A Two-Stage Approach for Bayesian Joint Models of Longitudinal and Survival Data: Correcting Bias with Informative Prior



Abstract
1. Introduction
2. Bayesian Joint Model Formulation
2.1. Longitudinal Submodel
2.2. Survival Submodel
2.3. Prior Distributions
3. Joint Specification (JS) Approach
4. Standard Two-Stage (STS) Approach
5. Novel Two-Stage (NTS) Approach
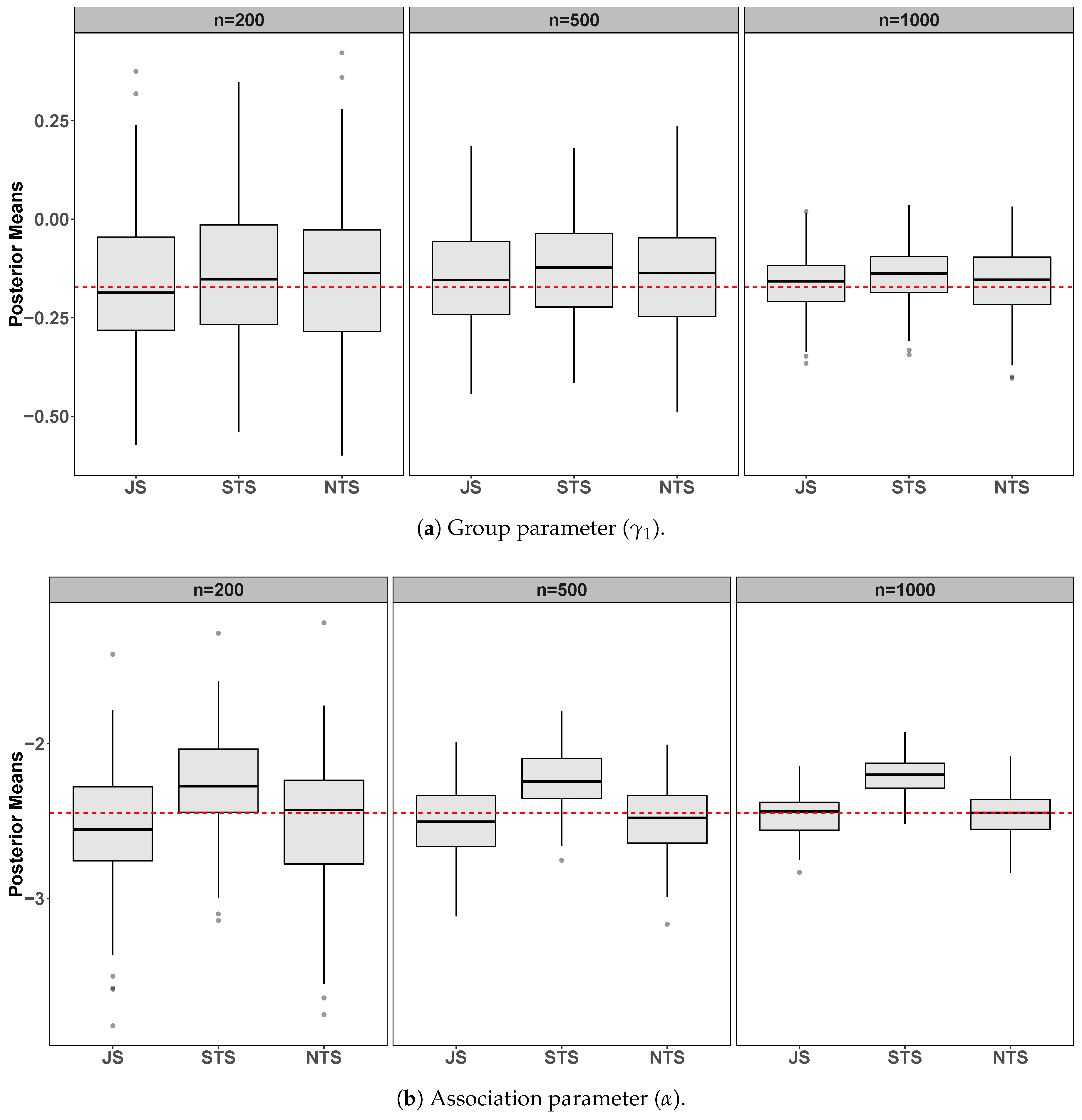
6. Simulation Study
6.1. Simulating Data for Joint Models
| Algorithm 1: Simulation scheme |
|
|
|
6.2. Scenarios
7. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
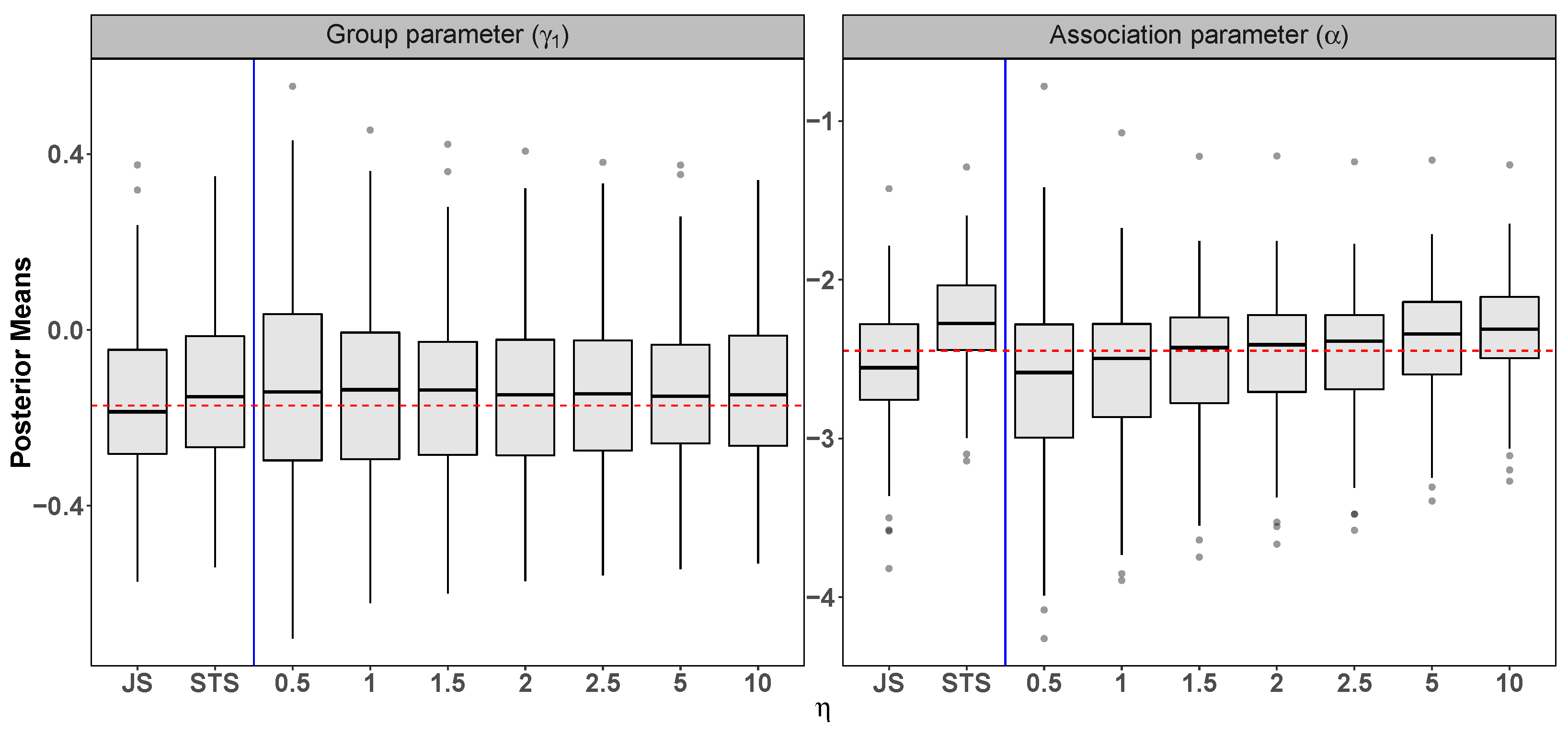
Appendix A. Sensitivity Analysis for η

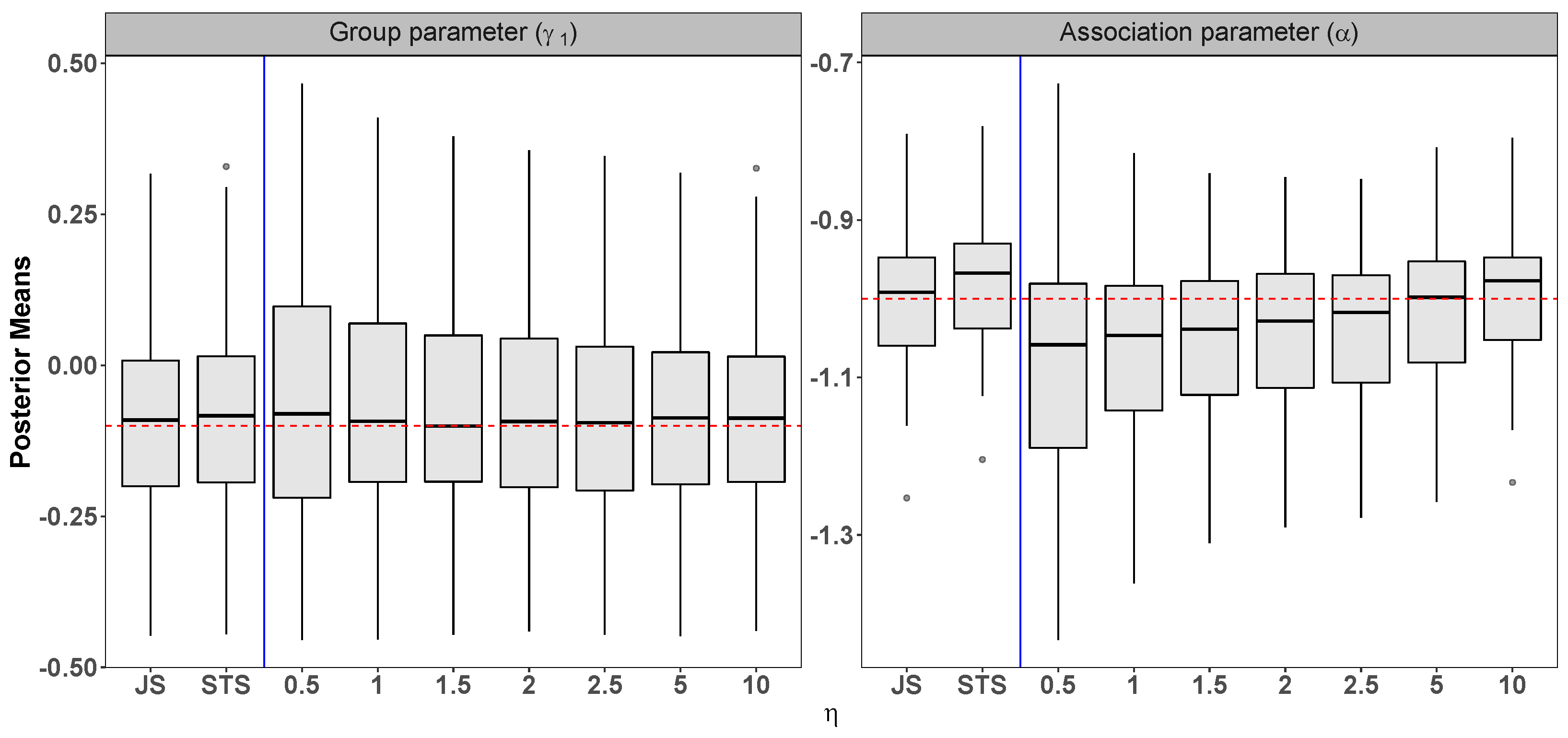
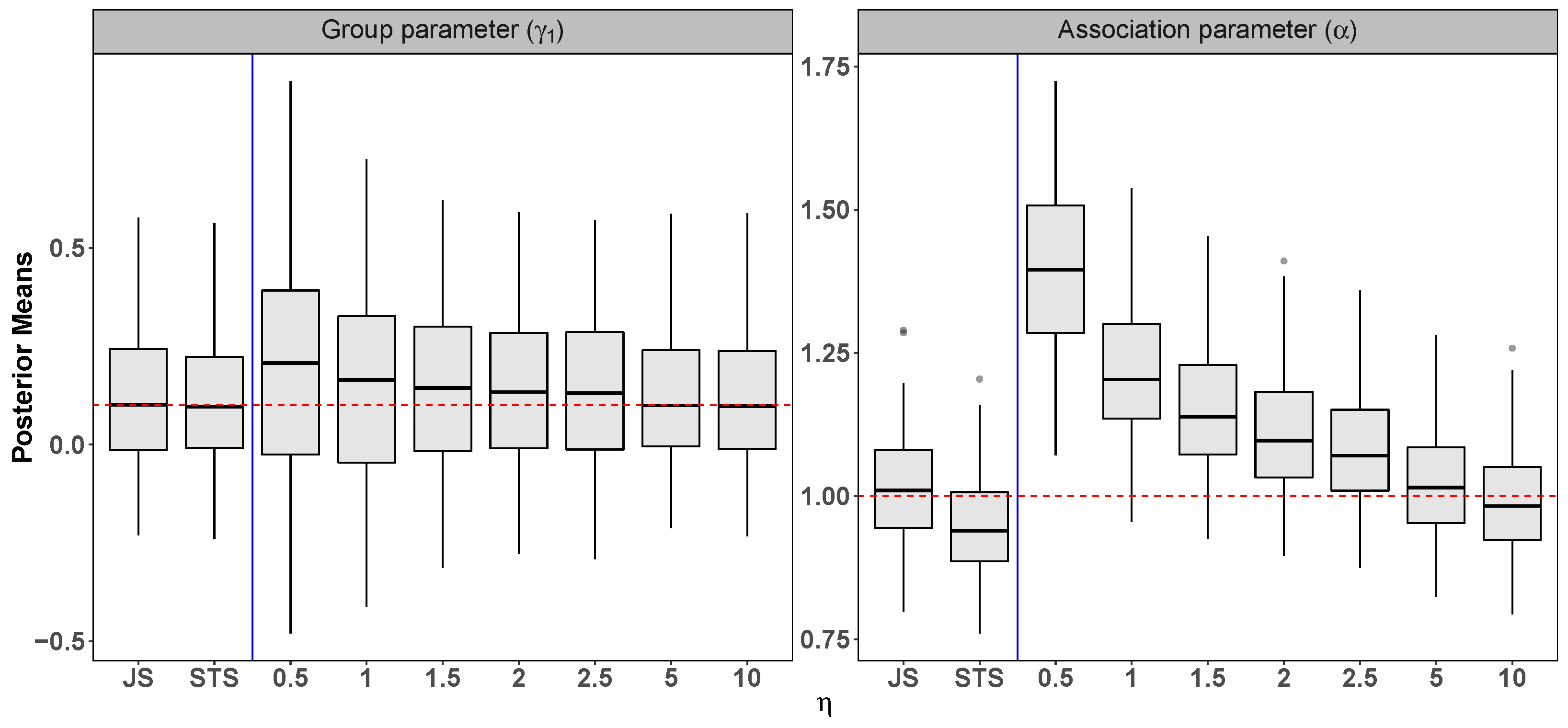
Appendix B. Other Simulation Studies
Appendix B.1. Scenario 1

Appendix B.2. Scenario 2

References
- Rizopoulos, D.; Verbeke, G.; Molenberghs, G. Multiple-imputation-based residuals and diagnostic plots for joint models of longitudinal and survival outcomes. Biometrics 2010, 66, 20–29. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Wei, L.; Yi, G.Y.; Huang, Y. Analysis of longitudinal and survival data: Joint modeling, inference methods, and issues. J. Probab. Stat. 2011, 2012, 1–17. [Google Scholar] [CrossRef]
- Muthén, B.; Asparouhov, T.; Boye, M.E.; Hackshaw, M.; Naegeli, A. Applications of Continuous-Time Survival in Latent Variable Models for the Analysis of Oncology Randomized Clinical Trial Data Using Mplus; Technical Report; Muthén & Muthén: Los Angeles, CA, USA, 2009. [Google Scholar]
- Ibrahim, J.G.; Chu, H.; Chen, L.M. Basic concepts and methods for joint models of longitudinal and survival data. J. Clin. Oncol. 2010, 28, 2796–2801. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Shen, W.; Boye, M.E. Joint modeling of longitudinal outcomes and survival using latent growth modeling approach in a mesothelioma trial. Health Serv. Outcomes Res. Methodol. 2012, 12, 182–199. [Google Scholar] [CrossRef] [PubMed]
- Elashoff, R.; Li, G.; Li, N. Joint Modeling of Longitudinal and Time-to-Event Data, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2016. [Google Scholar]
- Papageorgiou, G.; Mauff, K.; Tomer, A.; Rizopoulos, D. An overview of joint modeling of time-to-event and longitudinal outcomes. Annu. Rev. Stat. Its Appl. 2019, 6, 223–240. [Google Scholar] [CrossRef]
- Furgal, K.C.; Sen, A.; Taylor, J.M.G. Review and comparison of computational approaches for joint longitudinal and time-to-event models. Int. Stat. Rev. 2019, 87, 393–418. [Google Scholar] [CrossRef] [PubMed]
- Alsefri, M.; Sudell, M.; García-Fiñana, M.; Kolamunnage-Dona, R. Bayesian joint modelling of longitudinal and time to event data: A methodological review. BMC Med. Res. Methodol. 2020, 20, 1–17. [Google Scholar] [CrossRef]
- Henderson, R.; Diggle, P.; Dobson, A. Joint modelling of longitudinal measurements and event time data. Biostatistics 2000, 1, 465–480. [Google Scholar] [CrossRef]
- Wu, L. Mixed Effects Models for Complex Data, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2009. [Google Scholar]
- Gould, A.L.; Boye, M.E.; Crowther, M.J.; Ibrahim, J.G.; Quartey, G.; Micallef, S.; Bois, F.Y. Joint modeling of survival and longitudinal non-survival data: Current methods and issues. Report of the DIA Bayesian joint modeling working group. Stat. Med. 2015, 34, 2181–2195. [Google Scholar] [CrossRef]
- Wu, L.; Yu, T. Joint modeling of longitudinal and survival data. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons: Hoboken, NJ, USA, 2016; pp. 1–9. [Google Scholar]
- Lesaffre, E.; Spiessens, B. On the effect of the number of quadrature points in a logistic random effects model: An example. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2001, 50, 325–335. [Google Scholar] [CrossRef]
- Pinheiro, J.C.; Chao, E.C. Efficient Laplacian and adaptive Gaussian quadrature algorithms for multilevel generalized linear mixed models. J. Comput. Graph. Stat. 2006, 15, 58–81. [Google Scholar] [CrossRef]
- Rizopoulos, D.; Verbeke, G.; Lesaffre, E. Fully exponential Laplace approximations for the joint modelling of survival and longitudinal data. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2009, 71, 637–654. [Google Scholar] [CrossRef]
- Wu, L.; Liu, W.; Hu, X.J. Joint inference on HIV viral dynamics and immune suppression in presence of measurement errors. Biometrics 2010, 66, 327–335. [Google Scholar] [CrossRef] [PubMed]
- Barrett, J.; Diggle, P.; Henderson, R.; Taylor-Robinson, D. Joint modelling of repeated measurements and time-to-event outcomes: Flexible model specification and exact likelihood inference. J. R. Stat. Soc. Ser. B (Methodol.) 2015, 77, 131–148. [Google Scholar] [CrossRef] [PubMed]
- Self, S.; Pawitan, Y. Modeling a marker of disease progression and onset of disease. In AIDS Epidemiology; Springer: Berlin/Heidelberg, Germany, 1992; pp. 231–255. [Google Scholar]
- Tsiatis, A.A.; DeGruttola, V.; Wulfsohn, M.S. Modeling the relationship of survival to longitudinal data measured with error. Applications to survival and CD4 counts in patients with AIDS. J. Am. Stat. Assoc. 1995, 90, 27–37. [Google Scholar] [CrossRef]
- Wulfsohn, M.S.; Tsiatis, A.A. A joint model for survival and longitudinal data measured with error. Biometrics 1997, 53, 330–339. [Google Scholar] [CrossRef] [PubMed]
- Ye, W.; Lin, X.; Taylor, J.M.G. Semiparametric modeling of longitudinal measurements and time-to-event data—A two-stage regression calibration approach. Biometrics 2008, 64, 1238–1246. [Google Scholar] [CrossRef]
- Albert, P.S.; Shih, J.H. On estimating the relationship between longitudinal measurements and time-to-event data using a simple two-stage procedure. Biometrics 2010, 66, 983–987. [Google Scholar] [CrossRef]
- Huong, P.T.T.; Nur, D.; Pham, H.; Branford, A. A modified two-stage approach for joint modelling of longitudinal and time-to-event data. J. Stat. Comput. Simul. 2018, 88, 3379–3398. [Google Scholar] [CrossRef]
- Murawska, M.; Rizopoulos, D.; Lesaffre, E. A two-stage joint model for nonlinear longitudinal response and a time-to-event with application in transplantation studies. J. Probab. Stat. 2012, 2012, 1–18. [Google Scholar] [CrossRef]
- Viviani, S.; Alfó, M.; Rizopoulos, D. Generalized linear mixed joint model for longitudinal and survival outcomes. Stat. Comput. 2014, 24, 417–427. [Google Scholar] [CrossRef]
- Mauff, K.; Steyerberg, E.; Kardys, I.; Boersma, E.; Rizopoulos, D. Joint models with multiple longitudinal outcomes and a time-to-event outcome: A corrected two-stage approach. Stat. Comput. 2020, 30, 999–1014. [Google Scholar] [CrossRef]
- Faucett, C.L.; Thomas, D.C. Simultaneously modelling censored survival data and repeatedly measured covariates: A Gibbs sampling approach. Stat. Med. 1996, 15, 1663–1685. [Google Scholar] [CrossRef]
- Tsiatis, A.A.; Davidian, M. Joint modeling of longitudinal and time-to-event data: An overview. Stat. Sin. 2004, 14, 809–834. [Google Scholar]
- Rizopoulos, D. Joint Models for Longitudinal and Time-to-Event Data: With Applications in R, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2012. [Google Scholar]
- Verbeke, G. Linear mixed models for longitudinal data. In Linear Mixed Models in Practice; Springer: Berlin/Heidelberg, Germany, 1997; pp. 63–153. [Google Scholar]
- Pinheiro, J.C.; Bates, D.M. Linear mixed-effects models: Basic concepts and examples. In Mixed-Effects Models in S and S-Plus; Springer: Berlin/Heidelberg, Germany, 2000; pp. 3–56. [Google Scholar]
- Kumar, D.; Klefsjö, B. Proportional hazards model: A review. Reliab. Eng. Syst. Saf. 1994, 44, 177–188. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis, 3rd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]
- Schuurman, N.K.; Grasman, R.P.P.P.; Hamaker, E.L. A comparison of inverse-Wishart prior specifications for covariance matrices in multilevel autoregressive models. Multivar. Behav. Res. 2016, 51, 185–206. [Google Scholar] [CrossRef]
- Alvares, D. Sequential Monte Carlo Methods in Bayesian Joint Models for Longitudinal and Time-to-Event Data. Ph.D. Thesis, University of Valencia, Valencia, Spain, 2017. [Google Scholar]
- Wu, M.C.; Carroll, R.J. Estimation and comparison of changes in the presence of informative right censoring by modeling the censoring process. Biometrics 1988, 44, 175–188. [Google Scholar] [CrossRef]
- Wienke, A. Frailty Models in Survival Analysis, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Ibrahim, J.G.; Chen, M.H.; Sinha, D. Bayesian Survival Analysis, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Balan, T.A.; Putter, H. A tutorial on frailty models. Stat. Methods Med. Res. 2020, 29, 3424–3454. [Google Scholar] [CrossRef]
- Lee, E.T.; Go, O.T. Survival analysis in public health research. Annu. Rev. Public Health 1997, 18, 105–134. [Google Scholar] [CrossRef]
- Lázaro, E.; Armero, C.; Alvares, D. Bayesian regularization for flexible baseline hazard functions in Cox survival models. Biom. J. 2020. [Google Scholar] [CrossRef] [PubMed]
- Crowther, M.J.; Lambert, P.C. Simulating biologically plausible complex survival data. Stat. Med. 2013, 32, 4118–4134. [Google Scholar] [CrossRef] [PubMed]
- Andersen, P.K.; Borgan, O.; Gill, R.D.; Keiding, N. Statistical Models Based on Counting Processes, 1st ed.; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Vehtari, A.; Gelman, A.; Gabry, J. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 2016, 27, 1413–1432. [Google Scholar] [CrossRef]
- Gronau, Q.F.; Singmann, H.; Wagenmakers, E.J. bridgesampling: An R package for estimating normalizing constants. J. Stat. Softw. 2020, 92, 1–29. [Google Scholar] [CrossRef]
- Alvares, D.; Armero, C.; Forte, A.; Chopin, N. Sequential Monte Carlo methods in Bayesian joint models for longitudinal and time-to-event data. Stat. Model. 2020. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Posterior | Parameter | JS | STS | NTS | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| (True Value) | n = 200 | n = 500 | n = 1000 | n = 200 | n = 500 | n = 1000 | n = 200 | n = 500 | n = 1000 | |
| Mean | (−0.172) | −0.172 | −0.152 | −0.165 | −0.148 | −0.132 | −0.144 | −0.141 | −0.148 | −0.160 |
| (−2.447) | −2.574 | −2.505 | −2.460 | −2.271 | −2.237 | −2.204 | −2.537 | −2.491 | −2.456 | |
| SD | 0.193 | 0.120 | 0.084 | 0.184 | 0.115 | 0.082 | 0.241 | 0.149 | 0.106 | |
| 0.345 | 0.214 | 0.148 | 0.295 | 0.186 | 0.131 | 0.391 | 0.245 | 0.171 | ||
| Average Comp. Time | 4.291 | 11.055 | 23.428 | 1.885 | 4.692 | 11.906 | 2.224 | 5.836 | 13.845 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leiva-Yamaguchi, V.; Alvares, D. A Two-Stage Approach for Bayesian Joint Models of Longitudinal and Survival Data: Correcting Bias with Informative Prior. Entropy 2021, 23, 50. https://doi.org/10.3390/e23010050
Leiva-Yamaguchi V, Alvares D. A Two-Stage Approach for Bayesian Joint Models of Longitudinal and Survival Data: Correcting Bias with Informative Prior. Entropy. 2021; 23(1):50. https://doi.org/10.3390/e23010050
Chicago/Turabian StyleLeiva-Yamaguchi, Valeria, and Danilo Alvares. 2021. "A Two-Stage Approach for Bayesian Joint Models of Longitudinal and Survival Data: Correcting Bias with Informative Prior" Entropy 23, no. 1: 50. https://doi.org/10.3390/e23010050
APA StyleLeiva-Yamaguchi, V., & Alvares, D. (2021). A Two-Stage Approach for Bayesian Joint Models of Longitudinal and Survival Data: Correcting Bias with Informative Prior. Entropy, 23(1), 50. https://doi.org/10.3390/e23010050