1. Introduction
Compared with the traditional Compressive Sensing (CS) [
1,
2,
3], the adaptive CS can adapt to the changes of the signal more effectively and achieve more reasonable signal sampling by using an appropriate CS matrix, sparse basis, sparse dictionary or sampling rates, to reduce the overall sampling rates and improve the quality of reconstructed image. In this paper, the “sampling rate” is defined as the ratio of the number of CS measurements to the length of the original signal.
Due to the characteristics of the CS imaging method [
4], the original signal can be sampled without digital conversion and storage, thus the complexity of sampling calculation can be greatly reduced, the hardware requirements of the sampling equipment can be simplified, and the sampling rate can be improved. This makes the CS method have unique advantages in fields such as video compression [
5,
6], distributed coding [
7], sensor networks [
8], radar imaging [
9], medical imaging [
10], etc.
According to measurement models, CS methods can be divided into ones using global measurement scheme [
11] and some others using block compressive sensing scheme (BCS) [
12,
13]. In general, global measurement methods can get better performance in the non-adaptive case [
14]. However, the size of the measurement matrices in global measurement methods are often very large, so the total number of matrix multiplication in the sampling process will be large, and memory occupation of the measurement matrix is also large. In this paper, the BCS scheme is used to reduce the size of the measurement matrix and reduce the sampling computation. By allocating appropriate sampling rate to different blocks, the disadvantage of the BCS scheme can be overcome, and the performance of the method is greatly improved.
However, it is often difficult to implement adaptive rate sampling in the CS method. In CS applications, the original signal can be regarded as an unknown signal, which makes it difficult to implement adaptive methods. For the sampling device, the information that can be directly obtained is no longer the original signal, but the result of the CS measurement, which is called the “CS domain signal”. In earlier studies, researchers mainly used the CS domain signal to reconstruct the original signal, then used the reconstructed signal to estimate the characteristics of the original signal, and adaptively adjusted the CS matrix [
15,
16,
17], sparse basis [
18,
19], sparse dictionary [
20,
21] or sampling rate [
22,
23]. The advantage of these methods is that it can obtain the characteristics of the original signal with high accuracy, and then make full use of the characteristics of the signal to adjust one or more sampling elements. In addition, the accuracy of these adjustments is also high, which can follow the changes of the original signal well to make corresponding adjustments. However, an important problem of these methods is that the computational complexity of the signal reconstruction is quite high, and it is unlikely to be implemented in the sampling device of CS. If the adaptive adjustment is implemented in the decoder, a special feedback channel is needed, which will also greatly affect the real-time performance of the sampling process.
In order to solve the above problem, some researchers have proposed new research ideas in recent years. They hope that some interesting features can be extracted from the CS domain signal through some simple calculations to guide the sampling device to carry out adaptive sampling, to avoid the dependence on the reconstruction of the original signal.
According to this consideration, researchers have put forward some adaptive CS methods based on CS domain signals in recent years. In [
24], researchers proposed a method to estimate the statistical parameters of the original signal by using the CS domain signal, and then estimate the adaptive sampling rate. For image compressive sensing, the covariance of the original signal is estimated by designing a special autoregressive CS matrix, and then an appropriate sampling rate is allocated for each image block. In [
25], researchers proposed a method to estimate the motion of objects in the original video depending on the CS domain signal, and then judge the motion speed of objects and realize adaptive rate CS. In [
26], researchers proposed a BCS method for video signal, which judges the complexity of the original signal through the change of the CS domain signal in the spatial and temporal dimensions, and adjusts the sampling rate of each image block in real-time to realize adaptive rate CS. In our previous work [
27], an adaptive rate CS method for surveillance video is proposed, which uses the change of innovation energy to estimate the complexity of innovation, and then realizes adaptive rate CS. The signal foreground is obtained by the background subtraction method [
28]. The total energy of the foreground signal is estimated by using the CS domain signal, and then the number of large value points of the original signal are estimated.
These methods avoid the dependence on signal reconstruction, but there are still some problems in these methods, such as the dependence on some specially designed sampling matrix, inaccurate rate estimation, only suitable for simple surveillance video signals etc. Under the condition that the computing capacity of sampling equipment is strictly limited, the adaptive method of adjusting the sampling rate based on the CS domain signal is more difficult than the method based on the reconstructed signal, and the number of related research works is relatively small. In [
24,
26], researchers have mentioned that in the field of image CS and video CS, few researchers have reported the relevant research before them.
In this paper, a new adaptive rate CS method based on the BCS scheme is proposed which only uses the CS domain signal and some simple operations to realize adaptive rate sampling and achieves better reconstruction performance. The basic idea is as follows: the original signal is CS measured firstly, the number of measurements equals the length of the original signal, this kind of measurement is called “the full-speed measurement” in this paper. Then, the full-speed measurement result (the CS domain signal) is used to estimate the statistic characteristics of the original signal. According to the estimation of the statistic characteristics, the sparsity of the original signal is estimated in the wavelet transform domain and then the original signal can be classified. Different CS sampling rates are allocated for different signal classes. Finally, according to the allocated sampling rate, the redundant part of the full-speed measurement result is discarded and only the imperative samples are transmitted for reconstruction. Thus, adaptive rate CS can be implemented.
In order to make full use of the statistic characteristics of the wavelet transform coefficients, a new CS measurement scheme is designed, which can estimate the statistic characteristics of different subbands more accurately.
In order to make full use of the inter frame correlation of video signals, a dynamic reference block update and subtraction method is designed. Compared with the measurement method using only intra frame information, the proposed method may occupy more memory, however it can make better use of the inter frame correlation to reduce the total sampling rate. Meanwhile, in the proposed method, reference blocks are automatically updated, the total number of reference blocks stored in memory is equal to the number of blocks in an image frame, so the memory space occupied by the reference blocks is fixed and acceptable.
The rest parts of the paper are organized as follows: in the second section, we briefly introduce the BCS method. In the third section, we introduce the proposed adaptive rate compressive video sensing (CVS) method. In the fourth section, the experiment results and corresponding analysis of the results are given. The final section summarizes the whole work.
2. BCS
In CVS applications, in order to reduce the memory occupation of the measurement matrix and the amount of sampling computation, it is necessary to reduce the size of the signal. BCS is a common method. For a two-dimensional video frame with rows and columns at time , it can be decomposed into non-overlapping image blocks. The size of each image block is rows and columns, and the -th () image block is recorded as . Theoretically, the value of can be any positive integer, and in image and video processing, the value of is often the power of , such as or are commonly used. In this paper, we take .
In the process of the CS measurement, we first convert the image block
into a vector
, and then we can use the measurement matrix
and an appropriate sparse basis
to measure it, the measurement result
can be obtained as
where
and
,
is the sparse representation coefficients of
on the sparse basis
.
, this means that the signal is compressed into a low dimensional space.
3. Adaptive Rate Compressive Video Sensing
Because each frame in the actual video has different content, for blocks in a frame, it is possible that they have quite different characteristics, and the sparsities of different blocks are also completely different. In order to adapt to the changes in different blocks, a new adaptive rate BCS method is proposed to estimate the appropriate sampling rate for each block. At the same time, using the estimate of the sparsity of a block, a new method using inter frame correlation is also proposed.
3.1. Statistic Parameter Estimation Based on Restricted Isometry Property
For a signal vector
, assume that it is unknown to the sampling device and only its CS measurement result is obtained. In order to estimate an appropriate sampling rate for the signal, the sparsity of the sparse coefficient
needs to be estimated without reconstructing
. In this paper, we use the restricted isometry property (RIP) [
29] to estimate the mean and variance of
, and then to estimate the sparsity of
.
For a CS measurement matrix
and an appropriate sparse basis
, we have
. If
satisfies the RIP, for a Restricted Isometry Constant (RIC)
, there is:
In practice, we can approximate it as
Set a vector
with
, where
and
is a constant, and we have
From Equations (3) and (4), we have
Since
, Equation (5) can be written as:
If all elements in vector
are independent realizations of a random variable
, denote the expectation of
as
, it is easy to get the estimate of the expectation
with
Set up another vector
,
, Then the estimate of the variance of
can be recorded as
These allow us to estimate the characteristics of using only the CS domain signal.
3.2. Statistic Characteristics Estimation for Wavelet Subbands
The signal
is often not sparse, but it can be represented by a sparse coefficient vector
under a sparse base. If all elements in vector
are independent realizations of a random variable
, similar to Equations (7) and (10), the mean and variance of
can be estimated using
and
where
, and
.
In this paper, the wavelet basis is used to sparsely represent the original signal. We have noticed that for natural images and videos, there is some specific feature in their wavelet coefficient vector , which mainly shows the energy concentration property. Based on the characteristics of the wavelet transform, can be divided into several subbands according to the number of layers of the wavelet transform. The feature of energy concentration is that the main energy of the signal is concentrated in the lower frequency subbands, and the small amount of energy is left in the higher frequency subbands. The absolute values of the coefficients in lower frequency subbands tend to be larger, while the absolute values of the coefficients in the higher frequency subbands tend to be smaller. At the same time, within a subband, the absolute values of nonzero coefficients tend to be close, while the absolute values of nonzero coefficients between different subbands differ greatly.
Due to the above characteristics of the wavelet coefficients, estimating the sparsity of directly using the mean and variance of all coefficients in often leads to results that are not accurate enough. However, if the mean and variance of the coefficients in each subband can be obtained, the sparsity of each subband can be estimated separately, and then the sparsity of the entire wavelet transform coefficient vector can be more accurately estimated.
In order to obtain the mean and variance for each subband, a new CS measurement process is proposed. Consistent with previous assumptions, there is no need to know the digital conversion results of the original signal and the corresponding wavelet transformation coefficients during the measurement process.
For an
-layer wavelet transform, denote the wavelet transform matrix as
, the wavelet transform coefficient vector is
According to the rule of the wavelet transform, the coefficients can be divided into
subbands. Denote one of the coefficients subbands as
,
where
is the lowest frequency subband and
is the highest frequency subband,
represents a new vector composed by elements from the
-th element to the
-th element in
. And
is given by
Set
where
is a new matrix composed by the vectors from the
-th row to the
-th row in
. Then we have
If there is a random CS matrix
, set a submatrix
which is composed by the vectors of column
to
in
,
where
is the transpose of
.
Then
can be measured by
where
. The CS measurement results of a certain wavelet coefficient subband can be obtained directly from the CS matrix and the wavelet transform matrix. We can know from the matrix multiplication rules that,
which means the CS measurement result of
can be obtained from the CS measurement results of
.
If all elements in vector
are independent realizations of a random variable
, Similar to Equations (11) and (12), the mean and variance of
can be obtained as follows,
where
,
,
, and
where
.
3.3. Sparsity Estimation
In the process of the CS measurement, a threshold is often set, if the value of the measured signal sample is greater than , it is considered as a large value, otherwise it is considered as a small value. The value of determines how much energy in the original signal is considered as “noise”. If the value of is too small, many image blocks will be mistakenly considered as not sparse, resulting in unreasonable increase of sampling rate. If the value is too large, many pixels will be considered as small value affected by noise, which will eventually affect the quality of the reconstructed image. Therefore, the value of should be a small value that matches the reconstruction algorithm. In this paper, considering that the original signals are 256 level gray images, the value of is set to 8.
The number of large values in the measured signal determines the sparsity of the signal, which in turn, determines the number of measurements.
In the proposed method, we assume that coefficient values in
obey a certain distribution. For the wavelet coefficients, it is generally considered that Bessel K form densities (BKF) [
30] or generalized gaussian density (GGD) [
31] can better describe their distributions. However, it is difficult to get better estimates of the parameters which are necessary in the BKF and GGD distributions when only the CS domain signals are known, thus, we use the normal distribution to describe the coefficient distribution in
. Since the actual distribution of elements in
cannot be optimally approximated with a normal distribution, there will also be some error in the estimated result of the sparsity. However, in this paper, the estimated result of the sparsity is used to classify the image block instead of accurately solving the sampling rate, so approximating the real distribution using the normal distribution is still an effective method.
For an image block, its wavelet coefficients contain
subbands, one of the subband is
, we assume that coefficient values in
are normal distributed,
. The probability of an element in
taking a large value is
Denote the estimate of the number of large points in
by
In this paper, we classify blocks into four categories by , denoted C0, C1, C2, and C3. For three sparsity thresholds , and , where . If , can be classified into the C0 class, if , can be classified into the C1 class, if , can be classified into the C2 class, if , can be classified into the C3 class. Different number of measurements can be assigned to differently classified blocks. Denote the number of measurements as which takes corresponding values , , , .
The values setting of
,
,
and
,
,
,
is determined by the corresponding relationship between sparsity and necessary measurement number. According to the description in [
23,
32], these values can be determined. For
, when
, the signal can be considered as very sparse, and the corresponding number of measurements is set as
. For
, when
, using the mapping relationship provided in [
23], the number of measurements is set as
. For
, when
, the number of measurements is set as
. When
, the signal is considered as non-sparse, the number of measurements is set as
. The sampling rate of the block equals
. In particular,
means the block is not measured, and at the reconstruction side, a matrix with all elements of
is considered as the reconstruction result of this measurement.
3.4. Reference Block Subtraction
In video signals, there is often large redundancy between neighboring frames, so reducing the encoding codelength by exploiting the inter frame correlation is a common strategy in both traditional video encoding methods and CVS sampling methods. In this paper, using the estimated sparsity, a method to reduce the sampling rate by using the inter frame correlation in the sampling process is designed.
For an image block , assume that there is a similar image block at time , we can consider as the “reference block” of . Since is similar to , by subtracting from , the signal sparsity can be effectively improved.
One of the
measurement result vectors of the reference block is denoted as
. At the sampling side, since the CS domain signal
is known, thus we can set
. By subtracting
from
, we have
Similar to Equation (20), there is
Denote
and
. If all elements in vector
and
are considered to be independent realizations of random variables
and
, similar to Equations (21) and (22), the mean and variance can be estimated from
and
Using the method in
Section 3.3, the sparsity of
, i.e.,
, can be estimated.
By comparing and , the measurement target can be decided. For a coefficient , if , it can be considered that is sparser than , a shorter measurement result can be used to describe . Thus, can be chosen as the measurement target. If , it can be considered that the sparsity of and is close, choosing as the measurement target and update the reference block by setting will reduce the global sampling rate.
Denote the measurement result of the current block as
In this section, two alternative measurement targets and are set, by considering the sparsity of each image block, the measurement target can be selected, and the reference block is updated accordingly, so as to achieve the goal of reducing the overall video sampling rate by using the inter frame correlation. Each reference block can be updated automatically when the correlation between it and the current block becomes weak. Compared with the reference frame method, the proposed method can update the reference block more flexibly, which is also conducive to make better use of inter frame correlation to reduce the overall sampling rate. And the automatically update of reference blocks ensures a relatively small memory occupation.
3.5. Sampling Operations
Since CS reconstruction is not lossless and suffers from the error accumulation effect, the reconstruction quality of the reference block affects the reconstruction qualities of the corresponding blocks in the following frames, thus we expect that the reconstruction quality of the reference block could be higher than common blocks. In common blocks, the number of measurements is
, which is determined by the classification result. For reference blocks, a parameter
is used to achieve a higher number of measurements. Denote the final number of measurements of blocks as
where the value of
should not larger than
.
When is determined, can be transmitted to the reconstruction side, where is a new vector composed by elements from the 1st element to the -th element in . That means only a part of elements in is transmitted to the reconstruction side and the unnecessary part is discarded. Then the adaptive rate sampling of the current image block is completed.
Since only is transmitted, and cannot be obtained by the reconstruction method, the cannot be solved in the reconstruction equipment. Therefore, additional information (or the side information) including the classification result and the measurement target information should be transmitted to the reconstruction side. This increases the amount of data to be transmitted. However, for the classification result of a block, only 2 bits are needed to describe it, and the measurement target information of a block only needs 1 bit to describe. Take an image block with 64 points and each with 256 gray levels as an example, suppose that the sampling result is also quantized to 256 levels, and it has a small sampling rate, e.g., . At this time, the measurement result can be described by using bits. The additional 3 bits account for less than of the total number, and with the increase of sampling rate, the proportion will further decrease. Thus, it can be considered that such additional data transmission is acceptable.
3.6. Reconstruction Operations
In the process of reconstruction, for a block to be reconstructed, we first take the classification result and the measurement target information from the transmitted side information, the
can be determined. Then we can get
from the transmitted CS sampling result. Using
and a suitable CS reconstructed method, the
or
can be reconstructed. The SPGL1 [
33] method is used to reconstruct the signal here.
Assume that the reference block of current is , and a vector is used to store the reference block. In the reconstruction side, we use the reconstructed to approximate , i.e., . When reconstructing , if the measurement target information shows that it is to be reconstructed, the can be obtained from the reconstruction method. Using , the reconstructed block can be obtained by . The reference block vector needs to be updated after the reconstruction is completed, with . If the measurement target information shows that it is to be reconstructed, the can be obtained from the reconstruction method, and the reconstructed block can be obtained as .
4. Experiments
Video sequences Hall, Coastguard, Foremen and Soccer are used to test the performance of the proposed method. Sample frames of the four test videos are shown in
Figure 1.
All these videos are standard test videos, and they represent four very representative situations. Hall represents the common situation of surveillance video. Its background is constant, and the foreground is changing. Coastguard video is a typical representative of foreground object tracking. The background is changing rapidly, and the foreground is similar. Foreman video contains close-up of characters and some fast-changing scenes. The background and foreground of Soccer video are changing, and the speed of change is sometimes fast and sometimes slow. All these videos can be found from
https://media.xiph.org/video/derf/ (accessed on 31 July 2021)
In this section, firstly, the parameter settings used in experiments are introduced. Next, the corresponding experiments are designed to demonstrate the image block classification ability and the sampling rate allocation ability of the proposed method, and the corresponding results are analyzed. Then, we compare the performance of the proposed method with adaptive rate CS methods proposed in recent years and analyze the results.
4.1. Parameter Settings
In the following experiments, Haar Wavelet Bases is used, and . The Gaussian random matrix is adopted as the CS measurement matrix.
Parameters value setting of
and
are shown in
Table 1.
The parameter determines the update speed of the reference block. The larger the is, the slower the reference blocks update. If the value is too large, the reference blocks will be updated very slow, the inter frame correlation will not be used effectively, and the measurements will be wasted. If the value of is too small, the reference blocks will be updated too frequently. Because the measurement rate of the reference blocks is higher than that of the common blocks, the measurements will also be wasted.
The parameter determines how much higher the number of measurements of the reference block is than that of the common block. If the measurement number is too low, the quality of the whole reconstructed video will decline. If the measurement number is too high, considering the excessive measurement number contribute little to reconstruction quality, which will result in the waste of the measurement number.
The parameter values in
Table 1 are obtained by our experiments, which have good effect on the four videos with different characteristics.
4.2. Image Block Classification Result
In the process of the adaptive rate allocation, the classification of image blocks is a key step. If the classification result fit the actual sparsity, it brings a lower sampling rate and better image reconstruction quality. Therefore, an experiment is designed to show the classification performance of the proposed method.
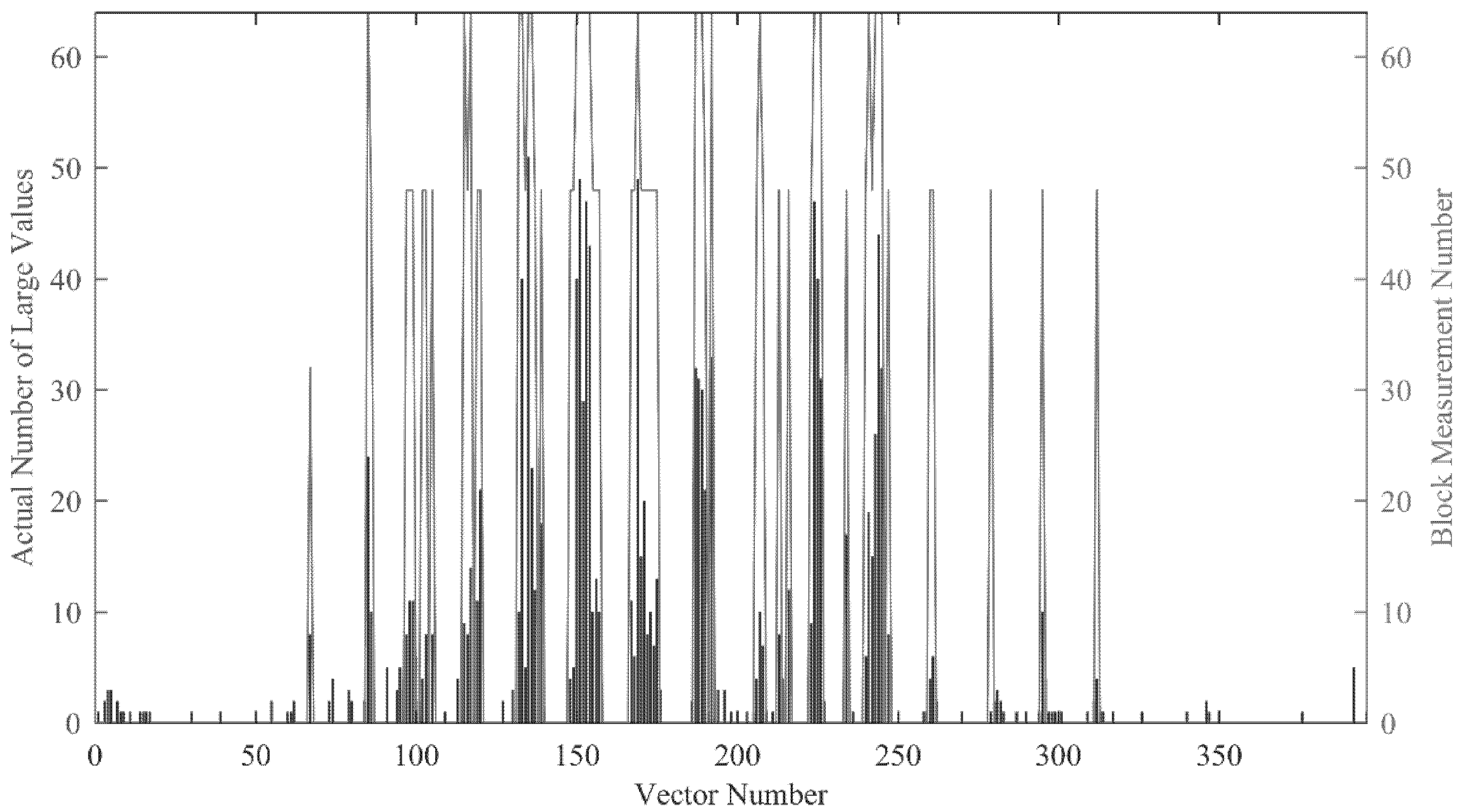
We use the classification results of all blocks in a frame to evaluate the classification performance. Take the 100th frame in the video Hall as an example. The experimental result is shown in
Figure 2, the bar represents the actual number of large points, and the line represents the allocated measurement number for each block.
It should be noted that the number of measurements is theoretically larger than the number of large value points in the majority of cases. The specific correspondence is described in
Section 3.3. It can be seen from
Figure 2 that the allocation of measurement number basically matches the actual sparsity, and it can be adjusted according to the change of the actual sparsity. Especially for the empty blocks and non-sparse blocks, the classification results are very good. However, there are still some misclassifications in the classification results. According to our statistics, the number of misclassified blocks accounts for about 10% of the total number of blocks. Almost all misclassifications allocate higher measurement number to those blocks, which leads to the waste of measurement. However, such misclassification can ensure that the quality of the reconstructed image does not decline significantly. Generally speaking, the classification result can be considered as a quite good result.
Through the above experiment results, we can get the conclusion that the proposed method can accurately classify the image blocks only according to the known CS domain signal, and the classification results are in good agreement with the actual sparsity of the signal.
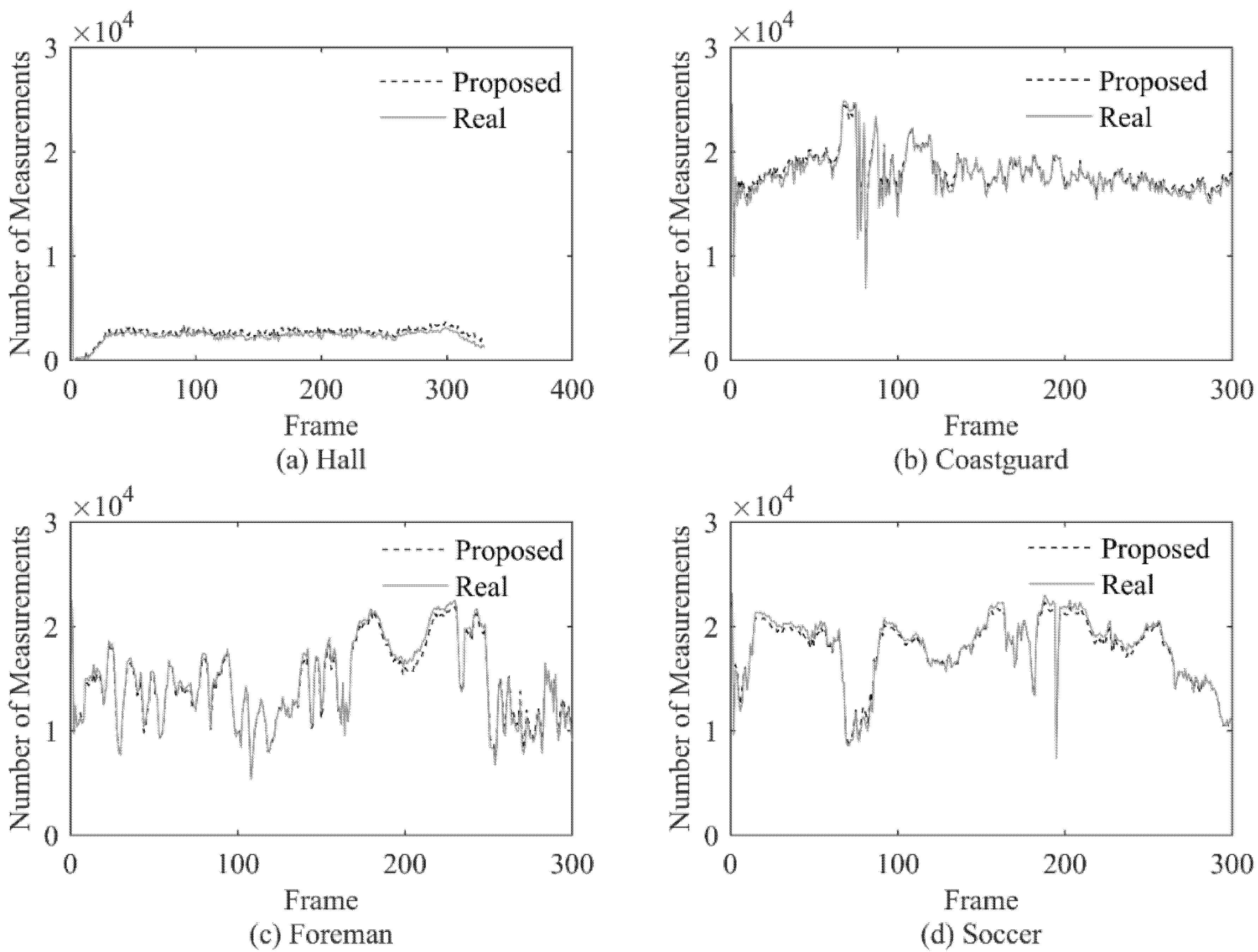
4.3. Measurement Number Allocation Results
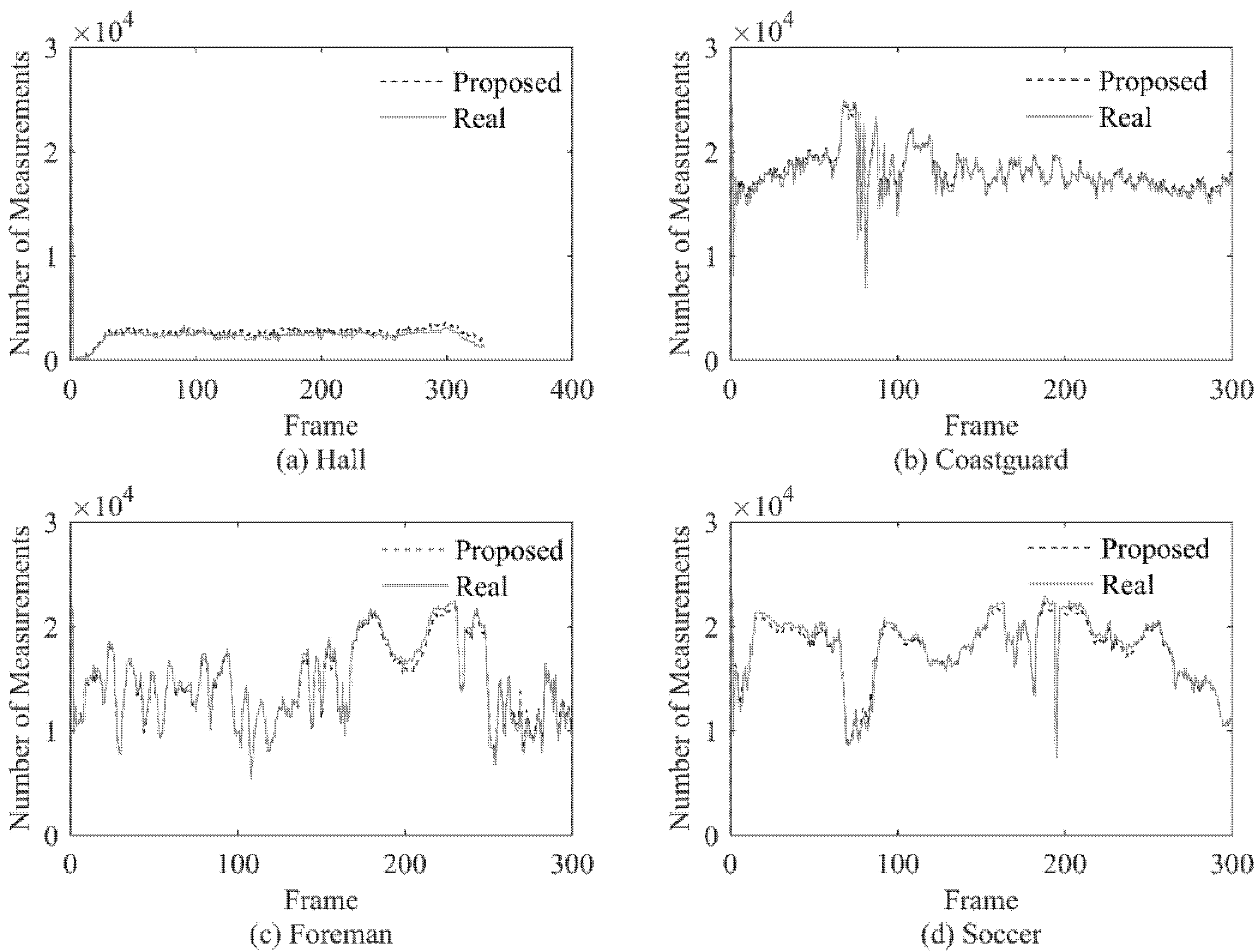
Based on the classification of blocks in a frame, different number of measurements can be assigned to different blocks. The measurement number of a frame is the sum of the number of all blocks in the frame. In order to verify whether the measurement number of each frame is appropriately assigned, a relevant experiment is designed.
Using the same BCS method and the reference block subtraction strategy, the actual sparsity of the wavelet coefficients in each image block is observed, and the measurement number is determined by the actual sparsity. It is necessary to point out that when only the CS domain signal is known, the actual sparsity cannot be observed directly. The measurement number determined by the actual sparsity (named as Real measurement number) is an ideal value. By comparing the deviation between the estimated measurement number and the Real measurement number, the measurement number assignment ability of the proposed method can be evaluated.
In the experiment, the real measurement number (Real) and the estimated measurement number with the proposed method (Proposed) are calculated for each frame of the 4 test videos, and the results are shown in
Figure 3.
The experiment results show that the proposed method can allocate the number of measurements very well for each frame, the allocation result is very close to the ideal value, and when the actual value changes dramatically, the estimated value can also make corresponding changes according to the actual value in time. At the same time, the proposed method can well adapt to videos with different characteristics. For the four test sequences with obvious different characteristics, there is no significant gap in the performance of the proposed method.
Through the above experiment, we can get the conclusion that the proposed method can allocate an appropriate measurement number for each frame under the condition that only the CS domain signal is known.
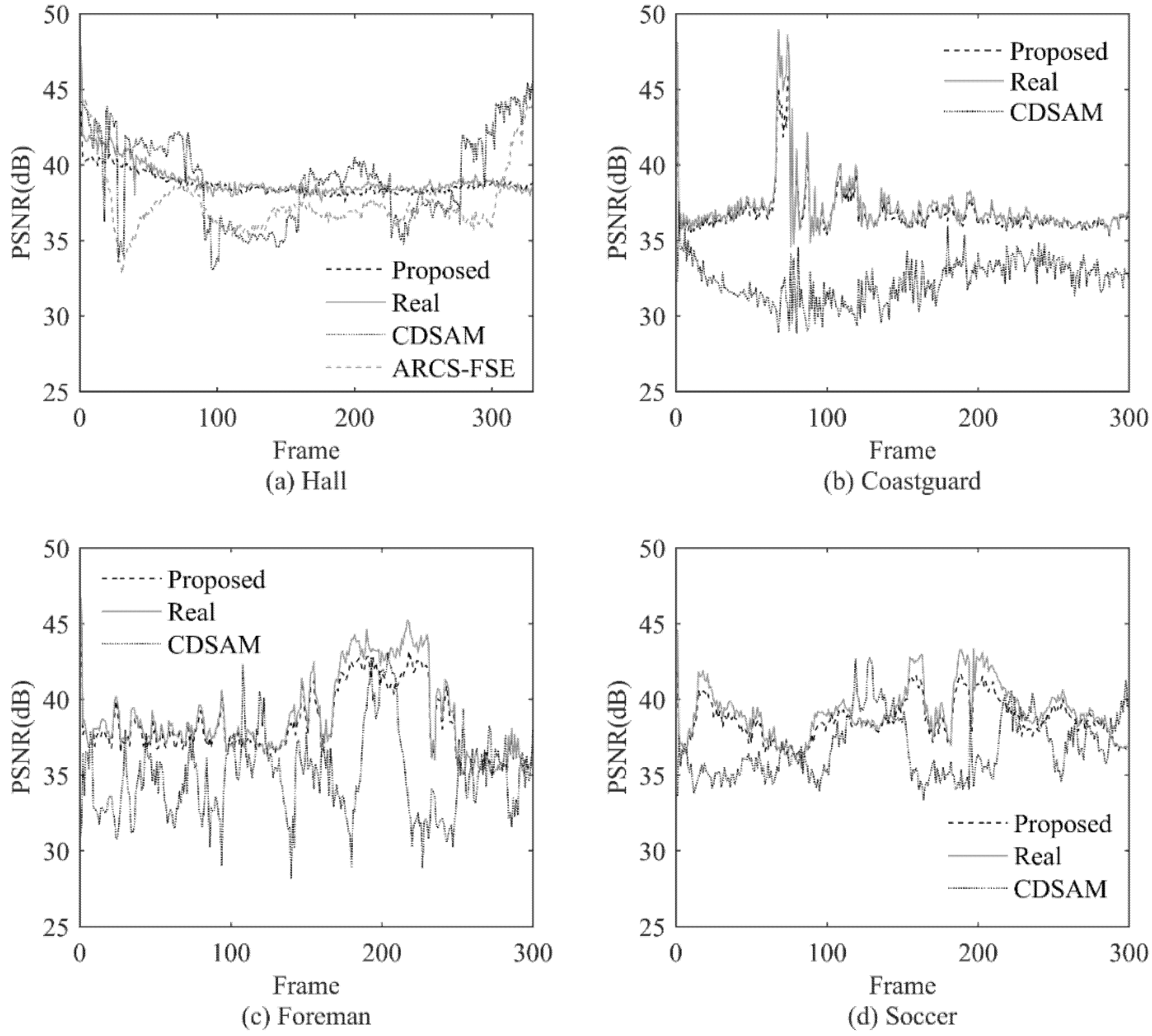
4.4. Comparison of Reconstructed Image Quality
In order to evaluate the performance of the proposed method, we design another experiment to show the Peak Signal to Noise Ratio (PSNR) [
34] performance of the proposed method frame by frame and compare it with the PSNR performance of several other methods. The example reconstructed images of these methods are also shown and compared.
As far as we know, there are not many adaptive rate CVS methods similar to the methods proposed in this paper. Two methods proposed in recent years are chosen for comparison, they are Compressive Domain Saliency-based Adaptive Measurement (CDSAM) [
26] and Adaptive-Rate Compressive Sensing based on Fast Sparsity Estimation (ARCS-FSE) [
27], respectively. The reconstructed result using Real measurement number which is mentioned in
Section 4.3 is also used for comparison and named as Real.
Here, we consider the PSNR of Real as an ideal value, and hope that the PSNR of the proposed method can be close to the ideal value. In particular, it should be pointed out that the ideal PSNR value here is not necessarily the highest PSNR value. Since the goal of the adaptive method is to allocate an appropriate sampling rate, it can be considered that it is inefficient to obtain a higher PSNR with a much higher sampling rate than the actual one.
In addition, because the frame measurement number of the Real method and the proposed method are close, if the PSNRs are also close, then the intra block measurement number allocation of the proposed method can be considered as reasonable.
The CDSAM method is an adaptive rate method based on blocked CVS. It adopts a fixed frame measurement number and dynamically changes the block measurement number in the frame. Compared with the fixed rate CVS method, it has an obviously improvement in performance. According to [
26], the method has the best performance compared with other adaptive rate CVS methods at that time.
ARCS-FSE is an adaptive rate CS method for surveillance videos. In the test videos used in this paper, Hall is the sequence with the characteristics of a surveillance video, so the ARCS-FSE method is applied for Hall. In other three test sequences, the ARCS-FSE method cannot be applied because of its limited applicability.
By comparing the sampling rate and the reconstructed image quality, the performance of the proposed method can be evaluated. The Real method, the proposed method and the ARCS-FSE method can adaptively determine the sampling rate for each frame, while the frame sampling rate of the CDSAM method needs to be set. Appropriate sampling rates are selected for CDSAM method so that the average PSNR of CDSAM can be close to other methods. The average sampling rates (ASR) and average PSNRs of different methods are shown in
Table 2.
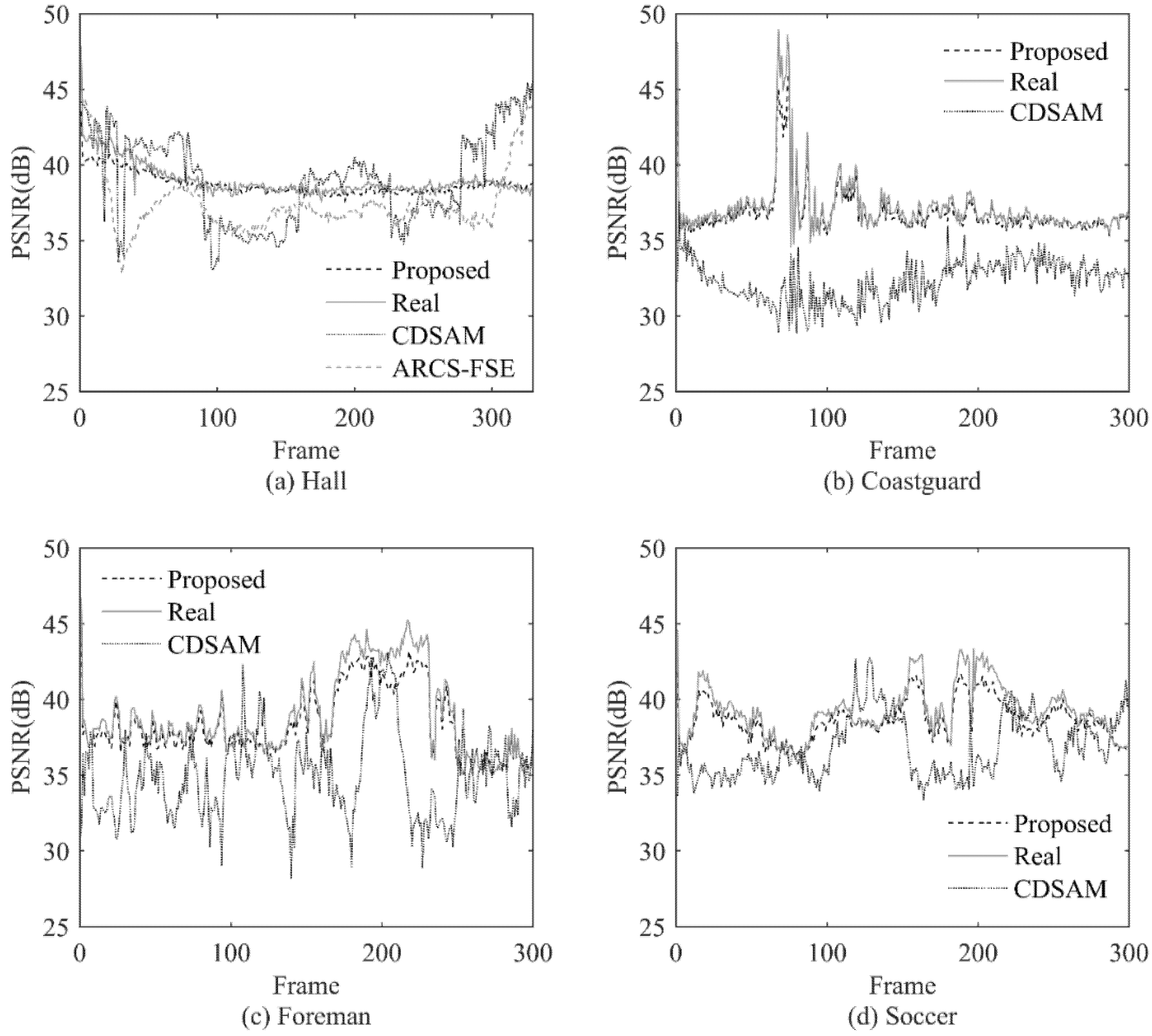
In order to better demonstrate the quality of reconstruction images, with the above sampling rate, PSNR of each frame for all methods are shown in
Figure 4.
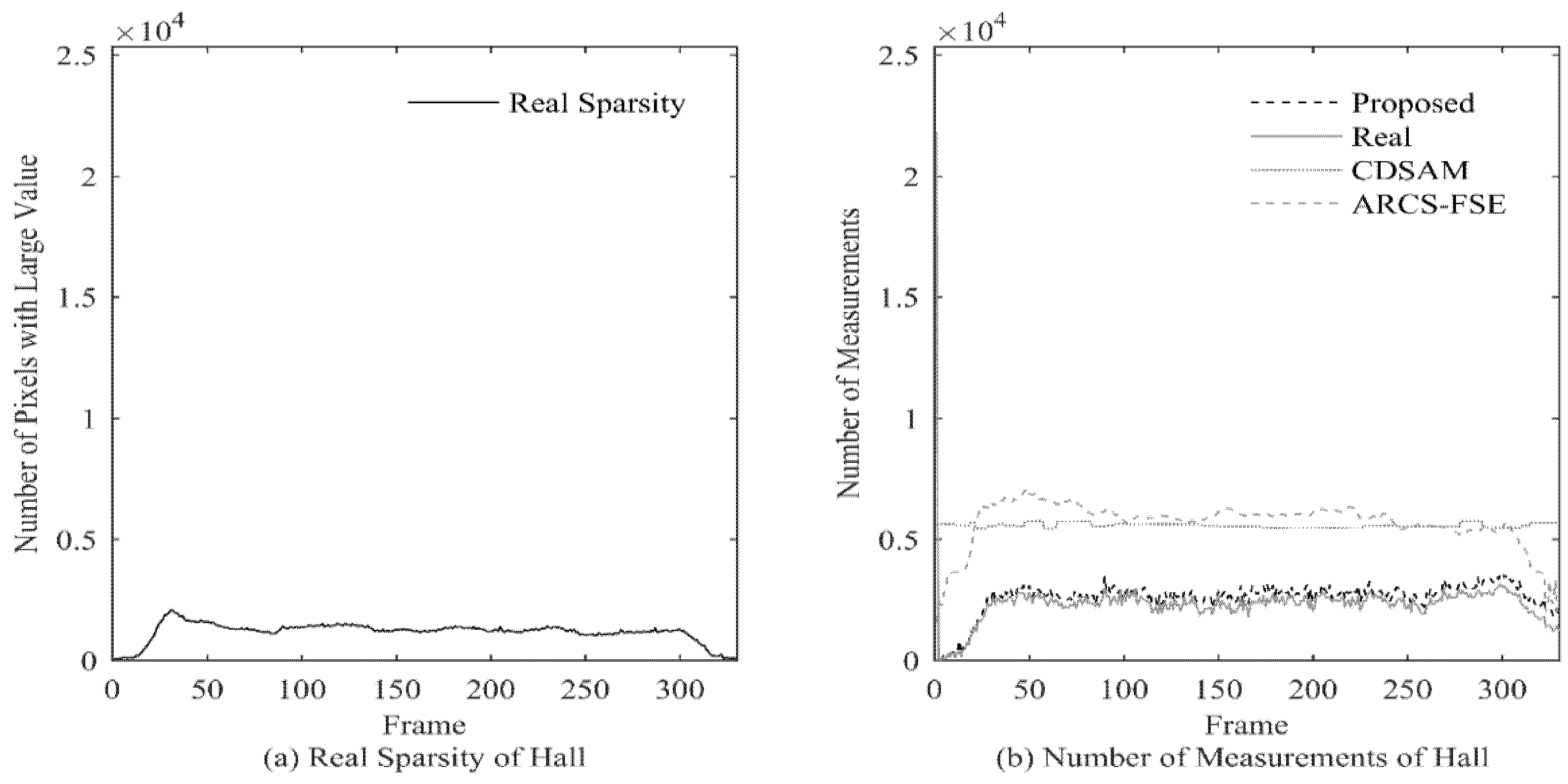
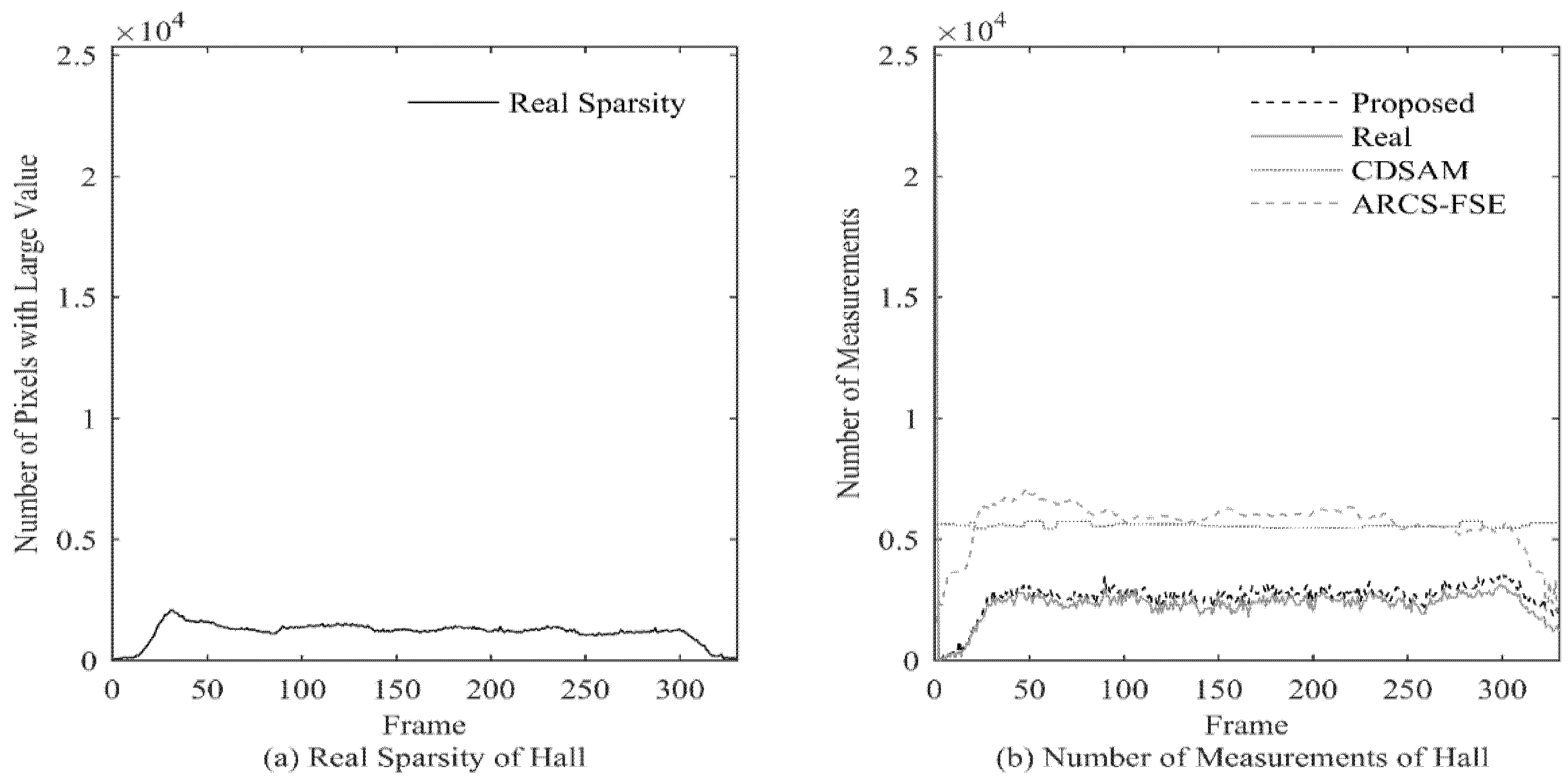
In order to further illustrate the influence of the sampling rate on PSNR, in
Figure 5, we take video Hall as an example to show the actual sparsity and the measurement number of each frame.
It can be seen that the variation of proposed measurement number is consistent with the variation of actual sparsity, while CDSAM and ARCS-FSE allocate too high measurement number in some sparse regions. Combining with
Figure 4a, we can see that at the end of the video, the CDSAM method achieves only a few dB of PSNR gain at a high number several times over the ideal value. At that part, because the PSNR achieved by the proposed method is relatively high, such gain is of little significance.
We also show the reconstructed frames for visual quality evaluation, a local part of the 150-th frame of each video is used as the example and shown in
Figure 6.
From the above experiment results, we can see that the reconstruction quality of the proposed method is close to the Real method and has good performance. The proposed method and the Real method have close PSNR values for similar measurement number, and there is no obvious blocking effect in the visual quality of the proposed method. It shows that the measurement number allocation for each block in the proposed method is also close to the actual situation.
Compared with the CDSAM method and the ARCS-FSE method, the proposed method can obtain better reconstruction quality at a lower sampling rate. The reconstruction quality of each frame is relatively consistent. At the same time, the reconstruction quality of each block is also relatively consistent. In addition, compared with the CDSAM method and the ARCS-FSE method, the proposed method has more advantages in adapting to different videos with different characteristics.
4.5. Computational Complexity Discussion
First, as we discussed in
Section 1, compared with the method relying on signal reconstruction, the method independent of signal reconstruction has obvious advantages in running speed. The proposed method, CDSAM and ARCS-FSE are independent of reconstruction, so they should have a great advantage in running speed compared with the methods that depend on signal reconstruction.
Secondly, the BCS scheme is used in this paper. Compared with the global measurement scheme, the measurement matrix size of BCS scheme is much smaller, which leads to less multiplication operation in the measurement process. The ARC-FSE method adopts the scheme of global measurement, which can be predicted that the proposed method should be faster in the execution speed of matrix multiplication. Compare with the CDSAM method, considering that the proposed method needs to measure each wavelet subband separately, it can be predicted that the matrix multiplication speed of proposed method will be slower than that of the CDSAM method.
Finally, as far as the sparsity estimation speed is concerned, the calculation of the proposed method is relatively simple, while the CDSAM method needs to operate on all adjacent blocks of each block in the sparsity estimation process, which makes it slower than the proposed method.
Note that the average matrix multiplication time is
, the average sparse estimation time is
, the average signal reconstruction time is
, and the average sampling time of each frame is
,
. CDSAM method, ARCS-FSE method and ARCS-CV [
23] method is taken as comparison methods, where the ARCS-CV method is a representation of methods relying on signal reconstruction. Taking hall video sampling time as an example, we carried out simulation experiments on the same platform to verify the above analysis. The simulation results are shown in
Table 3.
It can be seen that the simulation results are consistent with the theoretical analysis, and the proposed method has the best performance in terms of running speed in all these methods.
4.6. Conclusions of Experiments
It can be seen from the above experiment results that the proposed method can realize adaptive rate CVS when only the CS domain signal is known, the sampling calculation is simple. It can achieve good sampling rate adaptation and reconstructed image quality for a variety of videos with different characteristics. Compared with the existing adaptive rate CVS methods, the proposed method has obvious advantages.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}