1. Introduction
The rapid growth of Internet technologies has led to an enormous increase in the number of electronic documents used worldwide. To organize and manage documents effectively and efficiently, text categorization (TC) has been employed in recent decades. TC assigns text documents to pre-defined topics, categories, or classes, which is an important task in information retrieval [
1]. TC has been gaining additional traction in recent years owing to easily-available digitized text such as web pages, e-mails, blogs, social network services, product information or reviews, etc. [
2].
To conduct TC tasks, documents are usually represented using the bag-of-words model, because of its simplicity. In this representation, dimensionality is high [
3,
4] because all terms in the vocabulary are used to construct the feature vectors corresponding to the documents. As a matrix representation, the documents and terms correspond to rows and columns, respectively, and the number of terms may reach tens to hundreds of thousands [
5]. While dimensionality may be very high, a large number of terms may not be relevant to the topic, and can be considered as noise. Thus, many researchers have proposed different feature selection methods for TC [
6,
7,
8] to reduce dimensionality, to simplify the feature vectors, and to achieve high accuracy and efficiency.
For TC, conventional feature selection metrics measure the dependency between terms and the topic based on term frequency, such as
, mutual information, and information gain, and then rank the terms using the dependency values [
9]. However, these approaches may select redundant terms because, in large text documents, similar terms occur, and the metrics give similar scores to similar terms (for example, synonyms). Many recent feature selection methods used for TC are also based on these metrics, and may operate under this restriction. Thus, these redundant terms can impose a limit on the accuracy of TC.
In this paper, we propose a novel term selection method to reduce selection of redundant terms by considering term similarity. Term similarity is measured using a general method, such as
, and serves as a second measure in feature selection, in addition to term ranking. Our approach induces independent terms to avoid redundant terms and finds various terms for considering many documents that can cover various subjects. For this goal, the proposed method gives independent terms priority to avoid redundant terms. Thus, the method is not limited to select semantically-related terms. Moreover, to consider balance between term ranking and term similarity for selection of appropriate terms from a global perspective, we use a quadratic programming-based numerical optimization approach. Quadratic programming traditionally has been used to several studies because of usable computational procedure [
10,
11]. Our objective function is a quadratic function that consists of a quadratic term for term similarity and a linear term for term ranking. We calculate optimal weights for term similarity and ranking using quadratic programming, and select useful terms based on the weights.
2. Related Works
There have been studies on dimension reduction, such as random projection, that do not use topic information. For TC, Lin et al. discussed two dimensionality reduction techniques, namely latent semantic indexing and random projection, and proposed a hybrid method combining the two [
12]. Bingham et al. presented experimental results using random projection for dimensionality reduction in text document data [
13]. Torkkola proposed a feature transform method based on linear discriminant analysis using either random projection or latent semantic indexing [
14].
Henceforth, we introduce detailed definitions of three classical feature selection metrics that have been widely used and have achieved satisfactory performance in TC tasks. These metrics are
statistic, information gain, and mutual information. The following definitions are based on [
6,
15].
and
represent a specific term and a specific category, respectively, and the set of all categories is represented by
where
m is the number of categories.
a is the number of documents term in which and co-occur.
b is the number of documents term in which occurs without .
c is the number of documents in which occurs without .
d is the number of documents in which neither or occurs.
The
statistic is used to measure the lack of independence between
and
, and it can be regarded as the
distribution with one degree of freedom. It is defined as
where
M is the total number of documents and can be represented as
. Generally, the category-specific scores of a term can be captured with the average value as
where
can be estimated by
. The maximum value can also be used for the score as
Information Gain (IG) was first used as a feature selection measure in a decision tree. In a a typical example of a decision tree, the ID3 algorithm iteratively decides the feature that divides classes well using IG [
16]. Supervised feature selection methods such as ID3 can identify different categories. The IG of term
in multi class text data can be defined as [
15]
In the above definition,
,
, and
correspond to
,
, and
, respectively.
Mutual Information (MI) measures the mutual dependency of two random variables [
15], and is defined as
where
can be estimated by
. In MI, the category-specific scores of a term can also be captured using the average value as
To conclude, conventional feature selection methods for text categorization evaluate the importance of based on its dependency on categories C, and the top-scoring features are used in the categorization process without requiring a special search.
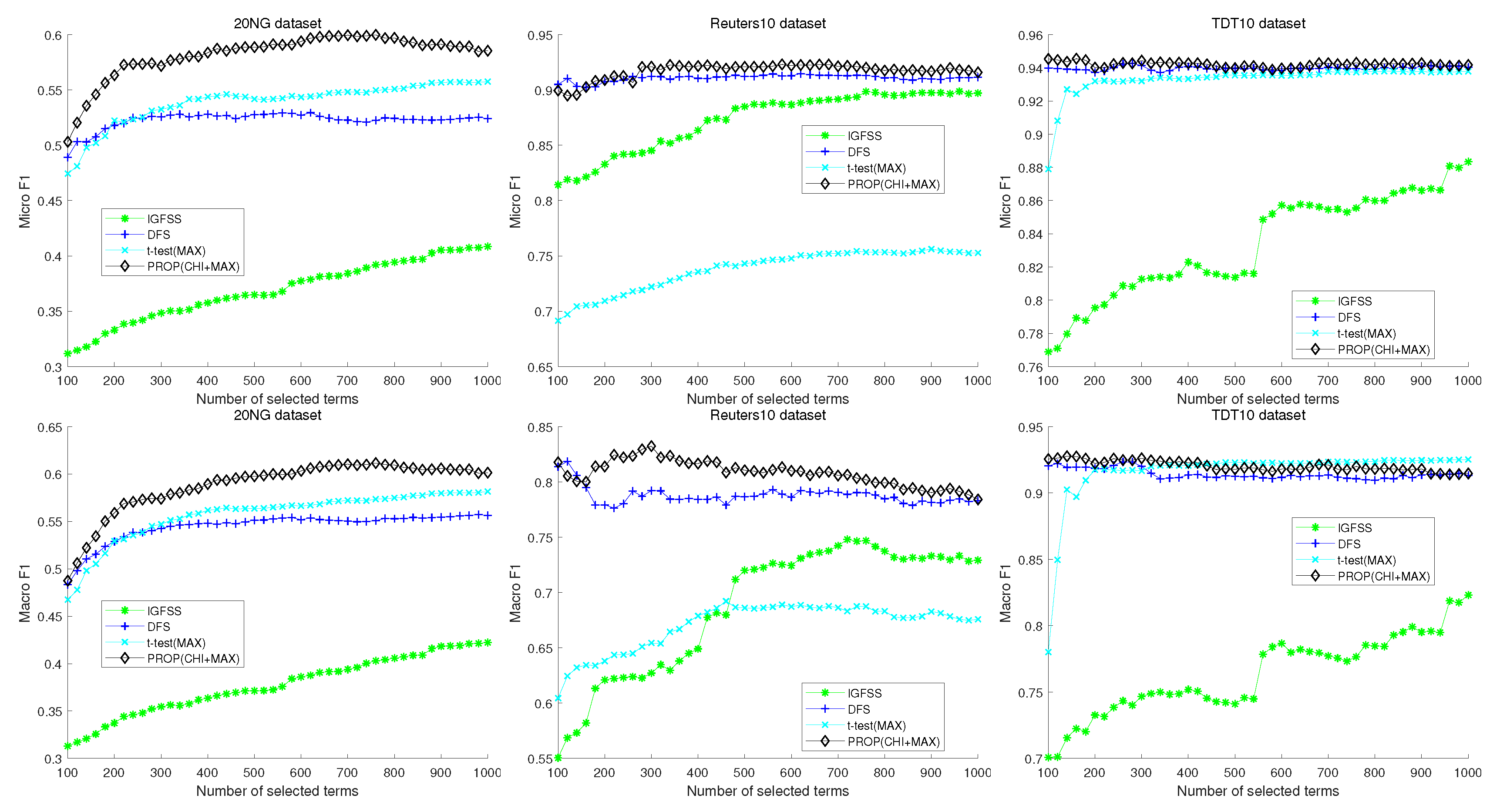
Recently, some feature selection methods have been introduced based on classical methods for TC. Uysal proposed an improved global feature selection scheme (IGFSS) that creates a feature set representing all classes almost equally [
17]. In the final step of the method, a common feature selection scheme is modified to obtain a more representative feature set. However, when the dataset is imbalanced, the IGFSS has difficulty in selecting a feature set that represents all classes equally. Tang et al. proposed a feature selection method based on a divergence measure for naive Bayes classification [
18]. Moreover, they analyzed the asymptotic properties of the divergence measure relating to Type I and II errors of a Bayesian classifier. However, the method is specialized only for the Bayesian classifier. Javed et al. proposed a two-stage feature selection method that combines conventional feature-ranking and feature search for improved efficiency [
19]. In their method, the first stage employs a feature-ranking metric such as IG, and in the second stage, a Markov blanket filter is applied. Wang et al. proposed an approach using Student’s
t-test to measure the diversity of the distributions of term frequency between a specific category and the entire corpus [
6]. Uysal et al. proposed a distinguishing feature selector using a filter-based probabilistic feature selection method [
20]. They assumed that an ideal filter should assign high scores to distinctive features while assigning lower scores to irrelevant ones. To achieve their objective, they defined a term as a distinctive term if that term frequently occurs in a single class and does not occur in other classes.
3. Proposed Method
Let
denote a function of the
ith feature that represents the dependency between the
ith term (
) and a specific category
C.
f is defined to select informative features for TC, and can be any conventional feature selection metric such as those in Equations (
2), (
4), or (
6). Then, the top
n features are selected by sorting on the function values. In our earlier studies [
21,
22], we proposed feature selection methods for a multi-label dataset. In this work, we first applied the method for the TC problem, and then used other conventional feature selection metrics for TC to model a new term selection method.
In the proposed method, a penalty is assigned to similar or redundant terms.
such as
used in TC is also used in the proposed method, and we add another penalty function. The penalty for similar terms is calculated based on the dependency among terms similar to
. To calculate the dependency among terms, we use the same function
f as
. Then, for
, we obtain values of
, and
. To select a term that is not similar to other terms, and simultaneously has a high dependency with category
C, we can define the score for a term
as
In this score, the first term on the right hand side is the conventional feature selection metric and the second is used to consider the similarity with other terms. To calculate the similarity among terms, we define new categories in the perspective of terms using a, b, c, and d in
Section 2 as:
a is the number of documents in which and co-occur.
b is the number of documents in which occurs without .
c is the number of documents in which occurs without .
d is the number of documents in which neither nor occurs.
is used as a generalized similarity function by using newly defined a, b, c, and d, and the function can be specifically chosen, e.g.,
, information gain, or mutual information. For instance, the similarity between
and
can be calculated as
However, all should not be calculated because, when the final term set contains only one of or , then is meaningless. In other words, the score function can be different based on the number of selected terms. For example, if we select three terms, numbered 1, 2, and 3 features from a total of five terms, then we need not calculate , … . Thus, we should consider the relative importance of the terms; and not the simple score function for a term .
Let
S be the final feature subset. Then, we can define the feature selection problem as
Although a score function that considers term similarity has been designed, selecting the best feature subset is impractical because the number of feature subset candidates can be
. To circumvent the combinatorial optimization problem, we transform the score function in Equation (
8) into a numerical optimization problem, namely quadratic programming.
Let
be a weight vector and
be an element that represents the relative importance of the
ith term. The relative importance of each term is represented as a continuous value between zero and one. The weight vector
x has the following constraints:
As a result, the score function (
8) for the term subset can be transformed to
In the new score function in Equation (
10), the combinatorial optimization problem in Equation (
8) has been transformed into a numerical optimization problem. Moreover, Equation (
10) can be rewritten in the quadratic form as
where
is a vector and each element of
c is defined as
and
is a symmetric matrix and each element of which is defined as
The score function in Equation (
11) is now in typical quadratic programming form. If matrix
Q is a positive definite matrix, then we can obtain the optimal
x because
is a convex function [
23]. In other words, the numerical optimization problem in Equation (
11) for TC can now be solved more easily. For the positive definiteness of matrix
Q, shift eigenvalue correction can be used a solution [
24]. The original matrix
Q is decomposed as
where
U and
contain the eigenvectors and corresponding eigenvalues of
Q. Then, the shift eigenvalue correction can be calculated as [
25]
where
and
is the smallest value of
. Other techniques for positive definiteness can also be used [
24,
26].
The steps of the algorithm for the proposed method are as follows;
Calculate feature ranking using a common measure such as
for Equation (
12).
Calculate the dependency among features using the same measure for Equation (
13).
Solve the optimization problem Equation (
11) and select the top
n features by
x
Algorithm 1 represents the detailed pseudo-code of the proposed method. On Line 14, to solve the optimization problem, we use the interior point method from the ‘optimization toolbox’ in MATLAB. Ye et al. demonstrated that convex quadratic programming can be done in
arithmetic operations by an iterative algorithm such as the interior point method where
N is the dimension of
x [
27]. The proposed method consumes time for three parts: calculating
and
, shift eigenvalue correction, and solving quadratic programming. Calculating
is the largest part in time consumption. Thus, the time complexity of the proposed method
.
| Algorithm 1 Pseudo-Code of the Proposed Method. |
- 1:
Input: - 2:
, , n; and are the ith term and jth topic of documents, respectively, and n is the number of terms to be selected - 3:
Output: - 4:
S; where S is the final subset with n terms - 5:
Process: - 6:
initialize - 7:
for all to N - 8:
using one among Equations ( 2), ( 3), ( 4), and ( 6) - 9:
for all to N - 10:
using one among Equations ( 2), ( 3), ( 4), and ( 6) - 11:
end for - 12:
end for - 13:
- 14:
Calculate eigenvectors U and corresponding eigenvalues of Q - 15:
the least value of - 16:
where - 17:
Solve the problem with constraints to and - 18:
Rank the terms with descending order of x and select the top n terms
|









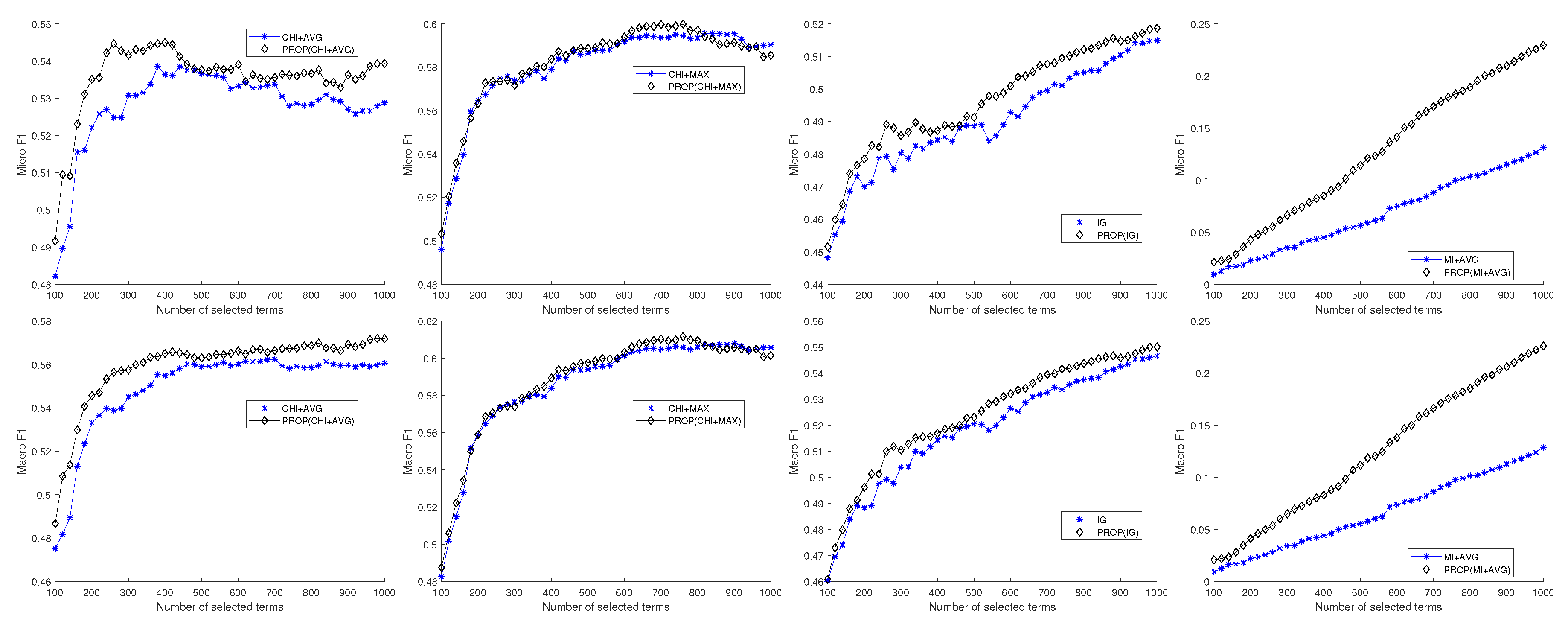{kind=link}
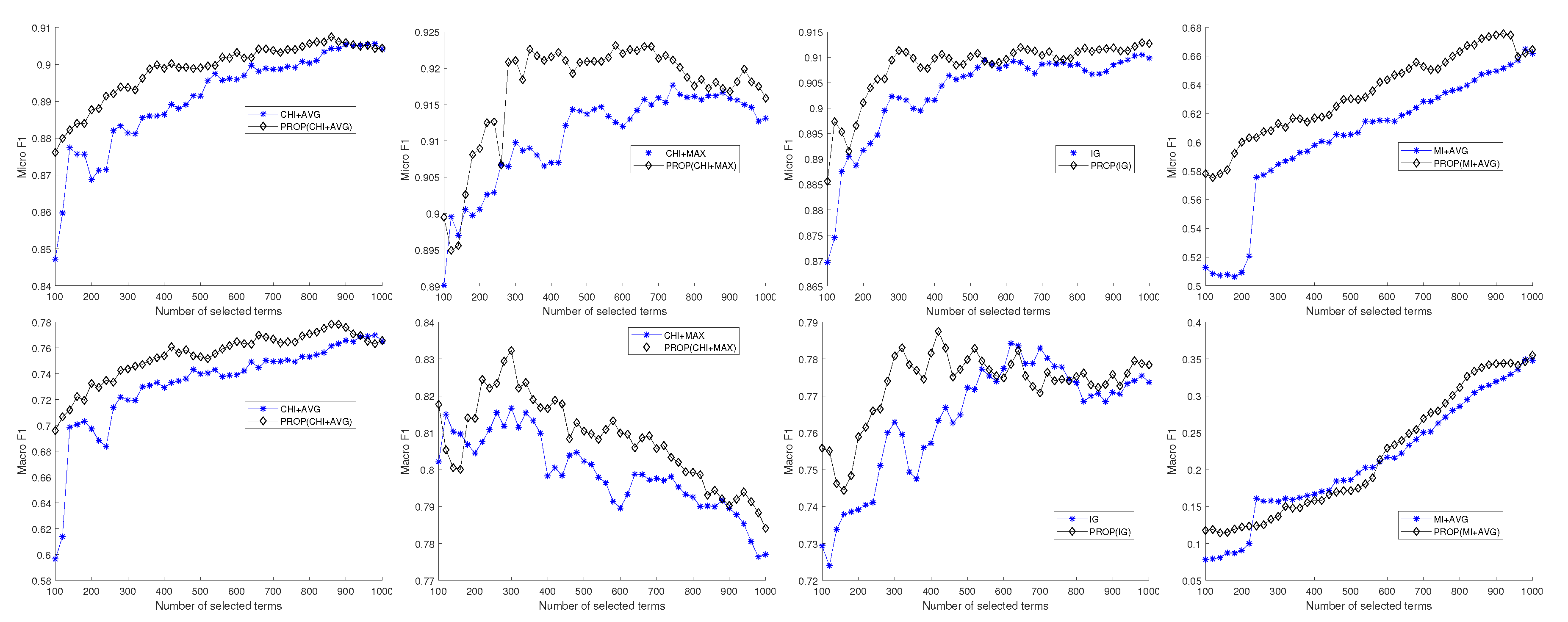{kind=link}
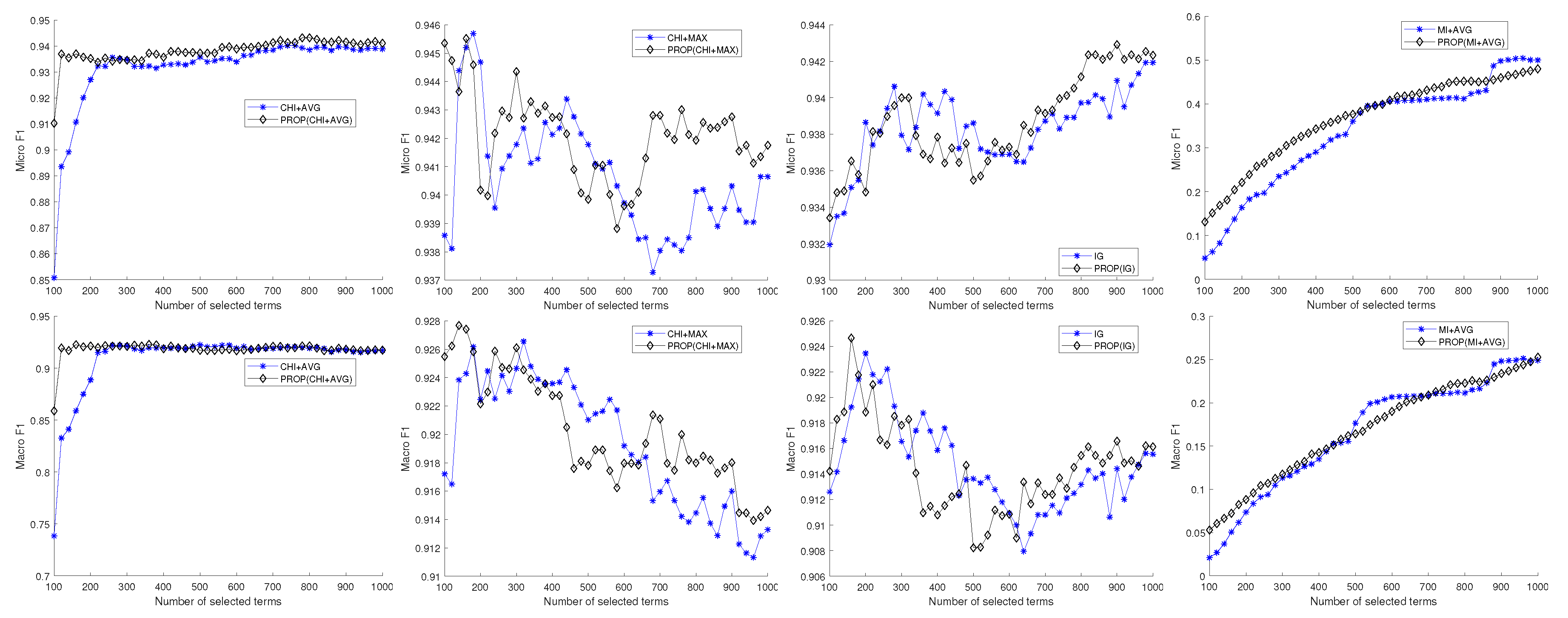{kind=link}
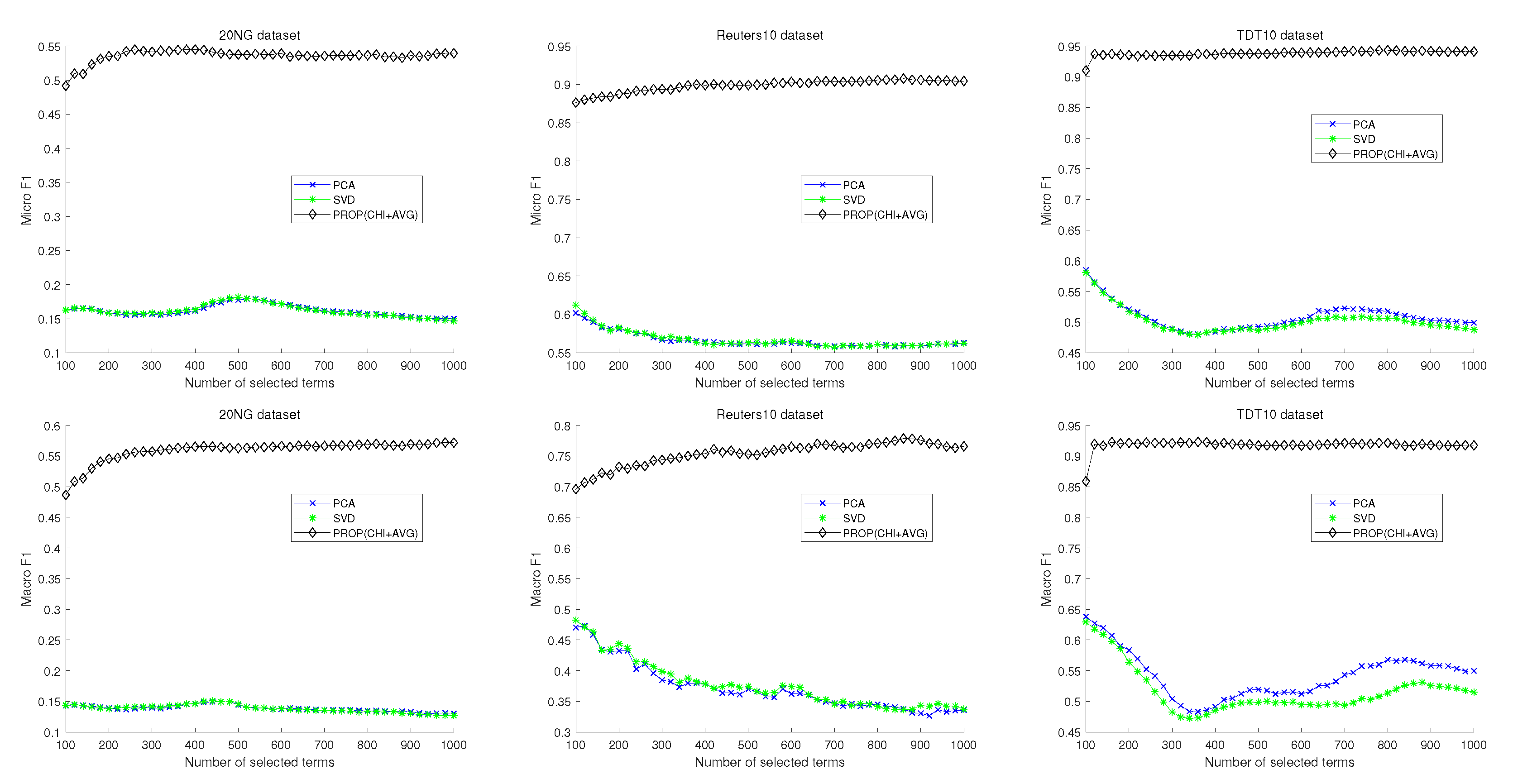{kind=link}
{kind=link}