1. Introduction
A stock market crash is one of the most significant systemic risks of the modern financial system, causing significant losses for investors. A recent example is the March 2020 stock market crash triggered by COVID-19 [
1], during which the New York Stock Exchange (NYSE) Composite Index plunged roughly 35% within a month. Meanwhile, rebounds of the stock market after crashes usually signal the recovery of investors’ confidence or the taking effect of bailout policies. Therefore, it is critical for investors and policy makers to detect stock market crashes and predict price rebounds.
In the past decades, different methods have been proposed to diagnose the stock market crashes and predict rebounds. One of the most representative methods is the log-periodic power-law (LPPL) model [
2]. Originally, the LPPL model was proposed to predict the bursting point of financial bubbles. Yan et al. [
3] adopt the LPPL model to study stock market crashes by considering them as the “mirror images” of financial bubbles, which are also known as “negative bubbles”. The fundamental insight of modeling financial crashes with the LPPL model is to capture a particular pattern of the price time series, which can be described as “the faster-than-exponential decline accompanied by accelerating oscillations” [
4]. The LPPL model and its extensions are successfully applied in diagnosing negative bubbles of many types of assets, such as crude oil [
5] and cryptocurrency [
6].
Despite previous achievements, all the existing LPPL-based models only focus on the price time series itself. However, it may not be sufficient to use only the price time series of the stock index when diagnosing stock market crashes. The price time series of the stock index can describe the overall fluctuation of the stock market, but it ignores the complex interactions among multiple assets.
Network analysis provides a novel tool for characterizing the complex interactions and co-movements in the stock market [
7,
8,
9]. In fact, it has been discovered that stock market crashes and recoveries are accompanied by drastic changes in the topological structure of stock correlation networks, which can be captured by some network statistics such as assortativity [
10], modularity [
11], von Neumann entropy [
12], the structural entropy [
13,
14] and the graph motif entropy [
15]. Although the above literature qualitatively analyzes the dynamical changes of stock correlation networks during stock market crashes and rebounds, there is still a lack of work that applies such phenomenon to quantitatively diagnose stock market crashes and predict price rebounds.
This paper contributes to the literature by incorporating the analysis of a time-evolving stock correlation network into the LPPL model. The contribution of this paper has three folds. First, extending the LPPL model, we propose to characterize stock market crashes by two distinct characteristics: (1) faster-than-exponential decline of the stock index price; (2) abnormal changes in the market structure (i.e., the topology of the stock correlation network). Second, we design a prediction-guided anomaly detection method based on the extreme value theory (EVT) in order to define and detect “anomalies” for Characteristic (2). The intuition is that a properly trained predictor can forecast most of the “normal” situations well, with significant deviations when “abnormal” situations occur. The “normal” and “abnormal” deviations are distinguished based on EVT. Third, we propose a framework by combining Characteristic (1) and (2), where Characteristic (1) is captured by a visibility graph (VG)-based representation of the LPPL model proposed by Yan et al. [
16]. A hybrid rebound indicator is calculated, which is a linear combination of Yan’s VG-based indicator and the anomalies of the stock correlation network. Specifically, we normalize the anomalies to 0 to 1 based on EVT and treat them as confidence levels (i.e., weights) of the VG-based rebound indicator.
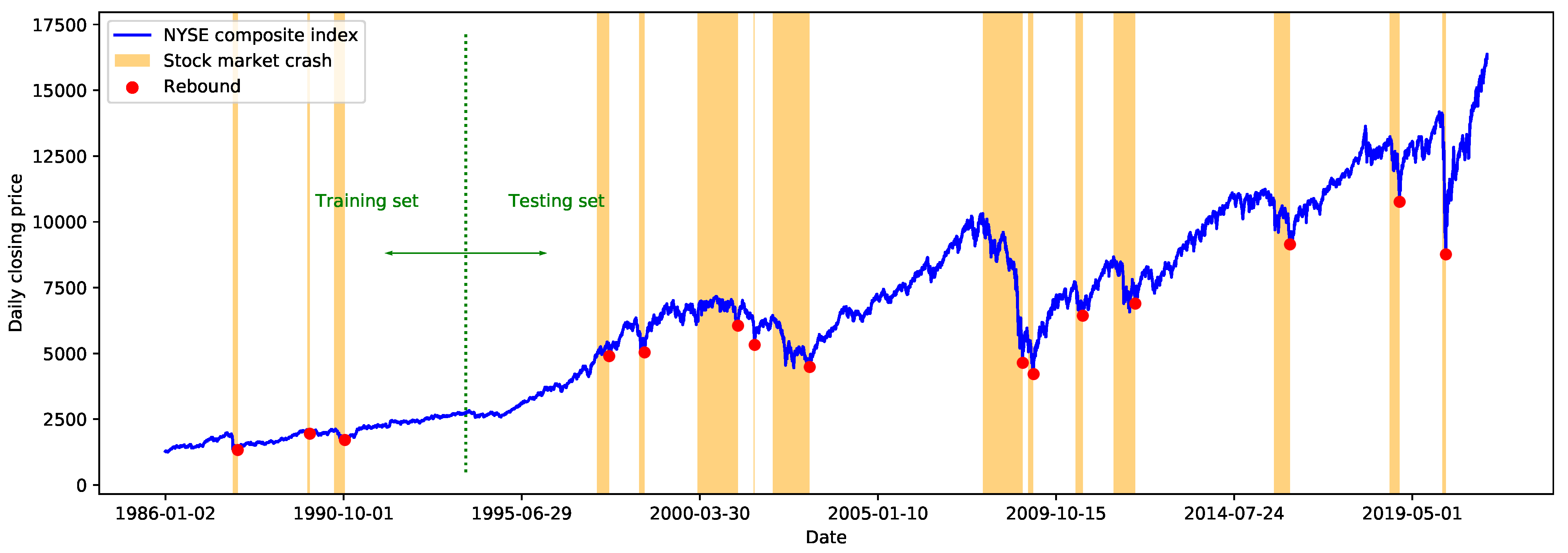
Experiments are conducted based on the data of the New York Stock Exchange (NYSE) Composite Index. We predict the subsequent price rebounds of the 12 major crashes in the U.S. stock market from 4 January 1991 to 7 May 2021. Experimental results demonstrate that our proposed prediction-guided anomaly detection algorithm is well capable of identifying abnormal changes in stock correlation networks during market crashes and recoveries. Furthermore, our proposed hybrid indicator outperforms Yan’s VG-based indicator by reducing the false alarm rate. These findings imply that incorporating the analysis of the time-evolving stock correlation network into the modeling of the stock index time series is a promising direction for diagnosing and predicting financial markets.
The rest of this paper is organized as follows.
Section 2 describes the data.
Section 3 introduces our proposed framework for stock market crash diagnosis and rebound prediction.
Section 4 presents the experimental results.
Section 5 discusses the main findings, implications and limitations of this study.
Section 6 concludes our work and provides future research directions.
3. Methodology
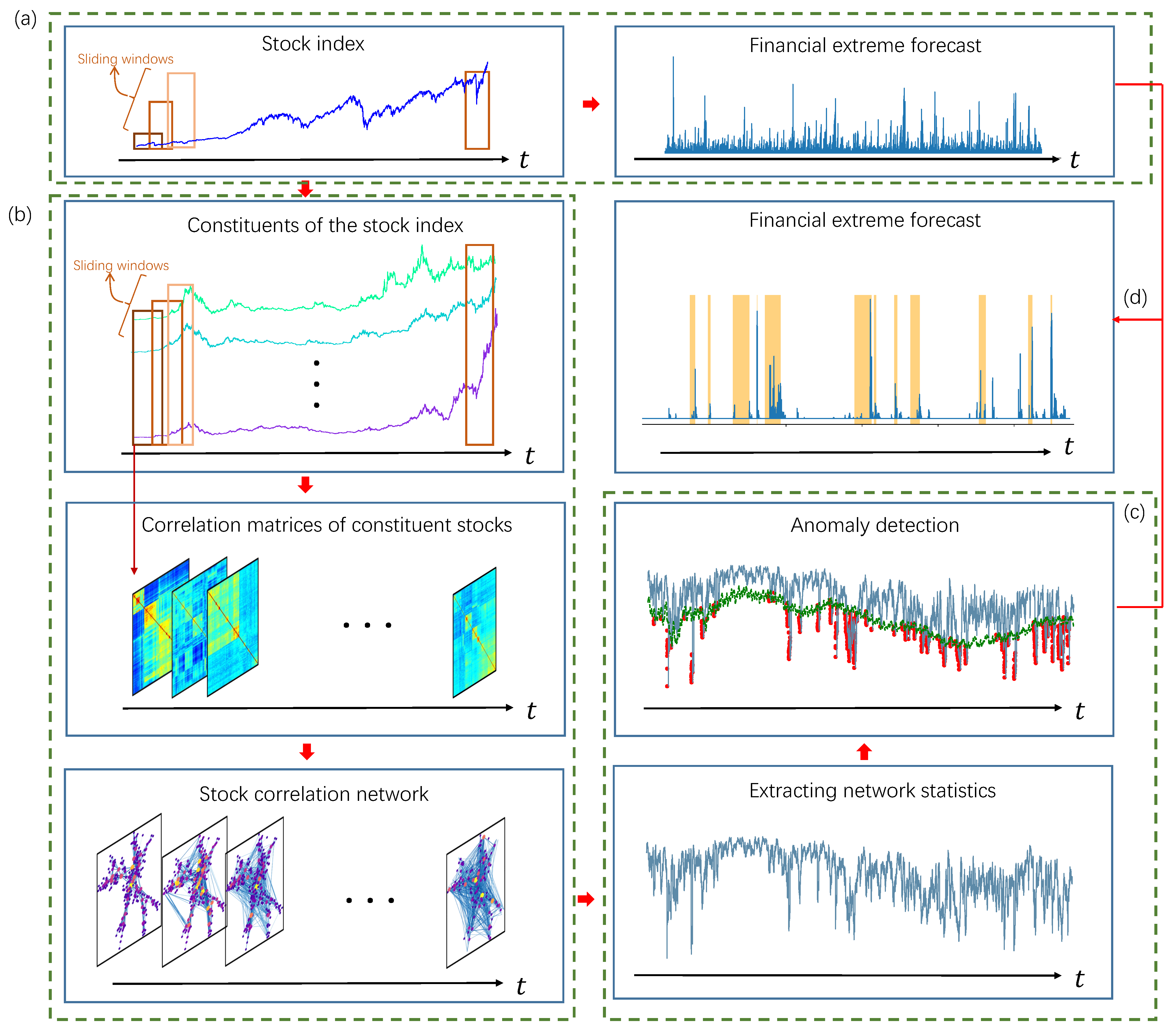
Our proposed framework predicts market rebounds by observing and quantifying a specific phenomenon, which is a faster-than-exponential decline in the stock index price time series accompanied by anomalous changes in the topology of the correlation network of constituent stocks. Therefore, our proposed framework consists of the following four steps: (1) quantifying faster-than-exponential decline in stock index price; (2) constructing time-evolving stock correlation network; (3) detecting anomalous topological changes of stock correlation networks; (4) calculating a rebound alarm index. In this section, we first introduce our proposed framework and then describe each of these four steps.
3.1. Our Proposed Framework
Our proposed framework is illustrated in detail in
Figure 2. We first measure the faster-than-exponential decline of the price time series of the stock index based on Yan’s VG-based LPPL model [
16] (step
a). The detailed procedures are described in
Section 3.2.
The time series of the stock index can describe the overall fluctuation of the financial market, but it ignores the complex interactions between different assets. In our proposed framework, we exploit information of the market structure by investigating the time-evolving topology of the stock correlation network (step
b and
c). In step
b, we first select the constituents of the stock index, then calculate the matrices of Pearson correlation coefficients based on the logarithmic return of the constituents through a sliding window, and finally extract the most important correlations in the matrix to form a stock correlation network. In step
c, topological measurements are extracted from the time-evolving stock correlation network. Anomaly detection is performed on the extracted topological measurements to identify the emergence and disappearance of anomalous network topology.
Section 3.3–
Section 3.5 describe the implementation of step
b,
c and step
d, respectively.
3.2. Quantifying Faster-Than-Exponential Decline in Stock Index Price
We adopt the method based on the visibility graph [
16] to quantitatively describe the faster-than-exponential decline of the stock index prices. This subsection first briefly introduces the basic idea of the visibility graph and then describes the quantification of the faster-than-exponential decline of the stock index price based on the VG.
The visibility graph (VG) is first presented by Lacasa et al. [
19] as an algorithm for converting time series into complex networks. Its basic idea is to map each time point in a discrete time series into a node in a network. The edges of the network are established based on the visibility criteria. The detailed procedure of constructing the visibility graph is introduced as follows.
For each pair of data points in the time series noted as
and
where
, the VG algorithm first connects them with a straight line. If all the data points between
i and
j are below the straight line,
and
are considered “visible” to each other, and an edge is created between them in the visibility graph. A more formal expression is: for a time series
of length
N, the adjacency matrix
W of its visibility graph is defined as
where
denotes the weight of the edge
in the visibility graph.
Yan et al. [
16] first represent the log periodic power law (LPPL) model with the visibility graph. Originally, the LPPL model characterizes the financial bubbles by the faster-than-exponential growth of the stock market prices. Yan et al. construct the visibility graph based on the logarithmic prices of stock indices. Since the exponential growth is a straight line in the logarithmic-linear scale, faster-than-exponential growth is represented as a convex curve. Therefore, as the price time series goes up super-exponentially, the degree of the last node of its VG increases. Furthermore, if two nodes
and
are “visible” to each other, the growth rate from
to
can be roughly considered as “faster-than-exponential”.
Since our goal is to characterize the financial crashes, we adopt the absolute invisibility graph, which is exactly the opposite of the visibility graph. Its adjacency matrix
is defined as
Similar to the visibility graph, if two nodes
and
are “absolutely invisible” to each other, we can roughly conclude a faster-than-exponential decline from
to
. For each data point
in a time series, we obtain
historical data before
through a sliding window of length
to construct the absolute invisibility graph. The magnitude of the faster-than-exponential decline at time point
is defined as
where
is the indicator function.
3.3. Constructing the Time-Evolving Stock Correlation Network
This paper studies the time-evolving nature of the correlation network, which is formed by the constituents of a stock index. Our basic assumption is that the topology of the stock correlation network changes significantly during financial crashes, and that the recovery of the network topology implies the recovery of the financial market.
The most straightforward way of studying a time-evolving network is to look at snapshots of the network taken at different time points. By stacking the snapshots in temporal order, a time-evolving network is denoted as . Each is a snapshot recorded as time t, where is the set of nodes and is the set of edges. Since this paper considers the time-evolving correlations among the same set of stocks, all the snapshots in share the same set of nodes, that is, .
In this paper, each snapshot is obtained from the correlation matrix by a filtering method. The construction procedure is composed of four steps: (1) dividing time windows; (2) determining the constituents of the stock index; (3) calculating correlation matrices; (4) extracting single layer networks from the correlation matrices. The detailed procedure is illustrated as follows.
3.3.1. Dividing Time Windows
In terms of dividing time windows, three parameters need to be determined: (1) the length
of the time window, (2) the step size
between two consecutive windows. The choice of time window length
is a trade-off between over-smoothed and too noisy data [
20]. In order to capture the dynamics of stock market correlations, we need to choose the smallest possible window length. On the other hand, the time window needs to be long enough to avoid the Epps effect [
21]. Here, we choose a commonly used empirical value
[
15], meaning that each time window contains 25 trading days. To have a continuous tracking of the stock correlations, the step size is set as
, shifting the time window 1 day forward at each step.
3.3.2. Determining Constituents of the Stock Index
In this step, we determine the name list of the stocks to track, that is, the set of nodes
. Notice that the constituents of the stock index are constantly adjusted over time. To ensure continuous and stable tracking of the market structure, we select the constituents of the stock index whose historical data are available during the entire experimental period. In this paper, we select
stocks from the NYSE dataset [
11,
22], whose daily closing prices are available from 2 January 1986 to 7 May 2021.
3.3.3. Calculating Correlation Matrices
For stock
i in
, its logarithm return at time
t is defined as
where
is the adjusted closure price of stock
i at time
t. Then the Pearson correlation coefficient between stock
i and stock
j is calculated as
where
represents the sample mean, ⊙ denotes element-wise multiplication of vectors and
is the logarithm return series of stock
i within the time window. Thus a
correlation matrix
is obtained.
3.3.4. Extracting Single-Layer Networks from Correlation Matrices
The threshold-based method [
23] is applied to extract the strong correlations and construct the network. For the correlation matrix
, we choose a threshold
and only keep
as the edges of the network
. This paper sets
as the 85th percentile of all elements in
. The connection criterion of network
is formally defined as
where
denotes the weight of the edge
in the network
.
3.3.5. Calculating Singular Value Decomposition Entropy
We further measure the topology of each layer
by the singular value decomposition (SVD) entropy, which has been applied to the analysis of financial market networks [
24,
25,
26,
27]. The definition of the SVD entropy is introduced below. It is worth noting that the topological characteristic is not limited to the SVD entropy, any proper network statistic, such as the von Neumann entropy [
28] or the graph motif entropy [
15], is applicable to our proposed framework.
The SVD entropy is based on the singular value decomposition of the
adjacent matrix
A of the network
G,
where
is a diagonal matrix of singular values,
The SVD entropy is defined as
where
is the normalized singular value defined as
By calculating the topological characteristics, we transform the time-evolving network into a time series, which is much easier to interpret. Based on the time series of the SVD entropy, we identify and measure anomalous changes in the topology of the stock temporal network in the following subsections.
3.4. Prediction-Guided Anomaly Detection Based on Extreme Value Theory
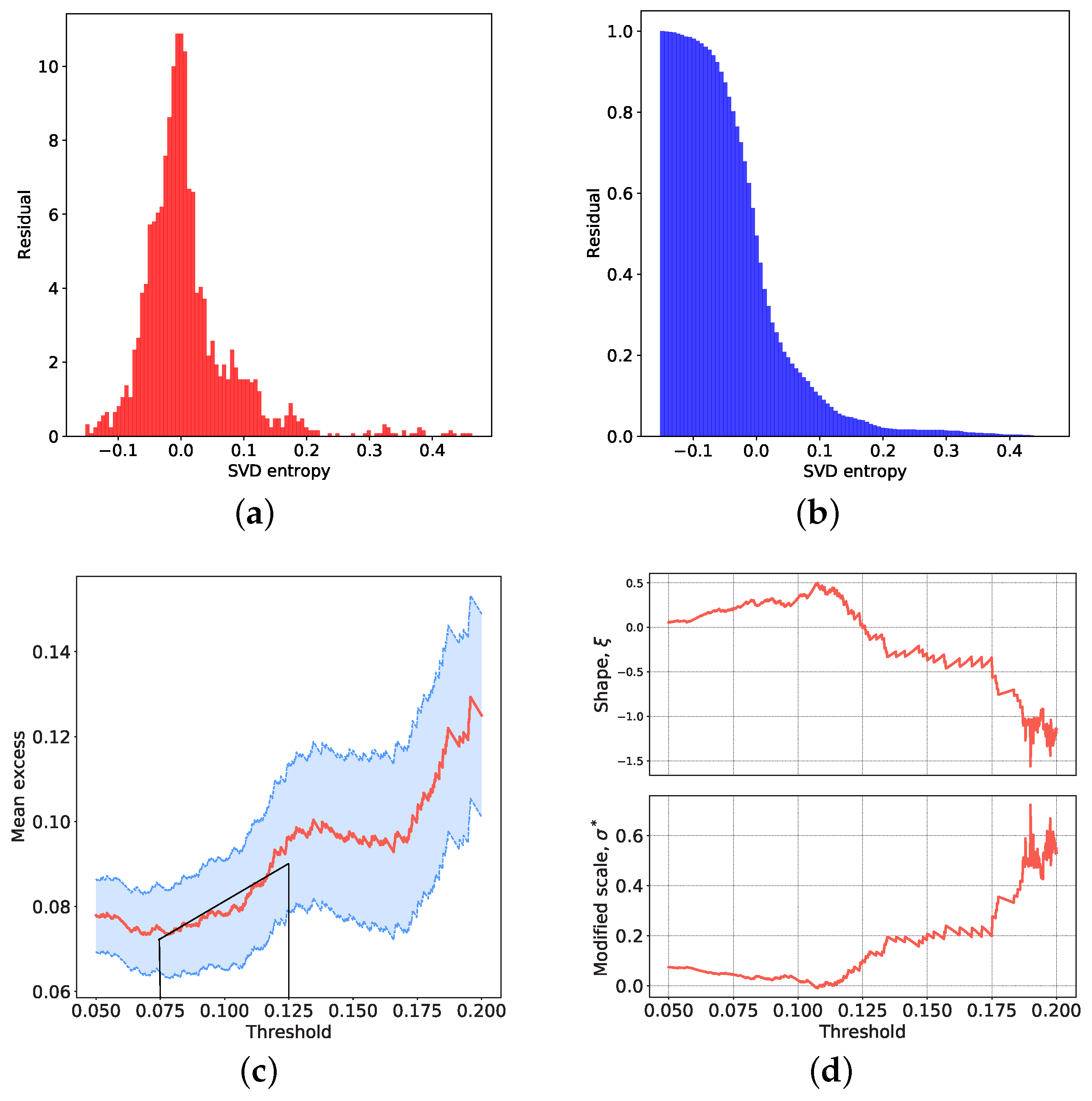
In this subsection, we detect the anomalous value of each of the topological indicators based on the extreme value theory (EVT) and time series prediction. Our intuition is that we first train advanced time series forecasting algorithms only based on “normal” values. We assume that such predictors are able to capture the “normal” dynamics properly, while being completely unaware of abnormal changes in the dynamics. Based on the commonly adopted normal distribution assumption of the forecasting error, the residuals between the predicted and true value should be small and normally distributed for “normal” data, while the residuals of “abnormal” data should be large and their distribution can be portrayed by EVT. We determine the threshold between the “normal” and “abnormal” residuals based on the training dataset, as well as the parameters of the distribution of the extreme values.
Subsequently, we make predictions and calculate the residual for each day in the testing dataset. If the residual exceeds the threshold, we treat it as an “abnormal” value and calculate its “anomaly score” based on the extreme value distribution. Inspired by [
29], our designed method can be divided into an initialization step and an execution step, whose detailed procedures are described below.
Initialization Step
In the initialization step, we first generate the training set that only contains “normal” data. The detailed procedure is described in
Appendix B. The training set is generated to train a predictor
. Without loss of generality, we assume that the predictor makes single-step predictions based on data from the previous
d days as
where
is a normally distributed error term.
To ensure that the predictor only learns the “normal” dynamics of the time series, we generate a training set that only contains the “normal” values. We first split time series into different segments based on the date of the financial crashes. For example, the first segment is the “normal period” from 1 January 1986 to 15 October 1987, which is followed by the financial crash from 19 October 1987 to 4 December 1987. We then extract training samples from the “normal periods” using a sliding window of length , where the data of the first d days are the inputs to the predictor, and the last datum is the expected output. Finally, we obtain the set of the training inputs and its corresponding target output set based on which the predictor is trained.
After training the predictor, for each day
t in the first
N days, we make the prediction based on the previous
d days as
Since we are looking for extremely small values, the residual is calculated as . Notice that here we consider both the “normal” periods and the financial crashes, so the set of the residuals should contain the extreme values corresponding to the financial crashes. Therefore, we analyze the tail distribution of the residual based on the EVT.
According to the EVT, the extreme values always follow the same type of distribution, regardless of the initial distribution of the data. It can be regarded as a theorem for the maximum values, which is similar to the central limit theorem for the mean values [
30]. A mathematical formulation is provided by the Pickands–Balkema–de Haan theorem [
31,
32], which can be written as:
This theorem shows that, for a random variable
, the excess over a sufficiently large threshold
tends to follow a generalized Pareto distribution (GPD) with parameters
and
[
29].
A practical implication of EVT is that extreme and non-extreme events follow different distributions because they are often generated by different driving forces [
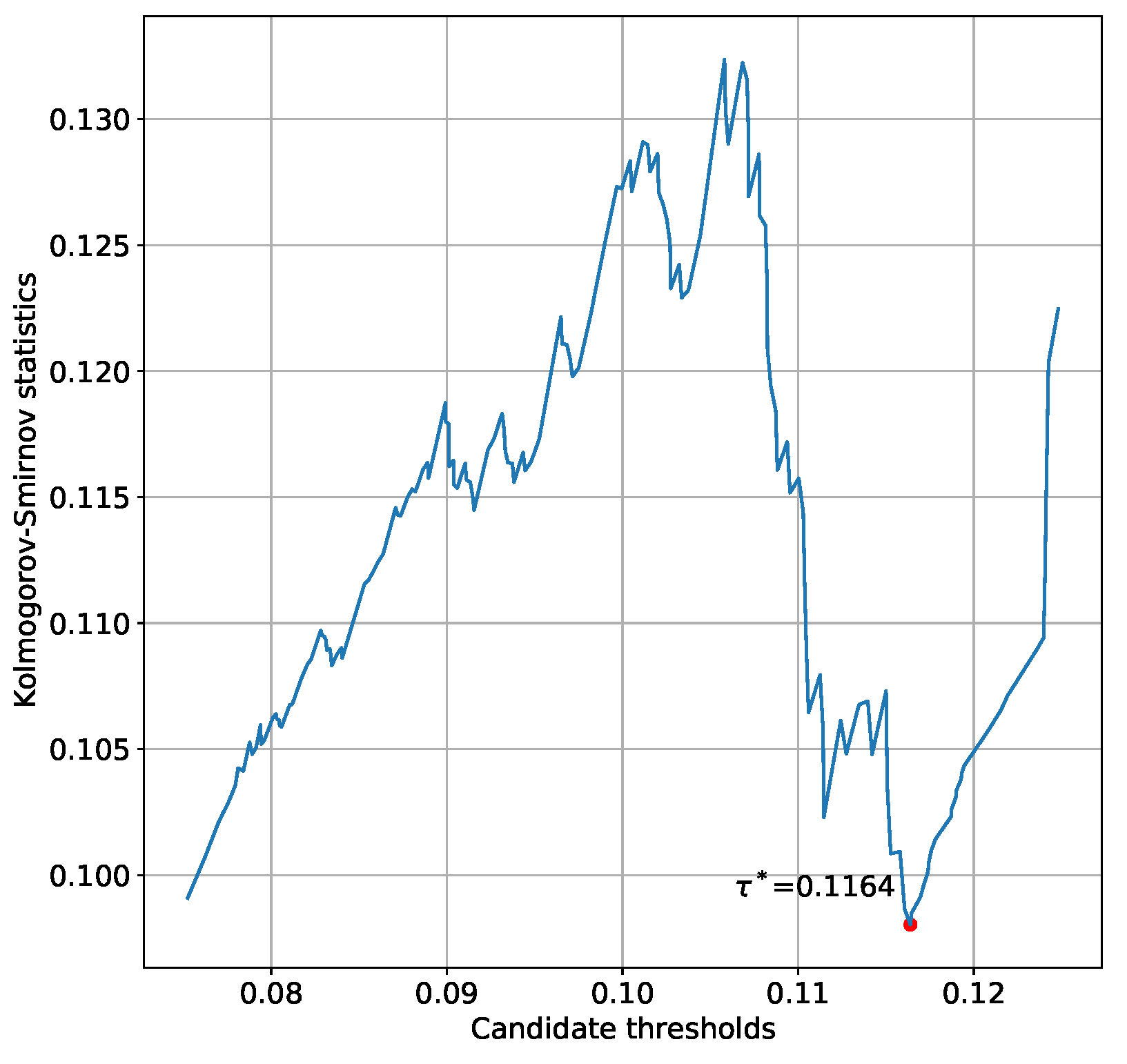
33]. This is the theoretical basis for our use of EVT to identify abnormal changes in network topology. We argue that normal and abnormal residuals are caused by different driving forces, thus we aim to find the outliers that follow GPD. Based on the idea of EVT, we select the most appropriate threshold
that allows GPD to fit the distribution of
properly. This means that any value greater than
can be regarded as an extreme value. Therefore, we consider a residual above the threshold
as an anomalous value. The detailed procedure for obtaining the optimal value of
is described in
Appendix C.
3.5. Execution Step and Hybrid Rebound Indicator
The detailed procedure of the execution step is shown in Algorithm A4. It is designed to deal with the streaming data. For each day
t, we calculate the residual
. If the residual exceeds the threshold
, we raise an alarm while calculating the corresponding alarm index by
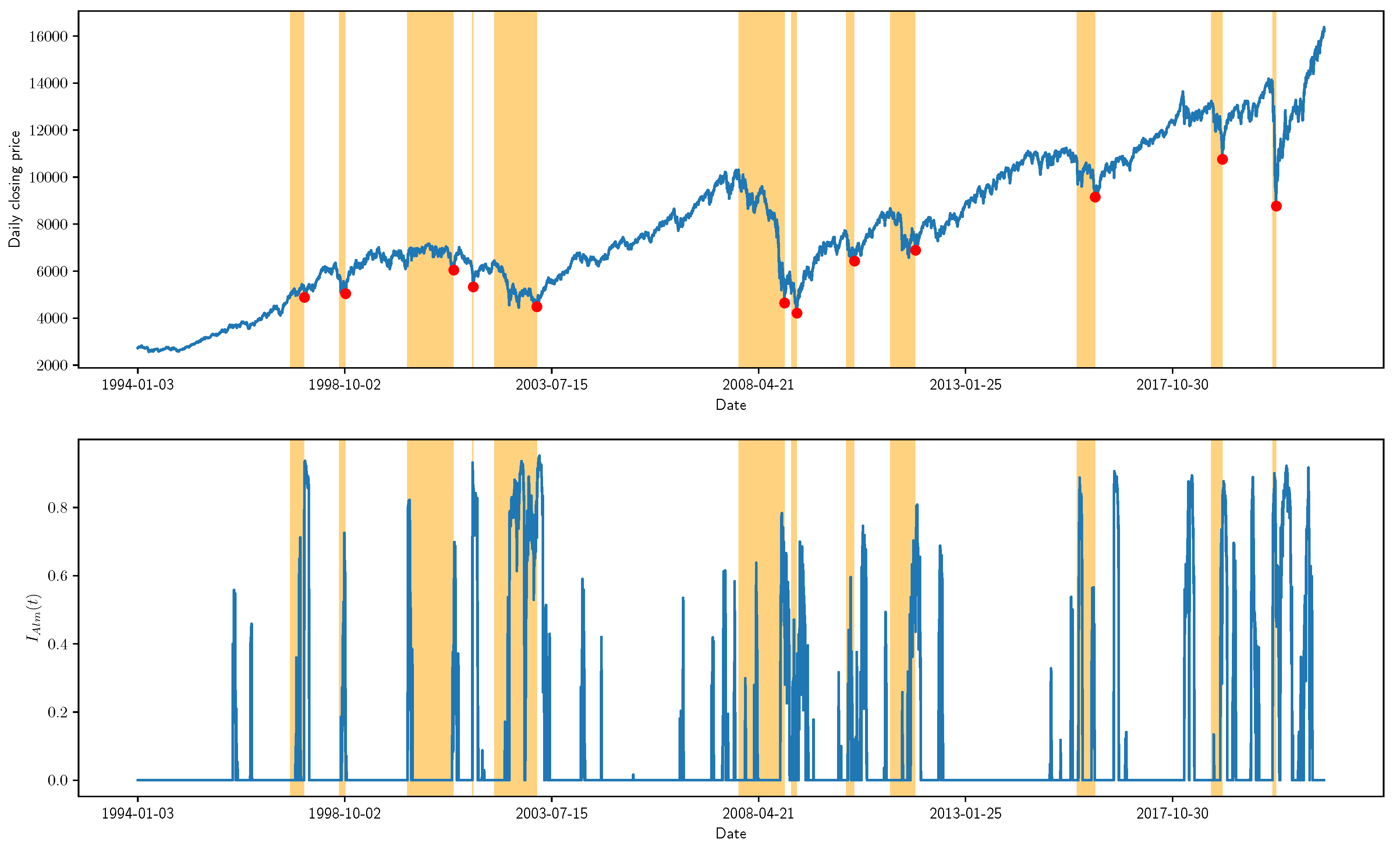
Notice that our alarm index is actually the CDF of the generalized Pareto distribution .
Considering the development of the financial market, the internal dynamics of the topological changes of the stock correlation network may also be changing. Therefore, we need to constantly update the predictor based on the new data. Because the predictor is not expected to learn any information about the abnormal changes of the network, we only include the “normal” data into the training set. After every K new samples are added into the training set, the predictor is retrained to ensure that it keeps tracking the latest dynamics of the system.
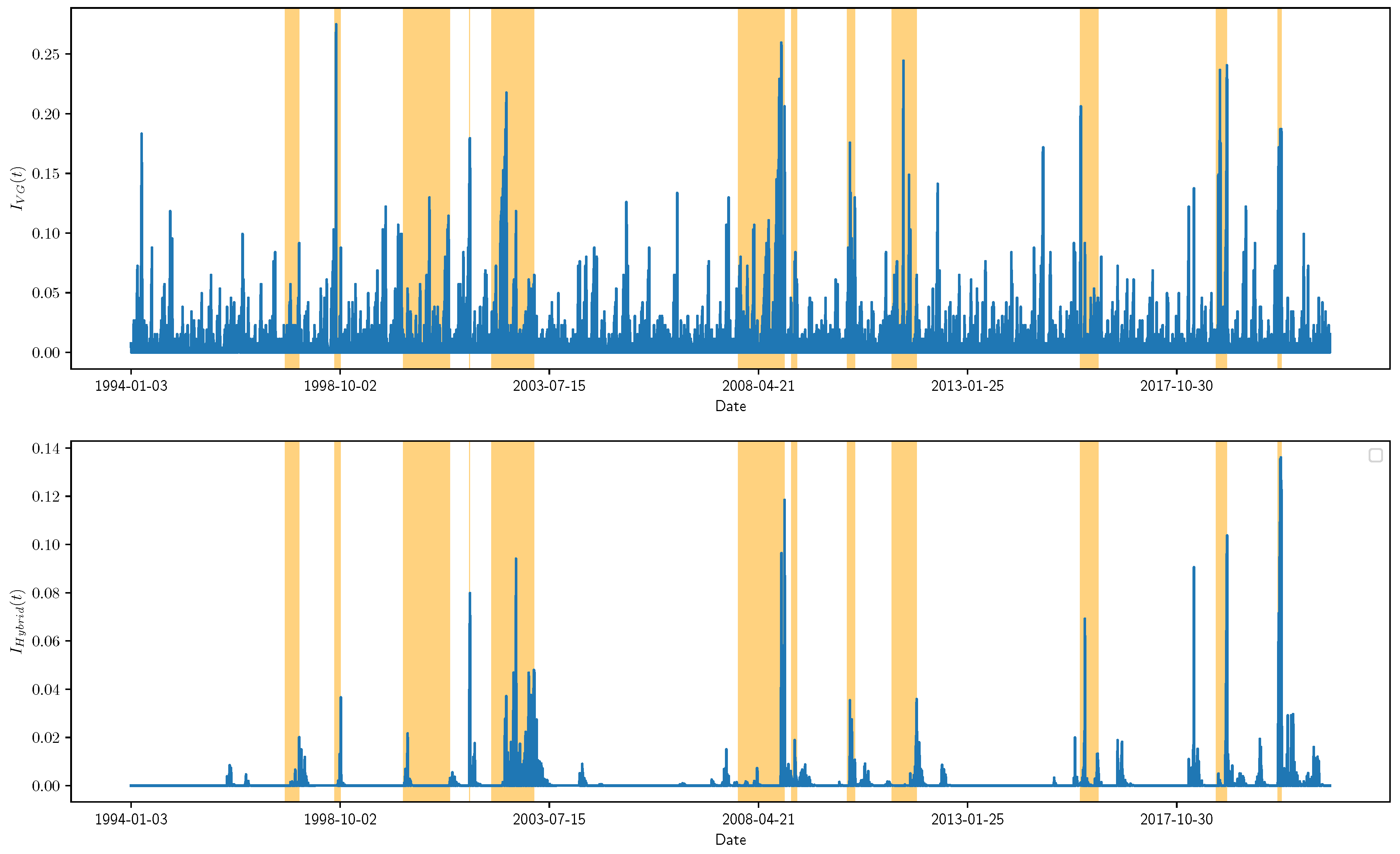
We finally propose an indicator to characterize the phenomenon of “faster-than-exponential decline in the stock index price accompanied by anomalous changes in the market structure”. The alarm index defined in Equation (
15) has a value range of
, and its magnitude indicates the extent to which we believe the network structure is anomalous. Therefore, it can be considered as a “confidence level”, which is used as a mask to multiply the indicator defined in Equation (
3). Considering that the anomalous changes in the stock correlation network are not necessarily perfectly synchronized with the plunge in the stock index, we make a moving average smoothing of
with sliding window length
. Notice that
should be a small integer. Based on the intuition that information from two weeks ago is hardly useful for forecasting, here we take
. Since our proposed rebound indicator considers both the time series and the network, it is named as a hybrid indicator, whose formal definition is given as
5. Discussion
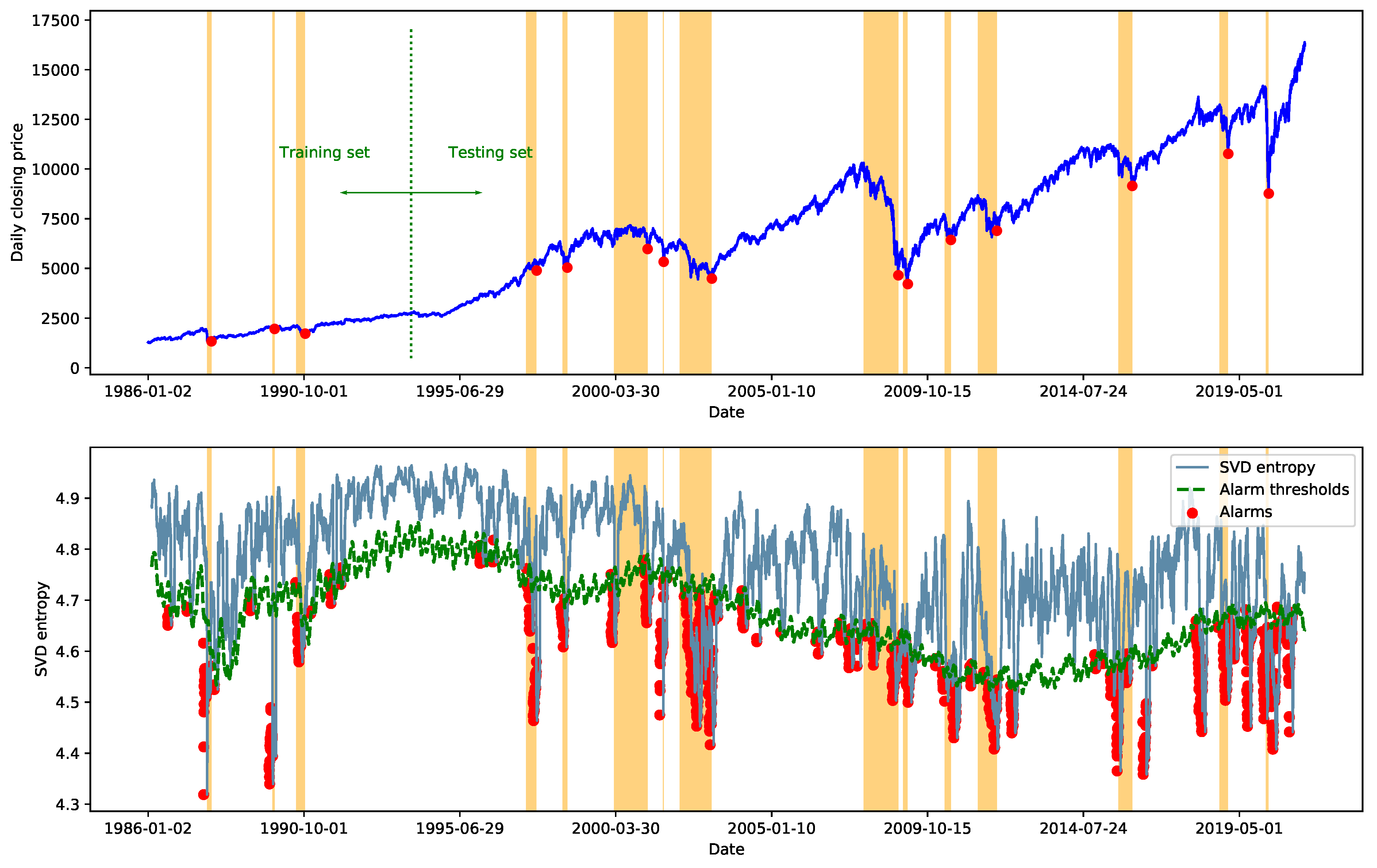
The findings of this study indicate that incorporating the analysis of a time-evolving network can improve the performance of traditional time series models. Qualitative observations show the rapid decline of SVD entropy during financial crashes and suggest that the network-based indicator helps with reducing the false alarm rate. Quantitative comparisons further confirm that the predictive power is improved by combining the network-based indicator.
According to the qualitative observations, the SVD entropy of the stock correlation network of the NYSE Composite Index decreases significantly during stock market crashes. This is consistent with the existing studies of various stock indices based on different definitions of network entropy [
13,
14,
15,
39]. For example, Zhang et al. [
15] have observed decreases in the von Neumann entropy and the graph motif entropy of the NYSE network during financial crashes. Furthermore, it is also observed that the structural entropy declines rapidly during crisis periods in the stock correlation network of FTSE100 and NIKKEI225 [
13]. Since “entropy” can be interpreted as “diversity”, such observations suggest that the “structural diversity” of the stock market commonly declines during financial crashes, and the recovery of structural diversity reflects the recovery of the market. We may further interpret this econophysics phenomenon from the perspective of behavioral finance. The structural diversity of the stock market may represent investors’ perceptions in the heterogeneity of different firms. During financial crashes, spillover effects and investors’ herding behavior may erase the differences between “good” and “bad” firms, and thus can eliminate the structural diversity of the stock market.
In addition, it can be observed that the network-based indicator helps with reducing the false alarm rate of the time series-based indicator. This finding can shed light on a better understanding of the stock market crashes. Traditionally, research on stock market crashes focuses on modeling the price time series of stock indices [
16,
17,
40,
41,
42,
43]. In particular, the benchmark indicator of this study (i.e., the VG-based LPPL indicator) [
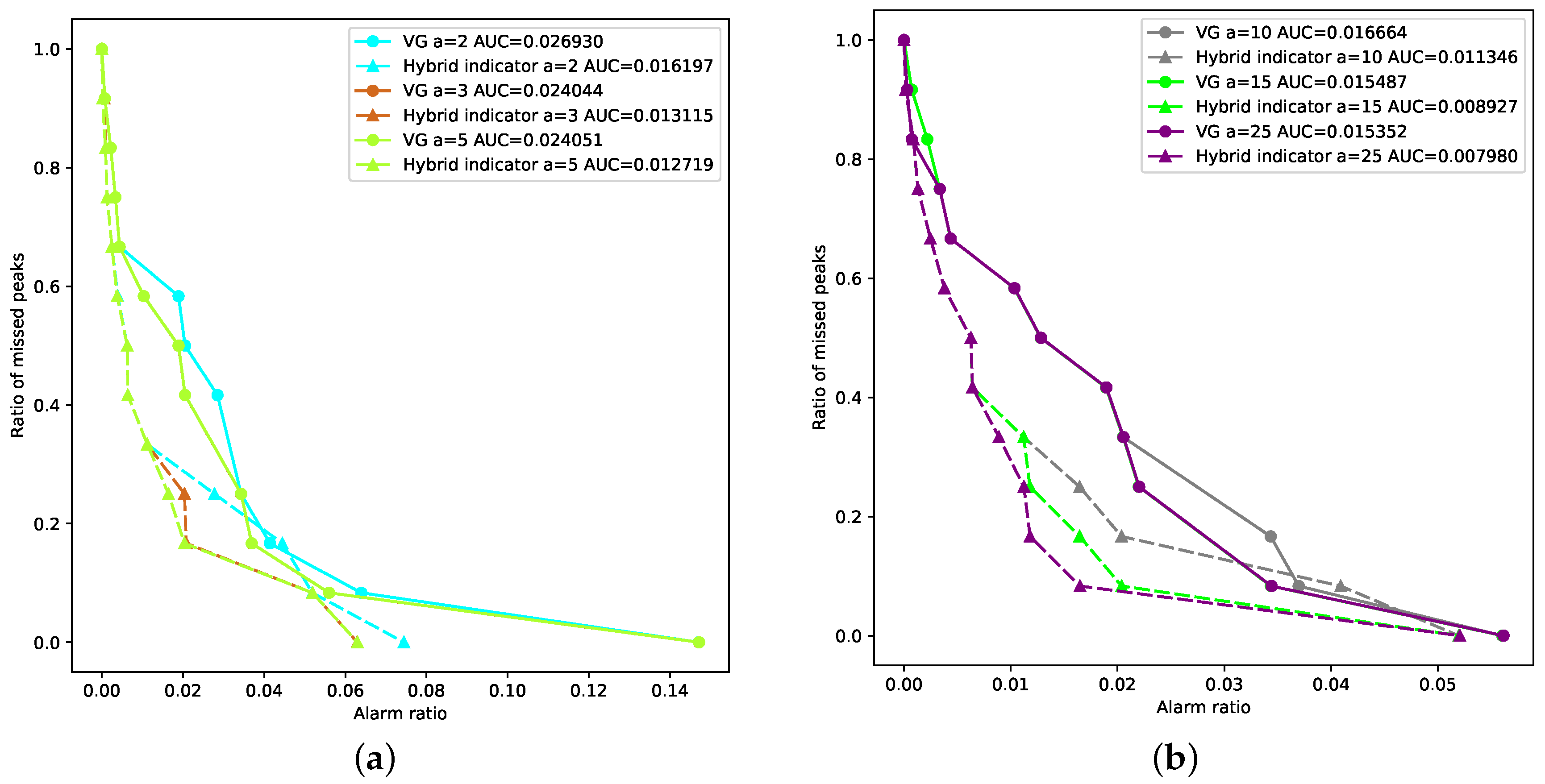
16] captures the faster-than-exponential decline in stock index price. However, our experimental results show that detection and prediction based on the time series alone can contain a number of false alarms. In other words, a rapid decline in stock index prices does not necessarily mean a financial crash. An intuitive explanation is that the plunge of highly weighted sectors or companies may drive down the stock index, but as long as the plunge is not propagated through the stock network, it will not trigger the crash of the whole market. By combining network-based and time series-based indicators, this study contributes to the LPPL-related literature and highlights that anomalous topological changes of the stock correlation network can be important criteria for confirming the occurrence and predicting the recovery of stock market crashes.
Quantitative comparisons confirm that the incorporation of SVD entropy improves the predictive power of the time series-based model. This finding agrees with the existing literature on the predictive power of SVD entropy for stock market dynamics [
24,
25,
26,
27]. For a number of representative stock indices such as the Dow Jones Industrial Average [
24], the Shenzhen Component Index [
25] and the Shanghai Component Index [
27], it has been found that the SVD entropy of the constituent stock network has a predictive ability to the dynamics of the stock index. However, the existing literature mainly focuses on examining the predictive power of SVD entropy using the Granger causality test, without developing methods or models to practically leverage such predictive ability. This study contributes to this research gap by proposing a framework that jointly considers the SVD entropy and the stock index price. It is demonstrated that the predictive power of the SVD entropy can be practically applied.
It should be acknowledged that this work has several limitations. First, this study transforms the time-evolving stock correlation network into the time series of a network statistic (i.e., the SVD entropy) and therefore ignores the finer topology in the network. In particular, our proposed framework is not able to recognize the potential micro- and meso-level structural changes. This limitation also hinders a more in-depth observation of the topological changes during and after financial crashes. As a consequence, a number of critical research questions are left unanswered. For example, it is still unclear if similar micro- and meso-level patterns can be observed among multiple financial crashes throughout history. If so, developing models and methods based on such patterns to detect crashes and predict rebounds can be another interesting research topic. Another limitation of this study is that an in-depth analysis of the mechanism is not performed. For example, this study focuses on the diagnosis of major financial crashes. However, we have also observed rapid declines in stock indices accompanied by anomalous network changes during some periods that are not regarded as major financial crashes. Furthermore, the topological changes in the stock correlation network have become increasingly drastic from 1968 to the present. The causes of these phenomena are still unclear.
This study has several practical implications for professionals in a variety of fields. For both institutional and individual investors, our proposed rebound indicator provides a referential signal for market timing strategies. It can be observed that weak signals start to appear when a stock market crash occurs. As the stock market crash progresses, the rebound indicator gradually gets stronger and clusters around certain dates. When the rebound indicator reaches the peak and starts to decline, a change of regime is more likely to occur. Therefore, in the aftermath of stock market crashes, investors can start applying long strategies after observing the clustering and peaking of the rebound indicator. For policymakers, this study provides useful information that can help with the detection and management of market risks. When abnormal changes in the stock network are detected, policymakers can be alerted to conduct further in-depth research to determine whether a systemic risk exists. Furthermore, this study recommends introducing policies to stabilize key firms and sectors once a systemic risk occurs, since the contagion of risks may destroy the market structure and trigger herding behavior of investors. From a broader perspective, this study also has practical implications for machine learning researchers and algorithm developers. Our findings highlight the importance of incorporating stock network analysis into traditional time series models. Novel algorithms can be developed along this direction to better diagnose and forecast extreme financial events.
6. Conclusions
This study proposes a framework to diagnose stock market crashes and predict the subsequent price rebounds by jointly modeling plunges in the stock index price and abnormal changes in the stock correlation network. Experiments based on the NYSE Composite Index show that our proposed framework outperforms the benchmark VG-based LPPL model. In line with the existing literature, we observe rapid declines of the stock network’s SVD entropy during market crashes. It suggests that the elimination of structural diversity in the stock market can be an important characteristic of financial crashes. In addition, it is observed that we reduce the false alarm rate of the LPPL-based indicator by incorporating the network anomaly-based indicator. This finding can shed light on bridging the gap between stock network analysis and financial time series modeling, which are often considered as two relatively independent research directions. From the perspective of market participants (e.g., policymakers and investors), this study can provide referential signals for risk management and market timing strategies.
The main limitation of this paper is the conversion of the time-evolving network into a time series, thus losing the micro- and meso-level topological patterns. Future research can benefit from using representation learning methods (e.g., graph neural network and tensor decomposition) that can directly process dynamic networks. Techniques for interpretable machine learning can also be applied to identify specific topological patterns in the course of market crashes and recoveries. Moreover, future research can be conducted to reveal the mechanism of abnormal topological changes in stock correlation networks during market crashes. Finally, practitioners can integrate our proposed rebound indicator into their trading strategies to control risk and make profits in the aftermath of stock market crashes.



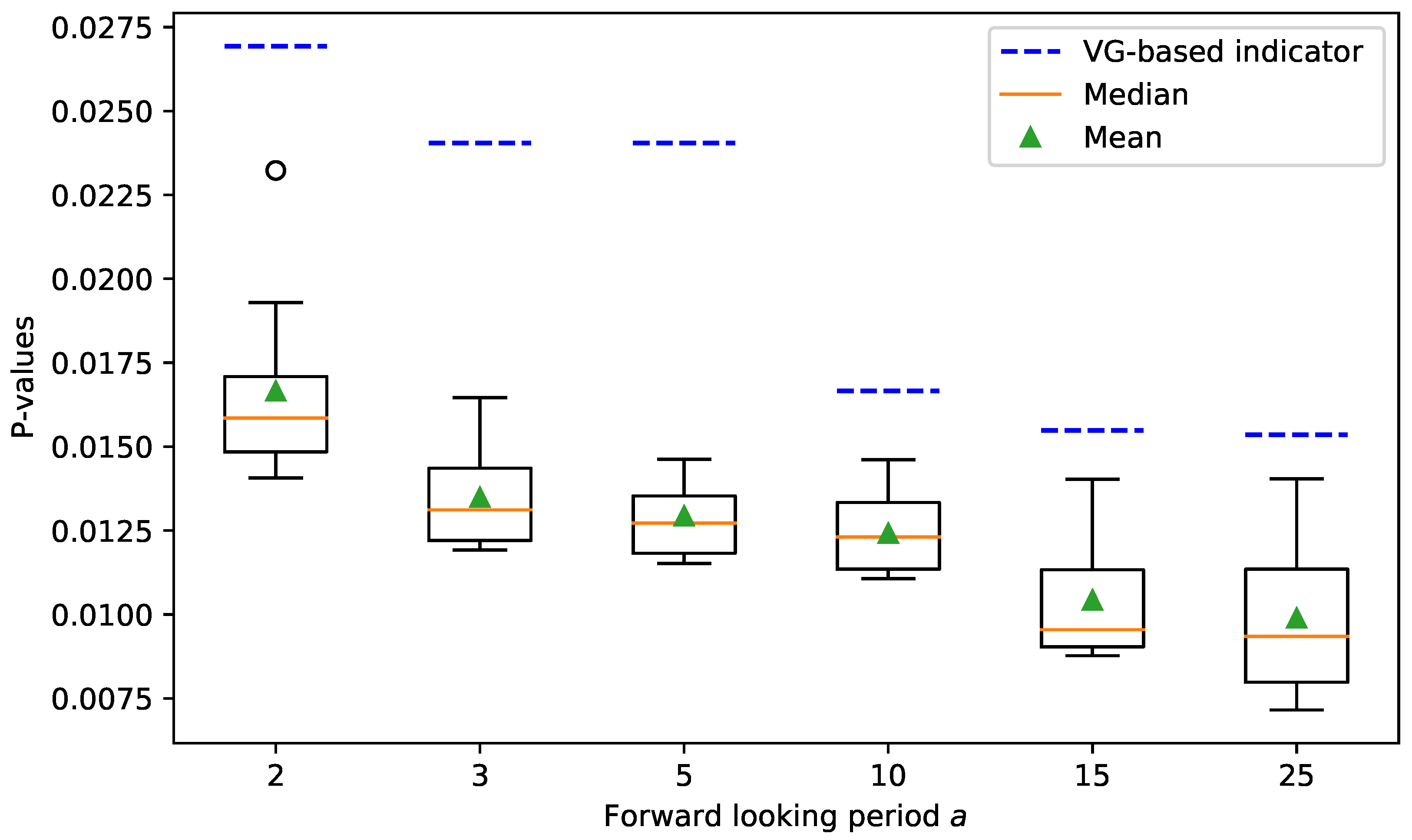

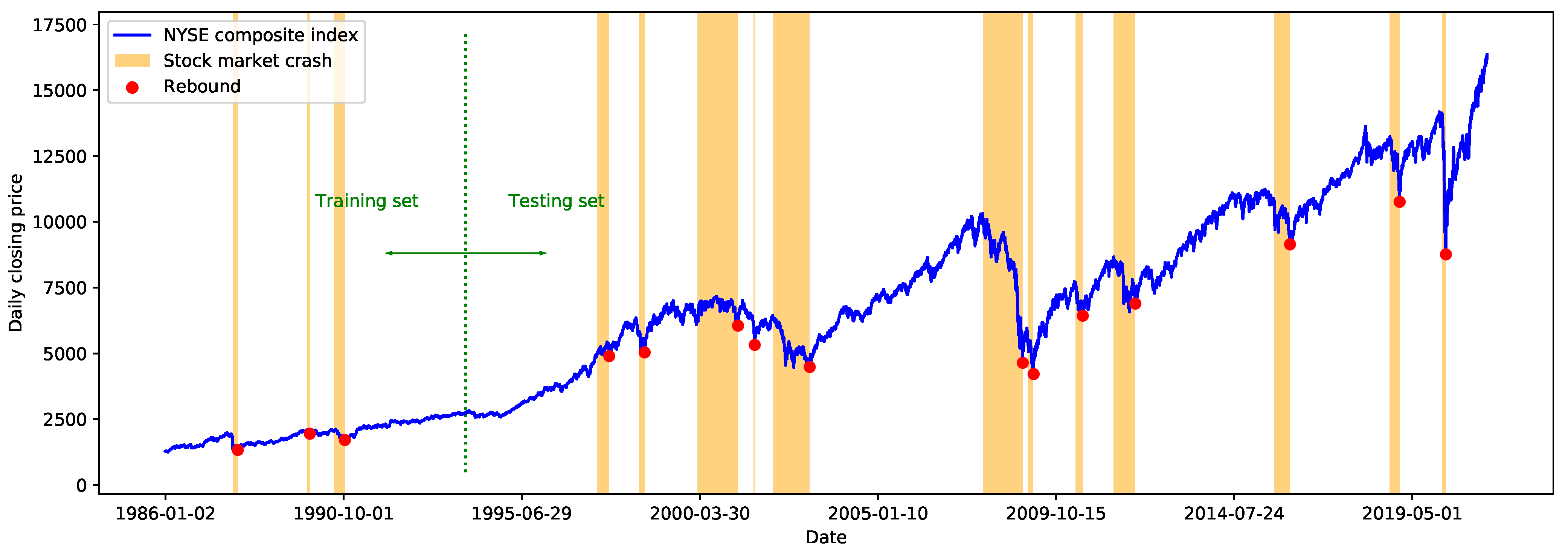{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}