Abstract
Uncertainty quantification for complex deep learning models is increasingly important as these techniques see growing use in high-stakes, real-world settings. Currently, the quality of a model’s uncertainty is evaluated using point-prediction metrics, such as the negative log-likelihood (NLL), expected calibration error (ECE) or the Brier score on held-out data. Marginal coverage of prediction intervals or sets, a well-known concept in the statistical literature, is an intuitive alternative to these metrics but has yet to be systematically studied for many popular uncertainty quantification techniques for deep learning models. With marginal coverage and the complementary notion of the width of a prediction interval, downstream users of deployed machine learning models can better understand uncertainty quantification both on a global dataset level and on a per-sample basis. In this study, we provide the first large-scale evaluation of the empirical frequentist coverage properties of well-known uncertainty quantification techniques on a suite of regression and classification tasks. We find that, in general, some methods do achieve desirable coverage properties on in distribution samples, but that coverage is not maintained on out-of-distribution data. Our results demonstrate the failings of current uncertainty quantification techniques as dataset shift increases and reinforce coverage as an important metric in developing models for real-world applications.
1. Introduction
Predictive models based on deep learning have seen a dramatic improvement in recent years [1], which has led to widespread adoption in many areas. For critical, high-stakes domains, such as medicine or self-driving cars, it is imperative that mechanisms are in place to ensure safe and reliable operation. Crucial to the notion of safe and reliable deep learning is the effective quantification and communication of predictive uncertainty to potential end-users of a system. In medicine, for instance, understanding predictive uncertainty could lead to better decision-making through improved allocation of hospital resources, detecting dataset shift in deployed algorithms, or helping machine learning models abstain from making a prediction [2]. For medical classification problems involving many possible labels (i.e., creating a differential diagnosis), methods that provide a set of possible diagnoses when uncertain are natural to consider and align more closely with the differential diagnosis procedure used by physicians. The prediction sets and intervals we propose in this work are an intuitive way to quantify uncertainty in machine learning models and provide interpretable metrics for downstream, nontechnical users.
Commonly used approaches to quantify uncertainty in deep learning generally fall into two broad categories: ensembles and approximate Bayesian methods. Deep ensembles [3] aggregate information from multiple individual models to provide a measure of uncertainty that reflects the ensembles’ agreement about a given data point. Bayesian methods offer direct access to predictive uncertainty through the posterior predictive distribution, which combines prior knowledge with the observed data. Although conceptually elegant, calculating exact posteriors of even simple neural models is computationally intractable [4,5], and many approximations have been developed [6,7,8,9,10,11,12]. Though approximate Bayesian methods scale to modern sized data and models, recent work has questioned the quality of the uncertainty provided by these approximations [4,13,14].
Previous work assessing the quality of uncertainty estimates has focused on calibration metrics and scoring rules, such as the negative log-likelihood (NLL), expected calibration error (ECE), and Brier score. Here we provide an alternative perspective based on the notion of empirical coverage, a well-established concept in the statistical literature [15] that evaluates the quality of a predictive set or interval instead of a point prediction. Informally, coverage asks the question: If a model produces a predictive uncertainty interval, how often does that interval actually contain the observed value? Ideally, predictions on examples for which a model is uncertain would produce larger intervals and thus be more likely to cover the observed value.
In this work, we focus on marginal coverage over a dataset for the canonical value of , i.e., 95% prediction intervals. For a machine learning model that produces a 95% prediction interval based on the training dataset , we consider what fraction of the points in the dataset have their true label contained in for . To measure the robustness of these intervals, we also consider cases when the generating distributions for and are not the same (i.e., dataset shift).
Figure 1 provides a visual depiction of marginal coverage over a dataset for two hypothetical regression models. Throughout this work, we refer to “marginal coverage over a dataset” as “coverage”.
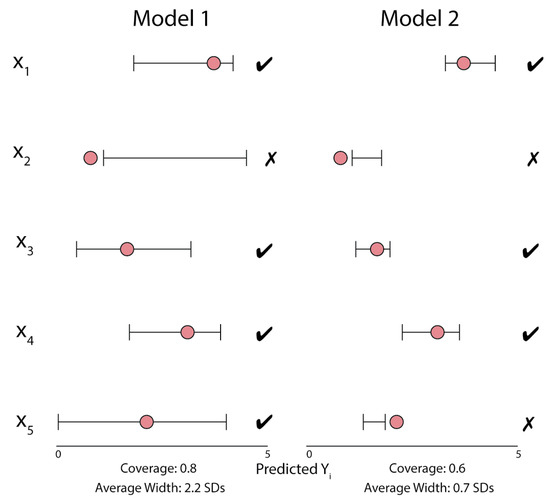
Figure 1.
An example of the coverage properties for two methods of uncertainty quantification. In this scenario, each model produces an uncertainty interval for each , which attempts to cover the true , represented by the red points. Coverage is calculated as the fraction of true values contained in these regions, while the width of these regions is reported in terms of multiples of the standard deviation of the training set values.
For a machine learning model that produces predictive uncertainty estimates (i.e., approximate Bayesian methods and ensembling), coverage encompasses both the aleatoric and epistemic uncertainties [16] produced by these models. In a regression setting, the predictions from these models can be written as:
where epistemic uncertainty is captured in the component, while aleatoric uncertainty is considered in the term. Since coverage captures how often the predicted interval of contains the true value, it captures the contributions from both types of uncertainty.
A complementary metric to coverage is width, which is the size of the prediction interval or set. In regression problems, we typically measure width in terms of the standard deviation of the true label in the training set. As an example, an uncertainty quantification procedure could produce prediction intervals that have 90% marginal coverage with an average width of two standard deviations. For classification problems, width is simply the average size of a prediction set. Width can provide a relative ranking of different methods, i.e., given two methods with the same level of coverage, we should prefer the method that provides intervals with smaller widths.
Contributions: In this study, we investigate the empirical coverage properties of prediction intervals constructed from a catalog of popular uncertainty quantification techniques, such as ensembling, Monte Carlo dropout, Gaussian processes, and stochastic variational inference. We assess the coverage properties of these methods on nine regression tasks and two classification tasks with and without dataset shift. These tasks help us make the following contributions:
- We introduce coverage and width over a dataset as natural and interpretable metrics for evaluating predictive uncertainty for deep learning models.
- A comprehensive set of coverage evaluations on a suite of popular uncertainty quantification techniques.
- An examination of how dataset shift affects these coverage properties.
2. Background and Related Work
2.1. Frequentist Coverage and Conformal Inference
Given features and a response for some dataset , Barber et al. [17] define distribution-free marginal coverage in terms of a set and a level . The set is said to have coverage at the level if for all distributions P such that and , the following inequality holds:
For new samples beyond the first n samples in the training data, there is a probability of the true label of the test point being contained in the set . This set can be constructed using a variety of procedures. For example, in the case of simple linear regression, a prediction interval for a new point can be constructed using a simple, closed-form solution [15].
Marginal coverage is typically considered in the limit of infinite samples. However, here we focus on marginal coverage over a dataset . We assess, for a given model and test set , the empirical coverage by assessing whether . Additionally, we consider how marginal coverage changes as there is data distribution shift such that a new dataset has a different data generating distribution. Despite the lack of infinite samples, this work establishes the motivation of considering coverage in critical, high-risk situations, such as medicine.
An important and often overlooked distinction is that of marginal and conditional coverage. In conditional coverage, one considers:
The probability has been conditioned on specific features. This is potentially a more useful version of coverage to consider because one could make claims for specific instances rather than over the broader distribution P. However, it is impossible in general to have conditional coverage guarantees [17].
Conformal inference [18,19] is one statistical framework that can provide marginal coverage under a certain set of assumptions (e.g., exchangeable data) that we do not assume here [20]. In this work, we specifically seek to measure the empirical coverage of the existing approximate Bayesian and alternative uncertainty quantification methods with and without dataset shift. These methods are extremely popular in practice, but nobody has yet considered the empirical coverage of their 95% posteriors. Conformal methods are not part of the approximate Bayesian methods that we set out to analyze in this work. There has been recent work on Bayes-optimal prediction with frequentist coverage control [21] and conformal inference under dataset shift [22,23]. However, adding the conformal framework to approximate Bayesian methods post hoc and measuring their coverage properties could be interesting future work. An additional distinction between our work and the broader conformal inference literature is that we do not aim to provide finite sample coverage guarantees.
Another important point to consider is that while the notion of a confidence interval may seem natural to consider in our analysis, confidence intervals estimate global statistics over repeated trials of data and generally come with guarantees about how often these statistics lie in said intervals. In our study, this is not the case. Although we estimate coverage across many datasets, we are not aiming to estimate an unknown statistic of the data. We would like to understand the empirical coverage properties of machine learning models.
2.2. Obtaining Predictive Uncertainty Estimates
Several lines of work focus on improving approximations of the posterior of a Bayesian neural network [6,7,8,9,10,11,12]. Yao et al. [4] provide a comparison of many of these methods and highlight issues with common metrics of comparison, such as test-set log-likelihood and RMSE. Good scores on these metrics often indicate that the model posterior happens to match the test data rather than the true posterior [4]. Maddox et al. [24] developed a technique to sample the approximate posterior from the first moment of stochastic gradient descent iterates. Wenzel et al. [13] demonstrated that despite advances in these approximations, in practice, approximate methods for the Bayesian modeling of deep networks do not perform as well as theory would suggest.
Alternative methods that do not rely on estimating a posterior over the weights of a model can also be used to provide uncertainty estimates. Gal and Ghahramani [16], for instance, demonstrated that Monte Carlo dropout is related to a variational approximation to the Bayesian posterior implied by the dropout procedure. Lakshminarayanan et al. [3] used an ensemble of several neural networks to obtain uncertainty estimates. Guo et al. [25] established that temperature scaling provides well-calibrated predictions on an i.i.d test set. More recently, van Amersfoort et al. [26] showed that the distance from the centroids in an RBF neural network yields high-quality uncertainty estimates. Liu et al. [27] also leveraged the notion of distance (in the form of an approximate Gaussian process covariance function) to obtain uncertainty estimates with their Spectral-normalized Neural Gaussian Processes.
2.3. Assessments of Uncertainty Properties under Dataset Shift
Ovadia et al. [14] analyzed the effect of dataset shift on the accuracy and calibration of a variety of deep learning methods. Their large-scale empirical study assessed these methods on standard datasets, such as MNIST, CIFAR-10, ImageNet, and other non-image-based datasets. Additionally, they used translations, rotations, and corruptions of these datasets [28] to quantify performance under dataset shift. They found stochastic variational inference (SVI) to be promising on simpler datasets, such as MNIST and CIFAR-10, but more difficult to train on larger datasets. Deep ensembles had the most robust response to dataset shift.
3. Methods
For features and a response or (for regression and classification, respectively) for some dataset , we consider the prediction intervals or sets in regression and classification settings, respectively. Unlike in the definitions of marginal and conditional coverage, we do not assume that always holds true. Thus, we consider the marginal coverage on a dataset for some new test sets that may have undergone dataset shift from the generating distribution of the training set .
In both the regression and classification settings, we analyzed the coverage properties of prediction intervals and sets of five different approximate Bayesian and non-Bayesian approaches for uncertainty quantification. These include dropout [16,29], ensembles [3], Stochastic Variational Inference [7,8,11,12,30], and last layer approximations of SVI and dropout [31]. Additionally, we considered prediction intervals from linear regression and the 95% credible interval of a Gaussian process with the squared exponential kernel as baselines in regression tasks. For classification, we also considered temperature scaling [25] and the softmax output of vanilla deep networks [28]. For more detail on our modeling choices, see Appendix B.
3.1. Regression Methods and Metrics
We evaluated the coverage properties of these methods on nine large real-world regression datasets used as a benchmark in Hernández-Lobato and Adams [6] and later Gal and Ghahramani [16]. We used the training, validation, and testing splits publicly available from Gal and Ghahramani [16] and performed nested cross-validation to find hyperparameters. On the training sets, we did 100 trials of a random search over hyperparameter space of a multi-layer-perceptron architecture with an Adam optimizer [32] and selected hyperparameters based on RMSE on the validation set.
Each approach required slightly different ways to obtain a 95% prediction interval. For an ensemble of neural networks, we trained vanilla networks and used the 2.5% and 97.5% quantiles as the boundaries of the prediction interval. For dropout and last layer dropout, we made 200 predictions per sample and similarly discarded the top and bottom 2.5% quantiles. For SVI, last layer SVI (LL SVI), and Gaussian processes we had approximate variances available for the posterior, which we used to calculate the prediction interval. We calculated 95% prediction intervals from linear regression using the closed-form solution.
Then we calculated two metrics:
- Coverage: A sample is considered covered if the true label is contained in this 95% prediction interval. We average over all samples in a test set to estimate a method’s marginal coverage on this dataset.
- Width: The width is the average over the test set of the ranges of the 95% prediction intervals.
Coverage measures how often the true label is in the prediction region, while width measures how specific that prediction region is. Ideally, we would have high levels of coverage with low levels of width on in-distribution data. As data becomes increasingly out of distribution, we would like coverage to remain high while width increases to indicate model uncertainty.
3.2. Classification Methods and Metrics
Ovadia et al. [14] evaluated model uncertainty on a variety of datasets publicly available. These predictions were made with the five approximate Bayesian methods described above, plus vanilla neural networks, with and without temperature scaling. We focus on the predictions from MNIST, CIFAR-10, CIFAR-10-C, ImageNet, and ImageNet-C datasets. For MNIST, we calculated coverage and width of model prediction intervals on rotated and translated versions of the test set. For CIFAR-10, Ovadia et al. [14] measured model predictions on translated and corrupted versions of the test set from CIFAR-10-C [28] (see Figure 2). For ImageNet, we only considered the coverage and width of prediction sets on the corrupted images of ImageNet-C [28]. Each of these transformations (rotation, translation, or any of the 16 corruptions) has multiple levels of shift. Rotations range from 15 to 180 degrees in 15 degrees increments. Translations shift images every 2 and 4 pixels for MNIST and CIFAR-10, respectively (see Figure 3). Corruptions have five increasing levels of intensity. Figure 2 shows the effects of the 16 corruptions in CIFAR-10-C at the first, third, and fifth levels of intensity.

Figure 2.
An example of the corruptions in CIFAR-10-C from [28]. The 16 different corruptions have 5 discrete levels of shift, of which 3 are shown here. The same corruptions were applied to ImageNet to form the ImageNet-C dataset.

Figure 3.
Several examples of the “rolling” translation shift that moves an image across an axis.
Given and predicted probabilities from a model for all K classes , the prediction set for a sample is the minimum sized set of classes such that:
This results in a set of size , which consists of the largest probabilities in the full probability distribution over all classes such that probability has been accumulated. This inherently assumes that the labels are unordered categorical classes such that including classes 1 and K does not imply that all classes between are also included in the set . Then we can define:
- Coverage: For each example in a dataset, we calculate the prediction set of the label probabilities, then coverage is what fraction of these prediction sets contain the true label.
- Width: The width of a prediction set is simply the number of labels in the set, . We report the average width of prediction sets over a dataset in our figures.
Although both calibration [25] and coverage can involve a probability over a model’s output, calibration only considers the most likely label, and its corresponding probability, while coverage considers the top- probabilities. In the classification setting, coverage is more robust to label errors as it does not penalize models for putting probability on similar classes.
4. Results
4.1. Regression
Figure 4 plots the mean test set coverage and width for the regression methods we considered averaged over the nine regression datasets. Error bars demonstrate that for low-performing methods, such as ensembling, dropout, and LL dropout, there is high variability in coverage levels and widths across the datasets.
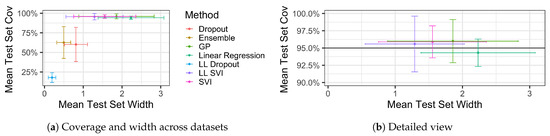
Figure 4.
The mean coverage and widths of models’ prediction intervals average over the nine regression datasets we considered (panel a). Error bars indicate the standard deviation for both coverage and width across all experiments. In general, one would desire a model with the highest coverage above some threshold (here 95%) with a minimum average test set width. Models in the upper left have the best empirical coverage. In (panel b), we observe that the four methods which maintained 95% coverage did so because they had appropriately wide prediction intervals. LL SVI had the lowest average width while maintaining at least 95% coverage.
We observe that several methods perform well across the nine datasets. In particular, LL SVI, SVI, and GPs all exceed the 95% coverage threshold on average, and linear regression comes within the statistical sampling error of this threshold. Over the regression datasets, we considered, LL SVI had the lowest mean width while maintaining at least 95% coverage. For specific values of coverage and width for methods on a particular dataset, see Table A1 and Table A2 in Appendix A.
Figure 4 also demonstrates an important point that will persist through our results. Coverage and width are directly related. Although high coverage can and ideally does occur when width is low, we typically observe that high levels of coverage occur in conjunction with high levels of width.
4.2. MNIST
In the classification setting, we begin by calculating coverage and width for predictions from Ovadia et al. [14] on MNIST and shifted MNIST data. Ovadia et al. [14] used a LeNet architecture, and we refer to their manuscript for more details on their implementation.
Figure 5 shows how coverage and width co-vary as dataset shift increases. The elevated width for SVI on these dataset splits indicate that the posterior predictions of label probabilities were the most diffuse to begin with among all models. In Figure 5, all seven models have at least 95% coverage with a 15-degree rotation shift. Most models do not see an appreciable increase in the average width of the 95% prediction set, except for SVI. The average width for SVI jumps to over 2 at 15 degrees rotation. As the amount of shift increases, coverage decreases across all methods in a comparable way. In the rotation shifts, we observe that coverage increases and width decreases after about 120 degrees of shift. This is likely due to some of the natural symmetry of several digits (i.e., 0 and 8 look identical after 180 degrees of rotation).

Figure 5.
The effect of rotation and translation on coverage and width, respectively, for MNIST. 0 degrees or 0 pixels of shift indicate results on the test set of MNIST.
SVI maintains higher levels of coverage but with a compensatory increase in width. In fact, there is a Pearson correlation of 0.9 between the width of the SVI prediction set and the distance from the maximum shift of 14 pixels. The maximum shift occurs when the original center of the image is broken across the edge as the image rolls to the right. Figure 3’s right-most example is a case of the maximum shift of 14 pixels on a MNIST digit. This strong correlation between width and severity of shift for some methods makes the width of a prediction set at a fixed level a natural proxy to detect dataset shift. For this simple dataset, SVI outperforms other models with regards to coverage and width properties. It is the only model that has an average width that corresponds to the amount of shift observed and provides the highest level of average coverage.
4.3. CIFAR-10
Next, we consider a more complex image dataset, CIFAR-10. Ovadia et al. [14] trained 20-layer and 50-layer ResNets. Figure 6 shows how the width of the prediction sets increases as the translation shift increases. This shift “rolls” the image pixel by pixel such that the right-most column in the image becomes the left-most image. Temperature scaling and ensemble, in particular, have at least 95% coverage for every translation, although all methods have high levels of coverage on average (though not exceeding 95%). We find that this high coverage comes with increases in width as shift increases. Figure 6 shows that temperature scaling has the highest average width across all models and shifts. Ensembling has the lowest width for the methods that maintain coverage of at least 95% across all shifts.
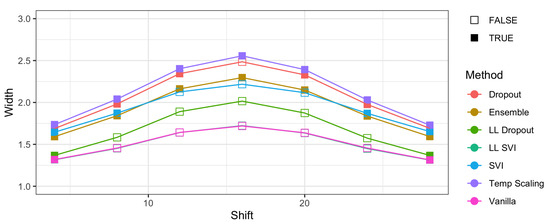
Figure 6.
The effect of translation shifts on coverage and width in CIFAR-10 images. Coverage remains robust across all pixel shifts while width increases. The shading of points indicates whether 95% coverage was maintained when translated. In general, models with every point shaded maintain high levels of coverage. Therefore, the models with the best empirical coverage properties are the lowest width models such that coverage is maintained.
All models have the same encouraging pattern of width increasing as shift increases up to 16 pixels, then decreasing. As CIFAR-10 images are 28 pixels in width and height, this maximum width occurs when the original center of the image is rolled over to and broken by the edge of the image. This likely breaks common features that the methods have learned for classification onto both sides of the image, resulting in decreased classification accuracy and higher levels of uncertainty.
Between the models which satisfy 95% coverage levels on all shifts, ensemble models have lower width than temperature scaling models. Under translation shifts on CIFAR-10, ensemble methods perform the best given their high coverage and lower width.
Additionally, we consider the coverage properties of models on 16 different corruptions of CIFAR-10 from Hendrycks and Gimpel [28]. Figure 7 shows coverage vs. width over varying levels of shift intensity. Models that have more dispersed points to the right have higher widths for the same level of coverage. An ideal model would have a cluster of points above the 95% coverage line and be far to the left portion of each facet. For models that have similar levels of coverage, the superior method will have points further to the left.
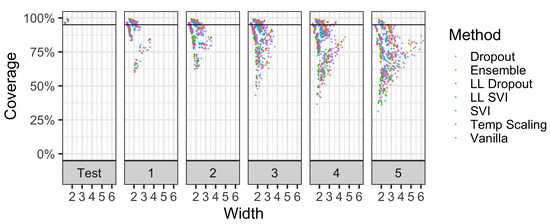
Figure 7.
The effect of corruption intensity on coverage levels vs. width in CIFAR-10-C. Each facet panel represents a different corruption level, while points are the coverage of a model on one of 16 corruptions. Each facet has 80 points per method since 5 iterations were trained per method. For methods with points at the same coverage level, the superior method is to the left as it has a lower width. Please see Figure 8 and Figure 9 for the additional synthesis of these results.
Figure 7 demonstrates that at the lowest shift intensity, ensemble models, dropout, temperature scaling, and SVI were able to generally provide high levels of coverage on most corruption types. However, as the intensity of the shift increases, coverage decreases. Ensembles and dropout models have, for at least half of their 80 model-corruption evaluations, at least 95% coverage up to the third intensity level. At higher levels of shift intensity, ensembles, dropout, and temperature scaling consistently have the highest levels of coverage. Although these higher-performing methods have similar levels of coverage, they have different widths.
We also present a way to quantify the relative strength of each method over a specific level of corruption. In Figure 8, for instance, we plot only the coverage and widths of methods at the third level of corruption and use the fraction of the points of a particular method that lie above the regression line. Methods that are more effective are providing higher coverage levels at lower widths and will have more points above this regression line.
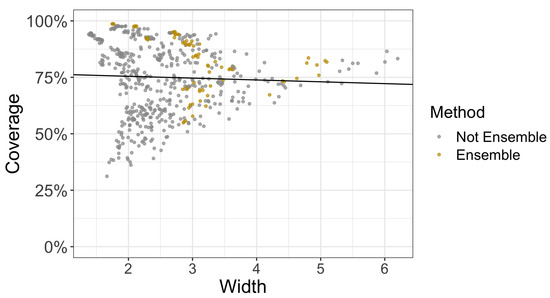
Figure 8.
The coverage and width of ensemble and non-ensemble methods at the fifth level out of five levels of corruption in CIFAR-10-C. The black line is a simple linear regression of coverage against width. We then can consider the fraction of points for a particular method (in this case, ensembling) that are above the regression line (see Figure 9 and Figure 10). The higher the fraction of these points above the regression line, the better the method is at providing higher coverage at a relatively smaller width than other methods.
For each of the five corruption levels, we calculated a regression line that modeled coverage as a function of width. Figure 9 presents the fraction of marginal coverages on various CIFAR-10-C datasets for each method that exceeded the linear regression prediction. The larger the fraction, the better the marginal coverage of a method given a prediction interval/set of a particular width. We observe that dropout and ensembles have a strong relative performance to the other methods across all five levels of shift.
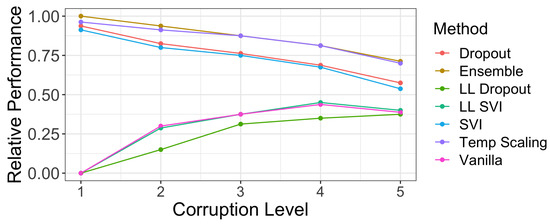
Figure 9.
The fraction of marginal coverage levels achieved on CIFAR-10-C corruptions by our assessed methods that are above a regression line of coverage vs. width at a specific corruption level. Methods that have better coverage levels at the same width will have a higher fraction of points above the regression line (see Figure 8 for an example). At low levels of shift, dropout, ensemble, SVI, and temperature scaling have strictly better relative performance. As shift increases, poor coverage levels in general cause models to have more parity.
Finally, we compared the relative rank order of these methods across coverage, as well as two common metrics in uncertainty quantification literature: Brier score and ECE. Figure 11 shows that the rankings are similar across methods. In particular, coverage has a nearly identical pattern to ECE, with changes only in the lower ranking methods.
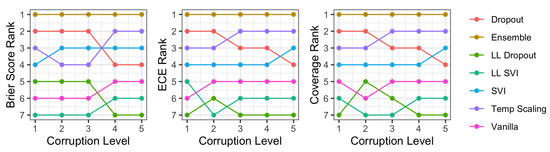
Figure 11.
The ranks of each method’s performance with respect to each metric we consider on CIFAR-10-C. For Brier Score and ECE, lower is better, while for coverage, higher is better. We observe that all three metrics have a generally consistent ordering, with coverage closely corresponding to the rankings of ECE.
4.4. ImageNet
Finally, we analyze coverage and width on ImageNet and ImageNet-C from Hendrycks and Gimpel [28]. Figure A1 shows similar coverage vs. width plots to Figure 7. We find that over the 16 different corruptions at 5 levels, ensembles, temperature scaling, and dropout models had consistently higher levels of coverage. Unsurprisingly, Figure A1 shows that these methods have correspondingly higher widths. Figure 10 reports the relative performance of each method across corruption levels. Ensembles had the highest fraction of marginal coverage on ImageNet-C datasets above the regression lines at each corruption level. Dropout, LL dropout, and temperature scaling all had similar performances, while LL SVI had a much lower fraction of marginal coverage above the regression lines. None of the methods have a commensurate increase in width to maintain the 95% coverage levels seen on in-distribution test data as dataset shift increases.
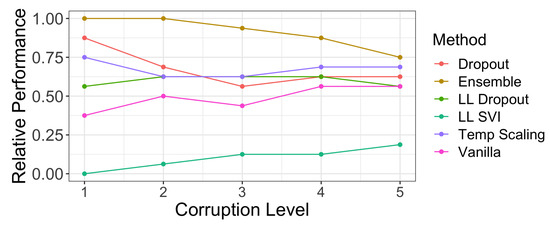
Figure 10.
The fraction of marginal coverage levels achieved on ImageNet-C corruptions by our assessed methods that are above a regression line of coverage vs. width at a specific corruption level. Methods that have better coverage levels at the same width will have a higher fraction of points above the regression line (see Figure 8 for an example). Ensembling produces the best coverage levels given specific widths across all levels of corruption. However, at a higher level of dataset shift, there is more parity between methods.
5. Discussion
We have provided the first comprehensive empirical study of the frequentist-style coverage properties of popular uncertainty quantification techniques for deep learning models. In regression tasks, LL SVI, SVI, and Gaussian processes all had high levels of coverage across nearly all benchmarks. LL SVI, in particular, had the lowest widths amongst methods with high coverage. SVI also had excellent coverage properties across most tasks with tighter intervals than GPs and linear regression. In contrast, the methods based on ensembles and Monte Carlo dropout had significantly worse coverage due to their overly confident and tight prediction intervals.
In the classification setting, all methods showed very high coverage in the i.i.d setting (i.e., no dataset shift), as coverage is reflective of top-1 accuracy in this scenario. On MNIST data, SVI had the best performance, maintaining high levels of coverage under slight dataset shift and scaling the width of its prediction intervals more appropriately as shift increased relative to other methods. On CIFAR-10 data and ImageNet, ensemble models were superior. They had the highest coverage relative to other methods, as demonstrated in Figure 9 and Figure 10.
An important consideration throughout this work is the choice of hyperparameters in most all of the analyzed methods makes a significant impact on the uncertainty estimates. We set hyperparameters and optimized model parameters according to community best practices in an attempt to reflect what a “real-world” machine learning practitioner might do: selecting hyperparameters based on minimizing validation loss over nested cross-validation. Our work is a measurement of the empirical coverage properties of these methods as one would typically utilize them, rather than an exploration of how pathological hyperparameters can skew uncertainty estimates to 0 or to infinity, while this is an inherent limitation in the applicability of our work to every context, our sensible choices will provide a relevant benchmark for models in practice.
Of particular note is that the width of a prediction interval or set typically correlated with the degree of dataset shift. For instance, when the translation shift is applied to MNIST, both prediction set width and dataset shift is maximized at around 14 pixels. There is a 0.9 Pearson correlation between width and shift. Width can serve as a soft proxy of dataset shift and potentially detect shift in real-world scenarios.
Simultaneously, the ranks of coverage, Brier score, and ECE are all generally consistent. However, coverage is arguably the most interpretable to downstream users of machine learning models. Clinicians, for instance, may not have the technical training to have an intuition about what specific values of Brier score or ECE mean in practice, while coverage and width are readily understandable. Manrai et al. [33] already demonstrated clinicians’ general lack of intuition about the positive predictive value, and these uncertainty quantification metrics are more difficult to internalize than PPV.
Moreover, proper scoring rules (e.g., Brier score and negative log-likelihood) can be misleading under model misspecification [34]. Negative log-likelihood, specifically, suffers from the potential impact of a few points with low probability. These points can contribute near-infinite terms to NLL that distort interpretation. In contrast, marginal coverage over a dataset is less sensitive to the impacts of outlying data.
In summary, we find that popular uncertainty quantification methods for deep learning models do not provide good coverage properties under moderate levels of dataset shift. Although the width of prediction regions do increase under increasing amounts of shift, these changes are not enough to maintain the levels of coverage seen on i.i.d data. We conclude that the methods we evaluated for uncertainty quantification are likely insufficient for use in high-stakes, real-world applications, where dataset shift is likely to occur. However, marginal coverage of a prediction interval or set is a natural and intuitive metric to quantify uncertainty. The width of a prediction interval/set is an additional tool that captures dataset shift and provides additional interpretable information to downstream users of machine learning models.
Author Contributions
Conceptualization, B.K., J.S. and A.L.B.; methodology, B.K. and A.L.B.; software, B.K. and J.S.; validation, B.K.; formal analysis, B.K., J.S. and A.L.B.; investigation, B.K.; resources, A.L.B.; data curation, B.K.; writing—original draft preparation, B.K.; writing—review and editing, B.K, J.S. and A.L.B.; visualization, B.K.; supervision, A.L.B.; project administration, A.L.B.; funding acquisition, A.L.B. All authors have read and agreed to the published version of the manuscript.
Funding
Beam was supported by award 5K01HL141771 from the NHLBI.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Code is available at https://github.com/beamlab-hsph/coverage-quantification (accessed on 28 November 2021) with additional links to the public datasets, model parameters, and model predictions used in this work.
Acknowledgments
We would like to thank Alex D’Amour and Balaji Lakshminarayanan for their insightful comments on a draft of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Additional Results
Appendix A.1. Regression Tables

Table A1.
The average coverage of six methods across nine datasets with the standard error over 20 cross-validation folds in parentheses.
Table A1.
The average coverage of six methods across nine datasets with the standard error over 20 cross-validation folds in parentheses.
| Dataset | Method | Linear Regression | GP | Ensemble | Dropout | LL Dropout | SVI | LL SVI |
|---|---|---|---|---|---|---|---|
| Boston Housing | |||||||
| Concrete | |||||||
| Energy | |||||||
| Kin8nm | |||||||
| Naval Propulsion Plant | |||||||
| Power Plant | |||||||
| Protein Tertiary Structure | |||||||
| Wine Quality Red | |||||||
| Yacht Hydrodynamics |
Table A2.
The average width of the posterior prediction interval of six methods across nine datasets with the standard error over 20 cross-validation folds in parentheses. Width is reported in terms of standard deviations of the response variable in the training set.
Table A2.
The average width of the posterior prediction interval of six methods across nine datasets with the standard error over 20 cross-validation folds in parentheses. Width is reported in terms of standard deviations of the response variable in the training set.
| Dataset | Method | Linear Regression | GP | Ensemble | Dropout | LL Dropout | SVI | LL SVI |
|---|---|---|---|---|---|---|---|
| Boston Housing | |||||||
| Concrete | |||||||
| Energy | |||||||
| Kin8nm | |||||||
| Naval Propulsion Plant | |||||||
| Power Plant | |||||||
| Protein Tertiary Structure | |||||||
| Wine Quality Red | |||||||
| Yacht Hydrodynamics |
Appendix A.2. Classification Results
Table A3.
MNIST average coverage and width for the test set, rotation shift, and translation shift.
Table A3.
MNIST average coverage and width for the test set, rotation shift, and translation shift.
| Method | Mean Test Set Coverage (SE) | Mean Test Set Width (SE) | Mean Rotation Shift Coverage (SE) | Mean Rotation Shift Width (SE) | Mean Translation Shift Coverage (SE) | Mean Translation Shift Width (SE) |
|---|---|---|---|---|---|---|
| Dropout | ||||||
| Ensemble | ||||||
| LL Dropout | ||||||
| LL SVI | ||||||
| SVI | ||||||
| Temp scaling | ||||||
| Vanilla |
Table A4.
CIFAR-10 average coverage and width for the test set and translation shift.
Table A4.
CIFAR-10 average coverage and width for the test set and translation shift.
| Method | Mean Test Set Coverage (SE) | Mean Test Set Width (SE) | Mean Translation Shift Coverage (SE) | Mean Translation Shift Width (SE) |
|---|---|---|---|---|
| Dropout | ||||
| Ensemble | ||||
| LL Dropout | ||||
| LL SVI | ||||
| SVI | ||||
| Temp scaling | ||||
| Vanilla |
Table A5.
The mean coverage and widths on the test set of CIFAR-10, as well as on the mean coverage and width averaged over 16 corruptions and 5 intensities.
Table A5.
The mean coverage and widths on the test set of CIFAR-10, as well as on the mean coverage and width averaged over 16 corruptions and 5 intensities.
| Method | Mean Test Set Coverage (SE) | Mean Test Set Width (SE) | Mean Corruption Coverage (SE) | Mean Corruption Width (SE) |
|---|---|---|---|---|
| Dropout | ||||
| Ensemble | ||||
| LL Dropout | ||||
| LL SVI | ||||
| SVI | ||||
| Temp Scaling | ||||
| Vanilla |
Table A6.
The mean coverage and widths on the test set of ImageNet, as well as on the mean coverage and width averaged over 16 corruptions and 5 intensities.
Table A6.
The mean coverage and widths on the test set of ImageNet, as well as on the mean coverage and width averaged over 16 corruptions and 5 intensities.
| Method | Mean Test Set Coverage | Mean Test Set Width | Mean Corruption Coverage (SE) | Mean Corruption Width (SE) |
|---|---|---|---|---|
| Dropout | ||||
| Ensemble | ||||
| LL Dropout | ||||
| LL SVI | ||||
| Temp Scaling | ||||
| Vanilla |
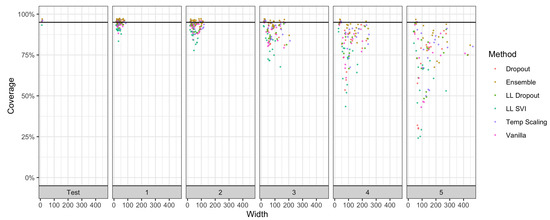
Figure A1.
The effect of corruption intensity on coverage levels vs. width in ImageNet-C. Each facet panel represents a different corruption level, while points are the coverage of a model on one of 16 corruptions. Each facet has 16 points per method, as only 1 iteration was trained per method. For methods equal coverage, the superior method is to the left as it has a lower width.
Appendix B. Hyperparameter Search and Model Details
A brief summary of the models utilized in this work:
- Vanilla networks in the style of [1], which are feedforward networks that were simply fully connected dense layers. Since there is no element of variability in the model’s prediction for the same sample, we could not consider the coverage of vanilla networks in regression tasks. They simply produce a single-point estimate given the same sample.
- Temperature Scaling was considered in classification tasks. This is a post-training calibration measure using a validation set as in [25].
- Dropout as in [16]. Feedforward networks had Monte Carlo dropout in between their dense layers. At test time, dropout still applied. In our work, we sampled networks 200 times to obtain a distribution of predictions.
- Ensembles as found in [3]. We took the outputs from 40 independently-trained vanilla networks, and these formed a predictive distribution.
- Stochastic Variational Inference (SVI) models, such as those of [7,8,11,30]. SVI models had difficult convergence properties in our experience and required the use of empirical Bayes for prior standard deviations.
- Last layer methods We considered LL dropout and LL SVI where dropout and mean-field stochastic variational inference were applied to only the last layer of an otherwise vanilla network, respectively.
- Gaussian Processes We implement sparse Gaussian processes [35] for regression with a RBF kernel and 10 inducing points.
- Linear regression We use the standard lm function in R to obtain prediction intervals for linear regression.
All models were implemented in Keras, with the exception of GPs (GPy) and linear regression (R). Hyperparameters were found for each model over 50 trials with a random sampling of the values described below.
Table A7.
The hyperparameters considered in our search for vanilla, dropout, ensemble, SVI, and LL models.
Table A7.
The hyperparameters considered in our search for vanilla, dropout, ensemble, SVI, and LL models.
| Hyperparameter | Range | Sampling Strategy |
|---|---|---|
| Dropout rate | [0, 0.5] | Uniform |
| Number of Hidden Layers | {1,2,3} | Uniform |
| Layer Width | {16, 32, 48, 64} | Uniform |
| Learning Rate | [, ] | Log uniform |
| Batch Size | 32 | Fixed |
| Max Epochs | 50 | Fixed |
We performed our hyperparameter search as part of K-fold cross validation. In regression tasks, we had 20 folds. On the larger split of each fold, we split the data 80/20 to form train/val splits for hyperparameter evaluation. In classification tasks, we were able to reuse the published predictions from these models from [14] for each sample in the held-out test set.
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kompa, B.; Snoek, J.; Beam, A.L. Second opinion needed: Communicating uncertainty in medical machine learning. NPJ Digit. Med. 2021, 4, 4. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4 December 2017; pp. 6405–6416. [Google Scholar]
- Yao, J.; Pan, W.; Ghosh, S.; Doshi-Velez, F. Quality of Uncertainty Quantification for Bayesian Neural Network Inference. arXiv 2019, arXiv:1906.09686. [Google Scholar]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer: New York, NY, USA, 1996. [Google Scholar]
- Hernández-Lobato, J.M.; Adams, R.P. Probabilistic Backpropagation for Scalable Learning of Bayesian Neural Networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; pp. 1861–1869. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight uncertainty in neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning (ICML’15), Lille, France, 6–11 July 2015; pp. 1613–1622. [Google Scholar]
- Graves, A. Practical Variational Inference for Neural Networks. In Proceedings of the 25th Conference on Neural Information Processing Systems (NeurIPS 2011), Grenada, Spain, 12–17 December 2011. [Google Scholar]
- Pawlowski, N.; Brock, A.; Lee, M.C.H.; Rajchl, M.; Glocker, B. Implicit Weight Uncertainty in Neural Networks. arXiv 2017, arXiv:1711.01297. [Google Scholar]
- Hernández-Lobato, J.M.; Li, Y.; Rowland, M.; Hernández-Lobato, D.; Bui, T.; Turner, R.E. Black-box α-divergence Minimization. Proceedings of The 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Louizos, C.; Welling, M. Structured and Efficient Variational Deep Learning with Matrix Gaussian Posteriors. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Louizos, C.; Welling, M. Multiplicative normalizing flows for variational Bayesian neural networks. In Proceedings of the International Conference of Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Wenzel, F.; Roth, K.; Veeling, B.S.; Świątkowski, J.; Tran, L.; Mandt, S.; Snoek, J.; Salimans, T.; Jenatton, R.; Nowozin, S. How Good is the Bayes Posterior in Deep Neural Networks Really? In Proceedings of the International Conference on Machine Learning, Vienna, Australia, 12–18 July 2020. [Google Scholar]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.V.; Lakshminarayanan, B.; Snoek, J. Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–13 December 2019. [Google Scholar]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Barber, R.F.; Candès, E.J.; Ramdas, A.; Tibshirani, R.J. The limits of distribution-free conditional predictive inference. Inf. Inference J. IMA 2021, 10, 455–482. [Google Scholar] [CrossRef]
- Vovk, V.; Gammerman, A.; Shafer, G. Algorithmic Learning in a Random World; Springer: Boston, MA, USA, 2005. [Google Scholar]
- Angelopoulos, A.N.; Bates, S. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification. arXiv 2021, arXiv:2107.07511. [Google Scholar]
- Shafer, G.; Vovk, V. A Tutorial on Conformal Prediction. J. Mach. Learn. Res. 2008, 9, 371–421. [Google Scholar]
- Hoff, P. Bayes-optimal prediction with frequentist coverage control. arXiv 2021, arXiv:2105.14045. [Google Scholar]
- Cauchois, M.; Gupta, S.; Ali, A.; Duchi, J.C. Robust Validation: Confident Predictions Even When Distributions Shift. arXiv 2020, arXiv:2008.04267. [Google Scholar]
- Barber, R.F.; Candes, E.J.; Ramdas, A.; Tibshirani, R.J. Conformal Prediction Under Covariate Shift. arXiv 2019, arXiv:1904.06019. [Google Scholar]
- Maddox, W.; Garipov, T.; Izmailov, P.; Vetrov, D.; Wilson, A.G. A Simple Baseline for Bayesian Uncertainty in Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- van Amersfoort, J.; Smith, L.; Teh, Y.W.; Gal, Y. Uncertainty Estimation Using a Single Deep Deterministic Neural Network. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Liu, J.Z.; Lin, Z.; Padhy, S.; Tran, D.; Bedrax-Weiss, T.; Lakshminarayanan, B. Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6 December 2020. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. In Proceedings of the International Conference on Learning Representations, Palais des Congrès Neptune, Toulon, France, 24–26 April 2017. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Proceedings of the Advances in Neural Information Processing Systems, Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Wen, Y.; Vicol, P.; Ba, J.; Tran, D.; Grosse, R. Flipout: Efficient Pseudo-Independent Weight Perturbations on Mini-Batches. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Riquelme, C.; Tucker, G.; Snoek, J. Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Manrai, A.K.; Bhatia, G.; Strymish, J.; Kohane, I.S.; Jain, S.H. Medicine’s uncomfortable relationship with math: Calculating positive predictive value. JAMA Intern. Med. 2014, 174, 991–993. [Google Scholar] [CrossRef] [Green Version]
- Martin, G.M.; Loaiza-Maya, R.; Frazier, D.T.; Maneesoonthorn, W.; Hassan, A.R. Optimal probabilistic forecasts: When do they work? Int. J. Forecast. 2021, in press. [Google Scholar] [CrossRef]
- Snelson, E.; Ghahramani, Z. Local and global sparse Gaussian process approximations. In Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, PMLR, San Juan, Puerto Rico, 21–24 March 2007; Volume 2, pp. 524–531. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).