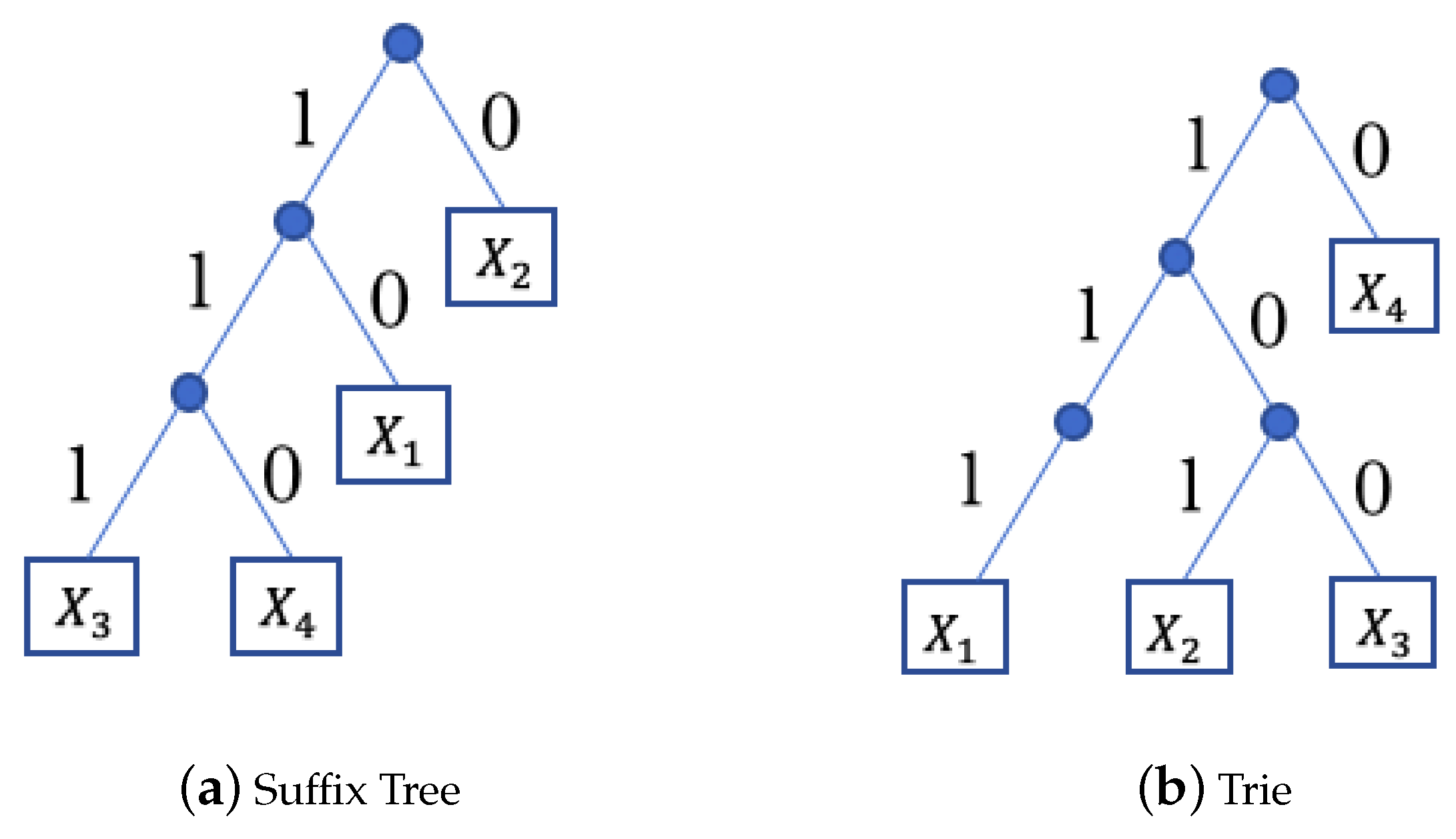
3.3. Analytic Properties of the Generating Functions
Here, we turn our attention to the smallest singularities of the two generating functions given in Lemma 3. It has been shown by Jacquet and Szpankowski [
21] that
has exactly one root in the disk
. Following the notations in [
21], we denote the root within the disk
of
by
, and by bootstrapping we obtain
We also denote the derivative of
at the root
, by
, and we obtain
In this paper, we will prove a similar result for the polynomial through the following work.
Lemma 5. If w and are two distinct binary words of length k and , there exists , such that and Proof. If the minimal degree of
is greater than
, then
for
. For a fixed
, we have
This leads to the following
□
Lemma 6. There exist , and such that , and such that, for every pair of distinct words w, and of length , and for , we have In other words, does not have any roots in .
Proof. There are three cases to consider:
Case
When either
or
, then every term of
has degree
k or larger, and therefore
There exists
, such that for
, we have
. This yields
Case
If the minimal degree for
or
is greater than
, then every term of
has degree at least
. We also note that, by Lemma 9,
. Therefore, there exists
, such that
Case
The only remaining case is where the minimal degree for
and
are both less than or equal to
. If
, then
, where
u is a word of length
. Then we have
There exists
, such that
Similarly, we can show that there exists
, such that
. Therefore, for
we have
We complete the proof by setting . □
Lemma 7. There exist and such that , and for every word w and of length , the polynomial has exactly one root in the disk .
Proof. There exist
,
large enough, such that, for
, we have
and for
,
If we define
, then we have, for
,
by Rouché’s theorem, as
has only one root in
, then also
has exactly one root in
. □
We denote the root within the disk
of
by
, and by bootstrapping we obtain
We also denote the derivative of
at the root
, by
, and we obtain
We will refer to these expressions in the residue analysis that we present in the next section.
3.4. Asymptotic Difference
We begin this section by the following lemmas on the autocorrelation polynomials.
Lemma 8 (Jacquet and Szpankowski, 1994).
For most words w, the autocorrelation polynomial is very close to 1, with high probably. More precisely, if w is a binary word of length k and , there exists , such that andwhere . We use Iverson notation Lemma 9 (Jacquet and Szpankowski, 1994).
There exist and , such that , and for every binary word w with length and , we haveIn other words, does not have any roots in .
Lemma 10. With high probability, for most distinct pairs , the correlation polynomial is very close to 0. More precisely, if w and are two distinct binary words of length k and , there exists , such that and We will use the above results to prove that the expected values in the Bernoulli model and the model built over a trie are asymptotically equivalent. We now prove Theorem 1 below.
Proof of Theorem 1. From Lemmas 3 and 4, we have
and
subtracting the two generating functions, we obtain
Therefore, by Cauchy integral formula (see [
20]), we have
where the path of integration is a circle about zero with counterclockwise orientation. We note that the above integrand has poles at
,
, and
(refer to expression (
29)). Therefore, we define
where the circle of radius
contains all of the above poles. By the residue theorem, we have
Then we obtain
and finally, we have
First, we show that, for sufficiently large n, the sum approaches zero. □
Lemma 11. For large enough n, and for , there exists such that Proof. The Mellin transform of the above function is
We define
which is negative and uniformly bounded for all
w. Also, for a fixed
s, we have
and therefore, we obtain
From this expression, and noticing that the function has a removable singularity at
, we can see that the Mellin transform
exists on the strip where
. We still need to investigate the Mellin strip for the sum
. In other words, we need to examine whether summing
over all words of length
k (where
k grows with
n) has any effect on the analyticity of the function. We observe that
Lemma 8 allows us to split the above sum between the words for which and words that have .
Such a split yields the following
This shows that is bounded above for and, therefore, it is analytic. This argument holds for as well, as would still be bounded above by a constant that depends on s and k.
We would like to approximate
when
. By the inverse Mellin transform, we have
We choose
for a fixed
. Then by the direct mapping theorem [
22], we obtain
and subsequently, we get
□
We next prove the asymptotic smallness of
in (
54).
Lemma 12. For large n and , we have Proof. For
, we show that the denominator in (
71) is bounded away from zero.
To find a lower bound for
, we can choose
large enough such that
We now move on to finding an upper bound for the numerator in (
71), for
.
Therefore, there exists a constant
such that
Summing over all patterns
w, and applying Lemma 8, we obtain
which approaches zero as
and
. This completes the proof of of Theorem 1. □
Similar to Theorem 1, we provide a proof to show that the second factorial moments of the kth Subword Complexity and the kth Prefix Complexity, have the same first order asymptotic behavior. We are now ready to state the proof of Theorem 2.
Proof of Theorem 2. As discussed in Lemmas 3 and 4, the generating functions representing
and
respectively, are
and
In Theorem 1, we proved that for every
(which does not depend on
n or
k), we have
Therefore, both (
77) and (
78) are of order
for
. Thus, to show the asymptotic smallness, it is enough to choose
, where
is a small positive value. Now, it only remains to show (
79) is asymptotically negligible as well. We define
Next, we extract the coefficient of
where the path of integration is a circle about the origin with counterclockwise orientation. We define
The above integrand has poles at
,
(as in (
46)), and
. We have chosen
such that the poles are all inside the circle
. It follows that
and the residues give us the following.
and
where
is as in (
47). Therefore, we get
We now show that the above two terms are asymptotically small. □
Lemma 13. There exists where the sum is of order O().
Proof. We define
The Mellin transform of the above function is
where
. We note that
is negative and uniformly bounded from above for all
.For a fixes
s, we also have,
and
Therefore, we have
To find the Mellin strip for the sum
, we first note that
Since
, we have
and
Therefore, we get
By Lemma 10, with high probability, a randomly selected
w has the property
, and thus
With that and by Lemma 8, for most words
w,
Therefore, both sums (
91) and (
93) are of the form
. The sums (
92) and (
94) are also of order
by Lemma 10. Combining all these terms we will obtain
By the inverse Mellin transform, for
,
and
, we have
□
In the following lemma we show that the first term in (
85) is asymptotically small.
Proof. First note that
We saw in (
73) that
, and therefore, it follows that
For
,
is also bounded below as the following
which is bounded away from zero by the assumption of Lemma 7. Additionally, we show that the numerator in (
98) is bounded above, as follows
This yields
By (
75), the first term above is of order
and by Lemma 10 and an analysis similar to (
75), the second term yields
as well. Finally, we have
Which goes to zero asymptotically, for
. □
This lemma completes our proof of Theorem 2.
3.5. Asymptotic Analysis of the kth Prefix Complexity
We finally proceed to analyzing the asymptotic moments of the
kth Prefix Complexity. The results obtained hold true for the moments of the
kth Subword Complexity. Our methodology involves poissonization, saddle point analysis (the complex version of Laplace’s method [
23]), and depoissonization.
Lemma 15 (Jacquet and Szpankowski, 1998). Let be the Poisson transform of a sequence . If is analytic in a linear cone with , and if the following two conditions hold:
(I) For and real values B, , ν where is such that, for fixed t, ;
(II) For and Then, for every non-negative integer n, we have On the Expected Value: To transform the sequence of interest,
, into a Poisson model, we recall that in (
25) we found
Thus, the Poisson transform is
To asymptotically evaluate this harmonic sum, we turn our attention to the Mellin Transform once more. The Mellin transform of
is
which has the fundamental strip
. For
, the inverse Mellin integral is the following
where we define
for
. We emphasize that the above integral involves
k, and
k grows with
n. We evaluate the integral through the saddle point analysis. Therefore, we choose the line of integration to cross the saddle point
. To find the saddle point
, we let
, and we obtain
and therefore,
where
.
By (
108) and the fact that
for
and
, we can see that there are actually infinitely many saddle points
of the form
on the line of integration.
We remark that the location of depends on the value of a. We have as , and as . We divide the analysis into three parts, for the three ranges , , and .
In the first range, which corresponds to
we perform a residue analysis, taking into account the dominant pole at
. In the second range, we have
and we get the asymptotic result through the saddle point method. The last range corresponds to
and we approach it with a combination of residue analysis at
, and the saddle point method. We now proceed by stating the proof of Theorem 3.
Proof of Theorem 3. We begin with proving part
which requires a saddle point analysis. We rewrite the inverse Mellin transform with integration line at
as
Step one: Saddle points’ contribute to the integral estimation
First, we are able to show those saddle points with
do not have a significant asymptotic contribution to the integral. To show this, we let
Since
as
, we observe that
which is very small for large
n. Note that for
,
is decreasing, and bounded above by
.
Step two: Partitioning the integral
There are now only finitely many saddle points to work with. We split the integral range into sub-intervals, each of which contains exactly one saddle point. This way, each integral has a contour traversing a single saddle point, and we will be able to estimate the dominant contribution in each integral from a small neighborhood around the saddle point. Assuming that
is the largest
j for which
, we split the integral
as following
By the same argument as in (
115), the second term in (
116) is also asymptotically negligible. Therefore, we are only left with
where
.
Step three: Splitting the saddle contour
For each integral
, we write the expansion of
about
, as follows
The main contribution for the integral estimate should come from an small integration path that reduces
to its quadratic expansion about
. In other words, we want the integration path to be such that
The above conditions are true when
and
. Thus, we choose the integration path to be
. Therefore, we have
Saddle Tails Pruning.
We show that the integral is small for
. We define
Note that for
, we have
where
. Thus,
Central Approximation.
Over the main path, the integrals are of the form
We have
and
Therefore, by Laplace’s theorem (refer to [
22]) we obtain
We finally sum over all
j, and we get
We can rewrite
as
where
, and
For part
, we move the line of integration to
. Note that in this range, we must consider the contribution of the pole at
. We have
Computing the residue at
, and following the same analysis as in part
i for the above integral, we arrive at
For part
of Theorem 3, we shift the line of integration to
, then we have
where
.
Step four: Asymptotic depoissonization
To show that both conditions in (15) hold for
, we extend the real values
z to complex values
, where
. To prove (
103), we note that
and therefore
is absolutely convergent for
. The same saddle point analysis applies here and we obtain
where
, and
is as in (
128). Condition (
103) is therefore satisfied. To prove condition (
104) We see that for a fixed
k,
Therefore, we have
This completes the proof of Theorem 3. □
On the Second Factorial Moment: We poissonize the sequence
as well. By the analysis in (
27),
which gives the following poissonized form
We show that in all ranges of
a the leftover sum in (
138) has a lower order contribution to
compared to
. We define
In the first range for
k, we take the Mellin transform of
, which is
and we note that the fundamental strip for this Mellin transform of is
as well. The inverse Mellin transform for
is
We note that this range of
corresponds to
The integrand in (
141) is quite similar to the one seen in (
107). The only difference is the extra term
. However, we notice that
is analytic and bounded. Thus, we obtain the same saddle points with the real part as in (
109) and the same imaginary parts in the form of
,
. Thus, the same saddle point analysis for the integral in (
107) applies to
as well. We avoid repeating the similar steps, and we skip to the central approximation, where by Laplace’s theorem (ref. [
22]), we get
which can be represented as
where
This shows that
, when
Subsequently, for
, we get
and for
, we get
It is not difficult to see that for each range of
a as stated above,
has a lower order contribution to the asymptotic expansion of
, compared to
. Therefore, this leads us to Theorem 4, which will be proved bellow.
Proof of Theorem 4. It is only left to show that the two depoissonization conditions hold: For condition (
103) in Theorem 15, from (
135) we have
and for condition (
104), we have, for fixed
k,
Therefore both depoissonization conditions are satisfied and the desired result follows. □
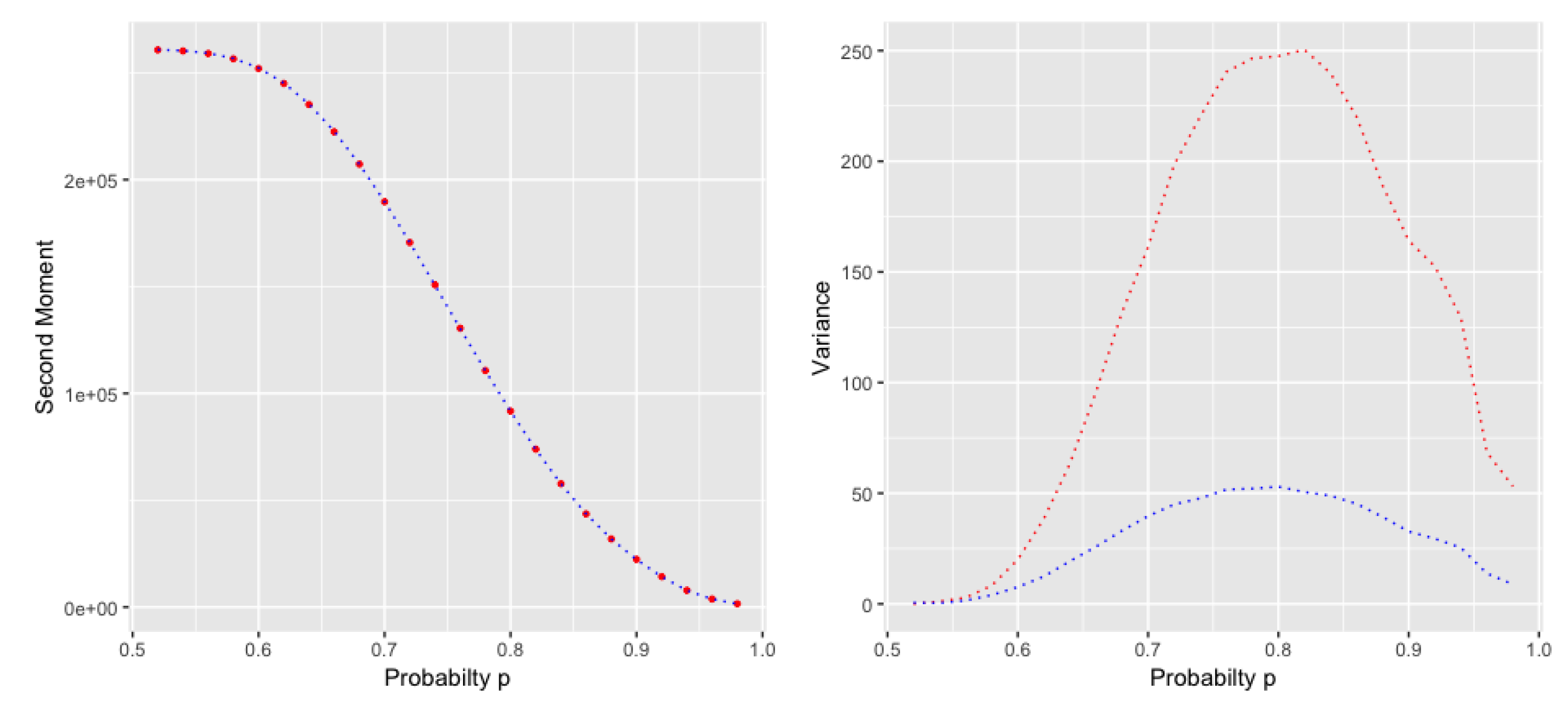
Corollary. A Remark on the Second Moment and the Variance
For the second moment we have
Therefore, by (
105) and (
138) the Poisson transform of the second moment, which we denote by
is
which results in the same first order asymptotic as the second factorial moment. Also, it is not difficult to extend the proof in Chapter 6 to show that the second moments of the two models are asymptotically the same. For the variance we have
Therefore the Poisson transform, which we denote by
is
The Mellin transform of the above function has the following form
This is quite similar to what we saw in (
106), which indicates that the variance has the same asymptotic growth as the expected value. But the variance of the two models do not behave in the same way (cf.
Figure 2).


{kind=link}
{kind=link}
{kind=link}


