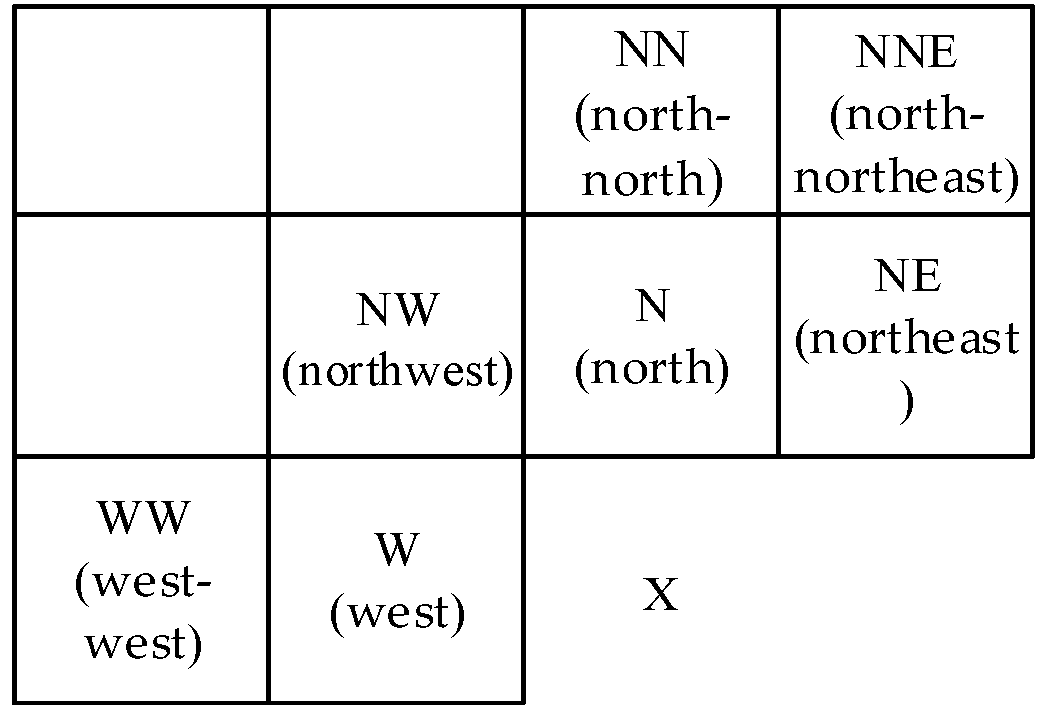
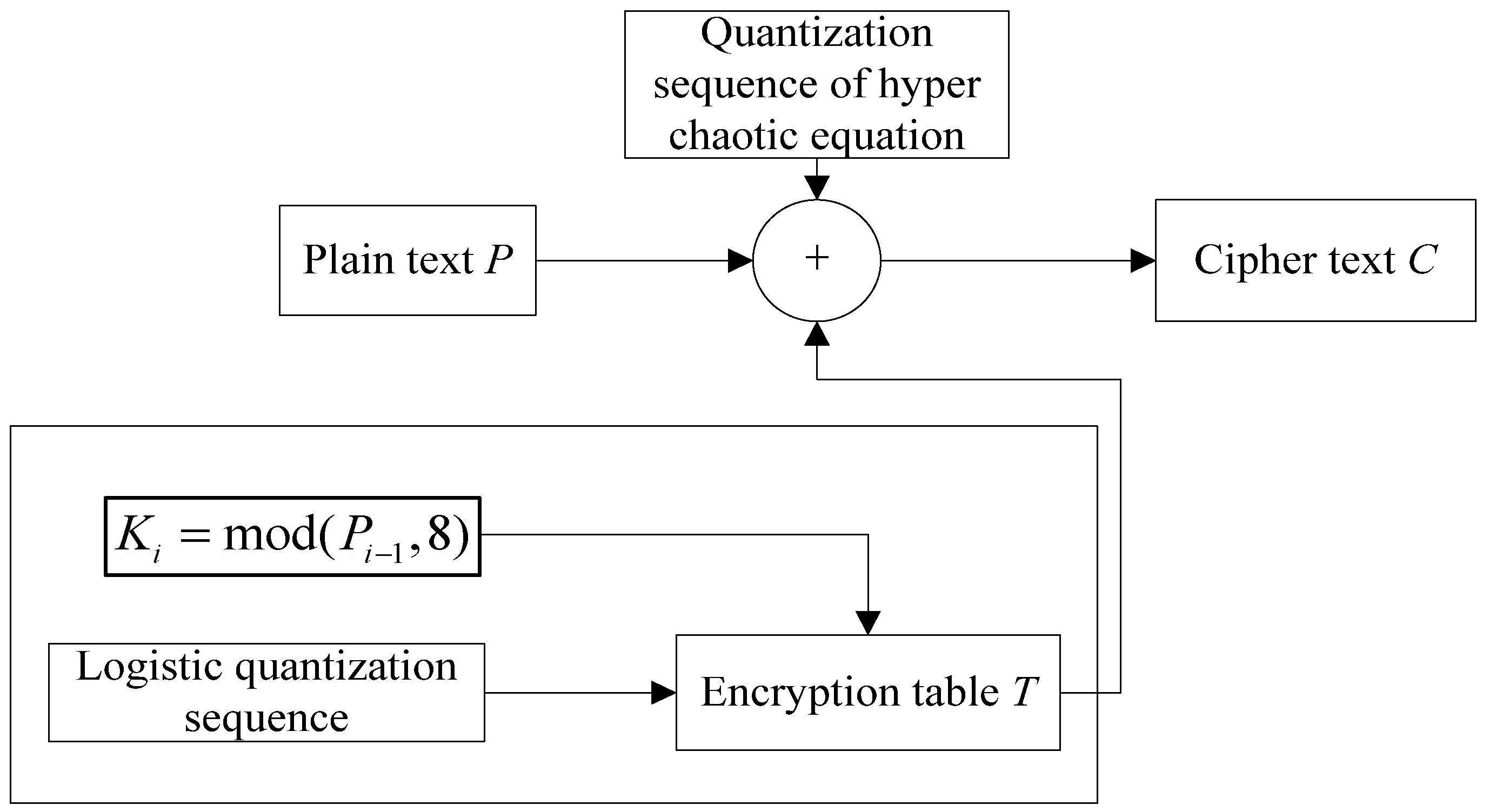
In two lines of original pixel and entropy coding encryption, the initial value of logistic map for selecting the entry of encryption operation table is x = 0.361846592847235.
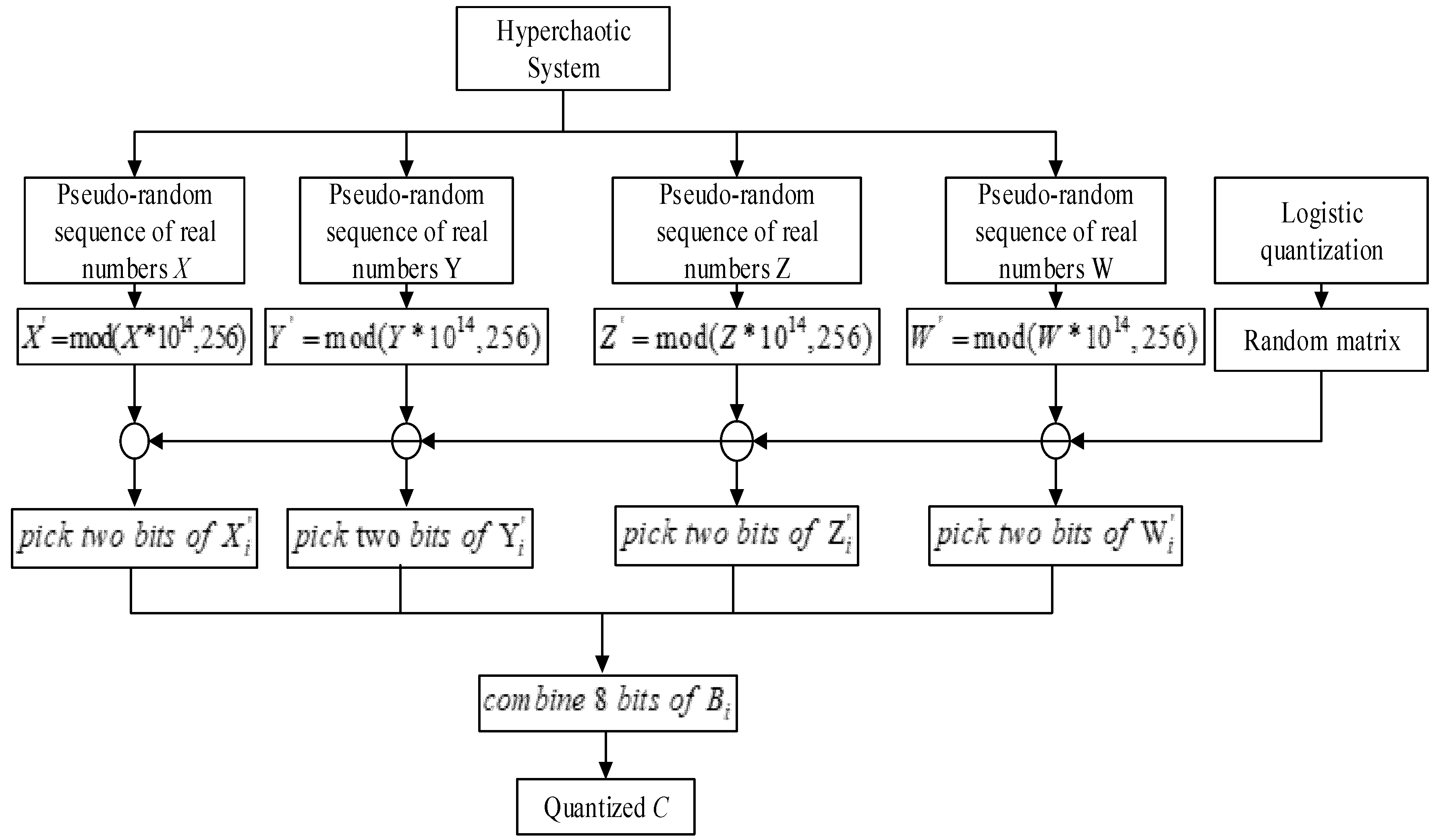
4.2. Security Analysis of Lossless Image Compression and Encryption Scheme
- 1.
Key Space
For a good encryption algorithm, key space should be large enough to resist the brute force attack. In our algorithm, there are two keys: the pseudo-random sequence generator key and image pixels and the entropy coding encryption key.
For the pseudo-random sequence generator key, there are four real numbers for initial parameters of the four-dimensional hyperchaotic system and one real number for initial parameter of logistic map. To avoid the negative effects caused by discretization, the real numbers should be stored and transmitted using a real data type with high precision. If the implementation language complies with IEEE Standard 754-2008, then it is recommended to use the double data type. The double data type stores real numbers in 8 bytes with an accuracy of 15 decimals. Thus, the length of key will be of 320 bits, which means the size of key space will be equal to 2320. In addition, for a random matrix used in pseudo-random sequence generator, there are 8! = 40,320 non repetitive permutations. Five permutations are randomly selected, and there are selections in total.
For image pixels and the entropy coding encryption key, there is a real number for the initial parameter of logistic map used in pixel diffusion with table lookup method. Thus, the length of key will be of 64 bits, which means the size of key space will be equal to 264.
Therefore, the total key space is 2384, together with random matrix space, which is strong enough to resist the brute force attack.
- 2.
Fault tolerance of algorithm
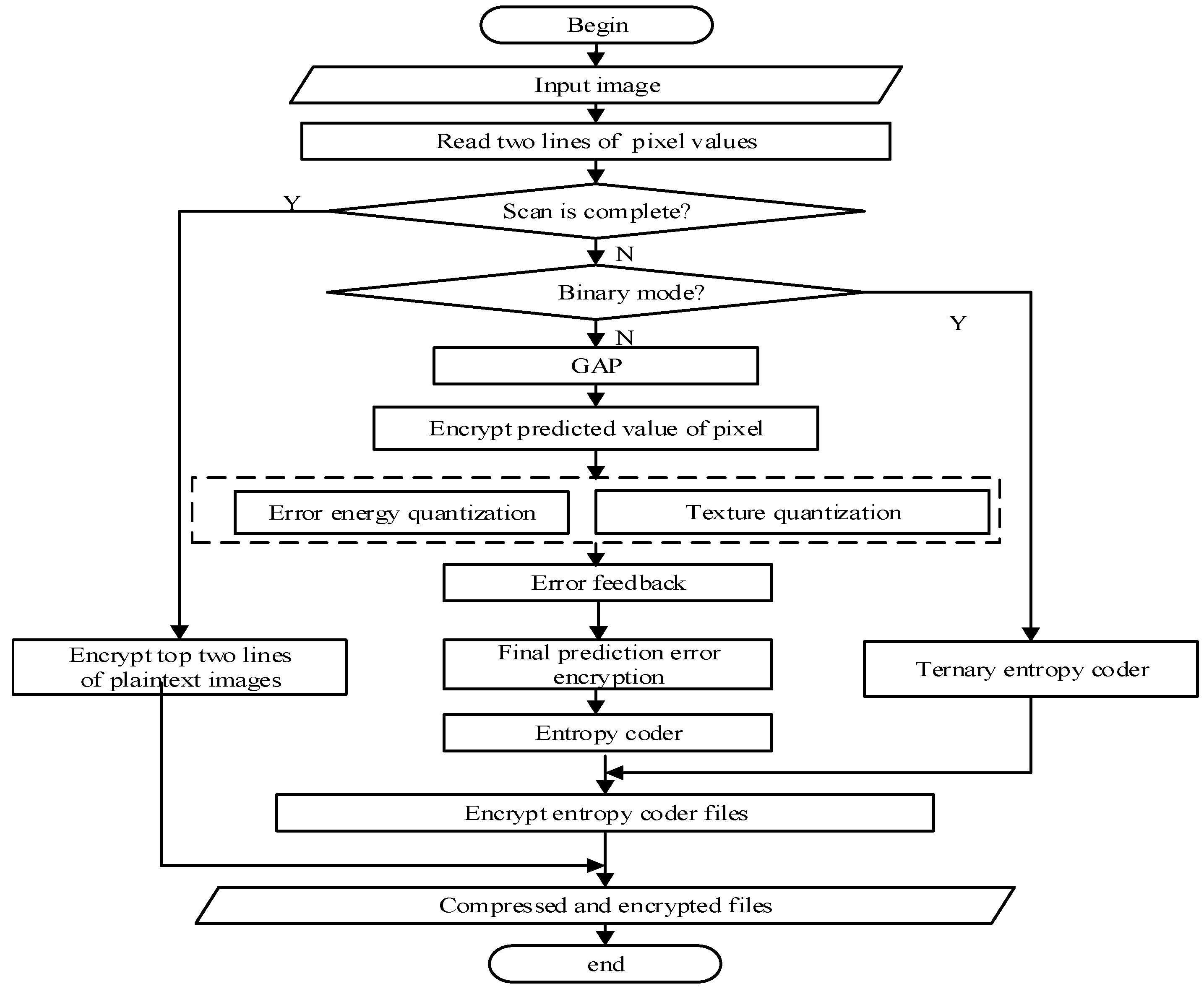
Fault tolerance of algorithm indicates whether the compressed file of the image can be recognized by the image reader in the case of error decryption. The image compression and encryption algorithm proposed in this paper adds an encryption mechanism to the original CALIC compression algorithm. A small error occurring in the decryption process will lead to the destruction of file format so that the image reader cannot correctly recognize the image. Therefore, it can further enhance the security. We judge whether the compressed file of the image can be recognized by the image reader by introducing small changes to keys in the decryption process of different encryption locations. The results are shown in
Table 8.
In
Table 8, the symbol √ indicates an image file that can be recognized, symbol × indicates an unrecognized image file. As can be seen from
Table 8, in the four encryption locations, only the image pixels with a wrong key will not interfere with the final integrity, which can achieve effective recognition. Predicted values, predicted errors and entropy coding encryption with the wrong key all will cause image damage which cannot be recognized by the image reader. This shows that the proposed algorithm has low fault tolerance but high security. The two lines of pixels are written to the coding file after coding and they are not involved in the coding process, so it has no effect on the file format.
- 3.
Key sensitivity analysis
A good encryption scheme should be sensitive to the key. A tiny modification of 1 bit to the keys is used to encrypt the image. Each bit in the resultant cipher-text is compared with the corresponding bit in the cipher-text with the original key, and the number of different bits is counted. The mean values of bit change rate of the cipher-text for the different keys are shown in
Table 9.
From
Table 9, bit change rate of the cipher-text is about 50%. It shows that the compression algorithm can also have a strong key sensitivity after the embedding of the encryption algorithm.
- 4.
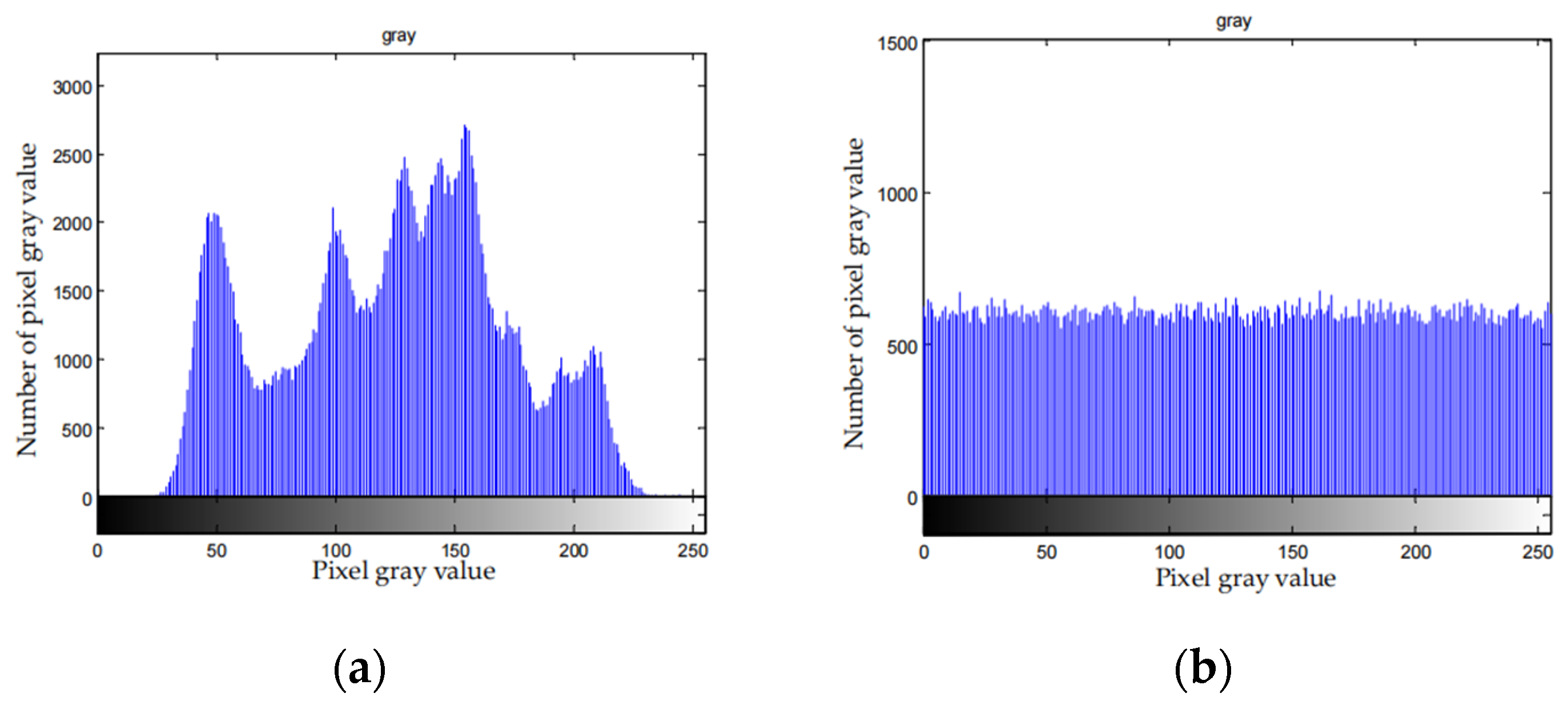
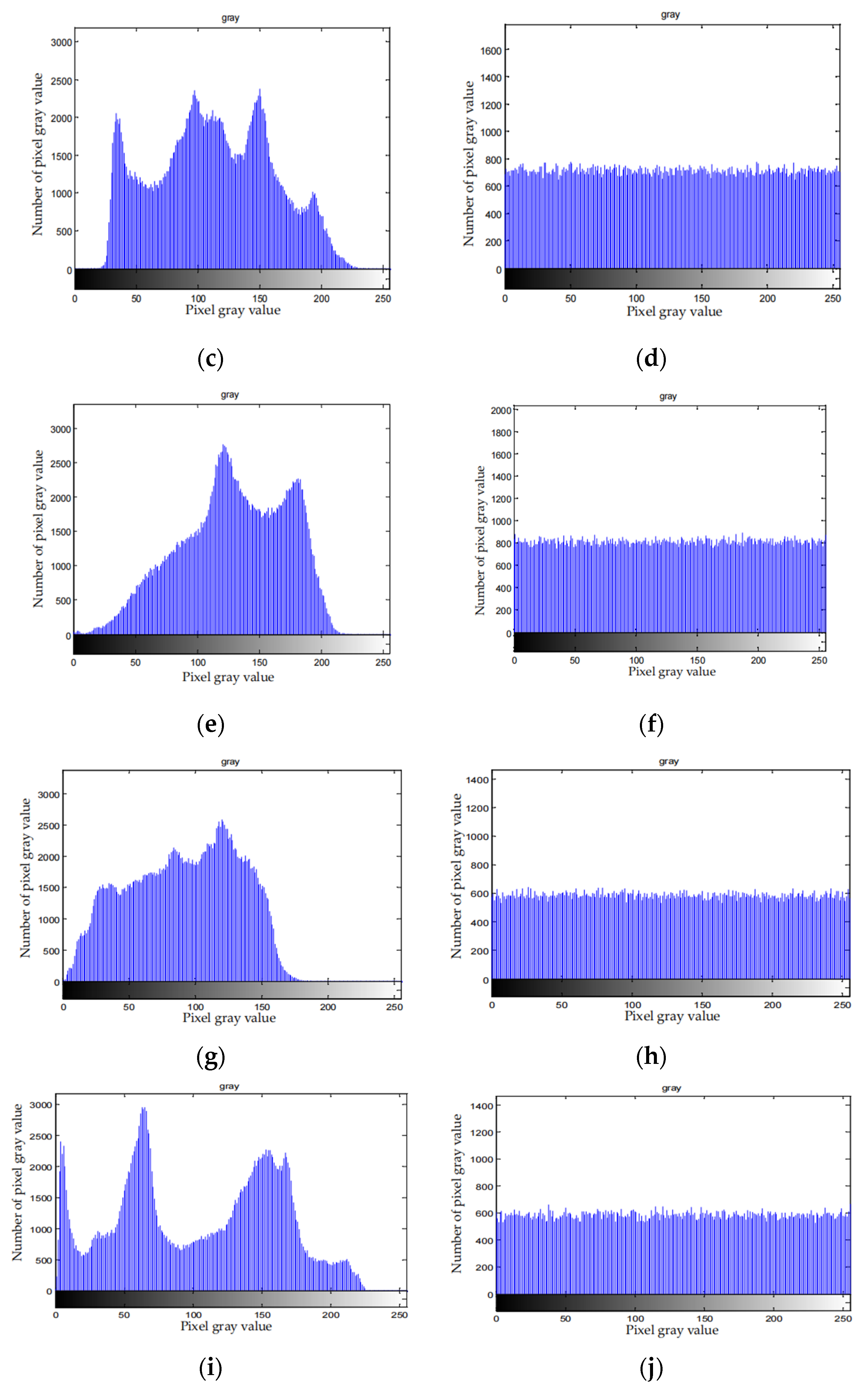
Statistical analysis
The pixel distribution of the image containing the valid information is not uniform. After encryption, the pixel distribution is uniform and can resist statistical analysis.
Figure 9 depicts the histograms of the original images and the corresponding cipher-texts.
From
Figure 9, distribution histogram is uniform after the compression and encryption. Therefore, attackers cannot attack the file with the statistical characteristics of the histogram of the cipher-text, which means the algorithm can effectively resist statistical attack.
- 5.
Correlation Analysis
Correlation between adjacent pixels is one of the important characteristics of images that are different from other common files. Plain image has a strong correlation. A good encryption algorithm can eliminate the correlation between the adjacent elements of the encrypted file so that the value of other elements cannot be inferred through one element. Correlation calculation is shown in Equation (24).
where
represents pixel correlation degree,
xj and
yj represent the gray values of two adjacent pixels and
N represents the number of pixels in the sample. The maximum absolute value of the correlation coefficient is 1, and the minimum absolute value is 0. The lower the correlation coefficient is, the lower the correlation of the image pixels. A good encryption algorithm should remove correlation of the image pixels to improve the resistance against an attack.
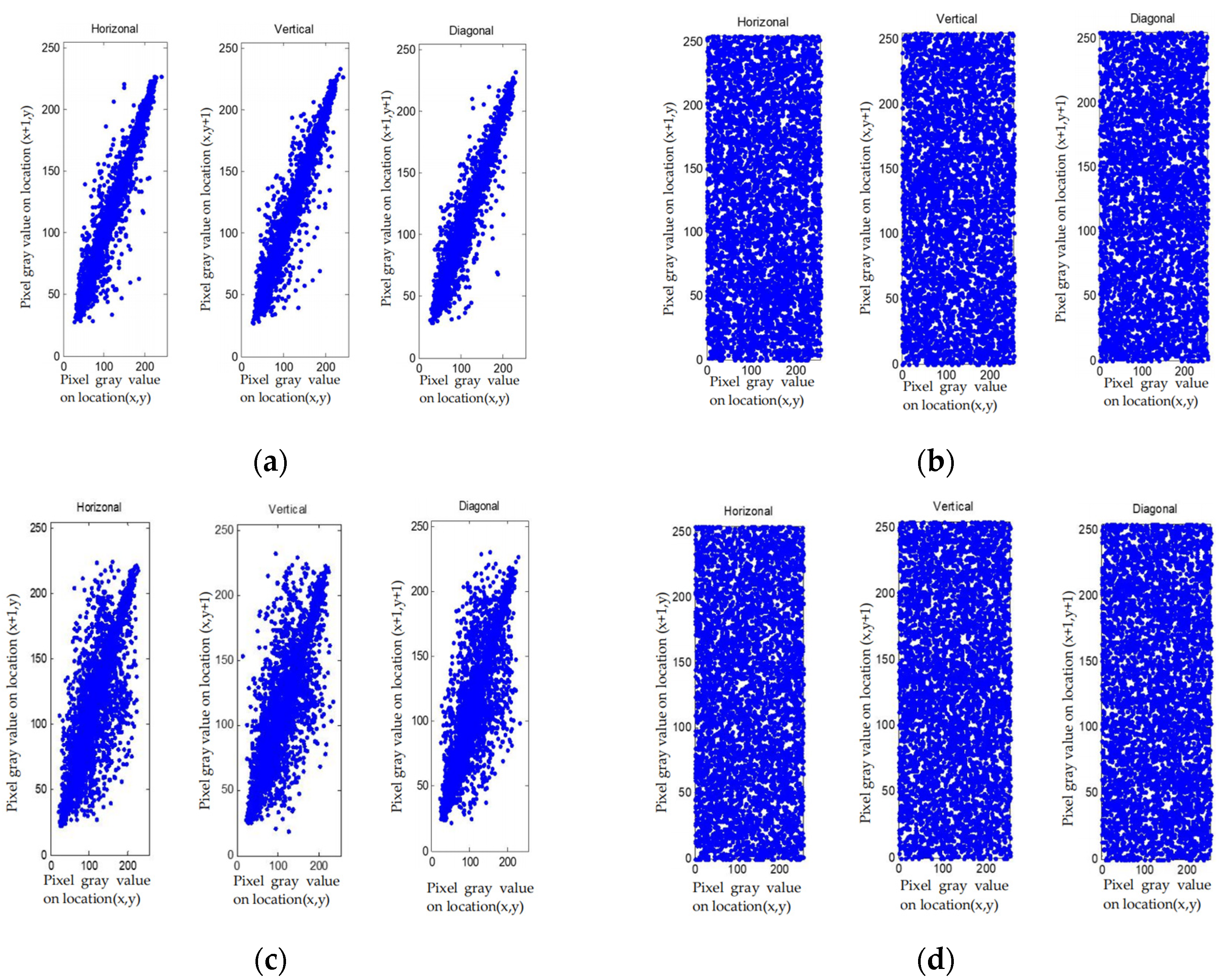
The pixel distribution of the plain images and cipher-images in horizontal, vertical and diagonal formats are shown in
Figure 10, and the correlation test results in different directions of the test images are shown in
Table 10.
According to correlation analysis from
Figure 10, the distribution of the elements after being encrypted and compressed is uniform. From
Table 10, correlation of plain image is large, and correlation of cipher-image is close to 0. All these indicate that the correlation between pixels is completely destroyed in the cipher-text, and we cannot obtain the pixels information via the adjacent pixels.
- 6.
Information entropy analysis
The value of image information entropy reflects the degree of confusion. The information entropy of the encrypted file reflects the intensity and quality of the file encryption, while the information entropy of predicted errors reflects the compression ratio. The small, predicted errors indicate that the predicted errors are small and evenly distributed, which directly reflects the compression ratio and shows the advantages and disadvantages of the compression algorithm. The information entropy is shown as:
In Equation (25),
p(
xi) denotes the probability of symbol
xi. Taking 8 bytes as a unit, if the probability of every symbol in accordance with a uniform distribution is 1/8, the entropy should be 8. A good encryption scheme should make the entropy approach 8. The entropies of the encryption file and predicted errors are shown in
Table 11.
From
Table 11, we can see that the information entropy of the encrypted file is close to the ideal value 8, which indicates that the encryption effect is good. Compared with this, the entropy of predicted errors is small, which indicates good compression performance.
- 7.
Analysis of image processing attack
In the field of image processing, some image processing methods can be used to restore or improve the quality of degraded images. If image encryption is regarded as an image degradation, the plaintext image information may be obtained by using these image processing methods. Therefore, the image processing method is used to attack the cipher-image to obtain the plaintext information. Since the filter is a common method, we use four common filters to restore the Lena cipher-image, and the results are shown in
Table 12.
It can be seen from the results in
Table 12 that the image quality restored by these image processing methods is very low, and some are even lower than the original cipherimage, which is not helpful for image information restoration.
- 8.
Security analysis of pseudo-random sequence
The security analysis of the pseudo-random sequence described in
Section 3.1 is described below.
Information entropy, approximate entropy and K entropy can be used to test the randomness of a pseudo-random sequence. The larger the value of information entropy, approximate entropy and K entropy, the better the randomness.
Information entropy indicates the confusion degree of information. The definition of information entropy is shown in Equation (25). Approximate entropy is used to calculate the probability of the new pattern in the pseudo-random sequence. The greater the probability, the larger the corresponding approximate entropy, the better the pseudo-random sequence is. Approximate entropy is shown in Equation (26).
where
πi =
Cj3,
j =
log2i.
Cim is frequency of
N overlapping blocks.
The pseudo-random sequence to be tested is divided into innumerable small boxes, and each box contains ε value.
represents a small time interval.
is joint probability of the value of sequence in the box of
i0 when
and the value of sequence in the box of
id when
. The
K entropy is defined as:
The approximate entropy, information entropy and
K entropy of pseudo-random sequence generated by the logistic map are compared with the pseudo-random sequence proposed, as shown in
Table 13.
From
Table 13, the pseudo-random sequence used in this paper is better than the pseudo-random sequence generated by the logistic map except that the information entropy of the pseudo-random key stream length of 800 is slightly less than that of the logistic map. It shows good randomness.
Autocorrelation test is an important indicator of the randomness of the pseudo-random sequence. Specific definition of sequence correlation is shown in Equation (28).
where
l1 and
l2 represent the two pseudo-random sequences, respectively.
A is the number of the same bit in
l1,
D is the number of the same bit in
l2 and
N represents the total length of the key stream sequences.
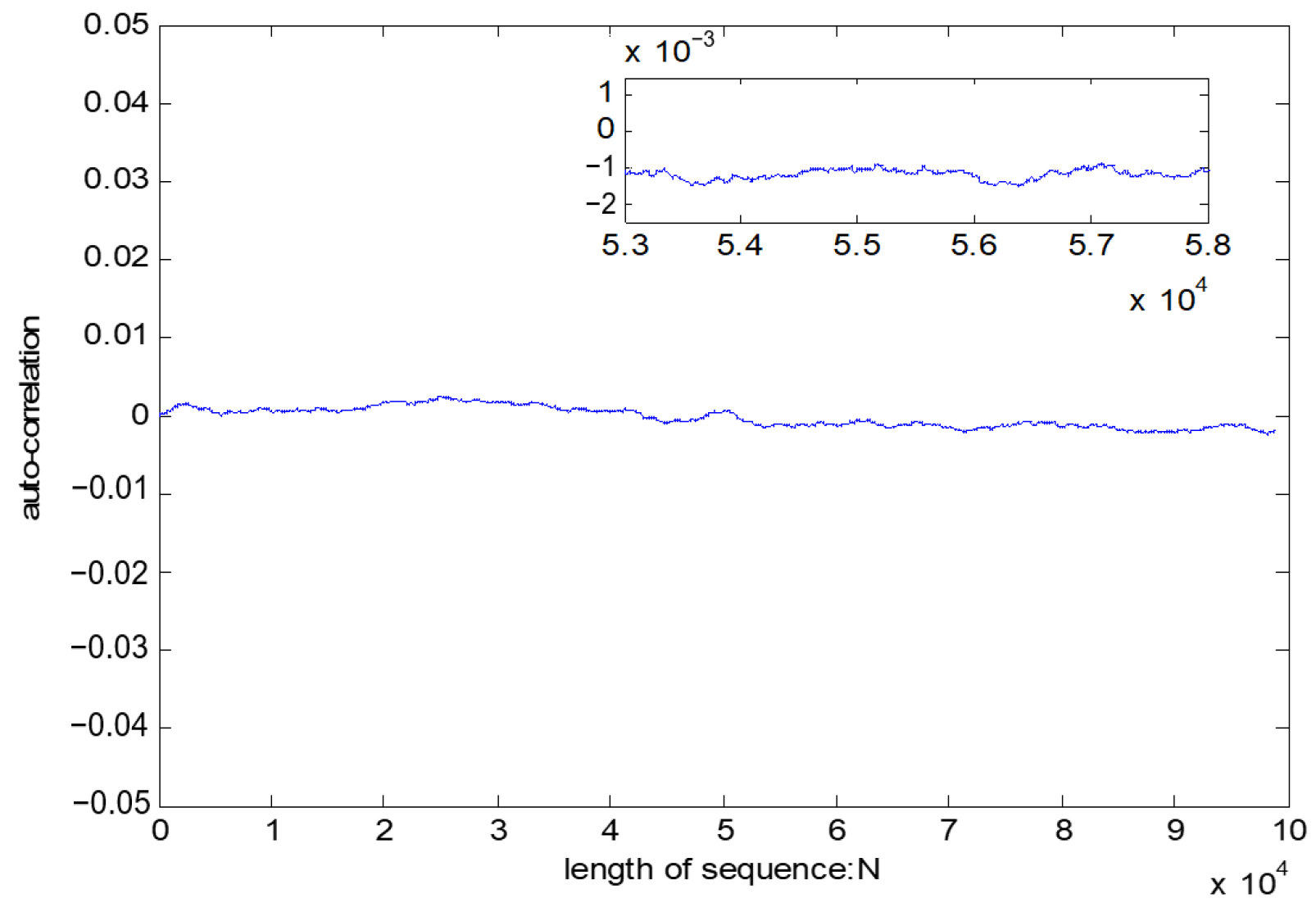
If l1 and l2 are the same sequence, is called autocorrelation. The best state of is close to a horizontal line. If the test result is a horizontal line close to 0, it shows that the test sequence has a good randomness.
The test result of the pseudo-random sequence is shown in
Table 14. The test result from
Figure 11 indicates that the test result is a horizontal line close to 0, which shows a good autocorrelation of pseudo-random sequence.
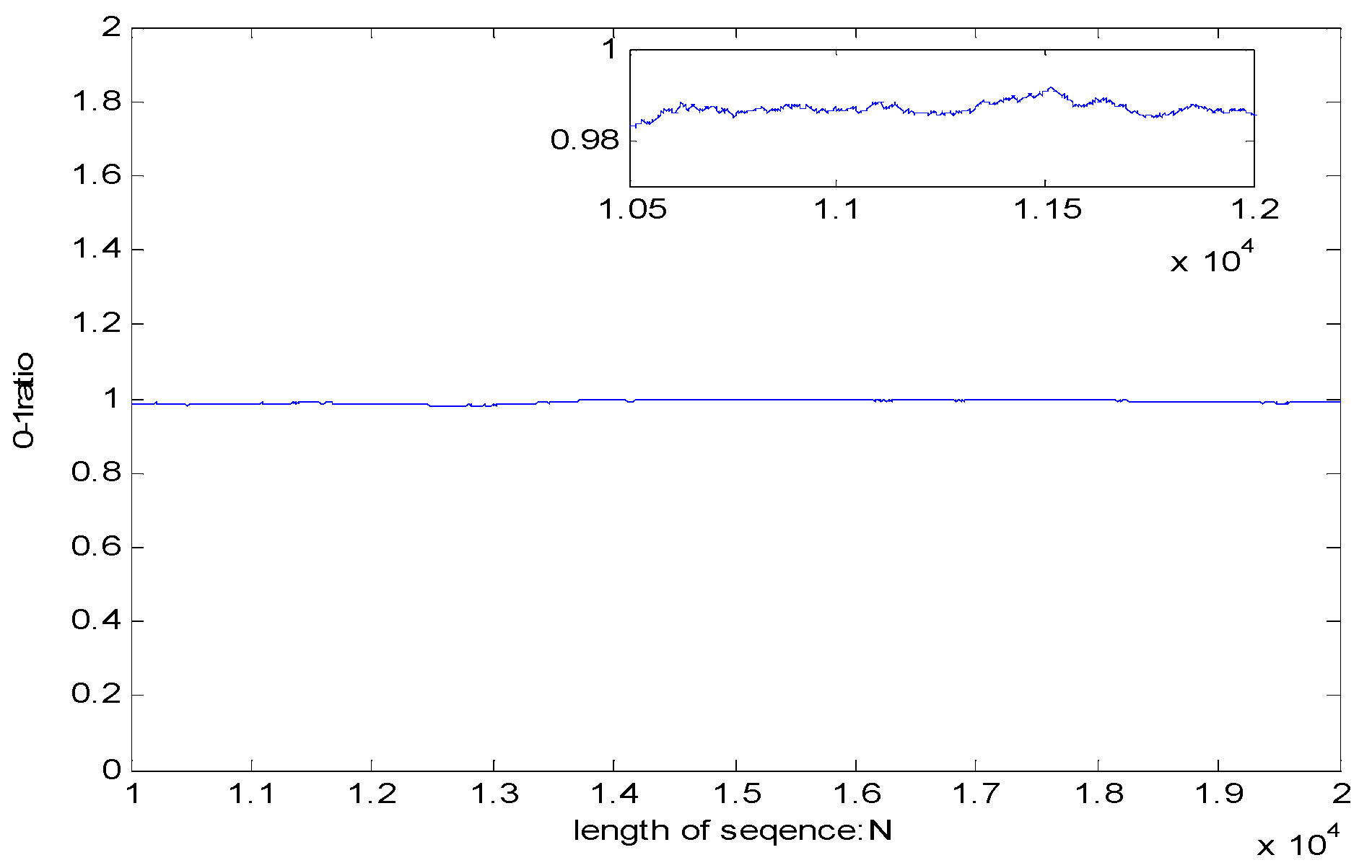
The balance test is used to count the ratio of 0 to 1 in the pseudo-random sequence. Ideally, the ratio of 0 to 1 is 1. The balance test is expressed as follows:
where
Sum(0) represents the total number of 0 in sequence, and
Sum(1) represents the total number of 1 in sequence. The results of balance test are shown in
Figure 12.
The results show that the 0, 1 distribution curve of pseudo-random sequence is close to 1, and the distribution is relatively uniform.
The sequence distribution reflects the distribution of the pseudo-random sequence value. The more uniform the sequence distribution is, the better the randomness of the sequence is. As shown in
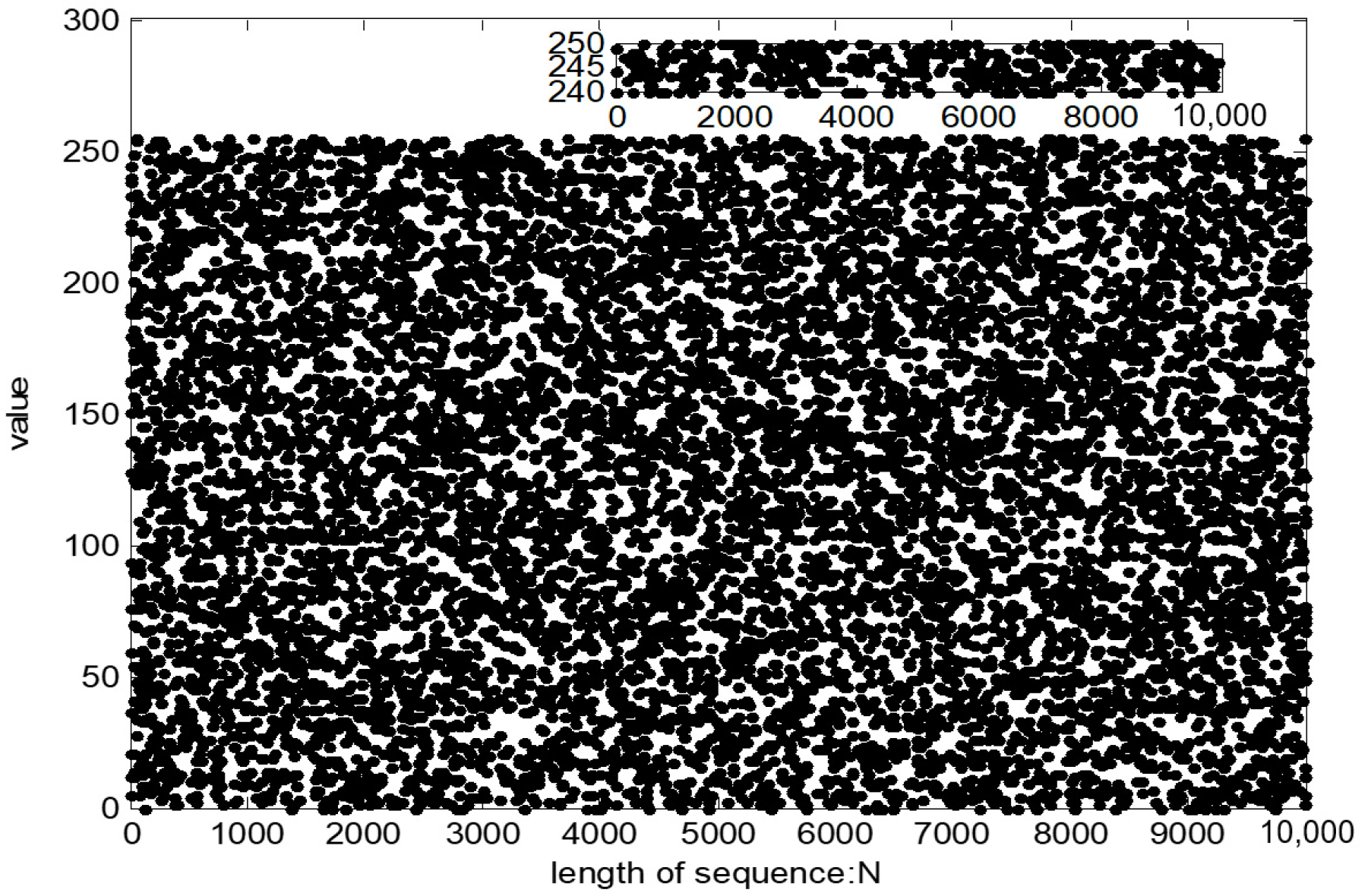
Figure 13, the distribution of sequences is relatively uniform, and there is no large-scale sequence aggregation phenomenon, indicating that the randomness of the pseudo-random sequence is good.
NIST SP800-22 tests are a testing standard to detect the deviation of a sequence from a true random sequence. It is issued by the American National Standardization Technical Committee and provides 15 methods for testing statistical characteristics. For each test, if the P-value is greater than a predefined threshold α, then it means the sequence passes the test. Commonly, α is set to 0.01. In this paper, 100 groups of sequence of 10
6 bits are tested. Test results are shown in
Table 14.
Table 14 shows that the pseudo-random sequence has a good randomness and a high security.
- 9.
Time complexity analysis
The lossless image compression and encryption scheme are performed on gray image with
N pixels. The time complexity of the algorithm is shown in
Table 15.
According to
Table 15, we can see that the time complexity of the CALIC algorithm is only related to the number of pixels that need to be scanned, and it is linear. Four encryption algorithms are stream ciphered based on different data, so the time complexity is linear. In general, the algorithm has low time complexity and high efficiency.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}