Limitations to Estimating Mutual Information in Large Neural Populations


{kind=link}
Abstract
1. Introduction
2. Results
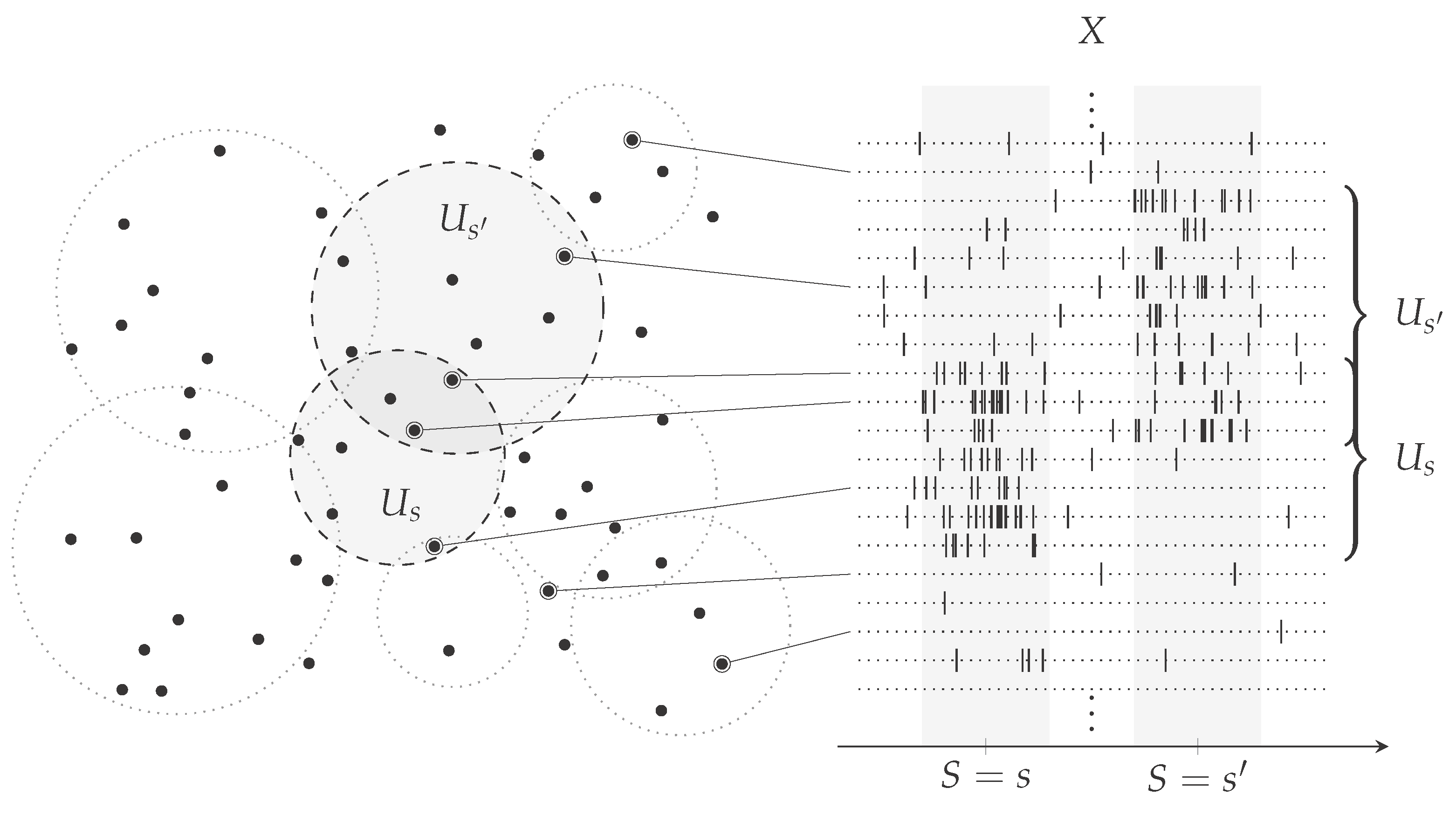
2.1. Analysis of a Computational Model of Sensory Processing Regarding Estimating Information Theoretic Quantities
2.2. Computing the Probability of a Finite Number of Independent and Identically Distributed Random Variables being Mutually Different
3. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pouget, A.; Dayan, P.; Zemel, R. Information processing with population codes. Nat. Rev. Neurosci. 2000, 1, 125–132. [Google Scholar] [CrossRef] [PubMed]
- Sakurai, Y. Population coding by cell assemblies—What it really is in the brain. Neurosci. Res. 1996, 26, 1–16. [Google Scholar] [CrossRef]
- Scanziani, M.; Häusser, M. Electrophysiology in the age of light. Nature 2009, 461, 930–939. [Google Scholar] [CrossRef] [PubMed]
- Jun, J.J.; Steinmetz, N.A.; Siegle, J.H.; Denman, D.J.; Bauza, M.; Barbarits, B.; Lee, A.K.; Anastassiou, C.A.; Andrei, A.; Aydın, Ç.; et al. Fully integrated silicon probes for high-density recording of neural activity. Nature 2017, 551, 232–236. [Google Scholar] [CrossRef]
- Quian Quiroga, R.; Panzeri, S. Extracting information from neuronal populations: Information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef]
- Kinney, J.B.; Atwal, G.S. Equitability, mutual information, and the maximal information coefficient. Proc. Natl. Acad. Sci. USA 2014, 111, 3354–3359. [Google Scholar] [CrossRef]
- Rhee, A.; Cheong, R.; Levchenko, A. The application of information theory to biochemical signaling systems. Phys. Biol. 2012, 9, 045011. [Google Scholar] [CrossRef]
- Dorval, A.D. Estimating Neuronal Information: Logarithmic Binning of Neuronal Inter-Spike Intervals. Entropy 2011, 13, 485–501. [Google Scholar] [CrossRef]
- Macke, J.H.; Murray, I.; Latham, P.E. How biased are maximum entropy models? Adv. Neural Inf. Process. Syst. 2011, 24, 2034–2042. [Google Scholar]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the Sampling Bias Problem in Spike Train Information Measures. J. Neurophysiol. 2007, 98, 1064–1072. [Google Scholar] [CrossRef]
- Treves, A.; Panzeri, S. The Upward Bias in Measures of Information Derived from Limited Data Samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Panzeri, S.; Treves, A. Analytical estimates of limited sampling biases in different information measures. Network 1996, 7, 87–107. [Google Scholar] [CrossRef] [PubMed]
- Adibi, M.; McDonald, J.S.; Clifford, C.W.G.; Arabzadeh, E. Adaptation Improves Neural Coding Efficiency Despite Increasing Correlations in Variability. J. Neurosci. 2013, 33, 2108–2120. [Google Scholar] [CrossRef] [PubMed]
- Takaguchi, T.; Nakamura, M.; Sato, N.; Yano, K.; Masuda, N. Predictability of Conversation Partners. Phys. Rev. X 2011, 1, 011008. [Google Scholar] [CrossRef]
- Pachitariu, M.; Lyamzin, D.R.; Sahani, M.; Lesica, N.A. State-Dependent Population Coding in Primary Auditory Cortex. J. Neurosci. 2015, 35, 2058–2073. [Google Scholar] [CrossRef]
- Lopes-dos Santos, V.; Panzeri, S.; Kayser, C.; Diamond, M.E.; Quian Quiroga, R. Extracting information in spike time patterns with wavelets and information theory. J. Neurophysiol. 2015, 113, 1015–1033. [Google Scholar] [CrossRef]
- Montgomery, N.; Wehr, M. Auditory Cortical Neurons Convey Maximal Stimulus-Specific Information at Their Best Frequency. J. Neurosci. 2010, 30, 13362–13366. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of Entropy and Mutual Information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- Zhang, Z. Entropy Estimation in Turing’s Perspective. Neural Comput. 2012, 24, 1368–1389. [Google Scholar] [CrossRef]
- Yu, Y.; Crumiller, M.; Knight, B.; Kaplan, E. Estimating the amount of information carried by a neuronal population. Front. Comput. Neurosci. 2010, 4, 10. [Google Scholar] [CrossRef]
- Archer, E.W.; Park, I.M.; Pillow, J.W. Bayesian entropy estimation for binary spike train data using parametric prior knowledge. Adv. Neural Inf. Process. Syst. 2013, 26, 1700–1708. [Google Scholar]
- Vinck, M.; Battaglia, F.P.; Balakirsky, V.B.; Vinck, A.J.H.; Pennartz, C.M.A. Estimation of the entropy based on its polynomial representation. Phys. Rev. E 2012, 85. [Google Scholar] [CrossRef] [PubMed]
- Xiong, W.; Faes, L.; Ivanov, P.C. Entropy measures, entropy estimators, and their performance in quantifying complex dynamics: Effects of artifacts, nonstationarity, and long-range correlations. Phys. Rev. E 2017, 95, 062114. [Google Scholar] [CrossRef] [PubMed]
- O’Donnell, C.; Gonçalves, J.T.; Whiteley, N.; Portera-Cailliau, C.; Sejnowski, T.J. The Population Tracking Model: A Simple, Scalable Statistical Model for Neural Population Data. Neural Comput. 2017, 29, 50–93. [Google Scholar] [CrossRef] [PubMed]
- Victor, J.D. Approaches to Information-Theoretic Analysis of Neural Activity. Biol. Theory 2006, 1, 302–316. [Google Scholar] [CrossRef] [PubMed]
- Timme, N.M.; Lapish, C. A Tutorial for Information Theory in Neuroscience. eNeuro 2018, 5. [Google Scholar] [CrossRef]
- Pregowska, A.; Szczepanski, J.; Wajnryb, E. Mutual information against correlations in binary communication channels. BMC Neurosci. 2015, 16, 32. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Stanley, R.P. Enumerative Combinatorics, 2nd ed.; Cambridge Studies in Advanced Mathematics; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar] [CrossRef]
- Malenfant, J. Finite, closed-form expressions for the partition function and for Euler, Bernoulli, and Stirling numbers. arXiv 2011, arXiv:1103.1585. [Google Scholar]
- Stringer, C.; Pachitariu, M.; Steinmetz, N.; Reddy, C.B.; Carandini, M.; Harris, K.D. Spontaneous behaviors drive multidimensional, brainwide activity. Science 2019, 364, eaav7893. [Google Scholar] [CrossRef]
- Triplett, M.A.; Pujic, Z.; Sun, B.; Avitan, L.; Goodhill, G.J. Model-based decoupling of evoked and spontaneous neural activity in calcium imaging data. bioRxiv 2019. [Google Scholar] [CrossRef]
- Schneidman, E.; Berry, M.J., II; Segev, R.; Bialek, W. Weak pairwise correlations imply strongly correlated network states in a neural population. Nature 2006, 440, 1007–1012. [Google Scholar] [CrossRef] [PubMed]
- Granot-Atedgi, E.; Tkačik, G.; Segev, R.; Schneidman, E. Stimulus-dependent Maximum Entropy Models of Neural Population Codes. PLoS Comput. Biol. 2013, 9, e1002922. [Google Scholar] [CrossRef] [PubMed]
- Tkačik, G.; Marre, O.; Mora, T.; Amodei, D.; Berry, M.J., II; Bialek, W. The simplest maximum entropy model for collective behavior in a neural network. J. Stat. Mech. 2013, 2013, P03011. [Google Scholar] [CrossRef]
- Tkačik, G.; Marre, O.; Amodei, D.; Schneidman, E.; Bialek, W.; Berry II, M.J. Searching for Collective Behavior in a Large Network of Sensory Neurons. PLoS Comput. Biol. 2014, 10, e1003408. [Google Scholar] [CrossRef] [PubMed]
- Park, I.M.; Archer, E.W.; Latimer, K.; Pillow, J.W. Universal models for binary spike patterns using centered Dirichlet processes. Adv. Neural Inf. Process. Syst. 2013, 26, 2463–2471. [Google Scholar]
- Tkačik, G.; Schneidman, E.; Berry, M.J., II; Bialek, W. Ising models for networks of real neurons. arXiv 2006, arXiv:q-bio/0611072. [Google Scholar]
- Tkačik, G.; Schneidman, E.; Berry, M.J., II; Bialek, W. Spin glass models for a network of real neurons. arXiv 2009, arXiv:0912.5409. [Google Scholar]
- Stevens, C.F.; Zador, A.M. Information through a Spiking Neuron. Adv. Neural Inf. Process. Syst. 1996, 8, 75–81. [Google Scholar]
- Strong, S.P.; Koberle, R.; de Ruyter van Steveninck, R.R.; Bialek, W. Entropy and Information in Neural Spike Trains. Phys. Rev. Lett. 1998, 80, 197–200. [Google Scholar] [CrossRef]
- Borst, A.; Theunissen, F.E. Information theory and neural coding. Nat. Neurosci. 1999, 2, 947–957. [Google Scholar] [CrossRef] [PubMed]

© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mölter, J.; Goodhill, G.J. Limitations to Estimating Mutual Information in Large Neural Populations. Entropy 2020, 22, 490. https://doi.org/10.3390/e22040490
Mölter J, Goodhill GJ. Limitations to Estimating Mutual Information in Large Neural Populations. Entropy. 2020; 22(4):490. https://doi.org/10.3390/e22040490
Chicago/Turabian StyleMölter, Jan, and Geoffrey J. Goodhill. 2020. "Limitations to Estimating Mutual Information in Large Neural Populations" Entropy 22, no. 4: 490. https://doi.org/10.3390/e22040490
APA StyleMölter, J., & Goodhill, G. J. (2020). Limitations to Estimating Mutual Information in Large Neural Populations. Entropy, 22(4), 490. https://doi.org/10.3390/e22040490