Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy


Abstract
1. Introduction
2. Materials and Methods
2.1. Database
2.1.1. Augsburg Dataset and Data Pre-Processing
2.1.2. DEAP Dataset and Data Pre-Processing
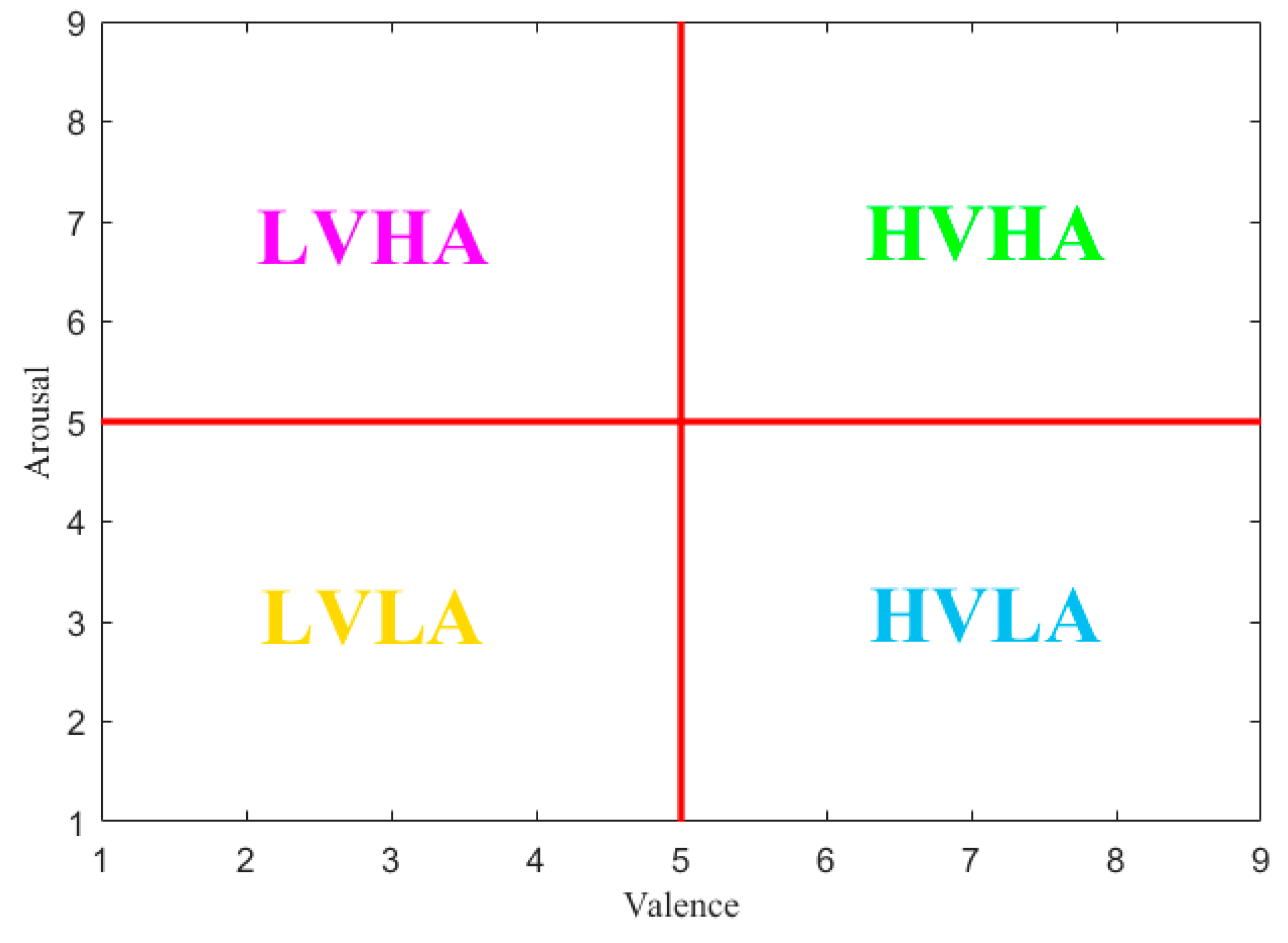
2.2. Emotion Labeling Schemes
2.3. Feature Extraction
2.3.1. Approximate Entropy
2.3.2. Sample Entropy
2.3.3. Fuzzy Entropy
2.3.4. Wavelet Packet Entropy
2.3.5. Multimodal Feature Fusion
2.4. Team-Collaboration Identification Strategy Based on SVM-DT-ELM
2.4.1. Support Vector Machine
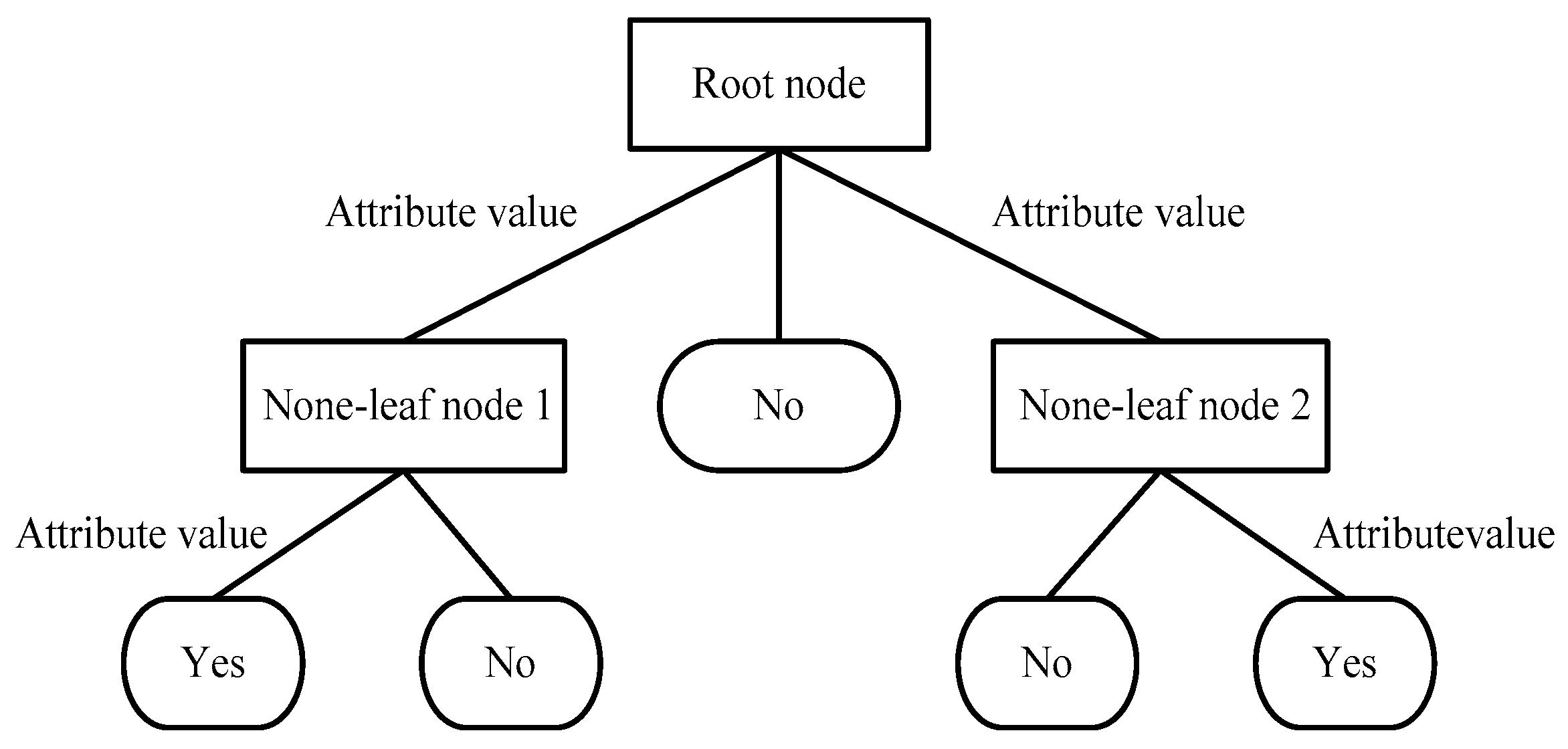
2.4.2. Decision Tree
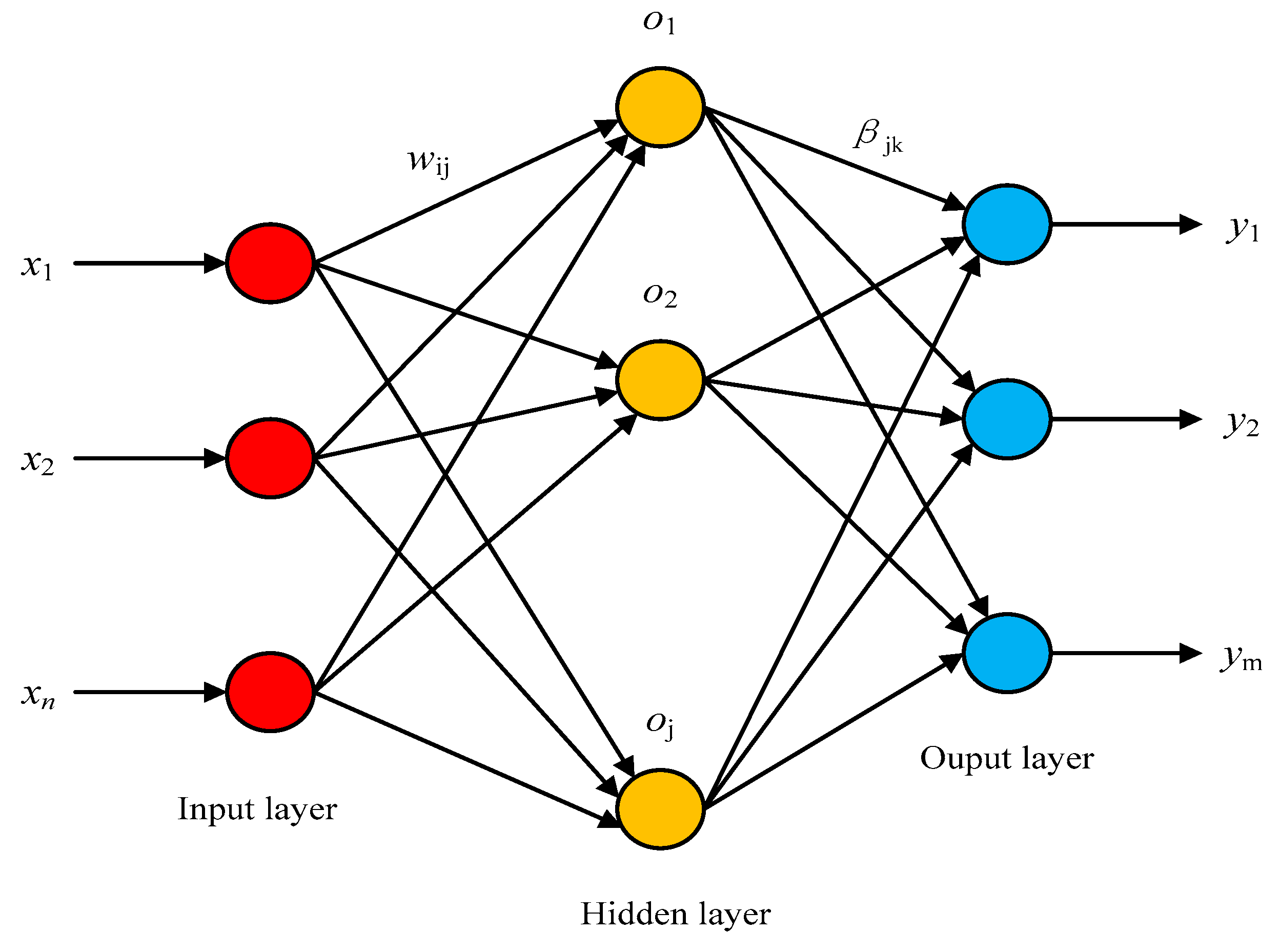
2.4.3. Extreme Learning Machine
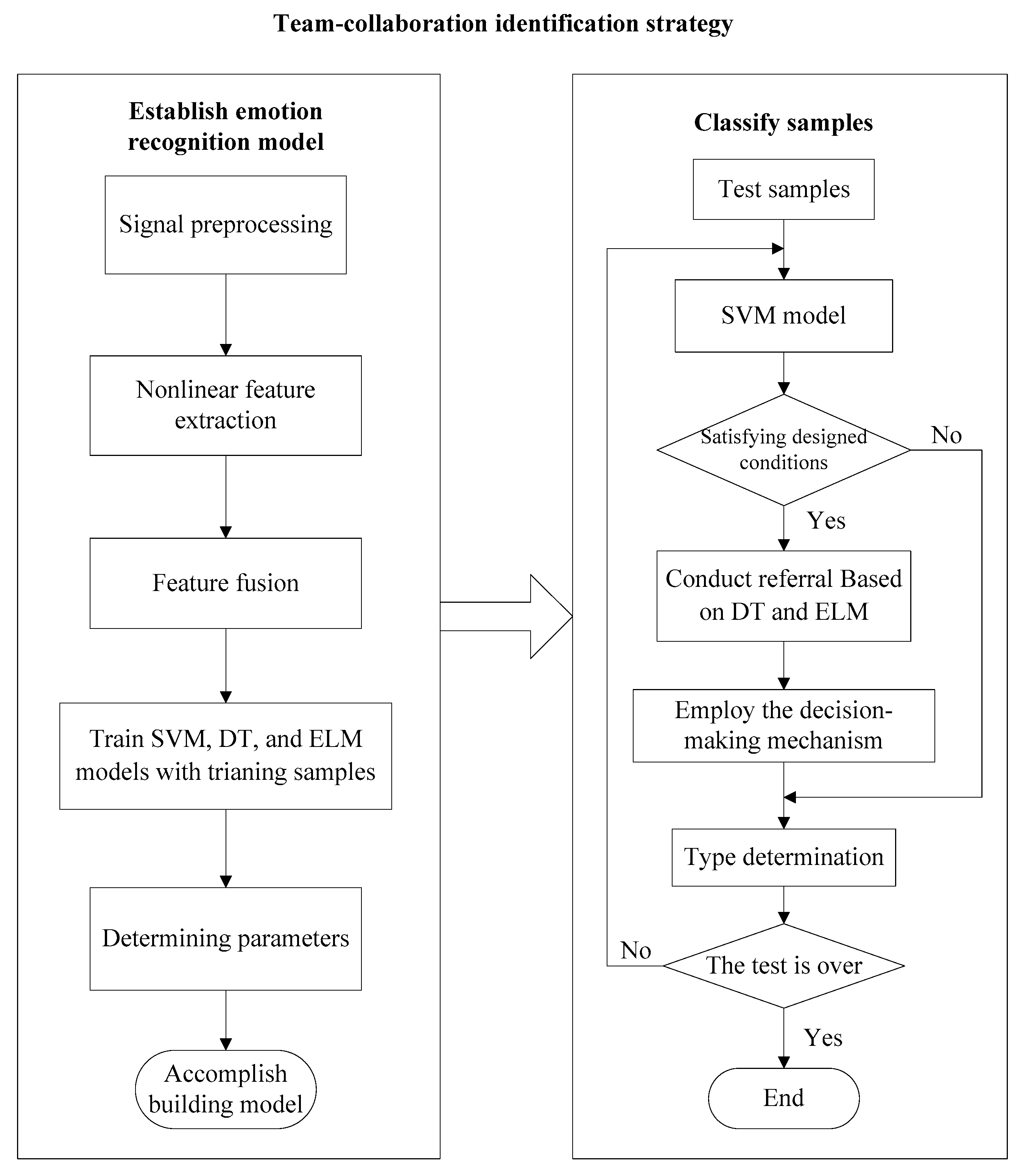
2.4.4. Team-Collaboration Identification Strategy
3. Results and Discussions
3.1. Experiment Environment
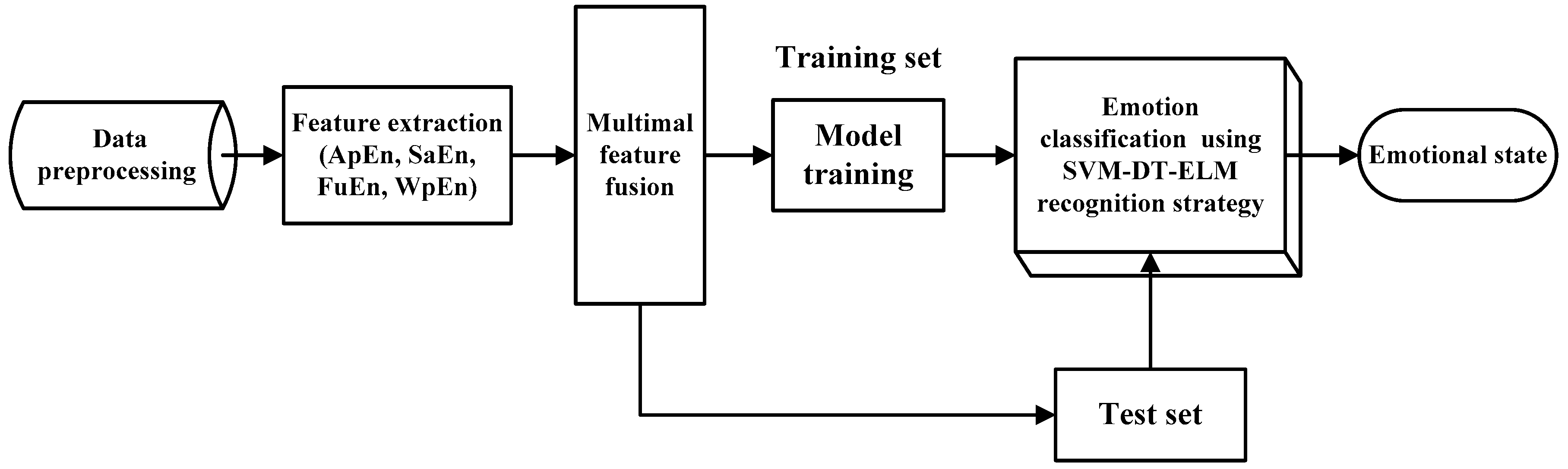
3.2. Procedure of Emotion Recognition
3.3. Model Performance Evaluation Method
3.4. Emotion Classification in Augsburg Dataset
3.4.1. Feature Level Fusion
3.4.2. Team-Collaboration Identification Strategy
3.4.3. Comparison with Existing Methods
3.5. Emotion Classification in DEAP Dataset
3.5.1. Feature Level Fusion
3.5.2. Team-Collaboration Identification Strategy
3.5.3. Comparison with Existing Methods
3.6. Discussions
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kwakkel, G.; Kollen, B.J.; Krebs, H.I. Effects of Robot-Assisted Therapy on Upper Limb Recovery After Stroke: A Systematic Review. Neurorehabilit. Neural Repair 2008, 22, 111–121. [Google Scholar] [CrossRef] [PubMed]
- Long, X.; Fonseca, P.; Foussier, J.; Haakma, R.; Aarts, R. Promoting interactions between humans and robots using robotic emotional behavior. IEEE Trans. Cyber. 2016, 46, 2911–2923. [Google Scholar] [CrossRef]
- Calvo, R.A.; D’Mello, S.K. Affect Detection: An Interdisciplinary Review of Models, Methods, and Their Applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Raoof, K.; Mbarki, M.; Mahjoub, M.A.; Cleder, C. Automatic speech emotion recognition using an optimal combination of features based on EMD-TKEO. Speech Commun. 2019, 114, 22–35. [Google Scholar] [CrossRef]
- Hassan, M.M.; Alam, G.R.; Uddin, Z.; Huda, S.; Almogren, A.; Fortino, G. Human emotion recognition using deep belief network architecture. Inf. Fusion 2019, 51, 10–18. [Google Scholar] [CrossRef]
- Hu, M.; Wang, H.; Wang, X.; Yang, J.; Wang, R. Video facial emotion recognition based on local enhanced motion history image and CNN-CTSLSTM networks. J. Vis. Commun. Image Represent. 2019, 59, 176–185. [Google Scholar] [CrossRef]
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Lu, B.-L. Investigating Critical Frequency Bands and Channels for EEG-Based Emotion Recognition with Deep Neural Networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Chen, P.; Zhang, J. Performance Comparison of Machine Learning Algorithms for EEG-Signal-Based Emotion Recognition. In Proceedings of the International Conference on Artificial Neural Networks (ICANN2017), Alghero, Italy, 11–14 September 2017; pp. 208–216. [Google Scholar]
- Yang, Z. Emotion Recognition Based on Nonlinear Features of Skin Conductance Response. J. Inf. Comput. Sci. 2013, 10, 3877–3887. [Google Scholar] [CrossRef]
- Song, T.; Zheng, W.; Lu, C.; Zong, Y.; Zhang, X.; Cui, Z. MPED: A Multi-Modal Physiological Emotion Database for Discrete Emotion Recognition. IEEE Access 2019, 7, 12177–12191. [Google Scholar] [CrossRef]
- Campbell, E.; Phinyomark, A.; Scheme, E. Feature Extraction and Selection for Pain Recognition Using Peripheral Physiological Signals. Front. Mol. Neurosci. 2019, 13, 437. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.F.; Wang, Y.; Dai, S.C.; Zhao, P.J.; Liu, Q.F. Heart sound signals can be used for emotion recognition. Sci. Rep. 2019, 9, 6486. [Google Scholar] [CrossRef]
- Dissanayake, T.; Rajapaksha, Y.; Ragel, R.; Nawinne, I. An Ensemble Learning Approach for Electrocardiogram Sensor Based Human Emotion Recognition. Sensors 2019, 19, 4495. [Google Scholar] [CrossRef] [PubMed]
- Levenson, R.W. The Autonomic Nervous System and Emotion. Emot. Rev. 2014, 6, 100–112. [Google Scholar] [CrossRef]
- Ali, M.; Al Machot, F.; Mosa, A.H.; Jdeed, M.; Al Machot, E.; Kyamakya, K. A Globally Generalized Emotion Recognition System Involving Different Physiological Signals. Sensors 2018, 18, 1905. [Google Scholar] [CrossRef]
- Abadi, M.K.; Subramanian, R.; Kia, S.M.; Avesani, P.; Patras, I.; Sebe, N. DECAF: MEG-Based Multimodal Database for Decoding Affective Physiological Responses. IEEE Trans. Affect. Comput. 2015, 6, 209–222. [Google Scholar] [CrossRef]
- Choi, J.; Ahmed, B.; Gutierrez-Osuna, R. Development and Evaluation of an Ambulatory Stress Monitor Based on Wearable Sensors. IEEE Trans. Inf. Technol. Biomed. 2012, 16, 279–286. [Google Scholar] [CrossRef]
- Kappeler-Setz, C.; Arnrich, B.; Schumm, J.; La Marca, R.; Troster, G.; Ehlert, U. Discriminating Stress From Cognitive Load Using a Wearable EDA Device. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 410–417. [Google Scholar] [CrossRef]
- Greco, A.; Valenza, G.; Lanata, A.; Scilingo, E.P.; Citi, L. cvxEDA: A Convex Optimization Approach to Electrodermal Activity Processing. IEEE Trans. Biomed. Eng. 2016, 63, 797–804. [Google Scholar] [CrossRef]
- He, L.; Lech, M.; Zhang, J.; Ren, X.; Deng, L. Study of wavelet packet energy entropy for emotion classification in speech and glottal signals. In Proceedings of the Fifth International Conference on Digital Image Processing, Beijing, China, 21–22 April 2013; Volume 8878. [Google Scholar] [CrossRef]
- Wang, X.-W.; Nie, D.; Lu, B.-L. Emotional state classification from EEG data using machine learning approach. Neurocomputing 2014, 129, 94–106. [Google Scholar] [CrossRef]
- Jie, X.; Cao, R.; Li, L. Emotion recognition based on the sample entropy of EEG. BioMed. Mater. Eng. 2014, 24, 1185–1192. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, S.A.; Naghibi-Sistani, M.-B. Emotion recognition method using entropy analysis of EEG signals. Int. J. Image Graph. Signal Process. 2011, 3, 30–36. [Google Scholar] [CrossRef]
- Vayrynen, E.; Kortelainen, J.; Seppanen, T. Classifier-based learning of nonlinear feature manifold for visualization of emotional speech prosody. IEEE Trans. Affect. Comput. 2013, 4, 47–56. [Google Scholar] [CrossRef]
- Li, X.; Cai, E.; Tian, Y.; Sun, X.; Fan, M. An improved electroencephalogram feature extraction algorithm and its application in emotion recognition. J. Biomed. Eng. 2017, 34, 510–517. [Google Scholar] [CrossRef]
- Mohammadi, Z.; Frounchi, J.; Amiri, M. Wavelet-based emotion recognition system using EEG signal. Neural Comput. Appl. 2017, 28, 1985–1990. [Google Scholar] [CrossRef]
- Wagner, J.; Kim, J.; André, E. From Physiological Signals to Emotions: Implementing and Comparing Selected Methods for Feature Extraction and Classification. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 940–943. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.-S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Izard, C.E. Basic Emotions, Natural Kinds, Emotion Schemas, and a New Paradigm. Perspect. Psychol. Sci. 2007, 2, 260–280. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S. Approximate entropy (ApEn) as a complexity measure. Chaos 1995, 5, 110–117. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M. Approximate entropy as a measure of irregularity for psychiatric serial metrics. Bipolar Disord. 2006, 8, 430–440. [Google Scholar] [CrossRef] [PubMed]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef]
- Chen, X.-J.; Li, Z.; Bai, B.-M.; Pan, W.; Chen, Q.-H. A New Complexity Metric of Chaotic Pseudorandom Sequences Based on Fuzzy Entropy. J. Electron. Inf. Technol. 2011, 33, 1198–1203. [Google Scholar] [CrossRef]
- Sun, K.H.; He, S.B.; Yin, L.Z.; Duo, L.K. Application of FuzzyEn algorithm to the analysis of complexity of chaotic sequence. Acta Phys. Sin. 2012, 61, 130507. [Google Scholar] [CrossRef]
- Cheng, B.; Liu, G.Y. Emotion recognition based on wavelet packet entropy of surface EMG signal. Comp. Eng. Appl. 2008, 44, 214–216. [Google Scholar] [CrossRef]
- Snoek, C.; Worring, M.; Smeulders, A.W.M. Early versus late fusion in semantic video analysis. In Proceedings of the 13th Annual ACM International Conference on Multimedia, Hilton, Singapore, 6–11 November 2005. [Google Scholar]
- Turk, M. Multimodal Human–Computer Interaction. Real-Time Vision for Human–Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Guironnet, M.; Pellerin, D.; Rombaut, M. Video Classification based on low-level feature fusion model. In Proceedings of the European Signal Processing Conference, Antalya, Turkey, 4–8 September 2005. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995; pp. 123–179. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Sorel, L.; Viaud, V.; Durand, P.; Walter, C. Modeling spatio-temporal crop allocation patterns by a stochastic decision tree method, considering agronomic driving factors. Agric. Syst. 2010, 103, 647–655. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Guendil, Z.; Lachiri, Z.; Maaoui, C.; Pruski, A. Emotion recognition from physiological signals using fusion of wavelet based features. In Proceedings of the 2015 7th International Conference on Modelling, Identification and Control (ICMIC), Sousse, Tunisia, 18–20 December 2015; pp. 1–6. [Google Scholar]
- Wong, W.M.; Tan, A.W.; Loo, C.; Liew, W.S. PSO optimization of synergetic neural classifier for multichannel emotion recognition. In Proceedings of the 2010 2nd World Congress on Nature and Biologically Inspired Computing (NaBIC), Fukuoka, Japan, 15–17 December 2010; pp. 316–321. [Google Scholar] [CrossRef]
- Zong, C.; Chetouani, M. Hilbert-Huang transform based physiological signals analysis for emotion recognition. In Proceedings of the 2009 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, UAE, 14–17 December 2009; pp. 334–339. [Google Scholar] [CrossRef]
- Gong, P.; Ma, H.T.; Wang, Y. Emotion recognition based on the multiple physiological signals. In Proceedings of the 2016 IEEE International Conference on Real-time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 140–143. [Google Scholar]
- Chen, J.; Hu, B.; Moore, P.; Zhang, X.; Ma, X. Electroencephalogram-based emotion assessment system using ontology and data mining techniques. Appl. Soft Comput. 2015, 30, 663–674. [Google Scholar] [CrossRef]
- Zhuang, N.; Zeng, Y.; Tong, L.; Zhang, C.; Zhang, H.; Yan, B. Emotion Recognition from EEG Signals Using Multidimensional Information in EMD Domain. BioMed Res. Int. 2017, 2017, 8317357. [Google Scholar] [CrossRef]
- Yin, Z.; Zhao, M.; Wang, Y.; Yang, J.; Zhang, J. Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Comput. Methods Programs Biomed. 2017, 140, 93–110. [Google Scholar] [CrossRef]
- Alazrai, R.; Homoud, R.; Alwanni, H.; Daoud, M.I. EEG-Based Emotion Recognition Using Quadratic Time-Frequency Distribution. Sensors 2018, 18, 2739. [Google Scholar] [CrossRef]
- Kwon, Y.-H.; Shin, S.-B.; Kim, S.-D. Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System. Sensors 2018, 18, 1383. [Google Scholar] [CrossRef]
- Zubair, M.; Yoon, C. EEG Based Classification of Human Emotions Using Discrete Wavelet Transform. In Proceedings of the Conference on IT Convergence and Security 2017, Seoul, Korea, 25–28 September 2017; pp. 21–28. [Google Scholar]
- Zheng, W.L.; Zhu, J.Y.; Lu, B.L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2019, 10, 417–429. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Elicitation Material | Music |
|---|---|
| Emotional states | Joy, anger, sadness, pleasure |
| Number of subjects | 1 |
| Collected signals | ECG, EMG, RSP, SC |
| Length | 120 seconds |
| Sampling frequency | ECG: 256 Hz; EMG, RSP and SC: 32 Hz; |
| Collected days | 25 |
| Elicitation Material | Videos |
|---|---|
| Emotion labels | Arousal, valence |
| Number of subjects | 32 |
| Collected signals | EEG, EOG, GSR, BVP, RSP, EMG, SKT |
| Length | 60 seconds |
| Sampling frequency | 128 Hz; |
| Rating values | Arousal: 1–9 Valence: 1–9 |
| Subject | HVHA | HVLA | LVLA | LVHA | Total |
|---|---|---|---|---|---|
| s01 | 130 | 60 | 100 | 110 | 400 |
| s02 | 160 | 60 | 100 | 80 | 400 |
| s03 | 10 | 210 | 110 | 70 | 400 |
| s04 | 120 | 40 | 200 | 40 | 400 |
| s05 | 130 | 110 | 100 | 60 | 400 |
| Total | 550 | 480 | 610 | 360 | 2000 |
| CPU | Intel Core i7-8750H |
|---|---|
| GPU | NVIDIA GeForce GTX1050Ti 4GB |
| OS | Windows 10 |
| RAM | DDR4 16GB |
| Frameworks | MATLAB (R2015b) |
| Physiological Sensor | Acc*(%) | |||
|---|---|---|---|---|
| SVM | DT | ELM | ||
| Single sensor | ECG | 65.7 ± 1.55 | 62.1 ± 1.92 | 58.4 ± 2.72 |
| EMG | 72.1 ± 0.97 | 60.1 ± 1.84 | 62.3 ± 2.47 | |
| RSP | 66.4 ± 1.22 | 66.2 ± 1.75 | 59.7 ± 2.62 | |
| SC | 70.9 ± 1.43 | 64.5 ± 1.54 | 60.6 ± 2.33 | |
| Multi sensors | ECG + EMG + RSP + SC | 95.5 ± 0.85 | 90.5 ± 1.27 | 89.4 ± 1.78 |
| Number of Experiments | Classification Methods (Acc*/%) | |||
|---|---|---|---|---|
| SVM | DT | ELM | SVM-DT-ELM | |
| 1 | 96 | 91 | 86 | 98 |
| 2 | 96 | 91 | 89 | 98 |
| 3 | 95 | 92 | 89 | 98 |
| 4 | 95 | 89 | 91 | 99 |
| 5 | 94 | 90 | 88 | 98 |
| 6 | 95 | 90 | 90 | 98 |
| 7 | 95 | 93 | 92 | 99 |
| 8 | 96 | 89 | 90 | 100 |
| 9 | 96 | 90 | 88 | 99 |
| 10 | 97 | 90 | 91 | 99 |
| Acc* (%) | 95.5 ± 0.85 | 90.5 ± 1.27 | 89.4 ± 1.78 | 98.6 ± 0.70 |
| Classification Method | Feature Dimension | Acc* (%) |
|---|---|---|
| LDF [29] | 32 | 92.05 |
| SVM [51] | 64 | 95 |
| PSO-SNC [52] | 32 | 86 |
| SVM [53] | 28 | 76 |
| C4.5 DT [54] | 155 | 93 |
| This paper | 16 | 98.6 |
| Subject | Physiological Sensors | ||||
|---|---|---|---|---|---|
| Single Sensor (Acc*/%) | Multi Sensors (Acc*/%) | ||||
| GSR | RSP | BVP | EMG | GSR + RSP + EMG + BVP | |
| s01 | 38.0 ± 1.46 | 43.3 ± 2.73 | 53.5 ± 3.06 | 50.6 ± 1.56 | 73.5 ± 2.07 |
| s02 | 34.0 ± 2.25 | 53.1 ± 1.73 | 43.2 ± 1.67 | 52.1 ± 3.03 | 65.1 ± 2.69 |
| s03 | 54.3 ± 1.51 | 60.8 ± 2.72 | 65.6 ± 1.83 | 63.2 ± 2.33 | 81.5 ± 1.35 |
| s04 | 48.6 ± 4.13 | 52.3 ± 3.67 | 56.5 ± 3.99 | 56.1 ± 2.17 | 62.7 ± 2.21 |
| s05 | 32.8 ± 2.56 | 43.1 ± 3.88 | 47.6 ± 3.69 | 42.5 ± 3.04 | 69.2 ± 2.70 |
| Subject | Physiological Sensors | ||||
|---|---|---|---|---|---|
| Single Sensor (Acc*/%) | Multi Sensors (Acc*/%) | ||||
| GSR | RSP | BVP | EMG | GSR + RSP + EMG + BVP | |
| s01 | 32.8 ± 2.95 | 39.8 ± 3.11 | 41.6 ± 4.34 | 46.4 ± 2.41 | 60.3 ± 1.95 |
| s02 | 35.6 ± 1.82 | 33.0 ± 2.23 | 50.0 ± 2.35 | 44.2 ± 3.70 | 53.3 ± 2.36 |
| s03 | 40.8 ± 1.30 | 49.4 ± 2.70 | 55.2 ± 0.84 | 57.4 ± 1.82 | 60.3 ± 2.00 |
| s04 | 40.8 ± 2.17 | 40.2 ± 3.03 | 40.4 ± 4.16 | 45.4 ± 1.95 | 59.4 ± 2.01 |
| s05 | 28.6 ± 1.52 | 41.4 ± 2.40 | 37.2 ± 1.48 | 41.6 ± 2.30 | 52.7 ± 2.83 |
| Subject | Physiological Sensors | ||||
|---|---|---|---|---|---|
| Single Sensor (Acc*/%) | Multi Sensors (Acc*/%) | ||||
| GSR | RSP | BVP | EMG | GSR + RSP + EMG + BVP | |
| s01 | 29.2 ± 1.64 | 47.0 ± 2.55 | 46.8 ± 1.92 | 43.4 ± 3.65 | 61.5 ± 2.37 |
| s02 | 30.4 ± 1.67 | 34.4 ± 2.70 | 49.6 ± 3.50 | 42.6 ± 1.82 | 55.4 ± 2.37 |
| s03 | 40.0 ± 3.08 | 54.6 ± 3.36 | 54.4 ± 2.97 | 54.6 ± 2.30 | 62.9 ± 1.29 |
| s04 | 39.6 ± 2.70 | 47.8 ± 2.56 | 42.6 ± 3.21 | 45.8 ± 3.56 | 50.1 ± 2.28 |
| s05 | 34.8 ± 3.35 | 44.4 ± 2.97 | 39.8 ± 3.83 | 43.2 ± 3.11 | 53.9 ± 2.73 |
| Subject | Method | The Identification Accuracy of Each Experiment (%) | Average (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| s01 | DT | 64 | 61 | 58 | 60 | 58 | 59 | 59 | 60 | 62 | 62 | 60.3 ± 1.95 |
| ELM | 62 | 60 | 64 | 58 | 62 | 58 | 64 | 60 | 64 | 63 | 61.5 ± 2.37 | |
| SVM | 75 | 72 | 72 | 76 | 75 | 77 | 72 | 73 | 71 | 72 | 73.5 ± 2.07 | |
| Proposed | 80 | 80 | 80 | 81 | 80 | 82 | 79 | 79 | 76 | 78 | 79.5 ± 1.65 | |
| s02 | DT | 55 | 51 | 53 | 53 | 50 | 56 | 51 | 57 | 52 | 55 | 53.3 ± 2.36 |
| ELM | 58 | 54 | 59 | 52 | 53 | 56 | 53 | 57 | 57 | 55 | 55.4 ± 2.37 | |
| SVM | 68 | 66 | 71 | 63 | 63 | 64 | 64 | 66 | 63 | 63 | 65.1 ± 2.69 | |
| Proposed | 72 | 70 | 76 | 70 | 69 | 70 | 68 | 70 | 68 | 70 | 70.3 ± 2.31 | |
| s03 | DT | 62 | 58 | 59 | 63 | 62 | 61 | 57 | 59 | 60 | 62 | 60.3 ± 2.00 |
| ELM | 65 | 63 | 61 | 63 | 62 | 62 | 63 | 63 | 65 | 62 | 62.9 ± 1.29 | |
| SVM | 84 | 82 | 80 | 82 | 83 | 81 | 80 | 81 | 80 | 82 | 81.5 ± 1.35 | |
| Proposed | 88 | 88 | 87 | 89 | 86 | 86 | 87 | 86 | 87 | 86 | 87 ± 1.05 | |
| s04 | DT | 58 | 62 | 60 | 57 | 61 | 58 | 59 | 58 | 63 | 58 | 59.4 ± 2.01 |
| ELM | 48 | 51 | 49 | 47 | 53 | 50 | 47 | 52 | 53 | 51 | 50.1 ± 2.28 | |
| SVM | 63 | 66 | 65 | 64 | 65 | 60 | 61 | 60 | 62 | 61 | 62.7 ± 2.21 | |
| Proposed | 70 | 70 | 72 | 72 | 73 | 68 | 70 | 70 | 68 | 67 | 70 ± 1.94 | |
| s05 | DT | 50 | 52 | 52 | 55 | 50 | 51 | 59 | 51 | 52 | 55 | 52.7 ± 2.83 |
| ELM | 57 | 58 | 52 | 50 | 56 | 53 | 54 | 51 | 52 | 56 | 53.9 ± 2.73 | |
| SVM | 69 | 67 | 68 | 66 | 76 | 69 | 70 | 70 | 69 | 68 | 69.2 ± 2.70 | |
| Proposed | 75 | 73 | 78 | 73 | 82 | 75 | 75 | 74 | 75 | 75 | 75.5 ± 2.68 | |
| Overall average | DT ELM SVM | 57.2 ± 2.23 56.8 ± 2.21 70.4 ± 2.20 | ||||||||||
| Proposed | 76.46 ± 1.93 | |||||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, L.; Yin, Z.; She, S.; Song, A. Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy. Entropy 2020, 22, 511. https://doi.org/10.3390/e22050511
Pan L, Yin Z, She S, Song A. Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy. Entropy. 2020; 22(5):511. https://doi.org/10.3390/e22050511
Chicago/Turabian StylePan, Lizheng, Zeming Yin, Shigang She, and Aiguo Song. 2020. "Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy" Entropy 22, no. 5: 511. https://doi.org/10.3390/e22050511
APA StylePan, L., Yin, Z., She, S., & Song, A. (2020). Emotional State Recognition from Peripheral Physiological Signals Using Fused Nonlinear Features and Team-Collaboration Identification Strategy. Entropy, 22(5), 511. https://doi.org/10.3390/e22050511