
Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions


Abstract
:1. Introduction
- Distortion function d(x, y) is subjectively defined, lacking the objective standard;
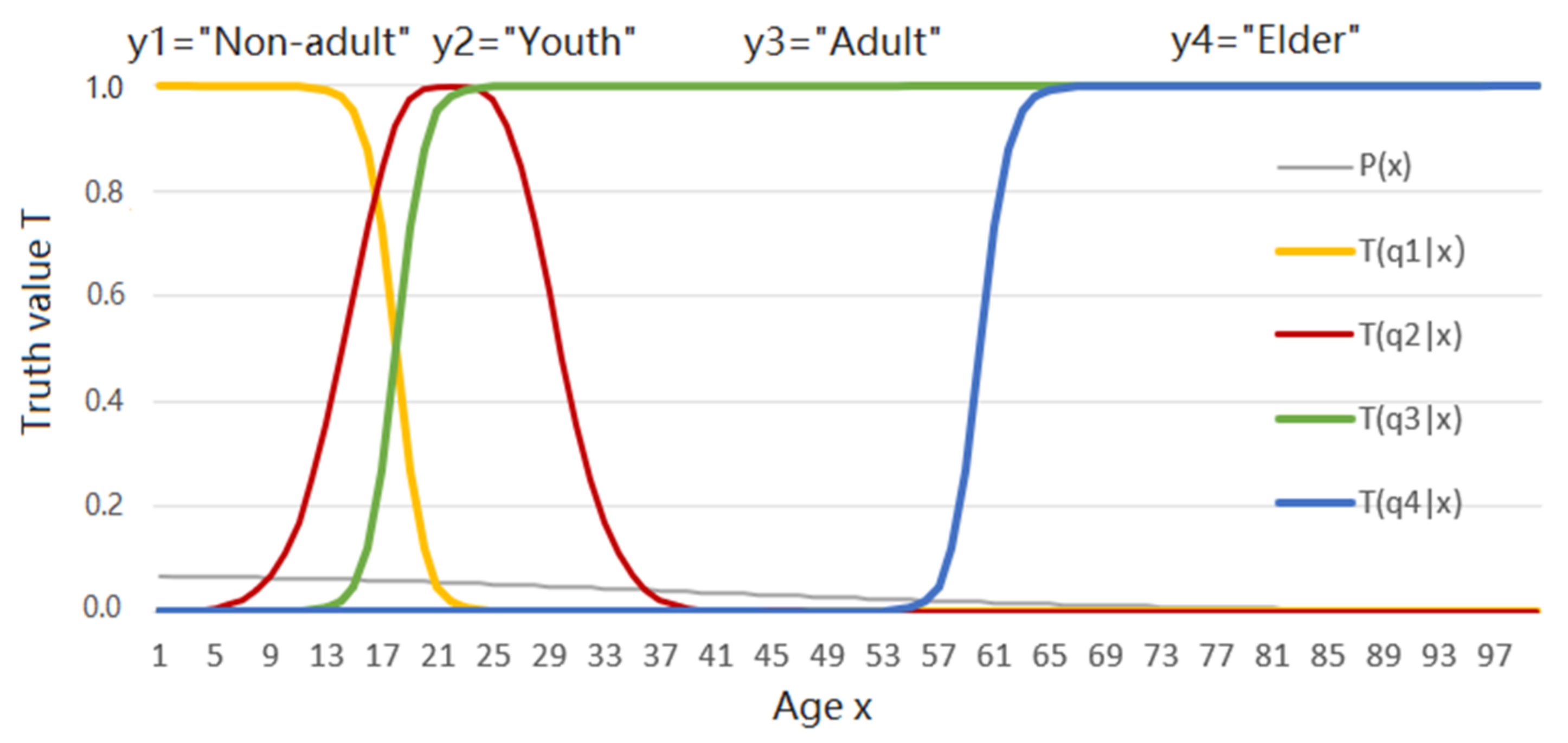
- It is hard to define the distortion function using distances when we use labels to replace instances in machine learning; where possible the labels’ number should be much less than the possible instances’ number. For example, we need to use “Light rain”, “Moderate rain”, “Heavy rain”, “Light to moderate rain”, etc., to replace daily precipitations in millimeters, or use “Child”, “Youth”, “Adult”, “Elder”, etc., to replace people’s ages. In these cases, it is not easy to construct distortion functions;
- We cannot apply the rate-distortion function for semantic compression, e.g., data compression according to labels’ semantic meanings.
- the truth function is a learning function; it can be obtained from a sample or sampling distribution [31] and hence is not subjectively defined;
- using the transformation relation, we can indirectly express the distortion function between any instance x and any label y by the truth function that may come from machine learning;
- truth functions indicate labels’ semantic meanings and, hence, can be used as the constraint condition for semantic compression.
- the NEF and the partition functions are the truth function and the logical probability, respectively;
- the formula, such as Equation (2), for the distribution of Minimum Mutual Information (MMI) or maximum entropy is the semantic Bayes’ formula;
- MMI R(D) can be expressed by the semantic mutual information formula;
- maximum entropy is equal to extremely maximum entropy minus semantic mutual information.
- help readers understand rate-distortion functions and maximum entropy distributions from the new perspective;
- combine machine learning (for the distortion function) and data compression;
- show that the rate-distortion function can be extended to the rate-truth function and the rate-verisimilitude function for communication data’s semantic compression.
2. Background
2.1. Shannon’s Entropies and Mutual Information
- Variable x denotes an instance; X denotes a discrete random variable taking a value x ∈ U = {x1, x2, …, xm}.
- Variable y denotes a hypothesis or label; Y denotes a discrete random variable taking a value y ∈ V = {y1, y2, …, yn}.
2.2. Rate-Distortion Function R(D)
2.3. The Maximum Entropy Method
3. The Author’s Related Work
3.1. The P-T Probability Framework
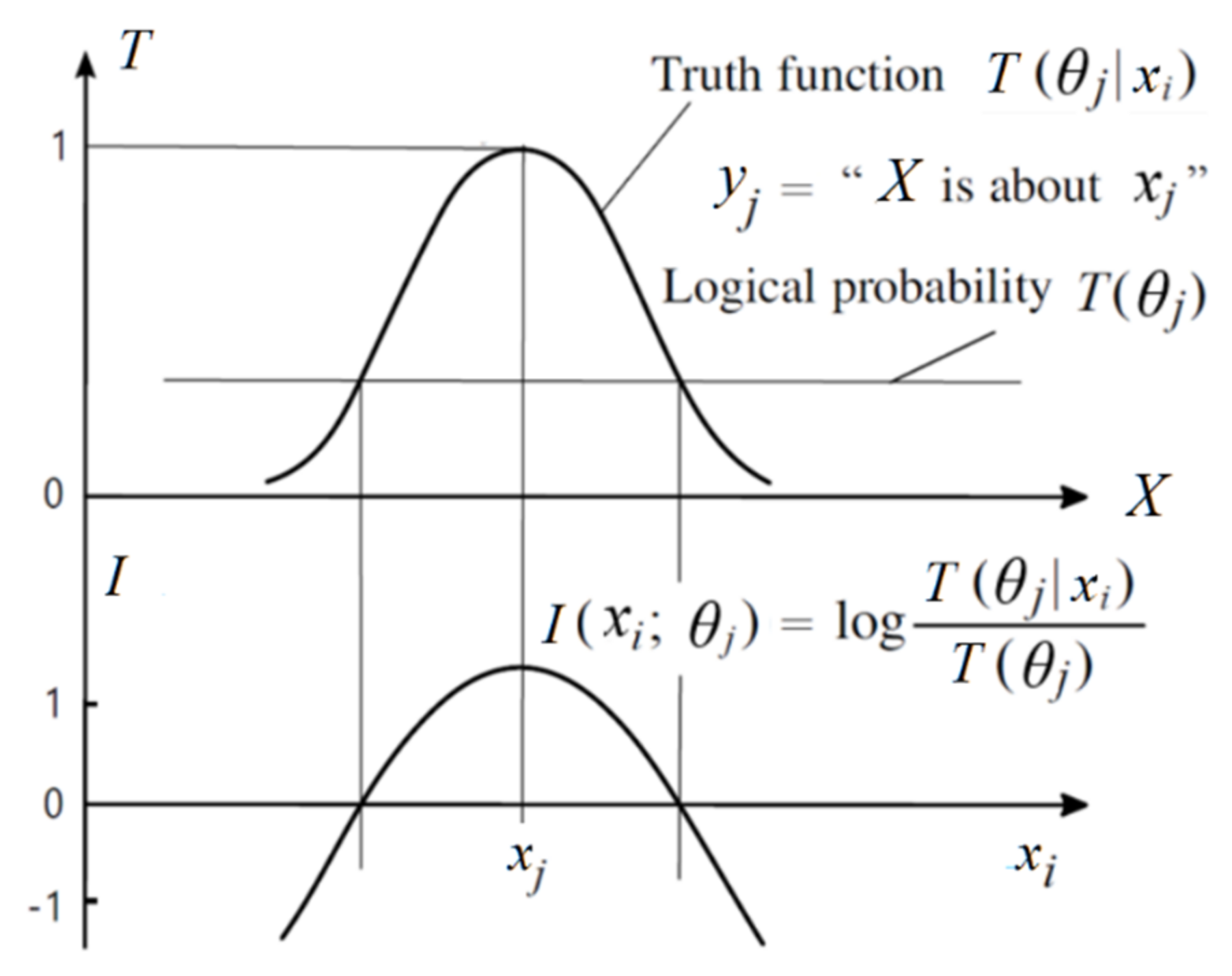
- The yj is a label or a hypothesis; yj(xi) is a proposition. The θj is a fuzzy subset of universe U, whose elements make yj true. We have yj(x) ≡“x∈ θj” ≡ “x belongs to θj”(“≡” means they are logically equivalent according to the definition). The θj may also be a model or a group of model parameters.
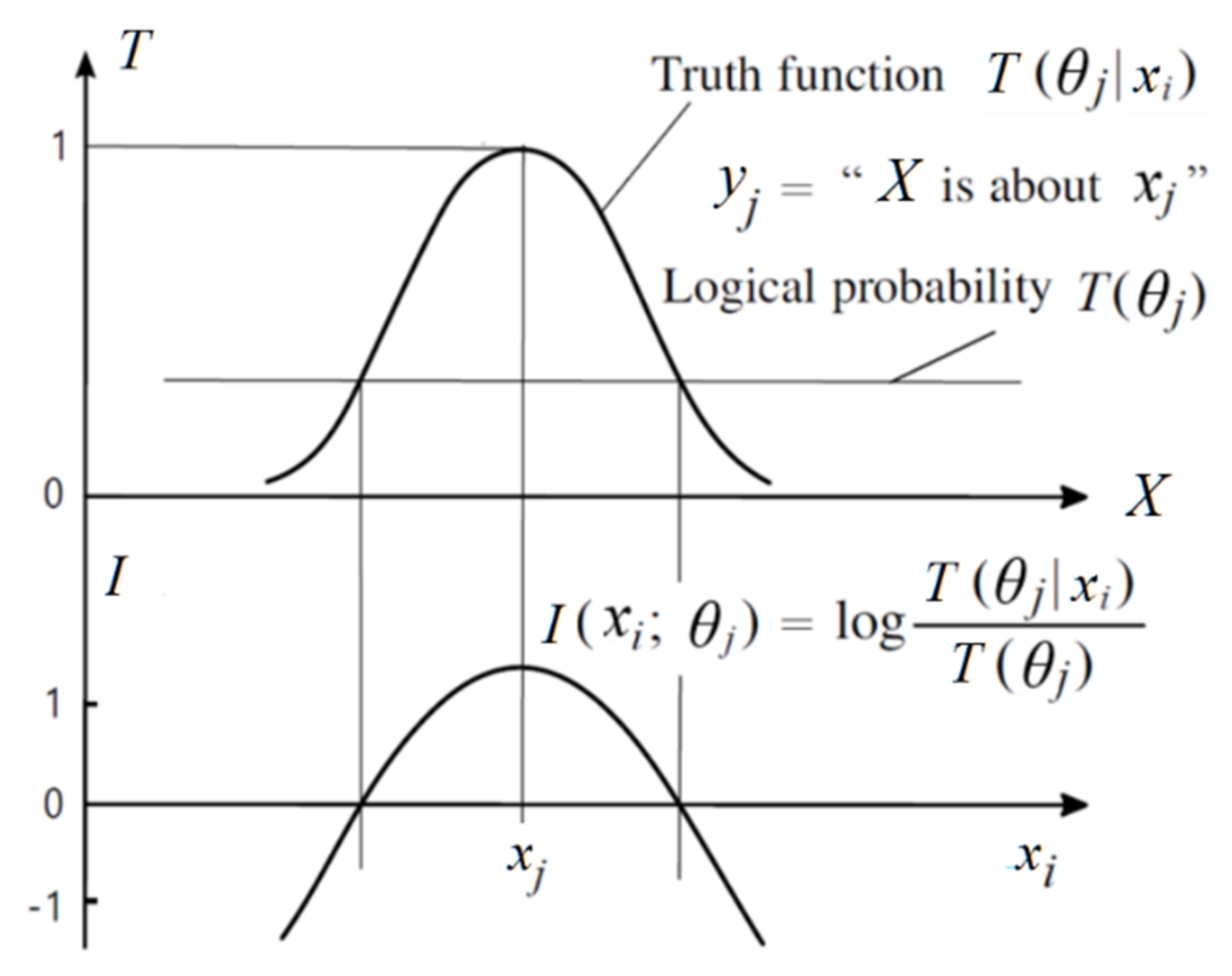
- A probability that is defined with “=”, such as P(yj) ≡ P(Y = yj), is a statistical probability. A probability that is defined with “∈”, such as P(X ∈ θj), is a logical probability. To distinguish P(Y = yj) and P(X ∈ θj), we define T(yj) ≡ T(θj) ≡ P(X ∈ θj) as the logical probability of yj.
- T(yj|x) ≡ T(θj|x) ≡ P(X ∈ θj|X = x) is the truth function of yj and the membership function of θj. It changes between 0 and 1, and the maximum of T(y|x) is 1.
3.2. The Semantic Information G Measure
4. Theoretical Results
4.1. The New Explanations of the MMI Distribution and the Rate-Distortion Function
4.2. Setting Up the Relation between the Truth Function and the Distortion Function
4.3. Rate-Truth Function R(Θ)
4.4. Rate-Verisimilitude Function R(G)
4.5. The New Explanation of the Maximum Entropy Distribution and the Extension
4.6. The New Explanation of the Boltzmann Distribution and the Maximum Entropy Law
5. Experimental Results
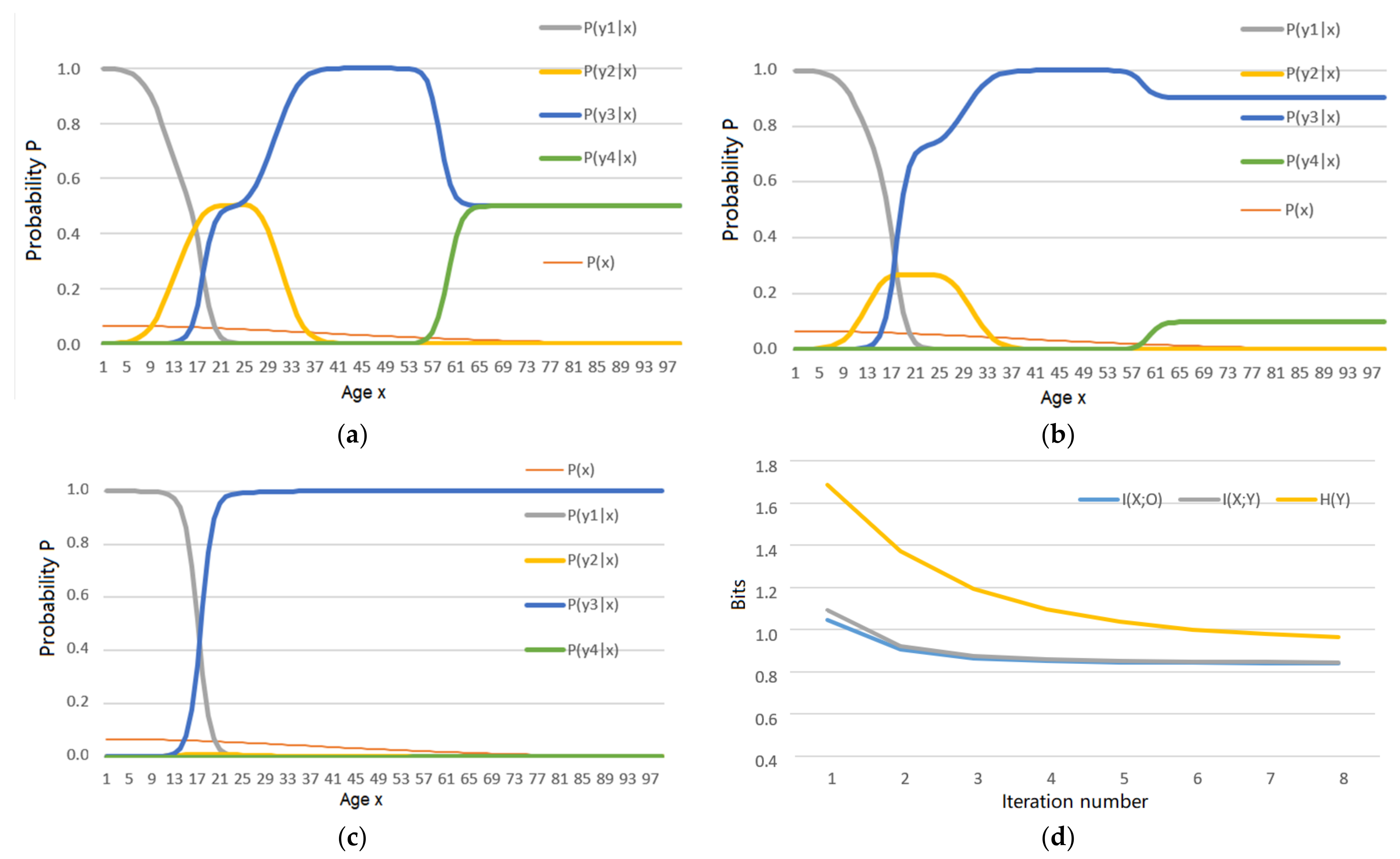
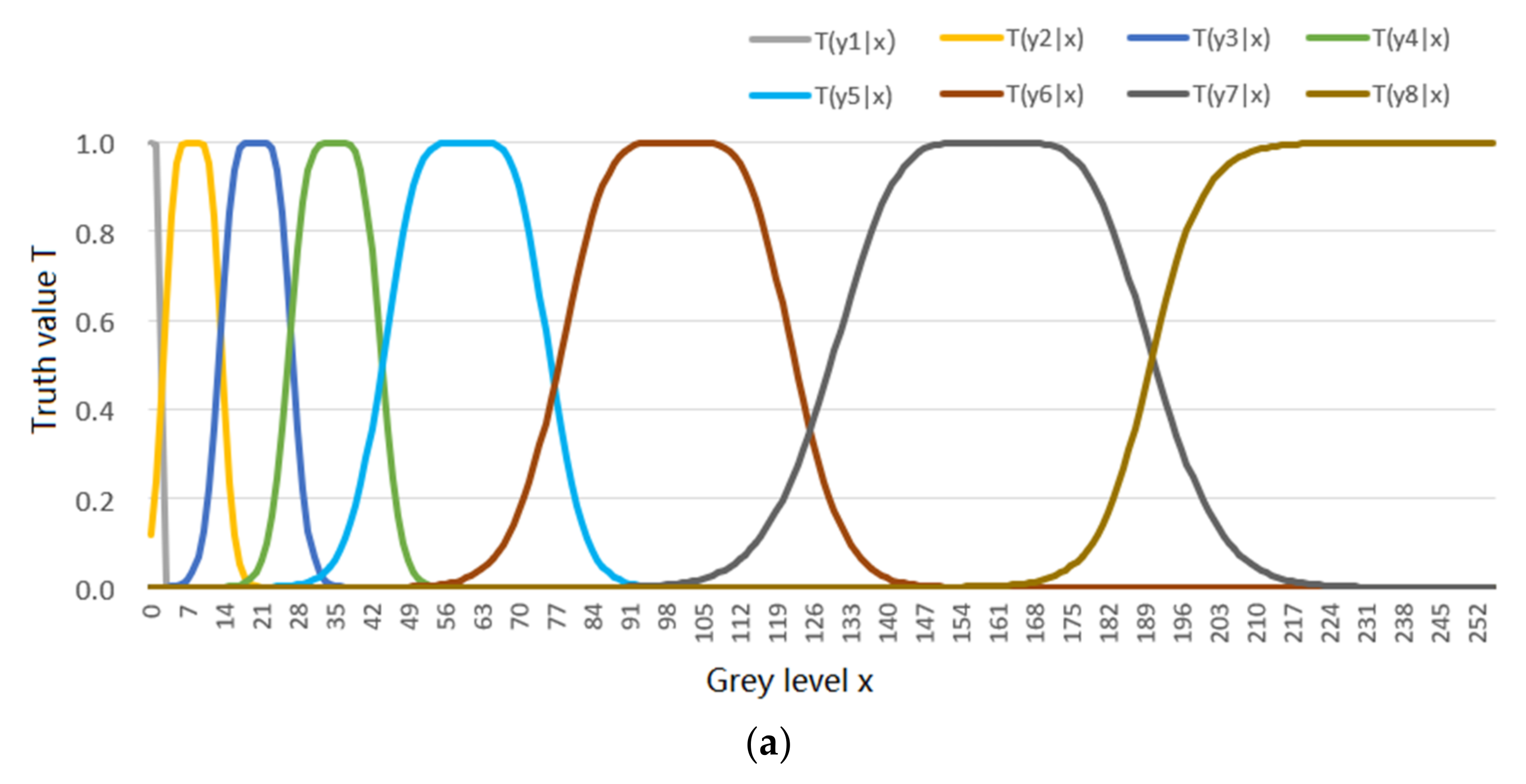
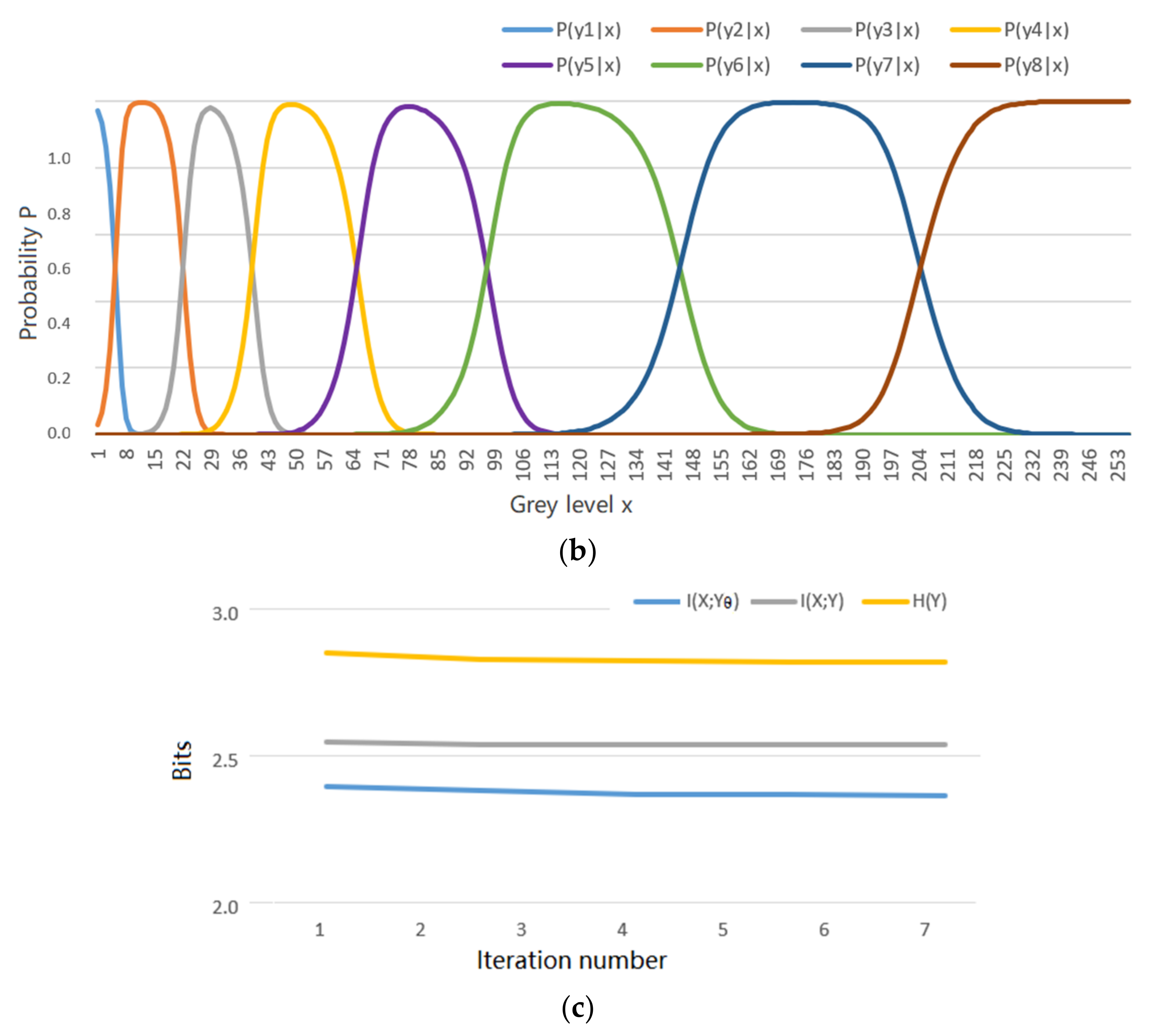
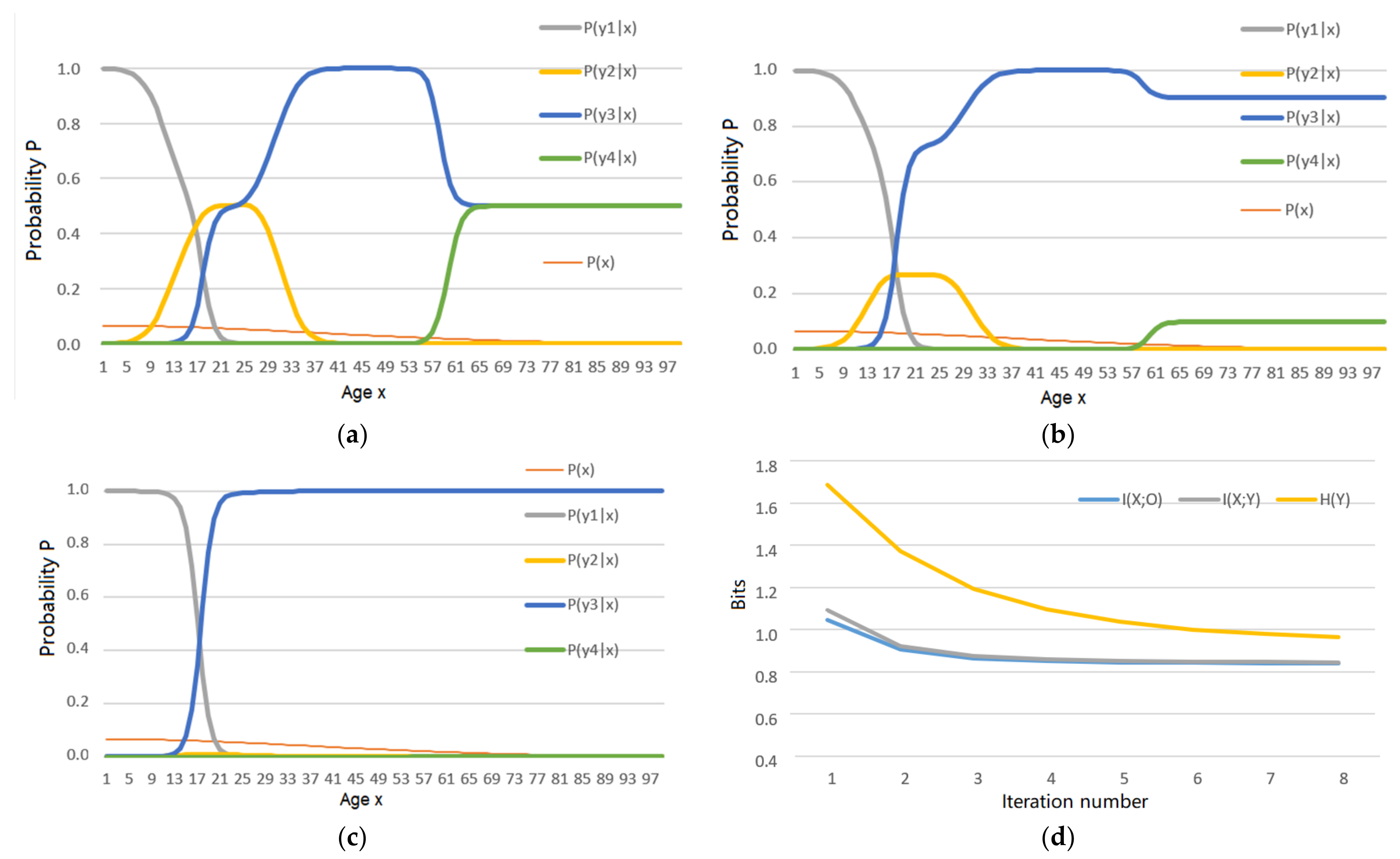
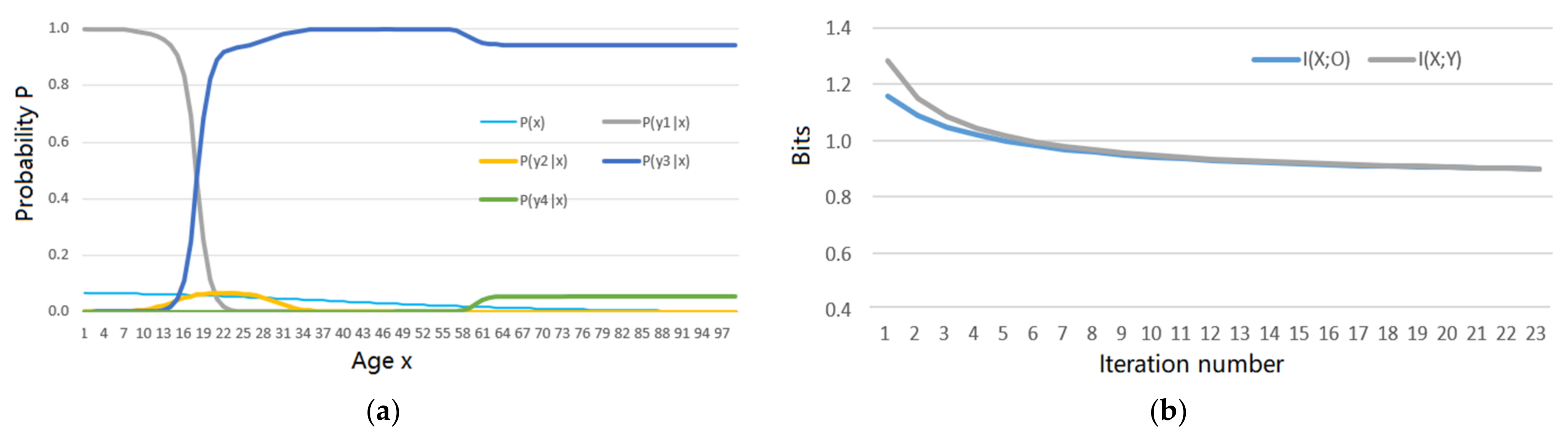
5.1. An Example Shows the Shannon Channel’s Changes in the MMI Iterations for R(Θ) and R(G)
- the MMI iteration lets the Shannon channel match the semantic channel, e.g., lets P(yj|x) ∝ T(yj|x), j = 1, 2, …, as far as possible for the functions R(D), R(Θ), and R(G);
- the MMI iteration can reduce mutual information.
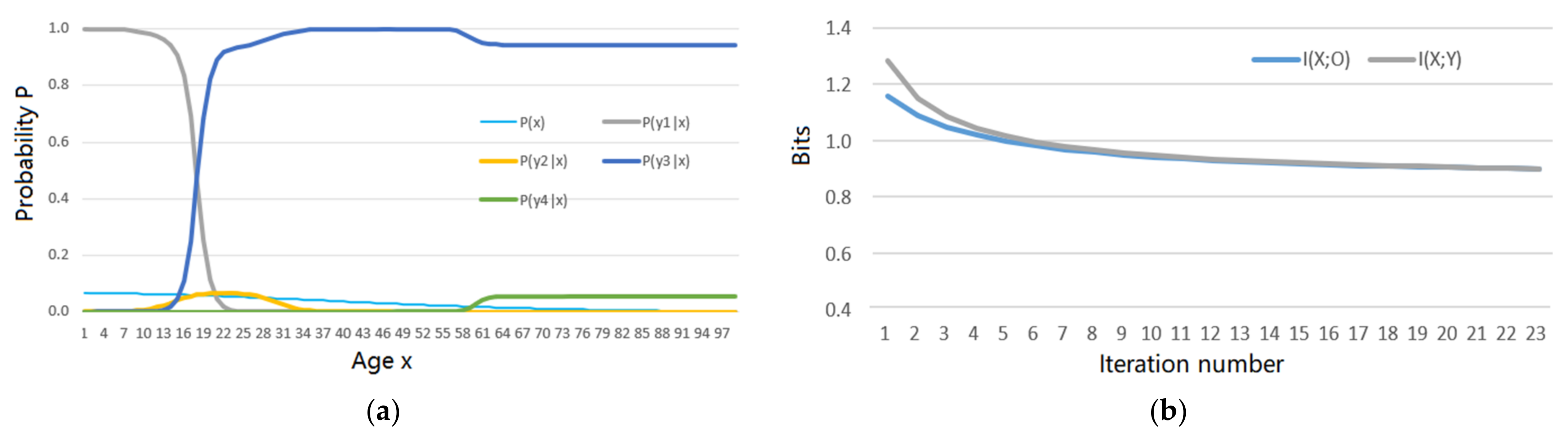
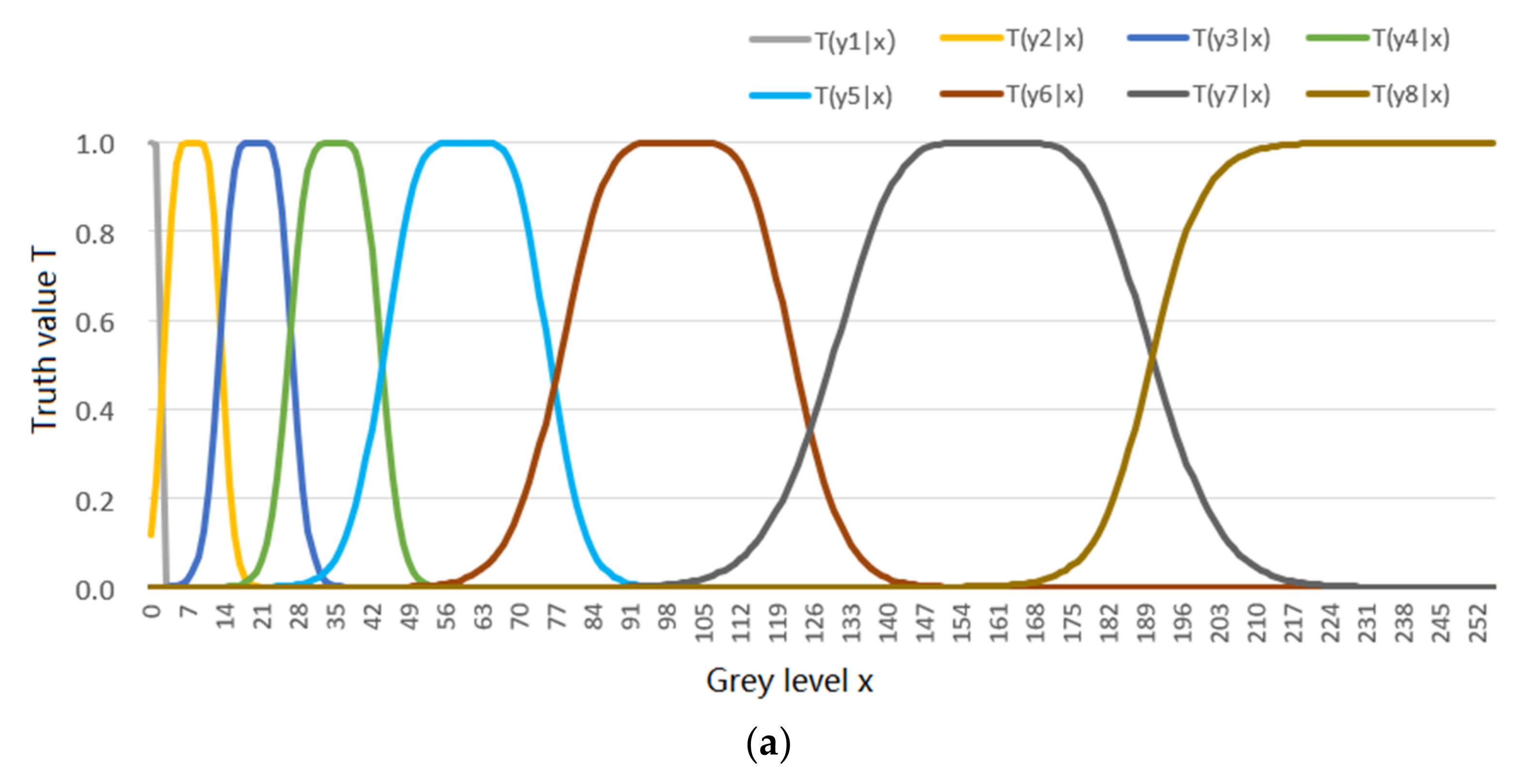
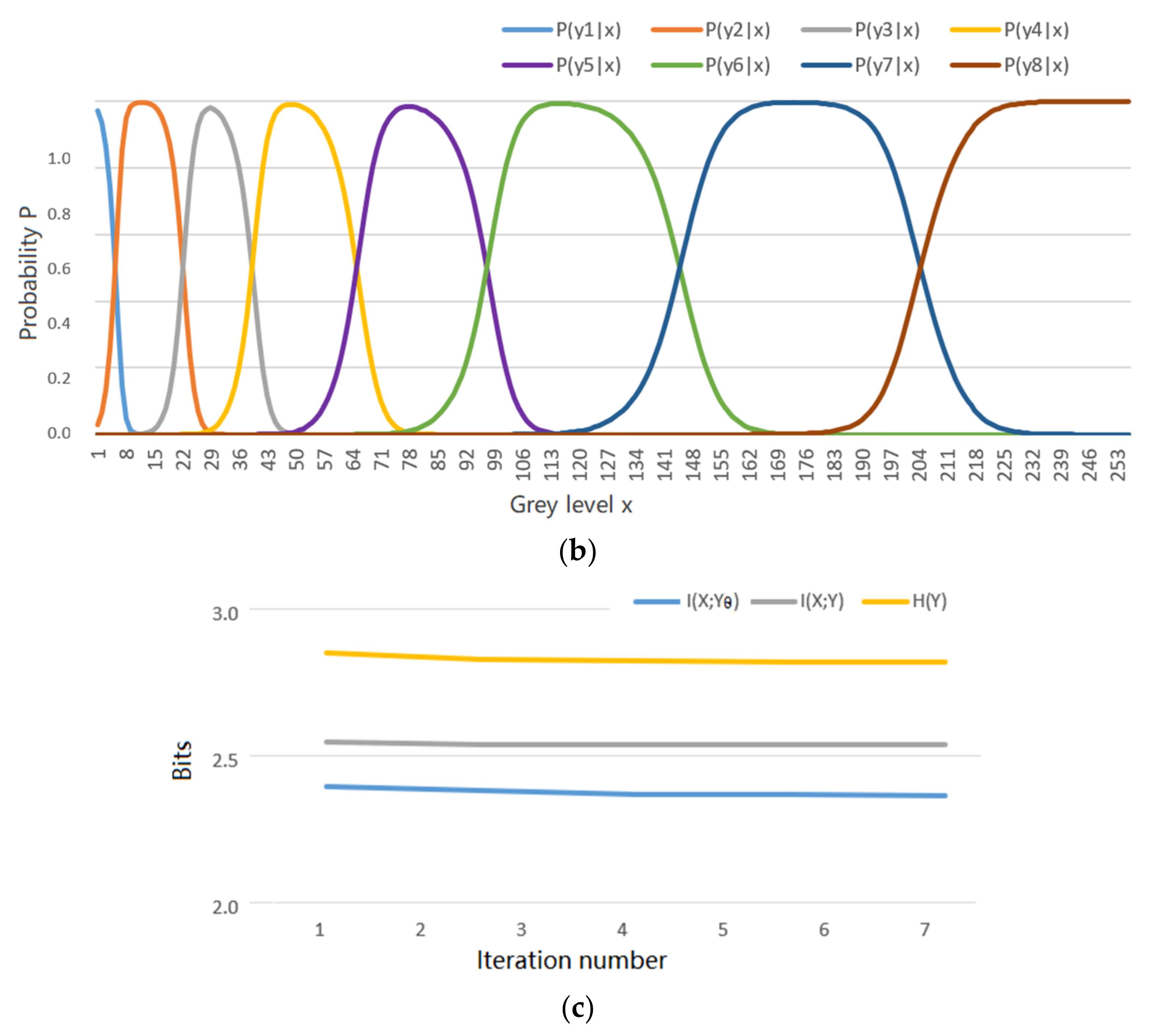
5.2. An Example about Greyscale Image Compression Shows the Convergent P(y|x) for the R(Θ)
6. Discussions
6.1. Connecting Machine Learning and Data Compression by Truth Functions
6.2. Viewing Rate-Distortion Functions and Maximum Entropy Distributions from the Perspective of Semantic Information G Theory
- For the rate-distortion function R(D), we seek MMI I(X; Y) = H(X) − H(X|Y), which is equivalent to maximizing the posterior entropy H(X|Y) of X. For R(D), we use an iterative algorithm to find the proper P(y). However, in the maximum entropy method, we maximize H(X, Y) or H(Y|X) for given P(x) without the iteration for P(y);
- The rate-distortion function can be expressed by the semantic information G measure (see Equation (31)). In contrast, the maximum entropy is equal or proportional to the extremely maximum entropy minus semantic mutual information (see Equations (41) and (47)).
6.3. How the Experimental Results Support the Explanation for the MMI Iterations
6.4. Considering Other Kinds of Semantic Information
- The G measure is only related to labels’ extensions, not to labels’ intensions. For example, “Old” means senility and closeness to death, whereas the G measure is only related to T(“Old”|x), which represents the extension of “Old”;
- The G measure is not enough for measuring the semantic information from fuzzy reasoning according to the context, although the author has discussed how to calculate compound propositions’ truth functions and fuzzy reasoning [32].
6.5. About the Importance of Semantic Information’s Studies
“These semantic aspects of communication are irrelevant to the engineering problem. The significance aspects is that the actual message is one selected from a set of possible messages. The system must be designed to operate for each possible selection, not just one which will actually be chosen since this is unknown at the time of design.”
7. Conclusions
- Why does the Bayes-like formula (see Equation (2)) with NEFs and partition functions widely exist in the rate-distortion theory, statistical mechanics, the maximum entropy method, and machine learning?
- Can we combine machine learning (for the distortion function) and data compression (with the rate-distortion function)?
- Can we use the rate-distortion function or similar functions for semantic compression?
Supplementary Materials
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The Derivation of Equation (47)
Appendix B
Appendix C

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| yj | T(y2|x) | T(y3|x) | T(y4|x) | T(y5|x) | T(y6|x) | T(y7|x) |
| μj | 14 | 30 | 52 | 80 | 120 | 170 |
| σj2 | 16 | 24 | 50 | 80 | 160 | 240 |
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–429+623–656. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. Coding theorems for a discrete source with a fidelity criterion. IRE Nat. Conv. Rec. 1959, 4, 142–163. [Google Scholar]
- Berger, T. Rate Distortion Theory; Prentice-Hall: Enklewood Cliffs, NJ, USA, 1971. [Google Scholar]
- Jaynes, E.T. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information Theory and Statistical Mechanics II. Phys. Rev. 1957, 108, 171. [Google Scholar] [CrossRef]
- Smolensky, P. Chapter 6: Information Processing in Dynamical Systems: Foundations of Harmony Theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations; Rumelhart, D.E., McLelland, J.L., Eds.; MIT Press: Cambridge, UK, 1986; pp. 194–281. [Google Scholar]
- Hinton, G.E. A Practical Guide to Training Restricted Boltzmann Machines. In Neural Networks: Tricks of the Trade, Lecture Notes in Computer Science; Montavon, G., Orr, G.B., Müller, K.R., Eds.; Springer: Berlin, Germany, 2012; Volume 7700, pp. 599–619. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G.E. Replicated softmax: An undirected topic model. Neural Inf. Process. Syst. 2009, 22, 1607–1614. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Softmax Units for Multinoulli Output Distributions. In Deep Learning; MIT Press: Cambridge, UK, 2016; pp. 180–184. [Google Scholar]
- Zadeh, L.A. Fuzzy Sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Harremoës, P. Maximum Entropy on Compact Groups. Entropy 2009, 11, 222–237. [Google Scholar] [CrossRef] [Green Version]
- Berger, T.; Gibson, J.D. Lossy Source Coding. IEEE Trans. Inf. Theory 1998, 44, 2693–2723. [Google Scholar] [CrossRef] [Green Version]
- Gibson, J. Special Issue on Rate Distortion Theory and Information Theory. Entropy 2018, 20, 825. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Davidson, D. Truth and meaning. Synthese 1967, 17, 304–323. [Google Scholar] [CrossRef]
- Willems, F.M.J.; Kalker, T. Semantic compaction, transmission, and compression codes. In Proceedings of the International Symposium on Information Theory ISIT 2005, Adelaide, Australia, 4–9 September 2005; pp. 214–218. [Google Scholar] [CrossRef]
- Babu, S.; Garofalakis, M.; Rastogi, R. SPARTAN: A Model-Based Semantic Compression System for Massive Data Tables. ACM SIGMOD Rec. 2001, 30, 283–294. [Google Scholar] [CrossRef]
- Ceglarek, D.; Haniewicz, K.; Rutkowski, W. Semantic Compression for Specialised Information Retrieval Systems. Adv. Intell. Inf. Database Syst. 2010, 283, 111–121. [Google Scholar]
- Blau, Y.; Michaeli, T. The perception-distortion tradeoff. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18 June 2018; pp. 6228–6237. [Google Scholar]
- Bardera, A.; Bramon, R.; Ruiz, M.; Boada, I. Rate-Distortion Theory for Clustering in the Perceptual Space. Entropy 2017, 19, 438. [Google Scholar] [CrossRef] [Green Version]
- Carnap, R.; Bar-Hillel, Y. An Outline of a Theory of Semantic Information. Available online: http://dspace.mit.edu/bitstream/handle/1721.1/4821/RLE-TR-247-03150899.pdf;sequence=1 (accessed on 1 July 2021).
- Klir, G. Generalized information theory. Fuzzy Sets Syst. 1991, 40, 127–142. [Google Scholar] [CrossRef]
- Floridi, L. Outline of a theory of strongly semantic information. Minds Mach. 2004, 14, 197–221. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.X. A theory of semantic information. China Commun. 2017, 14, 1–17. [Google Scholar] [CrossRef]
- D’Alfonso, S. On Quantifying Semantic Information. Information 2011, 2, 61–101. [Google Scholar] [CrossRef] [Green Version]
- Bhandari, D.; Pal, N.R. Some new information measures of fuzzy sets. Inf. Sci. 1993, 67, 209–228. [Google Scholar] [CrossRef]
- Dębowski, Ł. Approximating Information Measures for Fields. Entropy 2020, 22, 79. [Google Scholar] [CrossRef] [Green Version]
- Lu, C. A Generalized Information Theory; China Science and Technology University Press: Hefei, China, 1993; ISBN 7-312-00501-2. (In Chinese) [Google Scholar]
- Lu, C. Meanings of generalized entropy and generalized mutual information for coding. J. China Inst. Commun. 1994, 15, 37–44. (In Chinese) [Google Scholar]
- Lu, C. A generalization of Shannon’s information theory. Int. J. Gen. Syst. 1999, 28, 453–490. [Google Scholar] [CrossRef]
- Lu, C. Semantic information G theory and logical Bayesian inference for machine learning. Information 2019, 10, 261. [Google Scholar] [CrossRef] [Green Version]
- Lu, C. The P–T probability framework for semantic communication, falsification, confirmation, and Bayesian reasoning. Philosophies 2020, 5, 25. [Google Scholar] [CrossRef]
- Lu, C. Channels’ Confirmation and Predictions’ Confirmation: From the Medical Test to the Raven Paradox. Entropy 2020, 22, 384. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1963. [Google Scholar]
- Zadeh, L.A. Probability measures of fuzzy events. J. Math. Anal. Appl. 1986, 23, 421–427. [Google Scholar] [CrossRef] [Green Version]
- Cumulative_Distribution_Function. Available online: https://en.wikipedia.org/wiki/Cumulative_distribution_function (accessed on 10 April 2021).
- Popper, K. Conjectures and Refutations; Routledge: London, UK; New York, NY, USA, 2002. [Google Scholar]
- Wittgenstein, L. Philosophical Investigations; Basil Blackwell Ltd.: Oxford, UK, 1958. [Google Scholar]
- Sow, D.M.; Eleftheriadis, A. Complexity distortion theory. IEEE Trans. Inf. Theory 2003, 49, 604–608. [Google Scholar] [CrossRef] [Green Version]
- Lu, C. Understanding and Accelerating EM Algorithm’s Convergence by Fair Competition Principle and Rate-Verisimilitude Function. arXiv 2021, arXiv:2104.12592. [Google Scholar]
- Boltzmann Distribution. Available online: https://en.wikipedia.org/wiki/Boltzmann_distribution (accessed on 10 April 2021).
- Binary Images. Available online: https://www.cis.rit.edu/people/faculty/pelz/courses/SIMG203/res.pdf (accessed on 25 June 2021).
- Kutyniok, G. A Rate-Distortion Framework for Explaining Deep Learning. Available online: https://maths-of-data.github.io/Talk_Edinburgh_2020.pdf (accessed on 30 June 2021).
- Nokleby, M.; Beirami, A.; Calderbank, R. A rate-distortion framework for supervised learning. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar] [CrossRef]
- John, S.; Gadde, A.; Adsumilli, B. Rate Distortion Optimization Over Large Scale Video Corpus with Machine Learning. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1286–1290. [Google Scholar] [CrossRef]
- Song, J.; Yuan, C. Learning Boltzmann Machine with EM-like Method. arXiv 2016, arXiv:1609.01840. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, C. Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions. Entropy 2021, 23, 1050. https://doi.org/10.3390/e23081050
Lu C. Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions. Entropy. 2021; 23(8):1050. https://doi.org/10.3390/e23081050
Chicago/Turabian StyleLu, Chenguang. 2021. "Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions" Entropy 23, no. 8: 1050. https://doi.org/10.3390/e23081050
APA StyleLu, C. (2021). Using the Semantic Information G Measure to Explain and Extend Rate-Distortion Functions and Maximum Entropy Distributions. Entropy, 23(8), 1050. https://doi.org/10.3390/e23081050