Abstract
The traditional linear regression model that assumes normal residuals is applied extensively in engineering and science. However, the normality assumption of the model residuals is often ineffective. This drawback can be overcome by using a generalized normal regression model that assumes a non-normal response. In this paper, we propose regression models based on generalizations of the normal distribution. The proposed regression models can be used effectively in modeling data with a highly skewed response. Furthermore, we study in some details the structural properties of the proposed generalizations of the normal distribution. The maximum likelihood method is used for estimating the parameters of the proposed method. The performance of the maximum likelihood estimators in estimating the distributional parameters is assessed through a small simulation study. Applications to two real datasets are given to illustrate the flexibility and the usefulness of the proposed distributions and their regression models.
1. Introduction
Existing distributions do not always provide an adequate fit. Hence, generalizing distributions and studying their flexibility are of interest for researchers over recent decades. One of the earliest works on generating distributions was done by [1] who proposed a method of differential equation as a fundamental approach to generate statistical distributions. Ref. [2] also made a contribution in this category and developed another method based on differential equation. After that, other methods were developed such as the method of transformation [3] and the method of quantile function [4,5]. More recent techniques in generalizing statistical distributions emerged after the 1980s and can be summarized into five major categories [6]; the method of generating skew distributions, the method of adding parameters, the beta generated method, the transformed-transformer method, and the composite method.
The beta-generated (BG) family introduced by [7] has a cumulative distribution function (CDF) given by
where is the probability density function (PDF) of the beta random variable and is the CDF of any random variable. The PDF corresponding to (1) is given by
where Supp(F) is the support of F and
Since the proposal of BG family in 2002, several members of the BG family of distributions were investigated. For example, beta-normal [7,8,9], beta-Gumbel [10], beta-Frechet [11], beta-Weibull [8,12,13,14], beta-Pareto [15], beta generalized logistic of type IV [16] and beta-Burr XII [17]. Some extensions of the BG family are also appeared in literature such as Kw-G distribution [18,19], beta type I generalization [20], and generalized gamma-generated family [21].
The beta-generated family of distributions is formed by using the beta distribution in (1) with support between 0 and 1 as a generator. Ref. [22], in turn, were interested whether other distributions with different support can be used as a generator. They extended the family of BG distributions and defined the so called T-X family. In the T-X family, the generator was replaced by a generator where T is any random variable with support . The CDF of the T-X family is given by
where is a link function that satisfies and Ref. [23] studied a special case of the T-X family where the link function, is a quantile function of a random variable The proposed CDF is defined as
where and Y are random variables with CDF and The corresponding quantile functions are and where the quantile function is defined as If densities exist, we denote them by and Now, if the random variables and for and then the corresponding PDF of (4) is given by
If R follows the normal distribution , then (5) reduces to the T-normal family of distributions [24] with PDF given by
where and are the PDF and CDF of the standard normal distribution, respectively.
The T-normal family is a general base for generating many different generalizations of the normal distribution. The distributions generated from the T-normal family can be symmetric, skewed to right, skewed to the left, or bimodal. Some of the existing generalizations of normal distribution can be obtained using this framework. In particular, some generalizations of the normal distribution are beta-normal [7], Kumaraswamy normal [19] and gamma-normal distribution [25].
Other generalizations of the normal distribution is the skew-normal, first considered by [26], and it is defined as
Another generalization of the normal distribution is the power-normal distribution [27] with CDF given by
Several properties of the power-normal distribution are studied by [27]. Recently, Ref. [28] proposed a new extension of the normal distribution.
The rest of the paper is organized as follows. In Section 2, we introduce a class of skew-symmetric model by using the logistic kernel and the normal distribution as the baseline distribution. In Section 3, we discuss some structural properties of the logistic-normal (henceforth, LN in short) distribution including moments, tail behavior, and modes. In Section 4, the maximum likelihood estimation method is considered to estimate the model parameters, and a small simulation study is implemented to evaluate the performance of the method. In Section 5, a generalized normal regression model based on skew-LN distribution is developed. In Section 6, applications to two real datasets are given to demonstrate the flexibility and the usefulness of the new distribution and its regression model. We conclude this paper by providing some concluding remarks in Section 7.
2. The Symmetric Logistic-G Family of Distributions
If T follows the logistic distribution with PDF and Y follows the standard logistic distribution (), then Equation (4) reduces to the Logistic-G family of distributions with CDF given by
where is the CDF of any baseline probability density function. A special case of (7) was studied in some details in [29]. The corresponding PDF of (7) is given by
where is the PDF of .
Remark 1.
The Logistic-G family possesses the following properties
- i.
- ii.
- If a random variable T follows the logistic distribution with scale parameter λ, then the random variable follows the Logistic-G family in (7).
- iii.
- The quantile function of the Logistic-G family can be written as
Now setting to be the normal CDF with parameters and , say , then the Logistic-G family reduces to the Logistic-normal distribution with CDF given by
where and The associated PDF of (10) is
when the logistic-normal (LN, henceforth in short) in (10) reduces to the normal distribution. Thus LN distribution is a generalization of the normal distribution. Furthermore, the LN distribution is a member of the T-normal family proposed by [24]. In Figure 1, graphs of standard LN distribution (where ) for various values of are provided. Figure 1 shows that the logistic-normal PDF has several advantages, the parameter introduces the flexibility on kurtosis (see also Figure 2) and controls whether the distribution is unimodal or bimodal. Moreover, it appears that the bi-modality occurs when is approximately less than
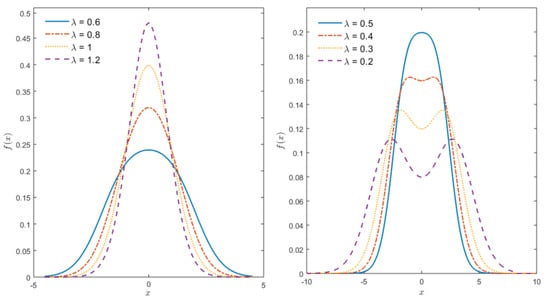
Figure 1.
The logistic-normal (LN) density for , and various values of .
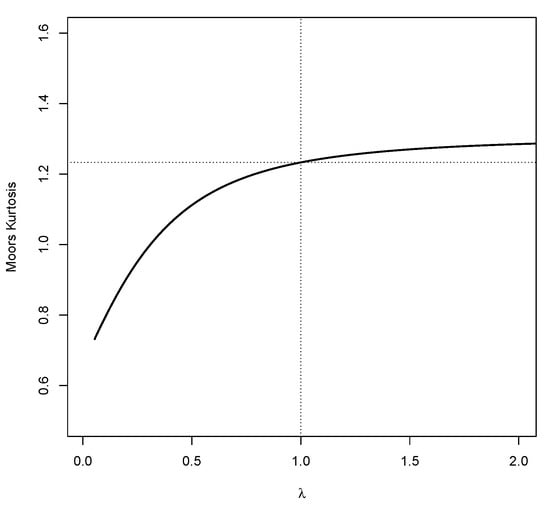
Figure 2.
Plot of Moore’s kurtosis of LN distribution for various value of . The dashed line represents the Moore’s kurtosis of the standard normal distribution.
3. Some Properties of LN Distribution
We begin our discussion by providing some useful remarks as listed below.
Remark 2.
- (i)
- It is easy to show from (11) that which implies that the LN is symmetric about the location parameter
- (ii)
- The mean and median of the LN distribution are μ which is the location parameter of the normal distribution.
- (iii)
- The quantile function of the LN distribution can be written as
- (iv)
- In order to generate random sample from the LN distribution, first simulate random sample, from logistic(λ) distribution and then compute .
Remark 3.
Using the fact that and setting the derivative of in (11) to one can show that Mode(s) of the LN distribution is/are at the point(s) , where satisfies the equation
From Remark 3, it is easy to see that 0 satisfies Equation (12). Therefore has a critical point at . We were able to observe numerically that for the distribution is always unimodal and hence, is the unique mode in this case. In addition, because of the fact that LN distribution is symmetric about for all values of then for the bimodal case, if is a mode then the second mode will be at
The tail behaviour of the standard LN distribution ( and ) as are discussed in the following Lemma.
Lemma 1.
Let , then as
Proof.
As and (see [17]). Consequently, as . Similarly, as □
Lemma 1 implies that as the tails of the standard LN distribution behave in similar way as the right tail of the function Note that when the tails of approaches 0 slowly, while for the tails of approaches 0 faster, meaning that the tail weight increases for higher values of A graphical representation of the association between the tail weight of LN and can be shown using the measure of Kurtosis defined by [30]. The Moore’s kurtosis is defined as
The values of Moore’s kurtosis of LN for various value of is depicted in Figure 2. It shows that as increases the Moore’s kurtosis increases. For there is a sharp change in the kurtosis, while for the change is gradual. Figure 1 indicates that for the tails of LN distribution are lighter than that of the normal distribution, while for the tails of LN distribution are heavier than that of the normal distribution.
Moments of LN Distribution
Using Remark 2 (ii), the rth moment of the LN distribution can be written as where the random variable T follows the logistic distribution with scale parameter Therefore,
Now, where This implies that
where
can be evaluated using numerical integration from any available software such as R or
Remark 4.
Let , then
- i.
- From Remark 2 (i), the rth central moment for any odd integer
- ii.
- implies that where Therefore,
4. Estimation and Simulation
In this section, the maximum likelihood method (MLE) is used to estimate the parameters of LN distribution. Moreover, a small simulation study is performed to assess the performance of the MLE method.
4.1. Parameter Estimation of LN Distribution
Let be a random sample of size n taken from LN distribution. Then the log-likelihood function is given by
The MLE of and of the parameters and can be obtained by maximizing numerically the log-likelihood function in (14). The initial value of is taken to be the moment estimator The initial value of is taken to be the sample standard deviation, To obtain the initial value of the parameter we use Remark 2 (iv) as follows; assume the random sample is taken from the logistic distribution with parameter By equating the population variance of logistic distribution with the sample variance, of the random sample and solving it for we obtain
The trust-region optimization routine in SAS (PROC IML and CALL NLPTR) is used in order to maximize the likelihood function in (14). The trust-region optimization routine is a powerful technique that can optimize complicated functions. It outputs the iteration details including parameter estimates, their standard errors, and the value of the gradient function at which iteration stops.
4.2. Simulation
In order to evaluate the performance of the ML method, a small simulation study is conducted with sample sizes and with three different parameter combinations. The study involved computing and analyzing the relative bias [(Estimate-Actual)/Actual] and the standard deviation of the estimates. The results of the study are reported in Table 1.

Table 1.
Relative bias and standard deviation of the maximum likelihood method (MLE) for LN distribution.
From Table 1, it is observed that the ML estimate of the parameter is overestimated. Moreover, when the ML estimates of and are overestimated. On the other hand, when ML estimates of and are underestimated. Moreover, for small sample size(s) and when MLE method does not perform well. In fact, standard deviations are higher than the corresponding estimated values. However, the results for higher sample sizes and when it can be seen that the MLE method performs quite well in estimating the model parameters.
5. Skew-LN and Its Generalized Normal Regression Model
In this section, we first propose a skewed type of LN distribution that can be used to fit skewed dataset. In Section 5.2, we propose a location-scale regression model based on the skew-LN distribution.
5.1. Skew Logistic-Normal Distribution
For skewed data, one can generate a skew-LN distribution in various ways. Once way is by exponentiating the CDF of the LN distribution as
Note that when , the skew-LN distribution in (15) reduces to LN distribution. Moreover, when , the skew-LN reduces to the eponentiated-normal distribution proposed by [27]. Finally, when , the skew-LN distribution reduces to normal distribution.
In order to analyze the skewness and kurtosis regions of the skew-LN distribution, the Refs. [30,31] measures were plotted against the parameter and Figure 3 shows that the distribution is right skewed for and left skewed for and The plot of kurtosis in Figure 3 demonstrates the flexibility of the proposed distribution. For the tails of the skewed LN can be heavier or lighter than that tail of the normal distribution.
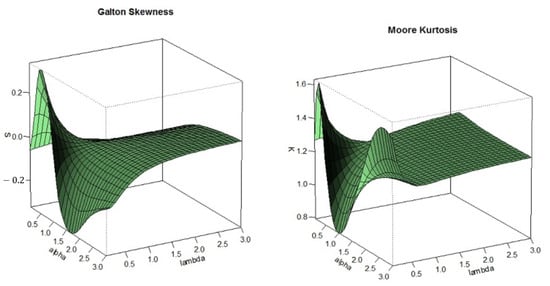
Figure 3.
Three-dimensional plots of Galton’s skewness and Moore’s kurtosis for various values of and .
The skew-LN distribution has several advantages; the parameter introduces the flexibility on the skewness and the parameter introduces the flexibility on the kurtosis. Furthermore, the main advantage of the skew-LN when compared with Azzalini skew-normal is the flexibility of fitting data with wider range of skewness and kurtosis. Based on numerical calculations, for the Azzalini skew-normal, the Galton’s skewness ranges between −0.1443 and 0.1443 and the Moor’s kurtosis ranges between 1.1746 and 1.2460. However, for the skew-LN, the Galton’s skewness ranges between −0.3000 and 0.3000 and the Moor’s kurtosis ranges between 0.8000 and 1.6000. It is also worth mentioning that the skew-LN can be unimodal or bimodal and has closed form CDF which is not the case of Azzalini skew-normal distribution.
5.2. Generalized Normal Regression Model Based on Skew-LN Distribution
The traditional linear regression model that assumes normal residuals is applied extensively in engineering and science. However, the normality assumption of the model residuals is often ineffective. This drawback can be overcome by using a generalized normal regression model that assumes non-normal response In this section, T is assumed to follow the skew-LN distribution. The following location-scale regression model is considered based on the skew-LN distribution
where pertains to the response variable with a skew-LN distribution in (15), and are unknown parameters. Every has a covariate vector that models the linear predictor The random error follows the skew-LN distribution.
Remark 5.
The skew-LN regression model in (16) has several nested regression models. These special cases are enumerated as follows:
- 1.
- The regression model in (16) is reduced to the traditional normal linear regression model when
- 2.
- The exponentiated-normal (Exp-N) regression model is obtained when This location-scale regression model is based on the power normal distribution introduced by [27].
- 3.
- The LN regression model based on the distribution (10) is obtained when
6. Applications
In this section, we apply the LN distribution and the generalized normal regression to two real-life datasets. The first dataset possesses a bimodal shape, and the fit of the LN distribution is compared with the mixture normal distribution. For the second application, the skew-normal regression model is compared with some nested sub-models and some other generalization of the normal regression models. Maximum likelihood method is used to estimate the model parameters.
6.1. Fitting LN Distribution to Buoys Data
In this subsection the LN distribution is fitted to a bimodal datasets using ML method. The dataset is obtained from National Data Buoy Center (NDBC). It represents the number of buoys situated in the North East Pacific: Buoy 46,005 (46 N, 131 W) for the time period 1 January 1983 to 31 December 2003. The data is available from [1]. The Histogram in Figure 4 shows that the distribution of the data possesses a bimodality shape, for this reason, we fitted the dataset to both LN and the mixture normal distributions. The results of the maximum likelihood estimates, the log-likelihood value, the AIC (Akaike Information Criterion) and the Kolmogorov-Smirnov (K-S) test statistic for the fitted distributions are reported in Table 2. Figure 4 displays both the empirical and the fitted cumulative distribution as well as the probability density functions for the fitted distributions. The results in Table 2 indicate that the LN distribution outperforms the mixture normal distribution. In fact, the fitted CDF in Figure 4 shows that the mixture normal distribution does not provide an adequate fit. The fact that the LN distribution has only three parameters adds an extra advantage to the distribution over the mixture normal distribution.
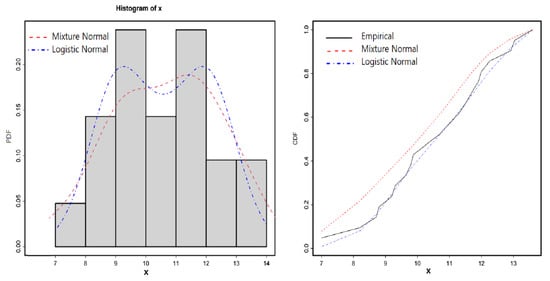
Figure 4.
Plots of fitted distributions for the Buoys dataset.
Table 2.
Estimates of the parameters and goodness of fit measures for the Buoys data.
6.2. Modeling Real Estate Valuation Using the Generalized Normal Regression Model
The dataset contains historical data on the real estate market from June 2012 to May The data is obtained from Sindian District in New Taipei City, Taiwan (for additional details, see [32]). The data consist of transaction records of real estate property. The data can be used to establish the relationship between housing price (per unit area) and its predictive regressors. The following variables are used (for ). Response variable y is the housing price per unit area ( New Taiwan Dollar/Ping, where 1 Ping = 3.3 m), the covariates are as follows: is the transaction date (e.g., March and June), is the house age (in years), is the distance to the nearest MRT station (in meters), is the number of convenience stores in the living circle on foot (integer), and is the geographic coordinate, latitude (in degrees). The data are analyzed on the basis of the following skew-LN regression model
where the error terms are independent random variables that assumed to follow the skew-LN distribution, and , are the standardized covariates, which are considered because of the fact that some covariates are measured using different scales. Additionally, the fit under the skew-LN regression model is compared with several regression models, including the regression model based on the beta-normal (BN) distribution [7], the regression model based on the skewed-normal (SN) distribution [26], and the extended normal (EN) regression model [28]. Furthermore, the skew-LN regression model is compared with its nested models, including LN, Exp-N, and normal regression. In this application, the model parameters are estimated using the maximum likelihood method and SAS programming language is used. The initial values of and are obtained from fitting the data to the normal regression model. The initial values of the other parameters are set to Table 3 shows the MLEs results of fitting skew-LN, LN, Exp-N, SN, EN, and normal regression models to the data.
Table 3.
MLEs of the parameters (SEs in parentheses) and p-values below SE for the real estate valuation data.
The fitted skew-LN an LN regression models show that the estimates and are significant at 5% level of error. Table 4 presents the goodness of fit statistics including AIC, consistent AIC (AICC) and Bayesian information criterion (BIC). The goodness of fit statistics show that the skew-LN regression model outperforms the other regression models. We also notice that the LN regression model has the second-lowest values of AIC, AICC, and BIC. Hence, skew-LN and LN regression models can be used effectively to analyze the real estate valuation data.
Table 4.
Goodness of fit statistics for the real estate valuation data.
The likelihood ratio (LR) statistic is utilized to compare the skew-LN regression model with its sub-models; normal, LN, and Exp-N regression models. The LR test statistic values and the corresponding p-values are given in Table 5. This Table shows that the skew-LN regression model has a better fit when compared with the other sub-models. The LN regression model also has a better fit when compared with the normal regression model.
Table 5.
LR statistics for the real estate valuation data.
7. Concluding Remarks
In this paper, two generalizations of the normal distribution namely; logistic-normal and skew logistic-normal distributions were investigated. Several mathematical and structural properties have been studied such as shape properties. The proposed generalizations of the normal distribution exhibit a great flexibility in modeling symmetric as well as skewed datasets. Moreover, new regression models based on both logistic-normal and skew logistic-normal were developed. Two real datasets were used to illustrate the applicability of the distributions and their regression models.
Future work could be devoted toward investigating other parameter estimation methods for the LN and the skew-LN distributions. The applicability of the skew-LN regression model to other fields could be further explored.
Author Contributions
Conceptualization, A.A. (Ayman Alzaatreh); Data curation, A.A. (Ayman Alzaatreh); Formal analysis, A.A. (Ayman Alzaatreh), M.A., A.A. (Ayanna Almagambetova) and N.Z.; Investigation, A.A. (Ayman Alzaatreh) and A.A. (Ayanna Almagambetova); Methodology, A.A. (Ayman Alzaatreh), M.A. and A.A. (Ayanna Almagambetova); Project administration, A.A. (Ayman Alzaatreh); Software, A.A. (Ayman Alzaatreh), M.A., A.A. (Ayanna Almagambetova) and N.Z.; Supervision, A.A. (Ayman Alzaatreh); Writing—original draft, A.A. (Ayman Alzaatreh), M.A., A.A. (Ayanna Almagambetova) and N.Z.; Writing—review & editing, A.A. (Ayman Alzaatreh), M.A. and A.A. (Ayanna Almagambetova). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by American University of Sharjah: AUS Open Access Fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
The authors are grateful for the comments and suggestions by the referees and the handling Editor. Their comments and suggestions have greatly improved the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pearson, K. Contributions to the mathematical theory of evolution. II. Skew variation in homogeneous material. Philos. Trans. R. Soc. Lond. Ser. A 1895, 186, 343–414. [Google Scholar]
- Burr, I.W. Cumulative frequency functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Johnson, N.L. Systems of frequency curves generated by methods of translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef]
- Hastings, J.C.; Mostseller, F.; Tukey, J.W.; Windsor, C. Low moments for small samples: A comparative study of order statistics. Ann. Stat. 1947, 18, 413–426. [Google Scholar] [CrossRef]
- Tukey, J.W. The Practical Relationship Between the Common Transformations of Percentages of Counts and Amounts; Technical Report 36; Statistical Techniques Research Group, Princeton University: Princeton, NJ, USA, 1960. [Google Scholar]
- Lee, C.; Famoye, F.; Alzaatreh, A. Methods for generating families of univariate continuous distributions in the recent decades. WIREs Comput. Stat. 2013, 5, 219–238. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. The beta-normal distribution and its applications. Commun. Stat.-Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Famoye, F.; Lee, C.; Eugene, N. Beta-normal distribution: Bimodality properties and applications. J. Mod. Appl. Stat. Methods 2004, 3, 85–103. [Google Scholar] [CrossRef]
- Rego, L.C.; Cintra, R.J.; Cordeiro, G.M. On some properties of the beta normal distribution. Commun. Stat. Theory Methods 2012, 41, 3722–3738. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. The beta Gumbel distribution. Math. Probl. Eng. 2004, 4, 323–332. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Cordeiro, G.M.; Simas, A.B. Some results for beta Frechet distribution. Commun. Stat. Theory Methods 2011, 40, 798–811. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Simas, A.B.; Stosic, B.D. Closed form expressions for moments of the beta Weibull distribution. Ann. Braz. Acad. Sci. 2011, 83, 357–373. [Google Scholar] [CrossRef]
- Lee, C.; Famoye, F.; Olumolade, O. Beta-Weibull distribution: Some properties and applications to censored data. J. Mod. Appl. Stat. Methods 2007, 6, 173–186. [Google Scholar] [CrossRef]
- Wahed, A.S.; Luong, T.M.; Jong-Hyeon, J.J.H. A new generalization of Weibull distribution with application to a breast cancer dataset. Stat. Med. 2009, 28, 2077–2094. [Google Scholar] [CrossRef]
- Akinsete, A.; Famoye, F.; Lee, C. The beta-Pareto distribution. Statistics 2008, 42, 547–563. [Google Scholar] [CrossRef]
- De Morais, A.L. A Class of Generalized Beta Distributions, Pareto Power Series and Weibull Power Series Dissertation; Universidade Federal de Pernambuco: Recife, Brazil, 2009. [Google Scholar]
- Paranaiba, P.F.; Ortega, E.M.M.; Cordeiro, G.M.; Pescim, R.R. The beta Burr XII distribution with application to lifetime data. Comput. Stat. Data Anal. 2011, 55, 1118–1136. [Google Scholar] [CrossRef]
- Jones, M.C. Kumaraswamy’s distribution: A beta type distribution with tractability advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; de Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Alexander, C.; Cordeiro, G.M.; Ortega, E.M.M.; Sarabia, J.M. Generalized beta-generated distributions. Comput. Stat. Data Anal. 2012, 56, 1880–1897. [Google Scholar] [CrossRef]
- Zografos, K.; Balakrishnan, N. On families of beta- and generalized gamma-generated distributions and associated inference. Stat. Methodol. 2009, 6, 344–362. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Lee, C.; Famoye, F. A new method for generating families of continuous distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Aljarrah, M.A.; Lee, C.; Famoye, F. On generating T-X family of distributions using quantile functions. J. Stat. Distrib. Appl. 2014, 1, 2. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Famoye, F.; Lee, C. T-normal family of distribution: A new approach to generalize the normal distribution. J. Stat. Distrib. Appl. 2014, 1, 16. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Famoye, F.; Lee, C. The gamma-normal distribution: Properties and applications. Comput. Stat. Data Anal. 2014, 69, 67–80. [Google Scholar] [CrossRef]
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Gupta, R.C.; Gupta, R.D. Analyzing skewed data by power-normal model. Test 2008, 17, 197–210. [Google Scholar] [CrossRef]
- Lima, M.C.S.; Cordeiro, G.M.; Ortega, E.M.M.; Nascimento, A.D.C. A new extended normal regression model: Simulations and applications. J. Stat. Distrib. Appl. 2019, 6, 7. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Sulieman, H. On fitting cryptocurrency log-return exchange rates. Empir. Econ. 2019, 15, 1–18. [Google Scholar] [CrossRef]
- Moors, J.J.A. A quantile alternative for Kurtosis. Statistician 1988, 37, 25–32. [Google Scholar] [CrossRef]
- Galton, F. Enquiries into Human Faculty and Its Development; Macmillan: London, UK, 1883. [Google Scholar]
- Yeh, I.C.; Hsu, T.K. Building real estate valuation models with comparative approach through case-based reasoning. Appl. Soft Comput. 2018, 65, 260–271. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).