1. Problem Statement
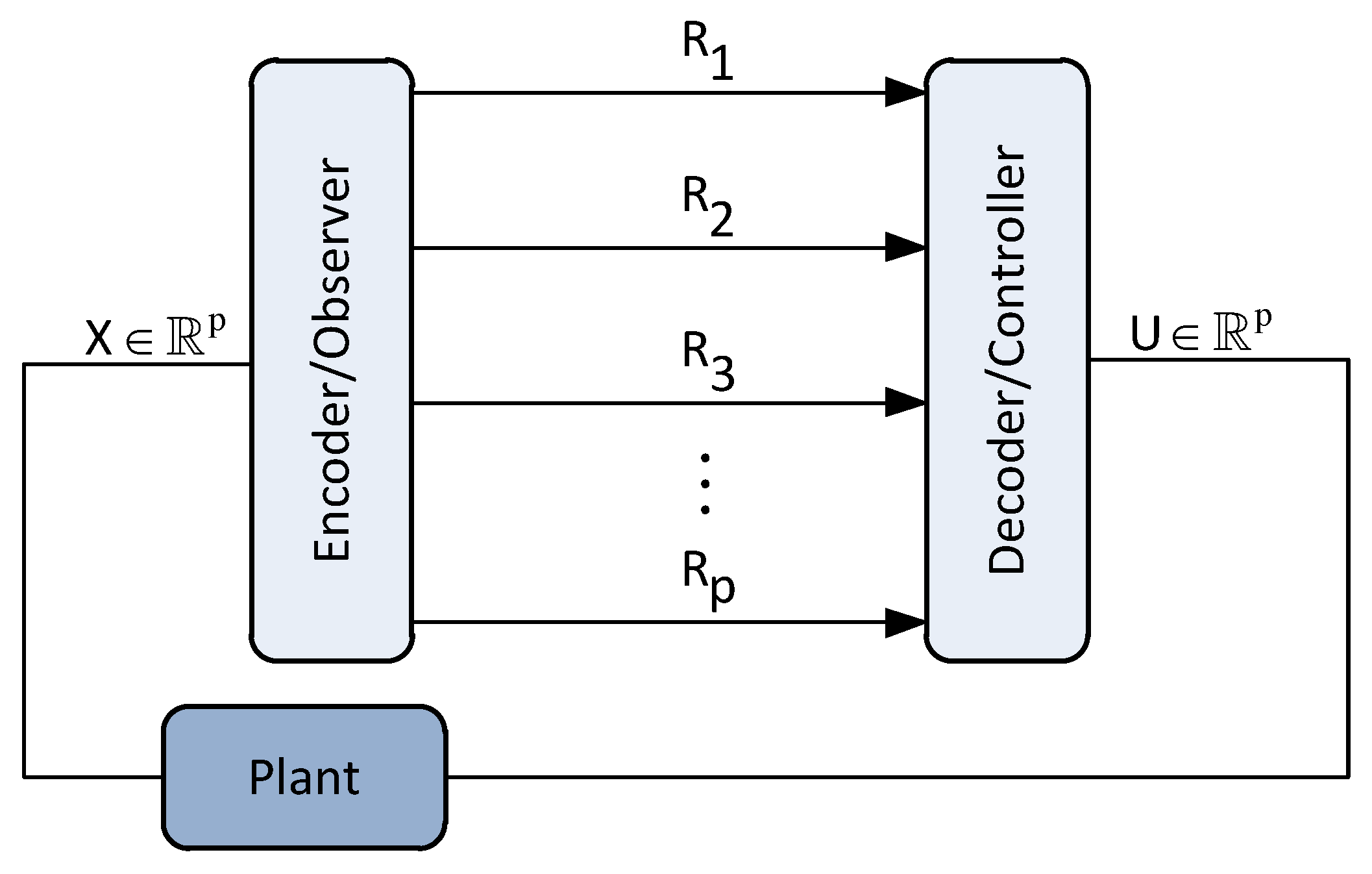
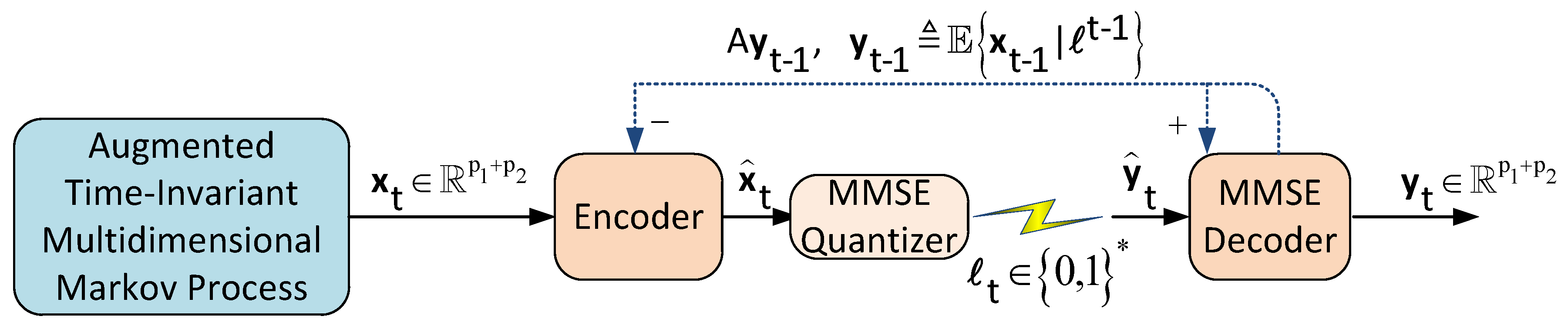
We consider the two-user causal encoding and causal decoding setup illustrated in
Figure 1. In this setup, users 1 and 2 are modeled by the following discrete-time time-invariant multidimensional Markov processes:
where
, with
not necessarily equal to
,
are known constant matrices of appropriate dimensions and
are additive
possibly non-Gaussian noise processes with zero mean and covariance matrix
, independent of
and from each other for all
. The initial states
are given by
. Finally, we restrict the eigenvalues of
to be within the unit circle, which means that each user’s system model in (
1) is asymptotically stable (i.e., asymptotically stationary).
The goal is to cast the performance of the setup in
Figure 1 under various distortion metrics when the encoder compress information causally whereas the lossless compression between the encoder and the decoder is done in one shot assuming their clocks are synchronized.
First, we apply state space augmentation [
1] to the state-space models in (
1) to transform them into a single augmented state-space model as follows:
where
,
A is a block diagonal matrix and
is an additive
possibly non-Gaussian noise process such that
where
are of the form
We note that the operation in (
3) can be mathematically denoted as
and similarly,
(see the notation section for “⊕”).
System Operation: The encoder at each time instant
t observes the augmented state
and generates the data packet
of instantaneous rate
. At time
t, the packet
is sent over a
noiseless channel with rate
. The decoder at each time
t, receives
to construct an estimate
of
. We assume that the clocks of the encoder and decoder are synchronized. Formally, the encoder (
) and the decoder (
) are specified by a sequence of measurable functions
as follows:
1.1. Generalizations
It should be noted that the setup in
Figure 1 can be generalized to any finite number of users. The only change will appear in the number of state-space equations and the dimension of the vectors and matrices in the augmented state-space representation of (
2).
Next, we explain the setup of two users that are correlated (in states). In such scenario, users 1 and 2 are modeled by the following discrete-time time-invariant multidimensional Markov processes:
where
, with
not necessarily equal to
,
are known constant matrices of appropriate dimensions whereas all the other assumptions remain similar to the user models described in (
1). The single augmented state-space model now is obtained as follows:
where
is a block matrix of the form
where
are square matrices but
may be rectangular matrices (if
). We will not consider this case in our paper because it is straightforward by replacing everywhere matrix
A with matrix
. Clearly, this case can be generalized to any finite number of users with appropriate modifications on the state-space models.
1.2. Distortion Constraints
In this work we consider three types of distortion constraints. These are articulated as follows:
- (i)
a per-dimension (spatial) distortion constraint on the asymptotically averaged total (across the time) MMSE covariance matrix;
- (ii)
an asymptotically averaged total (across the time and across the space) distortion constraint;
- (iii)
a covariance matrix distortion constraint.
Next, we give the definition of each distortion constraint and explain some of their utility in multi-user systems.
A per-dimension (spatial) distortion constraint imposed on the covariance distortion matrix
, where
, is defined as follows:
where
are given diagonal entries of the positive semidefinite matrix
, with
,
. Note that under this distortion constraint, it trivially holds that
.
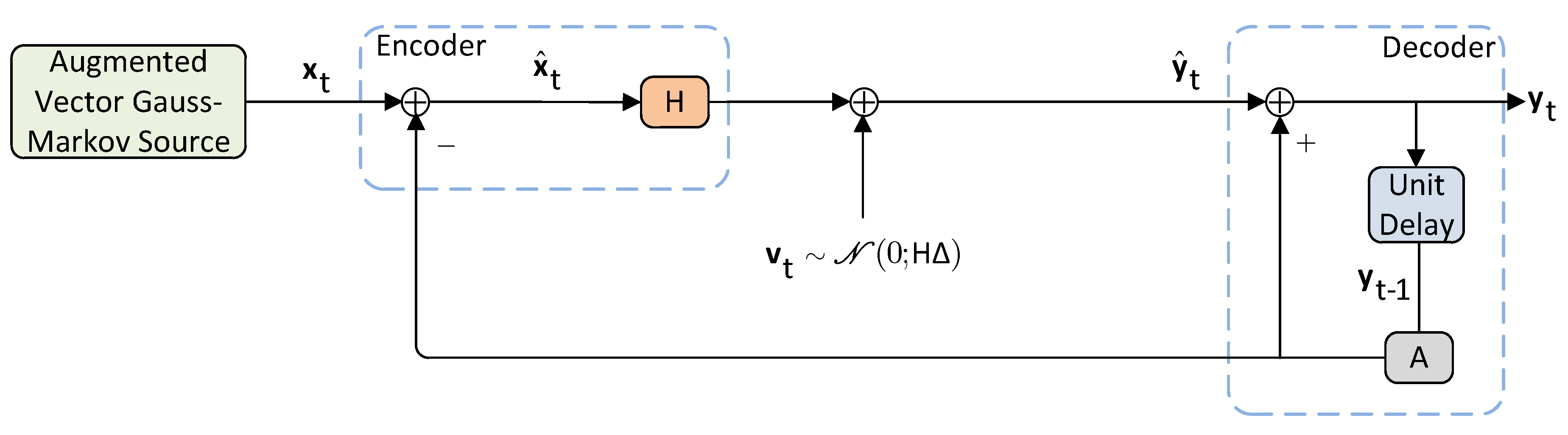
Utility: The choice of per-dimension distortion constraints is arguably more realistic in various network systems. For instance, one use of such hard constraints can be found in multivariable feedback control systems also called centralized multi-input multi-output (MIMO) systems [
2] (see
Figure 2). In such networks, it may be the case that one wishes to minimize the temporally total performance criterion or satisfy some total fidelity constraint. However, in addition it is always required that the resource allocation to the different nodes (or variables) to never exceed certain performance thresholds when the demands in data transmission within the communication link allows only limited rate. Nonetheless, the problem is that variables interact. Some variables could be considered more important for certain applications according to the demands of the system or the quality of service, which is why they need hard constraints.
An asymptotically averaged total (across the time and space) distortion constraint is defined as follows:
where
, with
not necessarily equal to
D.
Utility: The asymptotically averaged total (across the time and space) distortion constraint ensure shared or allocated distortion arbitrarily among the transmit dimensions. The combination of the per-dimension distortion constraint with the averaged total distortion constraints ensure a total allocated distortion budget in the system that depends on the allowable (by design) distortion budget at each dimension (or user).
A covariance matrix distortion constraint is a generalization of the per-dimension distortion constraint defined by
where
.
Utility: During the recent years, there has been a shift from conventional
distortion constraints (scalar-valued target distortions) to covariance matrix distortions in the areas of multiterminal and distributed source coding [
3,
4,
5,
6,
7] and signal processing [
7,
8,
9]. Nonetheless, the argument for considering covariance distortion constraints despite its difficulty is its generality and the flexibility in formulating new problems. For instance, one practical example would be wireless adhoc microphones, that transmit to receiver(s) over an MIMO channel. In such setups, perhaps the receiver(s) need to do beam forming or some multi-channel Wiener filtering variants. In both cases, one needs to know the covariance matrix of e.g., the error signal (covariance distortion matrix) to perform the desired signal enhancement. For example, if the quality of one of the signals is too bad, this could harm the overall signal enhancement, and one therefore need to trade-off the bits correctly among the microphones. In an adhoc microphone array, the different signals are naturally correlated, which adds an interesting interplay between them that goes beyond MSE distortion.
1.3. Operational Interpretations
In this subsection, we use the three types of distortion constraints introduced in
Section 1.2 to define the corresponding operational definitions for which we study lower and upper bounds in this paper.
Definition 1 (Causal
subject to (
8)).
The operational causal under per-dimension distortion constraints is defined as follows:where and . Definition 2 (Causal
subject to (
8) and (
9)).
The operational causal under joint per-dimension and asymptotically averaged total distortion constraints is defined as follows:where . Interplay between Definitions 1 and 2. Clearly, Definition 1 is a lower bound to Definition 2 because its constraint set of feasible solutions is larger. Note that, in general, the asymptotically averaged total distortion constraint in (
12) is active when
, otherwise, it is a trivial constraint and (
12) is equivalent to the optimization problem of (
11). This observation will be shown via a simulation study in the sequel of the paper.
Definition 3 (Causal
subject to (
10)).
The operational causal under covariance matrix distortion constraints is defined as follows:where . Literature Review. In information theory, causal coding and causal decoding also termed zero-delay coding (see, e.g., [
10,
11,
12,
13,
14]) does not rely on the traditional construction based on random codebooks that in turn allows asymptotically large source vector dimensions [
15] to establish achievability of a certain (non-causal) rate-distortion performance. Indeed, the optimal rate-distortion performance for causal source coding (with the clocks of the encoder and decoder to be synchronized), is hard to compute and often bounds are derived in the literature. For example, lower and upper bounds on the operational causal
subject to solely the distortion constraint in (
9) (or the more stringent per instant distortion constraint
) are already studied extensively for various special cases of the setup of
Figure 1, see, e.g., [
11,
14,
16,
17] and the references therein. In this work, we study new problems related to the causal
for the general multi-user source coding setup of
Figure 1 under various classes of distortion constraints that their utility (partly explained in
Section 1.2) has not been studied in the literature so far. These bounds are established using tools from information theory, convex optimization and causal MMSE estimation.
1.4. Contributions
In this paper we obtain the following results for the setup of
Figure 1.
Characterization and computation of the true lower bounds on (
11)–(
13) when the users’ augmented source model is driven by a Gaussian noise process (Lemma 3, Theorem 2).
Analytical lower bounds on (
11)–(
13) when the users’ augmented source model is driven by additive
noise process (including both additive Gaussian and non-Gaussian noise) (Theorem 3). As a consequence, we also obtain analytical lower bounds when only one of the users’ source model is driven by a Gaussian noise process (Corollary 2).
Characterizations and computation of achievable bounds on (
11)–(
13) when the users’ augmented source model is driven by a Gaussian noise process (Theorem 4).
Characterizations of achievable bounds on (
11)–(
13), when the users’ augmented source model is driven by additive
non-Gaussian noise process (Theorem 5).
Machinery and tools. The information theoretic rate distortion definitions that are used to obtain the lower bounds in this paper are derived using a data processing theorem (Theorem 1) that reveals the “suitable” information measure to use. The derivation of the steady-state characterization of the lower bounds in Lemma 3 is derived using inequalities from matrix algebra and a convexity argument that allows the use of Jensen’s inequality. To derive lower bounds beyond additive
Gaussian noise process, we use the fact that the characterizations of the lower bounds for the Gaussian case are in fact the characterizations obtained for the best linear coding policies (Lemma 4) hence these can serve as a benchmark to derive lower bounds beyond Gaussian noise process by leveraging certain trace/determinant inequalities and most importantly Minkowski’s determinant inequality ([
18], Exercise 12.13) and EPI [
19]. The upper bounds on the OPTA when the system’s noise is Gaussian, are derived using a causal sequential DPCM-based scheme with feedback loop which is equivalent to the scheme first derived in [
14], followed by an ECDQ scheme that uses vector quantization. The upper bounds on the OPTA, when the system’s noise is additive
non-Gaussian are obtained using precisely the same trick that is used to obtain the lower bounds, i.e., we use the linear test channel realization that achieves similar upper bounds for the Gaussian case and then, using an SLB type concept (Theorem 5) we obtain the desired results.
The paper is structured as follows. In
Section 2 we characterize and compute lower bounds on the OPTA of (
11)–(
13). In
Section 3 we characterize and compute achievable coding scheme on the OPTA of (
11)–(
13). We draw conclusions and future directions in
Section 4.
2. Lower Bounds
In this section, we first choose a suitable information measure that will be used to derive a lower bound on Definitions 1–3. This information measure is a variant of directed information subject to some conditional independence constraints. Then, we obtain lower bounds on Definitions 1–3 for jointly Gaussian Markov processes and for Markov processes driven by additive possibly non-Gaussian noise process.
First, we write the joint distribution of the communication system of
Figure 1, i.e., from the two users described by the augmented state
to the augmented output of the
decoder
. In particular, the joint distribution induced by the joint process
admits the following decomposition:
which means that the augmented state “source” process
, and the decoder’s output process
satisfy the following conditional independence constraints:
For (
14) we state the following technical remark.
Remark 1 (Trivial initial information).
In (14) we assume that the joint distribution generates trivial information. This means that , and . We next prove a data processing theorem.
Theorem 1 (Data processing theorem).
Provided the decomposition of the joint distribution in (14) holds, the augmented state-space representation of the system in Figure 1 admits the following data processing inequalities:whereassuming and . Proof. We first prove
(i).
where
follows because conditioning reduces entropy [
19];
follows because of the non-negativity of the discrete entropy [
19];
follows by definition.
Next, we prove
(ii). This can be shown as follows:
where
follows from an adaptation of ([
20], Lemma 3.3) to processes, i.e.,
and the second term is zero because of the conditional independence constraint (16);
follows by the chain rule of conditional mutual information (again an adaptation of ([
20], Lemma 3.3)) which decomposes the conditional mutual information in two different ways, i.e.,
follows because an adaptation of ([
20], Lemma 3.3) can be applied to
as follows
where
follows because
. This can be shown as follows.
where each
is assumed to be finite for any
t, and (
20) follows from the conditional independence constraint in (
15). From the non-negativity of conditional mutual information [
19], the result follows.
Finally, from (
19) we have
where (22) follows by applying the method of differences in (
21). The result follows because (22) is by definition non-negative. We note that if
also appeared in the cancellations, then, this would have been the telescopic sum of the series. This completes the derivation. □
We note that Theorem 1 is different from the data processing theorem derived in ([
21], Lemma 1) in that we assume the conditional independence constraint (
15) instead of the conditional independence constraint
, i.e., the source process is not allowed to have access via feedback to the previous output symbols
. This technical difference results into having the mutual information in (
18) subject to conditional independence constraints, instead of the well-known directed information [
22].
Before we introduce the information theoretic definitions that correspond to lower bounds on (
11)–(
13), we formally show the construction of
.
Source. The augmented source process induces the sequence of conditional distributions . Since no initial information is assumed, the distribution at is . In addition, by Bayes’ rule we obtain .
Reproduction or “test-channel”. The reproduction process parameterized by induces the sequence of conditional distributions, known as test-channels, by . At , no initial state information is assumed, hence . In addition, by Bayes’ rule we obtain .
From ([
23], Remark 1), it can be shown that the sequence of conditional distributions
and
uniquely define the family of conditional distributions on
and
parameterized by
, respectively, given by the joint distribution
In addition, from (
23), we can uniquely define the
marginal distribution by
and the conditional distributions
.
Given the above construction of distributions, we can formally introduce the information measure using relative entropy as follows:
where
follows by definition of relative entropy between
and the product distribution
;
is due to the Radon–Nikodym derivative theorem ([
23],
Appendix A and
Appendix C);
is due to chain rule of relative entropy;
follows by definition.
We now state as a definition the lower bounds on (
11)–(
13).
Definition 4 (Lower bounds).
Using the previous construction of distributions and the information measure of (24), we can define the following lower bounds on (11)–(13).- (1)
The sum-rate subject to per-dimension distortion constraint is defined as follows:withwhere , and . - (2)
The sum-rate subject to joint distortion constraints is defined as follows:where
. - (3)
The sum-rate subject to covariance matrix distortion constraints is defined as follows:where .
Next, we stress some technical remarks related to the new information theoretic measures in Definition 4 that can be obtained using known results in the literature and some known lower bounds that use the same objective function with (
26)–(
30).
Remark 2 (Comments on Definition 4).
It can be shown that the infimization problems (26), (28) and (30), in contrast to their operational counterparts (11)–(13) are convex with respect to their test channel. This can be shown following, for instance, the techniques of [23]. By the structural properties of the test channel derived in ([24], Section 4), if the source is first-order Markov, i.e., with distribution , the test channel distribution is of the form . Finally, combining this structural result, with ([25], Theorem 1.8.6), it can be shown that if is Gaussian then a jointly Gaussian process achieves a smaller value of the information rates, and if is Gaussian and Markov, then the infimum in (26), (28) and (30) can be restricted to test channel distributions which are Gaussian, of the form .We recall that when the distortion constraint set contains only (9), its finite time horizon counterpart or the per instant distortion constraint , we end up having the well known nonanticipatory-ϵ entropy [26] also found in the literature as sequential or nonanticipative [27,28]. Nonanticipatory-ϵ entropy received significant interest during the last twenty years in an anthology of papers (see, e.g., [11,16,24,29,30,31]) due to its utility in control related and delay-constrained applications. Moreover, the characterizations in (29) and (30) do not appear to be manageable to solve using standard techniques, and no closed-form statements are available for the general RDF in the literature. For this reason, we will seek only for non-tight bounds. In view of the above, in the sequel we characterize and compute lower bounds on Definitions 1–3 for Gauss–Markov processes and for Markov models driven by additive noise processes.
2.1. Characterization and Computation of Jointly Gaussian Processes
In this section, we assume that the augmented joint process
is jointly Gaussian. We use this assumption to first characterize and then to compute optimally (
26), (
28) and (
30).
We first use the following helpful lemma. We exclude the proof because it is already derived in other papers, see, e.g., [
14,
24]. The only modification is the augmented joint processes
.
Lemma 1 (Realization of ). Consider the class of conditionally Gaussian test channels . Then, the following statements hold.
- (1)
Any candidate of can be realized by the recursionwhere , is an independent Gaussian process independent of and , and are time-varying deterministic matrices. Moreover, the innovations process of (31) is the orthogonal process defined bywhere , and . - (2)
Let and . Then, satisfy the following vector-valued equations:where and . - (3)
Using estimation via the vector-valued KF recursions of (32), the following finite dimensional characterizations of can be obtained:where , and .
We note that one can directly study the finite-dimensional characterizations of Lemma 1,
(3), and try to come up with numerical solutions. However, it is much more insightful to use instead the identification of the design parameters
of the test-channel realization in (
31). This approach is already done in [
14,
24] hence we state it without a proof. Note, however, that compared to [
14,
24] that assume distortion constraints like (
9) (or the per time instant counterpart of (
9), i.e.,
), here we assume augmented state-space models and various spatio-temporal distortion constraints, namely, per-dimension, jointly per-dimension and averaged total distortion constraints, and covariance matrix distortion constraint.
Lemma 2 (Alternative characterizations of (
33)–(
35) via system identification).
Consider Lemma 1 and set and . Then, the following statements hold.- (1)
The test-channel distribution admits the following linear Markov additive noise realization:where - (2)
The finite-dimensional characterizations of can be simplified to the following alternative characterizations:where is defined precisely as .
Next, we give some technical remarks related to Lemma 2.
Remark 3 (Special case and technical remarks).
- (1)
Clearly, if in the forward test-channel realization with additive noise, we assume that the block diagonal matrix (null matrix), then, we recover the classical forward test-channel realization for vector memoryless Gaussian source subject to a distortion (see, e.g., ([32], Chapter 4.5), ([15], Chapter 9.7)) given byand the coefficients in (37) giveMoreover, the characterizations in (38)–(40) change in that . Clearly, (42) can be seen as reverse-waterfilling design parameters. - (2)
Compared to(1), we note that in (37) should not be confused with a positive semidefinite matrix defined in the usual quadratic form [33] but instead it can possibly be a non-symmetric matrix which however contains only real non-negative eigenvalues. This observation is important because it means that in general the design variables do not commute like in the classical reverse-waterfilling problems for memoryless multivariate Gaussian random variables or in processes (see, e.g., [19,25]). - (3)
For jointly Gaussian processes, the linear forward realization in (36) is the optimal realization among all realizations for this problem because the KF is the optimal causal MMSE estimator. Beyond Gaussian processes, and when the noise is zero-mean, uncorrelated and white (in our setup these properties hold), the optimal realization for Gaussian processes becomes the best linear realization (see, e.g., ([34], §3.2) or ([35], p. 130)) and similarly the corresponding characterizations in (38)–(40) are the best linear characterizations. By saying “best-linear” realization and characterizations, respectively, we mean that there may be non-linear realizations and hence non-linear-based characterizations that outperform the best linear. - (4)
The characterization of (39) is different from the characterization obtained in ([16], Theorem 1, (25e)) that uses weighted distortion constraints. The former optimization problem imposes hard constraints whereas the latter imposes soft constraints via weights. Nonetheless, an interesting open question is whether there exists a set of weights, which will give the same per dimension distortion when imposed as a weighted total distortion constraint. - (5)
It should also be stressed that the per-dimension constraints on the diagonal entries of are not the same as having constraints on the eigenvalues of . This further means that even for this class of distortion constraints, it is still possible to have rate-distortion resource allocation (i.e., a type of reverse-waterfilling optimization).
Remark 4 (Convexity).
The optimization problems in (38) and (39) are convex because the objective function is linear and the constraints are affine and positive semi-definite. Thus, the problem can be solved numerically using convex programming software (see, e.g, [36]) or the more challenging conditions that are first-order necessary conditions for global optimality ([37], Chapter 5.3). The latter, will give certain non-linear matrix Riccati equations that need to be solved in order to construct a reverse-waterfilling algorithm. Remark 5 (Existence of Solution).
A sufficient condition for existence of a solution with a finite value in (38)–(40) is to consider the strict LMI constraint that ensures the objective function is bounded. The strict LMI ensures that which further means that , and . In what follows, we derive lower bounds on (
11)–(
13).
Lemma 3 (Steady-state lower bounds on (
11)–(
13)).
Suppose that the conditions of Remark 5 hold. Moreover, let for some finite n. Then, the following statements hold.- (1)
where . - (2)
for some . - (3)
It should be remarked that instead of the derivation based on a convexity argument in Lemma 3, one can assume that the optimal minimizer
that achieves (
43)–(
45) is time-invariant and the output distribution
is also time-invariant with a unique invariant distribution, see, e.g., ([
14], Theorem 3). Moreover, the optimal linear forward test-channel that achieves the lower bounds in (
43)–(
45) correspond to the time-invariant realization (
36), given by
whereas the corresponding time-invariant scaling coefficients in (
37) are as follows
From Lemma 3, the following corollary can be immediately obtained.
Corollary 1 (Fixed design variable
).
If in Lemma 2 we assume that , , then we obtain (43)–(45). Proof. This is immediate from the derivation of Lemma 3. □
In what follows, we show that the lower bounds in Lemma 3 are semidefinite representable, thus, they can be readily computed.
Theorem 2 (Computation of the lower bounds in Lemma 3). Consider the variable , where . Then, the following semidefinite programming representations hold.
- (1)
For some , the lower bound in (43), denoted hereinafter by , is semidefinite representable as follows: - (2)
For some , the lower bound in (44), denoted hereinafter by , is semidefinite representable as follows: - (3)
For some , the lower bound in (45), denoted hereinafter by , is semidefinite representable as follows:
Next, we stress some comments on the semidefinite representation of the lower bounds in Theorem 2.
Remark 6 (Comments on Theorem 2).
- (1)
We note that a similar characterization to the characterizations derived in Theorem 2 (subject to the distortion constraint (9) or the per-instant distortion constraint , for a special case of the setup in Figure 1) is recently derived in ([16], Equation (27)). The log-determinant convex optimization problems in Theorem 2 are widely used in systems and control theories because they are able to deal efficiently with LMIs [38]. - (2)
Recently, the efficiency of SDP algorithm in solving linear and non-linear optimization problems attracted experts from the field of information theory who noticed its usefulness in solving distributed source coding problems (see, e.g., [3,39]). Such log-determinant problems when solved using the semidefinite programming method are known to have polynomial worst-case complexity (see, e.g., [40]). In addition, for an interior point method such as the SDP approach, the most computationally expensive step is the Cholesky factorization involved in the Newton steps. - (3)
On the other hand, due to its complexity, the SDP approach for high dimensional systems is often time consuming whereas for very large scale systems is occasionally impossible to obtain numerical solutions. Hence, ideally one could preferably consider alternative methods to solve a problem sacrificing for instance the optimality of the SDP algorithm but gaining in scalability and reducing the complexity. The most computationally efficient way to compute such problems and, additionally, to gain some insight from the solution is via the well-known reverse-waterfilling algorithm ([19], Theorem 10.3.3), which is however very hard to construct and compute because one needs to employ and solve complicated KKT conditions [37]. Such effort was recently made for multivariate Gauss-Markov processes under per instant, averaged total and asymptotically averaged total distortion constraints in [24,41].
Next, we perform some numerical illustrations using the semidefinite representations of Theorem 2. We also compare (
48) and (
50), to the known expression obtained only for the asymptotically averaged total MSE distortion constraint in ([
16], Equation (
27)). We note that the SDP algorithm for (
48)–(
51) is implemented using the CVX platform [
36].
Example 1 (Comparison of
,
and ([
16], Equation (27))).
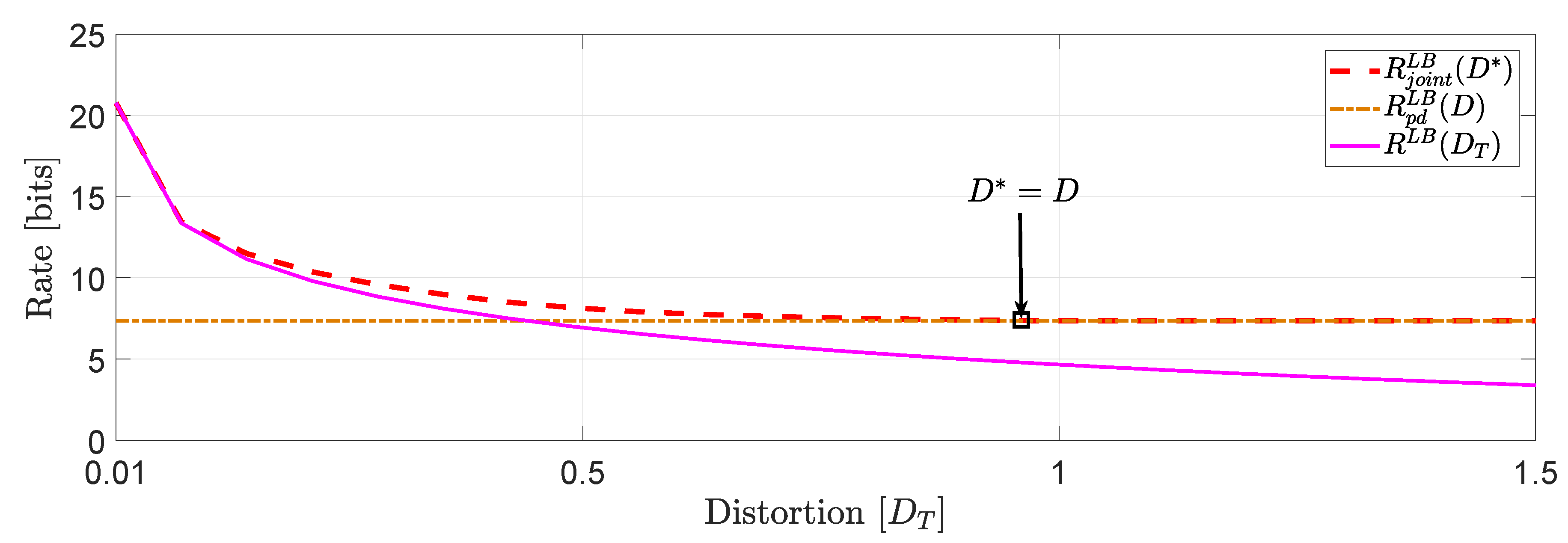
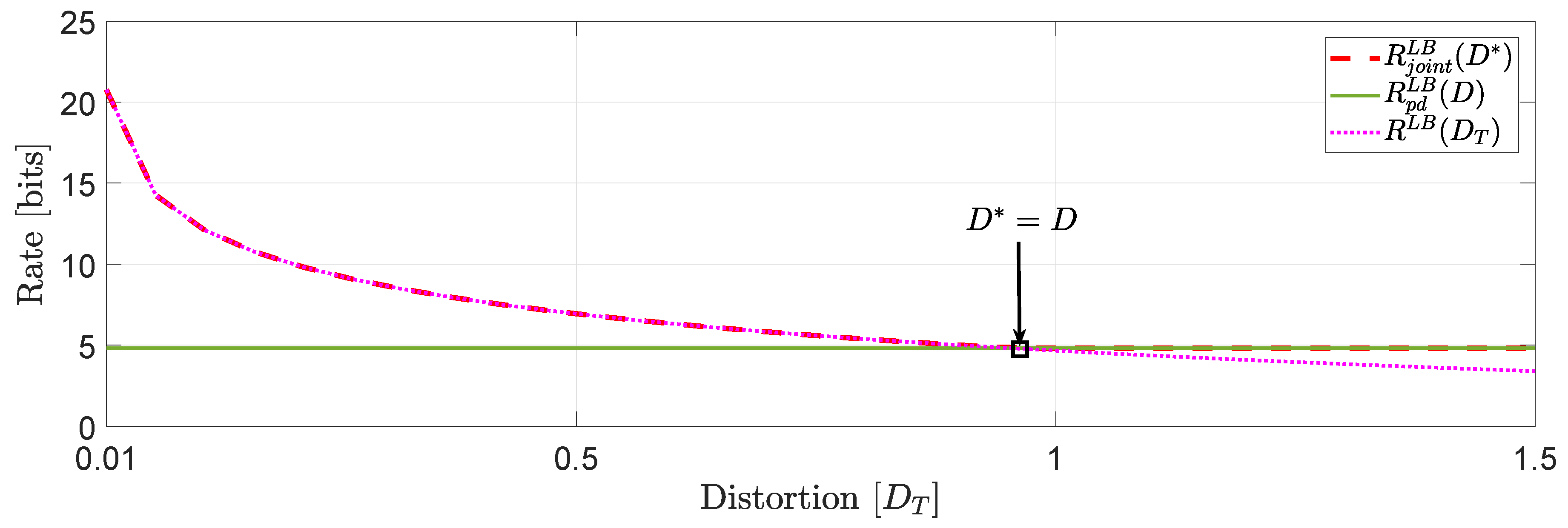
For the system in (1), we assume that user 1 is described by a -valued time-invariant Markov source driven by Gaussian noise process with parameters :whereas, user 2 is described by a -valued time-invariant Markov source driven by Gaussian noise process with parameters : Clearly, the augmented state space model (2) generates and . For this example, we assume that and , which implies that . This means that . In Figure 3, we compare the numerical solutions of and with ([16], Equation (27)), denoted hereinafter as . Based on this numerical study, we observe that for distortion levels between , whereas for values of greater than we observe that because the asymptotically averaged total MSE distortion constraint is inactive. This observation verifies our comment in Section 1.2 regarding the connection of (11) and (12). Clearly, at high rates (or high resolution) we observe that . Another interesting observation (illustrated in Figure 4) that can be made, is that if in the same example we allocate the total budget of per dimension distortion equally, i.e., , we observe that for distortion levels between , . Example 2 (Covariance matrix distortion constraint).
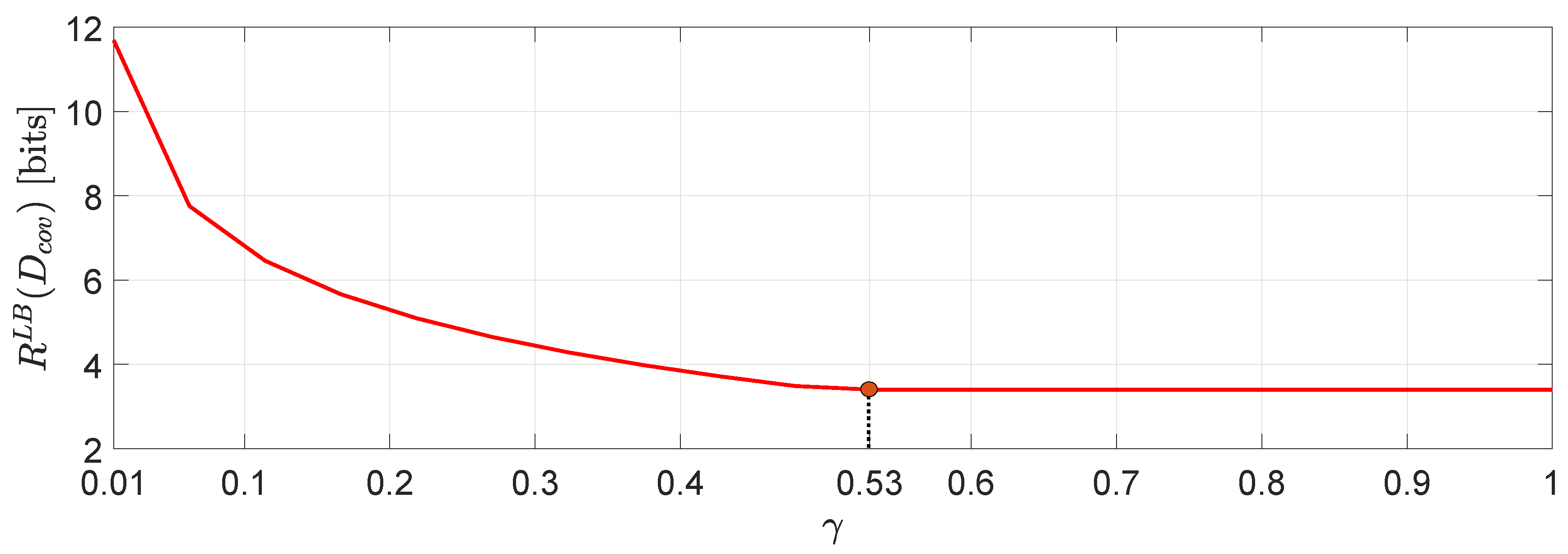
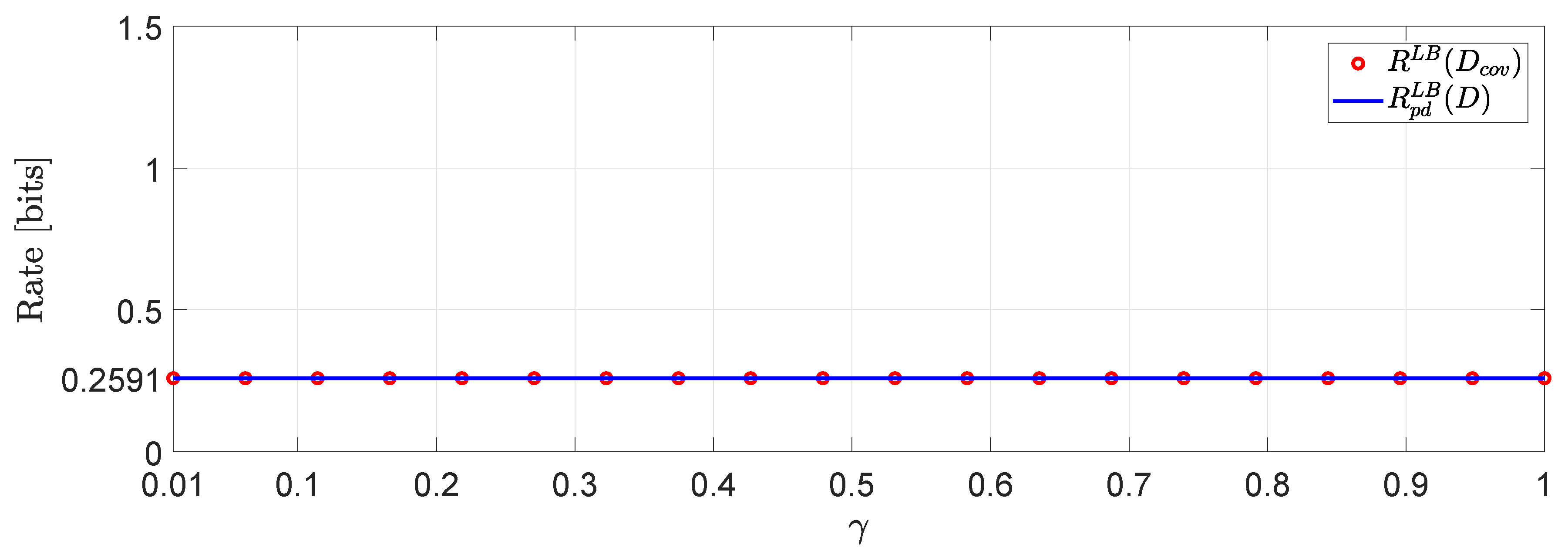
For the system in (1) we assume that user 1 is described by a -valued time-invariant Markov source driven by Gaussian noise process with parameters :whereas, user 2 is described by an -valued time-invariant Markov source driven by Gaussian noise process with parameters :The augmented state space model (2) is generated by and similarly . For this example, we assume a covariance matrix distortion constraint given by:where is the positive correlation coefficient between the distortion matrix components (i.e., diagonal entries) and it is chosen such that . In Figure 5 we demonstrate a comparison between evaluated for several different values of γ. One interesting observation that can be made is that higher distortion correlation in (56) leads to less bits with a , beyond which the value of remains unchanged. Another interesting observation is that for negative correlation γ, the approximation via SDP does not give a number. However, this is not the case, in general (see, e.g., ([42], Example 1)). Using the same simulation study, we can arrive to an interesting connection between the approximation in (51) and (48). In particular, if for instance in (56) we restrict the matrix distortion constraint only to the main diagonal elements (i.e., exactly like the the per-dimension constraints) then, we obtain the plot of Figure 6 which clearly demonstrates that . In fact, restricting the covariance matrix distortion constraint of (56) to the per dimension distortion constraint, is as if we optimize via a solution space in which γ is allowed to have any value in . As a result, the feasible set of solutions is larger when the constraint set is subject to per-dimension distortion constraints rather than the covariance matrix distortion constraint. 2.2. Analytical Lower Bounds for Markov Sources Driven by Additive Noise Processes
In this subsection, we derive analytical lower bounds on (
11)–(
13)) when the source model describing the behavior of user 1 or user 2 is driven by possibly
non-Gaussian noise process.
We first give a lemma which will facilitate the derivation of our lower bounds. We only consider the case of RDFs subject to per-dimension distortion constraints because the other classes of distortion constraints follow similarly.
Lemma 4 (Rate-distortion bounds).
For the augmented source model describing the behavior of users 1, 2 in (3), the following inequalities hold assuming distortion constraints in the class of (8):whereand holds with equality if the augmented state space model described in (2) is jointly Gaussian and the optimal minimizer, i.e., of is conditionally Gaussian. Equality holds trivially at . Proof. The RHS inequality follows from Theorem 1 and (
43) whereas the LHS inequality follows from the fact that the constraint set of
is larger than the constraint set of
which is restricted to linear coding policies. Now, under the specific augmented source model in (
3), and using Lemma 2,
(1), we obtain
defined as in (
58) because these are the best linear coding policies since KF algorithm is the best linear causal
estimator beyond additive Gaussian noise processes (see the discussion in Remark 3,
(3)). Clearly, if the augmented source in (
3) is jointly Gaussian and the optimal realization of
is conditionally Gaussian, then, the system model is jointly Gaussian and the optimal policies are linear given by the forward linear test channel realization obtained in (
36) hence the LHS inequality holds with equality. □
Remark 7 (Comments on Lemma 4).
We note that Lemma 4 holds if we assume RDFs with distortion constraints in the class of (9) or (10). The following theorem is a major result of this paper.
Theorem 3 (Analytical lower bounds on (
11)–(
13)).
Consider the source models of users in (1). Then, the following analytical lower bounds on (11)–(13) hold.- (1)
For , we obtainwhere with and . - (2)
For , and , we obtainwhere , with defined as in(1)and . - (3)
For we obtainwhere , with defined as in(1)and .
The following technical remarks can be made regarding Theorem 3.
Remark 8. - (1)
Note that if in Theorem 3 we allow , then, the analytical lower bound expressions take a negative finite value or , which cannot be the case ( is, by definition, non-negative). A way to include the case where is allowed to be in our lower bound expressions, is to set the objective functions in (59)–(61) to be . This will mean that whenever , the analytical lower bound expression will be zero. - (2)
The analytical lower bounds in (59)–(61) do not correspond to the best linear forward test channel realization of Lemma 3 (see (46)) which is also the optimal policy under the assumption of a MMSE decoder when the system’s noise is purely Gaussian (see Remark 3,(3)). Moreover, it is not clear what is the realization that achieves them the same way the bounds in Lemma 3 are achieved for Gaussian processes. - (3)
If in Theorem 3 we assume that the users have source models described by Markov processes driven by additive Gaussian noise processes then from the EPI (see, e.g., ([43], Equation (7))) and (59)–(61) change accordingly. - (4)
One can choose to further bound (61) using the inequality obtaining a further lower bound that coincides with the lower bound in (59) (see also the discussion in Example 2). Such lower bound will mean that we extend the set of feasible solutions that correspond to the initial problem statement (13), to be similar to the initial problem statement of (11) which cannot be the case, in general. Our bound in (61) encapsulates the off diagonal elements of the distortion covariance matrix distortion hence it is an appropriate lower bound for the specific problem.
In what follows, we give a numerical simulation where we compare the solution of
(that corresponds to the lower bound achieved by the optimal coding policies when the system is driven by additive
Gaussian noise processes) computed via the SDP representation of (
50), with the lower bound obtained in (
60) when the system’s noise is also Gaussian.
Example 3 (Comparison of (
50) with (
60) for jointly Gaussian processes).
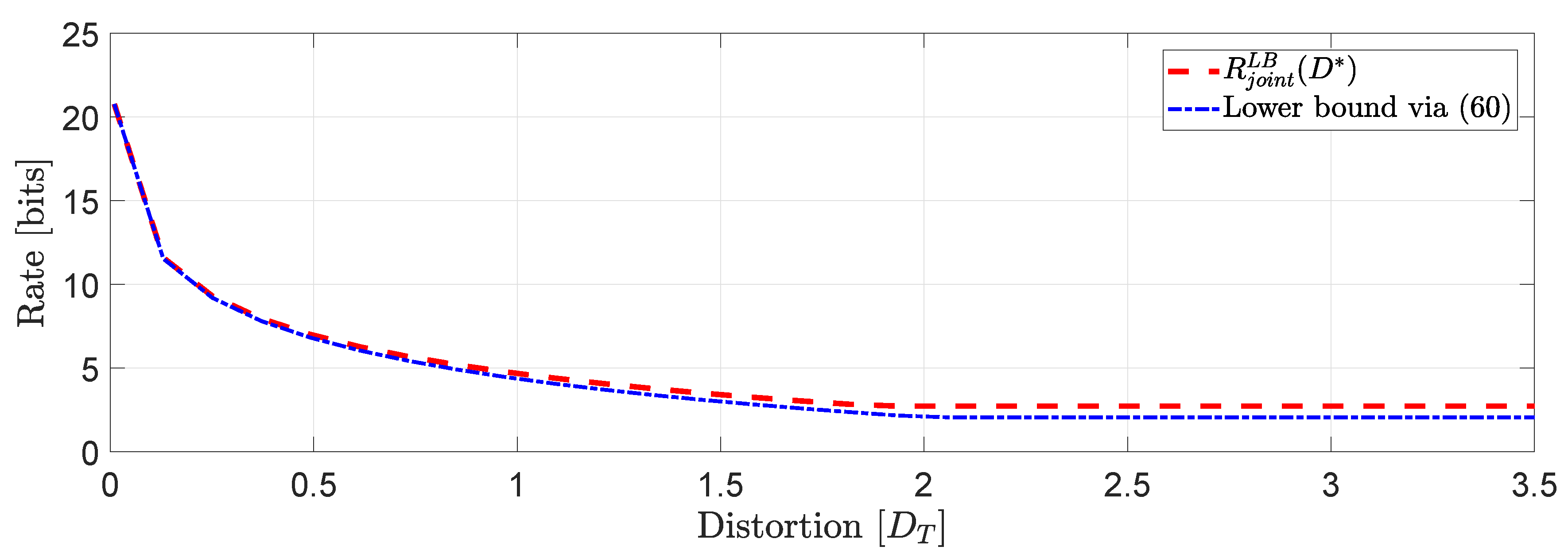
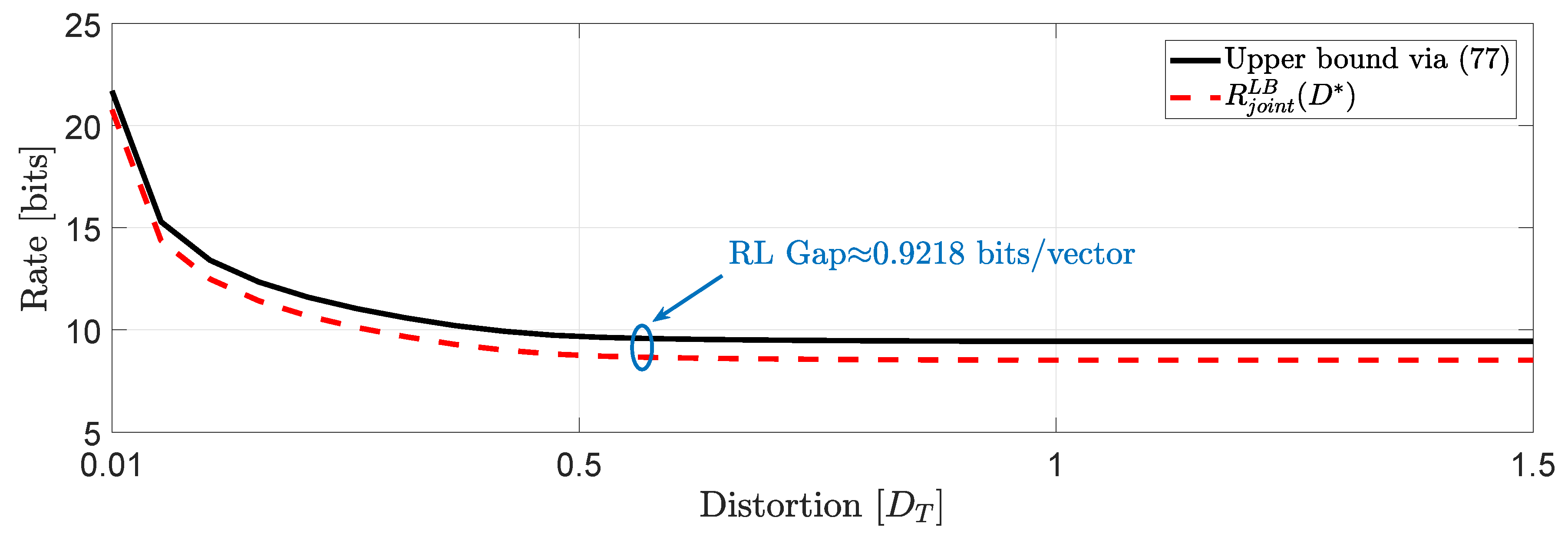
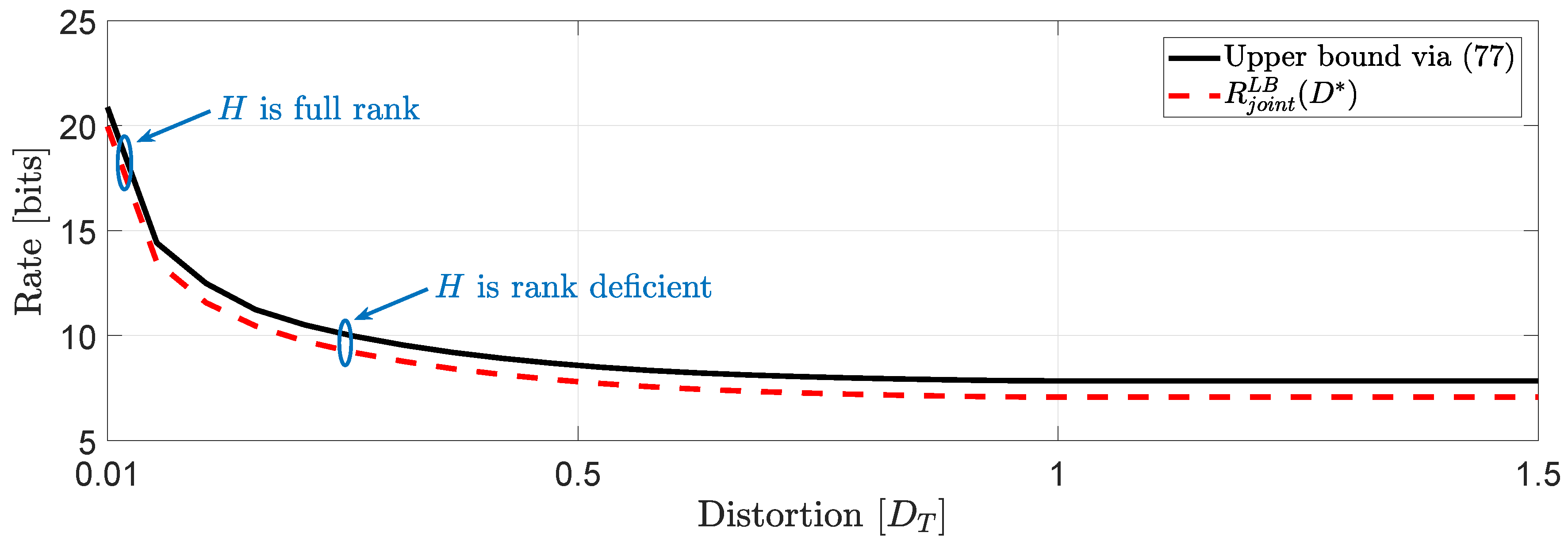
We consider the same input data assumed in Example 1 for users . Then, we proceed to compute the true lower bound of (50) and the lower bound obtained in (60).Our simulation study in Figure 7 shows that at high rates the performance of the two bounds is almost identical whereas to moderate and low rates we observe a gap that remains constant when , i.e., when the asymptotically averaged total distortion constraint is inactive. The same behavior is expected for systems of larger dimension (larger scale optimization problems) with a possibility of an increased gap to moderate and low rates depending on the structure of the block diagonal matrices A and . Next, we state a corollary of Theorem 3.
Corollary 2 (Analytical bounds when users
are not specified by the same additive noise process).
Consider the source models of users in (1). Moreover, assume that and with and and . Then, the following analytical lower bounds on (11)–(13) hold.- (1)
For , we obtainwhere with . - (2)
For , , we obtainwhere . - (3)
For we obtainwhere .
Proof. All cases
(1)–
(3) follow almost identical steps with the derivation of Theorem 3. The only different but crucial step lies in (A6) where we then use the fact that
where
follows from properties of block diagonal matrices ([
33], Section 0.9.2);
follows from the conditions of the corollary on the noise covariance matrices;
follows from the EPI ([
43], Equation (
7)). □
One can deduce the following for Corollary 2.
Remark 9. Corollary 2 will give similar analytical lower bounds (with appropriate modifications) if instead of user 1, we assume that the source model of user 2 is driven by a Gaussian noise process. The additional assumption on the covariance matrix of the noise process in both users is imposed because otherwise we cannot guarantee that the key series of inequalities (65) will be satisfied. 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










