
Detection of Coronary Artery Disease Using Multi-Domain Feature Fusion of Multi-Channel Heart Sound Signals

 ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
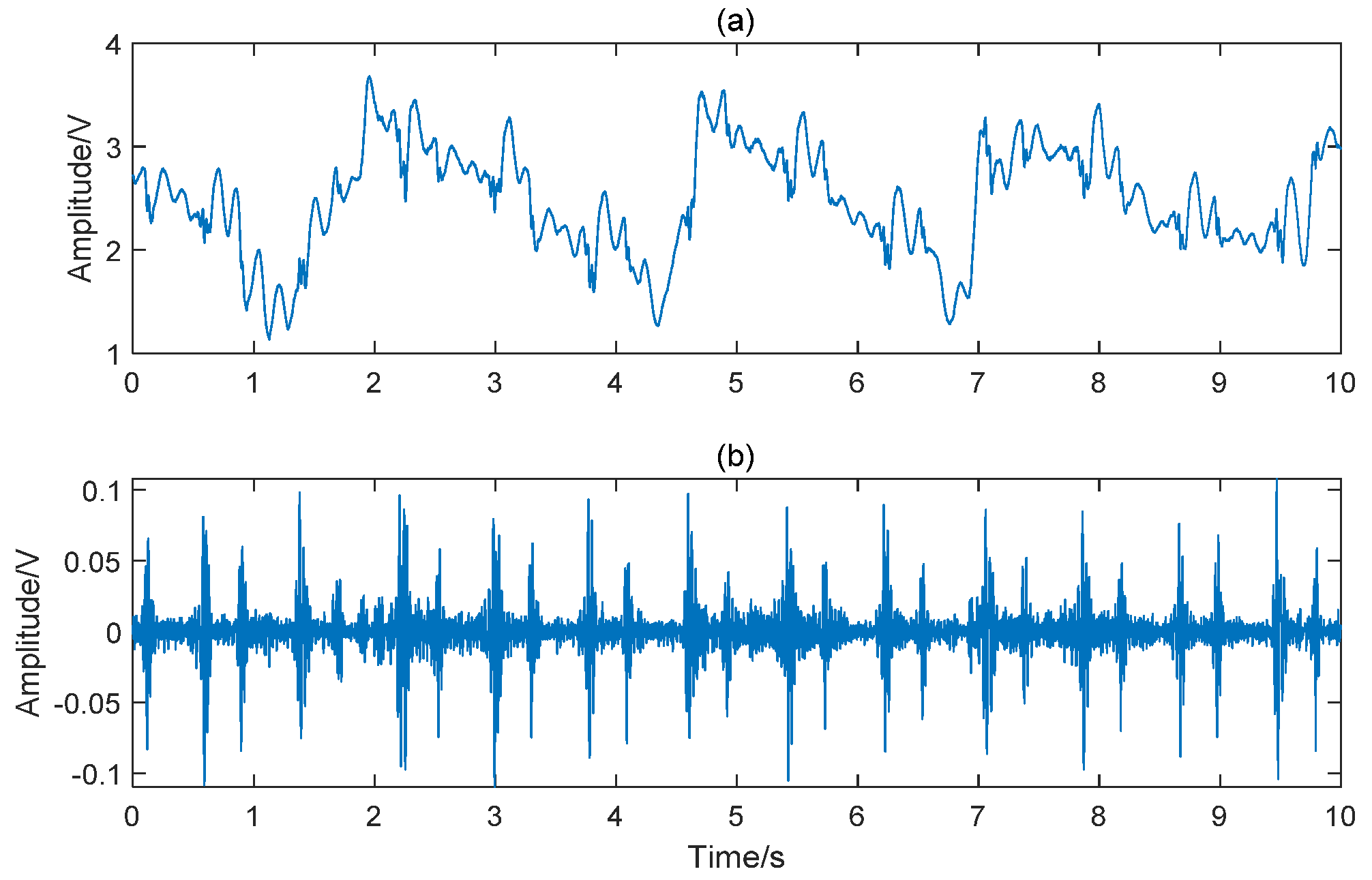
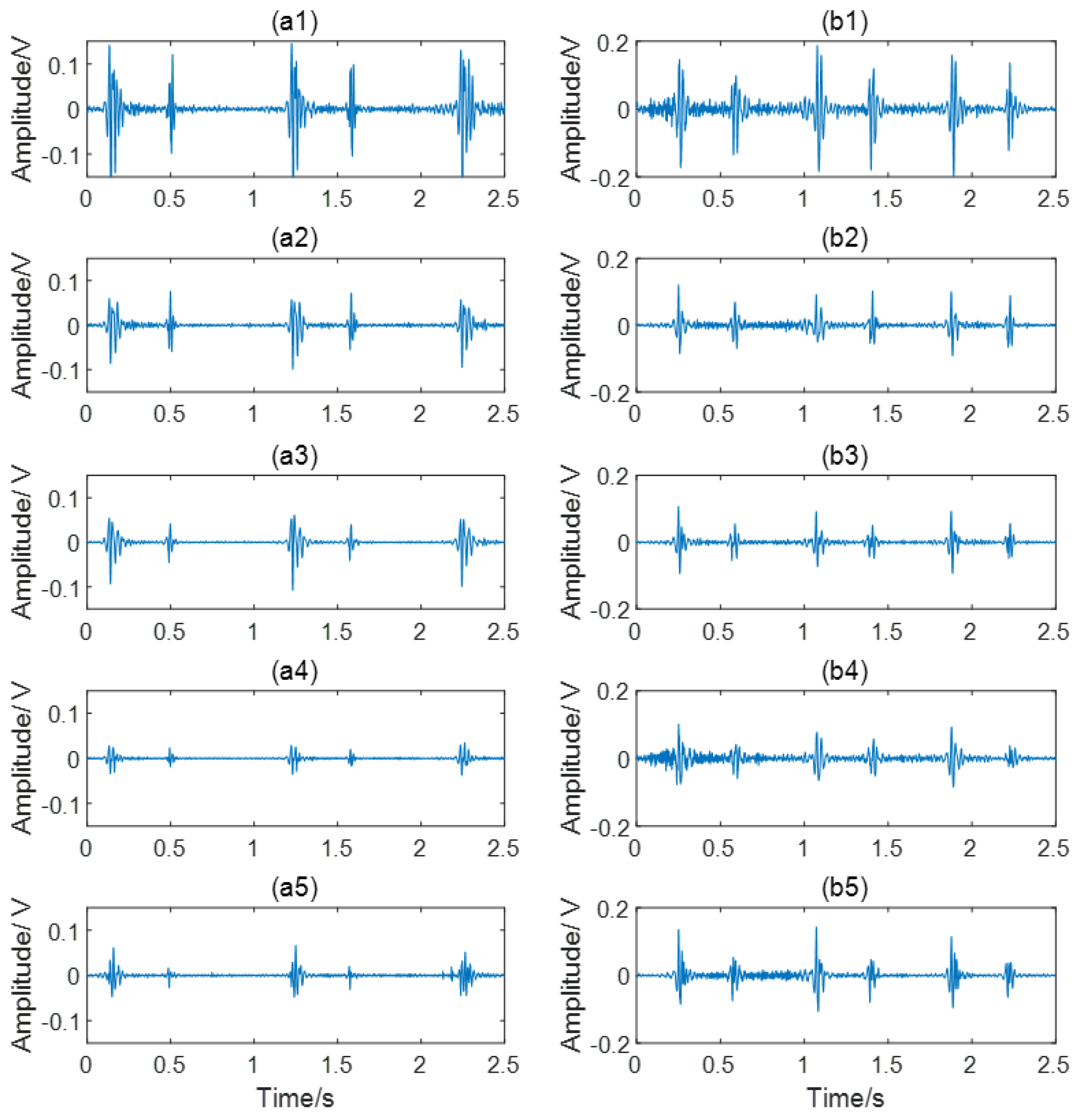
2.1. Data Acquisition
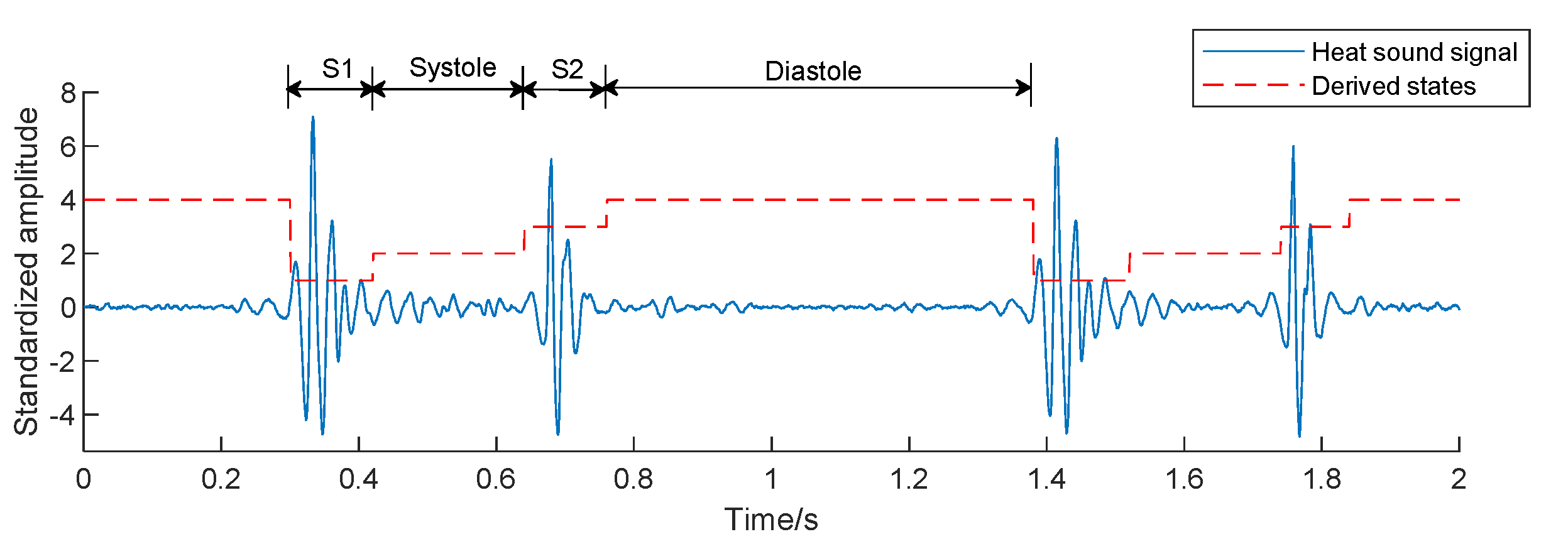
2.2. Signal Preprocessing
2.3. Features Extraction
2.3.1. Time-Domain Features (20 × 5 Features)
2.3.2. Frequency-Domain Features (16 × 5 Features)
2.3.3. Entropy Features (12 × 5 Features)
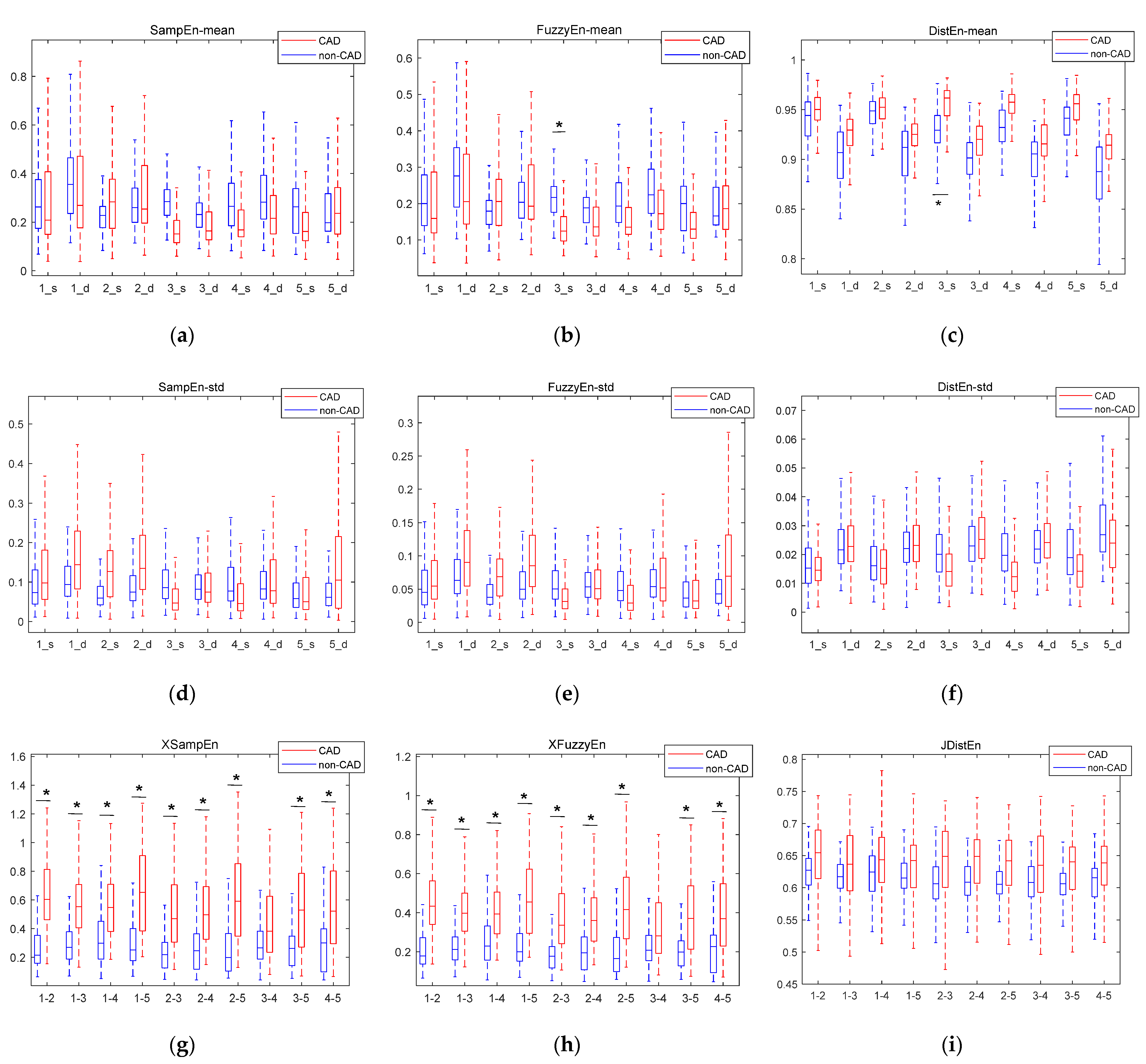
- SampEn is a nonlinear feature to calculate the probability of generating new patterns in signals [20]. It is also a common method to measure the complexity of time series [21]. SampEn can be calculated as follows:where N is the length of signals, m is the embedding dimension, r is the threshold parameter, and is the probability that any two epochs match each other.
- FuzzyEn [34] is actually a refined algorithm of SampEn. The difference between them lies in the thresholding procedure. The fuzzy membership function to determine the fuzzy similarity between and is:where is the distance between and . In this study, for SampEn and FuzzyEn, the pattern length m was set to 2, and matching tolerance r was set to 0.2 times the SD of the input time series [35]. It has been shown in published studies that the introduction of the fuzzy membership function significantly improves the stability and consistency of the algorithm [36].
- DistEn [23] uses empirical probability distribution functions (ePDF) to achieve the global measurement of the distance matrix, avoiding the parameter dependence caused by local evaluation. The ePDF of is estimated using a histogram with a predefined bin number B. Then DistEn is defined by the Shannon formula for entropy:Thus, the range of DistEn should be within [0, 1]. In this study, B was set to 2^8.
2.3.4. Cross Entropy Features (3 × 10 Features)
- XSampEn [20] is developed from SampEn. It measures the synchronization of two signals by focusing on the similarity of patterns between two signals. XSampEn is defined as:where m is the embedding dimension, τ is the time delay and r is the threshold parameter.
- XFuzzyEn [26] has the same algorithm framework as XSampEn. FuzzyEn substituted a Gaussian function for the Heaviside function as the membership function, i.e., the is defined by:The parameter m was set to 2 in this study. Since the signal is normalized, the SD is 1. In order to find out the best parameter r, the XSampEn and XFuzzyEn with r = 0.1, r = 0.15, r = 0.2, r = 0.25, and r = 0.3 were calculated. After comparing the results, r was set to 0.2.
- The JDistEn algorithm [27] is developed by combining the joint distance matrix and DistEn. The ePDF of is estimated by histogram with a predefined bin number B, which is denoted by where t = 1, 2, … B. Then JDistEn is defined by the Shannon formula for entropy:JDistEn has been shown to have especially good performance in short-length data [27]. In this study, the number of histogram bins B was set to 2^8.
2.4. Feature Set Construction
2.5. Statistical Analysis
2.6. Feature Selection
- Information gain [40] is a statistic used to describe the ability to distinguish data samples. Features with larger information gain values are considered to contribute more to classification. Information gain is defined as information entropy minus conditional entropy.
- SVM–RFE can repeatedly build SVM models to obtain the optimal feature subset. Features with the lowest contribution are iteratively eliminated from the training set, and the ranking from salient to non-salient features is generated [41]. Thus, the optimal feature subset is constructed by selecting the appropriate feature number.
2.7. Classification
2.8. Performance Evaluation
3. Results
3.1. Results Based on Statistical Analysis
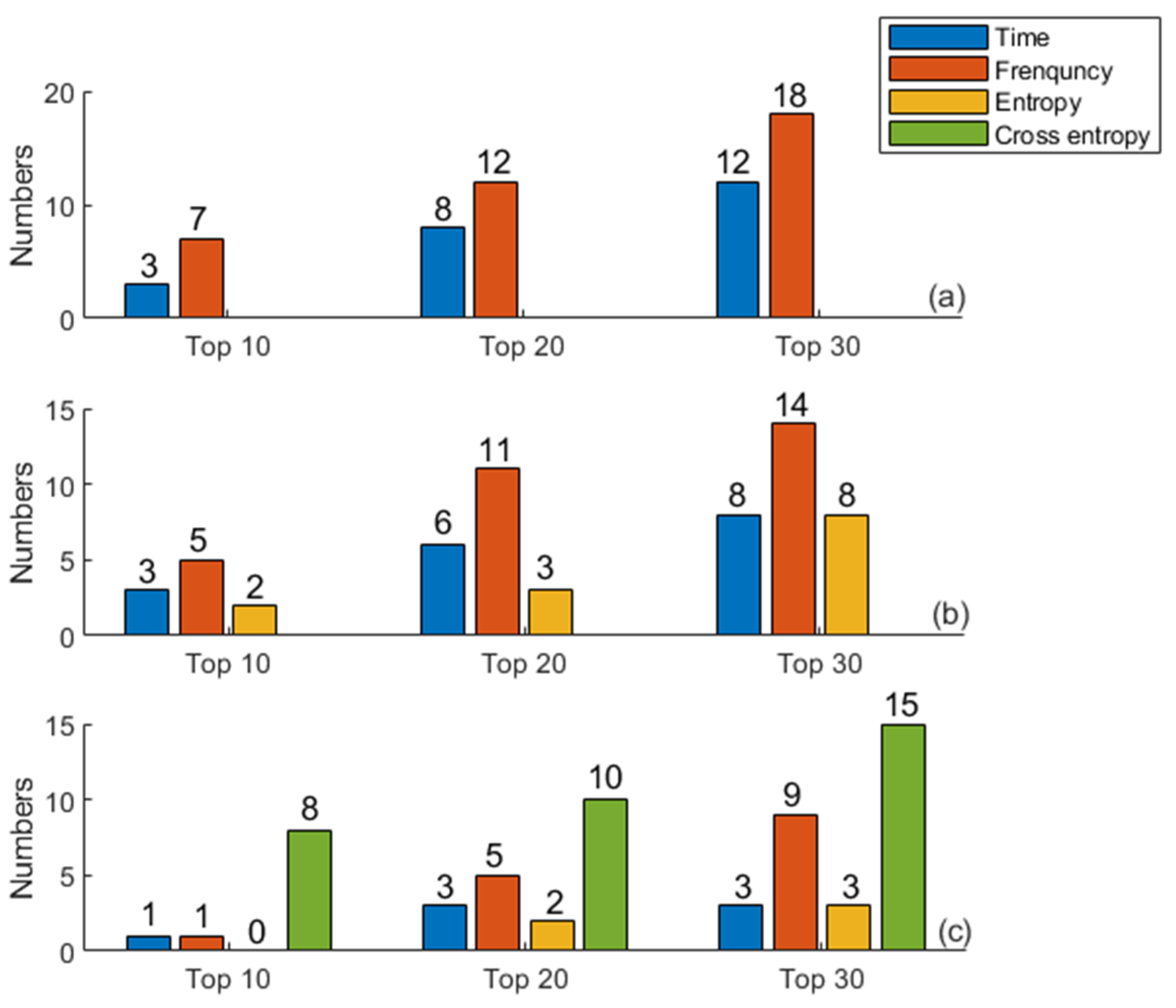
3.2. Ranking Results Based on Information Gain
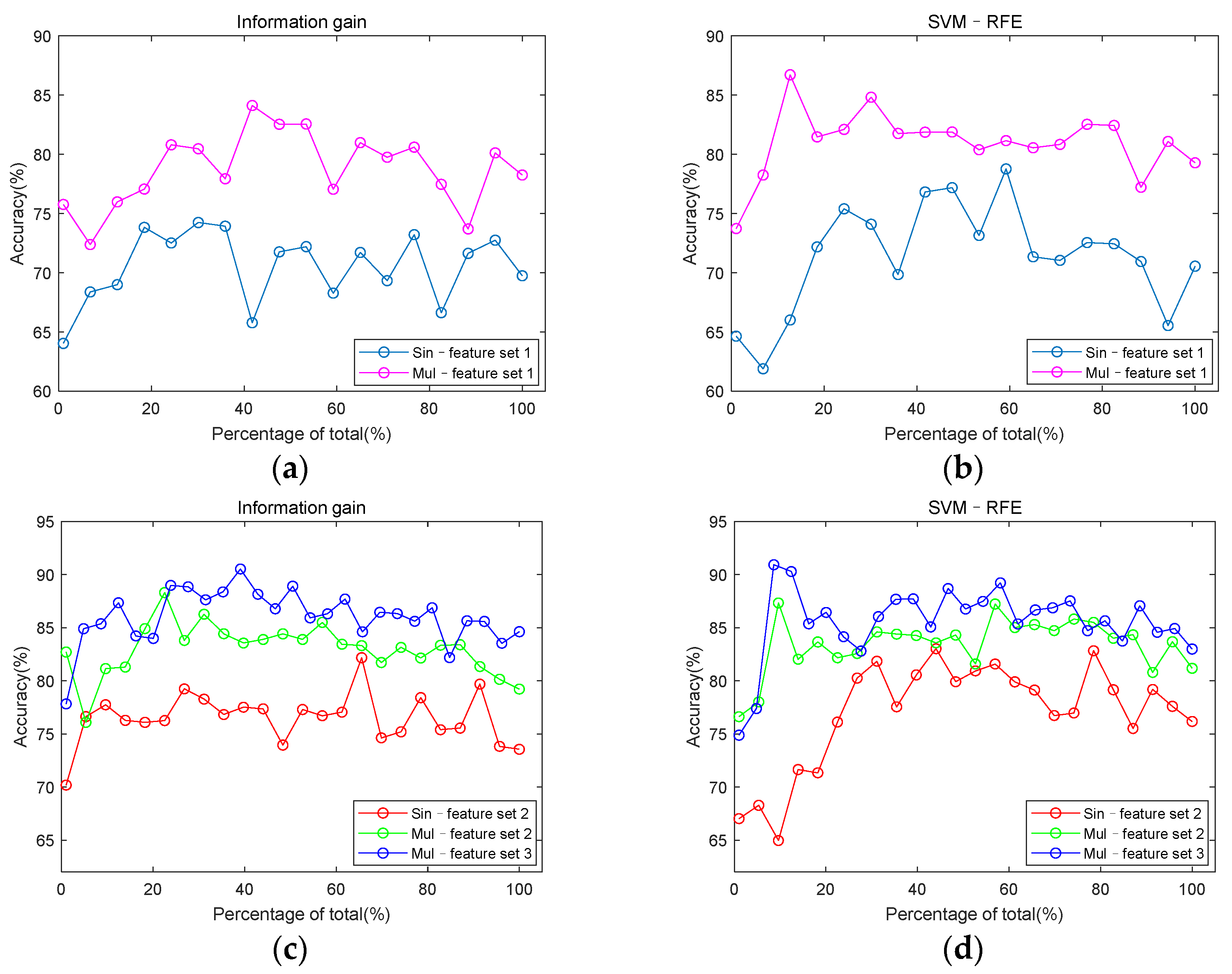
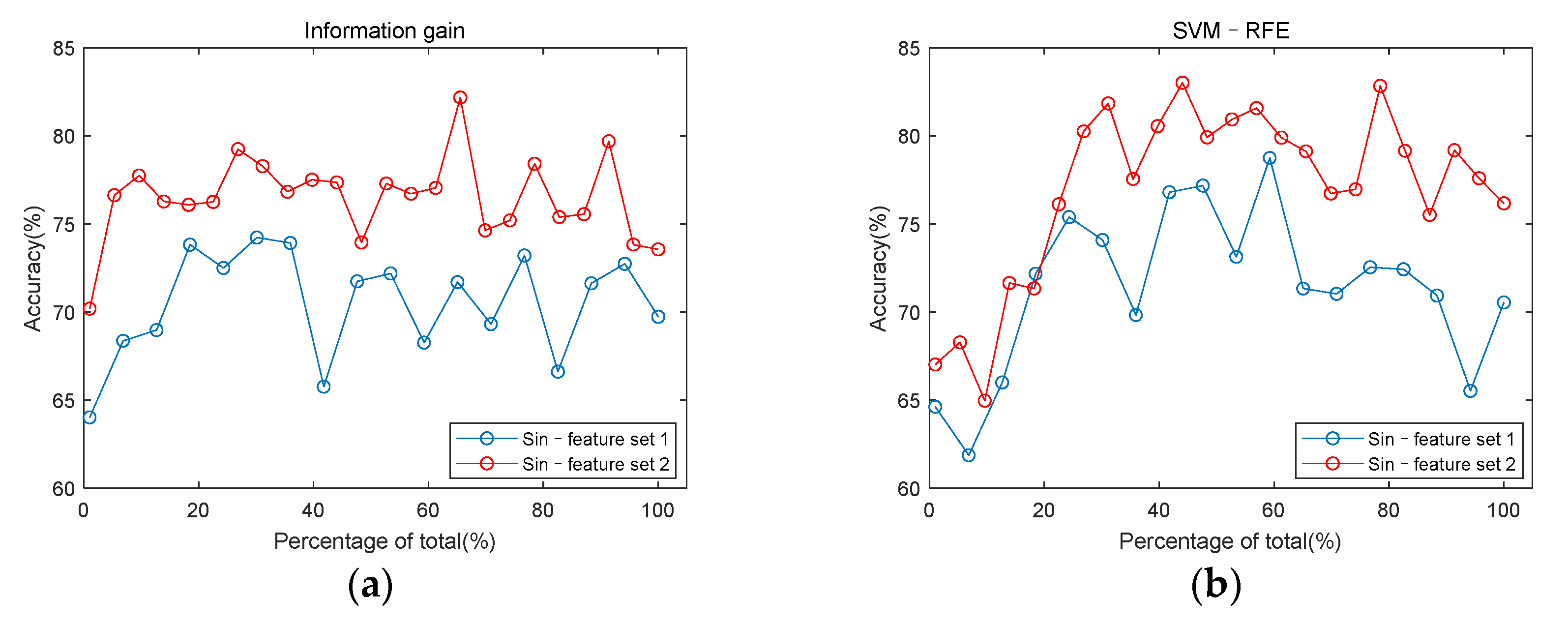
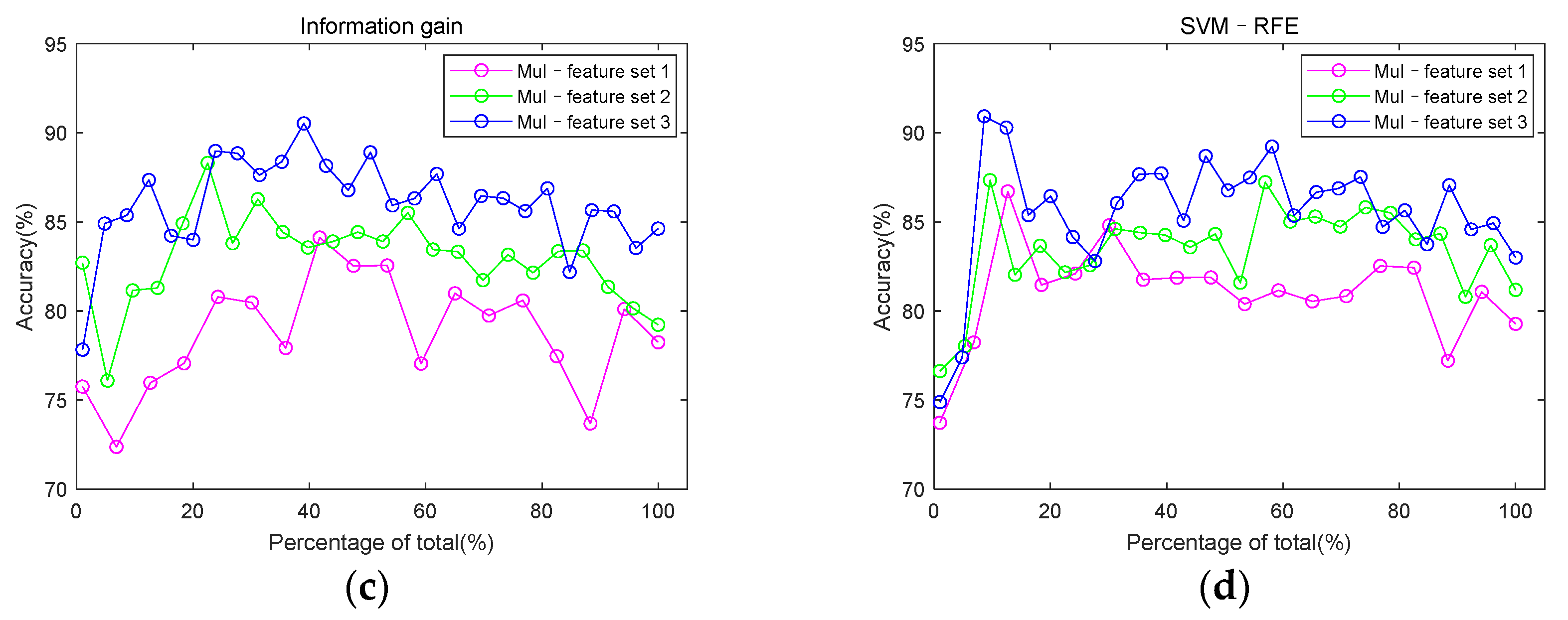
3.3. Classification Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benjamin, E.J.; Muntner, P.; Alonso, A.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Das, S.R.; et al. Heart disease and stroke statistics-2019 update: A report from the American heart association. Circulation 2019, 139, e56–e528. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, H.; Yokoyama, K.; Maruvama, Y.; Yamanoto, H.; Yoshida, S.; Hosoya, T. Investigation of coronary artery calcification and stenosis by coronary angiography (CAG) in haemodialysis patients. Nephrol. Dial. Transplant. 2006, 21, 1451–1452. [Google Scholar] [CrossRef][Green Version]
- Semmlow, J.; Rahalkar, K. Acoustic detection of coronary artery disease. Annu. Rev. Biomed. Eng. 2007, 9, 449–469. [Google Scholar] [CrossRef] [PubMed]
- Mahnke, C. Automated heartsound analysis/computer-aided auscultation: A cardiologist’s perspective and suggestions for future development. In Proceedings of the 2009 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, Minnesota, 2–6 September 2009; pp. 3115–3118. [Google Scholar]
- Akay, Y.M.; Akay, M.; Welkowitz, W.; Semmlow, J.L.; Kostis, J.B. Noninvasive acoustical detection of coronary artery disease: A comparative study of signal processing methods. IEEE Trans. Biomed. Eng. 1993, 40, 571–578. [Google Scholar] [CrossRef] [PubMed]
- Semmlow, J.; Welkowitz, W.; Kostis, J.; Mackenzie, J.W. Coronary artery disease—Correlates between diastolic auditory characteristics and coronary artery stenoses. IEEE Trans. Biomed. Eng. 1983, 2, 136–139. [Google Scholar] [CrossRef] [PubMed]
- Winther, S.; Winther, S.; Schmidt, S.E.; Schmidt, S.E.; Holm, N.R.; Holm, N.R.; Toft, E.; Toft, E.; Struijk, J.J.; Struijk, J.J.; et al. Diagnosing coronary artery disease by sound analysis from coronary stenosis induced turbulent blood flow: Diagnostic performance in patients with stable angina pectoris. Int. J. Cardiovasc. Imaging 2016, 32, 235–245. [Google Scholar] [CrossRef]
- Winther, S.; Nissen, L.; Schmidt, S.E.; Westra, J.S.; Rasmussen, L.D.; Knudsen, L.L.; Madsen, L.H.; Kirk Johansen, J.; Larsen, B.S.; Struijk, J.J.; et al. Diagnostic performance of an acoustic-based system for coronary artery disease risk stratification. Heart 2018, 104, 928–935. [Google Scholar] [CrossRef]
- Schmidt, S.E.; Holst-Hansen, C.; Hansen, J.; Toft, E.; Struijk, J.J. Acoustic features for the identification of coronary artery disease. IEEE Trans. Biomed. Eng. 2015, 62, 2611–2619. [Google Scholar] [CrossRef]
- Gauthier, D.; Akay, Y.M.; Paden, R.G.; Pavlicek, W.; Akay, M. Spectral Analysis of Heart Sounds Associated with Coronary Occlusions. In Proceedings of the 2007 6th International Special Topic Conference on Information Technology Applications in Biomedicine, Tokyo, Japan, 8–11 November 2007. [Google Scholar]
- Zhao, Z.D.; Wang, Y. Analysis of Diastolic Murmurs for Coronary artery Diseasebased on hilbert Huang Transform. In Proceedings of the 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007. [Google Scholar]
- Ari, S.; Hembram, K.; Saha, G. Detection of cardiac abnormality from PCG signal using LMS based least square SVM classifier. Expert Syst. Appl. 2010, 37, 8019–8026. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Zhang, L. Nonlinear analysis of diastolic heart sounds based on EMD and correlation dimension. Sens. Transducers 2014, 172, 157–164. [Google Scholar]
- Akay, M.; Akay, Y.M.; Gauthier, D.; Paden, R.G.; Pavlicek, W.; Fortuin, F.D.; Sweeney, J.P.; Lee, R.W. Dynamics of diastolic sounds caused by partially occluded coronary arteries. IEEE Trans. Biomed. Eng. 2009, 56, 513–517. [Google Scholar] [CrossRef]
- Griffel, B.; Zia, M.K.; Fridman, V.; Saponieri, C.; Semmlow, J.L. Microphone placement evaluation for acoustic detection of coronary artery disease. In Proceedings of the 2011 IEEE 37th Annual Northeast Bioengineering Conference (NEBEC), Troy, NY, USA, 1–3 April 2011. [Google Scholar]
- Akanksha; Samanta, P.; Mandana, K.; Saha, G. Identification of coronary artery disease using cross power spectral density. In Proceedings of the 2017 14th IEEE India Council International Conference (INDICON), Roorkee, India, 15–17 December 2017. [Google Scholar]
- Rujoie, A.; Fallah, A.; Rashidi, S.; Rafiei Khoshnood, E.; Seifi Ala, T. Classification and evaluation of the severity of tricuspid regurgitation using phonocardiogram. Biomed. Signal Process. Control 2020, 57, 101688. [Google Scholar] [CrossRef]
- Pathak, A.; Samanta, P.; Mandana, K.; Saha, G. An improved method to detect coronary artery disease using phonocardiogram signals in noisy environment. Appl. Acoust. 2020, 164, 107242. [Google Scholar] [CrossRef]
- Griffel, B.; Zia, M.K.; Fridman, V.; Saponieri, C.; Semmlow, J.L. Detection of coronary artery disease using automutual information. Cardiovasc. Eng. Technol. 2012, 3, 333–344. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiology. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Tang, H.; Jiang, Y.; Li, T.; Wang, X. Identification of pulmonary hypertension using entropy measure analysis of heart sound signal. Entropy 2018, 20, 389. [Google Scholar] [CrossRef]
- Zhang, D.; She, J.; Zhang, Z.; Yu, M. Effects of acute hypoxia on heart rate variability, sample entropy and cardiorespiratory phase synchronization. Biomed. Eng. Online 2014, 13, 73. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Li, P.; Liu, C.; Liu, C.; Li, K.; Li, K.; Zheng, D.; Zheng, D.; Liu, C.; Liu, C.; et al. Assessing the complexity of short-term heartbeat interval series by distribution entropy. Med. Biol. Eng. Comput. 2015, 53, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Udhayakumar, R.K.; Karmakar, C.; Li, P.; Palaniswami, M. Effect of data length and bin numbers on distribution entropy (DistEn) measurement in analyzing healthy aging. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milano, Italy, 25–29 August 2015; pp. 7877–7880. [Google Scholar]
- Shi, B.; Motin, M.A.; Wang, X.; Karmakar, C.; Li, P. Bivariate Entropy Analysis of Electrocardiographic RR-QT Time Series. Entropy 2020, 22, 1439. [Google Scholar] [CrossRef]
- Xie, H.-B.; Zheng, Y.-P.; Guo, J.-Y.; Chen, X. Cross-fuzzy entropy: A new method to test pattern synchrony of bivariate time series. Inf. Sci. 2010, 180, 1715–1724. [Google Scholar] [CrossRef]
- Li, P.; Li, K.; Liu, C.; Zheng, D.; Li, Z.-M.; Liu, C. Detection of Coupling in Short Physiological Series by a Joint Distribution Entropy Method. IEEE Trans. Biomed. Eng. 2016, 63, 2231–2242. [Google Scholar] [CrossRef] [PubMed]
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing; Prentice Hall: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Jiao, Y.; Wang, X.; Liu, C.; Li, H.; Zhang, H.; Hu, Y.; Liu, R.; Ji, B. Heart sound signal quality assessment based on multi-domain features. J. Med Imaging Health Inform. 2020, 10, 736–742. [Google Scholar] [CrossRef]
- Springer, D.B.; Tarassenko, L.; Clifford, G.D. Logistic regression-HSMM-based heart sound segmentation. IEEE Trans. Biomed. Eng. 2016, 63, 822–832. [Google Scholar] [CrossRef]
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.Z.; Tie, B.; Welkowitz, W.; Semmlow, J.L.; Kostis, J.B. Modeling sound generation in stenosed coronary arteries. IEEE Trans. Biomed. Eng. 1990, 37, 1087–1094. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, X.; Liu, C.; Liu, Y.; Li, P.; Yao, L.; Li, H.; Wang, J.; Jiao, Y. Detection of coronary artery disease using multi-modal feature fusion and hybrid feature selection. Physiol. Meas. 2020, 41, 115007. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef]
- Castiglioni, P.; Rienzo, M.D. How the Threshold “r” Influences Approximate Entropy Analysis of Heart-Rate Variability. In Proceedings of the 2008 Computers in Cardiology, Bologna, Italy, 14–17 September 2008; pp. 561–564. [Google Scholar]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med Eng. Phys. 2008, 31, 61–68. [Google Scholar] [CrossRef]
- Strogatz, S.J.P.T. Synchronization: A universal concept in nonlinear science. Phys. Today 2003, 56, 47. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, C.; Zhang, L.; Zhao, L.; Liu, C.; Wang, H. Measuring synchronization in coupled simulation and coupled cardiovascular time series: A comparison of different cross entropy measures. Biomed. Signal Process. Control 2015, 21, 49–57. [Google Scholar] [CrossRef]
- Malik, W.A.; Marco-Llorca, C.; Berendzen, K.; Piepho, H.-P. Choice of link and variance function for generalized linear mixed models: A case study with binomial response in proteomics. Commun. Stat. Theory Methods 2019, 49, 1–20. [Google Scholar] [CrossRef]
- Yang, Y.; Pedersen, J.O. A Comparative Study on Feature Selection in Text Categorization. In Proceedings of the Fourteenth International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; pp. 412–420. [Google Scholar]
- Yin, Z.; Wang, Y.; Liu, L.; Zhang, W.; Zhang, J. Cross-subject EEG feature selection for emotion recognition using transfer recursive feature elimination. Front. Neurorobot. 2017, 11, 19. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Davari, A.; Khadem, S.E.Z. Automated Diagnosis of Coronary Artery Disease (CAD) Patients Using Optimized SVM. Comput. Methods Programs Biomed. 2016, 138, 117–126. [Google Scholar] [CrossRef] [PubMed]
- Babaoğlu, I.; Fındık, O.; Bayrak, M. Effects of principle component analysis on assessment of coronary artery diseases using support vector machine. Expert Syst. Appl. 2010, 37, 2182–2185. [Google Scholar] [CrossRef]
- Sharma, D.; Yadav, U.B.; Sharma, P.J.M.E.R.J. The concept of sensitivity and specificity in relation to two types of errors and its application in medical research. Math. Ences Res. J. 2009, 2, 53–58. [Google Scholar]
- Tang, H.; Dai, Z.; Jiang, Y.; Li, T.; Liu, C. PCG classification using multidomain features and SVM classifier. BioMed Res. Int. 2018, 2018, 4205027. [Google Scholar] [CrossRef]
- Tian, J.-W.; Du, G.-Q.; Ren, M.; Sun, L.-T.; Leng, X.-P.; Su, Y.-X. Tissue Synchronization Imaging of Myocardial Dyssynchronicity of the Left Ventricle in Patients with Coronary Artery Disease. J. Ultrasound Med. 2007, 26, 893–897. [Google Scholar] [CrossRef]
- Arbogast, R.; Arbogast, R.; Bourassa, M.G.; Bourassa, M.G. Myocardial function during atrial pacing in patients with angina pectoris and normal coronary arteriograms: Comparison with patients having significant coronary artery disease. Am. J. Cardiol. 1973, 32, 257–263. [Google Scholar] [CrossRef]
- Crea, F.; Lanza, G.A. Angina pectoris and normal coronary arteries: Cardiac syndrome X. Heart 2004, 90, 457–463. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | CAD | Non-CAD | p Value |
|---|---|---|---|
| Age (year) | 57 ± 9 | 54 ± 7 | 0.27 |
| Male/Female | 12/9 | 9/6 | 0.57 |
| Height (cm) | 166 ± 7 | 167 ± 7 | 0.61 |
| Weight (kg) | 73 ± 10 | 74 ± 7 | 0.59 |
| Body mass index (kg/m2) | 27 ± 3 | 26 ± 2 | 0.90 |
| Systolic blood pressure (mmHg) | 135 ± 16 | 137 ± 11 | 0.48 |
| Diastolic blood pressure (mmHg) | 81 ± 15 | 80 ± 13 | 0.95 |
| Heart rate (beats/min) | 73 ± 13 | 79 ± 12 | 0.21 |
| Abbreviation | Description |
|---|---|
| CC | The cardiac cycle duration |
| IntS1 | The S1 interval duration |
| IntS2 | The S2 interval duration |
| IntSys | The systolic interval duration |
| IntDia | The diastolic interval duration |
| Ratio_SysCC | The ratio of systolic interval to the cardiac cycle duration |
| Ratio_DiaCC | The ratio of diastolic interval to the cardiac cycle duration |
| Ratio_SysDia | The ratio of systole interval to the diastole interval |
| Ratio_Amp_SysS1 | The ratio of average amplitude during systole to that during S1 |
| Ratio_Amp_DiaS2 | The ratio of average amplitude during diastole to that during S2 |
| Abbreviation | Description |
|---|---|
| HFAll_S1 | The proportion of high-frequency component in total spectrum S1s |
| LFAll_S1 | The proportion of low-frequency component in total spectrum S1s |
| HFAll_S2 | The proportion of high-frequency component in total spectrum S2s |
| LFAll_S2 | The proportion of low-frequency component in total spectrum S2s |
| HFAll_Sys | The proportion of high-frequency component in total spectrum systoles |
| LFAll_Sys | The proportion of low-frequency component in total spectrum systoles |
| HFAll_Dia | The proportion of high-frequency component in total spectrum diastoles |
| LFAll_Dia | The proportion of low-frequency component in total spectrum diastoles |
| Abbreviation | Description |
|---|---|
| SampEn_Sys | The sample entropy of systolic |
| SampEn_Dia | The sample entropy of diastolic |
| FuzzyEn_Sys | The fuzzy entropy of systolic |
| FuzzyEn_Dia | The fuzzy entropy of diastolic |
| DistEn_Sys | The distribution entropy of systolic |
| DistEn_Dia | The distribution entropy of diastolic |
| Parameter | Instructions |
|---|---|
| C | ‘2−5–25’ |
| Gamma | ‘2−5–25’ |
| Kernel function | ‘radial basis function’ |
| Scoring | ‘accuracy’ |
| Cv | 5 |
| Class_weight | ‘balanced’ |
| Feature | Domain | Odds Ratio | p Value | Feature | Domain | Odds Ratio | p Value |
|---|---|---|---|---|---|---|---|
| XSampEn_12 | Cro-en | 3.86 × 107 | 0.00 | m_Amp_SysS1_1 | Time | 1.17 | 0.01 |
| XSampEn_13 | Cro-en | 5.01 × 107 | 0.00 | m_LFAll_Sys_1 | Frequency | 9.63 × 10−25 | 0.01 |
| XSampEn_14 | Cro-en | 2.74 × 104 | 0.01 | m_LFAll_Dia_1 | Frequency | 1.56 × 10−22 | 0.01 |
| XSampEn_15 | Cro-en | 6.29 × 104 | 0.00 | m_Amp_SysS1_2 | Time | 1.25 | 0.00 |
| XSampEn_23 | Cro-en | 1.24 × 106 | 0.00 | m_HFAll_S1_2 | Frequency | 3.23 × 1061 | 0.00 |
| XSampEn_24 | Cro-en | 1.02 × 104 | 0.01 | m_LFAll_S1_2 | Frequency | 1.45 × 10−21 | 0.01 |
| XSampEn_25 | Cro-en | 4.53 × 104 | 0.00 | m_LFAll_Sys_2 | Frequency | 1.56 × 10−18 | 0.03 |
| XSampEn_35 | Cro-en | 7.19 × 103 | 0.01 | m_LFAll_S2_2 | Frequency | 2.91 ×10−22 | 0.00 |
| XSampEn_45 | Cro-en | 4.33 × 102 | 0.04 | m_LFAll_Dia_2 | Frequency | 3.34 × 10−22 | 0.01 |
| XFuzzyEn_12 | Cro-en | 3.39 × 1011 | 0.00 | m_Amp_SysS1_3 | Time | 1.35 | 0.00 |
| XFuzzyEn_13 | Cro-en | 9.99 × 1011 | 0.00 | m_FuzzyEn_Sys_3 | Entropy | 6.40 × 10−10 | 0.03 |
| XFuzzyEn_14 | Cro-en | 5.78 × 106 | 0.01 | m_DistEn_Sys_3 | Entropy | 5.33 × 1030 | 0.02 |
| XFuzzyEn_15 | Cro-en | 2.30 × 107 | 0.00 | m_Amp_SysS1_4 | Time | 1.21 | 0.03 |
| XFuzzyEn_23 | Cro-en | 2.15 × 109 | 0.00 | m_Amp_SysS1_5 | Time | 1.26 | 0.02 |
| XFuzzyEn_24 | Cro-en | 1.07 × 106 | 0.01 | m_HFAll_S1_5 | Frequency | 2.14 × 1026 | 0.03 |
| XFuzzyEn_25 | Cro-en | 1.00 × 107 | 0.00 | m_LFAll_Sys_5 | Frequency | 5.69 × 10−15 | 0.04 |
| XFuzzyEn_35 | Cro-en | 8.56 × 105 | 0.01 | m_LFAll_Dia_5 | Frequency | 1.22 × 10−15 | 0.03 |
| XFuzzyEn_45 | Cro-en | 8.18 × 103 | 0.04 |
| Information Gain | SVM–RFE | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Without Entropy | With Entropy | Without Entropy | With Entropy | |||||||||
| Acc. (%) | Se. (%) | Sp. (%) | Acc. (%) | Se. (%) | Sp. (%) | Acc. (%) | Se. (%) | Sp. (%) | Acc. (%) | Se. (%) | Sp. (%) | |
| Ch-1 | 75.94 ± 8.19 | 73.38 ± 15.41 | 77.56 ± 11.07 | 80.57 ± 5.98 | 79.87 ± 21.92 | 81.23 ± 17.22 | 77.55 ± 11.59 | 74.45 ± 23.12 | 80.14 ± 14.01 | 79.41 ± 7.02 | 77.75 ± 18.19 | 81.78 ± 10.62 |
| Ch-2 | 77.92 ± 10.52 | 73.00 ± 13.36 | 81.71 ± 10.72 | 80.77 ± 8.50 | 73.65 ± 24.95 | 87.38 ± 12.84 | 78.75 ± 6.94 | 79.93 ± 18.75 | 78.32 ± 4.43 | 83.02 ± 11.99 | 80.39 ± 18.72 | 84.07 ± 18.35 |
| Ch-3 | 74.09 ± 8.35 | 73.03 ± 15.08 | 74.11 ± 9.96 | 82.17 ± 6.55 | 78.89 ± 17.52 | 85.31 ± 11.18 | 74.52 ± 10.99 | 70.77 ± 26.94 | 78.55 ± 16.88 | 82.38 ± 8.18 | 76.42 ± 8.97 | 87.24 ± 9.75 |
| Ch-4 | 67.86 ± 9.37 | 66.28 ± 20.86 | 71.27 ± 25.60 | 69.03 ± 15.79 | 69.52 ± 14.52 | 69.48 ± 20.05 | 61.86 ± 10.99 | 50.79 ± 17.94 | 71.24 ± 14.16 | 66.76 ± 5.43 | 63.12 ± 17.49 | 68.76 ± 16.72 |
| Ch-5 | 68.48 ± 11.94 | 66.63 ± 6.98 | 70.81 ± 20.60 | 70.33 ± 5.80 | 68.97 ± 18.48 | 70.88 ± 5.57 | 70.10 ± 9.13 | 66.51 ± 16.92 | 72.80 ± 19.74 | 79.69 ± 12.78 | 75.79 ± 20.13 | 83.03 ± 14.60 |
| Information Gain | SVM–RFE | |||||
|---|---|---|---|---|---|---|
| Acc. (%) | Se. (%) | Sp. (%) | Acc. (%) | Se. (%) | Sp. (%) | |
| Mul–feature set 1 | 84.11 ± 5.47 | 75.76 ± 14.26 | 90.98 ± 6.42 | 86.70 ± 6.42 | 80.89 ± 16.74 | 91.01 ± 11.85 |
| Mul–feature set 2 | 88.30 ± 7.27 | 79.09 ± 13.07 | 95.06 ± 6.70 | 87.33 ± 8.55 | 80.28 ± 15.77 | 92.90 ± 3.50 |
| Mul–feature set 3 | 90.52 ± 5.67 | 80.66 ± 14.81 | 98.30 ± 2.85 | 90.92 ± 6.89 | 87.96 ± 8.71 | 93.04 ± 9.30 |
| Author | Database | Feature & Classifier | Result (%) |
|---|---|---|---|
| Gauthier et al. [10] (2007) | 30 subjects: 24 CAD & 6 normal | Fast Fourier Transform Optimal threshold detection | Acc. = 73.3 Se. = 71.0 Sp. = 83.0 |
| Akay et al. [15] (2009) | 40 subjects: 30 CAD & 10 normal | Approximate entropy Optimal threshold detection | Acc. = 77.0 Se. = 78.0 Sp. = 80.0 |
| Griffel et al. [14] (2012) | 31 subjects: 16 CAD & 15 non-CAD | Automutual information function Linear support vector machine classifier | Acc. = 81.0 Se. = 87.0 Sp. = 85.0 |
| Schmidt et al. [9] (2015) | 133 subjects: 63 CAD & 70 non-CAD | Frequency and nonlinear features Quadratic discriminant function | Acc. = 68.5 Se. = 72.0 Sp. = 65.2 |
| Akanksha et al. [17] (2017) | 50 subjects: 25 CAD & 25 normal | Cross power spectral density Support vector machine classifier | Acc. = 84.0 Se. = 82.0 Sp. = 81.3 |
| Pathak et al. [19] (2020) | 80 subjects: 40 CAD & 40 normal | Imaginary part of cross power spectral density Support vector machine classifier | Acc. = 75.0 Se. = 76.5 Sp. = 73.5 |
| This paper | 36 subjects: 21 CAD & 15 non-CAD | Multi-domain and multi-channel features Support vector machine classifier | Acc. = 90.9 Se. = 88.0 Sp. = 93.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Li, P.; Liu, Y.; Zhang, H.; Li, Y.; Jiao, Y.; Liu, C.; Karmakar, C.; Liang, X.; Ren, M.; et al. Detection of Coronary Artery Disease Using Multi-Domain Feature Fusion of Multi-Channel Heart Sound Signals. Entropy 2021, 23, 642. https://doi.org/10.3390/e23060642
Liu T, Li P, Liu Y, Zhang H, Li Y, Jiao Y, Liu C, Karmakar C, Liang X, Ren M, et al. Detection of Coronary Artery Disease Using Multi-Domain Feature Fusion of Multi-Channel Heart Sound Signals. Entropy. 2021; 23(6):642. https://doi.org/10.3390/e23060642
Chicago/Turabian StyleLiu, Tongtong, Peng Li, Yuanyuan Liu, Huan Zhang, Yuanyang Li, Yu Jiao, Changchun Liu, Chandan Karmakar, Xiaohong Liang, Mengli Ren, and et al. 2021. "Detection of Coronary Artery Disease Using Multi-Domain Feature Fusion of Multi-Channel Heart Sound Signals" Entropy 23, no. 6: 642. https://doi.org/10.3390/e23060642
APA StyleLiu, T., Li, P., Liu, Y., Zhang, H., Li, Y., Jiao, Y., Liu, C., Karmakar, C., Liang, X., Ren, M., & Wang, X. (2021). Detection of Coronary Artery Disease Using Multi-Domain Feature Fusion of Multi-Channel Heart Sound Signals. Entropy, 23(6), 642. https://doi.org/10.3390/e23060642