1. Introduction
Due to the focal lengths of optical lenses, the images obtained by the camera include focused and defocused parts. Focused parts are sharper in the image, while defocused parts appear blurry. In order to obtain full-focus images, a common solution is utilizing multi-focus image fusion technology, to combine the focused parts of different images in the same scene. The combined full-focus image contains global clarity and rich details, and is more suitable for visual perception and computer processing. As an important branch of image fusion, multi-focus image fusion can be studied on three different levels, i.e., pixel level, feature level, and decision level [
1]. Compared with the other two levels, pixel-level image fusion can maximally reserve the original information in the source image, giving it an edge over the other two in accuracy and robustness. Accordingly, it has become a common fusion method for multi-focus images. The method proposed in this paper is based on pixel-level multi-focus image fusion.
Multi-scale decomposition (MSD) is a technique usually applied in pixel-level multi-focus image fusion, and it was proven to be a very useful image analysis tool. The MSD-based fusion method can extract image feature information on different scales for image fusion. The mechanism of the MSD fusion method is as follows. Firstly, the source images are decomposed into multi-scale spaces by MSD, where there is one approximate component containing contours and several detail components storing salient features. Then, the decomposed coefficients of all scale spaces are fused, following the designed fusion strategies. Finally, the inverse multi-scale decomposed is used to reconstruct the final fused image. Undoubtedly, the choice of the multi-scale decomposition method and fusion strategy are two important factors of image fusion.
The selection of the multi-scale decomposition method needs to factor in the following aspects: firstly, the desirable feature extraction performance. One advantage of the MSD-based method is to separate spatially overlapping features in scales. Secondly, the decomposition algorithm. In practical applications, the execution efficiency of the algorithm is a key indicator. Finally, good generalization. It means being able to handle various types of images, including anisotropic blur and unregistration.
Since the 1980s and 1990s, various multi-scale decomposition methods have been applied in multi-focus image fusion [
2], mainly containing Laplacian pyramid (LP) [
3], gradient pyramid (GP) [
3], discrete wavelet transform (DWT) [
4], and so on. Although, DWT improves computational efficiency compared with LP and GP, it does not reflect shift invariance and direction selectivity, which undermine feature extraction. To address these problems, the dual-tree complex wavelet (DTCWT) [
5] is proposed, which has shift invariance and direction selectivity, and is successfully applied for multi-focus image fusion [
6]. Compared with the pyramid and wavelet transform, the multi-scale geometric analysis (MGA) [
7,
8,
9] methods better reflect the inherent geometric structure of the image, and outperform in feature extraction, but the calculation is more complex and time-consuming.
In recent years, scholars have proposed new and efficient multi-scale decomposition methods, which show good performance in multi-focus image fusion. Typical methods include the following: Li et al. [
10] proposed a two-scale decomposition method for multi-focus fusion with the guided filtering technique. Through simple average filtering, each source image is decomposed into a basic layer with large-scale variations and a detail layer containing small-scale details. The method is superior to many traditional MSD-based methods in terms of fusion performance and computational efficiency. Xiao et al. [
11] proposed that the multi-scale hessian matrix can decompose the source images into small-scale feature components and large-scale background components, and effectively remove the pseudo-edges, which are introduced by image blurring and unregistered. The method shows good feature extraction and generalization capabilities. Zhang et al. [
12] proposed a multi-scale decomposition scheme by changing the size of the structural elements, and extracting the morphological gradient information of the image on different scales to achieve multi-focus image fusion. The method shows the best execution efficiency. NaiduIn et al. [
13] and Wan et al. [
14] proposed multi-scale analysis and singular value decomposition are combined to perform multi-focus image fusion. This method achieves the stability and orthogonality equivalent of that achieved by SVD. Since no convolution operations are required, the fast decomposition speed means high execution efficiency of the algorithm.
In addition to developing novel methods for MSD, fusion rules also play a key role in image fusion. Advanced fusion rules and MSD methods form a complementary whole in image fusion, which promotes fusion performance. The fusion rules of multi-focus images are usually designed based on the focus measure between pixels. Commonly used focus measures incorporate spatial frequency (SF) [
15], sum-modified-Laplacian (SML) [
16], standard deviation (STD) [
17], energy of gradient (EOG) [
18], etc. Generally, simple pixel-based fusion rules are insensitive to anisotropic blur and misregistration. For example, fusion rules, such as direct comparison of decomposition coefficients and weighted average values based on spatial context. To improve fusion results, some complex fusion rules are proposed. Among these are block-based and area-based methods [
19,
20]. Firstly, the original images are divided into a number of blocks or regions. Then, the focus level and sharpness of each block or region is measured by image intensity. Finally, a block or region with a higher degree of focus as part of the fusion image is selected. However, the quality of image fusion depends on the selection of the image block sizes or the segmentation algorithms. When the image block is not selected correctly or the segmentation algorithm cannot correctly segment the area, the focus area cannot be correctly determined and extracted, and the boundary between the focus and the defocus area is prone to blur. Zhou et al. [
21] proposed a new focus measure fusion method based on a multi-scale structure, which uses large-scale and small-scale focus measures to determine the clear focus area and weight map of the transition area, respectively. This method can reduce the influence of anisotropic blur and unregistration on image fusion. However, the transition area is artificially set and cannot accurately reflect the focus of the boundary. Ma et al. [
22] proposed a random walk-based with two-scale focus measure for multi-focus image fusion. The method estimates a focus map directly from the two-scale imperfect observations obtained using small and large-scale focus measures. Since the random walk algorithm is used to model the estimation from the perspective of probability, this method is relatively time-consuming. In addition to the commonly used linear model fusion rules mentioned above, there are also some fusion rules based on non-linear methods. Dong et al. [
23] proposed a multi-focus image fusion scheme by memristor-based PCNN. Hao et al. [
24] review the state-of-the-art on the use of deep learning in various types of image fusion scenarios. The Generative Adversarial Network (GANS) proposed by Guo et al. [
25] has also been successfully applied to multi-focus image fusion. When it comes to the deep learning model of multi-focus image fusion, the measurement of pixel activity level is obtained through the model. However, the difficulties in training a large number of parameters and large datasets have directly affected the image fusion efficiency and quality. Compared with deep learning methods, the conventional fusion methods are more extensible and repeatable, facilitating real-world applications. Thus, the paper mainly aims to improve the conventional multi-focus image fusion algorithms.
According to the above analyses, decomposition schemes and focus measures involved in the fusion strategy play important roles in multi-focus image fusion. In recent years, many novel algorithms have been proposed to improve the image fusion quality, but some existing problems still need to be addressed. Firstly, due to the diversity of fused images, the contour and detailed information of images cannot be fully expressed when images are decomposed by fixed basis and filter functions. Secondly, the boundary between the focused and defocused areas of the image gives rise to false edges, mainly due to the fact that the boundary between the two areas are not clearly distinguished, or that the two images are not registered. Finally, the artifacts are easily generated between the focused and unfocused flat regions, since the image details in those regions are extremely scanty [
11].
In order to solve the problems, a novel multi-focus image fusion method based on multi-scale singular value decomposition (MSVD) is proposed in this paper. The method obtains low-frequency and high-frequency components with complementary information through two groups of double-layer decompositions with complementary structures and scales, and these components contain rich image structure and detailed information. The proposed fusion rules are then applied to fuse each component to obtain the final fusion image. Concretely, different fusion strategies and focusing measures are used to fuse the high-frequency and low-frequency sub-images, respectively, and two initial decision diagrams with complementary information are obtained. Hence, a definite focus area and a non-definite focus area are obtained. After that, the non-definite focus area is refined and transformed into a definite focus area, and the final decision map to complete the image fusion is obtained. The proposed method has the following advantages. Firstly, two groups of decomposition schemes with complementary structure and scale are designed to accurately obtain the focus of the boundary. Secondly, the proposed method combines multi-scale analysis and singular value decom-position for multi-focus image fusion. Singular value decomposition diagonalizes the image matrix according to the size of eigenvalues, so there is no redundancy between the decomposed images, which is suitable for different fusion rules for each component. Finally, by exploiting the image feature information contained in each decomposition layer of low-frequency components and high-frequency components, selecting different focus measures can better extract the image feature information.
Compared with the existing multi-focus image fusion method, the main innovations of the proposed method are as follows:
The paper uses MSVD decomposition with a complementary structure and size for the first time, enhances the complementarity of the extracted image feature information and improves the ability to detect the focus area, in order to fully extract the structure and detailed information of the image.
To fully extract the structure and details of the image, the complementary features extracted by different focus measures are developed as the external stimulus input of the PA-PCNN.
Experiments are performed to verify the efficiency of the proposed method. The results show that the proposed method can effectively eliminate the pseudo edges caused by anisotropic blur or unregistration.
The structure of this paper is organized as follows.
Section 2 proposes the multi-focus image fusion model based on multi-scale decomposition of information complementary.
Section 3 analyses and discusses the results of the comparison with the latest methods. Finally, conclusions for this paper are provided in
Section 4.
2. Proposed Multi-Focus Image Fusion Algorithm
Due to object displacement or camera shake during image acquisition, multi-focus images will produce unregistration and anisotropic blur. These factors can lead to erroneous focus judgment in the focus map obtained by the focus measure (FM), which make the fusion image appear blurred and distorted. In order to solve the above problems, Zhou et al. [
21] proposed a two-scale fusion scheme. A large scale can better reduce blur and unregistration, and a small scale can better retain some details, so that the Halo effect of the fused image can be mitigated. However, this algorithm calculates its saliency map based on the covariance matrix of the region, and the fusion effect is not good for images without obvious edges or corners. In addition, an unknown area is defined near the boundary pixels of the focus area, and its width is set as
. This artificially set unknown area cannot accurately reflect the focus of the boundary and will affect fusion. In response to the above problems, we propose a multi-focus image decomposition strategy based on a multi-scale singular value decomposition. In this strategy, two groups of low-frequency and high-frequency components with complementary information are obtained by two-level decomposition of the complementary structure and scale. According to the proposed fusion rules, each component is fused to obtain the final fusion image.
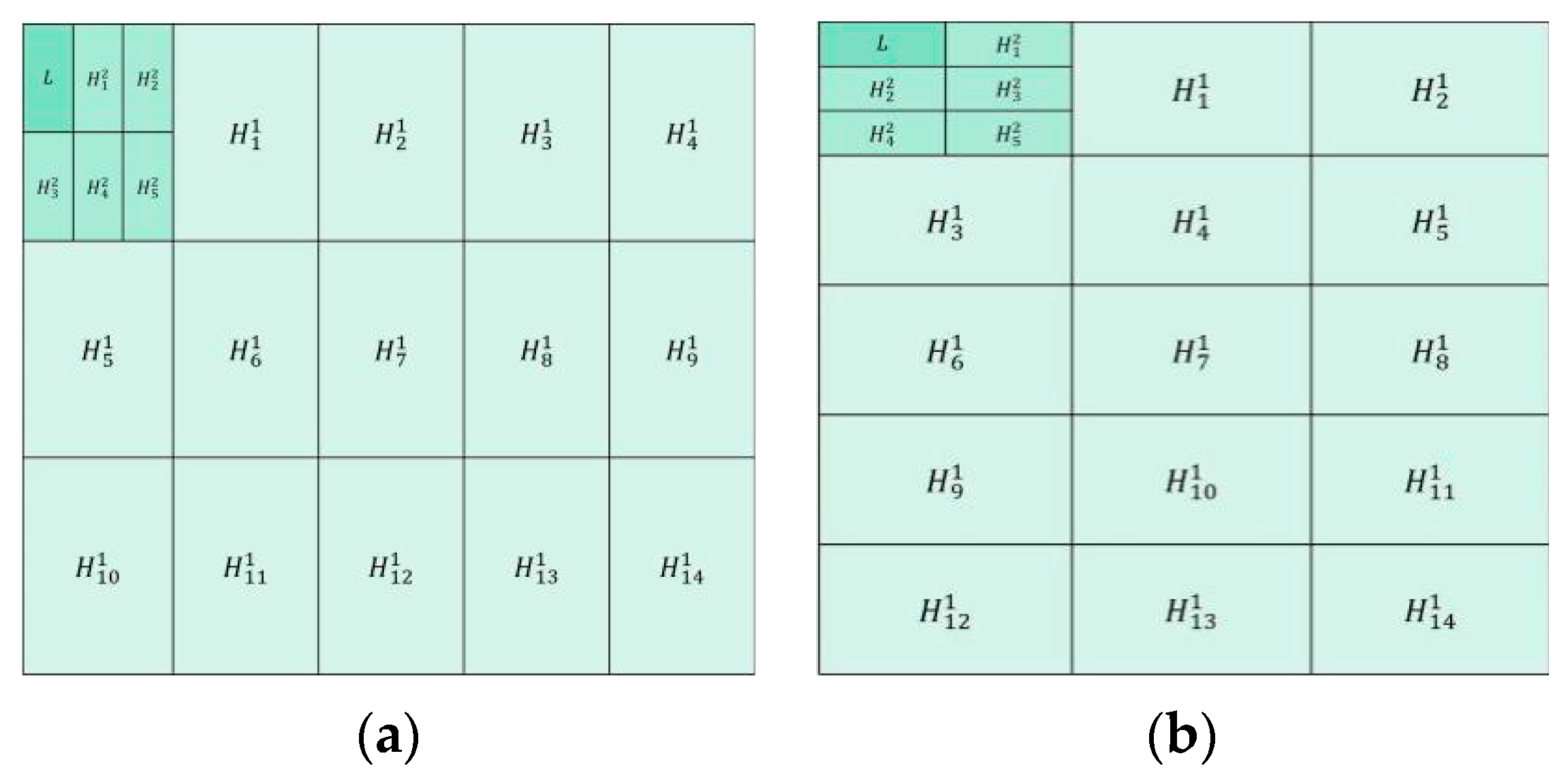
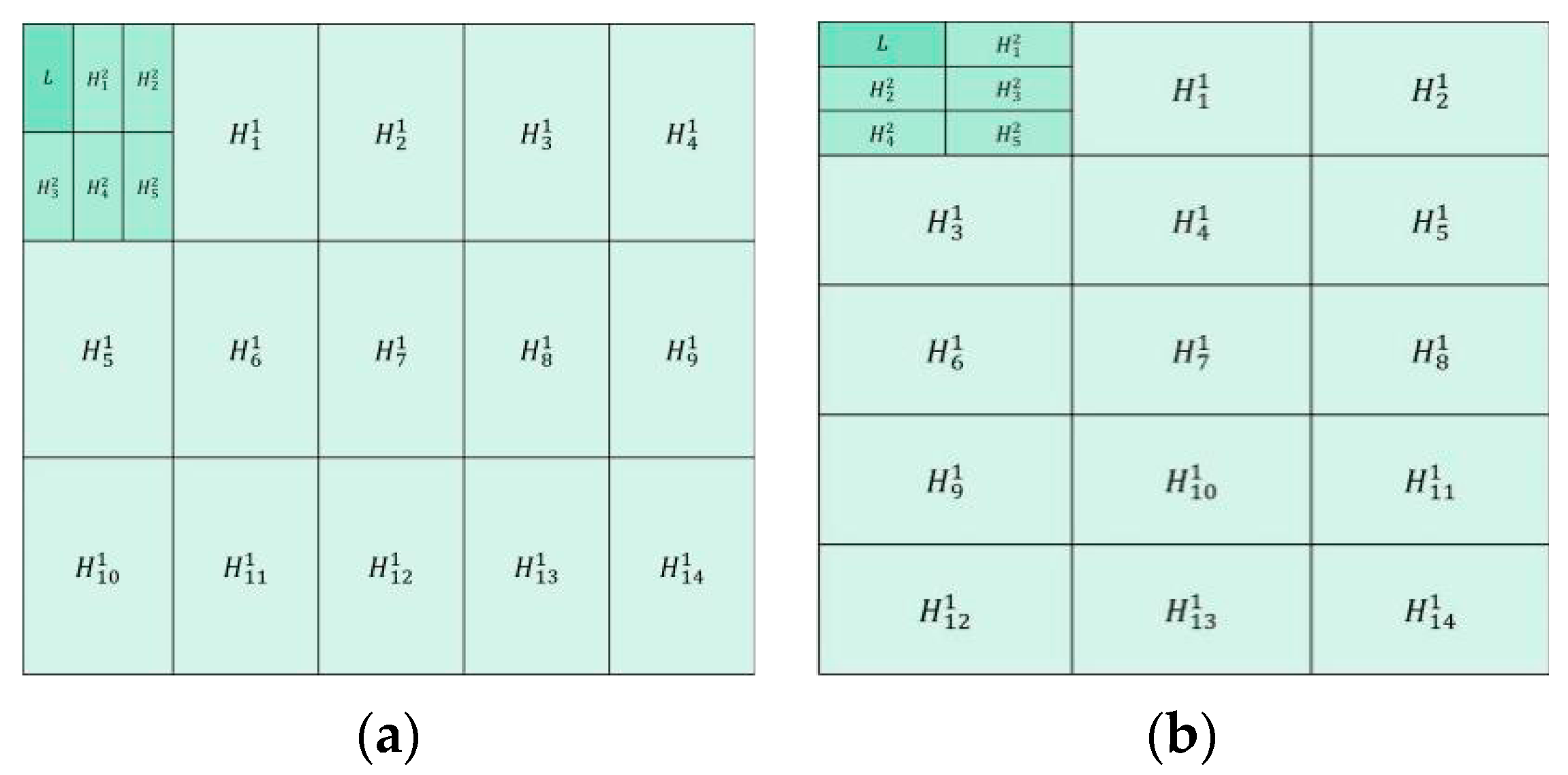
Figure 1a shows the first group of decomposition schemes. The first layer is to divide the source image into blocks in the size of 3 × 5 to achieve large-scale decomposition of the image. In the second layer, the low-frequency components obtained from the first layer are divided into blocks in the size of 2 × 3 to achieve small-scale image decomposition.
Figure 1b shows the second group of decomposition schemes. The first layer is to divide the source image into blocks in the size of 5 × 3 to achieve the large-scale decomposition of the image. In the second layer, the low-frequency components obtained from the first layer are divided into blocks in the size of 3 × 2 to achieve mall-scale image decomposition (in
Section 2.1.2 for details of image segmentation method).
The multi-scale decomposition scheme proposed in this paper uses block operation to achieve large-scale and small-scale decomposition of the image. Large-scale decomposition can better retain image structure information, and small-scale decomposition can better retain image detail information. Through the proposed fusion rule, the high and low frequency components obtained by the two decomposition schemes are fused, and two fusion decision maps with complementary information are obtained. These two fusion decision maps can make up for the poor fusion effect of images without giving rise to obvious edges and corners. It can also determine the blur region near the pixels of the focus region boundary.
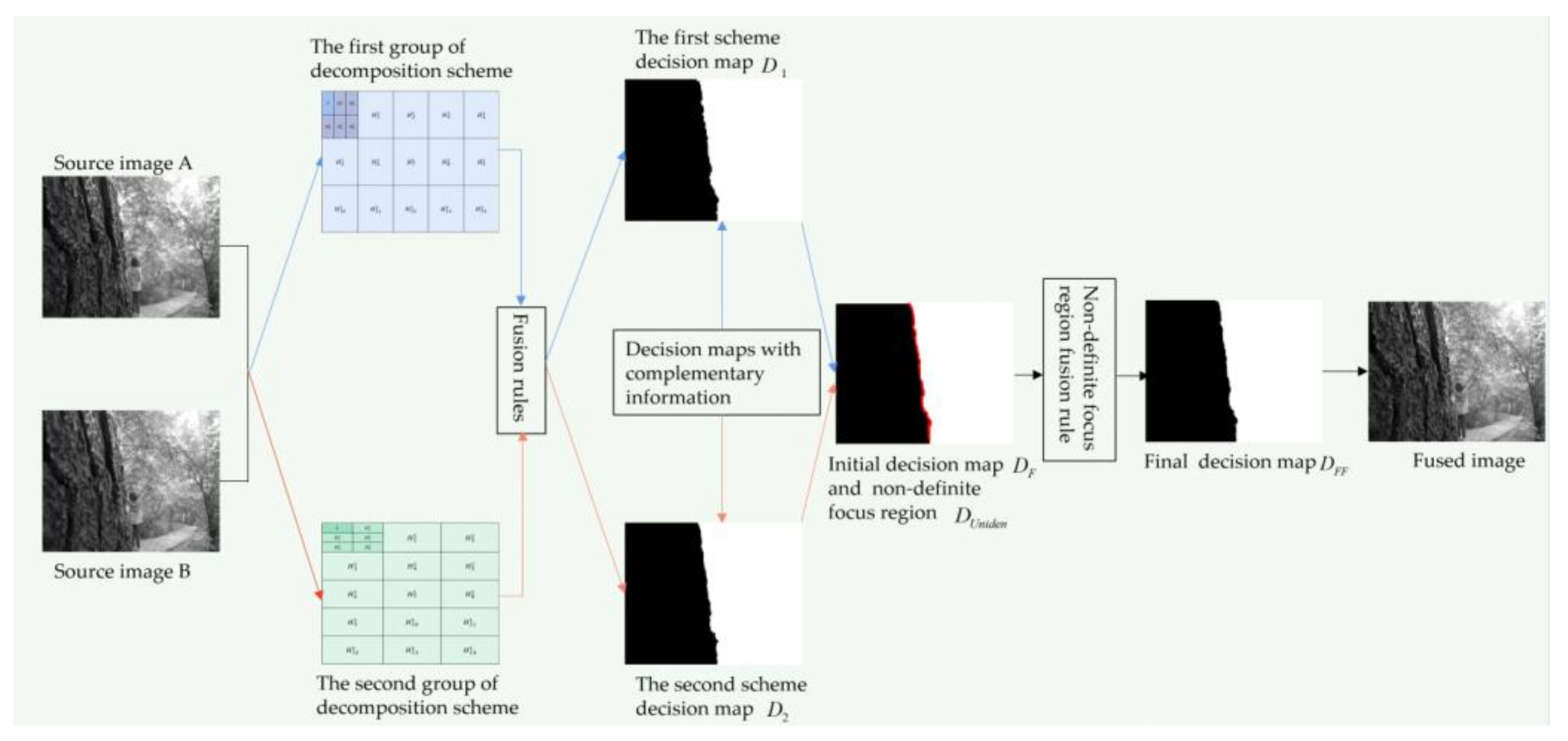
Figure 2 shows the two complementary information fusion decision maps obtained through the two decomposition schemes show in
Figure 1 and the initial decision map determined through them. The initial decision map contains the definite focus area and the non-definite focus area.
2.1. Multi-Scale Singular Value Decomposition of Multi-Focus Image
2.1.1. Multi-Scale Singular Value Decomposition
MSVD is an image decomposition method with simple calculations and is suitable for real-time applications. In image decomposition, it uses singular value decomposition (SVD) to perform a similar function to the FIR filter in wavelet transform, but MSVD is not like wavelet transform, which has a fixed set of basis vectors to decompose images, and its basis vectors depend on the image itself [
13].
X is the matrix form of image
,
. When orthogonal matrixes
and
exist, we can obtain:
According to the transformation of Equation (1), the singular value decomposition of
X can be obtained as:
In Equation (2), . r is the rank of the matrix X, is the singular value of X. The matrix singular value has strong stability, and will not change with image scaling and rotation. U and V are the eigenvectors corresponding to the singular values, and they depend on the image X. The amount of image information represented by eigenvector is positively related to the size of the corresponding singular value. The larger the singular value, the more image information it contains, which corresponds to the approximate part of the image. The smaller singular values correspond to the detailed parts of the image, which is the high frequency part of the image. Therefore, the image can be separated into approximate and detailed information according to the size of the singular values.
2.1.2. Decomposition of Multi-Focus Image
In order to achieve multi-scale decomposition of the multi-focus images, they are divided into non-overlapping
blocks, and each sub-block is arranged into an
mn × 1 vector. By combining these column vectors, a matrix
with a size of
can be obtained. The singular value decomposition of
is:
and
are orthogonal matrices, according to Equation (3):
The size of the matrix
S is
.
According to the singular value decomposition mentioned above, the first column vector of
corresponds to the maximum singular value. When it is left multiplied by the matrix
, the first row
of
S carries the main information from the original image, which can be regarded as the approximate or smooth component of the original image. Similarly, the other row
of
S corresponds to smaller singular values, which retains such detailed information as the texture and edges of the original image. Therefore, through singular value decomposition, the image can be decomposed into low-frequency and high-frequency subimages by the singular value to achieve the multi-scale decomposition of the image. The schematic diagram of the multi-focus image MSVD scheme proposed in this paper is illustrated in
Figure 1. In order to clearly illustrate the image decomposition process, it is assumed that there is a source image with a size of 300 × 300. According to the decomposition scheme in
Figure 1a and the above mentioned image decomposition steps, the source image is divided into blocks of size 3 × 5 to achieve the first-layer large-scale decomposition. After that, 1 low-frequency component and 14 high-frequency components are obtained, and the size of each component is 100 × 60. The second-layer of decomposition is to divide the low-frequency components of the first-layer into blocks of size 2 × 3 to achieve small-scale decomposition. Moreover, 1 low-frequency component and 5 high-frequency components are obtained, and the size of each component is 50 × 20. After fusion of the components, the final fusion image is acquired through the inverse MSVD transformation.
2.2. Low-Frequency Component Fusion
The low-frequency sub-image of the multi-focus image obtained by the MSVD decomposition scheme proposed in this paper reflects the overall characteristics of the image, and mainly contains contour and energy information. In this paper, we use the algebraic operations and spatial characteristics of quaternions to calculate the local energy of low-frequency components. Joint bilateral filter (JBF) is used to get the structure information of low-frequency components, combine the energy and structure information to calculate the weight to obtain the fusion decision map. The fused low-frequency components are obtained according to the decision map.
2.2.1. Quaternion
Quaternions were first introduced in 1843 by British mathematician Hamilton [
26]. They can be considered an extension of complex numbers. The general form of a quaternion is expressed as follows:
where
and where
a is the real part,
bi,
cj, and
dk are three imaginary parts. If the real part
a is zero,
Q is called a pure quaternion.
The modulus of a quaternion is defined as:
where
is defined as the conjugate of the quaternion
Q,
.
The unit vector of a quaternion
Q is defined as:
Define two quaternions as
In Equation (8), quaternion multiplication can be represented using the cross and dot product.
where
and
are the vector parts of each quaternion.
and
represent the dot product and cross product of the two vectors, respectively.
2.2.2. Joint Bilateral Filter
Bilateral filter (BF) is a nonlinear filtering method, which combines the spatial proximity and pixel value similarity of the image. BF can achieve edge preservation and denoising during image fusion. However, the weights of the bilateral filter are not stable enough, and the joint bilateral filter (JBF) introduces the guiding image on the basis of the bilateral filter, making the weights more stable. JBF can be expressed as follows:
W is the regularization factor, defined as:
The Gaussian kernel function G is expressed as:
In Equation (9), the set of adjacent pixels is denoted as , , and are the parameters of two Gaussian kernel functions, which are used to control the influence of Euclidean distance and pixel similarity. The Gaussian kernel function will attenuate as the distance between x and y increases. When the distance between x and y is less than or the difference between two pixel values is less than , the pixel value of y has a greater impact on the value of . Different from the bilateral filter, and are the guiding pixel values of x and y, respectively. The guiding image O can provide more reliable information for the structure of the output image and obtain a more optimized similarity Gaussian kernel weight.
2.2.3. Low-Frequency Component Fusion Rule
The low-frequency component contains most of the energy and contour information of the image. Therefore, in the low-frequency fusion process, the energy and contour information of the image should be taken into account. In this paper, a new low-frequency component fusion method is proposed. Firstly, the local energy of low-frequency component is calculated using the neighborhood of pixels represented by quaternions. Secondly, we use JBF to get the edge contour information of the low frequency component. Then, we combine the local energy and the edge energy to calculate the weight of the low-frequency component to obtain the fusion decision map. Finally, the fused low-frequency component is obtained according to the decision map. The detailed fusion process is as follows:
Select the pixel in the 3 × 3 domain of the target pixel to construct quaternion
, and calculate the local energy
of the low-frequency component:
In Equation (10), , represent the position of the low-frequency component pixel. is the quaternion formed by the front, back, left, and right pixels in the neighborhood of pixel . is the quaternion formed by diagonal pixels in the neighborhood of pixel . In the calculation of , is constructed as a unit vector according to Equation (7).
- 2.
JBF is used to process the local energy map
of low frequency components to get the energy map
of edge pixels:
In Equation (11), is the local energy of the low-frequency component, with low-frequency component as a guide map, represents the local window radius, is the standard deviation of the spatial domain kernel, and the standard deviation of the range kernel.
- 3.
According to the local energy
and edge energy
of the low-frequency component, the weight of the low-frequency component is calculated.
- 4.
The fusion image of the low-frequency component is obtained by the following formula:
2.3. High-Frequency Component Fusion
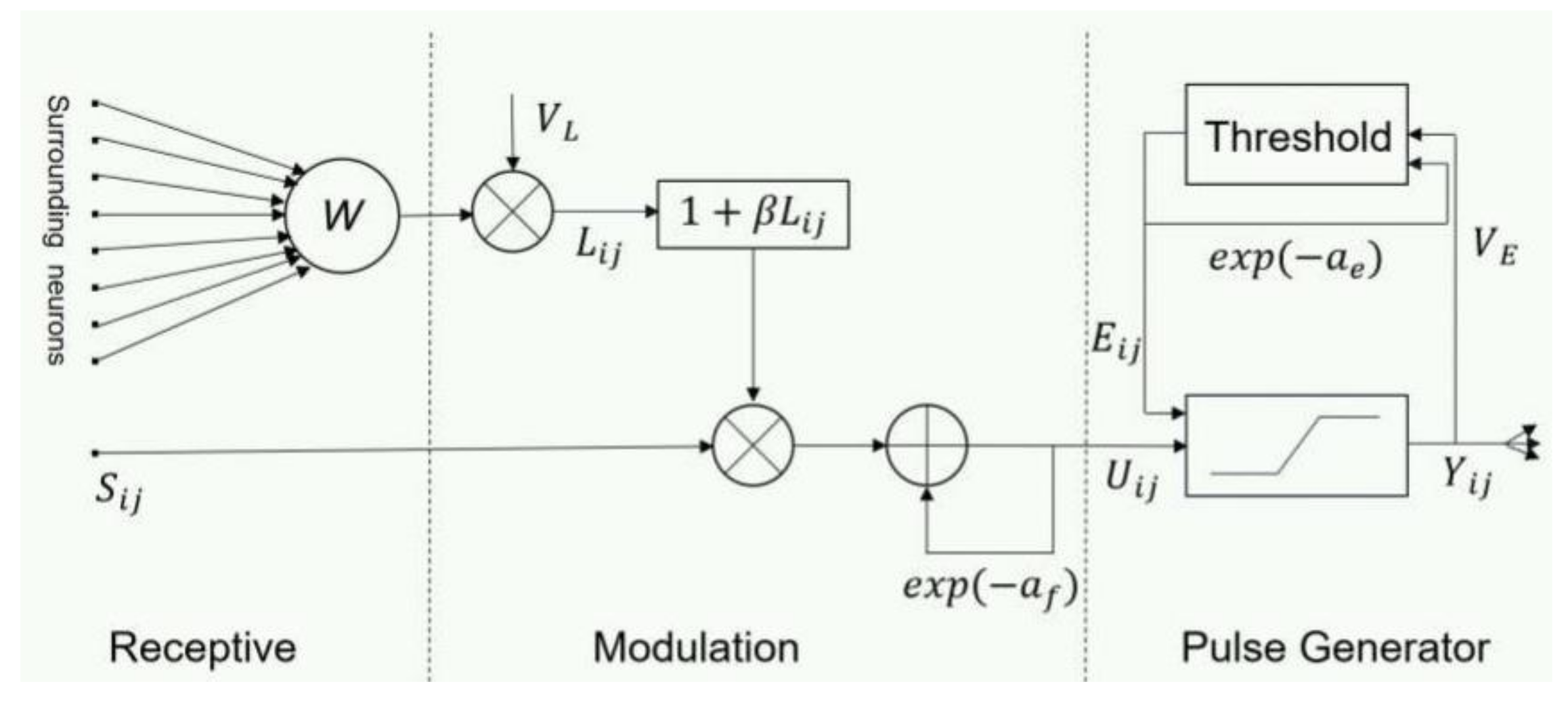
The high frequency component corresponds to the sharply changing part of the image, including the texture, details, and edge information of the image, which impacts the clarity and visual effects of the fused image. Pulse coupled neural network (PCNN) is a simplified artificial neural network constructed by Eckhorn based on the cat’s eye vision principle. Its signal form and processing mechanism are more in line with the physiological characteristics of the human visual nervous system. In order to improve the quality of the fused image, this paper proposes to use an adaptive PCNN strategy to fuse high-frequency components. The first layer of image decomposition selects the local spatial frequency (SF) as the external stimulus input of the PCNN, and the second layer selects the local standard deviation (STD) as the external stimulus input of PCNN.
2.3.1. PA-PCNN
PCNN can capture image edge and detailed information without any training process. It is a feedback single-layer network composed of several neurons connected with each other. It has three functional units: feedback input domain, connection input domain, and pulse generation domain. The traditional PCNN model needs to determine parameters, such as link strength, various amplitudes, and attenuation coefficients. In order to avoid the insufficiency of manually setting parameters, a simplified PCNN model [
27,
28] is proposed, which is described as follows:
and
are the external stimulus input and link input of the pixel at position (
i,
j) during the nth iteration, and
is the input image. The parameter
is the amplitude of the link input
, which controls
together with
and
, and
is the synaptic weight matrix. The internal activity item
consists of two parts: the first part
is the exponential decay part of the internal activity of the previous iteration, and
is the exponential decay coefficient. The second part
is the nonlinear modulation of
and
, where the parameter
is the link strength.
depends on the current internal activity item
and the dynamic threshold
during the last iteration. When
,
, PCNN is in an ignition state. By contrast,
, PCNN is in an unfired state.
and
are the exponential decay coefficient and amplitude of
, respectively. There are 5 free parameters in the parameter adaptive PCNN model:
. These parameters can be calculated by the following formula [
27,
28]:
The smaller the value of
, the greater the dynamic range of
.
is the standard deviation of normalized image
S.
β and
are the weights of
, it can be regarded as a whole as the weighted link strength. The maximum intensity value
Smax of the input image and the optimal histogram threshold
jointly determine the value of
.
and
are combined to get
and
.
Figure 3 shows the PA-PCNN model used in the multi-focus image fusion method proposed in this paper.
2.3.2. Space Frequency and Standard Deviation
The spatial frequency (SF) and standard deviation (STD) of an image are two important indicators of the details of the image.
Spatial frequency is defined as:
RF is the row frequency and CF is the column frequency. The spatial frequency (SF) of the image indicates the clarity of the spatial details of the image.
Standard deviation is defined as:
The image standard deviation represents the statistical distribution and contrast of the image. The larger the standard deviation, the more scattered the gray level distribution, the greater the contrast, and the more prominent the image details. μ is the mean value of the image.
Spatial frequency and standard deviation reflect the details of the image from different aspects, and the two indicators are complementary.
2.3.3. High-Frequency Component Fusion Rule
The high-frequency components of the source image obtained through multi-scale and multi-layer decomposition contain important details of the image. As the number of decom-position layers increases, the detailed features of high-frequency components become more prominent. In order to make the image fusion effect better meet the physiological characteristics of the human visual nervous system, in the first layer and second layer decomposition of high-frequency components, local spatial frequency (SF) and local standard deviation (STD) are, respectively, selected as external stimulus inputs of PA-PCNN, and to achieve the fusion of high-frequency components. The fusion procedure of high-frequency components is as follows:
In the first layer of decomposition, SF is used as the external stimulus input of PA-PCNN, and the number of ignitions of high-frequency components is obtained by
Weight coefficient of high-frequency components is obtained by:
High-frequency components after fusion is obtained by:
In the same way, STD is used as the external stimulus input of PA-PCNN to obtain the fused high-frequency components of the second layer decomposition.
H1 represents the high-frequency component decomposed in the first layer, and H2 represents the high-frequency component decomposed in the second.
2.4. Non-Definite Focus Region Fusion
A multi-focus image fusion method is commonly used to obtain the final fusion image based on the decision maps. However, the decision maps are often inaccurate, especially at the boundary between the focus and defocus regions. To better determine the focus attribute of the boundary, we propose to define the aliasing region of the two complementary initial decision graph boundaries as the undetermined focus region (the red region in
Figure 2e). On this basis, the measurement method combining local spatial frequency (SF) and local standard deviation (STD) (
Section 2.3.2) is used to convert the non-definite focus region into a definite focus region, and accurate fusion decision map is obtained, and can effectively address an out-of-focus blur caused by anisotropic blur and unregistration. The specific fusion process is as follows:
Based on the two complementary decision maps, an initial decision map
DF containing the definite focus region and the non-definite focus region is obtained.
where
D1 is the fusion decision map obtained by the first group of decomposition scheme (
Figure 2c),
D2 is the fusion decision map obtained by the second group of the decomposition scheme (
Figure 2d),
DF is the initial decision map (
Figure 2e). When
or
,
belongs to the definite focus region
DIden; when
,
belongs to the definite focus region
DUniden (the red region in
Figure 2e).
The weight coefficient of the non-definite focus region is calculated by
The non-definite focus region fusion is calculated by
where
and
are non-definite focus regions of the source multi-focus images.
2.5. The Proposed Multi-Focus Image Fusion Method
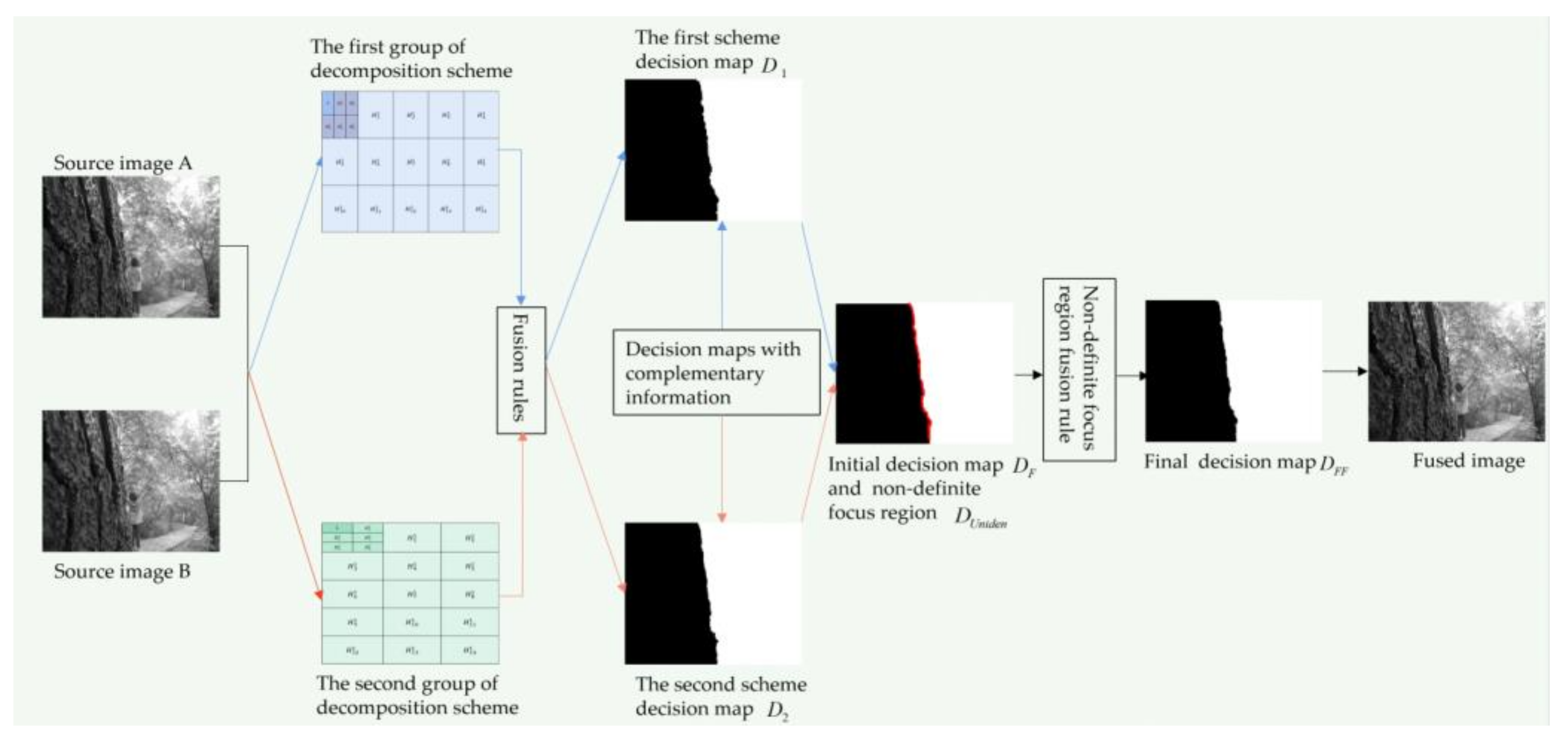
Step 1: the two-layer MSVD decomposition with the complementary structure and scale (
Figure 1) is performed on two multi-focus images, A and B, respectively, and two groups of information complementary low-frequency components and high-frequency components are obtained. In each group of decomposition, the source image is decomposed into a low-frequency component
L and multiple high-frequency components
.
Step 2: different fusion rules are used to fuse the low-frequency components L and high-frequency components respectively, and the information complementary decision map D1 and D2 are obtained.
Step 3: the complementary decision maps in Step 2 are exploited, and the initial decision map
DF containing the definite focus region and the non-definite focus region is obtained. The non-definite focus region
DUniden in
DF is the aliasing area at the boundary of the complementary decision maps. With the adoption of the proposed focus measurement method (in
Section 2.4), the non-definite focus region
DUniden is transformed into the definite focus region, and the final fusion decision map
DFF is obtained.
Step 4: according to the fusion decision map DFF obtained in Step 3, the final fusion image is obtained.
Figure 4 illustrates the principle diagram of the method in this paper, which corresponds to the above fusion steps.
3. Experiments and Discussion
In order to verify the effectiveness of the proposed method, we first compare the proposed method with some classic and state-of-the-art methods, which are fusion methods based on traditional ideas. They are the curvelet transform (CVT) [
29], the singular value decomposition in discrete cosine transform (DCT_SVD) [
30], the dual-tree complex wavelet transform (DTCWT) [
5,
29], the image matting for fusion of multi-focus images (IFM) [
31], the Laplacian pyramid (LP) [
29], the multi-resolution singular value decomposition (MSVD) [
13], the multi-scale weighted gradient-based fusion (MWGF) [
21], the nonsubsampled contourlet transform (NSCT) [
29,
32]. The codes for the eight methods for comparison are provided by the authors of the corresponding papers, the MATLAB programs are all available online, and the parameters are the default values presented in the original papers. In addition, we select 13 pairs of multi-focus images commonly used in image fusion for comparative experiments, where 6 pairs of source images are provided by Lu et al. [
1], and 4 pairs of source images are provided by Zhang et al. [
33], and 3 other pairs of source images are obtained from the website [
34]. In order to verify the performance of the proposed method, unregistered and pre-registered multi-focus images are specially selected for experimental analyses. Then, the proposed method is also compared with FuseGAN and CNN [
25] methods, which are related to deep learning. The data sets, objective metrics, and fusion results used in the FuseGAN and CNN all derive from [
25]. Finally, an ablation experiment is also carried out to test the effect of eliminating the PCNN method from the fusion result.
The decomposition parameters setting of the proposed method are: in the first group, the first layer is divided into 3 × 5 blocks, and the second layer is divided into 2 × 3 blocks; in the second group, the first layer is divided into 5 × 3 blocks, and the second layer is divided into 3 × 2 blocks (in
Section 2.1.2 and
Figure 1 for details of the parameters setting).
3.1. Comparative Analysis of Fusion Results Based on Traditional Methods
3.1.1. Subjective Analysis of Pre-Registered Image Fusion Results
Figure 5 shows the fusion results of the “wine” source image obtained by different multi-focus image fusion methods.
Figure 5a,b are the source images of the front focus and the back focus, respectively.
Figure 5c–j are the fusion results obtained by the curvelet, DCT_SVD, DTCWT, IFM, LP, MSVD, MWGF, and NSCT methods.
Figure 5k is the fusion results achieved by the proposed method.
Figure 6 and
Figure 7 are enlarged regions of the local details of
Figure 5. In
Figure 6, the part marked by the red frame shows that the fused image is introduced; the artefacts and blurred edges are produced by the fusion method of curvelet, DCT_SVD, DTCWT, MSVD, MWGF, and NSCT, respectively. In
Figure 7, the red regions near the gear also produce the pseudo-edges, and are generated by curvelet, DCT_SVD, DTCWT, IFM, LP, MSVD, MWGF, and NSCT. It is found that the proposed method achieves the best fusion results among these methods.
Figure 8 shows the fusion results of the “newspaper” source images obtained by different fusion methods.
Figure 8a,b are two source images of the left focus image and the right focus image, respectively.
Figure 8c–j are the fusion comparative results of the eight methods, and (k) is the fusion result of the proposed method.
Figure 9 presents the local detail magnified regions of
Figure 8. The red regions are the boundaries between the focus regions and the defocus regions. The fusion result suggests the proposed method is clearer at the boundary, and that the characteristics of the source image are better preserved than other methods, whose fusion results have blurred edges and artifacts.
3.1.2. Subjective Analysis of Unregistered Images Fusion Results
Figure 10 shows the fusion results of the “temple” source images obtained by nine different multi-focus image fusion methods.
Figure 10a,b are two source images of the front focus image and the back focus image, respectively. From the stones in the lower left corners of the source images (a) and (b), it can be see that the two images have been displaced and have not been registered.
Figure 10c,j are the fusion results obtained by the curvelet, DCT_SVD, DTCWT, IFM, LP, MSVD, MWGF, and NSCT methods.
Figure 10k is the fusion result obtained by the proposed method.
Figure 11 is the local detail magnified regions of
Figure 10. Although source images have misregistration, it can be seen from the part marked by the red regions in
Figure 11 that the fusion result of the proposed method is very clear at the boundary between the stone lion and the background with fonts. The fusion results of other methods have produced varying degrees of edge blur and artifacts. Obviously, due to the precise detection of the pixel-focus, the proposed method obtains the best fusion results.
3.1.3. Subjective Analysis of More Image Fusion Results
In order to further verify the effectiveness of the proposed method, we selected 10 pairs of popular multi-focus source images for comparative experiments, and the source images are shown in
Figure 12.
Figure 13 shows the fusion results obtained by the proposed method and the other eight methods for comparison. In contrast, the proposed method achieves desirable results in the fusion of 10 pairs of multi-focus images. The proposed method obtains a precise fusion boundary in the fusion results of “book”, “clock”, “flower”, “hoed”, and “lytro”. In the fusion results of “craft”, “grass”, and “seascape” images, clear fusion details are also obtained. In the case where there is a significant difference between the student’s eyes in the “lab” source image and the girl’s body posture in the “girl” source image, the proposed method also obtains a satisfactory fusion result.
3.1.4. Objective Analysis of Fusion Results
The quantitative evaluation of the fusion images has been acknowledged as a challenging task, since, in practice, it lacks of reference images for the source images. In this paper, we selected the edge similarity metric
QAB/F [
25], the normalized mutual information metric
QMI [
1], the phase congruency based fusion metric
QPC [
33], and gradient-based fusion performance metric
QG [
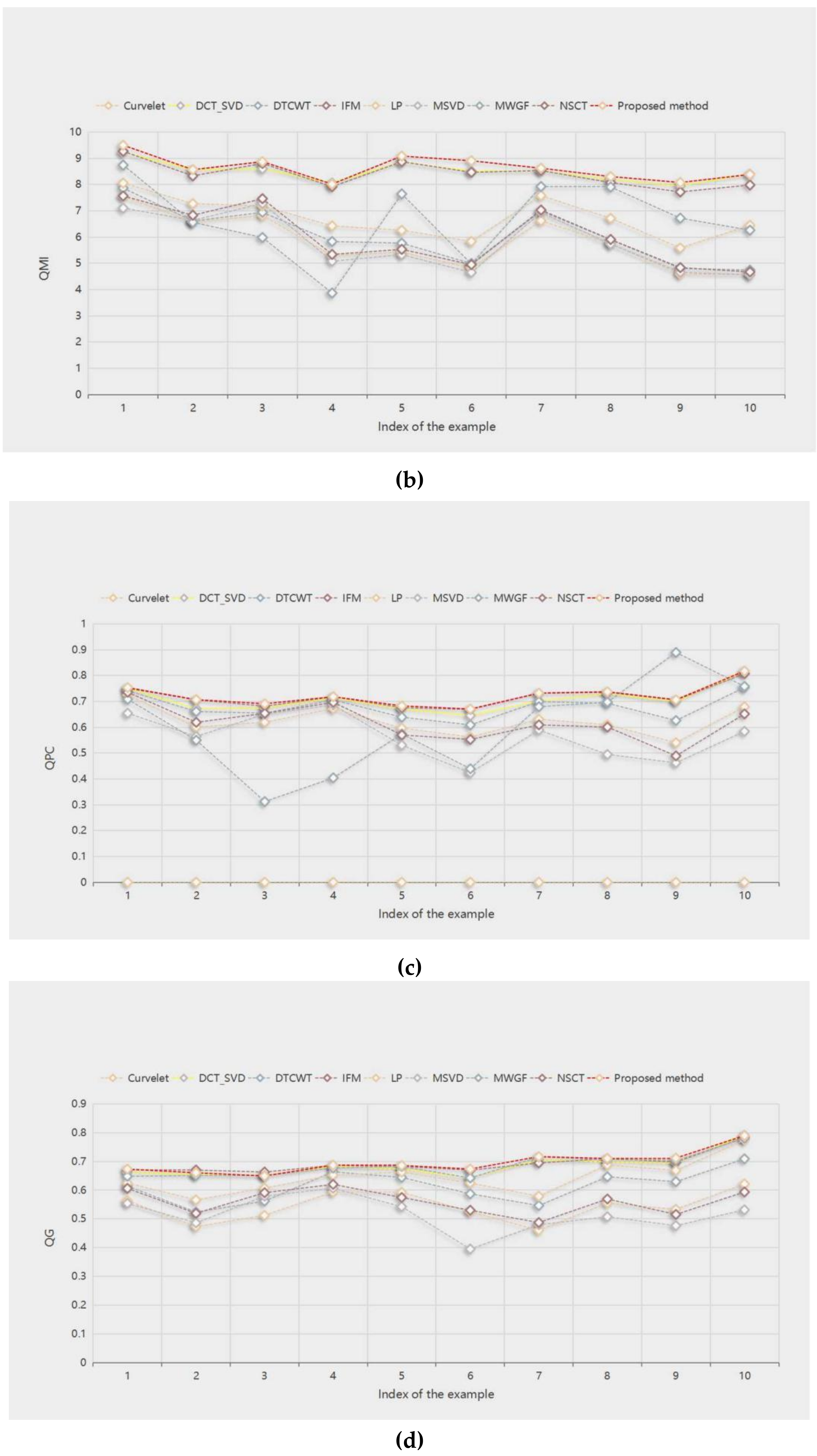
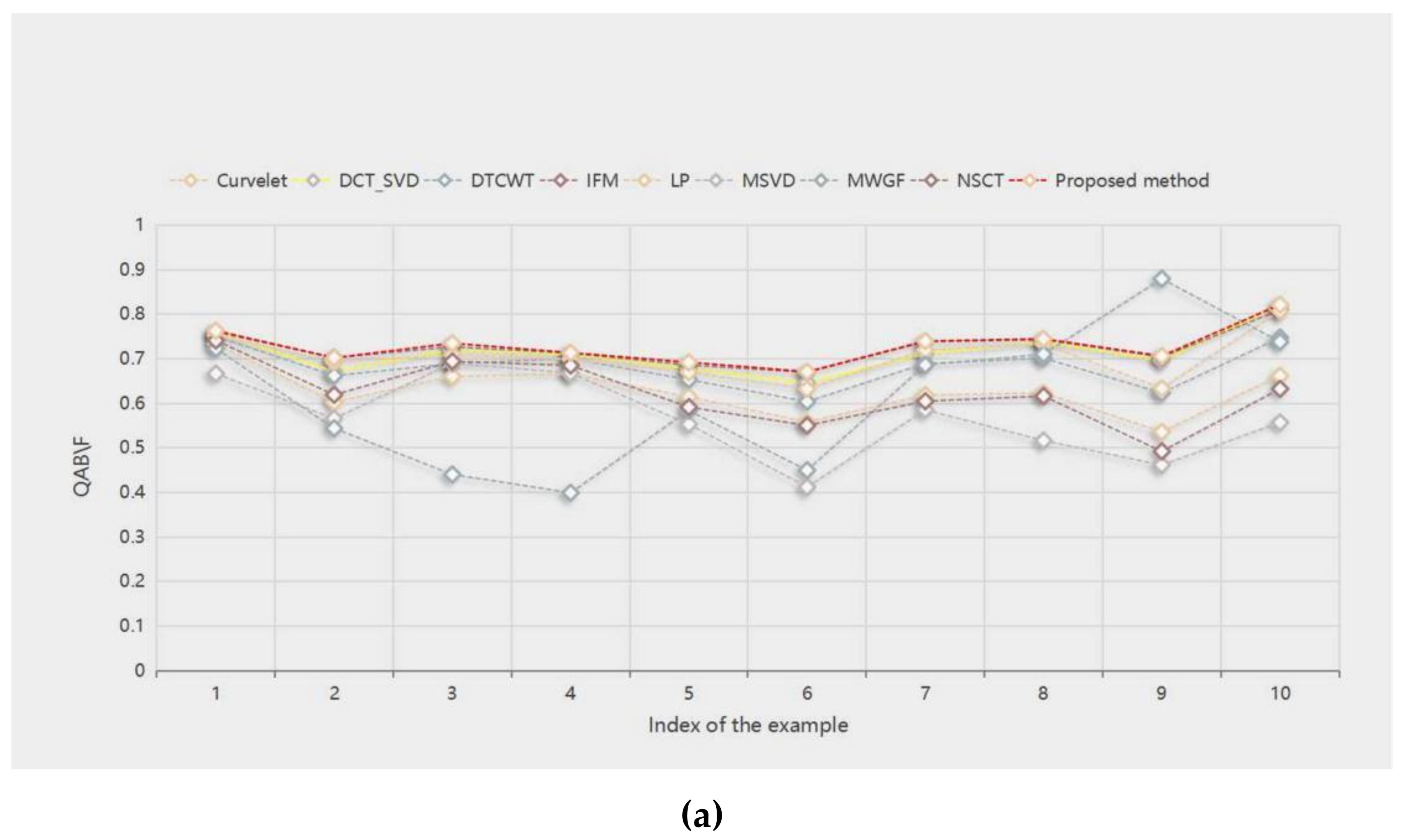
35] to evaluate the fusion results. For all four objective evaluation indicators, the larger the value, the better the fusion results. The highest value in the evaluation is bolded in all tables.
Table 1 shows the objective evaluation values of the fusion results of the nine methods, and the evaluation objects are the “wine” in
Figure 5, the “newspaper” in
Figure 8, and the “temple” in
Figure 10. We can see that the MWGF method has the largest
QAB/F value in the “newspaper”, and the proposed method fares the best in other evaluation indicators. The method obtains the largest values among the other objective evaluation indicators, which is consistent with the subjective visual effect of the fusion result.
Table 2 shows the
QAB/F objective evaluation values of the fusion results of 10 pairs of source images with different methods. The proposed method fares the best in other evaluation indicators. The method gets the best fusion results in “book”, “craft”, “flower”, “girl”, “grass”, “lab”, “lytro”, and “hoed”. IFM and MWGF get the best fusion results in “clock” and “seascape”, respectively. This means that, in most cases, the proposed method can incorporate important edge information into the fusion image.
Table 3 shows the
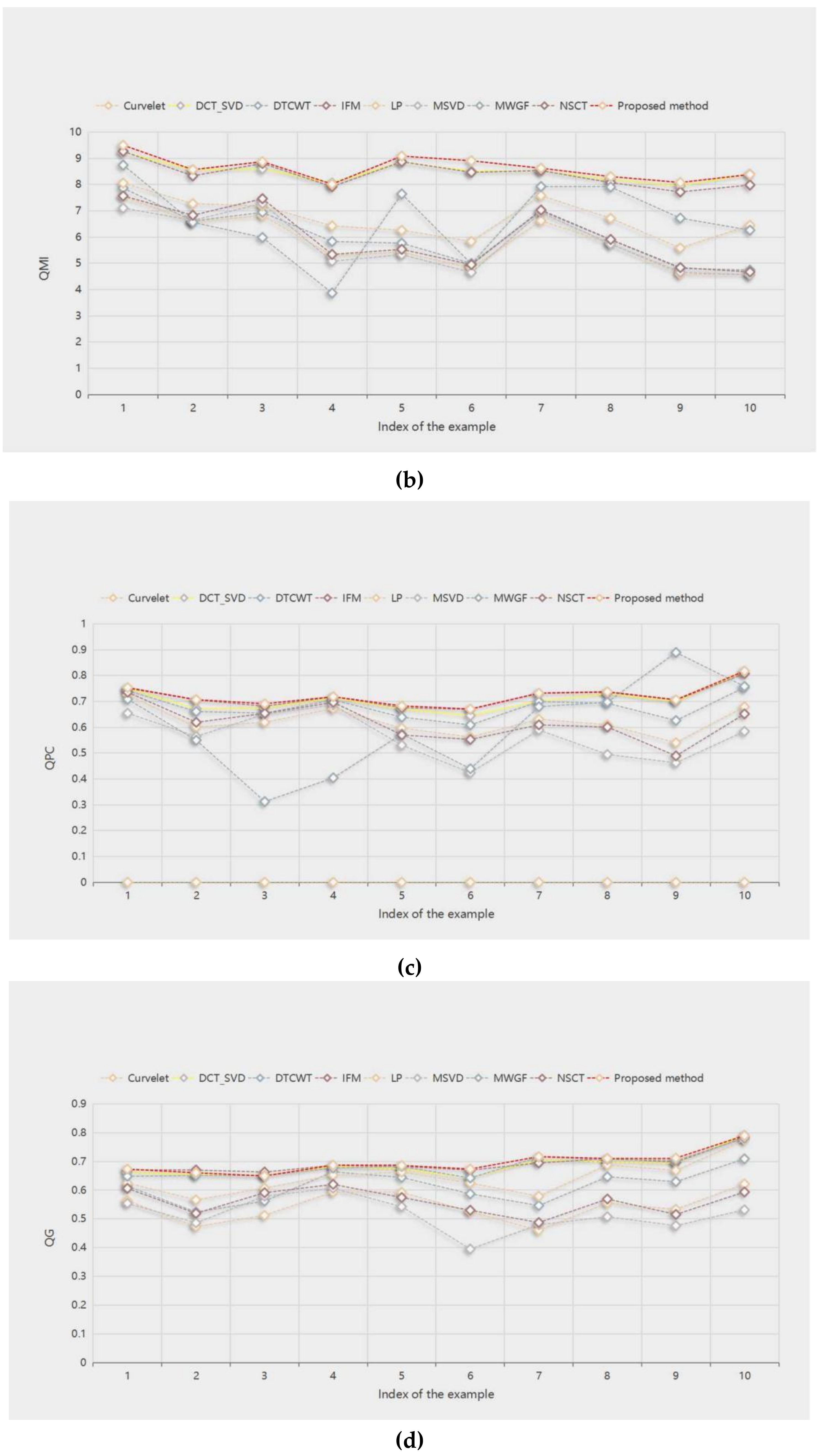
QMI objective evaluation of the fusion results of 10 pairs of source images with different methods. The proposed method obtains the best fusion results among the nine methods. Although the DCT_SVD method has the highest evaluation values in “flower” and “hoed”, the evaluation value of the proposed method is very close to it, and the variation is less than 0.04.
Table 4 shows the
QPC objective evaluation values of the fusion results of 10 pairs of source images with different methods. Except for the MWGF method, to obtain the best fusion result in “seascape”, the proposed method has the highest values in other evaluation indicators. This means that the proposed method can well retain important source image feature information of the fused image.
Table 5 shows the
QG objective evaluation of the fusion results of 10 pairs of source images with different methods. The IFM method achieves the best fusion results in “clock” and “craft”, and the DCT_SVD method in “hoed”. The proposed method fares the best in other evaluation indicators. These mean that the fused image obtained by the proposed method has high sharpness.
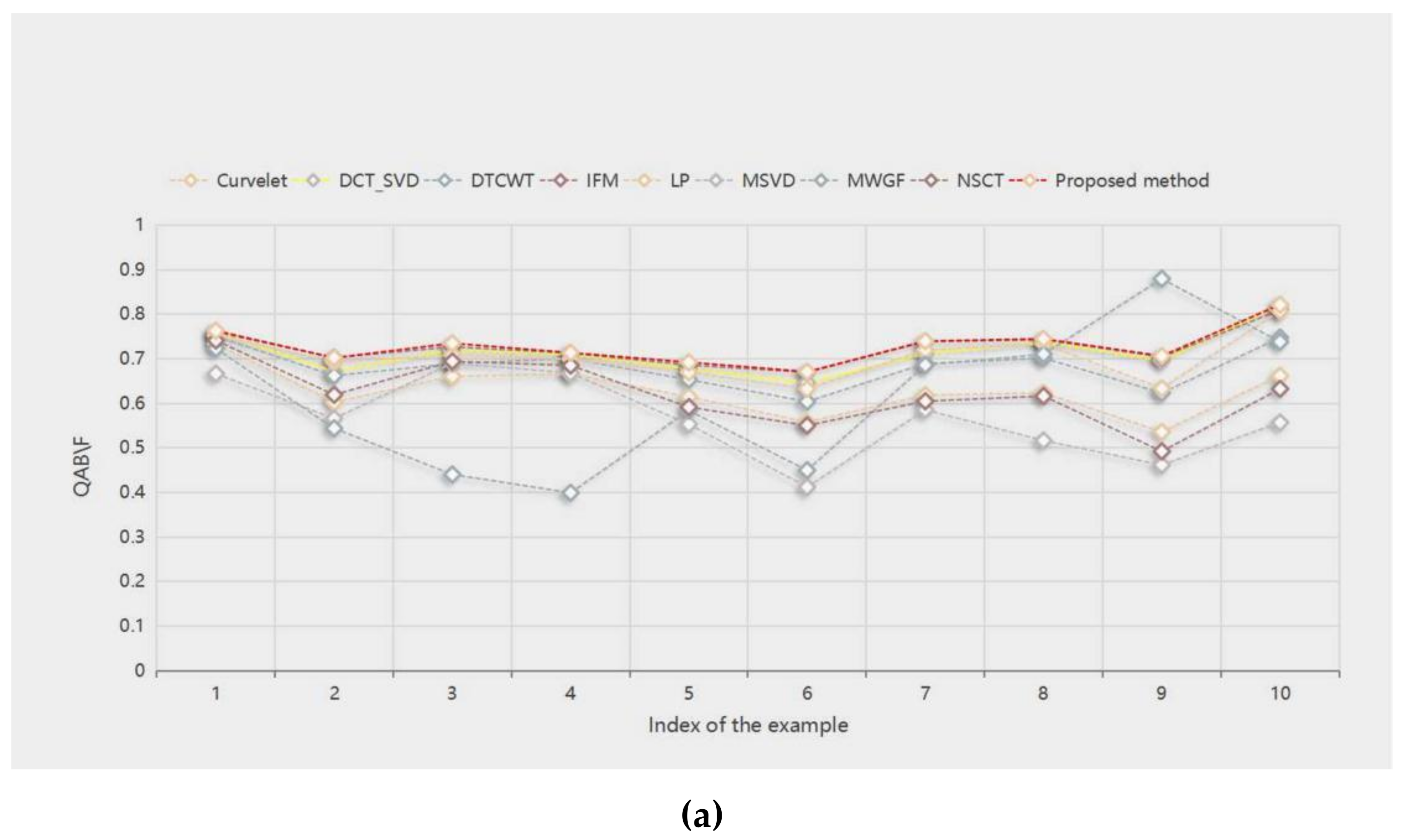
Figure 14a–d show the score line graphs of 9 methods on 4 evaluation indicators of 10 pairs of multifocal images, respectively. Obviously, the proposed method fares the best in other evaluation indicators and shows a better scoring trend, compared with other methods. This means that the proposed method fares the best in other evaluation indicators. The method not only suggests better performance in terms of visual perception, but also in quantitative analysis.
3.1.5. Comparison of Computational Efficiency
To compare the computational efficiency, we calculate and list the average fusion time of the nine methods in
Table 6. Noticeably, the proposed method takes less fusion time than the IFM and the MWGF methods. The IFM method consumes the most fusion time and the LP method consumes the least fusion time. Comparing the fusion results, it is worthwhile to improve the fusion quality at the cost of the time.
3.2. Comparative Analysis of Fusion Results Based on Deep Learning Methods
Deep learning, with powerful feature extraction capabilities, has been widely used in multi-focus image fusion. The fusion model obtained through the learning of a large amount of data generalizes well. In order to further verify the effectiveness of the proposed method, it is compared with the deep learning-based multi-focus image fusion methods FuseGAN and CNN proposed in [
25]. The comparative experiment in this paper inherits all of the experimental data in [
25], including the source images and the fusion results of deep learning methods. The source images in
Figure 15 and Figure 17 are from [
36] and the lytro dataset [
37].
3.2.1. Subjective Analysis of Image Fusion Results
Figure 15 shows the fusion results obtained by the deep learning fusion methods and the proposed fusion method. (a) and (b) are respectively the source images of the front focus and the back focus. (c) and (d) are the fusion results obtained by the CNN and FuseGAN methods. (e) is the fusion result achieved by the proposed method.
Figure 16 shows an enlarged region of the local details marked with a yellow frame in
Figure 15. In
Figure 16, the part marked by the red frame shows that the fused image introduce the blurred edges, which are, respectively, produced by the fusion method of CNN and FuseGAN. The results show that among these methods, the proposed method best preserves the edge information of the source image.
To further verify the effectiveness of the proposed method, 16 pairs of multi-focus source images are selected for comparative experiments.
Figure 17 shows the source images and the fusion results. The results reveal that both the proposed method and deep learning method have achieved satisfactory fusion results.
Figure 17c,g are the fusion results of the FuseGAN; (d) and (h) are the fusion results achieved by the proposed method.
3.2.2. Objective Analysis of Image Fusion Results
This article selects four evaluation metrics in [
25] to evaluate the fusion results, to compare with deep learning methods. They are the edge similarity metric
QAB/F, the spatial frequency metric
QSF, the structural similarity metric
QY, the feature contrast metric
QCB. For the above four evaluation metrics, the larger the value, the better the fusion results.
Table 7 shows the mean values of objective evaluations and the average fusion time corresponding to the four metrics when the fusion methods are applied to 29 pairs of source images, with evaluation values of FuseGAN and CNN derived from [
25]. The evaluation results show that the proposed method has the best average values in
QSF and
QCB. Although the
QAB/F and
Qy values of the proposed method are smaller than the other two, the difference between them is not greater than 0.015. In summary, the proposed method shows good performance in both visual perception and quantitative analysis.
Table 7 lists the computation efficiency of various methods. As it can be seen, FuseGAN and CNN respectively consume the least and most running times. The running time of the proposed method is slightly longer than that of FuseGAN. Compared with the depth learning method, the proposed method does not need to train the model and parameters in advance and, therefore, is more feasible.
3.3. More Analysis
3.3.1. Ablation Research
The parameter-adaptive pulse coupled neural network (PA-PCNN) model can effectively extract image edge and detail information without any training, and all the parameters can be adaptively estimated through the input frequency band. In order to fully investigate the role of PA-PCNN played in the proposed algorithm, the proposed method performs image fusion without it. Specifically, the PA-PCNN fusion strategy is not used in the high-frequency component fusion, but a conventional fusion strategy based directly on the high-frequency decomposition coefficients. This article selects two pairs of images from the lytro dataset for ablation research. In
Figure 18c is the fusion result with PA-PCNN, and (d) is the fusion result without PA-PCNN. The upper right corners of (c) and (d) are detailed enlarged views of the area marked with red boxes. In the enlarged detail, the edge of the boy’s hat in (d) and the edge of the Sydney Opera House model have obvious edge blurs, while the same area in (c) is clear. The analyses show that PA-PCNN plays a role in enhancing the fusion effect in the proposed fusion approach.
3.3.2. Series Multi-Focus Image Fusion
The proposed method can also realize image fusion with more than two multi-focus source images.
Figure 19 shows the fusion results of a sequence of three multi-focal sources images. The fusion process of the proposed method goes as follows. Firstly, two of the three source images are selected for fusion; the fused image in the previous step is then fused with the remaining source image to obtain the final fusion images. It can be seen that the focus information of the three source images is well preserved in the final fusion image, with good visual effects.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}