Modern Text Hiding, Text Steganalysis, and Applications: A Comparative Analysis



Abstract
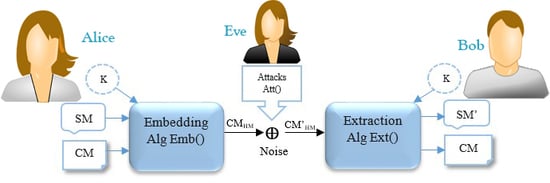
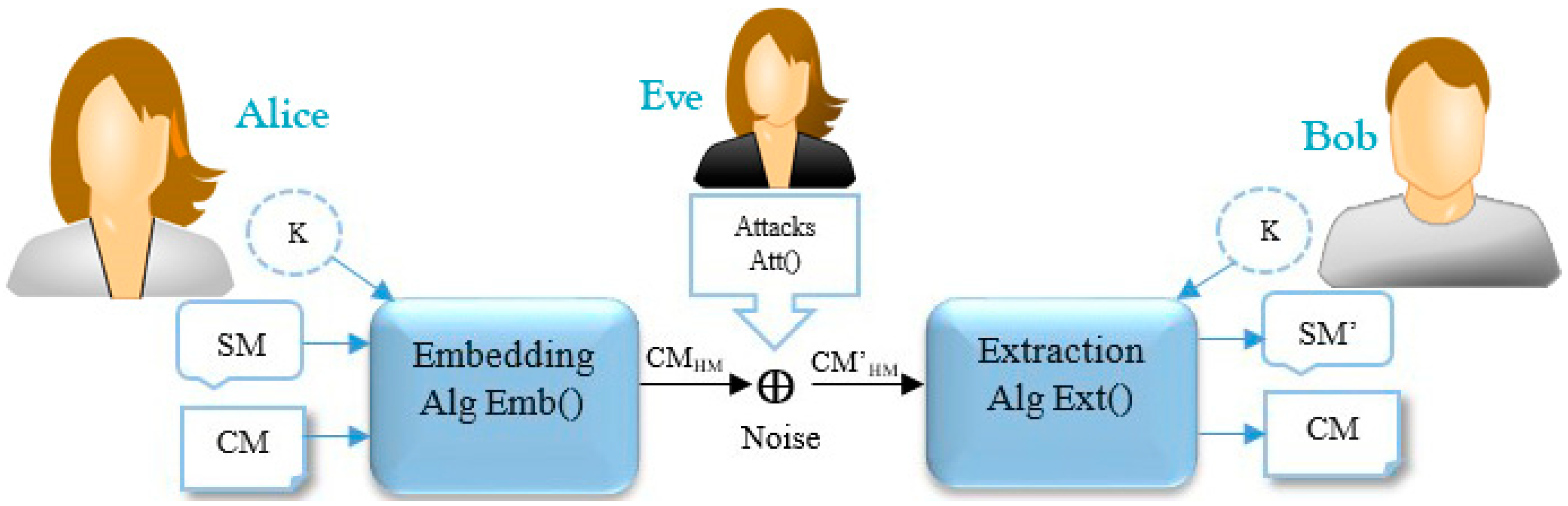
:
1. Introduction
- We provide a brief review of existing literature on text hiding schema, attacks, text steganalysis, applications, and fundamental criteria.
- We summarize some of the recently proposed text hiding techniques which are focused on altering the structure of the cover text message/file to conceal secret information.
- We present a comparative analysis of the structural based algorithms and evaluate their efficiency with respect to common criteria.
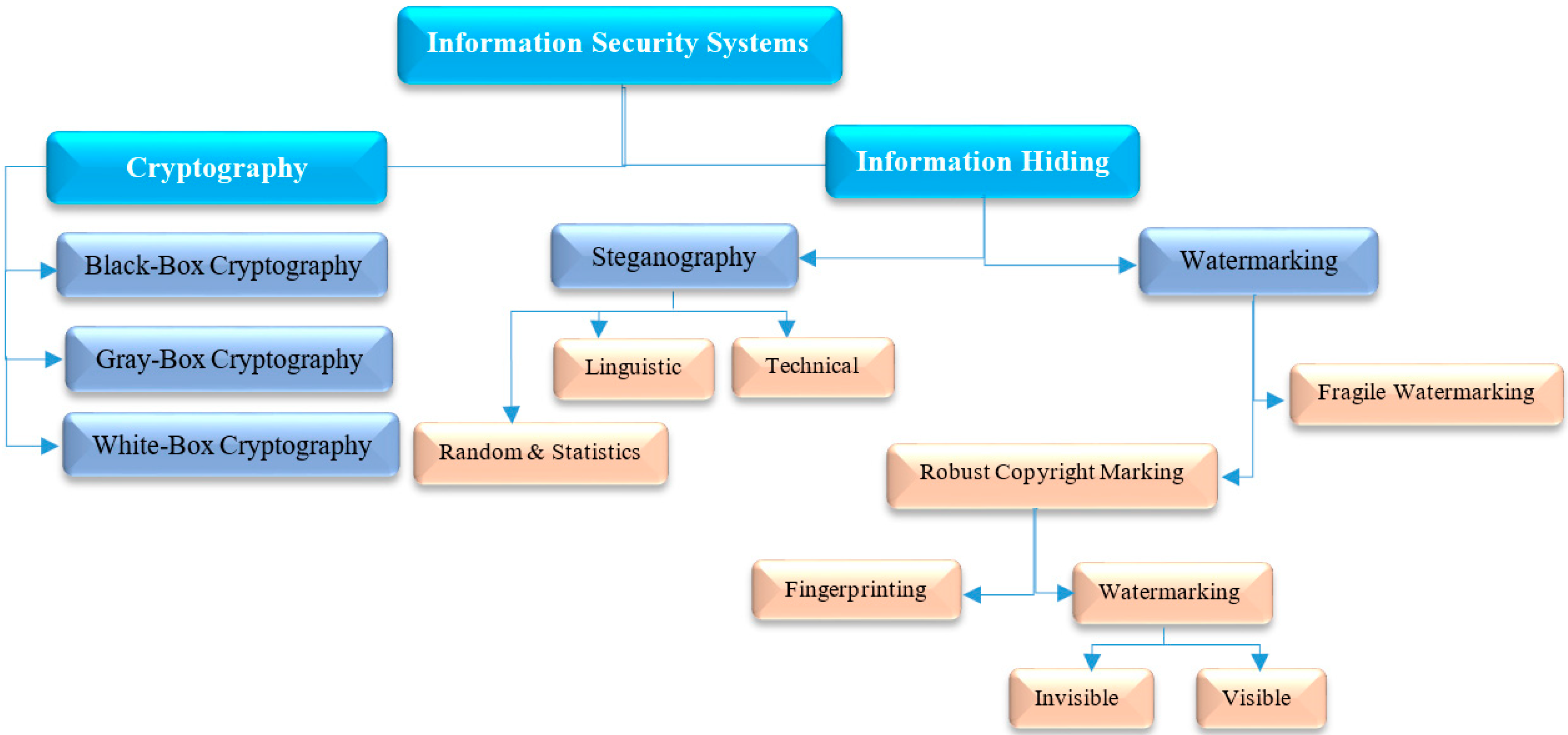
2. Literature Review
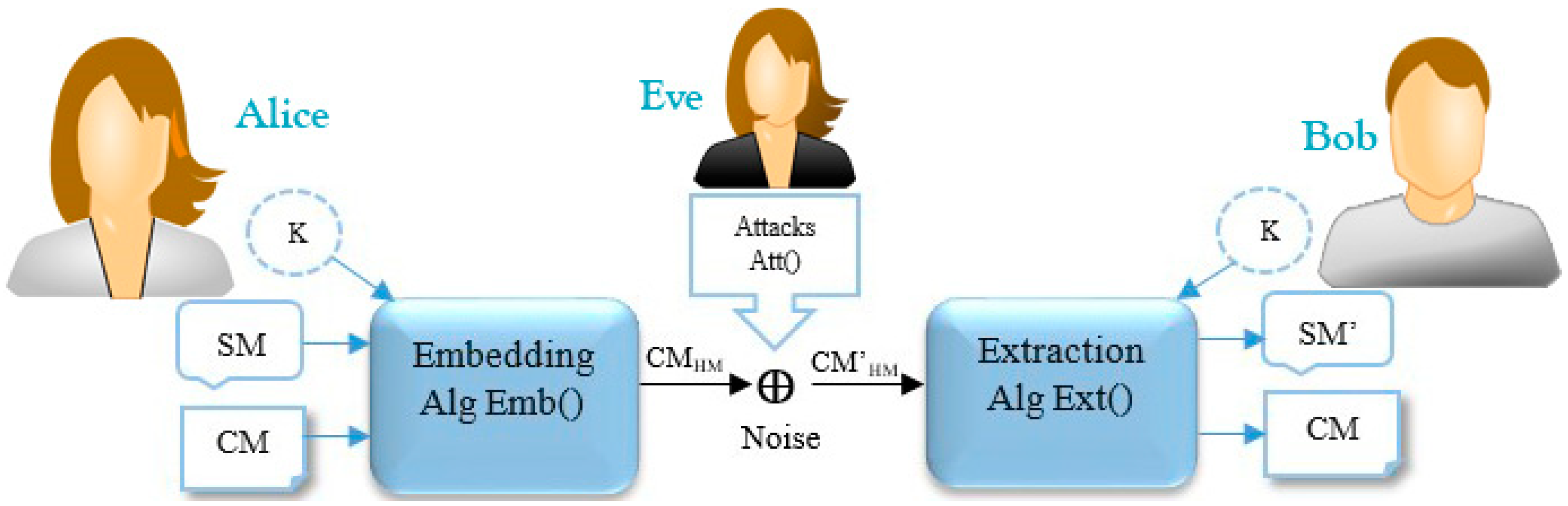
2.1. Text Hiding Schema
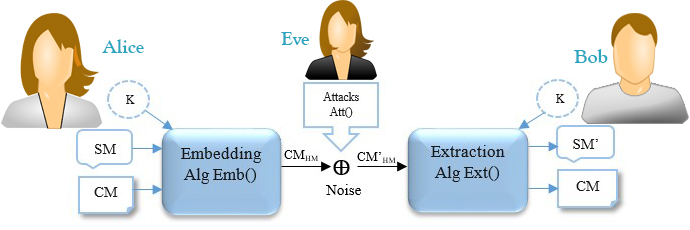
| Algorithm 1: Pseudocode of Emb() |
| Input: a cover text (CM), a secret message (SM), a secret key (K) Output: a carrier text message or stego-object (CMHM) which consists of CM and HM 1. SM← Secret Message (e.g., confidential information such as password, banking credentials, etc.); 2. CM← Cover Message (e.g., an innocent text message such as prank, joke, etc.); 3. K← Secret Key (e.g., a symmetric or asymmetric key algorithm such as One-Time-Pad, AES, DES, etc.); 4. for each do 5. SMbits← SMbits + Convert each to a 8-bit string based on the ASCII Code; 6. end for 7. Encrypted _SMbits← Encrypts the SMbits based on K using a special encryption function; 8. HM← Convert the Encrypted_SMbits to invisible symbols such as space between words, text color, etc.; 9. CMHM← Embed the HM into the CM, where the attacks may not detect/remove it easily; 10. Return CMHM; |
| Algorithm 2: Pseudocode of Att() |
| Input: a carrier message (CMHM), an estimated secret key (EK) Output: a compromised carrier message (CM’HM), an estimated Secret Message (ESM) 1. HS← Estimates the hidden/invisible symbols from the CMHM; 2. for each do 3. Estimated_SMbits ← Estimated_SMbits + Guess the binary string of each symbol based on the ; 4. EKbits← EKbits + Guess the secret key according to the using the conventional approaches; 5. end for 6. SMbits← Tries to decrypt the Estimated_SMbits based on the ESK; 7. ESM← If it is possible, estimates/decodes the SMbits using conventional approaches; 8. CM’HM← Manipulate the CM’HM in order to remove the HM; 9. Return CM’HM, ESM; |
| Algorithm 3: Pseudocode of Ext() |
| Input: an affected carrier message (CM’HM), a secret key (K) Output: a secret message (SM’) 1. HS← Discovers the existing hidden marks/symbols from the CM’HM; 2. K← Secret Key (e.g., the symmetric or asymmetric key algorithm such as One-Time-Pad, AES, DES, etc.); 3. for each do 4. Encrypted_SMbits← Encrypted_SMbits + Detects the binary string of each invisible symbol from ; 5. Kbits←Kbits+ Utilizes a shared key from Alice or Extracts the secret key from the CM’HM. 6. end for 7. SMbits← Decrypts the Encrypted _SMbits based on Kbits using corresponding decryption function; 8. SM’← Extracts the original SM characters from the SMbits based on their ASCII codes. 9. Return SM’; |
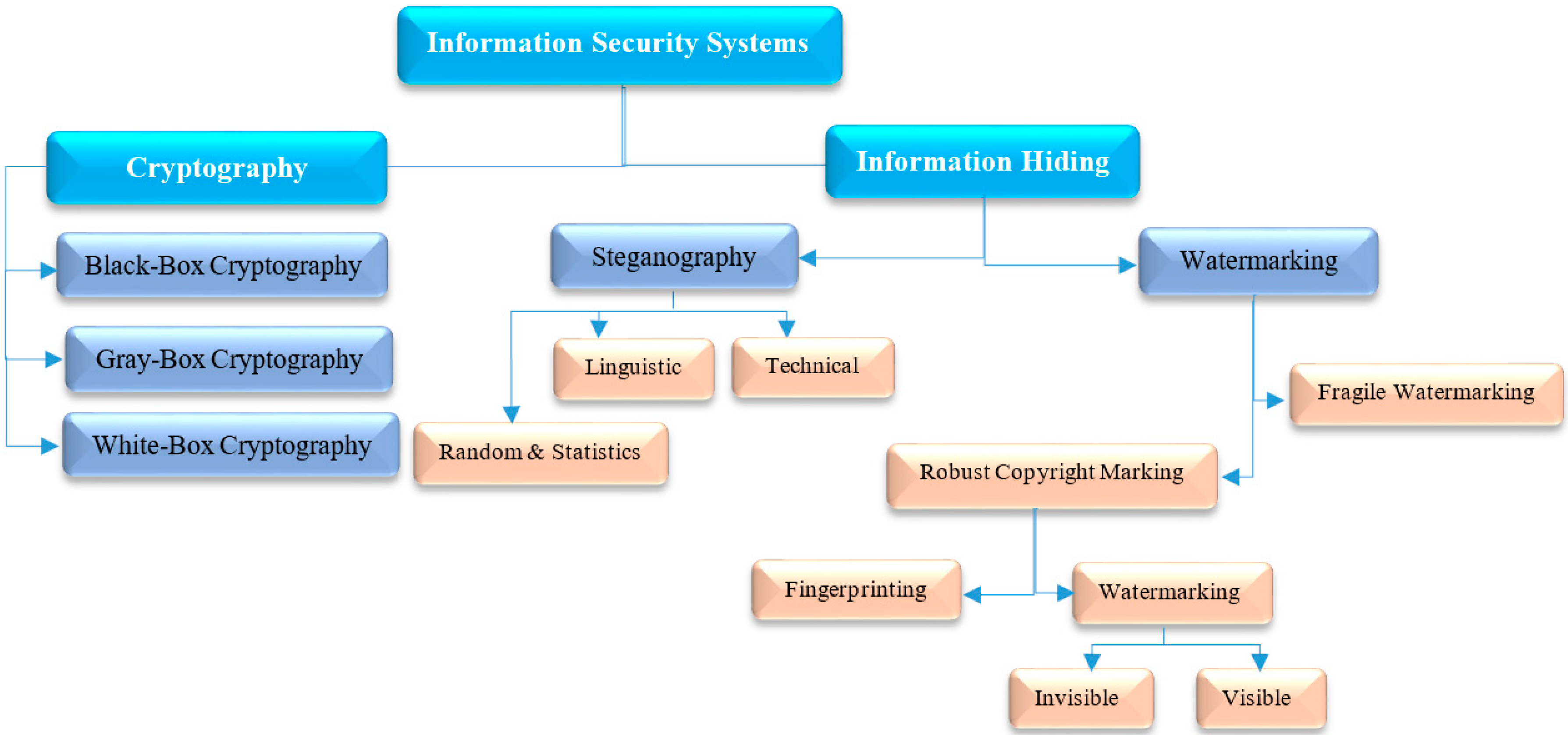
2.2. Information Theoretic and Modern Text Hiding
2.3. The Unicode Standard
2.4. Text Hiding Applications
2.4.1. Hidden Communication
2.4.2. Network Covert Channels
2.4.3. Unauthorized Access Detection
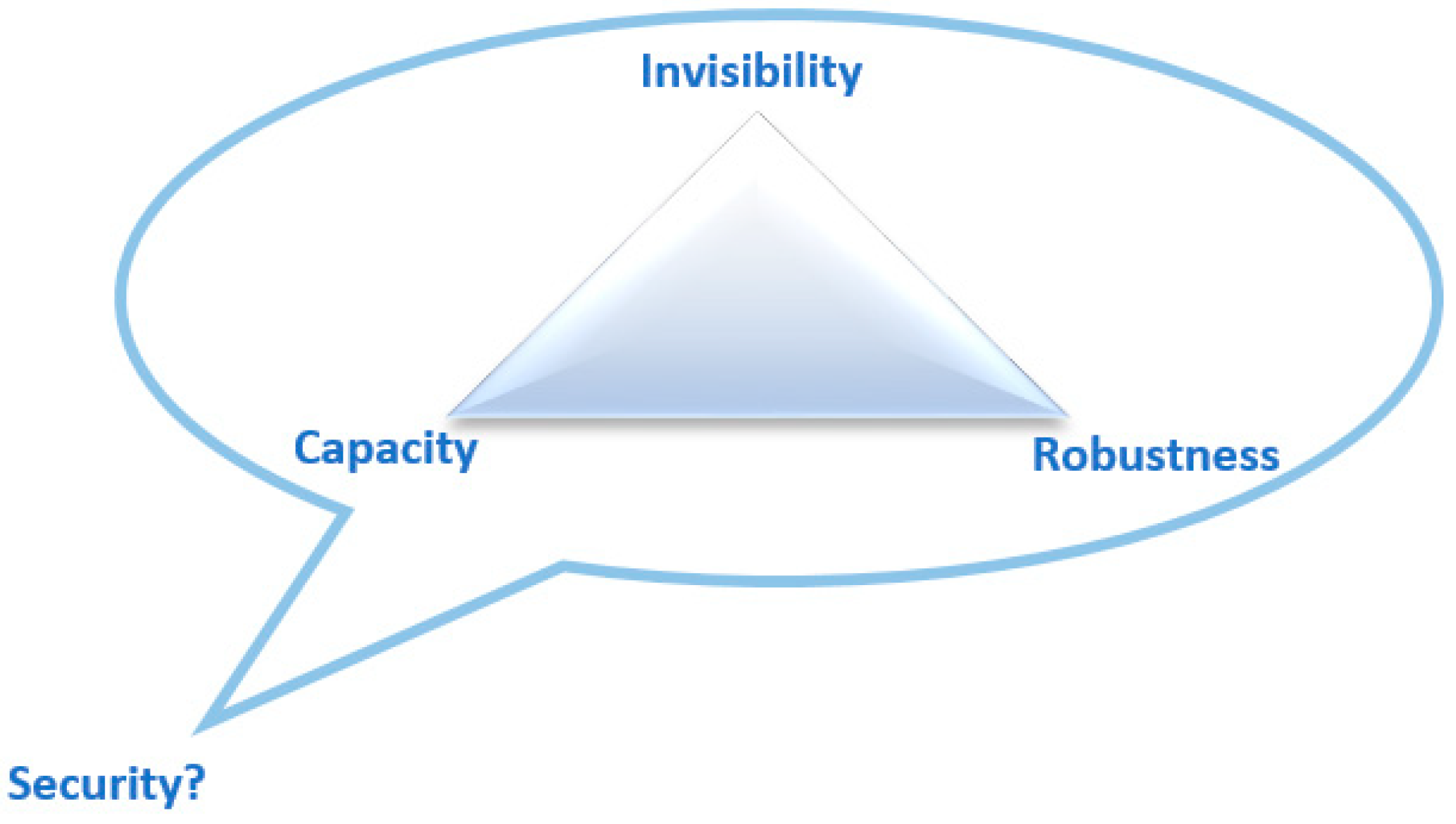
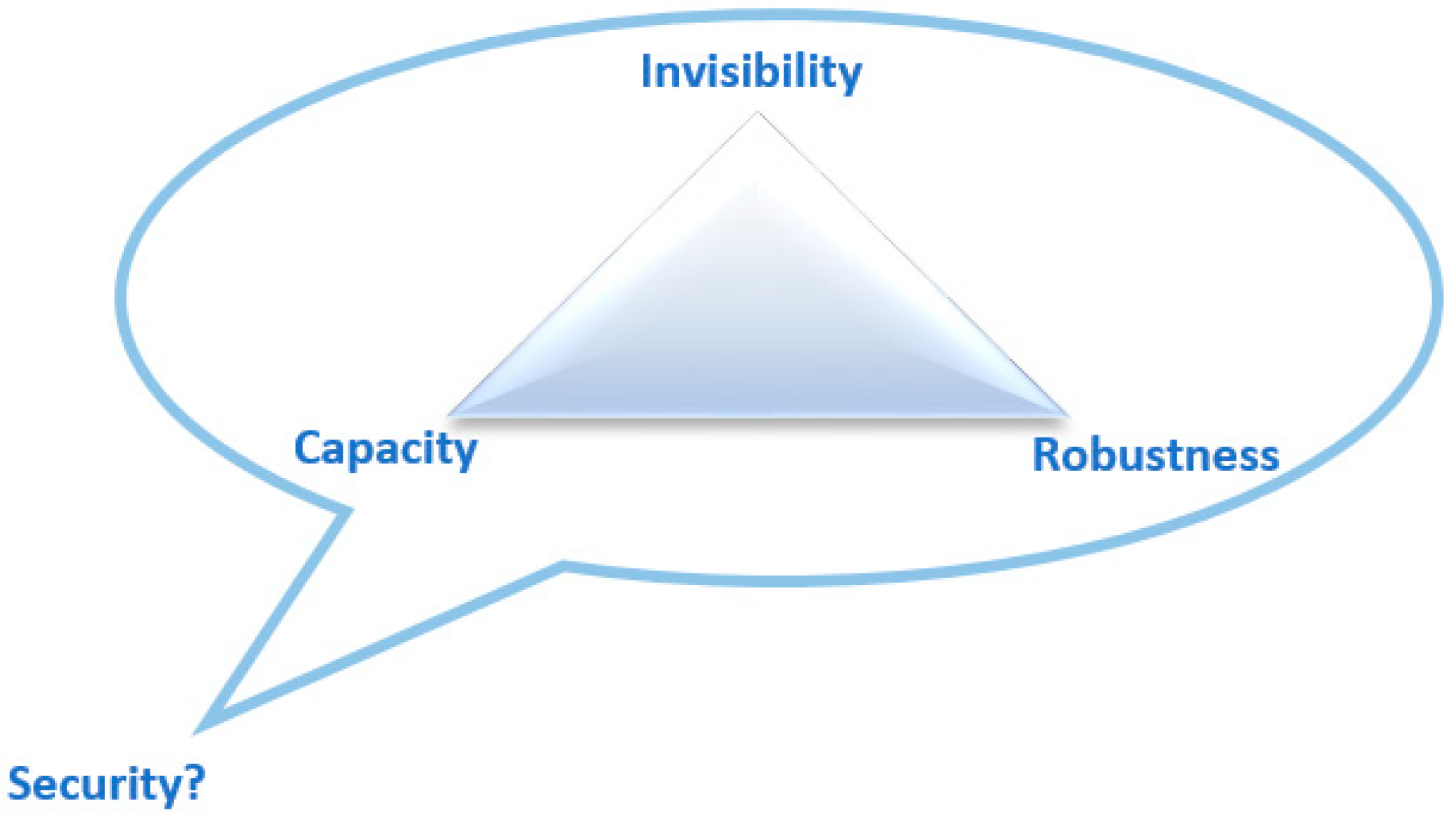
2.5. Text Hiding Criteria
2.5.1. Invisibility
2.5.2. Embedding Capacity (EC)
2.5.3. Distortion Robustness (DR)
2.5.4. Security
2.5.5. Computational Complexity
2.6. Modern Text Hiding & Kerckhoffs’s Principle
2.7. Text Steganalysis and Attacks
2.7.1. Visual Attacks
2.7.2. Structural Attacks
2.7.3. Statistical Attacks
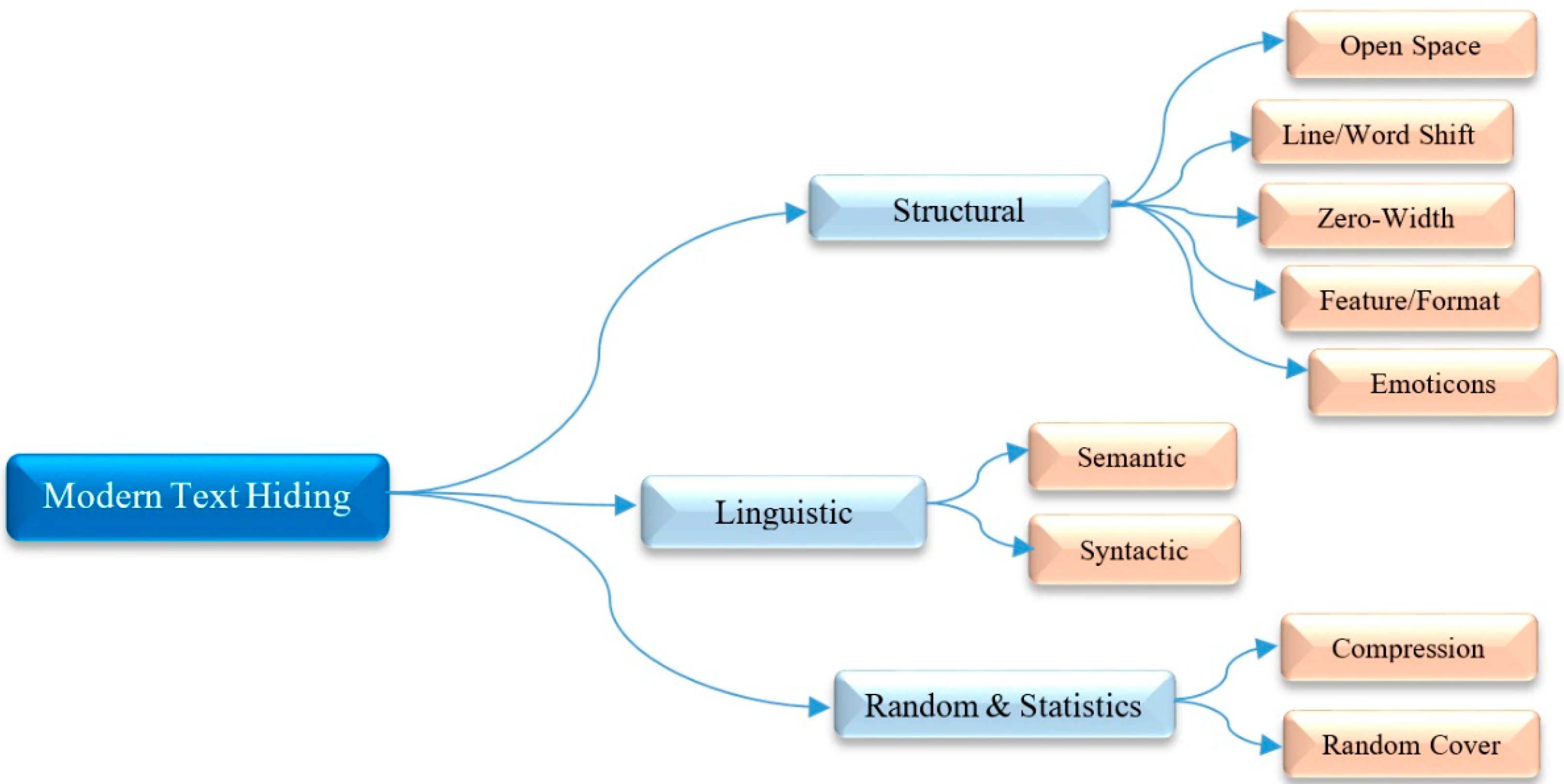
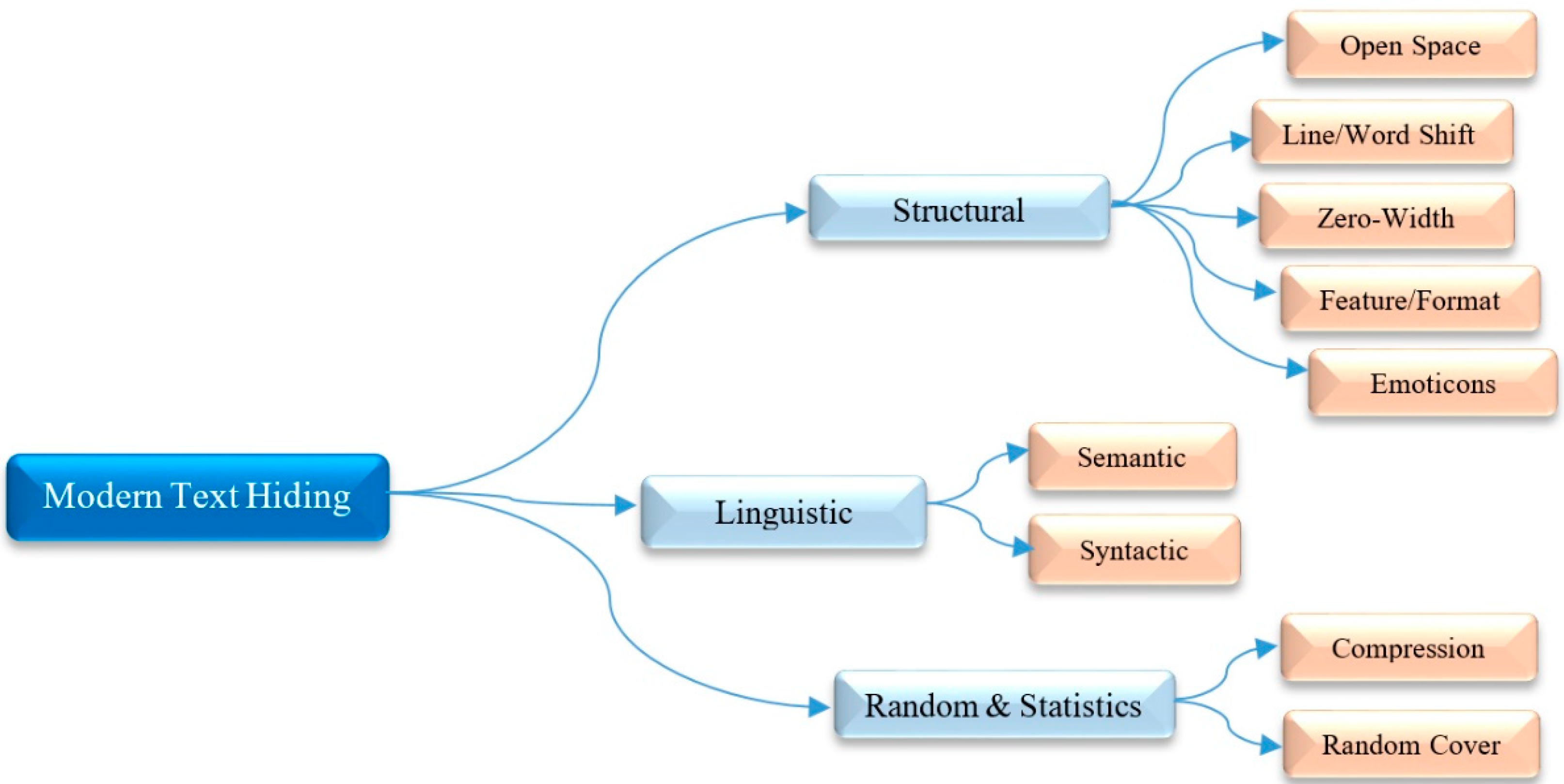
3. Various Types of Text Hiding Techniques
3.1. Structural Techniques
3.1.1. Open Space
3.1.2. Line/Word Shift
3.1.3. Zero-Width
3.1.4. Feature or Format
3.1.5. Emoticons or Emoji
 ”, B = “
”, B = “  ”, C = “
”, C = “  ”, and so on.). Moreover, they embed the produced emoticons between words through the CM. Although these approaches have high embedding capacity, they suffer from visible transparency (low invisibility), and low distortion robustness against visual attacks.
”, and so on.). Moreover, they embed the produced emoticons between words through the CM. Although these approaches have high embedding capacity, they suffer from visible transparency (low invisibility), and low distortion robustness against visual attacks.3.2. LinguisticTechniques
3.2.1. Semantic
3.2.2. Syntactic
3.3. Random and Statistics Techniques
3.3.1. Compression
3.3.2. Random Cover
3.4. An Empirical Comparison
4. Efficiency Analysis of Recent Structural Techniques
”, B=“ ”, C=“ ”, and so on.) and, thus embeds the emoticons between words through the CM. Practically, this scheme presents high EC, and visible transparency (low invisibility), and it suffers from low DR against visual attacks.5. Suggestions for Future Works
- Since most of the authentication systems utilize SMS to verify the authenticity of users, the structural-based technique can be employed as the best option to provide covert communication against unpredictable network attacks such as MITM, brute-force, and guessing attacks.
- Where the primary concern is the invisible transmission of secret information over public networks, the structural-based steganography algorithms could be utilized for providing that requirement.
- In the case of unauthorized access tracking, a combination of machine learning algorithms and the ZWC-based methods can be employed to mark sensitive documents over private networks. For instance, confidential documents in a governmental organization could be marked with identifiers such as an invisible signature which is difficult to detect.
- Due to the fact social media have become a significant part of the end users’ daily communications, a combination of unsupervised learning algorithms and structural-based text hiding can be used to intelligent information analysis during the resharing/reproduction of data to protect valuable information against malicious attacks.
- The lossless compression algorithms such as Huffman coding, LZW, arithmetic, and so on, could be utilized during the encoding section of structural-based methods to improve the embedding capacity criteria. An efficient text hiding algorithm should provide optimum trade-off among the three fundamental criteria to gain a certain level of security.
- To sum up, which type of text hiding algorithms provides better efficiency? We cannot give an accurate and unique answer to this question. Cybersecurity researchers must take into account many things like various pros and cons of text hiding algorithms, together with the recommendations that we have outlined. Also, they should ponder whether the text hiding techniques would be relevant or not for the particular application. When the researcher comprehends that some of the merits of a specific algorithm could provide a proper benefit to the exact needs of the application at issue; hence it should probably be given a try.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ahvanooey, M.T.; Li, Q.; Hou, J.; Mazraeh, H.D.; Zhang, J. AITSteg: An Innovative Text Steganography Technique for Hidden Transmission of Text Message via Social Media. IEEE Access 2018, 6, 65981–65995. [Google Scholar] [CrossRef]
- Kamaruddin, N.S.; Kamsin, A.; Por, L.Y.; Rahman, H. A Review of Text Watermarking: Theory, Methods, and Applications. IEEE Access 2018, 6, 8011–8028. [Google Scholar] [CrossRef]
- TAhvanooey, M.T.; Li, Q.; Shim, H.J.; Huang, Y. A Comparative Analysis of Information Hiding Techniques for Copyright Protection of Text Documents. Secur. Commun. Netw. 2018, 2018, 5325040. [Google Scholar]
- Ahvanooey, M.T.; Mazraeh, H.D.; Tabasi, S.H. An innovative technique for web text watermarking (AITW). Inf. Secur. J. Glob. Perspect. 2016, 25, 191–196. [Google Scholar] [CrossRef]
- Rizzo, S.G.; Bertini, F.; Montesi, D. Content-preserving Text Watermarking through Unicode Homoglyph Substitution. In Proceedings of the 20th International Database Engineering & Applications Symposium (IDEAS ’16), Montreal, QC, Canada, 11–13 July 2016; pp. 97–104. [Google Scholar]
- Rizzo, S.G.; Bertini, F.; Montesi, D.; Stomeo, C. Text Watermarking in Social Media. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017. [Google Scholar]
- Por, L.Y.; Wong, K.; Chee, K.O. UniSpaCh: A text-based data hiding method using Unicode space characters. J. Syst. Softw. 2012, 85, 1075–1082. [Google Scholar] [CrossRef]
- Patiburn, S.A.; Iranmanesh, V.; Teh, P.L. Text Steganography using Daily Emotions Monitoring. Int. J. Educ. Manag. Eng. 2017, 7, 1–14. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Z.; Zhao, W.; Yu, J. Attack Model of Text Watermarking Based on Communications. In Proceedings of the 2009 International Conference on Information Management, Innovation Management and Industrial Engineering, Xi’an, China, 26–27 December 2009. [Google Scholar]
- Cachin, C. An information-theoretic model for steganography. Inf. Comput. 2004, 192, 41–56. [Google Scholar] [CrossRef]
- Shiu, H.J.; Lin, B.S.; Lin, B.S.; Huang, P.Y.; Huang, C.H.; Lei, C.L. Data Hiding on Social Media Communications Using Text Steganography. In Proceedings of the International Conference on Risks and Security of Internet and Systems, Dinard, France, 19–21 September 2017; pp. 217–224. [Google Scholar]
- Wang, Y.; Moulin, P. Perfectly Secure Steganography: Capacity, Error Exponents, and Code Constructions. IEEE Trans. Inf. 2008, 54, 2706–2722. [Google Scholar] [CrossRef]
- Wendzel, S.; Caviglione, L.; Mazurczyk, W.; Lalande, J.-F. Network Information Hiding and Science 2.0: Can it be a Match? Int. J. Electron. Telecommun. 2017, 63, 217–222. [Google Scholar] [CrossRef]
- Zseby, T.; Vazquez, F.I.; Bernhardt, V.; Frkat, D.; Annessi, R. A Network Steganography Lab on Detecting TCP/IP Covert Channels. IEEE Trans. Educ. 2016, 59, 224–232. [Google Scholar] [CrossRef]
- Alotaibi, R.A.; Elrefaei, L.A. Utilizing Word Space with Pointed and Un-pointed Letters for Arabic Text Watermarking. In Proceedings of the 2016 UKSim-AMSS 18th International Conference on Computer Modelling and Simulation (UKSim), Cambridge, UK, 6–8 April 2016; pp. 111–116. [Google Scholar]
- Yu, Y.; Min, L.; JianFeng, W.; Bohuai, L.; Yang, Y.; Lei, M.; Wang, J.; Liu, B. A SVM based text steganalysis algorithm for spacing coding. China Commun. 2014, 11, 108–113. [Google Scholar]
- Banik, B.G.; Bandyopadhyay, S.K. Novel Text Steganography Using Natural Language Processing and Part-of-Speech Tagging. IETE J. Res. 2018, 1–12. [Google Scholar] [CrossRef]
- Ramakrishnan, B.K.; Thandra, P.K.; Srinivasula, A.V.S.M. Text steganography: A novel character-level embedding algorithm using font attribute. Secur. Commun. Netw. 2016, 9, 6066–6079. [Google Scholar] [CrossRef]
- Petitcolas, F.; Anderson, R.; Kuhn, M. Information hiding-a survey. Proc. IEEE 1999, 87, 1062–1078. [Google Scholar] [CrossRef]
- Fateh, M.; Rezvani, M. An email-based high capacity text steganography using repeating characters. Int. J. Comput. Appl. 2018, 1–7. [Google Scholar] [CrossRef]
- Malik, A.; Sikka, G.; Verma, H.K. A high capacity text steganography scheme based on LZW compression and color coding. Eng. Sci. Technol. Int. J. 2017, 20, 72–79. [Google Scholar] [CrossRef]
- Mahato, S.; Khan, D.A.; Yadav, D.K. A modified approach to data hiding in Microsoft Word documents by change-tracking technique. J. King Saud Univ. Comput. Inf. Sci. 2017. [Google Scholar] [CrossRef]
- Jalil, Z.; Mirza, A.M. A robust zero-watermarking algorithm for copyright protection of text documents. J. Chin. Inst. Eng. 2013, 36, 180–189. [Google Scholar] [CrossRef]
- Malik, A.; Sikka, G.; Verma, H.K. A high capacity text steganography scheme based on huffman compression and color coding. J. Inf. Optim. Sci. 2017, 38, 647–664. [Google Scholar] [CrossRef]
- Rahman, M.S.; Khalil, I.; Yi, X.; Dong, H. Highly imperceptible and reversible text steganography using invisible character based codeword. In Proceedings of the PACIS 2017: Twenty First Pacific Asia Conference on Information Systems, Langkawi, Malaysia, 19 July 2017; pp. 1–13. [Google Scholar]
- Rahma, A.M.S.; Bhaya, W.S.; Al-Nasrawi, D.A. Text steganography based on Unicode of characters in multilingual. Int. J. Eng. Res. Appl. (IJERA) 2013, 3, 1153–1165. [Google Scholar]
- Aman, M.; Khan, A.; Ahmad, B.; Kouser, S. A hybrid text steganography approach utilizing Unicode space characters and zero-width character. Int. J. Inf. Technol. Secur. 2017, 9, 85–100. [Google Scholar]
- Odeh, A.; Elleithy, K.; Faezipour, M.; Abdelfattah, E. Highly efficient novel text steganography algorithms. In Proceedings of the 2015 Long Island Systems, Applications and Technology, Farmingdale, NY, USA, 1 May 2015; pp. 1–7. [Google Scholar]
- Naqvi, N.; Abbasi, A.T.; Hussain, R.; Khan, M.A.; Ahmad, B. Multilayer Partially Homomorphic Encryption Text Steganography (MLPHE-TS): A Zero Steganography Approach. Wirel. Pers. Commun. 2018, 103, 1563–1585. [Google Scholar] [CrossRef]
- Maram, B.; Gnanasekar, J.M.; Manogaran, G.; BalaAnand, M. Intelligent security algorithm for UNICODE data privacy and security in IOT. Serv. Comput. Appl. 2018, 13, 1–13. [Google Scholar] [CrossRef]
- Rahman, M.S.; Khalil, I.; Yi, X. A lossless DNA data hiding approach for data authenticity in mobile cloud based healthcare systems. Int. J. Inf. Manag. 2019, 45, 276–288. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, Y.; Xin, G. A zero-watermarking algorithm based on merging features of sentences for Chinese text. J. Chin. Inst. Eng. 2014, 38, 391–398. [Google Scholar] [CrossRef]
- Odeh, A.; Elleithy, K.; Faezipour, M. Steganography in text by using MS word symbols. In Proceedings of the Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- Kumar, R.; Chand, S.; Singh, S. An efficient text steganography sheme using Unicode Space Characters. Int. J. Comput. Sci. 2015, 10, 8–14. [Google Scholar] [CrossRef]
- Satir, E.; Işık, H. A Huffman compression based text steganography method. Multimed. Tools Appl. 2012, 70, 2085–2110. [Google Scholar] [CrossRef]
- Kumar, R.; Malik, A.; Singh, S.; Chand, S. A high capacity email based text steganography scheme using Huffman compression. In Proceedings of the 2016 3rd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 11–12 February 2016; pp. 53–56. [Google Scholar]
- Tutuncu, K.; Hassan, A.A. New Approach in E-mail Based Text Steganography. Int. J. Intell. Syst. Appl. Eng. 2015, 3, 54. [Google Scholar] [CrossRef]
- Abdullah, A.H. Data Security Algorithm Using Two-Way Encryption and Hiding in Multimedia Files. Int. J. Sci. Eng. Res. 2014, 5, 471–475. [Google Scholar]
- Satir, E.; Isik, H.; Işık, H. A compression-based text steganography method. J. Syst. Softw. 2012, 85, 2385–2394. [Google Scholar] [CrossRef]
- Stojanov, I.; Mileva, A.; Stojanovic, I. A new property coding in text steganography of Microsoft Word documents. In Proceedings of the Eighth International Conference on Emerging Security Information, Systems and Technologies, Lisbon, Portugal, 16–20 November 2014; pp. 25–30. [Google Scholar]
- Rafat, K.F.; Sher, M. Secure Digital Steganography for ASCII Text Documents. Arab. J. Sci. Eng. 2013, 38, 2079–2094. [Google Scholar] [CrossRef]
- Baawi, S.S.; Mokhtar, M.R.; Sulaiman, R. Enhancement of Text Steganography Technique Using Lempel-Ziv-Welch Algorithm and Two-Letter Word Technique. In Proceedings of the International Conference of Reliable Information and Communication Technology, Kuala Lumpur, Malaysia, 23–24 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 525–537. [Google Scholar]
- Balajee, K.; Gnanasekar, J. Unicode Text Security Using Dynamic and Key-Dependent 16x16 S-Box (January 4, 2016). Aust. J. Basic Appl. Sci. 2016, 10, 26–36. [Google Scholar]
- Qadir, M.; Ahmad, I. Digital Text Watermarking: Secure Content Delivery and Data Hiding in Digital Documents. IEEE Aerosp. Electron. Syst. Mag. 2006, 21, 18–21. [Google Scholar] [CrossRef]
- Al-Maweri, N.A.A.S.; Ali, R.; Adnan, W.A.W.; Ramli, A.R.; Rahman, S.M.S.A.A. State-of-the-Art in Techniques of Text Digital Watermarking: Challenges and Limitations. J. Comput. Sci. 2016, 12, 62–80. [Google Scholar] [CrossRef]
- Singh, P.; Chadha, R.S. A Survey of Digital Watermarking Techniques, Applications and Attacks. Int. J. Eng. Innov. Technol. 2013, 2, 165–175. [Google Scholar]
- Agarwal, M. Text Steganographic Approaches: a comparison. Int. J. Netw. Secur. Its Appl. 2013, 5, 9–25. [Google Scholar] [CrossRef]
- Guru, J.; Damecha, H. Digital Watermarking Classification: A Survey. Int. J. Comput. Sci. Trends Technol. 2014, 2, 122–124. [Google Scholar]
- Alkawaz, M.H.; Sulong, G.; Saba, T.; Almazyad, A.S.; Rehman, A. Concise analysis of current text automation and watermarking approaches. Secur. Commun. Netw. 2016, 9, 6365–6378. [Google Scholar] [CrossRef]
- Alhusban, A.M.; Alnihoud, J.Q.O. A Meliorated Kashida Based Approach for Arabic Text Steganography. Int. J. Comput. Sci. Inf. Technol. 2017, 9, 99–109. [Google Scholar]
- Hamdan, A.M.; Hamarsheh, A. AH4S: An algorithm of text in text steganography using the structure of omega network. Secur. Commun. Netw. 2016, 9, 6004–6016. [Google Scholar] [CrossRef]
- Sumathi, C.P.; Santanam, T.; Umamaheswari, G. A Study of Various Steganographic Techniques Used for Information Hiding. Int. J. Comput. Sci. Eng. Surv. 2013, 4, 9–25. [Google Scholar]
- Mir, N. Copyright for web content using invisible text watermarking. Comput. Hum. Behav. 2014, 30, 648–653. [Google Scholar] [CrossRef]
- Sruthi, E.; Scaria, A.; Ambikadevi, A.T. Lossless Data Hiding Method Using Multiplication Property for HTML File. Int. J. Innov. Res. Sci. Technol. 2015, 1, 420–425. [Google Scholar]
- Ahvanooey, M.T.; Tabasi, S.H. A new method for copyright protection in digital text documents by adding hidden Unicode characters in Persian/English texts. Int. J. Curr. Life Sci. 2014, 8, 4895–4900. [Google Scholar]
- Ahvanooey, M.T.; Tabasi, S.H.; Rahmany, S. A Novel Approach for text watermarking in digital documents by Zero-Width Inter-Word Distance Changes. DAV Int. J. Sci. 2015, 4, 550–558. [Google Scholar]
- Bashardoost, M.; Rahim, M.S.M.; Hadipour, N. A novel zero-watermarking scheme for text document authentication. J. Teknol. 2015, 75, 49–56. [Google Scholar] [CrossRef]
- Alotaibi, R.A.; Elrefaei, L.A. Improved capacity Arabic text watermarking methods based on open word space. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 236–248. [Google Scholar] [CrossRef]
- Alginahi, Y.M.; Kabir, M.; Tayan, O. An enhanced Kashida-based watermarking approach for Arabic text-documents. In Proceedings of the 2013 International Conference on Electronics, Computer and Computation (ICECCO), Ankara, Turkey, 7–9 November 2013; pp. 301–304. [Google Scholar]
- Alginahi, Y.M.; Kabir, M.N.; Tayan, O. An Enhanced Kashida-Based Watermarking Approach for Increased Protection in Arabic Text-Documents Based on Frequency Recurrence of Characters. Int. J. Comput. Electr. Eng. 2014, 6, 381–392. [Google Scholar] [CrossRef]
- Preda, M.D.; Pasqua, M. Software Watermarking: A Semantics-based Approach. Electron. Notes Theor. Comput. Sci. 2017, 331, 71–85. [Google Scholar] [CrossRef]
- Gu, J.; Cheng, Y. A watermarking scheme for natural language documents. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering (ICICES 2010), Chengdu, China, 16–18 April 2010. [Google Scholar]
- Jaiswal, R.; Patil, N.N. Implementation of a new technique for web document protection using unicode. In Proceedings of the 2013 International Conference on Information Communication and Embedded Systems (ICICES 2013), Chennai, India, 21–22 February 2013; pp. 69–72. [Google Scholar]
- Liu, T.-Y.; Tsai, W.-H. A New Steganographic Method for Data Hiding in Microsoft Word Documents by a Change Tracking Technique. IEEE Trans. Inf. Forensics Secur. 2007, 2, 24–30. [Google Scholar] [CrossRef]
- Mohamed, A. An improved algorithm for information hiding based on features of Arabic text: A Unicode approach. Egypt. Inform. J. 2014, 15, 79–87. [Google Scholar] [CrossRef]
- Al-maweri, N.S.; Adnan, W.W.; Ramli, A.R.; Samsudin, K.; Rahman, S.M.S.A.A. Robust Digital Text Watermarking Algorithm based on Unicode Extended Characters. Indian J. Sci. Technol. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, H.; Kong, T. A novel robust text watermarking for word document. In Proceedings of the 3rd International Congress on Image and Signal Processing (CISP2010), Yantai, China, 16–18 October 2010. [Google Scholar]
- Kaur, M.; Mahajan, K. An Existential Review on Text Watermarking Techniques. Int. J. Comput. Appl. 2015, 120, 29–32. [Google Scholar] [CrossRef]
- Kim, M.Y. Text watermarking by syntactic analysis. In Proceedings of the 12th WSEAS International Conference on Computers (ICC’ 08), World Scientific and Engineering Academy and Society, Heraklion, Greece, 24–26 August 2008; pp. 904–909. [Google Scholar]
- Topkara, M.; Topkara, U.; Atallah, M.J. Words are not enough: Sentence level natural language watermarking. In Proceedings of the 4th ACM International Workshop on Contents Protection and Security, Xi’an, China, 30 May 2006. [Google Scholar]
- Topkara, U.; Topkara, M.; Atallah, M.J. The Hiding Virtues of Ambiguity: Quantifiably Resilient Watermarking of Natural Language Text through Synonym Substitutions. In Proceedings of the 8th Workshop on Multimedia and Security (MM&Sec ’06), Geneva, Switzerland, 26–27 September 2006; pp. 167–174. [Google Scholar]
- Bender, W.; Gruhl, D.; Morimoto, N.; Lu, A. Techniques for data hiding. IBM Syst. J. 1996, 35, 313–336. [Google Scholar] [CrossRef]
- Brassil, J.; Low, S.; Maxemchuk, N. Copyright protection for the electronic distribution of text documents. Proc. IEEE 1999, 87, 1181–1196. [Google Scholar] [CrossRef]
- Petrovic, R.; Tehranchi, B.; Winograd, J.M. Security of Copy-Control Watermarks. In Proceedings of the 8th International Conference on Telecommunications in Modern Satellite, Cable and Broadcasting Services—TELSIKS 2007, Nis, Serbia, 26–28 September 2007; pp. 117–126. [Google Scholar]
- Vybornova, O.; Macq, B. Natural Language Watermarking and Robust Hashing Based on Presuppositional Analysis. In Proceedings of the IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 13–15 August 2007; pp. 177–182. [Google Scholar]
- Jalil, Z.; Mirza, A.M.; Iqbal, T. A zero-watermarking algorithm for text documents based on structural components. In Proceedings of the IEEE International Conference on Information and Emerging Technologies, Karachi, Pakistan, 14–16 June 2010; pp. 1–5. [Google Scholar]
- Bashardoost, M.; Rahim, M.S.M.; Saba, T.; Rehman, A. Replacement Attack: A New Zero Text Watermarking Attack. 3D Res. 2017, 8, 2–9. [Google Scholar] [CrossRef]
- Ba-Alwi, F.M.; Ghilan, M.M.; Al-Wesabi, F.N. Content Authentication of English Text via Internet using Zero Watermarking Technique and Markov Model. Int. J. Appl. Inf. Syst. 2014, 7, 25–36. [Google Scholar]
- Tanha, M.; Torshizi, S.D.S.; Abdullah, M.T.; Hashim, F. An overview of attacks against digital watermarking and their respective countermeasures. In Proceedings of the IEEE International Conference on Cyber Security, Cyber Warfare and Digital Forensic (CyberSec), Kuala Lumpur, Malaysia, 26–28 June 2012; pp. 265–270. [Google Scholar]
- Meral, H.M.; Sevinç, E.; Unkar, E.; Sankur, B.; Özsoy, A.S.; Güngör, T. Natural language watermarking via morphosyntactic alterations. In Proceedings of the SPIE 6505, Security, Steganography, and Watermarking of Multimedia Contents, San Jose, CA, USA, 28 January 2007. [Google Scholar] [CrossRef]
- Meral, H.M.; Sankur, B.; Özsoy, A.S.; Güngör, T.; Sevinç, E. Natural language watermarking via morphosyntactic alterations. Comput. Lang. 2009, 23, 107–125. [Google Scholar] [CrossRef]
- Kim, M.-Y.; Zaiane, O.R.; Goebel, R. Natural Language Watermarking Based on Syntactic Displacement and Morphological Division. In Proceedings of the Computer Software and Applications Conference Workshops (IEEE COMPSACW), Seoul, South Korea, 19–23 July 2010. [Google Scholar]
- Halvani, O.; Steinebach, M.; Wolf, P.; Zimmermann, R. Natural language watermarking for german texts. In Proceedings of the 1st ACM Workshop on Information Hiding and Multimedia Security, Montpellier, France, 17–19 June 2013; pp. 193–202. [Google Scholar]
- Mali, M.L.; Patil, N.N.; Patil, J.B. Implementation of Text Watermarking Technique Using Natural Language Watermarks. In Proceedings of the IEEE International Conference on Communication Systems and Network Technologies, Gwalior, India, 6–8 April 2013; pp. 482–486. [Google Scholar]
- Lu, H.; Guangping, M.; Dingyi, F.; Xiaolin, G. Resilient natural language watermarking based on pragmatics. In Proceedings of the IEEE Youth Conference on Information, Computing and Telecommunication (YC-ICT ’09), Beijing, China, 20–21 September 2009. [Google Scholar]
- Lee, I.S.; Tsai, W.H. Secret communication through web pages using special space codes in HTML files. Int. J. Appl. Sci. Eng. 2008, 6, 141–149. [Google Scholar]
- Cheng, W.; Feng, H.; Yang, C. A robust text digital watermarking algorithm based on fragments regrouping strategy. In Proceedings of the IEEE International Conference on Information Theory and Information Security (ICITIS), Beijing, China, 17–19 December 2010; pp. 600–603. [Google Scholar]
- Gutub, A.A.A.; Ghouti, L.; Amin, A.A.; Alkharobi, T.M.; Ibrahim, M. Utilizing extension character ‘Kashida’ with pointed letters 469 for Arabic text digital watermarking. In Proceedings of the SECRYPT 2007, Barcelona, Spain, 28–31 July 2007; pp. 329–332. [Google Scholar]
- Chou, Y.-C.; Huang, C.-Y.; Liao, H.-C. A Reversible Data Hiding Scheme Using Cartesian Product for HTML File. In Proceedings of the Sixth International Conference on Genetic and Evolutionary Computing (ICGEC), Kitakushu, Japan, 25–28 August 2012; pp. 153–156. [Google Scholar]
- Odeh, A.; Elleithy, K. Steganography in Text by Merge ZWC and Space Character. In Proceedings of the 28th International Conference on Computers and Their Applications (CATA-2013), Honolulu, HI, USA, 4–6 March 2013; pp. 1–7. [Google Scholar]
- Shirali-Shahreza, M. Pseudo-space Persian/Arabic text steganography. In Proceedings of the IEEE Symposium on Computers and Communications ISCC, Marrakech, Morocco, 6–9 July 2008; pp. 864–868. [Google Scholar]
- Gutub, A.A.A.; Fattani, M.M. A Novel Arabic Text Steganography Method Using Letter Points and Extensions. Int. J. Comput. Electr. Autom. Control Inf. Eng. 2007, 1, 502–505. [Google Scholar]
- Gutub, A.A.A.; Al-Nazer, A.A. High Capacity Steganography Tool for Arabic Text Using ‘Kashida’. ISC Int. J. Inf. Secur. 2010, 2, 107–118. [Google Scholar]
- Gutub, A.A.A.; Al-Alwani, W.; Mahfoodh, A.B. Improved Method of Arabic Text Steganography Using the Extension ‘Kashida’ Character. Bahria Univ. J. Inf. Commun. Technol. 2010, 3, 68–72. [Google Scholar]
- Al-Nazer, A.; Gutub, A. Exploit Kashida Adding to Arabic e-Text for High Capacity Steganography. In Proceedings of the 2009 Third International Conference on Network and System Security, Gold Coast, QLD, Australia, 19–21 October 2009; pp. 447–451. [Google Scholar]
- Al-Nofaie, S.M.; Fattani, M.M.; Gutub, A.A.A. Capacity Improved Arabic Text Steganography Technique Utilizing ‘Kashida’ with Whitespaces. In Proceedings of the 3rd International Conference on Mathematical Sciences and Computer Engineering (ICMSCE 2016), Lankawi, Malaysia, 4–5 February 2016; pp. 38–44. [Google Scholar]
- Al-Nofaie, S.M.; Fattani, M.M.; Gutub, A.A.-A. Merging Two Steganography Techniques Adjusted to Improve Arabic Text Data Security. J. Comput. Sci. Comput. Math. 2016, 6, 59–65. [Google Scholar] [CrossRef]
- Keidel, R.; Wendzel, S.; Zillien, S.; Conner, E.S.; Haas, G. WoDiCoF-A Testbed for the Evaluation of (Parallel) Covert Channel Detection Algorithms. J. Univers. Comput. Sci. 2018, 24, 556–576. [Google Scholar]
- Gu, Y.X.; Wyseur, B.; Preneel, B. Software-Based Protection Is Moving to the Mainstream. IEEE Comput. Soc. 2011, 28, 56–59. [Google Scholar]
- Por, L.Y.; Ang, T.F.; Delina, B. Whitesteg: A new scheme in information hiding using text steganography. Wseas Trans. Comput. 2008, 7, 735–745. [Google Scholar]
- The Unicode Standard. December 2018. Available online: http://www.unicode.org/standard/standard.html (accessed on 30 March 2019).
- Unicode. Wikipedia (the Free Encyclopedia), December 2018. Available online: https://en.wikipedia.org/wiki/Unicode (accessed on 30 March 2019).
- Unicode Control Characters. March 2019. Available online: http://www.fileformat.info/info/unicode/char/search.htm (accessed on 30 March 2019).
- Kerckhoffs, A. La cryptographie militaire. J. Sci. Mil. 1883, IX, 161–191. [Google Scholar]
- Din, R.; Tuan Muda, T.Z.; Lertkrai, P.; Omar, M.N.; Amphawan, A.; Aziz, F.A. Text steganalysis using evolution algorithm approach. In Proceedings of the 11th WSEAS International Conference on Information Security and Privacy (ISP’12), Prague, Czech Republic, 24–26 September 2012. [Google Scholar]
- Din, R.; Samsudin, A.; Lertkrai, P. A Framework Components for Natural Language Steganalysis. Int. J. Comput. Eng. 2012, 641–645. [Google Scholar] [CrossRef]
- Mazurczyk, W.; Wendzel, S.; Cabaj, K. Towards Deriving Insights into Data Hiding Methods Using Pattern-based Approach. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018; p. 10. [Google Scholar]
- Simmons, G.J. The prisoner’s problem and the subliminal channel. In Advances in Cryptology; Plenum Press: New York, NY, USA, 1984; pp. 51–67. [Google Scholar]
- Khosravi, B.; Khosravi, B.; Khosravi, B.; Nazarkardeh, K. A new method for pdf steganography in justified texts. JISA. 2019, 145, 61–70. [Google Scholar]
- Ahvanooey, M.T.; Li, Q.; Rabbani, M.; Rajput, A.R. A Survey on Smartphones Security: Software Vulnerabilities, Malware, and Attacks. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 30–45. [Google Scholar]
- Khairullah, M. A novel steganography method using transliteration of Bengali text. J. King Saud Univ. Comput. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Kim, Y.-W.; Moon, K.-A.; Oh, I.-S. A text watermarking algorithm based on word classification and inter-word space statistics. In Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR ’03), Washington, DC, USA, 27 June–2 July 2003; Volume 2, p. 775. [Google Scholar]
- Alattar, A.M.; Alattar, O.M. Watermarking electronic text documents containing justified paragraphs and irregular line spacing. Electron. Imaging 2004, 5306, 685–695. [Google Scholar]
- Low, S.; Maxemchuk, N.; Brassil, J.; O’Gorman, L. Document marking and identification using both line and word shifting. In Proceedings of the Fourteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Bringing Information to People (INFOCOM ’95), Boston, MA, USA, 2–6 April 1995; Volume 2, pp. 853–860. [Google Scholar]
- Memon, M.Q.; Yu, H.; Rana, K.G.; Azeem, M.; Yongquan, C.; Ditta, A. Information hiding: Arabic text steganography by using Unicode characters to hide secret data. Int. J. Electron. Secur. Digit. Forensics 2018, 10, 61–78. [Google Scholar] [CrossRef]
- Shirali-Shahreza, M. A New Approach to Persian/Arabic Text Steganography. In Proceedings of the 5th IEEE/ACIS International Conference on Computer and Information Science and 1st IEEE/ACIS International Workshop on Component-Based Software Engineering, Software Architecture and Reuse (ICIS-COMSAR’06), Honolulu, HI, USA, 10–12 July 2006; pp. 310–315. [Google Scholar]
- Aabed, M.A.; Awaideh, S.M.; Elshafei, A.-R.M.; Gutub, A.A. Arabic Diacritics based Steganography. In Proceedings of the 2007 IEEE International Conference on Signal Processing and Communications, United Arab Emirates, 24–27 November 2007; pp. 756–759. [Google Scholar]
- Gutub, A.; Elarian, Y.; Awaideh, S.; Alvi, A. Arabic text steganography using multiple diacritics. In Proceedings of the 5th IEEE International Workshop on Signal Processing and its Applications (WoSPA08), University of Sharjah, Sharjah, UAE, 18–20 March 2008. [Google Scholar]
- Memon, J.A.; Khowaja, K.; Kazi, H. Evaluation of steganography for urdu/arabic text. J. Theor. Appl. Inf. Technol. 2005, 4, 232–237. [Google Scholar]
- Nagarhalli, T.P. A new approach to SMS text steganography using emoticons. In Proceedings of the International Journal of Computer Applications (0975–8887) National Conference on Role of Engineers in Nation Building (NCRENB-14), VIVA Institute of Technology, Maharashtra, India, 6–7 March 2014; pp. 1–3. [Google Scholar]
- Ahmad, T.; Sukanto, G.; Studiawan, H.; Wibisono, W.; Ijtihadie, R.M. Emoticon-based steganography for securing sensitive data. In Proceedings of the 2014 6th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 7–8 October2014; pp. 1–6. [Google Scholar]
- Iranmanesh, V.; Wei, H.J.; Dao-Ming, S.L.; Arigbabu, O.A. On using emoticons and lingoes for hiding data in SMS. In Proceedings of the 2015 International Symposium on Technology Management and Emerging Technologies (ISTMET), Melaka, Malaysia, 25–27 August 2015; pp. 103–107. [Google Scholar]
- Shirali-Shahreza, M. A New Persian/Arabic Text Steganography Using “La” Word. In Advances in Computer and Information Sciences and Engineering; Springer: Berlin/Heidelberg, Germany, 2008; pp. 339–342. [Google Scholar]
- Bhattacharyya, S.; Indu, P.; Sanyal, G. Hiding Data in Text using ASCII Mapping Technology (AMT). Int. J. Comput. Appl. 2013, 70, 29–37. [Google Scholar] [CrossRef]
- Kingslin, S.; Kavitha, N. Evaluative Approach towards Text Steganographic Techniques. J. Sci. Technol. 2015, 8. [Google Scholar] [CrossRef]
- Thamaraiselvan, R.; Saradha, A. A Novel approach of Hybrid Method of Hiding the Text Information Using Stegnography. Int. J. Comput. Eng. Res. 2012, 1405–1409. [Google Scholar]
- Ryabko, B.; Ryabko, D. Information-theoretic approach to steganographic systems. In Proceedings of the 2007 IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 2461–2464. [Google Scholar]
- Chen, R.X. A Brief Introduction on Shannon’s Information Theory. arXiv, 2016; arXiv:1612.09316. [Google Scholar]
- Verdü, S. Fifty years of Shannon theory. IEEE Trans. Inf. Theory 1998, 44, 2057–2078. [Google Scholar] [CrossRef]
- Yamano, T. A possible extension of Shannon’s information theory. Entropy 2001, 3, 280–292. [Google Scholar] [CrossRef]
- Rico-Larmer, S.M. Cover Text Steganography: N-gram and Entropybased Approach. In Proceedings of the 2016 KSU Conference on Cybersecurity Education, Research and Practice, Kennesaw State University, Kennesaw, GA, USA, 4 October 2016; Available online: https://digitalcommons.kennesaw.edu/ccerp/2016/Student/16 (accessed on 30 March 2019).
- Menzes, A.; van Oorschot, P.; Vanstone, S. Handbook of Applied Cryptography; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Ryabko, B.; Fionov, A. Basics of Contemporary Cryptography for IT Practitioners; World Scientific Pub. Co. Pte Lt.: Hackensack, NJ, USA, 2005. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Name | Hex Code | Decimal Code | Written Symbol |
|---|---|---|---|---|
| [1,27,28,33,42,55,58,91] | Zero-Width-Non-Joiner | U+200C | 8204 | No symbol and width |
| [1,4] | POP Directional | U+202C | 8236 | No symbol and width |
| [1,4] | Left-To-Right Override | U+202D | 8237 | No symbol and width |
| [1,28,33,42] | Left-To-Right Mark | U+200E | 8206 | No symbol and width |
| [4] | Right -To- Left Override | U+202E | 8238 | No symbol and width |
| [5,6,53,54,91] | Narrow No-Break Space | U+202F | 8239 | No symbol and width |
| [55,56] | Left-to-right embedding | U+202A | 8234 | No symbol and width |
| [55,56] | Right-to-left embedding | U+202B | 8235 | No symbol and width |
| [7,55,56] | Mongolian-vowel separator | U+180E | 6158 | No symbol and width |
| [28,33] | Right -To- Left Mark | U+200F | 8207 | No symbol and width |
| [28,33,42,55,56] | Zero-Width-Joiner | U+200D | 8205 | No symbol and width |
| [42,55,56,58] | Zero-Width-Space | U+200B | 8203 | No symbol and width |
| [55,56] | Zero-Width-Non-Break | U+FEFF | 65279 | No symbol and width |
| [5,6,7,27,34,53,54,58] | Hair Space | U+200A | 8202 | 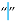 |
| [5,6,7,27,34,54] | Six-Per-Em Space | U+2006 | 8198 | 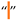 |
| [5,6,7,27,34,54] | Figure Space | U+2007 | 8199 | 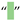 |
| [5,6,7,27,34,54] | Punctuation Space | U+2008 | 8200 |  |
| [5,6,7,34,54,58] | Thin Space | U+2009 | 8201 | 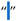 |
| [5,6,7,34,54] | En Quad | U+2000 | 8192 | 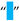 |
| [5,6,7,34,54] | Three-Per-Em Space | U+2004 | 8196 |  |
| [5,6,7,34,54] | Four-Per-Em Space | U+2005 | 8197 | 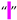 |
| [5,6,7,27,34,100] | Normal Space | U+0020 | 32 | 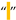 |
| Number | Social Media or Messenger Name | Message/Post | Text Limits Number of ASCII Characters | Text Limits Number of UTF-8 Characters |
|---|---|---|---|---|
| 1 | SMS | Message | 2048 | 1024 |
| 2 | Wall Post | 63,206 | 31,603 | |
| 3 | Post | 52,286 | 29,718 | |
| 4 | Tweet | 280 | 140 (Exclusive encoding) | |
| 5 | Google+ | Post | 100,000 | 50,000 |
| 6 | Pic Caption | 2200 | 1100 | |
| 7 | Pin Description | 500 | 250 | |
| 8 | YouTube | Video Description | 5000 | 2500 |
| 9 | Message | 30,000 | 30,000 | |
| 10 | Gmail | Mail Text | 35,000,000 | 35,000,000 |
| 11 | Message | 16,207 | 16,207 | |
| 12 | Imo | Message | Virtually Unlimited | Virtually Unlimited |
| 13 | Hangouts | Message | Virtually Unlimited | Virtually Unlimited |
| 14 | Telegram | Message | 4096 (Exclusive encoding) | 4096 (Exclusive encoding) |
| 15 | Line | Message | 10,000 | 10,000 |
| 16 | Tango | Message | 520 | 520 |
| 17 | Message | 16,207 | 16,207 |
| Type Name | Invisibility | EC | DR | Language Coverage | Pros & Cons |
|---|---|---|---|---|---|
| Linguistic [17,62,70,71,80,81,82,83,84,85,106,109] | Imperceptible | Low | Medium | Exclusive |
|
| Structural [1,2,3,4,5,6,7,8,11,20,34,41,54,65,66,100,112,113,114] | Imperceptible | High | High | Multilingual |
|
| Random & Statistics [21,23,24,29,34,35,39,47,51,124] | Perceptible | Modest | High | Exclusive |
|
| Type | Hidden Transmission | Network Cover Channels | Unauthorized Access Detection | Highlights and Limitations |
|---|---|---|---|---|
| Linguistic | ✓ | ✓ | × |
|
| Structural | ✓ | ✓ | ✓ |
|
| Random & Statistics | ✓ | ✓ | × |
|
| Right to Left Mark | Left to Right Mark | ZWJ | ZWNJ | SMbits |
|---|---|---|---|---|
| × | × | × | × | 0000 |
| × | × | × | - | 0001 |
| × | × | - | × | 0010 |
| × | × | - | - | 0011 |
| … | … | .. | .. | … |
| 2-Bit | Embeddable Location |
|---|---|
| ‘00′ | No ‘ZWC’ + ”U+0020” |
| ‘01′ | “U+0020” + No ‘ZWC’ |
| ‘10′ | “U+200B” + ”U+0020” |
| ‘11′ | “U+0020” + “U+200B” |
| 2-Bit Classification | Hex Code |
|---|---|
| 00 | U+200C |
| 01 | U+202C |
| 10 | U+202D |
| 11 | U+200E |
| Spaces Pattern | 4-bit Classification |
|---|---|
| Normal Space | 0000 |
| Normal Space + Three-Per-Em | 0001 |
| Three-Per-Em + Normal Space | 0010 |
| Normal Space + Four-Per-Em | 0011 |
| Four-Per-Em + Normal Space | 0100 |
| Normal Space + Six-Per-Em | 0101 |
| Six-Per-Em + Normal Space | 0110 |
| Normal Space + Figure | 0111 |
| Figure + Normal Space | 1000 |
| Normal Space + Thin | 1001 |
| Thin + Normal Space | 1010 |
| Normal Space + Hair | 1011 |
| Hair + Normal Space | 1100 |
| Normal Space + Punctuation | 1101 |
| Punctuation + Normal Space | 1110 |
| Normal Space + Narrow No-Break | 1111 |
| Narrow No-Break + Normal Space | 1111 |
| Spaces Pattern | 3-bit Classification |
|---|---|
| Three-Per-Em Space | 000 |
| Four-Per-Em Space | 001 |
| Six-Per-Em Space | 010 |
| Figure Space | 011 |
| Punctuation Space | 100 |
| Thin Space | 101 |
| Hair Space | 110 |
| Narrow No-Break Space | 111 |
| Algorithm | CM | CMHM | Embedded SMbits |
|---|---|---|---|
| AITSteg [1] | The only source of knowledge is experience. | The only source of knowledge is experience. | 12 |
| ZW_4B [33] | The only source of knowledge is experience. | The only source of knowledge is experience. | 16 |
| MHST [29] | The only source of knowledge is experience. | The only source of knowledge is experience. | 0 |
| ZWBSP [90] | The only source of knowledge is experience. | The only source of knowledge is experience. | 12 |
| TWSM [5,6] | The only source of knowledge is experience. |  | 16 |
| 4-SpaCh [58] | The only source of knowledge is experience. | 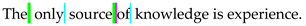 | 16 |
| WS_EL [11] | The only source of knowledge is experience. | The only source of knowledge is experience. | 6 |
| 4&3SpaCh [34] | The only source of knowledge is experience. | 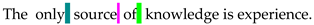 | 16 |
| UniSpaCh [7] | The only source of knowledge is experience. |  | 16 |
| EM_ST [13] | The only source of knowledge is experience. | The only source of knowledge is experience. | 16 |
| Name | Text Content | Reference |
|---|---|---|
| CM.1 | Science without religion is lame, religion without science is blind. | https://www.brainyquote.com |
| CM.2 | 君子之行,静以修身,俭以养德,非澹泊无以明志,非宁静无以致远。《诫子书》 | https://www.fluentu.com/ |
| CM.3 | Die größte Gefahr für die meisten von uns ist nicht, dass wir hohe Ziele anstreben und sie verfehlen, sondern dass wir uns zu niedrige setzen und sie erreichen. | https://www.germanpod101.com |
| CM.4 | جهان سوم جایی است که هر کس بخواهد مملکتش را آباد کند، خانه اش خراب می شود و هر کس بخواهد خانه اش را آباد کند باید در ویرانی مملکتش بکوشد. | http://www.bartarinha.ir/ |
| CM.5 | Chi vuol andar salvo per lo mondo, bisogna aver occhio di falcone, orecchio d’asino, viso di scimia, bocca di porcello, spalle di camello, è gambe di cervo. | http://oaks.nvg.org/ |
| Cover Name | Characters | Spaces | Words | Sentences | Lines | Language |
|---|---|---|---|---|---|---|
| CM.1 | 68 | 9 | 10 | 1 | 2 | English |
| CM.2 | 36 | 0 | 36 | 1 | 2 | Chinese |
| CM.3 | 160 | 27 | 28 | 1 | 4 | German |
| CM.4 | 137 | 30 | 31 | 1 | 3 | Persian |
| CM.5 | 156 | 26 | 27 | 1 | 4 | Italian |
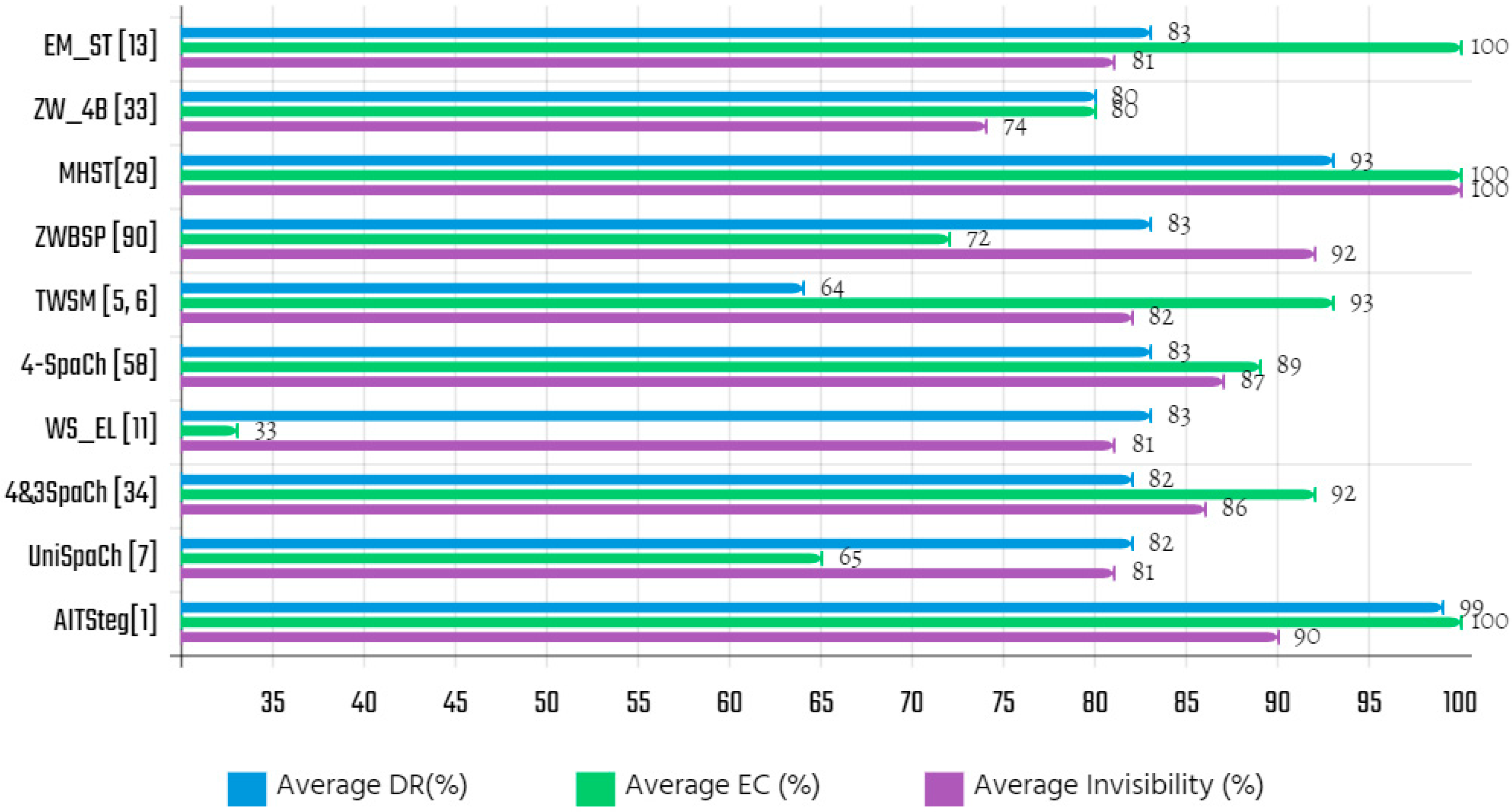
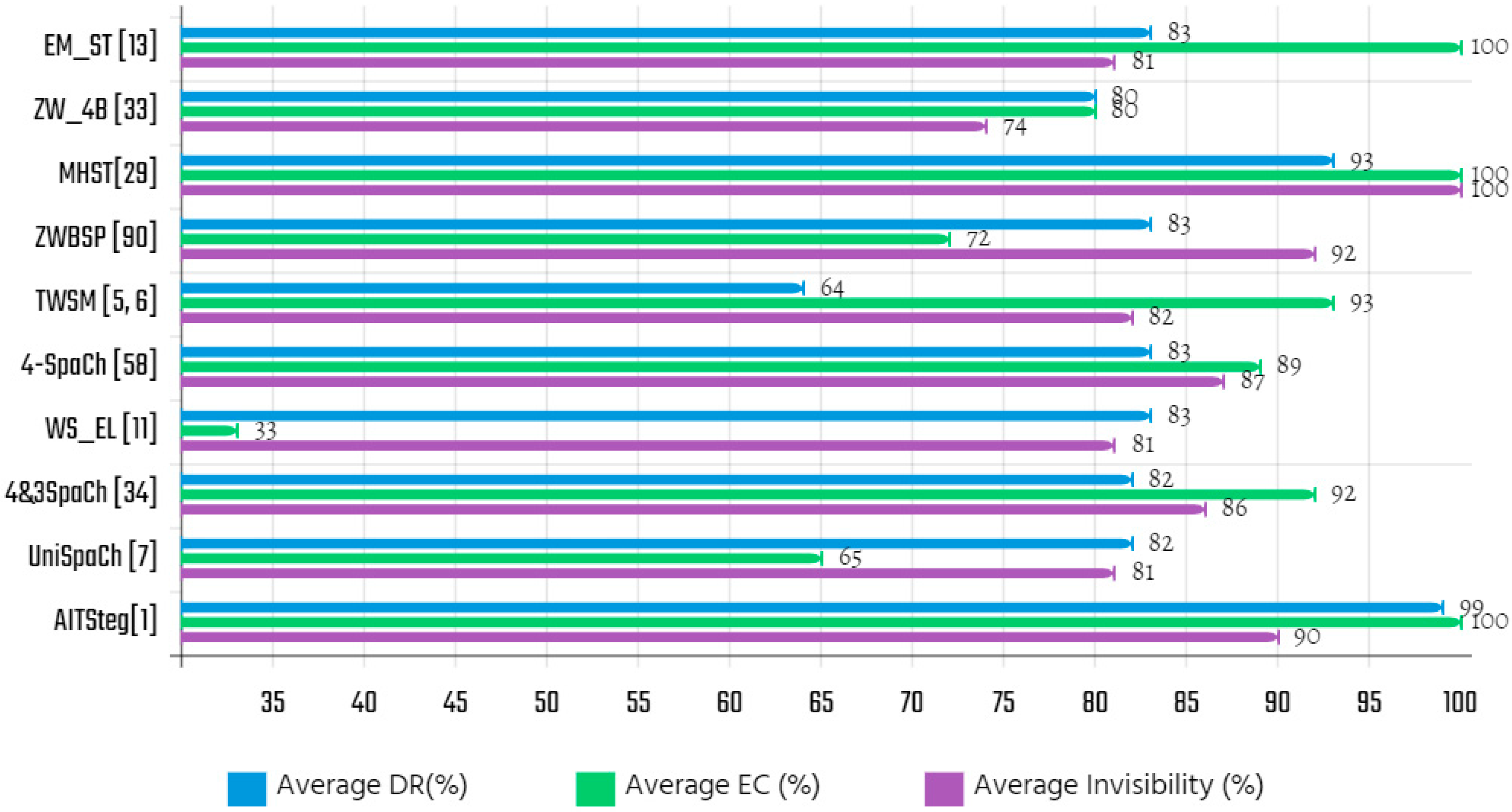
| Algorithm | CM.1 | CM.2 | CM.3 | CM.4 | CM.5 | Average Invisibility (%) |
|---|---|---|---|---|---|---|
| AITSteg [1] | 89.3 | 84.3 | 94.4 | 89.3 | 95.1 | ≅90 |
| UniSpaCh [7] | 83.8 | 0 | 80.8 | 79.9 | 80.4 | ≅81 |
| ZW_4B [33] | 62.5 | 47.2 | 94.0 | 0 | 93.4 | ≅74 |
| MHST [29] | 100 | 0 | 100 | 100 | 100 | ≅100 |
| ZWBSP [90] | 96.1 | 0 | 95.1 | 80.1 | 95 | ≅92 |
| TWSM [5,6] | 85.7 | 0 | 81.8 | 79.3 | 80.7 | ≅82 |
| 4-SpaCh [58] | 82.9 | 0 | 84 | 84.1 | 96.5 | ≅87 |
| WS_EL [11] | 83.4 | 0 | 81.1 | 80.3 | 80.6 | ≅81 |
| 4&3SpaCh [34] | 84.9 | 0 | 87 | 87.5 | 84.6 | ≅86 |
| EM_ST [13] | 83.2 | 0 | 81.1 | 80.1 | 80.1 | ≅81 |
| Algorithm | Type of Embedding | CM.1 | CM.2 | CM.3 | CM.4 | CM.5 | Average EC/64 (%) |
|---|---|---|---|---|---|---|---|
| AITSteg [1] | Bit-level | 64 | 64 | 64 | 64 | 64 | ≅ 64 => 100 |
| UniSpaCh [7] | Bit-level | 22 | 4 | 62 | 64 | 60 | ≅ 42 => 65 |
| ZW_4B [33] | Bit-level | 64 | 64 | 64 | 0 | 64 | ≅ 51 => 80 |
| MHST [29] | Character-Level | 8*8 = 64 | 0 | 8*8 = 64 | 0 | 8*8 = 64 | ≅ 64 => 100 |
| ZWBSP [90] | Bit-level | 18 | 0 | 56 | 60 | 52 | ≅ 46 => 72 |
| TWSM [5,6] | Bit-level | 47 | 0 | 64 | 64 | 64 | ≅ 60 => 93 |
| 4-SpaCh [58] | Bit-level | 36 | 0 | 64 | 64 | 64 | ≅ 57 => 89 |
| WS_EL [11] | Bit-level | 11 | 2 | 31 | 33 | 31 | ≅ 22 => 33 |
| 4&3SpaCh [34] | Bit-level | 45 | 9 | 64 | 64 | 64 | ≅ 59 => 92 |
| EM_ST [13] | Character-Level | 8*8 = 64 | 0 | 8*8 = 64 | 8*8 = 64 | 8*8 = 64 | ≅ 64 => 100 |
| Algorithm | CM.1 | CM.2 | CM.3 | CM.4 | CM.5 | Average DR (%) |
|---|---|---|---|---|---|---|
| AITSteg [1] | 98.5 | 97.2 | 99.3 | 99.2 | 99.3 | ≅99 |
| UniSpaCh [7] | 83.8 | 88.8 | 80.6 | 75.9 | 80.7 | ≅82 |
| ZW_4B [33] | 76.4 | 55.5 | 90 | 88.3 | 89.7 | ≅80 |
| MHST [29] | 88.2 | 0 | 95 | 0 | 94.8 | ≅93 |
| ZWBSP [90] | 86.7 | 0 | 83.1 | 78.1 | 83.3 | ≅83 |
| TWSM [5,6] | 57.3 | 0 | 66.8 | 78.1 | 51.9 | ≅64 |
| 4-SpaCh [58] | 86.7 | 0 | 83.1 | 78.1 | 83.3 | ≅83 |
| WS_EL [11] | 83.8 | 95 | 80.6 | 75.9 | 80.1 | ≅83 |
| 4&3SpaCh [34] | 82.3 | 91.6 | 80 | 75.1 | 80.1 | ≅82 |
| EM_ST [13] | 86.7 | 0 | 83.1 | 78.1 | 83.3 | ≅83 |
| Algorithm | EC | DR | Invisibility | Limitations | Language Coverage |
|---|---|---|---|---|---|
| AITSteg [1] | High | High | Imperceptible | Embeds additional ZWCs in front of the CM | Multilingual |
| UniSpaCh [7] | Low | Medium | Imperceptible | Depends on the spaces between words | Multilingual |
| ZW_4B [33] | Modest | Medium | Imperceptible | Embeds four ZWCs after each letter | Exclusive (Latin) |
| MHST [29] | High | High | Imperceptible | Depends on using an exclusive language in the SM | Exclusive (Latin) |
| ZWBSP [90] | Low | Medium | Imperceptible | Depends on the spaces between words | Multilingual |
| TWSM [5,6] | High | Low | Imperceptible | Depends on the spaces and font style of the CM | Exclusive (Latin) |
| 4-SpaCh [58] | Modest | Medium | Imperceptible | Depends on the spaces between words | Multilingual |
| WS_EL [11] | Low | Medium | Imperceptible | Embeds two spaces between words | Multilingual |
| 4&3SpaCh [34] | High | Medium | Imperceptible | Depends on the spaces between words | Multilingual |
| EM_ST [13] | High | Medium | Visible | Embeds additional emoticons between words | Multilingual |
| Algorithm | Having Robustness Against Attack: Yes (✓) and No (×) | Security Limitations | |||
|---|---|---|---|---|---|
| Visual | Structural | Statistical | Retyping | ||
| AITSteg [1] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| UniSpaCh [7] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| ZW_4B [33] | × | ✓ | ✓ | × | Medium safety (2) |
| MHST [29] | × | ✓ | ✓ | × | Medium safety (2) |
| ZWBSP [90] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| TWSM [5,6] | × | × | ✓ | × | Easy to lose (1) |
| 4-SpaCh [58] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| WS_EL [11] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| 4&3SpaCh [34] | ✓ | ✓ | ✓ | × | Optimum safety (3) |
| EM_ST [13] | × | ✓ | ✓ | × | Medium safety (2) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taleby Ahvanooey, M.; Li, Q.; Hou, J.; Rajput, A.R.; Chen, Y. Modern Text Hiding, Text Steganalysis, and Applications: A Comparative Analysis. Entropy 2019, 21, 355. https://doi.org/10.3390/e21040355
Taleby Ahvanooey M, Li Q, Hou J, Rajput AR, Chen Y. Modern Text Hiding, Text Steganalysis, and Applications: A Comparative Analysis. Entropy. 2019; 21(4):355. https://doi.org/10.3390/e21040355
Chicago/Turabian StyleTaleby Ahvanooey, Milad, Qianmu Li, Jun Hou, Ahmed Raza Rajput, and Yini Chen. 2019. "Modern Text Hiding, Text Steganalysis, and Applications: A Comparative Analysis" Entropy 21, no. 4: 355. https://doi.org/10.3390/e21040355
APA StyleTaleby Ahvanooey, M., Li, Q., Hou, J., Rajput, A. R., & Chen, Y. (2019). Modern Text Hiding, Text Steganalysis, and Applications: A Comparative Analysis. Entropy, 21(4), 355. https://doi.org/10.3390/e21040355