
Structure of Investor Networks and Financial Crises


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Set and Network Inference
2.2. Network Features
3. Results
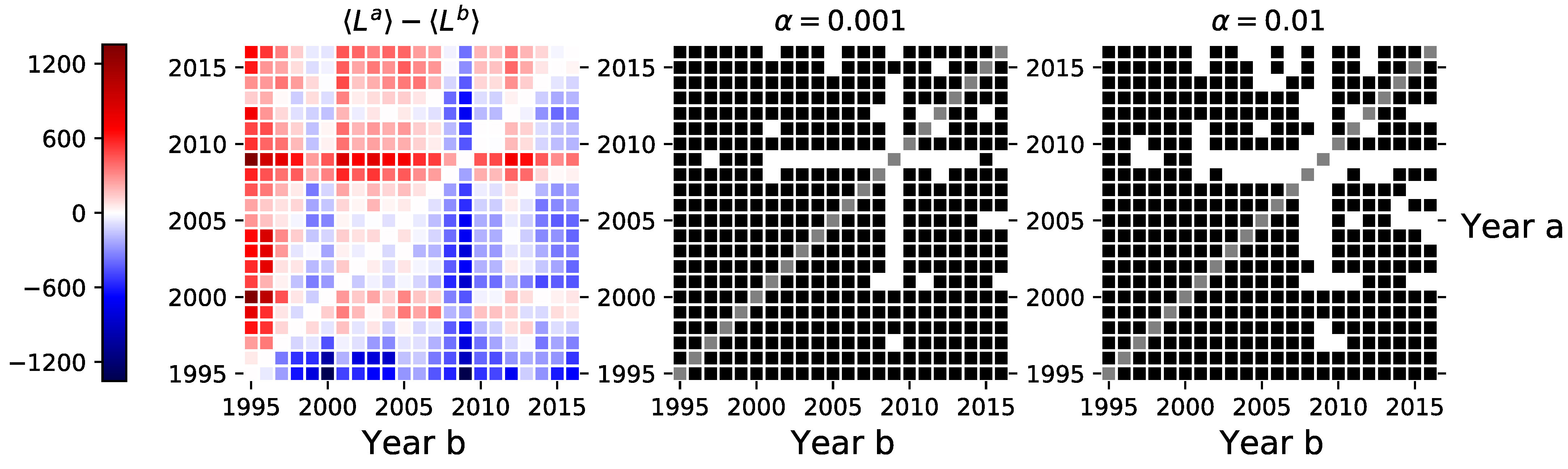
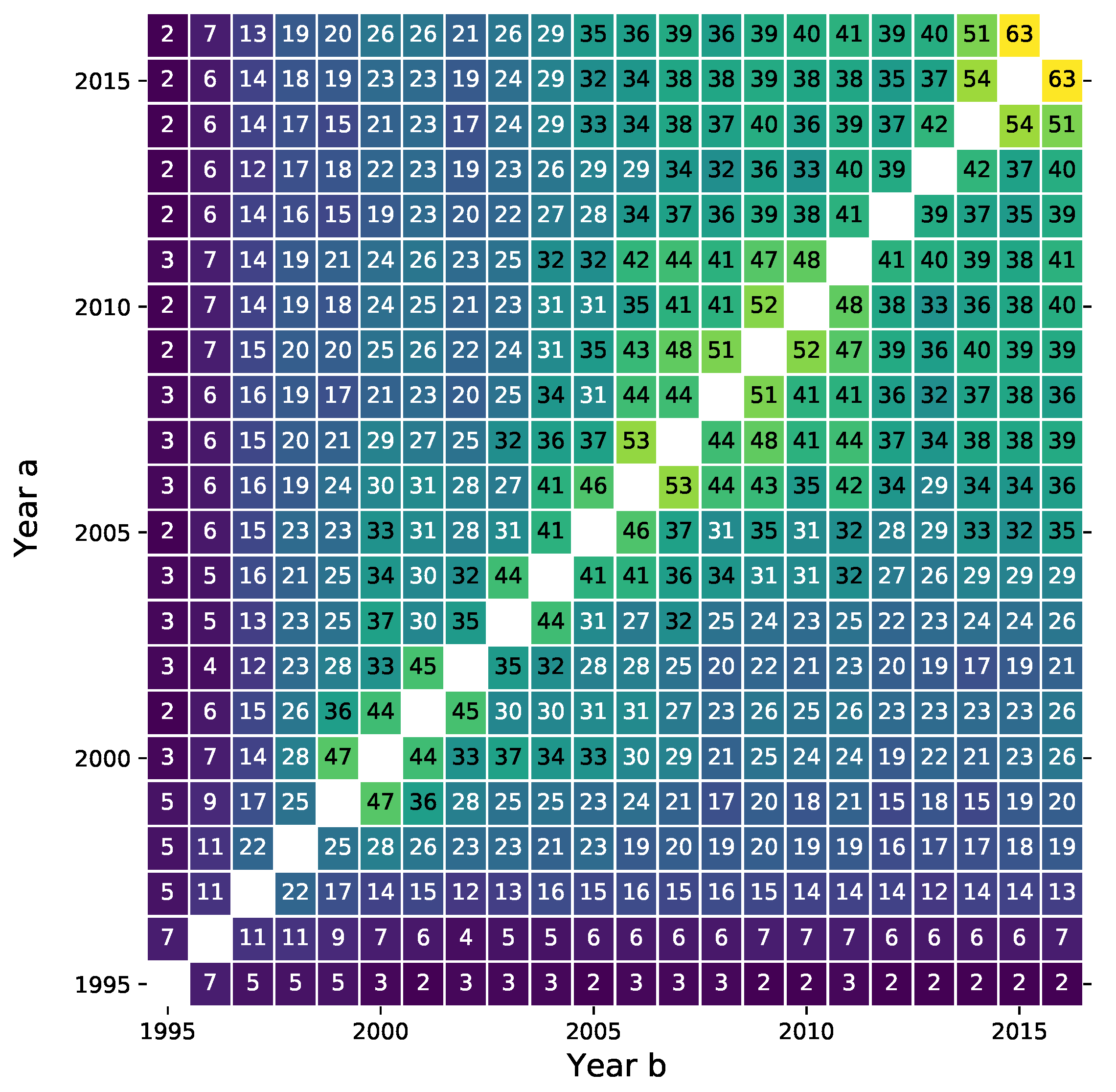
3.1. Links, Density, and Average Degree
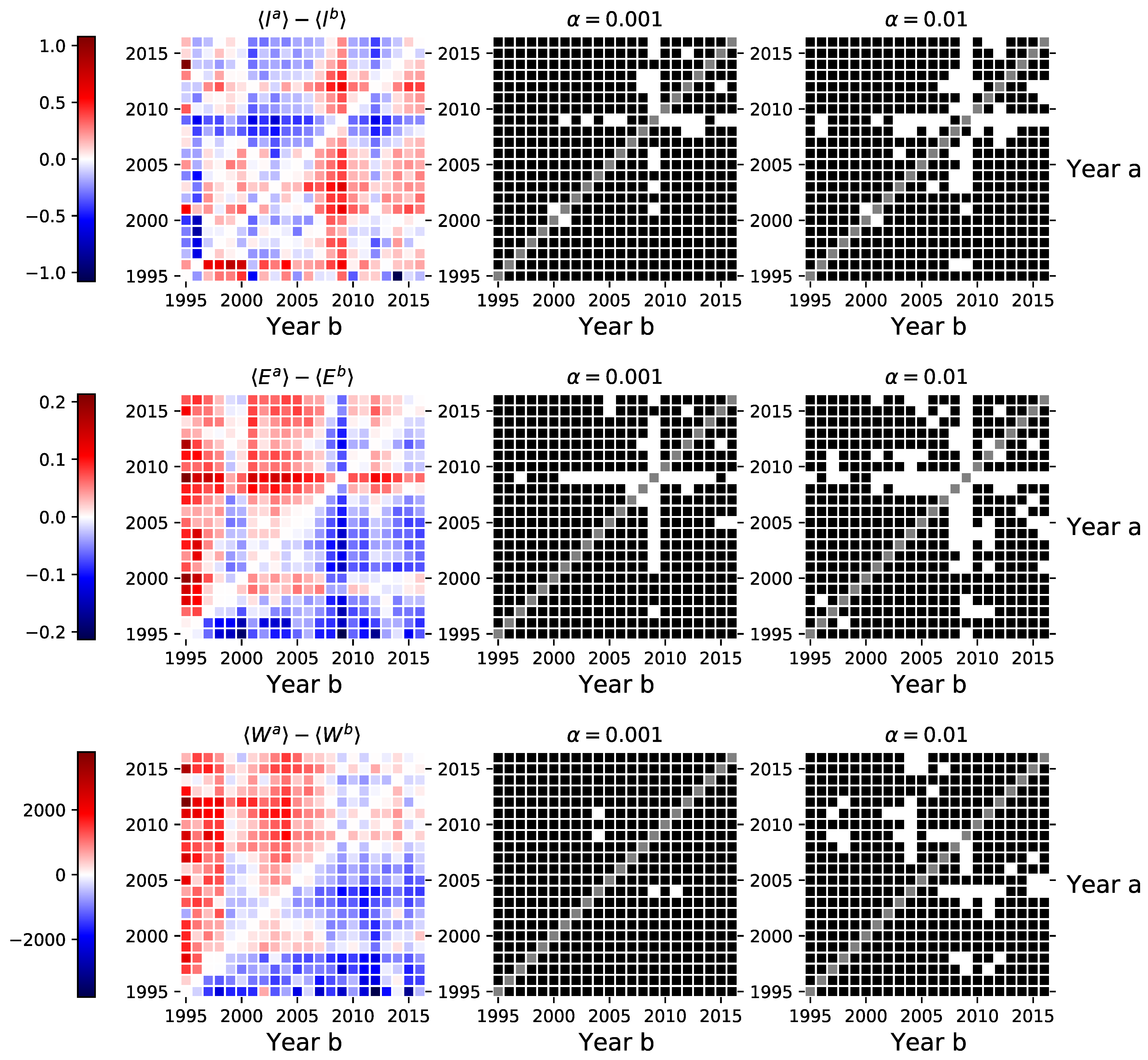
3.2. Global Clustering, Size of the Largest Connected Component, and the Average Number of Components
3.3. Average Distance, Wiener Index, and Global Efficiency
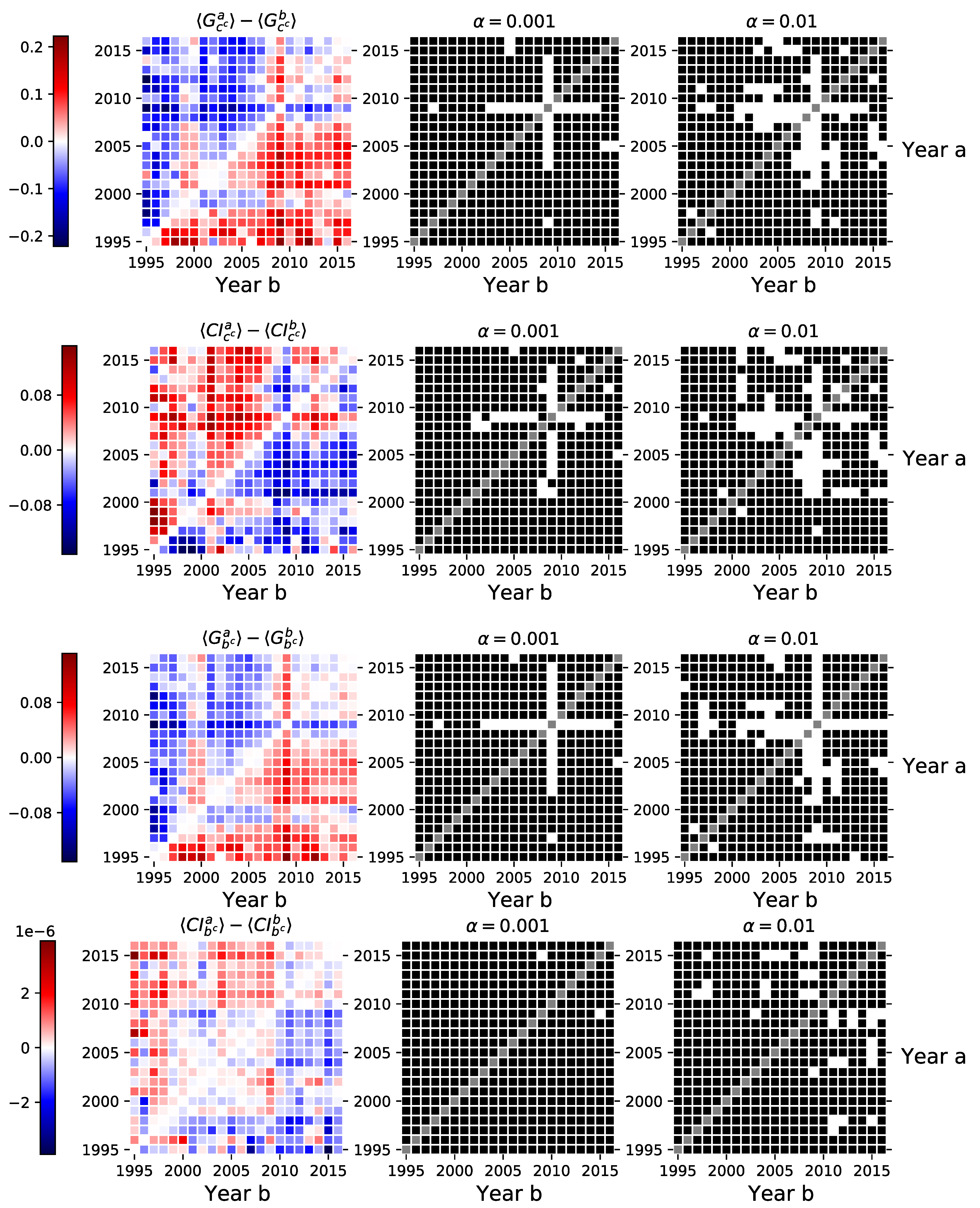
3.4. Network Centrality
3.5. Robustness Checks
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Descriptive Statistics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
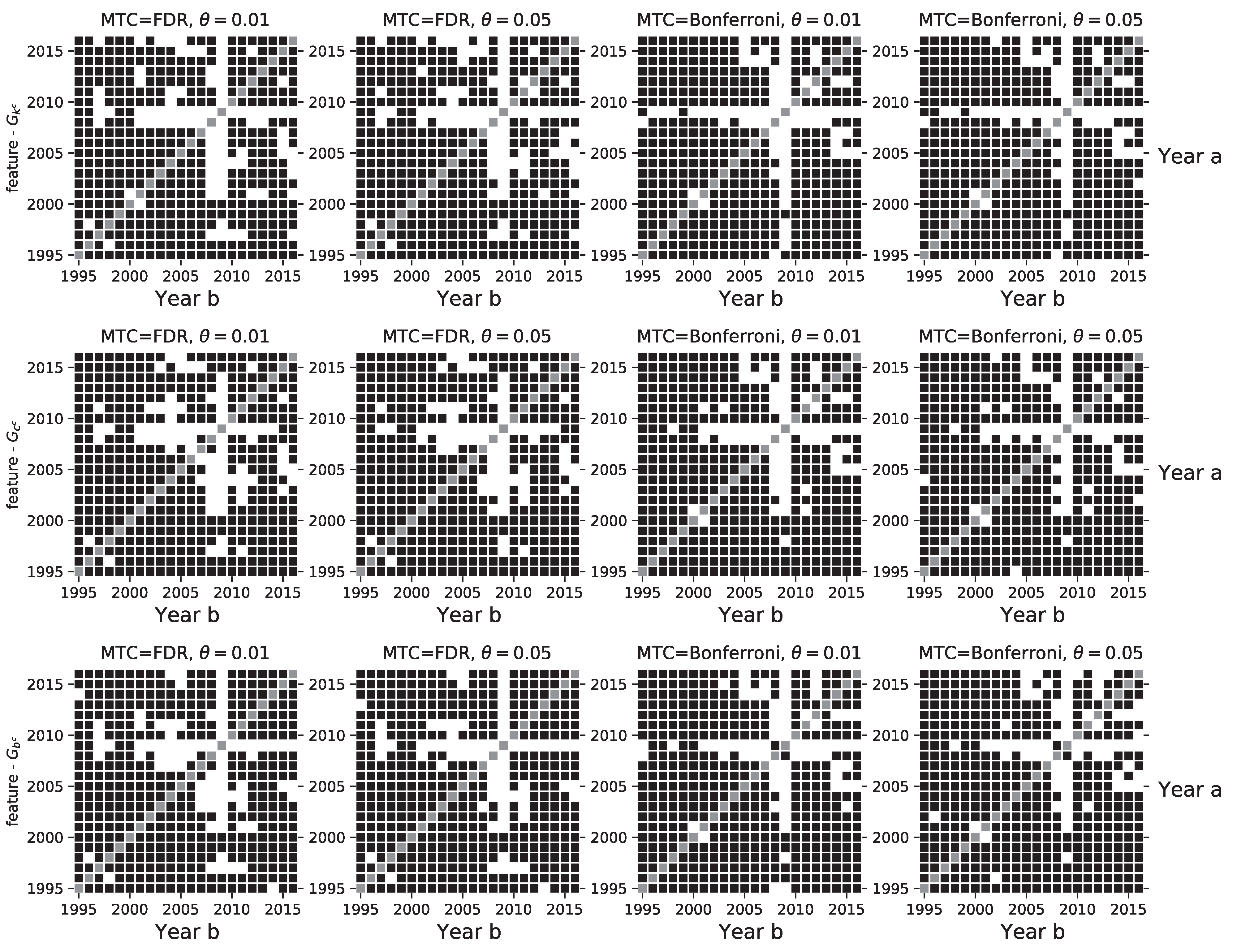{kind=link}
{kind=link}
{kind=link}
| Securities | No MTC | FDR MTC | FDR MTC () | |
|---|---|---|---|---|
| 1995 | 128 | 126 | 38 | 12 |
| 1996 | 135 | 134 | 62 | 27 |
| 1997 | 142 | 139 | 74 | 37 |
| 1998 | 166 | 163 | 92 | 55 |
| 1999 | 203 | 197 | 108 | 70 |
| 2000 | 225 | 213 | 118 | 89 |
| 2001 | 350 | 309 | 125 | 81 |
| 2002 | 527 | 453 | 160 | 89 |
| 2003 | 672 | 506 | 184 | 96 |
| 2004 | 885 | 667 | 244 | 138 |
| 2005 | 1137 | 851 | 298 | 161 |
| 2006 | 1503 | 1191 | 463 | 251 |
| 2007 | 2139 | 1663 | 501 | 230 |
| 2008 | 2126 | 1646 | 469 | 228 |
| 2009 | 1474 | 1133 | 421 | 230 |
| 2010 | 2456 | 1682 | 394 | 185 |
| 2011 | 4578 | 2617 | 424 | 174 |
| 2012 | 5682 | 2840 | 335 | 107 |
| 2013 | 5388 | 2980 | 460 | 178 |
| 2014 | 6747 | 3679 | 399 | 149 |
| 2015 | 10,086 | 4734 | 436 | 165 |
| 2016 | 11,090 | 4320 | 421 | 167 |







References
- De Bondt, W.F.; Thaler, R.H. Do security analysts overreact? Am. Econ. Rev. 1990, 53, 52–57. [Google Scholar]
- Daniel, K.; Hirshleifer, D.; Subrahmanyam, A. Investor psychology and security market under-and overreactions. J. Financ. 1998, 53, 1839–1885. [Google Scholar] [CrossRef]
- Barberis, N.; Thaler, R. A survey of behavioral finance. Handb. Econ. Financ. 2003, 1, 1053–1128. [Google Scholar]
- Shiller, R.J. Irrational Exuberance: Revised and Expanded Third Edition; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Ozsoylev, H.N.; Walden, J.; Yavuz, M.D.; Bildik, R. Investor networks in the stock market. Rev. Financ. Stud. 2013, 27, 1323–1366. [Google Scholar] [CrossRef]
- Tumminello, M.; Lillo, F.; Piilo, J.; Mantegna, R.N. Identification of clusters of investors from their real trading activity in a financial market. New J. Phys. 2012, 14, 013041. [Google Scholar] [CrossRef]
- Tumminello, M.; Micciche, S.; Lillo, F.; Piilo, J.; Mantegna, R.N. Statistically validated networks in bipartite complex systems. PLoS ONE 2011, 6, e17994. [Google Scholar] [CrossRef]
- Gualdi, S.; Cimini, G.; Primicerio, K.; Di Clemente, R.; Challet, D. Statistically validated network of portfolio overlaps and systemic risk. Sci. Rep. 2016, 6, 39467. [Google Scholar] [CrossRef]
- Baltakys, K.; Kanniainen, J.; Emmert-Streib, F. Multilayer Aggregation with Statistical Validation: Application to Investor Networks. Sci. Rep. 2018, 8, 8198. [Google Scholar] [CrossRef]
- Baltakienė, M.; Baltakys, K.; Kanniainen, J.; Pedreschi, D.; Lillo, F. Clusters of investors around initial public offering. Palgrave Commun. 2019, 5, 1–14. [Google Scholar] [CrossRef]
- Baltakienė, M.; Kanniainen, J.; Baltakys, K. Identification of information networks in stock markets. SSRN 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3750035 (accessed on 18 March 2021). [CrossRef]
- Musciotto, F.; Marotta, L.; Piilo, J.; Mantegna, R.N. Long-term ecology of investors in a financial market. Palgrave Commun. 2018, 4, 92. [Google Scholar] [CrossRef]
- Challet, D.; Chicheportiche, R.; Lallouache, M.; Kassibrakis, S. Statistically validated lead-lag networks and inventory prediction in the foreign exchange market. Adv. Complex Syst. 2018, 21, 1850019. [Google Scholar] [CrossRef]
- Ranganathan, S.; Kivelä, M.; Kanniainen, J. Dynamics of investor spanning trees around dot-com bubble. PLoS ONE 2018, 13, e0198807. [Google Scholar] [CrossRef] [PubMed]
- Cordi, M.; Challet, D.; Kassibrakis, S. The market nanostructure origin of asset price time reversal asymmetry. Quant. Financ. 2021, 21, 295–304. [Google Scholar] [CrossRef]
- Squartini, T.; Van Lelyveld, I.; Garlaschelli, D. Early-warning signals of topological collapse in interbank networks. Sci. Rep. 2013, 3, 3357. [Google Scholar] [CrossRef] [PubMed]
- Kojaku, S.; Cimini, G.; Caldarelli, G.; Masuda, N. Structural changes in the interbank market across the financial crisis from multiple core-periphery analysis. J. Netw. Theory Financ. 2018, 4, 35–51. [Google Scholar] [CrossRef]
- Barucca, P.; Lillo, F. The organization of the interbank network and how ECB unconventional measures affected the e-MID overnight market. Comput. Manag. Sci. 2018, 15, 33–53. [Google Scholar] [CrossRef]
- Di Gangi, D.; Lillo, F.; Pirino, D. Assessing systemic risk due to fire sales spillover through maximum entropy network reconstruction. J. Econ. Dyn. Control 2018, 94, 117–141. [Google Scholar] [CrossRef]
- Wang, G.J.; Yi, S.; Xie, C.; Stanley, H.E. Multilayer information spillover networks: Measuring interconnectedness of financial institutions. Quant. Financ. 2020, 1–23. [Google Scholar] [CrossRef]
- Cimini, G.; Squartini, T.; Saracco, F.; Garlaschelli, D.; Gabrielli, A.; Caldarelli, G. The statistical physics of real-world networks. Nat. Rev. Phys. 2019, 1, 58–71. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M.; Shi, Y. Fifty years of graph matching, network alignment and network comparison. Inf. Sci. 2016, 346, 180–197. [Google Scholar] [CrossRef]
- Dehmer, M.; Chen, Z.; Emmert-Streib, F.; Shi, Y.; Tripathi, S.; Musa, A.; Mowshowitz, A. Properties of graph distance measures by means of discrete inequalities. Appl. Math. Model. 2018, 59, 739–749. [Google Scholar] [CrossRef]
- Dehmer, M.; Emmert-Streib, F.; Shi, Y. Interrelations of graph distance measures based on topological indices. PLoS ONE 2014, 9, e94985. [Google Scholar] [CrossRef] [PubMed]
- Emmert-Streib, F.; Musa, A.; Baltakys, K.; Kanniainen, J.; Tripathi, S.; Yli-Harja, O.; Jodlbauer, H.; Dehmer, M. Computational Analysis of the structural properties of Economic and Financial Networks. arXiv 2017, arXiv:1710.04455. [Google Scholar] [CrossRef]
- Lin, J.H.; Primicerio, K.; Squartini, T.; Decker, C.; Tessone, C.J. Lightning Network: A second path towards centralisation of the Bitcoin economy. New J. Phys. 2020, 22, 083022. [Google Scholar] [CrossRef]
- Di Cerbo, L.F.; Taylor, S. Graph theoretical representations of equity indices and their centrality measures. Quant. Financ. 2020, 1–15. [Google Scholar] [CrossRef]
- Grinblatt, M.; Keloharju, M. The investment behavior and performance of various investor types: A study of Finland’s unique data set. J. Financ. Econ. 2000, 55, 43–67. [Google Scholar] [CrossRef]
- Baltakys, K. Investor Networks and Information Transfer in Stock Markets. 2019. Available online: https://trepo.tuni.fi/handle/10024/117344 (accessed on 18 March 2021).
- Baltakys, K.; Kanniainen, J.; Saramäki, J.; Kivela, M. Trading Signatures: Investor Attention Allocation in Stock Markets. SSRN 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3687759 (accessed on 18 March 2021). [CrossRef]
- Kenett, D.Y.; Tumminello, M.; Madi, A.; Gur-Gershgoren, G.; Mantegna, R.N.; Ben-Jacob, E. Dominating clasp of the financial sector revealed by partial correlation analysis of the stock market. PLoS ONE 2010, 5, e15032. [Google Scholar] [CrossRef]
- Kenett, D.Y.; Huang, X.; Vodenska, I.; Havlin, S.; Stanley, H.E. Partial correlation analysis: Applications for financial markets. Quant. Financ. 2015, 15, 569–578. [Google Scholar] [CrossRef]
- Ku, S.; Lee, C.; Chang, W.; Song, J.W. Fractal structure in the S&P500: A correlation-based threshold network approach. Chaos Solitons Fractals 2020, 137, 109848. [Google Scholar]
- Hong, Y.; Liu, Y.; Wang, S. Granger causality in risk and detection of extreme risk spillover between financial markets. J. Econom. 2009, 150, 271–287. [Google Scholar] [CrossRef]
- Mantegna, R.N. Hierarchical structure in financial markets. Eur. Phys. J. B-Condens. Matter Complex Syst. 1999, 11, 193–197. [Google Scholar] [CrossRef]
- Tumminello, M.; Aste, T.; Di Matteo, T.; Mantegna, R.N. A tool for filtering information in complex systems. Proc. Natl. Acad. Sci. USA 2005, 102, 10421–10426. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.J.; Xie, C. Tail dependence structure of the foreign exchange market: A network view. Expert Syst. Appl. 2016, 46, 164–179. [Google Scholar] [CrossRef]
- Boginski, V.; Butenko, S.; Pardalos, P.M. Statistical analysis of financial networks. Comput. Stat. Data Anal. 2005, 48, 431–443. [Google Scholar] [CrossRef]
- Saracco, F.; Straka, M.J.; Di Clemente, R.; Gabrielli, A.; Caldarelli, G.; Squartini, T. Inferring monopartite projections of bipartite networks: An entropy-based approach. New J. Phys. 2017, 19, 053022. [Google Scholar] [CrossRef]
- Gemmetto, V.; Cardillo, A.; Garlaschelli, D. Irreducible network backbones: Unbiased graph filtering via maximum entropy. arXiv 2017, arXiv:1706.00230. [Google Scholar]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B (Methodological) 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Glickman, M.E.; Rao, S.R.; Schultz, M.R. False discovery rate control is a recommended alternative to Bonferroni-type adjustments in health studies. J. Clin. Epidemiol. 2014, 67, 850–857. [Google Scholar] [CrossRef]
- Perneger, T.V. What’s wrong with Bonferroni adjustments. BMJ 1998, 316, 1236–1238. [Google Scholar] [CrossRef] [PubMed]
- Saracco, F.; Di Clemente, R.; Gabrielli, A.; Squartini, T. Detecting early signs of the 2007–2008 crisis in the world trade. Sci. Rep. 2016, 6, 1–11. [Google Scholar] [CrossRef] [PubMed]





| EU | F.&I. | Gov. | House. | n.EU | n.F. | n.Prof. | For. | Total | |
|---|---|---|---|---|---|---|---|---|---|
| 1995 | 74 | 214 | 106 | 52,356 | 6 | 4565 | 667 | 12 | 58,000 |
| 1996 | 51 | 287 | 118 | 63,425 | 6 | 4816 | 774 | 27 | 69,504 |
| 1997 | 68 | 340 | 122 | 91,306 | 5 | 6395 | 987 | 35 | 99,258 |
| 1998 | 90 | 339 | 129 | 129,276 | 3 | 8043 | 1213 | 69 | 139,162 |
| 1999 | 95 | 440 | 148 | 182,874 | 3 | 10,425 | 1556 | 368 | 195,909 |
| 2000 | 336 | 528 | 178 | 272,843 | 29 | 14,368 | 1664 | 509 | 290,455 |
| 2001 | 728 | 417 | 139 | 200,442 | 179 | 10,455 | 1382 | 760 | 214,502 |
| 2002 | 641 | 409 | 147 | 144,504 | 216 | 8205 | 1229 | 693 | 156,044 |
| 2003 | 997 | 456 | 139 | 147,467 | 466 | 8439 | 1198 | 539 | 159,701 |
| 2004 | 998 | 441 | 290 | 163,798 | 603 | 8822 | 1413 | 613 | 176,978 |
| 2005 | 1031 | 608 | 132 | 182,679 | 390 | 9445 | 1382 | 222 | 195,889 |
| 2006 | 1084 | 445 | 179 | 176,352 | 424 | 9768 | 1359 | 423 | 190,034 |
| 2007 | 1412 | 421 | 116 | 194,991 | 964 | 9948 | 1398 | 702 | 209,952 |
| 2008 | 629 | 402 | 94 | 153,957 | 216 | 8818 | 1010 | 598 | 165,724 |
| 2009 | 536 | 392 | 128 | 194,298 | 181 | 9635 | 1667 | 312 | 207,149 |
| 2010 | 830 | 527 | 108 | 217,414 | 406 | 12,117 | 1432 | 630 | 233,464 |
| 2011 | 981 | 532 | 100 | 247,829 | 558 | 12,489 | 1470 | 600 | 264,559 |
| 2012 | 1292 | 515 | 109 | 230,791 | 1128 | 11,397 | 1415 | 553 | 247,200 |
| 2013 | 2025 | 509 | 124 | 267,791 | 1996 | 12,534 | 1613 | 512 | 287,104 |
| 2014 | 2051 | 526 | 131 | 279,515 | 1894 | 12,901 | 1823 | 330 | 299,171 |
| 2015 | 2100 | 540 | 158 | 267,429 | 2327 | 12,849 | 1761 | 478 | 287,642 |
| 2016 | 2169 | 514 | 131 | 266,175 | 2535 | 12,473 | 1575 | 450 | 286,022 |
| avg. inv. tr. | n. inv. | n. trades | n. sec. | n. inv. sec. | |
|---|---|---|---|---|---|
| 1995 | 42.15 | 542.06 | 3117.70 | 66.70 | 3.75 |
| 1996 | 38.44 | 637.65 | 4321.51 | 78.32 | 4.23 |
| 1997 | 44.67 | 919.06 | 6370.85 | 87.13 | 4.15 |
| 1998 | 35.47 | 1276.72 | 8454.65 | 97.32 | 4.17 |
| 1999 | 22.09 | 1797.33 | 13,043.98 | 116.59 | 4.47 |
| 2000 | 21.19 | 2593.35 | 21,874.32 | 124.41 | 4.43 |
| 2001 | 24.16 | 1932.45 | 16,758.54 | 136.21 | 4.39 |
| 2002 | 24.17 | 1431.60 | 13,944.69 | 160.52 | 4.47 |
| 2003 | 22.20 | 1478.71 | 14,091.56 | 172.62 | 4.70 |
| 2004 | 21.78 | 1608.89 | 16,226.59 | 202.10 | 4.51 |
| 2005 | 29.90 | 1749.01 | 19,354.29 | 238.31 | 5.38 |
| 2006 | 30.56 | 1727.58 | 22,532.95 | 318.73 | 5.41 |
| 2007 | 30.42 | 1874.57 | 24,952.73 | 372.95 | 5.42 |
| 2008 | 31.38 | 1506.58 | 24,809.50 | 354.93 | 5.36 |
| 2009 | 25.59 | 1866.21 | 26,793.68 | 280.45 | 5.10 |
| 2010 | 36.27 | 2122.40 | 33,096.51 | 394.26 | 6.21 |
| 2011 | 37.32 | 2405.08 | 32,940.02 | 512.27 | 6.06 |
| 2012 | 30.82 | 2332.08 | 29,387.09 | 534.23 | 5.48 |
| 2013 | 32.55 | 2708.53 | 33,650.18 | 617.48 | 5.94 |
| 2014 | 37.09 | 2719.74 | 33,143.83 | 712.45 | 5.90 |
| 2015 | 35.27 | 2688.24 | 36,139.37 | 886.69 | 6.25 |
| 2016 | 37.06 | 2624.06 | 36,650.42 | 758.92 | 6.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baltakys, K.; Le Viet, H.; Kanniainen, J. Structure of Investor Networks and Financial Crises. Entropy 2021, 23, 381. https://doi.org/10.3390/e23040381
Baltakys K, Le Viet H, Kanniainen J. Structure of Investor Networks and Financial Crises. Entropy. 2021; 23(4):381. https://doi.org/10.3390/e23040381
Chicago/Turabian StyleBaltakys, Kęstutis, Hung Le Viet, and Juho Kanniainen. 2021. "Structure of Investor Networks and Financial Crises" Entropy 23, no. 4: 381. https://doi.org/10.3390/e23040381
APA StyleBaltakys, K., Le Viet, H., & Kanniainen, J. (2021). Structure of Investor Networks and Financial Crises. Entropy, 23(4), 381. https://doi.org/10.3390/e23040381