A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images


Abstract
1. Introduction
2. Background
- 1)
- We present a novel encoder-decoder deep network which employed a ResNet as encoder modual and a simple yet effective upsampling layers and PointRend algorithm as decoder module.
- 2)
- We use an Atrous Spatial Pyramid Pooling (ASPP) technique to trade off between precision and running time.
- 3)
- We apply a modified cross entropy loss function to enhance the performance of training process for road dataset.
- 4)
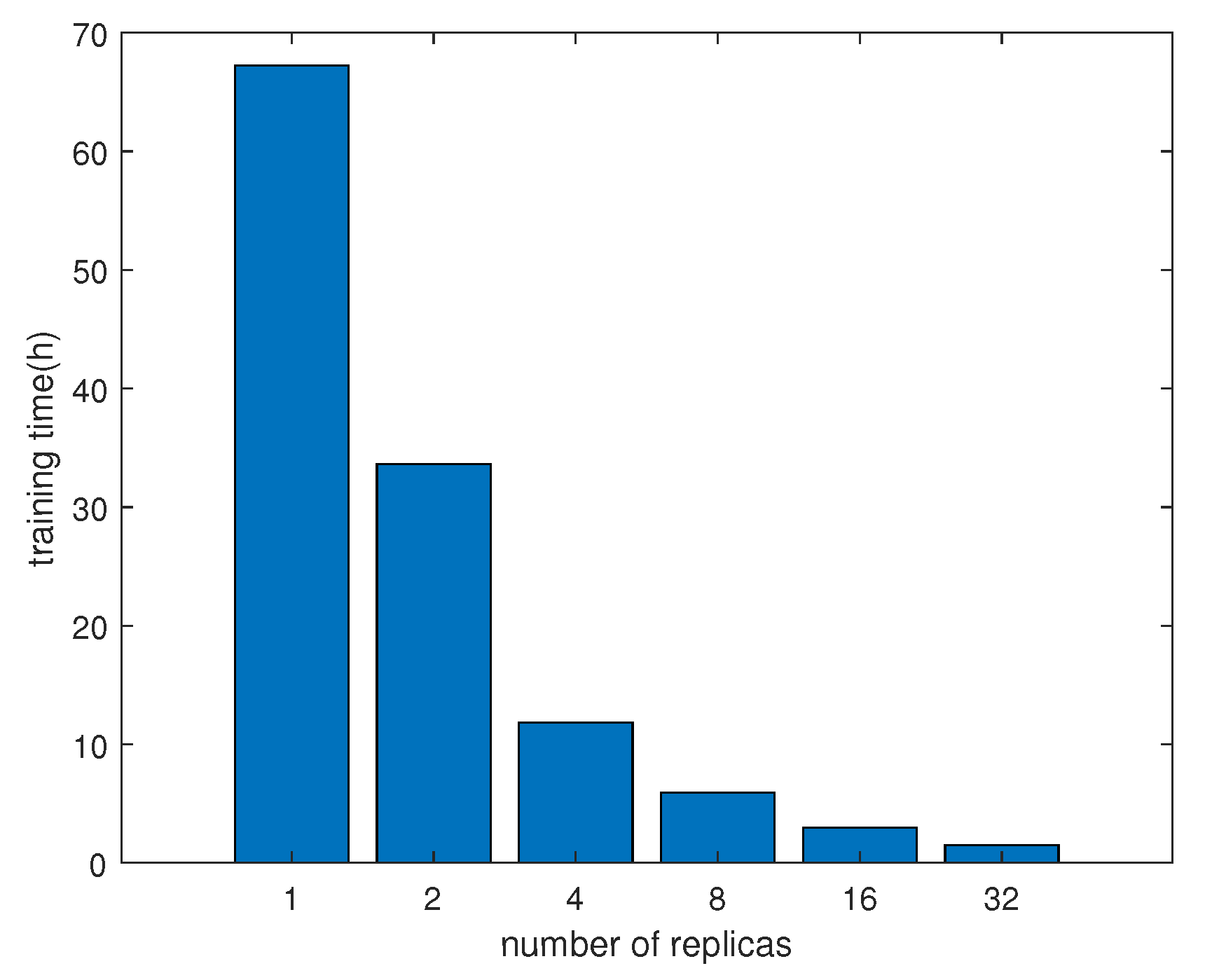
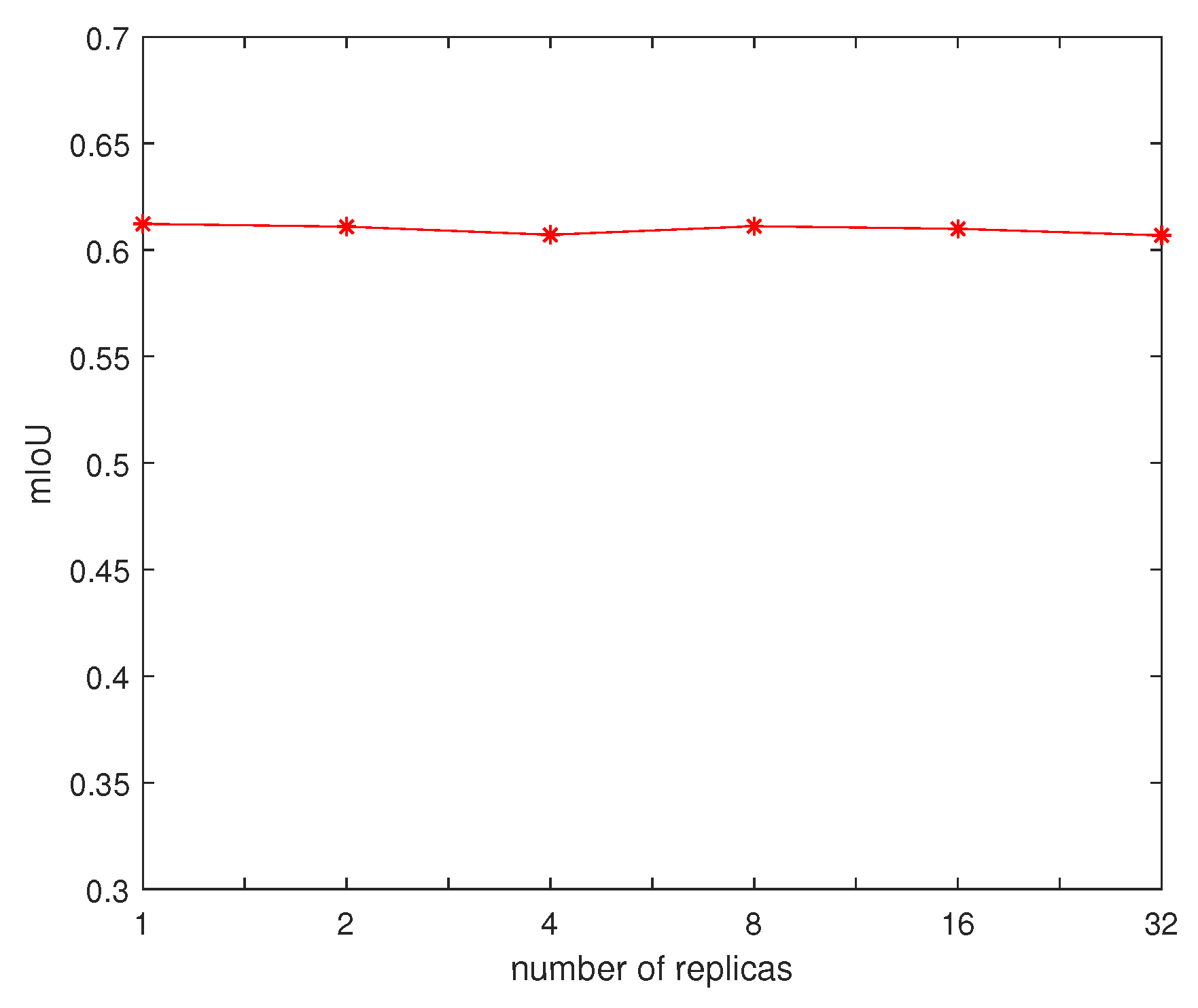
- We employ an asynchronous training method to speedup the training time without loss of performance.
- 5)
- Our proposed model achieves the excellent performance with less network comlexity compared with other deep networks.
3. Methods Description
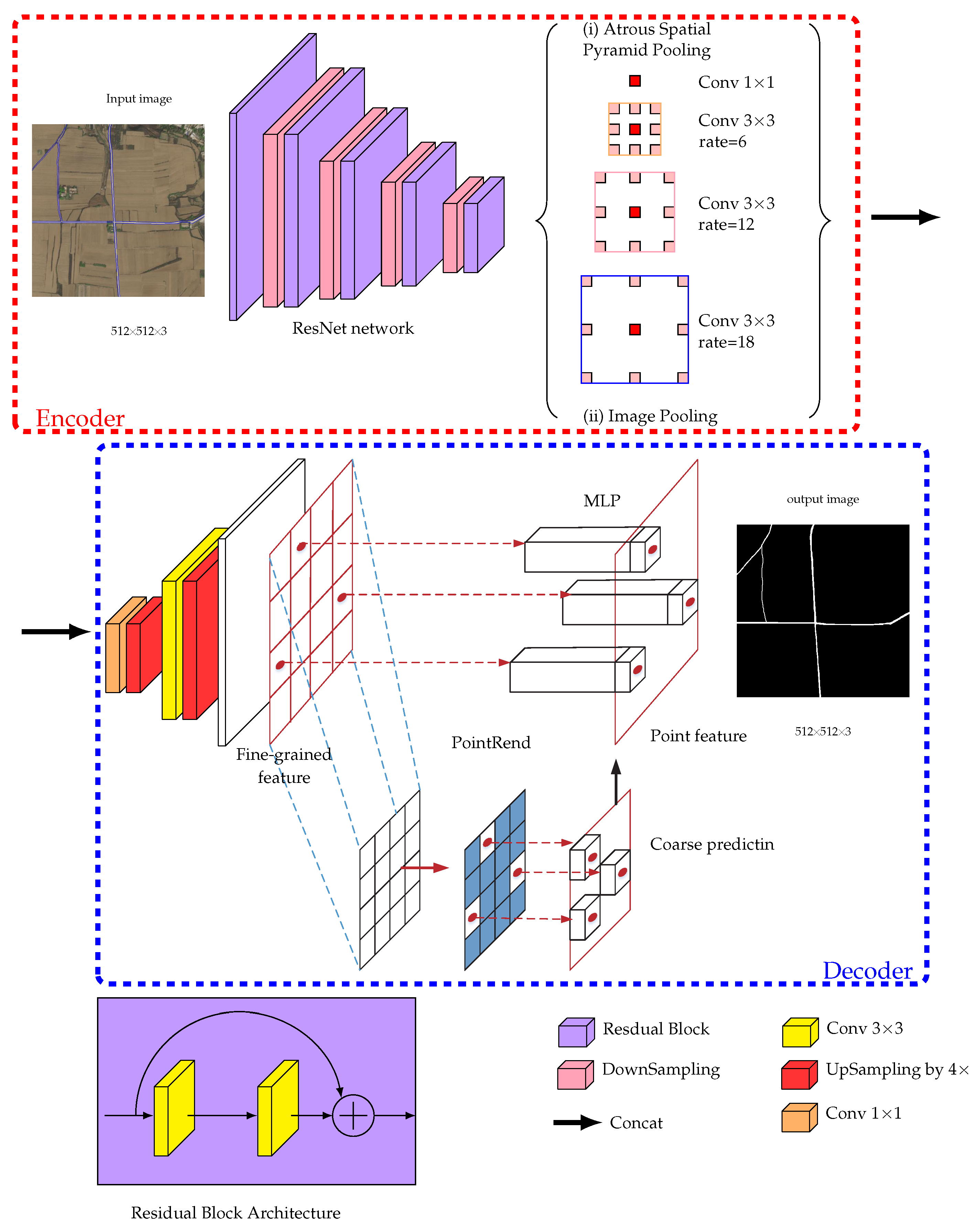
3.1. Encode-Decoder Architecture
3.2. Atrous Spatial Pyramid Pooling
3.3. Sigmoid Function
3.4. Modified Cross Entropy Loss Function
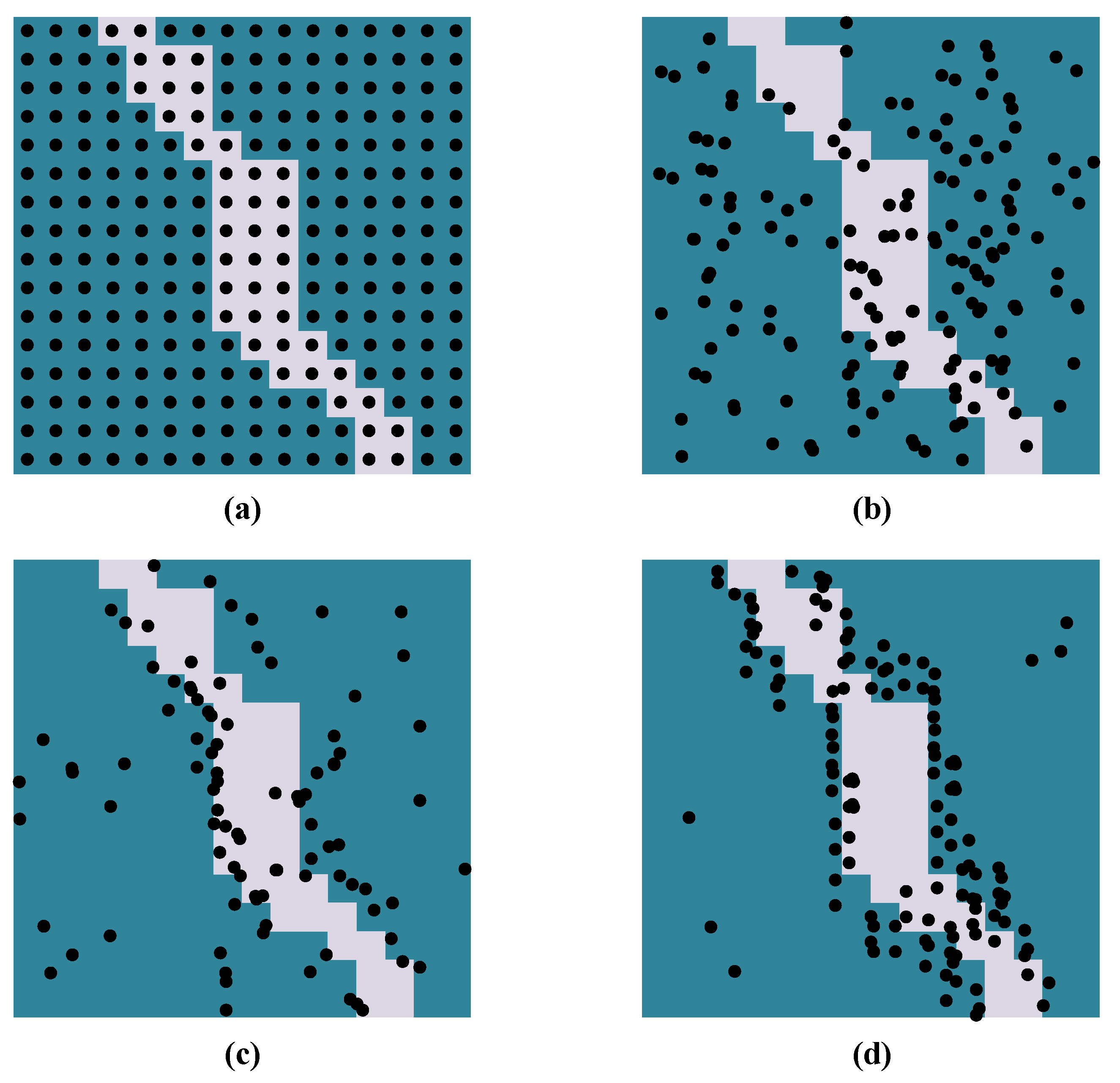
4. PointRend Algorithm
5. Experiments
5.1. Dataset
5.2. Evaluation Metric
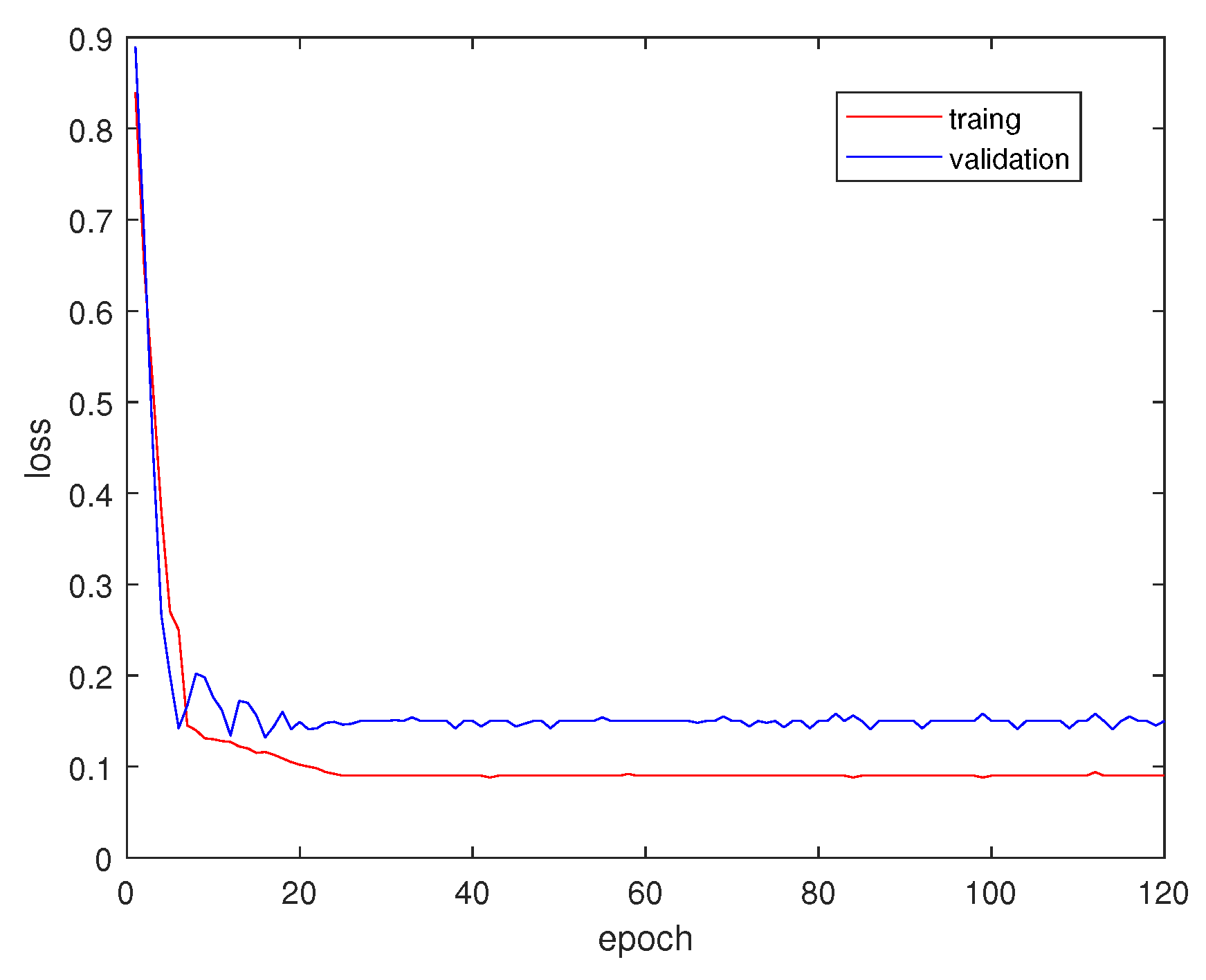
5.3. Training Process
5.4. Results
6. Discussion
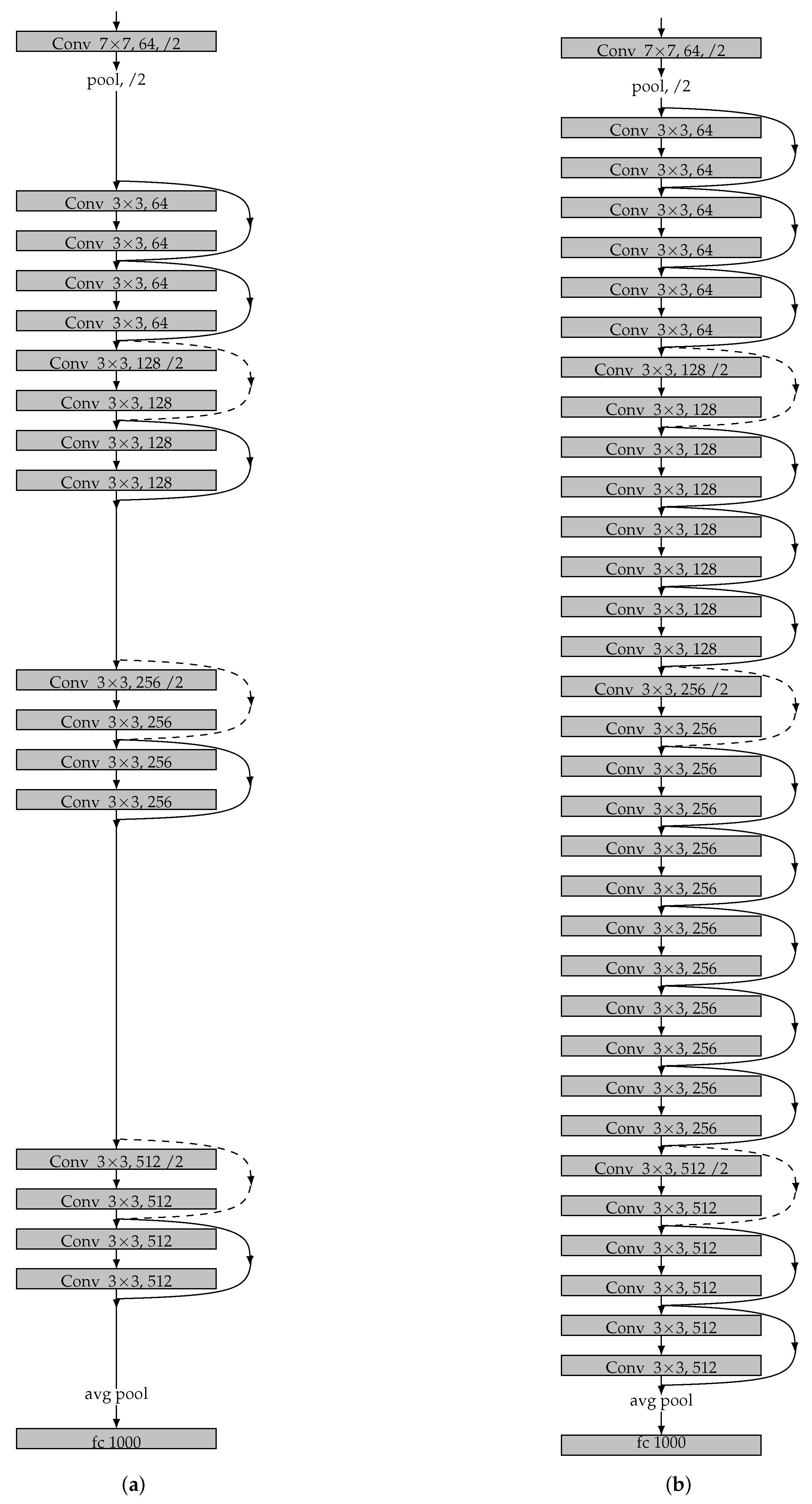
6.1. Effects of Depth
6.2. Effects of PointRend
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained domain transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4545–4554. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Bastani, F.; He, S.; Abbar, S.; Alizadeh, M.; Balakrishnan, H.; Chawla, S.; Madden, S.; DeWitt, D. RoadTracer: Automatic Extraction of Road Networks From Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4720–4728. [Google Scholar]
- Máttyus, G.; Luo, W.; Urtasun, R. Deeproadmapper:Extracting road topology from aerial images. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the ECCV, Heraklion, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. RoadNet: Learning to Comprehensively Analyze Road Networks in Complex Urban Scenes From High-Resolution Remotely Sensed Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2043–2056. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Artacho, B.; Savakis, A. Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation. Sensors 2019, 19, 5361. [Google Scholar] [CrossRef] [PubMed]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.I.; Hughes, F.; Tuia, D.; Raska, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Shpanskaya, K.; et al. Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. arXiv 2019, arXiv:1912.08193. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DRUnet | D-LinkNet | E-Road | ||
|---|---|---|---|---|
| Image 1 | F1(%) | 75.53 | 74.09 | 90.86 |
| recall(%) | 67.87 | 67.20 | 86.72 | |
| OA(%) | 91.81 | 91.43 | 97.15 | |
| IoU(%) | 70.68 | 78.85 | 83.25 | |
| Image 2 | F1(%) | 80.13 | 79.07 | 91.81 |
| recall(%) | 73.53 | 73.09 | 88.27 | |
| OA(%) | 91.34 | 90.97 | 96.67 | |
| IoU(%) | 66.84 | 65.38 | 84.85 | |
| Image 3 | F1(%) | 63.37 | 63.04 | 93.34 |
| recall(%) | 62.17 | 62.39 | 95.13 | |
| OA(%) | 60.50 | 60.19 | 96.25 | |
| IoU(%) | 61.49 | 61.01 | 87.51 |
| E-Road18 | E-Road34 | |
|---|---|---|
| Loss error | 0.089 | 0.087 |
| Training time (h) | 1.5 | 12.7 |
| IoU(%) | 98.82 | 98.23 |
| E-Road-noPR | E-Road | ||
|---|---|---|---|
| Image4 | F1(%) | 91.24 | 92.09 |
| recall(%) | 88.65 | 88.28 | |
| OA(%) | 98.23 | 98.43 | |
| IoU(%) | 91.89 | 99.05 | |
| Image5 | F1(%) | 94.23 | 94.77 |
| recall(%) | 91.53 | 94.09 | |
| OA(%) | 97.34 | 97.97 | |
| IoU(%) | 93.54 | 98.58 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, B.; Fang, Y. A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images. Entropy 2020, 22, 535. https://doi.org/10.3390/e22050535
Shan B, Fang Y. A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images. Entropy. 2020; 22(5):535. https://doi.org/10.3390/e22050535
Chicago/Turabian StyleShan, Bowei, and Yong Fang. 2020. "A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images" Entropy 22, no. 5: 535. https://doi.org/10.3390/e22050535
APA StyleShan, B., & Fang, Y. (2020). A Cross Entropy Based Deep Neural Network Model for Road Extraction from Satellite Images. Entropy, 22(5), 535. https://doi.org/10.3390/e22050535