Whole Time Series Data Streams Clustering: Dynamic Profiling of the Electricity Consumption



Abstract
1. Introduction
- We have created the framework and measures to compare and to evaluate time series data streams clustering algorithms;
- New Fast Fourier Transformation based features were created (calculated in liner time) to compress and to represent time series using the business context;
- Comparative study between the state-of-the-art time series data streams clustering algorithms was prepared;
- Comparative study between overlapping and non-overlapping windows and their impact on the choice of an optimal tariff was prepared; and
- Finally, an approach for dynamic consumer segmentation and prediction of an optimal tariff was proposed.
2. Literature Review
3. Time Series Data Streams Clustering Algorithms
3.1. Notations and Data Representation
3.2. Histogram-Based Clustering Algorithm
3.3. ClipStream Algorithm
3.4. Extended TS-Stream Algorithm
4. Research Framework and Settings
4.1. Numerical Implementation
4.2. Algorithms Parameters Setting
4.3. Tested Changeable Components
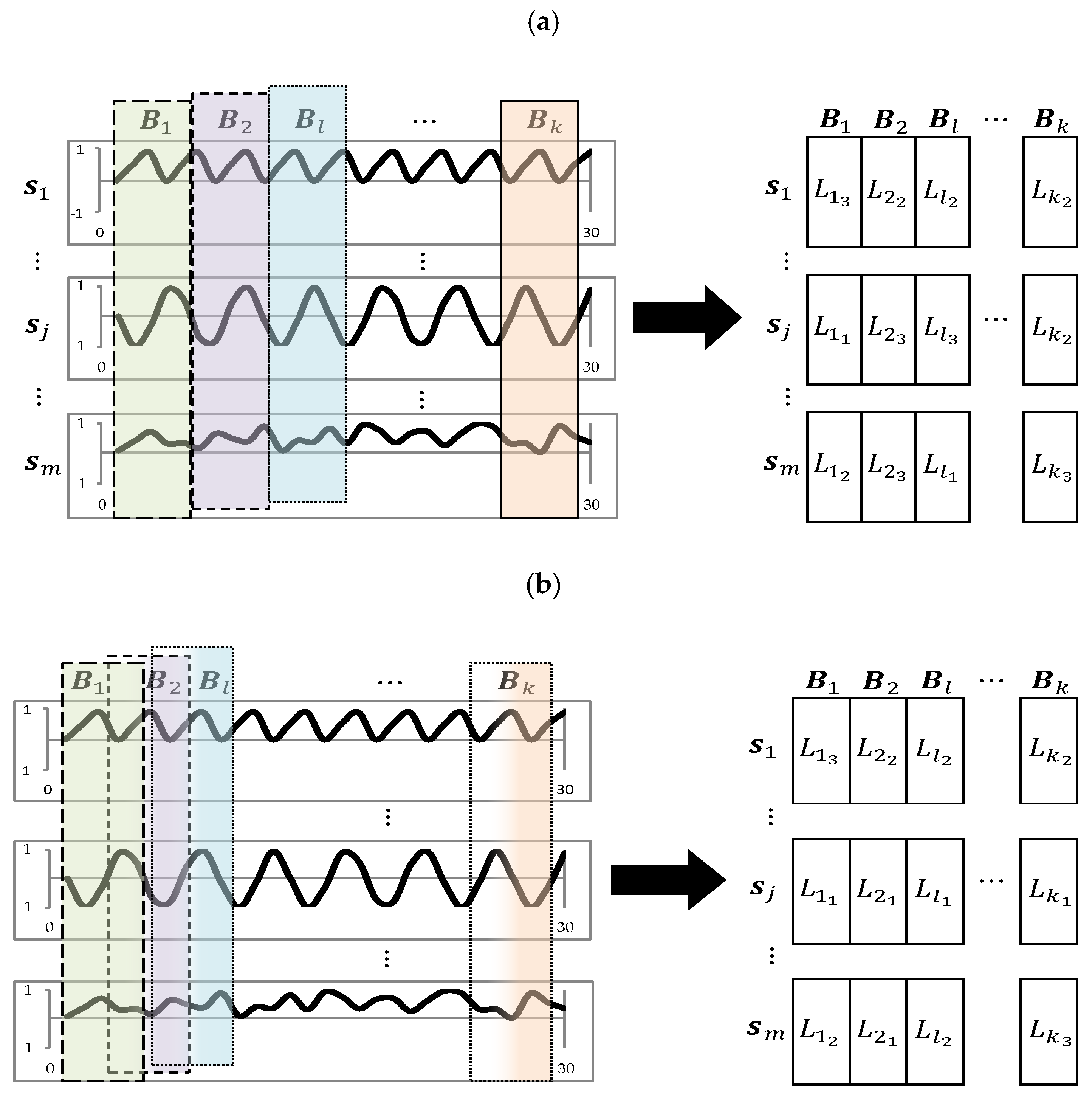
- Using non-overlapping window: This approach is in line with our previous study where the window length of each block , has been set to 30 days. As the electricity consumption data were recorded at 30-min intervals, each window has length of 1,440 (2 × 24 h × 30 days);
- Using overlapping window: This approach is in line with the article [35] implementing ClipStream algorithm where window is of length 21 days (3 weeks). In this case, each time there are two overlapping weeks led by the new arriving week (2 × 24 h × 21 days = 1008).
4.4. Framework and Measures for Clustering Comparison
- (1)
- For a particular time window apply a given clustering algorithm;
- (2)
- Assign a particular customer to his cluster;
- (3)
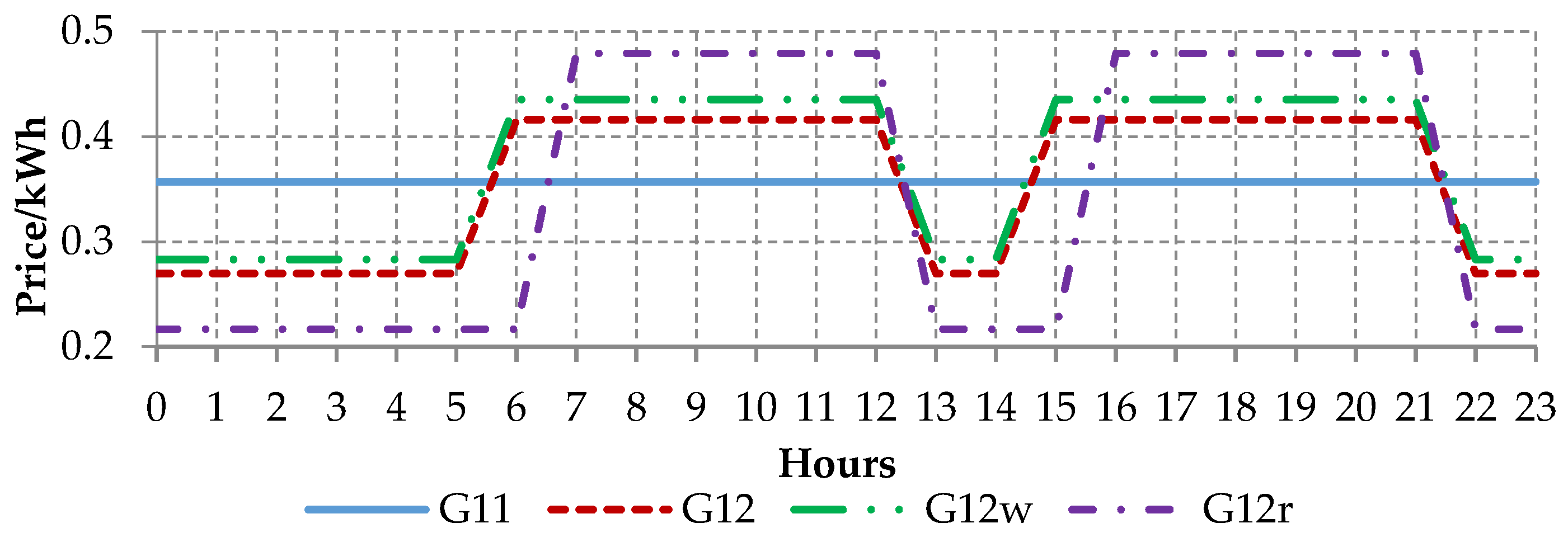
- Determine an optimal tariff for the entire cluster, i.e., the lowest price for an aggregate consumption of all customers in cluster by calculating the total electricity cost if they would belong to G11, G12, G12r or G12w tariff plan;
- (4)
- Select an optimal tariff from the previous step as an optimal tariff for a given customer;
- (5)
- Deploy an optimal tariff for each customer as a tariff for the next time window ;
- (6)
- Return to the first step.
5. Empirical Analysis
5.1. Data and Tariffs Characteristics
5.2. Clustering Results
5.3. Tariff Evaluation
5.4. Other Applications—Australian Case Study
5.5. Other Applications—London Case Study
6. Conclusions
- Concept drift of different kinds, such as incremental, recurring, sudden, or gradual;
- unstable number of sources (some sensors are newly created while other removed);
- heterogeneous and missing recordings;
- irregularly spaced data; and
- assuming application of other approaches for classifying incoming continuous data in dynamic systems e.g., stochastic learning weak estimators.
Author Contributions
Funding
Conflicts of Interest
Appendix A. Results Based on Irish Data Set

{kind=link}
{kind=link}
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.003 | 0.019 | 0.025 | 0.031 | 0.033 | 0.264 |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.003 | 0.024 | 0.034 | 0.044 | 0.050 | 0.326 |
| ClipStream (concept drift) | 0.011 | 0.046 | 0.059 | 0.091 | 0.082 | 1.000 |
| ClipStream (without concept drift) | 0.010 | 0.051 | 0.067 | 0.083 | 0.095 | 0.547 |
| ClipStream (Fourier coeff., concept drift) | 0.019 | 0.047 | 0.059 | 0.079 | 0.072 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | 0.020 | 0.049 | 0.062 | 0.070 | 0.076 | 0.405 |
| Histogram-based | 0.222 | 0.348 | 0.467 | 0.486 | 0.597 | 0.991 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −0.20% | 0.00% | 0.10% | 0.20% | 0.20% | 0.80% |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.20% | 0.00% | 0.10% | 0.10% | 0.20% | 0.80% |
| ClipStream (concept drift) | −0.30% | 0.00% | 0.10% | 0.10% | 0.20% | 0.80% |
| ClipStream (without concept drift) | −0.20% | 0.00% | 0.10% | 0.10% | 0.20% | 0.90% |
| ClipStream (Fourier coeff., concept drift) | −0.20% | 0.00% | 0.10% | 0.20% | 0.30% | 1.00% |
| ClipStream (Fourier coeff., without concept drift) | −0.20% | 0.00% | 0.10% | 0.20% | 0.30% | 1.00% |
| Histogram-based | −0.20% | 0.00% | 0.10% | 0.20% | 0.30% | 0.90% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 15.94 | 22.27 | 25.83 | 26.28 | 29.97 | 38.21 |
| Extended TS-Stream (Fourier coeff., concept drift) | 14.09 | 20.76 | 25.22 | 25.09 | 28.67 | 39.20 |
| ClipStream (concept drift) | 19.15 | 24.61 | 28.41 | 29.57 | 32.50 | 59.14 |
| ClipStream (without concept drift) | 21.73 | 29.45 | 37.42 | 39.64 | 45.89 | 82.29 |
| ClipStream (Fourier coeff., concept drift) | 24.31 | 42.71 | 53.23 | 55.94 | 68.91 | 99.47 |
| ClipStream (Fourier coeff., without concept drift) | 32.69 | 45.22 | 53.85 | 58.30 | 69.60 | 106.51 |
| Histogram-based | 15.73 | 19.59 | 23.45 | 24.29 | 27.19 | 36.41 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −9.28% | −0.40% | 0.10% | 0.21% | 0.74% | 5.45% |
| Extended TS-Stream (Fourier coeff., concept drift) | −8.52% | −0.40% | 0.08% | 0.20% | 0.73% | 6.22% |
| ClipStream (concept drift) | −2.77% | −0.17% | 0.07% | 0.43% | 0.74% | 7.90% |
| ClipStream (without concept drift) | −3.04% | −0.17% | 0.08% | 0.43% | 0.75% | 7.51% |
| ClipStream (Fourier coeff., concept drift) | −7.71% | −0.42% | 0.11% | 0.14% | 0.68% | 4.53% |
| ClipStream (Fourier coeff., without concept drift) | −7.58% | −0.42% | 0.12% | 0.15% | 0.66% | 4.69% |
| Histogram-based | −7.40% | −0.38% | 0.08% | 0.16% | 0.65% | 5.14% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −6.28% | −0.10% | 1.66% | 2.50% | 4.63% | 13.45% |
| Extended TS-Stream (Fourier coeff., concept drift) | −6.28% | −0.10% | 1.66% | 2.50% | 4.63% | 13.45% |
| ClipStream (concept drift) | −2.61% | 0.00% | 2.17% | 2.80% | 4.81% | 14.35% |
| ClipStream (without concept drift) | −3.69% | −0.01% | 2.11% | 2.77% | 4.76% | 14.35% |
| ClipStream (Fourier coeff., concept drift) | −6.53% | −0.12% | 1.43% | 2.45% | 4.60% | 13.27% |
| ClipStream (Fourier coeff., without concept drift) | −6.53% | −0.12% | 1.43% | 2.45% | 4.60% | 13.27% |
| Histogram-based | −6.47% | −0.10% | 1.50% | 2.49% | 4.64% | 13.45% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −6.55% | 0.13% | 1.89% | 2.69% | 4.79% | 13.48% |
| Extended TS-Stream (Fourier coeff., concept drift) | −6.63% | 0.09% | 1.82% | 2.68% | 4.80% | 13.38% |
| ClipStream (concept drift) | −2.76% | 0.12% | 2.32% | 2.91% | 4.92% | 14.45% |
| ClipStream (without concept drift) | −2.51% | 0.13% | 2.34% | 2.91% | 4.96% | 14.40% |
| ClipStream (Fourier coeff., concept drift) | −6.53% | 0.15% | 1.66% | 2.63% | 4.76% | 13.31% |
| ClipStream (Fourier coeff., without concept drift) | −6.16% | 0.15% | 1.70% | 2.63% | 4.74% | 13.46% |
| Histogram-based | −6.64% | 0.17% | 1.81% | 2.65% | 4.75% | 14.02% |
Appendix B. Results Based on Australian Data Set
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs worst individual tariff for each batch | 2.86% | 5.53% | 6.99% | 7.60% | 8.96% | 48.80% |
| Best individual tariff for each batch vs best individual tariff for the entire period | 0.00% | 0.66% | 1.08% | 1.04% | 1.363% | 4.26% |
| Number of dynamic individual tariff change | 0.00 | 4.00 | 6.00 | 6.22 | 8.00 | 13.00 |
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs worst individual tariff for each batch | 3.16% | 6.60% | 8.21% | 8.79% | 10.27% | 49.45% |
| Best individual tariff for each batch vs best individual tariff for the entire period | 0.00% | 1.32% | 1.70% | 1.67% | 1.95% | 6.63% |
| Number of dynamic individual tariff change | 0.00 | 16.00 | 24.00 | 22.97 | 30.00 | 50.00 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.024 | 0.047 | 0.063 | 0.066 | 0.082 | 0.165 |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.024 | 0.047 | 0.063 | 0.066 | 0.082 | 0.165 |
| ClipStream (concept drift) | 0.001 | 0.040 | 0.058 | 0.078 | 0.101 | 1.000 |
| ClipStream (without concept drift) | 0.001 | 0.040 | 0.057 | 0.071 | 0.094 | 0.245 |
| ClipStream (Fourier coeff., concept drift) | 0.085 | 0.134 | 0.149 | 0.188 | 0.169 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | 0.085 | 0.127 | 0.149 | 0.154 | 0.171 | 0.300 |
| Histogram-based | 0.286 | 0.400 | 0.457 | 0.491 | 0.524 | 0.935 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −0.06% | 0.03% | 0.21% | 0.96% | 0.75% | 13.36% |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.06% | 0.03% | 0.21% | 0.96% | 0.75% | 13.36% |
| ClipStream (concept drift) | −0.22% | 0.05% | 0.27% | 0.92% | 0.65% | 12.13% |
| ClipStream (without concept drift) | −0.22% | 0.04% | 0.25% | 0.91% | 0.65% | 12.13% |
| ClipStream (Fourier coeff., concept drift) | −0.13% | 0.05% | 0.20% | 0.93% | 0.74% | 13.36% |
| ClipStream (Fourier coeff., without concept drift) | −0.13% | 0.06% | 0.23% | 0.93% | 0.74% | 13.36% |
| Histogram-based | −0.11% | 0.03% | 0.21% | 0.91% | 0.76% | 11.74% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.015 | 0.037 | 0.049 | 0.067 | 0.079 | 0.438 |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.008 | 0.037 | 0.052 | 0.066 | 0.080 | 0.433 |
| ClipStream (concept drift) | 0.000 | 0.037 | 0.055 | 0.086 | 0.094 | 1.000 |
| ClipStream (without concept drift) | −0.004 | 0.038 | 0.059 | 0.080 | 0.099 | 0.654 |
| ClipStream (Fourier coeff., concept drift) | 0.040 | 0.120 | 0.142 | 0.165 | 0.164 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | 0.040 | 0.120 | 0.142 | 0.152 | 0.167 | 0.515 |
| Histogram-based | 0.218 | 0.405 | 0.537 | 0.540 | 0.648 | 0.996 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −0.17% | 0.02% | 0.10% | 0.14% | 0.23% | 10.23% |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.19% | 0.00% | 0.04% | 0.76% | 0.15% | 10.15% |
| ClipStream (concept drift) | −0.32% | 0.00% | 0.11% | 0.77% | 0.23% | 10.23% |
| ClipStream (without concept drift) | −0.34% | −0.03% | 0.07% | 0.74% | 0.21% | 10.21% |
| ClipStream (Fourier coeff., concept drift) | −0.18% | 0.00% | 0.04% | 0.76% | 0.15% | 10.15% |
| ClipStream (Fourier coeff., without concept drift) | −0.15% | 0.00% | 0.03% | 0.76% | 0.14% | 10.14% |
| Histogram-based | −0.13% | 0.01% | 0.05% | 0.77% | 0.15% | 10.15% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 4.33 | 5.79 | 7.70 | 7.65 | 9.13 | 10.89 |
| Extended TS-Stream (Fourier coeff., concept drift) | 4.33 | 5.79 | 7.70 | 7.65 | 9.13 | 10.89 |
| ClipStream (concept drift) | 5.18 | 8.06 | 11.45 | 12.86 | 14.33 | 28.73 |
| ClipStream (without concept drift) | 5.18 | 8.06 | 12.03 | 12.9 | 14.33 | 28.73 |
| ClipStream (Fourier coeff., concept drift) | 12.29 | 19.83 | 24.04 | 23.94 | 27.91 | 42.01 |
| ClipStream (Fourier coeff., without concept drift) | 12.29 | 19.83 | 23.15 | 24.1 | 27.91 | 42.01 |
| Histogram-based | 5.19 | 6.73 | 8.72 | 8.64 | 10.29 | 11.87 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 4.46 | 5.10 | 6.92 | 6.705 | 8.05 | 9.09 |
| Extended TS-Stream (Fourier coeff., concept drift) | 4.66 | 5.27 | 6.94 | 13.21 | 7.61 | 70.76 |
| ClipStream (concept drift) | 7.88 | 12.95 | 16.15 | 19.38 | 23.38 | 37.46 |
| ClipStream (without concept drift) | 7.88 | 12.27 | 17.82 | 19.62 | 25.12 | 37.46 |
| ClipStream (Fourier coeff., concept drift) | 12.85 | 22.7 | 24.62 | 25.02 | 30.10 | 37.61 |
| ClipStream (Fourier coeff., without concept drift) | 11.94 | 19.18 | 24.62 | 23.63 | 28.04 | 33.60 |
| Histogram-based | 4.83 | 6.22 | 8.251 | 7.98 | 9.554 | 10.32 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −6.29% | −1.12% | −0.27% | −0.18% | 0.62% | 14.57% |
| Extended TS-Stream (Fourier coeff., concept drift) | −6.29% | −1.12% | −0.27% | −0.18% | 0.62% | 14.57% |
| ClipStream (concept drift) | −4.69% | −0.79% | −0.09% | 0.19% | 0.75% | 23.41% |
| ClipStream (without concept drift) | −4.69% | −0.76% | −0.10% | 0.18% | 0.73% | 24.80% |
| ClipStream (Fourier coeff., concept drift) | −4.97% | −1.12% | −0.21% | −0.15% | 0.64% | 12.68% |
| ClipStream (Fourier coeff., without concept drift) | −5.39% | −1.07% | −0.23% | −0.15% | 0.62% | 13.92% |
| Histogram-based | −6.44% | −0.51% | −0.11% | −0.01% | 0.41% | 4.25% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −5.09% | −0.33% | 0.74% | 0.84% | 1.77% | 15.94% |
| Extended TS-Stream (Fourier coeff., concept drift) | −5.21% | −0.38% | 0.73% | 0.84% | 1.81% | 16.34% |
| ClipStream (concept drift) | −5.03% | 0.08% | 0.72% | 1.08% | 1.73% | 23.12% |
| ClipStream (without concept drift) | −5.00% | 0.03% | 0.71% | 1.06% | 1.66% | 23.65% |
| ClipStream (Fourier coeff., concept drift) | −6.33% | −0.44% | 0.70% | 0.82% | 1.82% | 16.83% |
| ClipStream (Fourier coeff., without concept drift) | −6.28% | −0.43% | 0.71% | 0.83% | 1.82% | 16.98% |
| Histogram-based | −7.40% | −0.38% | 0.08% | 0.16% | 0.65% | 5.14% |
Appendix C. Results Based on London Data Set
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs worst individual tariff for each batch | 2.39% | 4.79% | 6.61% | 7.21% | 8.82% | 33.37% |
| Best individual tariff for each batch vs best individual tariff for the entire period | 0.00% | 0.08% | 0.24% | 0.35% | 0.51% | 2.87% |
| Number of dynamic individual tariff change | 0.00 | 3.00 | 5.00 | 4.90 | 7.00 | 14.00 |
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs worst individual tariff for each batch | 2.72% | 5.33% | 7.22% | 7.71% | 9.43% | 36.14% |
| Best individual tariff for each batch vs best individual tariff for the entire period | 0.00% | 0.26% | 0.52% | 0.62% | 0.87% | 3.36% |
| Number of dynamic individual tariff change | 0.00 | 18.00 | 25.00 | 23.95 | 31.00 | 47.00 |
| Clustering algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.000 | 0.066 | 0.081 | 0.080 | 0.100 | 0.199 |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.000 | 0.066 | 0.081 | 0.080 | 0.100 | 0.199 |
| ClipStream (concept drift) | 0.080 | 0.140 | 0.173 | 0.213 | 0.215 | 1.000 |
| ClipStream (without concept drift) | 0.078 | 0.130 | 0.164 | 0.173 | 0.204 | 0.344 |
| ClipStream (Fourier coeff., concept drift) | 0.074 | 0.112 | 0.143 | 0.162 | 0.174 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | −0.001 | 0.110 | 0.136 | 0.136 | 0.168 | 0.368 |
| Histogram-based | 0.224 | 0.333 | 0.368 | 0.417 | 0.488 | 0.889 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −0.13% | 0.06% | 0.23% | 0.93% | 0.74% | 1.74% |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.25% | 0.01% | 0.07% | 0.19% | 0.20% | 1.72% |
| ClipStream (concept drift) | −0.05% | 0.08% | 0.20% | 0.35% | 0.41% | 1.58% |
| ClipStream (without concept drift) | −0.05% | 0.11% | 0.22% | 0.39% | 0.47% | 1.71% |
| ClipStream (Fourier coeff., concept drift) | −0.20% | 0.01% | 0.13% | 0.26% | 0.22% | 1.92% |
| ClipStream (Fourier coeff., without concept drift) | −0.16% | 0.02% | 0.13% | 0.27% | 0.22% | 1.92% |
| Histogram-based | −0.09% | 0.03% | 0.09% | 0.15% | 0.27% | 0.72% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.036 | 0.064 | 0.077 | 0.090 | 0.099 | 0.442 |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.031 | 0.064 | 0.078 | 0.090 | 0.098 | 0.447 |
| ClipStream (concept drift) | 0.060 | 0.125 | 0.150 | 0.176 | 0.190 | 1.000 |
| ClipStream (without concept drift) | 0.060 | 0.121 | 0.149 | 0.168 | 0.191 | 0.744 |
| ClipStream (Fourier coeff., concept drift) | 0.053 | 0.111 | 0.143 | 0.164 | 0.183 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | 0.055 | 0.110 | 0.139 | 0.155 | 0.177 | 0.658 |
| Histogram-based | 0.209 | 0.321 | 0.395 | 0.426 | 0.504 | 0.984 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −0.21% | 0.02% | 0.08% | 0.10% | 0.16% | 1.39% |
| Extended TS-Stream (Fourier coeff., concept drift) | −0.21% | 0.00% | 0.06% | 0.10% | 0.16% | 1.39% |
| ClipStream (concept drift) | −0.37% | 0.02% | 0.17% | 0.22% | 0.34% | 2.13% |
| ClipStream (without concept drift) | −0.41% | 0.01% | 0.17% | 0.21% | 0.35% | 2.13% |
| ClipStream (Fourier coeff., concept drift) | −0.55% | −0.03% | 0.04% | 0.10% | 0.15% | 2.43% |
| ClipStream (Fourier coeff., without concept drift) | −0.38% | −0.03% | 0.04% | 0.10% | 0.15% | 2.43% |
| Histogram-based | −0.17% | 0.00% | 0.04% | 0.07% | 0.11% | 1.14% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 6.75 | 8.47 | 9.84 | 10.11 | 12.16 | 164.98 |
| Extended TS-Stream (Fourier coeff., concept drift) | 6.75 | 8.47 | 9.84 | 10.11 | 12.16 | 164.98 |
| ClipStream (concept drift) | 19.36 | 23.72 | 26.63 | 29.58 | 33.91 | 48.24 |
| ClipStream (without concept drift) | 19.36 | 24.10 | 26.48 | 29.81 | 37.19 | 48.24 |
| ClipStream (Fourier coeff., concept drift) | 27.91 | 43.52 | 48.81 | 51.61 | 63.26 | 85.77 |
| ClipStream (Fourier coeff., without concept drift) | 27.91 | 43.52 | 48.81 | 57.82 | 70.38 | 164.32 |
| Histogram-based | 9.36 | 10.37 | 11.50 | 12.46 | 14.73 | 18.77 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 7.03 | 8.94 | 9.46 | 10.54 | 11.14 | 17.08 |
| Extended TS-Stream (Fourier coeff., concept drift) | 7.03 | 8.94 | 9.46 | 10.54 | 11.14 | 17.08 |
| ClipStream (concept drift) | 16.79 | 20.30 | 23.10 | 25.41 | 29.59 | 43.31 |
| ClipStream (without concept drift) | 16.79 | 20.30 | 23.10 | 25.15 | 29.59 | 39.00 |
| ClipStream (Fourier coeff., concept drift) | 24.99 | 28.92 | 41.69 | 42.91 | 53.07 | 62.66 |
| ClipStream (Fourier coeff., without concept drift) | 24.99 | 28.92 | 41.69 | 42.33 | 51.61 | 62.66 |
| Histogram-based | 8.86 | 10.91 | 11.77 | 12.76 | 13.55 | 21.39 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −5.37% | −0.67% | 0.27% | 0.39% | 1.27% | 7.14% |
| Extended TS-Stream (Fourier coeff., concept drift) | −5.37% | −0.67% | 0.27% | 0.39% | 1.27% | 7.14% |
| ClipStream (concept drift) | −3.96% | −0.46% | 0.11% | 0.36% | 0.78% | 12.72% |
| ClipStream (without concept drift) | −3.96% | −0.48% | 0.10% | 0.39% | 0.79% | 13.81% |
| ClipStream (Fourier coeff., concept drift) | −6.62% | −0.76% | 0.18% | 0.23% | 1.08% | 7.89% |
| ClipStream (Fourier coeff., without concept drift) | −6.62% | −0.75% | 0.18% | 0.23% | 1.10% | 7.89% |
| Histogram-based | −6.43% | −0.68% | 0.31% | 0.55% | 1.52% | 10.97% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −7.41% | −0.53% | 0.41% | 0.59% | 1.53% | 8.66% |
| Extended TS-Stream (Fourier coeff., concept drift) | −5.83% | −0.50% | 0.42% | 0.57% | 1.51% | 7.66% |
| ClipStream (concept drift) | −3.95% | −0.32% | 0.28% | 0.62% | 1.10% | 13.26% |
| ClipStream (without concept drift) | −5.14% | −0.32% | 0.31% | 0.65% | 1.22% | 13.27% |
| ClipStream (Fourier coeff., concept drift) | −6.08% | −0.51% | 0.37% | 0.49% | 1.33% | 7.86% |
| ClipStream (Fourier coeff., without concept drift) | −6.71% | −0.48% | 0.37% | 0.50% | 1.37% | 8.43% |
| Histogram-based | −7.61% | −0.48% | 0.37% | 0.68% | 1.64% | 10.90% |
References
- Zabkowski, T.; Gajowniczek, K.; Szupiluk, R. Grade analysis for energy usage patterns segmentation based on smart meter data. In Proceedings of the 2015 IEEE 2nd International Conference on Cybernetics (CYBCONF), Gdynia, Poland, 24–26 June 2015. [Google Scholar] [CrossRef]
- Nafkha, R.; Gajowniczek, K.; Ząbkowski, T. Do Customers Choose Proper Tariff? Empirical Analysis Based on Polish Data Using Unsupervised Techniques. Energies 2018, 11, 514. [Google Scholar] [CrossRef]
- Silva, J.A.; Faria, E.R.; Barros, R.C.; Hruschka, E.R.; Carvalho, A.C.P.L.F.; de Gama, J. Data stream clustering. ACM Comput. Surv. 2013, 46, 1–31. [Google Scholar] [CrossRef]
- Bhaduri, M.; Zhan, J.; Chiu, C.; Zhan, F. A Novel Online and Non-Parametric Approach for Drift Detection in Big Data. IEEE Access 2017, 5, 15883–15892. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T.; Sodenkamp, M. Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms. Appl. Sci. 2018, 8, 1654. [Google Scholar] [CrossRef]
- Bhaduri, M.; Zhan, J.; Chiu, C. A Novel Weak Estimator for Dynamic Systems. IEEE Access 2017, 5, 27354–27365. [Google Scholar] [CrossRef]
- Bhaduri, M.; Zhan, J. Using Empirical Recurrence Rates Ratio for Time Series Data Similarity. IEEE Access. 2018, 6, 30855–30864. [Google Scholar] [CrossRef]
- Balzanella, A.; Verde, R. Histogram-based clustering of multiple data streams. Knowl. Inf. Syst. 2019, 62, 203–238. [Google Scholar] [CrossRef]
- Macedo, M.N.; Galo, J.J.; Almeida, L.A.; Lima, A.C. Typification of load curves for DSM in Brazil for a smart grid environment. Int. J. Electr. Power Energy Syst. 2015, 67, 216–221. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Simulation Study on Clustering Approaches for Short-Term Electricity Forecasting. Complexity 2018, 2018, 3683969. [Google Scholar] [CrossRef]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Pitt, B.D.; Kitschen, D.S. Application of data mining techniques to load profiling. In Proceedings of the 21st 1999 IEEE International Conference on Power Industry Computer Applications–PICA’99, Santa Clara, CA, USA, 21 May 1999; pp. 131–136. [Google Scholar]
- Gerbec, D.; Gasperic, S.; Simon, I.; Gubina, F. Hierarchic clustering methods for consumers load profile determination. In Proceedings of the 2nd Balkan Power Conference, Belgrade, SR Yugoslavia, 19 June 2002; pp. 9–15. [Google Scholar]
- Nazarko, J.; Styczynski, Z.A. Application of statistical and neural approaches to the daily load profiles modelling in power distribution systems. In Proceedings of the 1999 IEEE Transmission and Distribution Conference, New Orleans, LA, USA, 11 April 1999; Volume 1, pp. 320–325. [Google Scholar]
- Espinoza, M.; Joye, C.; Belmans, R.; De Moor, B. Short-term load forecasting, profile identification, and customer segmentation: A methodology based on periodic time series. IEEE Transact. Power Syst. 2005, 20, 1622–1630. [Google Scholar] [CrossRef]
- Suganthi, L.; Samuel, A.A. Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 2012, 16, 1223–1240. [Google Scholar] [CrossRef]
- McLoughlin, F.; Duffy, A.; Conlon, M. A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 2015, 141, 190–199. [Google Scholar] [CrossRef]
- Lamedica, R.; Santolamazza, L.; Fracassi, G.; Martinelli, G.; Prudenzi, A. A novel methodology based on clustering techniques for automatic processing of MV feeder daily load patterns. In Proceedings of the IEEE Power Engineering Society Summer Meeting, Seattle, WA, USA, 16–20 July 2000; Volume 1, pp. 96–101. [Google Scholar]
- Chicco, G.; Napoli, R.; Postolache, P.; Scutariu, M.; Toader, C. Customer characterization options for improving the tariff offer. IEEE Transact. Power Syst. 2003, 18, 381–387. [Google Scholar] [CrossRef]
- Benítez, I.; Quijano, A.; Díez, J.L.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Electr. Power Energy Syst. 2014, 55, 437–448. [Google Scholar] [CrossRef]
- Rhodes, J.D.; Cole, W.J.; Upshaw, C.R.; Edgar, T.F.; Webber, M.E. Clustering analysis of residential electricity demand profiles. Appl. Energy 2014, 135, 461–471. [Google Scholar] [CrossRef]
- Tsekouras, G.J.; Hatziargyriou, N.D.; Dialynas, E.N. Two-stage pattern recognition of load curves for classification of electricity customers. IEEE Transact. Power Syst. 2007, 22, 1120–1128. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Transact. Power Syst. 2006, 21, 933–940. [Google Scholar] [CrossRef]
- Chen, J.-Y.; He, H.-H. A fast density-based data stream clustering algorithm with cluster centers self-determined for mixed data. Inf. Sci. 2016, 345, 271–293. [Google Scholar] [CrossRef]
- Amini, A.; Saboohi, H.; Herawan, T.; Wah, T.Y. MuDi-Stream: A multi density clustering algorithm for evolving data stream. J. Netw. Comput. Appl. 2016, 59, 370–385. [Google Scholar] [CrossRef]
- Chen, Y.; Tu, L. Density-based clustering for real-time stream data. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’07, San Jose, CA, USA, 12–15 August 2007. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S.; Han, J.; Wang, J. A Framework for Clustering Evolving Data Streams. In Proceedings of the 2003 VLDB Conference, Berlin, Germany, 9–12 September 2003; pp. 81–92. [Google Scholar] [CrossRef]
- Hahsler, M.; Bolaos, M. Clustering Data Streams Based on Shared Density between Micro-Clusters. IEEE Trans. Knowl. Data Eng. 2016, 28, 1449–1461. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM SIGMOD Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Udommanetanakit, K.; Rakthanmanon, T.; Waiyamai, K. E-Stream: Evolution-Based Technique for Stream Clustering. Lect. Notes Comput. Sci. 2007, 605–615. [Google Scholar] [CrossRef]
- Ackermann, M.R.; Märtens, M.; Raupach, C.; Swierkot, K.; Lammersen, C.; Sohler, C. StreamKM++. J. Exp. Algorithmics 2012, 17, 173–187. [Google Scholar] [CrossRef]
- Beringer, J.; Hllermeier, E. Fuzzy Clustering of Parallel Data Streams. Adv. Fuzzy Clust. Appl. 2007, 333–352. [Google Scholar] [CrossRef]
- Chen, Y. Clustering Parallel Data Streams. Data Min. Knowl. Discov. Real Life Appl. 2009. [Google Scholar] [CrossRef]
- Dai, B.R.; Huang, J.W.; Yeh, M.Y.; Chen, M.S. Adaptive Clustering for Multiple Evolving Streams. IEEE Trans. Knowl. Data Eng. 2006, 18, 1166–1180. [Google Scholar] [CrossRef]
- Laurinec, P.; Lucká, M. Interpretable multiple data streams clustering with clipped streams representation for the improvement of electricity consumption forecasting. Data Min. Knowl. Discov. 2018, 33, 413–445. [Google Scholar] [CrossRef]
- Khan, I.; Huang, J.Z.; Ivanov, K. Incremental density-based ensemble clustering over evolving data streams. Neurocomputing 2016, 191, 34–43. [Google Scholar] [CrossRef]
- Pereira, C.M.M.; de Mello, R.F. TS-stream: Clustering time series on data streams. J. Intell. Inf. Syst. 2014, 42, 531–566. [Google Scholar] [CrossRef]
- Rodrigues, P.P.; Gama, J.; Pedroso, J.P. Hierarchical Clustering of Time-Series Data Streams. IEEE Trans. Knowl. Data Eng. 2008, 20, 615–627. [Google Scholar] [CrossRef]
- Chen, L.; Zou, L.-J.; Tu, L. A clustering algorithm for multiple data streams based on spectral component similarity. Inf. Sci. 2012, 183, 35–47. [Google Scholar] [CrossRef]
- Alseghayer, R.; Petrov, D.; Chrysanthis, P.K.; Sharaf, M.; Labrinidis, A. Detection of Highly Correlated Live Data Streams. In Proceedings of the International Workshop on Real-Time Business Intelligence and Analytics, Munich, Germany, 28 August 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Sakurai, Y.; Papadimitriou, S.; Faloutsos, C. BRAID: Stream mining through group lag correlations. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 599–610. [Google Scholar] [CrossRef]
- Shafer, I.; Ren, K.; Boddeti, V.N.; Abe, Y.; Ganger, G.R.; Faloutsos, C. RainMon: An integrated approach to mining bursty timeseries monitoring data. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD 2012, Beijing, China, 12–16 August 2012; pp. 1158–1166. [Google Scholar] [CrossRef]
- Zhu, Y.; Shasha, D. Statstream: Statistical monitoring of thousands of data streams in real time. In Proceedings of the 28th International Conference on Very Large Databases 2002–VLDB’02, Hong Kong, China, 20–23 August 2002; pp. 358–369. [Google Scholar]
- Wu, Y.; Liu, Y.; Ahmed, S.H.; Peng, J.; Abd El-Latif, A.A. Dominant Data Set Selection Algorithms for Electricity Consumption Time-Series Data Analysis Based on Affine Transformation. IEEE Internet Things J. 2020, 7, 4347–4360. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Bator, M.; Ząbkowski, T.; Orłowski, A.; Loo, C.K. Simulation Study on the Electricity Data Streams Time Series Clustering. Energies 2020, 13, 924. [Google Scholar] [CrossRef]
- Irpino, A.; Verde, R. Basic statistics for distributional symbolic variables: A new metric-based approach. Adv. Data Anal. Classif. 2014, 9, 143–175. [Google Scholar] [CrossRef]
- Verde, R.; Irpino, A. Dynamic Clustering of Histogram Data: Using the Right Metric. Studies in Classification. Data Anal. Knowl. Organ. 2007, 123–134. [Google Scholar] [CrossRef]
- Diday, E.; Noirhomme-Fraiture, M. Symbolic Data Analysis and the SODAS Software; John Wiley & Sons: Chichester, UK, 2007; pp. 191–204. [Google Scholar] [CrossRef]
- Robinson, A.H.; Cherry, C. Results of a prototype television bandwidth compression scheme. Proc. IEEE 1967, 55, 356–364. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Chichester, UK, 2009; Volume 344. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Transact. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Lyons, R.G. Understanding Digital Signal Processing, 2/E; Prentice Hall PTR Upper: Saddle River, NJ, USA, 2004. [Google Scholar]
- BIRCH-Clustering-R-Package. Available online: https://github.com/rohitkata/BIRCH-Clustering-R-package (accessed on 10 March 2020).
- SymbolicDA: Analysis of Symbolic Data. Available online: https://rdrr.io/cran/symbolicDA/ (accessed on 10 March 2020).
- ClipStream. Available online: https://github.com/PetoLau/ClipStream (accessed on 10 March 2020).
- Langham, E.; Downes, J.; Brennan, T.; Fyfe, J.; Mohr, S.; Rickwood, P.; White, S. Smart Grid, Smart City, Customer Research Report; Institute for Sustainable Futures: Ultimo, NSW, Australia, June 2014. [Google Scholar]
- UK Power Networks Led Low Carbon London. Available online: https://data.london.gov.uk/dataset/smartmeter-energy-use-data-in-london-households (accessed on 1 December 2020).


| Fourier Coefficients No. | Non Overlapping Windows | Overlapping Windows |
|---|---|---|
| 1–6 | 20 days–120 days | 14 days–84 days |
| 7–30 | 4 days–17 days 3 h | 2 days 19 h–12 days |
| 31–240 | 12 h–3 days 21 h | 8.4 h–2 days 17 h |
| >240 | <12 h | <8.4 h |
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs. worst individual tariff for each batch | 2.39% | 5.76% | 7.67% | 8.08% | 9.88% | 19.27% |
| Best individual tariff for each batch vs. best individual tariff for the entire period | 0.00% | 0.06% | 0.21% | 0.28% | 0.40% | 2.39% |
| Number of dynamic individual tariff change | 0.00 | 2.00 | 5.00 | 4.81 | 7.00 | 12.00 |
| Min | 1st Quartile | Median | Mean | 3rd Quartile | Max | |
|---|---|---|---|---|---|---|
| Best vs. worst individual tariff for each batch | 2.68% | 6.27% | 8.13% | 8.47% | 10.32% | 19.28% |
| Best individual tariff for each batch vs. best individual tariff for the entire period | 0.00% | 0.23% | 0.43% | 0.51% | 0.69% | 3.52% |
| Number of dynamic individual tariff change | 0.00 | 18.00 | 25.00 | 24.40 | 32.00 | 50.00 |
| 0.100 | 0.088 | 0.062 | 0.062 | 0.062 | 0.040 | 0.040 | 0.040 | 0.049 | |
| 0.098 | 0.080 | 0.067 | 0.067 | 0.038 | 0.038 | 0.038 | 0.060 | ||
| 0.097 | 0.084 | 0.084 | 0.068 | 0.068 | 0.068 | 0.075 | |||
| 0.166 | 0.166 | 0.115 | 0.115 | 0.115 | 0.059 | ||||
| 1 | 0.199 | 0.199 | 0.199 | 0.064 | |||||
| 0.199 | 0.199 | 0.199 | 0.064 | ||||||
| 1 | 1 | 0.063 | |||||||
| 1 | 0.063 | ||||||||
| 0.063 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.014 | 0.024 | 0.033 | 0.035 | 0.043 | 0.070 |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.014 | 0.024 | 0.033 | 0.035 | 0.043 | 0.070 |
| ClipStream (concept drift) | 0.026 | 0.057 | 0.067 | 0.119 | 0.097 | 1.000 |
| ClipStream (without concept drift) | 0.021 | 0.054 | 0.070 | 0.079 | 0.091 | 0.232 |
| ClipStream (Fourier coeff., concept drift) | 0.029 | 0.053 | 0.066 | 0.120 | 0.082 | 1.000 |
| ClipStream (Fourier coeff., without concept drift) | 0.025 | 0.049 | 0.065 | 0.065 | 0.077 | 0.113 |
| Histogram-based | 0.149 | 0.230 | 0.309 | 0.335 | 0.419 | 0.740 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 15.10 | 18.93 | 21.06 | 23.22 | 26.15 | 37.18 |
| Extended TS-Stream (Fourier coeff., concept drift) | 15.10 | 18.93 | 21.06 | 23.22 | 26.15 | 37.18 |
| ClipStream (concept drift) | 20.50 | 27.40 | 32.69 | 37.08 | 47.93 | 61.93 |
| ClipStream (without concept drift) | 16.87 | 24.48 | 32.28 | 36.15 | 49.66 | 69.65 |
| ClipStream (Fourier coeff., concept drift) | 39.95 | 42.87 | 52.24 | 58.49 | 72.21 | 95.98 |
| ClipStream (Fourier coeff., without concept drift) | 39.95 | 42.87 | 52.24 | 55.83 | 64.88 | 90.06 |
| Histogram-based | 17.01 | 20.45 | 24.46 | 25.71 | 31.47 | 36.05 |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | 0.00% | 0.10% | 0.20% | 0.40% | 0.50% | 1.80% |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.00% | 0.10% | 0.20% | 0.40% | 0.50% | 1.80% |
| ClipStream (concept drift) | −0.20% | 0.10% | 0.20% | 0.30% | 0.40% | 1.50% |
| ClipStream (without concept drift) | −0.10% | 0.10% | 0.20% | 0.30% | 0.50% | 1.50% |
| ClipStream (Fourier coeff., concept drift) | −0.10% | 0.00% | 0.10% | 0.40% | 0.90% | 1.80% |
| ClipStream (Fourier coeff., without concept drift) | −0.10% | 0.00% | 0.10% | 0.40% | 0.80% | 1.80% |
| Histogram-based | 0.00% | 0.10% | 0.20% | 0.40% | 0.50% | 1.80% |
| Clustering Algorithm | Min | 1st Quartile | Median | Mean | 3rd Quartile | Max |
|---|---|---|---|---|---|---|
| Extended TS-Stream (Fourier coeff.) | −8.89% | −0.56% | −0.09% | 0.00% | 0.45% | 5.73% |
| Extended TS-Stream (Fourier coeff., concept drift) | −8.89% | -0.56% | −0.09% | 0.00% | 0.45% | 5.73% |
| ClipStream (concept drift) | −3.17% | −0.34% | −0.03% | 0.31% | 0.61% | 8.46% |
| ClipStream (without concept drift) | −2.90% | −0.32% | −0.04% | 0.28% | 0.53% | 8.19% |
| ClipStream (Fourier coeff., concept drift) | −5.76% | −0.49% | −0.10% | −0.05% | 0.40% | 2.90% |
| ClipStream (Fourier coeff., without concept drift) | −5.76% | −0.49% | −0.10% | −0.05% | 0.40% | 3.25% |
| Histogram-based | −6.44% | −0.51% | −0.11% | −0.01% | 0.41% | 4.25% |
| Clustering Algorithm | Tariff Improvement | Tariffs Improvement Comparing to the G11 | ||
|---|---|---|---|---|
| Non-Overlapping | Overlapping | Non-Overlapping | Overlapping | |
| Extended TS-Stream (Fourier coeff.) | 0.40% | 0.20% | 0.00% | 0.21% |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.40% | 0.10% | 0.00% | 0.20% |
| ClipStream (concept drift) | 0.30% | 0.10% | 0.31% | 0.43% |
| ClipStream (without concept drift) | 0.30% | 0.10% | 0.28% | 0.43% |
| ClipStream (Fourier coeff., concept drift) | 0.40% | 0.20% | −0.05% | 0.14% |
| ClipStream (Fourier coeff., without concept drift) | 0.40% | 0.20% | −0.05% | 0.15% |
| Histogram-based | 0.40% | 0.20% | −0.01% | 0.16% |
| Clustering Algorithm | Tariff Improvement | Tariffs Improvement Comparing to the G11 | ||
|---|---|---|---|---|
| Non-Overlapping | Overlapping | Non-Overlapping | Overlapping | |
| Extended TS-Stream (Fourier coeff.) | 0.96% | 0.14% | −0.18% | 0.84% |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.96% | 0.76% | −0.18% | 0.84% |
| ClipStream (concept drift) | 0.92% | 0.77% | 0.19% | 1.08% |
| ClipStream (without concept drift) | 0.91% | 0.74% | 0.18% | 1.06% |
| ClipStream (Fourier coeff., concept drift) | 0.93% | 0.76% | −0.15% | 0.82% |
| ClipStream (Fourier coeff., without concept drift) | 0.93% | 0.76% | −0.15% | 0.83% |
| Histogram-based | 0.91% | 0.77% | −0.01% | 0.16% |
| Clustering Algorithm | Tariff Improvement | Tariffs Improvement Comparing to the G11 | ||
|---|---|---|---|---|
| Non-Overlapping | Overlapping | Non-Overlapping | Overlapping | |
| Extended TS-Stream (Fourier coeff.) | 0.93% | 0.10% | 0.39% | 0.59% |
| Extended TS-Stream (Fourier coeff., concept drift) | 0.19% | 0.10% | 0.39% | 0.57% |
| ClipStream (concept drift) | 0.35% | 0.22% | 0.36% | 0.62% |
| ClipStream (without concept drift) | 0.39% | 0.21% | 0.39% | 0.65% |
| ClipStream (Fourier coeff., concept drift) | 0.26% | 0.10% | 0.23% | 0.49% |
| ClipStream (Fourier coeff., without concept drift) | 0.27% | 0.10% | 0.23% | 0.50% |
| Histogram-based | 0.15% | 0.07% | 0.55% | 0.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gajowniczek, K.; Bator, M.; Ząbkowski, T. Whole Time Series Data Streams Clustering: Dynamic Profiling of the Electricity Consumption. Entropy 2020, 22, 1414. https://doi.org/10.3390/e22121414
Gajowniczek K, Bator M, Ząbkowski T. Whole Time Series Data Streams Clustering: Dynamic Profiling of the Electricity Consumption. Entropy. 2020; 22(12):1414. https://doi.org/10.3390/e22121414
Chicago/Turabian StyleGajowniczek, Krzysztof, Marcin Bator, and Tomasz Ząbkowski. 2020. "Whole Time Series Data Streams Clustering: Dynamic Profiling of the Electricity Consumption" Entropy 22, no. 12: 1414. https://doi.org/10.3390/e22121414
APA StyleGajowniczek, K., Bator, M., & Ząbkowski, T. (2020). Whole Time Series Data Streams Clustering: Dynamic Profiling of the Electricity Consumption. Entropy, 22(12), 1414. https://doi.org/10.3390/e22121414