1. Introduction
Secure network coding offers a method for securely transmitting information from an authorized sender to an authorized receiver. Cai and Yeung [
1] discussed the secrecy of when a malicious adversary, Eve, wiretaps a subset
of the set
E of all the channels in a network. Using the universal hashing lemma [
2,
3,
4], the papers [
5,
6] showed the existence of a secrecy code that works universally for any type of eavesdropper when the cardinality of
is bounded. In addition, the paper [
7] discussed the construction of such a code. As another type of attack on information transmission via a network, a malicious adversary contaminates the communication by changing the information on a subset
of
E. Using an error correcting code, the papers [
8,
9,
10,
11] proposed a method to protect the message from contamination. That is, we require that the authorized receiver correctly recovers the message, which is called robustness.
As another possibility, we consider the case when the malicious adversary combines eavesdropping and contamination. That is, by contaminating a part of the channels in the network, the malicious adversary might increase the ability of eavesdropping, whereas a parallel network offers no such a possibility [
12,
13,
14]. In fact, in arbitrarily varying channel model, noise injection is allowed after Eve’s eavesdropping, but Eve does not eavesdrop the channel after Eve’s noise injection [
15,
16,
17,
18,
19]. The paper [
20] also discusses secrecy in the same setting while it addresses the network model. The studies [
7,
14] discussed the secrecy when Eve eavesdrops the information transmitted on the channels in
after noises are injected in
, but they assume that Eve does not know the information of the injected noise.
In contrast, this paper focuses on a network, and discusses the secrecy when Eve adds artificial information to the information transmitted on the channels in , eavesdrops on the information transmitted on the channels in , and estimates the original message from the eavesdropped information and the information of the injected noises. We call this type of attack an active attack and call an attack without contamination a passive attack. We call each of Eve’s active operations a strategy. When and any active attack are available for Eve, she is allowed to arbitrarily modify the information on the channels in sequentially based on the obtained information.
This paper aims to show a reduction theorem for an active attack, i.e., the fact that no strategy can increase Eve’s information when every operation in the network is linear and Eve’s contamination satisfies a natural causal condition. When the network is not well synchronized, Eve can make an attack across several channels. This reduction theorem holds even under this kind of attack. In fact, there is an example having a non-linear node operation such that Eve can increase her performance to extract information from eavesdropping an edge outgoing an intermediate node by adding artificial information to an edge incoming the intermediate node [
21] (The paper [
21] also discusses linear code; it discusses only code a on one-hop relay network. Our results can be applied to general networks.) This example shows the necessity of linearity for this reduction theorem. Although our discussion can be extended to the multicast and multiple-unicast cases, for simplicity, we consider the unicast setting in the following discussion.
Further, we apply our general result to the analysis of a concrete example of a network. In this network, we demonstrate that any active attack cannot increase the performance of eavesdropping. However, in the single transmission case over the finite field
, the error correction and the error detection are impossible over this contamination. To resolve this problem, this paper addresses the multiple transmission case in addition to the single transmission case. In the multiple transmission case, the sender uses the same network multiple times, and the topology and dynamics of the network do not change during these transmissions. While several papers discussed this model, many of them discussed the multiple transmission case only with contamination [
22,
23,
24] or eavesdropping [
5,
6,
25,
26,
27]. Only the paper [
20] addressed it with contamination and eavesdropping, and its distinction from the paper [
20] is summarized as follows. The paper [
20] assumes that all injections are done after eavesdropping, while this paper allows Eve to inject the artificial information before a part of eavesdropping.
We formulate the multiple transmission case when each transmission has no correlation with the previous transmission while injected noise might have such a correlation. Then, we show the above type of reduction theorem for an active attack even under the multiple transmission case. We apply this result to the multiple transmission over the above example of a network, in which the error correction and the error detection are possible over this contamination. Hence, the secrecy and the correctness hold in this case.
The remaining part of this paper is organized as follows.
Section 2 discusses the single transmission setting that has only a single transmission, and
Section 3 discusses the multiple transmission setting that has
n transmissions. Two types of multiple transmission setting are formulated. Then, we state our reduction theorem in both settings. In
Section 4, we state the conclusion.
2. Single Transmission Setting
2.1. Generic Model
In this subsection, we give a generic model, and discuss its relation with a concrete network model in the latter subsections. We consider the unicast setting of network coding on a network. Assume that the authorized sender, Alice, intends to send information to the authorized receiver, Bob, via the network. Although the network is composed of
edges and
vertecies, as shown later, the model can be simplified as follows when the node operations are linear. We assume that Alice inputs the input variable
in
and Bob receives the output variable
in
, where
is a finite field whose order is a power
q of a prime
p. We also assume that the malicious adversary, Eve, wiretaps the information
in
This network has
edges that are not directly linked to the source node. The parameters are summarized as
Table 1. (In this paper, we denote the vector on
by a bold letter, but we use a non-bold letter to describe a scalar and a matrix).
Then, we adopt the model with matrices
and
, in which the variables
,
, and
satisfy their relations
This attack is a conventional wiretap model and is called a passive attack to distinguish it from an active attack, which will be introduced later.
Section 2.3 will explain how this model is derived from a directed graph with
and linear operations on nodes.
In this paper, we address a stronger attack, in which Eve injects noise
. Hence, using matrices
and
, we rewrite the relations (
1) as
which is called a wiretap and addition model. The
i-th injected noise
(the
i-th component of
) is decided by a function
of
. Although a part of
is a function of
, this point does not make a problem for causality, as explained in
Section 2.5. In this paper, when a vector has the
j-th component
; the vector is written as
, where the subscript
expresses the range of the index
j. Thus, the set
of the functions can be regarded as Eve’s strategy, and we call this attack an active attack with a strategy
. That is, an active attack is identified by a pair of a strategy
and a wiretap, and an addition model decided by
. Here, we treat
, and
as deterministic values, and denote the pairs
and
by
and
, respectively. Hence, our model is written as the triplet
. As shown in the latter subsections, under the linearity assumption on the node operations, the triplet
is decided from the network topology (a directed graph with
and
) and dynamics of the network. Here, we should remark that the relation (
2) is based on the linearity assumption for node operations. Since this assumption is the restriction for the protocol, it does not restrict the eavesdropper’s strategy.
We impose several types for regularity conditions for Eve’s strategy , which are demanded from causality. Notice that is a function of the vector . Now, we take the causality with respect to into account. Here, we assume that the assigned index i for expresses the time-ordering of injection. That is, we assign the index i for according to the order of injections. Hence, we assume that is decided by a part of Eve’s observed variables. We say that subsets for are the domain index subsets for when the function is given as a function of the vector . Here, the notation means that the j-th eavesdropping is done before the i-th injection; i.e., expresses the set of indexes corresponding to the symbols that do effect the i-th injection. Hence, the eavesdropped symbol does not depend on the injected symbol for . Since the decision of the injected noise does not depend on the consequences of the decision, we introduce the following causal condition.
Definition 1. We say that the domain index subsets satisfy the causal condition when the following two conditions hold:
- (A1)
The relation holds for .
- (A2)
The relation holds.
As a necessary condition of the causal condition, we introduce the following uniqueness condition for the function , which is given as a function of the vector .
Definition 2. For any value of , there uniquely exists such thatThis condition is called the uniqueness condition for α. When the uniqueness condition does not hold, for an input
, there exist two vectors
and
to satisfy (
3). It means that both outputs
and
may happen; nevertheless, all the operations are deterministic. This situation is unlikely in a real word. Examples of a network with
,
will be given in
Section 2.6. Then, we have the following lemma, which shows that the uniqueness condition always holds under a realistic situation.
Lemma 1. When a strategy α has domain index subsets to satisfy the causal condition, the strategy α satisfies the uniqueness condition.
Proof. When the causal condition holds, we show the fact that is given as a function of for any by induction with respect to the index , which expresses the order of the injected information. This fact yields the uniqueness condition.
For , we have because is zero. Hence, the statement with holds. We choose . Let be the -th injected information. Due to conditions (A1) and (A2), is a function of . Since the assumption of the induction guarantees that are functions of , are functions of . Then, we find that is given as a function of for any . That is, the strategy satisfies the uniqueness condition. □
Now, we have the following reduction theorem.
Theorem 1 (Reduction theorem)
. When the strategy α satisfies the uniqueness condition, Eve’s information with strategy α can be calculated from Eve’s information with strategy 0 (the passive attack), and is also calculated from . Hence, we have the equation expresses the mutual information between and under the strategy α. Proof. This proof can be done by showing that Eve’s information with a strategy can be simulated by Eve’s information with a strategy 0 as follows.
Since and , due to the uniqueness condition of the strategy , we can uniquely evaluate from and . Therefore, we have . Conversely, since is given as a function () of , , and , we have the opposite inequality. □
This theorem shows that the information leakage of the active attack with the strategy
is the same as the information leakage of the passive attack. Hence, to guarantee the secrecy under an arbitrary active attack, it is sufficient to show secrecy under the passive attack. However, there is an example of non-linear network such that this kind of reduction does not hold [
21]. In fact, even when the network does not have synchronization so that the information transmission on an edges starts before the end of the information transmission on the previous edge, the above reduction theorem hold under the uniqueness condition.
2.2. Recovery and Information Leakage with Linear Code
Next, we consider the recovery and the information leakage when a linear code is used. Assume that a message
is generated subject to the uniform distribution and is sent via an encoding map, i.e., a linear map
from
to
. Additionally, Alice independently generates a scramble variable
subject to the uniform distribution and send it via another a linear map
from
to
. In this case, Alice transmits
, as is implicitly stated in many papers ([
22] Section V; [
23] Section V; [
20] Section IV).
Proposition 1. Bob is assumed to know the forms of and , . Bob can correctly recover the message with probability 1 if and only if and .
Proof. To recover the message M, the dimension needs to be ℓ. When , there exist vectors , , and such that . Thus, Bob may receive 0 when the message is 0 or . This fact means the impossibility of Bob’s perfect recovery.
When and , there exists a linear map P from to such that for and for . By applying the map P, Bob recovers the message . □
Assume that Bob knows but does not know the form of ; i.e., there are several possible forms as the candidate of . Additionally, we assume that all possible forms satisfy the condition of Proposition 1. In general, the map P used in the proof depends on the form of . When the map P can be chosen commonly with , Bob can recover the message . Otherwise, Bob cannot recover it.
However, when the condition holds in addition to the condition of Proposition 1 for , Bob can detect the existence of contamination as follows. In this case, when does not belong to , Bob considers that a contamination exists. In other words, when we choose a linear function such that , the existence of a contamination can be detected by checking the condition .
When the strategy satisfies the uniqueness condition, Eve’s recovery can be reduced to the case with due to Theorem 1. Therefore, Eve can correctly recover the message if and only if and .
For the amount of information leakage, the papers [
28] (Theorem 2), and [
29] (Corollary 3.3 and (25)) stated the following relation in a slightly different way.
Proposition 2. Information leakage to Eve can be evaluated as . In particular, if and only if .
Proof. Consider the case with . and . Hence, . □
Therefore, using Proposition 2, we can evaluate the amount of leaked information even for general strategy .
To check the condition , we introduce two matrices and by for and for . Then, we define low vectors for of the matrix . Considering an equivalent condition to , we have the following corollary.
Corollary 1. if and only if there does not exist a vector such that has a form with .
2.3. Construction of from Concrete Network Model
Next, we discuss how we can obtain the generic passive attack model (
1) from a concretely structured network coding, i.e., communications identified by directed edges and linear operations by parties identified by nodes. We consider the unicast setting of network coding on a network, which is given as a directed graph
, where the set
of vertices expresses the set of nodes and the set
of edges expresses the set of communication channels, where a communication channel means a packet in network engineering; i.e., a single communication channel can transmit single character in
. In the following, we identify the set
E with
; i.e, we identify the index of an edge with the edge itself. Here, the directed graph
is not necessarily acyclic. When a channel transmits information from a node
to another node
, it is written as
.
In the single transmission, the source node has several elements of and sends each of them via its outgoing edges in the order of assigned number of edges. Each intermediate node keeps received information via incoming edges. Then, for each outgoing edge, the intermediate node calculates one element of from previously received information, and sends it via the outgoing edge. That is, every outgoing piece of information from a node via a channel depends only on the information coming into the node via channels such that . The operations on all nodes are assumed to be linear on the finite field with prime power q. Bob receives the information in on the edges of a subset , where is a strictly increasing function from to . Let be the information on the edge . In the following, we describe the information on the edges that are not directly linked to the source node because expresses the number of Alice’s input symbols. When the edge is an outgoing edge of the node , the information is given as a linear combination of the information on the edges coming into the node . We chose an matrix such that , where is zero unless is an edge incoming to . The matrix is the coefficient matrix of this network.
Now, from causality, we can assume that each node makes the transmissions on the outgoing edges in the order of the numbers assigned to the edges. At the first stage, all
information generated at the source node is directly transmitted via
respectively. Then, at time
j, the information transmission on the edge
is done. Hence, naturally, we impose the condition
which is called the partial time-ordered condition for
. Then, to describe the information on
edges that is not directly linked to the source node, we define
matrices
. The
j-th
matrix
gives the information on the edge
as a function of the information on edges
at time
j. The
-th row vector of the matrix
is defined by
. The remaining part of
, i.e., the
i-th row vector for
, is defined by
and
is the Kronecker delta. Since
expresses the information on edge
at time
j, we have
While the output of the matrix
takes values in
, we focus the projection
to the subspace
that corresponds to the
components observed by Bob. That is,
is a
matrix to satisfy
. Similarly, we use the projection
(an
matrix) as
. Due to (
6), the matrix
satisfies the first equation in (
1).
The malicious adversary, Eve, wiretaps the information
in
on the edges of a subset
, where
is a strictly increasing function from
to
. Similar to (
6), we have
We employ the projection
(an
matrix) to the subspace
that corresponds to the
components eavesdropped by Eve. That is,
. Then, we obtain the matrix
as
. Due to (
6), the matrix
satisfies the second equation in (
1).
In summary the topology and dynamics (operations on the intermediate nodes) of the network, including the places of attached edges decides the graph
, the coefficients
, and functions
, uniquely give the two matrices
and
.
Section 2.6 gives an example for this model. Here, we emphasize that we do not assume the acyclic condition for the graph
. We can use this relaxed condition because we have only one transmission in the current discussion. That is, due to the partial time-ordered condition for
, we can uniquely define our matrices
and
, in a similar way to [
30] (Section V-B;
of Ahlswede–Cai–Li–Yeung corresponds to the number of edges that are not connected to the source node in our paper.) However, when the graph has a cycle and we have
n transmissions, there is a possibility of a correlation with the delayed information that is dependent on the time ordering. As a result, it is difficult to analyze secrecy for the cyclic network coding.
2.4. Construction of from a Concrete Network Model
We identify the wiretap and addition model from a concrete network structure. We assume that Eve injects the noise in a part of edges and eavesdrops the edges .
The elements of the subset
are expressed as
by using a function
from
to
, where the function
is not necessarily monotonically increasing function. To give the matrices
and
, while modifying the matrix
, we define the new matrix
as follows The
-th row vector of the new matrix
is defined by
. The remaining part of
, i.e., the
i-th row vector for
, is defined by
. Since
expresses the information on edge
at time
j, we have
When Eve eavesdrops the edges
, she obtains the information on
before her noise injection. Hence, to express her obtained information on
, we need to subtract her injected information on
. Hence, we need
in the second term of (
9). We introduce the projection
(an
matrix) as
. Due to (
8) and (
9), the matrices
and
satisfy conditions (
2) with the matrices
and
, respectively. This model (
,
,
,
) to give (
2) is called the wiretap and addition model determined by
and
, which expresses the topology and dynamics.
2.5. Strategy and Order of Communication
To discuss the active attack, we see how the causal condition for the subsets follows from the network topology in the wiretap and addition model. We choose the domain index subsets for ; i.e., Eve chooses the added error on the edge as a function of the vector . Since the order of Eve’s attack is characterized by the function from to , we discuss what condition for the pair guarantees the causal condition for the subsets .
First, one may assume that the tail node of the edge
sends the information to the edge
after the head node of the edge
receives the information to the edge
. Since this condition determines the order of Eve’s attack, the function
must be a strictly increasing function from
to
. Additionally, due to this time ordering, the subset
needs to be
or its subset. We call these two conditions the full time-ordered condition for the function
and the subsets
. Since the function
is strictly increasing, condition (A2) for the causal condition holds. Since the relation (
5) implies that
is a lower triangular matrix with zero diagonal elements, the strictly increasing property of
yields that
which implies condition (A1) for the causal condition. In this way, the full time-ordered condition for the function
and the subsets
satisfies the causal condition.
However, the full time ordered condition does not hold in general, even when we reorder the numbers assigned to the edges. That is, if the network is not well synchronized, Eve can make an attack across several channels; i.e., it is possible that Eve might intercept (i.e., wiretap and contaminate) the information of an edge before the head node of the previous edge receives the information on the edge. Hence, we consider the case when the partial time-ordered condition holds, but the full time-ordered condition does not necessarily hold. (For an example, we consider the following case. Eve gets the information on the first edge. Then, she gets the information on the second edge before she hands over the information on the first edge to the tail node of the first edge. In this case, she can change the information on the first edge based on the information on the first and second edges. Then, the time-ordered condition (
10) does not hold.) That is, the function
from
to
E is injective but is not necessarily monotonically increasing. Given the matrix
, we define the function
. Here, when no index
satisfies the condition
,
is defined to be
. Then, we say that the function
and the subsets
are admissible under
when
, the subsets
satisfy condition (A2) for the causal condition, and any element
satisfies
Here,
expresses the image of the function
. The condition (
11) and the condition (
5) imply the following condition; for
, there is no sequence
such that
This condition implies condition (A1) for the causal condition. Since the admissibility under
is natural, even when the full time-ordered condition does not hold, the causal condition can be naturally derived.
Given two admissible pairs
and
, we say that the pair
is superior to
for Eve when
for any
. Now, we discuss the optimal choice of
in this sense when
is given. That is, we choose the subset
as large as possible under the admissibility under
. Then, we choose the bijective function
from
to
such that
is monotonically increasing. Then, we define
, which satisfies the admissibility under
. conditions (A1) and (A2) for the causal condition. Further, when the pair
is admissible under
, the condition (
11) implies
for
; i.e.,
is the largest subset under the admissibility under
. Hence, we obtain the optimality of
. Although the choice of
is not unique, the choice of
for
is unique.
2.6. Secrecy in Concrete Network Model
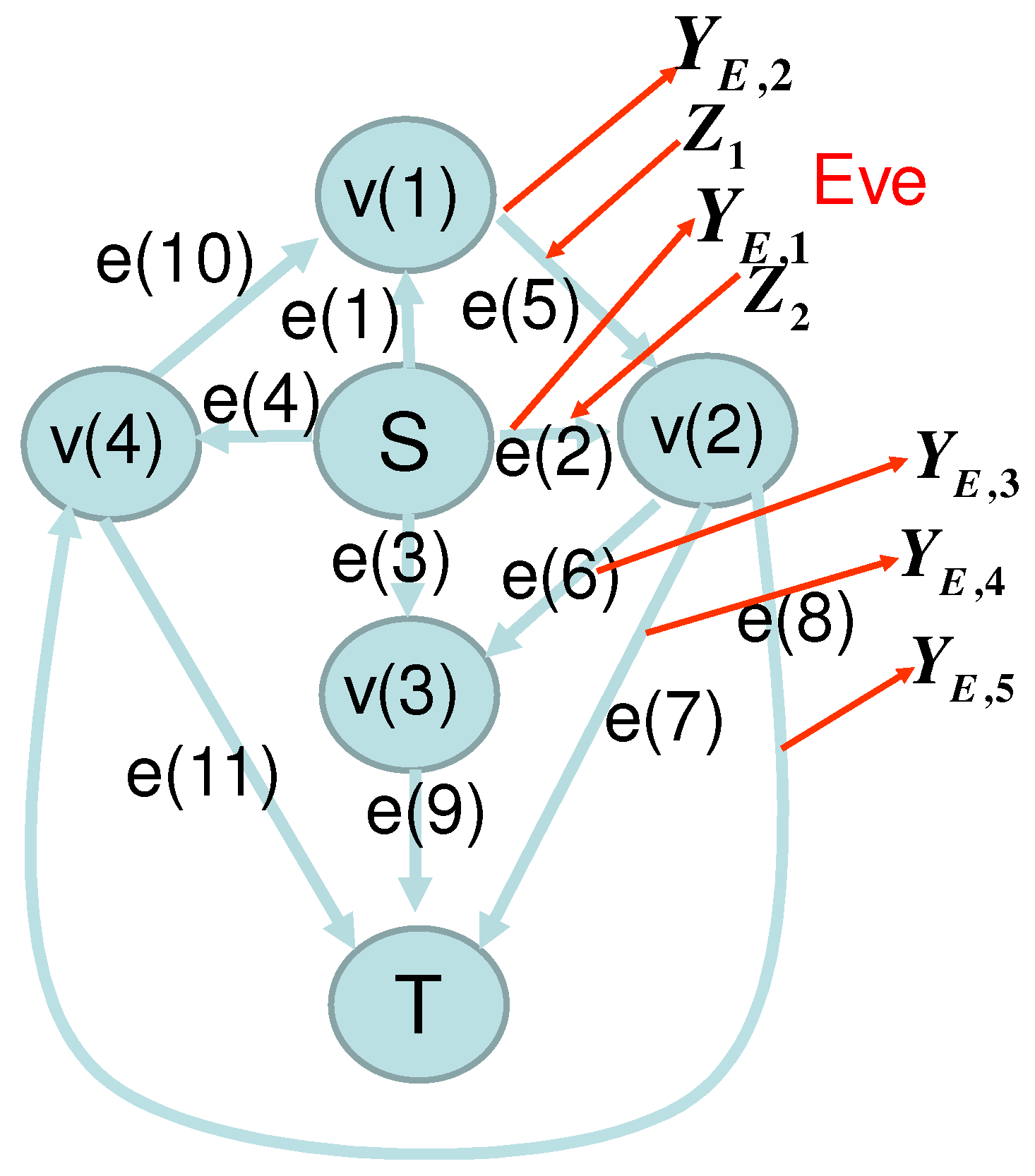
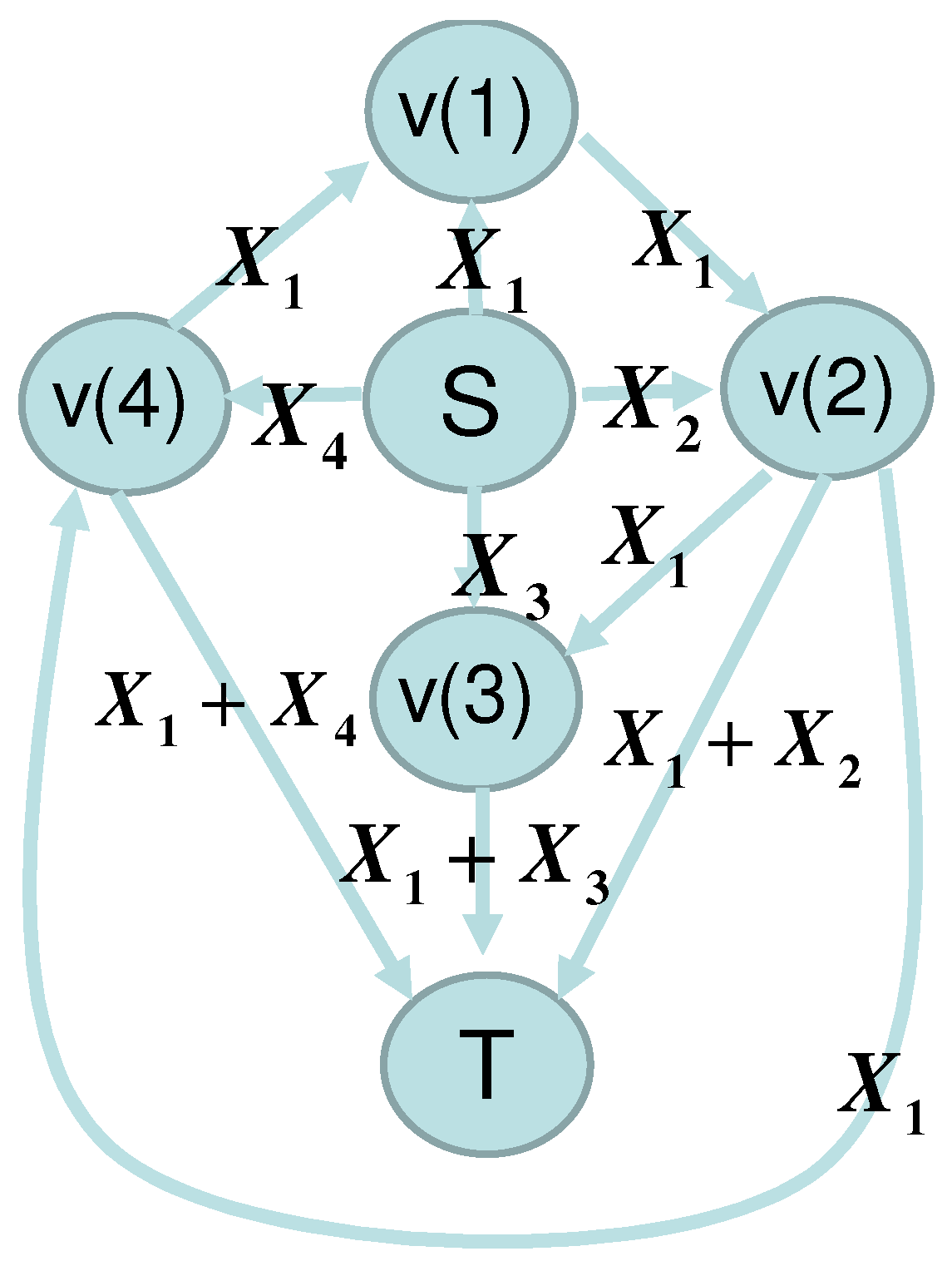
In this subsection, as an example, we consider the network given in
Figure 1 and
Figure 2, which shows that our framework can be applied to the network without synchronization. Alice sends the variables
to nodes
and
via the edges
, and
, respectively. The edges
send the elements received from the edges
, respectively. The edges
,
, and
send the sum of two elements received from the edge pairs
and
respectively.
Bob receives elements via the edges
and
which are written as
and
, respectively. Then, the matrix
is given as
Then,
and
.
Now, we assume that Eve eavesdrops the edges
and
, i.e., all edges connected to
, and contaminates the edge
. Then, we set
and
. Eve can choose the function
as
while
is possible. In the following, we choose (
14). Since
and
, the subsets
are given as
This case satisfies conditions (A1) and (A2). Hence, this model satisfies the causal condition. Lemma 1 guarantees that any strategy also satisfies the uniqueness condition.
We denote the observed information on the edges
and
by
and
. As in
Figure 1, Eve adds
and
in edges
and
. Then, the matrices
,
, and
are given as
In this case, to keep the secrecy of the message to be transmitted, Alice and Bob can use coding as follows. When Alice’s message is
, Alice prepares scramble random number
. These variables are assumed to be subject to the uniform distribution independently. She encodes them as
for
and
. As shown in the following, under this code, Eve cannot obtain any information for
M, even though she makes active attack. Due to Theorem 1, it is sufficient to show the secrecy when
. Since Eve’s information is
, and
, the matrix
A given in
Section 2.2 is
Thus, Proposition 2 guarantees that Eve cannot obtain any information for the message
M.
Indeed, the above attack can be considered as the following. Eve can eavesdrop all edges connected to the intermediate node and contaminate all edges incoming to the intermediate node . Hence, it is natural to assume that Eve similarly eavesdrops and contaminates at another intermediate node . That is, Eve can eavesdrop all edges connected to the intermediate node and contaminate all edges incoming to the intermediate node . For all nodes , this code has the same secrecy against the above Eve’s attack for node .
Furthermore, the above code has the secrecy even when the following attack.
- (B1)
Eve eavesdrops one of three edges and connected to the sink node, and eavesdrops and contaminates one of the remaining eight edges and that are not connected to the sink node.
To apply Corollary 1 for analysis of the secrecy, we denote the low vector in Corollary 1 corresponding to the edge by . Then, the vectors , , and are , , and . The remaining vectors , , , , , , , and are , , , , , , , and . Since any combination of the vector of the first group and the second group cannot be the combination of Corollary 1 and Theorem 2 guarantees that the secrecy holds under the above attack (B1).
2.7. A Problem in Error Detection in a Concrete Network Model
However, the network given in
Figure 1 and
Figure 2 has the problem for the detection of the error in the following meaning. When Eve makes an active attack, Bob’s recovering message is different from the original message due to the contamination. Further, Bob cannot detect the existence of the error in this case. It is natural to require the detection of the existence of the error when the original message cannot be recovered and the secrecy. As a special attack model, we consider the following scenario with the attack (B1).
- (B2)
Our node operations are fixed to the way as
Figure 2.
- (B3)
The message set and all information on all edges are .
- (B4)
The variables and are given as the output of the encoder. The encoder on the source node can be chosen, but is restricted to linear. It is allowed to use a scramble random number, which is an element of with a certain integer k. Formally, the encoder is given as a linear function from to .
- (B5)
The decoder on the sink node can be chosen dependently of the encoder and independently of Eve’s attack.
Then, it is impossible to make a pair of an encoder and a decoder such that the secrecy holds and Bob can detect the existence of error.
This fact can be shown as follows. In order to detect it, as discussed in
Section 2.2, Alice needs to make an encoder such that the vector
belongs to a linear subspace because the detection can be done only by observing that the vector does not belong to a certain linear subspace, which can be written as
with a non-zero vector
. That is, the encoder needs to be constructed so that the relation
holds unless Eve’s injection is made. Since our field is
, we have three cases. (C1)
is
,
, or
. (C2)
is
,
, or
. (C3)
is
. If we impose another linear condition, the transmitted information is restricted into a one-dimensional subspace, which means that the message
M uniquely decides the vector
. Hence, if Eve eavesdrops one suitable variable among three variables
and
, Eve can infer the original message.
In the first case (C1), one of three variables and is zero unless Eve’s injection is made. When , i.e., , Bob can detect an error on the edge or because the error on or affects so that is not zero. However, Bob cannot detect any error on the edge because the error does not affect . The same fact can be applied to the case when . When , Bob cannot detect any error on the edge because the error does not affect .
In the second case (C2), two of three variables and have the same value unless Eve’s injection is made. When , i.e., , Bob can detect an error on the edge or because the error on or affects or so that is not zero. However, Bob cannot detect any error on the edge because the error does not affect or . Similarly, When (), Bob cannot detect any error on the edge ().
In the third case (C3), the relation holds; i.e., . Then, the linearity of the code implies that the message has the form . Due to the relation , the value is limited to , , , or 0 because our field is . Since the message is not a constant, it is limited to one of , , or . Hence, when it is , Eve can obtain the message by eavesdropping the edge . In other cases, Eve can obtain the message in the same way.
To resolve this problem, we need to use this network multiple times. Hence, in the next section, we discuss the case with multiple transmission.
2.8. Wiretap and Replacement Model
In the above subsections, we have discussed the case when Eve injects the noise in the edges
and eavesdrops the edges
. In this subsection, we assume that
and Eve eavesdrops the edges
and replaces the information on the edges
by other information. While this assumption implies
and the image of
is included in the image of
, the function
does not necessarily equal the function
because the order that Eve sends her replaced information to the heads of edges does not necessarily equal the order that Eve intercepts the information on the edges. Additionally, this case belongs to general wiretap and addition model (
2) as follows. Modifying the matrix
, we define the new matrix
as follows. When there is an index
i such that
, the
-th row vector of the new matrix
is defined by
and the remaining part of
is defined as the identity matrix. Otherwise,
is defined to be
. Additionally, we define another matrix
F as follows. The
-th row vector of the new matrix
F is defined by
and the remaining part of
F is defined as the identity matrix. Hence, we have
Then, we choose matrices
,
,
, and
as
,
,
, and
, which satisfy conditions (
2) due to (
18) and (
19). This model (
,
,
,
) is called the wiretap and replacement model determined by
and
. Notice that the projections
and
are defined in
Section 2.3.
Next, we discuss the strategy under the matrices , , , and such that the added error is given as a function of the vector . Since the decision of the injected noise does not depend on the results of the decision, we impose the causal condition defined in Definition 4 for the subsets .
When the relation
holds with
, a strategy
on the wiretap and replacement model (
,
,
,
) determined by
and
is written by another strategy
on the wiretap and addition model
,
,
, and
determined by
and
, which is defined as
. In particular, due to the condition (
5), the optimal choice
under the partial time-ordered condition satisfies that the relation
holds with
. That is, under the partial time-ordered condition, the strategy on the wiretap and replacement model can be written by another strategy on the wiretap and addition model.
However, if there is no synchronization among vertexes, Eve can inject the replaced information to the head of an edge before the tail of the edge sends the information to the edge. Then, the partial time-ordered condition does not hold. In this case, the relation does not necessarily hold with . Hence, a strategy on the wiretap and replacement model (, , , ) cannot be necessarily written as another strategy on the wiretap and addition model (, , , ).
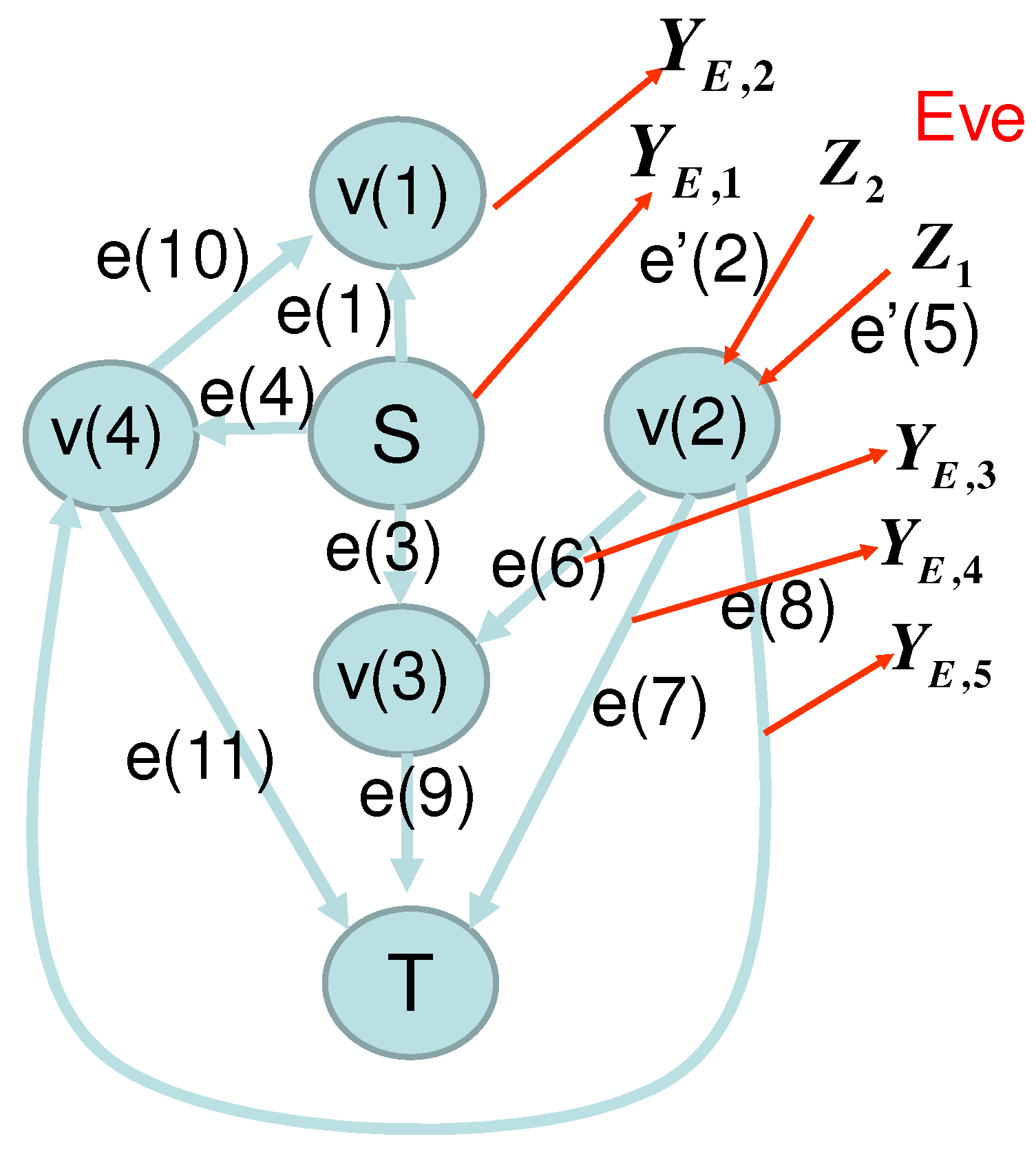
To see this fact, we discuss an example given in
Section 2.6. In this example, the network structure of the wiretap and replacement model is given by
Figure 3.
3. Multiple Transmission Setting
3.1. General Model
Now, we consider the
n-transmission setting, where Alice uses the same network
n times to send a message to Bob. Alice’s input variable (Eve’s added variable) is given as a matrix
(a matrix
), and Bob’s (Eve’s) received variable is given as a matrix
(a matrix
). Then, we consider the model
whose realization in a concrete network will be discussed in
Section 3.2 and
Section 3.3. Notice that the relations (
20) and (
21) with
(only the relation (
20)) were treated as the starting point of the paper [
20] (the papers [
22,
23,
24]).
In this case, regarding n transmissions of one channel as n different edges, we consider the directed graph composed of edges. Then, Eve’s strategy is given as functions from to the respective components of . In this case, we extend the uniqueness condition to the n-transmission version.
Definition 3. For any value of , there uniquely exists such thatThis condition is called the n-uniqueness condition. Since we have n transmissions on each channel, the matrix is given as an matrix. In the following, we see how the matrix is given and how the n-uniqueness condition is satisfied in a more concrete setting.
3.2. The Multiple Transmission Setting with Sequential Transmission
This section discusses how the model given in
Section 3.1 can be realized in the case with sequential transmission as follows. Alice sends the first information
. Then, Alice sends the second information
. Alice sequentially sends the information
. Hence, when an injective function
from
to
gives the time ordering of
edges, it satisfies the condition
Here, we assume that the topology and dynamics of the network and the edge attacked by Eve do not change during
n transmissions, which is called the stationary condition. All operations in intermediate nodes are linear. Additionally, we assume that the time ordering on the network flow does not cause any correlation with the delayed information like
Figure 1 unless Eve’s injection is made; i.e., the
l-th information
received by Bob is independent of
, which is called the independence condition. The independence condition means that there is no correlation with the delayed information. Due to the stationary and independence conditions, the
matrix
satisfies that
where
. When the
matrix
satisfies the partial time-ordered condition (
5), due to (
23) and (
24), the
matrix
satisfies the partial time-ordered condition (
5) with respect to the time ordering
. Since the stationary condition guarantees that the edges attacked by Eve do not change during
n transmissions, the above condition for
implies the model (
20) and (
21). This scenario is called the
n-sequential transmission.
Since the independence condition is not so trivial, it is needed to discuss when it is satisfied. If the
l-th transmission has no correlation with the delayed information of the previous transmissions for
, the independence condition holds. In order to satisfy the above independence condition, the acyclic condition for the network graph is often imposed. This is because any causal time ordering on the network flow does not cause any correlation with the delayed information and achieves the max-flow if the network graph has no cycle [
31]. In other words, if the network graph has a cycle, there is a possibility that a good time ordering on the network flow that causes correlation with the delayed information. However, there is no relation between the relations (
20) and (
21) and the acyclic condition for the network graph, and the relations (
20) and (
21) directly depend on the time ordering on the network flow. That is, the acyclic condition for the network graph is not equivalent to the existence of the effect of delayed information. Indeed, if we employ breaking cycles on intermediate nodes ([
31] Example 3.1), even when the network graph has cycles, we can avoid any correlation with the delayed information. (To handle a time ordering with delayed information, one often employs a convolution code [
32]. It is used in sequential transmission, and requires synchronization among all nodes. Additionally, all the intermediate nodes are required to make a cooperative coding operation under the control of the sender and the receiver. If we employ breaking cycles, we do not need such synchronization and avoid any correlation with the delayed information.) Additionally, see the example given in
Section 3.5.
To extend the causality condition, we focus on the domain index subsets of for Eve’s strategy . Then, we define the causality condition under the order function .
Definition 4. We say that the domain index subsets satisfy the n-causal condition under the order function and the function η from to when the following two conditions hold:
- (A1’)
The relation holds for .
- (A2’)
The relation holds when .
Next, we focus on the domain index subsets
and the function
from
to
. We say that the pair
are
n-admissible under
under the order function
when
, the subsets
satisfy condition (A2’) for the
n causal condition, and any element
satisfies
where the function
is defined as
Here, when no index
satisfies the condition
,
is defined to be
. In the same way as
Section 2.5, we find that the
n-admissibility of the pair
implies the
n-causal condition under
and
for the domain index subsets
.
Given two n-admissible pairs and , we say that the pair is superior to for Eve when for and . Then, we choose the bijective function from to such that is monotonically increasing, where is defined as . The function expresses the order of Eve’s contamination. Then, we define , which satisfies the n-admissibility under and the order function .
Further, when the pair
is
n-admissible under
and
, the condition (
25) implies
for
and
; i.e.,
is the largest subset under the
n admissibility under
and
. Hence, we obtain the optimality of
when
,
, and
are given. Although the choice of
is not unique, the choice of
for
and
is unique when
,
, and
are given.
In the same way as Lemma 1, we find that the n-causal condition with sequential transmission guarantees the n-uniqueness condition as follows.
Lemma 2. When a strategy α for the n-sequential transmission has domain index subsets to satisfy the n-causal condition, the strategy α satisfies the n-uniqueness condition.
Proof. Consider a big graph composed of
edges
and
vertecies
. In this big graph, the coefficient matrix is given in (
24). We assign the
edges the number
. The
n-causal and
n-uniqueness conditions correspond to the causal and uniqueness conditions of this big network, respectively. Hence, Lemma 1 implies Lemma 2. □
3.3. Multiple Transmission Setting with Simultaneous Transmission
We consider anther scenario to realize the model given in
Section 3.1. Usually, we employ an error correcting code for the information transmission on the edges in our graph. For example, when the information transmission is done by wireless communication, an error correcting code is always applied. Now, we assume that the same error correcting code is used on all the edges. Then, we set the length
n to be the same value as the transmitted information length of the error correcting code. In this case,
n transmissions are done simultaneously in each edge. Each node makes the same node operation for
n transmissions, which implies the condition (
24) for the
matrix
. Then, the relations (
20) and (
21) hold because the delayed information does not appear. This scenario is called the
n-simultaneous transmission.
In fact, when we focus on the mathematical aspect, the n-simultaneous transmission can be regarded as a special case of the n-sequential transmission. In this case, the independence condition always holds even when the network has a cycle. Further, the n-uniqueness condition can be derived in a simpler way without discussing the n-causal condition as follows.
In this scenario, given a function from to , Eve chooses the added errors on the edge as a function of the vector with subsets of . Hence, in the same way as the single transmission, domain index subsets for are given as subsets for . In the same way as Lemma 1, we have the following lemma.
Lemma 3. When a strategy α for the n-simultaneous transmission has domain index subsets to satisfy the causal condition, the strategy α satisfies the n-uniqueness condition.
In addition, the wiretap and replacement model in this setting can be introduced for the
n-sequential transmission and the
n-simultaneous transmission in the same way as
Section 2.8.
3.4. Non-Local Code and Reduction Theorem
Now, we assume only the model (
20) and (
21) and the
n-uniqueness condition. Since the model (
20) and (
21) is given, we manage only the encoder in the sender and the decoder in the receiver. Although the operations in the intermediate nodes are linear and operate only on a single transmission, the encoder and the decoder operate across several transmissions. Such a code is called a non-local code to distinguish operations over a single transmission. Here, we formulate a non-local code to discuss the secrecy. Let
and
be the message set and the set of values of the scramble random number, which is often called the private randomness. Then, an encoder is given as a function
from
to
, and the decoder is given as
from
to
. Here, the linearity for
and
is not assumed. That is, the decoder does not use the scramble random number
L because it is not shared with the decoder. Our non-local code is the pair
, and is denoted by
. Then, we denote the message and the scramble random number as
M and
L. The cardinality of
is called the size of the code and is denoted by
. More generally, when we focus on a sequence
instead of
, an encoder
is a function from
to
, and the decoder
is a function from
to
.
Here, we treat , and as deterministic values, and denote the pairs and by and , respectively, while Alice and Bob might not have the full information for and . Additionally, we assume that the matrices and are not changed during transmission. In the following, we fix . As a measure of the leaked information, we adopt the mutual information between M and Eve’s information and . Since the variable is given as a function of , we have . Since the leaked information is given as a function of in this situation, we denote it by .
Definition 5. When we always choose , the attack is the same as the passive attack. This strategy is denoted by .
When are treated as random variables independent of , the leaked information is given as the expectation of . This probabilistic setting expresses the following situation. Eve cannot necessarily choose edges to be attacked by herself. However, she knows the positions of the attacked edges, and chooses her strategy depending on the attacked edges.
Remark 1. It is better to remark that there are two kinds of formulations in network coding, even when the network has only one sender and one receiver. Many papers [1,8,9,28,29] adopt the formulation, where the users can control the coding operation in intermediate nodes. However, this paper adopts another formulation, in which the non-local coding operations are done only for the input variable and the output variable like the papers [7,14,20,22,23,24]. In contrast, all intermediate nodes make only linear operations over a single transmission, which is often called local encoding in [22,23,24]. Since the linear operations in intermediate nodes cannot be controlled by the sender and the receiver, this formulation contains the case when a part of intermediate nodes do not work and output 0 always. In the former setting, it is often allowed to employ the private randomness in intermediate nodes. However, we adopt the latter setting; i.e., no non-local coding operation is allowed in intermediate nodes, and each intermediate node is required to make the same linear operation on each alphabet. That is, the operations in intermediate nodes are linear and are not changed during n transmissions. The private randomness is not employed in intermediate nodes.
Now, we have the following reduction theorem.
Theorem 2 (Reduction theorem)
. When the triplet satisfies the uniqueness condition, Eve’s information with strategy can be calculated from Eve’s information with strategy 0 (the passive attack), and is also calculated from . Hence, we have the equation Proof. Since the first equation follows from the definition, we show the second equation. We define two random variables and . Due to the uniqueness condition of , for each , we can uniquely identify . Therefore, we have . Conversely, since is given as a function of , , and , we have the opposite inequality. □
Remark 2. Theorem 2 discusses the unicast case. It can be trivially extended to the multicast case because we do not discuss the decoder. It can also be extended to the multiple unicast case, whose network is composed of several pairs of senders and receivers. When there are k pairs in this setting, the messages M and the scramble random numbers L have the forms and . Thus, we can apply Theorem 2 to the multiple unicast case. The detail discussion for this extension is discussed in the paper [33]. Remark 3. One may consider the following type of attack when Alice sends the i-th transmission after Bob receives the -th transmission. Eve changes the edge to be attacked in the i-th transmission dependently of the information that Eve obtains in the previous transmissions. Such an attack was discussed in [34]; there was no noise injection. Theorem 2 does not consider such a situation because it assumes that Eve attacks the same edges for each transmission. However, Theorem 2 can be applied to this kind of attack in the following way. That is, we find that Eve’s information with noise injection can be simulated by Eve’s information without noise injection even when the attacked edges are changed in the above way. To see this reduction, we consider m transmissions over the network given by the direct graph . We define the big graph , where and and and express the vertex v and the edge e on the i-th transmission, respectively. Then, we can apply Theorem 2 with to the network given by the directed graph when the attacked edges are changed in the above way. Hence, we obtain the above reduction statement under the uniqueness condition for the network decided by the directed graph .
3.5. Application to Network Model in Section 2.6
We consider how to apply the multiple transmission setting with sequential transmission with
to the network given in
Section 2.6; i.e., we discuss the network given in
Figure 1 and
Figure 2 over the field
with
. Then, we analyze the secrecy by applying Theorem 2.
Assume that Eve eavesdrops edges
and contaminates edges
as
Figure 1. Then, we set the function
from
to
as
Under the choice of
given in (
14), the function
can be set in another way as
Since
,
,
,
, we have
However, when the function
is changed as
has a different form as follows. Under the choice of
given in (
14), while Eve can choose
in the same way as (
29), since
,
,
,
, we have
We construct a code, in which the secrecy holds and Bob can detect the existence of the error in this case. For this aim, we consider two cases: (i) there exists an element to satisfy the equation ; (ii) no element satisfies the equation . Our code works even with in the case (i). However, it requires in the case (ii). For simplicity, we give our code with even in the case (i).
Assume the case (i). Alice’s message is
, and Alice prepares scramble random numbers
with
. These variables are assumed to be subject to the uniform distribution independently. She encodes them as
,
,
, and
. When
, Bob receives
Then, since
, he recovers the message by using
.
As shown in the following, under this code, Eve cannot obtain any information for
M even though she makes active attack under the model given
Figure 1. Eve’s information is
when
. Proposition 2 guarantees that Eve cannot obtain any information for
M when
. Thus, due to Theorem 2, the secrecy holds even when
does not hold.
Indeed, the above attack can be considered as the following. Eve can eavesdrop all edges connected to the intermediate node and contaminate all edges incoming to the intermediate node . The above setting means that the intermediate node is partially captured by Eve. As other settings, we consider the case when Eve attacks another node for . In this case, we allow a slightly stronger attack; i.e., Eve can eavesdrop and contaminate all edges connected to the intermediate node . That is, Eve’s attack is summarized as
- (B1’)
Eve can choose any one of nodes . When is chosen, she eavesdrops all edges connected to and contaminates all edges incoming to . When is chosen for , she eavesdrops and contaminates all edges connected to .
To apply Corollary 1 for analysis of the secrecy, we write down the low vectors
in Corollary 1 under “Vector” in
Table 2. Hence, under this attack, this code has the same secrecy by the combination of Corollary 1 and Theorem 2.
In the case (ii), we set as the matrix . Then, we introduce the algebraic extension of the field by using the element e to satisfy the equation . Then, we identify an element with . Hence, the multiplication of the matrix in can be identified with the multiplication of in . The above analysis works by identifying with the algebraic extension in the case (ii).
3.6. Error Detection
Next, using the discussion in
Section 2.2, we consider another type of security, i.e., the detectability of the existence of the error when
with the assumptions (B1’), (B2) and the following alternative assumption:
- (B3’)
The message set is , and all information on all edges per single use are .
- (B4’)
The encoder on the source node can be chosen, but is restricted to linear. It is allowed to use a scramble random number, which is an element of with a certain integer k. Formally, the encoder is given as as a linear function from to .
We employ the code given in
Section 3.5 and consider that the contamination exists when
is not zero. This code satisfies the secrecy and the detectability as follows.
To consider the case with
, we set
. Regardless of whether Eve makes contamination,
. In the following,
for
expresses the variable when Eve makes contamination. Hence, Bob always recovers the original message
M. Therefore, this code satisfies the desired security in the case with
Figure 1.
In the case of , we set . Then, is calculated through . Hence, when , Bob detects no error. In this case, the contamination (, , and ) does not change , i.e., it does not cause any error for the decoded message. Hence, in order to detect an error in the decoded message, it is sufficient to check whether is zero or not. Since , we have . Hence, if Bob knows that only the edges , , and are contaminated, he can recover the message by .
In the case of , we set . When , Bob detects no error. In this case, the errors , , and do not change . Hence, it is sufficient to check whether is zero or not. In addition, if Bob knows that only the edges are contaminated, he can recover the message by .
Similarly, in the case of , we set , , . If Bob knows that only the edges are contaminated, he can recover the message by the original method because it equals . In summary, when this type attack is done, Bob can detect the existence of the error. If he identifies the attacked node by another method, he can recover the message.
3.7. Solution of Problem Given in Section 2.7
Next, we consider how to resolve the problem arisen in
Section 2.7. That is, we discuss another type of attack given as (B1), and study the secrecy and the detectability of the existence of the error under the above-explained code with the assumptions (B2), (B3’), (B4’), and (B5).
To discuss this problem, we divide this network into two layers. The lower layer consists of the edges and , which are connected to the sink node. The upper layer does of the remaining edges. Eve eavesdrops and contaminates any one edge among the upper layer, and eavesdrops on any one edge among the lower layer.
Again, we consider the low vectors in Corollary 1. The vectors corresponding to the edges of the upper layer are , , , and . The vectors corresponding to the edges of the lower layer are , , and . Any linear combination from the upper and lower layers is not , which implies the secrecy condition given in Corollary 1. Hence, the secrecy holds under the lower type attack. Since the contamination of this type of attack is contained in the contamination of the attack discussed in the previous subsection, the detectability also holds.







{kind=link}
{kind=link}
{kind=link}