Exploitation of Information as a Trading Characteristic: A Causality-Based Analysis of Simulated and Financial Data




Abstract
1. Introduction
2. Simulation Experiment Design
2.1. System S1 by Schelter et al. (2006)
2.2. Systems S2 by Montalto et al. (2014) and S3
3. Connectivity Measures and Performance Metrics
4. Simulated Series Results
5. Application to Real Financial Data
6. Implications
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lo, A.W.; Mackinlay, A.C. A Non-Random Walk Down Wall Street; Princeton University Press: Princeton, NJ, USA, 1999. [Google Scholar]
- Lo, A.W. Reconciling efficient markets with behavioral finance: The adaptive markets hypothesis. J. Invest. Consult. 2005, 7, 21–44. [Google Scholar]
- Assenza, T.; Brock, W.A.; Hommes, C.H. Animal Spirits, Heterogeneous Expectations, and the Amplification and Duration of Crises. Econ. Inq. 2017, 55, 542–564. [Google Scholar] [CrossRef]
- Hommes, C.H. The heterogeneous expectations hypothesis: Some evidence from the lab. J. Econ. Dyn. Control 2011, 35, 1–24. [Google Scholar] [CrossRef]
- Frijns, B.; Koellen, E.; Lehnert, T. On the determinants of portfolio choice. J. Econ. Behav. Organ. 2008, 66, 373–386. [Google Scholar] [CrossRef]
- Peiro, A. Skewness in individual stocks at different investment horizons. Quant. Financ. 2002, 2, 139–185. [Google Scholar] [CrossRef]
- Prakash, A.J.; Chang, C.-H.; Pactwa, T.E. Selecting a portfolio with skewness: Recent evidence from US, European, and Latin American equity markets. J. Bank. Financ. 2003, 27, 1375–1390. [Google Scholar] [CrossRef]
- Thurner, S.; Farmer, D.; Geanakoplos, J. Leverage causes fat tails and clustered volatility. Quant. Financ. 2012, 12, 695–707. [Google Scholar] [CrossRef]
- Daniel, K.; Moskowitz, T.J. Momentum crashes. J. Financ. Econ. 2016, 122, 221–247. [Google Scholar] [CrossRef]
- Barroso, P.; Santa-Clara, P. Momentum has its moments. J. Financ. Econ. 2015, 116, 111–120. [Google Scholar] [CrossRef]
- Jacobs, H.; Regele, T.; Weber, M. Expected Skewness and Momentum. 2016. Available online: https://ssrn.com/abstract=2600014 (accessed on 20 September 2020).
- Ekholm, A.; Pasternack, D. The negative news threshold—An explanation for negative skewness in stock returns. Eur. J. Financ. 2005, 11, 511–529. [Google Scholar] [CrossRef]
- Wen, F.; Huang, D.; Lan, Q.; Yang, X. Numerical Simulation for Influence of Overconfidence and Regret Aversion on Return Distribution. Syst. Eng. Theory Pract. 2007, 27, 10–18. [Google Scholar] [CrossRef]
- Xu, J. Price convexity and skewness. J. Financ. 2007, 62, 2521–2552. [Google Scholar] [CrossRef]
- Ruttiens, A. Mathematics of the Financial Markets: Financial Instruments and Derivatives Modelling; Valuation and Risk Issues; Wiley editions: West Sussex, UK, 2013. [Google Scholar]
- Hutson, E.; Kearney, C.; Lynch, M. Volume and skewness in international equity markets. J. Bank. Financ. 2008, 32, 1255–1268. [Google Scholar] [CrossRef]
- Albuquerque, R. Skewness in Stock Returns, Periodic Cash Payouts, and Investor Heterogeneity. In CEPR Discussion Papers; DP7573; Centre for Economic Policy Research (CEPR): London, UK, 2009. [Google Scholar]
- Bae, K.-H.; Lim, C.; Wei, K.C.J. Corporate governance and conditional skewness in the world’s stock markets. J. Bus. 2006, 79, 2999–3028. [Google Scholar] [CrossRef]
- Markowitz, H. Portfolio selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- Boginski, V.; Butenko, S.; Shirokikh, O.; Trukhanov, S.; Lafuente, J.G. A network-based data mining approach to portfolio selection via weighted clique relaxations. Ann. Oper. Res. 2014, 216, 23–34. [Google Scholar]
- Fernandez, A.; Gomez, S. Portfolio selection using neural networks. Comput. Oper. Res. 2007, 34, 1177–1191. [Google Scholar] [CrossRef]
- Huang, X. Portfolio selection with a new definition of risk. Eur. J. Oper. Res. 2008, 186, 351–357. [Google Scholar] [CrossRef]
- Kraft, H.; Stefensen, M. Asset allocation with contagion and explicit bankruptcy procedures. J. Math. Econ. 2009, 45, 147–167. [Google Scholar] [CrossRef]
- Diesinger, P.; Kraft, H.; Seifried, V. Asset allocation and liquidity breakdowns: What if your broker does not answer the phone? Financ. Stoch. 2010, 14, 343–374. [Google Scholar] [CrossRef][Green Version]
- Schelter, B.; Winterhalder, M.; Hellwig, B.; Guschlbauer, B.; Lucking, C.H.; Timmer, J. Direct or indirect? Graphical models for neural oscillators. J. Physiol. Paris 2006, 99, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Montalto, A.; Faes, L.; Marinazzo, D. MuTE: A MATLAB toolbox to compare established and novel estimators of the multivariate transfer entropy. PLoS ONE 2014, 9, e109462. [Google Scholar] [CrossRef] [PubMed]
- Kyrtsou, C.; Terraza, M. It is possible to study chaotic and ARCH behaviour jointly? Application of a noisy Mackey-Glass equation in the Paris Stock Exchange returns series. Comput. Econ. 2003, 21, 257–276. [Google Scholar] [CrossRef]
- Kyrtsou, C. Re-examining the sources of heteroskedasticity: The paradigm of noisy chaotic models. Phys. A Stat. Mech. Its Appl. 2008, 387, 6785–6789. [Google Scholar] [CrossRef]
- Ashley, R.A. On the origins of conditional heteroscedasticity in time series. Korean Econ. Rev. 2012, 28, 5–25. [Google Scholar]
- Geweke, J. Measurement of linear dependence and feedback between multiple time series. J. Am. Stat. Assoc. 1982, 77, 304–313. [Google Scholar] [CrossRef]
- Siggiridou, E.; Kugiumtzis, D. Granger causality in multivariate time series using a time-ordered restricted vector autoregressive model. IEEE Trans. Signal Process. 2016, 64, 1759–1773. [Google Scholar] [CrossRef]
- Kugiumtzis, D. Direct-coupling information measure from nonuniform embedding. Phys. Rev. E 2013, 87, 062918. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef]
- Papana, A.; Kyrtsou, C.; Kugiumtzis, D.; Diks, C. Simulation study of direct causality measures in multivariate time series. Entropy 2013, 15, 2635–2661. [Google Scholar] [CrossRef]
- Papana, A. Non-Uniform Embedding Scheme and Low-Dimensional Approximation Methods for Causality Detection. Entropy 2020, 22, 745. [Google Scholar] [CrossRef]
- Siggiridou, E.; Koutlis, C.; Tsimpiris, A.; Kimiskidis, V.K.; Kugiumtzis, D. Causality networks from multivariate time series and application to epilepsy. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4041–4044. [Google Scholar]
- Siggiridou, E.; Koutlis, C.; Tsimpiris, A.; Kugiumtzis, D. Evaluation of Granger causality measures for constructing networks from multivariate time series. Entropy 2019, 21, 1080. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 15, 81–93. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochim. Biophys. Acta 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Ocker, G.K.; Josić, K.; Shea-Brown, E.; Buice, M.A. Linking structure and activity in nonlinear spiking networks. PLoS Comput. Biol. 2017, 13, e1005583. [Google Scholar] [CrossRef]
- Choudhary, S.; Singhal, S. International linkages of Indian equity market: Evidence from panel co-integration approach. J. Asset Manag. 2020, 21, 333–341. [Google Scholar] [CrossRef]
- Andries, M.; Eisenbach, M.T.; Schmalz, C.M. Horizon-dependent risk aversion and the timing and pricing of uncertainty. In Federal Reserve Bank of New York Staff Reports; Federal Reserve Bank of New York: New York, NY, USA, 2019; no. 703. [Google Scholar]
- Baars, M.; Cordes, H.; Mohrschladt, H. How negative interest rates affect the risk-taking of individual investors: Experimental evidence. Financ. Res. Lett. 2020, 32, 101179. [Google Scholar] [CrossRef]
- Horwitz, R. Hedge Fund Risk Fundamentals: Solving the Risk Management and Transparency Challenge; Bloomberg Press: New York, NY, USA, 2004. [Google Scholar]
- Prat, G. Equity risk premium and time horizon: What do the U.S. secular data say? Econ. Model. 2013, 34, 76–88. [Google Scholar] [CrossRef]
- Nie, H.; Jiang, Y.; Yang, B. Do different time horizons in the volatility of the US stock market significantly affect the China ETF market? Appl. Econ. Lett. 2018, 25, 747–751. [Google Scholar] [CrossRef]
- Green, N.R.; Holliefiled, B. When Will Mean-Variance Efficient Portfolios Be Well Diversified? J. Financ. 1993, 45, 1785–1809. [Google Scholar] [CrossRef]
- Chicheportiche, R.; Bouchaud, J.P. A nested factor model for non-linear dependencies in stock returns. Quant. Financ. 2015, 15, 1789–1804. [Google Scholar] [CrossRef]
- Laloux, L.; Cizeau, P.; Potters, M.; Bouchaud, J.P. Random matrix theory and financial correlations. Int. J. Theor. Appl. Financ. 2000, 3, 391–397. [Google Scholar] [CrossRef]
- Odean, T. Are Investors Reluctant to Realize Their Losses? J. Financ. 1998, 53, 1775–1798. [Google Scholar] [CrossRef]
- Barber, B.M.; Odean, T. Trading is Hazardous to Your Wealth: The Common Investment Performance of Individual Investors. J. Financ. 2000, 55, 773–806. [Google Scholar] [CrossRef]
- Kyle, A. Continuous Auctions and Insider Trading. Econometrica 1985, 53, 1315–1335. [Google Scholar] [CrossRef]
- Ivkovic, Z.; Clemens, S.; Weisbenner, S. Portfolio Concentration and the Performance of Individual Investors. J. Financ. Quant. Anal. 2008, 43, 613–656. [Google Scholar] [CrossRef]
- Choi, N.; Fedenia, M.; Skiba, H.; Sokolyk, T. Portfolio concentration and performance of institutional investors worldwide. J. Financ. Econ. 2017, 123, 189–208. [Google Scholar] [CrossRef]





{kind=link}
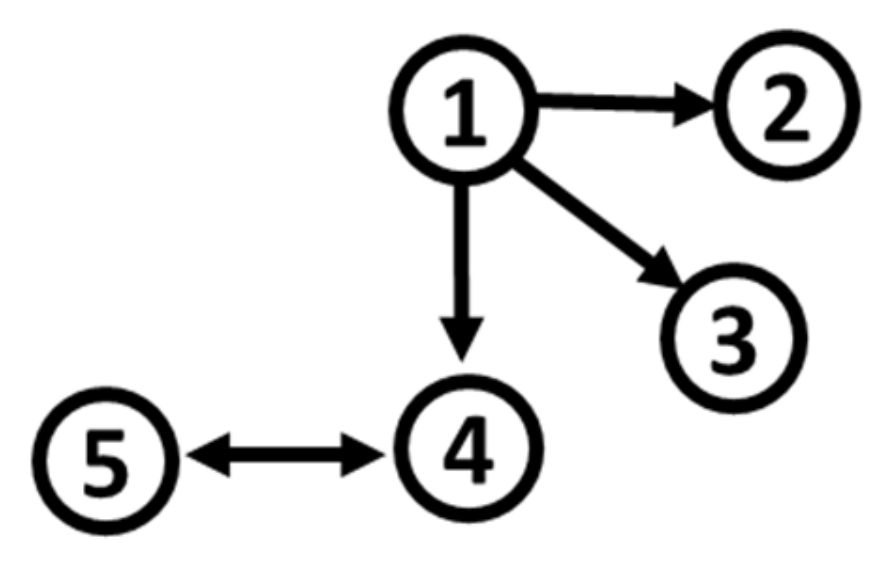{kind=link}
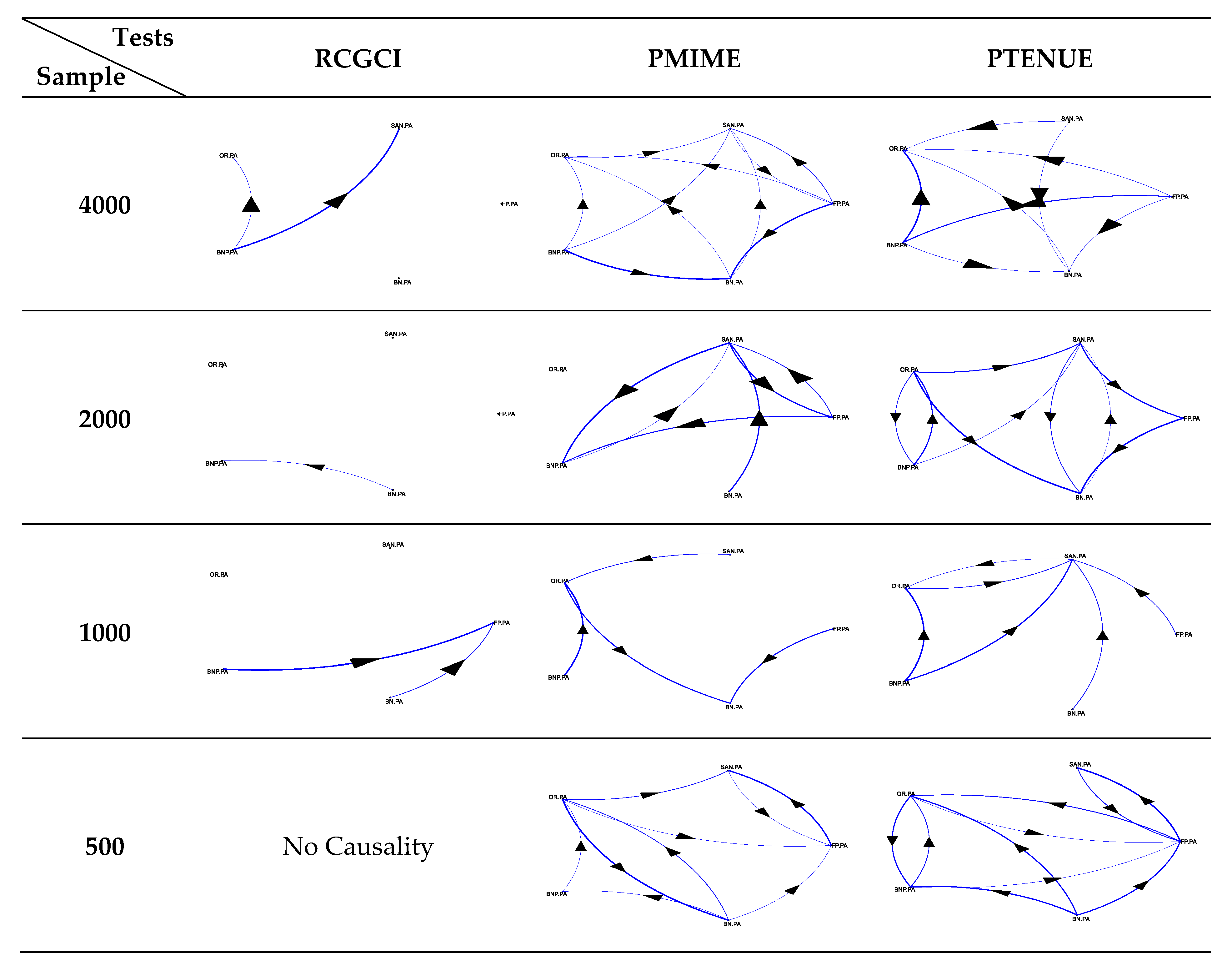{kind=link}
{kind=link}
| S2 | Statistics | X1 | X2 | X3 | X4 | X5 |
|---|---|---|---|---|---|---|
| n = 512 | Kurtosis | 2.8503 | 10.5592 | 2.9148 | 10.4099 | 8.3788 |
| Skewness | −0.0035 | 2.3476 | −0.0056 | −2.3153 | 1.88 | |
| n = 1024 | Kurtosis | 2.9718 | 12.4619 | 2.9718 | 12.2474 | 9.8692 |
| Skewness | −0.0041 | 2.5871 | 0.0052 | −2.542 | 2.0923 | |
| n = 2048 | Kurtosis | 3.0084 | 13.2875 | 3.0187 | 13.0753 | 10.514 |
| Skewness | 0.0069 | 2.6586 | −0.0049 | −2.6187 | 2.1609 | |
| n = 4096 | Kurtosis | 2.996 | 13.3986 | 2.99 | 13.1881 | 10.72 |
| Skewness | −0.001 | 2.6717 | −0.0006 | −2.6317 | 2.191 | |
| S3 | ||||||
| n = 512 | Kurtosis | 2.9718 | 6.1201 | 3.0166 | 5.2279 | 3.1684 |
| Skewness | 0.0004 | 1.1213 | 0.0169 | −0.8763 | 0.1126 | |
| n = 1024 | Kurtosis | 2.9317 | 6.2288 | 2.9997 | 5.2341 | 3.1281 |
| Skewness | −0.0022 | 1.1212 | 0.0044 | −0.8709 | 0.1167 | |
| n = 2048 | Kurtosis | 2.9323 | 6.0725 | 2.9903 | 5.2023 | 3.1374 |
| Skewness | 0.0021 | 1.0896 | −0.0029 | −0.8581 | 0.1115 | |
| n = 4096 | Kurtosis | 2.9317 | 6.2288 | 2.9997 | 5.2341 | 3.1281 |
| Skewness | −0.0022 | 1.1212 | 0.0044 | −0.8709 | 0.1167 | |
| S1 | Sensitivity | Specificity | MCC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RC | PM | PT | RC | PM | PT | RC | PM | PT | |
| n = 512 | 100 | 99.86 | 99.14 | 93.62 | 88.77 | 97.69 | 92.06 | 86.18 | 96.34 |
| n = 1024 | 100 | 100 | 100 | 95.77 | 87 | 97.31 | 94.57 | 84.53 | 96.57 |
| n = 2048 | 100 | 100 | 100 | 96.15 | 87.54 | 98 | 95.11 | 85.04 | 97.39 |
| n = 4096 | 100 | 100 | 100 | 97.15 | 87.38 | 97.15 | 96.36 | 85.04 | 96.32 |
| overall | 100 | 99.97 | 99.79 | 95.67 | 87.67 | 97.54 | 94.53 | 85.2 | 96.66 |
| S1t | |||||||||
| n = 512 | 100 | 100 | 99.86 | 95.92 | 87.15 | 96.77 | 94.83 | 84.71 | 95.79 |
| n = 1024 | 100 | 100 | 100 | 97.46 | 89.54 | 97.46 | 96.71 | 87.40 | 96.76 |
| n = 2048 | 100 | 100 | 100 | 97.15 | 90.15 | 98.38 | 96.31 | 87.99 | 97.87 |
| n = 4096 | 100 | 100 | 100 | 97.08 | 87.92 | 98 | 96.22 | 85.48 | 97.38 |
| overall | 100 | 100 | 99.97 | 96.90 | 88.69 | 97.65 | 96.02 | 86.4 | 96.95 |
| S1n | |||||||||
| n = 512 | 98.71 | 99 | 99 | 90.38 | 90.92 | 97.92 | 87.20 | 88.01 | 96.49 |
| n = 1024 | 99.71 | 99.86 | 100 | 90.69 | 92.62 | 98.15 | 88.52 | 90.78 | 97.62 |
| n = 2048 | 99.86 | 100 | 100 | 91.46 | 90.46 | 98.46 | 89.41 | 88.33 | 98 |
| n = 4096 | 100 | 100 | 100 | 89.62 | 94.38 | 99 | 87.49 | 93 | 98.7 |
| overall | 99.57 | 99.72 | 99.75 | 90.54 | 92.1 | 98.38 | 88.16 | 90.03 | 97.70 |
| S1b | |||||||||
| n = 512 | 100 | 100 | 100 | 95.92 | 87.15 | 96.77 | 94.83 | 84.71 | 95.79 |
| n = 1024 | 100 | 100 | 100 | 97.46 | 89.54 | 97.46 | 96.71 | 87.40 | 96.76 |
| n = 2048 | 100 | 100 | 100 | 97.15 | 90.15 | 98.38 | 96.31 | 87.99 | 97.87 |
| n = 4096 | 100 | 100 | 100 | 97.08 | 87.92 | 98 | 96.22 | 85.48 | 97.38 |
| overall | 100 | 100 | 100 | 96.90 | 88.69 | 97.65 | 96.02 | 86.4 | 96.95 |
| S1g | |||||||||
| n = 512 | 99.14 | 99.43 | 99.71 | 90.85 | 90.77 | 98.23 | 88.08 | 88.21 | 97.48 |
| n = 1024 | 99.57 | 100 | 100 | 91.54 | 91.54 | 98.38 | 89.24 | 89.56 | 97.89 |
| n = 2048 | 100 | 100 | 100 | 92.23 | 92.54 | 98.15 | 90.28 | 90.69 | 97.61 |
| n = 4096 | 100 | 100 | 100 | 90.77 | 93.69 | 99.31 | 88.77 | 92.13 | 99.41 |
| overall | 99.68 | 99.86 | 99.93 | 91.35 | 92.14 | 98.52 | 89.09 | 90.15 | 98.1 |
| S1f | |||||||||
| n = 512 | 96.43 | 92.43 | 88.86 | 92.85 | 84.46 | 94.92 | 87.95 | 75.09 | 84.69 |
| n = 1024 | 99.14 | 92.29 | 94.92 | 93.77 | 87.23 | 95.31 | 91.49 | 81.63 | 89.81 |
| n = 2048 | 99.71 | 98.86 | 98 | 94.46 | 85.62 | 96.54 | 92.88 | 81.98 | 94.06 |
| n = 4096 | 100 | 99.86 | 99.43 | 93.85 | 87.23 | 96.08 | 92.25 | 84.65 | 94.54 |
| overall | 98.82 | 95.86 | 95.30 | 93.73 | 86.14 | 95.71 | 91.14 | 80.84 | 90.78 |
| S2 | Sensitivity | Specificity | MCC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RC | PM | PT | RC | PM | PT | RC | PM | PT | |
| n = 512 | 54.4 | 82.2 | 81.4 | 84.73 | 89.8 | 93.6 | 38.98 | 70.42 | 76.02 |
| n = 1024 | 59.6 | 90.4 | 86.8 | 82.87 | 88.73 | 90.6 | 41.16 | 75.29 | 74.96 |
| n = 2048 | 67.4 | 99.8 | 99.4 | 82.2 | 85.6 | 85.2 | 46.9 | 78.3 | 76.88 |
| n = 4096 | 66 | 100 | 100 | 79.8 | 84.07 | 85.27 | 42.76 | 76.36 | 77.35 |
| overall | 61.85 | 93.1 | 91.9 | 82.4 | 87.05 | 88.67 | 42.45 | 75.09 | 76.30 |
| S2t | |||||||||
| n = 512 | 73.2 | 86.2 | 84.4 | 78 | 88.53 | 93.4 | 47.26 | 71.05 | 77.17 |
| n = 1024 | 80.2 | 88.2 | 90.4 | 73.4 | 87.6 | 92 | 48.06 | 71.42 | 79.23 |
| n = 2048 | 84.2 | 88.8 | 93 | 72.93 | 88.4 | 91.73 | 51.01 | 72.72 | 80.7 |
| n = 4096 | 90 | 90 | 96.8 | 69.93 | 89.27 | 91.47 | 52.59 | 74.85 | 83.21 |
| overall | 81.9 | 88.3 | 91.15 | 73.5 | 88.45 | 92.15 | 49.73 | 72.51 | 80.08 |
| S2n | |||||||||
| n = 512 | 72.8 | 94.2 | 93 | 76.47 | 88.47 | 95.53 | 45.58 | 77.68 | 87.41 |
| n = 1024 | 80.4 | 98.2 | 97.8 | 74.67 | 90.8 | 95.67 | 49.92 | 84.04 | 91 |
| n = 2048 | 83.4 | 99.6 | 99.6 | 69 | 90.87 | 95.2 | 46.85 | 84.98 | 91.64 |
| n = 4096 | 88.6 | 100 | 100 | 64.67 | 90.2 | 94.67 | 47.13 | 84.22 | 91.03 |
| overall | 81.3 | 98 | 97.6 | 71.2 | 90.09 | 95.27 | 47.37 | 82.73 | 90.27 |
| S2b | |||||||||
| n = 512 | 95.2 | 95.2 | 95.8 | 90.6 | 94.6 | 98.33 | 81.67 | 87.45 | 94.23 |
| n = 1024 | 99.6 | 100 | 100 | 93.27 | 96.6 | 98.47 | 88.75 | 94.33 | 97.35 |
| n = 2048 | 100 | 100 | 100 | 90.4 | 95.07 | 98.53 | 84.5 | 91.72 | 97.43 |
| n = 4096 | 100 | 100 | 100 | 87.2 | 94.33 | 97.93 | 80.16 | 90.58 | 96.41 |
| overall | 98.7 | 98.8 | 98.95 | 90.37 | 95.15 | 98.32 | 83.77 | 91.02 | 96.36 |
| S2g | |||||||||
| n = 512 | 74.6 | 95.6 | 92.2 | 75.4 | 89.13 | 96 | 45.78 | 79.46 | 87.64 |
| n = 1024 | 77.2 | 99.6 | 97.8 | 74.8 | 89.87 | 94.13 | 47.29 | 83.75 | 88.75 |
| n = 2048 | 84.4 | 99.6 | 99.8 | 70.07 | 89.13 | 94.73 | 48.7 | 82.58 | 90.9 |
| n = 4096 | 87 | 100 | 100 | 66.13 | 89.13 | 94.2 | 47.08 | 82.63 | 90.29 |
| overall | 80.8 | 98.7 | 97.45 | 71.6 | 89.32 | 94.77 | 47.21 | 82.11 | 89.4 |
| S2f | |||||||||
| n = 512 | 60.20 | 87.2 | 85.6 | 84 | 88.47 | 92.6 | 43.58 | 71.96 | 76.79 |
| n = 1024 | 59.80 | 91.4 | 92.2 | 82.67 | 86.8 | 91.53 | 41.29 | 73.17 | 80.34 |
| n = 2048 | 64.80 | 95.2 | 95.4 | 80.27 | 87 | 89.67 | 42.94 | 76.24 | 79.88 |
| n = 4096 | 70.80 | 96 | 98.2 | 78.93 | 86.6 | 89.13 | 46.02 | 76.14 | 81.52 |
| overall | 63.9 | 92.45 | 92.85 | 81.47 | 87.22 | 90.73 | 43.46 | 74.38 | 79.63 |
| S3 | Sensitivity | Specificity | MCC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RC | PM | PT | RC | PM | PT | RC | PM | PT | |
| n = 512 | 65.4 | 100 | 99.8 | 93.07 | 80.33 | 94.47 | 62.88 | 72.74 | 90.89 |
| n = 1024 | 63.8 | 100 | 100 | 92.87 | 78.93 | 95.33 | 61.4 | 70.80 | 94.02 |
| n = 2048 | 64.8 | 100 | 100 | 93.4 | 81.13 | 95.13 | 62.78 | 73.61 | 93.84 |
| n = 4096 | 62.8 | 100 | 100 | 91.2 | 80.13 | 94.47 | 56.9 | 72.25 | 92.91 |
| overall | 64.2 | 100 | 99.95 | 92.64 | 80.13 | 94.85 | 60.99 | 72.35 | 92.92 |
| S3t | |||||||||
| n = 512 | 87 | 98.6 | 99.2 | 89 | 88.73 | 97.13 | 72.68 | 81.56 | 94.56 |
| n = 1024 | 89 | 99.8 | 99.8 | 90.73 | 87.4 | 96.67 | 76.95 | 80.77 | 94.25 |
| n = 2048 | 93.4 | 100 | 100 | 92.53 | 85.87 | 96.47 | 82.71 | 78.63 | 94.17 |
| n = 4096 | 96.2 | 100 | 100 | 93.33 | 87.6 | 96.73 | 86.16 | 80.94 | 94.6 |
| overall | 91.4 | 99.6 | 99.75 | 91.39 | 87.4 | 96.75 | 79.63 | 80.48 | 94.4 |
| S3n | |||||||||
| n = 512 | 81 | 100 | 100 | 85.8 | 85.4 | 96 | 64.62 | 78.17 | 93.23 |
| n = 1024 | 87.4 | 100 | 100 | 78.13 | 87.53 | 96.4 | 60.14 | 80.83 | 93.98 |
| n = 2048 | 90.4 | 100 | 100 | 75.6 | 90.27 | 96.53 | 59.77 | 84.66 | 94.07 |
| n = 4096 | 94.8 | 100 | 100 | 67.33 | 89.53 | 97 | 54.87 | 83.48 | 95 |
| overall | 88.4 | 100 | 100 | 76.72 | 88.18 | 96.48 | 59.85 | 81.79 | 94.07 |
| S3b | |||||||||
| n = 512 | 100 | 93 | 84.6 | 73.07 | 92.47 | 94.13 | 64.03 | 82.2 | 83.68 |
| n = 1024 | 100 | 100 | 99.4 | 68.67 | 91.2 | 93.87 | 59.74 | 85.64 | 91.43 |
| n = 2048 | 100 | 100 | 100 | 65.73 | 90.60 | 95.8 | 57.13 | 84.94 | 92.68 |
| n = 4096 | 100 | 100 | 100 | 62.27 | 90.73 | 95.13 | 54.24 | 85.01 | 91.58 |
| overall | 100 | 98.25 | 96 | 67.44 | 91.25 | 94.73 | 58.79 | 84.45 | 89.84 |
| S3g | |||||||||
| n = 512 | 82 | 100 | 99.8 | 84.13 | 87.2 | 94.67 | 63.64 | 80.66 | 91.07 |
| n = 1024 | 89.4 | 100 | 100 | 77.2 | 86.4 | 96.53 | 61.47 | 79.56 | 94.27 |
| n = 2048 | 94 | 100 | 100 | 73.93 | 89.13 | 96.8 | 60.78 | 83.21 | 94.58 |
| n = 4096 | 96.6 | 100 | 100 | 67.73 | 89.6 | 96.6 | 56.91 | 83.74 | 94.25 |
| overall | 90.5 | 100 | 99.95 | 75.75 | 88.08 | 96.15 | 60.7 | 81.79 | 93.54 |
| S3f | |||||||||
| n = 512 | 71 | 95.8 | 91.8 | 87 | 81.6 | 93.87 | 58.16 | 70.82 | 84.04 |
| n = 1024 | 73.2 | 97.6 | 96 | 83.33 | 78.8 | 93.8 | 53.81 | 68.76 | 87.12 |
| n = 2048 | 76.6 | 99.2 | 98.8 | 80.60 | 76.93 | 90.67 | 53.82 | 67.76 | 84.34 |
| n = 4096 | 78.8 | 99.6 | 99.8 | 77.13 | 76.07 | 87.6 | 50.86 | 67.46 | 80.73 |
| overall | 74.9 | 98.05 | 96.6 | 82.02 | 78.35 | 91.49 | 54.16 | 68.7 | 84.06 |
| S2, S2t, S2n, S2b, S2g, S2f | X1 | X2 | X3 | X4 | X5 |
|---|---|---|---|---|---|
| X1 | - | 0.0000 0.0044 0.0294 0.0000 0.0344 0.0099 | 0.0990 0.1366 0.1911 0.1280 0.1830 0.1923 | 0.0053 0.0203 0.0824 0.0000 0.0957 0.0575 | 0.0973 0.1734 0.2493 0.4293 0.2699 0.1980 |
| X2 | - | 0.0280 0.0205 0.0568 0.1831 0.0535 0.0405 | 0.7509 0.9407 0.7874 1.2848 0.7892 1.0911 | 0.0818 0.1679 0.2241 0.0536 0.2179 0.2297 | |
| X3 | - | 0.0571 0.1070 0.1079 0.2644 0.1160 0.1494 | 0.1020 0.1691 0.1870 0.3169 0.1958 0.3289 | ||
| X4 | - | 0.1306 0.2648 0.3131 0.0958 0.3152 0.3562 | |||
| X5 | - |
| S3, S3t, S3n, S3b, S3g, S3f | X1 | X2 | X3 | X4 | X5 |
|---|---|---|---|---|---|
| X1 | - | 0.0111 0.0059 0.0232 0.7988 0.0269 0.0039 | 0.0022 0.0000 0.0140 0.3140 0.0054 0.0000 | 0.0052 0.0000 0.0259 0.9428 0.0206 0.0148 | 0.0000 0.0000 0.0177 0.6588 0.0104 0.0205 |
| X2 | - | 0.0120 0.0053 0.0072 0.2340 0.0000 0.0000 | 0.1329 0.2757 0.2330 1.1917 0.2524 0.6074 | 0.0034 0.0000 0.0301 0.6000 0.0401 0.0350 | |
| X3 | - | 0.0040 0.0020 0.0113 0.7189 0.0102 0.0005 | 0.0024 0.0024 0.0159 0.5489 0.0116 0.0126 | ||
| X4 | - | 0.0000 0.0734 0.0548 1.0924 0.0555 0.1048 | |||
| X5 | - |
| n = 4000 14/9/2004–30/04/2020 | FP | SAN | OR | BNP | BN |
|---|---|---|---|---|---|
| Kurtosis | 16.8693 | 8.9997 | 8.8949 | 12.7080 | 7.8091 |
| Skewness | −0.3475 | −0.1641 | 0.2020 | −0.0539 | −0.1539 |
| n = 2000 21/06/2012–30/04/2020 | |||||
| Kurtosis | 23.7631 | 7.1009 | 6.8242 | 13.3001 | 7.8363 |
| Skewness | −1.2257 | −0.4148 | 0.1141 | −0.9696 | −0.3779 |
| n = 1000 02/06/2016–30/04/2020 | |||||
| Kurtosis | 36.1905 | 7.3303 | 10.1418 | 19.8451 | 11.8267 |
| Skewness | −2.0231 | −0.1469 | 0.1186 | −1.9065 | −0.8756 |
| n = 500 17/05/2018–30/04/2020 | |||||
| Kurtosis | 28.1107 | 7.3561 | 9.4350 | 13.3472 | 13.4247 |
| Skewness | −1.9083 | −0.3948 | 0.1157 | −1.5374 | −1.2417 |
| n = 4000 14/9/2004–30/04/2020 | FP | SAN | OR | CILPA | BRITANNIA |
|---|---|---|---|---|---|
| Kurtosis | 16.8693 | 8.9997 | 8.8949 | 7.9616 | 23.1883 |
| Skewness | −0.3475 | −0.1641 | 0.2020 | 0.0052 | 1.7592 |
| n = 2000 21/06/2012–30/04/2020 | |||||
| Kurtosis | 23.7631 | 7.1009 | 6.8242 | 7.9316 | 11.9245 |
| Skewness | −1.2257 | −0.4148 | 0.1141 | 0.4215 | 0.4737 |
| n = 1000 02/06/2016–30/04/2020 | |||||
| Kurtosis | 36.1905 | 7.3303 | 10.1418 | 9.5737 | 14.8812 |
| Skewness | −2.0231 | −0.1469 | 0.1186 | 0.8919 | 0.1096 |
| n = 500 17/05/2018–30/04/2020 | |||||
| Kurtosis | 28.1107 | 7.3561 | 9.4350 | 9.5488 | 14.1208 |
| Skewness | −1.9083 | −0.3948 | 0.1157 | 1.0137 | −0.0525 |
| Portfolio A | Samples | FP | SAN | OR | BNP | BN |
|---|---|---|---|---|---|---|
| FP | 4000 | - | 0.1659 | 0.1928 | 0.2254 | 0.1456 |
| 2000 | - | 0.1628 | 0.1552 | 0.2257 | 0.1413 | |
| 1000 | - | 0.0499 | 0.0865 | 0.1816 | 0.0711 | |
| 500 | - | 0.0555 | 0.0785 | 0.2075 | 0.0737 | |
| SAN | 4000 | - | 0.2008 | 0.1463 | 0.1781 | |
| 2000 | - | 0.2295 | 0.1385 | 0.2169 | ||
| 1000 | - | 0.1139 | 0.0185 | 0.1143 | ||
| 500 | - | 0.1251 | 0.0129 | 0.1193 | ||
| OR | 4000 | - | 0.1285 | 0.2847 | ||
| 2000 | - | 0.1171 | 0.3382 | |||
| 1000 | - | 0.0685 | 0.2455 | |||
| 500 | - | 0.0784 | 0.2089 | |||
| BNP | 4000 | - | 0.1131 | |||
| 2000 | - | 0.1087 | ||||
| 1000 | - | 0.0469 | ||||
| 500 | - | 0.0535 | ||||
| BN | 4000 | - | ||||
| 2000 | - | |||||
| 1000 | - | |||||
| 500 | - | |||||
| Portfolio B | Samples | FP | SAN | OR | CIPLA | BRITANNIA |
| FP | 4000 | - | 0.1659 | 0.1928 | 0.0171 | 0.0044 |
| 2000 | - | 0.1628 | 0.1552 | 0.2257 | 0.1413 | |
| 1000 | - | 0.0499 | 0.0865 | 0.0000 | 0.0133 | |
| 500 | - | 0.0555 | 0.0785 | 0.0177 | 0.0246 | |
| SAN | 4000 | - | 0.2008 | 0.0154 | 0.0085 | |
| 2000 | - | 0.2295 | 0.1385 | 0.2169 | ||
| 1000 | - | 0.1139 | 0.0006 | 0.0043 | ||
| 500 | - | 0.1251 | 0.0174 | 0.0124 | ||
| OR | 4000 | - | 0.0082 | 0.0138 | ||
| 2000 | - | 0.1171 | 0.3382 | |||
| 1000 | - | 0.0022 | 0.0006 | |||
| 500 | - | 0.0216 | 0.0027 | |||
| CIPLA | 4000 | 0.5459 | ||||
| 2000 | 0.1087 | |||||
| 1000 | 0.5022 | |||||
| 500 | 0.5532 | |||||
| BRITANNIA | 4000 | - | ||||
| 2000 | - | |||||
| 1000 | - | |||||
| 500 | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kyrtsou, C.; Mikropoulou, C.; Papana, A. Exploitation of Information as a Trading Characteristic: A Causality-Based Analysis of Simulated and Financial Data. Entropy 2020, 22, 1139. https://doi.org/10.3390/e22101139
Kyrtsou C, Mikropoulou C, Papana A. Exploitation of Information as a Trading Characteristic: A Causality-Based Analysis of Simulated and Financial Data. Entropy. 2020; 22(10):1139. https://doi.org/10.3390/e22101139
Chicago/Turabian StyleKyrtsou, Catherine, Christina Mikropoulou, and Angeliki Papana. 2020. "Exploitation of Information as a Trading Characteristic: A Causality-Based Analysis of Simulated and Financial Data" Entropy 22, no. 10: 1139. https://doi.org/10.3390/e22101139
APA StyleKyrtsou, C., Mikropoulou, C., & Papana, A. (2020). Exploitation of Information as a Trading Characteristic: A Causality-Based Analysis of Simulated and Financial Data. Entropy, 22(10), 1139. https://doi.org/10.3390/e22101139