1. Introduction
As the proliferation of machine learning and algorithmic decision making continues to grow throughout industry, the net societal impact of them has been studied with more scrutiny. In the USA under the Obama administration, a report on big data collection and analysis found that “big data technologies can cause societal harms beyond damages to privacy” [
1]. The report feared that algorithmic decisions informed by big data may have harmful biases, further discriminating against disadvantaged groups. This along with other similar findings has led to a surge in research around algorithmic fairness and the removal of bias from big data.
The term
fairness, with respect to some sensitive feature or set of features, has a range of potential definitions. In this work, impact parity is considered. In particular, this work is concerned with group fairness under the following definitions as taken from [
2].
Group Fairness:A predictor achieves fairness with bias ϵ with respect to groups and being any subset of outcomes iff, The above definition can also be described as statistical or demographical parity. Group fairness has found widespread application in India and the USA, where affirmative action has been used to address discrimination against caste, race and gender [
3,
4,
5].
The above definition does not, unfortunately, have natural application to regression problems. One approach to get around this would be to alter the definition to bound the absolute difference between the respective marginal distributions over the output space. However, this is a strong requirement and may hinder the model’s ability to model the function space appropriately. Rather, a weaker and potentially more desirable constraint would be to force the expectation of the marginal distributions over the output space to equate. Therefore, statements such as “the average expected outcome for population A and B is equal“ would be valid. This can be seen as a constraint such that the total entropy of the partition is maximised.
The second issue encountered is that the generative distribution of groups A and B are generally unknown. In this work, it is assumed that the empirical distribution and , as observed from the training set, is equal to or negligibly perturbed from the true generative distributions.
Combining these two caveats, we arrive at the definition:
Group Fairness in Expectation:A regressor achieves fairness with respect to groups iff, There are many machine learning techniques with which
Group Fairness in Expectation constraints (GFE constraints) may be incorporated. While constraining kernel regression is introduced in
Section 3, the main focus of the paper is examining decision tree regression and respective ensemble methods which build on decision tree regression such as random forests, extra trees and boosted trees due to their widespread use in industry and hence their extensive impact on society [
6]. The reason for this is to show that such an approach will not affect the order of computational or memory complexity of the model.
The main contributions of this paper are:
- I
We use quadrature approaches to enforce GFE constraints on kernel regression with applications to Gaussian processes, support vector machines, neural network regression and decision tree regression, as outlined in
Section 3.
- II
We incorporate these constraints on decision tree regression without affecting the computational or memory requirements, as outlined in
Section 5 and
Section 6.
- III
We derive a tight bound for the variance of the perturbations due to the incorporation of GFE constraints on decision tree regression in terms of the number of leaves of the tree, as outlined in
Section 7.
- IV
We show that these
fair trees can be combined into random forests, boosted trees and other ensemble approaches while maintaining fairness, as shown in
Section 8.
2. Related Work
There are many ways in which the now huge volume of literature on algorithmic fairness may be split. One such approach is to break the proposed literature into three branches of research based upon the stage of the machine learning life cycle they belong. The first is the data alteration approach, which endeavours to modify the original dataset in order to prevent discrimination or bias due to the protected variable [
7,
8]. The second is an attempt to regularise such that the model is penalised for bias [
9,
10,
11,
12,
13]. Finally, the third endeavours to use post-processing to re-calibrate and mitigate against bias [
14,
15].
The literature also differs dramatically as to what is the objective of the fairness algorithm. Recent work has made efforts towards grouping these into consistent objective formalisation [
2,
16]. Often, the focus of algorithmic fairness is on classification problem with regression receiving very little attention.
The approach applied to enforce fairness may be from a plethora of definitions, anti-classification [
16], or fairness through unawareness as it is also referred to as [
2], endeavour to treat data agnostic of protected variables and hence enforces fairness via treatment rather than outcome. The second popular method is classification parity, i.e., the error with respect to some given measure is equal across groups defined by the protected variable. Finally, calibration is the term used when outcomes are independent of protected group conditioned on risk.
Narrowing our focus to regression, two contradicting objectives once again arise, namely group level fairness and individual fairness. Individual fairness implies that small changes to a given characteristic of an individual leads to small changes in outcome. Group fairness on the other hand endeavours to make aggregate outcomes of protected groups similar. The latter is the focus of this work and an overview of where this fits into the broader litterature may be found in
Table 1.
Our work endeavours to create group level parity of expected outcome, of Group Fairness in Expectation as introduced in this work, with application to all kernel based regression which minimise the L2 norm. This includes decision trees, Gaussian processes and multi-layer perceptrons.
Specifically to decision trees, discrimination aware decision trees have been introduced [
30] for classification. They offer dependency aware tree construction and leaf relabelling approach. Later, fair forests [
13] introduced a further tree induction algorithm to encourage fairness. They did this by introducing a new gain measure to encourage fairness. However, the issue with adding such regularisation is two-fold. Firstly, discouraging bias via a regularising term does not make any guarantee about the bias of the post trained model. Secondly, it is hard to make any theoretical guarantees about the underlying model or the effect the new regulariser has had on the model.
The approach offered in this work seeks to perform model inference in a constrained space, leveraging basic theory from Bayesian quadrature such that the predicted marginal distributions are guaranteed to have equal means. Such moment constraints have a natural relationship to maximum entropy methods. By utilising quadrature methods, it is also possible to derive bounds for the expected absolute perturbation induced by constraining the space. This is shown explicitly in
Section 7. Ultimately, the paper develops a general framework to perform group-fair regression, an important open problem as pointed out in [
23].
We emphasise to the reader that, as outlined in the next section, there are many definitions of fairness, each with reasonable motives but conflicting values. Group fairness, addressed in this work, inherently leads to individual unfairness, i.e., to create equal aggregate statistics between sub-population, individuals in each sub-population are treated inconsistently. The reverse is also true. As such, we should always think through the adverse effects of our approach before applying it in the real world. The experiments in this paper are aimed to explore and demonstrate the approach introduced, but are not meant to advocate using group fairness specifically for the task in hand.
3. Constrained Kernel Regression
We first show how one can create such linear constraints on kernel regression models. This work builds on the earlier contributions in [
31], where the authors examined the incorporation of linear constraints on Gaussian processes (GPs). Gaussian processes are a Bayesian kernel method most popular for regression. For a detailed introduction to Gaussian processes, we refer the reader to [
32]. However, for the reader unfamiliar with GPs specifically, they may simply think of a high dimensional Gaussian distribution parameterised by a kernel
, with zero mean and unit variance without loss of generality. Given a set of inputs and respective outputs,
, split into training and testing sets,
and
, inference is performed as,
where
denotes the kernel matrix between training examples,
is the kernel matrix between the test and training examples and
is the prior variance on the prediction point defined by the kernel matrix. Gaussian processes differ from high dimensional Gaussian distributions as they can model the relationships between points in continuous space, via the kernel function, as opposed to being limited to a finite dimension.
An important note is that any combination of Gaussian distributions via addition and subtraction is a closed space, i.e., the sum of Gaussians is also Gaussian and so on. While this may at first appear trivial, it is, in fact, a very useful artefact. For example, let us assume there are two variables,
a and
b, drawn from Gaussian distributions with mean and variance
, respectively. Further, assume that the correlation coefficient
describes the interaction between the two variables. Then, a new variable
c, which is equal to the difference
a and
b, is drawn from a Gaussian distribution with mean and variance,
We can thus write all three variables in terms of a single mean vector and covariance matrix,
Given any two of the above observations, the third can be inferred exactly. We refer to this as a degenerate distribution as K will naturally be low rank. If we observe that is equal to zero, we are thus constraining the distribution of a and b. This can easily be extended to the relationship between sums and differences of more variables.
Bayesian quadrature [
33] is a technique used to incorporate integral observations into the Gaussian process framework. Essentially, quadrature can be derived through an infinite summation and the above relationship between these summations can be exploited [
34]. An example covariance structure thus looks akin to,
where
is some probability distribution over the domain of
x, on which the Gaussian process is defined and against which the quadrature is performed against.
Reiterating the motivation of this work, given two generative distributions
and
which subpopulations
A and
B of the data are generated from, we wish to constrain the inferred function
such that,
This constraint can be rewritten as,
which allows us to incorporate the constraint on
as an observation in the above Gaussian process. Let
be the difference between the generative probability distributions of
A and
B; then, by setting the corresponding observation as zero, the covariance matrix becomes,
We refer to these as equality constrained Gaussian processes. Let us now turn to incorporate these concepts into decision tree regression.
4. Trees as Kernel Regression
Decision tree regression (DTR) and related approaches offer a white box approach for practitioners who wish to use them. These methods are among the most popular methods in machine learning [
6] in practice as they are generally intuitive even for those not from statistics, mathematics or computer science background. It is their proliferation, especially in businesses without machine learning researchers, that makes them of particular interest.
DTR regress data by sorting them down binary trees based partitions in the input domain. The trees are created by recursively partitioning the domain of input along axis aligned splits determined by a given metric of the data in each partition, such as information gain or variance reduction. In this work, we do not consider the many possible techniques for learning decision trees, but rather assume that the practitioner has a trained decision tree model. For a more complete description of decision trees, the authors refer the readers to [
35].
For the purposes of this work, DTR can be described as a partitioning of space such that predictions are made by averaging the observations in the local partition, referred to as the leaves of the tree. As such, DTR has a very natural formulation as a degenerate kernel whereby,
where
is the index of the leaf in which the argument belongs. The kernel hence becomes naturally block diagonal and the classifier/regressor written as,
with
denoting the vector of kernel values between
and the observations,
denoting the covariance matrix of the observations as defined by the implicit decision tree kernel and y denoting the values of the observations.
It is also worth noting how one can also write the decision tree as a two-stage model: first by averaging the observations of associated with each leaf and then by using a diagonal kernel matrix to perform inference. Trivially, the diagonal kernel matrix acts only as a lookup and outputs the leaf average that corresponds to the point being predicted. Let us refer to this compressed kernel matrix approach as the compressed kernel representation and the block diagonal variant as the explicit kernel representation.
5. Fairness Constrained Decision Trees
Borrowing concepts from the previous section on equality constrained Gaussian processes using Bayesian quadrature, decision trees may be constrained in a similar fashion. The first consideration to note is that we wish the constraint observation to act as a hard equality, i.e., noiseless. In contrast, we are willing for the observations to be perturbed in order to satisfy this hard equality constraint. To achieve this, let us add a constant noise term, , to the diagonals of the decision tree kernel matrix. Similar to ordinary least squares regression, the regressor now minimises the L2-norm of the error induced on the observations, conditioned on the equality constraint, which is noise free. In the explicit kernel representation, this implies the minimum induced noise per observation, whereas in compressed kernel representation this implies the minimum induced noise per leaf.
An important note is that the constraint is applied to the kernel regressor equations, hence the method is exact for regression trees or when the practitioner is concerned with relative outcomes of various predictions. However, in the case that the observations range within , as is the case in classification, then we must renormalise the output to . This no longer guarantees a minimum L2-norm perturbation and while potentially still useful, is not the focus of this work.
The second consideration is how to determine the generative probability distributions
and
. Given the frequentist nature of decision trees, it makes sense to consider
and
as the empirical distributions of subpopulations
A and
B, as described in
Section 1. Thus, the integral of the empirical distribution on a given leaf,
, is defined as the proportion of population
A observed in the partition associated with leaf
. We emphasise that how
and
are determined is not the core focus of this work and many approaches have merit. For example, a Gaussian mixture model could be used to model the input distribution, in which case
would equal the cumulative distribution of the generative PDF over the bounds defined by the leaf. This is demonstrated in the Experimental Section. Many other such models would also be valid and determining which method to use to model the generative distribution is left to the practitioner with domain expertise.
6. Efficient Algorithm For Equality Constrained Decision Trees
At this point, an equality constrained variant of a decision tree has been described, in both explicit representation and compressed representation. In this section, we show that equality constraints on a decision tree do not change the computational or memory order of complexity. The motivation for considering the order of complexities is that decision trees are one of the more scalable machine learning models, whereas kernel methods such as Gaussian processes naively scale at in computation and in memory, where n is the number of observations. While the approach presented in this work utilises concepts from Bayesian quadrature and linearly constrained Gaussian processes, the model’s usefulness would be drastically hindered if it no longer maintained the performance characteristics of the classic decision tree, namely computational cost, and memory requirements.
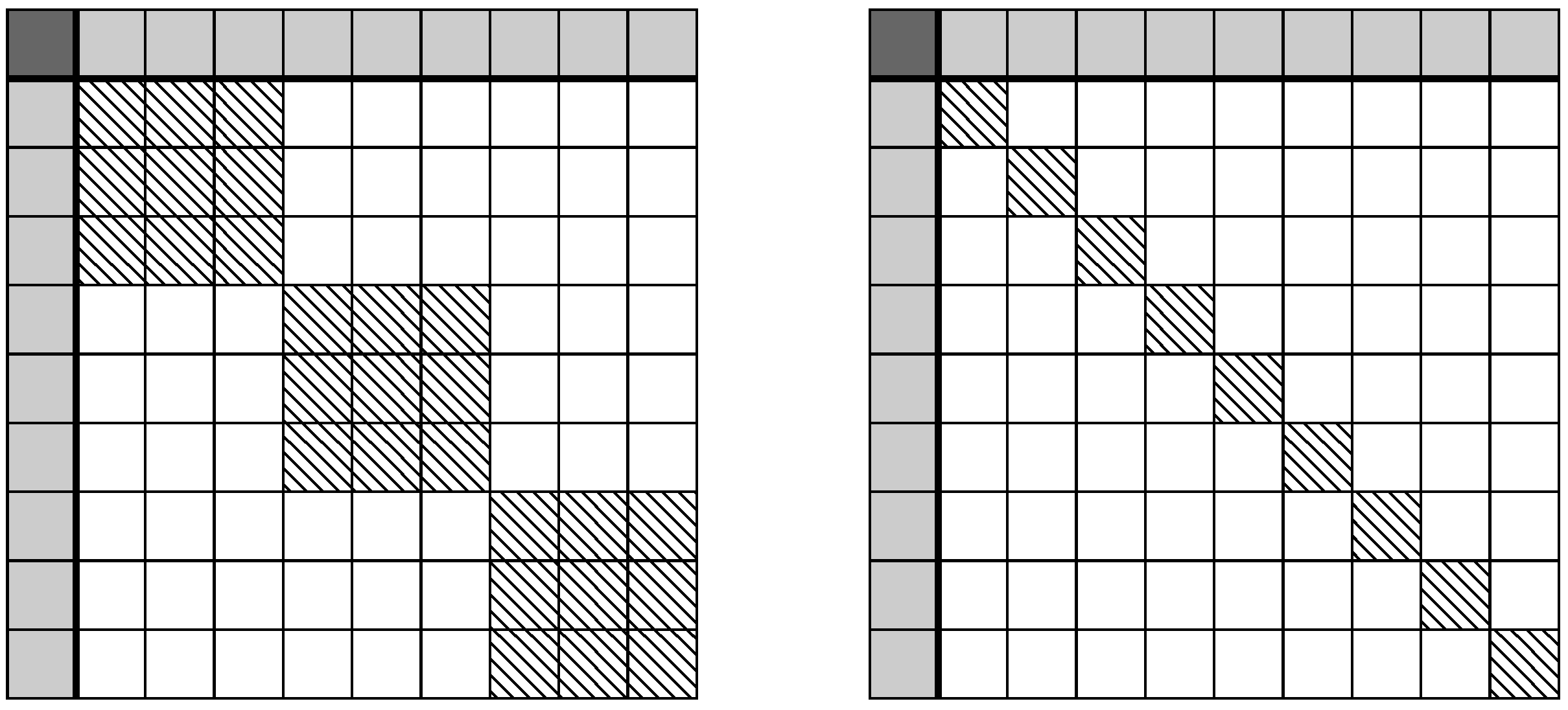
6.1. Efficiently Constrained Decision Trees in Compressed Kernel Representation
As
Figure 1 shows, the compressed kernel representation of the constrained decision tree creates an arrowhead matrix. It is well known that the inverse of an arrowhead matrix is a diagonal matrix with a rank-1 update. Letting
D represent the diagonal principal sub-matrix with diagonal elements equal to one,
z being vector such that the
ith element is equal to the relative difference in generative populations distributions for leaf
i,
, then the arrowhead inversion properties state that,
with
and
. Note that the integral of the difference between the two generative distributions when evaluated over the entire domain is equal to zero, as both
and
must sum to one by definition and hence their differences to zero. Returning to the equation of interest, namely
with y as the average value of each leaf of the tree, and subbing in
as a vector of zeros with a one indexing the
jth leaf in which the predicted point belongs to and is equal to zero, as it does not contribute to the empirical distributions, we arrive at,
The term is the effect of the prior under the Gaussian process perspective; however, by post-multiplying by , this prior effect can be removed. While relatively simple to derive, the above equation shows that only an additive update to the predictions is required to ensure group fairness in decision trees. Further, if the same relative population is observed for Group A and Group B on a single leaf j, then and no change is applied to the original inferred prediction before the constraint is applied other than the effect of the noise. In fact, the perturbation to a leaf’s expectation grows linearly with the bias in the population of the leaf.
From an efficiency standpoint, only the difference in generative distributions, z, needs to be stored, which is an additional extra memory requirement and the update per leaf can be pre-computed in . These additional memory and computational requirements are negligible compared to cost of the decision tree itself.
6.2. Efficiently Constrained Decision Trees in Explicit Kernel Representation
Let us now turn our attention to the explicit kernel representation case, where the
D in the previous subsection is replaced with the block diagonal matrix equivalent. First, let us state the
bordering method, a special case of the block diagonal inversion lemma,
with
once again. Substituting this into the kernel regression equation once more, we find,
where
denotes a vector of zeros with ones placed in all elements relating to observations in the same leaf. Expanding the above linear algebra,
As D is a block-diagonal matrix, it is straight forward to show
where
j is iterating over the set of leaves. Note that, when
for all
j, we arrive at the same value for
as we did in the previous subsection. We can continue to apply this result to the other terms of interest,
where
is once again the average output observation over leaf
j. The terms have been labelled
,
and
for shorthand. The computation time for the three terms, along with
, can be computed in linear time with respect to the size of the data,
, and can be pre-computed ahead of time, hence not affect the computational complexity of a standard decision tree. Once again, only
and
have to be stored for each leaf and hence the additional memory cost is only
. As such, we can simplify the full expression for the expected outcome as,
6.3. Expected Perturbation Bounds
In imposing equality constraints on the models, the inferred outputs become perturbed. In this section, the expected magnitude of the perturbation is analysed for the compressed kernel representation. We define the perturbation due to the equality constraint, not due to the incorporation of the noise, as,
Theorem 1. Given a decision tree with L leaves, with expected value of leaf observations denoted by the vector normalised to have zero mean and unit variance and leaf frequency imbalance denoted as , the expected variance induced by the perturbation due to the incorporating a Group Fairness in Expectation constraint is bounded by, Proof. As the expectation of
is zero due to it being the difference of two probability distributions, the variance is equal to the expectation of
,
with
equal to
z after normalisation. By Lemma 1, the expectation of the dot product
is equal to
. Further, the 2-norm of
z can be cancelled from the numerator and denominator. Finally, using the
norm inequality,
, we can then tightly bound the worst case introduced variance as,
□
Lemma 1. Given two vectors uniformly distributed on the unit hypersphere , the expectation of their dot product is zero and variance, Proof. As the inner product is rotation invariant when applied to both
and
y, let us denote the vector
as
without loss of generality. The first element of the vector
y, denoted by
, is thus equal to
. The probability density mass of the random variable
is proportional to the surface area lying at a height between
and
on the unit hypersphere. That proportion occurs within a belt of height
and radius
, which is a conical frustum constructed out of an
of radius
, of height
, and slope
. Hence, the probability is proportional to,
Substituting
. we find that,
Note that this last simplification of
is equal to the probability density function of the Beta distribution with both shape parameters equal
. The variance of the Beta distribution is,
Rescaling to find the variance of , we arrive at . As the expectation of due to the properties of symmetry, .
This is an interesting result as it implies that, if the model is not exploiting biases in the generative distribution evenly across all of the leaves of the tree, i.e., , then the resulting predictions receive the greatest expected absolute perturbation when averaged over all possible y.
For the explicit kernel representation, the expected absolute perturbation bound can be analysed whereby each leaf holds an even number of observations. In such a scenario,
is equal for all leaves
. Substituting this into the equations for
and
, we can find that the bounded expected perturbation is equal to,
□
For the sake of conciseness, the full derivation of the above is left to the reader but follows the same steps as the compressed kernel representation.
7. Combinations of Fair Trees
While it is intuitive to say that ensembles of trees with GFE constraints preserve the GFE constraint, for the sake of completeness, this is now shown more formally. Random forests [
36], extremely random trees (ExtraTrees) [
37] and tree bagging models [
38] combine tree models by averaging over their predictions. Denoting the predictions of the trees at point
x as
for each
, where
T is the number of trees, we can easily show that the combined difference in expectation marginalised over the space is equal to zero,
It can also be easily shown that modelling residual errors of the trees with other fair trees, such as is the case for boosted tree models [
39], also results in fair predictors. These concepts are not limited to tree methods either and the core concepts set out in this paper of constraining kernel matrices can have applications in models such as deep Gaussian process models [
40].
8. Experiments
8.1. Synthetic Demonstration
The first experiment was a visual demonstration to better communicate the validity of the approach. The models examined are ExtraTrees, Gaussian processes and a single hidden layer perceptron. They endeavour to model an analytic function,
, with observations drawn from two beta distributions,
and
, respectively. The parameters of the two beta distribution are presented in
Table 2.
Figure 2 shows the effect of perturbing the models using the approach presented to constrain the expected means of the two populations. The figure shows the greater is the disparity between
and
, the greater is the perturbation in the inferred function. Both the compressed and explicit kernel representation lead to very similar plots for the tree-based models, thus only the compressed kernel representation algorithm has been shown for conciseness. Note, in the case of the ExtraTrees model, each tree was individually perturbed before being combined. Further, in the case of the perceptron, a GMM was fit to the data in the inferred latent space rather than in the original input space.
A downside to group fairness algorithms more generally, as pointed out in [
7], is that candidate systems which impose group fairness can lead to qualified candidates being discriminated against. This can be visually verified as the perturbation pushes down the outcome of many orange points below the total population mean in order to satisfy the constraint. By choosing to incorporate group fairness constraints, the practitioner should be aware of these tradeoffs.
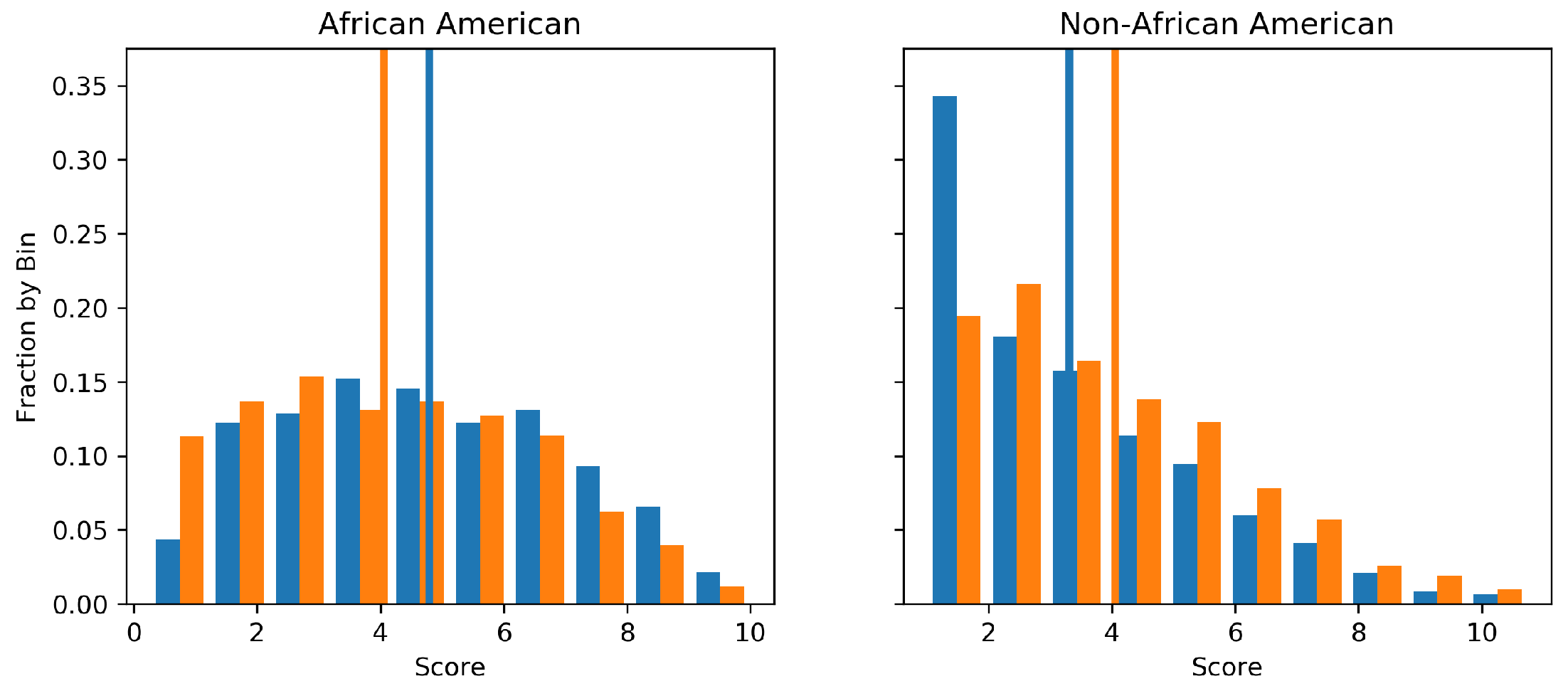
8.2. ProPublica Dataset—Racial Biases
Across the USA, judges, and probation and parole officers are increasingly using algorithms to aid in their decision making. The ProPublica dataset (
https://www.propublica.org/datastore/dataset/compas-recidivism-risk-score-data-and-analysis) contains data about criminal defendants from Florida in the United States. It is the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) algorithm [
41], which is often used by judges to estimate the probability that a defendant will be a recidivist, a term used to describe re-offenders. However, the algorithm is said to be racially biased against African Americans [
42]. To highlight the proposed algorithm, we first endeavoured to use a random forest to approximate the decile scoring of the COMPAS algorithm and then perturbed each tree to remove any racial bias from the system.
The two subpopulations we considered constraining are thus African American and non-African American. We encode the COMPAS algorithms decile score into an integer between zero and ten such that minimising perturbation is an appropriate objective function. The fact the decile scores are bounded in was not taken into account. The random forest used 20 decision trees as base estimators and the explicit kernel representation version of the algorithm was used for the sake of demonstrative purposes.
Figure 3 presents the marginal distribution of predictions on a 20% held out test set before and after the GFE constraint was applied. It is visible that both the expected outcome for African Americans is decreased and for non-African Americans is increased. Notice that, while the means are equal, the structure of the two of distributions are quite different, indicating that GFE constraints still allow greater flexibility than more strict group fairness such as that described in
Section 1. The root square difference between the predicted points before and after perturbation was 0.8. Importantly, the GFE constraint described in this work was verified numerically with the average outputs recorded as shown in
Table 3.
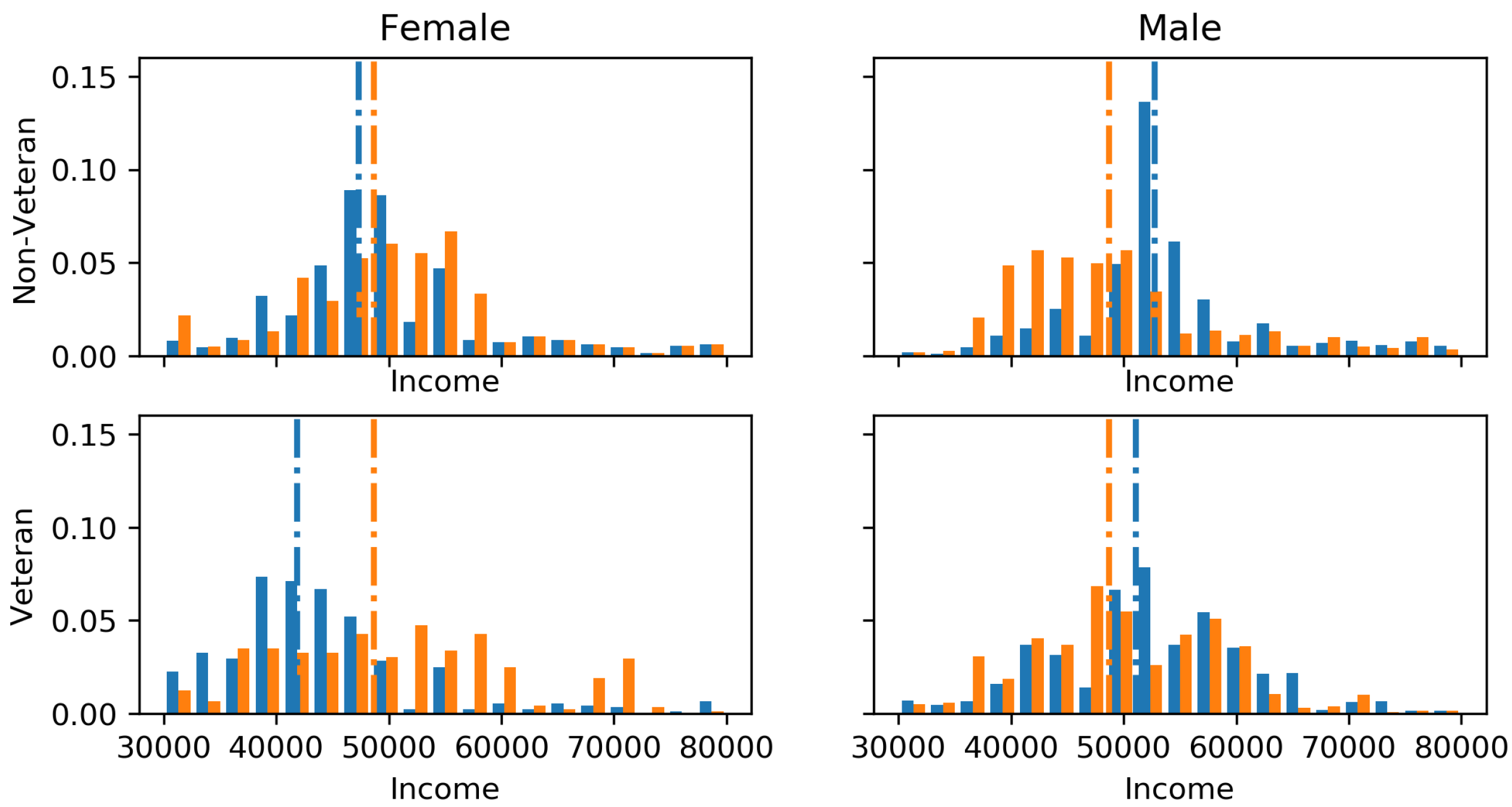
8.3. Intersectionality: Illinois State Employee Salaries
The Illinois state employee salaries (
https://data.illinois.gov/datastore/dump/1a0cd05c-7d17-4e3d-938d-c2bfa2a4a0b1) since 2011 can be seen to have a gender bias and bias between veterans and non-veterans. The motivation of this experiment was to show how we can deal with intersectionality issues (multiple compounding constraints) such as if one wished to predict a fair salary for future employees based on current staff. Gender labels were inferred using the employees’ first names, parsed through the gender-geusser Python library. GFE constraints were applied between all intersections of gender and veteran/non-veterans, the marginals of gender and the marginals of veteran/non-veterans.
Figure 4 visualises the perturbations to the marginals of each demographic intersection due to the GFE constraints. The train–test split was set as 80–20% and the incorporation of the GFE constraints increase the root mean squared error from
$12,086 to
$12,772, the cost of fairness. The only difference to allow for intersectionality is the
z is no longer a vector, but rather a matrix with a column for each constraint. Thus,
9. Conclusions
This work offers an easily implementable approach to constrain the means of kernel regression, which has direct applicability to decision tree regression, Gaussian process regression, neural network regression, random forest regression, boosted trees and other tree-based ensemble models.
References







{kind=link}
{kind=link}
{kind=link}
{kind=link}