Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Topic Models
- Let D be the number of documents in a dataset, W be the number of words.
- There is a fixed number of topics (T) which are discussed in the dataset.
- Datasets are regarded as sets of triples from the space , where is the set of words, is the set of documents, is the set of topics.
- ’Bag of words’. It is supposed that the order of words in documents and the order of documents in a collection are unimportant for TM.
- Probabilistic Latent Semantic Analysis (pLSA) [19] is a basic model with only one parameter—’number of topics’. Inference method for this model is based on E-M algorithm.
- Latent Dirichlet Allocation model with Gibbs sampling procedure (LDA GS) [20] can be considered a regularized extension of pLSA, where regularization is based on prior Dirichlet distributions for and with parameters and correspondingly. Unlike the above pLSA, the inference in this model is based on Gibbs sampling procedure.
- Variational Latent Dirichlet Allocation model (VLDA). This model uses variational E-M algorithm [1]. We consider the version of this model where regularization is based only on a prior Dirichlet distribution for with parameter . Selection of values of is built in the algorithm.
- The Additive Regularization of Topic Models (ARTM) [10] with smoothing/sparsing regularizers for matrix (smooth/sparse phi) and matrix (smooth/sparse theta), here termed sparse phi and sparse theta, respectively, is an alternative model to pLSA and LDA. These regularizers allow a user to obtain subsets of topics highly manifest in a small number of texts and/or words (sparsing effect), as well as subsets of topics relatively evenly distributed across all texts and words (smoothing effect). The parameter that controls the value of sparsing is a regularization coefficient termed . This model can be considered a regularization of pLSA, where regularization is embedded in E-M algorithm (regularized’ E-M algorithm).
- Hierarchical Dirichlet Process model (HDP) is an alternative approach, providing the possibility to restore hidden topics without selecting the number of topics in advance [21,22]. Although this model is non-parametric, in real scenarios, users need to set some parameters, e.g., truncation on the allowed number of topics in the entire corpus. Since HDP returns the same number of topics as the top-level truncation that is set before, it is assumed that by discarding empty ones, the true number of topics can be obtained [22].
2.2. Standard Metrics in the Field of Topic Modeling
2.3. Entropy Approach for Analysis of Topic Models
3. Results
3.1. Description of Data and Computer Experiments.
- ’Lenta’ dataset (from lenta.ru news agency [35]). This dataset contains 8,630 documents with a vocabulary of 23,297 unique words in the Russian language. Each of these documents is manually assigned with a class from a set of 10 topic classes. However, some of these topics are strongly correlated with each other. Thus, the documents in this dataset can be represented by 7–10 topics.
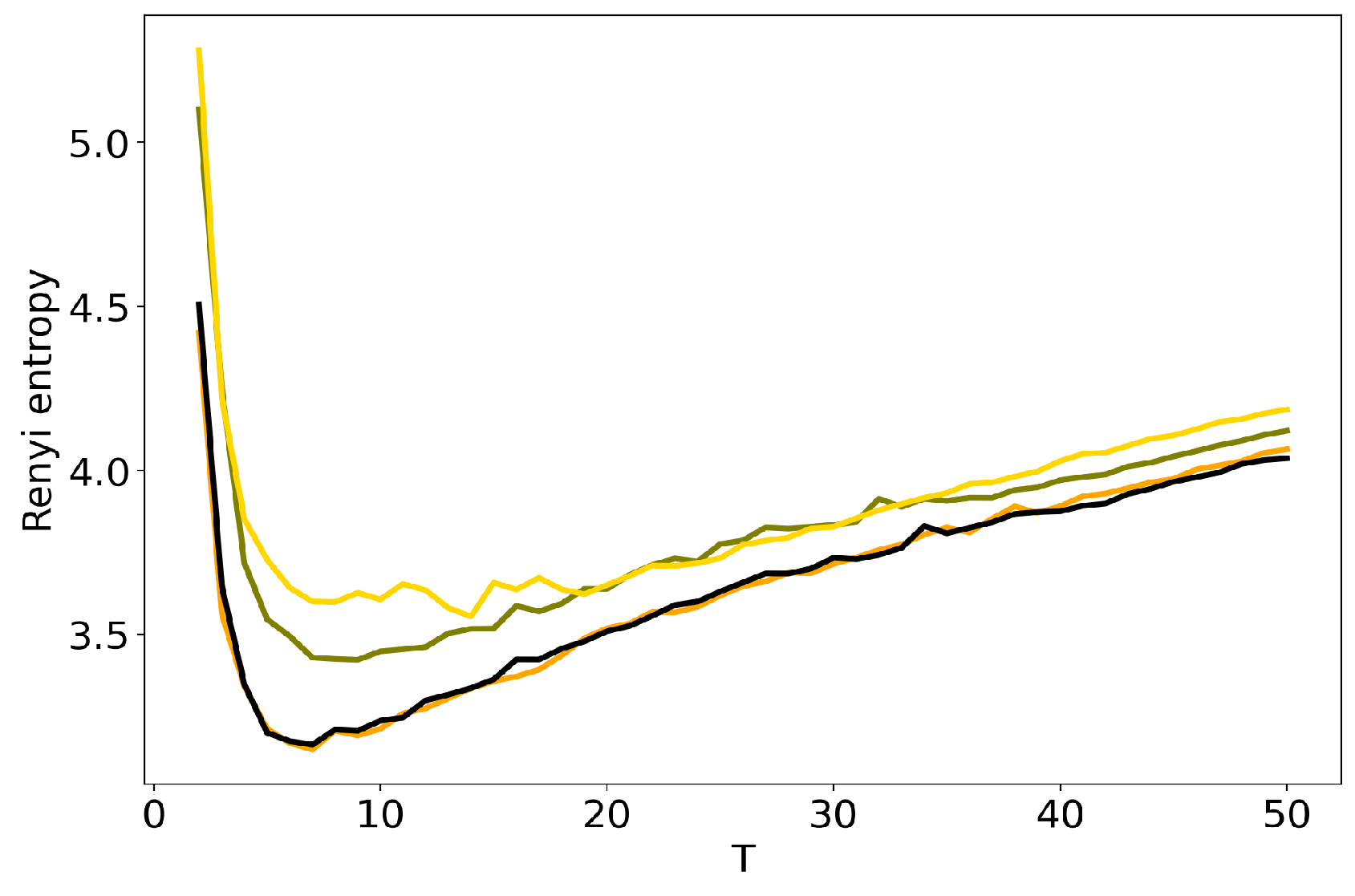
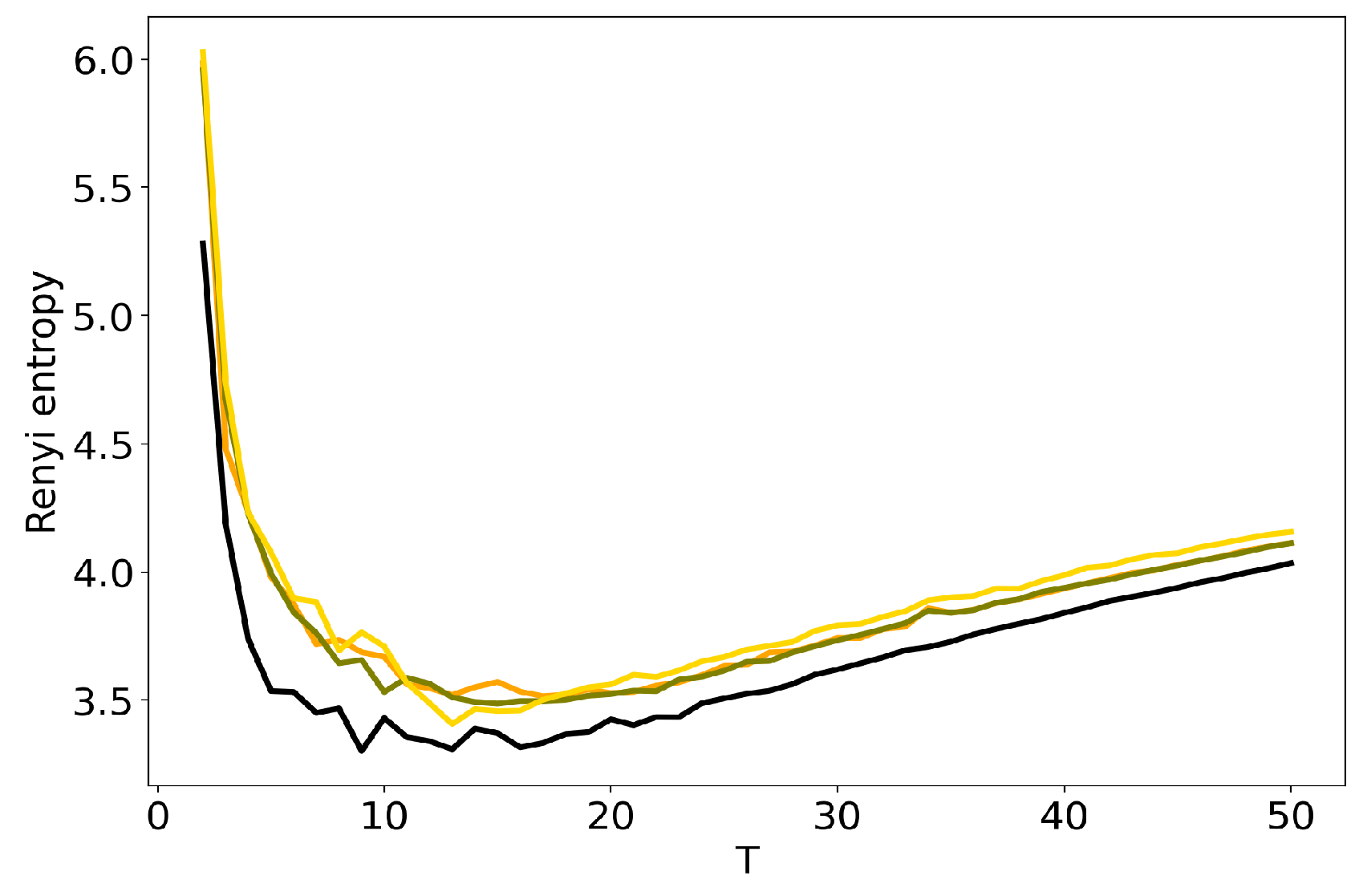
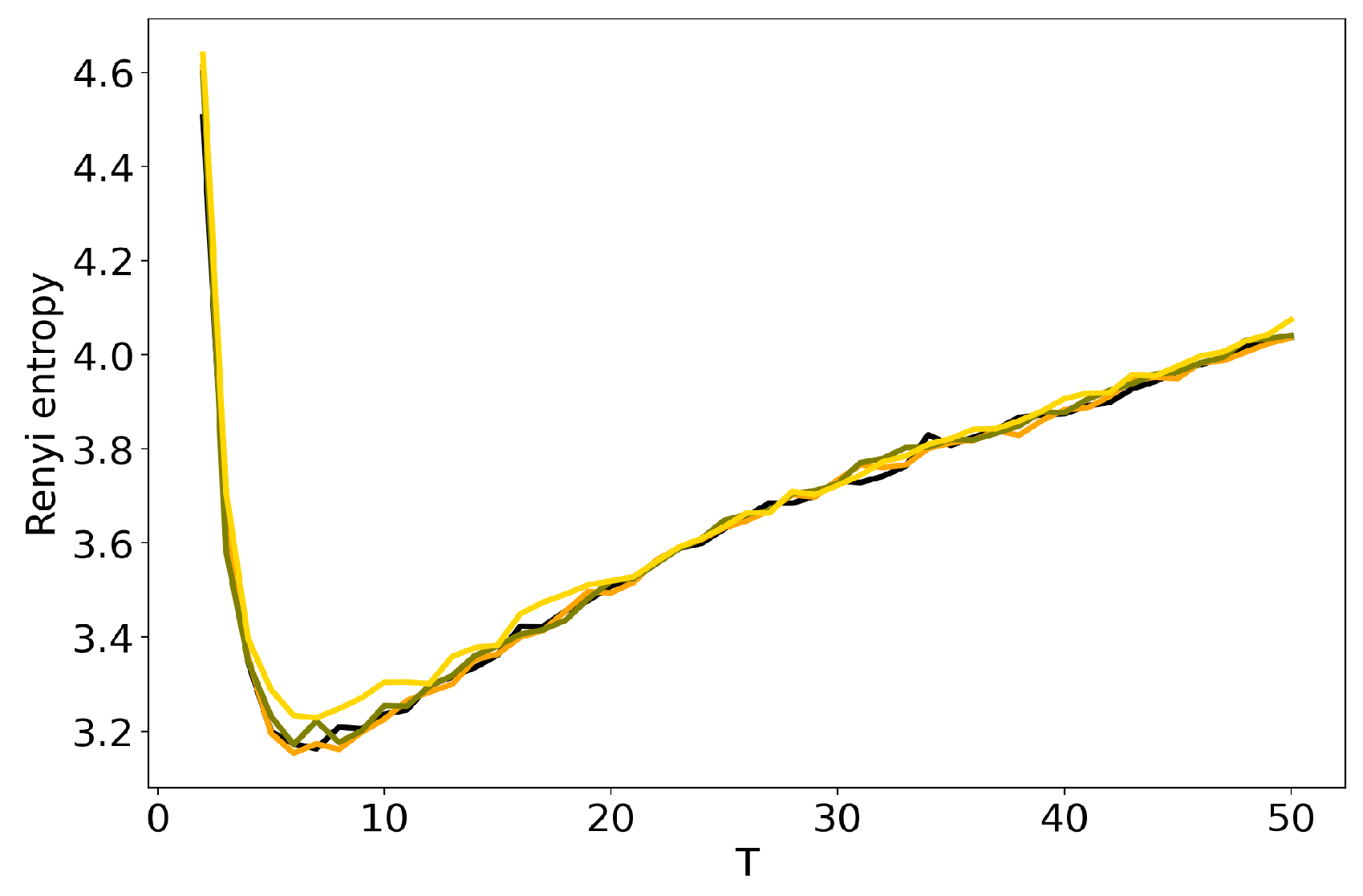
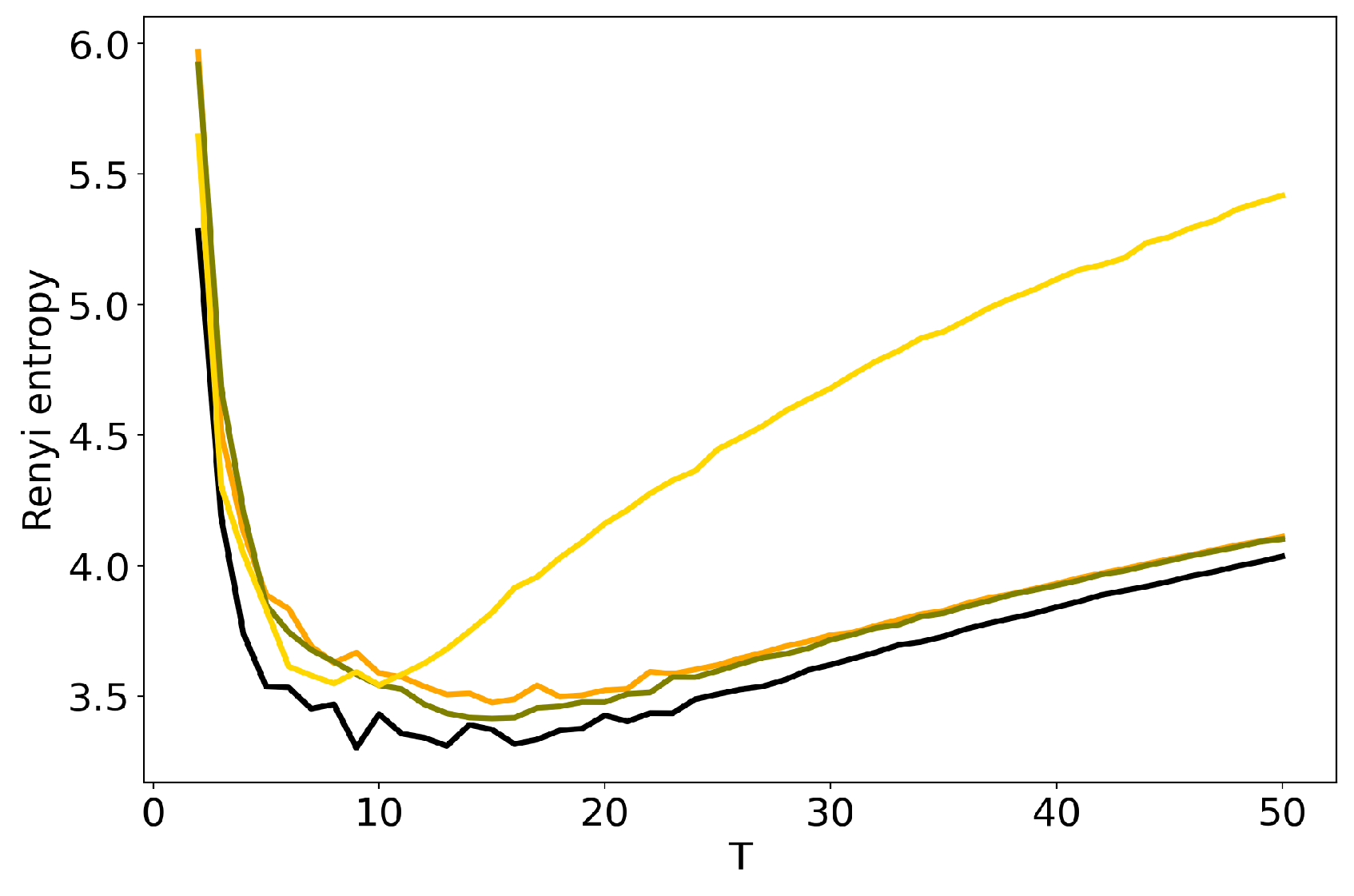
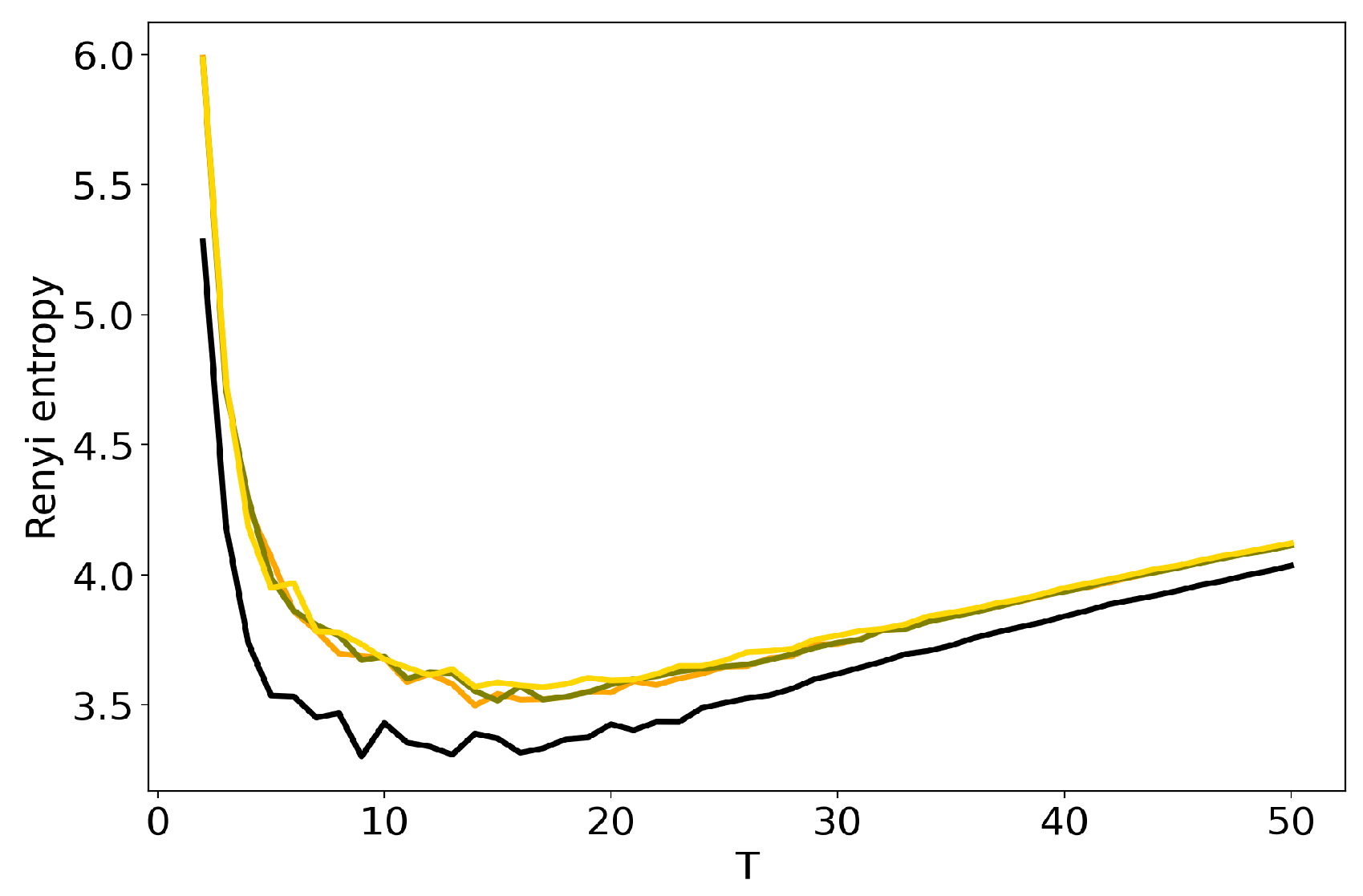
3.2. Optimal Number of Topics: HDP vs Renyi Entropy in LDA GS, VLDA and pLSA
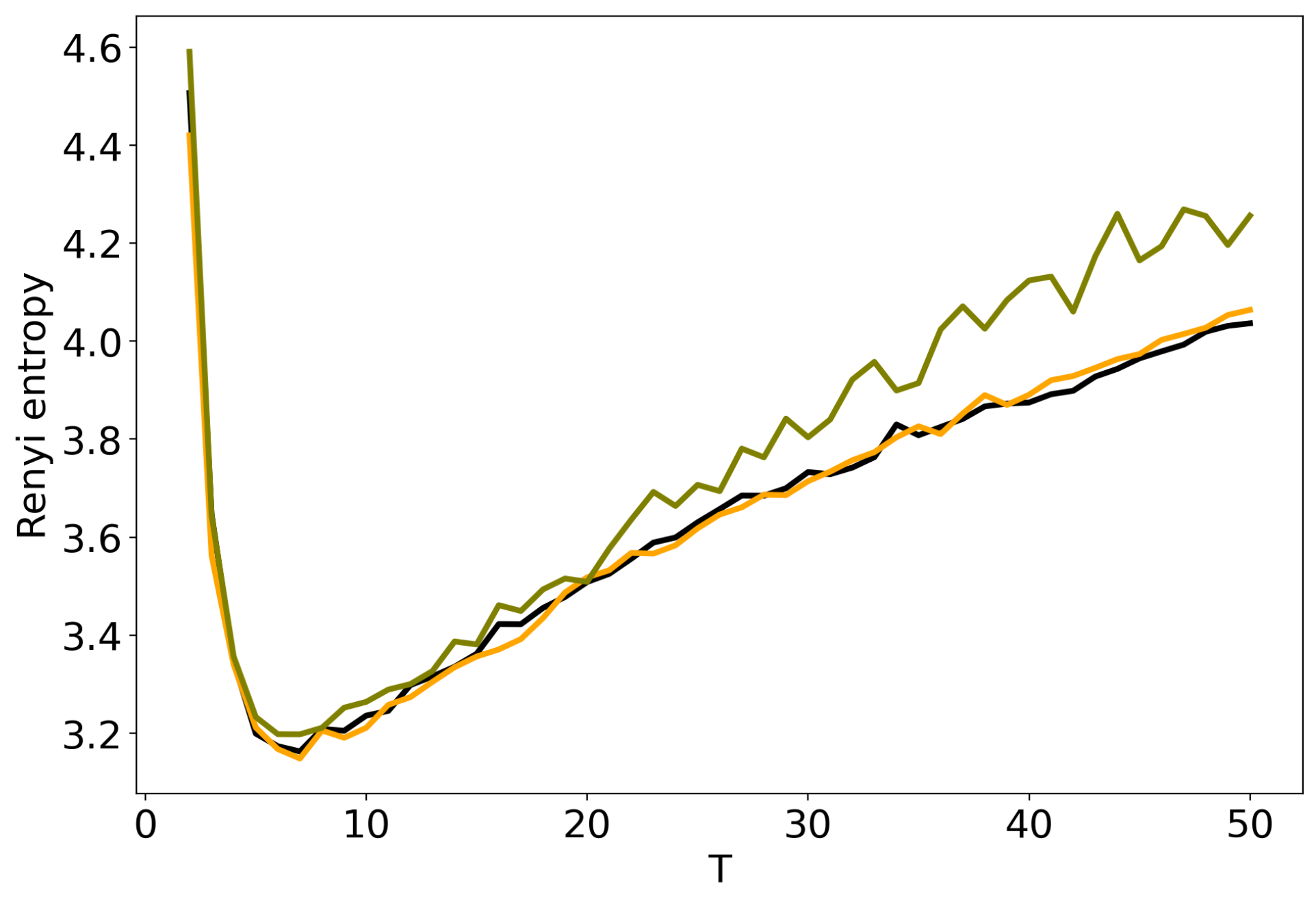
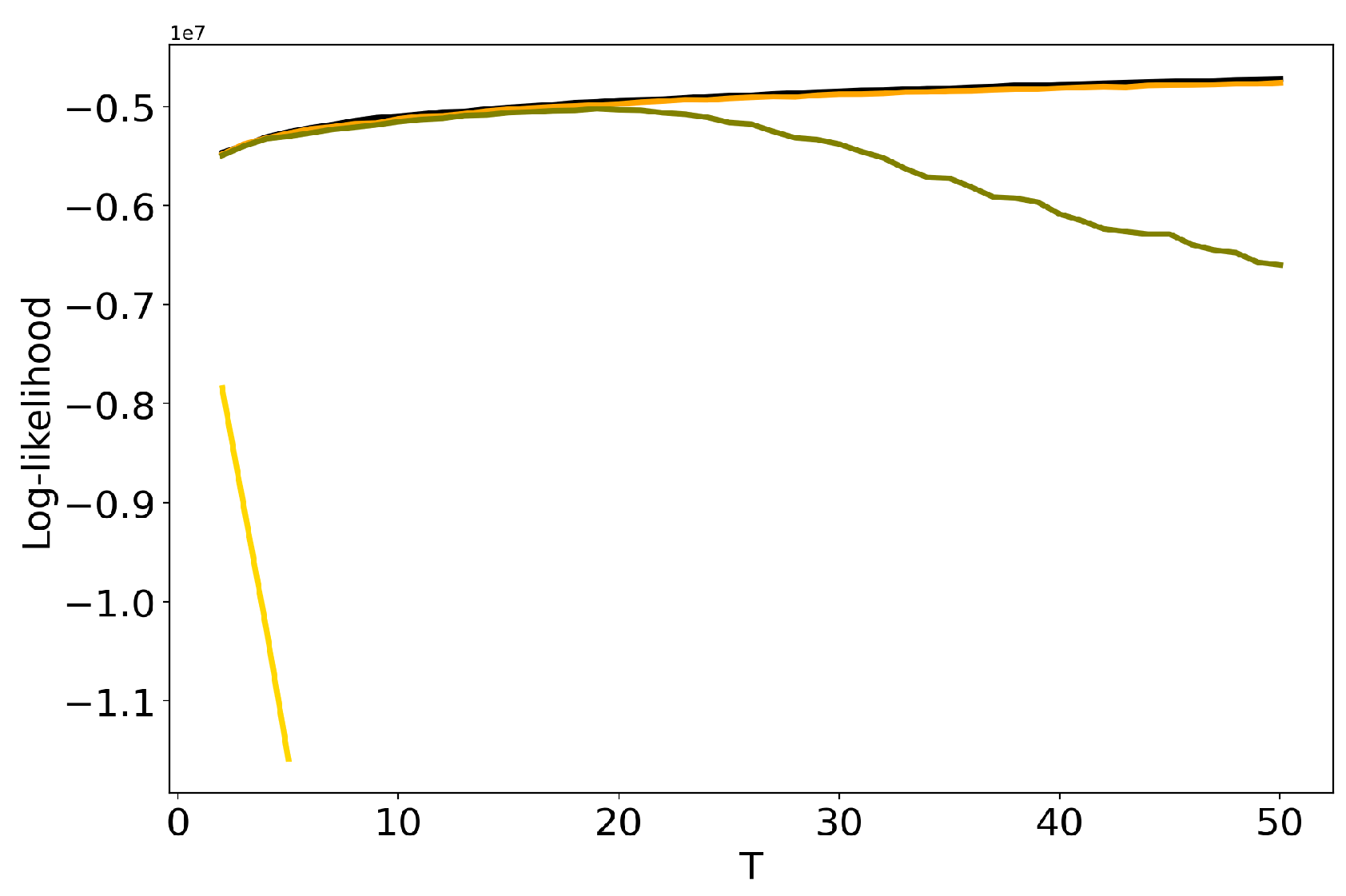
3.3. Influence of Hyper-Parameters: pLSA vs LDA GS Model
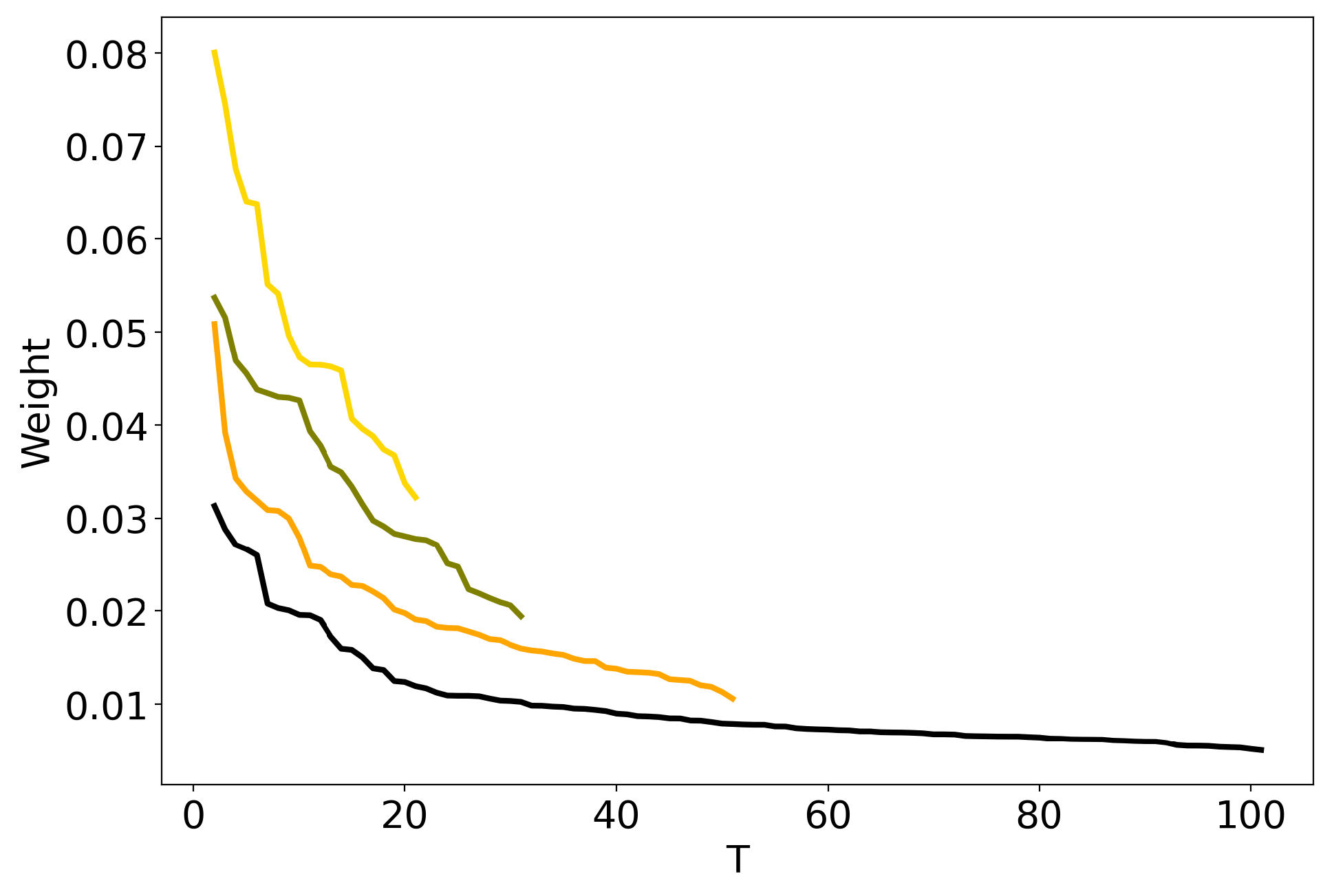
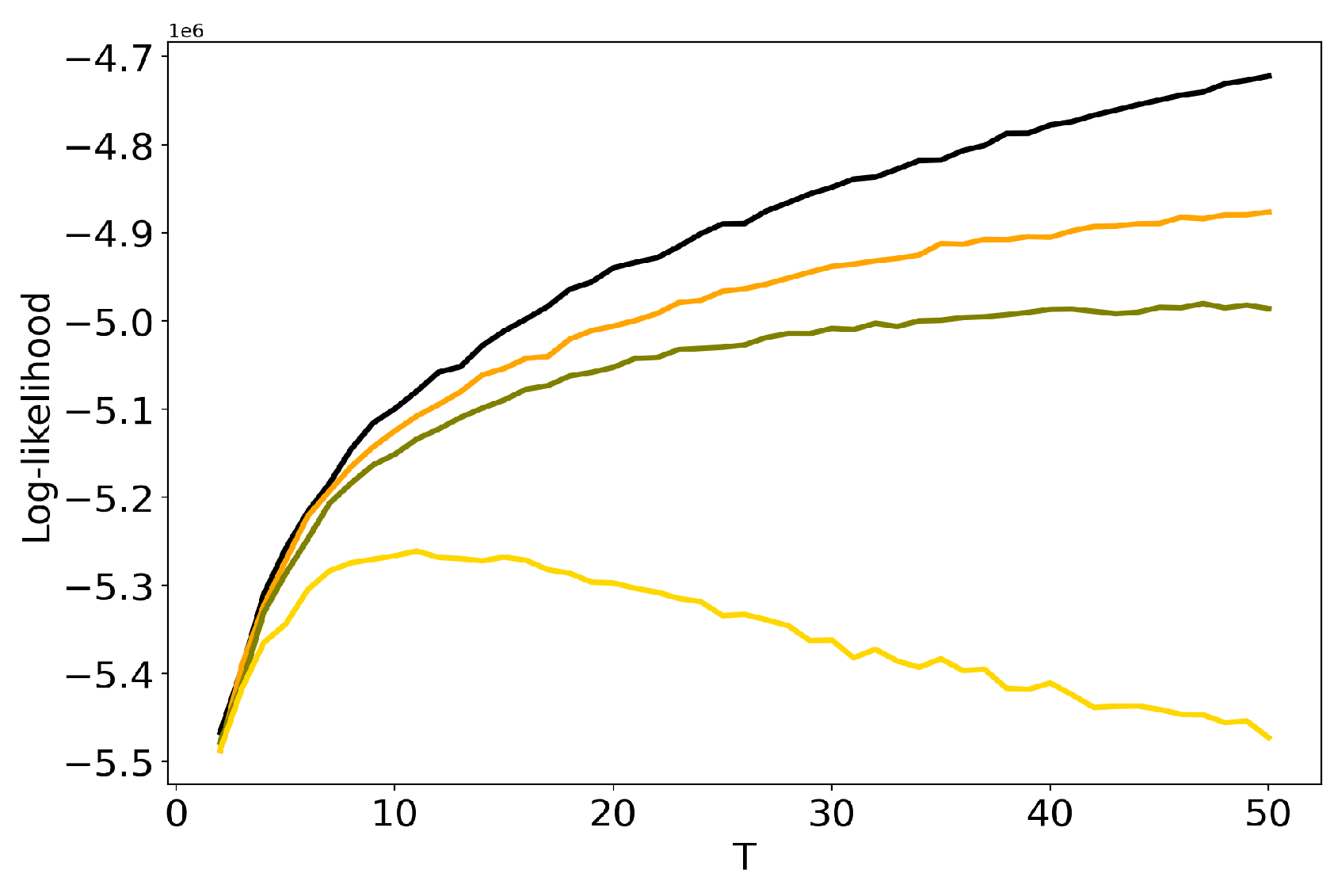
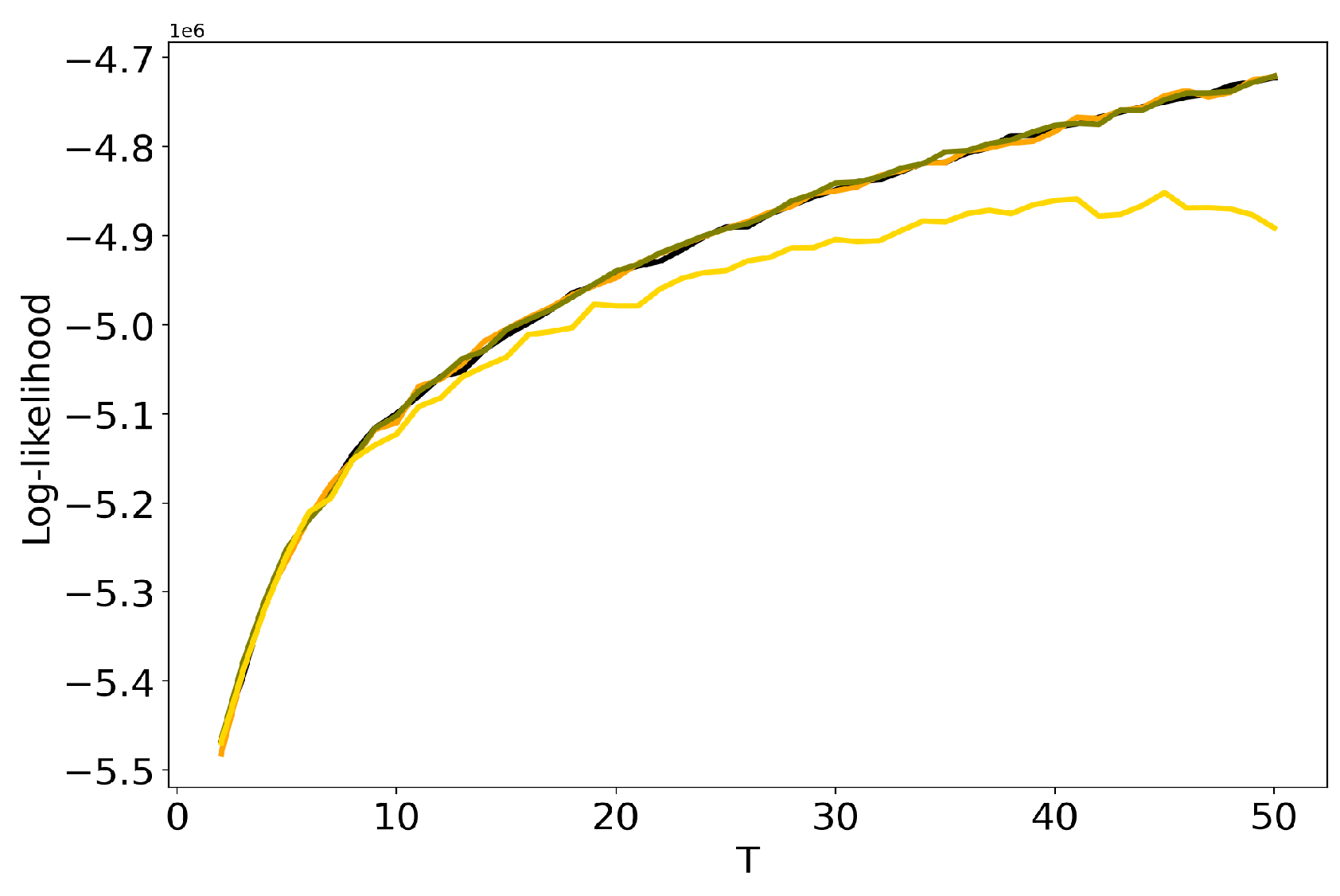
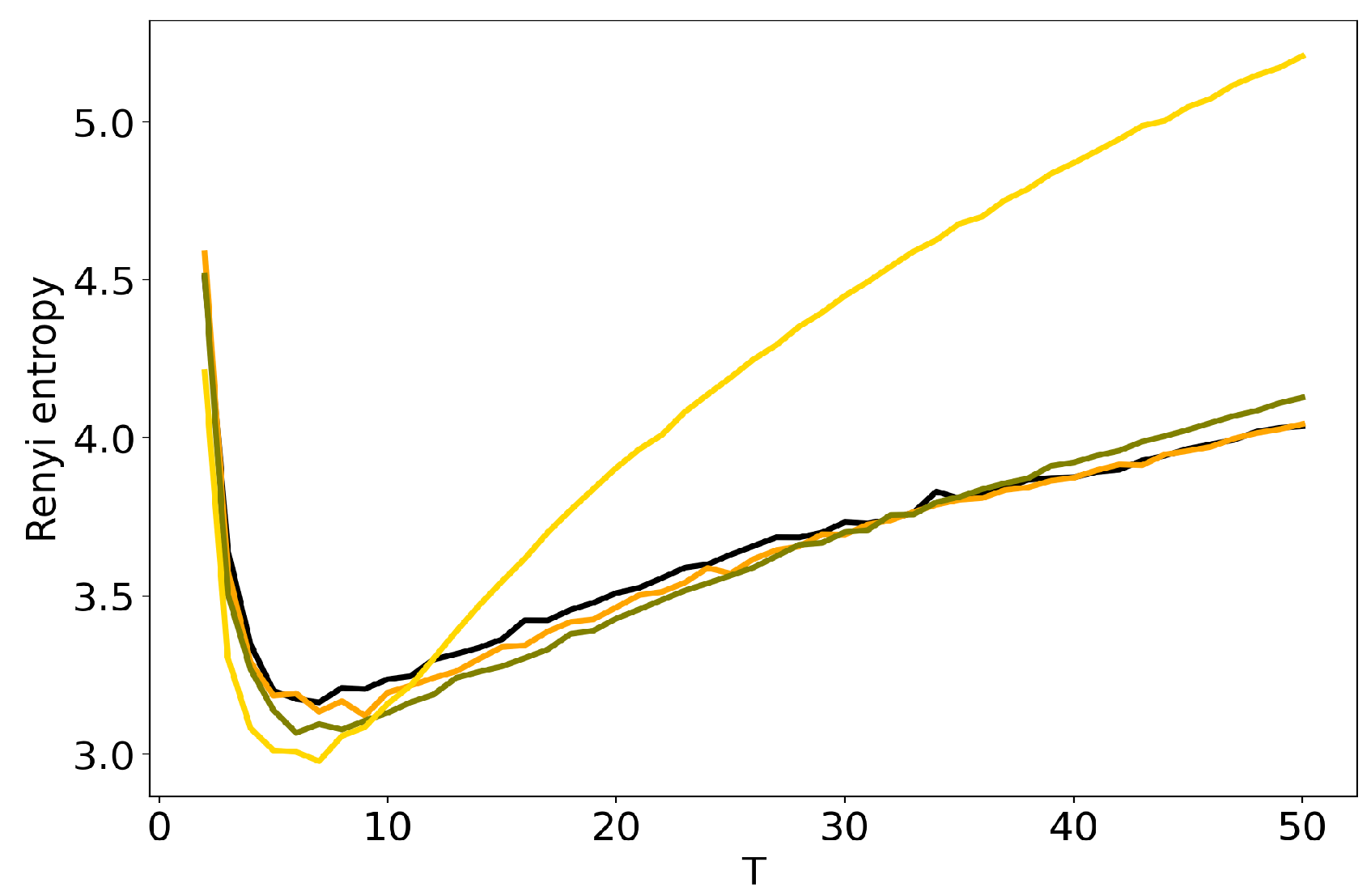
3.4. Influence of Regularization Coefficients: BigARTM vs pLSA
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Chernyavsky, I.; Alexandrov, T.; Maass, P.; Nikolenko, S.I. A Two-Step Soft Segmentation Procedure for MALDI Imaging Mass Spectrometry Data. Ger. Conf. Bioinform. 2012, 26, 39–48. [Google Scholar] [CrossRef]
- Yang, P.H.W.L.W.J.Z. Latent topic model for audio retrieval. Pattern Recognit. 2014, 47, 1138–1143. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic Relaxation, Gibbs Distributions, and the Bayesian Restoration of Images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Nelson, C.; Pottenger, W.M.; Keiler, H.; Grinberg, N. Nuclear detection using Higher-Order topic modeling. In Proceedings of the 2012 IEEE Conference on Technologies for Homeland Security (HST), Boston, MA, USA, 13–15 November 2012; pp. 637–642. [Google Scholar] [CrossRef]
- George, C.P.; Doss, H. Principled Selection of Hyperparameters in the Latent Dirichlet Allocation Model. J. Mach. Learn. Res. 2017, 18, 5937–5974. [Google Scholar]
- Koltcov, S. Application of Rényi and Tsallis entropies to topic modeling optimization. Phys. A Stat. Mech. Its Appl. 2018, 512, 1192–1204. [Google Scholar] [CrossRef]
- Vorontsov, K.V. Additive regularization for topic models of text collections. Dokl. Math. 2014, 89, 301–304. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of Ill-Posed Problems; V. H. Winston & Sons: Washington, DC, USA, 1977. [Google Scholar]
- Vorontsov, K.; Potapenko, A. Tutorial on Probabilistic Topic Modeling: Additive Regularization for Stochastic Matrix Factorization. In Analysis of Images, Social Networks and Texts; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Rose, K.; Gurewitz, E.; Fox, G.C. Statistical mechanics and phase transitions in clustering. Phys. Rev. Lett. 1990, 65, 945–948. [Google Scholar] [CrossRef] [PubMed]
- Rényi, A. Probability Theory; Elsevier: Amsterdam, The Netherlands, 1970. [Google Scholar]
- Steyvers, M.; Griffiths, T. Probabilistic Topic Models; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2007; pp. 427–448. [Google Scholar]
- Mimno, D.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, Stroudsburg, PA, USA, 27–31 July 2011; pp. 262–272. [Google Scholar]
- Chang, J.; Boyd-Graber, J.; Gerrish, S.; Wang, C.; Blei, D.M. Reading Tea Leaves: How Humans Interpret Topic Models. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 288–296. [Google Scholar]
- Hofmann, T. Probabilistic Latent Semantic Indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar] [CrossRef]
- Asuncion, A.; Welling, M.; Smyth, P.; Teh, Y.W. On Smoothing and Inference for Topic Models. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 27–34. [Google Scholar]
- Koltcov, S.; Koltsova, O.; Nikolenko, S. Latent Dirichlet Allocation: Stability and Applications to Studies of User-generated Content. In Proceedings of the 2014 ACM Conference on Web Science, Bloomington, IN, USA, 23–26 June 2014; pp. 161–165. [Google Scholar] [CrossRef]
- Hofmann, T. Unsupervised Learning by Probabilistic Latent Semantic Analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [PubMed]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Wang, C.; Paisley, J.; Blei, D. Online Variational Inference for the Hierarchical Dirichlet Process. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 752–760. [Google Scholar]
- Heinrich, G. Parameter Estimation for Text Analysis; Technical report in Fraunhofer IGD: Darmstadt, Germany, 2004. [Google Scholar]
- BUGRA. Entropy and Perplexity on Image and Text. Available online: http://bugra.github.io/work/notes/2014-05-16/entropy-perplexity-image-text/ (accessed on 28 March 2020).
- Goodman, J.T. A Bit of Progress in Language Modeling. Comput. Speech Lang. 2001, 15, 403–434. [Google Scholar] [CrossRef]
- Newman, D.; Asuncion, A.; Smyth, P.; Welling, M. Distributed Algorithms for Topic Models. J. Mach. Learn. Res. 2009, 10, 1801–1828. [Google Scholar]
- Zhao, W.; J Chen, J.; Perkins, R.; Liu, Z.; Ge, W.; Ding, Y.; Zou, W. A heuristic approach to determine an appropriate number of topics in topic modeling. In Proceedings of the 12th Annual MCBIOS Conference, Little Rock, AR, USA, 13–14 March 2015. [Google Scholar] [CrossRef]
- Balasubramanyan, R.; Dalvi, B.; Cohen, W.W. From Topic Models to Semi-supervised Learning: Biasing Mixed-Membership Models to Exploit Topic-Indicative Features in Entity Clustering. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 22–26 September 2013; pp. 628–642. [Google Scholar] [CrossRef]
- De Waal, A.; Barnard, E. Evaluating topic models with stability. In Proceedings of the Nineteenth Annual Symposium of the Pattern Recognition Association of South Africa, Cape Town, South Africa, 27–28 November 2008; pp. 79–84. [Google Scholar]
- Rosen-Zvi, M.; Chemudugunta, C.; Griffiths, T.; Smyth, P.; Steyvers, M. Learning Author-topic Models from Text Corpora. Acm Trans. Inf. Syst. 2010, 28, 1–38. [Google Scholar] [CrossRef]
- Wallach, H.M.; Mimno, D.; McCallum, A. Rethinking LDA: Why Priors Matter. In Proceedings of the 22nd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–12 December 2009; pp. 1973–1981. [Google Scholar]
- Wallach, H.M.; Murray, I.; Salakhutdinov, R.; Mimno, D. Evaluation Methods for Topic Models. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1105–1112. [Google Scholar] [CrossRef]
- Minka, T. Estimating a Dirichlet Distribution. Technical Report. 2000. Available online: https://tminka.github.io/papers/dirichlet/minka-dirichlet.pdf (accessed on 28 March 2020).
- Koltcov, S.; Ignatenko, V.; Koltsova, O. Estimating Topic Modeling Performance with Sharma–Mittal Entropy. Entropy 2019, 21, 660. [Google Scholar] [CrossRef]
- Lenta dataset. Available online: https://www.kaggle.com/yutkin/corpus-of-russian-news-articles-from-lenta (accessed on 5 March 2020).
- 20Newsgroups dataset. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 5 March 2020).
- Basu, S.; Davidson, I.; Wagstaff, K. (Eds.) Constrained Clustering: Advances in Algorithms, Theory, and Applications; Chapman & Hall/CRC: Boca Raton, FL, USA, 2008. [Google Scholar]
- Teh, Y.W.; Kurihara, K.; Welling, M. Collapsed Variational Inference for HDP. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 1481–1488. [Google Scholar]
- Yau, C.K.; Porter, A.; Newman, N.; Suominen, A. Clustering scientific documents with topic modeling. Scientometrics 2014, 100, 767–786. [Google Scholar] [CrossRef]
- Wang, C.; Blei, D.M. Truncation-free online variational inference for Bayesian nonparametric models. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Harrahs and Harveys, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 413–421. [Google Scholar]
- Fast approximation of variational Bayes Dirichlet process mixture using the maximization–maximization algorithm. Int. J. Approx. Reason. 2018, 93, 153–177. [CrossRef]
- Apishev, M.; Koltcov, S.; Koltsova, O.; Nikolenko, S.; Vorontsov, K. Additive Regularization for Topic Modeling in Sociological Studies of User-Generated Texts. In Proceedings of the Mexican International Conference on Artificial Intelligence, Enseneda, Mexico, 23–28 October 2017; pp. 169–184. [Google Scholar] [CrossRef]
- Koltsov, S.; Nikolenko, S.; Koltsova, O.; Filippov, V.; Bodrunova, S. Stable Topic Modeling with Local Density Regularization. In Proceedings of the International Conference on Internet Science, Florence, Italy, 12–14 September 2016; pp. 176–188. [Google Scholar] [CrossRef]











© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koltcov, S.; Ignatenko, V.; Boukhers, Z.; Staab, S. Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy. Entropy 2020, 22, 394. https://doi.org/10.3390/e22040394
Koltcov S, Ignatenko V, Boukhers Z, Staab S. Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy. Entropy. 2020; 22(4):394. https://doi.org/10.3390/e22040394
Chicago/Turabian StyleKoltcov, Sergei, Vera Ignatenko, Zeyd Boukhers, and Steffen Staab. 2020. "Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy" Entropy 22, no. 4: 394. https://doi.org/10.3390/e22040394
APA StyleKoltcov, S., Ignatenko, V., Boukhers, Z., & Staab, S. (2020). Analyzing the Influence of Hyper-parameters and Regularizers of Topic Modeling in Terms of Renyi Entropy. Entropy, 22(4), 394. https://doi.org/10.3390/e22040394