Multisensor Estimation Fusion with Gaussian Process for Nonlinear Dynamic Systems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- Detailed proofs are provided.
- The enhancement of the multisensor fusion algorithm with GP-UKF is presented.
- Additional set of extensive experiments are carried out.
- The equivalence condition of Proposition 1 is analyzed.
- Comparison between GP-ADF fusion and GP-UKF is given.
2. Preliminaries
2.1. Problem Formulation
2.2. Gaussian Processes
3. Multisensor Estimation Fusion
3.1. Centralized Estimation Fusion
3.2. Distributed Estimation Fusion
4. Numerical Examples
4.1. 1D Example
4.2. 2D Nonlinear Dynamic System
4.2.1. Experimental Setup
4.2.2. Experimental Analysis
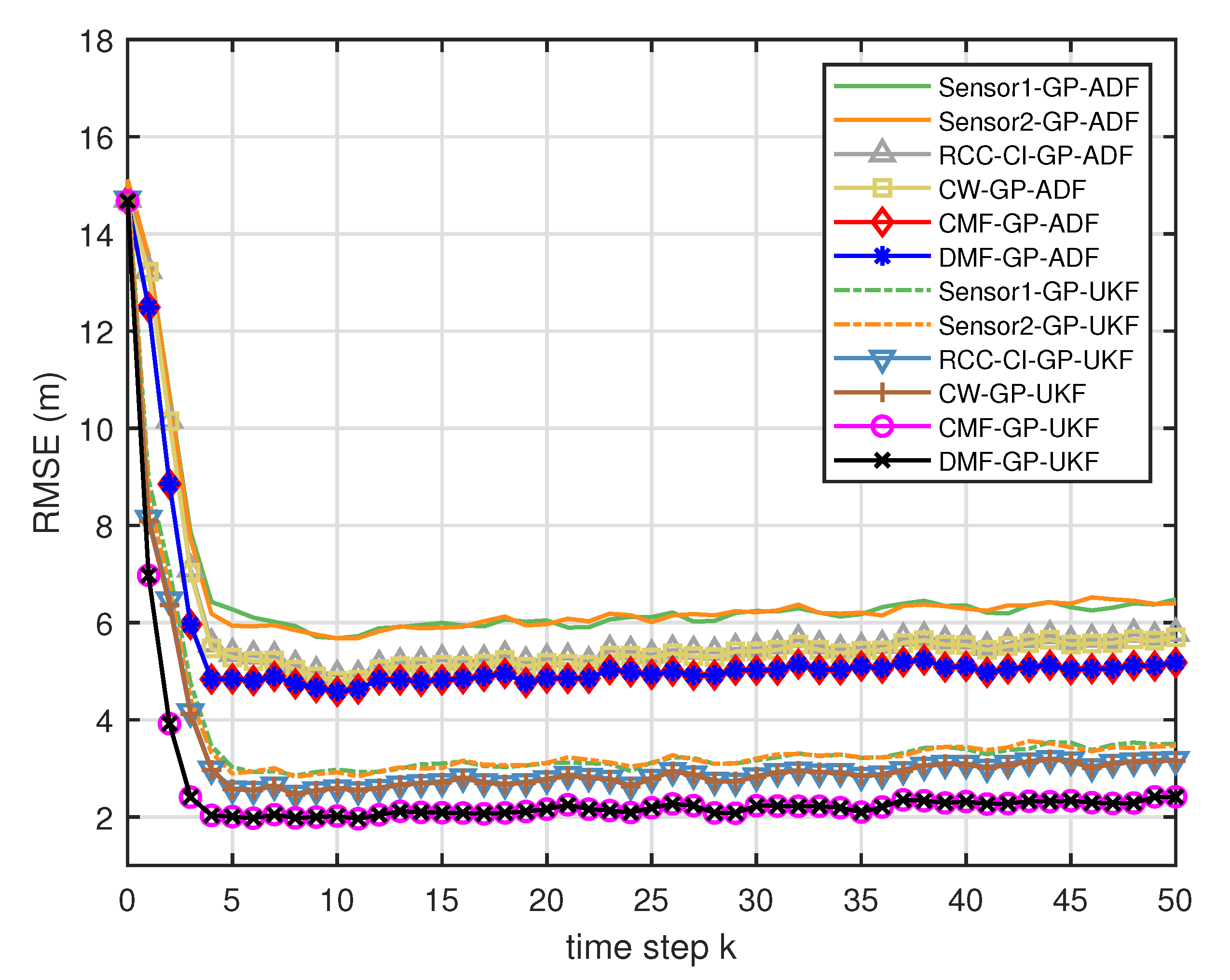
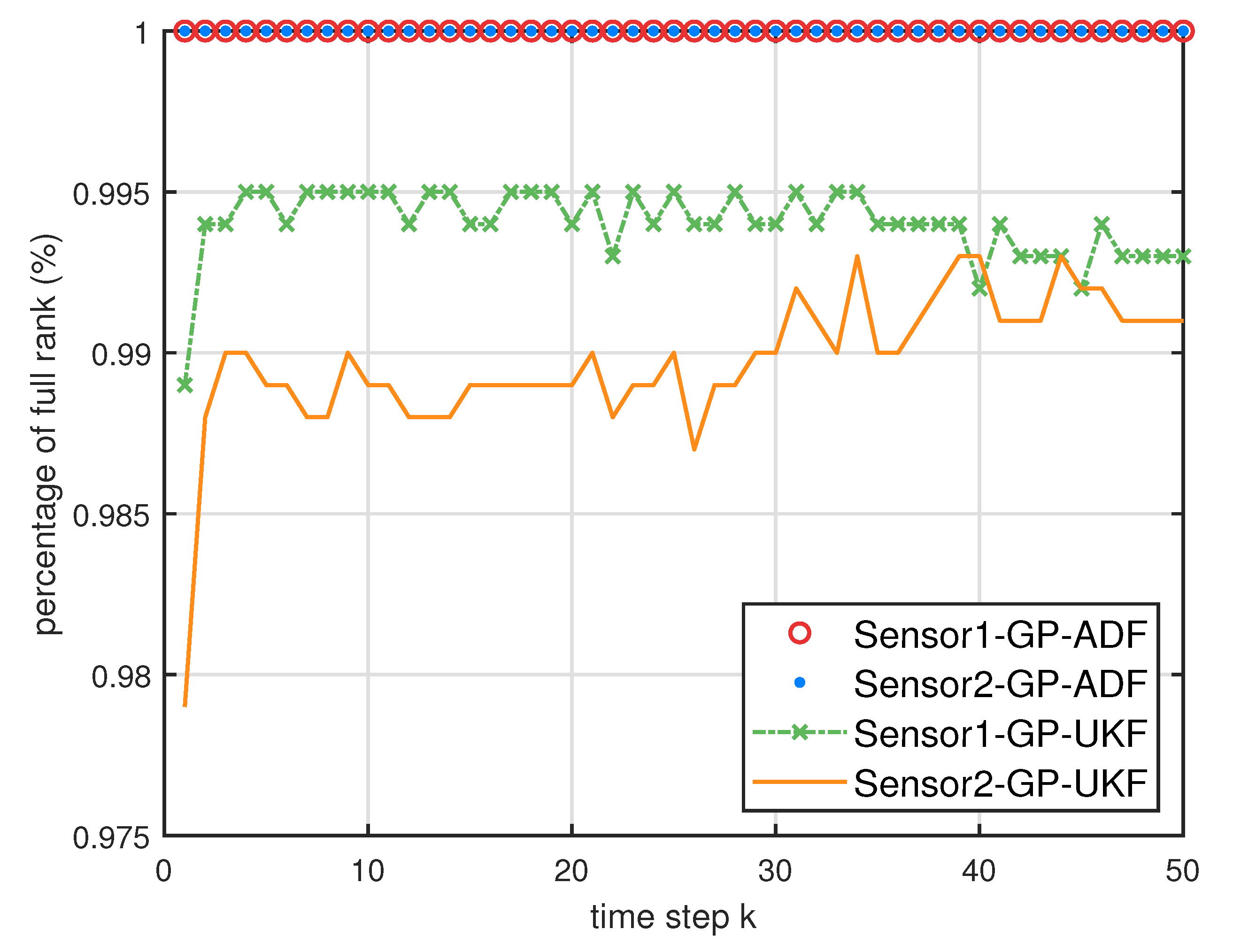
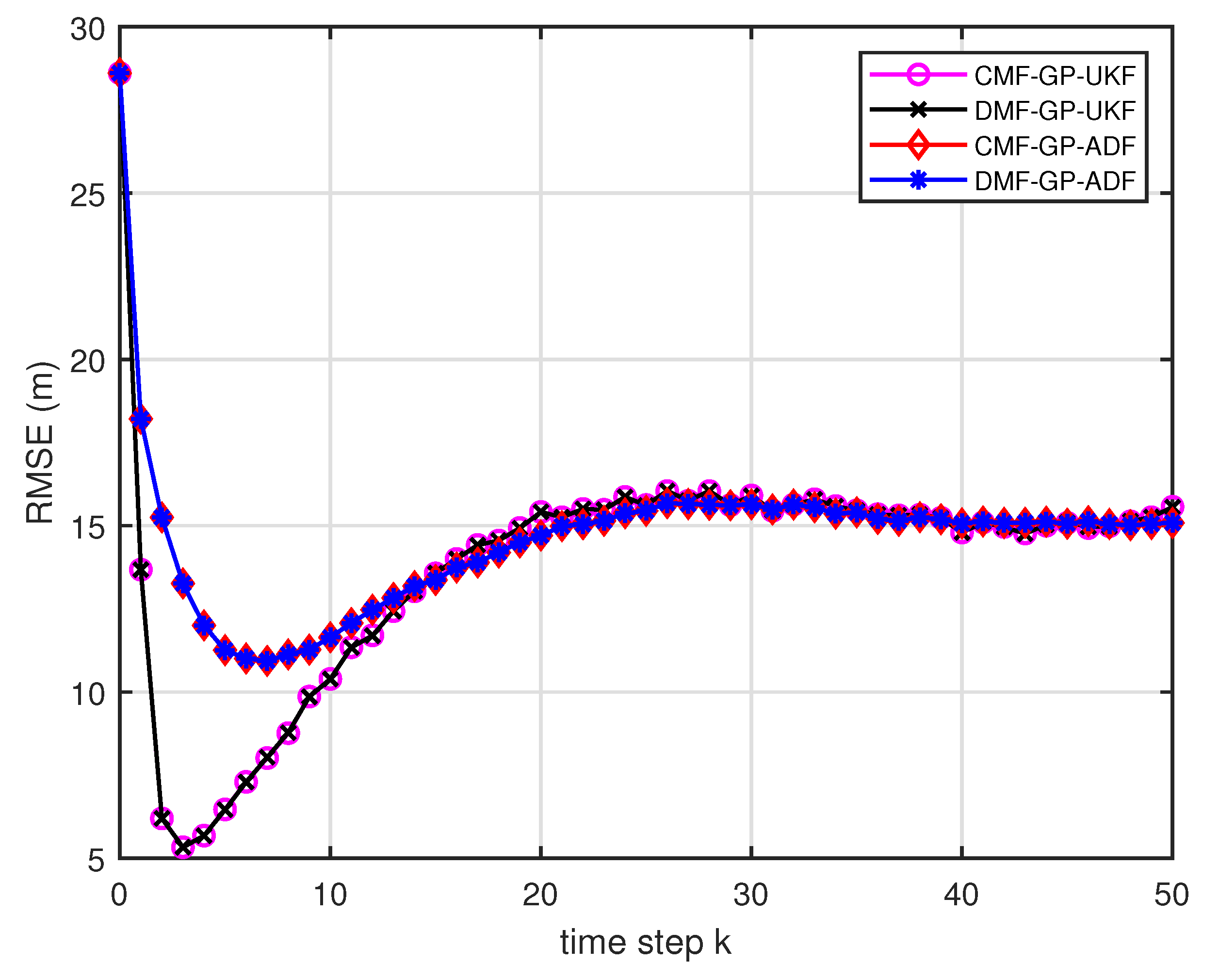
- From Figure 5, we can see that the ratios of full rank are all equal to . It means that the cross terms of the single sensor filters are all full column rank for the training data case and thus the equivalence condition of centralized fusion and distributed fusion is satisfied in Proposition 1. Meanwhile, from Figure 6 and Figure 7, the RMSE of the distributed estimation fusion is the same as that of the centralized estimation fusion based on GP-ADF and GP-UKF, respectively. It demonstrates the equivalence between the centralized estimation fusion and the distributed estimation fusion in Proposition 1 under the condition of full column rank.
- In addition, the RMSE of multisensor estimation fusion method is lower than that of the RCC-CI algorithm and the convex combination method. It implies the effectiveness of the fusion methods based on Gaussian processes. The possible reason is that our estimation fusion methods extract more extra correlation information, and the RCC-CI algorithm and the convex combination method only use the local estimates with mean and covariance.
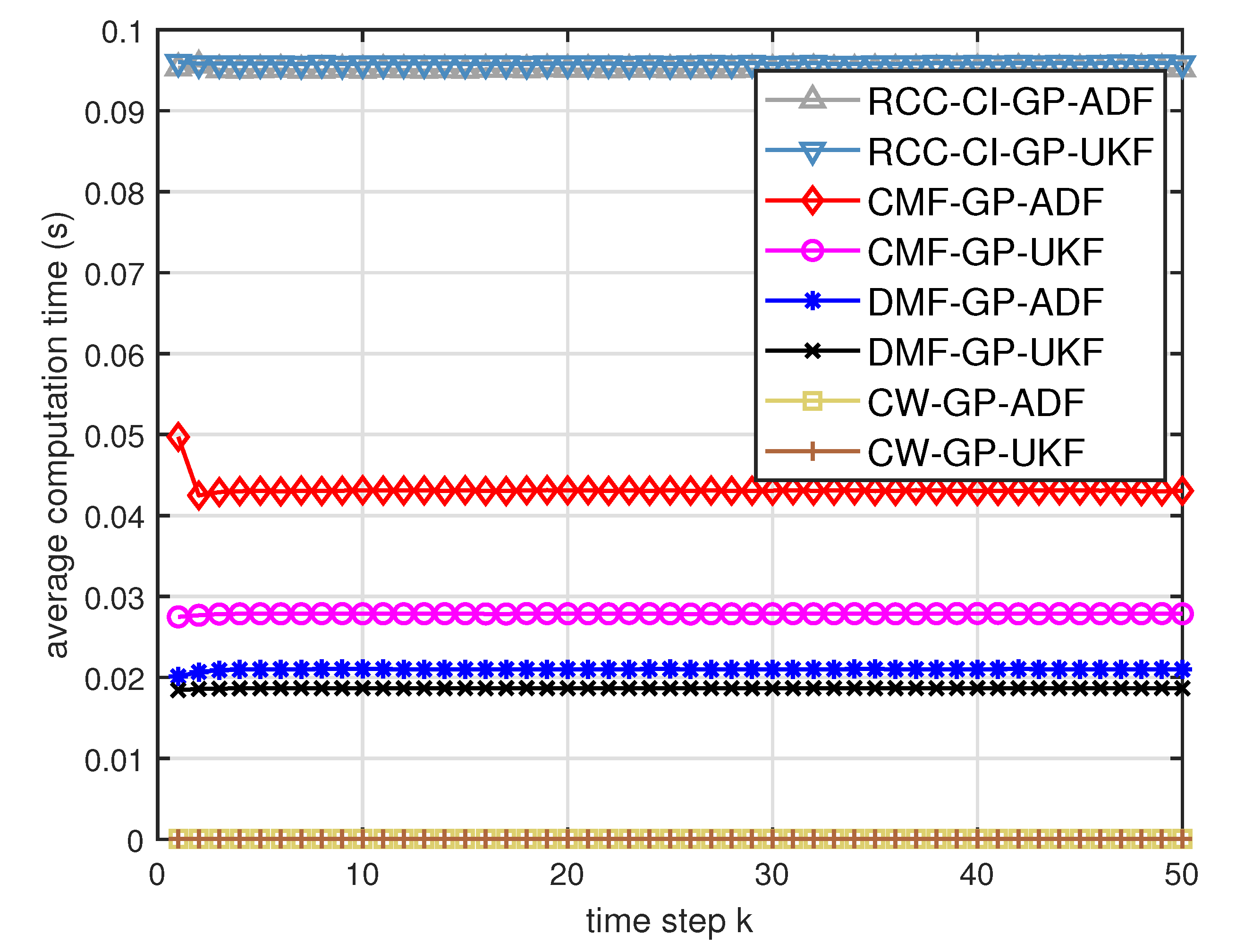
- From Figure 8 and Figure 9, we can find that the computation time of the distributed estimation fusion is less than that of the centralized estimation fusion. It demonstrates the superiority of the distributed estimation fusion under the same fusion performance. The computation time of the proposed fusion methods is much less than that of the RCC-CI algorithm. The possible reason is due to solve a optimization problem for the RCC-CI algorithm. The convex combination method takes the least computation time, since it directly uses the weight combination with covariance.
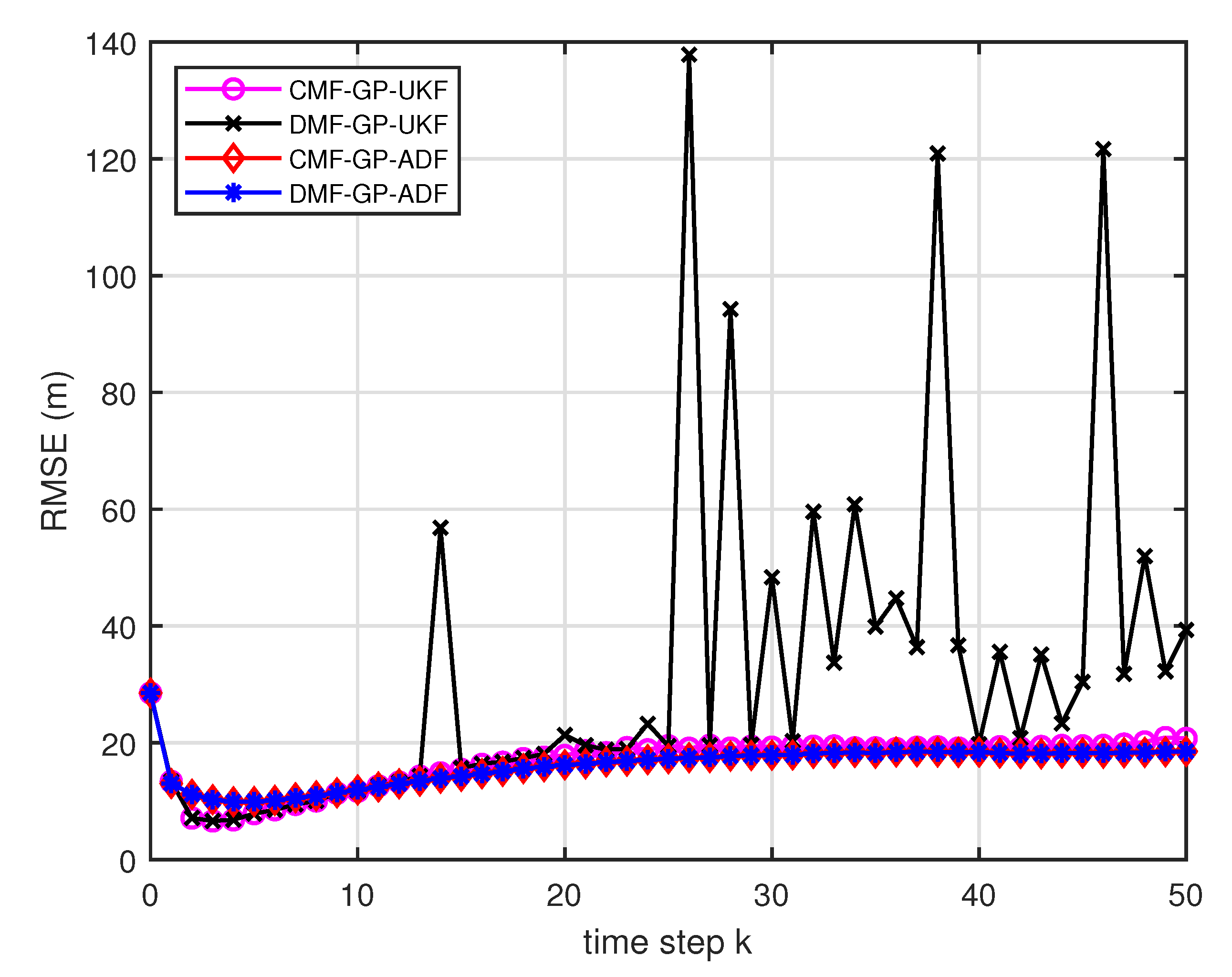
- From Figure 10 and Figure 11, it can be seen that the ratios of full rank are both less than for the single sensor GP-UKF case with and training data. Thus, the equivalence between the centralized and distributed estimation fusion with GP-UKF is broken in Figure 12 and Figure 13, respectively. The reason may be that the Gaussian models are relatively inaccurate with less training data, which can be known from the comparison with Figure 6, Figure 12 and Figure 13 for the same methods. At the same time, the finite-sample approximation of GP-UKF seriously depends on the Gaussian process models and the computation way of the cross terms is the sum about rank-one matrices for GP-UKF. However, the equivalence is still satisfied for the GP-ADF fusion. It implies GP-ADF is more stable than GP-UKF, which is also referred to in Reference [7].
- We can also see that the performance of GP-UKF fusion is better than that of GP-ADF fusion with training data from Figure 6 and a little worse with training data from Figure 12 and Figure 13. Meanwhile, from Figure 8, Figure 14 and Figure 15, the average computation time of GP-UKF fusion is less than that of GP-ADF fusion with training data and is contrary with training data. It may inspire us that the GP-UKF fusion is suitable for the enough training data case and GP-ADF fusion does well in the small number of training data case for the turn motion systems.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Lan, J.; Li, X.R. Multiple conversions of measurements for nonlinear estimation. IEEE Trans. Signal Process. 2017, 65, 4956–4970. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Li, X.R.; Kirubarajan, T. Estimation with Applications to Tracking and Navigation: Theory, Algorithms and Software; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H∞, and Nonlinear Approaches; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Huber, M.F.; Hanebeck, U.D. Analytic moment-based Gaussian process filtering. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Huber, M.F. Nonlinear Gaussian Filtering: Theory, Algorithms, and Applications. Ph.D. Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2015. [Google Scholar]
- Deisenroth, M.P.; Turner, R.D.; Huber, M.F.; Hanebeck, U.D.; Rasmussen, C.E. Robust filtering and smoothing with Gaussian processes. IEEE Trans. Automat. Control 2012, 57, 1865–1871. [Google Scholar] [CrossRef]
- Jacobs, M.A.; DeLaurentis, D. Distributed Kalman filter with a Gaussian process for machine learning. In Proceedings of the 2018 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2018; pp. 1–12. [Google Scholar]
- Guo, Y.; Li, Y.; Tharmarasa, R.; Kirubarajan, T.; Efe, M.; Sarikaya, B. GP-PDA filter for extended target tracking with measurement origin uncertainty. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 1725–1742. [Google Scholar] [CrossRef]
- Preuss, R.; Von Toussaint, U. Global optimization employing Gaussian process-based Bayesian surrogates. Entropy 2018, 20, 201. [Google Scholar] [CrossRef]
- Ko, J.; Fox, D. GP-BayesFilters: Bayesian filtering using Gaussian process prediction and observation models. Autonomous Robots 2009, 27, 75–90. [Google Scholar] [CrossRef]
- Lawrence, N.D. Gaussian process latent variable models for visualisation of high dimensional data. In Proceedings of the NIPS’03 16th International Conference on Neural Information Processing Systems, Whistler, BC, Canada, 9–11 December 2003; pp. 329–336. [Google Scholar]
- Wang, J.M.; Fleet, D.J.; Hertzmann, A. Gaussian process dynamical models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 1441–1448. [Google Scholar]
- Ko, J.; Fox, D. Learning GP-BayesFilters via Gaussian process latent variable models. Autonomous Robots 2011, 30, 3–23. [Google Scholar] [CrossRef]
- Csató, L.; Opper, M. Sparse on-line Gaussian processes. Neural Comput. 2002, 14, 641–668. [Google Scholar] [CrossRef]
- Snelson, E.; Ghahramani, Z. Sparse Gaussian processes using pseudo-inputs. In Proceedings of the 18th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; pp. 1257–1264. [Google Scholar]
- Seeger, M.; Williams, C.K.I.; Lawrence, N.D. Fast forward selection to speed up sparse Gaussian process regression. In Proceedings of the Workshop on AI and Statistics 9, Key West, FL, USA, 3–6 January 2003. [Google Scholar]
- Smola, A.J.; Bartlett, P. Sparse greedy Gaussian process regression. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27 November–2 December 2000. [Google Scholar]
- Quiñonero-Candela, J.; Rasmussen, C. A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 2005, 6, 1939–1959. [Google Scholar]
- Velychko, D.; Knopp, B.; Endres, D. Making the coupled Gaussian process dynamical model modular and scalable with variational approximations. Entropy 2018, 20, 724. [Google Scholar] [CrossRef]
- Yan, L.; Duan, X.; Liu, B.; Xu, J. Bayesian optimization based on K-optimality. Entropy 2018, 20, 594. [Google Scholar] [CrossRef]
- Ko, J.; Klein, D.J.; Fox, D.; Hähnel, D. Gaussian processes and reinforcement learning for identification and control of an autonomous blimp. In Proceedings of the IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007. [Google Scholar]
- Ko, J.; Klein, D.J.; Fox, D.; Haehnel, D. GP-UKF: Unscented Kalman filters with Gaussian process prediction and observation models. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007. [Google Scholar]
- Ferris, B.; Hähnel, D.; Fox, D. Gaussian processes for signal strength-based location estimation. In Proceedings of the Robotics: Science and Systems, Philadelphia, PA, USA, 16–19 August 2006; pp. 1–8. [Google Scholar]
- Maybeck, P.S. Stochastic Models, Estimation, and Control; Academic Press, Inc.: New York, NY, USA, 1979. [Google Scholar]
- Boyen, X.; Koller, D. Tractable inference for complex stochastic processes. In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 33–42. [Google Scholar]
- Opper, M. On-line learning in neural networks. In ch. A Bayesian Approach to On-line Learning; Cambridge University Press: Cambridge, UK, 1999; pp. 363–378. [Google Scholar]
- Liggins, M.E.; Hall, D.L.; Llinas, J. Handbook of Multisensor Data Fusion: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Bar-Shalom, Y.; Willett, P.K.; Tian, X. Tracking and Data Fusion: A Handbook of Algorithms; YBS Publishing: Storrs, CT, USA, 2011. [Google Scholar]
- Shen, X.; Zhu, Y.; Song, E.; Luo, Y. Optimal centralized update with multiple local out-of-sequence measurements. IEEE Trans. Signal Process. 2009, 57, 1551–1562. [Google Scholar] [CrossRef]
- Wu, D.; Zhou, J.; Hu, A. A new approximate algorithm for the Chebyshev center. Automatica 2013, 49, 2483–2488. [Google Scholar] [CrossRef]
- Li, M.; Zhang, X. Information fusion in a multi-source incomplete information system based on information entropy. Entropy 2017, 19, 570. [Google Scholar] [CrossRef]
- Gao, X.; Chen, J.; Tao, D.; Liu, W. Multi-sensor centralized fusion without measurement noise covariance by variational Bayesian approximation. IEEE Trans. Aerosp. Electron. Syst. 2011, 47. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.R. Distributed estimation fusion with unavailable cross-correlation. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 259–278. [Google Scholar] [CrossRef]
- Chong, C.-Y.; Chang, K.; Mori, S. Distributed tracking in distributed sensor networks. In Proceedings of the American Control Conference, Seattle, WA, USA, 18–20 June 1986; pp. 1863–1868. [Google Scholar]
- Zhu, Y.; You, Z.; Zhao, J.; Zhang, K.; Li, X.R. The optimality for the distributed Kalman filtering fusion with feedback. Automatica 2001, 37, 1489–1493. [Google Scholar] [CrossRef]
- Li, X.R.; Zhu, Y.; Jie, W.; Han, C. Optimal linear estimation fusion–Part I: Unified fusion rules. IEEE Trans. Inf. Theory 2003, 49, 2192–2208. [Google Scholar] [CrossRef]
- Duan, Z.; Li, X.R. Lossless linear transformation of sensor data for distributed estimation fusion. IEEE Trans. Signal Process. 2010, 59, 362–372. [Google Scholar] [CrossRef]
- Shen, X.J.; Luo, Y.T.; Zhu, Y.M.; Song, E.B. Globally optimal distributed Kalman filtering fusion. Sci. China Inf. Sci. 2012, 55, 512–529. [Google Scholar] [CrossRef]
- Chong, C.-Y.; Mori, S. Convex combination and covariance intersection algorithms in distributed fusion. In Proceedings of the 4th International Conference on Information Fusion, Montreal, QC, Canada, 7–10 August 2001. [Google Scholar]
- Sun, S.; Deng, Z.-L. Multi-sensor optimal information fusion Kalman filter. Automatica 2004, 40, 1017–1023. [Google Scholar] [CrossRef]
- Song, E.; Zhu, Y.; Zhou, J.; You, Z. Optimal Kalman filtering fusion with cross-correlated sensor noises. Automatica 2007, 43, 1450–1456. [Google Scholar] [CrossRef]
- Hu, C.; Lin, H.; Li, Z.; He, B.; Liu, G. Kullback–Leibler divergence based distributed cubature Kalman filter and its application in cooperative space object tracking. Entropy 2018, 20, 116. [Google Scholar] [CrossRef]
- Bakr, M.A.; Lee, S. Distributed multisensor data fusion under unknown correlation and data inconsistency. Sensors 2017, 17, 2472. [Google Scholar] [CrossRef]
- Xie, J.; Shen, X.; Wang, Z.; Zhu, Y. Gaussian process fusion for multisensor nonlinear dynamic systems. In Proceedings of the 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 4124–4129. [Google Scholar]
- Osborne, M. Bayesian Gaussian Processes for Sequential Prediction, Optimisation and Quadrature. Ph.D. Thesis, University of Oxford, Oxford, UK, 2010. [Google Scholar]
- Nguyen-Tuong, D.; Seeger, M.; Peters, J. Local Gaussian process regression for real time online model learning. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008. [Google Scholar]
- Deisenroth, M. Efficient Reinforcement Learning using Gaussian Processes; KIT Scientific Publishing: Karlsruhe, Germany, 2010. [Google Scholar]
- Ghahramani, Z.; Rasmussen, C.E. Bayesian Monte Carlo. Adv. Neural Inf. Process. Syst. 2003, 15, 489–496. [Google Scholar]
- Candela, J.Q.; Girard, A.; Larsen, J.; Rasmussen, C.E. Propagation of uncertainty in Bayesian kernel models - application to multiple-step ahead forecasting. IEEE Int. Conf. Acoust. Speech Signal Process. 2003, 2, 701–704. [Google Scholar]
- Zhu, Y. Multisensor Decision and Estimation Fusion; Kluwer Academic Publishers: Boston, MA, USA, 2003. [Google Scholar]
- Öfberg, J.L. Yalmip: A toolbox for modeling and optimization in matlab. In Proceedings of the CACSD Conference, Taipei, Taiwan, 2–4 September 2004. [Google Scholar]















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, Y.; Xie, J.; Wang, Z.; Shen, X. Multisensor Estimation Fusion with Gaussian Process for Nonlinear Dynamic Systems. Entropy 2019, 21, 1126. https://doi.org/10.3390/e21111126
Liao Y, Xie J, Wang Z, Shen X. Multisensor Estimation Fusion with Gaussian Process for Nonlinear Dynamic Systems. Entropy. 2019; 21(11):1126. https://doi.org/10.3390/e21111126
Chicago/Turabian StyleLiao, Yiwei, Jiangqiong Xie, Zhiguo Wang, and Xiaojing Shen. 2019. "Multisensor Estimation Fusion with Gaussian Process for Nonlinear Dynamic Systems" Entropy 21, no. 11: 1126. https://doi.org/10.3390/e21111126
APA StyleLiao, Y., Xie, J., Wang, Z., & Shen, X. (2019). Multisensor Estimation Fusion with Gaussian Process for Nonlinear Dynamic Systems. Entropy, 21(11), 1126. https://doi.org/10.3390/e21111126