
Image Statistics Preserving Encrypt-then-Compress Scheme Dedicated for JPEG Compression Standard



Abstract
1. Introduction
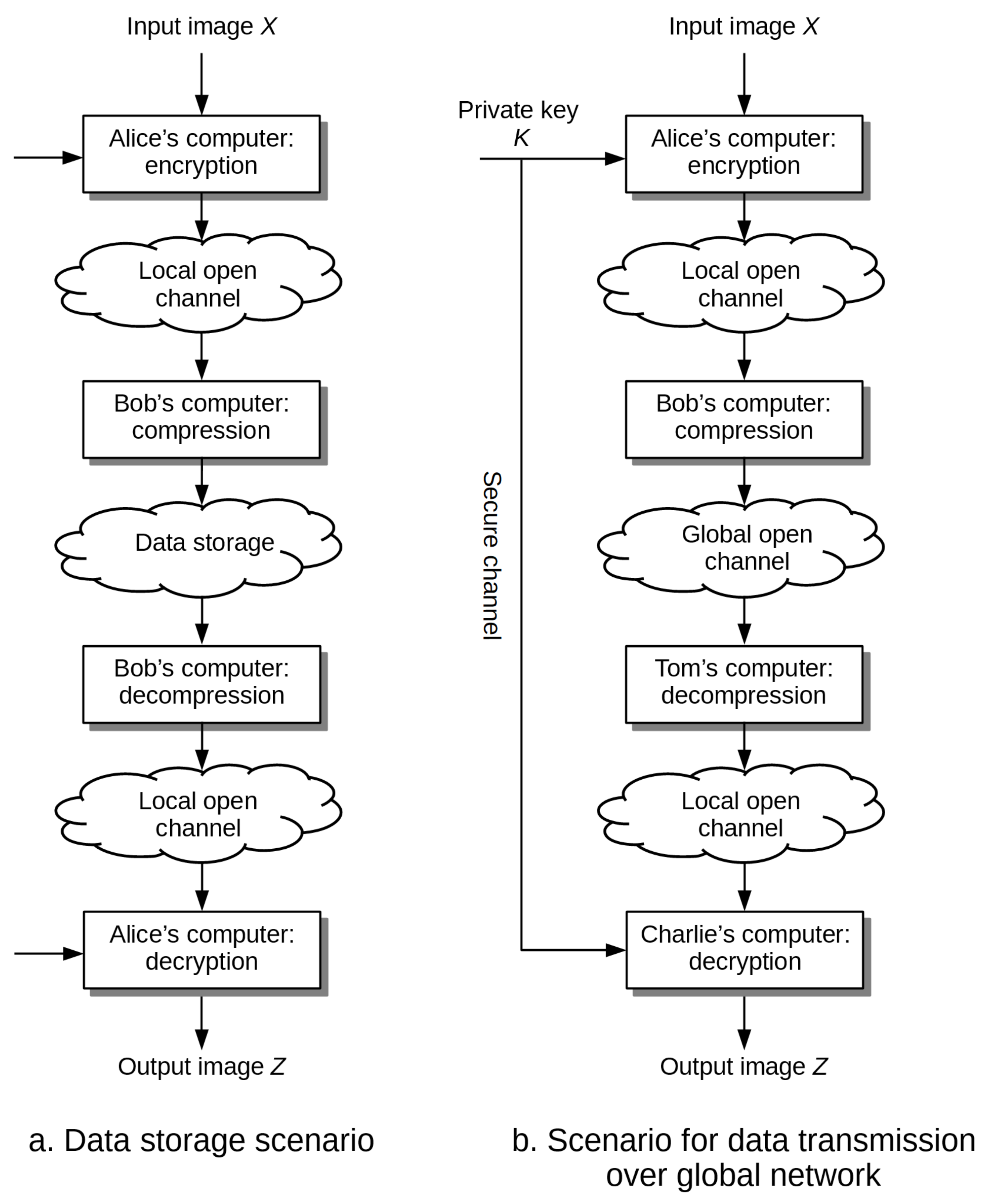
2. Review of Existing Solutions
- Source coding with additional information: compression is based on known statistical relationships between ciphertext and the private key. If the elements of the ciphertext and the private key are correlated to the extent that the Hamming distance between them can be bounded from above, that is, the distance is not greater than , then this information can be effectively used by the compression algorithm to reduce the size of the data without knowing the private key. It is enough to divide the set of values of ciphertext elements into layers in which we place those elements that are distant by more than bits, whereas to the output stream we write not the values of elements themselves, but the identifiers of the layers to which they belong. In paper [5] it was shown that under certain conditions it is possible to compress encrypted data to the same level as in the case of compression of original data, that is, not subjected to encryption. The Authors also proposed a scheme for the encryption and lossless compression of binary images using LDPC (Low-Density Parity Check Codes) correction codes and XOR operation at the compression and encryption stages respectively. It allowed to obtain the practical compression ratios at the level of . In paper [6], the original approach was improved by taking into account the spatial dependencies between the values of neighboring pixels in the image. This allowed to increase the value of the compression ratio to the level of . Another improvement of the original method for grayscale and color images was proposed in paper [7]. The average values of compression ratios were obtained at the level of . The essential drawbacks of approaches based on source coding are relatively low levels of the compression ratio, and the lack of symmetry of the entire scheme, which requires to combine decompression and decryption stages. In practice, it means that such approaches do not fully follow the scenarios depicted in Figure 1.
- Approximate representation of image pixels in the domain of linear transform: such approach was proposed in paper [8], here at the encryption stage the image pixels are scrambled with use of permutation determined on the basis of the private key, whereas the compression stage assumes to divide the elements of ciphertext into two sets: (a) rigid pixels that are not further modified, (b) flexible pixels. The values of flexible pixels are represented in the domain of linear orthogonal transform and then quantized, while the results are assigned to a specific equivalence classes resulting from the division operation. It allows to describe the value of each of the obtained coefficients in the form of a weighted sum of three components: (a) coarse, which can be estimated based on the values of the nearest rigid pixels, (b) the average, which next to the values of rigid pixels is written to the output stream, (c) detailed, which is rejected. The values of rigid pixels and representations of transform coefficients that describe the components of the average elastic pixels are written to the output stream. The compression itself is lossy. The reconstruction of the image is possible based on the proposed iterative procedure. The practical values of the compression ratio obtained with this method are at the level of with PSNR values around 35 dB.
- Image representation in the domain of discrete integer wavelet transform (DIWT) (see [9])—at the encryption stage, the grayscale input image is transformed using DIWT into one coarse band and nine bands containing detailed information. The data contained in the coarse band is encrypted by adding to it a sequence of pseudo-random numbers, while the range of resulting values is limited by the modulo division operation. The data contained in the remaining bands is permuted. Both the the pseudo-random sequence and the permutation are determined on the basis of the private key. The compression stage operates only on the encrypted data coming from the detailed bands. The data taken from those bands is quantized and then entropy coded using arithmetic coding. The compression and encryption stages are reversible, with the whole scheme being symmetrical. The practical results obtained with this method are very close to those obtained with JPEG standard. It should be emphasized that the compression method used here is a lossy one. Hence it is possible to obtain high compression ratios around at the expense of quality distortion, but still with PSNR above 30 dB.
- Compressive sensing (see [7])—at the encryption stage, the image is reshaped into a single vector, and then encrypted by a linear method consisting of multiplying the input vector by any matrix, for example, permutation matrix, which is generated on the basis of a private key. The compression stage is based on compressive sampling and relies on projecting the ciphertext vector onto a set of basis vectors from the subspace with reduced size. Such a basis is most often a set of linearly-independent vectors whose elements are randomized. In addition, the coefficients of projections are quantized. In this way the reduction in the size of the data can be obtained. The image decoding process is based on the theory of compression sensing, wherein the matrix of discrete cosine transform (DCT) is taken as a matrix allowing for a sparse representation of the input image. During the experiments the practical values of the compression ratios were at the level of with the PSNR coefficients around 30 dB. However, the discussed scheme is asymmetrical, which manifests in the way that the decompression and decryption stages must be combined.
- Game theory—proposed in paper [11], it is an improvement of the previously described approach from paper [8]. Here, at the encryption stage the image is divided into blocks of arbitrary sizes (e.g., pixels), the order of which, the same as the order of pixels within the blocks, is modified using permutations described by the private key. An additional action is to determine the block type, that is, whether it is a texture or a smooth part of an image. Its aim is to increase the efficiency of the compression step. However, such actions must be done by the sender, which is surely a disadvantage of this approach. The compression step is based on the [8] approach, wherein the algorithm is applied to subsequent blocks, not to the whole image. Then, depending on the type of block, the value of a coefficient describing the share of rigid and elastic pixels, as well as the quantization step can be selected individually for each block. The choice of parameter values is adaptive and controlled by an algorithm based on the game theory, where image quality is being maximized while keeping the limit on the size of image after compression. Image reconstruction is based on the iterative technique proposed in [8]. During the experimental research, the quality of smooth images and textures was at the level of 36 and 27 dB, with the compression ratios around , which is an improvement of about 3 and 1 dB respectively when compared to the original approach from paper [8].
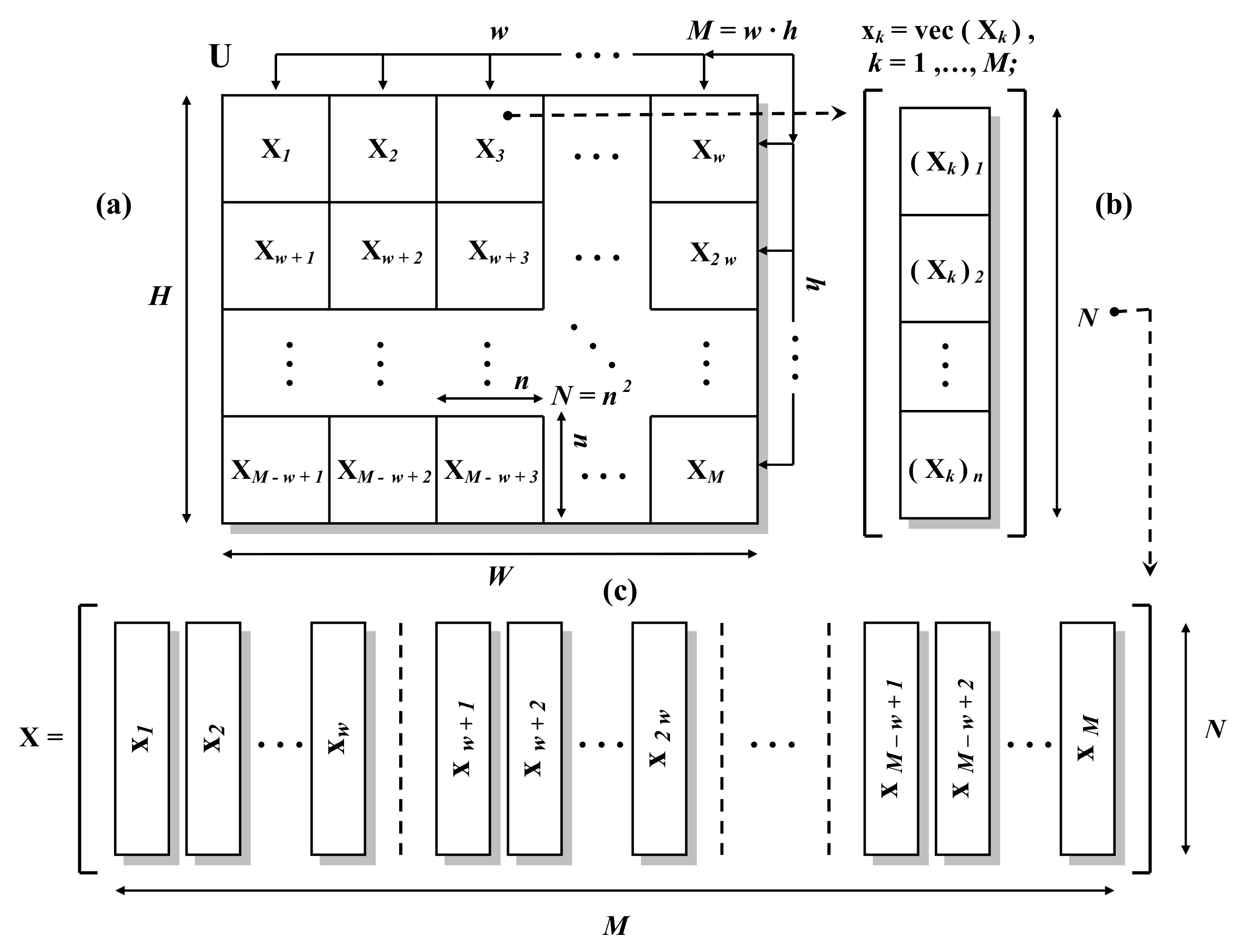
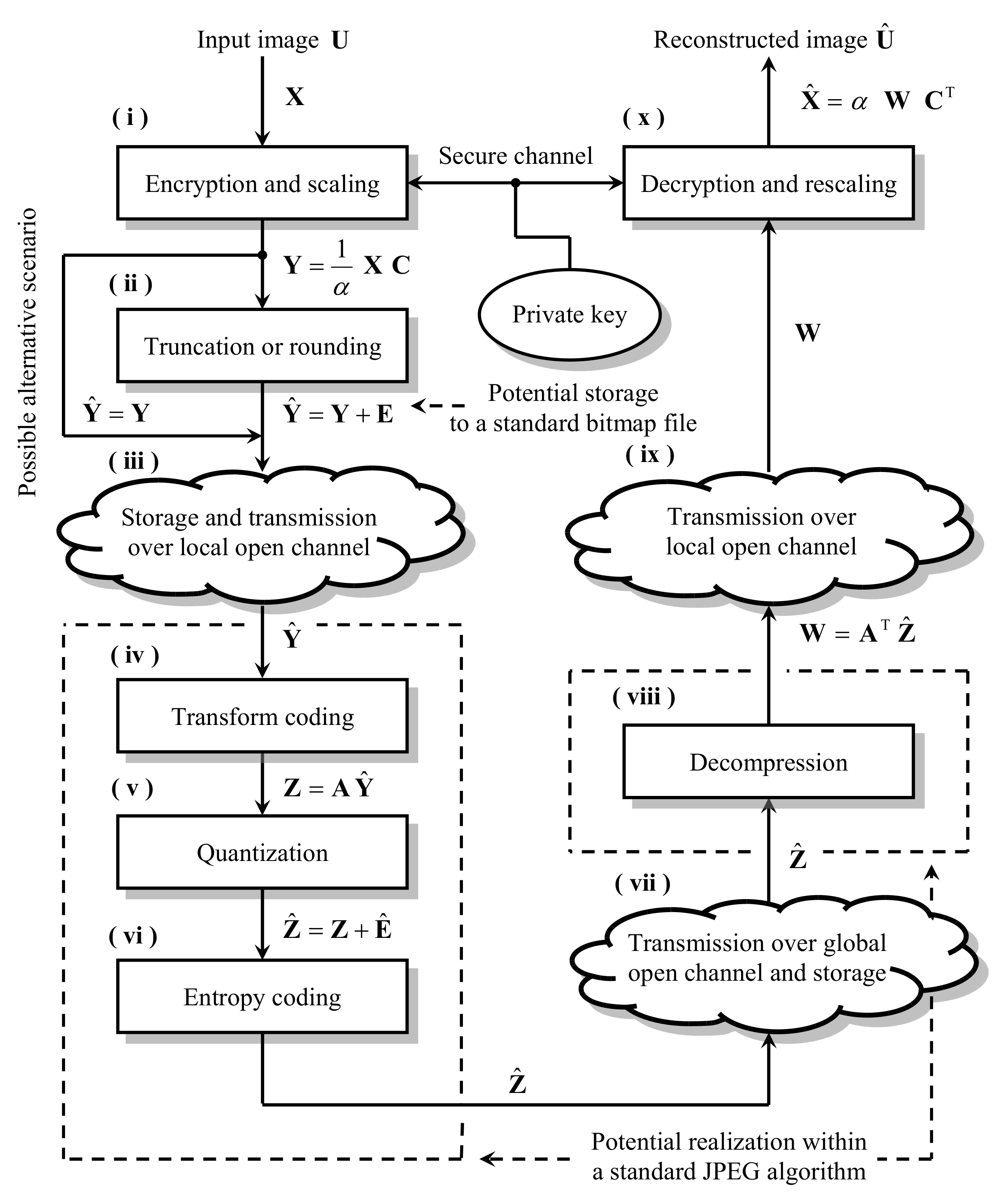
3. Mathematical Model of the Analyzed Scheme
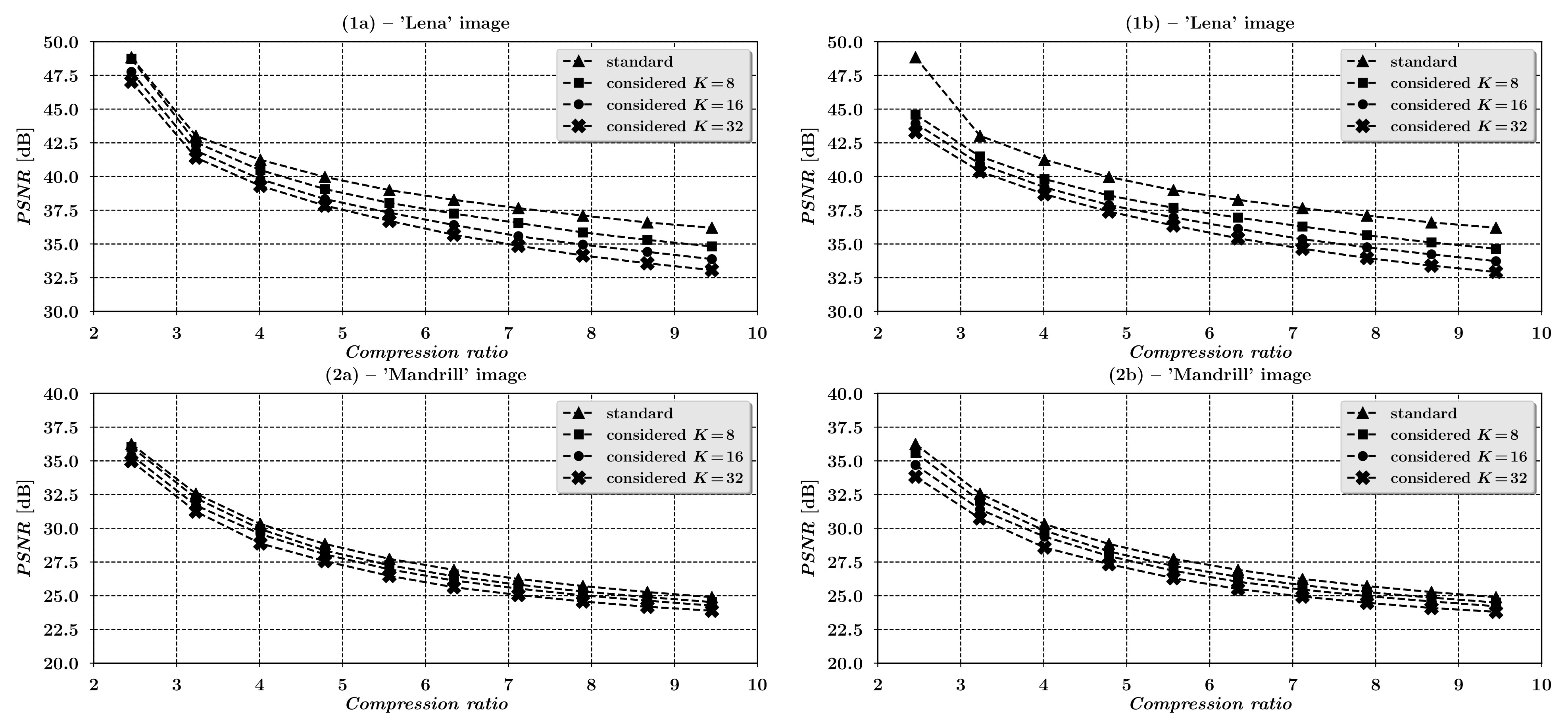
4. Compression Process Effectiveness Analysis
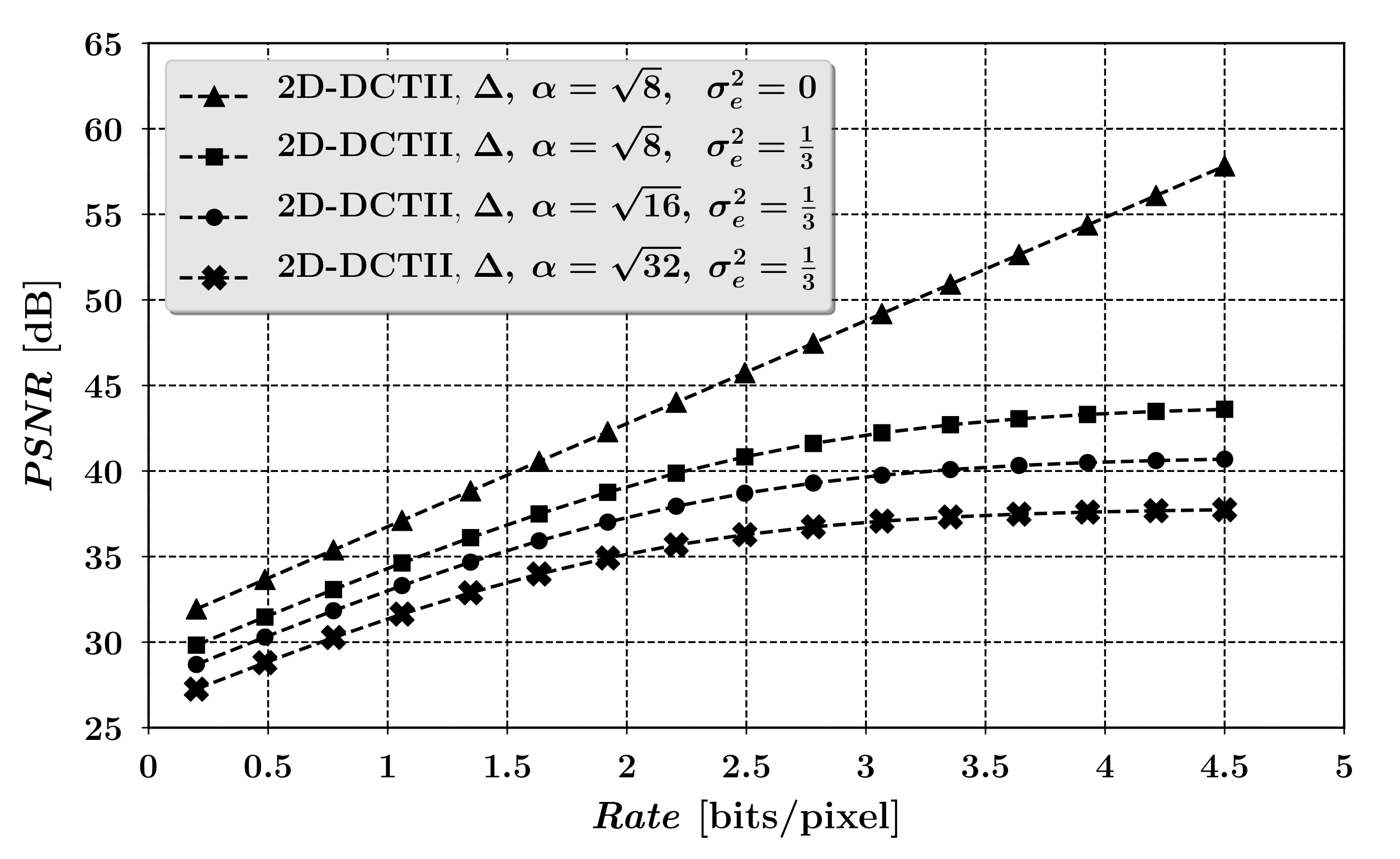
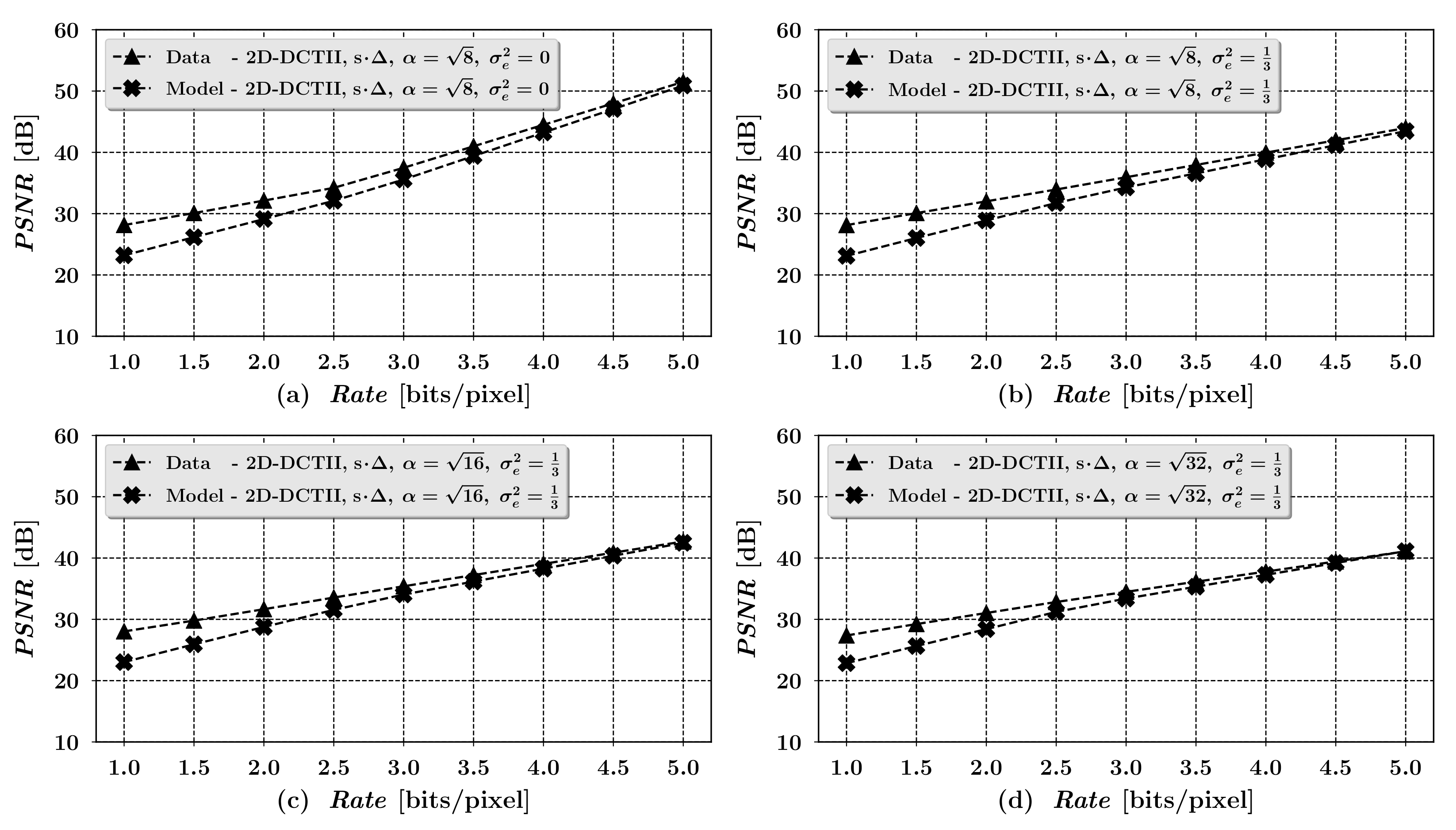
Examples of Compression Process Quality Characteristics
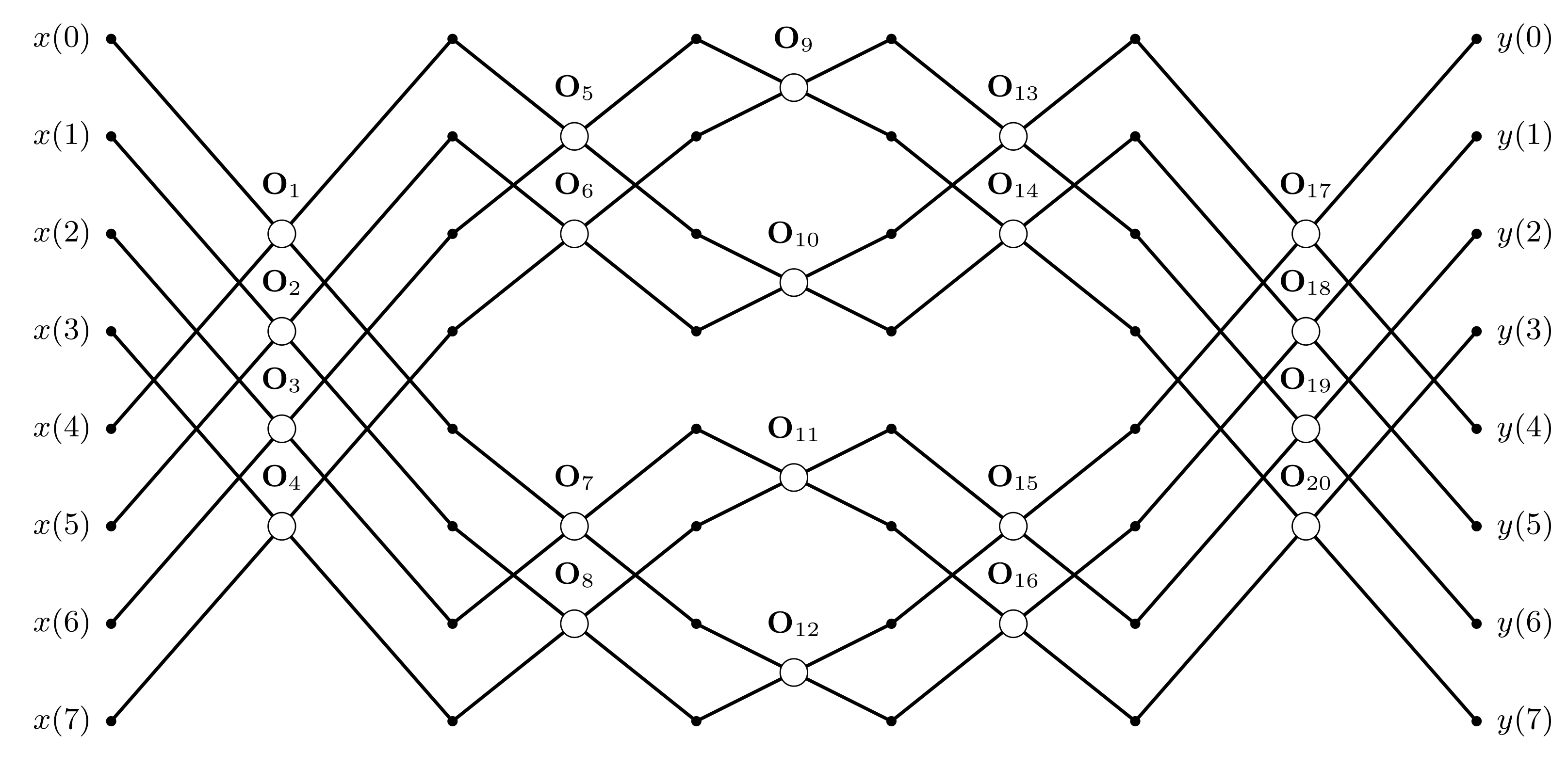
5. Fast Parametric Orthogonal Transforms
6. Analysis of the Encryption Efficiency of the Considered Scheme
6.1. Combinatorial Analysis
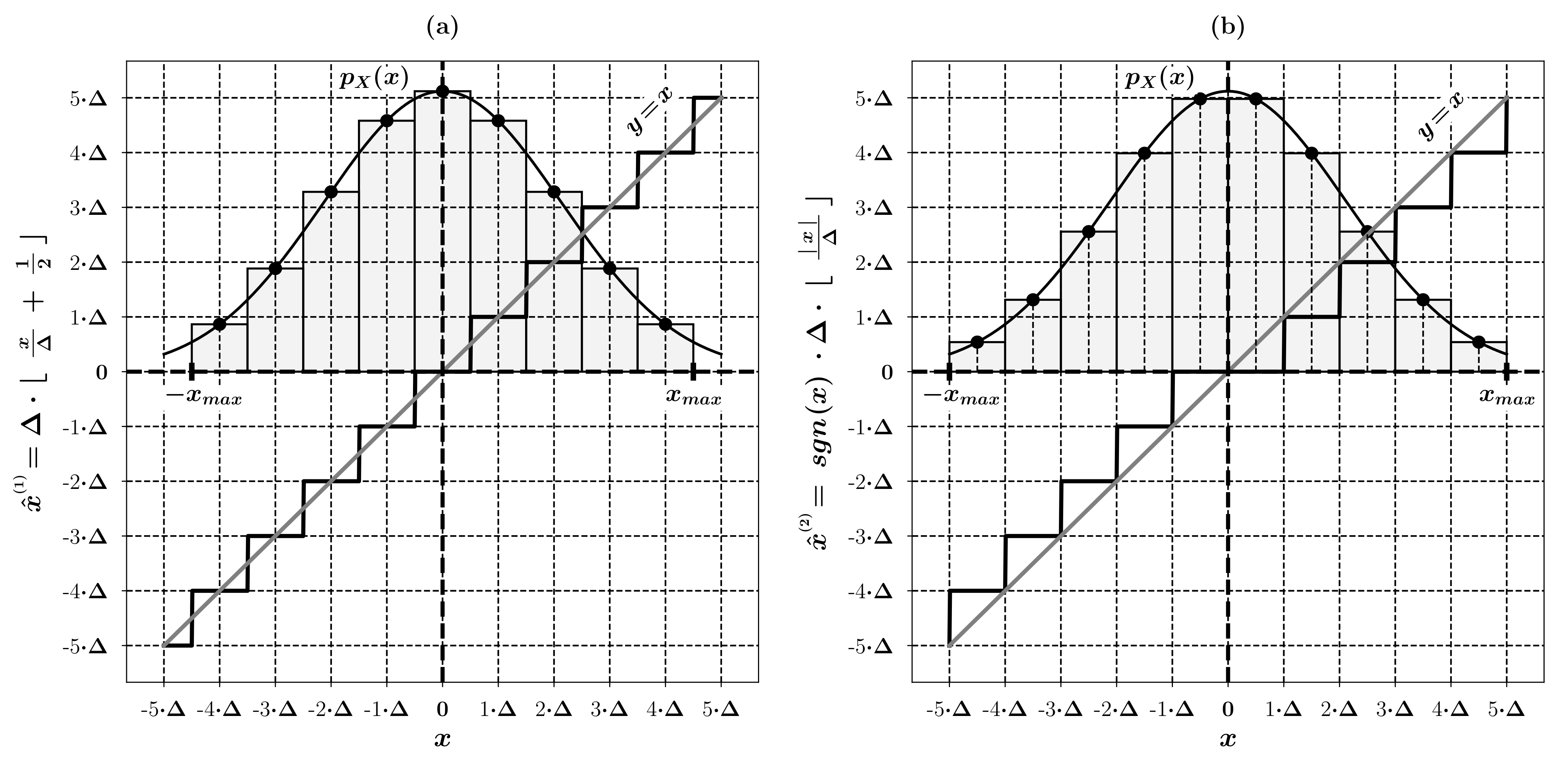
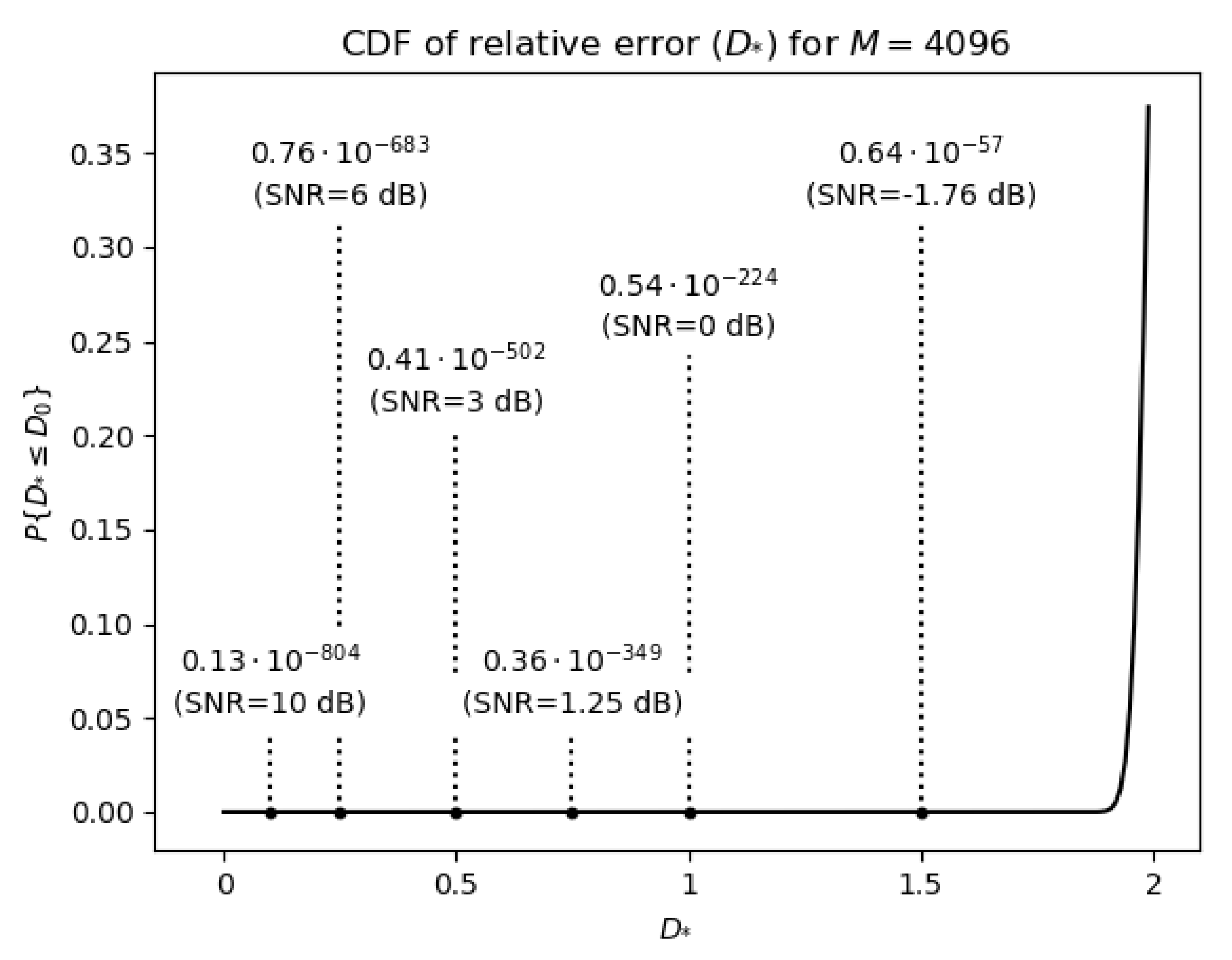
6.2. Statistical Analysis of the Decryption Error
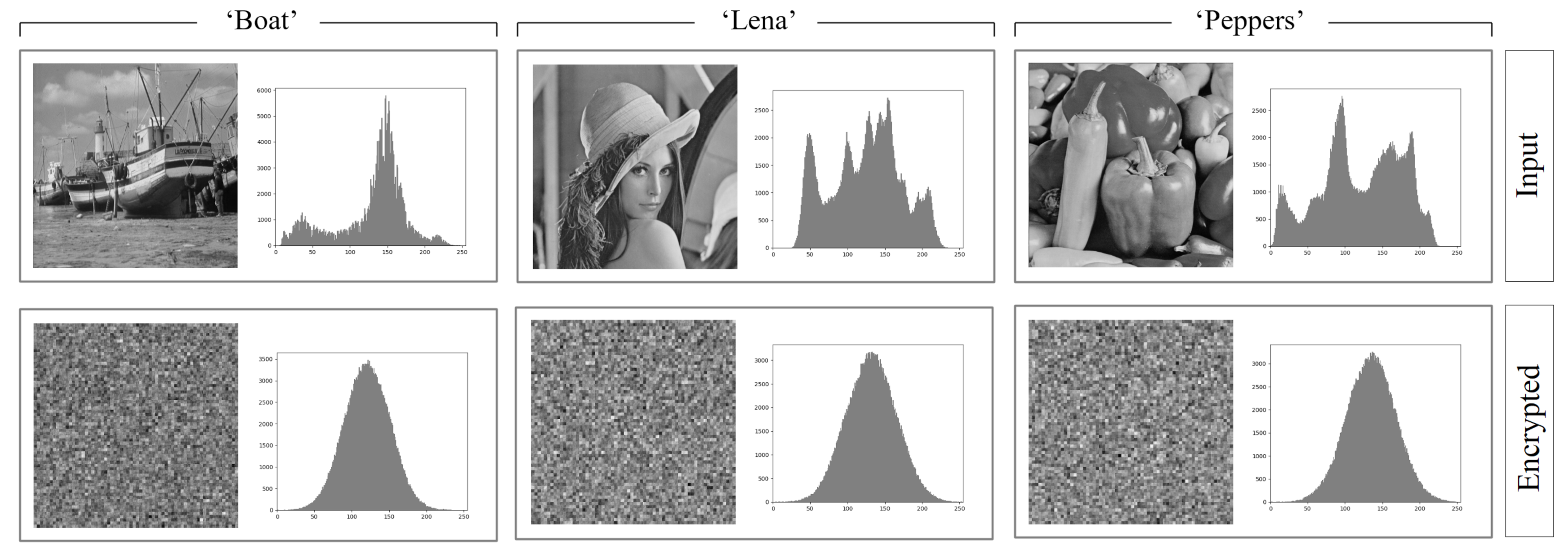
6.3. Analysis Based on the Histogram
6.4. Maximum Deviation Index
6.5. Correlation Coefficient Index
6.6. Irregular Deviation Index
7. Experimental Results in Efficiency of the Compression Process
8. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Data Encryption Standard (DES). Federal Information Processing Standards Publication, FIPS PUB 46-3; U.S. Department of Commerce/National Institute of Standards and Technology: Gaithersburg, MD, USA, 1999.
- Massey, J.L.; Lai, X. Device for the Conversion of a Digital Block and Use of Same. U.S. Patent 5214703, 25 May 1993. [Google Scholar]
- Advanced Encryption Standard (AES). Federal Processing Standards Application, FIPS 197; U.S. Department of Commerce/U.S. National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001.
- Furht, B.; Muharemagic, E.; Socek, D. Multimedia Encryption And Watermarking. Mult. Syst. Appl. Ser. 2005, 28. [Google Scholar] [CrossRef]
- Johnson, M.; Ishwar, P.; Prabhakaran, V.; Schonberg, D.; Ramchandran, K. On Compressing Encrypted Data. IEEE Trans. Signal Process. 2004, 52, 2992–3006. [Google Scholar] [CrossRef]
- Schonberg, D.; Draper, S.; Ramchandran, K. On Compression of Encrypted Images. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006. [Google Scholar]
- Kumar, A.A.; Makur, A. Distributed Source Coding Based Encryption And Lossless Compression of Gray Scale and Color Images. In Proceedings of the 2008 IEEE 10th Workshop on Multimedia Signal Processing, Cairns, Australia, 8–10 October 2008. [Google Scholar]
- Zhang, X. Lossy Compression and Iterative Reconstruction for Encrypted Image. IEEE Trans. Inf. Forensics Secur. 2011, 6, 53–58. [Google Scholar] [CrossRef]
- Wang, C.; Ni, J.; Huang, Q. A new encryption-then-compression algorithm using rate-distortion optimization. Elsevier Signal Process. Image Commun. 2015, 39, 141–150. [Google Scholar] [CrossRef]
- Kumar, A.A.; Makur, A. Lossy Compression of Encrypted Image by Compressive Sensing Technique. In Proceedings of the TENCON 2009—2009 IEEE Region 10 Conference, Singapore, 23–26 January 2009. [Google Scholar]
- Liu, S.; Paul, A.; Zhang, G.; Jeon, G. A game theory-based block image compression method in encryption domain. J. Supercomput. 2015, 71, 3353–3372. [Google Scholar] [CrossRef]
- Puchala, D.; Stokfiszewski, K.; Yatsymirskyy, M. Encryption Before Compression Coding Scheme for JPEG Image Compression Standard. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; pp. 313–322. [Google Scholar]
- Puchala, D.; Yatsymirskyy, M. Joint Compression and Encryption of Visual Data Using Orthogonal Parametric Transforms. Bull. Pol. Acad. Sci. 2016, 64, 373–382. [Google Scholar] [CrossRef]
- Brewer, J.W. Kronecker Products and Matrix Calculus in System Theory. IEEE Trans. Circuits Syst. 1978, CAS-25, 772–781. [Google Scholar] [CrossRef]
- Microsoft Corporation, Windows Metafile Format. Protoc. Revis. 2018, 15, 84–92.
- Diamantaras, K.I.; Strintzis, M.G. Optimal Transform Coding in the Presence of Quantization Noise. IEEE Trans. Image Process. 1999, 8, 1508–1515. [Google Scholar] [CrossRef]
- Diamantaras, K.I.; Hornik, K.; Strintzis, M.G. Optimal Linear Compression Under Unreliable Representation and Robust PCA Neural Models. IEEE Trans. Neural Netw. 1999, 10, 1186–1195. [Google Scholar] [CrossRef]
- Pennebaker, W.B.; Mitchell, J.L. JPEG: Still Image Data Compression Standard; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Gray, R.M.; Neuhoff, D.L. Quantization. IEEE Trans. Inf. Theory 1998, 44, 1–63. [Google Scholar] [CrossRef]
- Gersho, A. Principles of Quantization. IEEE Trans. Circuits Syst. 1978, CAS-25, 427–436. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Goyal, V.K.; Zhuang, J.; Vetterli, M. Transform Coding with Backward Adaptive Updates. IEEE Trans. Inf. Theory 2000, 46, 1623–1633. [Google Scholar] [CrossRef]
- Ahuja, N.; Schachter, B.J. Image Models. Comput. Surv. 1981, 13, 373–397. [Google Scholar] [CrossRef]
- Derin, H.; Kelly, P.A. Discrete-Index Markov-Type Random Processes. Proc. IEEE 1989, 77, 1485–1510. [Google Scholar] [CrossRef]
- Puchala, D.; Stokfiszewski, K. Parametrized Orthogonal Transforms for Data Encryption. Comput. Probl. Electr. Eng. J. 2013, 3, 93–97. [Google Scholar]
- Rao, K.R.; Yip, P. Discrete Cosine Transform: Algorithms, Advantages, Applications; Academic Press Professional: Cambridge, MA, USA, 1990. [Google Scholar]
- Kornblum, J.D. Using JPEG quantization tables to identify imagery processed by software. Digit. Investig. 2008, 5, 21–25. [Google Scholar] [CrossRef]
- Puchala, D. Approximating the KLT by Maximizing the Sum of Fourth-Order Moments. IEEE Signal Process. Lett. 2013, 20, 193–196. [Google Scholar] [CrossRef]
- Bouguezel, S.; Ahmad, O.; Swamy, M.N.S. A New Involutory Parametric Transform and Its Application to Image Encryption. In Proceeding of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS), Beijing, China, 19–23 May 2013; pp. 2605–2608. [Google Scholar]
- Puchala, D. Involutory Parametric Orthogonal Transforms of Cosine-Walsh Type with Application to Data Encryption. In Advances in Intelligent Systems and Computing II. CSIT 2017; Shakhovska, N., Stepashko, V., Eds.; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Benes, V.E. On rearrangeable three-stage connecting networks. Bell Syst. Tech. J. 1962, 41, 1481–1492. [Google Scholar] [CrossRef]
- El-Fishawy, N.; Abu Zaid, O.M. Quality of Encryption Measurement of Bitmap Images with RC6, MRC6, and Rijndael Block Cipher Algorithms. Inter. J. Netw. Secur. 2007, 5, 241–251. [Google Scholar]
- Kumar, R.; Safeeriya, F.; Aithal, G.; Shetty, S. A Survey on Key(s) and Keyless Image Encryption Techniques. Cybern. Inf. Technol. 2017, 17, 134–164. [Google Scholar]
- Stallings, W. Cryptography and Network Security: Principles and Practice, 8th ed.; Pearson: London, UK, 2020. [Google Scholar]
- Nguyen, H.C.; Katzenbeisser, S. Detecting Resized Double JPEG Compressed Images—Using Support Vector Machine. Proc. Commun. Multimed. Secur. 2013, 113–122. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Method [9] | Considered | AES + CBC | DES + CBC |
|---|---|---|---|---|
| ’Boat’ | 169,848.5 | 161,842.5 | 221,312 | 221,746.5 |
| ’Lena’ | 133,883 | 126,087 | 169,378.5 | 168,856.5 |
| ’Peppers’ | 133,755 | 192,357.5 | 144,174 | 144,084.5 |
| Image | Method [9] | Considered | AES + CBC | DES + CBC |
|---|---|---|---|---|
| ’Boat’ | ||||
| ’Lena’ | ||||
| ’Peppers’ |
| Image | Method [9] | Considered | AES + CBC | DES + CBC |
|---|---|---|---|---|
| ’Boat’ | 250,726 | 248,506 | 186,588 | 186,652 |
| ’Lena’ | 219,236 | 233,898 | 180,002 | 180,992 |
| ’Peppers’ | 243,636 | 247,716 | 166,458 | 166,104 |
| Compression Coefficient | PSNR Values [dB] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ’Lena’ Image | ’Mandrill’ Image | |||||||||||||
| Standard Method | Considered Method | Standard Method | Considered Method | |||||||||||
| Without Integer Projection | With Integer Projection | Without Integer Projection | With Integer Projection | |||||||||||
| 2.455 | 48.839 | 48.726 | 47.758 | 47.032 | 44.589 | 43.935 | 43.288 | 36.250 | 36.032 | 35.406 | 34.981 | 35.582 | 34.697 | 33.829 |
| 3.232 | 43.020 | 42.524 | 41.922 | 41.401 | 41.488 | 40.934 | 40.377 | 32.567 | 32.236 | 31.699 | 31.241 | 32.039 | 31.396 | 30.734 |
| 4.009 | 41.240 | 40.479 | 39.797 | 39.311 | 39.810 | 39.205 | 38.687 | 30.314 | 29.944 | 29.575 | 28.878 | 29.831 | 29.385 | 28.577 |
| 4.787 | 39.967 | 39.071 | 38.328 | 37.846 | 38.597 | 37.883 | 37.404 | 28.841 | 28.356 | 28.069 | 27.568 | 28.281 | 27.941 | 27.341 |
| 5.564 | 38.989 | 38.041 | 37.316 | 36.714 | 37.676 | 36.971 | 36.371 | 27.737 | 27.260 | 26.955 | 26.472 | 27.208 | 26.850 | 26.304 |
| 6.341 | 38.271 | 37.254 | 36.406 | 35.682 | 36.953 | 36.128 | 35.421 | 26.916 | 26.450 | 26.128 | 25.632 | 26.403 | 26.039 | 25.497 |
| 7.118 | 37.660 | 36.550 | 35.577 | 34.865 | 36.293 | 35.353 | 34.648 | 26.242 | 25.820 | 25.529 | 25.055 | 25.783 | 25.454 | 24.938 |
| 7.896 | 37.104 | 35.856 | 34.949 | 34.148 | 35.641 | 34.756 | 33.956 | 25.720 | 25.315 | 25.029 | 24.577 | 25.274 | 24.972 | 24.476 |
| 8.673 | 36.595 | 35.303 | 34.416 | 33.564 | 35.116 | 34.230 | 33.393 | 25.275 | 24.900 | 24.631 | 24.181 | 24.863 | 24.579 | 24.092 |
| 9.450 | 36.201 | 34.818 | 33.876 | 33.067 | 34.642 | 33.723 | 32.921 | 24.891 | 24.530 | 24.270 | 23.893 | 24.496 | 24.221 | 23.809 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Puchala, D.; Stokfiszewski, K.; Yatsymirskyy, M. Image Statistics Preserving Encrypt-then-Compress Scheme Dedicated for JPEG Compression Standard. Entropy 2021, 23, 421. https://doi.org/10.3390/e23040421
Puchala D, Stokfiszewski K, Yatsymirskyy M. Image Statistics Preserving Encrypt-then-Compress Scheme Dedicated for JPEG Compression Standard. Entropy. 2021; 23(4):421. https://doi.org/10.3390/e23040421
Chicago/Turabian StylePuchala, Dariusz, Kamil Stokfiszewski, and Mykhaylo Yatsymirskyy. 2021. "Image Statistics Preserving Encrypt-then-Compress Scheme Dedicated for JPEG Compression Standard" Entropy 23, no. 4: 421. https://doi.org/10.3390/e23040421
APA StylePuchala, D., Stokfiszewski, K., & Yatsymirskyy, M. (2021). Image Statistics Preserving Encrypt-then-Compress Scheme Dedicated for JPEG Compression Standard. Entropy, 23(4), 421. https://doi.org/10.3390/e23040421