Abstract
This paper considers several distinct mathematical and computational tools, namely complexity, dimensionality-reduction, clustering, and visualization techniques, for characterizing music. Digital representations of musical works of four artists are analyzed by means of distinct indices and visualized using the multidimensional scaling technique. The results are then correlated with the artists’ musical production. The patterns found in the data demonstrate the effectiveness of the approach for assessing the complexity of musical information.
1. Introduction
The relationships between music and mathematics have been studied for long [1,2]. However, it seems difficult to find a single model for describing a musical work, in spite of it being recognized that we have a glimpse of mathematical structures underneath all types of music [3,4]. A musical work can be represented as a set of one or more time-sequenced digital data streams, reflecting a given time sampling of the original musical source. If a single (`mono’) digital data stream is adopted, then a musical work is represented by a time series (TS), where each sample is a signed floating-point value.
Complexity is one important characteristic of a TS and embeds a description of properties, such as chaoticity, fractality, regularity, and memory [5,6]. In other words, while various properties can describe specific aspects of the TS, the complexity constitutes a general quantitative estimation of their characteristics [6]. Therefore, complexity has become an increasingly prevalent estimator in analyzing TS produced by complex systems, such as in economics [7], finance [8], geo [9], life [10], and social [11] sciences, with the objective of finding the fundamental principles that govern the systems’ behavior [12]. There are no definite guiding rules to the interpretation of the complexity measurements. In general, low complexity indicates that the observed system is more likely to follow some kind of deterministic process that can be finely captured. On the other hand, high complexity represents some data dynamics that are more unpredictable and difficult to understand [6].
A variety of complexity indices has been adopted for tackling art, namely entropy [13,14], Kolmogorov complexity [15,16], fractal dimension [17,18], and others [19,20]. Despite that some of these tools may be correlated, they capture different aspects of the system and, therefore, complement each other [21]. Specifically for the case of music, we can mention the work of Simonton [22] who studied 15,618 themes of classical music and established a connection between melodic complexity and popularity. Eerola and North [23] analyzed the melodic complexity of Beatles’ songs and observed an increasing trend over time. Additionally, they noted some kind of correlation between complexity and the songs’ popularity. Herrera and Streich [24] explored the relationship between the detrended fluctuation analysis exponent and several manually annotated semantic labels of musics. These researchers concluded that there was a link between the exponent and the idea of `danceability’. Li and Sleep [25] investigated the topic of melody classification using a similarity metric based on the Kolmogorov complexity. Ribeiro et al. [26] analyzed 10,000 songs using the complexity–entropy causality plane. The results indicated that this representation could not only discriminate, but also allow a quantitative comparison between songs. Several other works address the use of distinct complexity indices and the adoption of alternative approaches [27,28,29,30].
In this paper we take advantage of the synergies between several tools, namely complexity, dimensionality-reduction, clustering, and visualization techniques, for studying the musical repertories of three singers and one band of different nationalities and ways of being: Frank Sinatra, Rolling Stones, Johnny Hallyday, and Julio Iglesias. In a first phase, the original musical sources are converted into `mono’ digital format and processed using eight distinct complexity indices. Moreover, the results are correlated with the periods of the artists’ careers. In a second phase, a multidimensional scaling (MDS) algorithm is adopted for visualizing complexity. The MDS processes the dissimilarity information calculated with the arc cosine and Canberra distances between the complexity indices, and the loci generated are interpreted under the light of the emerging patterns.
Considering these ideas, Section 2 introduces the mathematical background. Section 3 analyses the musical portfolio of four well-known musicians in the perspective of the eight complexity indices. In addition, the MDS-generated maps are interpreted having in mind the evolution of the artists’ careers. Finally, Section 4 presents the conclusions.
2. Mathematical Background
2.1. Entropy
The information theory [31,32] has been successfully adopted in the study of complex systems [21,33].
Let us consider a discrete random variable X with sample space and probability distribution . The Shannon entropy, H, of X is given by:
The Jensen-Shannon divergence () measures the dissimilarity between two probability distributions and and is defined as [34]:
where X and Y are random variables with sample spaces and , respectively, and .
2.2. Permutation Entropy
Different entropy formulations and entropy-based indices have been proposed for data characterization [35,36,37,38,39]. The permutation entropy () was originally proposed to assess the complexity of TS [40]. Let us consider a TS consisting of a series of real-valued samples . We define the parameters , where the embedding dimension, , and the embedding delay, , represent the length of the TS partitioning sequences and the separation time between their elements, respectively. Let us denote by the set of all possible permutations of the ordinals , and by the Iverson bracket [41], such that: .
The procedure for calculating can be outlined as follows:
- For each , with ,1.1 compose the sequence ;1.2 construct the dimensional array ;1.3 sort the array by increasing order of the elements in the first row;1.4 denote by the sequence of numbers in the second row of the sorted array;
- Compute the probability distribution , where W is a random variable with sample space and , for ;
- Calculate as
The permutation entropy lies in the interval . The minimum value indicates that the TS is regular, or predictable, while the maximum value corresponds to a random TS. The embedding dimension must be chosen such that in order to obtain reliable values of . For practical purposes, the values and are recommended [40].
2.3. Statistical Complexity
Another complexity index is the statistical complexity, C, given by [42,43]:
where U is a random variable with sample space , probability distribution , and , so that:
is a normalization constant.
The statistical complexity, C, depends on a probability distribution associated with the system, , and on the uniform distribution, . Therefore, for a given , there exists a range of possible values of C. Indeed, the index C provides additional information not captured by the index , since it quantifies the existence of correlational structures in the data [42,44].
2.4. Kolmogorov Complexity
The Kolmogorov complexity, , of an object provides a measure of information that is independent of any probabilistic assumptions about the data sequences in . The measure is defined as the size of the shortest program that, given an empty object at its input, computes in a universal computer and then stops [45,46]. The exact value of is not computable [45,46]. Therefore, approximation schemes are used to obtain its upper bounds, such as the Lempel-Ziv [47], linguistic [48], and compression-based [49] methods.
Lossless compression algorithms approximate from the size of the compressed object, , where denotes the compression algorithm [46]. However, for obtaining a good approximation, the compressor has to be `normal’, meaning that, given and the concatenation of with itself, , the compressor must generate compressed objects such that [46]. Moreover, for obtaining a complexity index that is independent of we adopt the complexity ratio, , given by:
2.5. Multidimensional Scaling
Clustering and visualizing data with a large number of attributes is overly important in science [50,51,52,53,54]. The MDS is a computational technique for dimensionality-reduction, clustering, and visualization of multidimensional data [33,55,56,57]. Given a set of objects , , in a r-dimensional space, and a measure of dissimilarity between the pair i and j, , the procedure starts by calculating an symmetric matrix, , of object-to-object dissimilarities. The matrix is the input to the MDS computational algorithm. In fact, MDS represents objects by means of points located in a q-dimensional space () at distances . To accomplish this, the MDS iterates multiple configurations and calculates the matrix of distances that minimizes a fitness function. A widely used fitness function is the raw stress:
where is a linear or non-linear transformation.
The MDS interpretation is based on the patterns of points emerging in the MDS locus. Two similar (dissimilar) objects are shown as two points that are close to (far from) each other. Therefore, we can translate, rotate, and magnify the locus to have a good visualization, because the object-to-object distances remain identical. The MDS axes have neither units, nor special physical meaning.
The MDS quality can be quantified by means of the Shepard and stress plots. The Shepard diagram compares and , for a particular value of q. A narrow scattering of the points represents a good fit between and . The stress diagram represents the locus of versus q. Usually, we adopt or , because such values allow a direct visualization and establish a compromise between achieving low values of and q.
2.6. Musical Sounds
In the context of this study, a musical work is a TS, , representing the arithmetic average of two data streams that result from sampling the original musical source at kHz.
Using the discrete Fourier transform we can express the TS in the frequency domain, resulting in:
where and is the Fourier operator. Usually, we represent only the first half of the spectrum versus frequency, f, or angular frequency, , by considering and .
The musical sounds have a strong variability, making difficult their quantitative characterization through a single index. Therefore, often several distinct indices are used in the time and frequency domains to capture the rich information embedded in the signal. Figure 1 illustrates the musical work `LA is my lady’ by Frank Sinatra using its TS and amplitude spectrum representations, and , respectively.
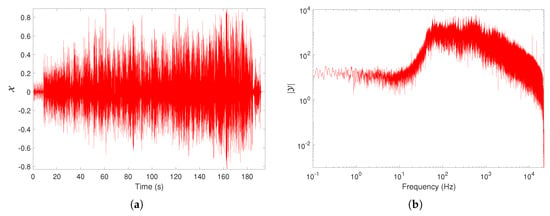
Figure 1.
Representation of the the musical work `LA is my lady’ by Frank Sinatra in the time and frequency domains: (a) Time series (TS), ; (b) amplitude spectrum, .
A variety of features have been proposed for characterizing musical sounds in terms of their dynamics, rhythm, timbre, pitch, and tonality. Music feature extraction involves many signal-processing techniques and forms the basis for many automatic classification algorithms. Several toolboxes are currently available for music and sound feature extraction, such as the MIRtoolbox [58], pyAudioAnalysis [59], and Librosa [60]. The toolboxes often provide not only a set of base features that capture various temporal, spectral, and spectrotemporal properties of the musical signal, but also a considerable number of descriptors derived from the base features by means of descriptive statistics. Typically, all toolboxes provide onset detection, pitch tracking, mel frequency cepstral coefficients (MFCC), chroma, and beat-related features [58,59]. Often, the feature extraction process includes three stages: (i) Dividing each musical work into a set of short-term time windows, or frames, (ii) calculating a collection of features for each frame, and (iii) computing some sort of simple statistics (e.g., mean and variance) of each feature for all frames. The window size is chosen as a compromise between statistical significance and approximate stationarity of the data in each frame. Typical window sizes vary from 20 to 100 ms [59,61,62].
3. Complexity Analysis and Visualization
This section addresses the musical repertories of Frank Sinatra, Rolling Stones, Johnny Hallyday, and Julio Iglesias in the perspective of eight complexity indices and the MDS. The musicians were selected for their long and prolific careers, for representing different musical genres, and for singing in different languages.
In a first phase, we apply Equations (1), (3), (4) and (6) to the time and frequency representations of the TS, and , respectively. Therefore, we characterize the musical works by means of the set of measures , where the subscripts denote the time and spectral complexity indices. For computing and the probabilities are obtained from the histograms of amplitudes of and , respectively, using 100 bins. For the , , , and , we adopt the parameters and , that were adjusted by means of numerical experiments. For computing and we adopt the Windows implementation of the gzip compressor, version 1.3.12 (built upon the Lempel-Ziv coding algorithm LZ77). The variability of the individual quantities in the set is analyzed and correlated with the artists’ musical careers.
In a second phase, we consider that each individual index captures distinct details of the musical works and that a more complete characterization is accomplished when using all indices simultaneously. However, since an 8-dimensional representation is not feasible, we adopt the MDS technique for dimensionality reduction and visualization.
3.1. Frank Sinatra
Frank Sinatra (1915–1998) was one of the most popular singers of the 20th century. Sinatra’s musical style is close to `vocal jazz’, but there is still controversy and debate about this classification. In his artistic career of about 55 years, Sinatra recorded almost 60 studio albums and 300 singles, along with compilations and live albums.
In this study we consider a total of 707 musical works included in 57 studio albums released in the period 1946–1993. The albums are ordered chronologically and referred to by the sequence . Therefore, we should note that the time lapse between two consecutive values of i is not precisely identical. Figure 2 depicts the evolution of the and (using the black marks + and ∘, respectively) of the musical works versus the index of the album, i, where they are included. Given the dispersion of the and values, we group the musical works in windows of albums centered at each i value (i.e., the window goes from to ), for improving the readability. Then, we calculate the 25, 50, and 75 percentiles, and represent the results by means of three continuous lines. Numerical experiments showed that this width establishes a good compromise between limited volatility and accurate discrimination. Lower values of increase the detail, but blur the charts, while higher values of tend to filter too much the time details. We verify that there exist relationships between the evolution of and and the different periods of Sinatra’s artistic career, even knowing that these periods are neither rigidly defined nor absolutely consensual. For the other complexity indices, we reach similar results and, therefore, their representation is omitted here for the sake of parsimony.
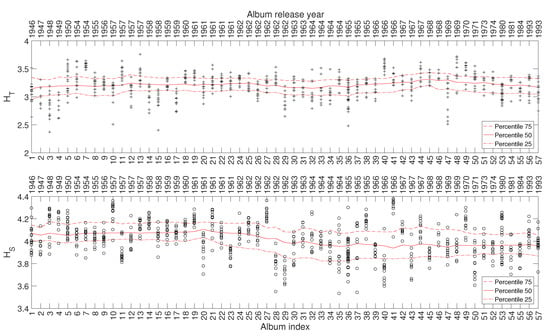
Figure 2.
The complexity indices and versus for Frank Sinatra’s music.
The MDS is adopted for reducing dimensionality from an 8- to a 3-dimensional space, allowing a direct interpretation of the results. We start by constructing a dimensional array, , where , , , represents the median of the kth complexity index when grouping the musical works into windows of albums centered at each i value. Then, we calculate the dissimilarity matrices and , , where and denote the arc cosine and Canberra distances between and , respectively. The two distances are given by:
Other distances can be adopted, but several numerical experiments with distinct alternatives [63] confirmed that the arc cosine and the Canberra distances yield good results. Each of the matrices and is processed by means of the MDS for constructing the loci of objects that represent the evolution of complexity.
Figure 3 depicts the MDS maps for Sinatra’s music, for and , with and . Figure 4a,b shows the corresponding MDS assessment charts. The Shepard diagram reveals a small scatter around the 45 degree line, demonstrating that there exists a good fit between the original and the reproduced distances. The stress plot shows that the maximum curvature of the line occurs close to . Therefore, we conclude that yields a good compromise between accuracy and readability of the locus of points, while just leads to a marginal improvement, since the z-MDS coordinate carries reduced additional information. Alternatively, for taking advantage of present day computational visualization, we adopt a distinct 3-dimensional representation, with and the z coordinate of the map representing the albums’ sequence, i, interpolated with radial basis interpolation (RBI) [64] at each point with coordinates produced by the MDS. The thin-plate spline RBI function is considered, where the variable denotes the Euclidean distance between the points generated by the MDS for and points in the MDS plane. Figure 5a,b depicts the results obtained for and , respectively. The Shepard and stress diagrams are omitted here, since they are of the same type as the ones presented in Figure 4.
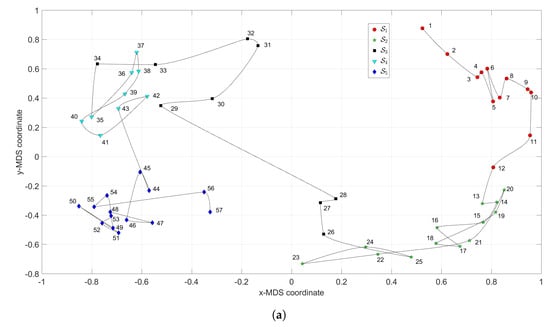
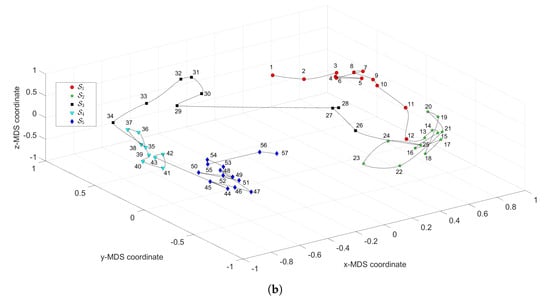
Figure 3.
The multidimensional scaling (MDS) maps for Sinatra’s music with and : (a) ; (b) .
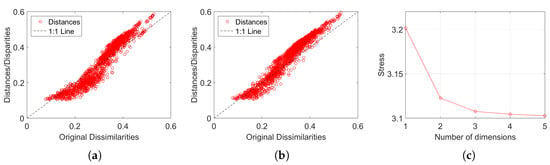
Figure 4.
The MDS assessment charts for Sinatra’s music, with and : (a) Sheppard for ; (b) Sheppard for ; (c) stress versus .
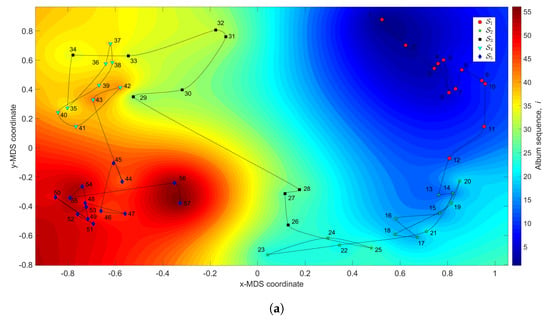
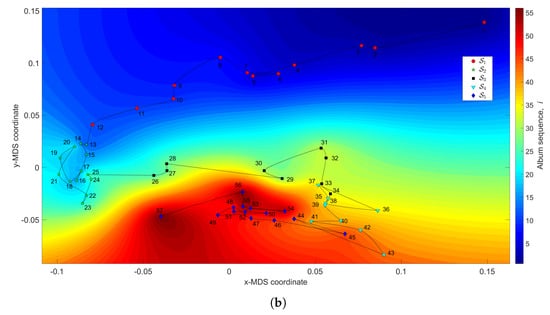
Figure 5.
The MDS maps for Sinatra’s music. The coordinates are generated by means of the MDS with and the matrices: (a) ; (b) . The z coordinate represents the albums’ sequence, i, interpolated with radial basis interpolation (RBI).
We verify the emergence of five clusters, , . In the first, (i.e., albums ), the complexity varies strongly, meaning that the characteristics of the musical works evolved considerably. This cluster corresponds to albums released in the years 1946–1957. For (), the complexity has limited evolution and corresponds to albums recorded during the years 1957–1962. In the cluster () the trajectory changes direction and has another large excursion, corresponding to musical albums recorded in the years 1962–1964. The cluster () includes albums from 1964 up to 1967 and we verify that the complexity has a limited evolution. Finally, for the cluster (), another route occurs, smaller than the previous ones for and . Here, the complexity evolves slowly until the two last albums, consisting of duets (`Duets I and II’), which explains the variation at the end of the career. It is also interesting to see that between two consecutive clusters and , ), we have always a trajectory tangle revealing the artist’s search for the new direction of work.
We now analyze the musical repertory of Frank Sinatra by means of classical musical features, instead of general complexity indices. Therefore, each of Sinatra’s musical works (707 in total) is split into 50 ms non-overlapping frames, and a collection of 34 features is extracted for each time frame. After, for each feature, the average, the standard deviation, and the ratio between the average and the standard deviation are computed. Thus, each piece of music is characterized by a dimensional vector, . Herein, we adopt the zero crossing rate, energy, energy entropy, spectral centroid, spectral spread, spectral entropy, spectral flux, spectral rolloff, mel frequency cepstral coefficients (13 values in total), chroma vector (12 values in total), and chroma deviation. For a detailed description about these features, interested readers can refer to [59]. It should be noted that a different set of features could have been used, since others are also available, and consequently many combinations are possible.
We compute the dimensional matrix , where denotes the arc cosine distance between the feature vectors and , . The matrix is used as the input to the MDS. Since the MDS technique outputs a large number of points, we post-process the results by (i) grouping the musical works into windows of albums centered at each i value, and (ii) calculating the medians of the corresponding MDS coordinates. Figure 6 depicts the resulting 57-point 2- and 3-dimensional maps. Contrary to the previous experiments, in Figure 3, we do not see the emergence of any pattern. This means that in the perspective of this study, general complexity measures unravel characteristics somehow overlooked by specialized feature descriptors. While a systematic comparison of the two possible strategies, that is, the balancing between general indices and specialized ones is of interest, hereafter we follow the first due to its superior performance in the present case.
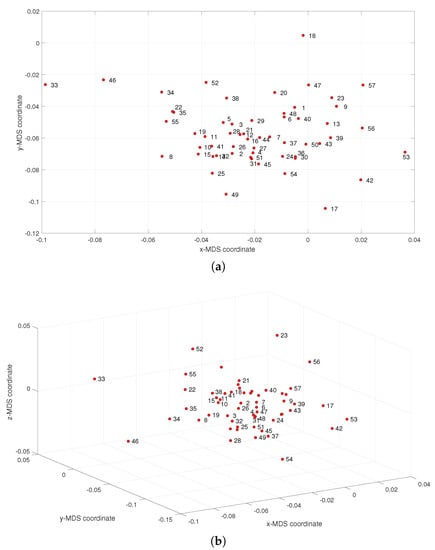
Figure 6.
The MDS maps for Sinatra’s music obtained the classical musical features and : (a) ; (b) .
3.2. Rolling Stones
The English rock band Rolling Stones was created in 1962. The original band included the vocalist Mick Jagger, the guitarists Keith Richards and Brian Jones, the bassist Bill Wyman, the drummer Charlie Watts, and the keyboardist Ian Stewart. Ian Stewart left the group in 1963 and Brian Jones in 1969, being replaced by Mick Taylor, who remained until 1974. In 1975, the guitarist Ron Wood joined the band. The Rolling Stones quickly became the `bad-boys’ band, with an image of sex, drugs, and rebelliousness, in contrast to their contemporary band `The Beatles’. Their music was influenced by different styles from blues and jazz to dance and early rock-and-roll. The Rolling Stones are one of the most successful and acclaimed rock bands of all time. For more than 50 years, they released about 30 studio albums along with several live albums and compilations.
In the sequel we consider a total of 317 musical works included in 27 studio albums released in the period 1964–2005.
Figure 7 depicts the 25, 50, and 75 percentiles of and versus , calculated as explained in the previous subsection. Again, we verify a relationship between the evolution of the indices and the different periods of the band’s artistic career. For the other complexity indices, we reach to similar results and, therefore, their representation is omitted here.
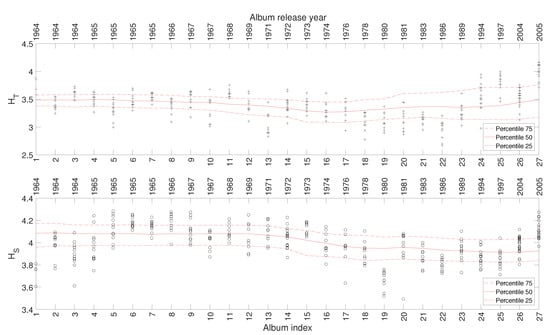
Figure 7.
The complexity indices and versus for the Rolling Stones’ music.
Figure 8 depicts the 3-dimensional map of the Rolling Stones’ career. The coordinates are obtained by the MDS with and the dissimilarity matrices and , while the z coordinate addresses the albums’ sequence, i, interpolated with RBI. The Shepard and stress diagrams are not represented, since they are of the same type as the ones presented in Figure 4.
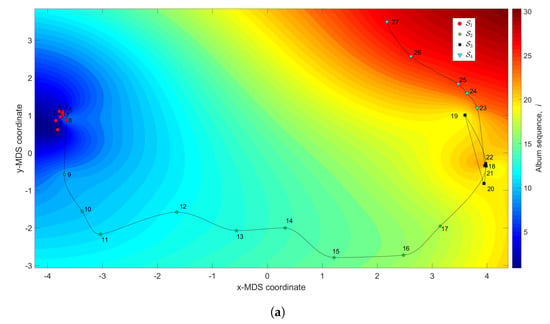
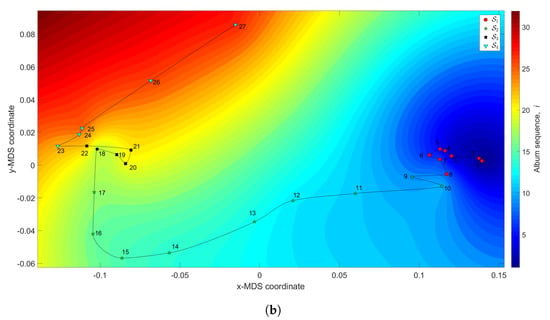
Figure 8.
The MDS maps for the Rolling Stones’ music. The coordinates are generated by means of the MDS, with and the matrices: (a) ; (b) . The z coordinate represents the albums’ sequence, i, interpolated with RBI.
We verify that the complexity loci have two small tangles, () and (), corresponding to albums released between the years 1964 and 1966, and 1978 and 1986, respectively. These tangles intermediate two large excursions, () and (), that include the albums released during the periods 1967–1976 and 1989–2005, respectively. In one hand, we can notice that the periods of complexity stagnation, and , comprise the early discography and the commercial success peak periods. On the other hand, the periods of strong complexity variation, and , include some troubled years and the entry of Ronnie Wood to the band, and the comeback and record-breaking tours that took place after the near break up.
3.3. Johnny Hallyday
Johnny Hallyday (1943–2017) was a French singer, songwriter, musician, and actor. He is considered the father of French rock and roll and sometimes he is referred to as the French Elvis Presley. Johnny’s artistic career lasted about 55 years and had plenty of musical success, especially in France and French-speaking countries. He recorded about 50 studio albums, as well as diverse compilations. He is well remembered for his spectacular live concerts with some shot of eccentricity.
Figure 9 depicts the 25, 50, and 75 percentiles of and versus , calculated for a total of 325 musical works included in 34 studio albums released in the period 1961–2011. As mentioned for the previous artists, a relationship emerges between the complexity indices and the evolution of Johnny Hallyday’s career.
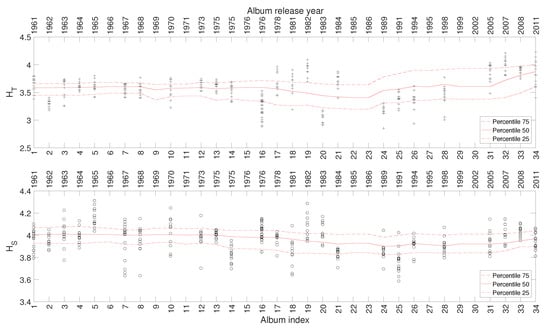
Figure 9.
The complexity indices and versus for Johnny Hallyday’s music.
Figure 10 represents the 3-dimensional map where the coordinates are generated by the MDS with and the dissimilarity matrices and , and the z coordinate denotes the albums’ sequence, i, interpolated with RBI.
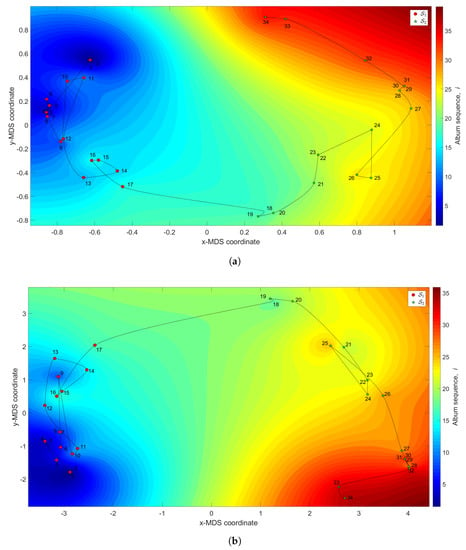
Figure 10.
The MDS maps for Johnny Hallyday’s music. The coordinates are generated by means of the MDS with and the matrices: (a) ; (b) . The z coordinate represents the albums’ sequence, i, interpolated with RBI.
We observe the emergence of two main clusters. The first is a large tangle, (), corresponding to albums released between the years 1961 and 1978. In this period, Hallyday recorded several French versions of American hits and French songs. The second, (), includes albums between the years 1981 and 2011. It begins in the early 1980s, when Johnny’s career seemed to be on the wane, and then evolves with a new breath triggered by the album “Rock’n’roll attitude”.
3.4. Julio Iglesias
Julio Iglesias is a Spanish songwriter and singer. Iglesias’ career started in 1968 and has had plenty of commercial success and artistic recognition, with more than 300 million records sold, about 5000 concerts for many millions of people, and dozens of awards worldwide. Iglesias is the most celebrated Latin music artist and one of the top 10 best-selling artists of all times.
Herein, we consider a total of 629 musical works included in 59 albums released in the period 1969–2007.
Figure 11 depicts the 25, 50, and 75 percentiles of and versus , showing a relationship between the evolution of the indices and the different periods of the artist’s career. Such a relationship also emerges in other complexity indices, but their corresponding charts are omitted here for the sake of parsimony.
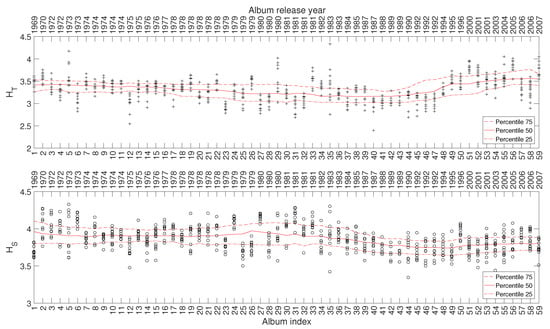
Figure 11.
The complexity indices and versus for Julio Iglesias’ music.
Figure 12 depicts the 3-dimensional map generated with and dissimilarity matrices and , with the z coordinate denoting the albums’ sequence, i, interpolated with RBI.
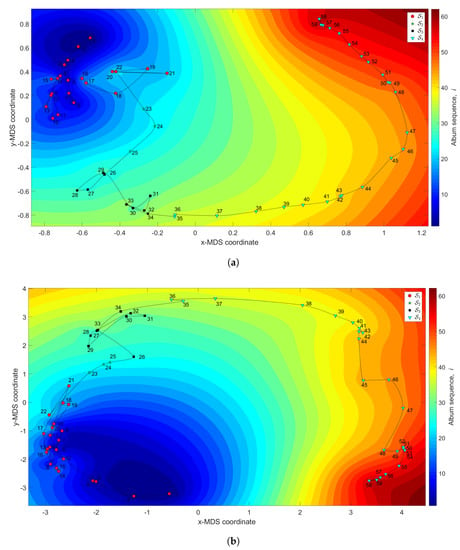
Figure 12.
The MDS maps for Julio Iglesias’s music. The coordinates are generated by means of the MDS with and the matrices: (a) ; (b) . The z coordinate represents the albums’ sequence, i, interpolated with RBI.
We verify the emergence of four clusters. The first, (i.e., albums ), coincides with the height of Iglesias’ success during the 1970s and 1980s of the twentieth century. In this period we observe that the complexity evolves as a tangle confined to a small region in the plane. For (), the complexity develops towards a new point, thanks to a few albums released in 1979. In the cluster (), the trajectory reaches another small tangle, corresponding to musical albums recorded between 1979 and 1982. This period precedes a fourth cluster, (), characterized by a large route and coinciding with albums released from 1983 up to 2007. Within this period, Iglesias started releasing many records tailored to suit American fans, including duets with some American stars. He then returned to the his Latin audience, including strengthening the relationship with his French followers, by releasing some French-language albums. In this period, Iglesias won the World Music Award and enjoyed major commercial success in Spain.
4. Conclusions
We adopted complexity, dimensionality-reduction, and visualization techniques for studying the music of several contemporary artists. The musical works were converted into digital format and represented in `mono’. The TS were assessed by means of eight distinct complexity indices. The 8-dimensional measurements were reduced to 2- and 3-dimensional by means of the MDS technique. The results revealed that the evolution of complexity is correlated with the artists’ musical careers. We conclude that the proposed indices represent reliable and assertive tools for assessing musical complexity.
Author Contributions
The authors contributed equally to this work.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Meredith, D. Computational Music Analysis; Springer: Berlin/Heidelberg, Germany, 2016; Volume 62. [Google Scholar]
- Roberts, G.E. From Music to Mathematics: Exploring the Connections; JHU Press: Baltimore, MD, USA, 2016. [Google Scholar]
- Burkholder, J.P.; Grout, D.J. A History of Western Music: Ninth International Student Edition; WW Norton & Company: New York, NY, USA, 2014. [Google Scholar]
- Christensen, T. The Cambridge History of Western Music Theory; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Davies, B. Exploring Chaos: Theory and Experiment; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Tang, L.; Lv, H.; Yang, F.; Yu, L. Complexity testing techniques for time series data: A comprehensive literature review. Chaos Solitons Fractals 2015, 81, 117–135. [Google Scholar] [CrossRef]
- Tarasov, V.E.; Tarasova, V.V. Time-dependent fractional dynamics with memory in quantum and economic physics. Ann. Phys. 2017, 383, 579–599. [Google Scholar] [CrossRef]
- Bonanno, G.; Lillo, F.; Mantegna, R.N. Levels of complexity in financial markets. Physica A 2001, 299, 16–27. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A.M. Analysis of natural and artificial phenomena using signal processing and fractional calculus. Fract. Calc. Appl. Anal. 2015, 18, 459–478. [Google Scholar] [CrossRef]
- Ionescu, C.; Lopes, A.; Copot, D.; Machado, J.T.; Bates, J. The role of fractional calculus in modeling biological phenomena: A review. Commun. Nonlinear Sci. Numer. Simul. 2017, 51, 141–159. [Google Scholar] [CrossRef]
- Perc, M.; Jordan, J.J.; Rand, D.G.; Wang, Z.; Boccaletti, S.; Szolnoki, A. Statistical physics of human cooperation. Phys. Rep. 2017, 687, 1–51. [Google Scholar] [CrossRef]
- Stanley, H.E. Phase Transitions and Critical Phenomena; Clarendon Press: Oxford, UK, 1971. [Google Scholar]
- Dogson, N.A. Mathematical characterisation of Bridget Riley’s stripe paintings. J. Math. Arts 2012, 5, 1–12. [Google Scholar]
- Sigaki, H.Y.; Perc, M.; Ribeiro, H.V. History of art paintings through the lens of entropy and complexity. Proc. Natl. Acad. Sci. USA 2018, 115, E8585–E8594. [Google Scholar] [CrossRef] [PubMed]
- Machado, J.T.; Lopes, A.M. Artistic painting: A fractional calculus perspective. Appl. Math. Model. 2019, 65, 614–626. [Google Scholar] [CrossRef]
- Boon, J.P.; Casti, J.; Taylor, R.P. Artistic forms and complexity. Nonlinear-Dyn.-Psychol. Life Sci. 2011, 15, 265. [Google Scholar]
- Taylor, R.; Micolich, A.; Jones, D. Fractal expressionism. Phys. World 1999, 12, 1–3. [Google Scholar] [CrossRef]
- De la Calleja, E.; Cervantes, F.; De la Calleja, J. Order-fractal transitions in abstract paintings. Ann. Phys. 2016, 371, 313–322. [Google Scholar] [CrossRef]
- Montagner, C.; Linhares, J.M.; Vilarigues, M.; Nascimento, S.M. Statistics of colors in paintings and natural scenes. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2016, 33, A170–A177. [Google Scholar] [CrossRef] [PubMed]
- Koch, M.; Denzler, J.; Redies, C. 1/f2 Characteristics and isotropy in the Fourier power spectra of visual art, cartoons, comics, mangas, and different categories of photographs. PLoS ONE 2010, 5, e12268. [Google Scholar] [CrossRef] [PubMed]
- Lopes, A.; Tenreiro Machado, J. Complexity Analysis of Global Temperature Time Series. Entropy 2018, 20, 437. [Google Scholar] [CrossRef]
- Simonton, D.K. Melodic structure and note transition probabilities: A content analysis of 15,618 classical themes. Psychol. Music 1984, 12, 3–16. [Google Scholar] [CrossRef]
- Eerola, T.; North, A. Cognitive complexity and the structure of musical patterns. In Proceedings of the 6th International Conference on Music Perception and Cognition, Keele, UK, 5–10 August 2000. [Google Scholar]
- Herrera, P.; Streich, S. Detrended fluctuation analysis of music signals: Danceability estimation and further semantic characterization. In Proceedings of the Audio Engineering Society 118th Convention, Barcelona, Spain, 28–31 May 2005. [Google Scholar]
- Li, M.; Sleep, R. Melody classification using a similarity metric based on Kolmogorov complexity. In Proceedings of the Sound and Music Computing Conference, Paris, France, 20–22 October 2004; Volume 2012. [Google Scholar]
- Ribeiro, H.V.; Zunino, L.; Mendes, R.S.; Lenzi, E.K. Complexity–entropy causality plane: A useful approach for distinguishing songs. Physica A 2012, 391, 2421–2428. [Google Scholar] [CrossRef]
- Hourdin, C.; Charbonneau, G.; Moussa, T. A multidimensional scaling analysis of musical instruments’ time-varying spectra. Comput. Music. J. 1997, 21, 40–55. [Google Scholar] [CrossRef]
- Machado, J.T.; Costa, A.C.; Lima, M.F. Dynamical analysis of compositions. Nonlinear Dyn. 2011, 65, 399–412. [Google Scholar]
- Knautz, K.; Neal, D.R.; Schmidt, S.; Siebenlist, T.; Stock, W.G. Finding emotional-laden resources on the World Wide Web. Information 2011, 2, 217–246. [Google Scholar] [CrossRef]
- Kostagiolas, P.; Lavranos, C.; Manolitzas, P. Survey Data for Measuring Musical Creativity and the Impact of Information. Data 2019, 4, 80. [Google Scholar] [CrossRef]
- Shannon, C. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Jaynes, E. Information Theory and Statistical Mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A.M. Multidimensional scaling analysis of soccer dynamics. Appl. Math. Model. 2017, 45, 642–652. [Google Scholar] [CrossRef]
- Cover, T.; Thomas, J. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Machado, J.T.; Lopes, A.M. Fractional Rényi entropy. Eur. Phys. J. Plus 2019, 134, 217. [Google Scholar] [CrossRef]
- Knuth, K.H.; Skilling, J. Foundations of inference. Axioms 2012, 1, 38–73. [Google Scholar] [CrossRef]
- Campión, M.J.; Gómez-Polo, C.; Induráin, E.; Raventós-Pujol, A. A Survey on the Mathematical Foundations of Axiomatic Entropy: Representability and Orderings. Axioms 2018, 7, 29. [Google Scholar] [CrossRef]
- Pramanik, S.; Dey, P.; Smarandache, F.; Ye, J. Cross entropy measures of bipolar and interval bipolar neutrosophic sets and their application for multi-attribute decision-making. Axioms 2018, 7, 21. [Google Scholar] [CrossRef]
- Tsallis, C. Approach of complexity in nature: Entropic nonuniqueness. Axioms 2016, 5, 20. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Berger, S.; Schneider, G.; Kochs, E.; Jordan, D. Permutation Entropy: Too Complex a Measure for EEG Time Series? Entropy 2017, 19, 692. [Google Scholar] [CrossRef]
- Lopez-Ruiz, R.; Mancini, H.L.; Calbet, X. A statistical measure of complexity. Phys. Lett. A 1995, 209, 321–326. [Google Scholar] [CrossRef]
- Martin, M.; Plastino, A.; Rosso, O. Generalized statistical complexity measures: Geometrical and analytical properties. Physica A 2006, 369, 439–462. [Google Scholar] [CrossRef]
- Rosso, O.; Larrondo, H.; Martin, M.; Plastino, A.; Fuentes, M. Distinguishing noise from chaos. Phys. Rev. Lett. 2007, 99, 154102. [Google Scholar] [CrossRef] [PubMed]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information’. Probl. Inf. Transm. 1965, 1, 1–7. [Google Scholar] [CrossRef]
- Antão, R.; Mota, A.; Machado, J.T. Kolmogorov complexity as a data similarity metric: Application in mitochondrial DNA. Nonlinear Dyn. 2018, 93, 1059–1071. [Google Scholar] [CrossRef]
- Lempel, A.; Ziv, J. On the complexity of finite sequences. IEEE Trans. Inf. Theory 1976, 22, 75–81. [Google Scholar] [CrossRef]
- Gordon, G. Multi-dimensionalensional linguistic complexity. J. Biomol. Struct. Dyn. 2003, 20, 747–750. [Google Scholar] [CrossRef]
- Dix, T.I.; Powell, D.R.; Allison, L.; Bernal, J.; Jaeger, S.; Stern, L. Comparative analysis of long DNA sequences by per element information content using different contexts. BMC Bioinform. 2007, 8, S10. [Google Scholar] [CrossRef]
- Molchanov, V.; Linsen, L. Upsampling for Improved Multidimensional Attribute Space Clustering of Multifield Data. Information 2018, 9, 156. [Google Scholar] [CrossRef]
- Gorokhovatskyi, O.; Gorokhovatskyi, V.; Peredrii, O. Analysis of Application of Cluster Descriptions in Space of Characteristic Image Features. Data 2018, 3, 52. [Google Scholar] [CrossRef]
- Li, Q.; Ma, Y.; Smarandache, F.; Zhu, S. Single-valued neutrosophic clustering algorithm based on Tsallis entropy maximization. Axioms 2018, 7, 57. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Wu, D.; Chen, J. Evolutionary Path of Factors Influencing Life Satisfaction among Chinese Elderly: A Perspective of Data Visualization. Data 2018, 3, 35. [Google Scholar] [CrossRef]
- Fiori, S. Visualization of Riemannian-manifold-valued elements by multidimensional scaling. Neurocomputing 2011, 74, 983–992. [Google Scholar] [CrossRef]
- Saeed, N.; Nam, H.; Haq, M.I.U.; Muhammad Saqib, D.B. A Survey on Multidimensional Scaling. ACM Comput. Surv. (CSUR) 2018, 51, 47. [Google Scholar] [CrossRef]
- Tenreiro Machado, J.; Lopes, A.; Galhano, A. Multidimensional scaling visualization using parametric similarity indices. Entropy 2015, 17, 1775–1794. [Google Scholar] [CrossRef]
- Machado, J.; Mendes Lopes, A. Fractional Jensen–Shannon analysis of the scientific output of researchers in fractional calculus. Entropy 2017, 19, 127. [Google Scholar] [CrossRef]
- Lartillot, O.; Toiviainen, P.; Eerola, T. A Matlab toolbox for music information retrieval. In Data Analysis, Machine Learning and Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 261–268. [Google Scholar]
- Giannakopoulos, T. pyAudioanalysis: An open-source python library for audio signal analysis. PLoS ONE 2015, 10, e0144610. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 18–25. [Google Scholar]
- Papakostas, M.; Giannakopoulos, T. Speech-music discrimination using deep visual feature extractors. Expert Syst. Appl. 2018, 114, 334–344. [Google Scholar] [CrossRef]
- Pikrakis, A.; Giannakopoulos, T.; Theodoridis, S. A speech/music discriminator of radio recordings based on dynamic programming and bayesian networks. IEEE Trans. Multimed. 2008, 10, 846–857. [Google Scholar] [CrossRef]
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Carr, J.C.; Fright, W.R.; Beatson, R.K. Surface interpolation with radial basis functions for medical imaging. IEEE Trans. Med Imaging 1997, 16, 96–107. [Google Scholar] [CrossRef] [PubMed]















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).