Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning †



Abstract
:1. Introduction
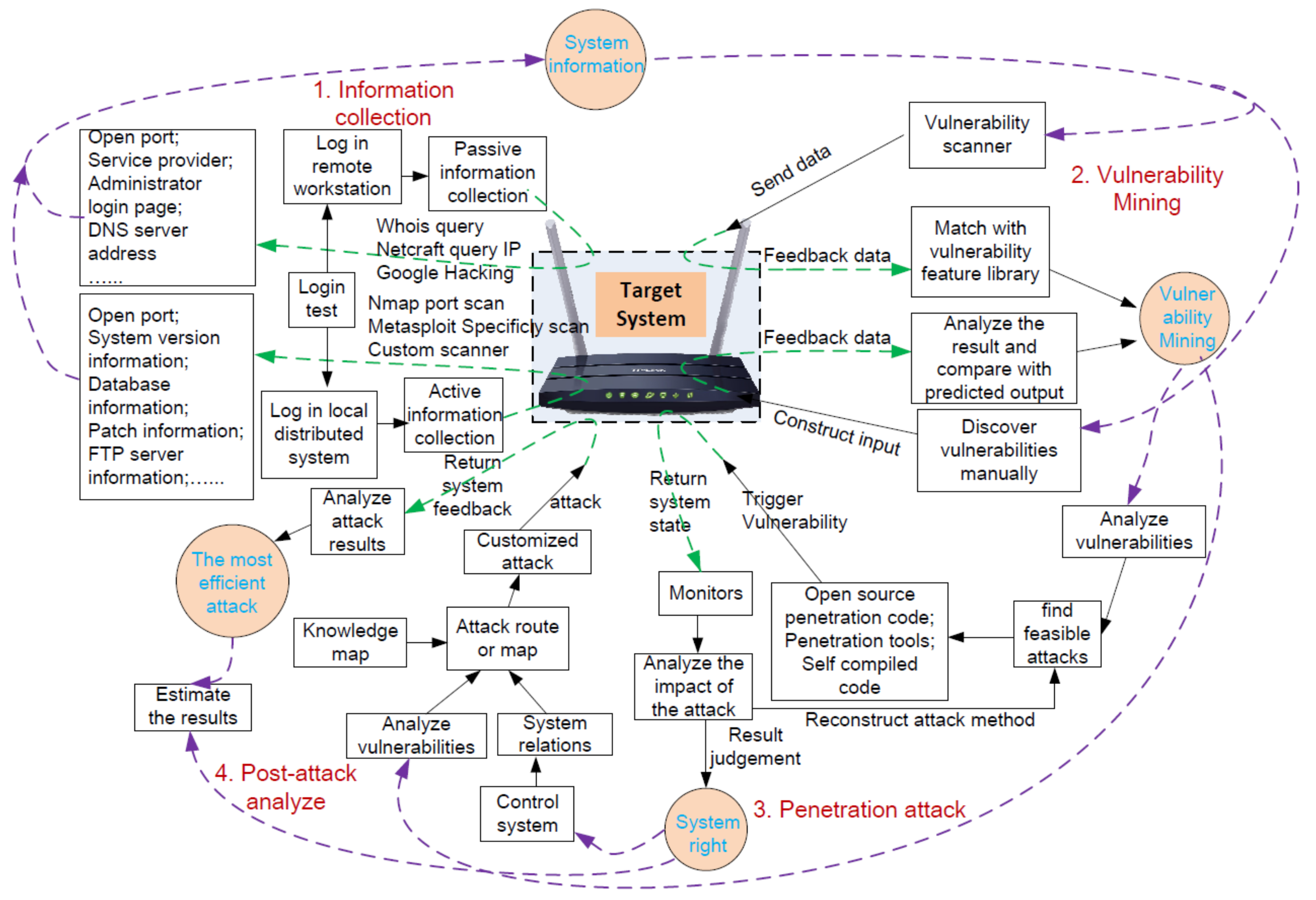
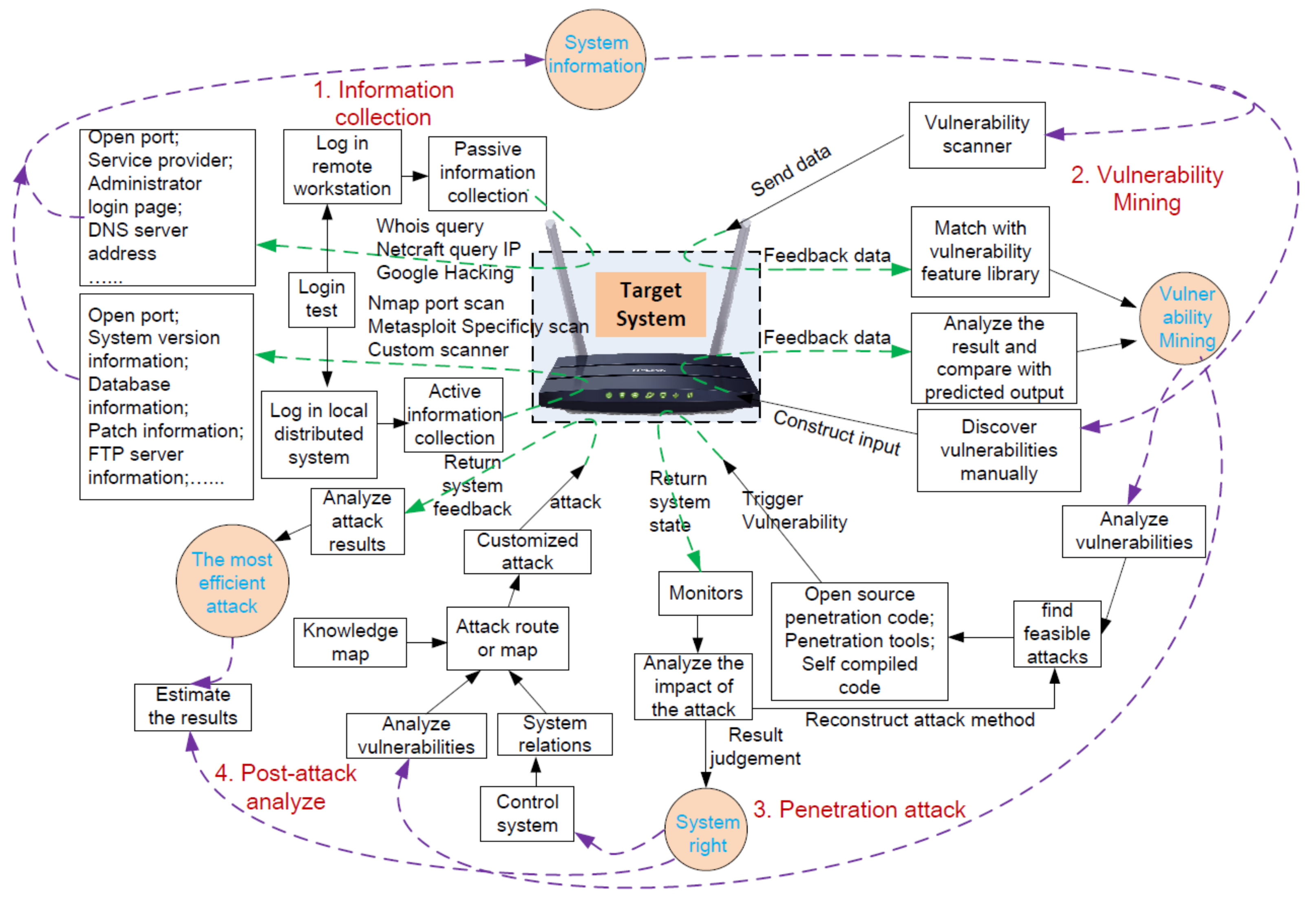
2. Related Work
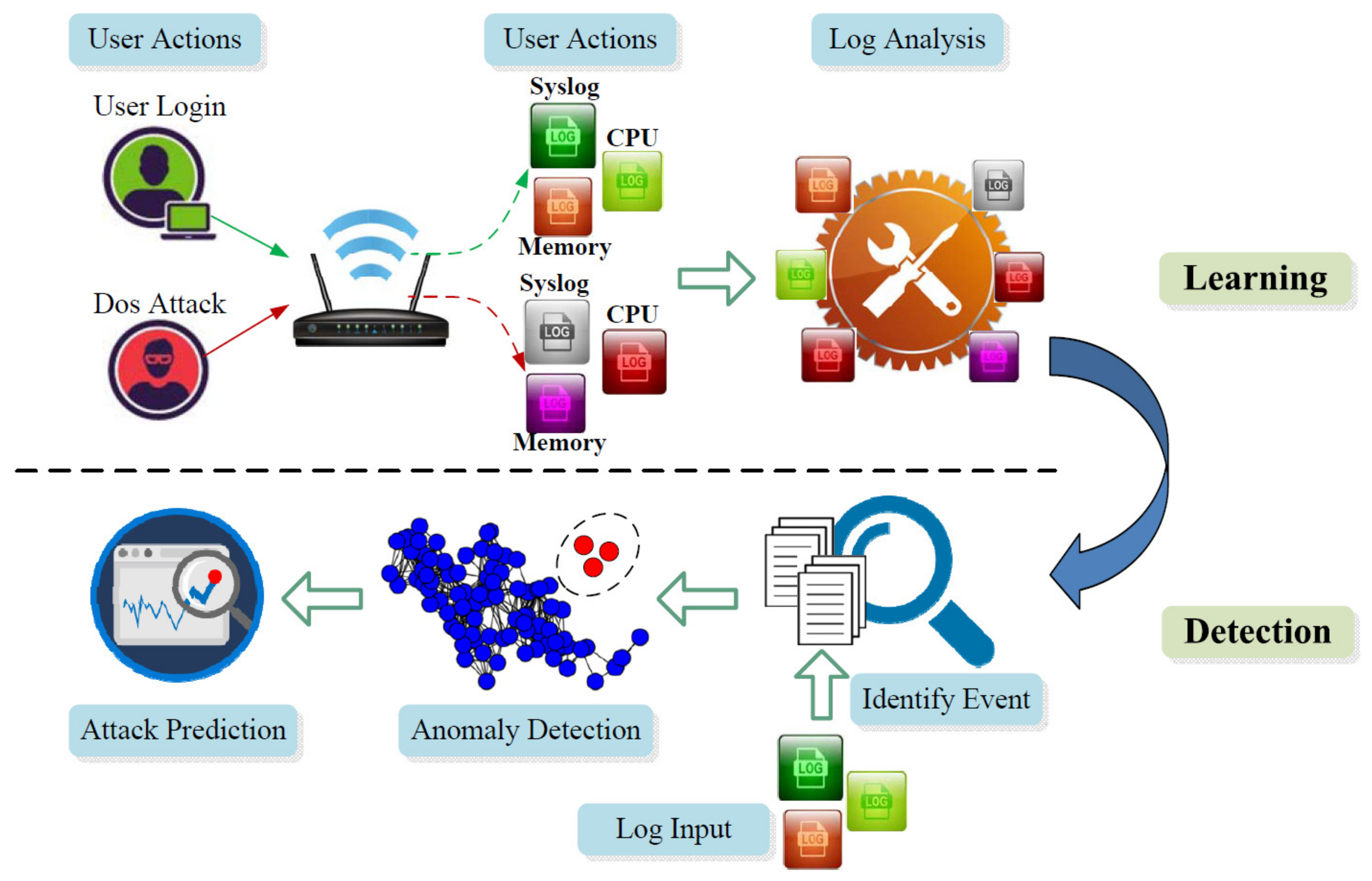
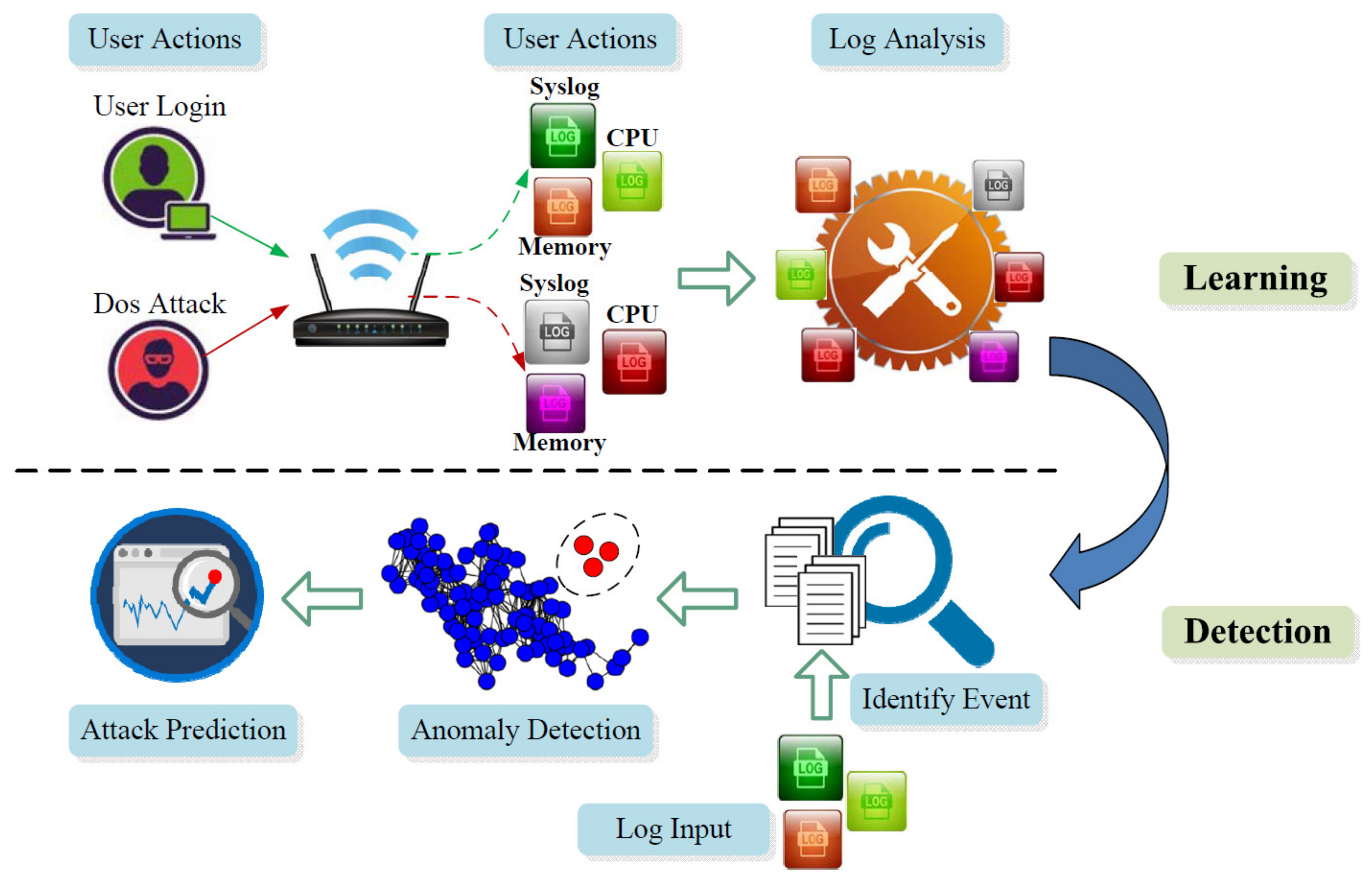
3. Overview and Roadmap
3.1. Offline Learning (Events → Logs)
3.2. Anomaly Detection (Logs → Events)
3.3. Anomaly Prediction (Logs → Events → Attack Chain)
4. Methodology
4.1. Data Preprocessing
4.2. Feature Vectorization
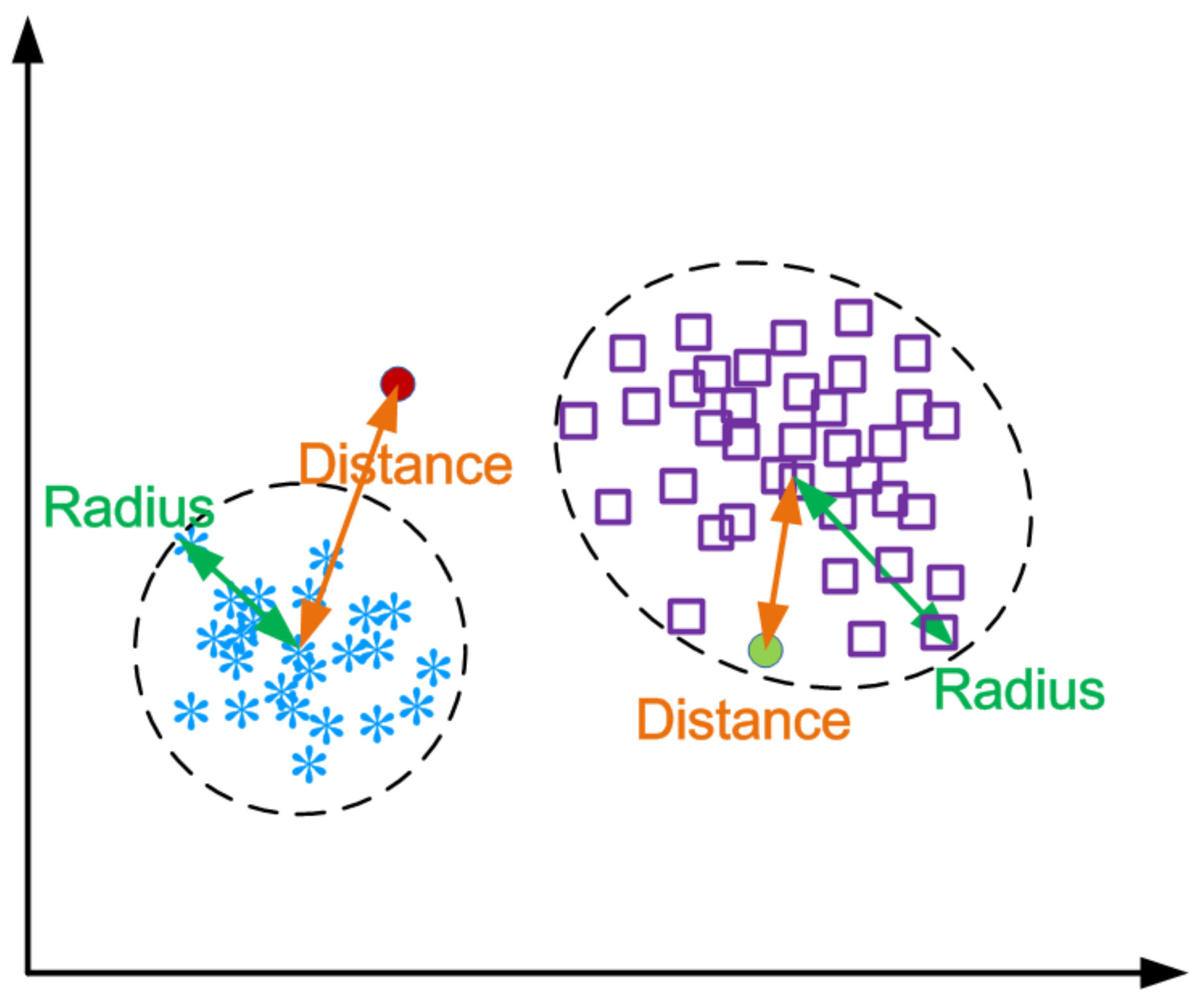
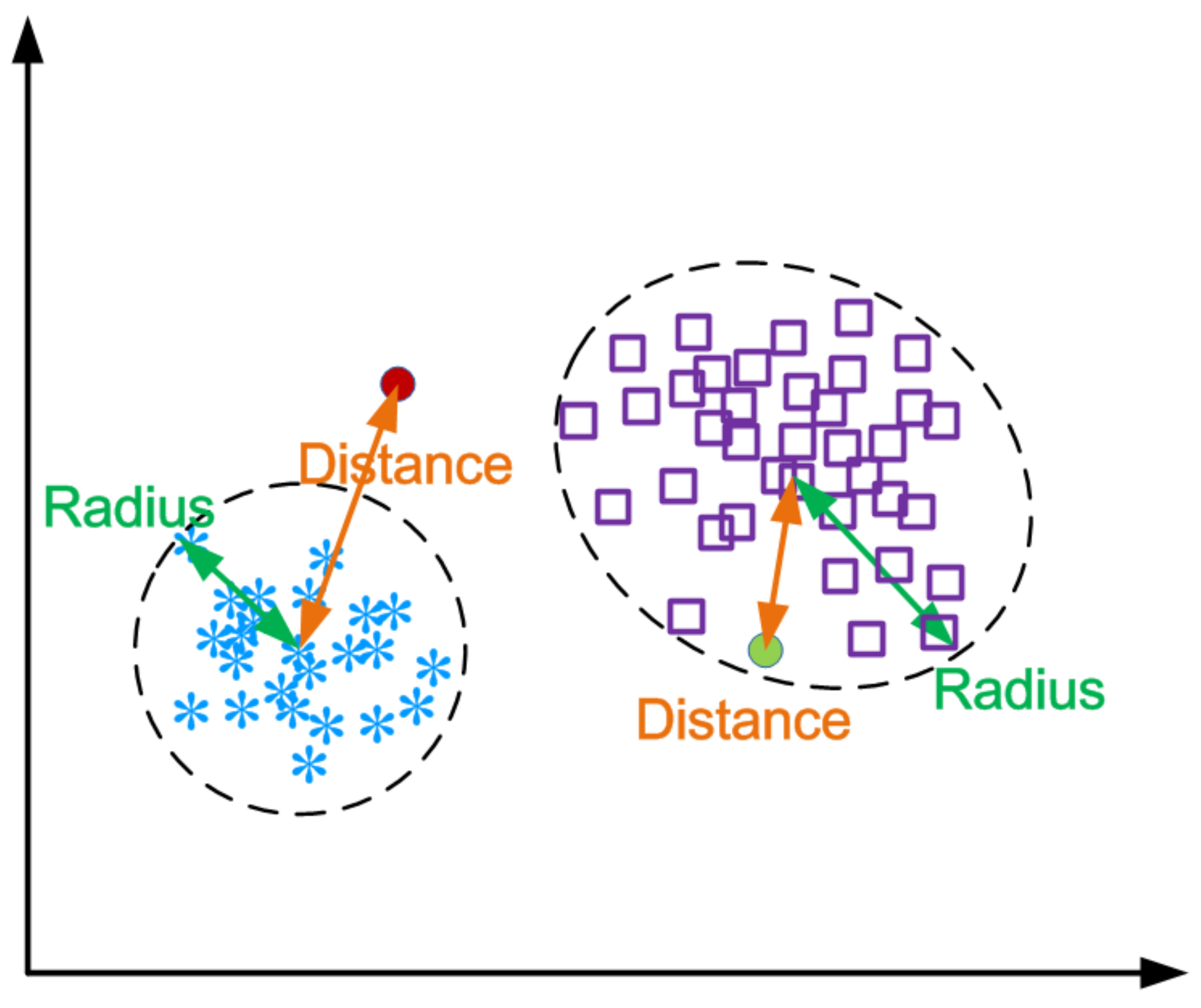
4.3. Clustering
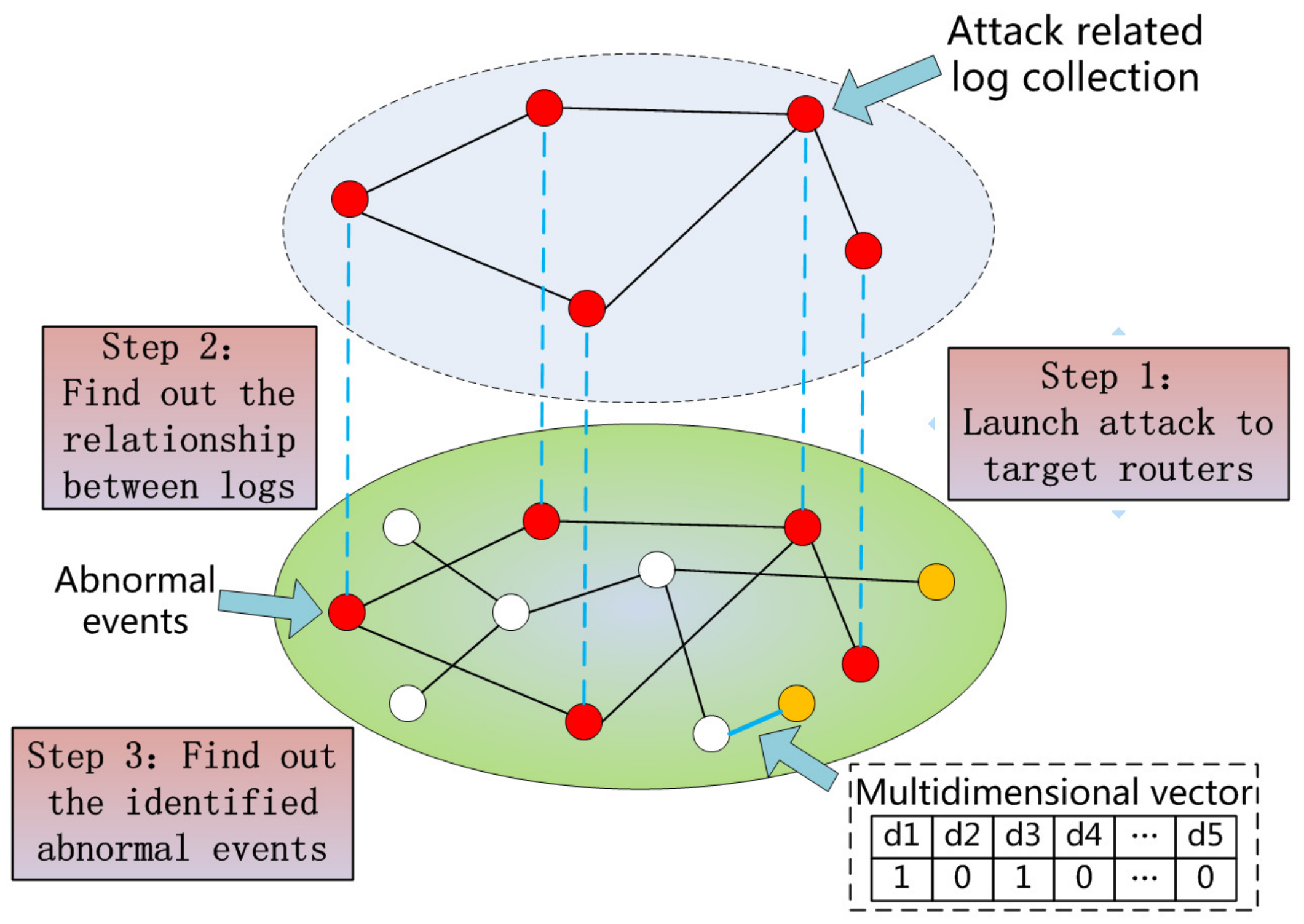
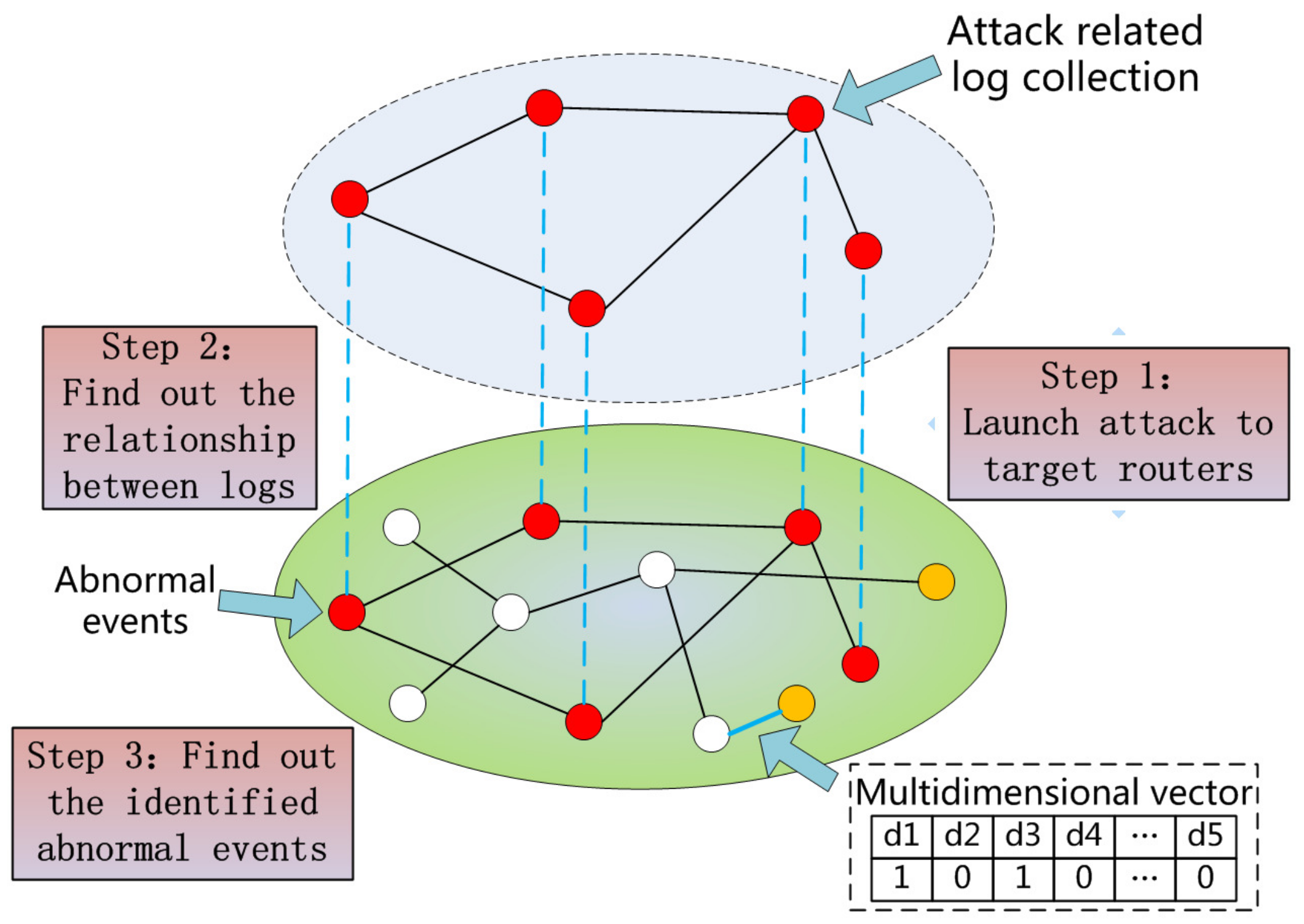
4.4. Anomaly Detection
4.5. Attack Prediction
| Algorithm 1 LCS cluster tree building algorithm. |
|
5. Evaluation
5.1. Experiment Setup
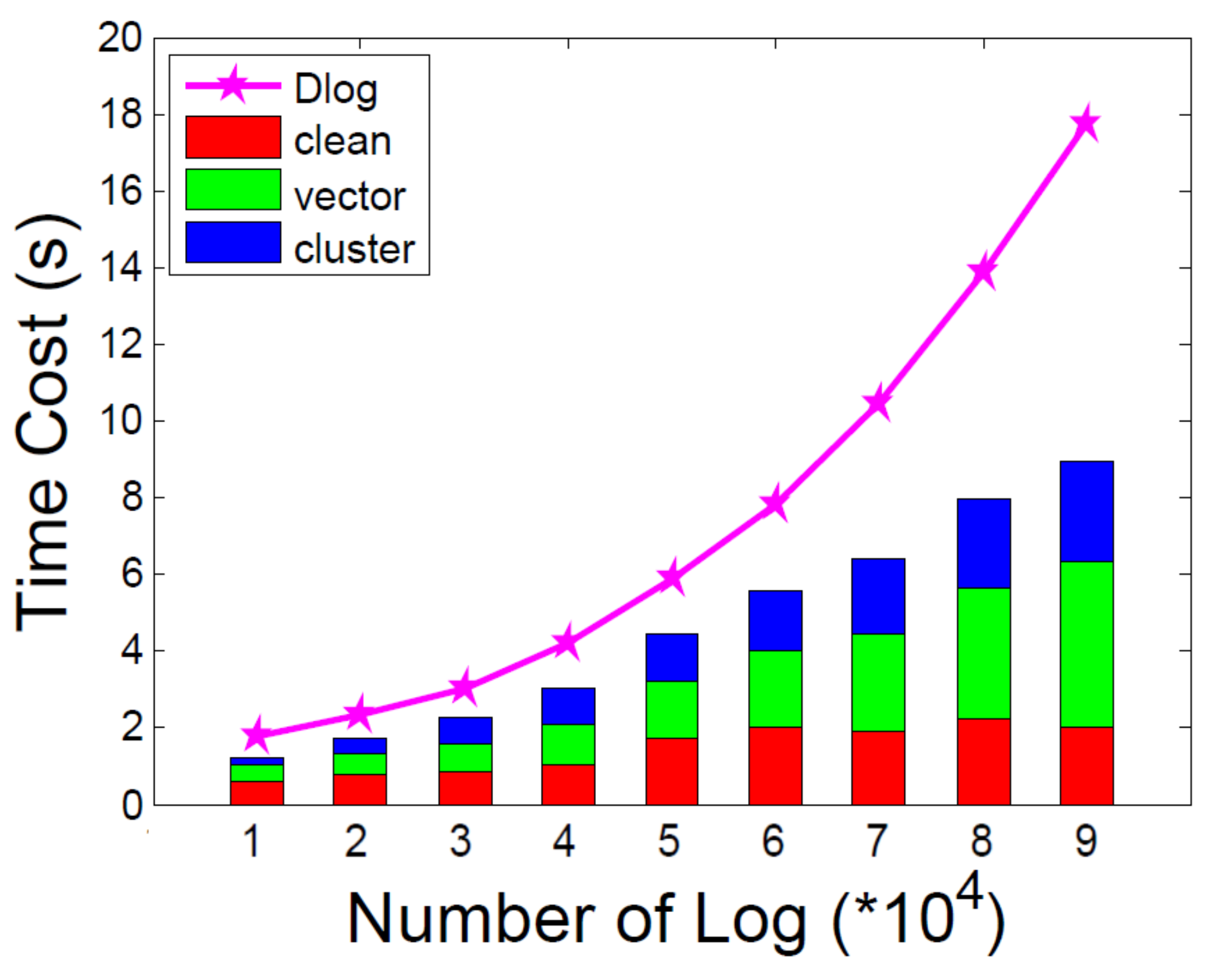
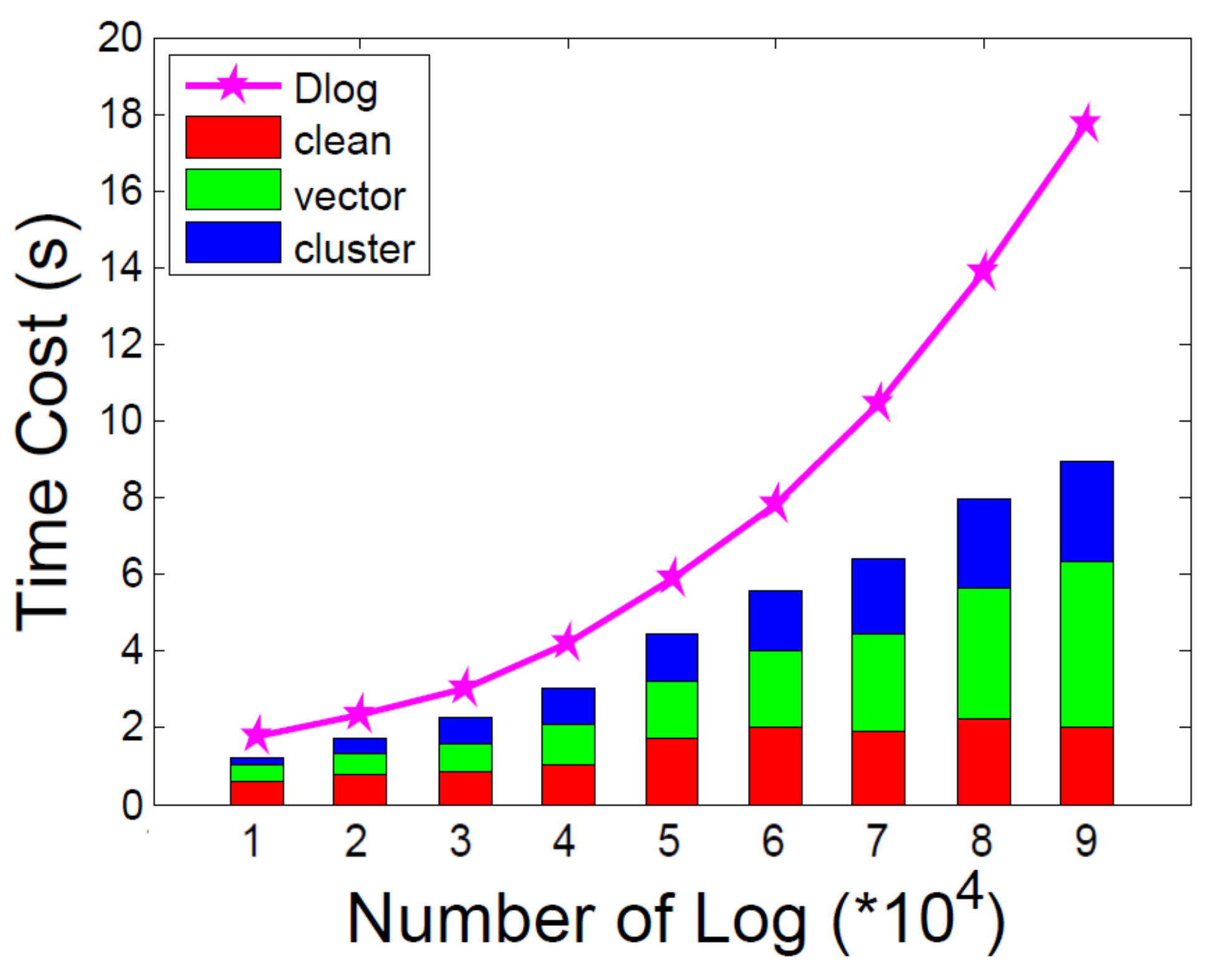
5.2. Performance of Multiple Information Learning
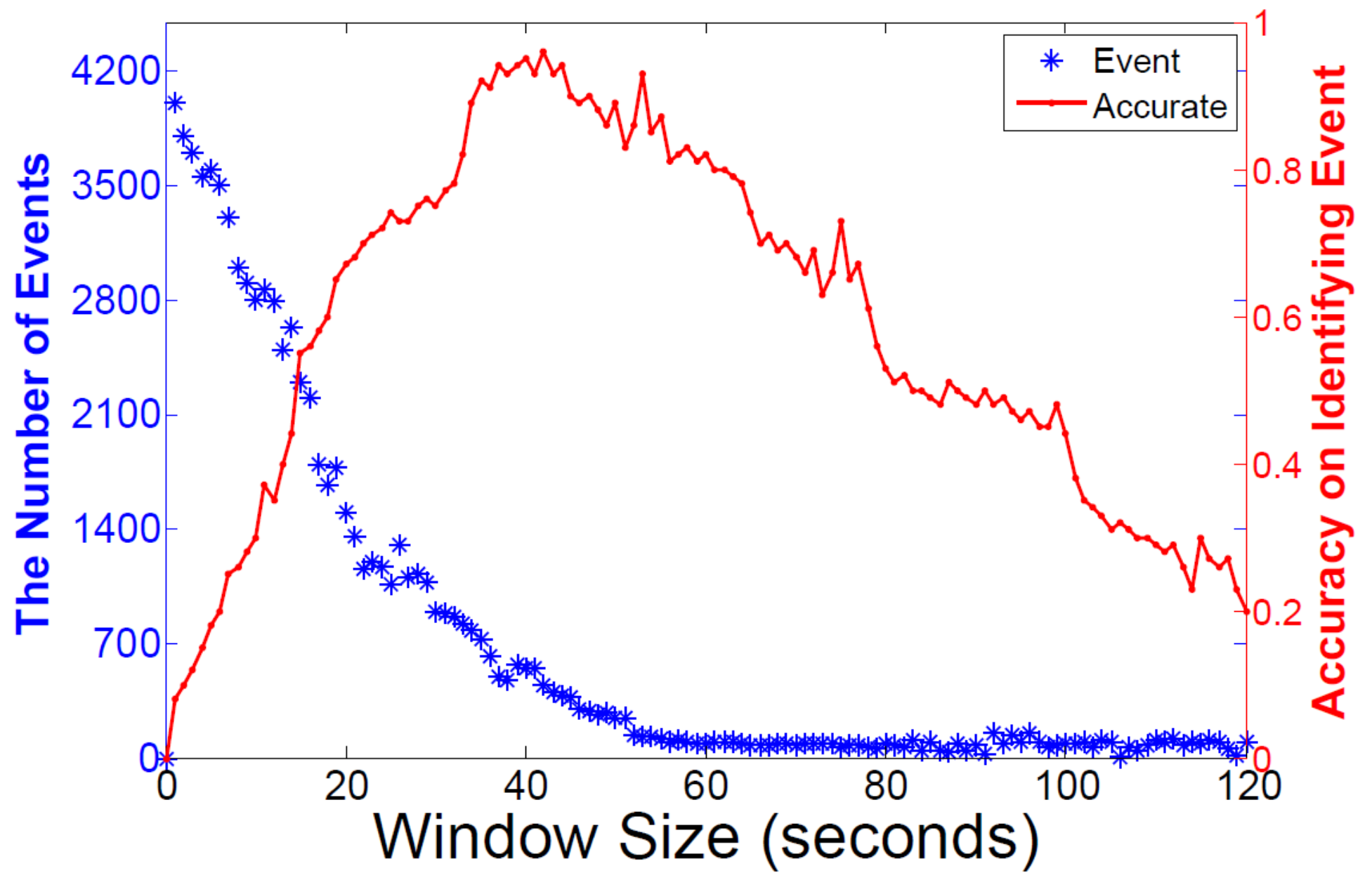
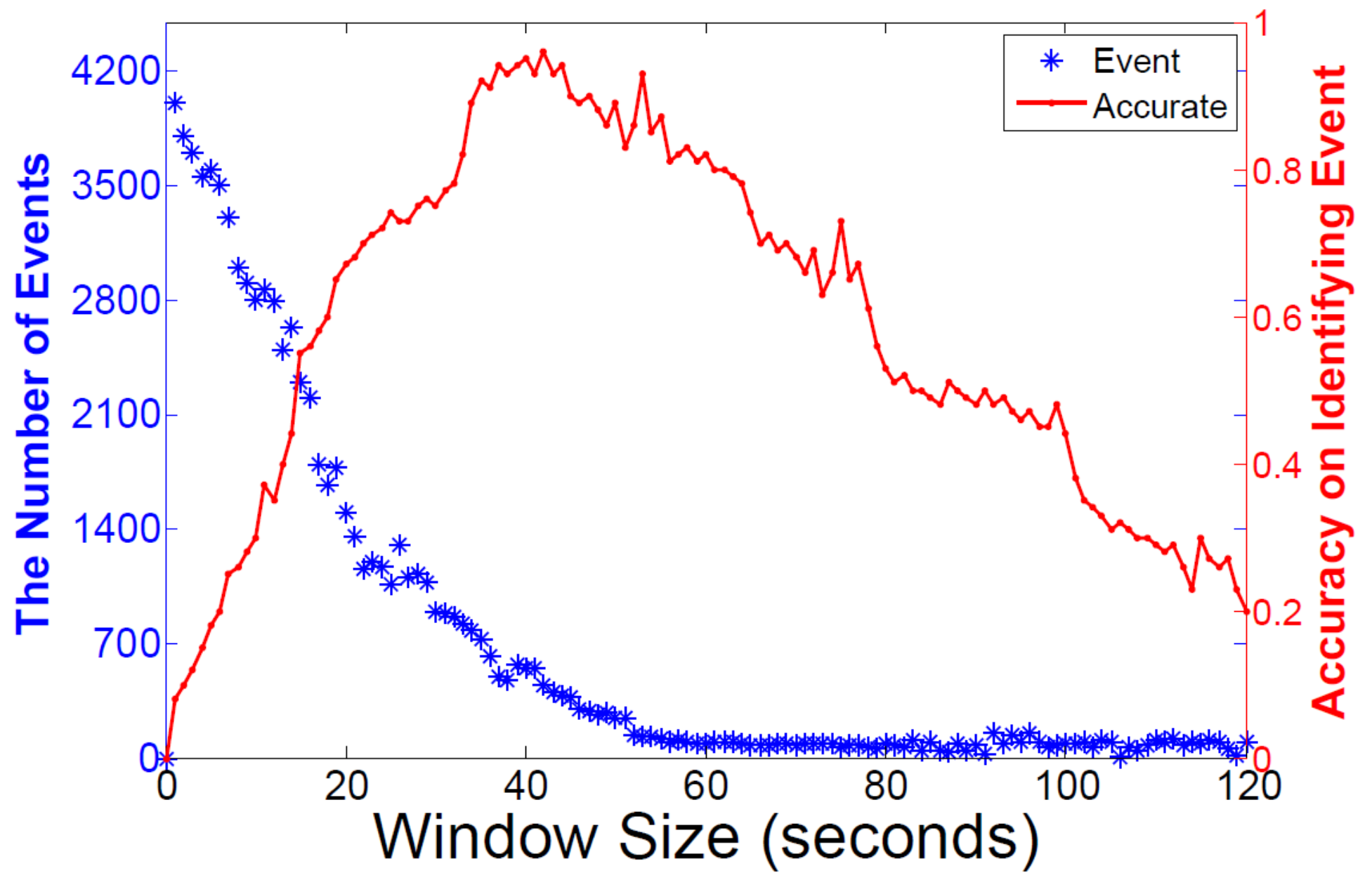
5.3. Time Window Setting
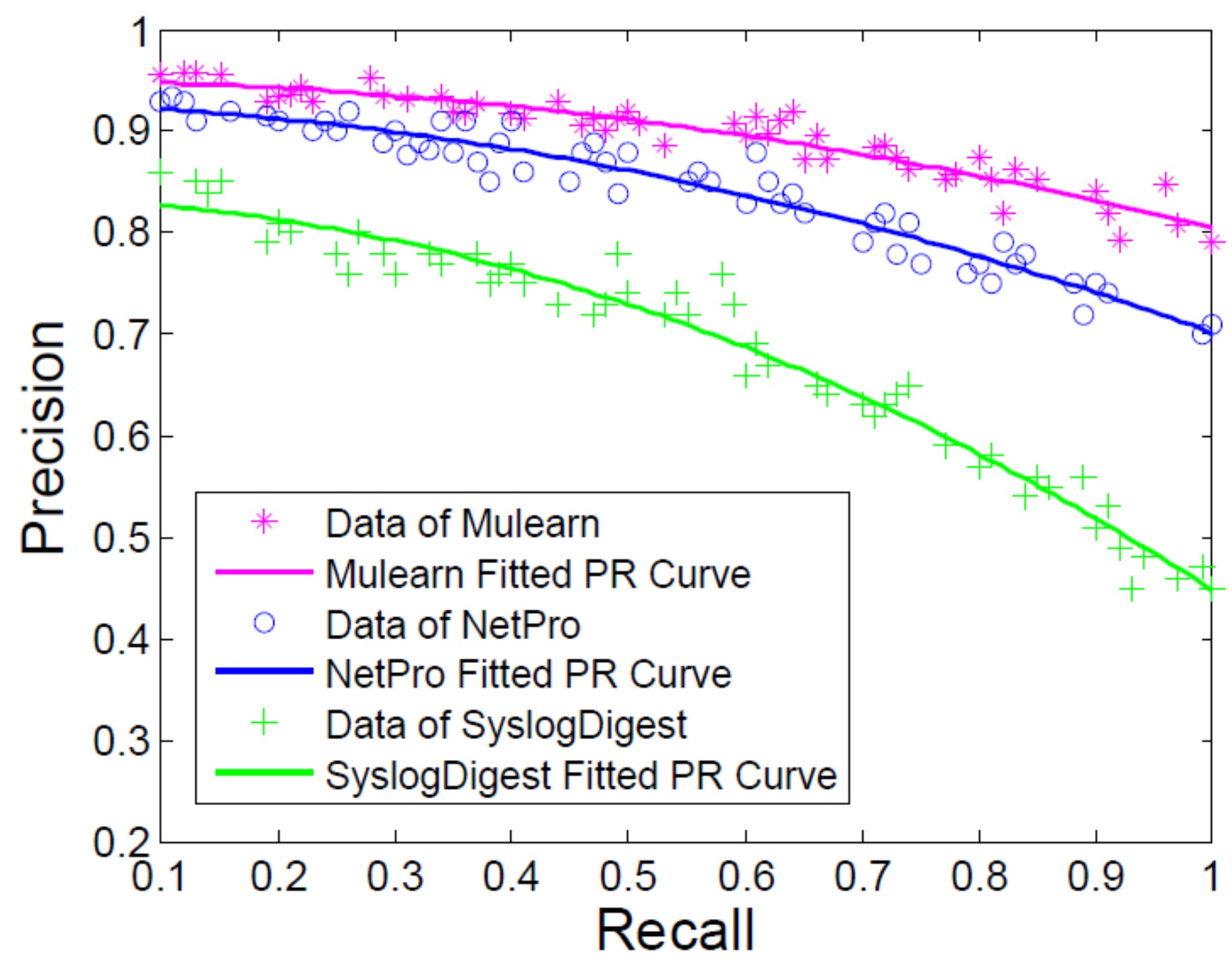
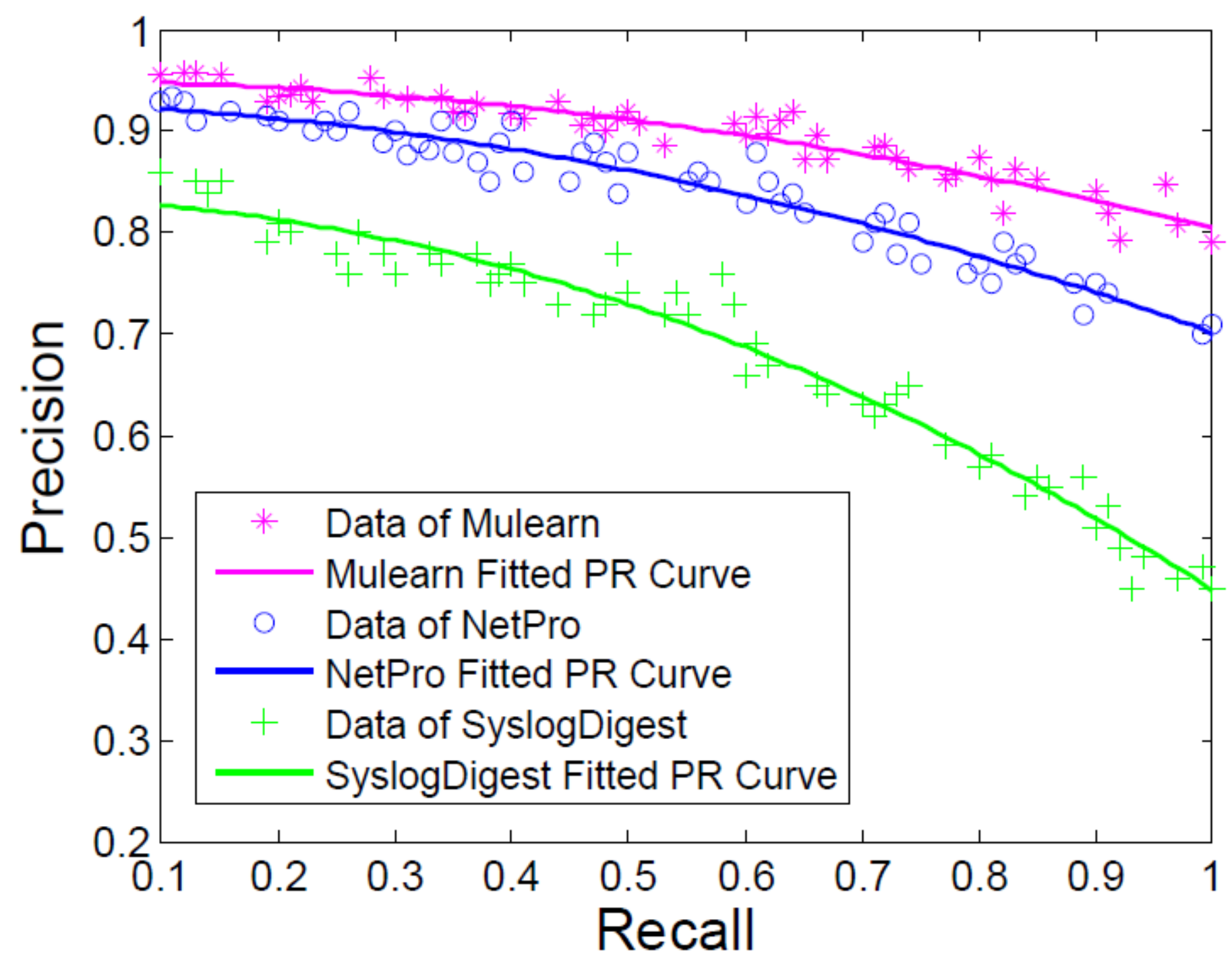
5.4. Anomaly Detection Accuracy
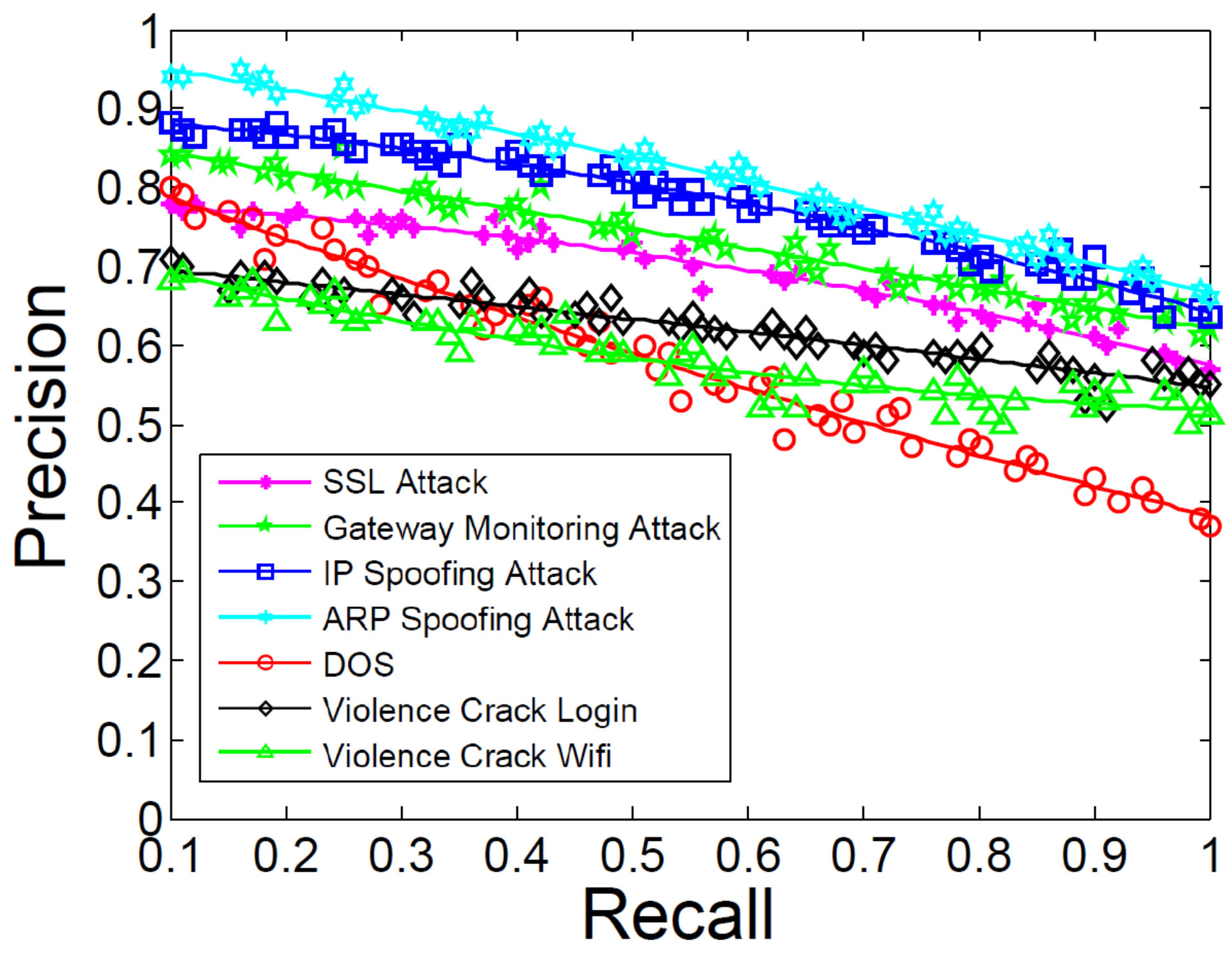
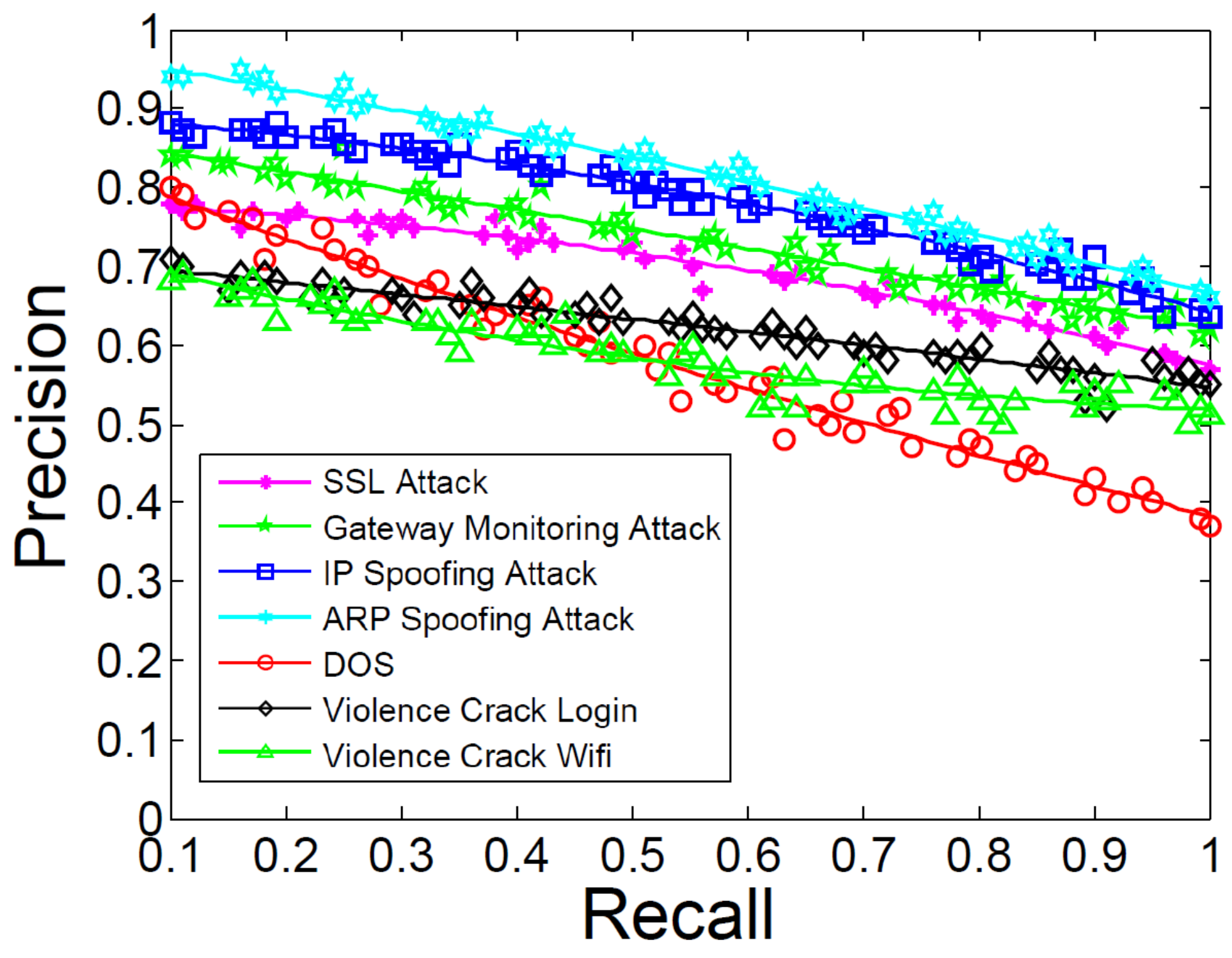
5.5. Attack Prediction Performance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Labovitz, C.; Iekel-Johnson, S.; McPherson, D.; Oberheide, J.; Jahanian, F. Internet inter-domain traffic. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 75–86. [Google Scholar] [CrossRef]
- Lee, Y.; Kang, W.; Son, H. An internet traffic analysis method with mapreduce. In Proceedings of the Network Operations and Management Symposium Workshops (NOMS Wksps), Osaka, Japan, 19–23 April 2010; pp. 357–361. [Google Scholar]
- Xu, W.; Huang, L.; Fox, A.; Patterson, D.; Jordan, M.I. Detecting large-scale system problems by mining console logs. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, Big Sky, MT, USA, 11–14 October 2009; pp. 117–132. [Google Scholar]
- Zhao, X.; Zhang, Y.; Lion, D.; Ullah, M.F.; Luo, Y.; Yuan, D.; Stumm, M. lprof: A Non-intrusive Request Flow Profiler for Distributed Systems. In Proceedings of the 11th USENIX Symposium on Operating System Implementation and Design 2014, Bloomfield, CO, USA, 6–8 October 2014; Volume 14, pp. 629–644. [Google Scholar]
- Lin, Z.; Jiang, X.; Xu, D.; Zhang, X. Automatic Protocol Format Reverse Engineering through Context-Aware Monitored Execution. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2008, San Diego, CA, USA, 10–13 February 2008; Volume 8, pp. 1–15. [Google Scholar]
- Wondracek, G.; Comparetti, P.M.; Kruegel, C.; Kirda, E.; Anna, S.S.S. Automatic Network Protocol Analysis. In Proceedings of the 15th Annual Network and Distributed System Security Symposium 2008, San Diego, CA, USA, 15–18 February 2008; Volume 8, pp. 1–14. [Google Scholar]
- Li, T.; Ma, J.; Sun, C. Dlog: Diagnosing router events with syslogs for anomaly detection. J. Supercomput. 2018, 74, 845–867. [Google Scholar] [CrossRef]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar]
- Dusi, M.; Gringoli, F.; Salgarelli, L. Quantifying the accuracy of the ground truth associated with Internet traffic traces. Comput. Netw. 2011, 55, 1158–1167. [Google Scholar] [CrossRef]
- Balzarotti, D.; Cova, M.; Karlberger, C.; Kirda, E.; Kruegel, C.; Vigna, G. Efficient Detection of Split Personalities in Malware. In Proceedings of the 17th Annual Network and Distributed System Security Symposium, San Diego, CA, USA, 28 February–3 March 2010. [Google Scholar]
- Beschastnikh, I.; Brun, Y.; Ernst, M.D.; Krishnamurthy, A. Inferring models of concurrent systems from logs of their behavior with CSight. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 468–479. [Google Scholar]
- Hassan, W.U.; Lemay, M.; Aguse, N.; Bates, A.; Moyer, T. Towards Scalable Cluster Auditing through Grammatical Inference over Provenance Graphs. In Proceedings of the Network and Distributed Systems Security Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Qiu, T.; Ge, Z.; Pei, D.; Wang, J.; Xu, J. What happened in my network: Mining network events from router syslogs. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement 2010, Melbourne, Australia, 1–3 November 2010; pp. 472–484. [Google Scholar]
- Yamanishi, K.; Maruyama, Y. Dynamic syslog mining for network failure monitoring. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 499–508. [Google Scholar]
- Kimura, T.; Ishibashi, K.; Mori, T.; Sawada, H.; Toyono, T.; Nishimatsu, K.; Watanabe, A.; Shimoda, A.; Shiomoto, K. Spatio-temporal factorization of log data for understanding network events. In Proceedings of the IEEE INFOCOM 2014—IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 610–618. [Google Scholar]
- Kimura, T.; Watanabe, A.; Toyono, T.; Ishibashi, K. Proactive failure detection learning generation patterns of large-scale network logs. In Proceedings of the 2015 11th International Conference on Network and Service Management (CNSM), Barcelona, Spain, 9–13 November 2015; pp. 8–14. [Google Scholar]
- Pei, K.; Gu, Z.; Saltaformaggio, B.; Ma, S.; Wang, F.; Zhang, Z.; Si, L.; Zhang, X.; Xu, D. Hercule: Attack story reconstruction via community discovery on correlated log graph. In Proceedings of the 2016 Conference on Computer Security Applications, Los Angeles, CA, USA, 5–8 December 2016; pp. 583–595. [Google Scholar]
- Krishnan, S.; Snow, K.Z.; Monrose, F. Trail of bytes: Efficient support for forensic analysis. In Proceedings of the 17th ACM Conference on Computer and Communications Security, CCS 2010, Chicago, IL, USA, 4–8 October 2010; pp. 50–60. [Google Scholar]
- Wu, Y.; Zhao, M.; Haeberlen, A.; Zhou, W.; Loo, B.T. Diagnosing missing events in distributed systems with negative provenance. ACM SIGCOMM Comput. Commun. Rev. 2015, 44, 383–394. [Google Scholar] [CrossRef]
- Lee, K.H.; Zhang, X.; Xu, D. High Accuracy Attack Provenance via Binary-based Execution Partition. In Proceedings of the 20th Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 24–27 February 2013. [Google Scholar]
- Kwon, Y.; Wang, F.; Wang, W.; Lee, K.H.; Lee, W.C.; Ma, S.; Zhang, X.; Xu, D.; Jha, S.; Ciocarlie, G.; et al. Mci: Modeling-based causality inference in audit logging for attack investigation. In Proceedings of the 25th Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Tak, B.C.; Tao, S.; Yang, L.; Zhu, C.; Ruan, Y. LOGAN: Problem diagnosis in the cloud using log-based reference models. In Proceedings of the 2016 IEEE International Conference on Cloud Engineering (IC2E), Berlin, Germany, 4–8 April 2016; pp. 62–67. [Google Scholar]
- Khan, M.N.A.; Ullah, S. A log aggregation forensic analysis framework for cloud computing environments. Comput. Fraud Secur. 2017, 2017, 11–16. [Google Scholar] [CrossRef]
- Fukuda, K. On the use of weighted syslog time series for anomaly detection. In Proceedings of the 2011 IFIP/IEEE International Symposium on Integrated Network Management (IM), Dublin, Ireland, 23–27 May 2011; pp. 393–398. [Google Scholar]
- Tan, T.; Gao, S.; Yang, W.; Song, Y.; Lin, C. Two New Term Weighting Methods for Router Syslogs Anomaly Detection. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications; IEEE 14th International Conference on Smart City; IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, Australia, 12–14 December 2016; pp. 1454–1460. [Google Scholar]
- Chuah, E.; Kuo, S.H.; Hiew, P.; Tjhi, W.C.; Lee, G.; Hammond, J.; Michalewicz, M.T.; Hung, T.; Browne, J.C. Diagnosing the root-causes of failures from cluster log files. In Proceedings of the 2010 International Conference on High Performance Computing, Dona Paula, India, 19–22 December 2010; pp. 1–10. [Google Scholar]
- Abad, C.; Taylor, J.; Sengul, C.; Yurcik, W.; Zhou, Y.; Rowe, K. Log correlation for intrusion detection: A proof of concept. In Proceedings of the 19th Annual Computer Security Applications Conference, Las Vegas, NV, USA, 8–12 December 2003; pp. 255–264. [Google Scholar]
- Dejaeger, K.; Verbeke, W.; Martens, D.; Baesens, B. Data mining techniques for software effort estimation: A comparative study. IEEE Trans. Softw. Eng. 2012, 38, 375–397. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Sánchez, D.L.; Revuelta, J.; De la Prieta, F.; Gil-González, A.B.; Dang, C. Twitter user clustering based on their preferences and the Louvain algorithm. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Seville, Spain, 1–3 June 2016; pp. 349–356. [Google Scholar]
- Li, T.; Ma, J.; Sun, C. NetPro: Detecting attacks in MANET routing with provenance and verification. Sci. China Inf. Sci. 2017, 60, 118101. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brand | Attack Event | Router Type | Time | Number of Influence |
|---|---|---|---|---|
| DLink | DNS Spoofing | DSL-2640B | April 2019 | 15,000 |
| HuaWei | Botnet | HG523a | March 2019 | 18,000 |
| Cisco | Remote Command Execution | RV320, RV325 | January 2019 | 10,000 |
| TP-LINK | Unrestricted remote control | TL-WR940N | February 2019 | 15,000 |
| Netgear | Auth Bypass and Loads of Other Bugs | RT1900ac | February 2018 | 12,000 |
| Action | Firewall | DNS | CPU Utilization | FTP | LAN Status | Auth | Memory |
|---|---|---|---|---|---|---|---|
| Admin Login | x | x | x | ||||
| Wireless Connect | x | x | x | ||||
| Remote Control | x | x | x | x | |||
| DOS Attack | x | x | x | x | |||
| Violence Crack Login | x | x | x | x | |||
| ARP Spoofing | x | x | x | x | x |
| Time | %usr | %sys | %nice | %idle | %io | %hardirq | %softirq |
|---|---|---|---|---|---|---|---|
| 19:45:18 | 10.4% | 85.1% | 0% | 5.8% | 3.3% | 1.2% | 0% |
| 19:45:20 | 10% | 85.7% | 0% | 4.5% | 3% | 1.3% | 0% |
| 19:45:22 | 9.7% | 86% | 0% | 6.1% | 2.7% | 1.6% | 0% |
| Time | Used | Free | Shared | Buff | Cached |
|---|---|---|---|---|---|
| 19:45:18 | 85,396 K | 34,592 K | 0 K | 9216 K | 23,888 K |
| 19:45:20 | 95,264 K | 19,820 K | 0 K | 8596 K | 21,920 K |
| 19:45:22 | 95,432 K | 19,652 K | 0 K | 8596 K | 22,076 K |
| No. | Attack Types | Method or Tool | OS |
|---|---|---|---|
| 1 | Login Password Violence Crack | Java code | Windows 7 |
| 2 | Wifi Password Violence Crack | fern-wifi-cracker | Ubuntu 12.07 |
| 3 | IP Spoofing Attack | Nmap | Windows 7 |
| 4 | SSL Attack | THC-SSL | Windows 7 |
| 5 | DOS Attack | HULK | Ubuntu 12.07 |
| 6 | ARP Spoofing Attack | WinArpAttacker | Windows 7 |
| 7 | Gateway Monitoring Attack | WinArpAttacker | Windows 7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Ma, J.; Shen, Y.; Pei, Q. Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning. Entropy 2019, 21, 734. https://doi.org/10.3390/e21080734
Li T, Ma J, Shen Y, Pei Q. Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning. Entropy. 2019; 21(8):734. https://doi.org/10.3390/e21080734
Chicago/Turabian StyleLi, Teng, Jianfeng Ma, Yulong Shen, and Qingqi Pei. 2019. "Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning" Entropy 21, no. 8: 734. https://doi.org/10.3390/e21080734
APA StyleLi, T., Ma, J., Shen, Y., & Pei, Q. (2019). Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning. Entropy, 21(8), 734. https://doi.org/10.3390/e21080734