A Hyperspectral Image Classification Approach Based on Feature Fusion and Multi-Layered Gradient Boosting Decision Trees



Abstract
1. Introduction
- (i)
- How can the right features be chosen where multiple features can be fused?
- (ii)
- For classification, how can model training be effective with a few parameters and low computational complexity?
- (iii)
- How can a satisfactory classification model be obtained in a short time under limited hardware conditions?
- We extract extended morphology profiles, linear multi-scale spatial characteristics, and nonlinear multi-scale spatial characteristics as final features. The original data of the HSI is a three-dimensional image, and the spatial dependence complementary to the spectral information behavior is naturally another information source. The introduction of spatial information improves the possibility of pixel-by-pixel classification.
- We utilize a decision tree-based model, namely, mGBDT, which has fewer parameters and is easier to train. Compared with deep learning model, the proposed model is easy for theoretical analysis and practical training, and only requires simple hardware conditions to perform model training.
2. Related Work
2.1. Principal Component Analysis
2.2. Extended Morphological Features
3. Methodologies
3.1. Linear Multi-Scale Spatial Characteristics
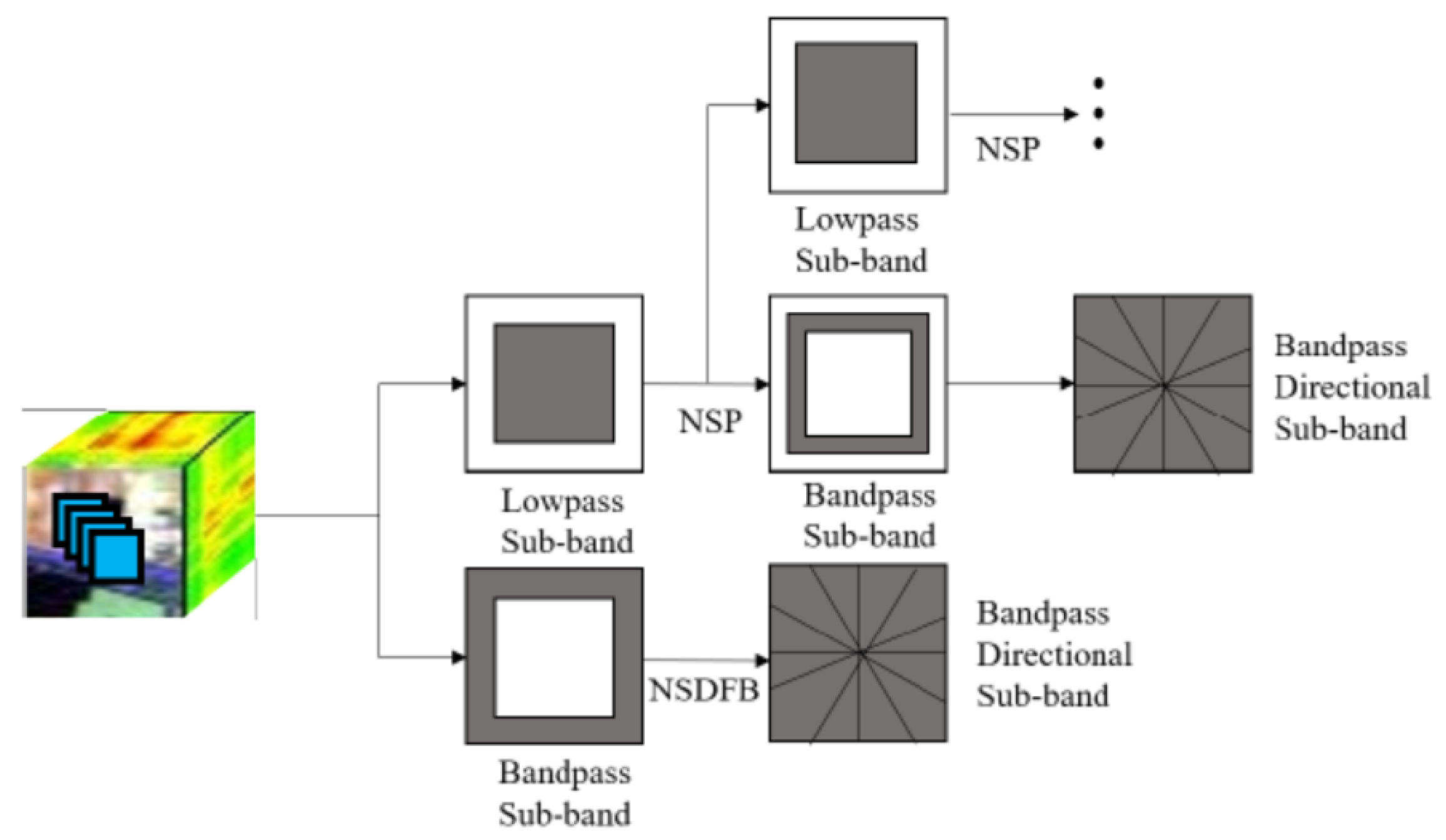
3.2. Nonlinear Multi-Scale Spatial Features
3.3. mGBDT
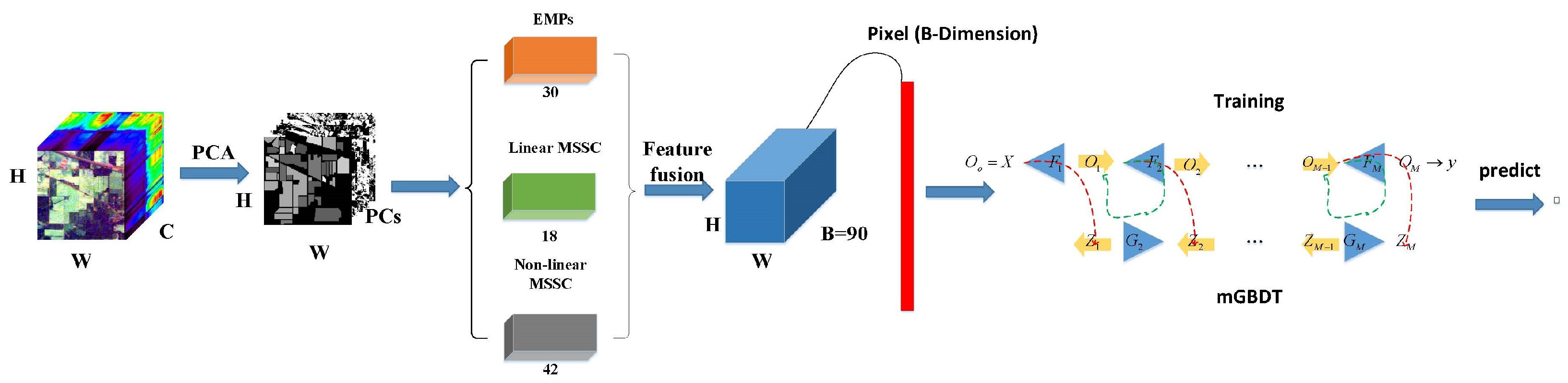
3.4. Hsi Classification Based on Feature Fusion and mGBDT
4. Experiment Designs
4.1. Datasets
4.2. Parameter Analysis
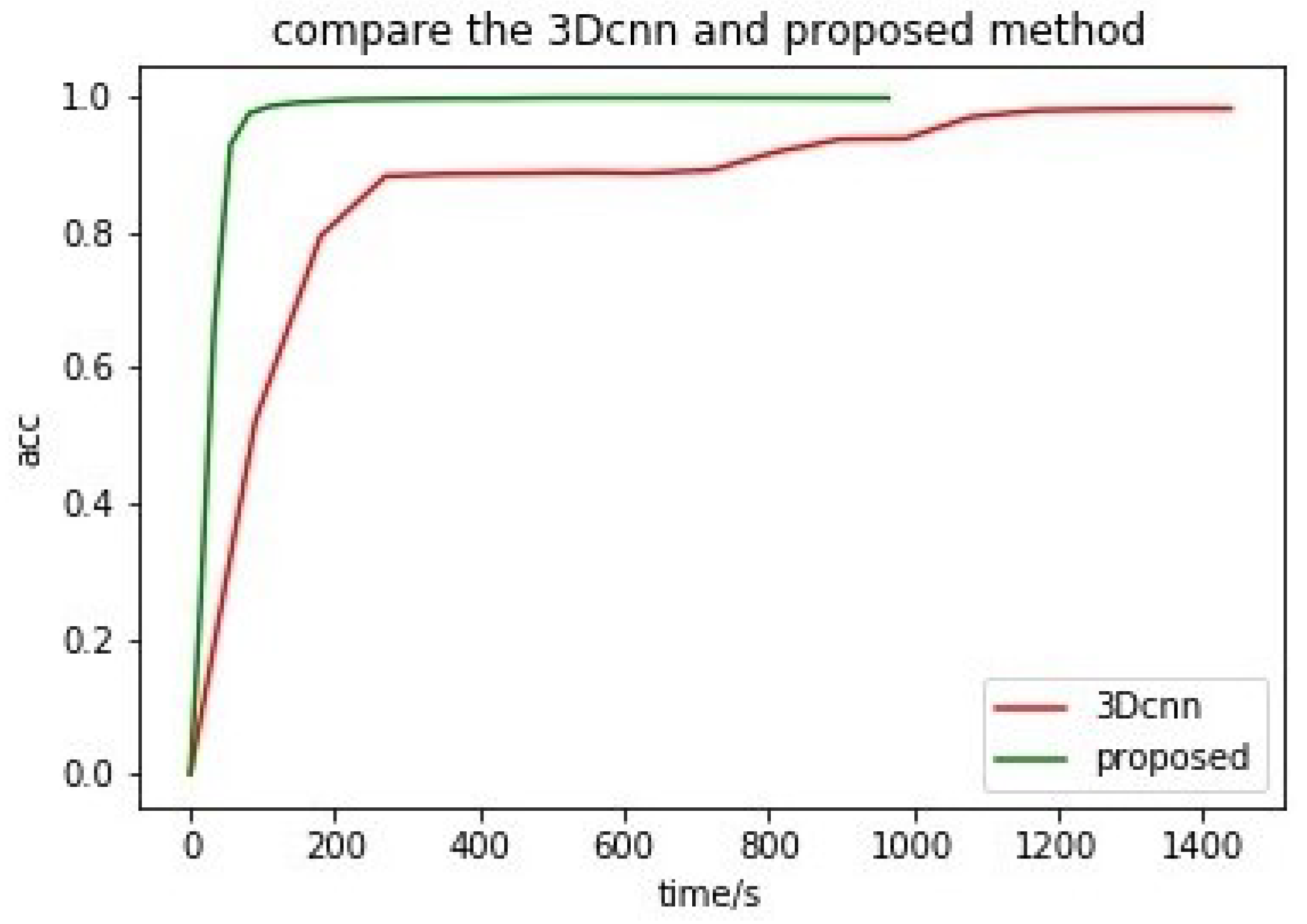
5. Results
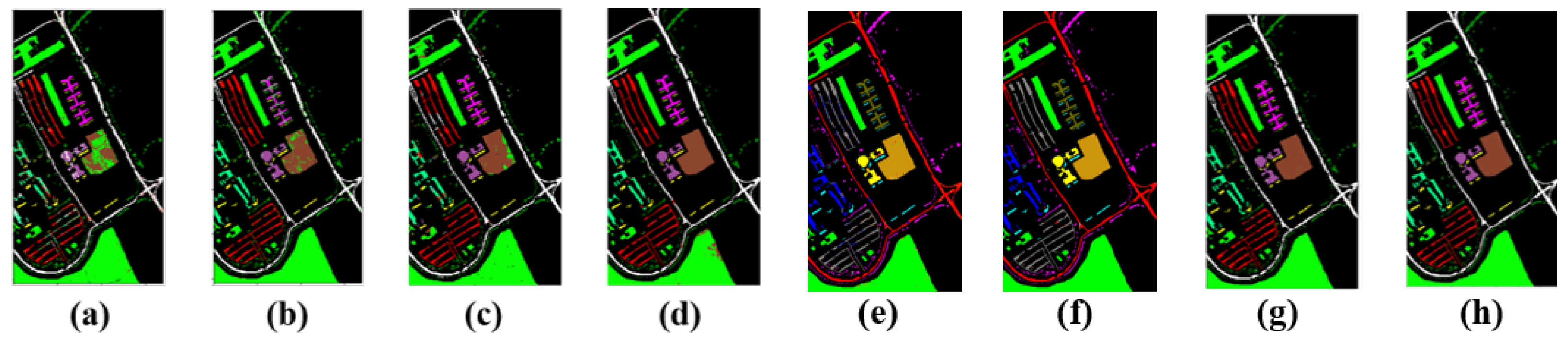
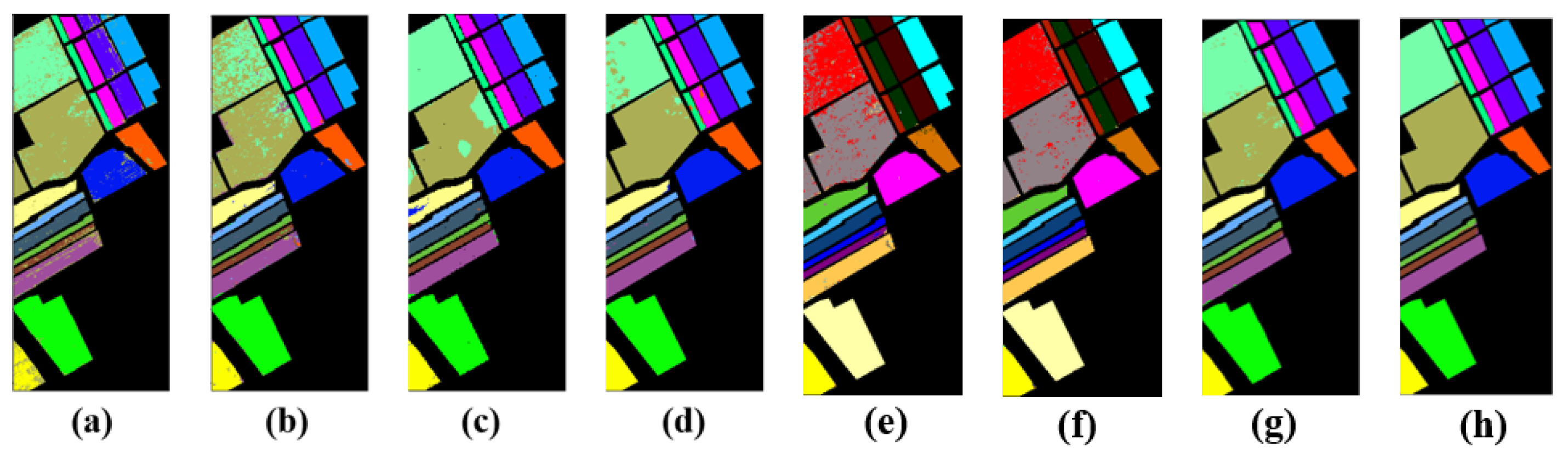
5.1. Classification Results of the Pavia University Dataset
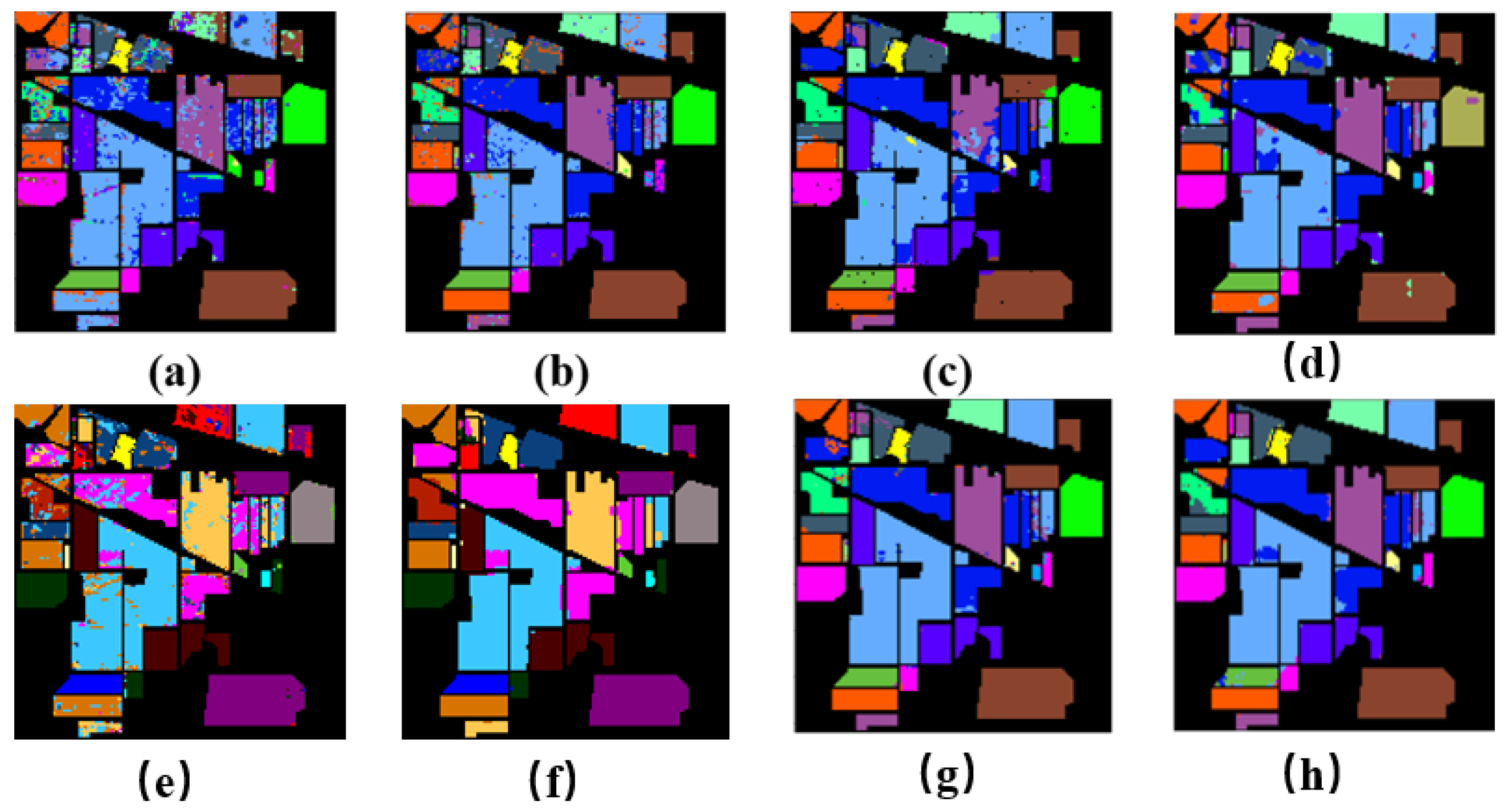
5.2. Classification Results on the Indian Pines Dataset
5.3. Classification Results on the Salinas Dataset
5.4. The Effect of Multi-Feature Fusion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Xu, P.; Song, R.; Li, P.; Ma, H. Development of High Performance Quantum Image Algorithm on Constrained Least Squares Filtering Computation. Entropy 2020, 22, 1207. [Google Scholar] [CrossRef] [PubMed]
- Vukotić, V.; Chappelier, V.; Furon, T. Are Classification Deep Neural Networks Good for Blind Image Watermarking? Entropy 2020, 22, 198. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, H.G.; ElKamchouchi, D.H.; Moussa, K.H. A novel color image encryption algorithm based on hyperchaotic maps and mitochondrial DNA sequences. Entropy 2020, 22, 158. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Yao, D.; Wang, M.; Li, C.; Liu, H.; Hua, Z.; Wang, J. A Hyperspectral Image Classification Method Based on Multi-Discriminator Generative Adversarial Networks. Sensors 2019, 19, 3269. [Google Scholar] [CrossRef] [PubMed]
- Chaudhary, S.; Ninsawat, S.; Nakamura, T. Non-Destructive Trace Detection of Explosives Using Pushbroom Scanning Hyperspectral Imaging System. Sensors 2019, 19, 97. [Google Scholar] [CrossRef] [PubMed]
- Plaza, A.; Martinez, P.; Perez, R.; Plaza, J. A new approach to mixed pixel classification of hyperspectral imagery based on extended morphological profiles. Pattern Recognit. 2004, 37, 1097–1116. [Google Scholar] [CrossRef]
- Bai, J.; Yuan, A.; Xiao, Z.; Zhou, H.; Wang, D.; Jiang, H.; Jiao, L. Class Incremental Learning With Few-Shots Based on Linear Programming for Hyperspectral Image Classification. IEEE Trans. Cybernet. 2020, 1–12. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of Hyperspectral Images by Using Extended Morphological Attribute Profiles and Independent Component Analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 542–546. [Google Scholar] [CrossRef]
- Sánchez-Sánchez, M.; Conde, C.; Gómez-Ayllón, B.; Ortega-Delcampo, D.; Tsitiridis, A.; Palacios-Alonso, D.; Cabello, E. Convolutional Neural Network Approach for Multispectral Facial Presentation Attack Detection in Automated Border Control Systems. Entropy 2020, 22, 1296. [Google Scholar] [CrossRef]
- Xia, J.; Dalla Mura, M.; Chanussot, J.; Du, P.; He, X. Random Subspace Ensembles for Hyperspectral Image Classification with Extended Morphological Attribute Profiles. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4768–4786. [Google Scholar] [CrossRef]
- He, L.; Li, Y.; Li, X.; Wu, W. Spectral–Spatial Classification of Hyperspectral Images via Spatial Translation-Invariant Wavelet-Based Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2696–2712. [Google Scholar] [CrossRef]
- Cui, Y.; Zeng, Z. Remote Sensing Image Classification Based on the HSI Transformation and Fuzzy Support Vector Machine. In Proceedings of the 2009 International Conference on Future Computer and Communication, Kuala Lumpar, Malaysia, 3–5 April 2009; pp. 632–635. [Google Scholar]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial-Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Hu, J.; Jia, S.; Jia, X.; Li, Q. Multiple 3-D Feature Fusion Framework for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1873–1886. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Wu, C.; Wang, M.; Gao, L.; Song, W.; Tian, T.; Choo, K.R. Convolutional Neural Network with Expert Knowledge for Hyperspectral Remote Sensing Imagery Classification. KSII Trans. Internet Inf. Syst. 2019, 13, 3917–3941. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Li, W.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619:1–258619:12. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Aryal, J.; Lucieer, A.; Bryan, B.A. Uncertainty Assessment of Hyperspectral Image Classification: Deep Learning vs. Random Forest. Entropy 2019, 21, 78. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef]
- Feng, J.; Yu, Y.; Zhou, Z. Multi-Layered Gradient Boosting Decision Trees. In Advances in Neural Information Processing Systems 31: Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; 2018; pp. 3555–3565. Available online: https://papers.nips.cc/paper/2018/file/39027dfad5138c9ca0c474d71db915c3-Paper.pdf (accessed on 24 December 2020).
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Deepa, P.; Thilagavathi, K. Feature extraction of hyperspectral image using principal component analysis and folded-principal component analysis. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 656–660. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, G.; Cao, M.; Jiang, N. Semi-supervised classification of hyperspectral image based on spectral and extended morphological profiles. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Plaza, A.; Martínez, P.; Plaza, J.; Pérez, R. Dimensionality reduction and classification of hyperspectral image data using sequences of extended morphological transformations. IEEE Trans. Geosci. Remote Sens. 2005, 43, 466–479. [Google Scholar] [CrossRef]
- Zhang, F.; Bai, J.; Zhang, J.; Xiao, Z.; Pei, C. An Optimized Training Method for GAN-Based Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 1–5. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear versus nonlinear PCA for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geosci. Remote Sens. Lett. 2011, 9, 447–451. [Google Scholar] [CrossRef]
- Manzo, M. Attributed Relational SIFT-Based Regions Graph: Concepts and Applications. Mach. Learn. Knowl. Extr. 2020, 2, 233–255. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale-Space Theory in Computer Vision; The Springer International Series in Engineering and Computer Science; Springer: Boston, MA, USA, 1994; Volume 256. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. A spatial-spectral kernel-based approach for the classification of remote-sensing images. Pattern Recognit. 2012, 45, 381–392. [Google Scholar] [CrossRef]
- Jia, P.; Zhang, M.; Yu, W.; Shen, F.; Shen, Y. Convolutional neural network based classification for hyperspectral data. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5075–5078. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Mou, L.; Lu, X.; Li, X.; Zhu, X.X. Nonlocal Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 54, 8246–8257. [Google Scholar] [CrossRef]
- Wan, S.; Gong, C.; Zhong, P.; Du, B.; Zhang, L.; Yang, J. Multiscale dynamic graph convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3162–3177. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | r-SVM | E-SVM | CNN | 3D-CNN | FuNet-C | MDGCN | FF-DT |
|---|---|---|---|---|---|---|---|
| 1 | 0.8790 | 0.9910 | 0.9960 | 0.9860 | 0.9492 | 0.9896 | 0.9980 |
| 2 | 0.8830 | 0.8770 | 0.9840 | 0.9720 | 0.9917 | 0.9963 | 0.9990 |
| 3 | 0.7090 | 0.9980 | 0.8310 | 0.9710 | 1.0000 | 0.8976 | 0.966 |
| 4 | 0.9470 | 0.9990 | 0.8360 | 0.9820 | 0.9782 | 0.9509 | 0.9930 |
| 5 | 0.9990 | 1.0000 | 0.9780 | 1.0000 | 1.0000 | 0.9728 | 1.0000 |
| 6 | 0.8680 | 0.9740 | 0.9150 | 1.0000 | 0.9990 | 0.9740 | 1.0000 |
| 7 | 0.8340 | 0.9960 | 0.9870 | 0.9980 | 0.8592 | 0.9804 | 0.9980 |
| 8 | 0.8390 | 0.9940 | 0.9360 | 0.9980 | 0.9025 | 0.9635 | 0.9980 |
| 9 | 1.0000 | 1.0000 | 0.8820 | 0.8910 | 0.9993 | 0.9039 | 0.9840 |
| OA | 0.8780 | 0.9340 | 0.9530 | 0.9810 | 0.9720 | 0.9881 | 0.9980 |
| AA | 0.8840 | 0.9810 | 0.9270 | 0.9710 | 0.9591 | 0.9758 | 0.9970 |
| KAPPA | 0.8340 | 0.9110 | 0.9380 | 0.9720 | 0.9629 | 0.9841 | 0.9980 |
| Macro Avg | Weighted Avg | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| EMP-SVM | 98.1% | 98.4% | 98.2% | 98.8% | 98.8% | 98.7% |
| RBF-SVM | 98.1% | 97.1% | 97.6% | 98.5% | 98.4% | 98.4% |
| CNN | 98.2% | 97.7% | 97.9% | 98.6% | 98.6% | 98.5% |
| 3D-CNN | 95.2% | 93.8% | 94.3% | 95.0% | 94.8% | 94.7% |
| FF-DT | 99.8% | 99.7% | 99.7% | 99.8% | 99.8% | 99.8% |
| Class | r-SVM | E-SVM | CNN | 3D-CNN | FuNet-C | MDGCN | FF-DT |
|---|---|---|---|---|---|---|---|
| 1 | 0.1432 | 0.9296 | 0.9723 | 0.8053 | 0.8793 | 0.8857 | 0.7863 |
| 2 | 0.6663 | 0.8839 | 0.8732 | 0.9042 | 0.7672 | 0.9275 | 0.9286 |
| 3 | 0.6053 | 0.8924 | 0.9113 | 0.8796 | 0.8256 | 0.9434 | 0.9943 |
| 4 | 0.5474 | 0.7662 | 0.8591 | 0.6023 | 0.7394 | 0.9553 | 0.9766 |
| 5 | 0.8537 | 0.8535 | 0.6940 | 0.8931 | 0.9271 | 0.9352 | 0.8323 |
| 6 | 0.9747 | 0.9713 | 0.9667 | 0.9740 | 0.9735 | 0.9803 | 1.0000 |
| 7 | 0 | 0.5772 | 0.5216 | 0.9129 | 0.9590 | 0.8176 | 1.0000 |
| 8 | 0.9957 | 1.0000 | 1.0000 | 0.9645 | 0.9841 | 0.9939 | 0.9769 |
| 9 | 0.1677 | 0.5561 | 0.4528 | 0.8236 | 1.0000 | 0.8058 | 0.9843 |
| 10 | 0.7377 | 0.8837 | 0.8346 | 0.963 | 0.7947 | 0.8997 | 0.7714 |
| 11 | 0.8566 | 0.9128 | 0.9377 | 0.949 | 0.8767 | 0.9776 | 0.9798 |
| 12 | 0.6223 | 0.8242 | 0.8768 | 0.7524 | 0.7641 | 0.9417 | 0.9890 |
| 13 | 0.9952 | 0.9958 | 0.9249 | 0.9125 | 0.9936 | 0.9824 | 0.8083 |
| 14 | 0.9693 | 0.9972 | 0.9764 | 0.9846 | 0.9433 | 0.9811 | 0.9981 |
| 15 | 0.464 | 0.9224 | 0.9595 | 1.000 | 0.6738 | 0.9555 | 0.7786 |
| 16 | 0.9171 | 0.8811 | 0.4562 | 0.9632 | 0.9512 | 0.8175 | 0.9711 |
| OA | 0.7875 | 0.9113 | 0.9123 | 0.9256 | 0.8797 | 0.9650 | 0.9721 |
| AA | 0.6572 | 0.8674 | 0.8264 | 0.8422 | 0.9033 | 0.9493 | 0.9233 |
| KAPPA | 0.7557 | 0.8981 | 0.8933 | 0.9142 | 0.8629 | 0.8601 | 0.9662 |
| Macro Avg | Weighted Avg | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| EMP-SVM | 94.9% | 96.2% | 95.4% | 93.6% | 93.5% | 93.5% |
| RBF-SVM | 84.9% | 81.4% | 82.4% | 96.0% | 96.4% | 96.1% |
| CNN | 92.1% | 92.5% | 92.0% | 96.2% | 96.3% | 96.1% |
| 3D-CNN | 91.3% | 92.6% | 91.7% | 91.4% | 91.3% | 91.2% |
| FF-DT | 96.0% | 92.3% | 93.9% | 97.1% | 97.0% | 97.0% |
| Class | r-SVM | E-SVM | CNN | 3D-CNN | FuNet-C | MDGCN | FF-DT |
|---|---|---|---|---|---|---|---|
| 1 | 0.9991 | 1.0000 | 0.9780 | 0.9860 | 0.9951 | 0.9711 | 1.0000 |
| 2 | 0.9911 | 1.0000 | 1.0000 | 1.0000 | 0.9985 | 0.8983 | 0.9998 |
| 3 | 0.9642 | 0.9983 | 1.0000 | 1.0000 | 0.9690 | 0.9879 | 0.9570 |
| 4 | 0.9863 | 0.9966 | 0.9777 | 0.9538 | 0.9905 | 0.9741 | 0.9988 |
| 5 | 0.9954 | 0.9993 | 1.0000 | 0.9670 | 0.9569 | 0.9824 | 0.8834 |
| 6 | 1.0000 | 1.0000 | 0.9941 | 1.0000 | 0.9990 | 0.9947 | 0.9866 |
| 7 | 0.9994 | 1.0000 | 0.9972 | 1.0000 | 0.9983 | 0.9971 | 0.9957 |
| 8 | 0.7453 | 0.7369 | 0.8694 | 0.9826 | 0.8655 | 0.8490 | 1.0000 |
| 9 | 0.9914 | 0.9975 | 1.0000 | 0.9987 | 0.9817 | 0.9878 | 0.9985 |
| 10 | 0.8313 | 1.0000 | 0.9816 | 0.9954 | 0.9676 | 0.9853 | 0.9797 |
| 11 | 0.9414 | 1.0000 | 0.9855 | 1.0000 | 0.9635 | 0.9916 | 0.9994 |
| 12 | 0.9715 | 1.0000 | 0.9999 | 0.9728 | 1.0000 | 0.9957 | 1.0000 |
| 13 | 0.9493 | 1.0000 | 1.0000 | 0.9983 | 0.9975 | 0.9944 | 1.0000 |
| 14 | 0.9795 | 0.9997 | 0.9914 | 0.9947 | 0.9473 | 0.9944 | 0.9990 |
| 15 | 0.8013 | 0.9416 | 0.9993 | 0.9193 | 0.7846 | 0.9616 | 1.0000 |
| 16 | 0.9985 | 1.0000 | 0.9892 | 0.9975 | 0.9886 | 0.9771 | 0.9993 |
| OA | 0.9023 | 0.9225 | 0.9736 | 0.9813 | 0.9422 | 0.9564 | 0.9956 |
| AA | 0.9465 | 0.9795 | 0.9855 | 0.9858 | 0.9686 | 0.9801 | 0.9870 |
| KAPPA | 0.8883 | 0.9114 | 0.9726 | 0.9785 | 0.9356 | 0.9515 | 0.9941 |
| Macro Avg | Weighted Avg | |||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| EMP-SVM | 98.8% | 98.5% | 98.6% | 97.1% | 97.1% | 97.1% |
| RBF-SVM | 98.4% | 98.7% | 98.5% | 96.7% | 96.7% | 96.7% |
| CNN | 98.7% | 98.8% | 98.7% | 98.4% | 98.9% | 98.5% |
| 3D-CNN | 94.9% | 94.3% | 94.0% | 90.8% | 89.8% | 88.9% |
| FF-DT | 99.4% | 98.7% | 99.0% | 99.5% | 99.5% | 99.5% |
| Features | Pavia U | Salinas | Indian Pines |
|---|---|---|---|
| EMP (30) | 0.9074 | 0.9916 | 0.9689 |
| Linear MSSC | 0.9522 | 0.8433 | 0.8510 |
| Non-Linear MSSC | 0.9961 | 0.9876 | 0.9675 |
| Feature Fusion | 0.9984 | 0.9955 | 0.9707 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Liu, S.; Wang, H.; Chen, W.; Zhang, F.; Xiao, Z. A Hyperspectral Image Classification Approach Based on Feature Fusion and Multi-Layered Gradient Boosting Decision Trees. Entropy 2021, 23, 20. https://doi.org/10.3390/e23010020
Xu S, Liu S, Wang H, Chen W, Zhang F, Xiao Z. A Hyperspectral Image Classification Approach Based on Feature Fusion and Multi-Layered Gradient Boosting Decision Trees. Entropy. 2021; 23(1):20. https://doi.org/10.3390/e23010020
Chicago/Turabian StyleXu, Shenyuan, Size Liu, Hua Wang, Wenjie Chen, Fan Zhang, and Zhu Xiao. 2021. "A Hyperspectral Image Classification Approach Based on Feature Fusion and Multi-Layered Gradient Boosting Decision Trees" Entropy 23, no. 1: 20. https://doi.org/10.3390/e23010020
APA StyleXu, S., Liu, S., Wang, H., Chen, W., Zhang, F., & Xiao, Z. (2021). A Hyperspectral Image Classification Approach Based on Feature Fusion and Multi-Layered Gradient Boosting Decision Trees. Entropy, 23(1), 20. https://doi.org/10.3390/e23010020