible solutions for the implementation of DP in practical applications. The two solutions take check-in data as an example, but are not limited to it. They can also be used to other category data for privacy protection where the perturbation model is one input and one output. In the future work, we will make a further discussion on other mechanisms with binary inputs in LDP, where the perturbation model can support one input is perpurbed to multiple outputs, such as RAPPOR, and design them to achieve better B-DP. Moreover, it is an interesting problem about correlated B-DP.
Author Contributions
The problem was conceived by Y.C. and Z.X. The theoretical analysis and experimental verification were performed by Y.C., Z.X. and J.C. Y.C. and J.C. wrote the paper. S.J. reviewed the writing on grammar and structure of the paper. All authors have read and agreed to the published version of the manuscript.
Funding
Natural Science Foundation of China (No.41971407), China Postdoctoral Science Foundation (No.2018M633354), Natural Science Foundation of Fujian Province, China (Nos.2020J01571, 2016J01281) and Science and Technology Innovation Special Fund of Fujian Agriculture and Forestry University (No.CXZX2019119S).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Two publicly available datasets were analyzed in this study. Both datasets can be found here: http://snap.stanford.edu/data/loc-gowalla.html and http://snap.stanford.edu/data/loc-brightkite.html (accessed on 5 March 2022).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 5
Proof.
(1) From Definition 11, . According to the definition of LDP, it can be seen that -EXP satisfies -LDP.
If it wants to proof (2) and (3) of Theorem 5, it needs the following theorems and corollary first.
Theorem A1.
In perturbation mechanism EXP, where and , it has
(a) ; if , and , then .
(b) ; if , and , then .
(c) for .
(d) for , where are the distribution probabilities of and after perturbation, respectively.
Proof.
See Appendix B. □
Theorem A2.
In perturbation mechanism EXP, it satisfies the following inequalities, where .
For ,
(i) if and , then ;
(ii) if , and , then ;
(iii) if and , then .
For ,
(i) if and , then ;
(ii) if and , then .
For ,
(i) if and , then ;
(ii) if and , then .
Proof.
See Appendix C. □
From Theorems A1 and A2, it has following Corollary A1.
Corollary A1.
For any , let be the actual privacy budget provided by EXP for , it has the following properties.
- (1)
- For ,
- (i)
- if , then ;
- (ii)
- if and , then ;
- (iii)
- if , then .
- (2)
- For ,
- (i)
- if , then ;
- (ii)
- if , then .
- (3)
- For ,
- (i)
- if , then ;
- (ii)
- if , then .
Let , where is the privacy setting parameter of EXP that satisfies the EDU . According to Theorem A2, the actual privacy budget for each can be set to , which is a function of and . It is easy to obtain that is a monotonic non-decreasing function according to Theorem A2 and Corollary A1 for a fixed .
Therefore, the -EXP satisfies (2) and (3) of Theorem 5 that can be proved as follows.
(2) When is fixed and the point belief degree of -EXP is , if is maximized, then -EXP satisfies -Best-B-DP. According to Corollary A1, it can be known that the larger is, the smaller is, indicating that in the same , can satisfy at first, and the proportion that it satisfies is . According to Theorem A2, when is larger, will always be larger too. Hence, is also maximized under a fixed .
(3) According to Definition 10 and Corollary A1, in EXP, the data distribution satisfies and the actual privacy budget satisfies . Suppose , then the probability of satisfying the EPP under the EDU is Let , then . Hence, For any user u and , it has
Therefore, it is easy to obtain
for any user u and .
Therefore, according to Definitions 2, 3 and Theorem A2, -EXP with the point belief degree satisfies -LDP.
Appendix B. Proof of A1
Proof.
Because of the perturbation mechanism EXP, the check-in data distribution satisfies . In accordance with the and , it can be discussed for three cases. For , if the perturbation mechanism EXP satisfies Theorem A1, then the other two cases, and , are also proved by using the same method.
For , it can be discussed as follows based on Theorem 4.
For any , the probability that the check-in state of is perturbed to that of satisfies the following cases.
For and , it has . Moreover, for , and , it has .
For and , it has . Moreover, for , , and , it has .
For , , and , it has .
From the above discussions (i–iii), the property in this theorem holds for and .
For , the probability that the check-in state of is perturbed to that of satisfies the following cases.
For and , it has
For , and , it has
For , and , it has
For , and , it has
From the above discussions (i–iv), it can be seen that for .
For , and , the probability that the check-in state of is perturbed to that of and the probability that the check-in state of is perturbed to that of satisfy the following cases.
For and , it has
For and , it has
For , and , it has
From the above discussions (i–iii) of , when , for , and , . When , for , and , we can use the similar method to get . Then it has for , and .
Hence, from , when , the part of Theorem A1 holds.
According to the property and its proof process, it is easy to get , i.e., holds for and .
Since for it has that implies , and it has Formula (A10). According the property and Formula (A10), it can be seen that .
If it wants to prove always stands up for , then it just has to prove . Similarly, it only wants to discuss the following case , and the other two cases, that is, and can also be proved by using the same method.
For , it has
For and , it can also obtain
For , it can also get
From the above discussions , the part in Theorem A1 is true.
Therefore, from , the result follows. □
Appendix C. Proof of Theorem A2
Proof.
It is only to deal with case (1) here, and a similar statement can be made of cases (2) or (3). From Theorem A1, it can be seen that for and it has for , and . Hence, it has the following cases to discuss for .
If and , then it has Formula (A14).
Therefore, according Formula (A14), if it wants to show , then it needs to show , i.e.,
always stands up. Let , where and . If it takes the derivative of with respect to x, it gets , i.e., decreases monotonically with x. It implies that always stands up. Therefore, the inequation always stands up for . From the above discussion, it can be seen that
Similarly, it has
For , and , it has
Hence, if we want to show according the Formula (A18), then it needs to show that , i.e.,
always stand up. Let , where and . If we take the derivative of with respect to x, we get , that is, increases monotonically with x. Then always stand up. Therefore, the inequation always stand up for .
Similarly, it has
For and , it has
Similarly, it has
From the above discussion of , it can be seen that the part of Theorem A2 holds. □
References
- Patil, S.; Norcie, G.; Kapadia, A.; Lee, A.J. Reasons, rewards, regrets: Privacy considerations in location sharing as an interactive practice. In Proceedings of the 8th Symposium on Usable Privacy and Security (SOUPS), Washington, DC, USA, 11–13 July 2012; pp. 1–15. [Google Scholar]
- Patil, S.; Norcie, G.; Kapadia, A.; Lee, A. “Check out where I am!”: Location-sharing motivations, preferences, and practices. In Proceedings of the Extended Abstracts on Human Factors in Computing Systems (CHI), Austin, TX, USA, 5–10 May 2012; pp. 1997–2002. [Google Scholar]
- Lindqvist, J.; Cranshaw, J.; Wiese, J.; Hong, J.; Zimmerman, J. I’m the mayor of my house: Examining why people use foursquare-a social-driven location sharing application. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Vancouver, BC, Canada, 7–12 May 2011; pp. 2409–2418. [Google Scholar]
- Guha, S.; Birnholtz, J. Can you see me now?: Location, visibility and the management of impressions on foursquare. In Proceedings of the 15th International Conference on Human-computer Interaction with Mobile Devices and Services ( MobileHCI), Munich, Germany, 27–30 August 2013; pp. 183–192. [Google Scholar]
- Gruteser, M.; Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings of the 1st International Conference on Mobile Systems, Applications and Services (MOBISYSP), San Francisco, CA, USA, 5–8 May 2003; pp. 31–42. [Google Scholar]
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD), San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
- Huo, Z.; Meng, X.; Zhang, R. Feel free to check-in: Privacy alert against hidden location inference attacks in GeoSNs. In Proceedings of the International Conference on Database Systems for Advanced Applications (DASFAA), Wuhan, China, 22–25 April 2013; pp. 377–391. [Google Scholar]
- Naghizade, E.; Bailey, J.; Kulik, L.; Tanin, E. How private can I be among public users? In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UBICOMP), Osaka, Japan, 7–11 September 2015; pp. 1137–1141. [Google Scholar]
- Rossi, L.; Williams, M.J.; Stich, C.; Musolesi, M. Privacy and the city: User identification and location semantics in location-based social networks. In Proceedings of the 9th International AAAI Conference on Web and Social Media (ICWSM), Oxford, UK, 26–29 May 2015; pp. 387–396. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzz. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. l-diversity: Privacy beyond k-anonymitty. ACM Trans. Knowl. Discov. Data 2007, 1, 3–54. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the 3rd Theory of Cryptography Conference (TCC), New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Hay, M.; Rastogi, V.; Miklau, G.; Dan, S. Boosting the accuracy of differentially private histograms through consistency. arXiv 2010, arXiv:0904.0942v5. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Wang, G.; Gehrke, J. Differential privacy via wavelet transforms. IEEE Trans. Knowl. Data Eng. 2011, 23, 1200–1214. [Google Scholar] [CrossRef]
- Rastogi, V.; Nath, S. Differentially private aggregation of distributed time-series with transformation and encryption. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (SIGMOD), Indianapolis, IN, USA, 6–10 June 2010; pp. 735–746. [Google Scholar]
- Dwivedi, A.D.; Singh, R.; Ghosh, U.; Mukkamala, R.R.; Tolba, A.; Said, O. Privacy preserving authentication system based on non-interactive zero knowledge proof suitable for internet of things. J. Amb. Intel. Hum. Comp. 2021, in press. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages, and Programming (ICALP), Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]
- Xiao, X.; Bender, G.; Hay, M.; Gehrke, J. iReduct: Differential privacy with reduced relative errors. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of data (SIGMOD), Athens, Greece, 12–16 June 2011; pp. 229–240. [Google Scholar]
- Liu, H.; Wu, Z.; Zhou, Y.; Peng, C.; Tian, F.; Lu, L. Privacy-preserving monotonicity of differential privacy mechanisms. Appl. Sci. 2018, 8, 2081. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT), St. Petersburg, Russia, 28 May–1 June 2006; pp. 486–503. [Google Scholar]
- Tang, J.; Korolova, A.; Bai, X.; Wang, X.; Wang, X. Privacy loss in Apple’s implementation of differential privacy on MacOS 10.12. arXiv 2017, arXiv:1709.02753. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation (TAMC), Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Liu, H.; Wu, Z.; Peng, C.; Tian, F.; Lu, H. Adaptive gaussian mechanism based on expected data utility under conditional filtering noise. KSII Trans. Internet. Inf. 2018, 12, 3497–3515. [Google Scholar]
- Kairouz, P.; Bonawitz, K.; Ramage, D. Discrete distribution estimation under local privacy. In Proceedings of the 33rd International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 2436–2444. [Google Scholar]
- Kairouz, P.; Oh, S.; Viswanath, P. Extremal mechanisms for local differential privacy. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Cambridge, MA, USA, 8–13 December 2014; pp. 2879–2887. [Google Scholar]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local privacy and statistical minimax rates. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science (FOCS), Berkeley, CA, USA, 26–29 October 2013; pp. 429–438. [Google Scholar]
- Hale, M.T.; Egerstedty, M. Differentially private cloud-based multi-agent optimization with constraints. In Proceedings of the 2015 American Control Conference (ACC), Chicago, IL, USA, 1–3 July 2015; pp. 1235–1240. [Google Scholar]
- Erlingsson, U.; Pihur, V.; Korolova, A. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM Conference on Computer and Communications Security (CCS), Scottsdale, AZ, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
- Chen, R.; Li, H.; Qin, A.K.; Kasiviswanathan, S.P.; Jin, H. Private spatial data aggregation in the local setting. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 289–300. [Google Scholar]
- Ligett, K.; Neel, S.; Roth, A.; Bo, W.; Wu, Z.S. Accuracy first: Selecting a differential privacy level for accuracy-constrained ERM. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Red Hook, NY, USA, 4–9 December 2017; pp. 2563–2573. [Google Scholar]
- Shoaran, M.; Thomo, A.; Weber, J. Differential privacy in practice. In Proceedings of the Workshop on Secure Data Management (SDM), Istanbul, Turkey, 27 August 2012; pp. 14–24. [Google Scholar]
- Bassily, R.; Smith, A. Local, private, efficient protocols for succinct histograms. In Proceedings of the 47th annual ACM symposium on Theory of Computing (STOC), Portland, OR, USA, 14–17 June 2015; pp. 127–135. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy; Now Publisher: Norwell, MA, USA, 2014; pp. 28–64. [Google Scholar]
- Liu, H.; Wu, Z.; Zhang, L. A Differential Privacy Incentive Compatible Mechanism and Equilibrium Analysis. In Proceedings of the 2016 International Conference on Networking and Network Applications (NaNA), Hakodate, Hokkaido, Japan, 23–25 July 2016; pp. 260–266. [Google Scholar]
- Warner, S.L. Randomized response: A survey technique for eliminating evasive answer bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef] [PubMed]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. ACM Commun. 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the Lasso. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Blum, A.; Ligett, K.; Roth, A. A learning theory approach to noninteractive database privacy. J. ACM 2013, 60, 1–25. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, D.; Xiao, F.; Wang, K.; Gu, J.; Wang, R. Privacy-preserving approach PBCN in social network with differential privacy. IEEE Trans. Netw. Serv. Man. 2020, 17, 931–945. [Google Scholar] [CrossRef]
- Hu, X.; Zhu, T.; Zhai, X.; Zhou, W.; Zhao, W. Privacy data propagation and preservation in social media: A real-world case study. IEEE Trans. Knowl. Data Eng. 2021, in press. [Google Scholar]
- Shin, H.; Kim, S.; Shin, J.; Xiao, X. Privacy enhanced matrix factorization for recommendation with local differential privacy. IEEE Trans. Knowl. Data Eng. 2018, 30, 1770–1782. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, S.; Zhu, T.; Liao, Y. Privately publishing internet of things data: Bring personalized sampling into differentially private mechanisms. IEEE Internet Things 2008, 9, 80–91. [Google Scholar] [CrossRef]
- Ou, L.; Qin, Z.; Liao, S.; Hong, Y.; Jia, X. Releasing correlated trajectories: Towards high utility and optimal differential privacy. IEEE Trans. Depend. Secur. Comput. 2020, 17, 1109–1123. [Google Scholar] [CrossRef]
- Ren, X.; Yu, C.M.; Yu, W.; Yang, S.; Yang, X.; McCann, J.A.; Yu, P.S. LoPub: High-dimensional crowdsourced data publication with local differential privacy. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2151–2166. [Google Scholar] [CrossRef] [Green Version]
- Chamikara, M.A.P.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S.; Atiquzzaman, M. Local differential privacy for deep learning. IEEE Internet Things 2020, 7, 5827–5842. [Google Scholar]
- Ye, D.; Zhu, T.; Cheng, Z.; Zhou, W.; Yu, P.S. Differential advising in multiagent reinforcement learning. IEEE Trans. Cybern. 2020, in press. [Google Scholar]
- Ying, C.; Jin, H.; Wang, X.; Luo, Y. Double Insurance: Incentivized federated learning with differential privacy in mobile crowdsensing. In Proceedings of the 2020 International Symposium on Reliable Distributed Systems (SRDS), Shanghai, China, 21–24 September 2020; pp. 81–90. [Google Scholar]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS), Providence, RI, USA, 21–23 October 2007; pp. 94–103. [Google Scholar]
- McSherry, F.D. Privacy integrated queries: An extensible platform for privacy-preserving data analysis. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data (SIGMOD), New York, NY, USA, 29 June–2 July 2009; pp. 19–30. [Google Scholar]
- Garofalakis, M.; Kumar, A. Wavelet synopses for general error metrics. ACM Trans. Database Syst. 2005, 30, 888–928. [Google Scholar] [CrossRef]
- Vitter, J.S.; Wang, M. Approximate computation of multidimensional aggregates of sparse data using wavelets. ACM Sigm. Rec. 1999, 28, 193–204. [Google Scholar] [CrossRef]
- Gini, C. Measurement of inequality of incomes. Econ. J. 1921, 31, 124–126. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).