Double-Granule Conditional-Entropies Based on Three-Level Granular Structures


Abstract
1. Introduction
2. Decision Table and Its Existing Entropy Measures
- (1)
- The condition attribute subset induces an equivalence relationand the latter provides the condition granulation or partition , where represents the equivalence granule to exhibit number .
- (2)
- Similarly, the decision attribute set D induces the equivalence relation and further decision classification , which consists of decision classes.
3. Double-Granule Conditional-Entropies Based on Three-Level Granular Structures
- (1)
- According to Equation (5), the locality mainly refers to less range in universe U. More essentially, we can stand on the dual granules and to propose a novel notion of double-granule conditional-entropies, and it differs from the usual entropy system with only the single-granule representation which implies a kind of first-order style. Moreover, the measure properties are lacking in [18], and we will provide in-depth properties such as restriction bounds and granulation non-monotonicity.
- (2)
- Regarding granular structures, all decision classes () (or decision classification ) are considered, but condition granules involve only two factors and . A condition partition ) needs considering in practice to provide a system description of knowledge granulation, so we also focus on granulation to introduce three-level granular structures for hierarchical constructions of double-granule conditional-entropies.
- (3)
- Finally, the initial concept is limited to only C for expressing the discernibility matrix and reduction core, and a general subset has better theoretical and practical prospects, especially for the knowledge-based applications (such as attribute reduction or feature selection).
3.1. Double-Granule Conditional-Entropy at Micro-Bottom
| Algorithm 1: Calculation of double-granule conditional-entropy at micro-bottom |
| Input: Decision table , target subset , and two special indexes ; Output: Double-granule conditional-entropy at micro-bottom .
|
3.2. Double-Granule Conditional-Entropy at Meso-Middle
| Algorithm 2: Calculation of double-granule conditional-entropy at meso-middle |
| Input: Decision table , target subset , and a special index ; Output: Double-granule conditional-entropy at meso-middle .
|
3.3. Double-Granule Conditional-Entropy at Macro-Top
| Algorithm 3: Calculation of double-granule conditional-entropy at macro-top |
| Input: Decision table , target subset ; Output: Double-granule conditional-entropy at Macro-Top .
|
4. Decision Table Example
- (1)
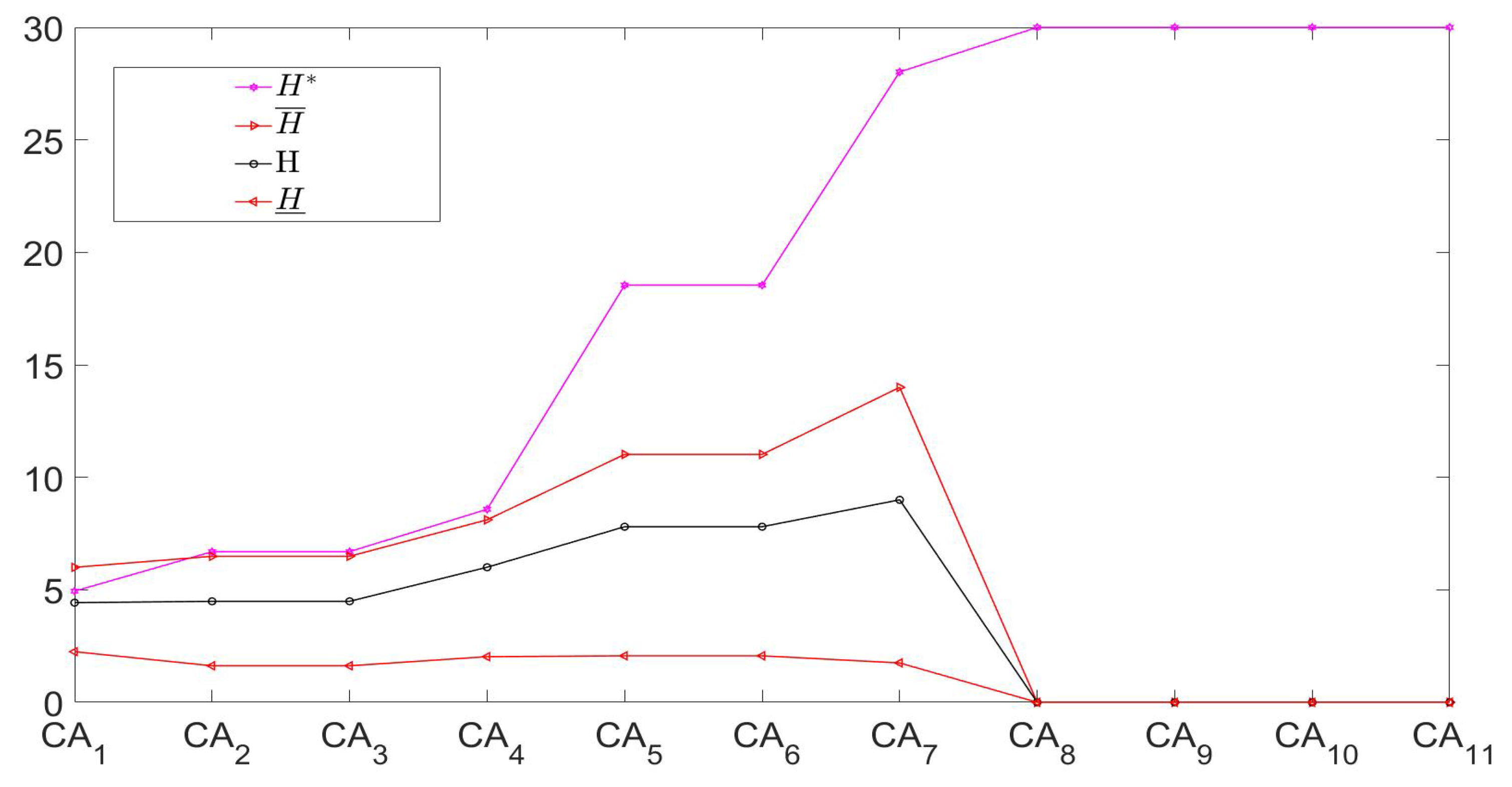
- Since different chain subsets may have different equivalence partitions and granule numbers, the measures at micro-bottom and meso-middle consider condition granules to have a distinctive number and difficult correspondence. Table 9 focuses on the small and the same granule number, but relevant granules have different connotations. For example, the granules of the first one — ()—may be different. Thus, we cannot acquire the so-called granulation non-monotonicity assertion because of granulation incompletion, although the values at micro-bottom and meso-middle actually exhibit a kind of non-monotonic change in Table 9.
- (2)
- In contrast, macro-top offers the complete condition granulation, so we can effectively focus on value monotonicity/non-monotonicity for both double-granule conditional-entropies and their three bounds. Observing the bottom part of Table 9 in the enlargement chain direction, we can discover that the three types of information measures are all non-monotonic, i.e.,More vividly, the entropy and its three bounds regarding the chain are depicted in Figure 3, so the related granulation non-monotonicity becomes clearer. For example, the macro entropy value first increases and then decreases in the addition chain direction. Moreover, Table 9 and Figure 3 reflect the restriction properties of three bounds.
5. Data Experiments
- (1)
- (2)
- (3)
6. Conclusions
- (1)
- In contrast to the relevant technology in [56], the hierarchical granulation of three-level granular structures focuses on the conditional granulation and relevant number, and it can be generalized for granular computing.
- (2)
- The double-granule conditional-entropies and their three bounds become new types of information measures with the second-order feature. In contrast to the traditional first-order entropy system, their description power and application advantage need further practical verification.
- (3)
- The double-granule conditional-entropies have three-restrictive bounds and granulation non-monotonicity, which have been experimentally verified by a granulation-hierarchical sequence (i.e., Equation (34)). These results are worth deeply utilizing in uncertainty measurement and data mining.
- (4)
- The double-granule conditional-entropies originate from the local conditional-entropies to carry a potential and distinctive advantage of discernibility matrix representation, and they also have the complete conditional granulation to have application prospects in knowledge reasoning or acquisition. Both their relationships with the discernibility matrix and their functions on attribute reduction need be deeply researched by promoting the previous studies in [18].
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pawlak, Z. Rough set. Int. J. Comput. Inf. Sci. 1982, 11, 38–39. [Google Scholar] [CrossRef]
- Raza, M.S.; Qamar, U. Redefining core preliminary concepts of classic rough set theory for feature selection. Eng. Appl. Artif. Intell. 2017, 65, 375–387. [Google Scholar] [CrossRef]
- Saha, I.; Sarkar, J.P.; Maulik, U. Integrated rough fuzzy clustering for categorical data analysis. Fuzzy Sets Syst. 2019, 361, 1–32. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, X.Y.; Wang, Q.; Liang, J.Y.; Liu, B.; Andrzej, S.; Yao, Y.Y.; Ma, J.M.; Dang, C.Y. Local rough set: A solution to rough data analysis in big data. Int. J. Approx. Reason. 2018, 97, 38–63. [Google Scholar] [CrossRef]
- Hu, M.J.; Yao, Y.Y. Structured approximations as a basis for three-way decisions in rough set theory. Knowl.-Based Syst. 2019, 165, 92–109. [Google Scholar] [CrossRef]
- Yang, X.B.; Liang, S.C.; Yu, H.L.; Gao, S.; Qian, Y.H. Pseudo-label neighborhood rough set: Measures and attribute reductions. Int. J. Approx. Reason. 2019, 105, 112–129. [Google Scholar] [CrossRef]
- Wang, Z.H.; Feng, Q.R.; Wang, H. The lattice and matroid representations of definable sets in generalized rough sets based on relations. Inf. Sci. 2019, 485, 505–520. [Google Scholar] [CrossRef]
- Luo, C.; Li, T.R.; Chen, H.M.; Fujita, H.; Zhang, Y. Incremental rough set approach for hierarchical multicriteria classification. Inf. Sci. 2018, 429, 72–87. [Google Scholar] [CrossRef]
- Yao, Y.Y.; Zhang, X.Y. Class-specific attribute reducts in rough set theory. Inf. Sci. 2017, 418–419, 601–618. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Yang, J.L.; Tang, L.Y. Three-way class-specific attribute reducts from the information viewpoint. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Ma, X.A.; Yao, Y.Y. Three-way decision perspectives on class-specific attribute reducts. Inf. Sci. 2018, 450, 227–245. [Google Scholar] [CrossRef]
- Miao, D.Q.; Zhao, Y.; Yao, Y.Y.; Li, H.X.; Xu, F.F. Relative reducts in consistent and inconsistent decision tables of the Pawlak rough set model. Inf. Sci. 2009, 179, 4140–4150. [Google Scholar] [CrossRef]
- Lang, G.M.; Cai, M.J.; Fujita, H.; Xiao, Q.M. Related families-based attribute reduction of dynamic covering decision information systems. Knowl.-Based Syst. 2018, 162, 161–173. [Google Scholar] [CrossRef]
- Gao, C.; Lai, Z.H.; Zhou, J.; Wen, J.J.; Wong, W.K. Granular maximum decision entropy-based monotonic uncertainty measure for attribute reduction. Int. J. Approx. Reason. 2019, 104, 9–24. [Google Scholar] [CrossRef]
- Wang, C.Z.; Shi, Y.P.; Fan, X.D.; Shao, M.W. Attribute reduction based on k-nearest neighborhood rough sets. Int. J. Approx. Reason. 2019, 106, 18–31. [Google Scholar] [CrossRef]
- Wei, W.; Wu, X.Y.; Liang, J.Y.; Cui, J.B.; Sun, Y.J. Discernibility matrix based incremental attribute reduction for dynamic data. Knowl.-Based Syst. 2018, 140, 142–157. [Google Scholar] [CrossRef]
- Ma, F.M.; Ding, M.W.; Zhang, T.F.; Cao, J. Compressed binary discernibility matrix based incremental attribute reduction algorithm for group dynamic data. Neurocomputing 2019, 344, 20–27. [Google Scholar]
- Nie, H.M.; Zhou, J.Q. A new discernibility matrix and the computation of a core. J. Sichuan Univ. (Nat. Sci. Ed.) 2007, 44, 277–283. (In Chinese) [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shiraz, R.K.; Fukuyama, H.; Tavana, M.; Caprio, D.D. An integrated data envelopment analysis and free disposal hull framework for cost-efficiency measurement using rough sets. Appl. Soft Comput. 2016, 46, 204–219. [Google Scholar] [CrossRef]
- Liang, J.Y.; Shi, Z.Z.; Li, D.Y.; Wierman, M.J. Information entropy, rough entropy and knowledge granularity in incomplete information systems. Int. J. Gen. Syst. 2006, 35, 641–654. [Google Scholar] [CrossRef]
- Wei, W.; Liang, J.Y. Information fusion in rough set theory: An overview. Inf. Fusion 2019, 48, 107–118. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.R.; Xie, Z.X.; Liu, J.F. Fuzzy probabilistic approximation spaces and their information measures. IEEE Trans. Fuzzy Syst. 2006, 14, 191–201. [Google Scholar]
- Dai, J.H.; Wei, B.J.; Zhang, X.H. Uncertainty measurement for incomplete interval-valued information systems based on α-weak similarity. Knowl.-Based Syst. 2017, 136, 159–171. [Google Scholar] [CrossRef]
- Chen, Y.M.; Xue, Y.; Ma, Y.; Xu, F.F. Measures of uncertainty for neighborhood rough sets. Knowl.-Based Syst. 2017, 120, 226–235. [Google Scholar] [CrossRef]
- Miao, D.Q. Rough Set Theory and Its Application in Machine Learing. Ph.D. Thesis, Institute of Automation, The Chinese Academy of Sciences, Beijing, China, 1997. (In Chinese). [Google Scholar]
- Wang, G.Y.; Zhao, J.; An, J.J.; Wu, Y. A comparative study of algebra viewpoint and information viewpoint in attribute reduction. Fundam. Inf. 2005, 68, 289–301. [Google Scholar]
- Jiang, F.; Sui, Y.F.; Zhou, L. A relative decision entropy-based feature selection approach. Pattern Recognit. 2015, 48, 2151–2163. [Google Scholar] [CrossRef]
- Slezak, D. Approximate entropy reducts. Fundam. Inf. 2002, 53, 365–390. [Google Scholar]
- Qian, W.B.; Shu, W.H. Mutual information criterion for feature selection from incomplete data. Neurocomputing 2015, 168, 210–220. [Google Scholar] [CrossRef]
- Liang, J.Y.; Chin, K.S.; Dang, C.Y.; Yam, R.C.M. A new method for measuring uncertainty and fuzziness in rough set theory. Int. J. Gen. Syst. 2002, 31, 331–342. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y. Combination entropy and combination granulation in rough set theory. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2008, 16, 179–193. [Google Scholar]
- Hu, Q.H.; Che, X.J.; Zhang, L. Rank entropy-based decision trees for monotonic classifcation. IEEE Trans. Knowl. Data Eng. 2012, 24, 2052–2064. [Google Scholar] [CrossRef]
- Dai, J.H.; Xu, Q.; Wang, W.T.; Tian, H.W. Conditional entropy for incomplete decision systems and its application in data mining. Int. J. Gen. Syst. 2012, 41, 713–728. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, X.Y.; Xu, J.C.; Zhang, S.G. An attribute reduction method using neighborhood entropy measures in neighborhood rough sets. Entropy 2019, 21, 155. [Google Scholar] [CrossRef]
- Chen, D.G.; Yang, W.X.; Li, F.C. Measures of general fuzzy rough sets on a probabilistic space. Inf. Sci. 2008, 178, 3177–3187. [Google Scholar] [CrossRef]
- Mi, J.S.; Leung, Y.; Wu, W.Z. An uncertainty measure in partition-based fuzzy rough sets. Int. J. Gen. Syst. 2005, 34, 77–90. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, L.; Zhang, D.; Pan, W.; An, S.; Pedrycz, W. Measuring relevance between discrete and continuous features based on neighborhood mutual information. Expert Syst. Appl. 2011, 38, 10737–10750. [Google Scholar] [CrossRef]
- Zhao, J.Y.; Zhang, Z.L.; Han, C.Z.; Zhou, Z.F. Complement information entropy for uncertainty measure in fuzzy rough set and its applications. Soft Comput. 2015, 19, 1997–2010. [Google Scholar] [CrossRef]
- Deng, X.F.; Yao, Y.Y. A multifaceted analysis of probabilistic three-way decisions. Fundam. Inf. 2014, 132, 291–313. [Google Scholar]
- Deng, X.F.; Yao, Y.Y. An information-theoretic interpretation of thresholds in probabilistic rough sets. Lect. Notes Comput. Sci. 2012, 7414, 369–378. [Google Scholar]
- Ma, X.A.; Wang, G.Y.; Yu, H.; Li, T.R. Decision region distribution preservation reduction in decision-theoretic rough set model. Inf. Sci. 2014, 278, 614–640. [Google Scholar] [CrossRef]
- Zadeh, L.A. Towards a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst. 1997, 90, 111–127. [Google Scholar] [CrossRef]
- Yao, Y.Y. A triarchic theory of granular computing. Granul. Comput. 2016, 1, 145–157. [Google Scholar] [CrossRef]
- Skowron, A.; Stepaniuk, J.; Swiniarski, R. Modeling rough granular computing based on approximation spaces. Inf. Sci. 2012, 184, 20–43. [Google Scholar] [CrossRef]
- Chiaselotti, G.; Gentile, T.; Infusino, F. Granular computing on information tables: Families of subsets and operators. Inf. Sci. 2018, 442–443, 72–102. [Google Scholar]
- Eissa, M.M.; Elmogy, M.; Hashem, M. Rough-granular computing knowledge discovery models for medical classification. Egypt. Inf. J. 2016, 17, 265–272. [Google Scholar] [CrossRef][Green Version]
- Qian, Y.H.; Zhang, H.; Sang, Y.L.; Liang, J.Y. Multigranulation decision-theoretic rough sets. Int. J. Approx. Reason. 2014, 55, 225–237. [Google Scholar] [CrossRef]
- Li, J.H.; Mei, C.L.; Xu, W.H.; Qian, Y.H. Concept learning via granular computing: A cognitive viewpoint. Inf. Sci. 2015, 298, 447–467. [Google Scholar] [CrossRef]
- Wang, G.Y.; Ma, X.A.; Yu, H. Monotonic uncertainty measures for attribute reduction in probabilistic rough set model. Int. J. Approx. Reason. 2015, 59, 41–67. [Google Scholar] [CrossRef]
- Jia, X.Y.; Shang, L.; Zhou, B.; Yao, Y.Y. Generalized attribute reduct in rough set theory. Knowl.-Based Syst. 2016, 91, 204–218. [Google Scholar]
- Zhang, X.Y.; Miao, D.Q. Double-quantitative fusion of accuracy and importance: Systematic measure mining, benign integration construction, hierarchical attribute reduction. Knowl.-Based Syst. 2016, 91, 219–240. [Google Scholar]
- Calvanese, D.; Dumas, M.; Laurson, U.; Maggi, F.M.; Montali, M.; Teinemaa, I. Semantics analysis and simplification of DMN decision tables. Inf. Syst. 2018, 78, 112–125. [Google Scholar] [CrossRef]
- Liu, G.L.; Hua, Z.; Zou, J.Y. Local attribute reductions for decision tables. Inf. Sci. 2018, 422, 204–217. [Google Scholar] [CrossRef]
- Ge, H.; Li, L.S.; Xu, Y.; Yang, C.J. Quick general reduction algorithms for inconsistent decision tables. Int. J. Approx. Reason. 2017, 82, 56–80. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Miao, D.Q. Three-layer granular structures and three-way informational measures of a decision table. Inf. Sci. 2017, 412–413, 67–86. [Google Scholar]
- Wang, J.; Tang, L.Y.; Zhang, X.Y.; Luo, Y.Y. Three-way weighted combination-entropies based on three-layer granular structures. Appl. Math. Nonlinear Sci. 2017, 2, 329–340. [Google Scholar]
- Yao, Y.Y. An outline of a theory of three-way decisions. In Rough Sets and Current Trends in Computing, Proceedings of the International Conference on Rough Sets and Current Trends in Computing, Chengdu, China, 17–20 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–17. [Google Scholar]
- Yao, Y.Y. Three-way decision and granular computing. Int. J. Approx. Reason. 2018, 103, 107–123. [Google Scholar] [CrossRef]
- Fard, A.M.F.; Hajaghaei-Keshteli, M. A tri-level location-allocation model for forward/reverse supply chain. Appl. Soft Comput. 2018, 62, 328–346. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Mirjalili, S. Hybrid optimizers to solve a tri-level programming model for a tire closed-loop supply chain network design problem. Appl. Soft Comput. 2018, 70, 701–722. [Google Scholar] [CrossRef]
- Gu, Y.; Cai, X.J.; Han, D.R.; Wang, D.Z.W. A tri-level optimization model for a private road competition problem with traffic equilibrium constraints. Eur. J. Operat. Res. 2019, 273, 190–197. [Google Scholar] [CrossRef]
- Ye, D.Y.; Chen, Z.J. A new discernibility matrix and the computation of a core. Acta Electr. Sin. 2002, 30, 1086–1088. (In Chinese) [Google Scholar]
- Zhang, X.Y.; Miao, D.Q. Quantitative/qualitative region-change uncertainty/certainty in attribute reduction: Comparative region-change analyses based on granular computing. Inf. Sci. 2016, 334–335, 174–204. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 3 July 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure Naming | Composition System | Granular Scale | Granular Level | Number of Parallel Patterns |
|---|---|---|---|---|
| Micro-Bottom | Micro | Bottom | ||
| Meso-Middle | Meso | Middle | n | |
| Macro-Top | Macro | Top | 1 |
| ⋯ | ⋯ | ||||
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ |
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ |
| ⋯ | ⋯ |
| ⋯ | ⋯ | ||||
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ |
| ⋯ | ⋯ | ||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ |
| ⋯ | ⋯ |
| ⋯ | ⋯ | Meso-Middle | ||||
| ⋯ | ⋯ | |||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ | ⋮ |
| ⋯ | ⋯ | |||||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋱ | ⋮ | ⋮ |
| ⋯ | ⋯ | |||||
| Meso-Middle | ⋯ | ⋯ | Macro-Top: |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| Macro-Top |
| U | D | |||||||||||
| 2 | 2 | 4 | 4 | 4 | 3 | 4 | 4 | 4 | 2 | 4 | 1 | |
| 2 | 2 | 4 | 4 | 2 | 2 | 4 | 4 | 4 | 2 | 3 | 1 | |
| 3 | 4 | 3 | 4 | 2 | 4 | 2 | 4 | 4 | 2 | 2 | 0 | |
| 2 | 4 | 2 | 3 | 2 | 4 | 2 | 4 | 2 | 2 | 4 | 0 | |
| 4 | 4 | 2 | 4 | 2 | 4 | 3 | 4 | 4 | 4 | 3 | 0 | |
| 2 | 4 | 2 | 4 | 2 | 2 | 2 | 4 | 4 | 4 | 4 | 0 | |
| 2 | 2 | 4 | 4 | 2 | 2 | 2 | 3 | 4 | 4 | 2 | 0 | |
| 2 | 2 | 4 | 4 | 2 | 2 | 2 | 4 | 4 | 3 | 4 | 1 |
| U | Meso-Middle | ||||||
| 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | |||
| 0 | 0 | 0 | 0 | 0 | |||
| Meso-Middle | Macro-Top: |
| U | Meso-Middle | ||||||
0 | 1 | 1 | 1 | 1 | |||
1 | 1 | 1 | 1 | ||||
1 | 1 | 0 | 0 | 0 | 0 | ||
1 | 1 | 0 | 0 | 0 | 0 | ||
1 | 1 | 0 | 0 | 0 | 0 | ||
1 | 1 | 0 | 0 | 0 | 0 | ||
| Meso-Middle | Macro-Top: |
| Level | Measure | |||||||||||
| Micro-Bottom | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 | 0 0 | 0 1 0 0 0 | 0 1 0 0 0 | 0 1 0 0 0 | 0 1 0 0 0 | 0 1 0 0 0 | |
| Meso-Middle | 0 0 0 | 0 0 0 | 0 0 0 | 0 0 0 | ||||||||
| Macro-Top | 0 0 0 30 | 0 0 0 30 | 0 0 0 30 | 0 0 0 30 |
| U | Meso-Middle | ||||
| 0 | 0 | 0 | |||
| 0 | 0 | 0 | |||
| 0 | 0 | 0 | |||
| Meso-Middle | Macro-Top: |
| Label | Name | |||||
|---|---|---|---|---|---|---|
| (1) | VOTING | 435 | 16 | 342 | 1 | 2 |
| (2) | SPECT | 187 | 22 | 169 | 1 | 2 |
| (3) | Tic-Tac-Toe | 958 | 9 | 958 | 1 | 2 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | |||||||
| 0.9867 | 0.9782 | 0.8369 | 2.8018 | ⋯ | 0 | ⋯ | 0 | 0 | ||
| 0.9782 | 0.8113 | 0.6578 | 2.4473 | ⋯ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |
| 0.8369 | 0.6578 | 0.6479 | 2.1427 | ⋯ | 0 | ⋯ | 0 | 0 | ||
| Meso-Middle | 2.8018 | 2.4473 | 2.1427 | Macro-Top: 7.3918 | ⋯ | Meso-Middle | 0 | ⋯ | 0 | Macro-Top: 0 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | |||||||
| ⋯ | 0 | ⋯ | 0 | |||||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |||||
| ⋯ | 0 | ⋯ | 0 | |||||||
| Meso-Middle | Macro-Top: | ⋯ | Meso-Middle | ⋯ | Macro-Top: 50132 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | ||||||
| 0.2108 | 0.3815 | 0.5924 | ⋯ | 0 | ⋯ | 0 | 1.5335 | ||
| ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |||||
| 0.3815 | 0.5399 | 0.9215 | ⋯ | 0 | ⋯ | 0 | 1.5335 | ||
| Meso-Middle | 0.5924 | 0.9215 | Macro-Top: 1.5139 | ⋯ | Meso-Middle | 1.5335 | ⋯ | 1.5335 | Macro-Top: 513.0879 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | ||||||
| ⋯ | 0 | ⋯ | 0 | ||||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | ||||
| ⋯ | 0 | ⋯ | 0 | ||||||
| Meso-Middle | Macro-Top: | ⋯ | Meso-Middle | ⋯ | Macro-Top: 2867 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | |||||||
| 0.8742 | 0.9248 | 0.8794 | 2.6784 | ⋯ | 0 | ⋯ | 0 | 0 | ||
| 0.9248 | 0.9881 | 0.9509 | 2.8638 | ⋯ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |
| 0.8794 | 0.9509 | 0.8901 | 2.7203 | ⋯ | 0 | ⋯ | 0 | 0 | ||
| Meso-Middle | 2.6784 | 2.8638 | 2.7203 | Macro-Top: 8.2625 | ⋯ | Meso-Middle | 0 | ⋯ | 0 | Macro-Top: 0 |
| Meso-Middle | ⋯ | ⋯ | Meso-Middle | |||||||
| ⋯ | 0 | ⋯ | 0 | 332 | ||||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ | |||||
| ⋯ | 0 | ⋯ | 0 | 626 | ||||||
| Meso-Middle | Macro-Top: | ⋯ | Meso-Middle | 332 | ⋯ | 626 | Macro-Top: 415664 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, T.; Zhang, X.; Mo, Z. Double-Granule Conditional-Entropies Based on Three-Level Granular Structures. Entropy 2019, 21, 657. https://doi.org/10.3390/e21070657
Mu T, Zhang X, Mo Z. Double-Granule Conditional-Entropies Based on Three-Level Granular Structures. Entropy. 2019; 21(7):657. https://doi.org/10.3390/e21070657
Chicago/Turabian StyleMu, Taopin, Xianyong Zhang, and Zhiwen Mo. 2019. "Double-Granule Conditional-Entropies Based on Three-Level Granular Structures" Entropy 21, no. 7: 657. https://doi.org/10.3390/e21070657
APA StyleMu, T., Zhang, X., & Mo, Z. (2019). Double-Granule Conditional-Entropies Based on Three-Level Granular Structures. Entropy, 21(7), 657. https://doi.org/10.3390/e21070657