Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms


Abstract
1. Introduction
2. Methods
2.1. Accuracy Weighted Ensemble
| Algorithm 1 AWE pseudocode. |
| Input: S: new data chunk |
| K: size of the ensemble |
| C: ensemble of K classifiers |
| Output: C: ensemble of K classifiers with updated weights |
| Train new classifier with S; |
| Calculate weight of based on 1 using cross-validation on S; |
| for in C do |
| Calculate weight of based on 1 |
| end for |
| C ← K classifiers with highest weights from ; |
| return C; |
2.2. Accuracy Updated Ensemble
| Algorithm 2 AUE pseudocode. |
| Input: S: new data chunk |
| K: size of the ensemble |
| C: ensemble of K classifiers |
| Output: C: ensemble of K updated classifiers with updated weights |
| Train new classifier on S; |
| Estimate the weight of based on 4 using cross-validation on S; |
| for do |
| Calculate weight based on 4; |
| end for |
| C ← K classifiers with the highest weights from ; |
| for in C do |
| if and then |
| update with S |
| end if |
| end for |
2.3. Proposed Changes in AUE and AWE Algorithms to Deal with Imbalanced Classification Problem
| Algorithm 3 Pseudocode of imbalanced metric-driven models based on AWE. |
| Input: S: new data chunk |
| C: ensemble of classifiers |
| K: size of the ensemble |
| Output: C: ensemble of classifiers with updated weights |
| X ← sampled S |
| Train new classifier on X; |
| Estimate weight of with cross-validation on S based on (5), (6) or (7); |
| for in C do |
| Calculate weight of on S based on (5), (6) or (7); |
| end for |
| C ← K classifiers with the highest weights from ; |
| for in C do |
| end for |
| return C; |
| Algorithm 4 Pseudocode of imbalanced metric-driven models based on AUE. |
| Input: S: new data chunk |
| C: ensemble of classifiers |
| K: size of the ensemble |
| Output: C: ensemble of updated classifiers with updated weights |
| X ← sampled S |
| Train new classifier na X; |
| Estimate weight of using cross-validation on S based on 5, 6 or 7; |
| for in C do |
| Calculate weight of on S based on 5, 6 or 7; |
| end for |
| Calculate weight of random classifier on S based on 5, 6 or 6 and a priori probabilities; |
| for in C do |
| if then |
| Update with S; |
| end if |
| end for |
| C ← K classifiers with the highest weights from ; |
| for in C do |
| end for |
| return C; |
3. Experimental Set-Up
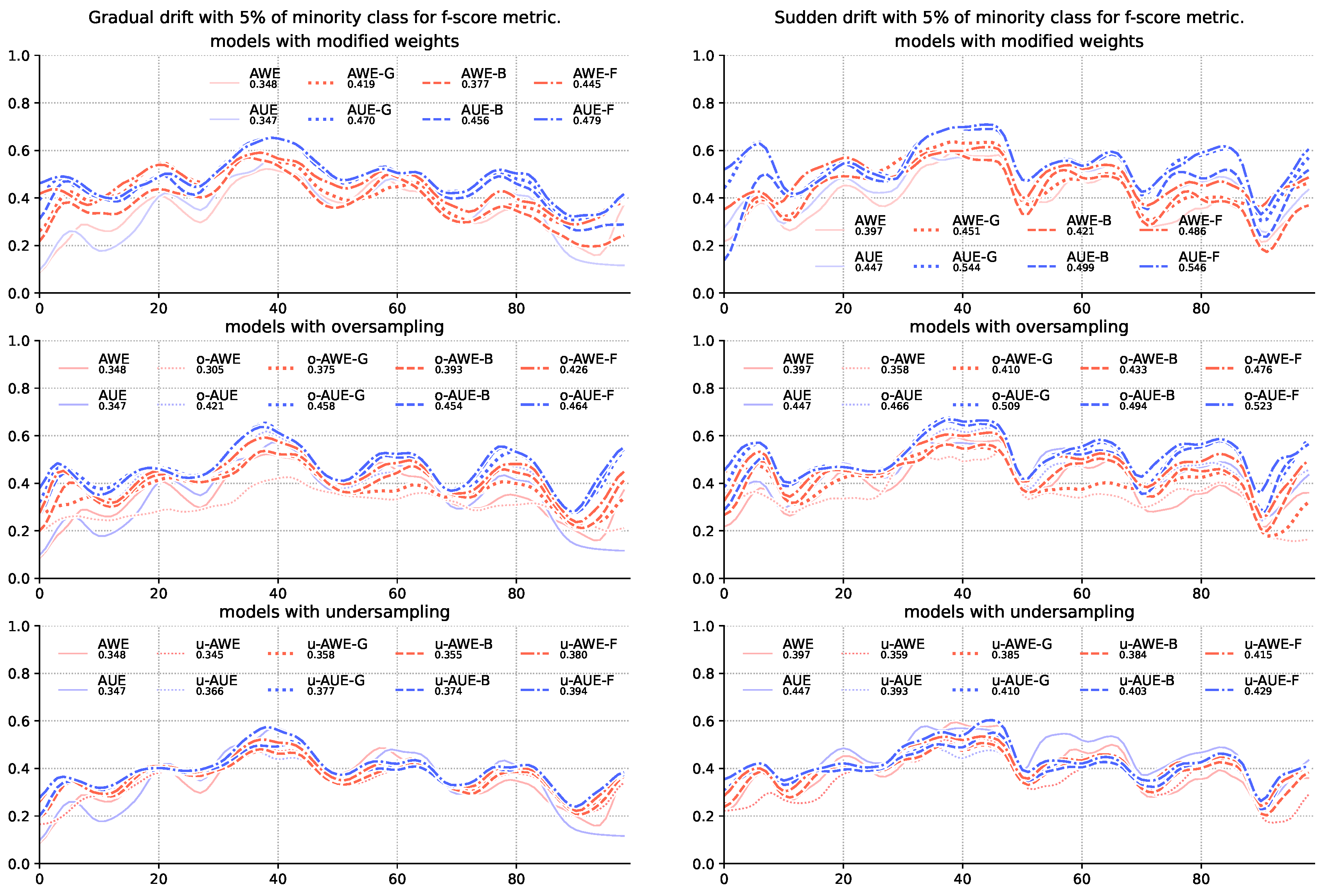
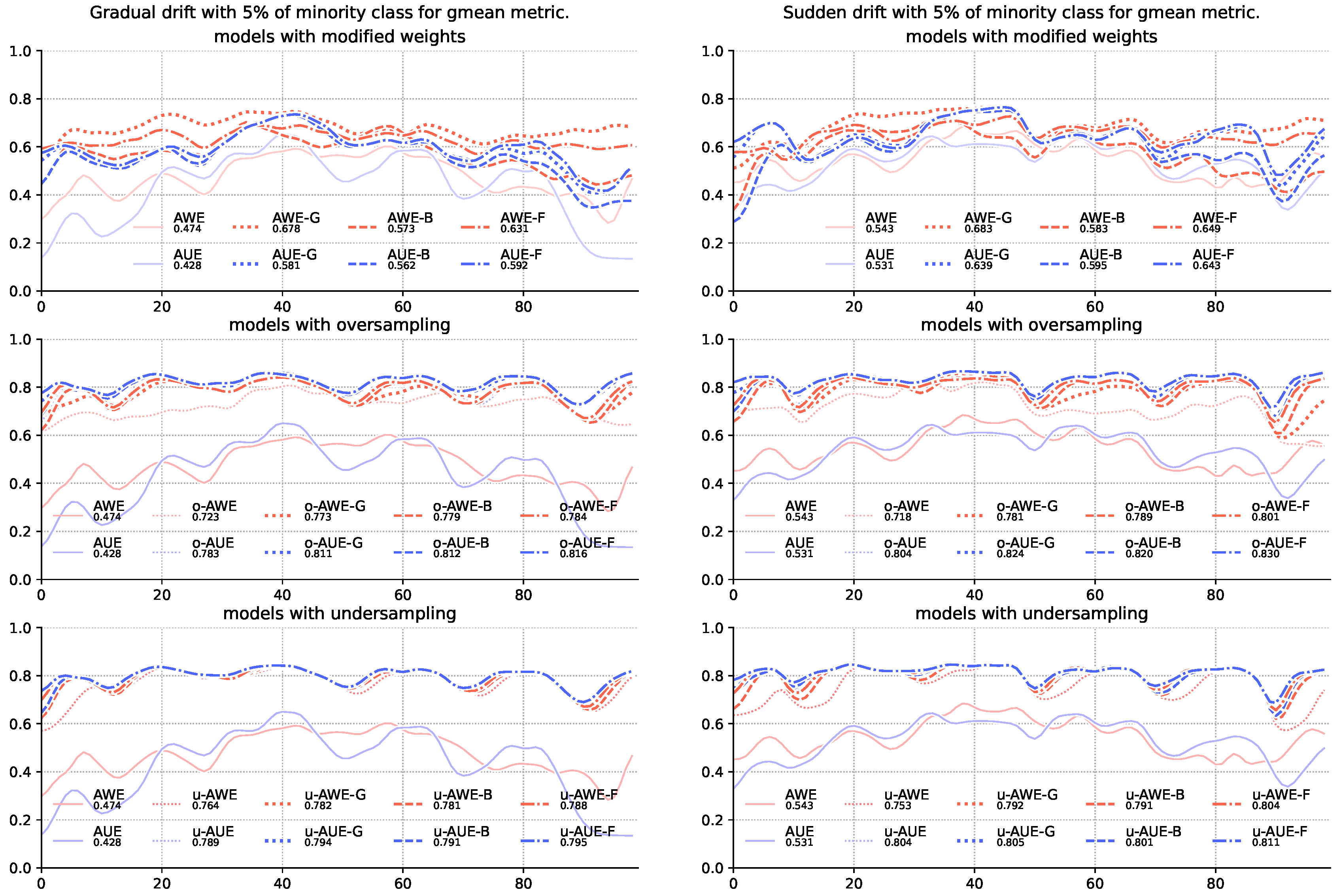
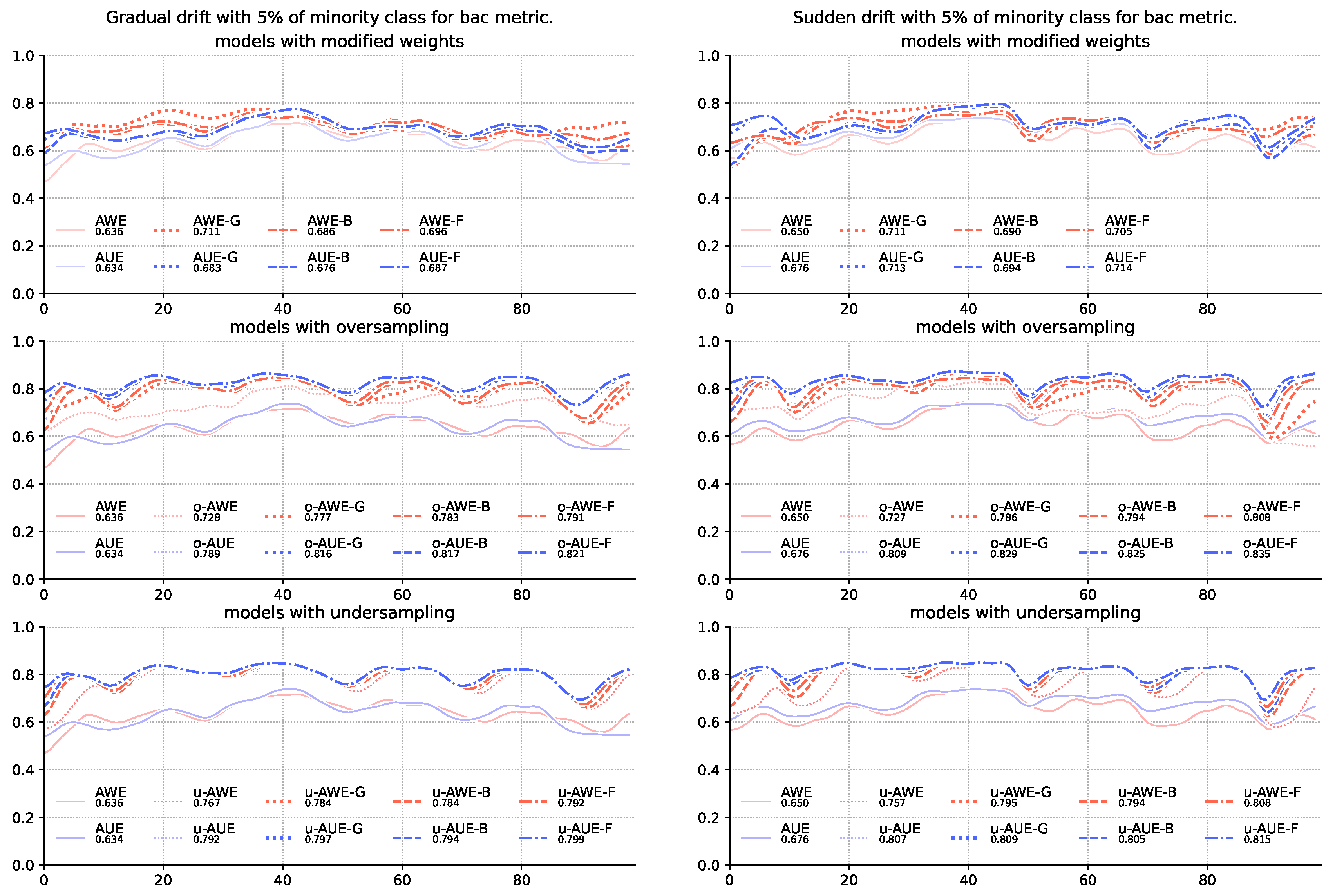
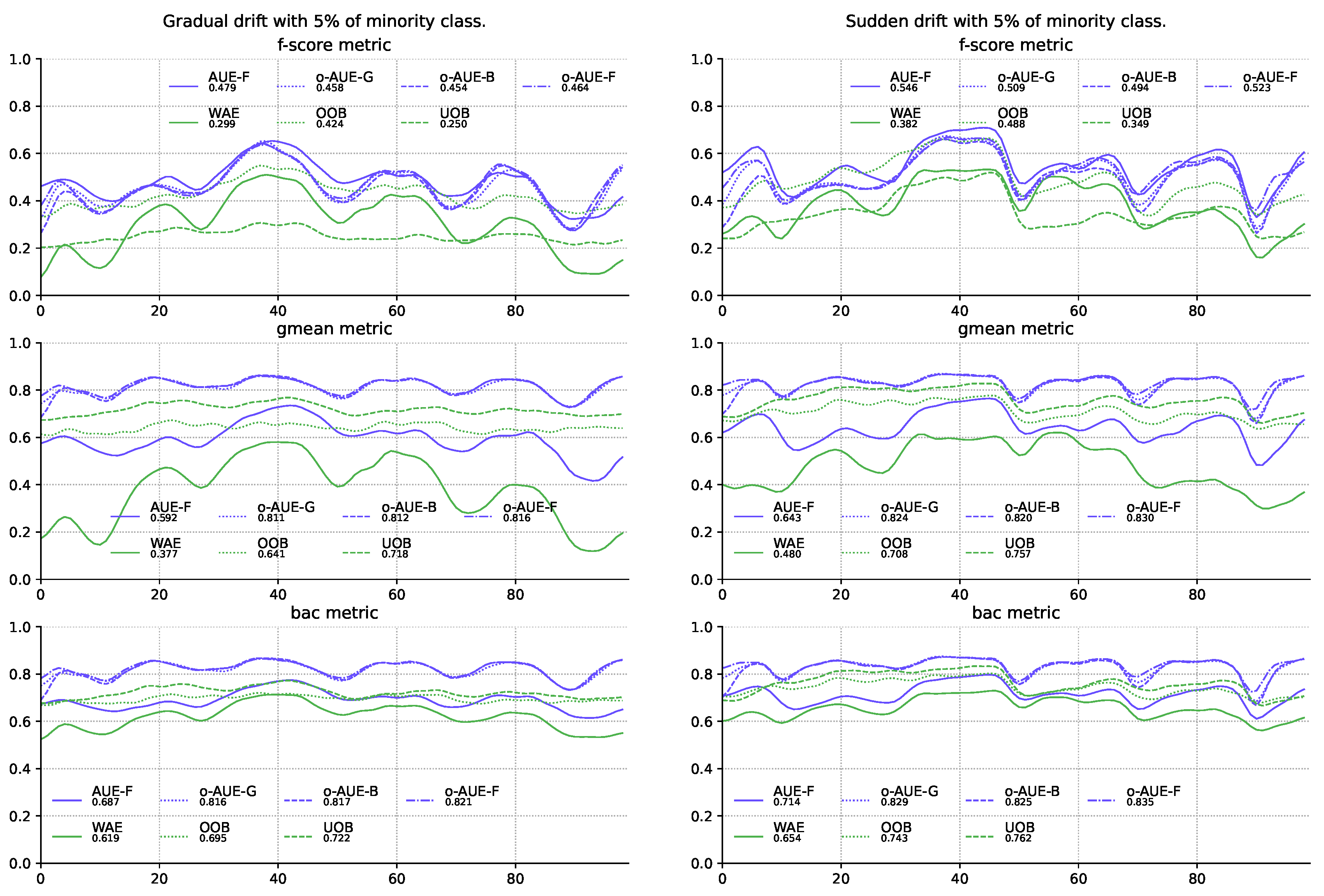
4. Experimental Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krawczyk, B.; Minku, L.L.; Gama, J.; Stefanowski, J.; Woźniak, M. Ensemble learning for data stream analysis: A survey. Inf. Fusion 2017, 37, 132–156. [Google Scholar] [CrossRef]
- Gomes, H.M.; Barddal, J.P.; Enembreck, F.; Bifet, A. A survey on ensemble learning for data stream classification. Acm Comput. Surv. (CSUR) 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Adeniyi, D.A.; Wei, Z.; Yongquan, Y. Automated web usage data mining and recommendation system using K-Nearest Neighbor (KNN) classification method. Appl. Comput. Inform. 2016, 12, 90–108. [Google Scholar] [CrossRef]
- CISCO. Cisco Visual Networking Index: Forecast and Trends, 2017–2022. Available online: https://www.cisco.com/c/dam/m/en_us/network-intelligence/service-provider/digital-transformation/knowledge-network-webinars/pdfs/1213-business-services-ckn.pdf (accessed on 15 December 2018).
- Dal Pozzolo, A.; Caelen, O.; Le Borgne, Y.A.; Waterschoot, S.; Bontempi, G. Learned lessons in credit card fraud detection from a practitioner perspective. Expert Syst. Appl. 2014, 41, 4915–4928. [Google Scholar] [CrossRef]
- Yuan, X.; Li, C.; Li, X. DeepDefense: Identifying DDoS attack via deep learning. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017; pp. 1–8. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data–recommendations for the use of performance metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and issues in data stream systems. In Proceedings of the Twenty-First ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar]
- Tsymbal, A. The problem of concept drift: Definitions and related work. Comput. Sci. Dep. Trinity Coll. Dublin 2004, 106, 58. [Google Scholar]
- Woźniak, M.; Kasprzak, A.; Cal, P. Weighted aging classifier ensemble for the incremental drifted data streams. In Proceedings of the International Conference on Flexible Query Answering Systems, Granada, Spain, 18–20 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 579–588. [Google Scholar]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with drift detection. In Brazilian Symposium on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany 2004; pp. 286–295. [Google Scholar]
- Wang, S.; Minku, L.L.; Yao, X. Online class imbalance learning and its applications in fault detection. Int. J. Comput. Intell. Appl. 2013, 12, 1340001. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE world Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Laurikkala, J. Improving identification of difficult small classes by balancing class distribution. In Proceedings of the Conference on Artificial Intelligence in Medicine in Europe, Cascais, Portugal, 1–4 July 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 63–66. [Google Scholar]
- Burduk, R.; Kurzyński, M. Two-stage binary classifier with fuzzy-valued loss function. Pattern Anal. Appl. 2006, 9, 353–358. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M. One-class classifiers with incremental learning and forgetting for data streams with concept drift. Soft Comput. 2015, 19, 3387–3400. [Google Scholar] [CrossRef]
- Zyblewski, P.; Ksieniewicz, P.; Woźniak, M. Classifier selection for highly imbalanced data streams with minority driven ensemble. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 16–20 June 2019; Springer: Cham, Switzerland, 2019; pp. 626–635. [Google Scholar]
- Wang, H.; Fan, W.; Yu, P.S.; Han, J. Mining concept-drifting data streams using ensemble classifiers. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery And Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 226–235. [Google Scholar]
- Brzeziński, D.; Stefanowski, J. Accuracy updated ensemble for data streams with concept drift. In Proceedings of the International Conference On Hybrid Artificial Intelligence Systems, Wroclaw, Poland, 23–25 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 155–163. [Google Scholar]
- Brzezinski, D.; Stefanowski, J. Reacting to different types of concept drift: The accuracy updated ensemble algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 81–94. [Google Scholar] [CrossRef] [PubMed]
- Spyromitros-Xioufis, E.; Spiliopoulou, M.; Tsoumakas, G.; Vlahavas, I. Dealing with concept drift and class imbalance in multi-label stream classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the 4th Conference on Message Understanding (MUC4’92), McLean, VA, USA, 16–18 June 1992; Association for Computational Linguistics: Stroudsburg, PA, USA, 1992; pp. 22–29. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proc. 14th International Conference on Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1997; Volume 97, pp. 179–186. [Google Scholar]
- Guyon, I. Design of experiments of the NIPS 2003 variable selection benchmark. In Proceedings of the NIPS 2003 Workshop on Feature Extraction And Feature Selection, Whistler, BC, Canada, 11–13 December 2003. [Google Scholar]
- Gehan, E.A. A generalized Wilcoxon test for comparing arbitrarily singly-censored samples. Biometrika 1965, 52, 203–224. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ksieniewicz, P.; Zyblewski, P. stream-learn–open-source Python library for difficult data stream batch analysis. arXiv 2020, arXiv:2001.11077. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Montiel, J.; Read, J.; Bifet, A.; Abdessalem, T. Scikit-Multiflow: A Multi-output Streaming Framework. J. Mach. Learn. Res. 2018, 19, 2914–2915. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | DRIFT TYPE | MINORITY CLASS % | CLASS RATIO |
|---|---|---|---|
| 1 | sudden | 5% | 1:19 |
| 2 | sudden | 10% | 1:9 |
| 3 | sudden | 20% | 1:4 |
| 4 | sudden | 30% | 3:7 |
| 5 | gradual | 5% | 1:19 |
| 6 | gradual | 10% | 1:9 |
| 7 | gradual | 20% | 1:4 |
| 8 | gradual | 30% | 3:7 |
| # | BASE ENSEMBLE | WEIGHTING METHOD | SAMPLING | PLOT LABEL |
|---|---|---|---|---|
| 1 | AWE | proportional to G-mean | undersampling | u-AWE-g |
| 2 | proportional to balanced accuracy score | undersampling | u-AWE-b | |
| 3 | proportional to F1-score | undersampling | u-AWE-f | |
| 4 | proportional to G-mean | oversampling | o-AWE-g | |
| 5 | proportional to balanced accuracy score | oversampling | o-AWE-b | |
| 6 | proportional to F1-score | oversampling | o-AWE-f | |
| 7 | proportional to G-mean | — | AWE-g | |
| 8 | proportional to balanced accuracy score | — | AWE-b | |
| 9 | proportional to F1-score | — | AWE-f | |
| 10 | in inverse proportion to MSE | undersampling | u-AWE | |
| 11 | in inverse proportion to MSE | oversampling | o-AWE | |
| 12 | AUE | proportional to G-mean | undersampling | u-AUE-g |
| 13 | proportional to balanced accuracy score | undersampling | u-AUE-b | |
| 14 | proportional to F1-score | undersampling | u-AUE-f | |
| 15 | proportional to G-mean | oversampling | o-AUE-g | |
| 16 | proportional to balanced accuracy score | oversampling | o-AUE-b | |
| 17 | proportional to F1-score | oversampling | o-AUE-f | |
| 18 | proportional to G-mean | — | AUE-g | |
| 19 | proportional to balanced accuracy score | — | AUE-b | |
| 20 | proportional to F1-score | — | AUE-f | |
| 21 | in inverse proportion to MSE | undersampling | u-AUE | |
| 22 | in inverse proportion to MSE | oversampling | o-AUE |
| # | METHOD | SUDDEN DRIFT | GRADUAL DRIFT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 30% | 5% | 10% | 20% | 30% | ||
| 1 | AWE | 0.385 | 0.496 | 0.690 | 0.780 | 0.358 | 0.495 | 0.674 | 0.760 |
| 2 | AWE | 0.384 | 0.486 | 0.704 | 0.781 | 0.355 | 0.483 | 0.681 | 0.758 |
| 3 | AWE | 0.415 | 0.515 | 0.722 | 0.785 | 0.380 | 0.505 | 0.690 | 0.761 |
| 4 | AWE | 0.410 | 0.547 | 0.720 | 0.783 | 0.375 | 0.507 | 0.690 | 0.761 |
| 5 | AWE | 0.433 | 0.577 | 0.720 | 0.784 | 0.393 | 0.539 | 0.688 | 0.763 |
| 6 | AWE | 0.476 | 0.612 | 0.734 | 0.791 | 0.426 | 0.567 | 0.699 | 0.767 |
| 7 | AWE | 0.451 | 0.579 | 0.722 | 0.784 | 0.419 | 0.538 | 0.681 | 0.755 |
| 8 | AWE | 0.421 | 0.600 | 0.725 | 0.785 | 0.377 | 0.548 | 0.686 | 0.756 |
| 9 | AWE | 0.486 | 0.627 | 0.742 | 0.791 | 0.445 | 0.569 | 0.692 | 0.760 |
| 10 | AWE | 0.359 | 0.429 | 0.628 | 0.740 | 0.345 | 0.449 | 0.624 | 0.744 |
| 11 | AWE | 0.358 | 0.464 | 0.663 | 0.741 | 0.305 | 0.442 | 0.646 | 0.741 |
| 12 | AWE | 0.397 | 0.550 | 0.674 | 0.744 | 0.348 | 0.518 | 0.679 | 0.763 |
| 13 | AUE | 0.410 | 0.582 | 0.740 | 0.810 | 0.377 | 0.548 | 0.707 | 0.787 |
| 14 | AUE | 0.403 | 0.567 | 0.733 | 0.807 | 0.374 | 0.541 | 0.708 | 0.786 |
| 15 | AUE | 0.429 | 0.598 | 0.750 | 0.818 | 0.394 | 0.557 | 0.714 | 0.791 |
| 16 | AUE | 0.509 | 0.657 | 0.776 | 0.828 | 0.458 | 0.604 | 0.741 | 0.805 |
| 17 | AUE | 0.494 | 0.645 | 0.756 | 0.819 | 0.454 | 0.607 | 0.737 | 0.803 |
| 18 | AUE | 0.523 | 0.663 | 0.779 | 0.831 | 0.464 | 0.610 | 0.743 | 0.806 |
| 19 | AUE | 0.544 | 0.671 | 0.775 | 0.821 | 0.470 | 0.613 | 0.735 | 0.796 |
| 20 | AUE | 0.499 | 0.646 | 0.757 | 0.815 | 0.456 | 0.611 | 0.732 | 0.794 |
| 21 | AUE | 0.546 | 0.682 | 0.780 | 0.827 | 0.479 | 0.618 | 0.740 | 0.797 |
| 22 | AUE | 0.393 | 0.543 | 0.746 | 0.813 | 0.366 | 0.522 | 0.707 | 0.788 |
| 23 | AUE | 0.467 | 0.610 | 0.760 | 0.820 | 0.421 | 0.563 | 0.724 | 0.800 |
| 24 | AUE | 0.447 | 0.642 | 0.766 | 0.820 | 0.347 | 0.547 | 0.736 | 0.798 |
| 25 | WAE | 0.382 | 0.571 | 0.745 | 0.805 | 0.299 | 0.460 | 0.698 | 0.774 |
| 26 | OOB | 0.488 | 0.529 | 0.624 | 0.679 | 0.424 | 0.524 | 0.624 | 0.682 |
| 27 | UOB | 0.349 | 0.440 | 0.605 | 0.682 | 0.250 | 0.412 | 0.581 | 0.678 |
| # | METHOD | SUDDEN DRIFT | GRADUAL DRIFT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 30% | 5% | 10% | 20% | 30% | ||
| 1 | AWE | 0.792 | 0.791 | 0.826 | 0.845 | 0.781 | 0.804 | 0.822 | 0.832 |
| 2 | AWE | 0.791 | 0.771 | 0.836 | 0.845 | 0.781 | 0.777 | 0.826 | 0.831 |
| 3 | AWE | 0.804 | 0.780 | 0.844 | 0.848 | 0.788 | 0.789 | 0.828 | 0.833 |
| 4 | AWE | 0.781 | 0.799 | 0.842 | 0.846 | 0.773 | 0.785 | 0.827 | 0.833 |
| 5 | AWE | 0.789 | 0.819 | 0.842 | 0.847 | 0.779 | 0.810 | 0.826 | 0.834 |
| 6 | AWE | 0.801 | 0.831 | 0.847 | 0.851 | 0.784 | 0.815 | 0.830 | 0.836 |
| 7 | AWE | 0.683 | 0.733 | 0.807 | 0.836 | 0.678 | 0.725 | 0.786 | 0.817 |
| 8 | AWE | 0.583 | 0.729 | 0.809 | 0.837 | 0.573 | 0.712 | 0.786 | 0.818 |
| 9 | AWE | 0.649 | 0.735 | 0.815 | 0.840 | 0.631 | 0.714 | 0.786 | 0.820 |
| 10 | AWE | 0.753 | 0.704 | 0.761 | 0.804 | 0.764 | 0.744 | 0.769 | 0.815 |
| 11 | AWE | 0.718 | 0.707 | 0.783 | 0.805 | 0.723 | 0.709 | 0.780 | 0.810 |
| 12 | AWE | 0.543 | 0.681 | 0.762 | 0.798 | 0.474 | 0.647 | 0.769 | 0.819 |
| 13 | AUE | 0.805 | 0.832 | 0.858 | 0.868 | 0.794 | 0.822 | 0.843 | 0.853 |
| 14 | AUE | 0.801 | 0.824 | 0.852 | 0.865 | 0.791 | 0.819 | 0.843 | 0.853 |
| 15 | AUE | 0.811 | 0.840 | 0.863 | 0.874 | 0.795 | 0.823 | 0.845 | 0.856 |
| 16 | AUE | 0.824 | 0.859 | 0.881 | 0.881 | 0.811 | 0.844 | 0.865 | 0.867 |
| 17 | AUE | 0.820 | 0.853 | 0.866 | 0.874 | 0.812 | 0.846 | 0.862 | 0.866 |
| 18 | AUE | 0.830 | 0.866 | 0.882 | 0.883 | 0.816 | 0.849 | 0.866 | 0.868 |
| 19 | AUE | 0.639 | 0.749 | 0.837 | 0.863 | 0.581 | 0.712 | 0.810 | 0.847 |
| 20 | AUE | 0.595 | 0.733 | 0.824 | 0.858 | 0.562 | 0.708 | 0.808 | 0.845 |
| 21 | AUE | 0.643 | 0.756 | 0.839 | 0.868 | 0.592 | 0.713 | 0.813 | 0.848 |
| 22 | AUE | 0.804 | 0.814 | 0.859 | 0.868 | 0.789 | 0.813 | 0.840 | 0.854 |
| 23 | AUE | 0.804 | 0.841 | 0.869 | 0.875 | 0.783 | 0.822 | 0.852 | 0.863 |
| 24 | AUE | 0.531 | 0.726 | 0.830 | 0.862 | 0.428 | 0.632 | 0.808 | 0.847 |
| 25 | WAE | 0.480 | 0.669 | 0.815 | 0.852 | 0.377 | 0.547 | 0.781 | 0.830 |
| 26 | OOB | 0.708 | 0.686 | 0.735 | 0.754 | 0.641 | 0.706 | 0.745 | 0.759 |
| 27 | UOB | 0.757 | 0.757 | 0.776 | 0.774 | 0.718 | 0.744 | 0.763 | 0.772 |
| # | METHOD | SUDDEN DRIFT | GRADUAL DRIFT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 5% | 10% | 20% | 30% | 5% | 10% | 20% | 30% | ||
| 1 | AWE | 0.795 | 0.796 | 0.827 | 0.846 | 0.784 | 0.806 | 0.823 | 0.833 |
| 2 | AWE | 0.794 | 0.791 | 0.837 | 0.846 | 0.784 | 0.794 | 0.827 | 0.832 |
| 3 | AWE | 0.807 | 0.805 | 0.846 | 0.849 | 0.791 | 0.803 | 0.830 | 0.834 |
| 4 | AWE | 0.785 | 0.801 | 0.843 | 0.848 | 0.777 | 0.787 | 0.829 | 0.834 |
| 5 | AWE | 0.794 | 0.821 | 0.843 | 0.848 | 0.783 | 0.812 | 0.827 | 0.835 |
| 6 | AWE | 0.807 | 0.834 | 0.849 | 0.852 | 0.791 | 0.818 | 0.832 | 0.838 |
| 7 | AWE | 0.711 | 0.753 | 0.816 | 0.840 | 0.711 | 0.744 | 0.795 | 0.822 |
| 8 | AWE | 0.690 | 0.758 | 0.818 | 0.840 | 0.686 | 0.744 | 0.797 | 0.822 |
| 9 | AWE | 0.705 | 0.765 | 0.825 | 0.844 | 0.696 | 0.747 | 0.799 | 0.825 |
| 10 | AWE | 0.757 | 0.710 | 0.762 | 0.806 | 0.767 | 0.750 | 0.771 | 0.816 |
| 11 | AWE | 0.727 | 0.712 | 0.785 | 0.806 | 0.728 | 0.714 | 0.782 | 0.812 |
| 12 | AWE | 0.650 | 0.712 | 0.771 | 0.802 | 0.636 | 0.706 | 0.786 | 0.825 |
| 13 | AUE | 0.809 | 0.835 | 0.859 | 0.869 | 0.797 | 0.825 | 0.844 | 0.855 |
| 14 | AUE | 0.805 | 0.828 | 0.853 | 0.866 | 0.794 | 0.822 | 0.844 | 0.854 |
| 15 | AUE | 0.815 | 0.843 | 0.864 | 0.875 | 0.799 | 0.826 | 0.846 | 0.857 |
| 16 | AUE | 0.829 | 0.861 | 0.882 | 0.882 | 0.816 | 0.846 | 0.866 | 0.868 |
| 17 | AUE | 0.825 | 0.855 | 0.867 | 0.875 | 0.817 | 0.848 | 0.863 | 0.867 |
| 18 | AUE | 0.835 | 0.868 | 0.883 | 0.884 | 0.821 | 0.851 | 0.867 | 0.869 |
| 19 | AUE | 0.713 | 0.781 | 0.846 | 0.867 | 0.683 | 0.756 | 0.824 | 0.851 |
| 20 | AUE | 0.694 | 0.768 | 0.833 | 0.862 | 0.676 | 0.754 | 0.822 | 0.850 |
| 21 | AUE | 0.714 | 0.787 | 0.849 | 0.872 | 0.687 | 0.757 | 0.826 | 0.853 |
| 22 | AUE | 0.807 | 0.819 | 0.861 | 0.870 | 0.792 | 0.816 | 0.841 | 0.855 |
| 23 | AUE | 0.809 | 0.843 | 0.870 | 0.876 | 0.789 | 0.824 | 0.853 | 0.864 |
| 24 | AUE | 0.676 | 0.766 | 0.839 | 0.865 | 0.634 | 0.726 | 0.824 | 0.853 |
| 25 | WAE | 0.654 | 0.739 | 0.826 | 0.855 | 0.620 | 0.691 | 0.802 | 0.836 |
| 26 | OOB | 0.743 | 0.724 | 0.755 | 0.766 | 0.695 | 0.735 | 0.760 | 0.768 |
| 27 | UOB | 0.761 | 0.759 | 0.778 | 0.776 | 0.722 | 0.747 | 0.765 | 0.773 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wegier, W.; Ksieniewicz, P. Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms. Entropy 2020, 22, 849. https://doi.org/10.3390/e22080849
Wegier W, Ksieniewicz P. Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms. Entropy. 2020; 22(8):849. https://doi.org/10.3390/e22080849
Chicago/Turabian StyleWegier, Weronika, and Pawel Ksieniewicz. 2020. "Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms" Entropy 22, no. 8: 849. https://doi.org/10.3390/e22080849
APA StyleWegier, W., & Ksieniewicz, P. (2020). Application of Imbalanced Data Classification Quality Metrics as Weighting Methods of the Ensemble Data Stream Classification Algorithms. Entropy, 22(8), 849. https://doi.org/10.3390/e22080849