Beyond Moments: Extending the Maximum Entropy Principle to Feature Distribution Constraints


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Jaynes’ Maximum Entropy Principle
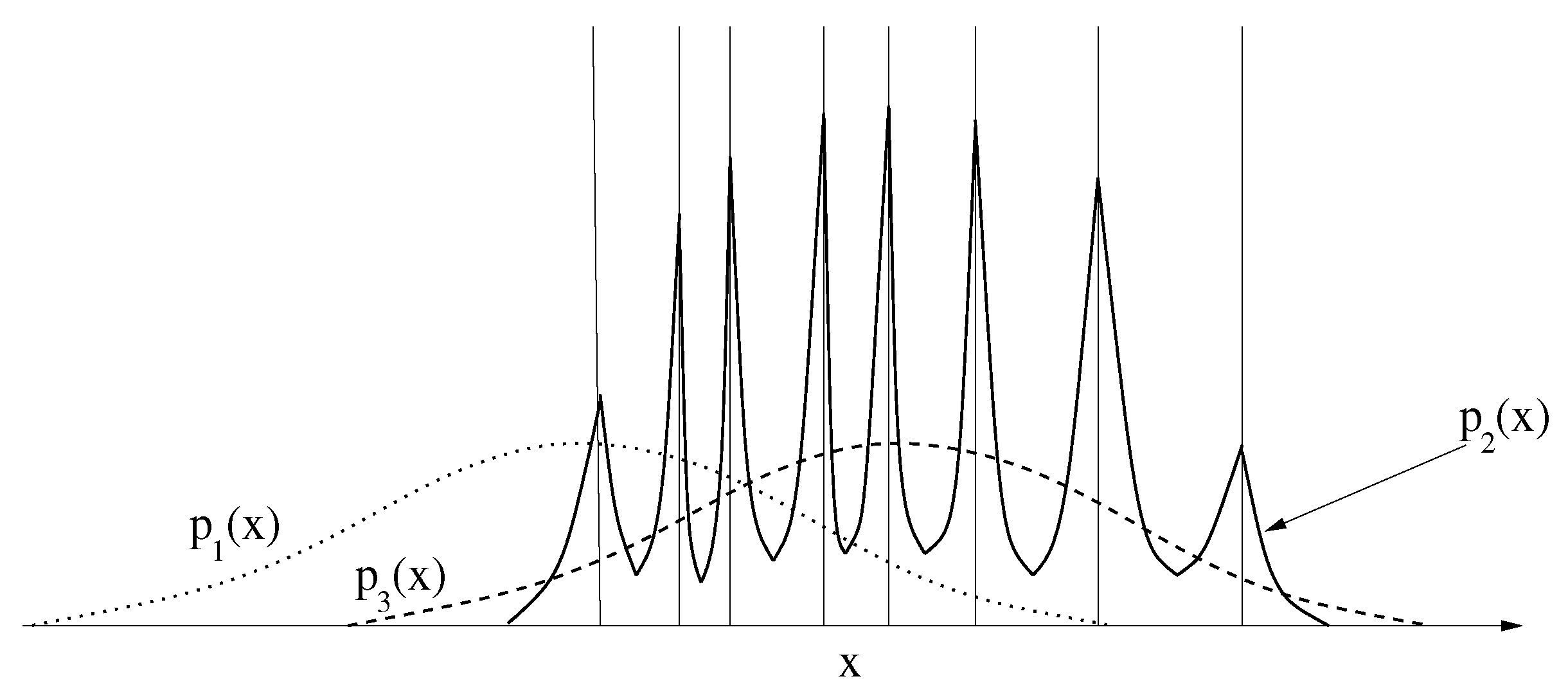
1.2. Feature Distribution Constraints
1.3. Significance
2. Main Results
2.1. MaxEnt PDF Projection
- Identify a norm valid in A norm must meet the properties of scalability , triangle inequality , and
- Identify a scalar statistic (energy statistic) from which it is possible to compute :
- Use a reference hypothesis depending only on .
- From the known distribution , draw a sample denoted by .
- Now identify the set of all samples mapping to , denoted by
- Draw a sample from this set, uniformly, so that no member of is more likely to be chosen than another.
3. Examples
3.1. Unbounded Data
3.2. Positive Data
3.3. Unit Hypercube,
4. Advanced Concepts
4.1. Implementation Issues
- Saddle Point Approximation. If is not available in closed form, the moment-generating function (MGF) might be tractable. This allows the saddle point approximation (SPA) to be used (see Section III in [11]). Note that the term “approximation” is misleading because the SPA approximates the shape of the MGF on a contour, not the absolute value, so the SPA expression for remains very accurate, in the far tails, even when itself cannot be evaluated in machine precision. Examples of this include general linear transformations of exponential and chi-squared random variables (see Section III.C and Section IV in [11]), general linear transformations of uniform random variables (Appendix in [13]), a set of linear-quadratic forms [14], and order statistics [15].
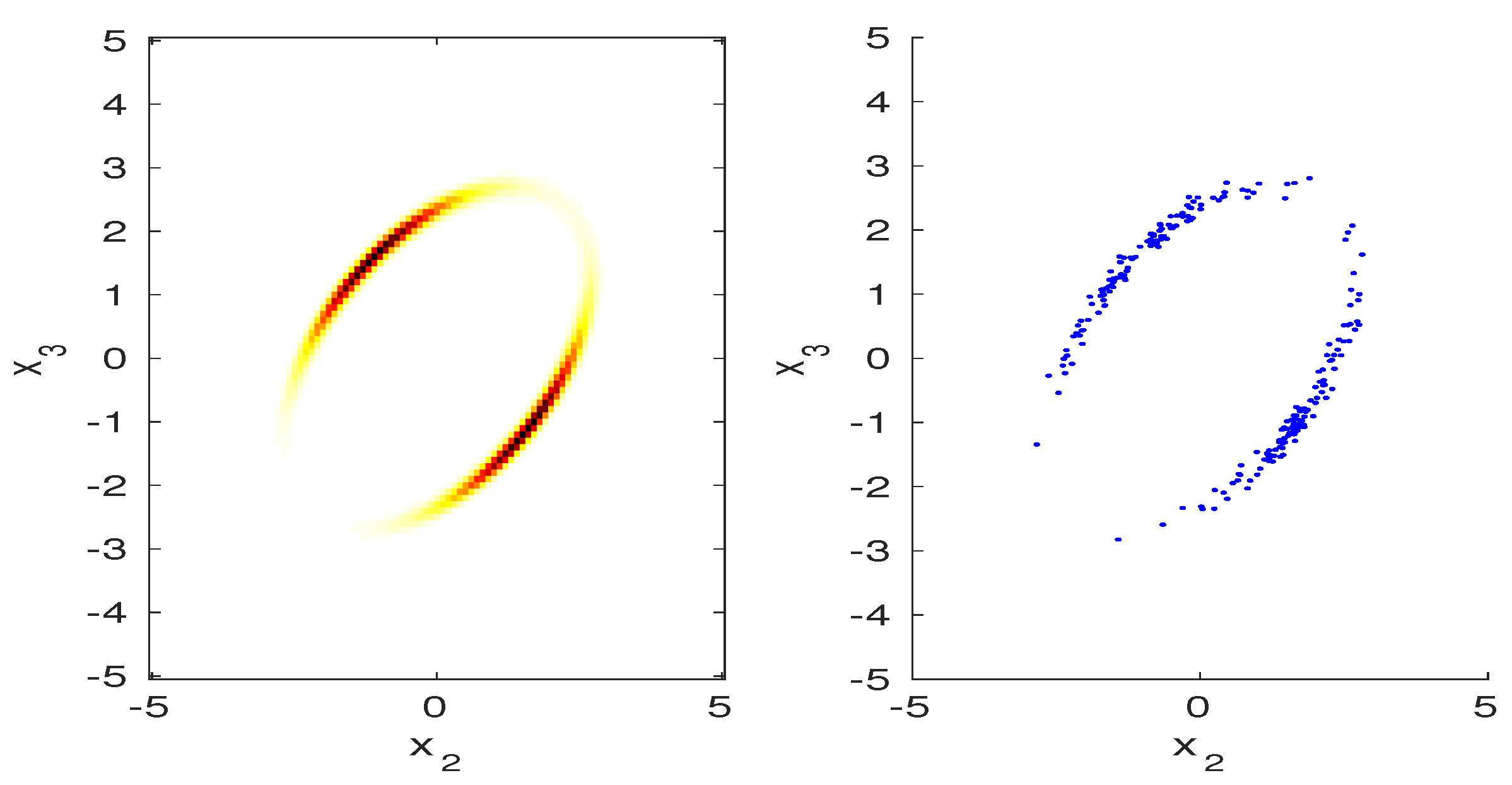
- Floating reference hypothesis. There are conditions under which the MaxEnt reference hypothesis is not unique, so it can depend on a parameter , so we write . An example is when the feature contains the sample mean and sample variance (see example in Section 3.1). In this case, a Gaussian reference hypothesis can be modified to have any mean and variance , and can serve as the MaxEnt reference hypothesis with no change at all in the resulting projected PDF. In other words, (13) is independent of —this can be verified by cancelling terms. Therefore, there is no reason that cannot be made to track the data—that is, let , . By doing this, will track , allowing simple approximations based on central limit theorem to be used to approximate .
- Chain Rule. When cannot be derived for a feature transformation, it may be possible to break the feature transformation into stages, where each stage can be easily analyzed. The next section is devoted to this.
4.2. Chain Rule
- The second step is to sum energy in a set of K MEL-spaced band functions. This results in a set of K band energies. This can be written using the matrix as the linear transformation This feature transformation is explained in Section 3.2 above so an exponential reference distribution can be assumed for . Care must be taken that the K band functions add to a constant—this insures the energy statistic is “contained in the features”.
- The next step is to compute the log of the K band energies, . This is a 1:1 transformation for which PDF projection simplifies to computing the determinant of the transformation’s Jacobian matrix (see Section VI.A, p. 46 in [12]).
- The last step is the discrete cosine transform (DCT), which can be written as a linear transformation . If some DCT coefficients are discarded, then the transformation must be analyzed as in Section 3.1 above by including the energy statistic
4.3. Large-N Conditional Distributions and Applications.
5. Applications
5.1. Classification
- Class-specific features. One can specify a different feature transformation per class, ,but the numerator is common, so the classifier rule becomesThis amounts to just comparing the likelihood ratio between class hypothesis and the reference distribution, computed using a class-dependent feature [16].
- It is not necessary to use a common reference hypothesis. A class-dependent reference hypothesis can be selected so that the feature is an approximately sufficient statistic to discriminate the given class from the class-dependent reference hypothesis. Then,where is the class-dependent reference hypothesis. Note that, when using the chain-rule (14), there is not a single reference hypothesis associated with each class, but a series of stage-wise reference hypotheses. Note that here we have relaxed the MaxEnt requirement for the reference hypothesis.
- Using a different feature to test each class hypothesis is not always a good idea. Some data can be “contaminated” with noise or interference, so they may not be suitable to test a hypothesis with just one feature. In this case, a class-specific feature mixture (CSFM) [17,18,19] may be appropriate. For the CSFM, we define a set of feature transformations . (We assume here that the number of feature transformations equals the number of classes, but this is not necessary.) Then, is constructed as a mixture density using all the features:where is the MaxEnt reference hypothesis corresponding to each feature transformation .
- To solve the classification problem (15), it is necessary to obtain a segment of data that can be classified into one of M classes. The problem is often not that simple, and the location of the classifiable “event” may be unknown within a longer data recording, or the data recording may contain multiple events from multiple classes. Using MaxEnt PDF projection, it is possible to solve the data segmentation problem simultaneously with the classification problem [20,21].
5.2. Other Applications
6. Conclusions
Funding
Conflicts of Interest
References
- Jaynes, E.T. Information Theory and Statistical Mechanics I. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Kesavan, H.K.; Kapur, J.N. The Generalized maximum Entropy Principle. IEEE Trans. Syst. Man Cybern. 1989, 19, 1042–1052. [Google Scholar] [CrossRef]
- Banavar, J.R.; Maritan, A.; Volkov, I. Applications of the principle of maximum entropy: From physics to ecology. J. Phys. Condens. Matter 2010, 22, 063101. [Google Scholar] [CrossRef] [PubMed]
- Holmes, D.E. (Ed.) Entropy, Special Issue on Maximum Entropy and Its Application; MDPI: Basel, Switzerland, 2018. [Google Scholar]
- Martino, A.D.; Martino, D.D. An introduction to the maximum entropy approach and its application to inference problems in biology. Heliyon 2018, 4, e00596. [Google Scholar] [CrossRef] [PubMed]
- Picone, J.W. Signal Modeling Techniques in Speech Recognition. Proce. IEEE 1993, 81, 1215–1247. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Maximum entropy PDF projection: A review. AIP Conf. Proc. 2017. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Maximum Entropy PDF Design Using Feature Density Constraints: Applications in Signal Processing. IEEE Trans. Signal Process. 2015, 63, 2815–2825. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Uniform Manifold Sampling (UMS): Sampling the Maximum Entropy PDF. IEEE Trans. Signal Process. 2017, 65, 2455–2470. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. The PDF Projection Theorem and the Class-Specific method. IEEE Trans. Signal Process. 2003, 51, 672–685. [Google Scholar] [CrossRef]
- Kay, S.M.; Nuttall, A.H.; Baggenstoss, P.M. Multidimensional probability density function approximations for detection, classification, and model order selection. IEEE Trans. Signal Process. 2001, 49, 2240–2252. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. The Class-Specific Classifier: Avoiding the Curse of Dimensionality (Tutorial). IEEE Aerosp. Electron. Syst. Mag. Spec. Tutor. Add. 2004, 19, 37–52. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Evaluating the RBM Without Integration Using PDF Projection. In Proceedings of the EUSIPCO 2017, Kos, Greece, 28 August–2 Septemper 2017. [Google Scholar]
- Nuttall, A.H. Saddlepoint Approximation and First-Order Correction Term to The Joint Probability Density Function of M Quadratic and Linear Forms in K Gaussian Random Variables With Arbitrary Means and Covariances; NUWC Technical Report 11262; US Naval Undersea Warfare Center: Newport, RI, USA, 2000. [Google Scholar]
- Nuttall, A.H. Joint Probability Density Function of Selected Order Statistics And the Sum of the Remaining Random Variables; NUWC Technical Report 11345; US Naval Undersea Warfare Center: Newport, RI, USA, 2002. [Google Scholar]
- Baggenstoss, P.M. Class-Specific Features in Classification. IEEE Trans. Signal Process. 1999, 47, 3428–3432. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Optimal Detection and Classification of Diverse Short-Duration Signals. In Proceedings of the International Conference on Cloud Engineering, Boston, MA, USA, 11–14 March 2014; pp. 534–539. [Google Scholar]
- Baggenstoss, P.M. Class-specific model mixtures for the classification of time-series. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2014. [Google Scholar]
- Baggenstoss, P.M. Class-Specific Model Mixtures for the Classification of Acoustic Time-Series. IEEE Trans. AES 2016, 52, 1937–1952. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. A multi-resolution hidden Markov model using class-specific features. IEEE Trans. Signal Process. 2010, 58, 5165–5177. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Acoustic Event Classification using Multi-resolution HMM. In Proceedings of the European Signal Processing Conference (EUSIPCO) 2018, Rome, Italy, 3–7 September 2018. [Google Scholar]
- Baggenstoss, P.M. On the Duality Between Belief Networks and Feed-Forward Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 1–11. [Google Scholar] [CrossRef] [PubMed]




© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baggenstoss, P.M. Beyond Moments: Extending the Maximum Entropy Principle to Feature Distribution Constraints. Entropy 2018, 20, 650. https://doi.org/10.3390/e20090650
Baggenstoss PM. Beyond Moments: Extending the Maximum Entropy Principle to Feature Distribution Constraints. Entropy. 2018; 20(9):650. https://doi.org/10.3390/e20090650
Chicago/Turabian StyleBaggenstoss, Paul M. 2018. "Beyond Moments: Extending the Maximum Entropy Principle to Feature Distribution Constraints" Entropy 20, no. 9: 650. https://doi.org/10.3390/e20090650
APA StyleBaggenstoss, P. M. (2018). Beyond Moments: Extending the Maximum Entropy Principle to Feature Distribution Constraints. Entropy, 20(9), 650. https://doi.org/10.3390/e20090650