1. Introduction
Spiking neuronal networks are perhaps the most sophisticated information processing devices that are available for scientific inquiry. There exists already an understanding of their basic mechanisms and functionality: they are composed by interconnected neurons which fire action potentials (also known as “spikes”) collectively in order to accomplish specific tasks, e.g., sensory information processing or motor control [
1]. However, the interdependencies in the spiking activity of populations of neurons can be extremely complex. In effect, these interdependencies can involve neighboring or also distant cells, being established either via structural connections, i.e., physical mediums such as synapses, or by functional connections reflected through spike correlations [
2].
Understanding the way in which neuronal networks process information requires disentangling structural and functional connections while clarifying their interplay, which is a challenging but critical issue [
3,
4]. For this aim, networks of spiking neurons are usually measured using in vitro or in vivo multi-electrode-arrays, which connect neurons to electronic sensors specially designed for spike detection. Recent progress in acquisition techniques allows the simultaneous measurement of the spiking activity from increasingly large populations of neurons, enabling the collection of large amounts of experimental data [
5]. Prominent examples of spike train recordings have been obtained from vertebrate retina (salamander, rabbit, and degus) [
6,
7,
8] and cat cortex [
9].
However, despite the progress in multi-electrode and neuroimaging recording techniques, modeling the collective spike train statistics is still one of the key open challenges in computational neuroscience. Analysis over recorded data has shown that, although the neuronal activity is highly variable (even when presented repeatedly the same stimulus), the statistics of the response is highly structured [
10,
11]. Therefore, it seems that much of the inner dynamics of neuronal networks is encoded in the statistical structure of the spikes. Unfortunately, traditional methods of estimation, inference, and model selection are not well-suited for this scenario since the number of possible binary patterns that a neuronal network can adopt grows exponentially with the size of the population. In fact, even long experimental recordings usually contain only a small subset of the possible spiking patterns, which makes the empirical frequencies poor estimators for the underlying probability distribution. For practical purposes, this induces dramatic limitations, as standard inference tools become unreliable as soon as the number of considered neurons grows beyond 10 [
6].
Given the binary nature of the spiking data, it is natural to relate neuronal networks and digital communication system via Shannon’s information theory. A possibly more subtle way of establishing this link is provided by the physics literature that studies stochastic spins systems. In fact, a succession of research efforts has helped develop a framework to study the spike train statistics based on tools of statistical physics, namely the maximum entropy principle (MEP), which provides an intuitive and tractable procedure to build a statistical model for the whole neuronal network. In 2006, Schneidman et al. [
6] and Pillow et al. [
12] used the MEP to characterize the spike train statistics of the vertebrate retina responding to natural stimuli, constraining only range one features, namely firing rates and instantaneous pairwise interactions. Since then, the MEP approach has become a standard tool to build probability measures in the field of spike train statistics [
6,
8,
12,
13]. This approach has triggered fruitful analyses of the neural code, including works about criticality [
14], redundancy and error correction [
7] among other intriguing and promising topics.
Although relatively successful, this approach for linking neuronal populations and statistical mechanics is based on assumptions that go against fundamental biological knowledge. Firstly, these works assume that the spike patterns are statistically independent of past and future activities of the network. In fact, and not surprisingly, there exists strong evidence supporting the fact that memory effects play a major role in spike train statistics [
8,
9,
15]. Secondly, most studies that apply statistical mechanics to analyze neuronal data use tools that assume that the underlying system is in thermodynamic equilibrium. However, it has been recognized that being out-of-equilibrium is one of the distinctive properties of living systems [
16,
17,
18]. Consequently, any statistical description that is consistent with the out-of-equilibrium condition of living neuronal networks should reflect some degree of time asymmetry (i.e., time irreversibility), which can be characterized using Markov chains [
19,
20,
21,
22,
23,
24].
As a way of addressing the above observations, some recent publications study maximum entropy Markov chains (MEMC) based on a variational principle from the thermodynamic formalism of dynamical systems (see for instance [
8,
24,
25]). This framework is an extension of the classic approach based on the MEP that considers correlation of spikes among neurons simultaneously and with different time delays as constraints, being able in this way to account for various memory effects.
Most of the literature in spike train statistics via the MEP pays little attention to the fact that model estimation is done based on finite data (errors due to statistical fluctuations are likely to occur in this context). As the MEP can be seen as a statistical inference procedure, it is natural to inquire about the uncertainty (i.e., fluctuations and convergence properties) related to the inferred MEMC, or, in other words, ask for the robustness of the inference as a function of the sampling size of the underlying data set. Quantifying this error is particularly relevant in the light of recent results that suggest that the parameters inferred by the MEP approach in the context of experimental biological recordings are sharply poised at criticality [
7,
26]. On the other hand, once the MEMC has been inferred, it is also important to quantify how well a sample of the MEMC reproduce the average values of features of interest and how likely is that a sample of the MEMC produce a “rare” or unlikely event.
To provide some first steps in addressing the above issues, this paper studies the MEMC framework using tools from large deviation theory (LDT) [
27,
28]. We exploit the fact that the average values of features obtained from samples of the MEMC satisfy a large deviation property, and use LDT techniques to estimate their fluctuations in terms of the sampling size. We also show how to compute the rate functions using the tilted transition matrix technique and the Gärtner–Ellis theorem. It is to be noted that there is a large body of theoretical work linking the maximum entropy principle and large deviations [
27,
29]. However, these techniques have been scarcely used in spike train analysis (only to study the i.i.d case [
30,
31,
32,
33]), most likely because of the lack of a suitable introduction of these concepts within the neuroscientific literature. It is our hope that these applications might trigger the interest of the computational neuroscience community into the large deviation literature. Consequently, another goal of this paper is to provide an accessible introduction of the MEMC and LDT formalisms to the community of computational neuroscience, avoiding some technicalities while preserving the core ideas and intuitions. To the best of our knowledge, this manuscript presents the first attempt to bring these two topics together in the context of spike train statistics. This article is part of a more ambitious program that attempts to build a more unified theoretical structure and a complete toolbox helpful to approach spike train statistics using the thermodynamic formalism [
24,
25].
The rest of this paper is organized as follows.
Section 2 presents the basic definitions and tools needed to apply large deviations techniques further in the paper. In particular, we present the maximum entropy principle framed in the thermodynamic formalism as a variational principle. In
Section 3, we introduce some basic aspects of the theory of large deviations. In
Section 4, we focus on the empirical averages of features. We present some examples of relevance in spike train statistics, where we are able to compute explicitly the rate function for each feature in the maximum entropy potential. In
Section 5, we present further applications of the theory of large deviations in this field with a list of illustrative examples and finally we present our conclusions in
Section 6.
2. Preliminaries
This section introduces the general definitions, notations and conventions that are used throughout the paper, providing in turn the necessary background for the unfamiliar reader.
2.1. Data Binarization and Spike Trains
Let us consider a set of measurements from a network of
N interacting neurons. The “raw data” consist of
N continuous signals containing the extra-cellular potential (electrical potential measured outside of the cell) of each of the neurons recorded over the length of the experiment. These data are processed by spike sorting algorithms [
34,
35], which are signal processing techniques designed to extract the spiking activity of each neuron.
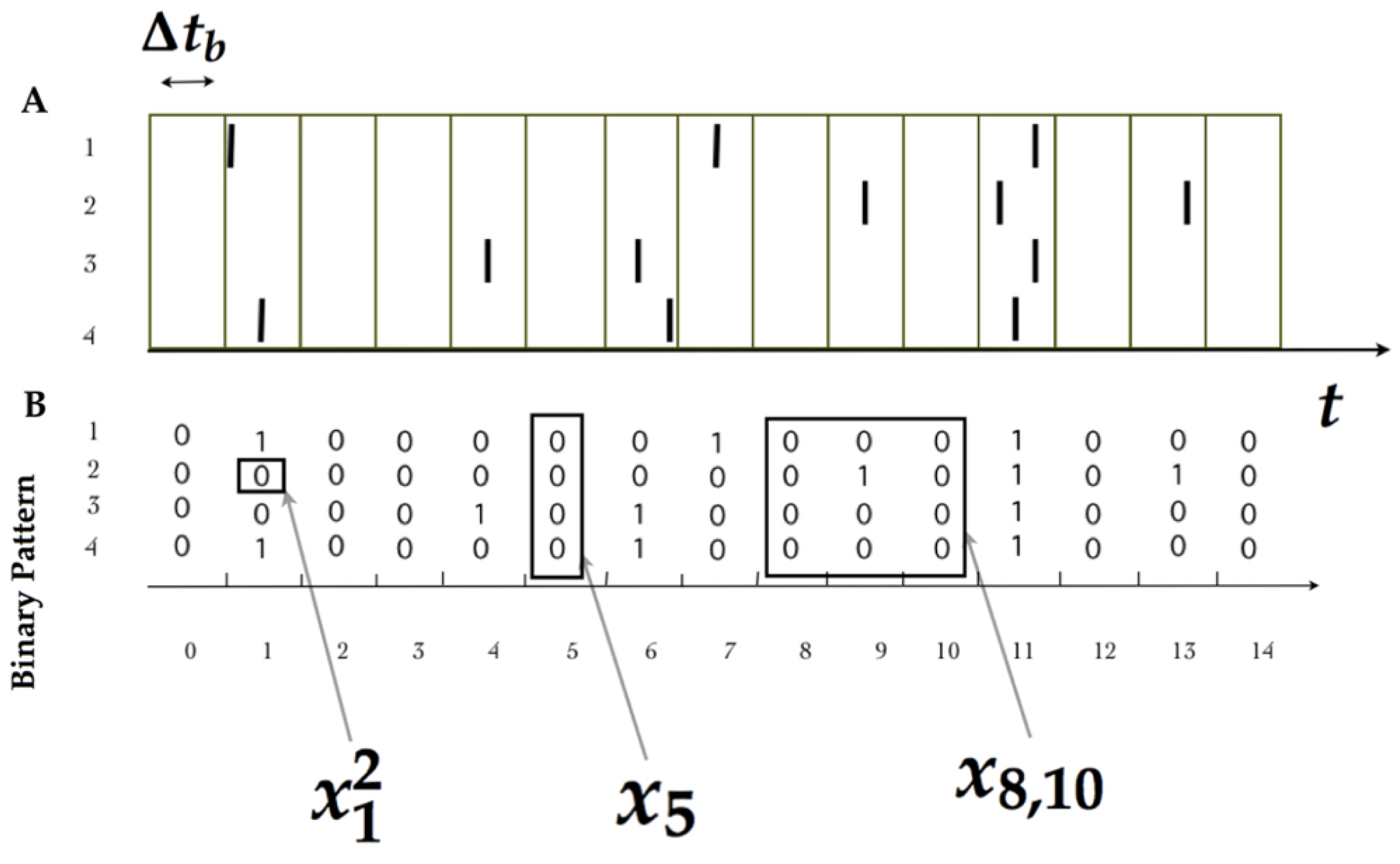
Neurons have a minimal characteristic time in which no two spikes can occur, called “refractory period” [
36], which provides a natural time-scale that can be used for “binning” (i.e., for discretizing) the time index of the measurements, denoted by
(When binning, sometimes it can be useful to go beyond the refractory period. In those cases, two spikes may occur within the same time bin. The convention is to consider this event equivalent to just one spike.). Denoting the time index by the integer variable
t, one can say that
whenever the
k-th neuron emits a spike during the
t-th time bin, while
otherwise. This standard procedure transforms experimental data into sequences of binary patterns (see
Figure 1).
A spike pattern is the spike-state of all the measured neurons at time bin t, which is denoted by . A spike block is a consecutive sequence of spike patterns, denoted by . While the length of the spike block is , is also useful to consider spike blocks of infinite length starting from time , which are denoted by . Finally, is this paper, we consider that a spike train is either a spike block of finite length or an infinite sequence of spiking patterns, which will be useful later when discussing asymptotic properties. The set of all possible spike blocks of length R corresponding to a network of N neurons is denoted by . The set of all spike blocks of infinite length is denoted by , which is a useful mathematical object as clarified below. Let us define the natural projection given by .
2.2. Features
Following the machine-learning nomenclature, a
feature is a function that extracts a property of interest from the data. Formally, is defined as a function
that associates a real number to each
. The feature
f is said to have a temporal range or simply a range
R if for every
such that
, one has that
if and only if
, that is, if
f only depends on the first
R spike patterns of the spike-train. A special class of features, over which this work is focused on, are binary functions consisting of finite products of spike states, i.e.,
Above,
l is a shorthand notation for the set
, where
and
are collections of time and neuron indexes, respectively, and
q is the number of spikes considered by the feature. Correspondingly, for a given index
l, one has
if and only if the
-th neuron spikes at time
for all
in the spike-train
, while
otherwise. Note that, when considering features of range
, the firing times
are constrained within the interval
. We define the reduced feature
such that
2.3. Statistical Structure
For a given spiking neuronal network involved in a particular experimental protocol, the measured activity usually contains a significant amount of stochasticity that is characteristic of measurements at this spatiotemporal scale. This randomness is caused mostly by:
- (i)
the random variation in the ionic flux of charges crossing the cellular membrane per unit time at the post synaptic button due to the binding of neurotransmitter;
- (ii)
the fluctuations in the current resulting from the large number of opening and closing of ion channels [
37,
38];
- (iii)
noise coming from electrical synapses [
39].
To capture this stochasticity within our modeling, it is natural to endow
with a probabilistic structure. For this, we assume there exists a probability distribution
over
that quantifies the intrinsic randomness that is associated to the spiking phenomena. From this point of view, all
are events that might take place with probability
. Following a standard practice in computational neuroscience, we assume that the stochastic process generating the spikes is stationary, i.e., that their statistics do not change in time. As we discuss below, this assumption is crucial for the maximum entropy inference. Although an extension of our approach to a non-stationary scenario is possible, we focus here on the stationary case as it greatly simplifies the presentation. Using the stationary assumption, given the probability distribution of the whole process
one can define a unique corresponding probability distribution over
following the natural projection, given by:
As a consequence of assuming a stochastic process guiding the neuronal activity, a feature
becomes a random variable. Consequently, the statistics of
f are defined by
In particular, considering the feature
, one can note that individual spike-states (as well as spike patterns and spike blocks) become discrete random variables. As a convention, we denote
a random spike-state that follows an implicit underlying probability distribution
, while lower-case expressions (e.g.,
) are used for denoting concrete realization of these random variables. The mean value of a feature
f with respect to the probability
is given by:
For the case of features of range
R, the mean value can be expressed alternatively as:
which is a finite sum. Above,
is the reduced feature, as defined in
Section 2.2.
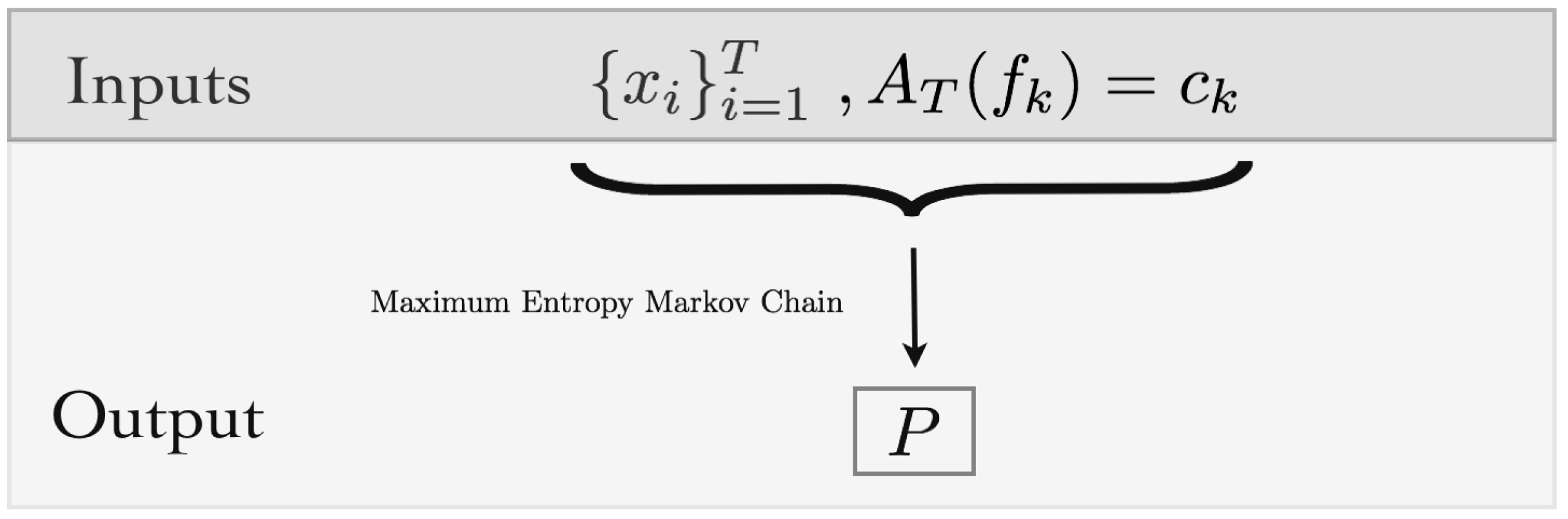
2.4. Empirical Averages
Let us consider spiking data of the form
, where
T is the sample length. Although in general the underlying probability measure
that governs the spiking activity is unknown, it is useful to use the available data to estimate the mean values of specific features. If
f is a feature of range
R, the empirical average value of
f from the sample
is
In particular, for features of range one, the previous expression becomes .
An interesting questions is under which conditions
as
T grows. This, and other convergence issues, are explored in
Section 4.
4. Large Deviations and Applications in MEMC
4.1. Preliminary Considerations
This subsection reviews two elementary tools for studying the convergence of random variables while providing corresponding references. In the sequel, first the central limit theorem is introduced in
Section 4.1.1, and then large deviation theory is discussed in
Section 4.1.2.
4.1.1. Central Limit Theorem
Let us first assume that one can have access to arbitrarily large data sequences. Consider and let be the spike-block of length t (which is allowed to increase), and let be an arbitrary feature (not necessarily belonging to the set of features chosen to fit the MEMC). In this section, we establish asymptotic properties of sampled with respect to the MEMC characterized by .
Throughout this work, we assume that
is an ergodic Markov probability measure, meaning that every spiking block in
is attainable from every other block in the Markov chain within
R time steps as discussed in
Section 3. Thanks to the ergodic assumption, it is guaranteed that the empirical averages become statistically more accurate as the sampling size grows [
51], i.e.,
However, the above result does not clarify the rate at which the estimate accuracy improves. To answer this question, one can use the central limit theorem (CLT) for ergodic Markov chains (see [
52]). This theorem states that there exists a constant
such that for large values of
t, the random variable
distributes as a standard Gaussian random variable (technically, the central limit theorem says that
where the convergence is in distribution), with
being the square-root of the auto-covariance function of
f [
52]. This, in turn, implies that “typical” fluctuations of
around its mean value
are of the order of
.
4.1.2. Large Deviations
Although the central limit theorem for ergodic Markov chains is accurate in describing typical events (which are fluctuations around the mean value), it does not say anything about the likelihood of larger fluctuations. Even though it is clear that the probability of such large fluctuations goes to zero as the sample size increases, it is valuable to describe the corresponding decrease rate. In particular, one says that an empirical average
satisfies a large deviation principle (LDP) with rate function
, defined as
if the above limit exists. Intuitively, the above condition for large
t implies that
. In particular, if
the Law of Large Numbers (LLN) guarantees that
tends to zero as
t grows; the rate function quantifies the speed at which this happens.
Calculating
directly, i.e., by using the definition (Equation (
18)), can be a formidable task. However, the Gärtner–Ellis theorem provides a smart shortcut for avoiding this problem [
27]. To this end, let us introduce the
scaled cumulant generating function (SCGF) (the name comes from the fact that the
n-th cumulant of
f can be obtained by
t successive differentiation operations over of
with respect to
k, and then evaluating the result at
) associated to the random variable
f, by
when the limit exists (further general details about cumulant generating functions are found in
Appendix B). Note that, while
is an empirical average taken over a sample, the expectation in Equation (
19) is taken over the probability distribution given by the corresponding model
. If
is differentiable, then the Gärtner-Ellis theorem ensures that the average
satisfies a LDP with rate function given by the Legendre transform of
, that is
Therefore, in summary, one can study the large deviations of empirical averages by first computing their SCGF from the selected model and then finding their Legendre transform.
One of the most useful applications of the LDP is to estimate the likelihood that
adopts a value far from its expected value. To illustrate this, let us assume that
is a positive differentiable convex function (A classical result in LDP states that
is a convex function if
is differentiable [
28]. For a discussion about the differentiability of
see [
53].). Then, because of the properties of convex functions
has a unique global minimum. Denoting this minimum by
, it follows from the differentiability of
that
, and using properties of the Legendre transform
. This is the LLN, i.e.,
gets concentrated around
. Consider a value
and assume that
admits a Taylor series around
given by
Since
must correspond to a zero and a minimum of
, the first two terms in this series vanish, and as
is convex function
. For large values of
k, we obtain from Equation (
18)
so the small deviations of
around
are Gaussian-distributed as for i.i.d. sums
. In this sense, large deviation theory can be seen as an extension of the CLT because it gives information not only about the small deviations around
but also about large deviations (not Gaussian) of
.
4.2. Large Deviations for Features of MEMC
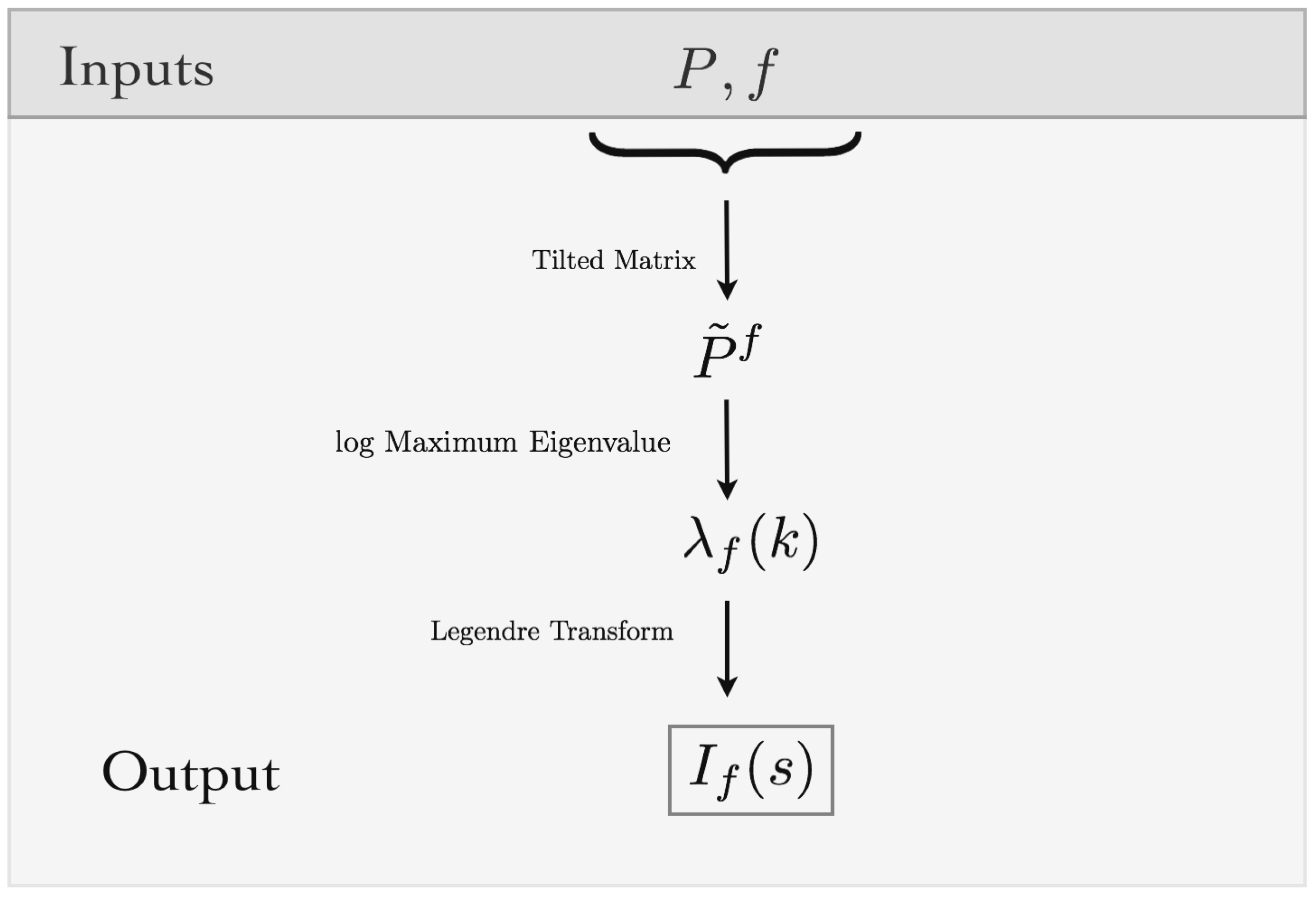
In this section, we focus on the statistical properties of features sampled from the inferred MEMC. For example, one may be interested in measuring the probability of obtaining “rare” average values of features such as firing rates, pairwise correlations, triplets or spatiotemporal events. This characterization is relevant as these features are likely to play an important role in neuronal information processing, and rare values may hinder the whole enterprise of conveying information. We show in this section how to obtain the large deviations rate functions of arbitrary features through the Gärtner–Ellis theorem via the SCGF. In particular, we show that the SCGF can be directly obtained from the inferred Markov transition matrix P.
Consider MEMC taking values on the state space
with transition matrix
P. Let
f be a feature of range
R which consider only the block and
, we introduce
, the
tilted transition matrix by f of
P, parameterized by
k, whose elements are given by:
For transition matrices
P inferred from the MEP, the tilted transition matrix can be built directly from the spectral properties of the transfer matrix Equation (
10) as follows,
Recall that V is the right eigenvector of the transfer matrix . Here, we also have used the shortcut notation to indicate that the energy function takes the contributions from the blocks i and j. Remarkably, the feature f does not need to belong to the set of chosen features to fit the MEMC.
Now, we can take advantage of the structure of the given process in order to obtain more explicit expressions for the SCGF
, for instance, if one considers i.i.d. random variables
X then, from the very definition, one can obtain that
which is the case of range one features. Thus, using Equation (
22), we get that the maximum eigenvalue of the tilted matrix, denoted by
is,
Since is a positive matrix, the Perron–Frobenius theorem ensures the uniqueness of .
Next, for the case of additive features, one deals with positive Markov chains, and under the assumption of ergodicity, an straightforward calculation (see, for instance, [
54]) leads us to obtain that
It also can be proven that
, in this case, is differentiable [
54], setting up the scene to apply the Gärtner–Ellis theorem, which bypasses the direct calculation of
in Equation (
18), i.e., having
, its Legendre transform leads to the rate function of
f as shown in
Figure 3.
4.3. Large Deviations for the Entropy Production
A stochastic process is said to be in equilibrium if one cannot notice the effect of time on it. It is worth noticing that non-equilibrium stochastic processes are natural candidates to model spike train statistics as time plays a non-symmetrical role [
25]. One of the consequences of including features of range
as constraints in the maximum entropy problem is that it opens the possibility to break the time-reversal symmetry present in the time-independent models. This captures the irreversible character of the underlying biological process and, thus, allows fitting more realistic statistical models from the biological point of view.
To characterize this mathematically, we study how the distribution changes when the time order is reversed. For this aim, let us consider a spike block containing T spike patterns, and define the time-reversed spike block obtained by re-ordering the time index in reverse order, i.e., .
A spiking network modeled by
is said to be in equilibrium if
for all
[
55]. For a homogeneous discrete time ergodic Markov chain characterized by the Markov measure
taking values in
, to be in equilibrium is equivalent to satisfy the
detailed balance conditions, which is given by the following set of equalities:
Conversely, when these conditions are not satisfied, the statistical model of the spiking activity is said to be a non-equilibrium system. Since non-equilibrium is expected to occur generically in neuronal network models, one would like to quantify how far from equilibrium is the inferred MEMC. For this purpose, one can define the
information entropy production (IEP) for
p, which is given by
when the limit exists. For the maximum entropy Markov measure
, the IEP is explicitly given by:
(see [
56] for the calculation). We remark that it is still possible to obtain the information entropy production rate also in the non-stationary case. Clearly, for features of range one,
always, meaning that the process is time-reversible, therefore the probabilities of every path and its corresponding time-reversal path are equal. For features of range
,
generically (we refer the interested reader to [
25] for details and examples).
However, since in practice one only have access to limited amount of data, a natural question is to ask for the entropy production of the system considered up to a finite amount of time. It turns out that this characterization can be obtained through a LDP. With this in mind one may define the following feature:
Since we have assumed that samples are produced by a stationary ergodic Markov chain characterized by
, the ergodic theorem assures that for
p-almost every sample, the quantity
when
t goes to infinity converges, and it is by definition the IEP,
Once we have the convergence for
, we may ask for its large deviation properties. Under the same idea above, and following [
57], we introduce the following matrix:
this matrix help us to build the SCGF associated to
, through the logarithm of the maximum eigenvalue
. Using the Gärtner–Ellis theorem one gets the rate function
for the IEP.
4.4. Large Deviations and MEMC Distinguishability
It is clear that there exist a relationship between accuracy of the estimation and sample size. The larger the sample size the more information is available and the uncertainty diminish. In the context of maximum entropy models, this idea has been well conceptualized using tools from information geometry [
30,
58]. The main idea of this approach is that the maximum entropy models form a manifold of probability measures whose coordinates are the parameters
. Consider a spike train dataset
consisting of
T spike patterns obtained from a spiking neuronal network. Given a set of features
and their empirical averages, one may infer the parameters
characterizing the MEMC
. We may use the inferred MEMC to generate a sample
of the same size as the original dataset. Considering the same set of features one may apply again the MEP to infer a new set of parameters
from
, which is, in general, expected to be different from
. These maximum entropy models will belong to a certain volume in the manifold which will decrease as the sample size increase [
30]. On the other hand, increasing the sample size of
, one expects that the Markov chain
specified by
gets “closer” to the one characterized by
. The idea of relating a distance in the parameter space with a distance in the space of probability measures can be rigorously formulated using large deviations techniques. Let us start by defining the relative entropy between these two MEMC (Gibbs measures in the sense of Bowen in Equation (
15)), which provides a notion of “distance” (the relative entropy is not a metric as is not symmetric and do not satisfy the triangle inequality). To do that in the context of MEMCs, consider a Gibbs measure
p associated to the energy function
, and let
q be another Gibbs measure. The Ruelle–Föllmer theorem gives us an expression for the relative entropy density between two Gibbs measures in terms of the pressure, the entropy rate and the expected value of the energy function with respect to
q (see [
29]), as follows:
Observe that if
, we obtain the variational characterization of Gibbs measures in Equation (
14).
Consider the potential
associated with a MEMC
. Given a set of empirical averages
generated by a sample of
we obtain new maximum entropy parameters
. The probability that the maximum entropy parameters
associated with an ergodic Markov Chain
get close to
follows the following large deviation principle [
28]:
where
. Calling and the vector
and choosing
close to 0, we informally rewrite the above corollary in the form:
Thus, for large
T, we get:
which implies that close-by parameters are associated to close-by probability measures [
30].
Consider now two MEMCs
and
specified by
and
, respectively with the same family of features. We say that the MEMCs are
-
indistinguishable if:
As both MEMCs satisfy the variational principle (Equation (
14)), the relative entropy between
p and
(Equation (
26)) reads:
Taking the Taylor expansion of
around
we get:
Since
is minimized at
, we obtain,
Taking the second derivative of
from (Equation (
30)), one also has that,
The second partial derivatives of the topological pressure with respect to the parameters
and
can be conveniently arranged in a matrix
L with components
. Given two MEMCs specified by
and
, in the limit of large
t they are
-indistinguishable if:
where
denotes transpose. The matrix
L can be obtained from data without need to fit the parameters. Equation (
32) characterize a region in the space of MEMC of indistinguishable models, whose volume can be calculated in the large
t limit using spectral properties of the matrix
L [
30]. This result generalizes a previous result for maximum entropy distributions for range one energy functions in [
31].
5. Illustrative Examples
In this section, we illustrate the presented methods in some simple scenarios. In these examples, we follow a set of steps:
Choose the features and build the energy function (Equation (
7)).
Build the transfer matrix (Equation (
10)).
Compute the free energy and find the maximum entropy parameters using (Equation (
17)).
Build the Markov transition matrix using (Equation (
12)).
Choose the observable to examine and build the tilted transition matrix using Equation (
22).
Compute the Legendre transform of the log maximum eigenvalue of the tilted transition matrix to obtain the rate function (Equation (
24)).
For the sake of clarity, in this section, we focus on small neuronal networks. It is clear, however, that the extension of these techniques to larger neural populations is straightforward.
5.1. First Example: Maximum Entropy Model of a Range Two Feature
Consider spiking data from two interacting neurons. We measure only the average value of a of a range two feature from the spiking data to fit a MEMC. The feature denoted by is given by , which detects when a spike of the second neuron is followed by a spike in the first one. The system can be described with the help of an energy function .
For a given dataset of
T spike blocks of range two, the empirical average reads,
This means that in the data one finds that this event appears of the time.
The transfer matrix
(cf. Equation (
10)) is primitive by construction (cf. Equation (
10)) and satisfies the hypothesis of the Perron–Frobenius theorem. In fact, its unique maximum eigenvalue is
. Given the restriction in Equation (
33), using Equation (
17) we obtain the following relationship between the parameter
and the value of the restriction
c:
This equation can be solved numerically. Using the obtained value of
in Equation (
12), one can find the corresponding Markov transition matrix. Note that, among all the Markov chains that match exactly the restriction, the selected one maximizes the KSE. Moreover, it is direct to check that the variational principle in Equation (
14) is satisfied. Examples of values of
for different values of
c and IEP (
25) for each value of
are given in the following table:
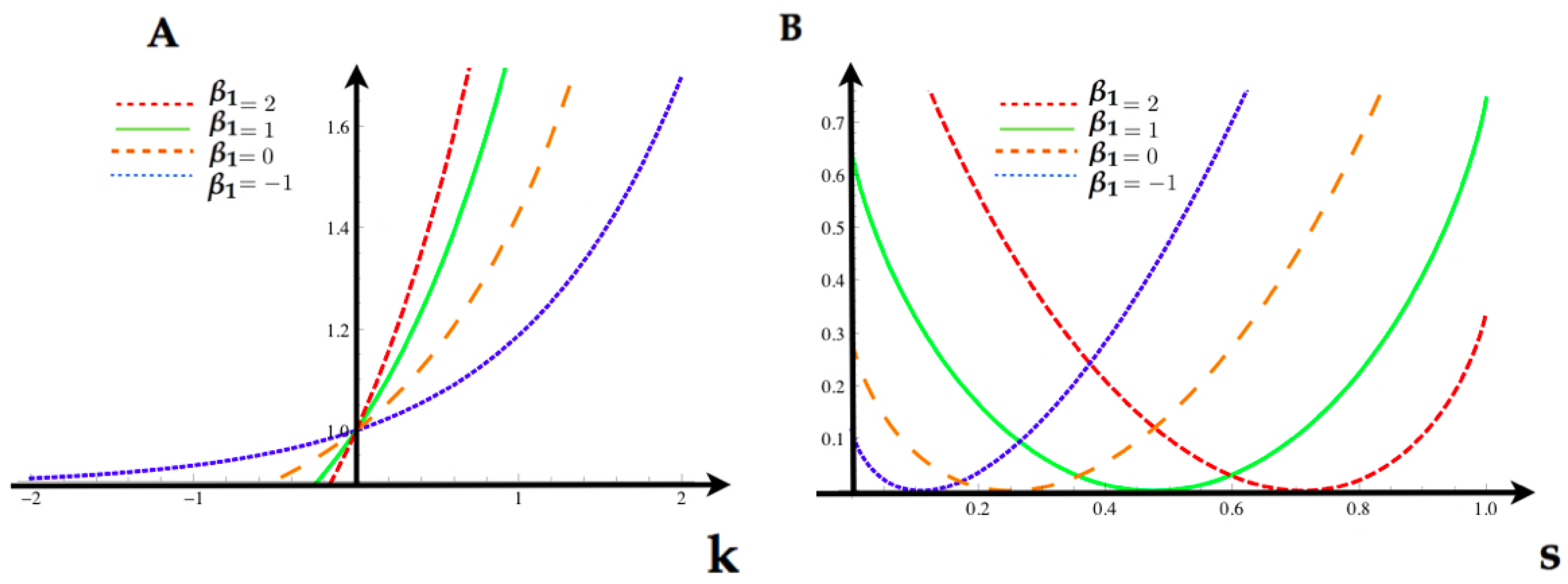
Having the MEMC, we are now interested in analyzing the statistical fluctuations of the feature
. Using Equation (
22), we obtain the tilted transition matrix
for each of the values in the
Table 1. In
Figure 4, we compute for each value of
we compute the SCGF
(
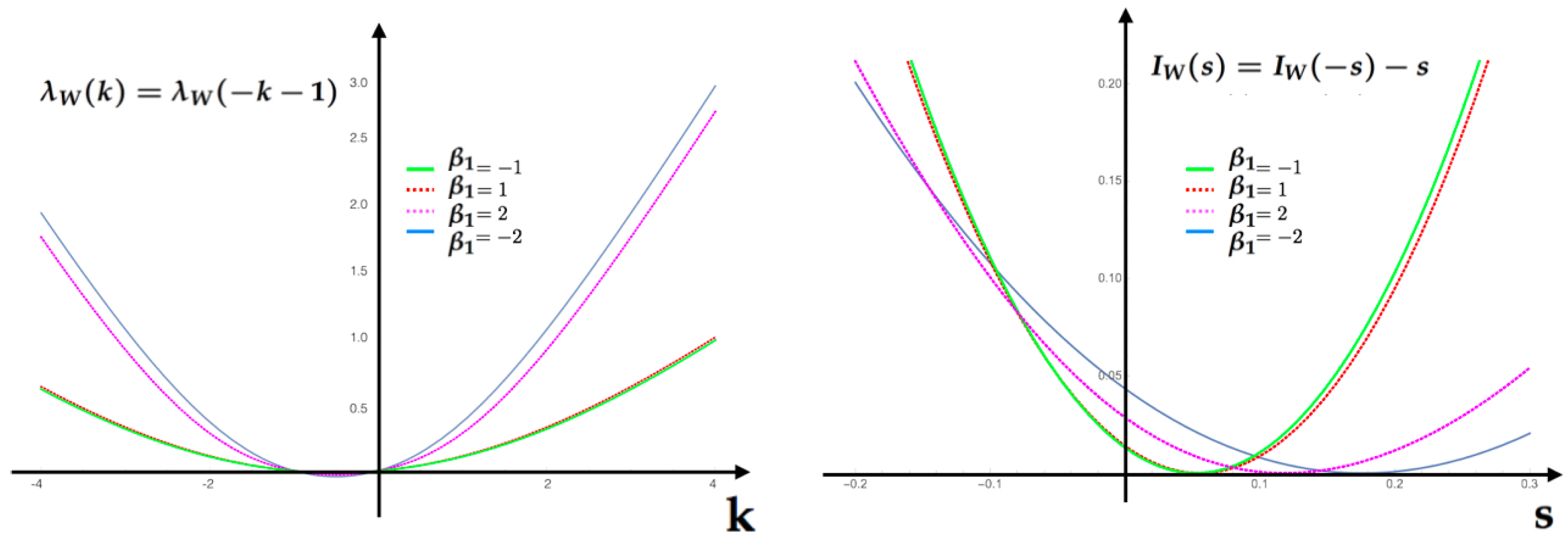
24) and the Legendre transform (rate function) associated to the feature
.
In
Figure 5, we compute for each value of IEP in the table the rate function and illustrate for this example the symmetry relationship (Equation (
A9)).
5.2. Second Example: Maximum Entropy Model With Only Synchronous Constraints
Let us now consider a network of three neurons. We focus here on range one features. In this example, we consider features related to the firing rates and synchronous pairwise correlations (Ising model [
6,
7]). Specifically, we consider the following energy function:
with the six parameters
. Following (Equation (
10)), the transfer matrix
indexed by the states of
is the following:
This matrix is primitive, and the unique maximum eigenvalue is
The right eigenvector associated to this eigenvalue has all the components equal to 1. We obtain the topological pressure
. To find the MEMC parameters, we solve this set of equations:
From Equation (
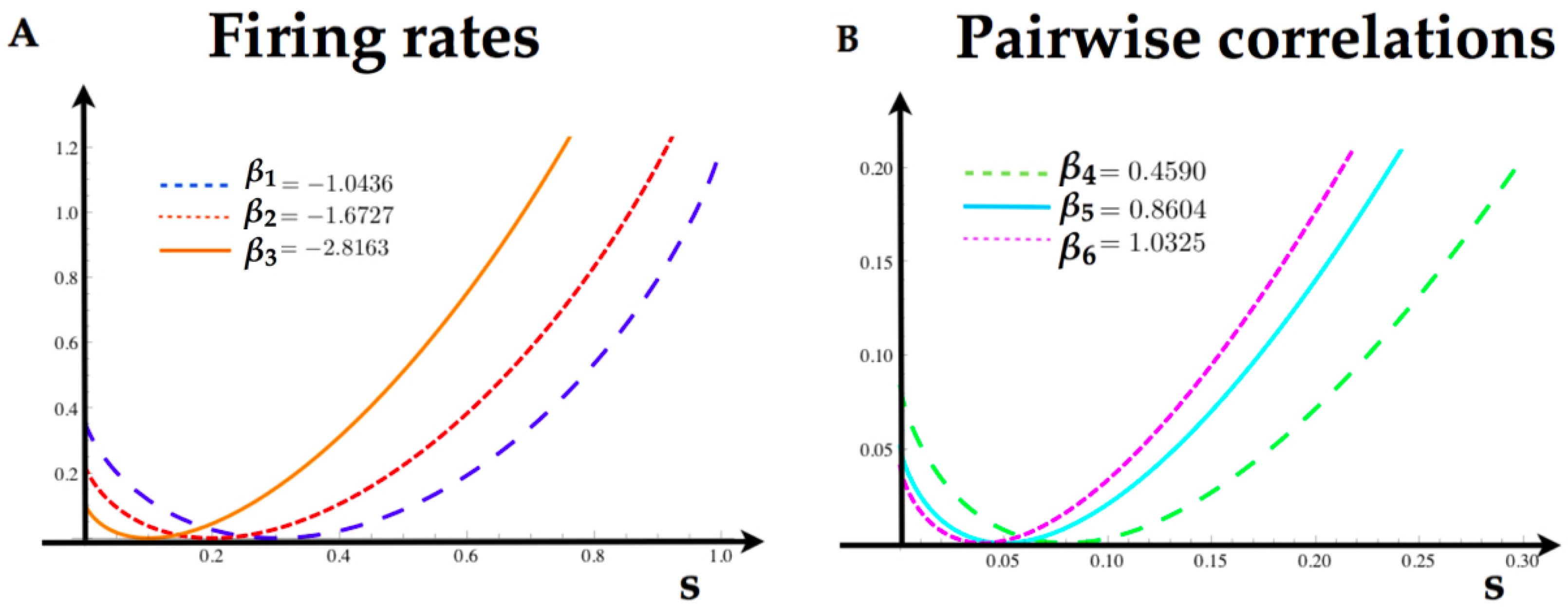
34), provided some constraints on the average value of the features, we can solve the maximum entropy problem (see
Table 2).
From Equation (
12), one can find the Markov transition matrix. To compute the rate function of each feature in this model, we take the logarithm of the maximum eigenvalue of the tilted matrix, and obtain the tilted cumulant generating function
. In
Figure 6, we illustrate the rate functions for each feature in the model.
5.3. Third Example: Past Independent and Markov Maximum Entropy Measures
To illustrate the difference between synchronous and non-synchronous maximum entropy models, we study a simple model composed of two interacting neurons:
We build a Markov chain by fixing the parameters of
at
in the state space
, given by
whose corresponding transition matrix is given by
We focus on the synchronous feature , whose average value with respect to the Markov measure p fixed by the parameters is .
Using this particular Markov chain, we generate a sample of size
. Then, we consider these data as a spike train of two neurons from which we have no other information. Starting from this data, we find the maximum entropy distribution that only considers the empirical average of the synchronous feature
as constraint. Therefore, we build a second model that uses the following energy function:
Using the constraint, we obtain from Equation (
8),
fixing the maximum entropy distribution
. Note that by construction
.
For both energy functions (Equations (
35) and (
36)) with the parameters mentioned before, we compute the rate functions of the synchronous feature. Additionally, from the sample of the Markov chain we compute the empirical averages of the synchronous feature using sliding windows of 50 samples. As expected, these empirical averages fluctuate around the overall average, as shown in
Figure 7.
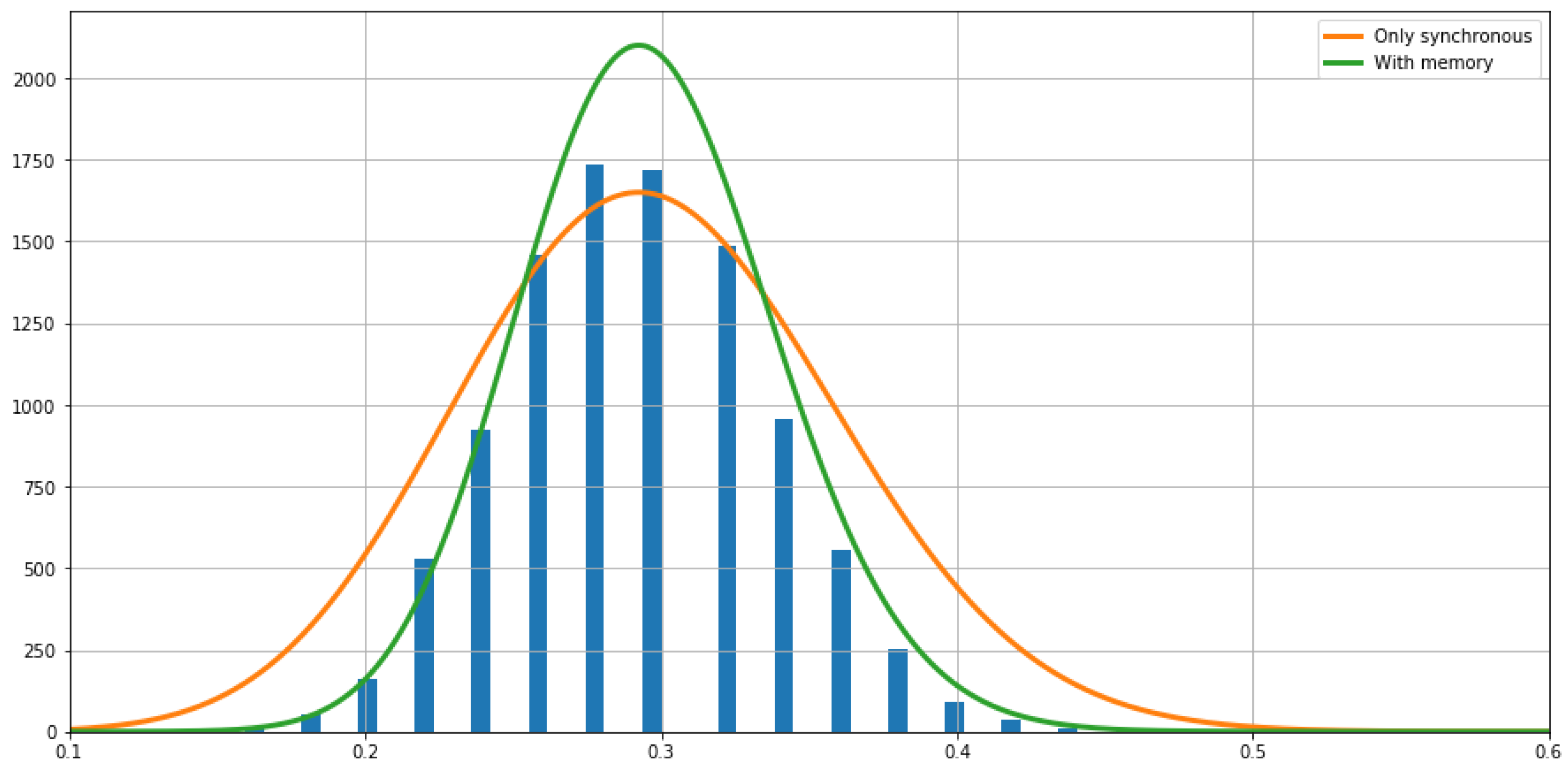
To test the relevance of including memory into the model (and assess the performance of memoryless features), we compared the statistics of the fluctuations seen in the empirical average with the prediction by the rate functions of the two models.
Figure 8 shows the histogram of empirical fluctuations, and plots the theoretical estimations of the fluctuations given by
, where
is the window size,
s is the fluctuation size,
is the rate function, and
K is a constant that is adapted for visualization purposes.
Results show that the rate function of the model with memory fits accurately the relative frequencies of the empirical large fluctuations. In contrast, the model with no memory overestimates the fluctuation frequencies, having a much larger variance than the data, and underestimates near the expected value.
6. Conclusions
In the past few years, new experimental techniques combined with clever ideas from statistical mechanics have made it possible to infer maximum entropy models of spike trains directly from experimental recordings. However, a very important issue, namely quantifying the accuracy of the estimation obtained from a finite empirical sample, is usually ignored in this field. This is probably because the maximum entropy approach has a dual nature; one side is a convex optimization problem, which provides a unique solution independent of the sampling size, and on the other side is a Bayesian inference procedure, from which it is more natural to ask this question. As we have discussed in the
Section 1 this characterization is relevant in the field of computational neuroscience as, in practice, experimental recordings are performed during a finite amount of time which causes fluctuations over the estimated quantities.
A fundamental goal of spike train analysis over networks of sensory neurons involves building accurate statistical models that predict the response of the network to a stimulus of interest. In particular, the aim of statistical inference of spiking neurons using the MEP, is that the fitted parameters shed light on some aspects of the neuronal code, therefore it is extremely important to quantify the accuracy of the statistical procedure. Additionally, one may be interested in measuring some properties of the inferred statistical model characterizing the spiking neuronal network, for example, the convergence rate of a sample or to quantify the probability of rare events of features such as firing rates, pairwise correlations, triplets or spatiotemporal events, mainly because these features are likely to play an important role in neuronal information processing. It is possible that rare and unlikely events have been generated by internal states of the neuronal tissue and not driven by the external stimulus. The events that are unlikely to occur deserve a better understanding as may carry important information about the network internal structure and may play a role in organizing a coherent dynamic to convey sensory information to the cerebral cortex.
The present contribution addressed this issue using tools from large deviations theory in the context of the MEMC. In particular, we showed that the transfer matrix technique used to build the MEMC is well adapted to compute large deviation rate functions using the Gärtner–Ellis theorem. We also provide tools to investigate how sharply determined are the parameters of a MEMC with respect to the amount of empirical data using the concept of distinguishability. Additionally, we present a non-trivial relation between the distance in the parameter space and the distance in the manifold of maximum entropy probability measures using a LDP.
We have illustrated our method using simple examples. However, these examples might give a false impression that large deviations rate functions can always be calculated explicitly. In fact, exact and explicit expressions can be found only in small simple cases; fortunately, there exist numerical methods to evaluate rate functions [
53].
Here, we have focused our attention on large deviations properties on maximum entropy models arising from spike train statistics, however, these results can be used in other fields of applications of maximum entropy models.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}