Emotion Recognition from Skeletal Movements



Abstract
1. Introduction
- (a)
- We propose a different representation of affective movements, based on sequence of joints positions and orientations. Together with classification using selected neural networks and a comparison of classification performance with methods used in action recognition, for seven affective states: neutral, sadness, surprise, fear, disgust, anger and happiness.
- (b)
- The presented algorithms utilise a sequential model of affective movement based on low level features, which are positions and orientation of joints within the skeleton provided by Kinect v2. By using such intuitive and easily interpretable representation, we created an emotional gestures recognition system independent of skeleton specifications and with minimum preprocessing requirements (eliminating features extraction from the process).
- (c)
- Research is carried out on a new, comprehensive database that comprises a large variety of emotion expressions [31]. Although the recordings are performed by professional actors/actresses, the movements were freely portrayed not imposed by the authors. Thus, it may be treated as quasi-natural.
- (d)
- By comparing results with action/posture recognition approaches, we have shown that emotion recognition is a more complex problem. The analysis should focus on dependencies in the sequence of frames rather than describing whole movement by general features.
2. The Proposed Method
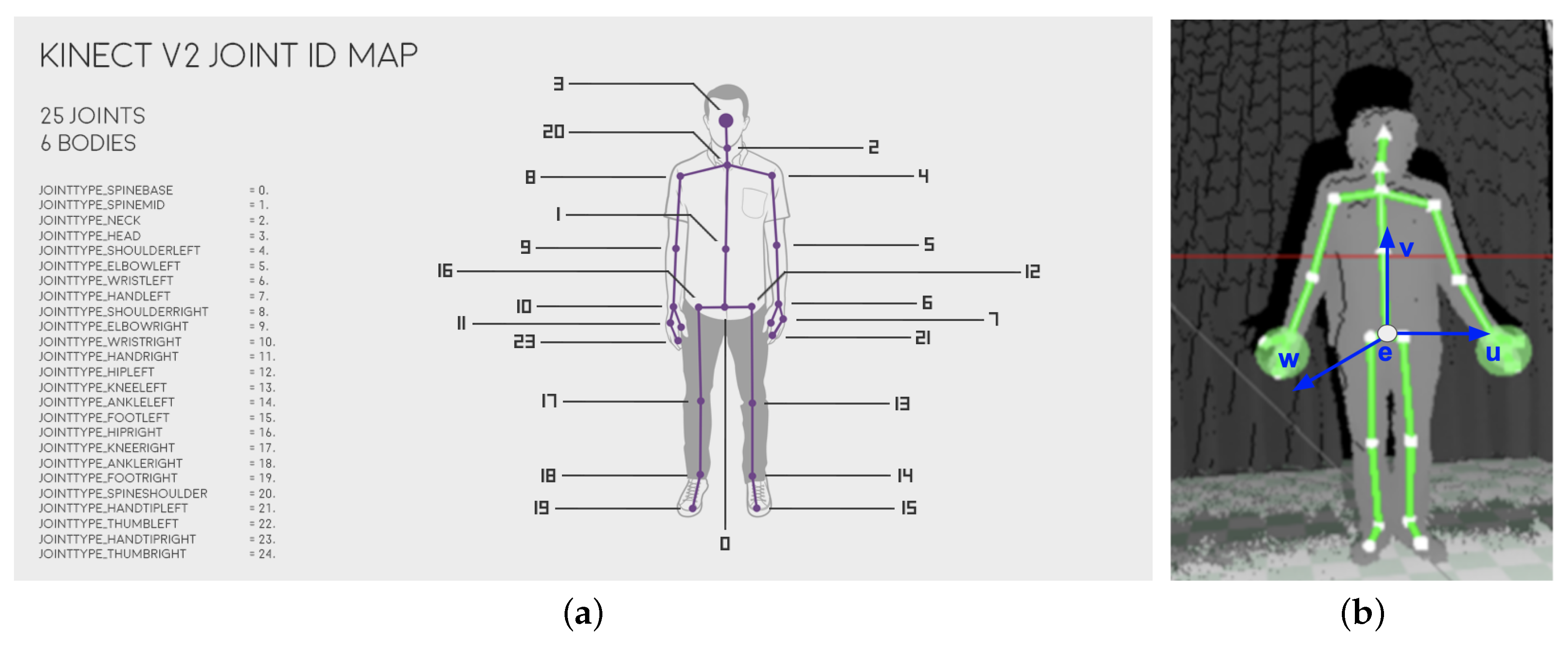
2.1. 3D Point Data—Emotional Gestures and Body Movements Corpora
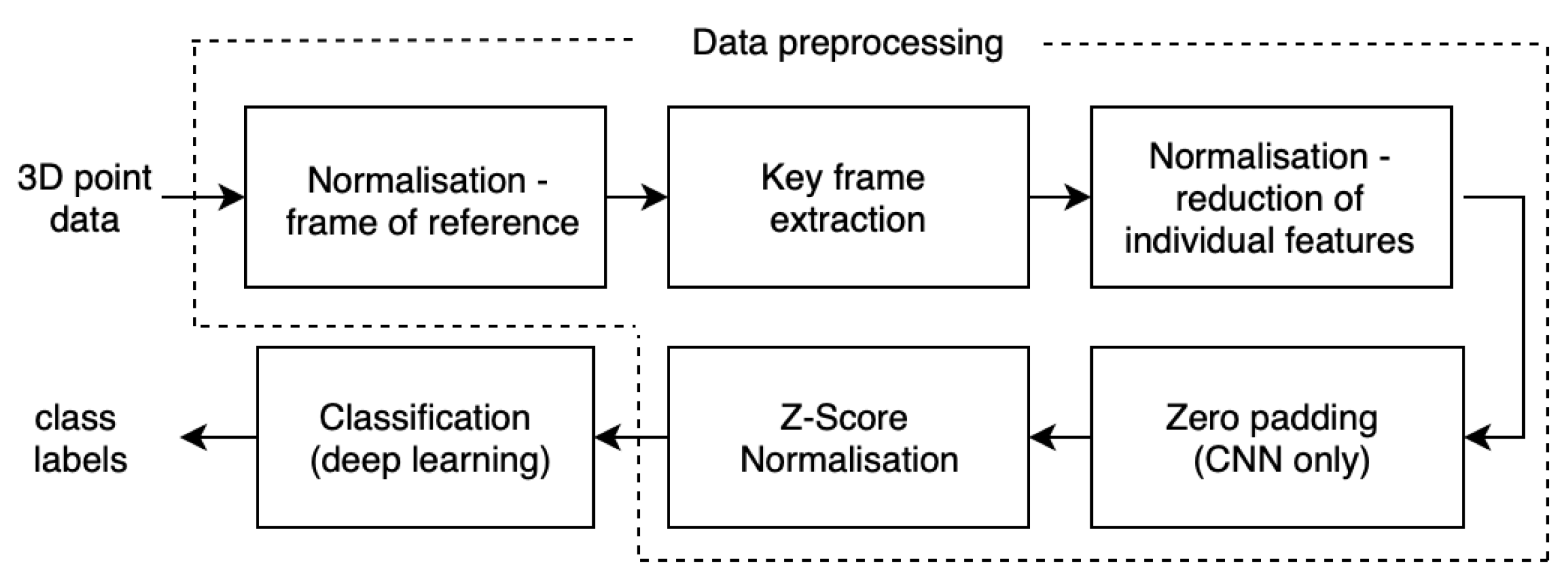
2.2. Preprocessing
2.2.1. Normalisation—Frame of Reference
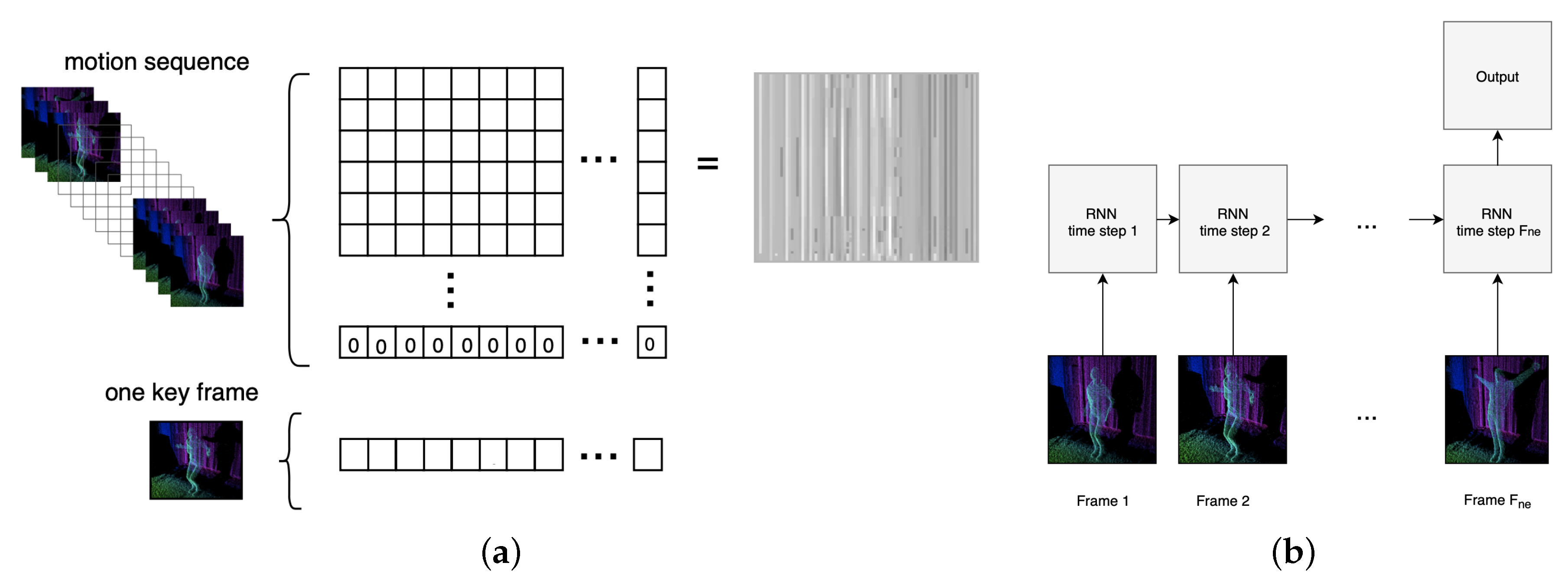
2.2.2. Key Frame Extraction
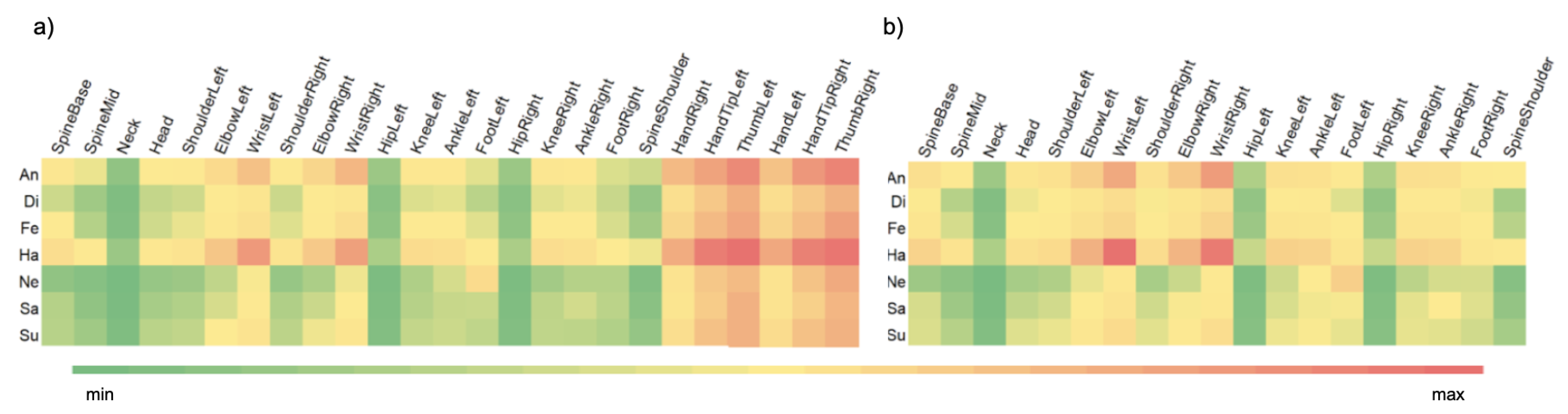
2.2.3. Normalisation—Reduction of Individual Features
2.3. Datasets Division
2.4. Classification—Models of Neural Networks
2.4.1. Convolutional Neural Network
2.4.2. Recurrent Neural Network
3. Results and Discussion
Selection of the Optimal Classification Model
- CNN networks containing from 2 to 3 convolution layers (each convolution layer was followed by a max pooling layer) followed by 1 to 2 dense layers, from 50 to 400 neurons for convolution and 50 to 200 for dense neurons;
- RNN networks containing from 2 to 4 layers, built from 50 to 400 neurons;
- RNN-LSTM networks containing from 2 to 4 layers, built from 50 to 400 neurons;
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Moment Estimation |
| CNN | Convolutional Neural Network |
| CS | Curve Simplification |
| HMM | Hidden Markov Model |
| k-NN | k-nearest neighbors |
| LSTM | Long short-term memory |
| NN | Neural Network |
| RBM | Restricted Boltzmann Machine |
| RNN | Recurrent Neural Network |
| ResNet | Residual Network |
| SVM | Support Vector Machine |
| MLP | Multilayer perceptron |
References
- Ekman, P. Facial action coding system (FACS). A Human Face 2002. Available online: https://www.cs.cmu.edu/~face/facs.htm (accessed on 28 June 2019).
- Pease, A.; McIntosh, J.; Cullen, P. Body Language; Camel; Malor Books: Los Altos, CA, USA, 1981. [Google Scholar]
- Izdebski, K. Emotions in the Human Voice, Volume 3: Culture and Perception; Plural Publishing: San Diego, CA, USA, 2008; Volume 3. [Google Scholar]
- Kim, J.; André, E. Emotion recognition based on physiological changes in music listening. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2067–2083. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. Emotions Revealed: Understanding Faces and Feelings; Hachette: London, UK, 2012. [Google Scholar]
- Hess, U.; Fischer, A. Emotional mimicry: Why and when we mimic emotions. Soc. Personal. Psychol. Compass 2014, 8, 45–57. [Google Scholar] [CrossRef]
- Kulkarni, K.; Corneanu, C.; Ofodile, I.; Escalera, S.; Baro, X.; Hyniewska, S.; Allik, J.; Anbarjafari, G. Automatic recognition of facial displays of unfelt emotions. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Mehrabian, A. Nonverbal Communication; Routledge: London, UK, 2017. [Google Scholar]
- Mehrabian, A. Silent Messages; Wadsworth: Belmont, CA, USA, 1971; Volume 8. [Google Scholar]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Corneanu, C.; Noroozi, F.; Kaminska, D.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Sequence of the most informative joints (smij): A new representation for human skeletal action recognition. J. Vis. Commun. Image Represent. 2014, 25, 24–38. [Google Scholar] [CrossRef]
- Gunes, H.; Piccardi, M. Affect recognition from face and body: Early fusion vs. late fusion. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005; Volume 4, pp. 3437–3443. [Google Scholar]
- Ofodile, I.; Helmi, A.; Clapés, A.; Avots, E.; Peensoo, K.M.; Valdma, S.M.; Valdmann, A.; Valtna-Lukner, H.; Omelkov, S.; Escalera, S.; et al. Action Recognition Using Single-Pixel Time-of-Flight Detection. Entropy 2019, 21, 414. [Google Scholar] [CrossRef]
- Kipp, M.; Martin, J.C. Gesture and emotion: Can basic gestural form features discriminate emotions? In Proceedings of the 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops (ACII 2009), Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–8. [Google Scholar]
- Bernhardt, D.; Robinson, P. Detecting emotions from connected action sequences. In Visual Informatics: Bridging Research and Practice, Proceedings of the International Visual Informatics Conference (IVIC 2009), Kuala Lumpur, Malaysia, 11–13 November 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–11. [Google Scholar]
- Rasti, P.; Uiboupin, T.; Escalera, S.; Anbarjafari, G. Convolutional neural network super resolution for face recognition in surveillance monitoring. In Articulated Motion and Deformable Objects (AMDO 2016); Springer: Cham, Switzerland, 2016; pp. 175–184. [Google Scholar]
- Demirel, H.; Anbarjafari, G. Data fusion boosted face recognition based on probability distribution functions in different colour channels. Eurasip J. Adv. Signal Process. 2009, 2009, 25. [Google Scholar] [CrossRef]
- Litvin, A.; Nasrollahi, K.; Ozcinar, C.; Guerrero, S.E.; Moeslund, T.B.; Anbarjafari, G. A Novel Deep Network Architecture for Reconstructing RGB Facial Images from Thermal for Face Recognition. Multimed. Tools Appl. 2019. [Google Scholar] [CrossRef]
- Nasrollahi, K.; Escalera, S.; Rasti, P.; Anbarjafari, G.; Baro, X.; Escalante, H.J.; Moeslund, T.B. Deep learning based super-resolution for improved action recognition. In Proceedings of the IEEE 2015 International Conference on Image Processing Theory, Tools and Applications (IPTA), Orleans, France, 10–13 November 2015; pp. 67–72. [Google Scholar]
- Glowinski, D.; Mortillaro, M.; Scherer, K.; Dael, N.; Volpe, G.; Camurri, A. Towards a minimal representation of affective gestures. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 498–504. [Google Scholar]
- Castellano, G. Movement Expressivity Analysis in Affective Computers: From Recognition to Expression of Emotion. Ph.D. Thesis, Department of Communication, Computer and System Sciences, University of Genoa, Genoa, Italy, 2008. (Unpublished). [Google Scholar]
- Kaza, K.; Psaltis, A.; Stefanidis, K.; Apostolakis, K.C.; Thermos, S.; Dimitropoulos, K.; Daras, P. Body motion analysis for emotion recognition in serious games. In Universal Access in Human-Computer Interaction, Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Toronto, ON, Canada, 17–22 July 2016; Springer: Cham, Switzerland, 2016; pp. 33–42. [Google Scholar]
- Kleinsmith, A.; Bianchi-Berthouze, N.; Steed, A. Automatic recognition of non-acted affective postures. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2011, 41, 1027–1038. [Google Scholar] [CrossRef]
- Savva, N.; Scarinzi, A.; Bianchi-Berthouze, N. Continuous recognition of player’s affective body expression as dynamic quality of aesthetic experience. IEEE Trans. Comput. Intell. Games 2012, 4, 199–212. [Google Scholar] [CrossRef]
- Venture, G.; Kadone, H.; Zhang, T.; Grèzes, J.; Berthoz, A.; Hicheur, H. Recognizing emotions conveyed by human gait. Int. J. Soc. Robot. 2014, 6, 621–632. [Google Scholar] [CrossRef]
- Samadani, A.A.; Gorbet, R.; Kulić, D. Affective movement recognition based on generative and discriminative stochastic dynamic models. IEEE Trans. Hum. Mach. Syst. 2014, 44, 454–467. [Google Scholar] [CrossRef]
- Barros, P.; Jirak, D.; Weber, C.; Wermter, S. Multimodal emotional state recognition using sequence-dependent deep hierarchical features. Neural Netw. 2015, 72, 140–151. [Google Scholar] [CrossRef] [PubMed]
- Gunes, H.; Piccardi, M. A bimodal face and body gesture database for automatic analysis of human nonverbal affective behavior. In Proceedings of the IEEE 18th International Conference on Pattern Recognition (ICPR 2006), Hong Kong, China, 20–24 August 2006; Volume 1, pp. 1148–1153. [Google Scholar]
- Li, B.; Bai, B.; Han, C. Upper body motion recognition based on key frame and random forest regression. Multimed. Tools Appl. 2018, 1–16. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. In Pattern Recognition and Information Forensics, Proceedings of the International Conference on Pattern Recognitionm, Beijing, China, 20–24 August 2018; Springer: Cham, Switzerland, 2018; pp. 153–163. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124. [Google Scholar] [CrossRef]
- Microsoft Kinect. Available online: https://msdn.microsoft.com/ (accessed on 11 January 2018).
- Bulut, E.; Capin, T. Key frame extraction from motion capture data by curve saliency. Comput. Animat. Soc. Agents 2007, 119. Available online: https://s3.amazonaws.com/academia.edu.documents/42103016/casa.pdf?response-content-disposition=inline%3B%20filename%3DKey_frame_extraction_from_motion_capture.pdf&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWOWYYGZ2Y53UL3A%2F20190629%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20190629T015324Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=7c38895c4f79ebe3faf97dc8839ec237a2851828bd91bc26c8518cabfce692d6 (accessed on 29 June 2019).
- Lowe, D.G. Three-dimensional object recognition from single two-dimensional images. Artif. Intell. 1987, 31, 355–395. [Google Scholar] [CrossRef]
- Bogin, B.; Varela-Silva, M.I. Leg length, body proportion, and health: a review with a note on beauty. Int. J. Environ. Res. Public Health 2010, 7, 1047–1075. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Laurent, C.; Pereyra, G.; Brakel, P.; Zhang, Y.; Bengio, Y. Batch normalized recurrent neural networks. In Proceedings of the IEEE 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2657–2661. [Google Scholar]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. A Study of Language and Classifier-independent Feature Analysis for Vocal Emotion Recognition. arXiv 2018, arXiv:1811.08935. [Google Scholar]
- Avots, E.; Sapiński, T.; Bachmann, M.; Kamińska, D. Audiovisual emotion recognition in wild. Mach. Vis. Appl. 2018, 1–11. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Avola, D.; Bernardi, M.; Cinque, L.; Foresti, G.L.; Massaroni, C. Exploiting recurrent neural networks and leap motion controller for the recognition of sign language and semaphoric hand gestures. IEEE Trans. Multimed. 2018, 21, 234–245. [Google Scholar] [CrossRef]
- Hermans, M.; Schrauwen, B. Training and analysing deep recurrent neural networks. Adv. Neural Inf. Process. Syst. 2013, 1, 190–198. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. CoRR 2014. abs/1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 28 June 2019).
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Pham, H.H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Learning and recognizing human action from skeleton movement with deep residual neural networks. 2017. Available online: https://arxiv.org/abs/1803.07780 (accessed on 28 June 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Holmes, G.; Donkin, A.; Witten, I.H. Weka: A machine learning workbench. In Proceedings of the ANZIIS ’94—Australian New Zealnd Intelligent Information Systems Conference, Brisbane, Australia, 29 November–2 December 1994. [Google Scholar]
- Güler, R.A.; Neverova, N.; Kokkinos, I. Densepose: Dense human pose estimation in the wild. arXiv 2018, arXiv:1802.00434. [Google Scholar]
- Zhang, S.; Liu, X.; Xiao, J. On geometric features for skeleton-based action recognition using multilayer lstm networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 148–157. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Minh, T.L.; Inoue, N.; Shinoda, K. A fine-to-coarse convolutional neural network for 3d human action recognition. arXiv 2018, arXiv:1805.11790. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotional State | Neutral | Sadness | Surprise | Fear | Anger | Disgust | Happiness |
|---|---|---|---|---|---|---|---|
| No. of samples | 64 | 63 | 70 | 72 | 70 | 65 | 70 |
| Average recordings length in second | 3.7 | 4.16 | 4.59 | 3.79 | 4.15 | 4.76 | 4.03 |
| Dataset | Dataset Content | Dataset Features Count |
|---|---|---|
| PO | Positions and orientation, upper and lower body | 115 |
| POU | Positions and orientation, upper body | 67 |
| P | Positions, upper and lower body | 58 |
| O | Orientation, upper and lower body | 58 |
| PU | Positions, upper body | 34 |
| OU | Orientation, upper body | 34 |
| Features Set | PO | POU | P | O | PU | OU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Error Rate | 3 | 5 | 3 | 5 | 3 | 5 | 3 | 5 | 3 | 5 | 3 | 5 |
| CNN | 56.6 | 54.8 | 38.8 | 38.8 | 58.1 | 56.8 | 33.6 | 33.0 | 41.6 | 38 | 50.2 | 49.0 |
| RNN | 55.4 | 55.2 | 49.2 | 49.0 | 59.4 | 59.4 | 36.4 | 33.8 | 54.6 | 54.2 | 34.4 | 31.8 |
| RNN-LSTM | 65.2 | 59.6 | 64.6 | 61.25 | 69.0 | 67.0 | 55.0 | 54.6 | 65.8 | 64.2 | 54.2 | 53.8 |
| ResNet20 | - | - | - | - | 27.8 | 27.5 | - | - | 25 | 23.7 | - | - |
| Features Set | PO | POU | P | O | PU | OU | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Emotions / #Classes | 6 | 4 | 6 | 4 | 6 | 4 | 6 | 4 | 6 | 4 | 6 | 4 |
| CNN | 50.5 | 55.2 | 51.5 | 55.5 | 54.2 | 63.6 | 47.8 | 50.5 | 53.7 | 60.7 | 47.4 | 49.2 |
| RNN | 54.4 | 66.8 | 58.6 | 70.8 | 59.2 | 80.8 | 39 | 55.2 | 54.4 | 66.8 | 40 | 57.2 |
| RNN-LSTM | 66.2 | 80 | 59.6 | 74.2 | 72 | 82.7 | 51.8 | 62.4 | 64.6 | 75.8 | 47.4 | 58.9 |
| ResNet20 | - | - | - | - | 30.6 | 40.2 | - | - | 30.1 | 39.7 | - | - |
| Classifier | #Emotions/#Classes | ||
|---|---|---|---|
| 7 | 6 | 4 | |
| J48 | 45.36 | 37.07 | 56.36 |
| Random Forests | 52.95 | 50.73 | 64 |
| k-NN | 43.46 | 42.92 | 61.09 |
| S-PCA + k-NN | 35.86 | 37.33 | 51.27 |
| SVM | 41.98 | 42.93 | 59.27 |
| MLP | 42.19 | 46.09 | 61.45 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sapiński, T.; Kamińska, D.; Pelikant, A.; Anbarjafari, G. Emotion Recognition from Skeletal Movements. Entropy 2019, 21, 646. https://doi.org/10.3390/e21070646
Sapiński T, Kamińska D, Pelikant A, Anbarjafari G. Emotion Recognition from Skeletal Movements. Entropy. 2019; 21(7):646. https://doi.org/10.3390/e21070646
Chicago/Turabian StyleSapiński, Tomasz, Dorota Kamińska, Adam Pelikant, and Gholamreza Anbarjafari. 2019. "Emotion Recognition from Skeletal Movements" Entropy 21, no. 7: 646. https://doi.org/10.3390/e21070646
APA StyleSapiński, T., Kamińska, D., Pelikant, A., & Anbarjafari, G. (2019). Emotion Recognition from Skeletal Movements. Entropy, 21(7), 646. https://doi.org/10.3390/e21070646