
Multivariate Tail Probabilities: Predicting Regional Pertussis Cases in Washington State


Abstract
:1. Introduction
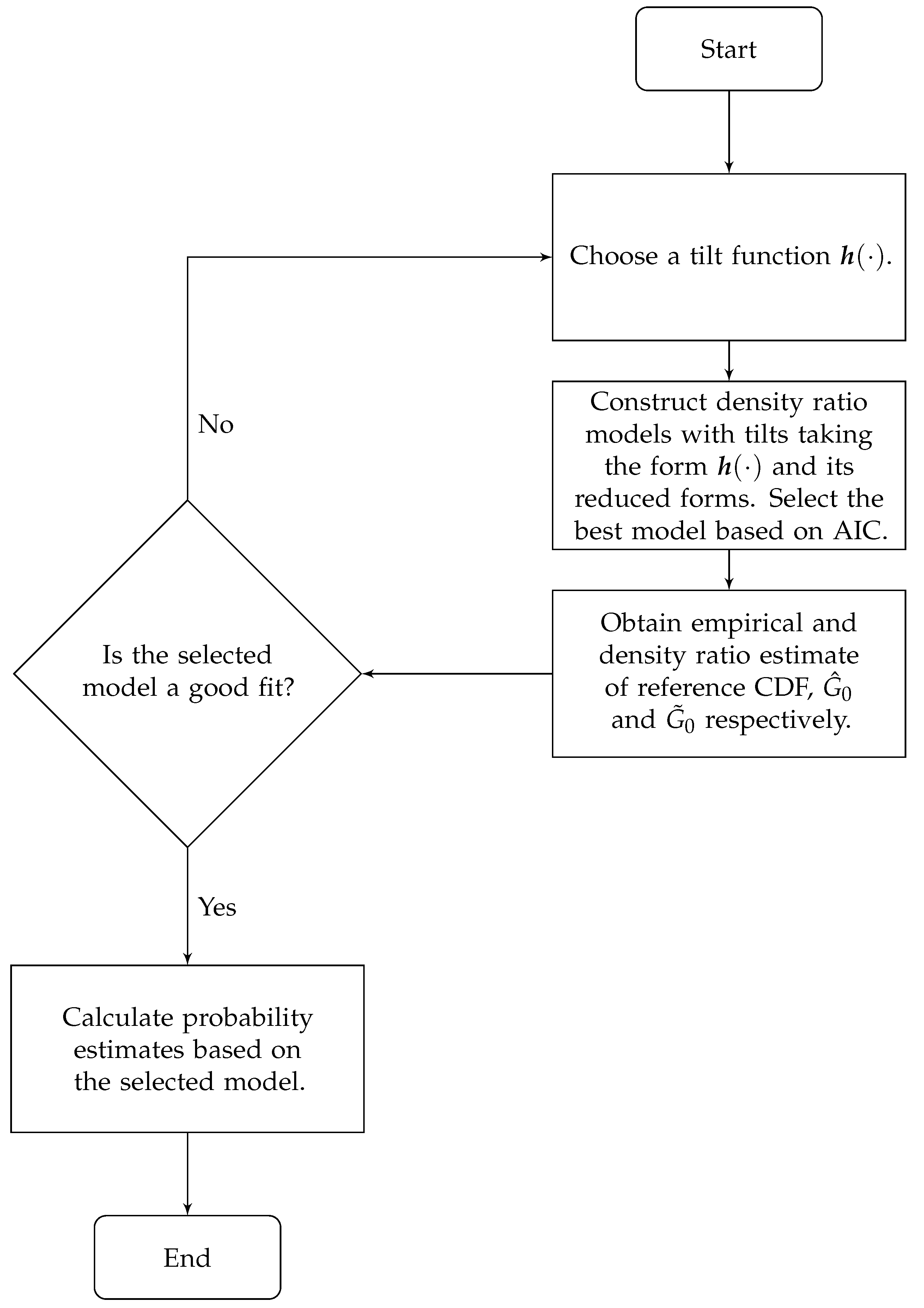
2. Density Ratio Model
3. Application: County-level Pertussis Cases in Washington State
3.1. Univariate Analysis
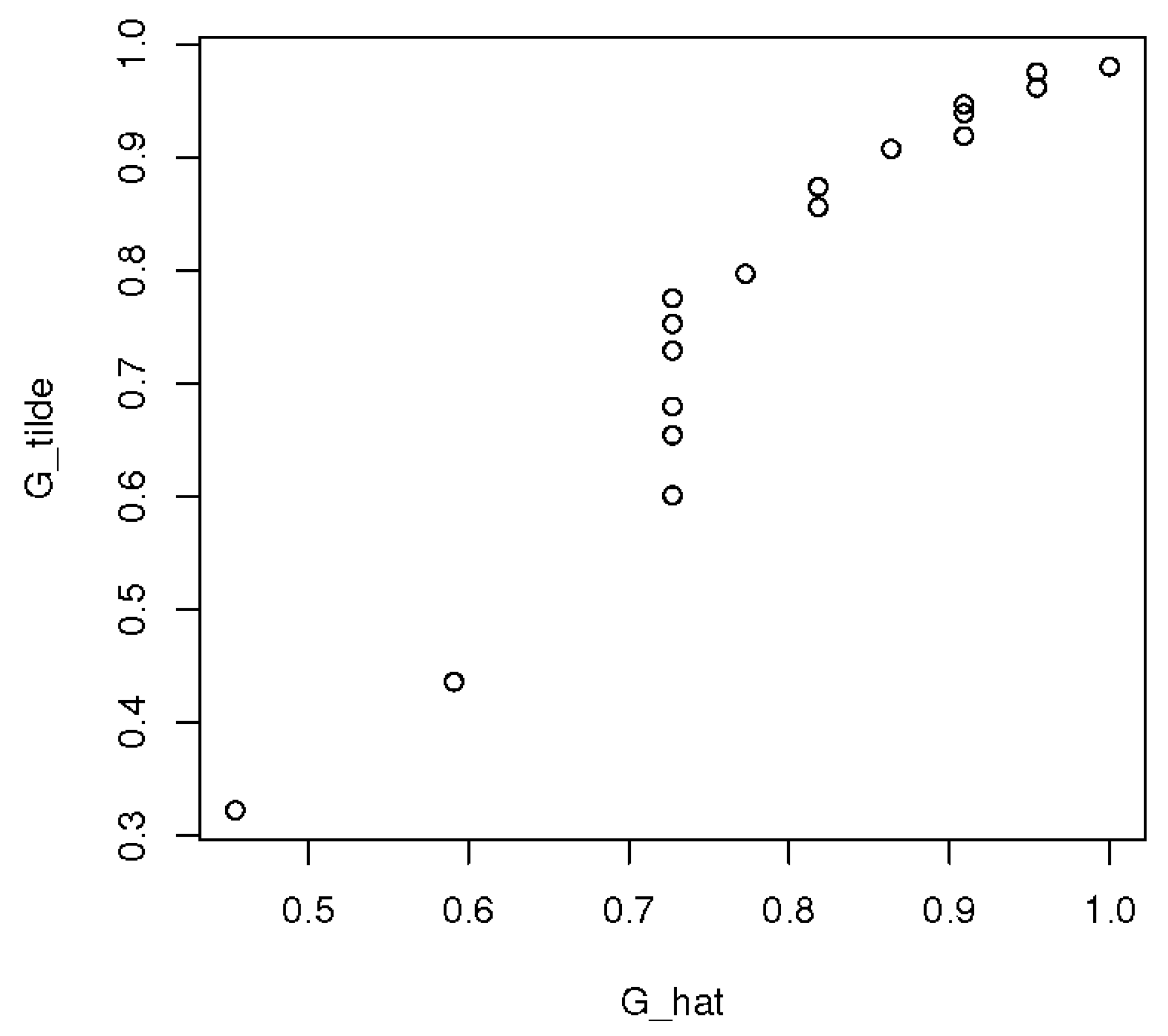
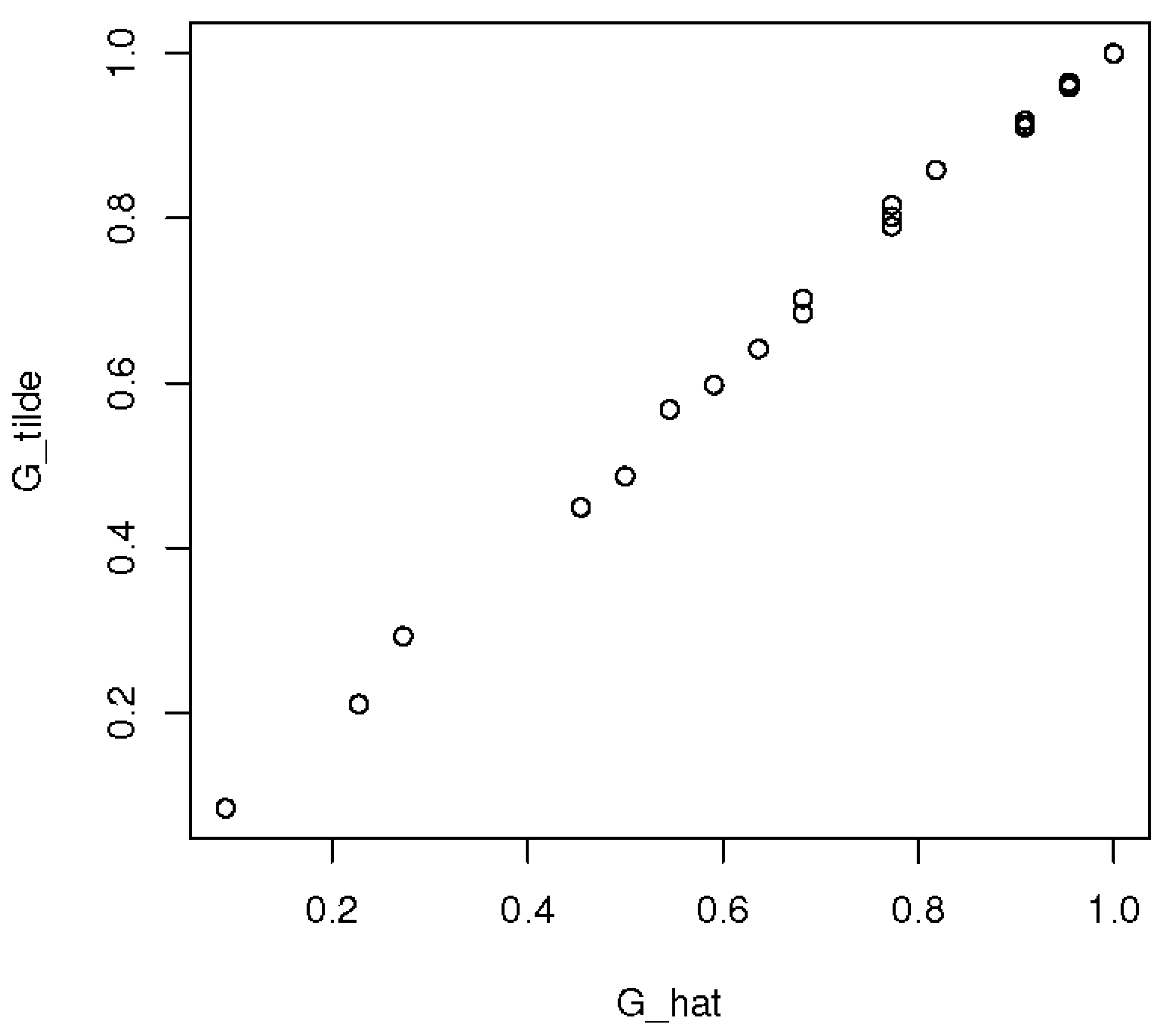
3.2. Multivariate Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Risk Factors of Pertussis Incidence

{kind=link}
{kind=link}
{kind=link}
| County | Population | Household | %Hispanic | %Vaccine | %Below5 | Density | Rural/Urban | SES |
|---|---|---|---|---|---|---|---|---|
| Grays Harbor | 72,490 | 2.43 | 9.8 | 80.7 | 5.5 | 14.78 | Mostly Rural | Mid |
| Jefferson | 31,210 | 2.07 | 3.7 | 80.8 | 2.9 | 6.70 | Mostly Rural | Mid |
| Clallam | 75,637 | 2.25 | 5.8 | 87.1 | 4.7 | 16.74 | Mostly Rural | Mid |
| Clark | 474,381 | 2.69 | 8.7 | 84.7 | 6.2 | 290.74 | Semi-Urban | High |
| Cowlitz | 106,805 | 2.52 | 8.4 | 94.1 | 6.2 | 36.13 | Semi-Urban | High |
| Lewis | 78,320 | 2.52 | 9.7 | 91.5 | 5.9 | 12.56 | Mostly Rural | Mid |
| King | 2,203,836 | 2.45 | 9.4 | 91.4 | 5.9 | 400.75 | Urban | Mid/High |
| Snohomish | 802,089 | 2.68 | 9.7 | 90.7 | 6.4 | 147.82 | Semi-Urban | High |
| Skagit | 125,860 | 2.55 | 17.8 | 90.4 | 6.1 | 28.03 | Semi-Urban | High |
References
- Kedem, B.; Pyne, S. Estimation of Tail Probabilities by Repeated Augmented Reality. J. Stat. Theory Pract. 2021, 15, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Yeung, K.H.T.; Duclos, P.; Nelson, E.A.S.; Hutubessy, R.C.W. An update of the global burden of pertussis in children younger than 5 years: A modelling study. Lancet Infect. Dis. 2017, 17, 974–980. [Google Scholar] [CrossRef]
- Broutin, H.; Guégan, J.F.; Elguero, E.; Simondon, F.; Cazelles, B. Large-scale comparative analysis of pertussis populations dynamics: Periodicity, synchrony and impact of vaccination. Am. J. Epidemiol. 2005, 161, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Rohani, P.; Drake, J.M. The decline and resurgence of pertussis in the US. Epidemics 2011, 3, 183–188. [Google Scholar] [CrossRef] [PubMed]
- Van Panhuis, W.; Cross, A.; Burke, D. Counts of Pertussis reported in United States of America: 1888–2017; Project Tycho Data Release; University of Pittsburgh: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Centers for Disease Control and Prevention (CDC). Pertussis epidemic—Washington, 2012. MMWR Morb. Mortal. Wkly. Rep. 2012, 61, 517–522. [Google Scholar]
- Skoff, T.H.; Baumbach, J.; Cieslak, P.R. Tracking pertussis and evaluating control measures through enhanced pertussis surveillance, Emerging Infections Program, United States. Emerg. Infect. Dis. 2015, 21, 1568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barlow, R.S.; Reynolds, L.E.; Cieslak, P.R.; Sullivan, A.D. Vaccinated children and adolescents with pertussis infections experience reduced illness severity and duration, Oregon, 2010–2012. Clin. Infect. Dis. 2014, 58, 1523–1529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanstead, E.; Kenyon, C.; Rowley, S.; Enns, E.; Miller, C.; Ehresmann, K.; Kulasingam, S. Understanding trends in pertussis incidence: An agent-based model approach. Am. J. Public Health 2015, 105, e42–e47. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xu, C.; Wang, Z.; Zhang, S.; Zhu, Y.; Yuan, J. Time series modeling of pertussis incidence in China from 2004 to 2018 with a novel wavelet based SARIMA-NAR hybrid model. PLoS ONE 2018, 13, e0208404. [Google Scholar] [CrossRef] [PubMed]
- Kedem, B.; De Oliveira, V.; Sverchkov, M. Statistical Data Fusion; World Scientific: Singapore, 2017. [Google Scholar]
- Lu, G. Asymptotic Theory for Multiple-Sample Semiparametric Density Ratio Models and Its Application to Mortality Forecasting. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 3 October 2007. [Google Scholar]
- Qin, J. Biased Sampling, Over-Identified Parameter Problems and Beyond; Springer: Singapore, 2017. [Google Scholar]
- Qin, J.; Zhang, B. A goodness-of-fit test for logistic regression models based on case-control data. Biometrika 1997, 84, 609–618. [Google Scholar] [CrossRef]
- Voulgaraki, A.; Kedem, B.; Graubard, B.I. Semiparametric regression in testicular germ cell data. Ann. Appl. Stat. 2012, 6, 1185–1208. [Google Scholar] [CrossRef] [Green Version]
- Fokianos, K. Density ratio model selection. J. Stat. Comput. Simul. 2007, 77, 805–819. [Google Scholar] [CrossRef]
- Fokianos, K.; Kaimi, I. On the effect of misspecifying the density ratio model. Ann. Inst. Stat. Math. 2006, 58, 475–497. [Google Scholar] [CrossRef]
- Zhang, X.; Pyne, S.; Kedem, B. Model selection in radon data fusion. Stat. Transit. New Ser. 2020, 21, 167–174. [Google Scholar] [CrossRef]
- Nielsen, F.; Marti, G.; Ray, S.; Pyne, S. Clustering patterns connecting COVID-19 dynamics and Human mobility using optimal transport. Sankhya B 2021, 83, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Omer, S.B.; Enger, K.S.; Moulton, L.H.; Halsey, N.A.; Stokley, S.; Salmon, D.A. Geographic clustering of nonmedical exemptions to school immunization requirements and associations with geographic clustering of pertussis. Am. J. Epidemiol. 2008, 168, 1389–1396. [Google Scholar] [CrossRef] [PubMed]
- Omer, S.B.; Pan, W.K.; Halsey, N.A.; Stokley, S.; Moulton, L.H.; Navar, A.M.; Pierce, M.; Salmon, D.A. Nonmedical exemptions to school immunization requirements: Secular trends and association of state policies with pertussis incidence. JAMA 2006, 296, 1757–1763. [Google Scholar] [CrossRef] [PubMed]
- Phadke, V.K.; Bednarczyk, R.A.; Salmon, D.A.; Omer, S.B. Association between vaccine refusal and vaccine-preventable diseases in the United States: A review of measles and pertussis. JAMA 2016, 315, 1149–1158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolf, E.; Rowhani-Rahbar, A.; Tasslimi, A.; Matheson, J.; DeBolt, C. Parental country of birth and childhood vaccination uptake in Washington State. Pediatrics 2016, 138, e20154544. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ismail, M.B.; Al Omari, S.; Rafei, R.; Dabboussi, F.; Hamze, M. COVID-19 in children: Could pertussis vaccine play the protective role? Med. Hypotheses 2020, 145, 110305. [Google Scholar] [CrossRef] [PubMed]
| Statistics | Min. | Q1 | Median | Q3 | Max. | |
|---|---|---|---|---|---|---|
| County | ||||||
| Jefferson | 0.00 | 0.00 | 1.00 | 6.50 | 30.00 | |
| Cowlitz | 0.00 | 3.00 | 8.00 | 23.25 | 108.00 | |
| Snohomish | 7.00 | 36.25 | 46.50 | 54.75 | 549.00 | |
| Probability | Estimate | 95% Confidence Interval |
|---|---|---|
| 0.0200 | (−0.0204, 0.0604) | |
| 0.0084 | (−0.0124, 0.0292) | |
| 0.0021 | (−0.0041, 0.0083) |
| Statistics | Min. | Q1 | Median | Q3 | Max. | |
|---|---|---|---|---|---|---|
| County | ||||||
| Grays Harbor | 0.00 | 1.00 | 2.50 | 4.75 | 24.00 | |
| Jefferson | 0.00 | 0.00 | 1.00 | 6.50 | 30.00 | |
| Clallam | 0.00 | 1.00 | 2.00 | 4.75 | 25.00 | |
| Clark | 3.00 | 20.25 | 33.50 | 85.00 | 326.00 | |
| Cowlitz | 0.00 | 3.00 | 8.00 | 23.25 | 108.00 | |
| Lewis | 0.00 | 2.00 | 5.00 | 10.75 | 71.00 | |
| King | 38.00 | 115.00 | 141.00 | 194.25 | 785.00 | |
| Snohomish | 7.00 | 36.25 | 46.50 | 54.75 | 549.00 | |
| Skagit | 1.00 | 5.00 | 9.00 | 17.75 | 559.00 | |
| - | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AIC | ||||||||||
| - | 553.03 | 554.32 | 552.37 | 554.39 | 554.19 | 556.22 | 554.22 | 556.11 | ||
| 527.36 | 487.62 | 529.32 | 526.98 | 483.92 | 489.53 | 528.98 | 485.89 | |||
| 525.03 | 524.09 | 516.98 | 525.37 | 518.98 | 525.56 | 518.94 | 520.94 | |||
| 549.19 | 551.19 | 549.92 | 547.88 | 551.36 | 549.45 | 547.50 | 549.45 | |||
| 523.36 | 485.04 | 515.77 | 522.57 | 485.22 | 487.03 | 517.24 | 487.17 | |||
| 558.58 | 489.07 | 530.52 | 528.38 | 485.37 | 486.05 | 530.36 | 483.22 | |||
| 527.03 | 526.08 | 518.97 | 526.34 | 520.97 | 526.85 | 520.93 | 522.92 | |||
| 524.91 | 486.51 | 517.25 | 524.33 | 486.71 | 483.32 | 519.19 | 485.22 | |||
| Probability | Estimate | 95% Confidence Interval |
|---|---|---|
| , | ||
| , | ||
| , | ||
| (, ) | ||
| (, ) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Pyne, S.; Kedem, B. Multivariate Tail Probabilities: Predicting Regional Pertussis Cases in Washington State. Entropy 2021, 23, 675. https://doi.org/10.3390/e23060675
Zhang X, Pyne S, Kedem B. Multivariate Tail Probabilities: Predicting Regional Pertussis Cases in Washington State. Entropy. 2021; 23(6):675. https://doi.org/10.3390/e23060675
Chicago/Turabian StyleZhang, Xuze, Saumyadipta Pyne, and Benjamin Kedem. 2021. "Multivariate Tail Probabilities: Predicting Regional Pertussis Cases in Washington State" Entropy 23, no. 6: 675. https://doi.org/10.3390/e23060675
APA StyleZhang, X., Pyne, S., & Kedem, B. (2021). Multivariate Tail Probabilities: Predicting Regional Pertussis Cases in Washington State. Entropy, 23(6), 675. https://doi.org/10.3390/e23060675