1. Introduction
The usage of language, both in its written and oral expressions (texts and speech), follows very strong statistical regularities. One of the goals of quantitative linguistics is to unveil, analyze, explain, and exploit those linguistic statistical laws. Perhaps the clearest example of a statistical law in language usage is Zipf’s law, which quantifies the frequency of occurrence of words in such written and oral forms [
1,
2,
3,
4,
5,
6], establishing that there is no unarbitrary way to distinguish between rare and common words (due to the absence of a characteristic scale in “rarity”). Surprisingly, Zipf’s law is not only a linguistic law, but seems to be a rather common phenomenon in complex systems where discrete units self-organize into groups, or types (persons into cities, money into persons, etc. [
7]).
Zipf’s law can be considered as the “tip of the iceberg” of text statistics. Another well-known pattern of this sort is Herdan’s law, also called Heaps’ law [
2,
8,
9], which states that the growth of vocabulary with text length is sublinear (however, the precise mathematical dependence has been debated [
10]). Herdan’s law has been related to Zipf’s law, sometimes with too simple arguments, although rigorous connections have been established as well [
8,
10]. The authors of [
11] provide another example of relations between linguistic laws, but, in general, no general framework encompassing all laws exists.
Two other laws—the law of word length and the so-called Zipf’s law of abbreviation or brevity law— are of particular interest in this work. As far as we know, and in contrast to the Zipf’s law of word frequency, these two laws do not have non-linguistic counterparts. The law of word length finds that the length of words (measured in number of letter tokens, for instance) is lognormally distributed [
12,
13], whereas the brevity law determines that more frequent words tend to be shorter, and rarer words tend to be longer. This is usually quantified between a negative correlation between word frequency and word length [
14].
Very recently, Torre et al. [
13] parameterized the dependence between mean frequency and length, obtaining (using a speech corpus) that the frequency averaged for fixed length decays exponentially with length. This is in contrast with a result suggested by Herdan (to the best of our knowledge not directly supported by empirical analysis), who proposed a power-law decay, with exponent between 2 and 3 [
12]. This result probably arose from an analogy with the word-frequency distribution derived by Simon [
15], with an exponential tail that was neglected.
The purpose of our paper is to put these three important linguistic laws (Zipf’s law of word frequency, the word-length law, and the brevity law) into a broader context. By means of considering word frequency and word length as two random variables associated to word types, we will see how the bivariate distribution of those two variables is the appropriate framework to describe the brevity-frequency phenomenon. This leads us to several findings: (i) a gamma law for the word-length distribution, in contrast to the previously proposed lognormal shape; (ii) a well-defined functional form for the word-frequency distributions conditioned to fixed length, where a power-law decay with exponent for the bulk frequencies becomes dominant; (iii) a scaling law for those distributions, apparent as a collapse of data under rescaling; (iv) an approximate power-law decay of the characteristic scale of frequency as a function of length, with exponent ; and (v) a possible explanation for Zipf’s law of word frequency as arising from the mixture of conditional distributions of frequency at different lengths, where Zipf’s exponent is determined by the exponents and .
2. Preliminary Considerations
Given a sample of natural language (a text, a fragment of speech, or a corpus, in general), any word type (i.e., each unique word) has an associated word length, which we measure in number of characters (as we deal with a written corpus), and an associated word absolute frequency, which is the number of occurrences of the word type on the corpus under consideration (i.e., the number of tokens of the type). We denote these two random variables as ℓ and n, respectively.
Zipf’s law of word frequency is written as a power-law relation between
and
n [
6], i.e.,
where
is the empirical probability mass function of the word frequency
n, the symbol ∝ denotes proportionality,
is the power-law exponent, and
c is a lower cut-off below which the law losses its validity (so, Zipf’s law is a high-frequency phenomenon). The exponent
takes values typically close to 2. When very large corpora are analyzed (made from many different texts an authors) another (additional) power-law regime appears at smaller frequencies [
16,
17],
with
a new power law exponent smaller than
, and
a and
b lower and upper cut-offs, respectively (with
). This second power law is not identified with Zipf’s law.
On the other hand, the law of word lengths [
12] proposes a lognormal distribution for the empirical probability mass function of word lengths, that is,
where LN denotes a lognormal distribution, whose associated normal distribution has mean
and variance
(note that with the lognormal assumption it would seem that one is taking a continuous approximation for
; nevertheless, discreteness of
is still possible just redefining the normalization constant). The present paper challenges the lognormal law for
. Finally, the brevity law [
14] can be summarized as
where
is a correlation measure between
ℓ and
n, as, for instance, Pearson correlation, Spearman correlation, or Kendall correlation.
We claim that a more complete approach to the relationship between word length and word frequency can be obtained from the joint probability distribution of both variables, together with the associated conditional distributions . To be more precise, is the joint probability mass function of type length and frequency, and is the probability mass function of type frequency conditioned to fixed length. Naturally, the word-frequency distribution and the word-length distribution are just the two marginal distributions of .
The relationships between these quantities are
Note that we will not use in this paper the equivalent relation
, for sampling reasons (
n takes many more different values than
ℓ; so, for fixed values of
n one may find there is not enough statistics to obtain
). Obviously, all probability mass functions fulfil normalization,
We stress that, in our framework, each type yields one instance of the bivariate random variable
, in contrast to another equivalent approach for which it is each token that gives one instance of the (perhaps-different) random variables, see [
7]. The use of each approach has important consequences for the formulation of Zipf’s law, as it is well known [
7], and for the formulation of the word-length law (as it is not so well known [
12]). Moreover, our bivariate framework is certainly different to the that in [
18], where the frequency was understood as a four-variate distribution with the random variables taking 26 values from
a to
z, and also to the generalization in [
19].
3. Corpus and Statistical Methods
We investigate the joint probability distribution of word-type length and frequency empirically, using all English books in the recently presented Standardized Project Gutenberg Corpus [
20], which comprises more than 40,000 books in English, with a total number of tokens equal to 2,016,391,406 and a total number of types of 2,268,043. We disregard types with
(relative frequency below
) and also those not composed exclusively by the 26 usual letters from
a to
z (previously, capital letters were transformed to lower-case). This sub-corpus is further reduced by the elimination of types with length above 20 characters; to avoid typos and “spurious” words (among the eliminated types with
we only find three true English words:
incomprehensibilities, crystalloluminescence, and
nitrosodimethylaniline). This reduces the numbers of tokens and types, respectively, to 2,010,440,020 and 391,529. Thus, all we need for our study is the list of all types (a dictionary) including their absolute frequencies
n and their lengths
ℓ (measured in terms of number of characters).
Power-law distributions are fitted to the empirical data by using the version for discrete random variables of the method for continuous distributions outlined in [
21] and developed in Refs. [
22,
23], which is based on maximum-likelihood estimation and the Kolmogorov–Smirnov goodness-of-fit test. Acceptable (i.e., non-rejectable) fits require
p-values not below 0.20, which are computed with 1000 Monte Carlo simulations. Complete details in the discrete case are available in Refs. [
6,
24]. This method is similar in spirit to the one by Clauset et al. [
25], but avoiding some of the important problems that the latter presents [
26,
27]. Histograms are drawn to provide visual intuition for the shape of the empirical probability mass functions and the adequacy of fits; in the case of
and
, we use logarithmic binning [
22,
28]. Nevertheless, the computation of the fits does not make use of the graphical representation of the distributions.
On the other side, the theory of scaling analysis, following the authors of [
21,
29], allows us to compare the shape of the conditional distributions
for different values of
ℓ. This theory has revealed a very powerful tool in quantitative linguistics, allowing in previous research to show that the shape of the word-frequency distribution does not change as a text increases its length [
30,
31].
4. Results
First, let us examine the raw data, looking at the scatter plot between frequency and length in
Figure 1, where each point is a word type represented by an associated value of
n and an associated value of
ℓ (note that several or many types can overlap at the same point, if they share their values of
ℓ and
n, as these are discrete variables). >From the tendency of decreasing maximum
n with increasing
ℓ, clearly visible in the plot, one could arrive to an erroneous version of the brevity law. Naturally, brevity would be apparent if the scatter plot were homogenously populated (i.e., if
would be uniform in the domain occupied by the points). However, of course, this is not the case, as we will quantify later. On the contrary, if
were the product of two independent exponentials, with
, the scatter plot would be rather similar to the real one (
Figure 1), but the brevity law would not hold (because of the independence of
ℓ and
m, that is, of
ℓ and
n). We will see that exponentials distributions play an important role here, but not in this way.
A more acceptable approach to the brevity-frequency phenomenon is to calculate the correlation between
ℓ and
n. For the Pearson correlation, our dataset yields
, which, despite looking very small, is significantly different from zero, with a
p-value below 0.01 for 100 reshufflings of the frequency (all the values obtained after reshuffling the frequencies keeping the lengths fixed are between
and
). If, instead, we calculate the Pearson correlation between
ℓ and the logarithm
m of the frequency we get
, again with a
p-value below 0.01. Nevertheless, as neither the underlying joint distributions
or
resemble a Gaussian at all, nor the correlation seems to be linear (see
Figure 1), the meaning of the Pearson correlation is difficult to interpret. We will see below that the analysis of the conditional distributions
provides more useful information.
4.1. Marginal Distributions
Let us now study the word-length distribution,
, shown in
Figure 2. The distribution is clearly unimodal (with its maximum at
), and although it has been previously modeled as a lognormal [
12], we get a nearly perfect fit using a gamma distribution,
with shape parameter
and inverted scale parameter
(where the uncertainty corresponds to one standard deviation, and
denotes the gamma function). Notice then that, for large lengths, we would get an exponential decay (asymptotically, strictly speaking). However, there is an important difference between the lognormal distribution proposed in [
13] and the gamma distribution found here, which is that the former case refers to the length of tokens, whereas in our case we deal with the length of types (of course, length of tokens and length of types is the same length, but the relative number of tokens and types is different, depending on length). This was already distinguished by Herdan [
12], who used the terms occurrence distribution and dictionary distribution, and proposed that both of them were lognormal. In the caption of
Figure 2 we provide the log-likelihoods of both the gamma and lognormal fits, concluding that the gamma distribution yields a better fit for the “dictionary distribution” of word lengths. The fit is specially good in the range
.
Regarding the other marginal distribution, which is the word-frequency distribution
represented in
Figure 3, we get that, as expected, Zipf’s law is fulfilled with
for
(this is almost three orders of magnitude), see
Table 1. Another power-law regime in the bulk, as in [
16], is found to hold for one order of magnitude and a half (only), from
to
, with exponent
, see
Table 2. Note that although the truncated power law for the bulk part of the distribution is much shorter than the one for the tail (1.5 orders of magnitude in front of almost 3), the former contains many more data (50,000 in front of ~1000), see
Table 1 and
Table 2 for the precise figures. Note also that the two power-law regimes for the frequency translate into two exponential regimes for
m (the logarithm of
n).
4.2. Power Laws and Scaling Law for the Conditional Distributions
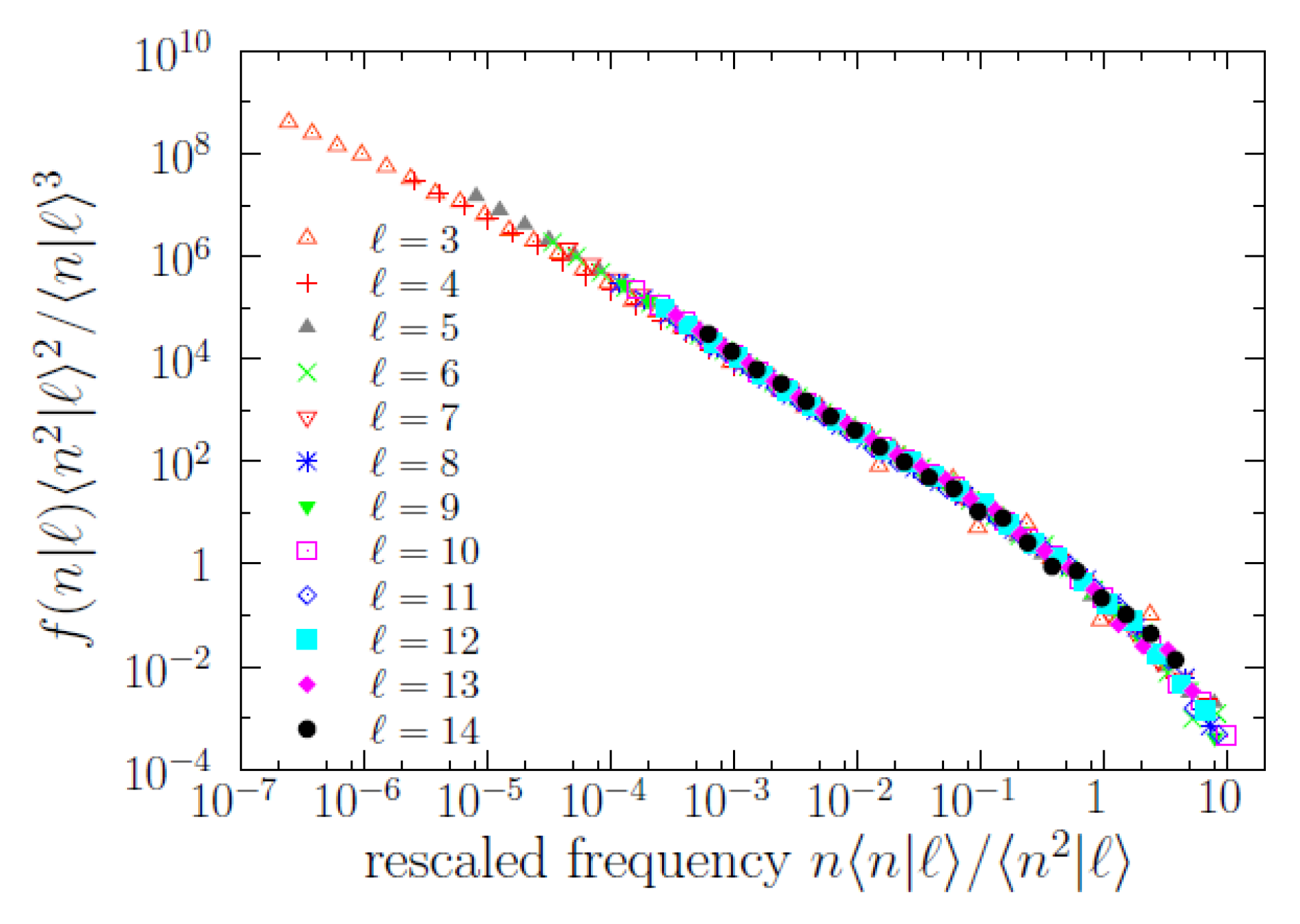
As mentioned, the conditional word-frequency distributions
are of substantial relevance. In
Figure 4, we display some of those functions, and it turns out that
n is broadly distributed for each value of
ℓ (roughly in the same qualitative way it happens without conditioning to the value of
ℓ). Remarkably, the results of a scaling analysis [
21,
29], depicted in
Figure 5, show that all the different
(for
) share a common shape, with a scale determined by a scale parameter in frequency. Indeed, rescaling
n as
and
as
, where the first and second empirical moments,
and
, are also conditioned to the value of
ℓ, we obtain an impressive data collapse, valid for ~7 orders of magnitude in
n, which allows us to write the scaling law
where the key point is that the scaling function
is the same function for any value of
ℓ. For
the statistics is low and the fulfilment of the scaling law becomes uncertain. Defining the scale parameter
, we get alternative expressions for the same scaling law,
where constants of proportionality have been reabsorbed into
g, and the scale parameter has to be understood as proportional to a characteristic scale of the conditional distributions (i.e.,
is the characteristic scale, up to a constant factor; it is the relative change of
what will be important for us). The reason for the fulfillment of these relations is the power-law dependence between the moments and the scale parameter when a scaling law holds, this power-law dependence is
and
for
, see [
21,
29].
The data collapse also unveils more clearly the functional form of the scaling function
g, allowing to fit its power-law shape in two different ranges. The scaling function turns out to be compatible with a double power-law distribution, i.e., a (long) power law for
with exponent
at ~1.4 and another (short) power law for
with exponent
at ~2.75; in one formula,
for
. In other words, there is a (smooth) change of exponent (a change of log-log slope) at a value of
, with the proportionality constant
C taking some value in between 0.1 and 1 (as the transition from one regime to the other is smooth there is not a well defined value of
C that separates both). Fitting power laws to those ranges we get the results shown in
Table 1 and
Table 2. Note that
can be understood as the characteristic scale of
mentioned before, and can be also called a frequency crossover.
Nevertheless, although the power-law regime for intermediate frequencies () is very clear, the validity of the other power law (the one for large frequencies) is questionable, in the sense that the power law provides an “acceptable” fit but other distributions could do the same good job, due to the limited range spanned by the tail (less than one order of magnitude). Our main reason to fit a power law to the large-frequency regime is the comparison with Zipf’s law (), and, as we see, the resulting value of for turns out to be rather large (the results of for all turn out to be statistically compatible with ). In addition, we will show in the next subsection that the high-frequency behavior of the conditional distributions (power law or not) has nothing to do with Zipf’s law.
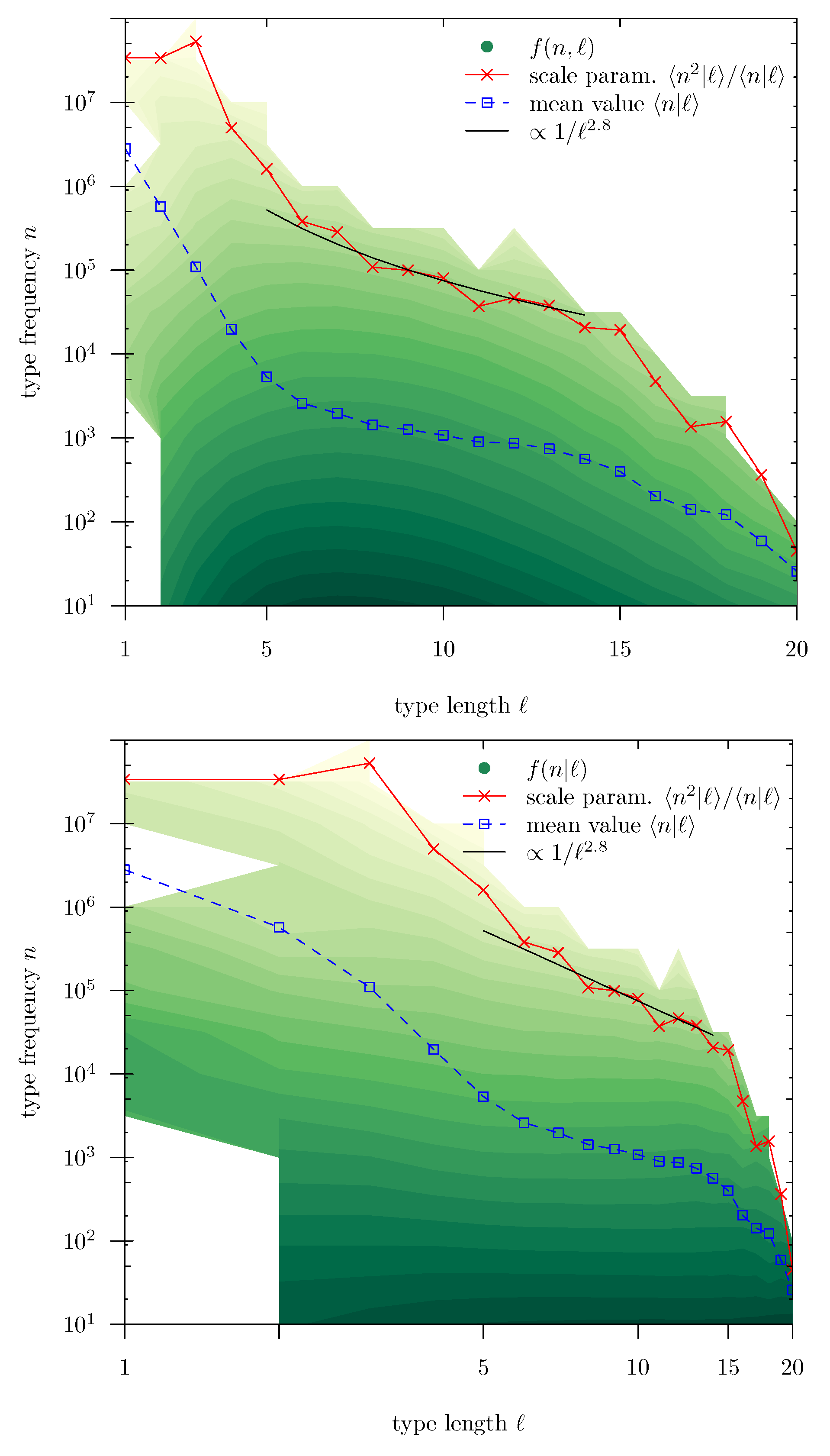
4.3. Brevity Law and Possible Origin of Zipf’s Law
Coming back to the scaling law, its fulfillment has an important consequence: it is the scale parameter
and not the conditional mean
what sets the scale of the conditional distributions
.
Figure 6 represents the brevity law in terms of the scale parameter as a function of
ℓ (the conditional mean value is also shown, for comparison, overimposed to maps of
and
). Note that the authors of [
13] dealt with the conditional mean, finding an exponential decay
. Using our corpus (which is certainly different), we find that such an exponential decay for the mean is valid in a range of
ℓ between 1 and 5, approximately. In contrast, the scale parameter
shows an approximate power-law decay from about
to 15, with an exponent
around 3 (or 2.8, to be more precise), i.e.,
(note that Herdan assumed this exponent to be 2.4, with no clear empirical support [
12]). Beyond
, the decay of
is much faster. Nevertheless, these results are somewhat qualitative.
With these limitations, we could write a new version of the scaling law as
where the proportionality constant between
and
has been reabsorbed in the scaling function
g. The corresponding data collapse is shown in
Figure 7, for
. Despite the rough approximation provided by the power-law decay of
, the data collapse in terms of scaling law (
3) is nearly excellent for
. This version of the scaling law provides a clean formulation of the brevity law: the characteristic scale of the distribution of
n conditioned to the value of
ℓ decays with increasing
ℓ as
; i.e., the larger
ℓ, the shorter the conditional distribution
, quantified by the exponent
.
However, in addition to a new understanding of the brevity law, the scaling law in terms of
ℓ provides, as a by-product, an empirical explanation of the origin of Zipf’s law. In the regime of
ℓ in which the scaling law is approximately valid, i.e., for
, we can obtain the distribution of frequency as a mixture of conditional distributions (by the law of total probability),
(where we take a continuous approximation, replacing sum over
ℓ by integration; this is essentially a mathematical rephrasing). Substituting the scaling law and introducing the change of variables
we get
where we also have taken advantage of the fact that, in the region of interest,
can be considered (in a rough approximation) as constant.
From here, we can see that in the case where the frequency is small (
), the integration limits are also small, and then the last integral scales with
n as
(because we have that
), which implies that we recover a power law with exponent
for
, i.e.,
. However, for larger frequencies (
n above
but below
), the integral does not scale with
n but can be considered instead as constant and then we get Zipf’s law as
This means that Zipf’s exponent can be obtained from the values of the intermediate-frequency power-law conditional exponent
and the brevity exponent
as
where we have introduced a subscript
z in
to stress that this is the
exponent appearing in Zipf’s law, corresponding to the marginal distribution
, and to distinguish it from the one of the conditional distributions, that we may call
. Note then that
plays no role in the determination of
, and, in fact, the scaling function does not need to have a power-law tail to obtain Zipf’s law. This sort of argument is similar to the one used in statistical seismology [
32], but in that case the scaling law was elementary (i.e.,
).
We can check the previous exponent relation using the empirical values of the exponent. We do not have a unique measure of
, but from
Table 2, we see that its value for the different
is quite well defined. Taking the harmonic mean between the values
we get
, which together with
leads to
, not far from the ideal Zipf’s value
and closer to the empirical value
. The reason to calculate the harmonic mean of the exponents comes from the fact that it is the maximum-likelihood outcome when untruncated power-law datasets are put together [
33]; when the power laws are truncated, the result is closer to the untruncated case when the range
is large.
5. Conclusions
Using a large corpus of English texts, we have seen how three important laws of quantitative linguistics, which are the type-length law, Zipf’s law of word frequency, and the brevity law, can be put into a unified framework just considering the joint distribution of length and frequency.
Straightforwardly, the marginals of the joint distribution provide both the type-length distribution and the word-frequency distribution. We reformulate the type-length law, finding that the gamma distribution provides an excellent fit of type lengths for values larger than 2, in contrast to the previously proposed lognormal distribution [
12] (although some previous research was dealing not with type length but with token length [
13]). For the distribution of word frequency, we confirm the well-known Zipf’s law, with an exponent
; we also confirm the second intermediate power-law regime that emerges in large corpora [
16], with an exponent
.
The advantages of the perspective provided by considering the length-frequency joint distribution become apparent when dealing with the brevity phenomenon. In concrete, this property arises very clearly when looking at the distributions of frequency conditioned to fixed length. These show a well-defined shape, characterized by a power-law decay for intermediate frequencies followed by a faster decay, which is well modeled by a second power law, for larger frequencies. The exponent for the intermediate regime turns out to be the same as the one for the usual (marginal) distribution of frequency, . However, the exponent for higher frequencies turns out to be larger than 2 and unrelated to Zipf’s law.
At this point, scaling analysis reveals as a very powerful tool to explore and formulate the brevity law. We observe that the conditional frequency distributions show scaling for different values of length, i.e., when the distributions are rescaled by a scale parameter (proportional to the characteristic scale of each distribution), these distributions collapse into a unique curve, showing that they share a common shape (although at different scales). The characteristic scale of the distributions turns out to be well described by the scale parameter (given by the ratio of moments
), instead than by the mean value (
). This is the usual case when the distributions involved have a power-law shape (with exponent
) close to the origin [
29]. This also highlights the importance of looking at the whole distribution and not to mean values when one is dealing with complex phenomena.
Going further, we obtain that the characteristic scale of the conditional frequency distributions decays, approximately, as a power law of the type length, with exponent
, which allows us to rewrite the scaling law in a form that is reminiscent to the one used in the theory of phase transitions and critical phenomena. Despite that the power-law behavior for the characteristic scale of frequency is rather rough, the derived scaling law shows an excellent agreement with the data. Note that taking together the marginal length distribution, Equation (
1), and the scaling law for the conditional frequency distribution, Equation (
3), we can write for the joint distribution
with the scaling function
given by Equation (
2), up to proportionality factors.
Finally, the fulfilment of a scaling law of this form allows us to obtain a phenomenological (model free) explanation of Zipf’s law as a mixture of the conditional distributions of frequencies. In contrast to some accepted explanations of Zipf’s law, which put the origin of the law outside the linguistic realm (such as Simon’s model [
15], where only the reinforced growth of the different types counts; other explanations are in [
19,
34]), our approach indicates that the origin of Zipf’s law can be fully linguistic, as it depends crucially on the length of the words (and the length is a purely linguistic attribute). Thus, at fixed length, each (conditional) frequency distribution shows a scale-free (power-law) behavior, up to a characteristic frequency where the power law (with exponent
) breaks down. This breaking-down frequency depends on length through the exponent
. The mixture of different power laws, with exponent
and cut at a scale governed by the exponent
, yields a Zipf’s exponent
. Strictly speaking, our explanation of Zipf’s law does not fully explain Zipf’s law, but transfers the explanation to the existence of a power law with a smaller exponent (
) as well as to the crossover frequency that depends on length as
. Clearly, more research is necessary to explain the shape of the conditional distributions. It is noteworthy that a similar phenomenology for Zipf’s law (in general) was proposed in [
34], using the concept of “underlying unobserved variables”, which in the case of word frequencies were associated (without quantification) to part of speech (grammatical categories). From our point of view, the “underlying unobserved variables” in the case of word frequencies would be instead word (type) lengths.
Although our results are obtained using a unique English corpus, we believe they are fully representative of this language, at least when large corpora are used. Naturally, further investigations are needed to confirm the generality of our results. Of course, a necessary extension of our work is the use of corpora on other languages, to establish the universality of our results, as done, e.g., in [
14]. The length of words is simply measured in number of characters, but nothing precludes the use of number of phonemes or mean time duration of types (in speech, as in [
13]). At the end, the goal of this kind of research is to pursue a unified theory of linguistic laws, as proposed in [
35]. The line of research shown in this paper seems to be a promising one.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}