1. Introduction
Hopfield neural networks are a particular kind of recurrent neural networks (RNN), for this reason, we may refer to them as Hopfield RNN. Hopfield RNN have several applications, [
1,
2]. Among others, these neural networks can be used as storage devices capable of storing patterns, and can model “associative memory”. The general concept in this applications is that the attractor states of these neural networks can be considered as stored patterns. This is possible because, given sufficient time, Hopfield neural networks assign to each initial activation pattern
a final activation pattern which can be composed by a steady state
, or a limit cycle composed of several states. Consequently, if we set the values of the initial activation pattern
to an input vector, which we call stimulus, we find that the network evolves from
to a final activation pattern that corresponds to a recovered memory pattern. Thus, in this framework, an RNN is a dynamical system, which connects an input-stimulus to an output-memory, and can be regarded as a content addressing memory that connects input states to output states.
This is possible because a Hopfield neural network is an RNN defined in discrete-time, and it is a deterministic dynamical system. This is why a Hopfield RNN is completely characterized by N neurons connected in a network formed of at most edges, the weights of which form the connectivity matrix . The neural network’s instantaneous state is defined by a neuron activation vector , which in Hopfield RNNs is a binary vector. The collection of all the neurons’ activation vectors forms a discrete space that contains all the possible binary vectors. The neural activation vectors may be separated in three categories: states that belong to limit cycles, steady states, and transient states. Limit cycles are neural activation states that repeat cyclically after a given number of transitions. Steady states are states that do not change in time. Transient states are neither limit cycles nor steady states, thus they are states that, if visited, are never visited again. Clearly, steady states may be regarded as limit cycles of length 1. Because a Hopfield RNN has a deterministic dynamics, any state can only transit into a single state . Consequently, any input pattern always converges to the same limit cycle or steady state. For this reason, RNNs do not exclusively model associative memories, but more generally RNNs model how responses are associated with stimuli in stimulus-response behaviors.
It has been shown that, if we train an RNN with Hebbian learning, in the long time limit, all the network’s limit cycle are steady states, while, more generally, deterministic RNN may evolve to limit cycles of length larger than 1. In conclusion, Hopfield RNNs may have interesting applications as memory storage devices because, in principle, a Hopfield RNN can store an arbitrary number of
binary vectors in a structure defined by
continuous parameters [
3,
4,
5].
RNNs belong to a broader class of synchronous distributed systems that perform tasks collectively [
6,
7]. Because RNNs offer a versatile model of stimulus response association, RNN models are not restricted to memory storage. Indeed, neuroscientists started using RNNs to model brain activity in different cognitive tasks. Monte et al. [
8] and Carnevale et al. [
9] use RNNs respectively to model the prefrontal cortex integration of context information, and the response modulation of the premotor cortex. The majority of approaches that use RNNs to model the storage of responses in association with stimuli can be divided into two main categories, the “Hebbian” approach and the innate approach. The “Hebbian” approach was proposed by Hebb himself [
8]. In this approach, the neural network starts without connections between neurons, and, at each time, a new memory pattern is stored in the neural network, connections are added or updated to allow the new memory pattern to become a stationary state in the network dynamics. Consequently, in these systems, we have a recall when a state is absorbed by the correctly associated memory. Moreover, we get a recall error when a previously stored memory fails to form a stable state. Thus, when the network activation states are set to the memory, the network evolves outside of the memory. A limit of Hebb’s approach is that, as new patterns are stored, they start interfering with the previously stored patterns. The second approach is the “innate” approach [
5,
10], in which the neural network is innate and does not change. New memories are added, by associating to each new memory an existing stable state through an addressing system. Perin et al. find that innate neural assemblies can be found in the rats’ neural cortex [
10]. Moreover, they present data that shows how analogous neural assemblies from different animals have similar connectivity properties, and they argue that these assemblies are used as building blocks for the formation of composite complex memories. In both learning strategies, the neural network
is represented by a set of interconnected neurons with an associated RNN model dynamics. The major difference between the two approaches is how
develops. For either learning strategy, the limit of the number of stimuli-response associations that can be stored in a neural network
is given by the maximum storage capacity
C which is bounded by the number of attractors in the RNN. In this paper, we focus on a generalized form of the “Hebbian” approach in which we allow autapses and we surround each stored memory with a neighborhood of redundant stable states. This approach allows us to greatly overcome the well known storage limit of the more traditional Hopfield RNN constructed with a Hebbian approach.
The storage capacity limit of Hopfield RNNs without autapses was immediately recognized by Amit, Gutfreund, and Sompolinsky [
11,
12]. This limit is linear with
N because the attempt to store a number
P of memory elements larger than
, with
, results in a “divergent” number of retrieval errors (order
P). In plain words, for a Hopfield RNN to be effective, the retrieval error probability must be low, and a Hopfield RNN can only be efficient if the stored memories do not exceed 14% of the network size. This strongly limits the application of neural networks for information storage. Nevertheless, this observation is hard to reconcile with what we observe in randomly generated (symmetric) neural networks, where the number of limit behaviours is exponentially large
with
[
13,
14], which leads us to believe the opposite conclusions.
After Amit et al. [
11,
12] results, the following research focused on how modifications of the Hebbian rule affected the behavior of a Hopfield RNN, with the objective of finding more efficient learning strategies. Abu-Mostafa and St. Jaques [
15] claimed that, for a Hopfield model with a generic coupling matrix, the upper bound value of the storable patterns is the number of neurons
N (i.e.,
). Immediately afterwards, McEliece and colleagues [
16], found an even more severe upper bound when considering matrices constructed exclusively with the Hebbian dyadic form. The authors in [
16] claims that the maximum
P scales as
. More recently, the authors in [
17] discussed how to design networks of specific topologies, and how to reach
values larger than 0.14. Unfortunately, it still finds a bound on the number of limiting behaviours that scale linearly to
N. Clearly, the optimal storage problem is still open and how to achieve this optimal storage is still the subject of research [
18].
The authors in [
19] give an analytical expression for the number of retrieval errors, and, when it restricts itself to the region
, it retrieves the bound
, which is analytically predicted in [
11,
12]. On the contrary, when it allows autapses, which implies that the diagonal elements in the connectivity matrix
may be different from zero, it finds that a new region exists, with
, where the number of retrieval errors decreases on increasing
P. In this new region, the number of retrieval errors reaches values lower than one, thus it finds new favorable conditions for an effective and efficient storage of memory patterns in an RNN. Moreover, it shows that, in this region, the number of storable patterns grows exponentially with
N. In response to these results, Rocchi et al. [
20] found that, in the thermodynamic limit at
, the basin of attraction of the stationary states vanishes. Thus, asymptotically, the basing of attraction of the stationary state coincides with the stationary state itself. Once more, this observation raises a serious doubt on the effective potential of this method for the development of realistic memory storage applications. In this paper, we discuss how to effectively overcome this limitation.
Here, we show that we can overcome the limitations of previous storage approaches when we introduce the concept of “memory neighborhood”, where a neighbor is a state that has a number of flipped neural states smaller than a value k. This neighborhood forms a set of redundant network states that are almost identical. Thus, to store a certain memory , we do not use Hebbs’ rule to only store the state , but we apply Hebbs’ rule to the entire neighborhood. We find from the analytical results and the simulations that, because these neighbor states are similar, they end up cooperating to form a set of stable states inside the neighborhood of . Each attractor from this set forms a basin of attraction, and, altogether, the union of their basins of attraction forms a composite basin of attraction that forces the states in the neighborhood to stay inside. We find through analytical considerations that the optimal size of the neighborhoods includes states with neuron patterns that differ at most for of the total neurons. This allows us to store a number of memory patterns that grows exponentially with N. Furthermore, surrounding the stored memory patterns, we form a basin of attraction that includes all states with an activation pattern that differs at most for of the neurons.
4. Storing Patterns
Research on RNN memory storage was influenced by the pioneering observations discussed by Hebb [
21], which lead to the Hebbian rule, and the “Hebbian” approach for memory storage. This approach emphasizes the role of “synaptic plasticity”, and is based on the concept that a neural network is born without connections, such that, for all
i and
j,
. Each time, a new memory is stored.
New links are reinforced or added to this network. Thus, the neural network connectivity matrix dynamically evolves as new memories are added. More specifically, in the “Hebbian” approach, to store a set of
P memory patterns
, where
is an integer index,
, we recursively add all the dyadic products of each memory
with itself, and we obtain a connectivity matrix given by
As mentioned earlier, this leaning strategy has an upper limit for the number of patterns
P that it is able to store [
11,
12]. The number
P of memory elements that can be stored must be lower than
, with
.
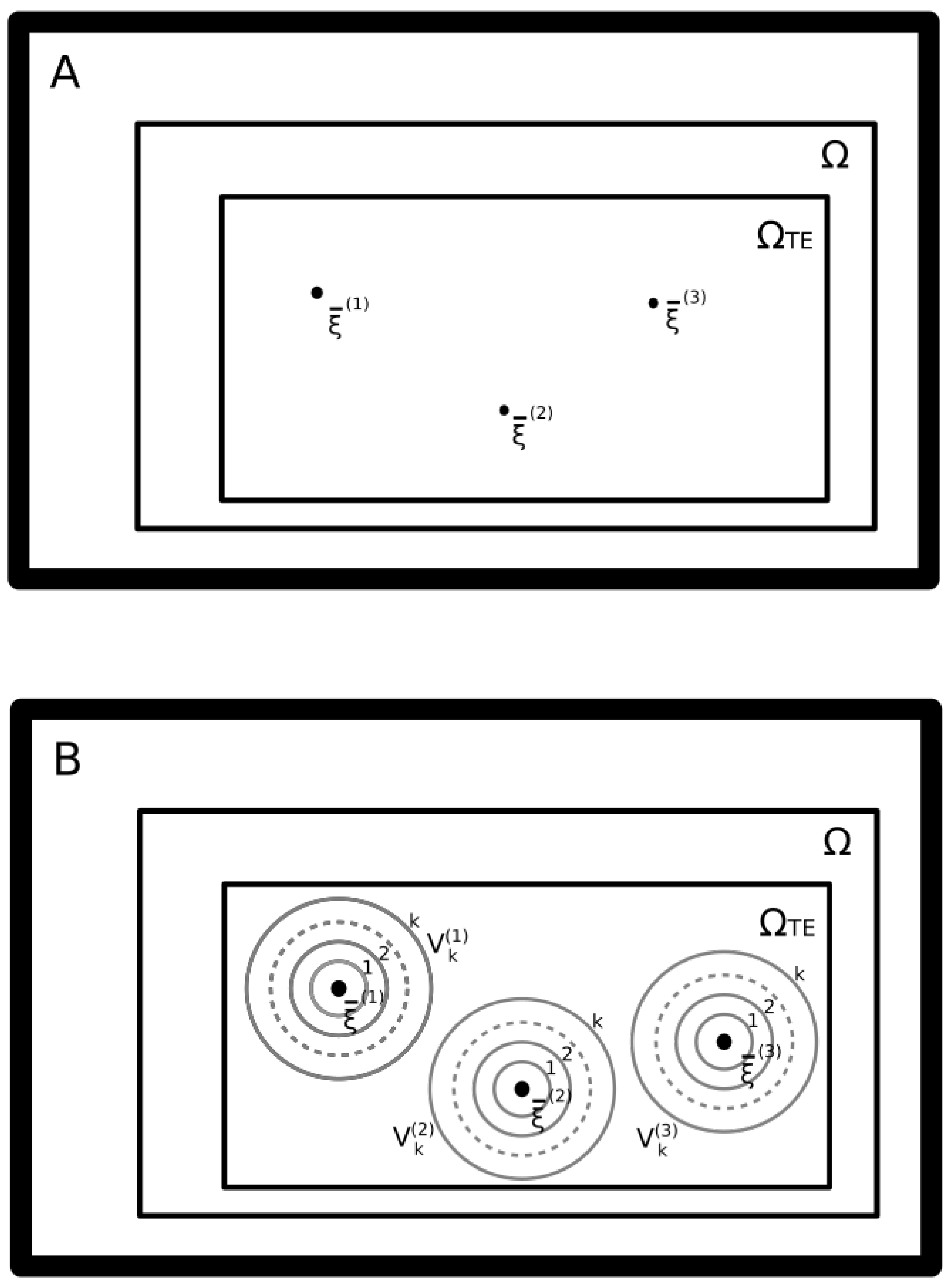
Figure 1 depicts the learning strategy we propose. This strategy is aimed at overcoming the
limit. A given memory vector
is represented in the picture as a single point in the
N-dimensional binary space
. Consequently,
collects all possible RNN states,
. In general, as discussed earlier, a memory is effectively stored, if it becomes a stable state, regardless of the learning strategy we employ. Thus, given that the recall error is given by the fraction of memory patterns that are not stable states, as more memories are effectively stored, the recall error tends to zero. In the “Hebbian” learning approach, if
P different memory patterns are stored, then the connectivity matrix
takes the form reported in Equation (
2).
Figure 1 depicts two conditions that overcome the “Hebbian” learning approach. In the upper pannel, as reported in [
19], we show how, given autopses, the number of stored memories
P can be much larger than
N. Furthermore, at the same time, autapses allow a retrieval probability larger than the error probability by a factor of
e in [
19]. It is important to point out that, even if greater than
N, the number of stored patterns
P must be smaller than
. It is also important to consider that, most likely,
P must be smaller than the number of average fixed points that are present in a random symmetric fully connected matrix, which is
with
[
13]. We thus bound the maximum number of storable points with
[
13]. Unfortunately, as pointed out by Rocchi et al. [
20], the basin of attraction of these points shrinks to the point that it contains only the stable states. In the lower panel, we show how, with our approach, we overcome this limit. Our approach consists of associating a set of neighbor vectors to each memory vector
in order to form a cloud of surrounding neighborhood vectors similar to the original memory. To do this, we have to choose a distance relation in order to define a neighborhood surrounding an arbitrary vector. The distance relation that we choose is the Hamming distance, which, given two binary vectors
and
, is defined as the number of different elements such that
. Furthermore, we consider two binary vectors
and
as neighbors, if they have a Hamming distance
smaller than an integer value
k. Thus, the set of
neighbor vectors is
, where
k is an integer parameter (
). Given
, the number of vector states that are at a Hamming distance of
k or lower is
. Clearly,
is equal to the number of elements in
. Consequently, to add the redundancy of all the neighbor states and with the objective of obtaining a neighborhood of attractor stable states, we change the Hebbian rule expressed with Equation (
2) with the new rule
In this sum,
terms are added to form a connectivity matrix
that we expect should store
P memory states, by forming around each memory state a neighborhood of absorbing states of size
. Here, we must redefine the concept of recall error because we use a set of absorbing states instead of single absorbing states. Thus, we define the recall error for a neighborhood
, as a failure to retrieve an attractor inside
starting from a state inside of the neighborhood
. Consequently, the recall error rate would correspond to the rate of states in
that evolve to attractors outside this state. Now, we have to set
k considering two constraints,
k must scale with
N, and the absorbing-neighborhood must not vanish in the thermodynamic limit. Consequently, we chose
. This straightforward storage strategy works, if and only if, for each memory pattern, there is enough “room” for all
neighbor vector-sets. At the same time, we assume that the redundant stable states we add here should not exceed the theoretical maximum storage capacity that we obtain in a randomly fully connected network. Thus, to fulfill an efficient and effective memory storage,
. The explicit expression for
is given by
Unfortunately, this quantity does not have a closed expression, nevertheless, for
, we can write a lower and upper bound of the form [
22]
where
is the binary entropy of
,
. If we set aside the logarithmic corrections which vanish in the limit for large
N, the condition
can be promptly rewritten as
where
is expressed as
with
[
13]. This condition tells us that an exponentially large number of memory patterns may be allowed providing that
. Clearly, this condition implies
. Furthermore, if we set
then the
are the sums of the contribution of all the
’s neighbor vectors. Now, we may rewrite Equation (
3) as
Counting the contribution of the different states that form the neighborhood, Equation (
8) can be explicitly expanded.
Notice that neurons cooperate by either increasing their reciprocal tendency to align or to misalign with each other.
5. Simulation Results
To run the simulations, we considered different values of
N, and selected the values of
and
P according to Equation (
6), because for
, we expect from the arguments in the previous section that we have a retrieval error close to 0. Indeed, as mentioned previously,
must be smaller than
, thus we chose
because, for
, the value of
grows extremely slowly and we can take advantage of the exponential scaling of
P only for large values of
N. Thus, as a representative case, we show simulations for
with
. Consequently, we run our simulation in the conditions for which we expect that most of the states in the neighborhood
are recalled, which means that any state in the neighborhood evolves to an attractor in the neighborhood.
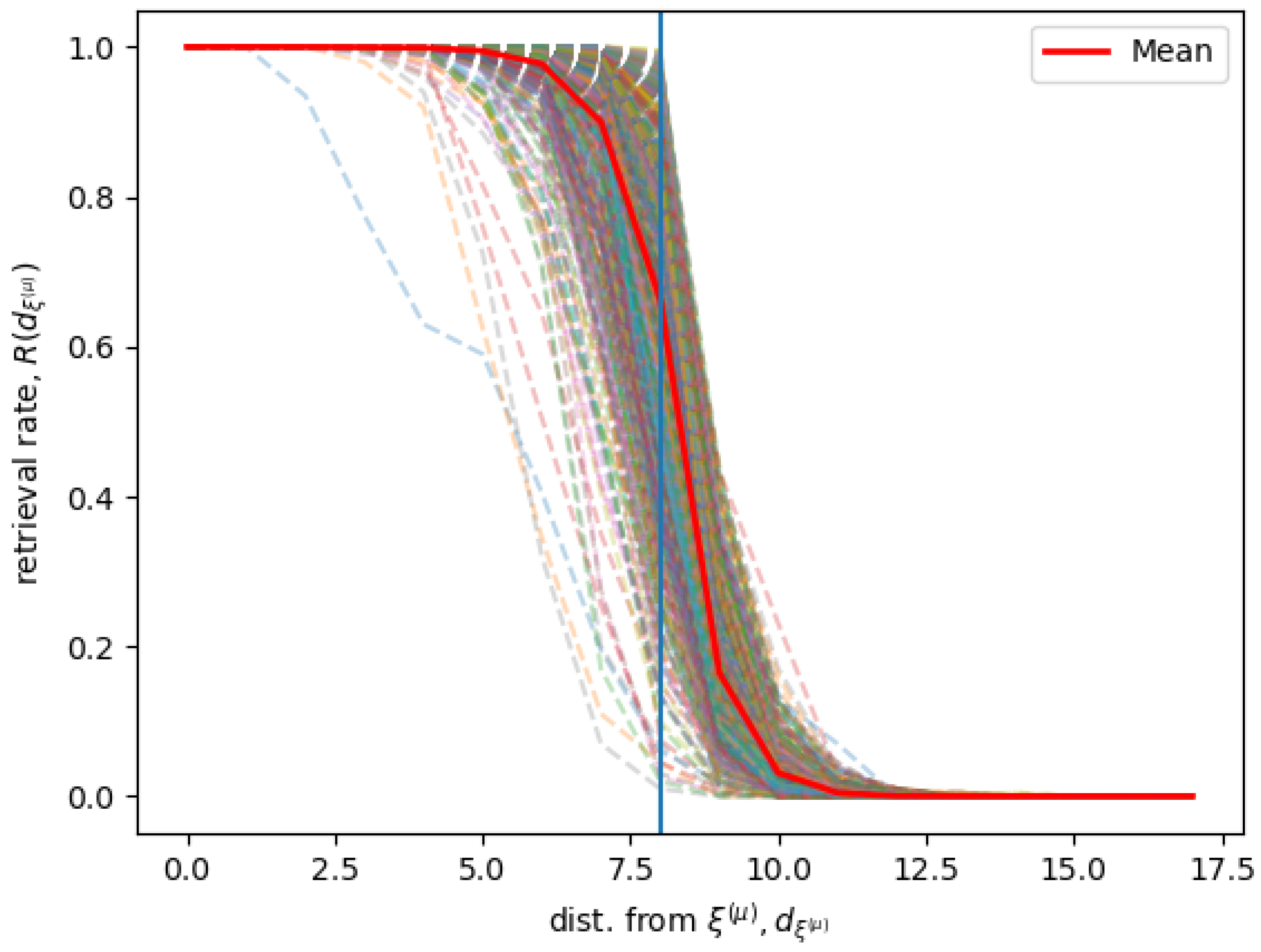
Figure 2 shows simulation results for a Hopfield RNN with a connectivity matrix
trained on 745 memories
with Equation (
9). We used
and
, and consequently
and
. We define the distance
as the distance of any state from a given memory
, and the retrieval rate
at a distance
as the rate of states at a certain distance
form the memory
that in the long time limit is attracted by a stable state in the neighborhood of
.
The figure shows the for all the different stored memories, and the average computed over all the different memories . Given a memory and its neighborhood , for different values of , the rate is when possible computed extensively and otherwise sampled, according to the following conditions. If the shell of states in a neighborhood at a certain distance has less then 1000 states, the recall rate is computed considering all the states in the shell. Otherwise, for shells of states at a distance with more than 1000 states, only 200 states are sampled. We find that the system has a sharp transition when the state is at the border of the memories neighborhood. This indicates that the states inside of the neighborhood are correctly recalled, while, on average, the states outside the neighborhood are not associated with the neighborhood’s memory.
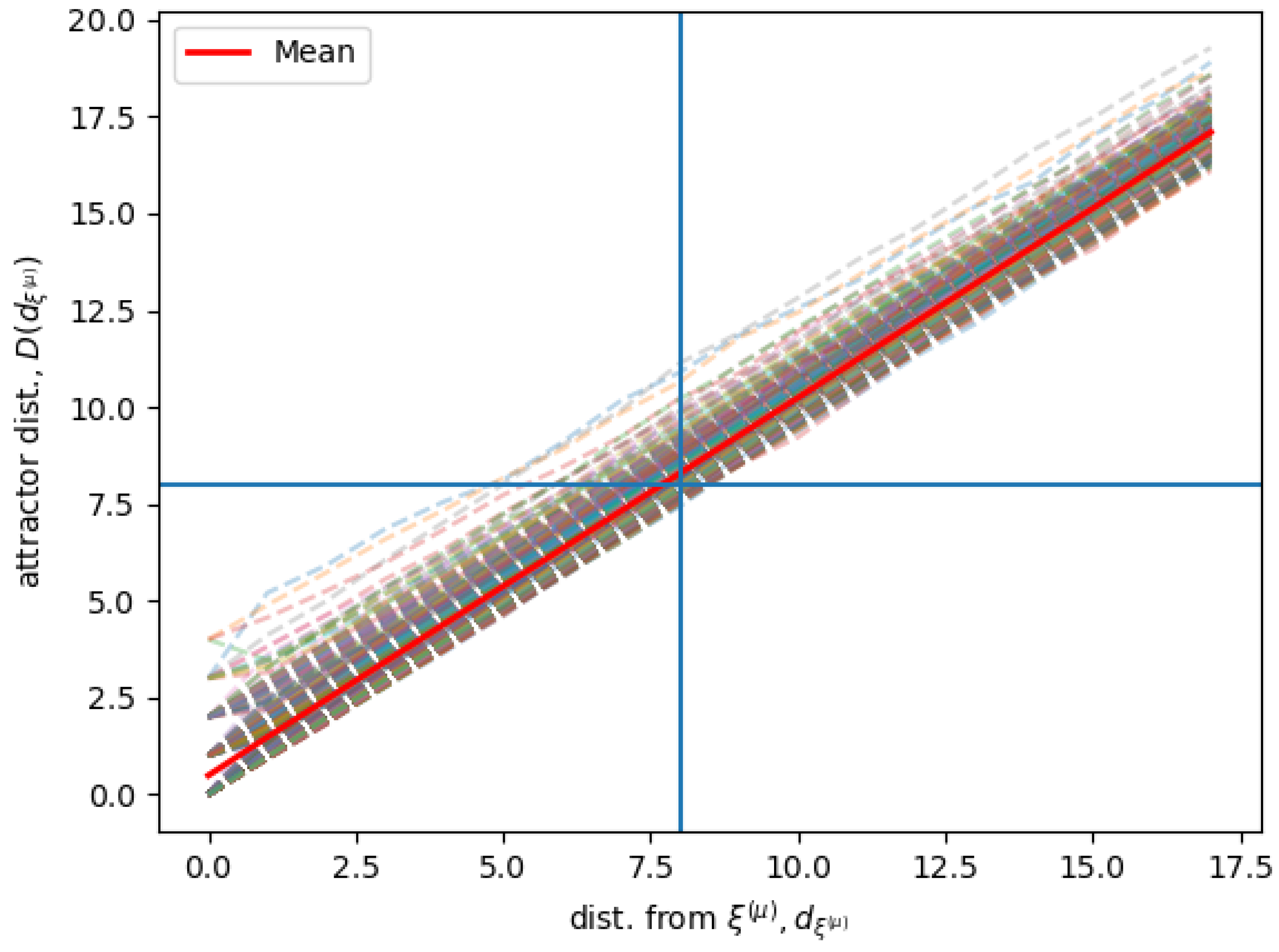
Figure 3 shows simulation results for the same Hopfield RNN as for
Figure 2, given that each state in the neighborhood is associated with an attractor stable state in the limit behavior. The figure shows the distance of the attractor stable states
for the associated states that are found at a distance
from each memory
. The figure shows
for all the
different stored memories, and the average
computed over all the different memories.
is sampled as in
Figure 2.
Now, we replicated the simulation eight times for different values of
N. Each time we selected uniformly at random
solutions, and we generated the corresponding connectivity matrix
with Equation (
9), with
.
Figure 4 shows the mean
averaged over all Hopfield RNN replications
r, and all the memories
of each replication, for different network sizes
N. We find that, for
, we get the sharp transition behavior that we expected, while, for smaller
N, we get size effects that influence the stability of the states. We have three different outcomes at different ranges. For small
, the size effects do not impact the performance of the storage algorithm, and, on the contrary, seem to increase the basin of attraction of the memories. Differently, in the middle range, e.g.,
N∼100, it appears that the larger number of memories causes them to interfere with each other, completely destroying the basin of attraction of 1 or 2 of the memories. Indeed, in this network, sometimes one or two neighborhoods have a very low retrieval rate. Consequently, the average overall value of
decreases.
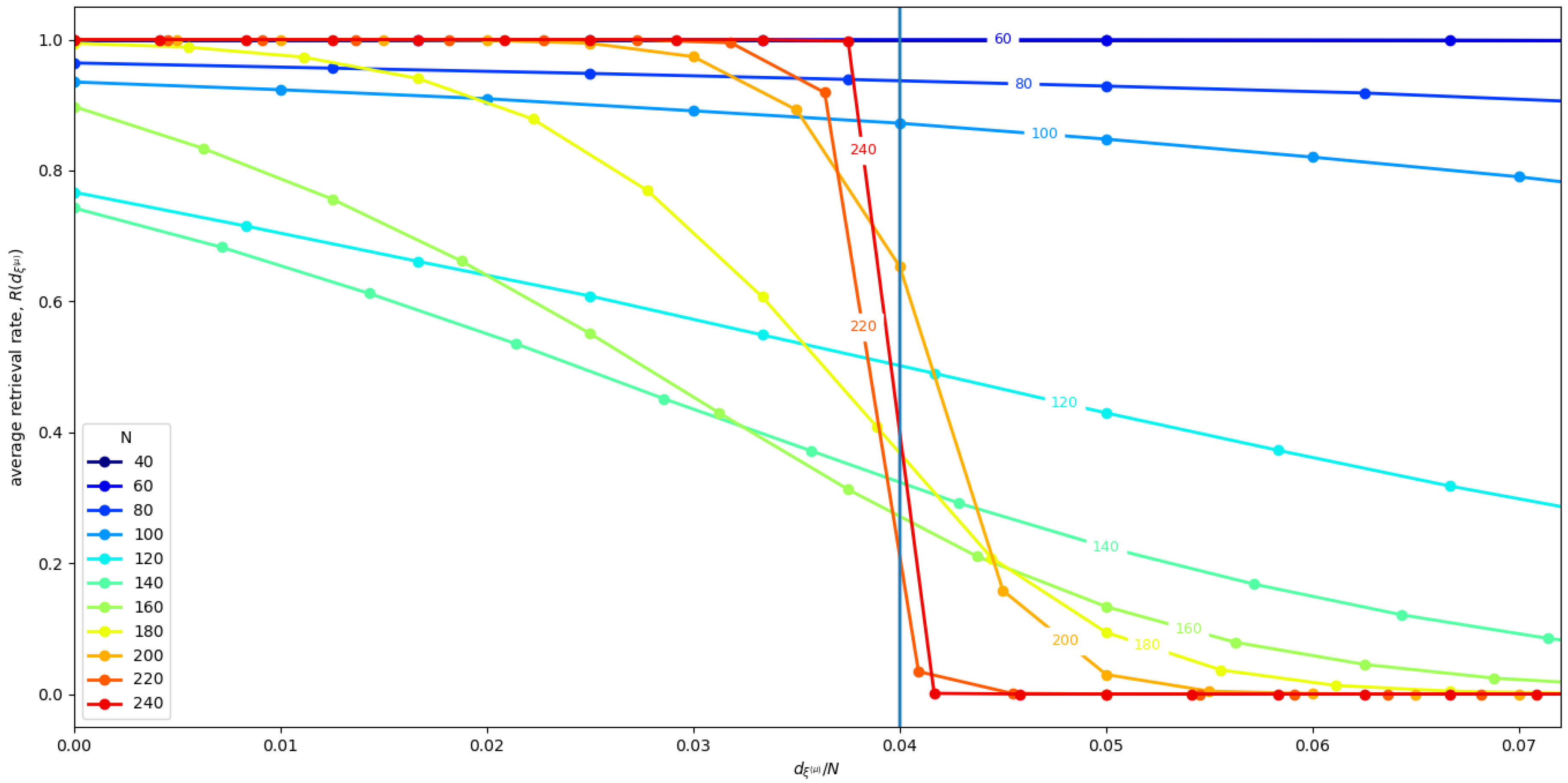
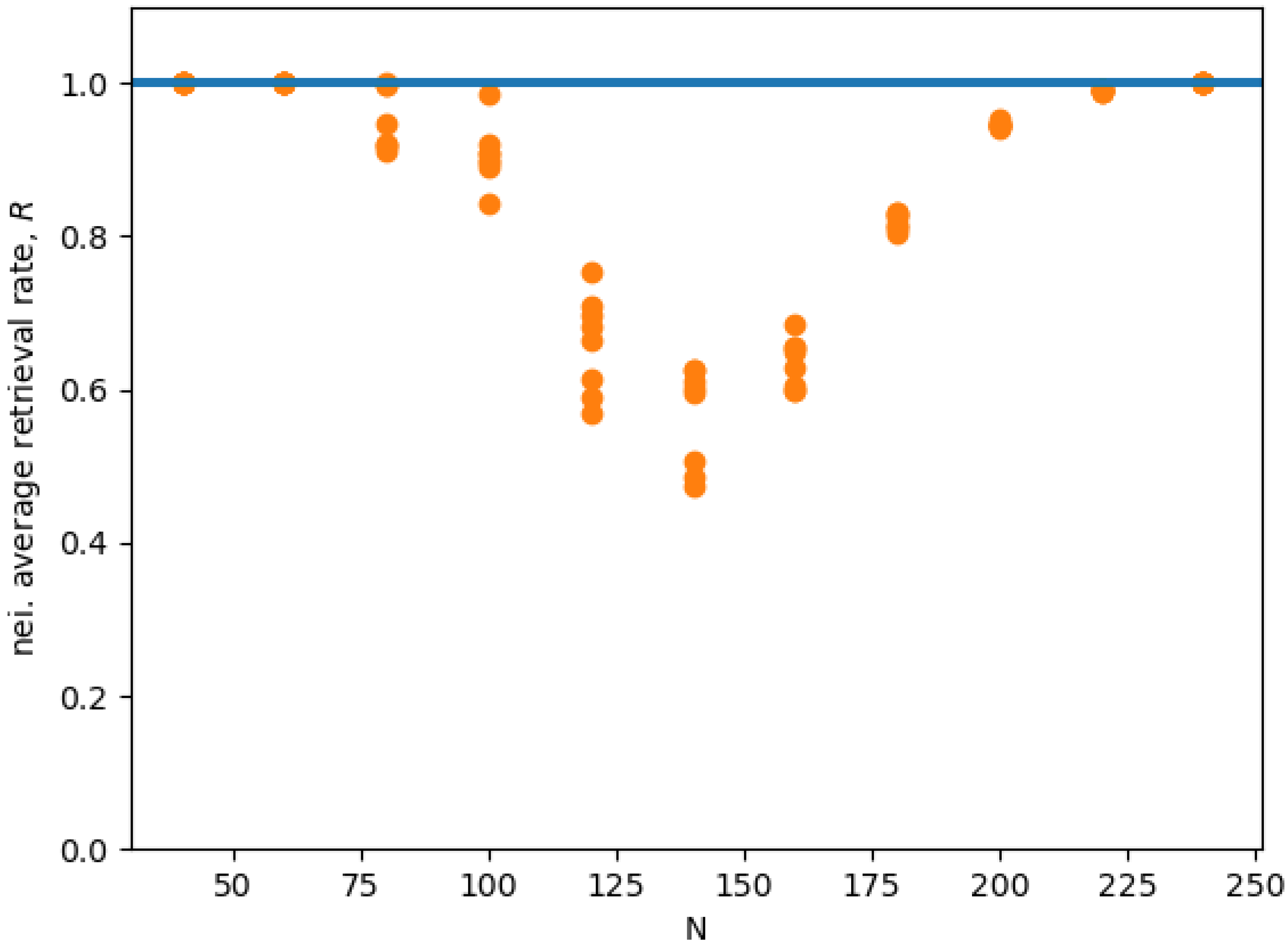
Figure 5 shows the average retrieval rate
R for the state in the neighborhood of each memory
. We see that, for small
, and, for
, we have a retrieval rate close to 1, which indicates an almost optimal retrieval. In the middle range, the retrieval rate is clearly sub-optimal. In conclusion, we speculate that the reason this interference disappears for larger
N probably has to do with the randomness of the contribution of all the memories’ interacting with any single given memory, as described in [
19]. Indeed, in [
19], the authors argue that, given a single memory, the effects of the memories interacting with it contribute with a random term. Thus, the total effect of all these random terms coming from different uncorrelated memories vanishes as the number of interacting memories increase as a result of the law of large numbers.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




