Blind Tone-Mapped Image Quality Assessment Based on Regional Sparse Response and Aesthetics

Abstract
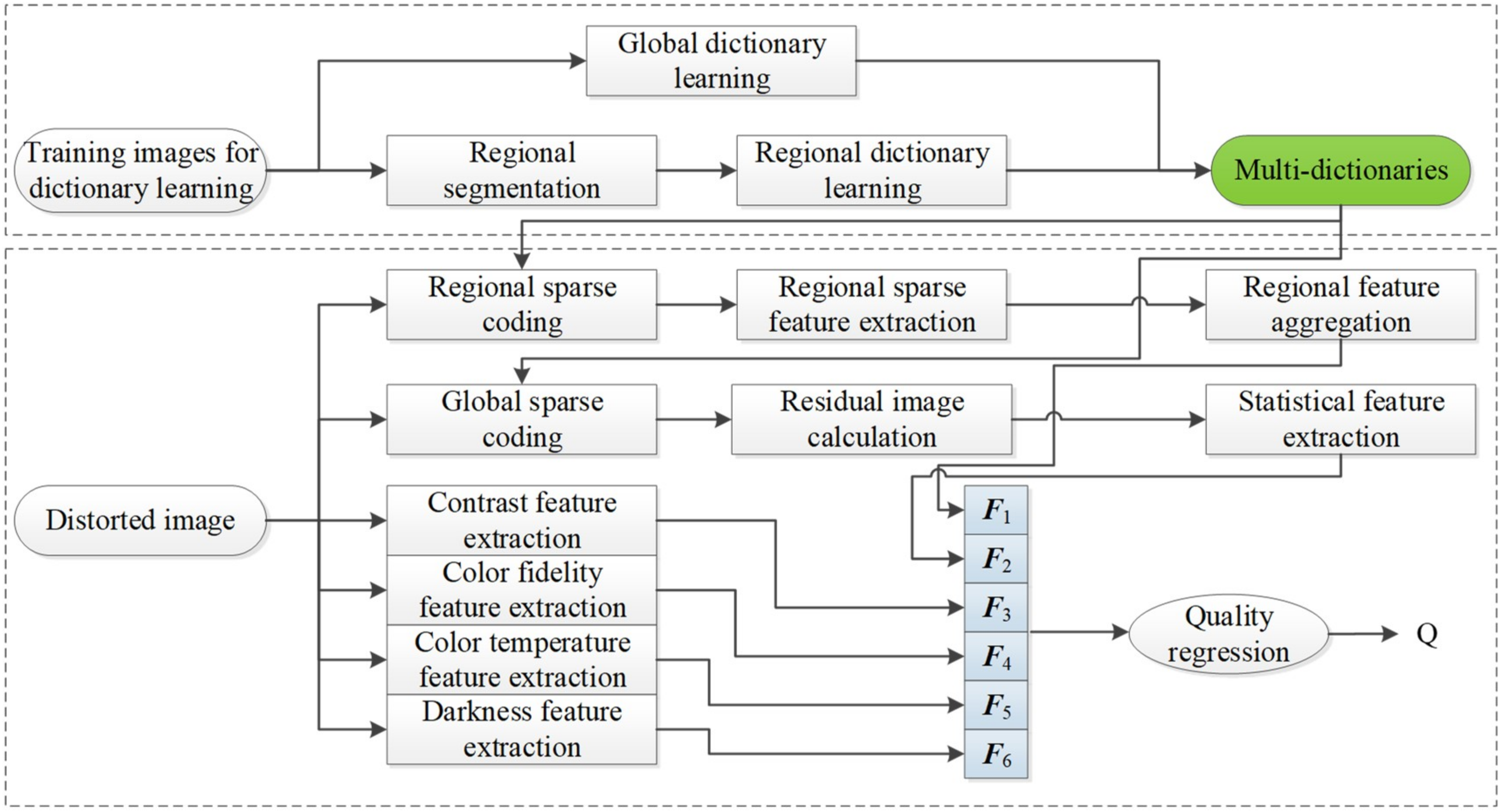
:1. Introduction
- (1)
- Inspired by the viewing properties in visual physiology, i.e., the quality of images is perceived by HVS from global to local regions, multi-dictionaries are specially designed for DB-regions of TMIs and entire TMIs via dictionary learning. Moreover, the self-built TMIs training dataset for dictionary learning in this study is available for the further research demand.
- (2)
- Each region is sparsely represented to obtain the corresponding sparse atoms activity for describing the regional visual information of TMIs, which is closely related to visual activity in the receptive fields of simple cells. In addition, a regional feature fusion strategy based on entropy weighting is presented to aggregate the above local features.
- (3)
- Motivated by the fact that HVS prefers an image with saturated and natural color, the relevant aesthetic features, e.g., contrast, color fidelity, color temperature and darkness, are extracted for global chrominance analysis. Besides, residual information of entire TMIs is fully utilized to simulate global perception of HVS, and the NSS based features extracted from residual images are combined with the aesthetic features to form the final global features.
2. The Proposed RSRA-BTMI Method
2.1. Multi-Dictionary Learning Based on Region Segmentation
2.1.1. Constructing Dataset for Multi-Dictionary Learning
2.1.2. TMI Segmentation for Multi-Dictionaries
2.1.3. Multi-Dictionary Learning
2.2. Regional Sparse Response Feature Extraction
2.2.1. Sparse Atomic Activity in Each Region
2.2.2. Global Reconstruction Residual Statistics
2.3. Aesthetic Feature Extraction
2.3.1. Global Contrast
2.3.2. Color Fidelity
2.3.3. Color Temperature
2.3.4. Darkness
2.4. Quality Regression
3. Experiment Results and Discussion
3.1. Parameter Setting and Feature Analysis of the Proposed RSRA-BTMI Method
3.2. Influence of Training Set Sizes
3.3. Feature Selection
3.4. Overall Performance Comparison
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Masia, B. Computational Imaging and Displays: Capturing and displaying richer representations of the world. IEEE Comput. Graph. Appl. 2018, 38, 112–120. [Google Scholar] [CrossRef]
- Artusi, A.; Mantiuk, R.K.; Richter, T.; Hanhart, P.; Korshunov, P.; Agostinelli, M.; Ten, A.; Ebrahimi, T. Overview and evaluation of the JPEG XT HDR image compression standard. J. Real Time Image Process. 2019, 16, 413–428. [Google Scholar] [CrossRef]
- Yang, X.; Xu, K.; Song, Y.; Zhang, Q.; Wei, X.; Lau, R.W.H. Image correction via deep reciprocating HDR transformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 1798–1807. [Google Scholar]
- Kwon, H.J.; Lee, S.H. CAM-based HDR image reproduction using CA–TC decoupled JCh decomposition. Signal Process Image Commun. 2019, 70, 1–13. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Yeganeh, H.; Wang, Z. Objective quality assessment of tone-mapped images. IEEE Trans. Image Process. 2013, 22, 657–667. [Google Scholar] [CrossRef]
- Ma, K.; Yeganeh, H.; Zeng, K.; Wang, Z. High dynamic range image tone mapping by optimizing tone mapped image quality index. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014. [Google Scholar]
- Nasrinpour, H.R.; Bruce, N.D. Saliency weighted quality assessment of tone-mapped images. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4947–4951. [Google Scholar]
- Nafchi, H.Z.; Shahkolaei, A.; Moghaddam, R.F.; Cheriet, M. FSITM: A feature similarity index for tone-mapped images. IEEE Signal Process. Lett. 2015, 22, 1026–1029. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Jiang, G.; Yu, M.; Peng, Z.; Chen, F. Quality assessment method based on exposure condition analysis for tone-mapped high-dynamic-range images. Signal Process. 2018, 146, 33–40. [Google Scholar] [CrossRef]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef]
- Zhang, Y.; Moorthy, A.K.; Chandler, D.M.; Bovik, A.C. C-DIIVINE: No-reference image quality assessment based on local magnitude and phase statistics of natural scenes. Signal Process Image Commun. 2014, 29, 725–747. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Sun, L.; Yamasaki, T.; Aizawa, K. Photo aesthetic quality estimation using visual complexity features. Multimed. Tools Appl. 2018, 77, 5189–5213. [Google Scholar] [CrossRef]
- Mavridaki, E.; Mezaris, V. A comprehensive aesthetic quality assessment method for natural images using basic rules of photography. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 887–891. [Google Scholar]
- Gu, K.; Wang, S.; Zhai, G.; Ma, S.; Yang, X.; Lin, W.; Zhang, W.; Gao, W. Blind quality assessment of tone-mapped images via analysis of information, naturalness, and structure. IEEE Trans. Multimed. 2016, 18, 432–443. [Google Scholar] [CrossRef]
- Jiang, G.; Song, H.; Yu, M.; Song, Y.; Peng, Z. Blind Tone-Mapped Image Quality Assessment Based on Brightest/Darkest Regions, Naturalness and Aesthetics. IEEE Access 2018, 6, 2231–2240. [Google Scholar] [CrossRef]
- Kundu, D.; Ghadiyaram, D.; Bovik, A.C.; Evans, B.L. No-reference quality assessment of tone-mapped HDR pictures. IEEE Trans. Image Process. 2017, 26, 2957–2971. [Google Scholar] [CrossRef]
- Yue, G.; Hou, C.; Zhou, T. Blind quality assessment of tone-mapped images considering colorfulness, naturalness, and structure. IEEE Trans. Ind. Electron. 2019, 66, 3784–3793. [Google Scholar] [CrossRef]
- Jiang, Q.; Shao, F.; Lin, W.; Jiang, G. BLIQUE-TMI: Blind quality evaluator for tone-mapped images based on local and global feature analyses. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 323–335. [Google Scholar] [CrossRef]
- Zhao, M.; Shen, L.; Jiang, M.; Zheng, L.; An, P. A Novel No-Reference Quality Assessment Model of Tone-Mapped HDR Image. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3202–3206. [Google Scholar]
- Chi, B.; Yu, M.; Jiang, G.; He, Z.; Peng, Z.; Chen, F. Blind tone mapped image quality assessment with image segmentation and visual perception. J. Vis. Commun. Image Represent. 2020, 67, 102752. [Google Scholar] [CrossRef]
- Liu, X.; Fang, Y.; Du, R.; Zuo, Y.; Wen, W. Blind quality assessment for tone-mapped images based on local and global features. Inf. Sci. 2020, 528, 46–57. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.W.; Yang, H.; Gan, Y.; Wang, M.H. Sparse feature fidelity for perceptual image quality assessment. IEEE Trans. Image Process. 2013, 22, 4007–4018. [Google Scholar] [CrossRef] [PubMed]
- Ahar, A.; Barri, A.; Schelkens, P. From sparse coding significance to perceptual quality: A new approach for image quality assessment. IEEE Trans. Image Process. 2018, 27, 879–893. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Q.; Shao, F.; Lin, W.; Gu, K.; Jiang, G.; Sun, H. Optimizing multistage discriminative dictionaries for blind image quality assessment. IEEE Trans. Multimed. 2018, 20, 2035–2048. [Google Scholar] [CrossRef]
- Korshunov, P.; Hanhart, P.; Richter, T.; Artusi, A.; Mantiuk, R.; Ebrahimi, T. Subjective quality assessment database of HDR images compressed with JPEG XT. In Proceedings of the 2015 Seventh International Workshop on Quality of Multimedia Experience (QoMEX), Pylos-Nestoras, Greece, 26–29 May 2015; pp. 1–6. [Google Scholar]
- Narwaria, M.; da Silva, M.P.; Le Callet, P.; Pepion, R. Tone mapping-based high-dynamic-range image compression: Study of optimization criterion and perceptual quality. Opt. Eng. 2013, 52, 102008. [Google Scholar] [CrossRef]
- Parraga, C.A.; Otazu, X. Which tone-mapping operator is the best? A comparative study of perceptual quality. JOSA A 2018, 35, 626–638. [Google Scholar]
- Kundu, D.; Ghadiyaram, D.; Bovik, A.; Evans, B. Large-scale crowd-sourced study for tone mapped HDR pictures. IEEE Trans. Image Process. 2017, 26, 4725–4740. [Google Scholar] [CrossRef]
- Mohammadi, P.; Pourazad, M.T.; Nasiopoulos, P. An Entropy-based Inverse Tone Mapping Operator for High Dynamic Range Applications. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Jraissati, Y.; Douven, I. Does optimal partitioning of color space account for universal color categorization? PLoS ONE 2017, 12, e0178083. [Google Scholar] [CrossRef] [Green Version]
- McCamy, C.S. Correlated color temperature as an explicit function of chromaticity coordinates. Color Res. Appl. 1992, 17, 142–144. [Google Scholar] [CrossRef]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind image quality assessment by relative gradient statistics and adaboosting neural network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Tone-Mapping Operator | Number of Images | MOS |
|---|---|---|---|
| ESPL-LIVE HDR | WardHistAdjTMO | 181 | 0–100 |
| DurandTMO | 187 | 0–100 | |
| FattalTMO | 187 | 0–100 | |
| ReinhardTMO | 192 | 0–100 |
| Features | TMIs | |||
|---|---|---|---|---|
| PLCC | SROCC | SROCC-STD | RMSE | |
| F1 | 0.7163 | 0.6770 | 0.0435 | 7.1565 |
| F2 | 0.6542 | 0.6001 | 0.0494 | 7.7211 |
| F1 + F2 | 0.7782 | 0.7365 | 0.0379 | 6.4265 |
| F3 | 0.7399 | 0.6916 | 0.0380 | 6.8578 |
| F4 | 0.6532 | 0.6111 | 0.0490 | 7.7180 |
| F5 | 0.6980 | 0.6272 | 0.0496 | 7.3233 |
| F6 | 0.7306 | 0.6272 | 0.0498 | 7.0143 |
| F3 + F4 + F5 + F6 | 0.8011 | 0.7678 | 0.0319 | 6.1003 |
| All | 0.8266 | 0.7972 | 0.0312 | 5.7520 |
| Activity of Different Sparse Coefficients | TMIs | |||
|---|---|---|---|---|
| PLCC | SROCC | SROCC-STD | RMSE | |
| SCcoeff-g | 0.7098 | 0.6706 | 0.0438 | 7.2417 |
| SCcoeff-lg | 0.7086 | 0.6698 | 0.0435 | 7.2410 |
| SCcoeff-l | 0.7163 | 0.6770 | 0.0435 | 7.1565 |
| Features | TMIs | |||
|---|---|---|---|---|
| PLCC | SROCC | SROCC-STD | RMSE | |
| S + A | 0.8058 | 0.7699 | 0.0330 | 6.0572 |
| M + A | 0.8266 | 0.7972 | 0.0312 | 5.7520 |
| Train-Test | ESPL-LIVE | |
|---|---|---|
| PLCC | SROCC | |
| 10–90% | 0.7379 | 0.7054 |
| 20–80% | 0.7714 | 0.7416 |
| 30–70% | 0.7873 | 0.7562 |
| 40–60% | 0.7961 | 0.7659 |
| 50–50% | 0.7998 | 0.7684 |
| 60–40% | 0.8056 | 0.7757 |
| 70–30% | 0.8124 | 0.7813 |
| 80–20% | 0.8266 | 0.7972 |
| 90–10% | 0.8301 | 0.8043 |
| Type | Methods | PLCC | SROCC | RMSE |
|---|---|---|---|---|
| 2D-BIQA | C-DIIVINE [14,21] | 0.453 | 0.453 | 9.167 |
| DIIVINE [13,21] | 0.530 | 0.523 | 8.805 | |
| BLIINDS-II [15,21] | 0.4421 | 0.4120 | 9.330 | |
| BRISQUE [16,21] | 0.3701 | 0.3402 | 9.535 | |
| OG [39] | 0.4993 | 0.4899 | 8.8637 | |
| TM-BIQA | BTMQI [19,20] | 0.6914 | 0.6778 | / |
| HIGRADE [20,21] | 0.7940 | 0.7600 | / | |
| Yue’s [22] | 0.7422 | 0.7356 | 6.713 | |
| BTMIQA [20] | 0.8234 | 0.7835 | / | |
| BLIQUE-TMI [23] | 0.7120 | 0.7040 | / | |
| Chi’s [25] | 0.8301 | 0.7887 | 5.7193 | |
| Proposed (RSRA-BTMI) | 0.8266 | 0.7972 | 5.7520 | |
| Proposed with Fc (RSRA-BTMI) | 0.8365 | 0.8076 | 5.5408 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Yu, M.; Chen, F.; Peng, Z.; Xu, H.; Song, Y. Blind Tone-Mapped Image Quality Assessment Based on Regional Sparse Response and Aesthetics. Entropy 2020, 22, 850. https://doi.org/10.3390/e22080850
He Z, Yu M, Chen F, Peng Z, Xu H, Song Y. Blind Tone-Mapped Image Quality Assessment Based on Regional Sparse Response and Aesthetics. Entropy. 2020; 22(8):850. https://doi.org/10.3390/e22080850
Chicago/Turabian StyleHe, Zhouyan, Mei Yu, Fen Chen, Zongju Peng, Haiyong Xu, and Yang Song. 2020. "Blind Tone-Mapped Image Quality Assessment Based on Regional Sparse Response and Aesthetics" Entropy 22, no. 8: 850. https://doi.org/10.3390/e22080850
APA StyleHe, Z., Yu, M., Chen, F., Peng, Z., Xu, H., & Song, Y. (2020). Blind Tone-Mapped Image Quality Assessment Based on Regional Sparse Response and Aesthetics. Entropy, 22(8), 850. https://doi.org/10.3390/e22080850