1. Introduction
The deepening of the reform and opening and the rapid development of the national economy has simultaneously seen the improvement of the economic capacity and living standard of the Chinese people. An increasing number of Chinese people now focus on better quality of life and higher levels of spiritual pursuit. The recent years witness the government’s development of tourism. The development of the national tourism industry has been substantially promoted with various policies and activities. According to the 2018 report published by the National Tourist Bureau of China on the development of culture and tourism in 2018, the domestic tourism market maintained its steady growth; inbound tourism market grew slowly and steadily, whereas the outbound tourism market developed rapidly. Moreover, the total number of domestic tourists was 5.539 billion, inbound tourists was 141.2 million, outbound tourists was 149.72 million, and the total tourism revenue was 5.97 trillion yuan. In 2018, the total number of tourists was 6.024 billion of the 11,924 A-level scenic spots in China. The total tourism revenue of all A-level scenic spots had an increase of 7.8% over the previous year [
1].
With the continuous evolution of information theory, system theory, and cybernetics, “information” has become an academic term and scientific concept and been applied to many fields of natural sciences and social sciences. Since the entropy value is a concept that indicates the degree of uncertainty or confusion of the system, the elimination of uncertainty means a reduction in the entropy value, information can also be called negative entropy [
2]. Entropy has been widely used in the field of prediction. Mirna et al. [
3] and Guan et al. [
4] used the theory of entropy in predicting time series. Carles et al. [
5] combined entropy with machine learning to predict macroeconomics. The current tourism information discipline system is developing rapidly, and tourism information as a development basis of tourism information science has also gained great development space. In her book “Tourism Information Science”, Sharda [
6] described tourism information science from three aspects: travel recommendation system, community and user interface design. Tourism information refers to the general term for tourism-related materials and information, including tourist attractions, transportation, and weather. Because tourism information is complex and diverse, a tourism information flow will form in the tourism system. There is always the emergence and connection of information flows inside and outside the tourism system. It is necessary to use information theory to study the problem of information and information flow in the tourism system. Lu [
7] defines the travel information flow as the exchange and dissemination of travel information related to travel activities and accompanying travel.
As early as the 1960s, scholars began to research the prediction of tourist flow, and many prediction models were proposed, such as classic time series models, econometric models, artificial intelligence models, and deep neural network models. So many research results have been achieved in theory and practice.
Classic time series models make predictions based on trends analysis about the past. They can highlight the role of time factors in prediction. However, classic time series models are sensitive to the accuracy of experimental data. Appearance of bad data will affect the experiment results. Meanwhile, classic time series models can only handle the linear data, not non-linear data. Classic time series models include autoregressive, moving average, autoregressive moving average (ARMA), autoregressive integrated moving average (ARIMA), and so on. Gustavsson and Nordström [
8] predicted tourist flow in different areas by ARMA. Lim and McAleer used ARMA for monthly [
9] and seasonal forecasts [
10]. Econometric models are also extensively used in the prediction of tourist flow. The advantage of these models is that they can accurately draw causal correlations between all influencing factors and prediction. However, econometric models are generally considered from the perspective of economics and are directly applied for making assumptions. Consequently, they lack theoretical basis of empirical analysis. Econometric models include error correction model (ECM), vector autoregressive (VAR), autoregressive distributed lag model (ADLM), and almost ideal demand system (AIDS). Kim and Song [
11] predicted tourism demand in Korea by ECM; they proved that the prediction of ECM is better than ARMIA and VAR for a limited account of time. S. I. Ao [
12] used VAR and genetic algorithm (GA) and neural network (NN) to predict the tourism demand of Hong Kong. Lin et al. [
13] predicted the number of outbound tourists of China by AIDS.
With the development of computer technology, artificial intelligence has been generally used in the prediction of tourist flow. Chen et al. [
14] built a model on the basis of empirical mode decomposition and artificial neural networks to predict tourism demand. Law [
15] extended the adaption of neural networks in tourist flow forecasting by integrating backpropagation neural network (BPNN) into non-linear and separable travel demand data. Pai et al. [
16] built a hybrid model on the basis of support vector machine (SVR) to predict the number of tourists who travel between Hong Kong and Taiwan. In addition, some researchers study tourism prediction from new directions. Sun et al. [
17] established a machine learning framework combined with online data (e.g., network search data), which proved that model combined with Baidu and Google search indexes can improve accuracy of prediction. Li et al. [
18] used online data to predict the number of tourists in Beijing.
For daily tourist flow, many prediction models were proposed. Owing to the complex non-linear characteristics of the daily number of tourists on holidays and the obvious seasonal trend of holiday tourist flow, Chen et al. [
19] proposed an approach which hybridizes SVR model with adaptive genetic algorithm (AGA) and the seasonal index adjustment, namely AGA-SSVR, to predict holiday daily tourist flow. In addition, holiday daily tourist flow data for Huangshan Mountain in China were employed as an example. The experimental results indicated that the AGA-SSVR model is an effective approach with more accuracy than the other alternative models including SVR model with adaptive genetic algorithm (AGA-SVR) and BPNN. Li et al. [
20] proposed a BPNN model optimized by a fruit fly optimization algorithm (FOA) method that includes web search data to forecast daily tourist flow. The experimental results proved that compared with other prediction models, higher accuracy can be obtained when it comes to the peak season. Song et al. [
21] proposed prediction method of optimized BPNN based on modified GA. They designed new chromosomes with multi-layer Step-structure, improve the encoding mode, fitness function and genetic operator, and introduce the self-adaptive crossover and mutation probability, which optimizes the network structure and initial network weights of BPNN synchronously. The experimental results proved that the nonlinear fitting and accuracy of the modified prediction methods are better than other prediction methods in prediction of daily tourist flow.
In predicting tourist flow, algorithms such as random forest (RF) and SVM are widely used, but each algorithm has its own disadvantages. RF makes the algorithm very slow due to the use of a large number of trees and cannot make real-time predictions. At the same time, RF often performs poorly when it encounters noisy data, and in tourism prediction, there are many and complex influencing factors, which will cause RF to be unsuitable. SVM also has the problem of slow operation speed. At the same time, it shows poor forecasting ability when the range of data changes is large. However, the tourist flow data usually fluctuates greatly with seasons, weather and other factors. The forecast performance did not meet expectations. Long-short-term memory network (LSTM) is very good at processing time-series data that it is used in predicting tourist flow. Li and Cao [
22] used LSTM to predict tourist flow for the first time. They proved that LSTM could improve accuracy of prediction compared with ARIMA and BPNN, especially in the long term. Although, LSTM can fully reflect the long-term historical process about time-series data, it cannot mine the effective information and potential linkages between discontinuous data. To solve this urgent problem, new models based on LSTM were built. Khalid et al. [
23] proposed a new Jaya-LSTM model to predict the future values of electricity demand and price. The hyperparameters of this algorithm are tuned using the Jaya optimization algorithm to improve the forecasting ability and increase the training mechanism of the model. Wei et al. [
24] built CNN-LSTM model for short-time travel time prediction. CNN-LSTM model can play a role in other existing fields. Shen et al. [
25] proposed a deep learning framework named Tensor-CNN-LSTM (TCL) to predict the travel time of a given path. Kim and Cho [
26] proposed a CNN-LSTM model that can extract features to effectively predict the housing energy consumption. Chen et al. [
27] predicted the intensity of typhoons by CNN-LSTM. Huang and Kuo [
28] predicted particulate matter (PM
2.5) CNN-LSTM. All those studies prove that CNN-LSTM model has excellent performance in prediction. On the basis of those studies, the current research scientifically selects the number of neurons of CNN-LSTM model by GA, which is scientific and efficient and makes CNN-LSTM model adaptive to predict tourist flow.
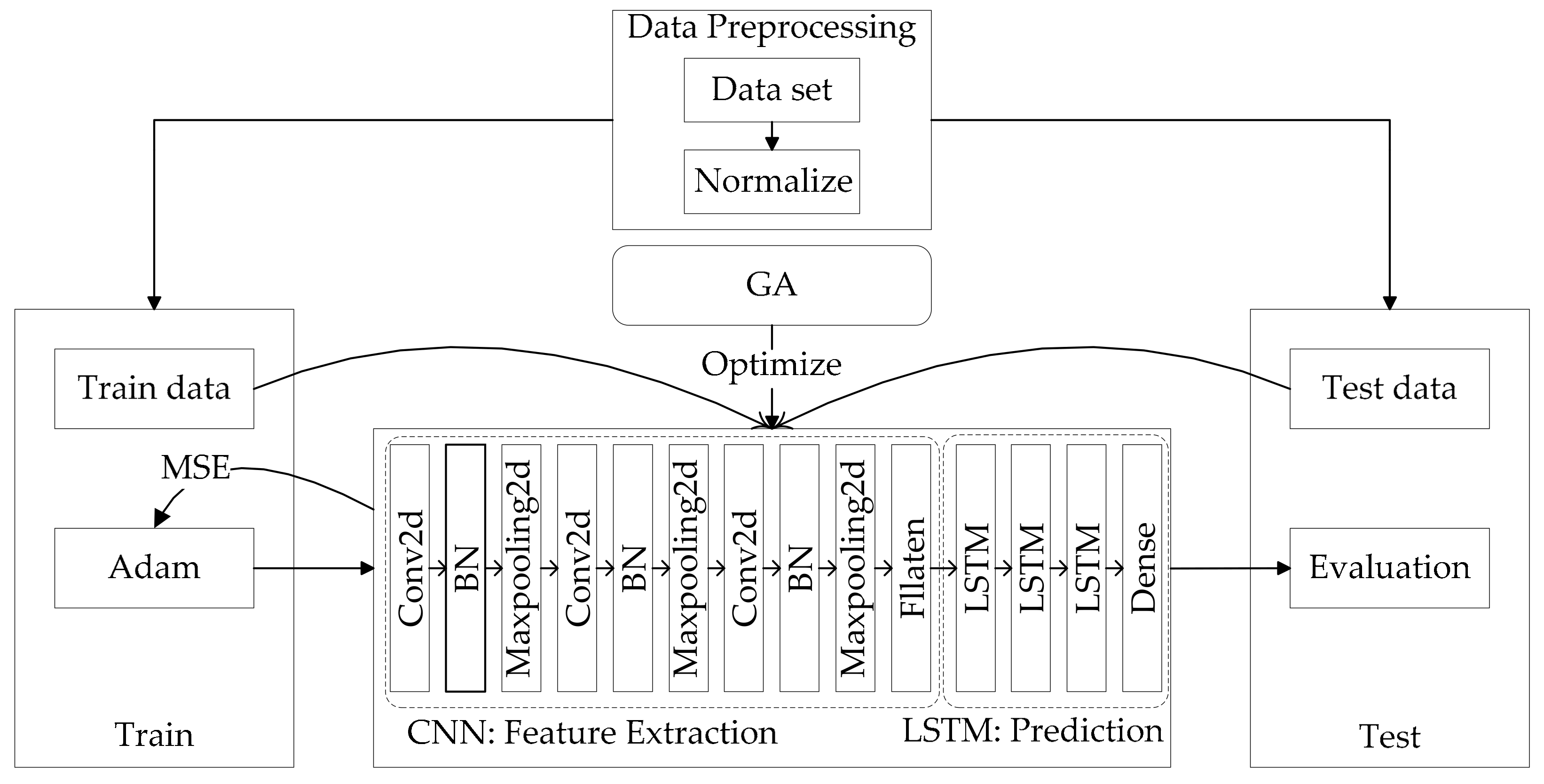
3. Method Based on GA-CNN-LSTM
GA-CNN-LSTM hybrid model proposed in this study includes CNN for feature extraction, LSTM for prediction, and GA for optimization.
The main part of the method of prediction is CNN-LSTM. CNN module includes convolutional layer, pooling layer, and flatten. Convolutional layer (Conv2d) is set to m-layer. CNN can set the size of the convolution kernel to perform feature extraction on the data of different time periods. To maximize existing data, the size of the convolution kernel is set to n × n. At the same time, the number of convolution kernels of each convolutional layer is input into the genetic algorithm as the individual genes of the genetic algorithm. Pooling layer (Maxpooling2D) is set to m-layer, and the size of the pooling layer is set to n × n. The study adds batch normalization before the pooling layer to improve training efficiency. Then, the data are compressed by flatten to perform global feature extraction. Finally, the data are input to the LSTM module for prediction.
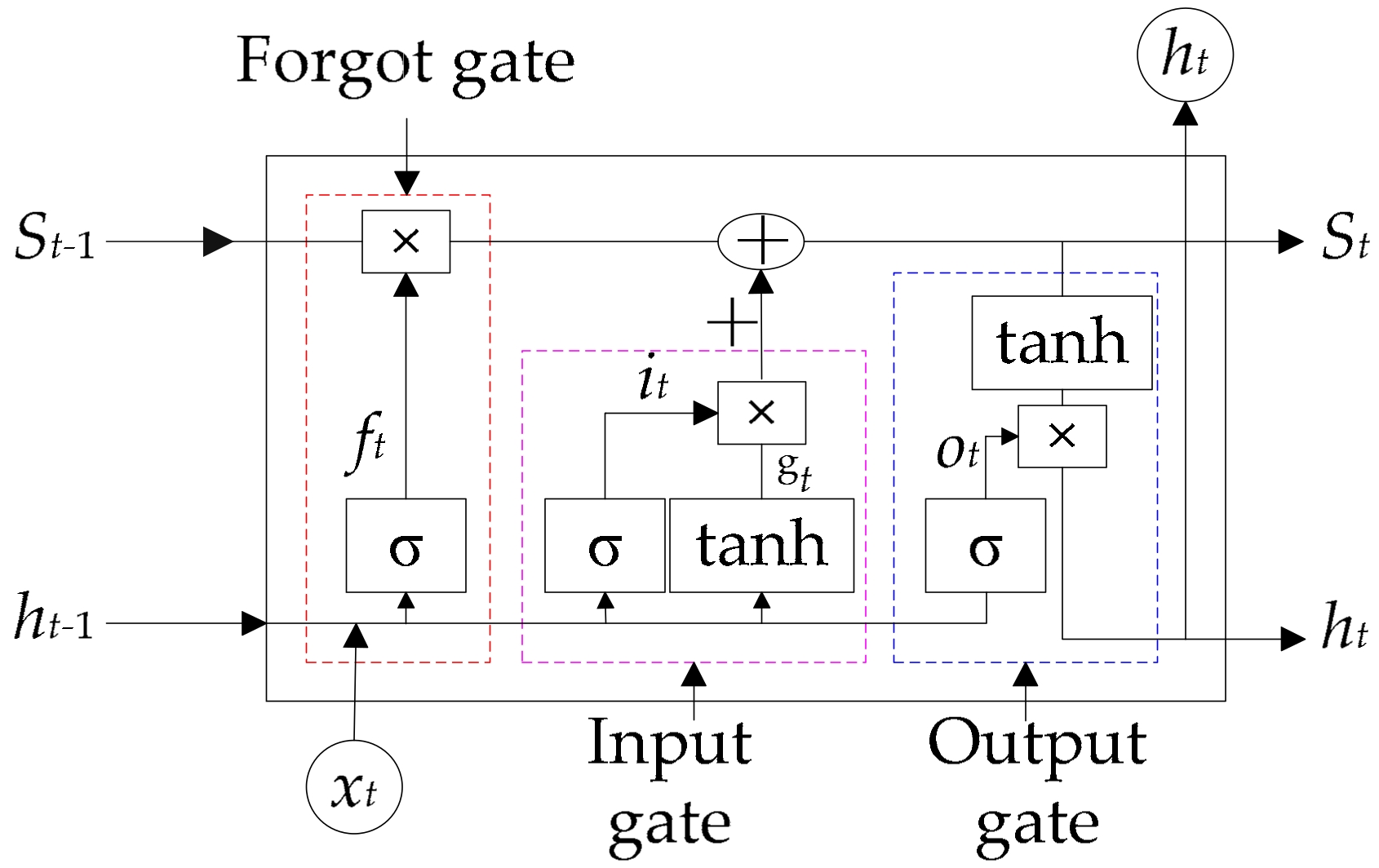
As learned through experiments, increasing the depth of the model by increasing the number of LSTM network elements helps improve the predictive capability of the model. Therefore, the LSTM module is set to the x-layer, and the number of neurons in each layer of the LSTM is input into the genetic algorithm as the individual genes of the genetic algorithm. LSTM uses Dropout to prevent overfitting. Finally, the vector of the specified format is output through Dense, that is, the daily tourist flow prediction value.
The GA-CNN-LSTM algorithm proposed in this article is an improvement on the CNN-LSTM algorithm. Regarding the CNN-LSTM algorithm, many papers have verified its effectiveness, especially in the field of prediction. The GA-CNN-LSTM algorithm uses the data extracted from CNN to input LSTM for prediction, and LSTM has unique advantages for prediction of time series data. In long-term time series prediction, LSTM will avoid the problem of gradient disappearance. However, for the selection of parameters in the CNN-LSTM model, most of the researches use manual selection methods such as grid search, which is time-consuming and laborious, and it is difficult to choose the most suitable parameters. Therefore, this article chooses GA, and uses the genetic and mutation process in GA algorithm for scientific selection of parameters, which will be more efficient from the perspective of time efficiency.
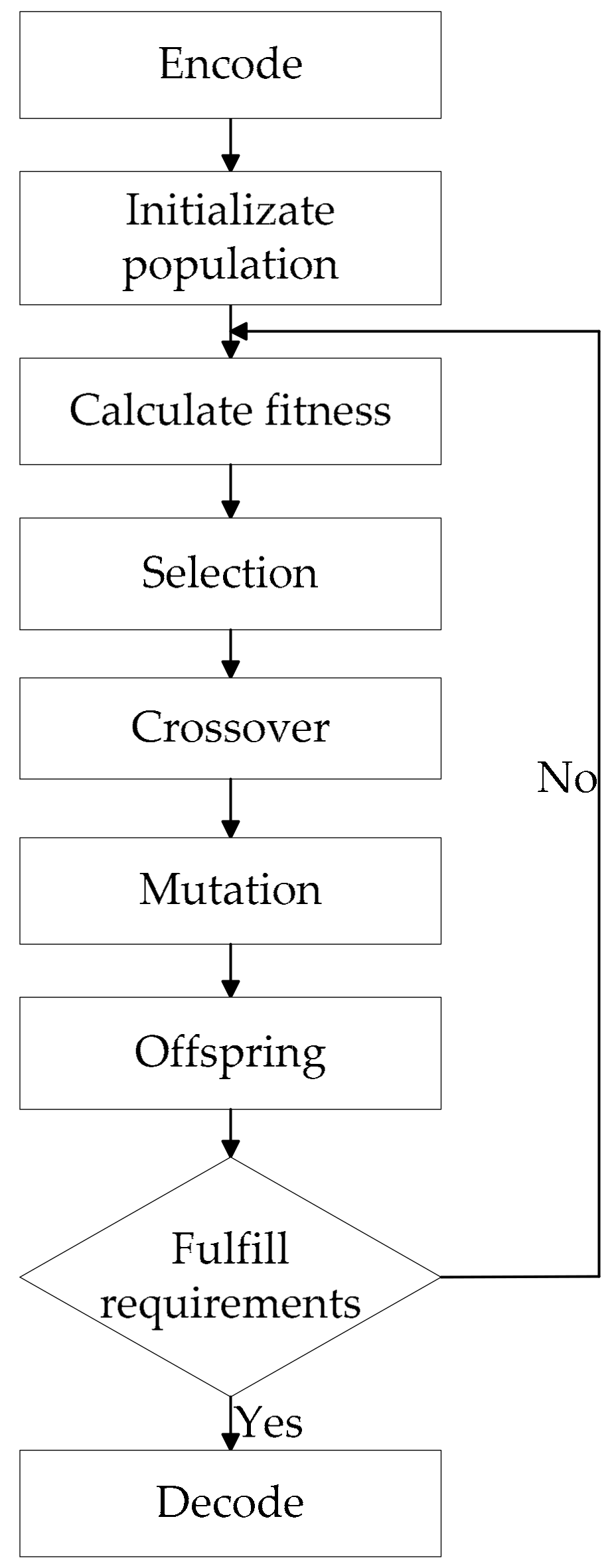
In this study, GA uses the process of selection, crossover, and mutation to choose scientifically the number of convolution kernels and neurons in each layer of the LSTM. By iterating and training the model until the preset number of iterations is reached or the requirements are met, the individual with the best fitness is obtained, and the genes of the individual are input as parameters into the CNN-LSTM to predict the tourist flow.
The individual fitness function is shown below:
where F is individual fitness; E is the error; this article uses MAPE as E; α is the influence of the convolution layer on the network performance; β is the influence of the LSTM on the network performance; in this article, α is 0.8, β is 0.2; n
conv is the number of convolution kernels; n
1stm is the number of neurons of LSTM; n
all is the total number of convolution kernels of CNN and neurons of LSTM.
In the GA-CNN-LSTM model, the individual fitness F and the MAPE have established an inverse proportional relationship, and the MAPE can be calculated to obtain the individual fitness, thereby evaluating the performance of the model and serving as the basis for the final parameters. From the perspective of time efficiency, this will take much less time than selecting all parameters of CNN-LSTM model with best performance by exhaustive method.
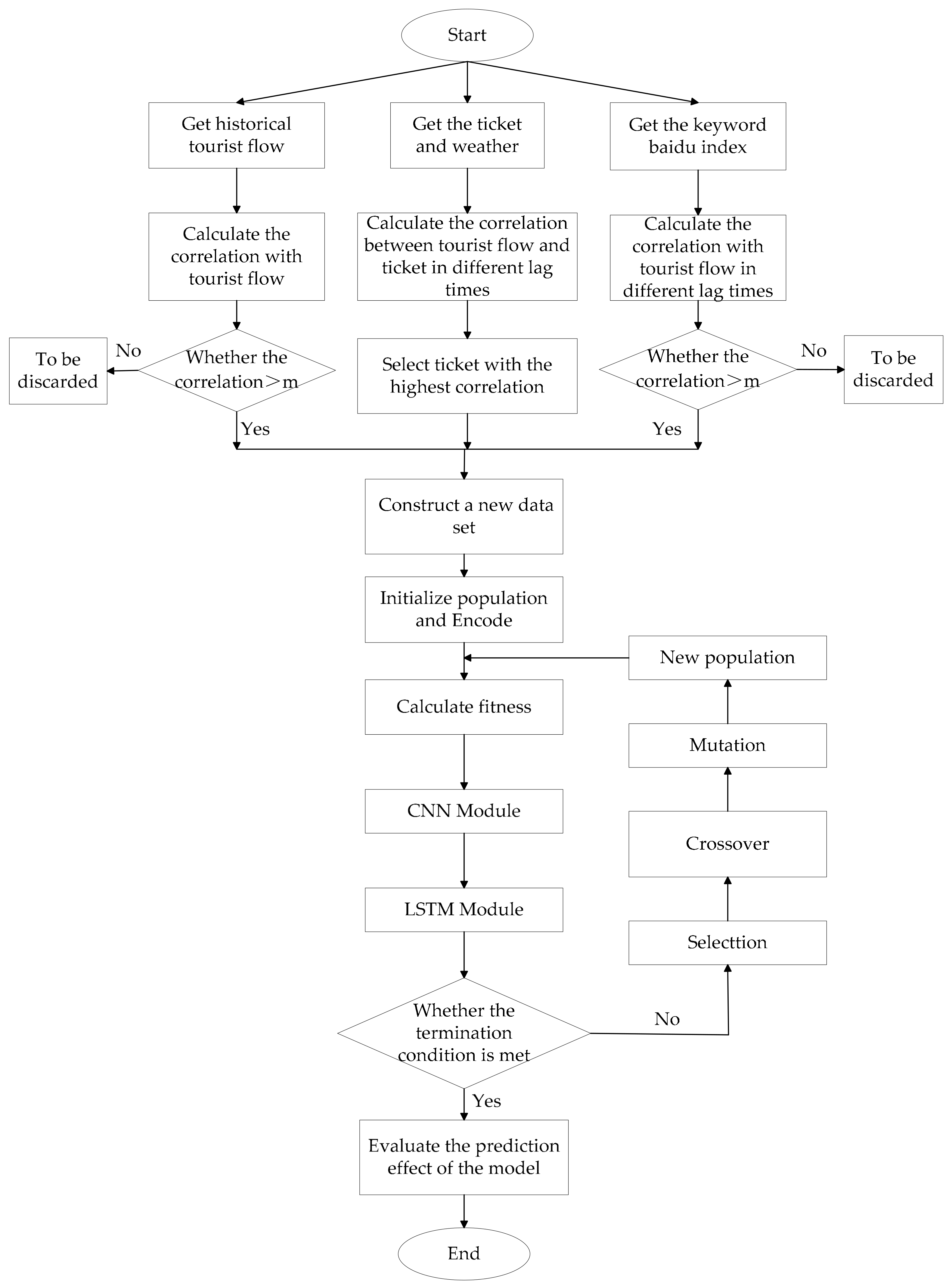
Based on the GA-CNN-LSTM model, this study proposes a complete modeling process to make predictions and evaluate the corresponding performance. The steps proceed as follows:
Preliminarily selecting factors related to the scenic spot, such as historical tourist flow data, meteorological data, tickets data, and so on. Correlation analysis is performed on historical tourist flow data, meteorological data, and tickets data. Moreover, high correlation is selected as input.
Selecting keywords of Baidu search index, which depends on what scenic spot the tourist is considering. Before traveling, tourists may search for information related to the scenic spot, such as weather, price, hotel, and so on.
Performing a correlation analysis between the keywords of Baidu search index which are obtained in Step 2 and tourist flow; selecting keywords with higher correlation as input.
Considering the lag of network search; setting a lag period and analyzing the correlation between Baidu index and tourist flow; choosing the lag period with the highest correlation.
Constructing a new data set that is input into the GA-CNN-LSTM model for daily tourist flow prediction.
Assessing accuracy of the GA-CNN-LSTM model; selecting relevant evaluation criteria for evaluation and comparing with related algorithms.
Figure 4 shows the research flow of this article.
4. Empirical Study
4.1. Data Set Construction
This study takes China’s 5A-level scenic spot Huangshan as the research object and extracts features from related parameters to predict the change in tourist flow. It selects daily historical data from 2015 to 2018 as the original data. Each piece of data contains daily historical data of 16 related factors, which are divided into four categories, namely, tourist flow-related historical data, time factors, meteorological factors, and Baidu search index. All data come from a research project in cooperation with Huangshan Scenic Spot, web search index in Baidu search engine, and meteorological data from weather stations near Huangshan. Data correlation refers to the regularity between two or more variable values in a certain sense [
33]; thus, correlation analysis is required for original data.
Tourist flow-related historical data include tourist flow for 30 days ago, 365 days ago, same day last week, the day before yesterday, yesterday, and tickets data. Based on the correlation analysis between tourist flow-related historical data and target total number of tourists, this study selects data with correlation bigger than 0.4 that is tourist flow for 365 days ago, same day last week, the day before yesterday, and yesterday.
Table 1 shows the correlation analysis results of tourist flow-related historical data and target total number of tourists with a confidence level of 0.01.
For tickets, considering the existence of lags in booking, the correlation analysis is performed on the tickets of different lag periods. Finally, the lag period with the highest correlation is determined as the number of tickets 1 day in advance, that is, the number of tickets yesterday.
Table 2 presents the correlation analysis results of tickets and target total number of tourists with a confidence level of 0.01.
For tourist spots, the number of people on holidays and weekends is significantly more than weekdays, so the time factors are used as a key feature. In this article, the time factors are expressed by two characteristics. First, 1 to 7 is used to represent the day from Monday to Sunday, and 0 or 1 is used to represent whether the day is weekdays or holidays.
Huangshan is a mountain-type scenic spot. Meteorological factors will inevitably influence tourists’ decision. This study selects four meteorological factors, namely, weather, wind speed, average temperature, and average humidity. The weather uses 1–14 to represent 14 types of weather, namely, overcast, sunny, sunny to cloudy, shower, cloudy, light rain, moderate rain, heavy rain, rainstorm, light snow, moderate snow, heavy snow, blizzard, and sleet.
The selection and analysis of web search keywords are directly related to research that can accurately predict the tourist flow of scenic spots [
34,
35]. Based on searching the contents of scenic spots through the Internet before traveling, this paper selects relevant keyword benchmarks, such as, destination, tourist routes, maps, weather, food, tickets, etc. Based on the correlation analysis, this paper selects the five keywords with the highest correlation bigger than 0.4.
Table 3 shows the results of the correlation analysis between keywords and total number of tourists with a confidence level of 0.01.
At the same time, considering the lag between information searched on the Internet and travel time. This paper analyzes the correlation between target tourist flow and keywords when the lag period is one day, two days, one week, 15 days and one month.
Table 4 shows the correlation between total number of tourists and keywords under different lag period with a confidence level of 0.01.
According to the magnitude of the correlation under different lag periods, Baidu search index with lag period of 2 days is selected as an input.
To sum it up, this article uses tourist flow-related historical data, time factors, meteorological factors, and Baidu search index.
Table 5 shows the specific characteristics.
The GA-CNN-LSTM hybrid model proposed in this study takes the time series feature map as the input. Tourist flow-related historical data, time factors, meteorological factors, and Baidu search index are independent time series. This study refers to the word vector method in natural language processing. The number of tourists at a time is represented by a series of related features into a vector; then, brand-new time series data are formed. The number of historical tourists at each moment is collectively represented by its related features. Then, the input time series data generated feature map is input into the CNN module by window sliding. To facilitate subsequent network calculations, the sliding window width is set to 16, the step size is set to 1, and the size of the unit feature map is 16 × 16. The input feature map is also arranged in time series.
4.2. Data Preprocessing
To improve the prediction accuracy and stabilize the data before using GA-CNN-LSTM neural network for prediction, the original data sequences must be normalized to [0, 1]. This study uses the min-max normalization method, and the formula is shown below:
where
is the normalized data; x
i is the influencing factor of a certain tourist flow on day i, x
max, x
min are the maximum and minimum values of the data of the corresponding sequence.
4.3. Data Set Partition
This article selects daily historical data of Huangshan Scenic Spot from 2015 to 2018 as the original data. Then, data from 2015 to 2017 are used as the training set; data from 2018 are used as the test set.
4.4. Experimental Environment
The experiments in this article are performed in the following hardware environment: CPU: Intel i5 9400f, Memory: 16GB, GPU: 1660ti. The software framework is a Tensorflow framework based on Keras deep learning tools, which is written by Python. Keras provides a simple and consistent programming interface that can help users quickly understand the neural network architecture and reduce the repetitive work in the code implementation process. Keras has the characteristics of modularity, and supports the free combination of model layers and layer-by-layer overlay.
4.5. Model Building
The constructed data set is divided into training and test sets, and the training set data are input into the model for training. The three-layer convolutional and pooling layers are selected according to the size of the unit feature map and the principle of the convolutional neural network. In the convolutional layer of the CNN module, the size of the unit feature map is 16 × 16, the size of the convolution kernel is set to 2, and the step size of the convolution kernel is set to 1. The pooling layer sets the same parameters as the convolutional layer. Then, weight of CNN is initialized. Meanwhile, CNN module also adds Dropout to reduce the probability of overfitting. The activation function is set to Selu (Scaled Exponential Linear Units) function [
36]. Compared with traditional Relu (Rectified Linear Unit) function, the Selu function has better convergence performance and can effectively avoid the problem of gradient disappearance:
where
=1.05;
= 1.67.
Some problems in deep neural network training are identified. For example, owing to the large number of layers in a deep neural network, changes occurring in the parameters of one layer will affect the output of all subsequent layers and result in frequent parameter modification and low training efficiency. In addition, before the data pass through the activation function, the output value of the nerve cell may also cause the failure of the latter to work if it remarkably exceeds the appropriate range of the activation function itself. Batch Normalization (BN) [
37] is designed to solve this problem. In BN, momentum = 0.99. In this study, BN is added into CNN. The formula for BN is as follows:
where x
i is input value; y
i is the output value after BN; m is the size of the mini-batch, that is, a mini-batch with m inputs;
is the average of all inputs in the same mini-batch;
is the variance of all inputs in the same mini-batch; next, obtaining the normalized
according to
,
,
, and formula (12), putting
into formula (13), and obtaining y
i;
and
are obtained through machine learning. Using BN can maximize the neurons in deep neural networks to improve training efficiency.
In the LSTM module, the weight is initialized using MSE as the loss function and Adam function as the optimizer, learning rate = 0.001, beta_1 = 0.9, beta_2 = 0.999. Here, our objective is to minimize the forecasting error of the model:
where n is the total number of samples in the test set;
is prediction result;
is the number of tourists.
To keep the impartiality of performance evaluation, only the training data is used during the training, while the testing data is not used. Each time the training data are input to the GA-CNN-LSTM, a loss value is generated, according to which the optimizer uses a backpropagation method to adjust the parameters of GA-CNN-LSTM. The forecast result of GA-CNN-LSTM will be more and more accurate with the increase of training iterations. After the GA-CNN-LSTM training is finished, the testing data is input into the GA-CNN-LSTM, and the testing results and real results are compared to evaluate the performance of the GA-CNN-LSTM.
When there is not enough training data or when there is overtraining, overfitting may occur. However, there are many ways to avoid overfitting, such as regularization, data augmentation, dropout, dropconnect, or early stopping. The method used in this paper is dropout. CNN and LSTM module both add dropout to reduce the probability of overfitting.
Figure 5 shows the specific training and prediction process of the model.
5. Result and Discussion
This study uses CNN-LSTM, CNN, LSTM, and BP as comparative experiments. The results of CNN-LSTM, CNN, LSTM, and BP will be compared with the experimental results of GA-CNN-LSTM. In addition, mean absolute percentage error (MAPE), root mean squared error (RMSE), Pearson correlation coefficient (r), Kling–Gupta efficiency (KGE) and index of agreement (IA) are used as the criteria for measuring the pros and cons of the model, with MAPE as the main evaluation criterion:
where n is the total number of samples in the test set;
is prediction result;
is the number of tourists;
is the average of tourists.
and
are
SDs of prediction result and the number of tourists.
is the average value of prediction result.
First, four CNN-LSTMs are manually selected with different numbers of neurons.
Table 6 shows the number of neurons in four different CNN-LSTM models.
Table 7 shows the comparison of MAPE GA-CNN-LSTM model and 4 different CNN-LSTM models under 5 experiments, respectively. For GA-CNN-LSTM model, MAPE
avg= 20.77. For 4 different CNN-LSTMs, MAPE
avg = 23.08, 22.97, 22.89, 22.62, respectively. From the experimental results, the performance of GA-CNN-LSTM on MAPE can be concluded to be better than CNN-LSTM.
GA-CNN-LSTM, CNN-LSTM with the best performance, CNN, LSTM, and BP are selected as comparison experiments.
Table 8,
Table 9 and
Table 10 show the comparison results of MAPE, MAE, r, and IA, respectively. From these tables, BP’s performance in tourist flow prediction can be seen as poor. CNN’s performance is better than BP, but a large error remains. Although a large error also exists, GA-CNN-LSTM and CNN-LSTM are more effective and accurate than LSTM. In addition, other specific details can be obtained from
Table 8,
Table 9 and
Table 10. On the performance of MAPE, the average of the five experiments from small to large is GA-CNN-LSTM (20.77%), CNN-LSTM (22.63%), LSTM (25.12%), BP (28.18%), and CNN (29.81%). On the performance of r, the average of five experiments from small to large is GA-CNN-LSTM (0.913), CNN-LSTM (0.904), CNN (0.887), BP (0.887), and LSTM (0.844). On the performance of IA, the average of five experiments from small to large is GA-CNN-LSTM (0.919), CNN-LSTM (0.917), CNN (0.916), BP (0.904), and LSTM (0.889). From these data, on the performance of MAPE, GA-CNN-LSTM is generally better than CNN-LSTM and other algorithms, it is approximately 8.22% higher than CNN-LSTM, 16.68% higher than LSTM, 29.11% higher than CNN, and 26.59% higher than BP. On r, the performance of GA-CNN-LSTM is about 0.91% higher than CNN-LSTM, about 8.15% higher than LSTM, about 2.93% higher than CNN, and about 3.05% higher than BP. On IA, the performance of GA-CNN-LSTM is about 0.33% higher than CNN-LSTM, about 0.39% higher than LSTM, about 1.72% higher than CNN, and about 3.40% higher than BP. Although GA-CNN-LSTM performs better on r, and IA, none of them has made substantial improvements.
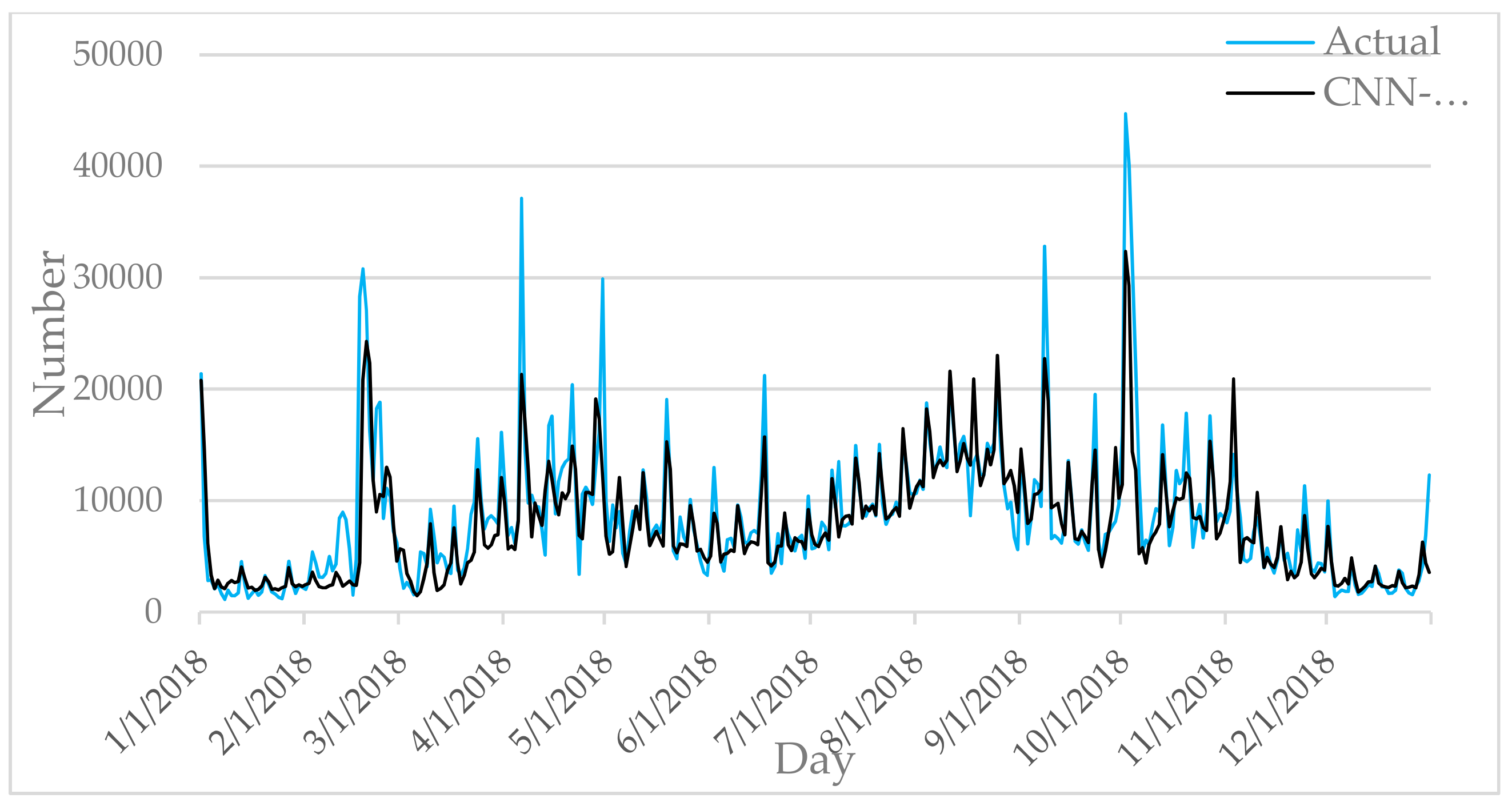
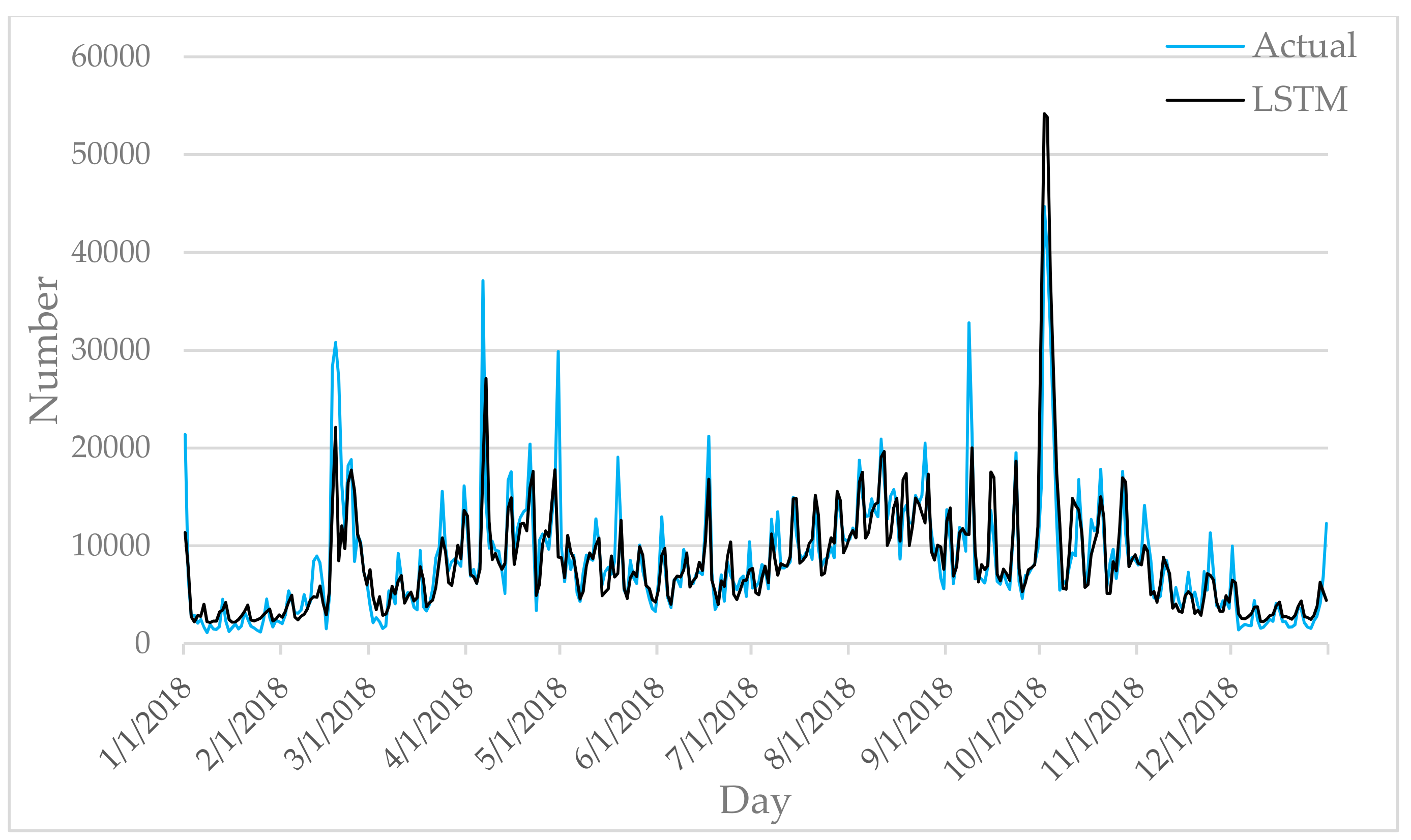
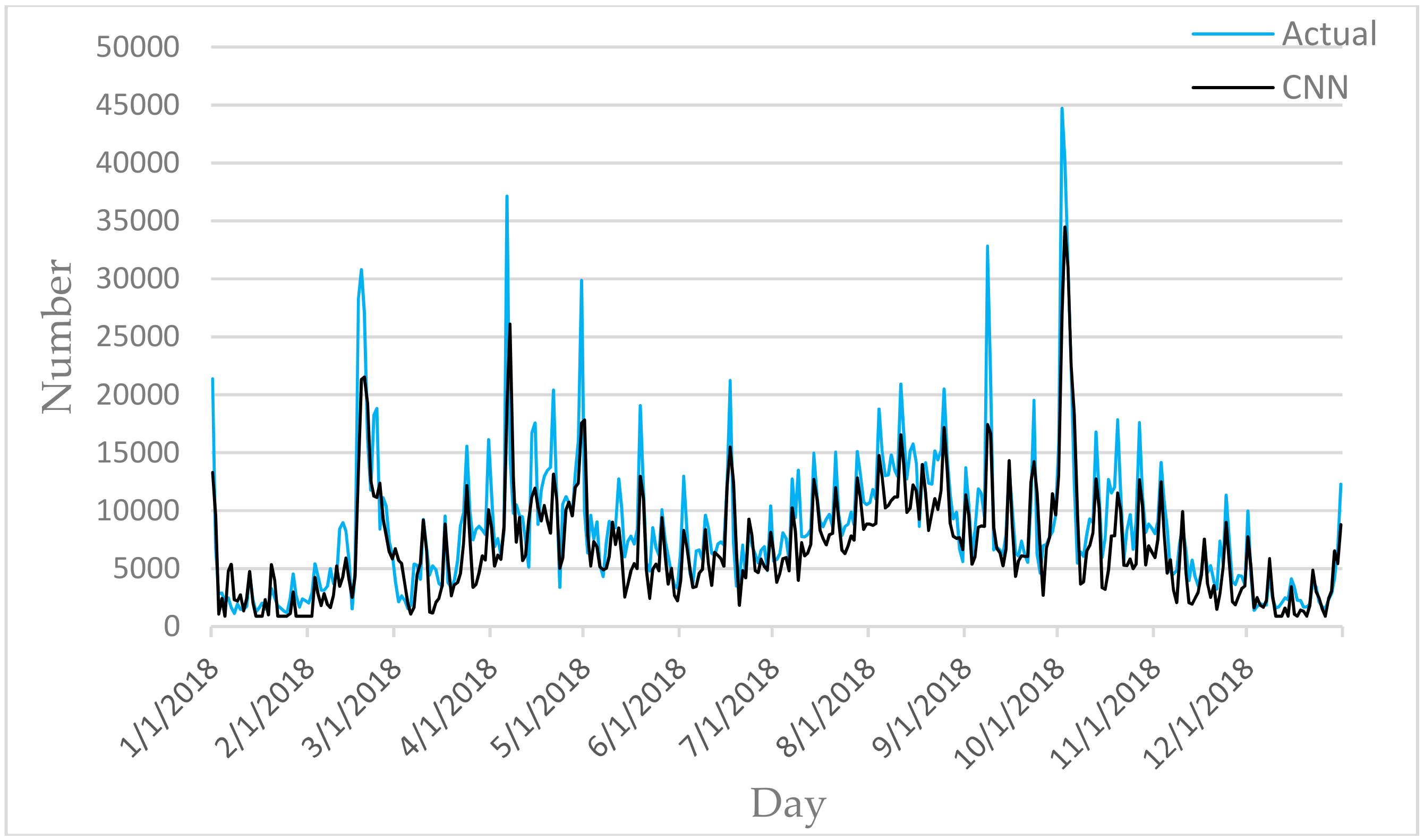
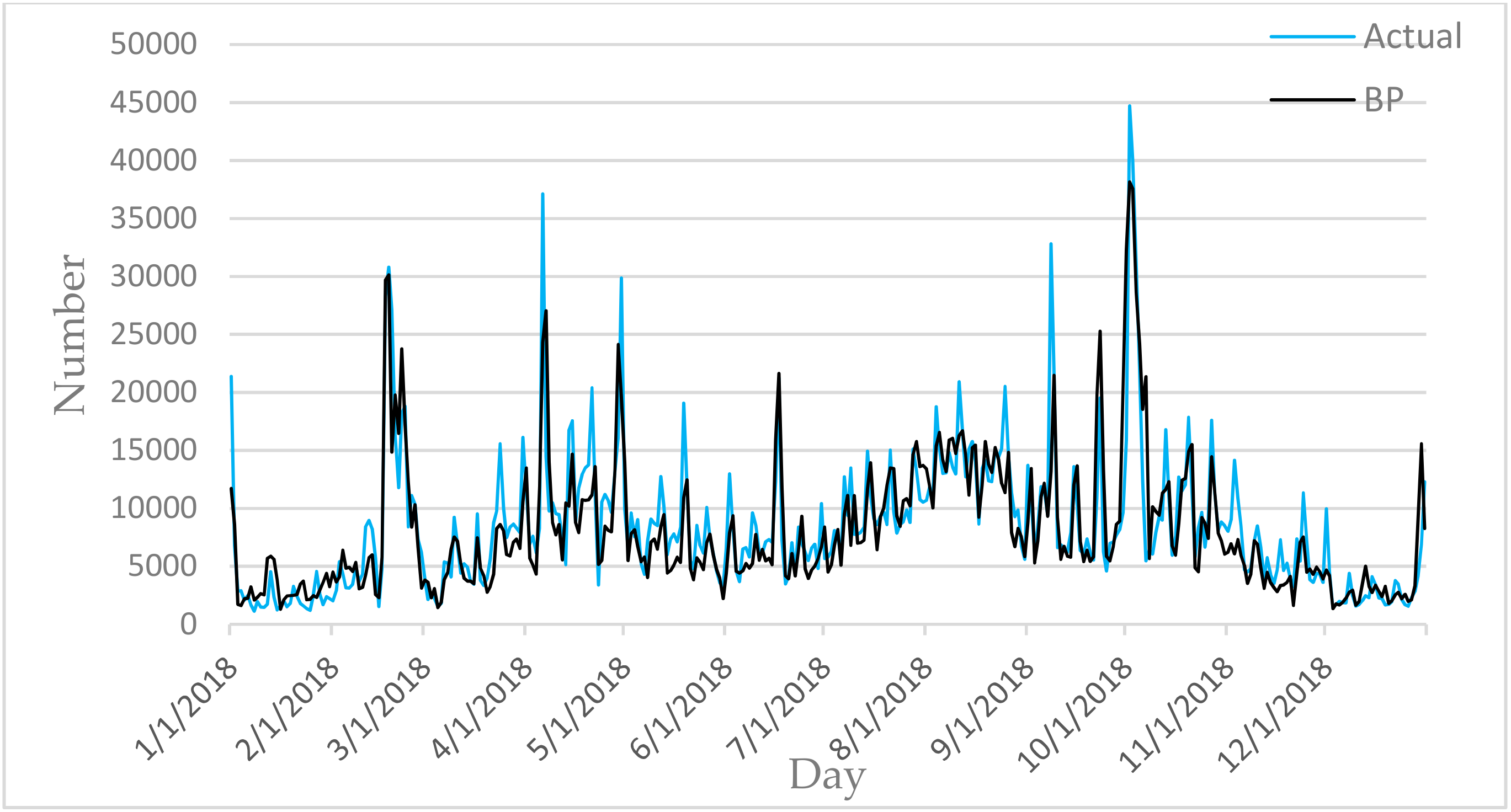
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 show the comparison between the prediction results of each algorithm in Test2 and the number of tourist flow. From these figures, the prediction results of BP and CNN algorithms can be summarized to fluctuate substantially than the number of tourist flow; a big gap exists between the changing trend predicted by BP and CNN algorithms and the changing trend of tourist flow; and the prediction results of the CNN algorithm are generally lower than the number of tourist flow. By contrast, GA-CNN-LSTM, CNN-LSTM, and LSTM show better prediction accuracy. GA-CNN-LSTM has an accurate grasp of the number of tourist flow throughout the year. However, the GA-CNN-LSTM, CNN-LSTM, LSTM, CNN, and BP algorithms all show inadequacy in predicting the number of tourist flow during peak time, and the prediction of the number of tourist flow in the peak time was generally low. In addition, the five algorithms have large errors in the predictions for January and February and thus require further research.
On the performance of KGE in Test2, the results of the five algorithms from small to large is CNN (0.695), GA-CNN-LSTM (0.767), CNN-LSTM (0.772), LSTM (0.839), BP (0.872). KGE have an ideal value of 1. Therefore, from the perspective of KGE, GA-CNN-LSTM performs poorly. This is where improvement is needed. On the performance of RMSE in Test2, the results of the five algorithms from small to large is GA-CNN-LSTM (2983.33), CNN-LSTM (3185.16), CNN (3290.35), BP (3296.08), LSTM (3423.17). This proves that GA-CNN-LSTM is more accuracy.
Table 11 and
Table 12 show the monthly and seasonal MAPE results of Test2. From
Table 11, GA-CNN-LSTM’s prediction results can be seen as accurate in six months of the year, which shows the stability of GA-CNN-LSTM’s prediction. Evidently, GA-CNN-LSTM also has a series of problems. The performance is poor in February and March, and the prediction error is large. At the same time, during the peak season of tourism in Huangshan, the performances in July, August, and September are not as good as CNN-LSTM, BP, and LSTM. Nonetheless, the gap in error is not large. From
Table 12, GA-CNN-LSTM can be seen to perform better than other algorithms in the first and fourth seasons. Owing to the geographical limitation of Huangshan Scenic Spot, the number of tourist flow in the first and fourth season often experiences considerable changes. However, GA-CNN-LSTM still shows better prediction accuracy, thereby demonstrating its efficiency for prediction in complex environments.
On the predictions for the second and third seasons, although GA-CNN-LSTM is not the best, its performance still belongs to the acceptable range, and the gap among the best algorithms is small. For annual performance, GA-CNN-LSTM shows better stability than the others.
All these experimental results reflect the reliability and efficiency of GA-CNN-LSTM in tourist flow prediction. Although the prediction performance of both CNN and LSTM is good, GA-CNN-LSTM is better. It further proves that the method of extracting data features through CNN and predicting through LSTM is reliable.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}