On the Interactive Capacity of Finite-State Protocols †


Abstract
1. Introduction
Main Contributions
2. The Interactive Communication Problem
Background and Related Work
3. Finite-State Protocols
4. Basic Concepts of the Coding Schemes
4.1. Vertical Simulation
- Assume that Alice and Bob have and .
- Alice uses to calculate according to (6).
- Alice encodes using a block code with rate , and sends it to Bob over the channel, using times. This code will be referred to as a vertical block code.
- Bob decodes the output of the channel and obtains .
- Alice (resp. Bob) uses and (resp. and ) to calculate (resp. ) according to (7).
- Alice and Bob advance j by one.
4.2. Efficient State Lookahead
- For every block, the last state can be calculated by both parties given the first state, without knowing the entire transcript of the block, using only (clean) bits exchanged between the parties.
- The bits required for this calculation for the entire protocol, can be reliably exchanged over the noisy channels at a strictly positive rate.
4.3. Efficient Exhaustive Simulation
- At every block, the transcripts associated with all possible M initial states, can be encoded using only bits.
- The required bits can be reliably conveyed over the noisy channels at any rate below Shannon capacity.
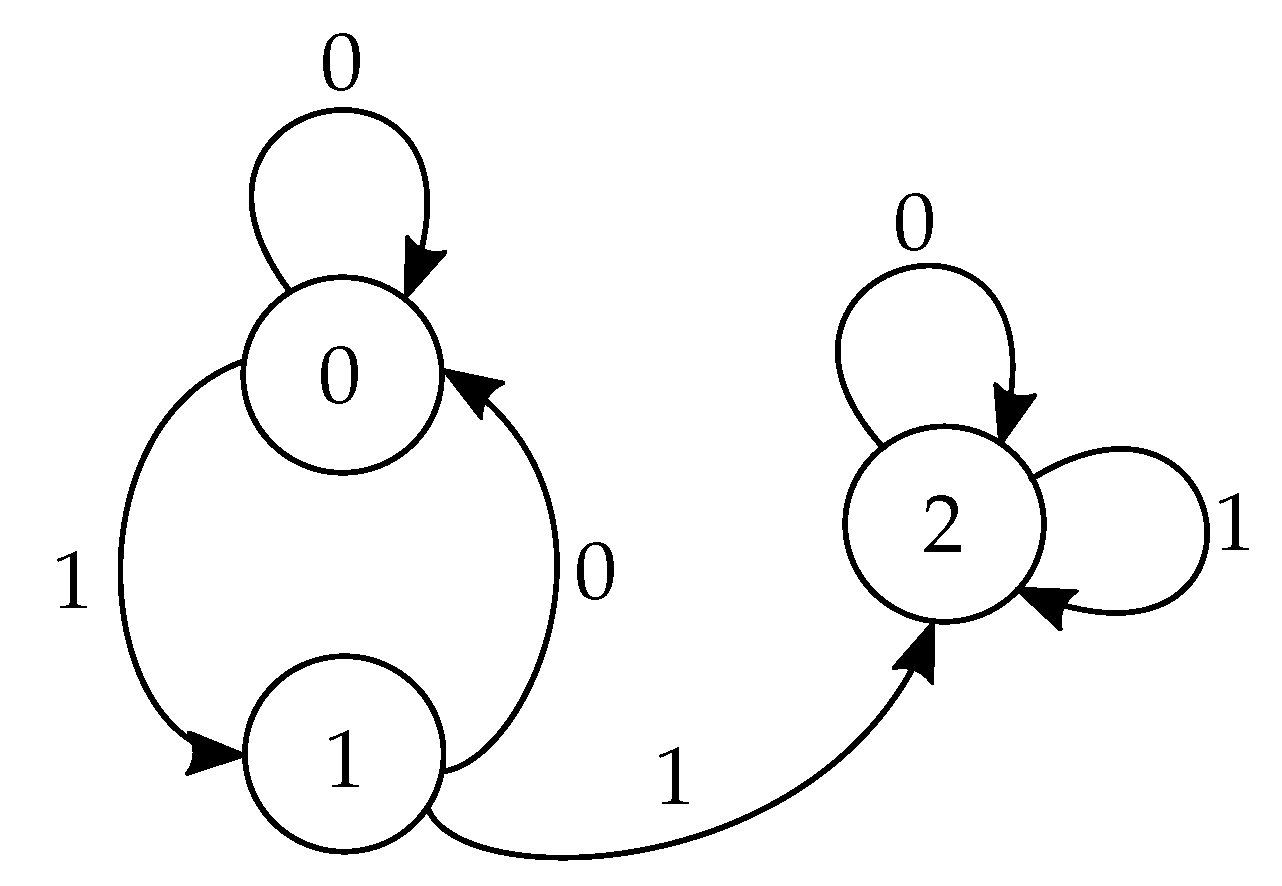
5. Achieving Shannon Capacity with Two States
- Alice sends Bob her latest (odd) time index in the block for which , (i.e., her latest constant composite function), along with value of . If such an index does not exist she sends zero to Bob. Bob then repeats the same process with the appropriate alterations. We use to denote the maximum of the indices, which therefore represents the location of the last constant composite function in the block. We now set if and if . This process requires exchanging bits between Alice and Bob.
- We now note, that since is the index of the latest constant composite function in the block, then for all , for some . The final state in the block, , can therefore be calculated bywhereWe finally note, that and are single bits that can be calculated by their respective parties and then exchanged, leaving the total number of required exchanged bits for the algorithm .
- Before the simulation begins, both parties communicate the locations of the first (rather than the last) constant composite function in the block: the smallest value for which , for some . This process requires exchanging bits.
- The parties exchange the identities of their transmission functions (i.e., ) before the location of the first constant composite function in the block, using a single bit per time index. In the sequel we show that there are indeed only two relevant functions to describe, so their description requires only a single bit. At the end of this process, the parties can independently simulate the transcripts for both initial states until the location of the first constant composite function.
- For time indices after the location of the first constant composite function, the transcripts associated with both initial states coincide, so they can both be simulated using a single bit per time index.
6. Failure of the Coding Scheme for Three States
7. Achieving Shannon Capacity with More than Two States
8. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of Lemma 1
References
- Shannon, C.E. Two-way communication channels. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, the Regents of the University of California, Oakland, CA, USA, 20–30 July 1960; University of California Press: Berkeley, CA, USA, 1961. [Google Scholar]
- Gelles, R. Coding for Interactive Communication: A Survey. 2019. Available online: http://www.eng.biu.ac.il/~gellesr/survey.pdf (accessed on 24 December 2020).
- Schulman, L.J. Communication on noisy channels: A coding theorem for computation. In Proceedings of the 33rd Annual Symposium on Foundations of Computer Science, Pittsburgh, PA, USA, 24–27 October 1992; IEEE: Piscataway, NJ, USA, 1992; pp. 724–733. [Google Scholar]
- Ben-Yishai, A.; Kim, Y.-H.; Ordentlich, O.; Shayevitz, O. A Lower Bound on the Interactive Capacity of Binary Memoryless Symmetric Channels. arXiv 2019, arXiv:1908.07367. [Google Scholar]
- Haeupler, B.; Velingker, A. Bridging the capacity gap between interactive and one-way communication. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Barcelona, Spain, 16–19 January 2017; pp. 2123–2142. [Google Scholar]
- Ben-Yishai, A.; Shayevitz, O.; Kim, Y.-H. Shannon Capacity Is Achievable for a Large Class of Interactive Markovian Protocols. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar]
- Schulman, L.J. Coding for interactive communication. IEEE Trans. Inf. Theory 1996, 42, 1745–1756. [Google Scholar] [CrossRef]
- Yao, A.C.C. Some complexity questions related to distributive computing (preliminary report). In Proceedings of the eLeventh Annual ACM Symposium on Theory of Computing, Atlanta, GA, USA, 30 April–2 May 1979; ACM: New York City, NY, USA, 1979; pp. 209–213. [Google Scholar]
- Cover, T.M.; Thomas, J. Elements of Information Theory, 2nd ed.; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Kol, G.; Raz, R. Interactive channel capacity. In Proceedings of the Forty-Fifth Annual ACM Symposium on Theory of Computing, Palo Alto, CA, USA, 1–4 June 2013; ACM: New York City, NY, USA, 2013; pp. 715–724. [Google Scholar]
- Haeupler, B. Interactive channel capacity revisited. In Proceedings of the 2014 IEEE 55th Annual Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 19–21 October 2014; pp. 226–235. [Google Scholar]
- Ghaffari, M.; Haeupler, B.; Sudan, M. Optimal error rates for interactive coding I: Adaptivity and other settings. In Proceedings of the Forty-Sixth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 31 May–3 June 2014; pp. 794–803. [Google Scholar]
- Agrawal, S.; Gelles, R.; Sahai, A. Adaptive protocols for interactive communication. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; IEEE: Piscataway, New Jersey, NJ, USA, 2016; pp. 595–599. [Google Scholar]
- Polyanskiy, Y.; Poor, H.V.; Verdú, S. Channel coding rate in the finite blocklength regime. IEEE Trans. Inf. Theory 2010, 56, 2307. [Google Scholar] [CrossRef]
- Kushlevitz, E.; Nisan, N. Communication Complexity; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Kalyanasundaram, B.; Schintger, G. The probabilistic communication complexity of set intersection. SIAM J. Discret. Math. 1992, 5, 545–557. [Google Scholar] [CrossRef]
- Razborov, A.A. On the distributional complexity of disjointness. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin, Germany, 1990; pp. 249–253. [Google Scholar]
- Bar-Yossef, Z.; Jayram, T.S.; Kumar, R.; Sivakumar, D. An information statistics approach to data stream and communication complexity. J. Comput. Syst. Sci. 2004, 68, 702–732. [Google Scholar] [CrossRef]
- Braverman, M.; Rao, A. Information equals amortized communication. IEEE Trans. Inf. Theory 2014, 60, 6058–6069. [Google Scholar] [CrossRef]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons: New York, NY, USA, 1968. [Google Scholar]



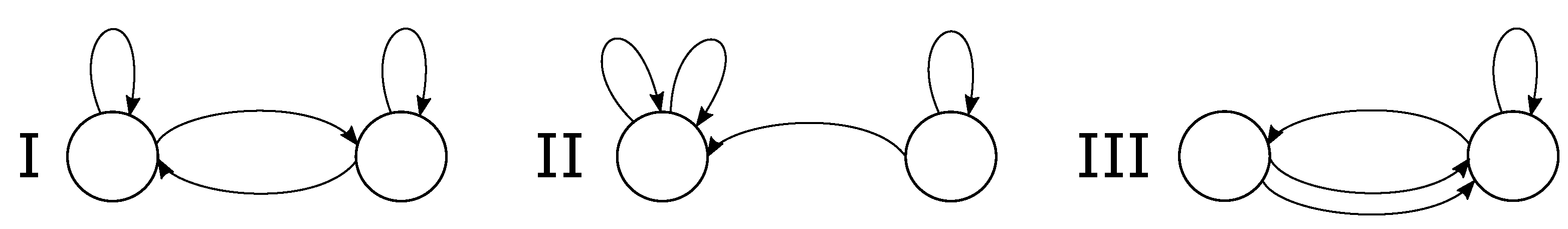{kind=link}
{kind=link}
| Block # | Initial State | Transcript | ||||
|---|---|---|---|---|---|---|
| 1 | … | |||||
| 2 | … | |||||
| 3 | … | |||||
| ⋮ | ⋮ | ⋮ | ⋮ | |||
| … | ||||||
| speaker | Alice | Bob | … | Alice | Bob | |
| vertical block # | 1 | 2 | ⋯ | m | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben-Yishai, A.; Kim, Y.-H.; Oshman, R.; Shayevitz, O. On the Interactive Capacity of Finite-State Protocols. Entropy 2021, 23, 17. https://doi.org/10.3390/e23010017
Ben-Yishai A, Kim Y-H, Oshman R, Shayevitz O. On the Interactive Capacity of Finite-State Protocols. Entropy. 2021; 23(1):17. https://doi.org/10.3390/e23010017
Chicago/Turabian StyleBen-Yishai, Assaf, Young-Han Kim, Rotem Oshman, and Ofer Shayevitz. 2021. "On the Interactive Capacity of Finite-State Protocols" Entropy 23, no. 1: 17. https://doi.org/10.3390/e23010017
APA StyleBen-Yishai, A., Kim, Y.-H., Oshman, R., & Shayevitz, O. (2021). On the Interactive Capacity of Finite-State Protocols. Entropy, 23(1), 17. https://doi.org/10.3390/e23010017