
A Novel Approach to the Partial Information Decomposition


Abstract
:1. Introduction
2. Notation and Preliminaries
3. Background on the Partial Information Decomposition (PID)
- Synergy , the information found in the joint outcome of all sources, but not in any of their individual outcomes. Synergy is defined as [17]
- Unique information in source , , the non-redundant information in each particular source. Unique information is defined as
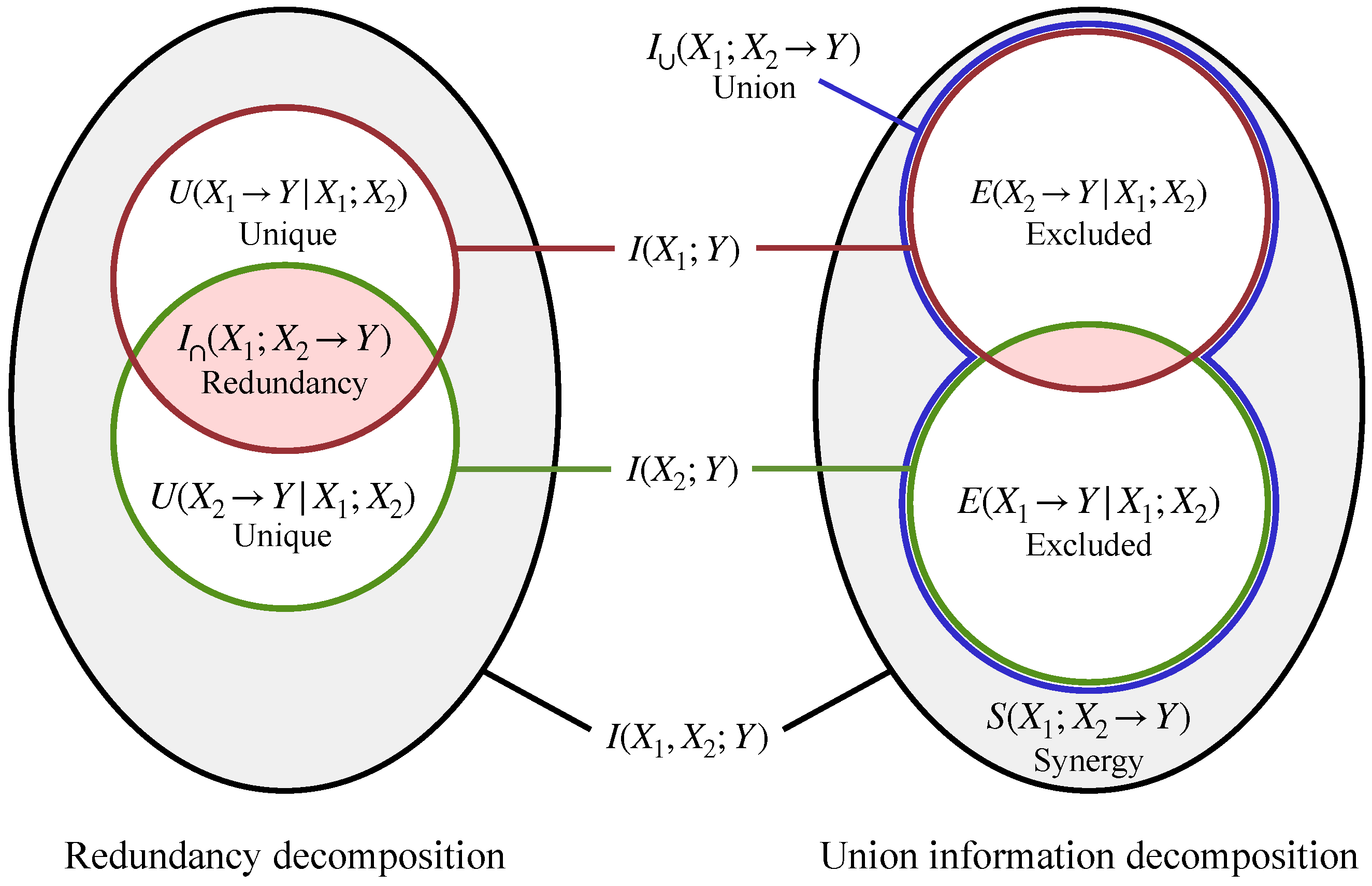
4. Part I: Redundancy and Union Information from an Ordering Relation
4.1. Introduction
- Monotonicity of mutual information: (less informative sources have less mutual information).
- Reflexivity: for all A (each source is at least as informative as itself).
- For all sources , , where O indicates a constant random variable with a single outcome and indicates all sources considered jointly (each source is more informative than a trivial source and less informative than all sources jointly).
4.2. Axiomatic Derivation
- Symmetry: is invariant to the permutation of .
- Self-redundancy: .
- Monotonicity: .
- Order equality: if for some .
- Existence: There is some Q such that and for all i.
- Symmetry: is invariant to the permutation of .
- Self-union: .
- Monotonicity: .
- Order equality: if for some .
- Existence: There is some Q such that and for all i.
4.3. Inclusion-Exclusion Principle
4.4. Relation to Prior Work
4.5. Further Generalizations
- Shannon information theory (beyond mutual information). In Section 4.1, was the mutual information between each random variable and some target Y. This can be generalized by choosing a different “amount of information” function , so that redundancy and union information are quantified in terms of other measures of statistical dependence. Among many other options, possible choices of include Pearson’s correlation (for continuous random variables) and measures of statistical dependency based f-divergences [52], Bregman divergences [53], and Fisher information [54].
- Shannon information theory (without a fixed target). The PID can also be defined for a different setup than the typical one considered in the literature. For example, consider a situation where the sources are channels , while the marginal distribution over the target Y is left unspecified. Here one may take as the set of channels, as the channel capacity , and ⊏ as some ordering relation on channels [24]
- Algorithmic information theory. The PID can be defined for other notions of information, such as the ones used in Algorithmic Information Theory (AIT) [55]. In AIT, “information” is not defined in terms of statistical uncertainty, but rather in terms of the program length necessary to generate strings. For example, one may take as the set of finite strings, ⊏ as algorithmic conditional independence (, where is conditional Kolmogorov complexity), and as the “algorithmic mutual information” with some target string y. (This setup is closely related to the notion of algorithmic “common information” [47]).
- Quantum information theory. As a final example, the PID can be defined in the context of quantum information theory. For example, one may take as the set of quantum channels, ⊏ as quantum Blackwell order [56,57,58], and , where is the Ohya mutual information for some target density matrix under channel [59].
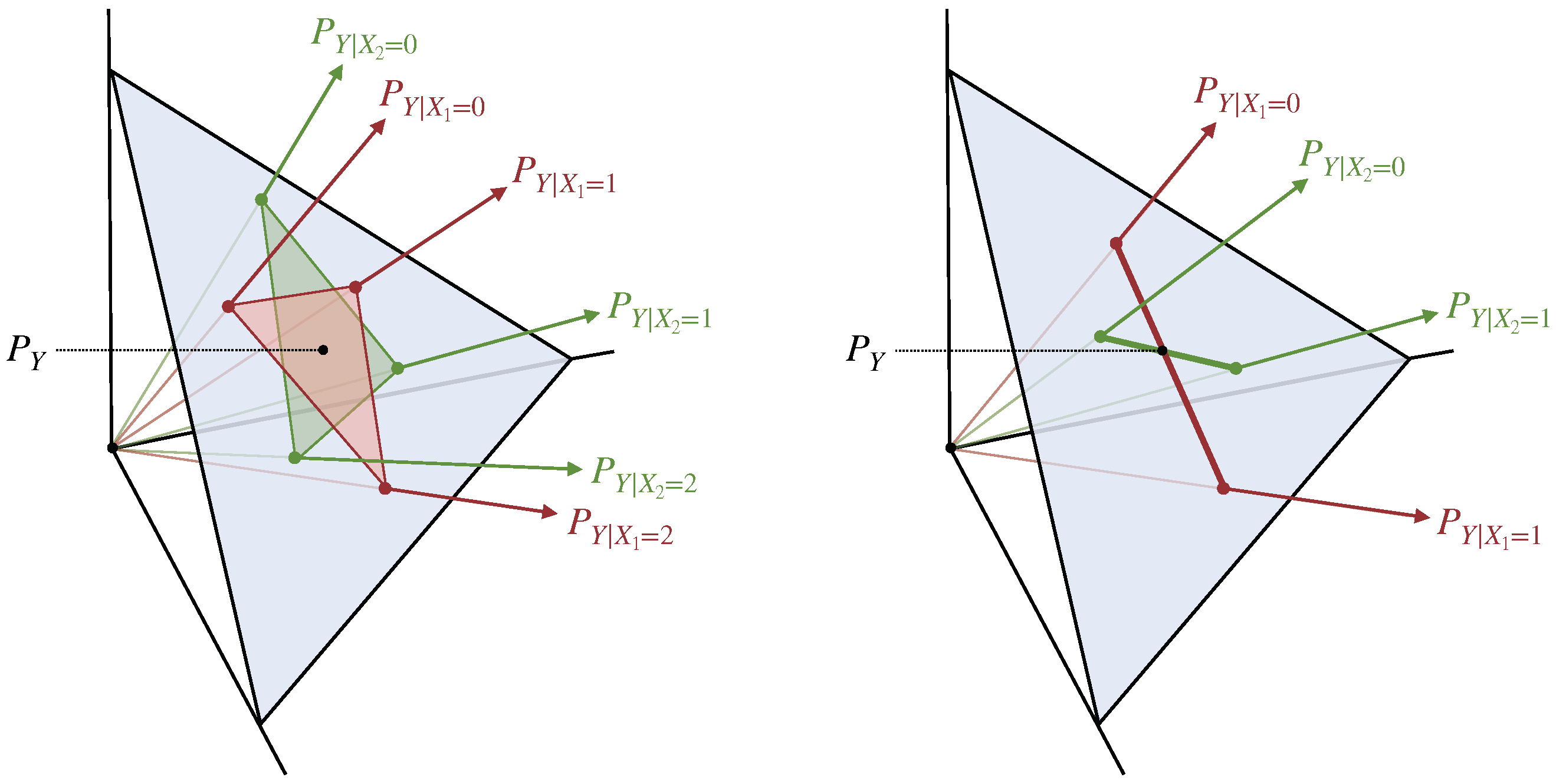
5. Part II: Blackwell Redundancy and Union Information
5.1. The Blackwell Order
5.2. Blackwell Redundancy
5.3. Blackwell Union Information
5.4. Relation to Prior Work
5.5. Continuity of Blackwell Redundancy and Union Information
5.6. Behavior on the COPY Gate
6. Examples and Comparisons to Previous Measures
6.1. Qualitative Comparison
- Has it been defined for more than 2 sources
- Does it obey the Monotonicity axiom from Section 4.2
- Is it compatible with the inclusion-exclusion principle (IEP) for the bivariate case, such that union information as defined in Equation (14) obeys
- Does it obey the Independent identity property, Equation (4)
- Does it obey the Blackwell property (possibly in its multivariate form, Theorem 3)
6.2. Quantitative Comparison
- The SUM gate: , with and independent.
- The UNQ gate: . Here (marked with ∗) gave values that increased with the amount of correlation between and but were typically larger than .
- The COPY gate: . Here, our redundancy measure is equal to the Gács-Körner common information between X and Y, as discussed in Section 5.6. The same holds for the redundancy measures and , which can be shown using a slight modification of the proof of Theorem 6. For this gate, (marked with ∗) gave the same values as for the UNQ gate, which increased with the amount of correlation between and but were typically larger than .
- Three-way AND gate: , where the sources are binary and uniformly and independently distributed.
- Three-way SUM gate: , where the sources are binary and uniformly and independently distributed.
- “Overlap” gate: we defined four independent uniformly distributed binary random variables, . These were grouped into three sources as , , . The target was the joint outcome of all three sources, . Note that the three sources overlap on a single random variable A, which suggests that the redundancy should be 1 bit.
7. Discussion and Future Work
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. PID Axioms
- Symmetry: is invariant to the permutation of .
- Self-redundancy: .
- Monotonicity: .
- Deterministic equality: if for some and deterministic function f.
- Symmetry: is invariant to the permutation of .
- Self-union: .
- Monotonicity: .
- Deterministic equality: if for some and deterministic function f.
Appendix B. Uniqueness Proofs
Appendix C. Computing
Appendix D. Continuity of
Appendix E. Behavior of on Gaussian Random Variables
Appendix F. Operational Interpretation of the
Appendix G. Equivalence of and
Appendix H. Relation between and Our General Framework
Appendix I. Miscellaneous Derivations
References
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, Redundancy, and Independence in Population Codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [CrossRef] [PubMed]
- Daniels, B.C.; Ellison, C.J.; Krakauer, D.C.; Flack, J.C. Quantifying collectivity. Curr. Opin. Neurobiol. 2016, 37, 106–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tax, T.; Mediano, P.; Shanahan, M. The partial information decomposition of generative neural network models. Entropy 2017, 19, 474. [Google Scholar] [CrossRef]
- Amjad, R.A.; Liu, K.; Geiger, B.C. Understanding individual neuron importance using information theory. arXiv 2018, arXiv:1804.06679. [Google Scholar]
- Lizier, J.; Bertschinger, N.; Jost, J.; Wibral, M. Information decomposition of target effects from multi-source interactions: Perspectives on previous, current and future work. Entropy 2018, 20, 307. [Google Scholar] [CrossRef] [Green Version]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [Green Version]
- Timme, N.; Alford, W.; Flecker, B.; Beggs, J.M. Synergy, redundancy, and multivariate information measures: An experimentalist’s perspective. J. Comput. Neurosci. 2014, 36, 119–140. [Google Scholar] [CrossRef]
- Chan, C.; Al-Bashabsheh, A.; Ebrahimi, J.B.; Kaced, T.; Liu, T. Multivariate Mutual Information Inspired by Secret-Key Agreement. Proc. IEEE 2015, 103, 1883–1913. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.; Jensen, H.J.; Seth, A.K.; Barrett, A.B.; Carhart-Harris, R.L.; Bor, D. Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 2020, 16, e1008289. [Google Scholar] [CrossRef]
- Cang, Z.; Nie, Q. Inferring spatial and signaling relationships between cells from single cell transcriptomic data. Nat. Commun. 2020, 11, 2084. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Williams, P.L. Information dynamics: Its theory and application to embodied cognitive systems. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, 2011. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying unique information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef] [Green Version]
- Quax, R.; Har-Shemesh, O.; Sloot, P. Quantifying synergistic information using intermediate stochastic variables. Entropy 2017, 19, 85. [Google Scholar] [CrossRef] [Green Version]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique information via dependency constraints. J. Phys. Math. Theor. 2018, 52, 014002. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Chong, E.K.; James, R.G.; Ellison, C.J.; Crutchfield, J.P. Intersection information based on common randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 159–190. [Google Scholar]
- Griffith, V.; Ho, T. Quantifying redundant information in predicting a target random variable. Entropy 2015, 17, 4644–4653. [Google Scholar] [CrossRef] [Green Version]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. 2013, 87, 012130. [Google Scholar] [CrossRef] [Green Version]
- Ince, R. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Lizier, J. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C. The lattice theory of information. Trans. Ire Prof. Group Inf. Theory 1953, 1, 105–107. [Google Scholar] [CrossRef]
- Shannon, C.E. A note on a partial ordering for communication channels. Inf. Control 1958, 1, 390–397. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J.; Kempermann, J.H.; Zbaganu, G. Comparisons of Stochastic Matrices with Applications in Information Theory, Statistics, Economics and Population; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Le Cam, L. Sufficiency and approximate sufficiency. Ann. Math. Stat. 1964, 35, 1419–1455. [Google Scholar] [CrossRef]
- Korner, J.; Marton, K. Comparison of two noisy channels. Top. Inf. Theory 1977, 16, 411–423. [Google Scholar]
- Torgersen, E. Comparison of Statistical Experiments; Cambridge University Press: Cambridge, UK, 1991; Volume 36. [Google Scholar]
- Blackwell, D. Equivalent comparisons of experiments. Ann. Math. Stat. 1953, 24, 265–272. [Google Scholar] [CrossRef]
- James, R.; Emenheiser, J.; Crutchfield, J. Unique information and secret key agreement. Entropy 2019, 21, 12. [Google Scholar] [CrossRef] [Green Version]
- Whitelaw, T.A. Introduction to Abstract Algebra, 2nd ed.; OCLC: 17440604; Blackie & Son: London, UK, 1988. [Google Scholar]
- Halmos, P.R. Naive Set Theory; Courier Dover Publications: Mineola, NY, USA, 2017. [Google Scholar]
- McGill, W. Multivariate information transmission. Trans. Ire Prof. Group Inf. Theory 1954, 4, 93–111. [Google Scholar] [CrossRef]
- Fano, R.M. The Transmission of Information: A Statistical Theory of Communications; Massachusetts Institute of Technology: Cambridge, MA, USA, 1961. [Google Scholar]
- Reza, F.M. An Introduction to Information Theory; Dover Publications, Inc.: Mineola, NY, USA, 1961. [Google Scholar]
- Ting, H.K. On the amount of information. Theory Probab. Its Appl. 1962, 7, 439–447. [Google Scholar] [CrossRef]
- Yeung, R.W. A new outlook on Shannon’s information measures. IEEE Trans. Inf. Theory 1991, 37, 466–474. [Google Scholar] [CrossRef]
- Bell, A.J. The co-information lattice. In Proceedings of the Fifth International Workshop on Independent Component Analysis and Blind Signal Separation: ICA, Nara, Japan, 1–4 April 2003. [Google Scholar]
- Tilman. Examples of Common False Beliefs in Mathematics (Dimensions of Vector Spaces). MathOverflow. 2010. Available online: https://mathoverflow.net/q/23501 (accessed on 4 January 2022).
- Rauh, J.; Bertschinger, N.; Olbrich, E.; Jost, J. Reconsidering unique information: Towards a multivariate information decomposition. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2232–2236. [Google Scholar]
- Rauh, J. Secret Sharing and Shared Information. Entropy 2017, 19, 601. [Google Scholar] [CrossRef] [Green Version]
- Chicharro, D.; Panzeri, S. Synergy and Redundancy in Dual Decompositions of Mutual Information Gain and Information Loss. Entropy 2017, 19, 71. [Google Scholar] [CrossRef] [Green Version]
- Ay, N.; Polani, D.; Virgo, N. Information decomposition based on cooperative game theory. arXiv 2019, arXiv:1910.05979. [Google Scholar] [CrossRef]
- Rosas, F.E.; Mediano, P.A.; Rassouli, B.; Barrett, A.B. An operational information decomposition via synergistic disclosure. J. Phys. A Math. Theor. 2020, 53, 485001. [Google Scholar] [CrossRef]
- Davey, B.A.; Priestley, H.A. Introduction to Lattices and Order; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Bertschinger, N.; Rauh, J. The Blackwell relation defines no lattice. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2479–2483. [Google Scholar]
- Li, H.; Chong, E.K. On a connection between information and group lattices. Entropy 2011, 13, 683–708. [Google Scholar] [CrossRef] [Green Version]
- Gács, P.; Körner, J. Common information is far less than mutual information. Probl. Control Inf. Theory 1973, 2, 149–162. [Google Scholar]
- Aumann, R.J. Agreeing to disagree. Ann. Stat. 1976, 4, 1236–1239. [Google Scholar] [CrossRef]
- Banerjee, P.K.; Griffith, V. Synergy, Redundancy and Common Information. arXiv 2015, arXiv:1509.03706v1. [Google Scholar]
- Hexner, G.; Ho, Y. Information structure: Common and private (Corresp.). IEEE Trans. Inf. Theory 1977, 23, 390–393. [Google Scholar] [CrossRef]
- Barrett, A.B. Exploration of synergistic and redundant information sharing in static and dynamical Gaussian systems. Phys. Rev. E 2015, 91, 052802. [Google Scholar] [CrossRef] [Green Version]
- Pluim, J.P.; Maintz, J.A.; Viergever, M.A. F-information measures in medical image registration. IEEE Trans. Med. Imaging 2004, 23, 1508–1516. [Google Scholar] [CrossRef]
- Banerjee, A.; Merugu, S.; Dhillon, I.S.; Ghosh, J.; Lafferty, J. Clustering with Bregman divergences. J. Mach. Learn. Res. 2005, 6, 1705–1749. [Google Scholar]
- Brunel, N.; Nadal, J.P. Mutual information, Fisher information, and population coding. Neural Comput. 1998, 10, 1731–1757. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Vitányi, P. An Introduction to Kolmogorov Complexity and Its Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 3. [Google Scholar]
- Shmaya, E. Comparison of information structures and completely positive maps. J. Phys. A Math. Gen. 2005, 38, 9717. [Google Scholar] [CrossRef] [Green Version]
- Chefles, A. The quantum Blackwell theorem and minimum error state discrimination. arXiv 2009, arXiv:0907.0866. [Google Scholar]
- Buscemi, F. Comparison of quantum statistical models: Equivalent conditions for sufficiency. Commun. Math. Phys. 2012, 310, 625–647. [Google Scholar] [CrossRef] [Green Version]
- Ohya, M.; Watanabe, N. Quantum entropy and its applications to quantum communication and statistical physics. Entropy 2010, 12, 1194–1245. [Google Scholar] [CrossRef]
- Rauh, J.; Banerjee, P.K.; Olbrich, E.; Jost, J.; Bertschinger, N.; Wolpert, D. Coarse-Graining and the Blackwell Order. Entropy 2017, 19, 527. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Makur, A.; Polyanskiy, Y. Comparison of channels: Criteria for domination by a symmetric channel. IEEE Trans. Inf. Theory 2018, 64, 5704–5725. [Google Scholar] [CrossRef]
- Benson, H.P. Concave minimization: Theory, applications and algorithms. In Handbook of Global Optimization; Springer: Berlin/Heidelberg, Germany, 1995; pp. 43–148. [Google Scholar]
- Kolchinsky, A. Code for Computing I∩≺. 2022. Available online: https://github.com/artemyk/redundancy (accessed on 3 January 2022).
- Banerjee, P.K.; Rauh, J.; Montúfar, G. Computing the unique information. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 141–145. [Google Scholar]
- Banerjee, P.K.; Olbrich, E.; Jost, J.; Rauh, J. Unique informations and deficiencies. In Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 32–38. [Google Scholar]
- Wolf, S.; Wultschleger, J. Zero-error information and applications in cryptography. In Proceedings of the Information Theory Workshop, San Antonio, TX, USA, 24–29 October 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 1–6. [Google Scholar]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J. Shared information - new insights and problems in decomposing information in complex systems. In Proceedings of the European Conference on Complex Systems 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 251–269. [Google Scholar]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. dit: A Python package for discrete information theory. J. Open Source Softw. 2018, 3, 738. [Google Scholar] [CrossRef]
- Kovačević, M.; Stanojević, I.; Šenk, V. On the entropy of couplings. Inf. Comput. 2015, 242, 369–382. [Google Scholar] [CrossRef]
- Horst, R. On the global minimization of concave functions. Oper.-Res.-Spektrum 1984, 6, 195–205. [Google Scholar] [CrossRef]
- Pardalos, P.M.; Rosen, J.B. Methods for global concave minimization: A bibliographic survey. Siam Rev. 1986, 28, 367–379. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Generalized measures of information transfer. arXiv 2011, arXiv:1102.1507. [Google Scholar]
- Dubins, L.E. On extreme points of convex sets. J. Math. Anal. Appl. 1962, 5, 237–244. [Google Scholar] [CrossRef] [Green Version]
- Yeung, R.W. A First Course in Information Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lewis, A.D. Semicontinuity of Rank and Nullity and Some Consequences. 2009. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.709.7290&rep=rep1&type=pdf (accessed on 3 January 2022).
- Hoffman, A.J. On Approximate Solutions of Systems of Linear Inequalities. J. Res. Natl. Bur. Stand. 1952, 49, 174–176. [Google Scholar] [CrossRef]
- Daniel, J.W. On Perturbations in Systems of Linear Inequalities. SIAM J. Numer. Anal. 1973, 10, 299–307. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| More than 2 sources | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Monotonicity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| IEP for bivariate case | ✓ | ✓ | ? | ? | ✓ | ✓ | ✓ | |||
| Independent identity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Blackwell property | ✓ | ✓ | ✓ | |||||||
| Pairwise marginals | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Target equality | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Target | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.311 | 0.311 | 0.311 | 0 | 0.123 | 0.104 | 0.561 | 0.311 | 0.082 | |
| 0.5 | 0.5 | 0.5 | 0 | 0 | 0 | 0.5 | 0.5 | 0.189 | |
| * | 1 | ||||||||
| 1 | 1 | * | 1 |
| Target | ||||||
|---|---|---|---|---|---|---|
| 0.138 | 0.138 | 0.138 | 0 | 0.024 | 0.294 | |
| 0.311 | 0.311 | 0.311 | 0 | 0 | 0.561 | |
| 1 | 2 | 2 | 1 | 1 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolchinsky, A. A Novel Approach to the Partial Information Decomposition. Entropy 2022, 24, 403. https://doi.org/10.3390/e24030403
Kolchinsky A. A Novel Approach to the Partial Information Decomposition. Entropy. 2022; 24(3):403. https://doi.org/10.3390/e24030403
Chicago/Turabian StyleKolchinsky, Artemy. 2022. "A Novel Approach to the Partial Information Decomposition" Entropy 24, no. 3: 403. https://doi.org/10.3390/e24030403
APA StyleKolchinsky, A. (2022). A Novel Approach to the Partial Information Decomposition. Entropy, 24(3), 403. https://doi.org/10.3390/e24030403