Distributed Attack Modeling Approach Based on Process Mining and Graph Segmentation


Abstract
1. Introduction
- We employ the process-mining algorithm to generate an attack graph. By applying the process-mining algorithm, the security alerts are aggregated and the dependency relationship, short loop relationship, and long-distance dependency among them are analyzed. The chronological order of the related cyber-attack behaviors is also extracted and the exclusive OR(XOR in short)/AND relationship within each event are examined to obtain the logical relationship among cyber-attack behaviors and the attack graph is accordingly generated. Therefore, the process mining based algorithm can effectively extract the relation between security alerts and obtain deep insight into the attack strategies.
- To produce an attack graph more comprehensible to humans, we propose a graph segmentation algorithm for complex attack graphs. The proposed algorithm begins with a search for the branch points from which the subgraphs are split, followed by completion of the subgraphs according to their structure. An incremental update method for the subgraphs is also proposed to adapt to the dynamic change of the attack graph. The proposed algorithm reduces the complexity of the attack graph without ruining its structure facilitating manual analysis by the network security administrator.
- According to the standalone algorithms previously mentioned, a distributed attack graph generation algorithm based on MapReduce and a distributed cyber-attack graph segmentation method based on Spark GraphX are proposed to efficiently address massive security alerts.
2. Related Work
2.1. Generation of Attcak Graphs
2.2. Graph Segmentation
3. Background Knowledge
4. Attack Modeling
4.1. Framework of Proposed Algorithm
4.2. Initial Attack Graph Generation
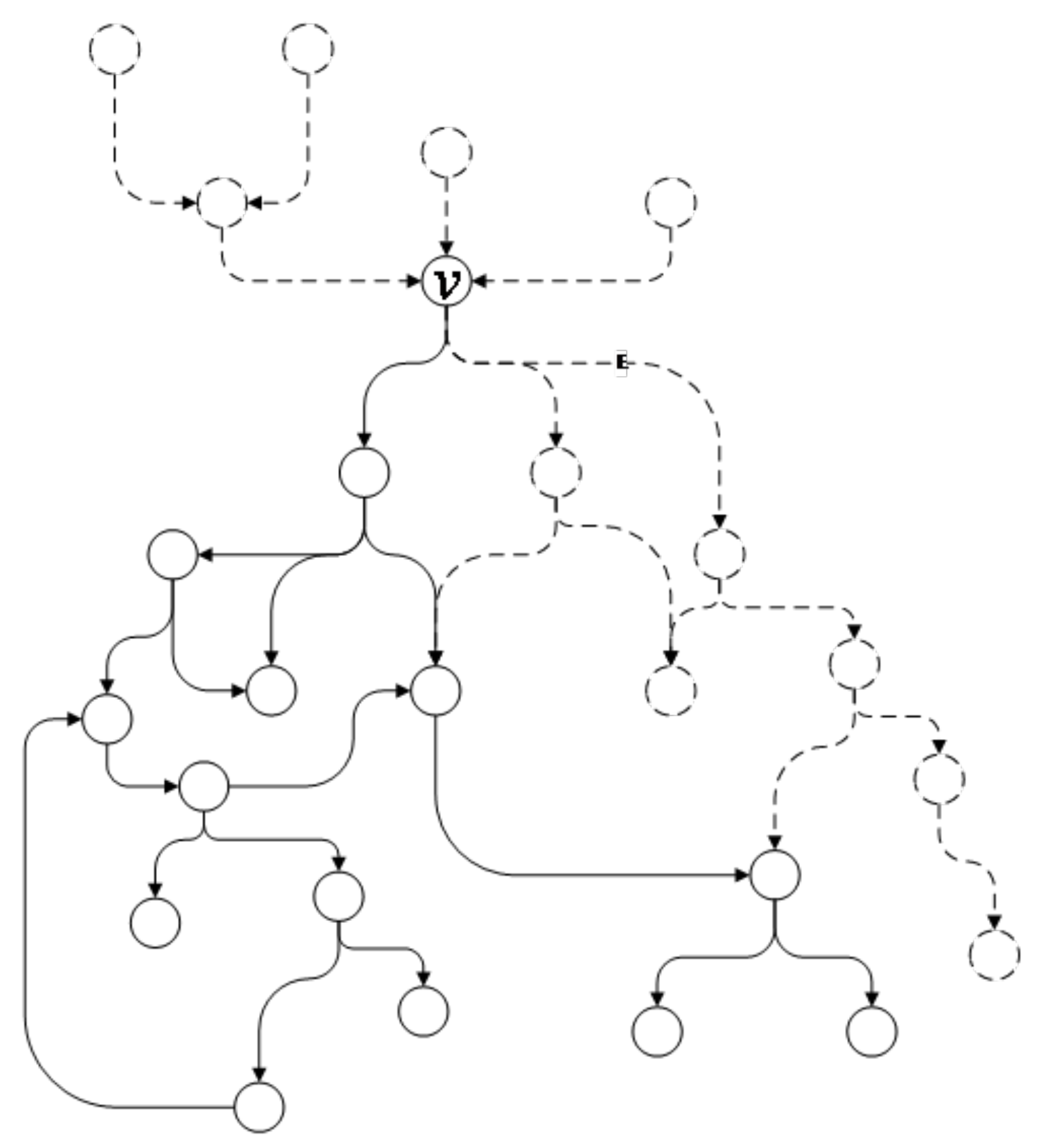
4.3. Attack Graph Segmentation
4.3.1. Problem Definition
4.3.2. Algorithm Overview
4.3.3. Evaluating Attack Graph Complexity
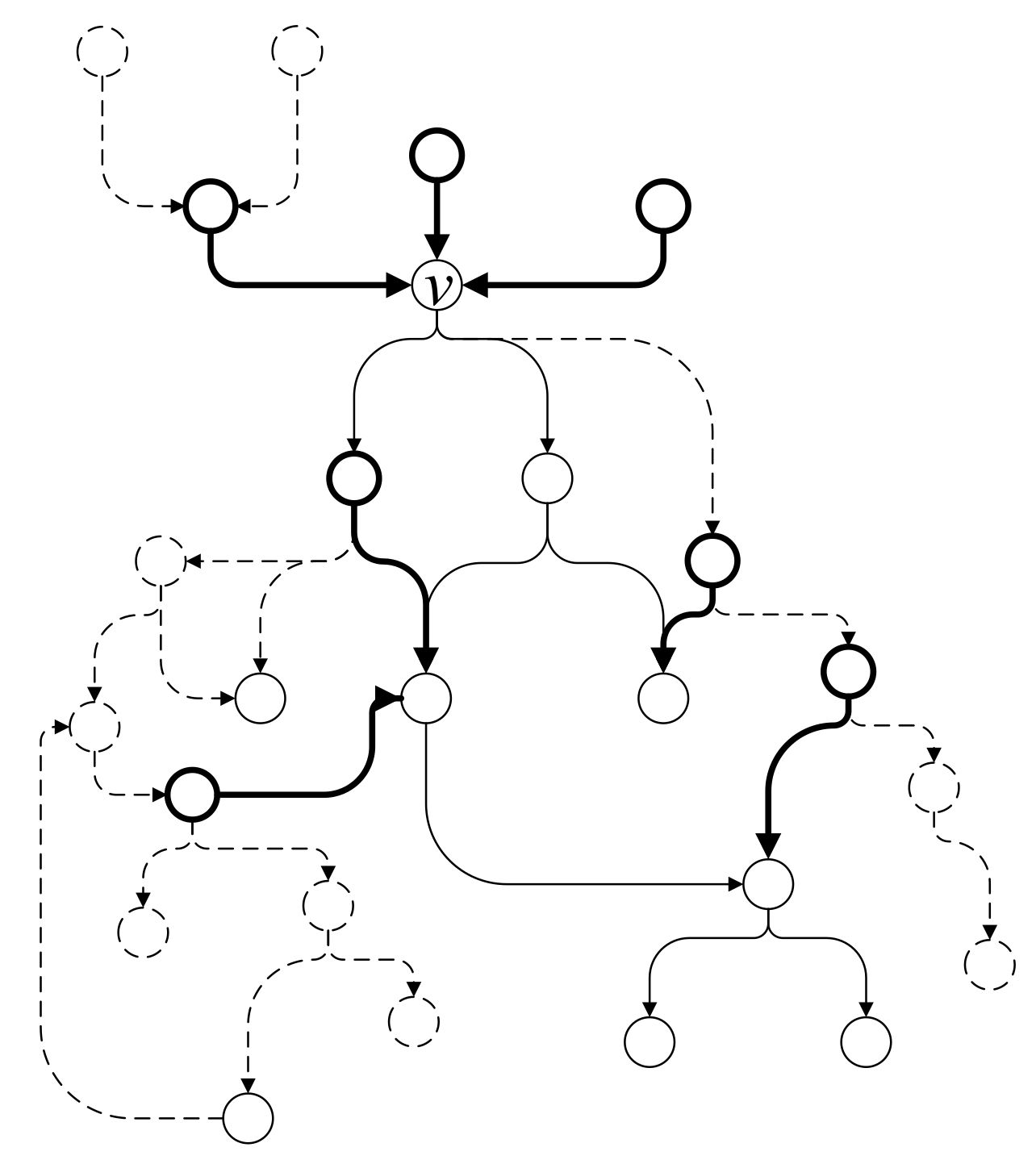
4.3.4. Segmentation of Independent Subgraphs
4.3.5. Segmentation of the Remaining Subgraphs
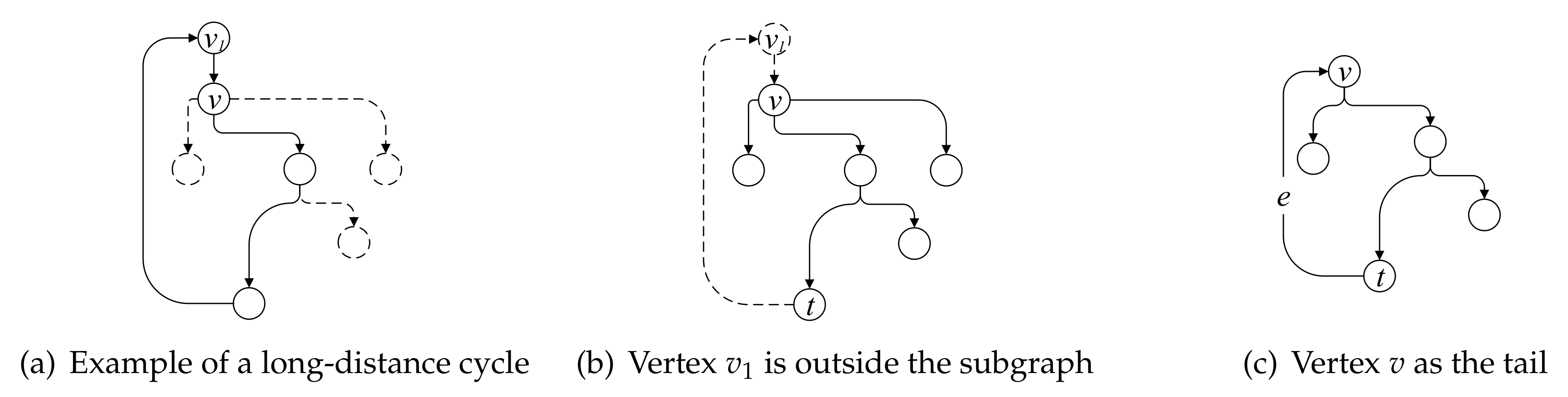
4.3.6. Remove Long-Distance Cycle
4.3.7. Completing Generated Subgraphs
4.3.8. Algorithm Description
4.4. Analyzing Algorithm Complexity
| Algorithm 1 Complex Graph Segmentation Algorithm |
|
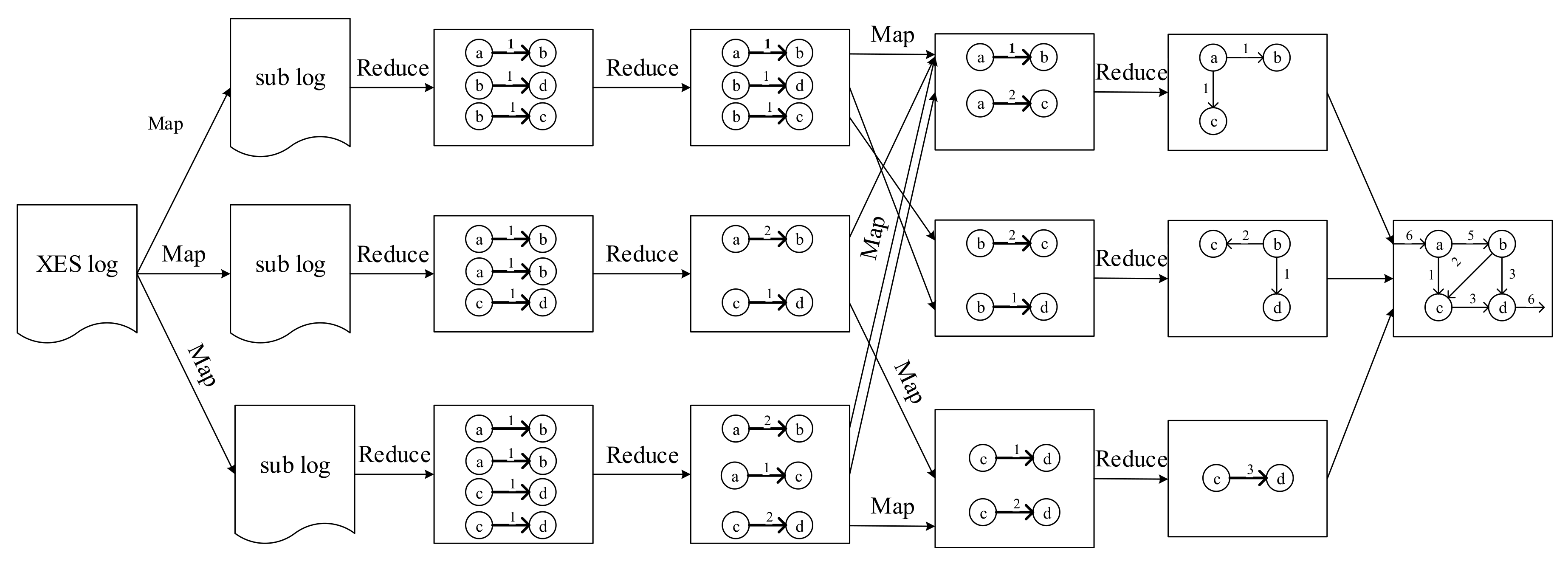
5. Distributed Network Attack Modeling
5.1. Distributed Initial Attack Graph Generation
| Algorithm 2 AttackGraphMiningAlgorithm |
|
5.2. Distributed Attack Graph Segmentation
6. Experiment and Analysis
6.1. Experimental Setting and Dataset
6.1.1. Experimental Environment and Dataset
6.1.2. Comparing Algorithms and Evaluation Metrics
6.2. Experiment Analysis
6.2.1. Analysis of Attack Graph Generation
6.2.2. Analysis of Attack Graph Segmentation
6.2.3. Time Performance Analysis
Time Performance of HPM
Time Performance of Graph Segmentation
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Al-Mamory, S.O.; Zhang, H. Intrusion detection alarms reduction using root cause analysis and clustering. Comput. Commun. 2009, 32, 419–430. [Google Scholar] [CrossRef]
- Siraj, M.M.; Maarof, M.A.; Hashim, S.Z. Intelligent Alert Clustering Model for Network Intrusion Analysis. Int. J. Adv. Soft Comput. Appl. 2009, 1, 1–16. [Google Scholar]
- Bopche, G.S.; Mehtre, B.M. Attack Graph Generation. Visualization and Analysis: Issues and Challenges. In Proceedings of the International Symposium on Security in Computing & Communication (SSCC 2014), Delhi, India, 24–27 September 2014; pp. 379–390. [Google Scholar]
- Van der Aalst, W. Process Mining: Discovery Conformance and Enhancement of Business Processes; Springer: Berlin, Germany, 2011. [Google Scholar]
- Van der Aalst, W.M.; van Dongen, B.F.; Herbst, J.; Maruster, L.; Schimm, G.; Weijters, A.J. Workflow Mining: A Survey of Issues and Approaches. Data Knowl. Eng. 2003, 47, 237–267. [Google Scholar] [CrossRef]
- Van Der Aalst, W.M.; Reijers, H.A.; Weijters, A.J.; van Dongen, B.F.; De Medeiros, A.A.; Song, M.; Verbeek, H.M. Business Process Mining: An Industrial Application. Inf. Syst. 2007, 32, 713–732. [Google Scholar] [CrossRef]
- Mishra, V.P.; Shukla, B. Process Mining in Intrusion Detection—The Need of Current Digital World. Adv. Inform. Comput. Res. 2017, 712, 238–246. [Google Scholar]
- Phillips, C.; Swiler, L.P. A Graph-based System for Network-vulnerability Analysis. In Proceedings of the 1998 Workshop on New Security Paradigms, Charlottsville, VA, USA, 22–25 September 1998; pp. 71–79. [Google Scholar]
- Kordy, B.; Piètre-Cambacédès, L.; Schweitzer, P. DAG-based attack and defense modeling: Don’t miss the forest for the attack trees. Comput. Sci. Rev. 2014, 13–14, 1–38. [Google Scholar] [CrossRef]
- Shittu, R.; Healing, A.; Ghanea-Hercock, R.; Bloomfield, R.; Rajarajan, M. Intrusion alert prioritisation and attack detection using post-correlation analysis. Comput. Secur. 2015, 50, 1–15. [Google Scholar] [CrossRef]
- Za, C.; Ane, O.R.; Goebel, R.G.; Hand, D.P.; Keim, D.P.; NG, R.P. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; Association for Computing Machinery: New York, NY, USA, 2002. [Google Scholar]
- Zong, B.; Wu, Y.; Song, J.; Singh, A.K.; Cam, H.; Han, J.; Yan, X. Towards scalable critical alert mining. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1057–1066. [Google Scholar]
- Loreti, D.; Chesani, F.; Ciampolini, A.; Mello, P. Distributed Compliance Monitoring of Business Processes over MapReduce Architectures. Future Gener. Comput. Syst. 2017, 104–118. [Google Scholar] [CrossRef]
- Loreti, D.; Chesani, F.; Ciampolini, A.; Mello, P. A distributed approach to compliance monitoring of business process event streams. Future Gener. Comput. Syst. 2018, 82, 104–118. [Google Scholar] [CrossRef]
- Weijters, A.J.M.M.; Ribeiro, J.T.S. Flexible Heuristics Miner (FHM). In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 310–317. [Google Scholar] [CrossRef]
- De Alvarenga, S.C.; Barbon, S., Jr.; Miani, R.S.; Cukier, M.; Zarpelão, B.B. Process mining and hierarchical clustering to help intrusion alert visualization. Comput. Secur. 2018, 73, 474–491. [Google Scholar] [CrossRef]
- Lee, S.; Chung, B.; Kim, H.; Lee, Y.; Park, C.; Yoon, H. Real-time analysis of intrusion detection alerts via correlation. Comput. Secur. 2006, 25, 169–183. [Google Scholar] [CrossRef]
- Ning, P.; Xu, D. Learning attack strategies from intrusion alerts. In Proceedings of the 10th ACM Conference on Computer and Communications Security, Washington, DC, USA, 27–31 October 2003; pp. 200–209. [Google Scholar]
- Vigo, R.; Nielson, F.; Nielson, H.R. Automated Generation of Attack Trees. In Proceedings of the IEEE Computer Security Foundations Symposium, Vienna, Austria, 19–22 July 2014. [Google Scholar]
- Paul, S. Towards automating the construction & maintenance of attack trees: A feasibility study. Electron. Proc. Theor. Comput. Sci. 2014, 148, 31–46. [Google Scholar]
- Birkholz, H.; Edelkamp, S.; Junge, F.; Sohr, K. Efficient automated generation of attack trees from vulnerability databases. In Proceedings of the Working Notes for the 2010 AAAI Workshop on Intelligent Security (SecArt), Atlanta, GA, USA, 11–12 July 2010; pp. 47–55. [Google Scholar]
- Ahmadinejad, S.H.; Jalili, S.; Abadi, M.J.C.N. A hybrid model for correlating alerts of known and unknown attack scenarios and updating attack graphs. Comput. Netw. 2011, 55, 2221–2240. [Google Scholar] [CrossRef]
- Spathoulas, G.P.; Katsikas, S.K.J.C. Enhancing IDS performance through comprehensive alert post-processing. Comput. Secur. 2013, 37, 176–196. [Google Scholar] [CrossRef]
- Sadoddin, R.; Ghorbani, A.A.J.C. An incremental frequent structure mining framework for real-time alert correlation. Comput. Secur. 2009, 28, 153–173. [Google Scholar] [CrossRef]
- Lagzian, S.; Amiri, F.; Enayati, A.R.; Gharaee, H. Frequent item set mining-based alert correlation for extracting multi-stage attack scenarios. In Proceedings of the Sixth International Symposium on Telecommunications, Tehran, Iran, 6–8 November 2012. [Google Scholar]
- Kawakani, C.T.; Barbon, S.; Miani, R.S.; Cukier, M.; Zarpelão, B.B. Discovering attackers past behavior to generate online hyper-alerts. ISys-Rev. Bras. Sist. Informação 2017, 10, 122–147. [Google Scholar] [CrossRef]
- De Alvarenga, S.C.; Zarpelão, B.B.; Barbon, S., Jr.; Miani, R.S.; Cukier, M. Discovering attack strategies using process mining. In Proceedings of the Eleventh Advanced International Conference on Telecommunications (AICT 2015), Brussels, Belgium, 21–26 June 2015. [Google Scholar]
- Lempitsky, V.; Kohli, P.; Rother, C.; Sharp, T. Image Segmentation with A Bounding Box Prior. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Tao, L.; Zhao, Y.C.; Thulasiraman, K.; Swamy, M.N. Simulated annealing and tabu search algorithms for multiway graph partition. J. Circuits Syst. Comput. 1992, 2, 159–185. [Google Scholar] [CrossRef]
- Farshbaf, M.; Feizi-Derakhshi, M.R. Multi-objective Optimization of Graph Partitioning Using Genetic Algorithms. In Proceedings of the International Conference on Advanced Engineering Computing & Applications in Sciences, Sliema, Malta, 11–16 October 2009. [Google Scholar]
- Parpinelli, R.S.; Lopes, H.S.; Freitas, A.A. Data mining with an ant colony optimization algorithm. IEEE Trans. Evol. Comput. 2002, 6, 321–332. [Google Scholar] [CrossRef]
- Maitra, M.; Chatterjee, A. A hybrid cooperative–comprehensive learning based PSO algorithm for image segmentation using multilevel thresholding. Expert Syst. Appl. 2008, 34, 1341–1350. [Google Scholar] [CrossRef]
- Chauhan, S.; Girvan, M.; Ott, E. Spectral properties of networks with community structure. Phys. Rev. E 2009, 80, 056114. [Google Scholar] [CrossRef]
- Donetti, L.; Munoz, M.A. Detecting network communities: A new systematic and efficient algorithm. J. Stat. Mech. Theory Exp. 2004, 2004, P10012. [Google Scholar] [CrossRef]
- Shen, H.W.; Cheng, X.Q. Spectral methods for the detection of network community structure: A comparative analysis. J. Stat. Mech. Theory Exp. 2010, 2010, P10020. [Google Scholar] [CrossRef]
- Kernighan, B.W.; Lin, S. An Efficient Heuristic Procedure for Partitioning Graphs. Bell Syst. Tech. J. 1970, 49, 291–307. [Google Scholar] [CrossRef]
- Brunetta, L.; Conforti, M.; Rinaldi, G. A branch-and-cut algorithm for the equicut problem. Math. Program. 1997, 78, 243–263. [Google Scholar] [CrossRef]
- Karisch, S.E.; Rendl, F.; Clausen, J. Solving Graph Bisection Problems with Semidefinite Programming. INFORMS J. Comput. 2000, 12, 177–191. [Google Scholar] [CrossRef]
- Weijters, A.J.; van Der Aalst, W.M.; De Medeiros, A.A. Process mining with the heuristics miner-algorithm. Tech. Univ. Eindh. 2006, 166, 1–34. [Google Scholar]
- Van der Aalst, W.; Weijters, T.; Maruster, L. Workflow mining: Discovering process models from event logs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1128–1142. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Processor | 4 |
| OS | Ubuntu 14.04 |
| Hadoop | 2.6.0 |
| Spark | 2.2.0 |
| Number of nodes in a cluster | 4 |
| Field | Meaning | Description |
|---|---|---|
| Timestamp | Timestamp | Specifies the time when alerts occur; used as a basis for grouping |
| SourceIp | Source IP | Specifies the IP address initiating an attack |
| SourcePort | Source port | Specifies the port number of the attack source |
| DestIP | Destination IP | Specifies the IP address of the target host; used as a basis for grouping |
| DestPort | Destination port | Specifies the port number of the target host |
| Protocol | Protocol | Specifies the protocol of the traffic |
| Signature | Signature | Specifies the attack information; used as the event input for process mining |
| LogID | Log ID | Specifies the primary key of a log; the unique identifier of an alert |
| Subgraph No. | Number of Vertices | Number of Edges | Complex or Not |
|---|---|---|---|
| 1 | 15 | 43 | N |
| 2 | 13 | 37 | N |
| 3 | 13 | 31 | N |
| 4 | 16 | 39 | N |
| 5 | 7 | 25 | N |
| 6 | 9 | 30 | N |
| 7 | 11 | 34 | N |
| 8 | 22 | 57 | N |
| 9 | 6 | 24 | N |
| 10 | 15 | 55 | N |
| 11 | 17 | 58 | Y |
| 12 | 14 | 40 | N |
| 13 | 10 | 22 | N |
| 14 | 7 | 28 | N |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liu, Z.; Liu, Y.; Dong, C. Distributed Attack Modeling Approach Based on Process Mining and Graph Segmentation. Entropy 2020, 22, 1026. https://doi.org/10.3390/e22091026
Chen Y, Liu Z, Liu Y, Dong C. Distributed Attack Modeling Approach Based on Process Mining and Graph Segmentation. Entropy. 2020; 22(9):1026. https://doi.org/10.3390/e22091026
Chicago/Turabian StyleChen, Yuzhong, Zhenyu Liu, Yulin Liu, and Chen Dong. 2020. "Distributed Attack Modeling Approach Based on Process Mining and Graph Segmentation" Entropy 22, no. 9: 1026. https://doi.org/10.3390/e22091026
APA StyleChen, Y., Liu, Z., Liu, Y., & Dong, C. (2020). Distributed Attack Modeling Approach Based on Process Mining and Graph Segmentation. Entropy, 22(9), 1026. https://doi.org/10.3390/e22091026