Abstract
We consider the one helper source coding problem posed and investigated by Ahlswede, Körner and Wyner. Two correlated sources are separately encoded and are sent to a destination where the decoder wishes to decode one of the two sources with an arbitrary small error probability of decoding. In this system, the error probability of decoding goes to one as the source block length n goes to infinity. This implies that we have a strong converse theorem for the one helper source coding problem. In this paper, we provide the much stronger version of this strong converse theorem for the one helper source coding problem. We prove that the error probability of decoding tends to one exponentially and derive an explicit lower bound of this exponent function.
1. Introduction
For single or multi terminal source encoding systems, the converse coding theorems state that, at any data compression rates below the fundamental theoretical limit of the system, the error probability of decoding can not go to zero when the block length n of the codes tends to infinity.
In this paper, we study the one helper source coding problem posed and investigated by Ahlswede, Körner [1] and Wyner [2]. We call the above source coding system (the AKW system). The AKW system is shown in Figure 1.
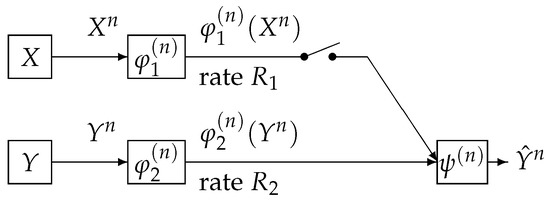
Figure 1.
Source encoding with or without side information at the decoder.
In this figure, the AKW system corresponds to the case where the switch is closed. In Figure 1, the sequence represents independent copies of a pair of dependent random variables which take values in the finite sets , respectively. We assume that has a probability distribution denoted by . For each , the encoder outputs a binary sequence which appears at a rate bits per input symbol. The decoder function observes and to output a sequence , which is an estimation of . When the switch is open, it is well known that the minimum transmission rate such that the error probability of decoding tends to zero as n tends to infinity is given by . Csiszár and Longo [3] proved that, if , then the correct probability of decoding decay exponentially and derived the optimal exponent function. When the switch is open and , Slepian and Wolf [4] proved that is the minimum transmission rate such that the error probability of decoding tends to zero as n tends to infinity. Oohama and Han [5] proved that, if , then the correct probability of decoding decay exponentially and derived the optimal exponent function.
In this paper, we consider the strong converse theorem in the case where the switch is closed and . Let be the rate region of the AKW system. This region consists of the rate pair such that the error provability of decoding goes to zero as n tends to infinity. The rate region was determined by Ahlswede, Körner [1] and Wyner [2]. On the converse coding theorem, Ahlswede et al. [6] proved that, if is outside the rate region, then, must tends to zero as n tends to infinity. Gu and Effors [7] examined a speed of convergence for to tend to zero as by carefully checking the proof of Ahlswede et al. [6]. However, they could not obtain a result on an explicit form of the exponent function with respect to the code length n.
Our main results on the strong converse theorem for the AKW system are as follows. For the AKW system, we prove that, if is outside the rate region , must go to zero exponentially and derive an explicit lower bound of this exponent. This result corresponds to Theorem 3. As a corollary from this theorem, we obtain the strong converse result, which is stated in Corollary 2. This result states that we have an outer bound with gap from the rate region .
To derive our result, we use a new method called the recursive method. This method, which is a new method introduced by the author, includes a certain recursive algorithm for a single letterization of exponent functions. In a standard argument of proving converse coding theorems, single letterization methods based on the chain rule of the entropy functions are used. In general, the functions representing multi letter characterizations of exponent functions do not have the chain rule property. In such cases, the recursive method is quite useful for deriving single letterized bounds. The recursive method is a general powerful tool to prove strong converse theorems for several coding problems in information theory. In fact, the recursive method plays important roles in deriving exponential strong converse exponent for communication systems treated in [8,9,10,11,12].
On the strong converse theorem for the one helper source coding problem, we have two recent other works [13,14]. The above two works proved the strong converse theorem using different methods from our method. In [13], Watanabe found a relationship between the AKW system and the Gray–Wyner network. Using this relationship and the second order rate region for the Gray–Wyner network obtained by him [15], Watanabe established the strong converse theorem for the AKW system. In [14], Liu et al. introduced a new method to derive sharp strong converse bounds via a reverse hypercontractivity. Using this method, they obtained an outer bound of the rate region for the AKW system with gap from the rate region. Furthermore, in [14], an extension of the AKW system to the case of Gaussian source and quadratic distortion is investigated, obtaining an outer bound with gap from the rate distortion region for the extended source coding system. In his resent paper [16], Liu showed a lower bound (converse) on the dispersion of AWK as the variance of the linear combination of information densities.
The strong converse theorems seem to be regarded just as a mathematical problem and have been investigated mainly from theoretical interest. Recently, Watanabe and Oohama [17] have found an interesting security problem, which has a close connection with the strong converse theorem for the AKW system. Furthermore, Oohama and Santoso [18] and Santoso and Oohama [19] clarify that the exponential strong converse theorem obtained by this paper plays an essential role in deriving a strong sufficient secure condition for the privacy amplification in their new theoritical model of side channel attacks to the Shannon chipher systems. From the above two cases, we expect that exponential strong converse theorems for multiterminal source networks will serve as a strong tool to several information theoretical security problems.
2. Problem Formulation
Let and be finite sets and be a stationary discrete memoryless source. For each , the random pair takes values in , and has a probability distribution
We write n independent copies of and , respectively as
We consider a communication system depicted in Figure 2. This communication system corresponds to the case where the switch is closed in Figure 1. Data sequences and are separately encoded to and and those are sent to the information processing center. At the center, the decoder function observes to output the estimation of . The encoder functions and are defined by
where for each , stands for the range of cardinality of . The decoder function is defined by
The error probability of decoding is
where . A rate pair is -achievable if, for any , there exists a positive integer and a sequence of triples such that, for ,
For , the rate region is defined by
Furthermore, define
We can show that the two rate regions , and satisfy the following property.
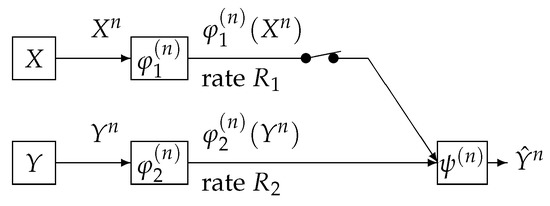
Figure 2.
One helper source coding system [20].
Property 1.
- (a)
- The regions , , and are closed convex sets of , where
- (b)
- has another form using -rate region , the definition of which is as follows. We setUsing , can be expressed as
Proof of this property is given in Appendix A. It is well known that was determined by Ahlswede, Körner and Wyner. To describe their result, we introduce an auxiliary random variable U taking values in a finite set . We assume that the joint distribution of is
The above condition is equivalent to . Define the set of probability distribution by
Set
We can show that the region satisfies the following property.
Property 2.
- (a)
- The region is a closed convex subset of .
- (b)
- For any , we haveThe minimum is attained by . This result implies thatFurthermore, the point always belongs to .
Property 2 part a is a well known property. Proof of Property 2 part b is easy. Proofs of Property 2 parts a and b are omitted. A typical shape of the rate region is shown in Figure 3.
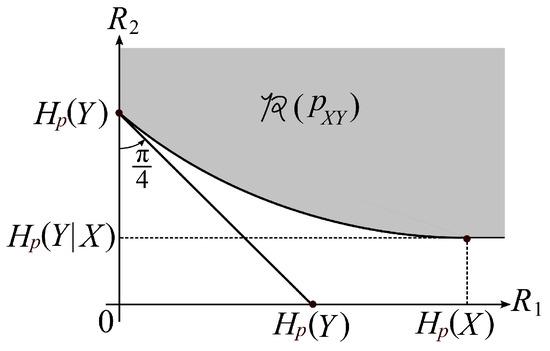
Figure 3.
A typical shape of .
The rate region was determined by Ahlswede and Körner [1] and Wyner [2]. Their results are the following.
Theorem 1
(Ahlswede, Körner [1] and Wyner [2]).
On the converse coding theorem, Ahlswede et al. [6] obtained the following.
Theorem 2
(Ahlswede et al. [6]). For each fixed ε, we have
Gu and Effors [7] examined a speed of convergence for to tend to 1 as by carefully checking the proof of Ahlswede et al. [6]. However, they could not obtain a result on an explicit form of the exponent function with respect to the code length n.
Our aim is to find an explicit form of the exponent function for the error probability of decoding to tend to one as when . To examine this quantity, we define the following quantity. Set
By time sharing, we have that
Choosing in the inequality (5), we obtain the following subadditivity property on :
from which this, and Fekete’s subadditive lemma, we have that exists and satisfies the following:
The exponent function is a convex function of . In fact, from the inequality (5), we have that for any
The region is also a closed convex set. Our main aim is to find an explicit characterization of . In this paper, we derive an explicit outer bound of whose section by the plane coincides with .
3. Main Results
In this section, we state our main result. We first explain that the region can be expressed with a family of supporting hyperplanes. To describe this result, we define a set of probability distributions on by
For , define
Furthermore, define
Then, we have the following property.
Property 3.
- (a)
- The bound is sufficient to describe .
- (b)
- For every , we have
- (c)
- For any we have
Property 3 part a is stated as Lemma A1 in Appendix B. Proof of this lemma is given in this appendix. Proofs of Property 3 parts b and c are given in Appendix C. Set
For , and for , define
We next define a function serving as a lower bound of . For and for , define
Furthermore, set
We can show that the above functions satisfy the following property.
Property 4.
- (a)
- The cardinality bound in is sufficient to describe the quantity . Furthermore, the cardinality bound in is sufficient to describe the quantity .
- (b)
- For any , we have
- (c)
- For any and any , we have
- (d)
- Fix any and . For , we define a probability distribution byThen, for , is twice differentiable. Furthermore, for , we haveThe second equality implies that is a concave function of .
- (e)
- For every , defineand setThen, we have Furthermore, for any , we have
- (f)
- For every , the condition implieswhere g is the inverse function of .
Property 3 part a is stated as Lemma A2 in Appendix B. Proof of this lemma is given in this appendix. Proof of Property 4 part b is given in Appendix D. Proofs of Property 4 parts c, d, e, and f are given in Appendix E.
Our main result is the following.
Theorem 3.
For any , any , and for any satisfying we have
It can be seen from Property 4 parts b and f that is strictly positive if is outside the rate region . Hence, by Theorem 3, we have that, if is outside the rate region, then the error probability of decoding goes to one exponentially and its exponent is not below . It immediately follows from Theorem 3 that we have the following corollary.
Corollary 1.
Proof of Theorem 3 will be given in the next section. The exponent function at rates outside the rate region was derived by Oohama and Han [5] for the separate source coding problem for correlated sources [4]. The techniques used by them is a method of types [21], which is not useful to prove Theorem 3. Some novel techniques based on the information spectrum method introduced by Han [22] are necessary to prove this theorem.
From Theorem 3 and Property 4 part e, we can obtain an explicit outer bound of with an asymptotically vanishing deviation from . The strong converse theorem established by Ahlswede et al. [6] immediately follows from this corollary. To describe this outer bound, for , we set
which serves as an outer bound of . For each fixed , we define by
Step (a) follows from . Since as , we have the smallest positive integer such that for . From Theorem 3 and Property 4 part e, we have the following corollary.
Corollary 2.
For each fixed ε, we choose the above positive integer . Then, for any , we have
The above result together with
yields that, for each fixed , we have
This recovers the strong converse theorem proved by Ahlswede et al. [6].
Proof of this corollary will be given in the next section.
4. Proof of the Main Result
Let be a pair of random variables from the information source. We set . Joint distribution of is given by
It is obvious that . Then, we have the following lemma, which is well known as a single shot infomation spectrum bound.
Lemma 1.
For any and for any , satisfying we have
The probability distributions appearing in the three inequalities (12), (13), and (14) in the right members of (15) have a property that we can select them as arbitrary. In (12), we can choose any probability distribution on . In (13), we can choose any distribution on . In (14), we can choose any stochastic matrix : .
This lemma can be proved by a standard argument in the information spectrum method [22]. The detail of the proof is given in Appendix F. Next, we single letterize the four information spectrum quantities inside the first term in the right members of (15) in Lemma 1 to obtain the following lemma.
Lemma 2.
Proof.
As in the standard converse coding argument, we identify auxiliary random variables, based on the bound in Lemma 2. The following lemma is necessary for such identification.
Lemma 3.
Suppose that, for each , the joint distribution of the random vector is a marginal distribution of . Then, we have the following Markov chain:
or equivalently that . Furthermore, we have the following Markov chain:
or equivalently that . The above two Markov chains are equivalent to the following one long Markov chain:
Proof of this lemma is given in Appendix G. For , set . Define a random variable by . From Lemmas 2 and 3, we identify auxiliary random variables to obtain the following lemma.
Lemma 4.
Now, the challenge is that, although the quantities inside the first term in the right members of (23) in Lemma 4 have n sum of information spectrum quantities, the measure does not have an i.i.d. structure in general. To resolve this, we first use the large deviation theory to upper bound the first quantity in the right members of (23). For each , set Let be a set of all . We define a quantity which serves as an exponential upper bound of . Let be a set of all probability distributions on having a form:
For simplicity of notation, we use the notation for . For each , is a marginal distribution of . For , we simply write . For , , , and , we define
where for each , the probability distribution and the conditional probability distribution appearing in the definition of can be chosen as arbitrary.
The following is well known as the Cramèr’s bound in the large deviation principle.
Lemma 5.
For any real valued random variable Z and any , we have
By Lemmas 4 and 5, we have the following proposition.
Proposition 1.
For any any , and any satisfying there exists such that
Proof.
By Lemma 4, for , we have the following chain of inequalities:
Step (a) follows from Lemma 5. When , the bound we wish to prove is obvious. In the following argument, we assume that . We choose so that
Solving (25) with respect to , we have
For this choice of and (24), we have
completing the proof. □
Set
By Proposition 1, we have the following corollary.
Corollary 3.
For any and any satisfying we have
We shall call the communication potential. The above corollary implies that the analysis of leads to an establishment of a strong converse theorem for the one helper source coding problem. Note here that is still a multi letter quantity. However, we successfully single letterize this quantity. This result which will be stated later in Proposition 2 is a mathematical core of our main result.
In the following argument, we drive an explicit lower bound of . For each , set and
For , define a function of by
By definition, we have
For each , we define the probability distribution
by
where
are constants for normalization. For , define
where we define . Then, we have the following lemma.
Lemma 6.
For each , and for any , we have
Furthermore, we have
Proof of this lemma is given in Appendix H. Define
Then, we have the following lemma, which is a key result to derive a single letterized lower bound of .
Lemma 7.
For any and any , we have
Proof.
The following proposition is a mathematical core to prove our main result.
Proposition 2.
For any and any , we have
Proof.
Set
For each , we define by
Equation (33) implies that Furthermore, for each , we choose appearing in
such that For this choice of , we have the following chain of inequalities:
Step (a) follows from Lemma 7 and (33). Step (b) follows from the choice of for . Step (c) follows from for . Step (d) follows from and the definition of . Step (e) follows from Property 4 part a. Hence, we have the following:
Step (a) follows from Lemma 7. Step (b) follows from (34). Since (35) holds fo any and any satisfying , we have that, for any ,
Thus, Proposition 2 is proved. □
Proof of Theorem 3.
For any , for any and for any satisfying we have the following:
Step (a) follows from Corollary 3. Step (b) follows from Proposition 2. Since the above bound holds for any and any , we have
Thus, (10) in Theorem 3 is proved. □
Proof. of Corollary 2.
Since g is an inverse function of , the definition (11) of is equivalent to
By the definition of , we have that for . We assume that, for , Then, there exists a sequence such that, for , we have
Then, by Theorem 3, we have
for any . From (38), we have that for ,
Step (a) follows from (36). Hence, by Property 4 part e, we have that, under , the inequality (39) implies
Since (40) holds for any and , we have
completing the proof. □
5. One Helper Problem Studied by Wyner
We consider a communication system depicted in Figure 4. Data sequences , , and , respectively are separately encoded to , , and . The encoded data and are sent to the information processing center 1. The encoded data and are sent to the information processing center 2. At center 1, the decoder function observes to output the estimation of . At center 2, the decoder function observes to output the estimation of . The error probability of decoding is
where and .
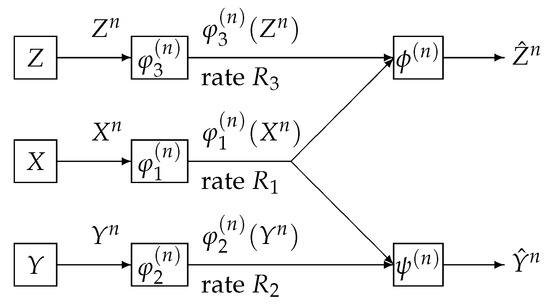
Figure 4.
One helper source coding system investigated by Wyner.
A rate triple is -achievable if, for any , there exist a positive integer and a sequence of three encoders and two decoder functions such that, for ,
The rate region is defined by
Furthermore, define
We can show that the two rate regions , and satisfy the following property.
Property 5.
- (a)
- The regions , , and are closed convex sets of .
- (b)
- We setwhich is called the -rate region. Using , can be expressed as
It is well known that was determined by Wyner. To describe his result, we introduce an auxiliary random variable U taking values in a finite set . We assume that the joint distribution of is
The above condition is equivalent to . Define the set of probability distribution on by
Set
We can show that the region satisfies the following property.
Property 6.
- (a)
- The region is a closed convex subset of .
- (b)
- For any , and any , we haveThe minimun is attained by . This result implies thatFurthermore, the point always belongs to .
The rate region was determined by Wyner [2]. His result is the following.
Theorem 4
(Wyner [2]).
On the strong converse theorem, Csiszár and Körner [21] obtained the following.
Theorem 5
(Csiszár and Körner [21]). For each fixed ε, we have
To examine a rate of convergence for the error probability of decoding to tend to one as for , we define the following quantity. Set
By time sharing, we have that
Choosing in (42), we obtain the following subadditivity property on :
from which we have that exists and satisfies the following:
The exponent function is a convex function of . In fact, by time sharing, we have that
from which we have that for any
The region is also a closed convex set. Our main aim is to find an explicit characterization of . In this paper, we derive an explicit outer bound of whose section by the plane coincides with . We first explain that the region has another expression using the supporting hyperplane. We define two sets of probability distributions on by
For , set
Furthermore, define
Then, we have the following property.
Property 7.
- (a)
- The bound is sufficient to describe .
- (b)
- For every , we have
- (c)
- For any we have
For , and for , define
We next define a function serving as a lower bound of . For each , define
Furthermore, set
We can show that the above functions and sets satisfy the following property.
Property 8.
- (a)
- The cardinality bound in is sufficient to describe the quantity . Furthermore, the cardinality bound in is sufficient to describe the quantity .
- (b)
- For any , we have
- (c)
- For any and any , we have
- (d)
- Fix any and . We define a probability distribution byThen, for , is twice differentiable. Furthermore, for , we haveThe second equality implies that is a concave function of .
- (e)
- For , defineand setThen, we have . Furthermore, for any , we have
- (f)
- For every , the condition implies
Since proofs of the results stated in Property 8 are quite parallel with those of the results stated in Property 4, we omit them. Our main result is the following.
Theorem 6.
For any , any , and for any satisfying we have
It follows from Theorem 6 and Property 8 part d) that, if is outside the capacity region, then the error probability of decoding goes to one exponentially and its exponent is not below . It immediately follows from Theorem 3 that we have the following corollary.
Corollary 4.
Proof of Theorem 6 is quite parallel with that of Theorem 3. We omit the detail of the proof. From Theorem 6 and Property 8 part e, we can obtain an explicit outer bound of with an asymptotically vanishing deviation from . The strong converse theorem established by Csiszár and Körner [21] immediately follows from this corollary. To describe this outer bound, for , we set
which serves as an outer bound of . For each fixed , we define by
Step (a) follows from . Since as , we have the smallest positive integer such that for . From Theorem 6 and Property 8 part e, we have the following corollary.
Corollary 5.
For each fixed , we choose the above positive integer . Then, for any , we have
The above result together with
yields that for each fixed , we have
This recovers the strong converse theorem proved by Csiszár and Körner [21].
Proof of this corollary is quite parallel with that of Corollary 2. We omit the detail.
6. Conclusions
For the AWZ system, the one helper source coding system posed by Ahlswede, Körner [1] and Wyner [2], we have derived an explicit lower bound of the optimal exponent function on the correct probability of decoding for . We have described this result in Theorem 3. Furthermore, for the source coding system posed and investigated Wyner [2], we have obtained an explicit lower bound of the optimal exponent function on the correct probability of decoding for . We have described this result in Theorem 6. The determination problems of and still remain to be resolved. Those problems are our future works.
Funding
This research was funded by JSPS Kiban (B) 18H01438.
Acknowledgments
The author is very grateful to Shun Watanabe and Shigeaki Kuzuoka for their helpful comments.
Conflicts of Interest
The author declares no conflict of interest.
Appendix A. Properties of the Rate Regions
In this appendix, we prove Property 1. Property 1 part a can easily be proved by the definitions of the rate distortion regions. We omit the proofs of this part. In the following argument, we prove the part b.
Proof of Property 1 part b:
We set
By the definitions of and , we have that for . Hence, we have that
We next assume that . Set
Then, by the definitions of and , we have that, for any , there exists such that for any , which implies that
Here, we assume that there exists a pair belonging to such that
Since the set on the right-hand side of (A3) is a closed set, we have
for some small . On the other hand, we have , which contradicts (A2). Thus, we have
Note here that is a closed set. Then, from (A5), we conclude that
completing the proof. □
Appendix B. Cardinality Bound on Auxiliary Random Variables
We first prove the following lemma.
Lemma A1.
Proof.
We bound the cardinality of U to show that the bound is sufficient to describe . Observe that
where
For each , is a continuous function of . Then, by the support lemma, is sufficient to express values of (A6) and one value of (A7). □
Next, we prove the following lemma.
Lemma A2.
The cardinality bound in is sufficient to describe the quantity . The cardinality bound in is sufficient to describe the quantity .
Proof.
We first bound the cardinality of U in to show that the bound is sufficient to describe . Observe that
where
The value of included in must be preserved under the reduction of . For each , is a continuous function of . Then, by the support lemma, is sufficient to express values of (A8) and one value of (A9). We next bound the cardinality of U in to show that the bound is sufficient to describe . Observe that
where
The value of included in must be preserved under the reduction of . For each , is a continuous function of . Then, by the support lemma, is sufficient to express values of (A10) and one value of (A11). □
Appendix C. Supporting Hyperplain Expressions of
In this appendix we prove Property 3 parts (b), (c). We first prove the part (b).
Proof of Property 3 part b:
For any we have the following chain of inequalities:
Step (a) follows from Lemma A1 stating that the cardinality bound in can be reduced to that in . □
We next prove part c. We first prepare a lemma useful to prove this property. From the convex property of the region , we have the following lemma.
Lemma A3.
Suppose that does not belong to . Then, there exist and such that for any we have
Proof of this lemma is omitted here. Lemma A3 is equivalent to the fact that if the region is a convex set; then, for any point outside the region , there exists a line which separates the point from the region .
Proof of Property 3 part c:
We first prove . We assume that . Then, by Lemma A3, there exist and such that for any , we have
Then, we have
Step (a) follows from the definition of . The inequality (A12) implies that . Thus is concluded. □
Appendix D. Proof of Property 4 Part b
In this appendix, we prove Property 4 part b. Fix and arbitrary. For , , and induced by q, define
Then, we have the following two lemmas.
Lemma A4.
For any μ, , and any , there exists such that
Lemma A5.
For any satisfying μ, , any , and any stochastic matrix induced by , we have
From Lemmas A4 and A5, we have the following corollary.
Corollary A1.
For any satisfying μ, , and any , there exists such that
From (A15), we have that for any μ, , we have
Proof of Lemma A4:
We fix arbitrary. For each , we choose so that . Then, we have the following:
where we set
Step (a) follows from Hölder’s inequality. From (A17), we can see that it suffices to show to complete the proof. When , we have . When , we apply Hölder’s inequality to A to obtain
Hence, we have (A13) in Lemma A4. □
Proof of Lemma A5:
We fix , , arbitrary. For any , and any , we have the following chain of inequalities:
where we set
Step (a) follows from Hölder’s inequality. From (A18), we can see that it suffices to show to complete the proof. In a manner quite smilar to the proof of in the proof of (A13) in Lemma A4, we can show that . Thus, we have (A14) in Lemma A5. □
Proof of Property 4 part b:
We evaluate lower bounds of to obtain the following chain of inequalities:
Step (a) follows from the definition of and (A16) in Corollary A1. Steps (b) and (c) follow from that
From (A19), we have
completing the proof. □
Appendix E. Proof of Property 4 Parts c, d, e, and f
In this appendix, we prove Property 4 parts c, d, e, and f. We first prove part c and then prove parts d and e. We finally prove part f.
Proof of Property 4 part c:
We first prove the second inequality in (8) in part c. We first observe that
Let be the uniform distribution on and let be the uniform distribution on . On lower bound of for and , we have the following chain of inequalities:
Step (a) follows from that and for any . Step (b) follows from the reverse Hölder’s inequality. The bound (A21) implies the second inequality in (8). We next show that for . On upper bounds of for and , we have the following chain of inequalities:
Step (a) follows from (A20) and for any . Step (b) follows from and Hölder’s inequality. □
Proof of Property 4 parts d and e:
We first prove that, for each and , is twice differentiable for . For simplicity of notations, set
Then, we have
The quantity has the following form:
By simple computations, we have
On upper bound of for , we have the following chain of inequalities:
Step (a) follows from (A25). Step (b) follows from (A24). Step (c) follows from Cauchy–Schwarz inequality and (A23). Step (d) follows from that for . Note that exists for . Furthermore, we have the following:
Hence, by (A26), exists for . We next prove part e. We derive the lower bound (9) of . Fix any and any . By the Taylor expansion of with respect to around , we have that for any and for some
Step (a) follows from ,
and the definition of . Let be a pair which attains . By this definition, we have that
and that, for any
On lower bounds of , we have the following chain of inequalities:
Step (a) follows from (A28). Step (b) follows from (A27). Step (c) follows from (A29). Step (d) follows from the definition of . □
To prove part f, we use the following lemma.
Lemma A6.
When , the maximum of
for is attained by the positive satisfying
Let be the inverse function of for . Then, the condition of (A30) is equivalent to . The maximum is given by
By an elementary computation, we can prove this lemma. We omit the detail.
Proof of Property 4 part f.
By the hyperplane expression of stated Property 3 part b, we have that, when , we have
for some . Then, for each positive , we have the following chain of inequalities:
Step (a) follows from Property 4 part d. Step (b) follows from (A31). Step (c) follows from Lemma A6. □
Appendix F. Proof of Lemma 1
To prove Lemma 1, we prepare a lemma. Set
Furthermore, set
Then, we have the following lemma.
Lemma A7.
Proof.
We first prove the first inequality.
Step (a) follows from the definition of . In the second inequality, we have
Step (a) follows from the definition of . We next prove the third inequality:
Finally, we prove the fourth inequality. We first observe that
We have the following chain of inequalities:
Step (a) follows from that the number of correctly decoded does not exceed . □
Proof of Lemma 1:
By definition, we have
Then, for any , satisfying we have
Hence, it suffices to show
to prove Lemma 1. By definition, we have Then, we have the following.
Step (a) follows from Lemma A7. □
Appendix G. Proof of Lemma 3
In this appendix, we prove Lemma 3.
Proof of Lemma 3:
We first prove the Markov chain in (18) in Lemma 3. We have the following chain of inequalities:
Step (a) follows from that is a function of . Step (b) follows from the memoryless property of the information source . Next, we prove the Markov chain in (19) in Lemma 3. We have the following chain of inequalities:
Step (a) follows from that is a function of . Step (b) follows from the memoryless property of the information source . □
Appendix H. Proof of Lemma 6
In this appendix, we prove Lemma 6.
Proof of Lemma 6.
By the definition of , for , we have
Then, we have the following chain of equalities:
Steps (a) and (b) follow from (A32). From (A33), we have
Taking summations of (A34) and (A35) with respect to , we obtain
completing the proof. □
References
- Ahlswede, R.F.; Körner, J. Source coding with side information and a converse for degraded broadcast channels. IEEE Trans. Inf. Theory 1975, 21, 629–637. [Google Scholar] [CrossRef]
- Wyner, A.D. On source coding with side information at the decoder. IEEE Trans. Inf. Theory 1975, 21, 294–300. [Google Scholar] [CrossRef]
- Csiszár, I.; Longo, G. On the exponent function for source coding and for testing simple statistical hypotheses. Studia Sci. Math. Hungar 1971, 6, 181–191. [Google Scholar]
- Slepian, D.; Wolf, J.K. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Oohama, Y.; Han, T.S. Universal coding for the Slepian-wolf data compression system and the strong converse theorem. IEEE Trans. Inf. Theory 1994, 40, 1908–1919. [Google Scholar] [CrossRef]
- Ahlswede, R.; Gács, P.; Körner, J. Bounds on conditional probabilities with applications in multi-user communication. Probab. Theory Relat. Fields 1976, 34, 157–177. [Google Scholar] [CrossRef]
- Gu, W.; Effors, M. A strong converse for a collection of network source coding problems. In Proceedings of the IEEE International Symposium on Information Theory, Soul, Korea, 28 June–3 July 2009; pp. 2316–2320. [Google Scholar]
- Oohama, Y. Strong converse exponent for degraded broadcast channels at rates outside the capacity region. In Proceedings of the 2015 IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 939–943. [Google Scholar]
- Oohama, Y. Strong converse theorems for degraded broadcast channels with feedback. In Proceedings of the 2015 IEEE International Symposium on Information Theory, Hong Kong, China, 14–19 June 2015; pp. 2510–2514. [Google Scholar]
- Oohama, Y. Exponent function for asymmetric broadcast channels at rates outside the capacity region. In Proceedings of the 2016 IEEE International Symposium on Information Theory and its Applications, Monterey, CA, USA, 30 October–2 Novomber 2016; pp. 568–572. [Google Scholar]
- Oohama, Y. New Strong Converse for Asymmetric Broadcast Channels. Available online: https://arxiv.org/pdf/1604.02901.pdf (accessed on 31 May 2019).
- Oohama, Y. Exponential strong converse for source coding with side information at the decoder. Entropy 2018, 20, 352. [Google Scholar] [CrossRef]
- Watanabe, S. A converse bound on Wyner-Ahlswede-Körner network via Gray–Wyner network. In Proceedings of the 2017 IEEE Information Theory Workshop (ITW), Kaohsiung, Taiwan, 6–10 November 2017; pp. 81–85. [Google Scholar]
- Liu, J.; van Handel, R.; Verdu, S. Beyond the blowing-up lemma: Sharp converses via reverse hypercontractivity. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 943–947. [Google Scholar]
- Watanabe, S. Second-order region for Gray–Wyner network. IEEE Trans. Inform. Theory 2017, 63, 1006–1018. [Google Scholar] [CrossRef]
- Liu, J. Dispersion bound for the Wyner-Ahlswede-Körner network via reverse hypercontractivity on types. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1854–1858. [Google Scholar]
- Watanabe, S.; Oohama, Y. Privacy amplification theorem for bounded storage eavesdropper. In Proceedings of the 2012 IEEE Information Theory Workshop (ITW), Lausanne, Switzerland, 3–7 September 2012; pp. 177–181. [Google Scholar]
- Oohama, Y.; Santoso, B. Information Theoretic Security for Side-Channel Attacks to the Shannon Cipher System. Available online: https://arxiv.org/pdf/1801.02563v5.pdf. (accessed on 31 May 2019).
- Santoso, B.; Oohama, Y. Information Theoretic Security for Shannon Cipher System under Side-Channel Attacks. Entropy 2019, 21, 469. [Google Scholar] [CrossRef]
- Oohama, Y. Exponent Function for One Helper Source Coding Problem at Rates outside the Rate Region. arXiv 2015, arXiv:1504.05891. [Google Scholar]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: London, UK, 1981. [Google Scholar]
- Han, T.S. Information-Spectrum Methods in Information Theory; Springer Nature Switzerland AG: Basel, Switzerland, 2002. [Google Scholar]
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).