1. Introduction
Automatic visual recognition consists of learning visual categories using a computer to later identify new instances of such categories. The vast majority of computer vision tasks are primarily based on the ability to recognize categories as well as specific objects. This area has gained great development at present due to the variety of potential applications in multiple areas of information, among which are content-based image search, video data mining, or object identification for mobile robots [
1]. Visual category recognition seeks to recognize different instances of a generic category that belong to the same conceptual class, for example, people, houses, or cars. The great difficulty in this task is due to the fact that there are multiple variations in appearance between different instances of the same category due to pose, occlusion, deformation, or lighting [
2,
3]. Currently, notable progress has been made in this area through the use of deep learning algorithms [
4].
Deep learning consists of the training of artificial neural networks that are made up of multiple processing layers. Deep learning tasks mainly encompass two types of learning: Supervised and unsupervised learning. Supervised learning [
5] is based on creating a model that returns the label of an input data using examples where its respective label is known. For example, in the object classification task, each object image is associated with the label that represents the object’s category. On the other hand, unsupervised learning is based on creating a model that allows finding hidden patterns of the data. In contrast to supervised learning, there are no explicit labels associated with each input. Typical tasks of unsupervised learning are clustering and density estimation [
6].
Visual recognition using deep learning techniques typically requires a large number of labeled images due to the huge number of parameters of such neural network models [
4,
7]. On the other hand, the number of unlabeled images is usually much greater proportionally to the number of labeled images [
8]. The required work to label the images needs a human who manually perform the labeling. This process can be costly, as it requires a lot of human time to label these images, as well as being prone to human factor errors. Therefore, a reasonable way to use the information from the unlabeled data is through semi-supervised learning. A detailed review of semi-supervised algorithms can be found in [
9]. A popular semi-supervised learning technique is the co-training algorithm where it is assumed that you have information from complementary views; these views allow us to use few labeled data to build a more robust model than the initial one given by the labeled data [
10].
The co-training algorithm requires knowing the views of the training images, which are generally not in a visual object database. On the other hand, deep neural networks tend to overfit in the presence of little data, so it can be expected that when training several neural networks, within a co-training algorithm, they cannot generalize correctly at the beginning. Furthermore, they do not necessarily evolve in a complementary way when considering a training based on fine adjustment, that is, where the weights are similar at the beginning. Although there are complex proposals based on adversarial learning or adversarial networks, we believe that a solution based on the original co-training algorithm has the advantage of being algorithmically simple.
In this research, the development of a variant of co-training model based on multiple views and on deep neural networks is proposed. The model uses self-supervised learning algorithms for complementary aspects of objects, such as degree of rotation or type of filter. The use of such aspects allows the views to differ from each other initially. To facilitate the diversity of view models, required by the co-training algorithm [
10], we propose to differentiate the outputs of the views by incorporating the maximization of the cross-entropy between them. Cross-entropy can be interpreted as a measure of distance between two probability functions. Therefore, the cross-entropy function acts as an entropic regularizer for the neural network classification cost function of views by allowing the outputs of the views to differ from each other. The idea of entropic regularization has been applied in the context of optimal transport problems [
11], Markov Decision Process [
12], and data classification [
13]. On the other hand, this regularization is facilitated because the cost function is also given by the cross-entropy between the results of the view and the actual results, that is, the cost and regularization functions have similar scales. By achieving different views during the training process, the co-training algorithm enables efficient learning of visual object classifiers by considering a small initial amount of labeled data.
This work is organized as follows:
Section 2 shows the theoretical framework as well as a bibliographic review of the applied co-training methods in visual recognition.
Section 3 presents and justifies the proposed variant of co-training.
Section 4 shows the results of the experiments carried out to validate the proposed model. Finally, conclusions and further developments are presented in
Section 5.
3. Proposed Method
Our proposal is based on the idea that self-supervised learning algorithms can generate views that complement each other, without requiring the use of labels in the data. Regarding complementary, we can see that the self-supervised variant based on the pretext task of predicting image rotation is quite a different task from predicting the degree of filtering of an image, which suggests that these tasks can bring diversity to the co-training algorithm. Based on this idea, we propose a co-training model based on classifiers given by deep neural networks to the views of the main algorithm. In our work, these views correspond to object recognizers based on pre-trained deep convolutional neural networks. These views incorporate supplementary information given by the output of an upper layer of a self-supervised neural network which will reinforce the complementary of the views, according to the initial idea. On the other hand, deep networks tend to fit well to the data when starting from an initial training given by massive databases; therefore it is feasible that the outputs of the networks tend to resemble each other as the co-training algorithm advances. Therefore, in training we additionally consider a view differentiation cost; in other words, we want the views to differ while simultaneously seeking to minimize the difference with the actual labels of the images. Since this proposal merges the concepts of co-training and self-supervised learning considering the differentiation of outputs, we call this algorithm Differential Self-Supervised Co-Training (DSSCo-Training).
We should note that the self-supervised and semi-supervised components share the use of unlabeled data. Nonetheless, both methods are essentially different. While self-supervised learning does not require the original labels, semi-supervised learning requires a small number of labeled samples. In relation to our proposal, the focus is on semi-supervised learning given by the proposed variant of the co-training algorithm. Self-supervised networks are used as complementary networks that help improving the performance of DSSCo-Training and are trained once in the initial step of our method which corresponds to line 5 of Algorithm 1.
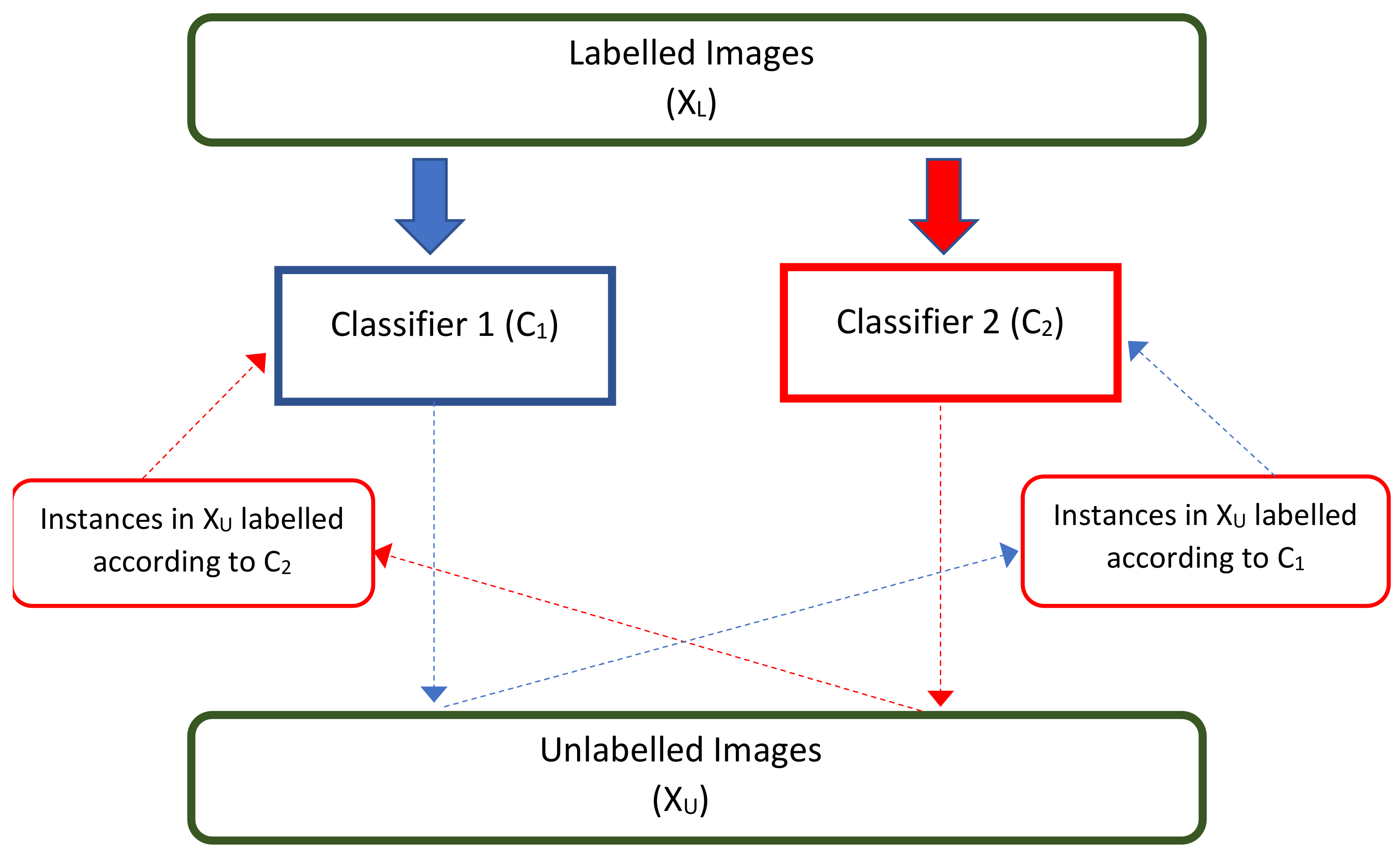
Our method seeks to generate a reliable classifier considering a small proportion of labeled images compared to unlabeled images. We think that the set of unlabeled images can improve the performance of the initial model based on training with the labeled data. Our algorithm considers the incorporation of a selection process and addition of unlabeled images. While our algorithm requires the classification agreement between the views as a requirement for the addition of the unlabeled images, the classic co-training algorithm adds unlabeled images considering each view independently. For example, when considering views 1 and 2, if the view classifier 1 determines that the label of an image is 1 and the view classifier 2 determines that that same image has a label 0, then the labeled image is considered unreliable, so it will not be added to the training.
| Algorithm 1: Proposed model training algorithm. |
 |
Algorithm 1 shows the complete process of the proposed model considering the use of two views, which can be extended to more. It starts with training the neural networks of the two views (
and
) using the data labeled
according to the proposed optimization (see details in
Section 3.3). Then, it generates the sort prediction by view using the unlabeled data
getting
and
. These outputs are compared with each other, and if they are equal and have a high level of accuracy
(in our case we use 0.9), then we use them as new labeled data. In case an image does not meet the previous condition, this image will not be labeled in the current iteration, therefore it will remain in the
set. We may note that both views networks use the same labels because the labeled set
is common for both networks. This process is repeated until there is no data left to label or the maximum number of iterations
is reached. If the number of iterations reaches the value of the variable
, the data from the unlabeled set
will not be used to train the neural networks of the views.
After the execution of Algorithm 1, the result will be two independent neural networks trained with the same data set. During the network testing phase, only one network of the two available views will be used. In the experiments, we observed that the networks already trained have quite similar performance, which is also observed within the co-training framework in [
29]. For this reason, we choose the same network for all experiments. In particular, we always used the rotation view neural network during testing.
3.1. Self-Supervised Neural Network Training
The views initially correspond to the supervised model that considers the labeled data, this model refers to the base neural network; they consider complementary information that allows them to generate differential training. Each original view will be coupled to a complementary neural network through the penultimate layer of the latter. While one network corresponds to the supervised model of the original view, the other complementary network corresponds to a predefined self-supervised model. That is, the prediction of the labeled data will take into its training the characteristics given by both the supervised and self-supervised models.
Two self-supervised models will be generated, the first one will be for predicting the degree of image rotation and the second will be for predicting the type of filters applied to images. These models are initially trained on all the images in the databases considering standard convolutional neural networks. Then, these are used as complementary networks in the proposed co-training model. For the training of the predictor model of the degree of rotation, the inputs will be the total set of images (labeled and not labeled), to which a label will be associated with its respective rotation given randomly (with values: 90, 180, 270, and 360 degrees). This network can be visualized in
Figure 3.
For the training of the filter type model, the inputs will again be the total set of images, to which a label will be assigned that will indicate the type of filter applied randomly (averaged, blurred, Gaussian, and based on median). These pretext tasks were selected for the experiments to reinforce the complementary information between the views.
3.2. Coupling Complementary Networks to Original Views
After the previous step, the outputs of the penultimate layer of the self-supervised neural network are added to the penultimate layer of the supervised model network; that is, the outputs of the self-supervised model are the intermediate input of the supervised model. It should be noted that the weights of the self-supervised networks do not change during the training of the main algorithm. In
Figure 4, the coupling of the original view 1 with the complementary characteristics of the semi-supervised filter model is shown, where the output of the penultimate layer of the filter model is extracted. It is then resized and applied as an input that connects to the final layers of the original network of the view 1.
The procedure shown in
Figure 4 will be applied in a similar way to view 2 of this semi-supervised model, that is, a view contemplates a model that receives as an intermediate parameter the output of the penultimate layer of a self-supervised model considering the rotation and filter cases according to the training view. Finally, the goal of each of the views will be the prediction of the label of the labeled data set using the neural object classification network.
3.3. Model Optimization
The proposed model is based on the co-training algorithm, where each training image of the unlabeled dataset is added to the labeled dataset if both views agree with high confidence. This is considered using a threshold , which is selected experimentally. With the new labeled dataset, the neural network of each view is optimized.
Assuming that in each iteration we have a set
where
D represents the data labeled in an arbitrary iteration and which is formed by the input data
and output
. Assuming two-view optimization, the total cost function is given by:
The classification cost function for view 1 is given by
, while the corresponding one for view 2 is given by
. On the other hand, the success of the co-training algorithm requires that the views be complementary. For such reason, we add the differentiation function
between views 1 and 2, which is graduated according to the hyperparameter
, which is estimated experimentally. The function
regularizes the cost classification functions
and
because it constrains their optimizations incorporating the diversity of the models. Considering the view 1 and the instance
i, the classification function corresponds to the cross-entropy of the output of the network of the view 1,
, with respect to the true output
. The same function is considered for view 2. In the case of the differentiation function
, since instead of minimizing the difference it sought to maximize it, it corresponds to the negative of the cross-entropy of the output of view 1 with respect to the output of view 2. Therefore, the differentiation function
corresponds to a cross-entropy regularization function. In relation to parameter learning of the model, when we optimize the parameters of view 2, we freeze the values of differentiation function
. The resulting cost function for both views are given by:
These equations imply that we only differentiate the outputs of view 1 with respect to the outputs of view 2, which simplifies the code. The experiments evidence that the proposed solution is able to differentiate between views. Note that this model can be directly extended to the use of more views following the scheme of [
29].
4. Experimental Results
In this section, the experiments carried out to test the proposed model, DSSCo-Training, are described by specifying the datasets, the configurations, as well as the results in comparison with other similar models. The basic neural network model associated to each view and which performs the task of visual recognition is the Resnet-50 [
35]. The Resnet architecture has been used successfully in various object recognition tasks and is based on residual processing layers that are sequentially coupled. In particular, our hardware consists of an Intel Xeon machine with 16GB RAM and Tesla V100 GPU. Due to the balance between performance and available hardware, we consider a number of layers for the Resnet equal to 50.
The proposed algorithm is applied to four standard databases of visual objects. Each one is detailed below.
MNIST: This dataset presents a total of 70,000 images of handwritten digits divided evenly into 10 categories [
36].
CIFAR-10: This dataset presents a total of 60,000 images divided evenly into 10 categories. Examples of categories are: airplane, car, dog, boat, etc. [
37].
CIFAR-100: This dataset presents a total of 60,000 images divided equally into 100 categories. Examples of categories are: Dinosaur, oak, tank, raccoon, etc. [
37].
SVHN: This dataset presents a total of 600,000 (99,289 assigned to the training and 531,131 as additional samples) images of the house digits in Google Street images, evenly divided into 10 categories [
38].
For the experiments, we followed the scheme proposed in [
29] to partition the training and test data. For the MNIST database, we used the 20% of the total data (12,000 images) as the labeled set while the rest of images was used as the unlabeled set (48,000 images). For the CIFAR-10 and CIFAR-100 databases, 4000 labeled images were used corresponding to 6.6% of the total data, the rest of the images (46,000) were used as unlabeled data set in support of unsupervised training of the proposed algorithm. A total of 1000 labeled data was used for the SVHN database and the rest (72,257) as unlabeled data. For ending the proposed algorithm, two term criteria were considered: The ending of the complete labeling of the unlabeled data and the number of iterations to perform, that is, the number of times that update the networks of each view.
The algorithm parameter settings are shown in
Table 1. The number of iterations is considered as the number of times the algorithm is executed, which is a term criterion of the algorithm. The number of epochs corresponds to the number of iterations for training the neural network model. Finally, the error percentage was used as an evaluation metric, which consists of the number of misclassified images divided with the total number of images.
The choice of the configuration of the parameters, number of iterations, number of epochs, and
of the proposed model was based on several experiments with the training partition of CIFAR-10 dataset considering a hold-out scheme. In particular, we tried the combinations of the values of the sets {5,10}, {20,50,100}, and {0.001,0.01,0.1}, respectively, for number of iterations, number of epochs, and the regularization parameter
. The same hyperparameters were considered for all datasets. These values were not optimized for each dataset because we wanted to obtain a fair comparison of our method with respect to the competing methods, however, our results indicated that the chosen values are acceptable. Nonetheless, it is possible to improve the resulting metrics considering a careful selection of hyperparameters for each database, as can be seen in the sensibility analysis given in
Section 4.1.2.
Table 1 shows the values of the main parameters of the model that were used in all the performed experiments, excluding the sensitivity analysis.
The experiments carried out are based on the quantitative and qualitative analysis of the proposed model, DSSCo-Training. In the quantitative analysis, we will first compare the performance of DSSCo-Training with the classic co-training algorithm, as well as with state-of-the-art techniques of semi-supervised learning based on classic variants [
8,
26,
30], in adversarial generative networks [
24,
25], and using adversarial instances [
29]. In addition, we will perform a sensitivity analysis on CIFAR-10 to study the effect of the regularization factor based on cross-entropy and the number of internal iterations. Finally, a qualitative analysis will be carried out where we will visually review the instances used by the DSSCo-Training through the iterations of the external loop of DSSCo-Training given in Algorithm 1.
The experiments and the construction of the models were carried out using the Python programming language, where the Keras library specialized in deep networks was used. This library, which is based on TensorFlow, contains the implementation of multiple models that have accelerated the implementation of this proposal. In the case of state-of-the-art algorithms, we consider the results published for each of them. The demo source code for this work can be found at
https://github.com/Anonim1121/DSSCoTraining (accessed on 27 March 2021).
4.1. Quantitative Analysis
4.1.1. Classification Performance
Table 2 shows the results of the application of the proposed algorithm, making a comparison with other state-of-the-art proposals considering the databases
CIFAR-100 and
SVHN.
Table 3 shows the results obtained with the CIFAR-100 and MNIST databases. The results of the experiments are compared with those of other works. For a better visualization, we report these datasets in a separate table given the available results of the compared techniques.
Regarding the databases
CIFAR-10 and
SVHN, the obtained results show that the DSSCo-Training is superior to the other methods with the exception of the Deep Co-training method. With regards to the databases
CIFAR-100 and
MNIST, the results obtained through the proposed method, DSSCo-Training, show a superiority in terms of the classification error in relation to the models found in the state of the art. In particular, as shown in
Table 3, with respect to
CIFAR-100, our method presents an relative improvement of 4.02% compared to deep co-training and 2.41% respect to co-teaching. In the case of
MNIST, our method obtains a relative improvement of 6.01% over co-teaching.
In relation to the comparison with deep co-training, we observe that while this algorithm uses an optimization process to generate new data in addition to those of the original training set, the proposed model does not make any alteration to the data and is not dependent on an optimization external to co-training as required by the generation of adversarial data. Furthermore, the use of the general scheme of the co-training algorithm considerably simplifies the implementation of our model.
4.1.2. Sensibility Analysis
This section shows the sensitivity analysis of the performance of DSSCo-Training with respect to the value of the regularization hyperparameter and the number of epochs used in the training of the neural networks of the views. The number of epochs is included in this analysis because it experimentally influences the performance of the model. This is explained because the small number of data tagged at the beginning facilitates the overtraining of neural networks. In these experiments for the value of the hyperparameter the values are tested, while the numbers of epochs tested correspond to .
Table 4 shows the precision obtained in CIFAR-10 by varying the value of
and the number of epochs. This experiment is only performed on this database due to the high computational cost required.
The results of
Table 4 show that if the value of
is very large, the error percentage tends to be too. It can also be seen that the best results correspond to a value of
between 0.01 and 0.05. We experimentally observe that a value of
greater than or equal to 0.8 causes the algorithm to learn a model that does not converge during the training process. We suggest that this is because the difference between view models is over-prioritized. Because of this, only
is reported up to 0.7. We observe that cross-entropy-based regularization requires a small weight with respect to the classification cost function, as seen in the best value of
, that is, 0.02. However, a not very small value of
appears decisive in the performance obtained, as can be observed when experimenting with
equal to 0.001. Note that the value of
equal to 0 is equivalent to the classic co-training algorithm, whose results are shown in
Table 2 and
Table 3. We believe that the poor results of the classical training algorithm are due to the fact that the deep neural networks of the views tend to give similar results to each other during training, which hinders the usefulness of the co-training algorithm. Furthermore, we hypothesize that this collapse of view models, in terms of their outputs, is explained because the two view networks are not complementary in contrast to our method. This collapse of models was also observed in [
29]. This hypothesis is supported by the fact that in all the experiments our proposal improves the classic co-training algorithm. In this work, we focus on the comparison of our method with respect to classical co-training and several state-of-art methods, however, an interesting future topic is the study of the view representations, e.g., how different are the resulting views considering the iterations of the main algorithm? Overall, this analysis suggests that DSSCo-Training performance can be improved by making a careful choice of the regularization hyperparameter, as well as the number of internal iterations of training views.
4.2. Qualitative Analysis
In order to visualize the unlabeled images incorporated into the training set in each of the iterations and to qualitatively analyze the capacity of the presented model to incorporate more complex characteristics in each one of them, a random sample of these images was extracted in the truck category of dataset CIFAR-10. As shown in
Figure 5 for each iteration, a selection of images with different and more complex characteristics can be seen. This suggests that the model is able to recognize more difficult objects after each iteration of the co-training algorithm. For example, in iteration 1, the front of the trucks is well delimited; while in iteration 3, the trucks are more mixed with surroundings, as in the last example where the boundary of the black truck appears mixed with the background.
5. Conclusions
This work introduces DSSCo-Training, a semi-supervised learning method for visual object recognition based on the co-training algorithm using deep neural networks supported by self-supervised auxiliary networks considering rotation and filter models. In particular, the high improvement obtained over the classic co-training model is related to the use of regularization based on the cross-entropy of the outputs of the neural models of the views. The experiments consider real databases of visual objects of various characteristics. The results show that the proposed technique is competitive with state-of-the-art techniques of semi-supervised learning in several databases, or even outperform them in some cases. We believe that it is relevant to highlight that this proposal only uses self-supervised patterns already known from the unsupervised data, that is, it does not add higher computational cost during the training of the co-training algorithm. On the other hand, this proposal uses a version of the co-training algorithm without resorting to extra optimizations as in more complex models. This work provides evidence, for the first time, of the utility of self-supervised neural networks in the co-training algorithm.
As future work, we plan to improve the model by incorporating joint optimization of the co-training models simultaneously with the self-supervised neural models of the auxiliary classifiers. Another possible route is the exploration of more sophisticated self-supervised models than those used in this work. Finally, we hope to investigate the use of adversarial models to further improve the classification performance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}