1. Introduction
Currently, many organizations deploy various applications for business management. Rather than developing new solutions in-house, these applications are frequently constructed by integrating components produced by outside firms [
1,
2,
3]. Web services are self-contained application components created on many platforms and advertised, hosted, and accessed via the Internet [
4,
5,
6]. An elementary Web service is a network-accessible process that performs a defined task. When two or more elementary Web services are combined, a new Web service is created that performs a complex composite task that no single elementary service can accomplish alone [
7,
8,
9]. In this case, the new Web service that contains the elementary Web services is called the composite service, and these elementary Web services are called the component services. The process of creating composite services can be performed iteratively, with one composite service serving as a component of a more complicated composite service. The true power of Web services, as demonstrated above, is their ability to be dynamically integrated into composite services, performing new tasks and conducting new business transactions [
10,
11,
12].
To create a successful composite service, the correct component services need to be selected [
2]. In the sector of Web services, how to select desirable Web services and composite appropriate Web services has been a major issue. Both for direct interactions and for specifying composite services, service selection is critical. The rapid growth of the Internet has resulted in a massive increase in the number of Web services, posing a challenge to consumers’ ability to quickly and precisely locate their desirable services [
13,
14,
15]. Furthermore, an increasing number of Web services from diverse service providers provide the same functionality [
16]. Businesses today must comprehend not just what a Web service can do but also how well the Web service can do it. How to select the desired component services and recommend the satisfactory composite services are very important issues [
17]. The non-functional characteristics of Web services, such as QoS (Quality of Service) and trust, are very essential criteria when selecting and composing the desirable Web services [
18,
19,
20,
21].
The QoS determines the performance of a Web service [
22], so the QoS is regarded as the most important non-functional criterion for service selection and composition [
23,
24,
25]. However, the QoS that a given Web service will supply is not predictable and foreseeable due to dynamic changes in network performance [
3,
8,
17,
26,
27,
28]. Furthermore, various customers may be concerned with different QoS attributes, and different customers may assign different priority to the same QoS attributes [
12,
29,
30]. To replace QoS-aware service selection and composition procedures, the attention has recently shifted to social techniques based on trust or reputation. The trust mechanism provides a smart and accurate solution to the issue of service selection and composition [
2,
31].
Trust in a Web service represents a certain level of confidence that the service will perform as expected [
2]. Trust should be applicable to both elementary and composite services. Trust is based on a consumer’s past interactions with or observations of a Web service, either directly with the customer or as reported by other customers. Each customer in a community can function as a rater, giving a service a rating based on his/her interactions with it. Individuals’ ratings on the quality of a service are reflected in trust, which is customized and subjective. The higher a service’s quality, the more trust the consumer has in it. Trust can be used to assess the overall quality of a service [
32]. A trust model for Web services integrates past experiences or interactions to generate trust, allowing customers to identify good from bad services based on customers’ ratings, and assisting customers in forecasting and selecting the best quality services [
33,
34].
Because trust can only exist in a risky and uncertain environment, where certain parts of the application are not within our control, trust is inherently uncertain. Our previous work defined trust in Web services using a mathematical model based on fuzzy theory and probability theory, and presented a customer-centric trust evaluation model for personalized service selection [
35]. However, our previous work did not consider bootstrapping trust for the newcomer services and deriving trust for the composite services, which are two key issues in Web service trust architectures. This work will improve the previous work to form a complete Web service trust evaluation approach.
This work combines the solutions to numerous issues to develop a comprehensive and unified Web service trust evaluation approach. A motivation example is discussed in
Section 2. The present research on bootstrapping trust for the newcomer services and deriving trust for the composite services are investigated in
Section 3. The integrated trust evaluation approach is described in
Section 4. Through a case study,
Section 5 describes the proposed approach’s practical applicability. This work compares the proposed approach to existing approaches in
Section 6.
Section 7 of the work finishes with an overview of the vast potentials of such an approach.
2. Motivation
First and foremost, a motivating case is offered to emphasize this work’s motivation.
Service-oriented architecture (SOA) systems have capabilities to dynamically compose Web services [
6,
36], including the following:
Service tracking to detect all available services and their rating information;
Service planning to design a composite service’s execution process;
Service selection to determine the optimum service for each task node in a composite service process;
Service composition to generate a new service that performs the expected complex task by compositing the selected component services;
Service execution to perform the expected complex task according to the optimal composed plan.
A service workflow, i.e., a composite service, includes a set of tasks [
37]. According to service planning, there may be more than one way to build a composite service [
36].
Figure 1 depicts a composite service that can take one of two paths:
,
,
,
or
,
,
. Each task
may be performed by any elementary service in service class
. The rating information of each elementary service is shown in
Table 1.
Assume that Alice and Bob both need to select desired services in order to build the composite service.
Table 1 shows that Alice and Bob are faced with the following three service selection scenarios:
Alice and Bob have used and rated all of the candidate services (for example, in service class ). They can make decisions directly based on their own ratings. Of course, they can also make decisions based on ratings from previous customers who have used these services.
Alice and Bob have never used any of the candidate services and have no knowledge of how well they perform (for example, in service class ). Only ratings submitted by other consumers who have used these services can help them make decisions.
Alice and Bob have used some of the candidate services, but they have no knowledge of the performance of others (for example, in the service class ). They can make decisions based on ratings submitted by other consumers who have used these services, similar to the second scenario.
In this motivating example, there are three issues that should be noted. The first issue is to bootstrap trust for new Web services. is a new Web service in service class . No consumer has interacted with it, and no rating exists of its past behavior. Consequently, consumers are unable to evaluate its trustworthiness. A mechanism for assigning trust to new services must be specified so that they can compete for market share with existing services. The second issue is to reduce the influence of subjectivity and contingency when the ratings are few. In service class , there are only three ratings on , while there are 1540 ratings on . These three ratings cannot completely and effectively reflect the performance of , so consumers need to reduce the decision-making risk caused by the subjective and contingency when ratings on services are few. This issue is closely related to the first issue. The third issue is deriving trust for composite services. The composite service has two alternative paths, so customers need to choose one to execute. Choosing the option to implement the composite service is actually a decision to implement a more trustworthy composite service. Another mechanism must be defined to derive trust for composite services, allowing customers to select them as elementary services.
Our previous work has modeled the uncertainty of trust and implemented personalized service selection. This work will improve our previous work and address the following issues:
How do new services without past experience and customer ratings take part in the competition;
How to derive the trust value of a composite service according to the trust values of its component services while ensuring that the resultant trust values have the same properties.
3. Related Work
Trust in Web services is a critical prerequisite for their widespread acceptance in an open and dynamic network environment [
10,
38]. To ensure Web service trust, a set of trust criteria and frameworks should be supplied. Academics have different perspectives on trust, so studies were based on distinct perspectives [
39]. Some academics investigated policy-based Web service trust, while others investigated reputation-based Web service trust. Mahmud and Usman conducted a systematic literature review with the aim of identifying and classifying existing studies on trust establishment and estimation in services [
40]. This work’s major goal is to investigate reputation-based trust in Web service, so here we mainly survey the relevant literature on reputation-based trust evaluation approaches for Web services. A reputation-based trust system can be used to identify suitable services or service providers based on past experiences or consumer ratings and gauge customer satisfaction with Web services [
41].
Web services are typically represented and defined over three main architectures: single, composite, and communities [
33], and this work deals with both single and composite architectures. Trust evaluation research in the single architecture focuses on bootstrapping trust, rating credibility, trust dynamics, and the processes of developing and upgrading trust or reputation. Our previous work has addressed issues other than bootstrapping trust.
Bootstrapping trust for a newcomer Web service means assigning an initial trust value for it [
42], which is a key issue in Web service trust models [
43,
44]. Because historical information on newcomer Web services is unavailable, bootstrapping trust becomes a significant difficulty that most existing Web service trust models overlook [
44,
45]. Malik and Bouguettaya looked at a variety of ways for bootstrapping new Web service reputations equitably and properly, as well as their shortcomings [
44]. Existing bootstrapping trust solutions fall into three main categories: default, punishment-based, and adaptive [
46]. The default value-based approach assigns a default trust value to each newcomer service, while the punishment-based approach assigns a low trust value to newcomer services. Both these two approaches have drawbacks; if the initial trust value is high, existing services will be disadvantaged, while a low initial trust value will prevent newcomer services from competing. The adaptive bootstrapping trust approaches assign the initial trust value of a newcomer service by measuring the similarity between the newly deployed service and some existing services. The adaptive bootstrapping is the current resident bootstrapping trust solution. Nguyen et al. presented a trust bootstrapping approach with three auxiliary mechanisms, including inheritance, recommendation, and assurance mechanisms, which is distinguished by the fact that the bootstrapping mechanisms are combined with existing trust models to maximize the accuracy of the trust assessment process in the initial stage [
45]. This approach is based on the characteristics and nature of the newcomer Web service itself, as well as the community, in order to apply appropriate bootstrapping mechanisms so that the assigned initial trust value is truly indicative of the newcomer’s capabilities. Yahyaoui and Zhioua introduced a new approach to bootstrap Web service trust by observing Web service interactions with customers over a certain time horizon [
42]. The observation sequence is modeled as a Hidden Markov Model and matched with a predefined trust model to evaluate the behavior of such a Web service. The predefined trust model is a specification of the possible behavior of the Web service. Based on the matching results, an initial trust value is assigned to the Web service. Wahab and his colleagues suggested a peer-reviewed solution [
46]. The trust bootstrapping mechanism is made up of a machine learning method for obtaining endorsements for newcomer services, a dishonesty-resistant endorsement aggregation technique, and a credibility updating mechanism for endorsers. Wu et al. presented a new technique to reputation bootstrapping in which artificial neural networks are utilized to learn correlations between existing service attributes and performance and then extend them to generate a provisional reputation when evaluating new and unknown services. The reputation bootstrapping also includes the reputations of previously published services from the same provider [
47]. The above-mentioned bootstrapping trust methods are all adaptive methods, and the common shortcoming of these methods is that they require some priori information, but the bootstrapping trust problem is precisely caused by the lack of information.
The trust evaluation problem of composite services is a major focus of composite architecture research. It is important to involve trust in Web service composition when generating trustworthy composite Web services [
48]. Yang et al. proposed a trust management system based on understanding and trust policies that are built on experience [
49]. The trust of the participating Web services is assessed based on previous experiences, allowing the composite service’s trust to be determined based on the evaluation of each Web service and the composite service’s aggregation topology. Paradesi et al. conceptualized behavior-based trust of Web services with a mathematical model that matches many of the intuitions one has about trustworthy Web services [
50]. The model allows modeling the uncertainty of people’s initial trust or distrust of Web services when there is no prior experience dealing with them. As the number of experiences with Web services increases, the level of certainty increases, although the proportion of positive experiences may remain fixed. Furthermore, when the same number of positive and negative experiences are gained, certainty is lowest. They also showed how the trust model for a single service may be used to derive trust for compositions. Yahyaoui suggested a trust-based game theoretical model with the goal of simulating the rivalry between services desiring to be assigned tasks and selecting the best candidate [
51]. Web services utilize a Bayesian model to calculate a trust value for any other service willing to collaborate with them and then play a game to choose the best candidates. Kim et al. proposed a trust model that allows for the discovery and composition of services depending on their trustworthiness [
52]. To determine the trustworthiness of services and service providers, the model relied on both direct and indirect consumer experience. Consumers can obtain a very trustworthy service that meets their quality and functional needs by using composing services. Gao et al. presented a formal service composition architecture for service selection [
23]. They offered a subjective probability-theory-based trust evaluation approach for service composition plans, as well as a trust-oriented genetic algorithm to generate a near-optimal service composition plan with QoS limitations. Karimian et al. proposed a formulation for computing trust based on the transferable belief model using the basic concepts of belief combination and transferability [
53]. Customer ratings of different interactions are combined to form a direct trust value. Trust in composite services is modeled over time using the generalized Bayes theorem in the transferable belief model, which takes into account the structure of each component in the service. Guo et al. proposed a trust-based service composition framework that uses a static program analysis approach to analyze the trust dependency between component services in a composite service. Based on this, the rating and trust dependency information is aggregated into a global trust calculation for the composite service [
20]. It is important to note that a composite service can be used as a component of another more complex composite service. These current approaches to deriving trust for composite services lack the ability to generalize further.
Although there are already many approaches to serve bootstrapping trust for the newcomer services and deriving trust for the composite services, these existing trust evaluation approaches are limited in their scope of addressing issues. Their shortcomings are mainly as follows:
Existing trust evaluation approaches tend to focus only on one or some specific issues of trust and cannot cover the whole lifecycle and scope of trust in Web services.
Existing trust evaluation approaches often involve only customer preferences, and the subjective initiative of customers in the trustworthy representation is insufficient.
Bootstrapping trust for the newcomer services often requires additional information, but in fact, bootstrapping trust is caused by insufficient information about the newcomer services.
Deriving trust for the composite services was often algorithmically complex and lacked global generalization capability.
This work incorporates the solutions to multiple major challenges, and our goal is to develop a comprehensive and unified Web service trust evaluation approach. The proposed approach has the following advantages:
The proposed approach covers three phases of trust development, including the initial trust establishment phase, the trust improvement phase, and the trust stabilization phase, and involves two main architectures of Web services, namely, single architecture and composition architecture.
The proposed approach fully considers the subjective initiative of customers, involves not only their preferences but also their expectations, and leaves the setting of algorithm parameters to customers, realizing the personalization of trust evaluation.
Bootstrapping trust in the proposed approach cleverly utilizes customer expectations without any priori information and only needs to set the distribution of virtual ratings according to the maximum entropy principle.
In this work, the principle of deriving trust for composite services is simple to understand, the characteristics are stable, the algorithm is easy to implement, and the method has good global generalization ability.
4. Trust Evaluation Model
4.1. Trust Specification
Researchers have begun to recognize that Web service trust is an important attribute to measure and evaluate. Based on exploration and analysis of trust literature and extension of the online trust principles, Aljazzaf et al. presented some trust principles that form the basis of trust in Web services [
54]. After a comprehensive reference to other literature [
55,
56], we believe that a Web service trust model should consider at least the following trust principles:
Trust is based on information: There is a need to know information about a Web service to establish trust.
Dynamic nature of trust: Trust is dynamic and changes over time and with future experiences. This requires a continuous evaluation of Web services’ trustworthiness.
Trust and identity: Trust depends on identity. Having identity enables the past experience of the interactions to be built on and mapped to that identity.
Trust is based on context: Trust is not a fixed value connected with a Web service; rather, it is dependent on the performance of the service and only applies in a certain context at a specific time.
Categories of trust semantics: Semantic characteristics of trust ratings are important to interpret the meaning of those measurements.
Individual and collective ratings: Considering individual and collective ratings to predict the trust in Web services helps the customer to make a better selection decisions.
Customer expectations: Trust is not absolute but a matter of degree. Therefore, a trust-based system helps the customer to select a Web service based on the customer’s expectations.
Trust development phases: Trust in Web services should consider the three trust development phase (initial trust establishment, trust improvement, and trust stabilization).
Trust approaches: Using a hybrid of multiple trust methods results in a better and more robust method to model trust in Web services.
Our previous work has addressed some of the above Web service trust principles. This work is a further extension of the previous work and will address all the above principles. To facilitate description, we firstly defines some symbols, as shown in Symbol description list 1.
Symbol description list 1:
represents a concrete element in a service market.
represents a concrete customer in a community.
Direct trust is personal and subjective, representing an individual’s rating on a Web service. , which is in the range of , represents customer ’s direct trust in service .
Indirect trust is the collective view of a Web service’s character or standing. The collective view synthesizes the ratings submitted by the customers who have been interacted with the service. , which is called indirect trust in , represents the aggregation of individual direct trust in and is processed as a random variable in the range of .
is given subjectively by according to his/her historical interactions with , which evolves over time and with new interactions. If has engaged with and has given it a rating, ; otherwise, . must keep updating his/her rating on in response to the successive QoS of supplied to him/her. The subjective evaluation disparities in the ratings on submitted by different customers represent the cognitive differences and preferences of these customers. is relatively objective and represents a collective evaluation of a group of customers. The ratings on submitted by customers are seen as samples of the random variable . In theory, should be continuous.
Due to the differences in characteristics between direct and indirect trust, this work expresses direct and indirect trust in distinct forms. This work tries to combine these two trust expressive forms to create a stronger and more comprehensive way for evaluating trust in Web services.
The process of selecting a service has evolved into a comparison of Web service trust. Because direct trust values are expressed as determinate values with a fairly basic comparison procedure, this work does not go into detail. It is worth noting that indirect trust values are random variables that can’t be directly compared as determinate values. The statistical features of indirect trust values should be compared by service customers when comparing candidate services.
and are two Web services that perform the same task with the indirect trust values and . Both and are continuous random variables with values in the range. To compare random variables and , a variety of methods can be employed, the most popular of which is to compare the expected values of and , that is, if and only if . In this work, a novel random variable comparison method is employed, as indicated in Symbol description list 2.
Symbol description list 2:
- 5.
Expected trust level is the lowest degree of trust that a consumer can expect from a Web service’s competency in real-world situations.
- 6.
If , it is said that is greater than and is more trustworthy than for an expected trust level . These two relationships are symbolically represented by the formulas and , respectively.
- 7.
The probability density functions of and are and , respectively. can be converted to .
In different contexts, there may be different trust evaluation strategies [
57], and different customers have different trust expectations for Web services, so the expected trust level
should be determined by the specific context and customer requirements. By setting different expected trust levels, the service comparison method enables personalized service selection because, for different expected trust levels, the results of the service comparison may be different.
This method of comparison seems very abstract, but in fact, we use it all the time. Many e-commerce sites such as Amazon now have customer ratings of the items they buy. These ratings are generally set at five levels, one to five stars. Customers who want to buy the items can refer to these ratings. Some customers pay attention to the proportion of four-star and above ratings, while others pay more attention to the proportion of five-star ratings. This reflects that different customers have different expectations of the items.
4.2. Deriving Trust for Composite Services
A composite service’ trustworthiness is determined by the trustworthiness of its underlying component services [
58]. A service composition system that may use the trustworthiness of separate components to evaluate the composite service’s derived trustworthiness is currently a work in progress. This is due in part to the lack of a flexible trust evaluation paradigm. This challenge is addressed by the trust evaluation approach given in this work.
“A chain is no stronger than its weakest link”, says an English proverb. Any system has a common characteristic in that different parts contribute differently to the system’s performance, but the weakest part often determines the overall system’s reliability. The whole is only as reliable as its weakest part. Similarly, a composite service is only as trustworthy as its least trustworthy component service.
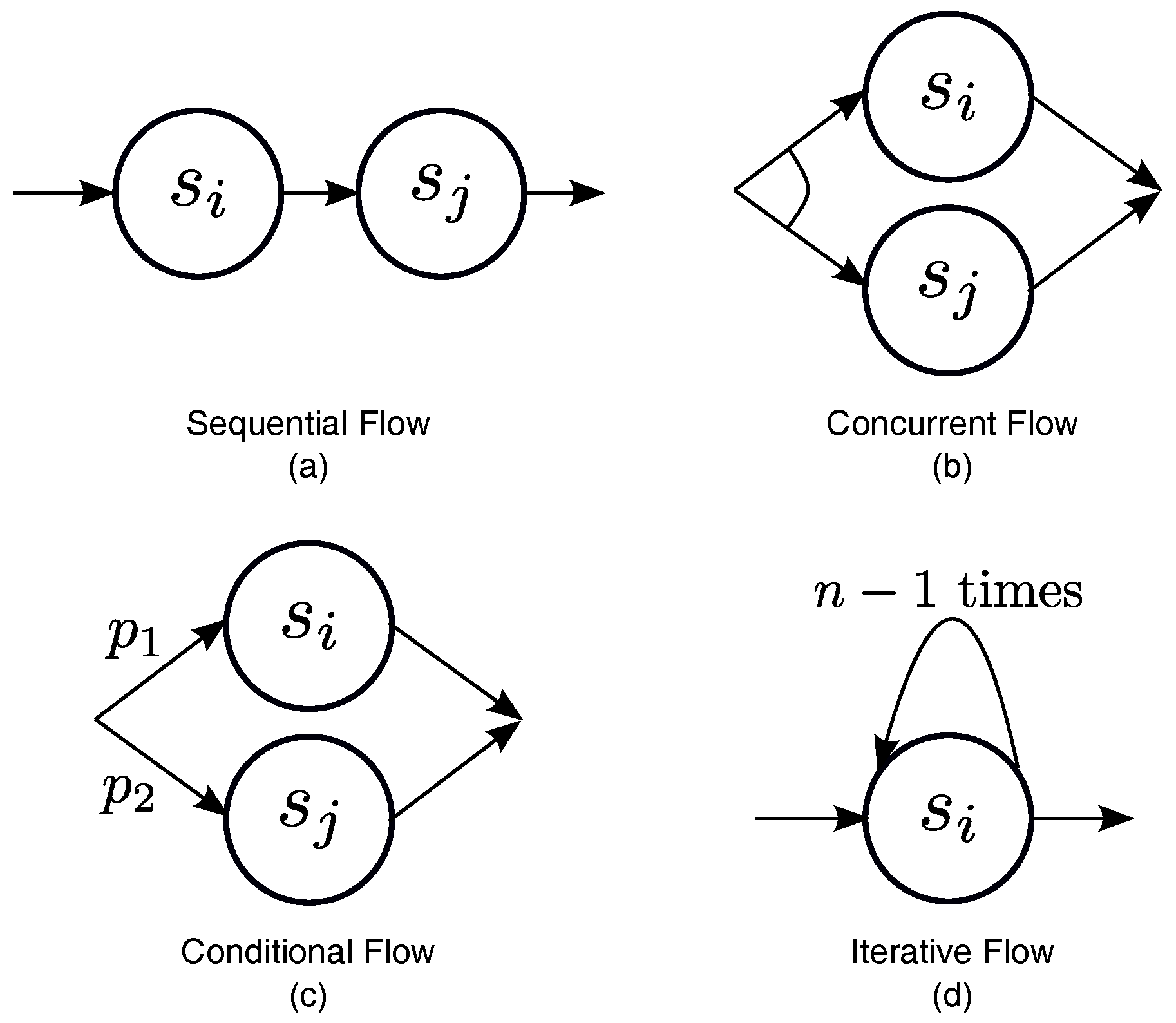
In order to evaluate the trustworthiness of composite services, this work investigates four types of typical control flows that are frequently encountered in service compositions (see
Figure 2) [
9,
19,
50,
59,
60,
61]. For the sake of simplicity, this work considers a composition of two Web services,
and
, with the indirect trust values,
and
, respectively.
and
are continuous random variables with probability density functions
and
, respectively, in the range
.
and
are simple to find.
stands for the composite service, and
stands for its indirect trust value. It is reasonable to assume that
is a continuous random variable with the probability density function
as well.
- (a)
Sequential Flow: Define ⊙ as a sequence operator.
represents that the composite service
executes the component service
before moving on to the component service
. In a sequential flow (see
Figure 2a), each component service must be executed. According to the previously described idea about how to evaluate the trustworthiness of composite services,
can be computed as follows:
The above formula shows that the composite service is only as trustworthy as its least trustworthy component service.
- (b)
Concurrent Flow: Define ‖ as a parallel operator.
represents that the composite service
executes both component service
and component service
concurrently. In a concurrent flow (see
Figure 2b), like a sequential flow, each of the component services must be executed, existing only in the difference of execution sequence. As a result,
is computed in the same way as
for a sequential flow, i.e.:
- (c)
Conditional Flow: Define ⊕ as a choice operator.
represents that the composite service
behaves as either component service
or service
. As shown in
Figure 2c, any one of the component services is executed in a conditional flow. For example, let
and
be followed with executed probabilities,
and
, respectively. By examining the composite task, these probability can be anticipated.
can be thought of as a weighted sum of
and
, i.e.:
- (d)
Iterative Flow: Define
as an iteration operator.
represents that the composite service
executes
n times the component service
. In an iterative flow, the component service must be executed similarly to a sequential flow. The difference is that the service is executed
n times instead of just once (see
Figure 2d). The value of
n may not be constant and may vary depending on the runtime situation. The procedure for computing
is similar to that for a sequential flow, except ⊙ must be applied
times iteratively, as follows:
Theorem 1. Consider a composition of two Web services, and , with indirect trust values, and , respectively. For an expected trust level, , there are: Proof of Theorem 1. In a sequential flow or concurrent flow,
, thus:
i.e.,
and
.
In a conditional flow,
, thus:
i.e.,
.
In an iterative flow, it is easy to see that:
i.e.,
. □
In the above formulae, and are the cumulative distribution functions of random variables and , respectively, namely, and . No matter what kind of control flows is deployed, we can always find , i.e., the random variable is also in the range of like and . This ensures the Web service trust evaluation model maintains consistency for both elementary services and composite services.
This paper has mathematically shown the methods to evaluate the trust of each flow. These evaluation methods can all be generalized to more than two component services in a straightforward way. In practice, a composition may consist of one or more of these basic control flows. No matter how complicated the composition is, the trustworthiness of the composition can be always evaluated.
4.3. Extension of Trust Evaluation Model
Customers should enter numerical values in the range of
when rating
. In practice, however, it is more appropriate for a consumer to express his/her direct trust in
through a subjective qualitative evaluation rather than a quantitative evaluation. According to previous interactions with
, customers make subjective qualitative ratings on
initially, then convert these subjective qualitative ratings to quantitative forms. A comparison between a subjective qualitative rating and a reference value is used in the conversion. This work creates a conversion comparison table (see
Table 2). Based on the semantic characteristics of these ratings, this work divides them into 11 categories, which correspond to 11 values. For example, the subjective qualitative rating “very untrustworthy” corresponds to the value 0.2, indicating that
is 0.2, and the subjective qualitative rating “rather trustworthy” corresponds to the value 0.7, indicating that
is 0.7. Note that a value in the middle, such as 0.78, indicates that
has a subjective qualitative rating that is somewhere between “rather trustworthy” and “very trustworthy” but is closer to the latter.
In doing so,
will be treated as a discrete random variable with 101 possible values
. To make the statement easier to understand, let
symbolize the potential values of
, namely,
for
.
’s probability function is defined as follows:
where
,
and
.
is the number of
when
in Formula (
5). Similarly,
is the number of
when
, also known as the number of actual ratings on
. Because
cannot be 0, Formula (
5) is applicable to the case where ratings are required on
. In the discrete case,
is equivalent to
, where
.
The above trust evaluation model has not taken into account the time decay of the ratings and the credibility of the raters. Older ratings are less important than newer ones since older ratings may become obsolete or meaningless as time passes. On the other hand, ratings submitted by more reliable raters are more significant. In Symbol description list 3, we have introduced some new symbols for the simplicity of expression.
Symbol description list 3:
- 8.
represents the number of actual ratings on , i.e., =.
- 9.
represents current moment, represents the moment when last updated the rating on , and represents the time interval between and , i.e., .
- 10.
, which is in the range of , represents a function of . The smaller is, the nearer the value of to unity; the larger is, the nearer the value of to 0. In other words, indicates the newness degree of .
- 11.
, which is in the range of , represents customer ’s trust in another customer and also refers to the preference similarity between and in ’s individual opinion.
- 12.
represents personalized indirect trust in from ’s perspective and is also processed as a random variable in the range of .
and
have completely different connotations, but they both emphasize the importance of a rating. A mechanism is needed to integrate them. Referring to the literature [
62], the authors define a new function
Z, which allows customers to express different preferences for the credibility of raters and the time decay of ratings.
Z is defined as follows:
where
,
and
.
gauges the relative relevance of
to
in Formula (
6). When
,
gives equal weight to
and
; when
,
gives more weight to
; and when
,
gives more weight to
.
The probability function of
is defined as follows:
where
,
and
.
is the sum of
when
in Formula (
7). Similarly,
is the sum of
when
, also known as the number of
’s calculated ratings on
. Formula (
7), like Formula (
5), is applicable to the case that there must be ratings on
.
and are two Web services that perform the same task. From the perspective of , and are personalized indirect trust values of and , respectively. It is said that is greater than and is more trustworthy than in ’s viewpoint if for an expected trust level . These two relationships are symbolically described by the equations and , respectively.
Our previous work designed a trust management mechanism based on peer-to-peer network, where each customer in the community is both a provider and a requester of ratings. This mechanism makes it easy to store and manage , and , and allows flexible and robust support for personalized trust evaluation.
4.4. Bootstrapping Trust for Newcomer Services
Trust in Web services is established based on the historical ratings. It is tough to give a recommendation for a new service if no ratings are available [
13] because there is usually no way to judge its initial trust value [
42,
44,
45]. As a result, the new service cannot be compared with other services. The new service should be given an initial trust value. Existing services will be disadvantaged if the initial trust value is high, whereas a low initial trust value will deter new services from competing [
42]. Furthermore, if a system relies on a few ratings to establish trust, the subjectivities of the raters may have an undue influence. One of the first issues service selection must address is how to allow a new service to compete. Introducing virtual ratings can effectively solve this problem. Virtual ratings are not real user ratings, and their introduction aims at constructing the indirect trust probability distribution for a new service. The values of the virtual ratings are hypothetical, i.e., possible values of user ratings in the absence of the a priori information available.
According to the law of large numbers, the frequency of a random event, as the number of trials increases, tends to a stable value. That is, plenty of ratings on can effectively and objectively reflect the statistical properties of . However, the question is, how much is plenty? There is no one-size-fits-all response to this question. The statistical features of can be portrayed more effectively and objectively the more calculated ratings on . Plenty is a fuzzy term similar to trust in that it is not a precise amount. In order to simplify the expression, we define some new symbols in Symbol description list 4.
Symbol description list 4:
- 13.
represents the set containing all non-negative numbers, while represents the number of ’s calculated ratings on , i.e., = and .
- 14.
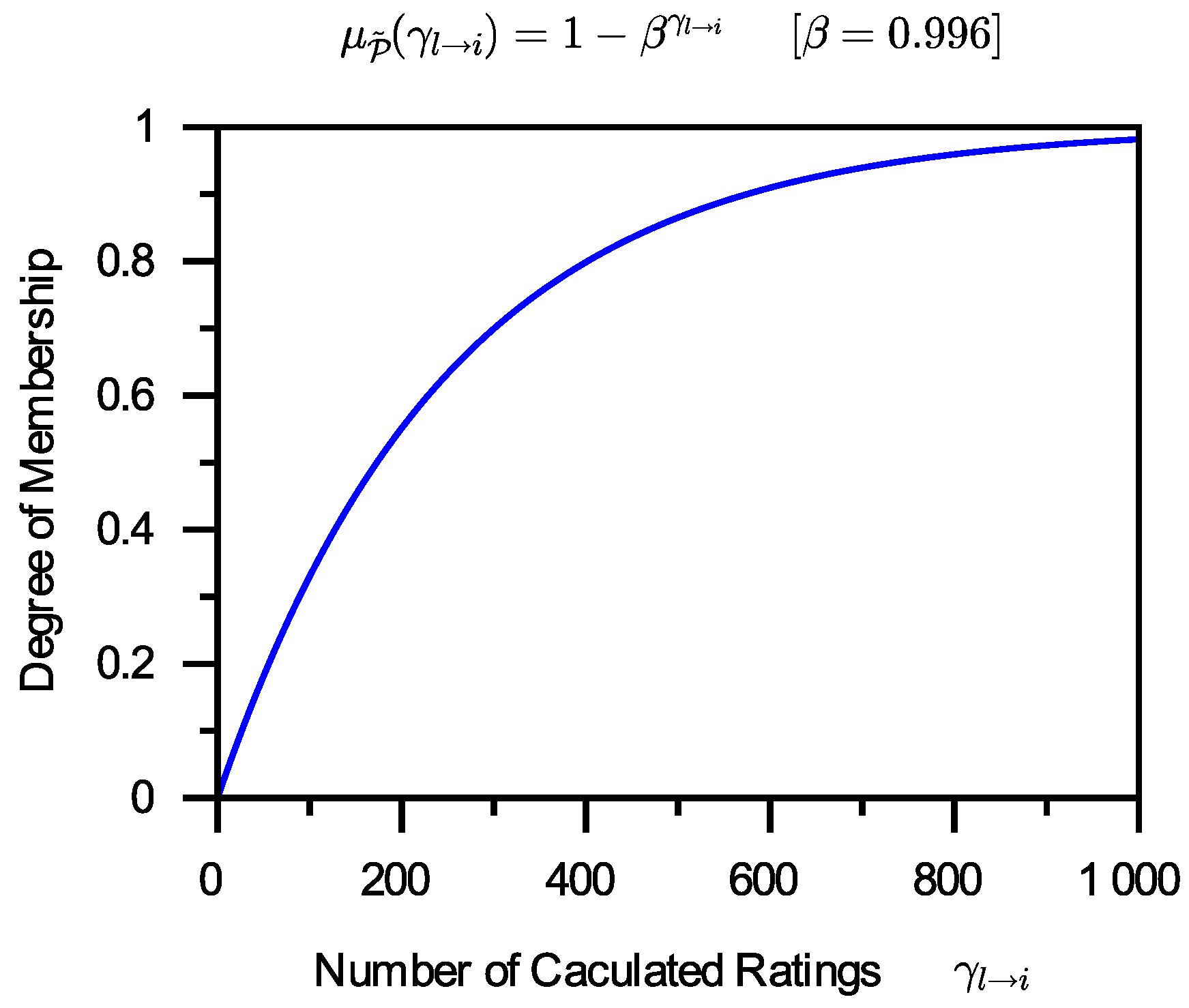
Plenty, denoted by , is called a fuzzy set defined on , which has a membership function . For each , is called a fuzzy member of . The value is called the grade of membership of in .
It is self-evident that the larger
, the more
belongs to
. The grade of membership of 0 in
is 0, and the grade of membership of
in
is 1. There is no one-size-fits-all way to create fuzzy membership functions. It is possible that more than one function can be utilized as the fuzzy membership function of
. This work simply chooses one of these based on the present application needs. The function that has been chosen is as follows:
In Formula (
8),
is a parameter of the membership function. If
presets
to various values, the function curve will be varied. Smaller
values can result in faster changes, whereas bigger
values can result in slower changes. However, the curve change trend is essentially the same. One instance of this function is shown in
Figure 3.
The goal of introducing virtual ratings is to build the probability distribution of
for the new service
that has few or no calculated ratings. If there are too many virtual ratings on
introduced, the calculated ratings on
will be buried; if there are too few virtual ratings on
introduced, virtual ratings will not be able to play the role they should. The more calculated ratings on
, the fewer virtual ratings on
should be introduced. Of course, fewer is in relation to the number of calculated ratings on
. Assume that there are
calculated ratings on
and that
virtual ratings on
should be introduced. It is reasonable to suppose that
is associated with
and
. In the case where there are
calculated ratings on
, this work recommends that
virtual ratings on
should be introduced, i.e.:
Figure 4 depicts the relationship between the number of calculated ratings on
and the number of virtual ratings on
. When the number of calculated ratings on
increases from 0, the number of virtual ratings on
that need be introduced also increases from 101. The number of virtual ratings on
reaches a peak as the number of calculated ratings on
grows, then progressively drops until it is near to 0. When the number of calculated ratings on
is minimal, constructing probability function of
needs to introduce virtual ratings on
; when the number of calculated ratings on
is large, these calculated ratings on
can construct probability function of
effectively without the use of virtual ratings on
.
Figure 4 shows a curve changing trend that meets our perception of this issue.
The next issue is how to set values for virtual ratings on
. There is no reason to prefer one possible value over the others. The only plausible assumption is that each possible virtual rating value is assigned the same probability. This assumption is consistent with the maximum entropy principle. The essence of maximum entropy principle is that the most reasonable inference about the unknown distribution, given the known partial knowledge, is the most uncertain or random inference, which is the unbiased choice we can make. Under this assumption,
should be evenly divided into 101 smaller numbers. The probability function of
in Formula (
7) can be redefined as follows:
4.5. Two Corollaries
A question to examine in service composition is how to ensure that the composite service composed of optimal component services is also optimal. Formula (
1) can be rewritten as follows in the discrete case:
According to Theorem 1 and Formula (
11), the following equation can be found:
Because and , we can find and , i.e., and .
As the number of component services in a composite service grows, the composite service’s trustworthiness may deteriorate. People’s perceptions are compatible with this finding. The following two corollaries can be found based on the prior discussion and Theorem 1:
Corollary 1. Let and , and be Web services offering the same function with ’s indirect trust values and , and respectively. For an expected trust level , if and , then Corollary 2. Consider a composition of two Web services, and , with ’s indirect trust values and respectively. For an expected trust level , 5. Case Study
Our previous work has shown the feasibility of the proposed approach, which models the social features of trust in the sector of Web services and can be exploited to personalize service selection. This study will not repeat the feasibility of the proposed approach but will instead undertake a case study to illustrate the details of bootstrapping trust for the newcomer services and deriving trust for the composite services so that they may be graphically described. The case study is programmed with Scilab and MySQL, and executed on a MacBook Pro computer with the following confgurations: Intel Core i5-4308U CPU, 8 GB RAM, and Windows 10 operating system.
To the best of our knowledge, no dataset exists that perfectly matches the proposed approach. We used some synthetic data based on the extended Epinions dataset, which is a real-world dataset from Trustlet (
http://www.trustlet.org/extended_epinions.html, accessed on 19 December 2021) [
63,
64]. Trustlet.org is a wiki-based platform for open trust metric research with the purpose of collecting and disseminating trust network datasets and trust metric scripts to facilitate comparing different trust metric algorithms. Epinions is a website where people can review products. Customers can sign up for free and write subjective reviews about many different types of items. The extended Epinions dataset contains 13,668,320 customer ratings of items, in addition to the time when these ratings were last modified and the trust or distrust values that one customer has for other customers. In general, the extended Epinions dataset is more suitable for the proposed approach, but some transformations and modifications are still needed.
In the extended Epinions dataset, the values of original ratings are 1–5, which we need to transform to within the interval [0, 1]. The approach we take is to first correspond and convert 1, 2, 3, 4, and 5 to 0.1, 0.3, 0.5, 0.7, and 0.9, respectively. Then, we calculate the mean and variance of the post-transformation rating values of a given item and use them to estimate the parameters of the Beta distribution. Finally, the Beta distribution is used to generate the same number of generated ratings as the original ratings. These generated ratings are the final values we need. We randomly replace the original ratings with the generated ratings. The original trust value of a customer to another customer is 1, and the original distrust value is −1. We modify the distrust value to 0 and set the non-existent trust value of a customer to another customer to 0.5.
Assume that the customer with MEMBER_ID 239694 is the current customer
. Consider the sequential flow consisting of
and
in
Figure 1. The composite task performed by the sequential flow is denoted as
. There are a set of candidate Web services
that can be used to perform
, while there is only one candidate Web service
that can be used to perform
.
needs to select one in
for deployment.
is a new service so there is no actual rating on it. The only candidate service
for
naturally is selected to deploy. Assume that the item with OBJECT_ID 18887577220 is
, the item with OBJECT_ID 17124462212 is
, and the item with OBJECT_ID 1549857 is
. They have 244, 125, and 1195 actual ratings, respectively. The latest date in the extended Epinions dataset is 2003-08-12, which we have taken as the current time
. The unit for time interval
is days, and the function
is set to
, i.e.,
. The parameter
of
is set to 0.3, indicating that
considers
to be more important than
.
After calculating according to Formula (
7), the original probability distributions for
,
,
, and
are shown in
Figure 5.
As can be seen from
Figure 5,
has no actual and calculated ratings and hence cannot participate in the competition; the actual and calculated rating numbers for both
and
are low, which can not effectively reflect their actual quality. In this instance, we must incorporate virtual ratings into the service selection process. Comparison of the number of actual ratings, the number of calculated ratings and the number of virtual ratings about the four services is shown in
Table 3.
After introducing virtual ratings, the probability distributions of
,
,
, and
are shown in
Figure 6. From
Figure 6, it can be seen that virtual ratings’ effect on the probability distribution of
reduces with the increasing number of calculated ratings on
.
is at initial trust establishment phase, while
and
are at trust improvement phase. It can be considered that
is coming to trust stabilization phase. The comparisons of
,
, and
are shown in
Table 4.
When , there is , so can find ; when , there is , so can find .
This case study shows that for different expected trust levels, the services selected in the service selection process may be different, i.e., the optimal service is relatively optimal, rather than absolutely optimal. This case study also shows that a Web service with few or no ratings can participate in the competition and has the opportunity to be selected as the optimal service. This result accords with the fact that a consumer may try to select a new service when the existing services do not meet his/her expectations well, even though there is a decision-making risk.
As mentioned above,
has been selected to perform
. If
set
,
will be selected to perform
, then there is a composite service
. In the same way, if
set
, there is a composite service
. The probability distributions of
and
that are derived according to Formula (
11) are shown in
Figure 7, and the comparisons of
and
are shown in
Table 5.
When , there is , so can find ; when , there is , so can find .
From
Table 4 and
Table 5, the following phenomena can be seen. For a given expected trust level
and the same service
, if
, there is
; if
, there is
, i.e., if the component services selected are optimal, the composite services containing these component services are also optimal.
It is worth noting that our proposed bootstrapping trust approach is applicable to the case when the overall rating values of the existing services are small. Only in this case, the new service is likely to be selected as the optimal service, i.e., it indicates that customers try the new service only if they are dissatisfied with the existing services. When the overall rating values of existing services are large, the new service is inhibited from competing. This is when additional mechanisms may be needed to enable the new service to be competitive.
6. Comparison with Other Approaches
The Web service trust evaluation approach proposed in this work is based on a new theory and focuses on personalized trust evaluation from the customers’ perspective. This work introduces an unprecedented concept of expected trust level to express the lowest degree of trust that a consumer can expect from a Web service’s competency. The approach proposed in this work is based on this concept. This concept is extremely subjective, and we cannot determine in advance the expected trust level for each customer. Customers set different trust expectations and may obtain different results. So, it is not meaningful for this approach to compare accuracy, efficiency, and other indicators with other approaches. Additionally, an exact benchmark trust value for a service does not exist. Various approaches for trust evaluation usually tackle different characteristics of trust. Trust evaluation is a socialization research method, and a feasible comparison scheme for trust evaluation approaches is to compare which approach is closer to the real society and better reflects the socialization characteristics of trust.
In the sector of Web services, reputation-based trust approaches primarily address concerns such as bootstrapping trust, rating credibility, trust dynamism, and trust derivation for composite services, among others. This work defines a set of criteria for the success and efficacy of reputation-based trust approaches targeting the sector of Web services, based on the reference [
33].
Table 6 summarizes these criteria.
The approaches used for comparison were selected from articles published in refereed journals, all with different underlying principles. The common features of these selected articles are that they all consider both direct and indirect trust, and they all deal with Web service composition architectures. The approaches are compared in
Table 7 using the criteria stated in
Table 6.
The proposed approach does not take into account the filtering of unfair ratings, which could lead to collusion and deception issues. Some academics in the Web service management environment have undertaken research on identifying and filtering unfair ratings [
65,
66]. However, because there are no differences in their values, distinguishing between fair and unfair ratings is extremely difficult. Any type of customer rating is possible in an open environment because dynamic changes in network performance result in dynamic changes in QoS attributes. The vast majority of system participants are usually trustworthy, according to social network data [
67]. The majority of the ratings will most likely be reasonable. Although this assumption is not always valid, it provides the foundation for building a trust/reputation system. A trust/reputation system would be pointless if the bulk of the ratings were unfair.
It is difficult to identify and filter out unfair ratings. Another technique to filter out unfair ratings is to assess the credibility of the raters. A trust evaluation approach should not just filter a rating if it differs from the majority opinion but should also consider whether the rating’s inconsistency is attributable to real-life experience. As a result, just the rater’s credibility is affected, but the rating remains [
67]. Customers, for the most part, do not interact directly with one another. The association between trust and customer preference similarity has been proven in some research studies [
68,
69]. The trust that one customer has in another is based on their similarity in prior preferences. A rating given by a reputable customer carries more weight. This is how the issue is addressed in this work.
It is worth suggesting that the comparison of approaches here does not reflect methodological merits or demerits. Society is large and complicated, trust is full of fuzziness and randomness, these approaches all simulate only a part of trust socialization, and the effectiveness of these approaches can be tested only in the practice of real social relations.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}