Optimization of Big Data Scheduling in Social Networks




Abstract
:1. Introduction
Related Work
2. Entropy in Social Networks
3. Material Method
3.1. Scheduling Model
3.1.1. Partition Calculation for Scheduling Task Volume
3.1.2. Construction of Massive Data Scheduling Model for Social Networks
3.2. Optimized Implementation of Massive Data Scheduling Model in Social Networks
3.2.1. Analysis of Schedulable Conditions for Massive Data Classification Tasks in Social Networks
3.2.2. Big Data Classification and Optimization Scheduling Method in Social Networks
- In classification optimization of big data scheduling, the optimal minimum time (min time) ( to ) is calculated by Equation (22)where represents the minimum time consumption of big data classification optimization scheduling.
- When classifying and optimizing big data, Equation (23) is used to obtain the two-dimensional array .
- When big data classification optimization scheduling is performed, is sorted to obtain a minimum .
- is dispatched to when big data classification optimization scheduling.
4. Results
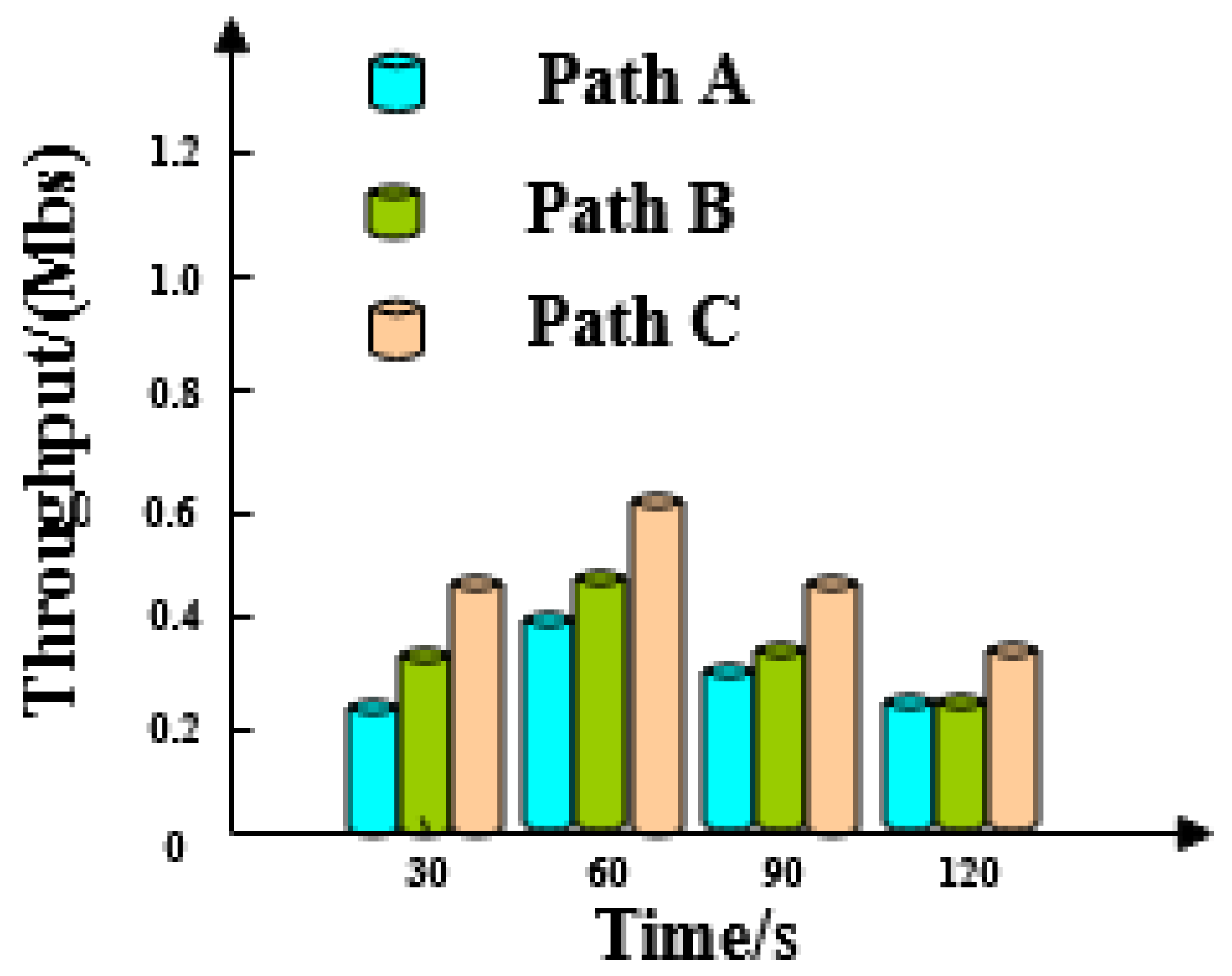
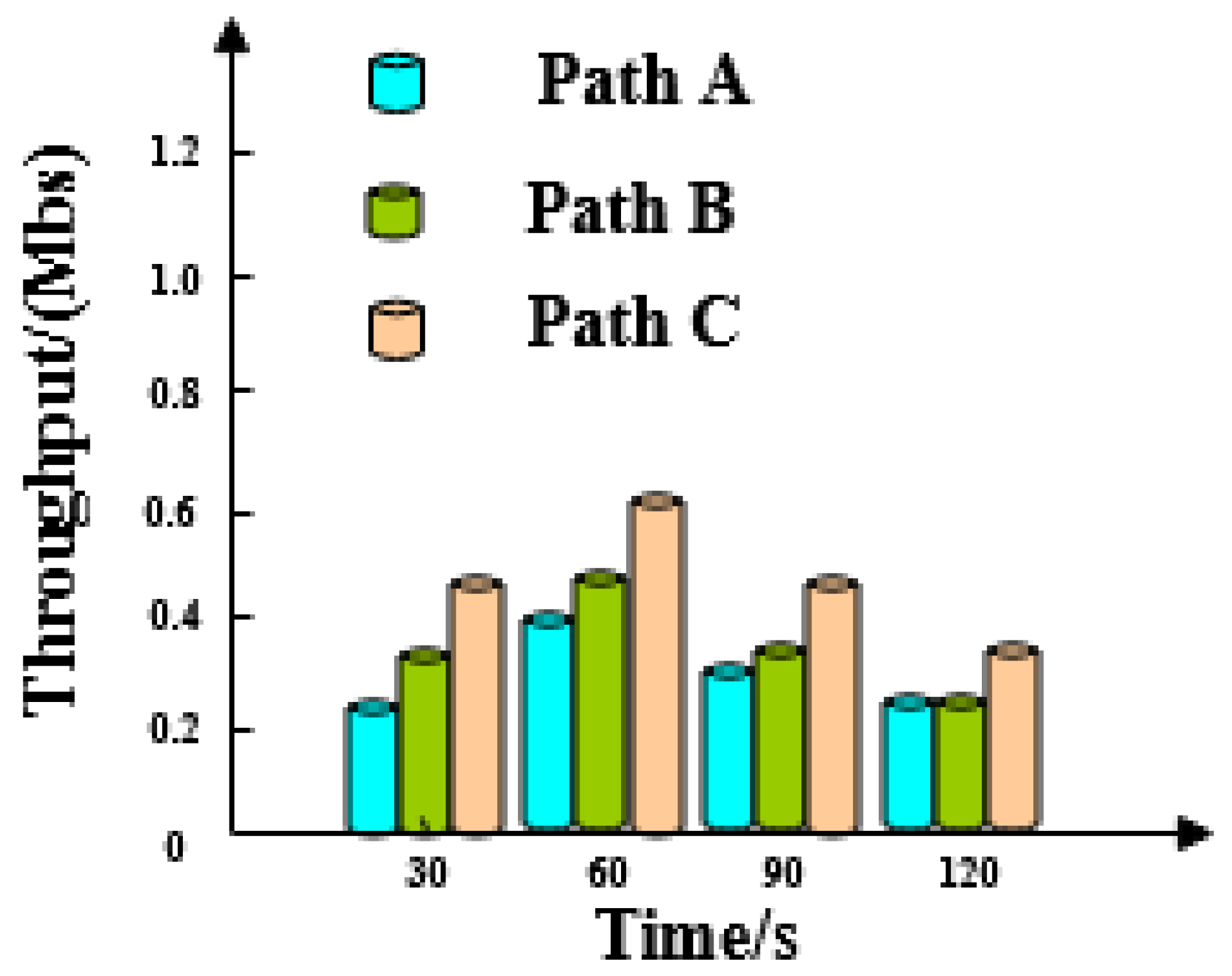
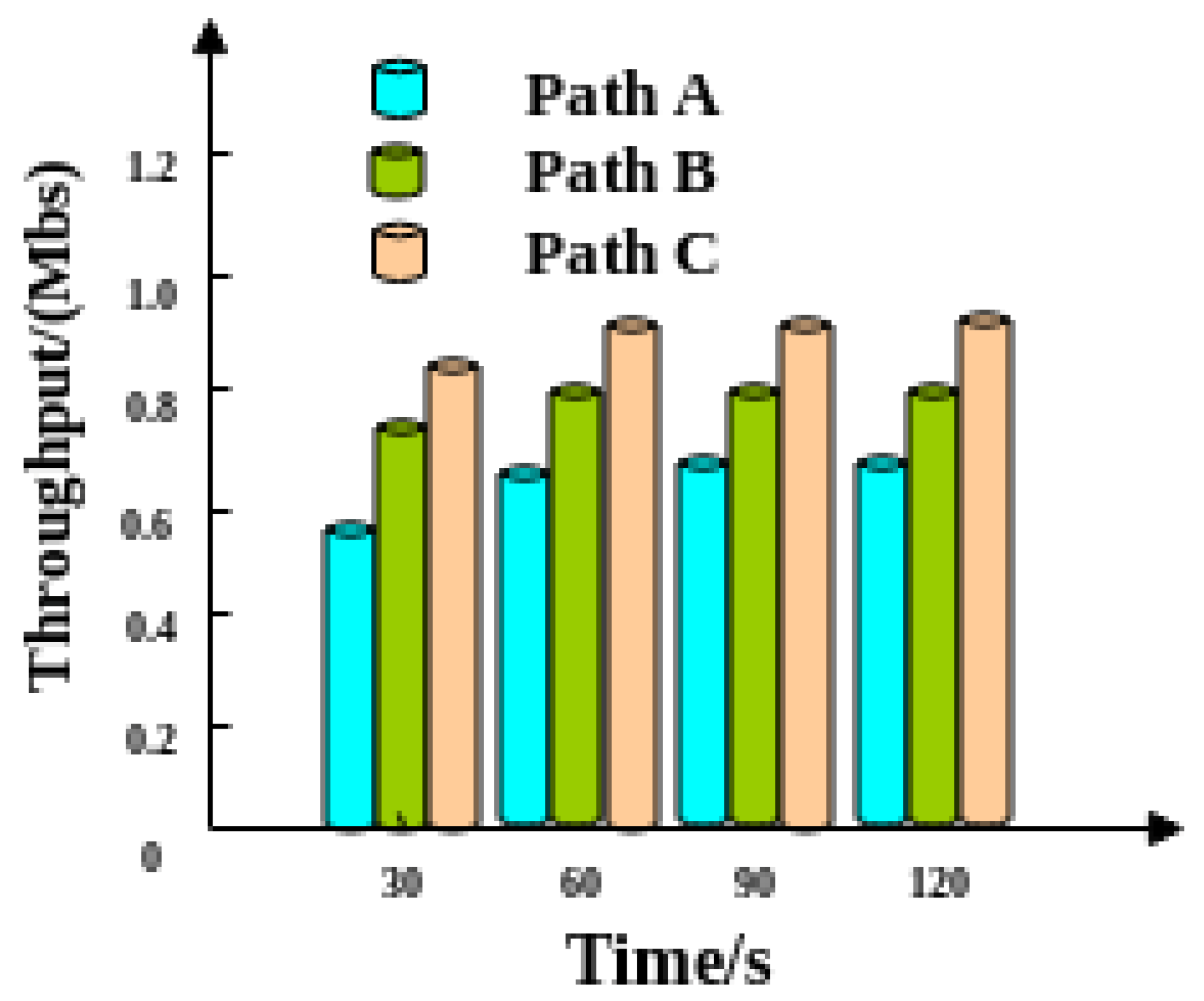
4.1. Throughput Analysis
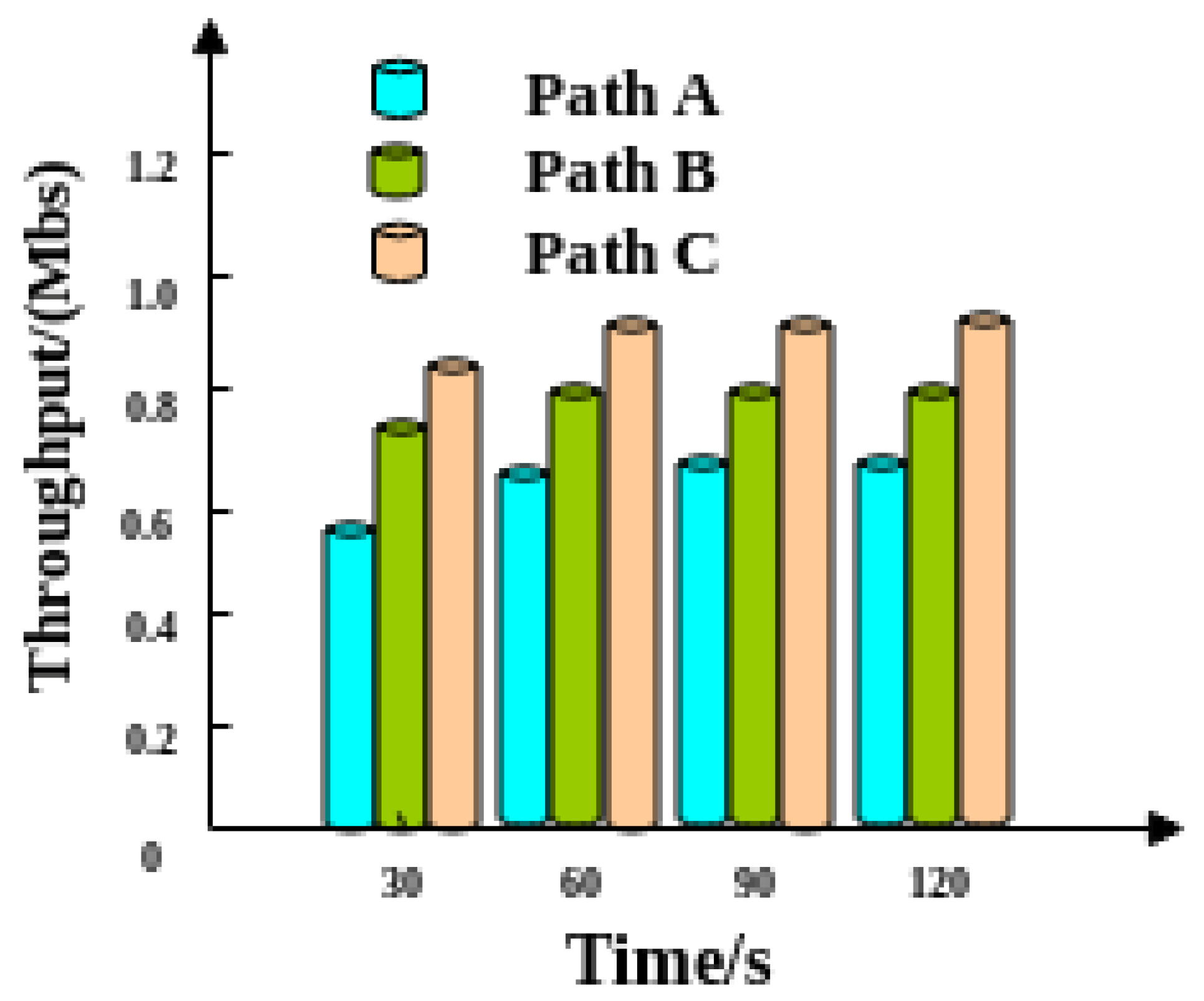
4.2. Analysis of Transmission Efficiency
4.3. Performance Comparison
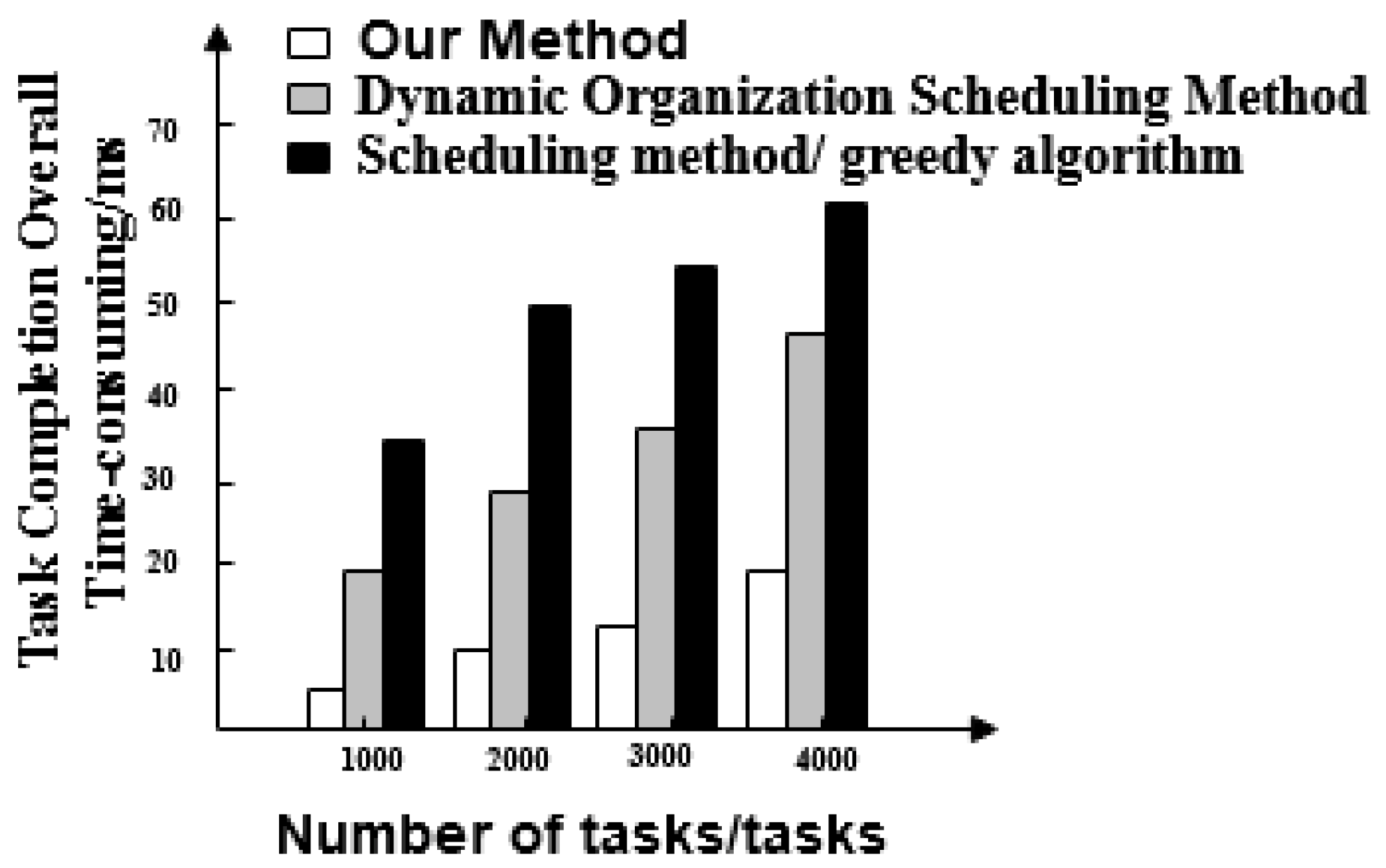
- Task response time for three methods. This can be understood as the reaction time when a massive data scheduling task in a social network starts and stops.
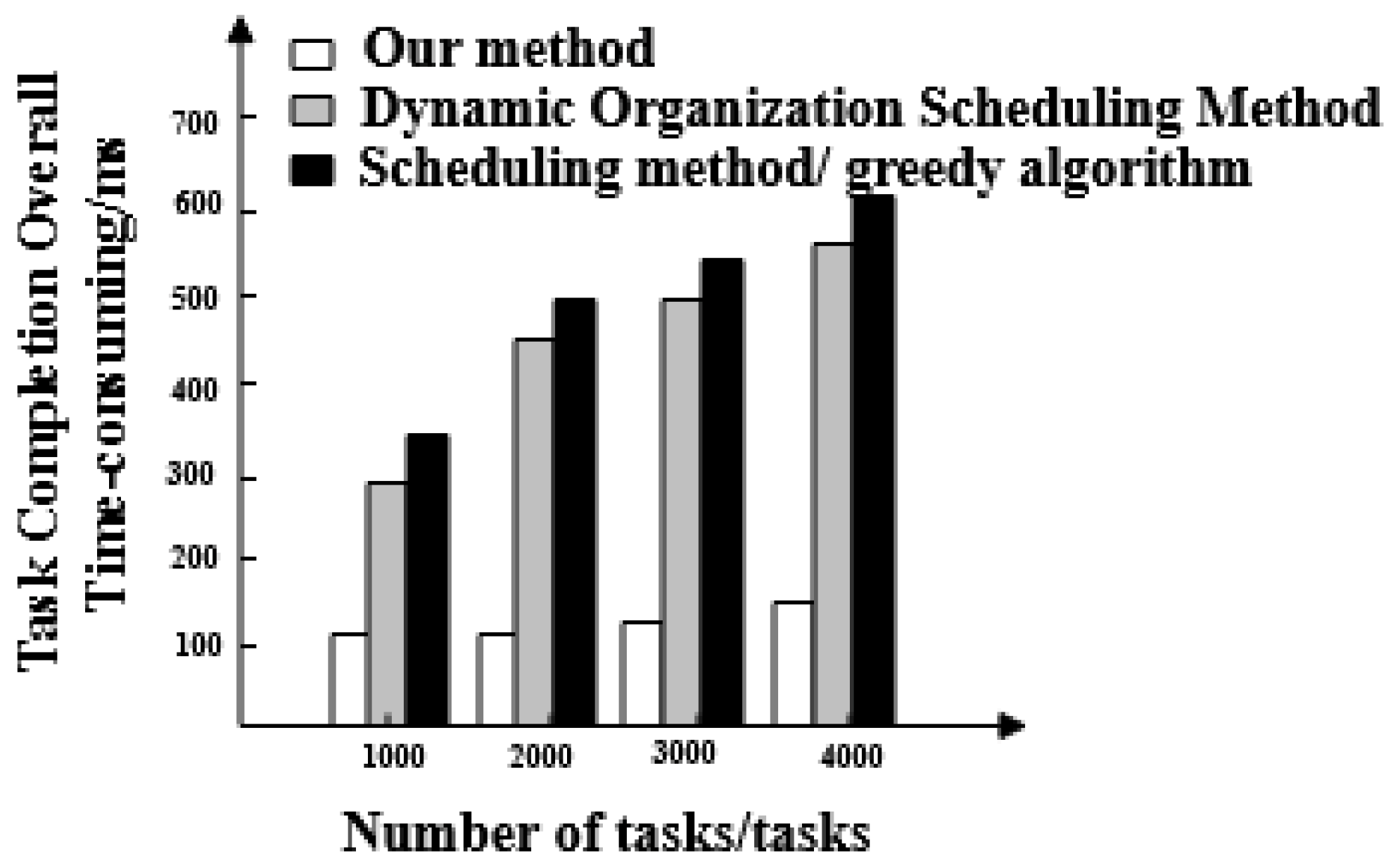
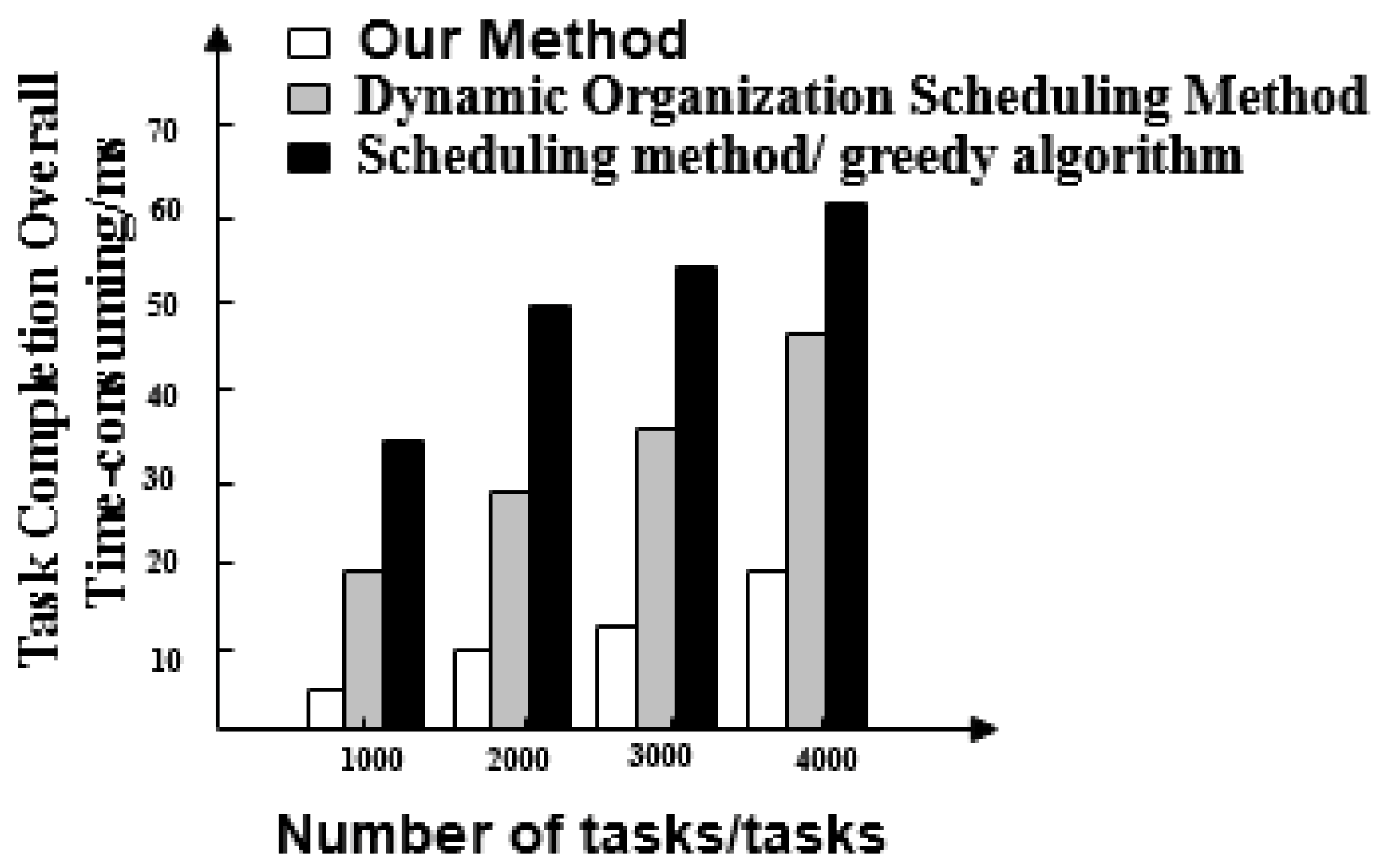
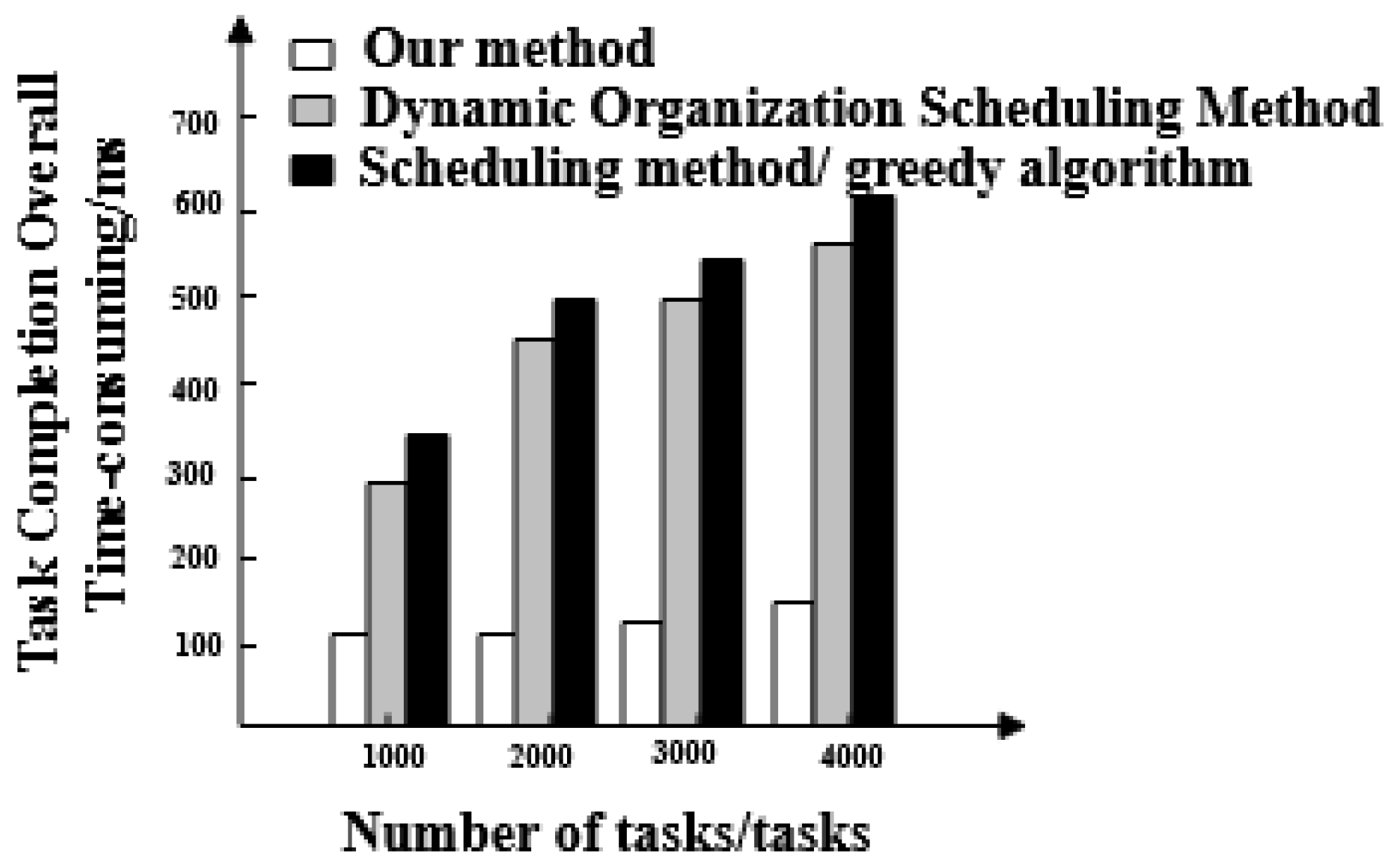
- Overall time taken for the task completion of three methods. This can be understood as the time it takes for big data scheduling optimization to start after the first task starts and the last task stops.
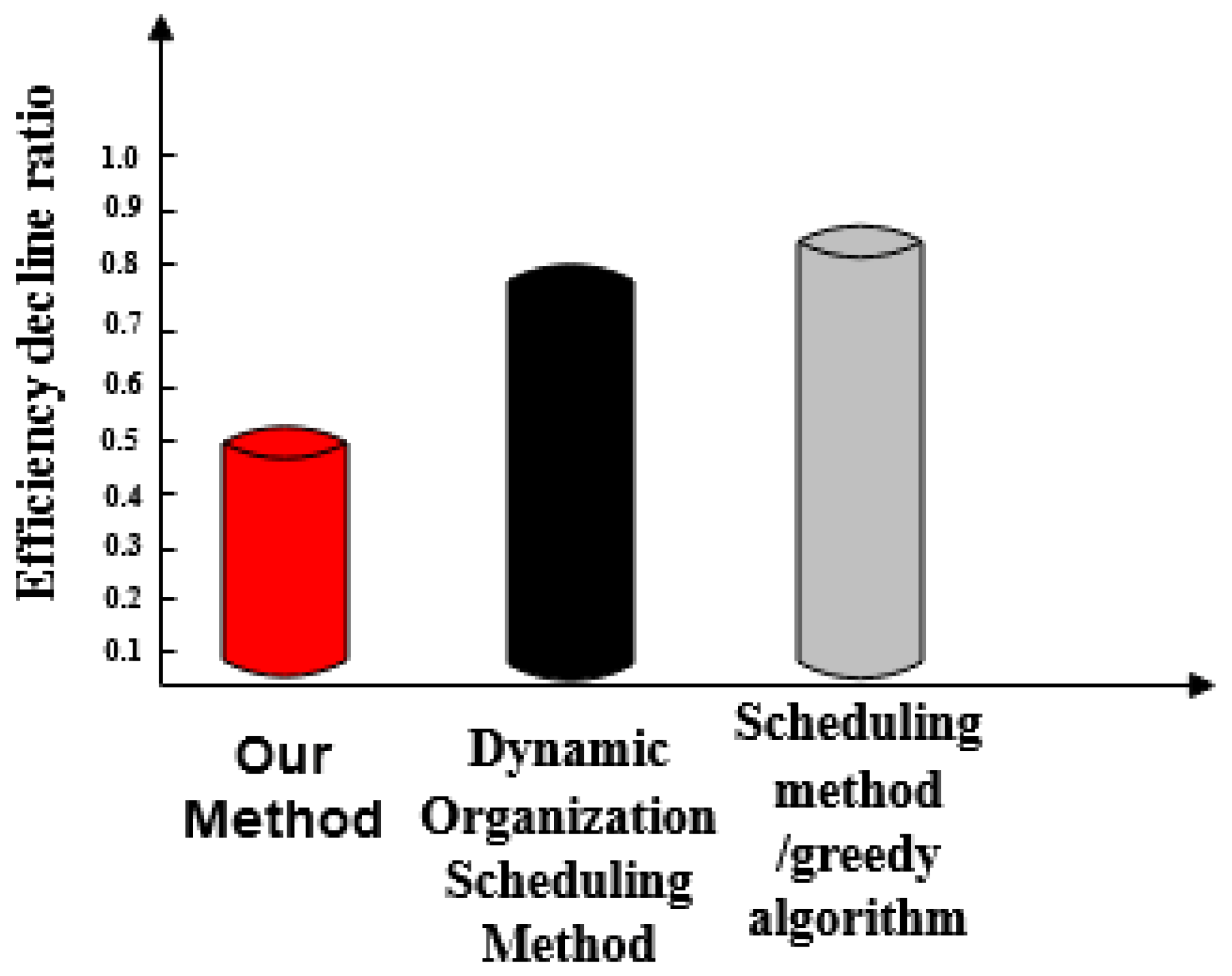
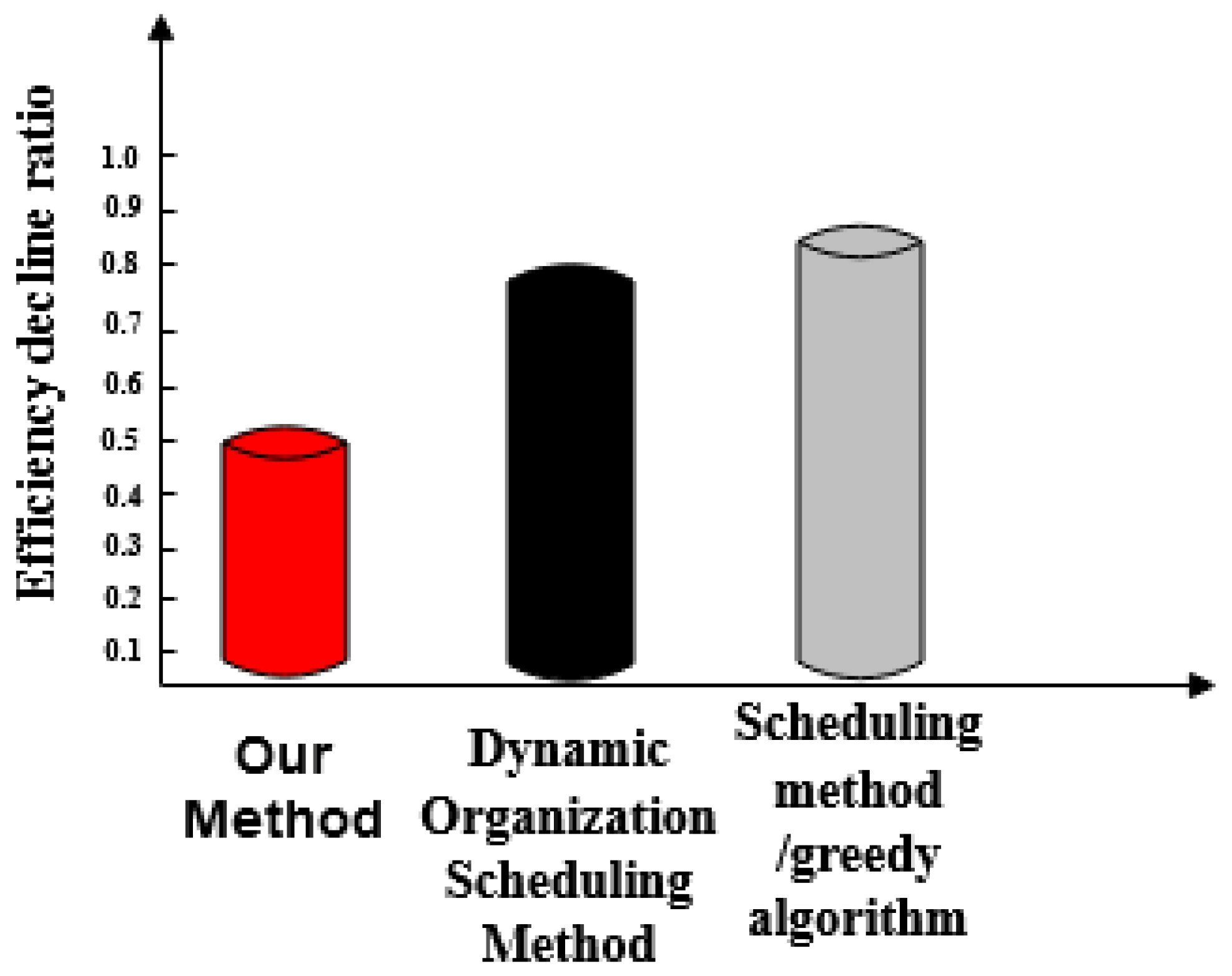
- Efficiency reduction ratio of three methods. This can be understood as a comparison of the response times and actual completion times of the three methods.
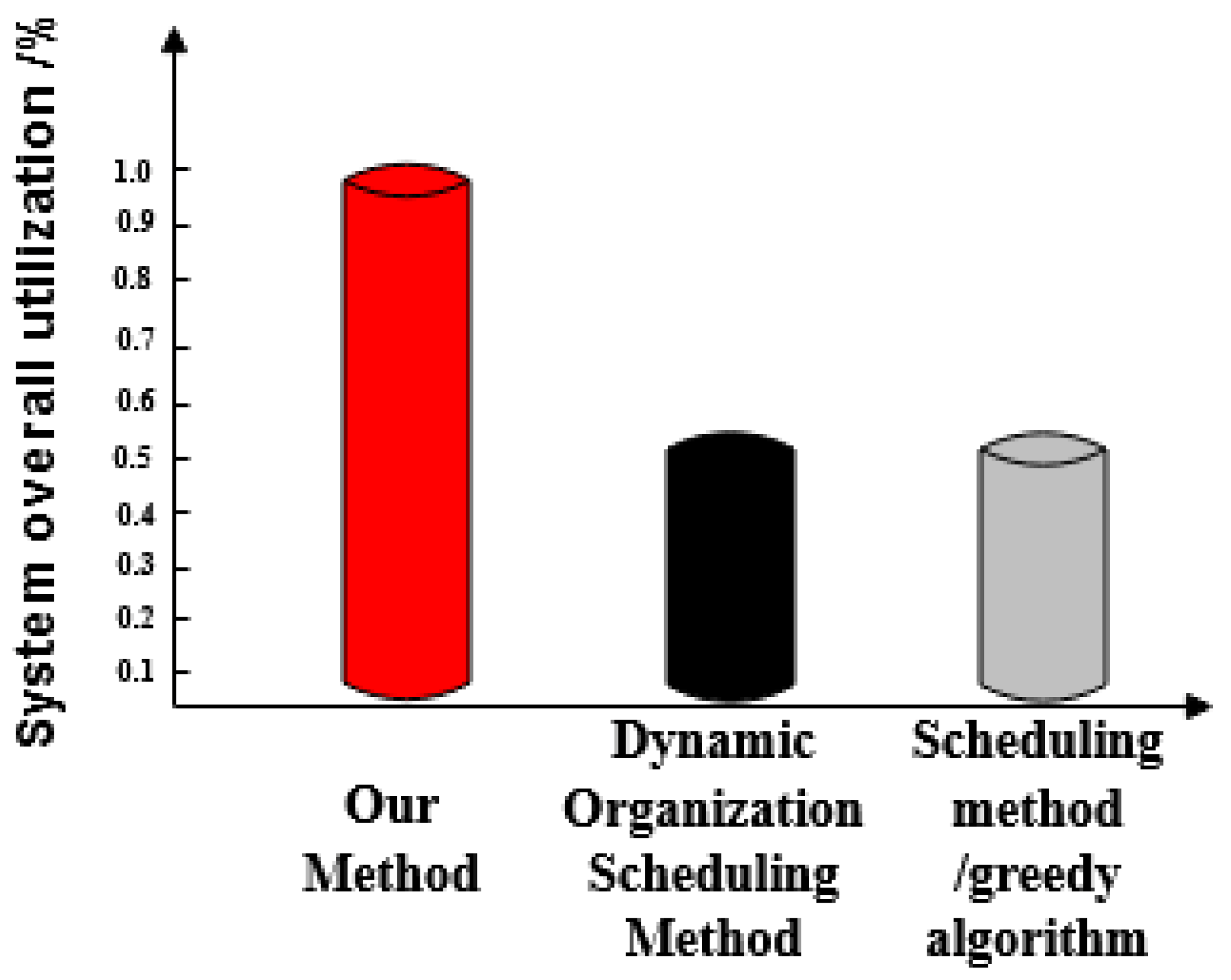
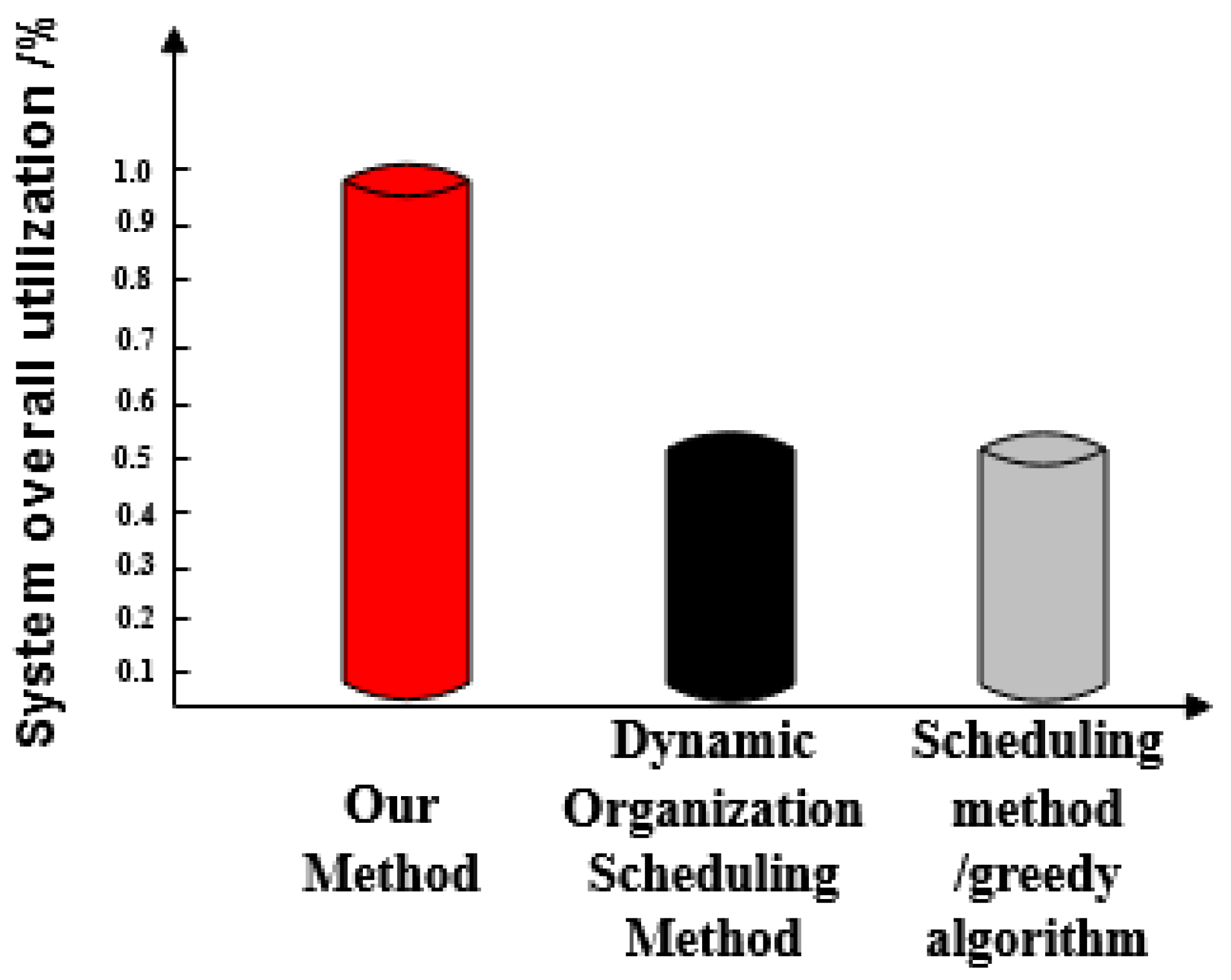
- Optimized social network resource usage rate. This can be understood as a comparison between the effective sharing of a social network resources and the maximum utilization after optimization of three methods.
- Set different amounts of target data, compare three methods of scheduling optimization with the actual number and analyze the comprehensiveness of scheduling optimization for three methods.
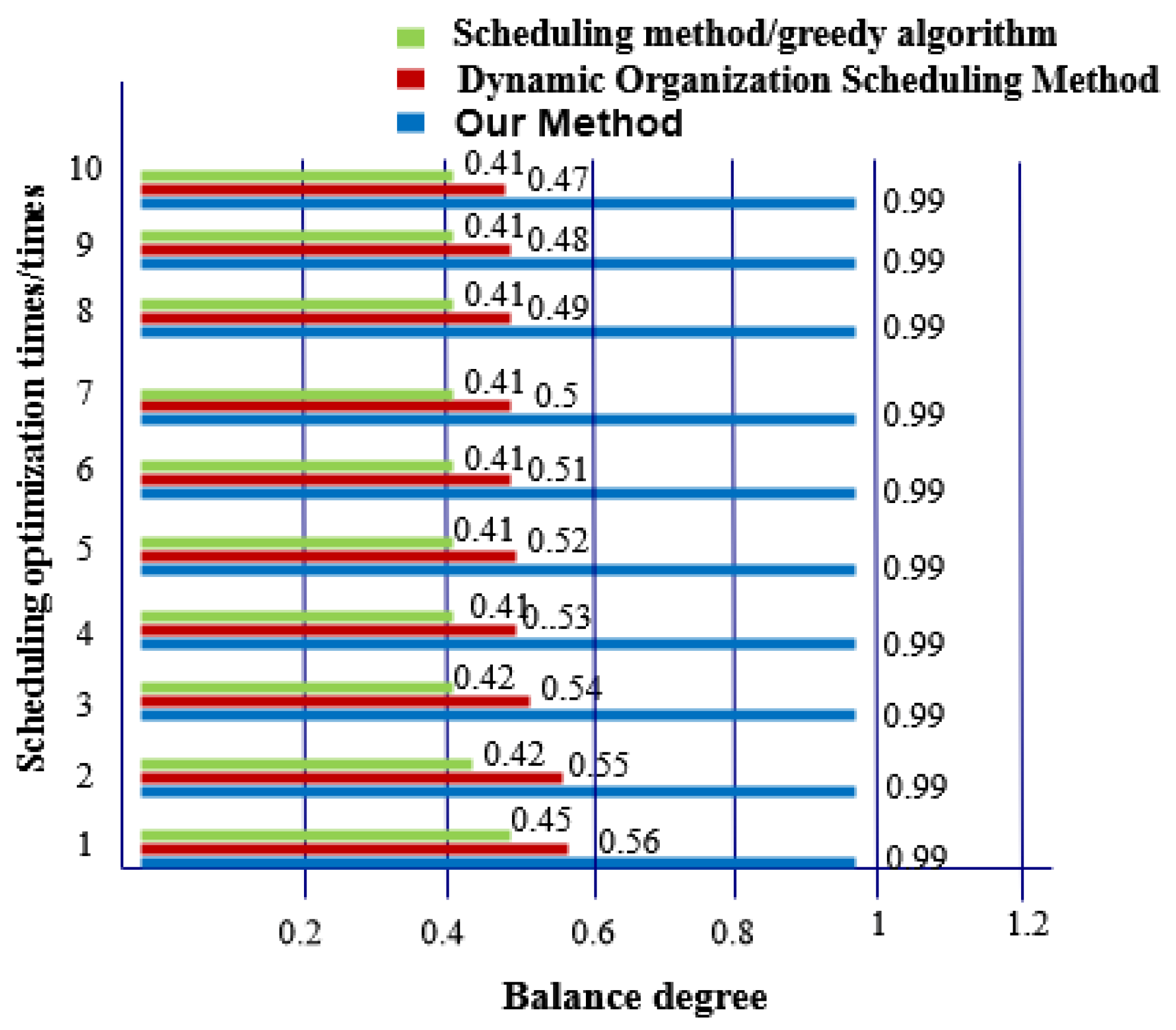
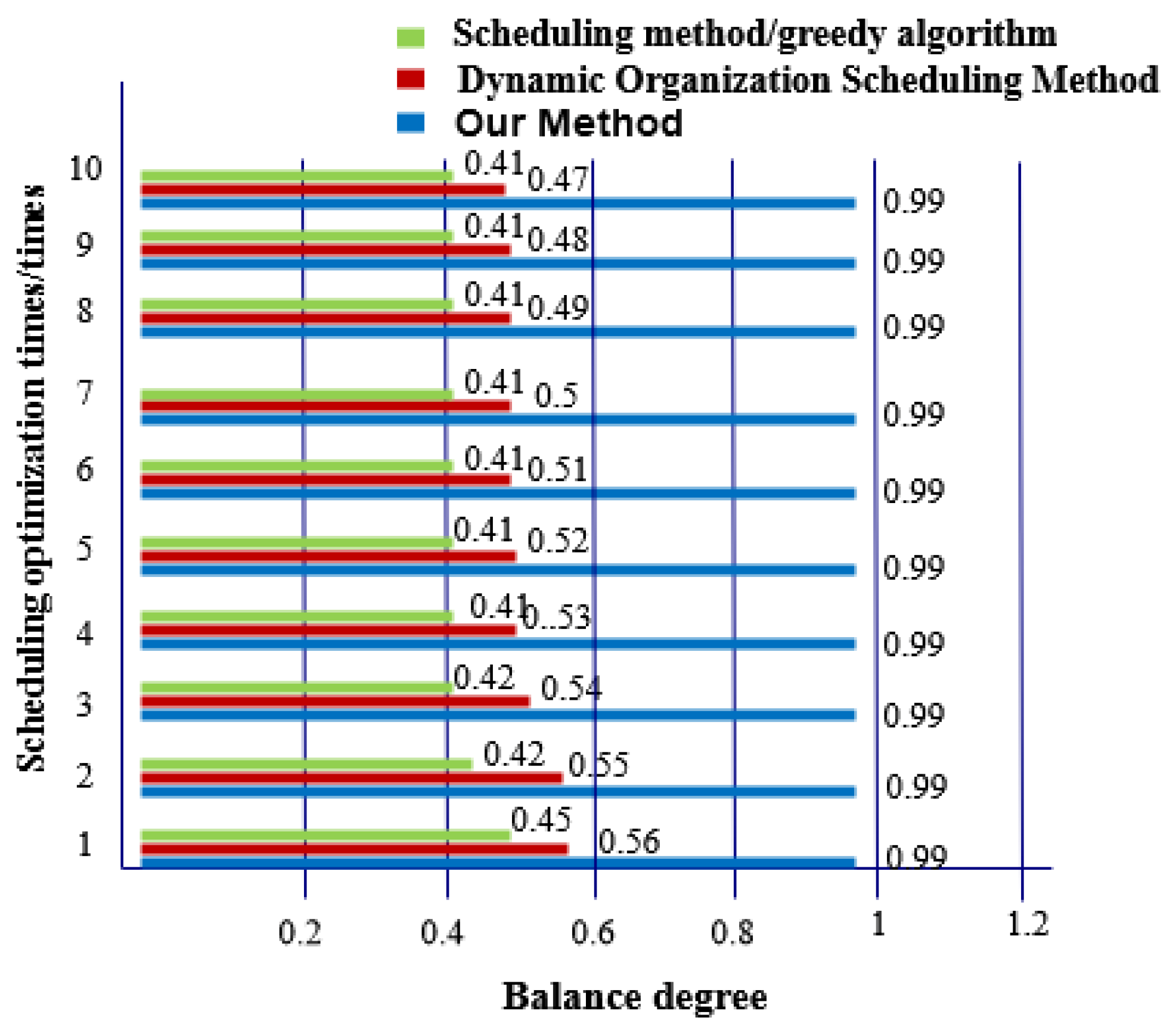
- Balance. This shows the balance of data nodes.
- Frequency normalized value. This is used to evaluate the stability of a scheduling optimization method. The smaller the numerical fluctuation, the stronger the stability of a scheduling optimization method.
5. Discussion
- The three methods have a large difference in scheduling response time. The task response time of the proposed method increases with the number of tasks and the maximum response time is 20 ms. The maximum time-consuming response time of dynamic organization scheduling method and greedy algorithm-based scheduling method is 48 ms and 64 ms, respectively. The task response time of the proposed method is the shortest and tasks are executed quickly.
- The overall completion time of each task under the proposed method is less than 200 ms. Overall, tasks scheduled under the dynamic organization scheduling method and the greedy algorithm based scheduling method take more time as the number of tasks increases. Their task completion time also gradually increases and takes longer than with the proposed method. The overall completion time of tasks by the proposed method is the shortest of the three.
- The efficiency reduction ratio of the proposed method is lower than that of the dynamic organization scheduling method and the greedy algorithm based scheduling method. The proposed method exhibits the same efficiency and high stability throughout.
- The optimized social network resource usage rate under the proposed method is as high as 100%, which is greater than the resource usage rate of the dynamic organization scheduling method and the greedy algorithm-based scheduling method. This demonstrates that there is no redundant data in big data optimized by the proposed method and its availability is high.
- When the proposed method optimizes big data scheduling in social networks, the maximum difference between the target data volume and the actual data volume is one and its error is small. For the other two methods, the maximum difference between the target data volume and the actual data volume is greater than the proposed method. It can be seen that the optimal scheduling of the proposed method is more comprehensive.
- There is a big gap in the balance of big data in social networks after the three methods are used. The balance of big data in a social network after scheduling optimization by the proposed method is as high as 0.99, indicating that the probability of conflict between data is only 0.01. After scheduling optimization by the other two methods, the balance of big data in social networks is not more than 0.6, the conflict between data is large and the scheduling optimization process is hindered.
- The frequency of the scheduling model optimized by the proposed method is between 0.5 and 0.7 and its fluctuation is small. It has the advantage of high stability compared with the other two methods.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhan, W.; Dai, L. Massive Random Access of Machine-to-Machine Communications in LTE Networks: Modeling and Throughput Optimization. IEEE Trans. Wirel. Commun. 2017, 17, 2771–2785. [Google Scholar] [CrossRef]
- Lu, Q.; Li, S.; Zhang, W. A genetic algorithm-based job scheduling model for big data analytics. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 152. [Google Scholar] [CrossRef] [PubMed]
- Zenteno, A.C.; Carnes, T.; Levi, R. Systematic OR Block Allocation at a Large Academic Medical Center: Comprehensive Review on a Data-driven Surgical Scheduling Strategy. Ann. Surg. 2016, 264, 973–981. [Google Scholar] [CrossRef] [PubMed]
- Kanoun, K.; Tekin, C.; Atienza, D. Big-Data Streaming Applications Scheduling Based on Staged Multi-Armed Bandits. IEEE Trans. Comput. 2016, 65, 3591–3605. [Google Scholar] [CrossRef]
- Li, J.C.; Han, X.Q.; Liu, Y.M. Capacity optimization of hybrid storage in schedulable PV power station. Chin. J. Power Sources 2016, 40, 392–396. [Google Scholar]
- Sun, D.; Yan, H.; Shang, G. Rethinking elastic online scheduling of big data streaming applications over high-velocity continuous data streams. J. Supercomput. 2018, 74, 615–636. [Google Scholar] [CrossRef]
- Hanani, A.; Rahmani, A.M.; Sahafi, A. A multi-parameter scheduling method of dynamic workloads for big data calculation in cloud computing. J. Supercomput. 2017, 73, 4796–4822. [Google Scholar] [CrossRef]
- Chang, C.; Choi, C.; Choi, J. Improved performance optimization for massive small files in cloud computing environment. Ann. Oper. Res. 2016, 265, 305–317. [Google Scholar]
- Yang, J.B.; Zhang, J.Y.; Song, P.G. Multi-objective Optimization of Energy Management Strategy for A Tramway with Onboard Energy Storage System. J. Power Supply 2017, 15, 137–143. [Google Scholar]
- Xie, H.; Gao, F.; Zhang, S. A Unified Transmission Strategy for TDD/FDD Massive MIMO Systems with Spatial Basis Expansion Model. IEEE Trans. Veh. Technol. 2017, 66, 3170–3184. [Google Scholar] [CrossRef]
- Persico, V.; Pescapé, A.; Picariello, A.; Sperlí, G. Benchmarking big data architectures for social networks data processing using public cloud platforms. Future Gener. Comput. Syst. 2018, 89, 98–109. [Google Scholar] [CrossRef]
- Albanese, M.; Erbacher, R.F.; Jajodia, S.; Molinaro, C.; Persia, F.; Picariello, A.; Subrahmanian, V.S. Recognizing unexplained behavior in network traffic. In Network Science and Cybersecurity; Springer: New York, NY, USA, 2014; pp. 39–62. [Google Scholar]
- Hoang, D.T.; Niyato, D.; Wang, P.; Kim, D.I.; Le, L.B. Optimal data scheduling and admission control for backscatter sensor networks. IEEE Trans. Commun. 2017, 65, 2062–2077. [Google Scholar] [CrossRef]
- Pang, J.; Xu, G.; Fu, X. SDN-based data center networking with collaboration of multipath TCP and segment routing. IEEE Access 2017, 5, 9764–9773. [Google Scholar] [CrossRef]
- Sun, D.; Zhao, K.; Fang, Y.; Cui, J. Dynamic Traffic Scheduling and Congestion Control across Data Centers Based on SDN. Future Internet 2018, 10, 64. [Google Scholar] [CrossRef]
- Khabbaz, M.; Shaban, K.; Assi, C. Delay-aware flow scheduling in low latency enterprise datacenter networks: Modeling and performance analysis. IEEE Trans. Commun. 2017, 65, 2078–2090. [Google Scholar] [CrossRef]
- Hou, Y.; Zheng, Y.; Li, M. Fair QoS multi-resource allocation for uplink traffic in WLAN. Wirel. Networks 2017, 23, 467–486. [Google Scholar] [CrossRef]
- Ebrahimi, D.; Assi, C. On the Interaction between Scheduling and Compressive Data Gathering in Wireless Sensor Networks. IEEE Trans. Wirel. Commun. 2015, 15, 2845–2858. [Google Scholar] [CrossRef]
- Huo, C.Y. Algorithm of business priorities power dispatching data network congestion avoidance. Autom. Instrum. 2016, 5, 177–178. [Google Scholar]
- Bethanabhotla, D.; Caire, G.; Neely, M.J. WiFlix: Adaptive Video Streaming in Massive MU-MIMO Wireless Networks. IEEE Trans. Wirel. Commun. 2015, 15, 4088–4103. [Google Scholar] [CrossRef]
- Su, S.; Wang, Y.; Jiang, S. Efficient algorithms for scheduling multiple bulk data transfers in inter-datacenter networks. Int. J. Commun. Syst. 2015, 27, 4144–4165. [Google Scholar] [CrossRef]
- Liu, S.; Bai, W.; Liu, G.; Li, W.; Srivastava, H.M. Parallel Fractal Compression Method for Big Video Data. Complexity 2018, 2016976. [Google Scholar] [CrossRef]
- Liang, X.; Jin, S.; Wong, K.K. Multi-pair massive MIMO relay networks: Power scaling laws and user scheduling strategy. IET Commun. 2017, 11, 1619–1625. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, Z.; Yang, L.T. A nodes scheduling model based on Markov chain prediction for big streaming data analysis. Int. J. Commun. Syst. 2015, 28, 1610–1619. [Google Scholar] [CrossRef]
- Shi, J.; Li, M.; Huang, Y. Pilot scheduling schemes for multi-cell massive multiple-input–multiple-output transmission. IET Commun. 2015, 9, 689–700. [Google Scholar]
- Zheng, P.; Shuai, L.; Sangaiah, A.K.; Muhammad, K. Visual attention feature (VAF): A novel strategy for visual tracking based on cloud platform in intelligent surveillance systems. J. Parallel Distrib. Comput. 2018, 120, 182–194. [Google Scholar]
- Shuai, L.; Gaocheng, L.; Huiyu, Z. A Robust Parallel Object Tracking Method for Illumination Variations. Mob. Netw. Appl. 2019, 24, 5–17. [Google Scholar]
- Adhikary, A.; Dhillon, H.S.; Caire, G. Massive-MIMO Meets HetNet: Interference Coordination Through Spatial Blanking. IEEE J. Sel. Areas Commun. 2015, 33, 1171–1186. [Google Scholar] [CrossRef]
- Chester, S.; Kapron, B.M.; Srivastava, G.; Venkatesh, S. Complexity of social network anonymization. Soc. Netw. Anal. Min. 2013, 3, 151–166. [Google Scholar] [CrossRef]
- Chester, S.; Kapron, B.M.; Ramesh, G.; Srivastava, G.; Thomo, A.; Venkatesh, S. Why Waldo befriended the dummy? k-Anonymization of social networks with pseudo-nodes. Soc. Netw. Anal. Min. 2013, 3, 381–399. [Google Scholar] [CrossRef]
- Chester, S.; Kapron, B.M.; Ramesh, G.; Srivastava, G.; Thomo, A.; Venkatesh, S. k-Anonymization of Social Networks by Vertex Addition. ADBIS 2011, 789, 107–116. [Google Scholar]
- Chester, S.; Srivastava, G. Social network privacy for attribute disclosure attacks. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining, Kaohsiung, Taiwan, 25–27 July 2011; pp. 445–449. [Google Scholar]
- Kapron, B.; Srivastava, G.; Venkatesh, S. Social network anonymization via edge addition. In Proceedings of the 2011 International Conference on Advances in Social Networks Analysis and Mining, Kaohsiung, Taiwan, 25–27 July 2011; pp. 155–162. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task Ordinal Oumber | Bandwidth/(Mb/s) | ||
|---|---|---|---|
| Path A | Path B | Path C | |
| 1 | 0 | 1.6 | 2.4 |
| 2 | 0.1 | 1.5 | 2.3 |
| 3 | 0.2 | 1.4 | 2.2 |
| 4 | 0.3 | 1.3 | 2.1 |
| 5 | 0.4 | 1.2 | 2.0 |
| 6 | 0.5 | 1.1 | 1.9 |
| 7 | 0.6 | 1.0 | 1.8 |
| 8 | 0.7 | 0.9 | 1.7 |
| 9 | 0.8 | 0.8 | 1.6 |
| Task Ordinal Number | Path A | Path B | Path C | |||
|---|---|---|---|---|---|---|
| Before Adopting This Method | After Adopting the Method Presented in This Paper | Before Adopting This Method | After Adopting the Method Presented in This Paper | Before Adopting This Method | After Adopting the Method Presented in This Paper | |
| 1 | 11.89 | 9.45 | 12.56 | 8.56 | 13.25 | 8.25 |
| 2 | 35.26 | 9.56 | 13.25 | 8.52 | 22.54 | 8.45 |
| 3 | 23.56 | 9.25 | 18.25 | 8.54 | 20.32 | 8.25 |
| 4 | 18.22 | 9.54 | 16.26 | 8.26 | 15.26 | 8.26 |
| 5 | 14.24 | 9.24 | 15.25 | 8.15 | 14.23 | 8.14 |
| 6 | 13.58 | 9.25 | 12.33 | 8.75 | 12.35 | 8.75 |
| 7 | 11.95 | 9.36 | 13.44 | 8.49 | 11.25 | 8.76 |
| 8 | 11.42 | 9.37 | 12.65 | 8.29 | 11.04 | 8.29 |
| 9 | 11.25 | 9.38 | 12.47 | 8.47 | 11.07 | 8.61 |
| Scheduling Optimization Times/Times | Target Data Volume/Number | Article Method | Dynamic Organization Scheduling Method | Scheduling Method Based on Greedy Algorithm |
|---|---|---|---|---|
| 1 | 500 | 500 | 489 | 491 |
| 2 | 1000 | 999 | 989 | 988 |
| 3 | 1500 | 1499 | 1489 | 1487 |
| 4 | 2000 | 1999 | 1991 | 1989 |
| 5 | 2500 | 2499 | 2488 | 2476 |
| 6 | 3000 | 2999 | 2997 | 2967 |
| 7 | 3500 | 3499 | 3498 | 3467 |
| 8 | 4000 | 3999 | 3989 | 3943 |
| 9 | 4500 | 4499 | 4478 | 4456 |
| 10 | 5000 | 4999 | 4967 | 4934 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, W.; Liu, S.; Srivastava, G. Optimization of Big Data Scheduling in Social Networks. Entropy 2019, 21, 902. https://doi.org/10.3390/e21090902
Fu W, Liu S, Srivastava G. Optimization of Big Data Scheduling in Social Networks. Entropy. 2019; 21(9):902. https://doi.org/10.3390/e21090902
Chicago/Turabian StyleFu, Weina, Shuai Liu, and Gautam Srivastava. 2019. "Optimization of Big Data Scheduling in Social Networks" Entropy 21, no. 9: 902. https://doi.org/10.3390/e21090902
APA StyleFu, W., Liu, S., & Srivastava, G. (2019). Optimization of Big Data Scheduling in Social Networks. Entropy, 21(9), 902. https://doi.org/10.3390/e21090902