Software Code Smell Prediction Model Using Shannon, Rényi and Tsallis Entropies

 , , ,
, , , 
Abstract
:1. Introduction
- Calculated different measures of entropy namely, Shannon’s entropy, Rényi entropy and Tsallis entropy, for the bad smells on real data of Apache Abdera versions.
- Applied the non-linear regression on the computed entropy.
- Compared the predicted code smells with the observed code smells.
- Goodness of fit criteria and statistical performance metrics have been calculated to validate the proposed model.
- Calculated value to justify the model.
2. Related Work and Motivation
3. Information Theoretic Approach
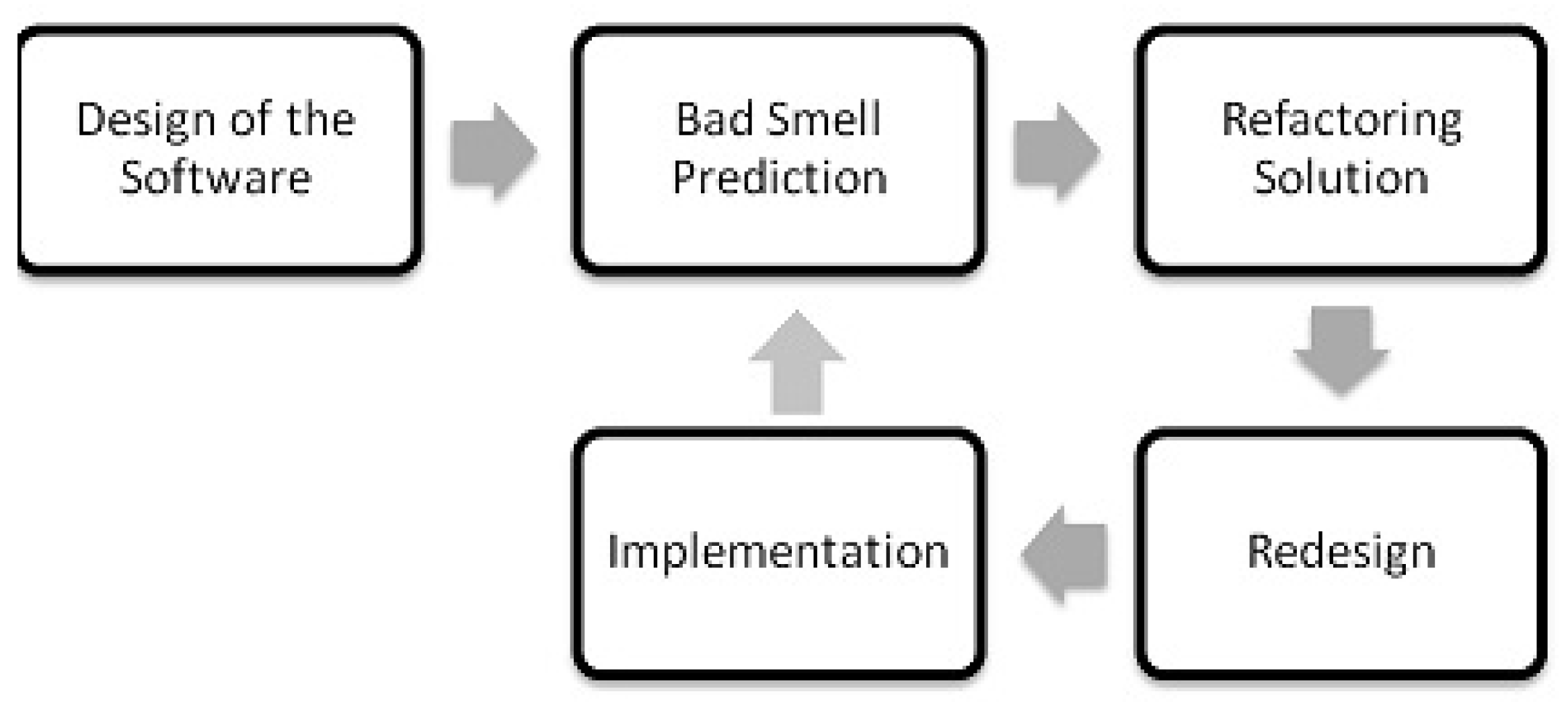
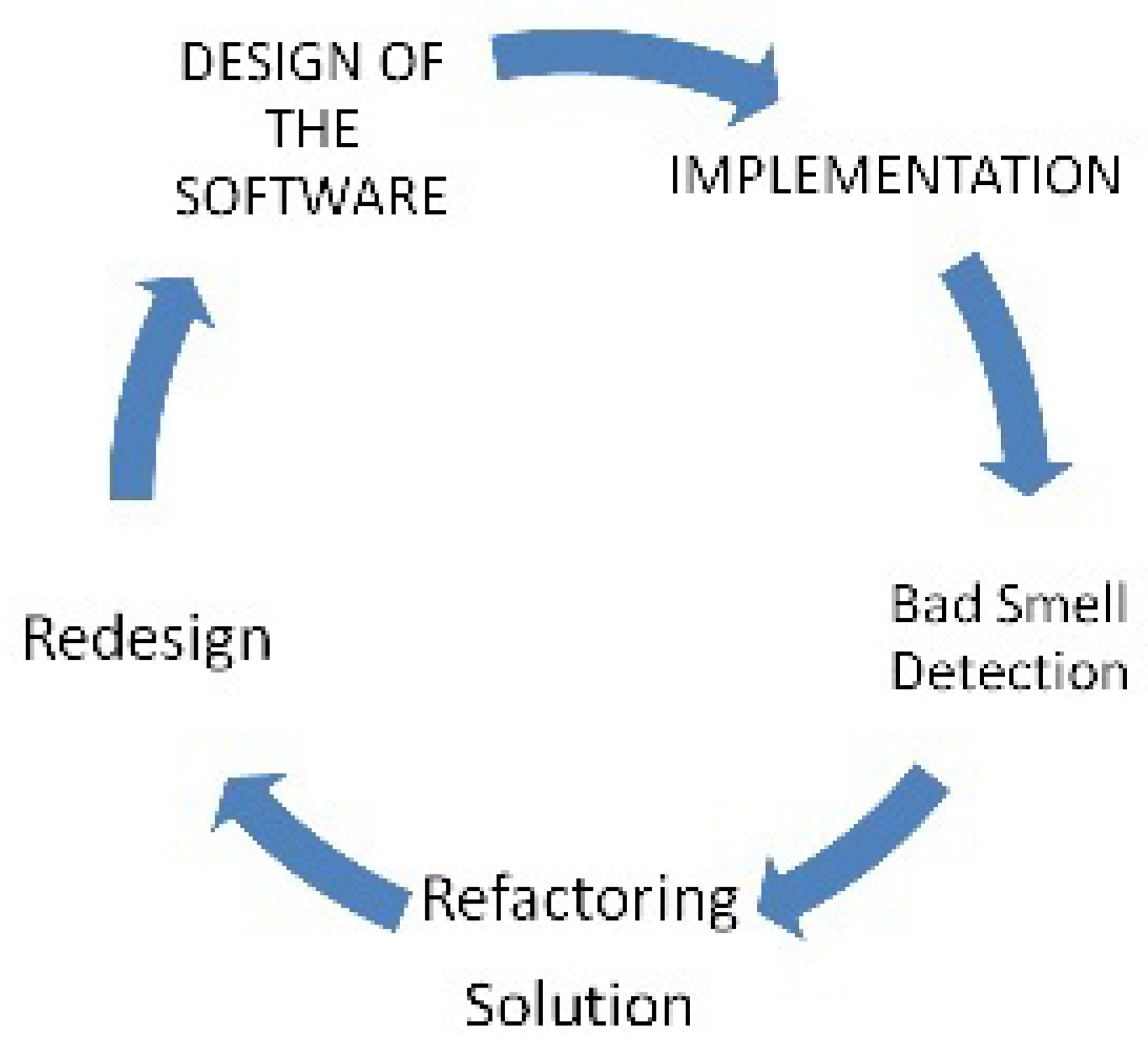
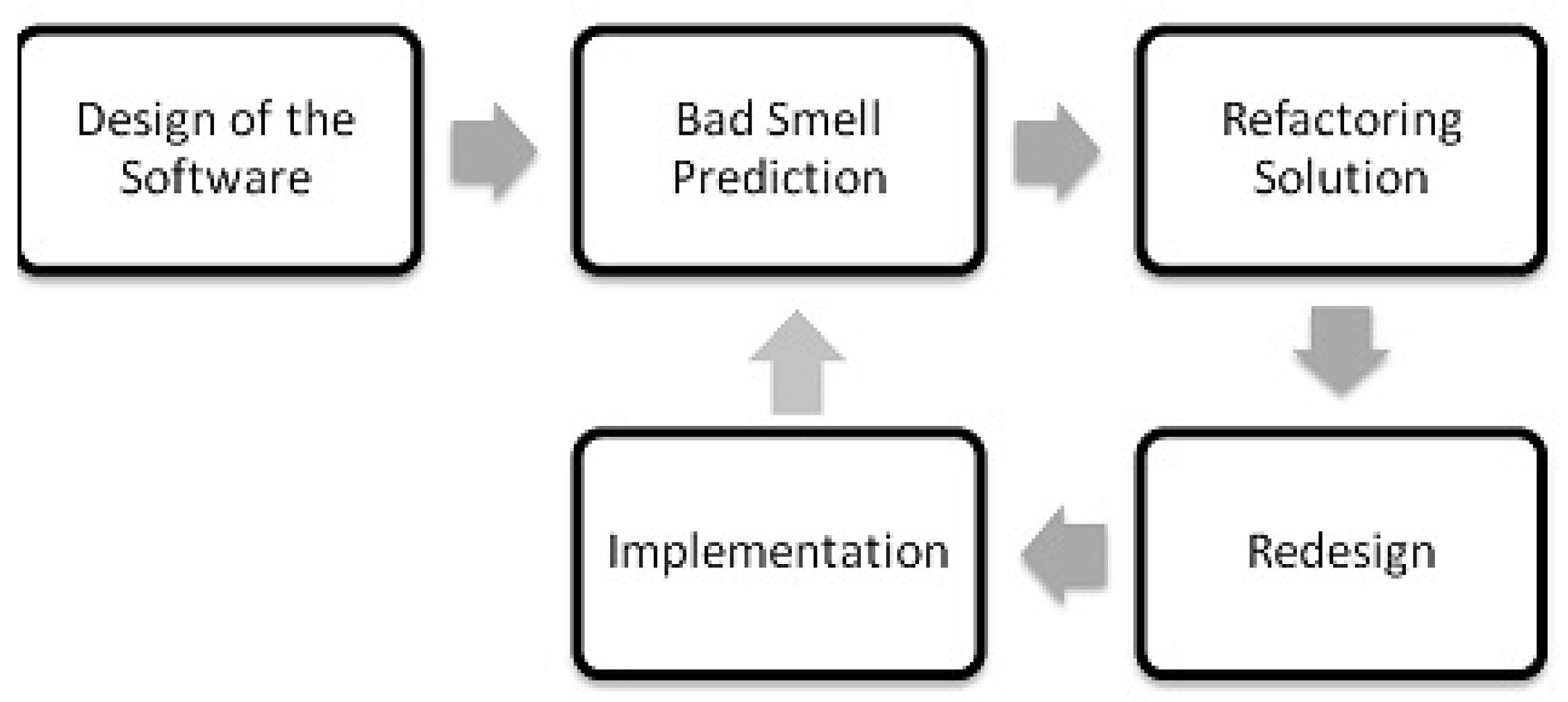
4. Experiment Design and Bad Smell Prediction Modeling
4.1. Evaluation of Entropy
4.2. Bad Smell Prediction Modeling
- E = (S, R(0.1), R(0.3), R(0.5), R(0.7), R(0.9), T(0.1), T(0.3), T(0.5), T(0.7), T(0.9)) are entropies,
- Y are predicted bad smells,
- A, B, C are the regression coefficients.
5. Data Collection and Preprossessing
5.1. Software Project Used as a Case Study
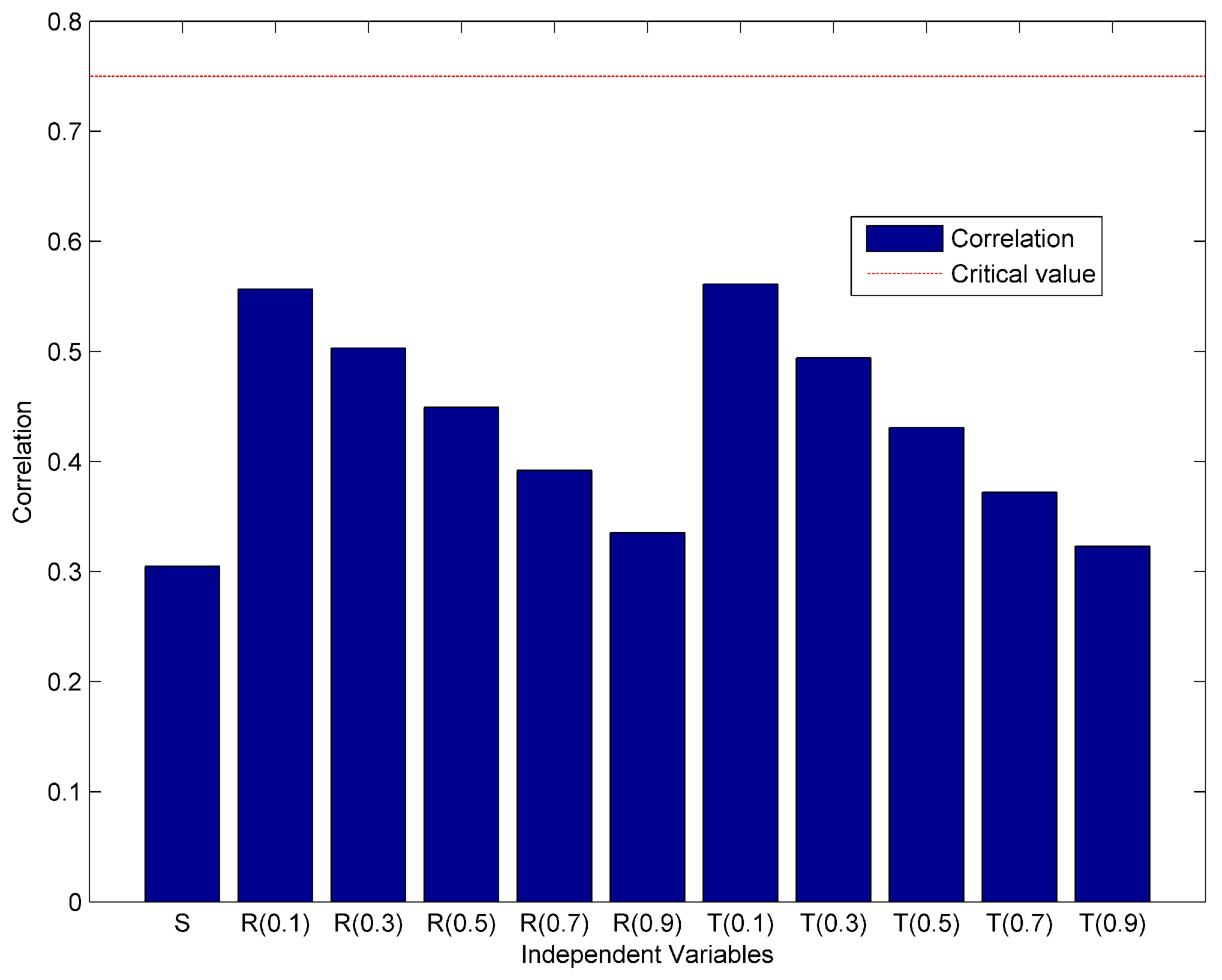
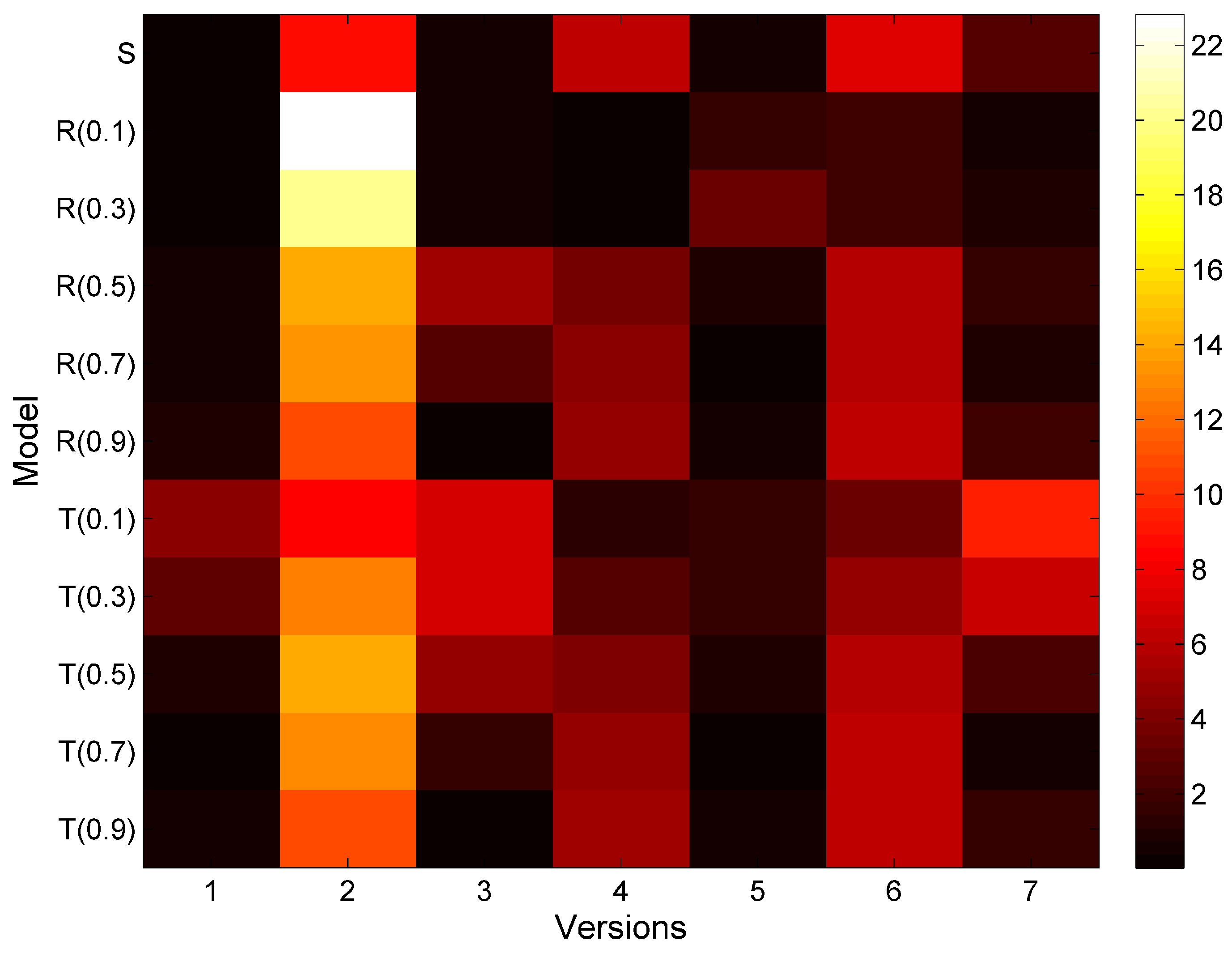
5.2. Assessment of Shannon, Rényi and Tsallis Entropy
5.3. Model Construction
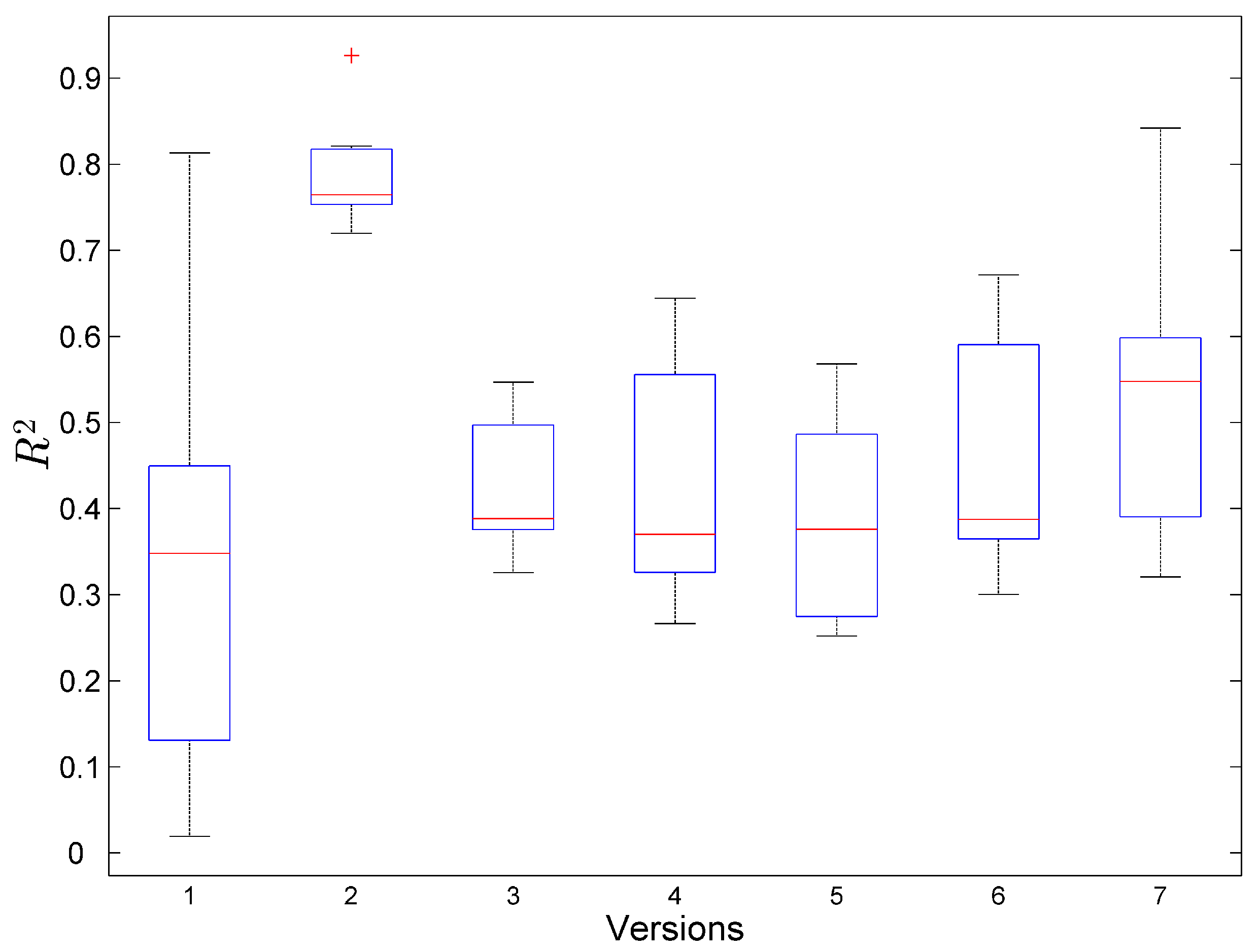
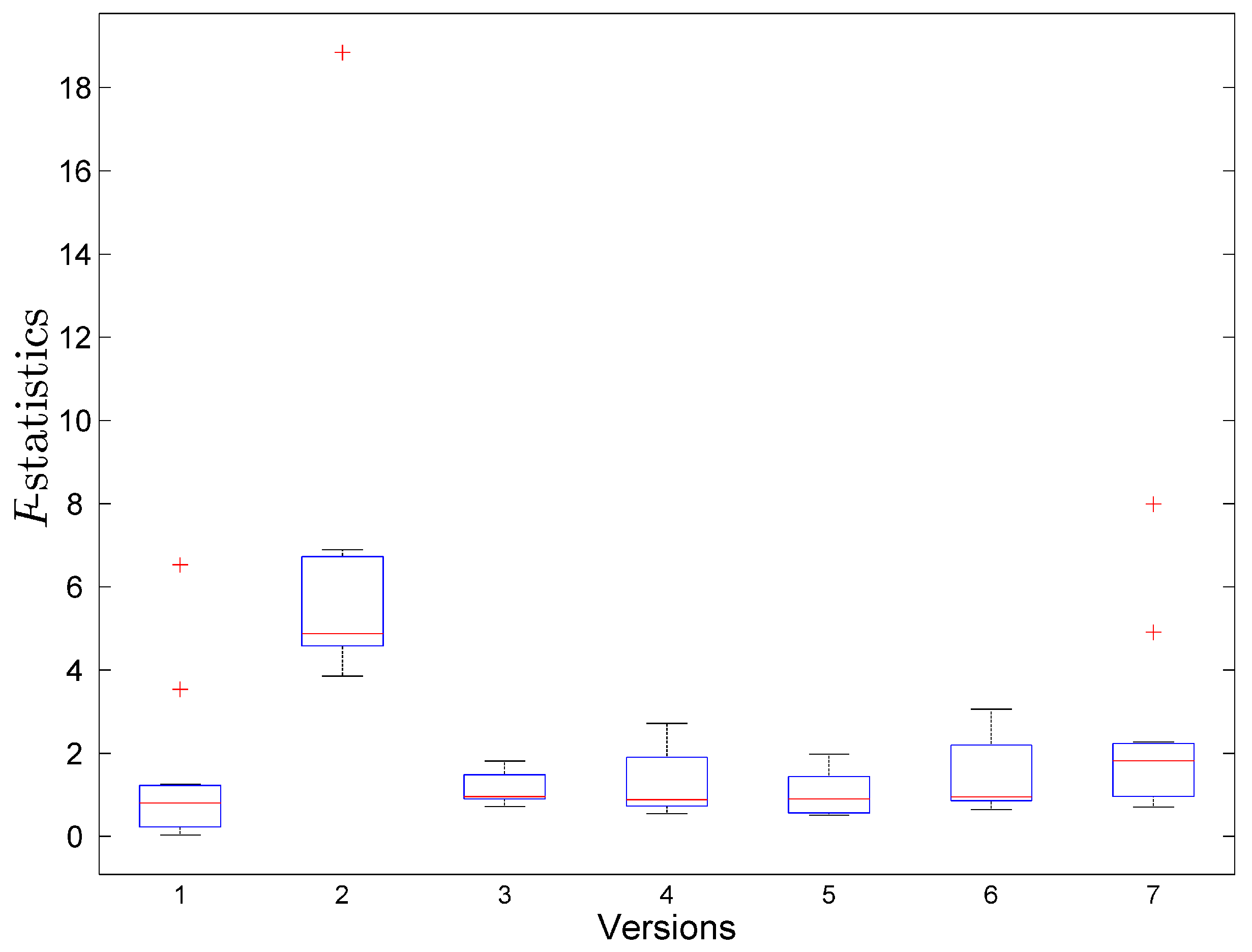
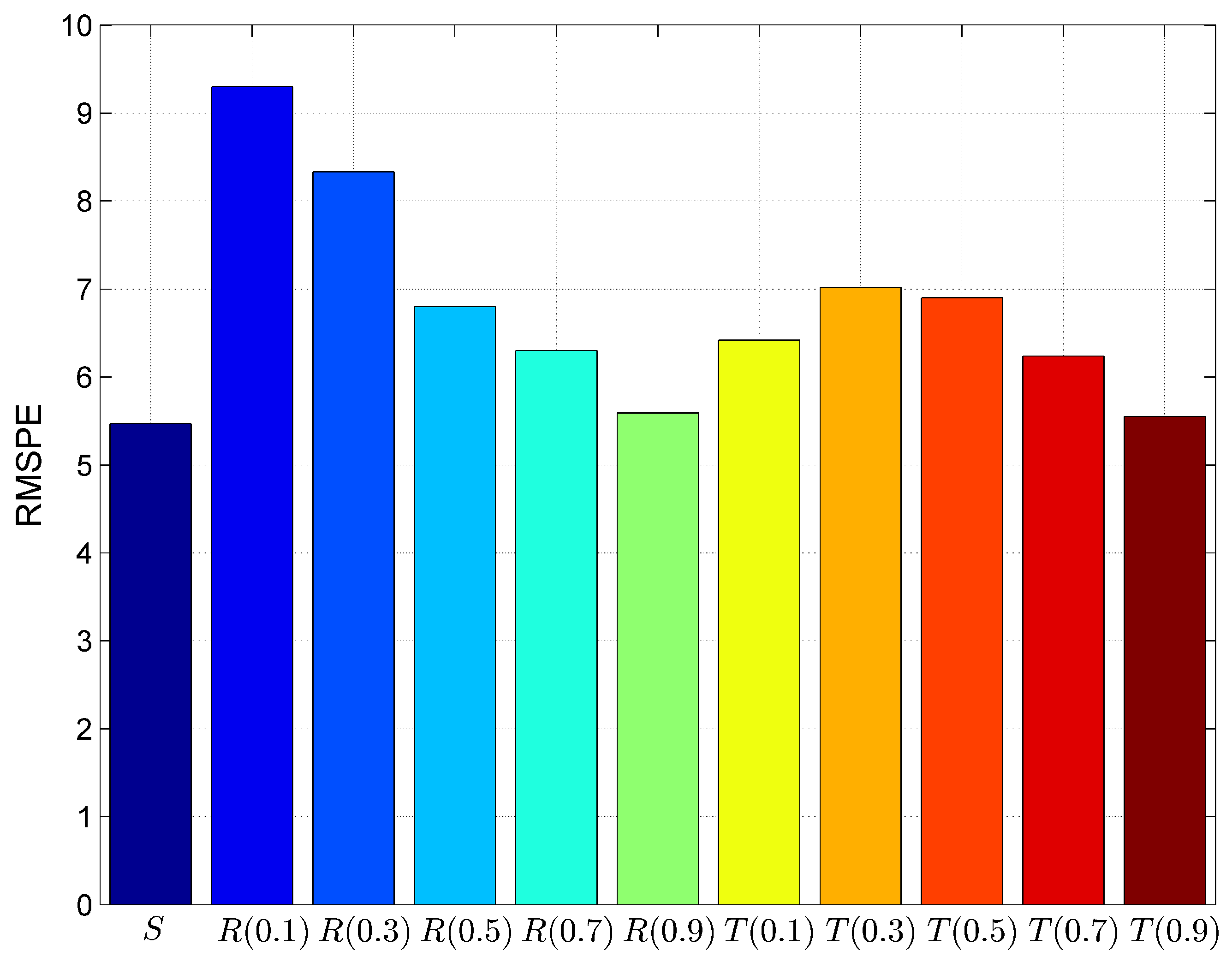
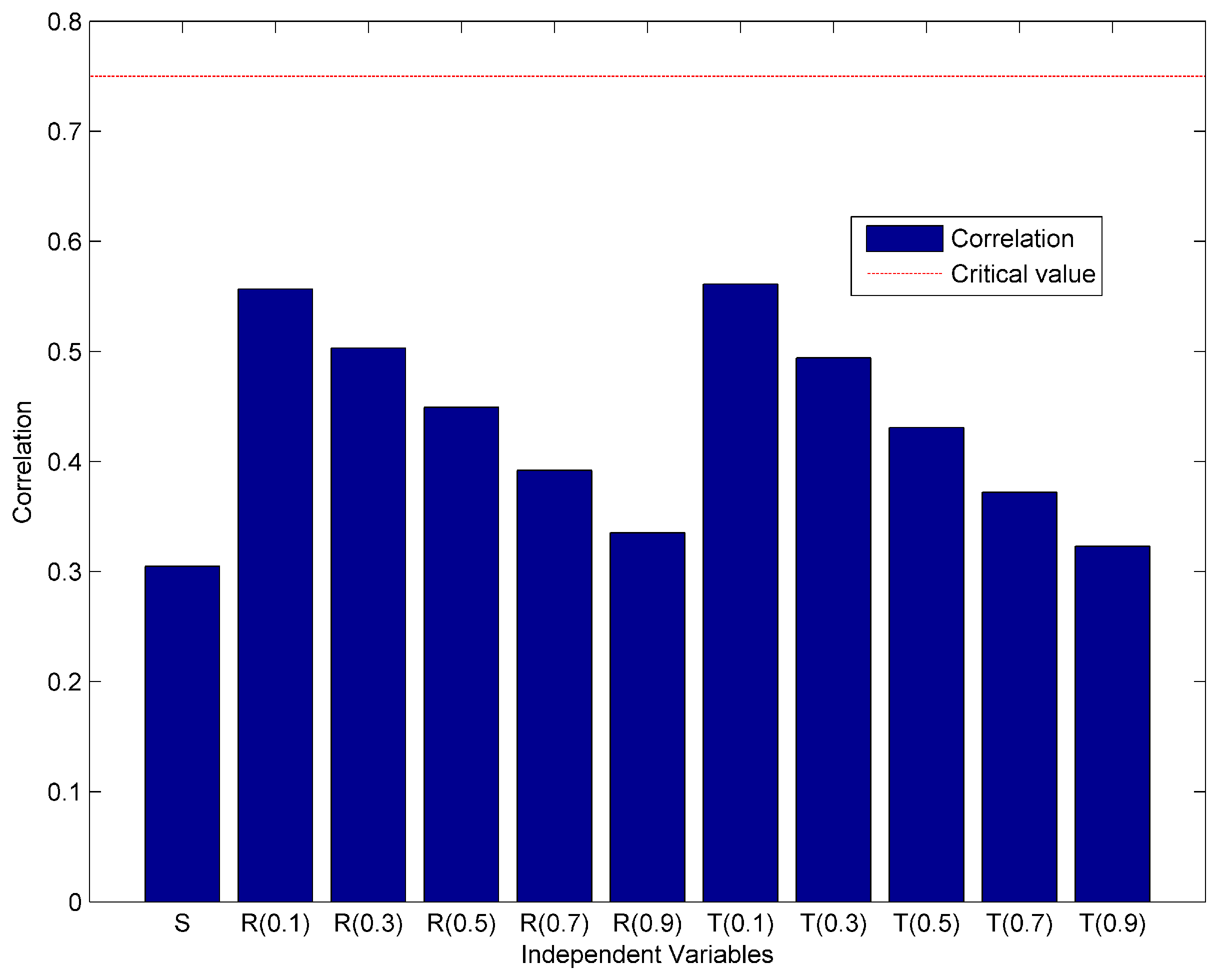
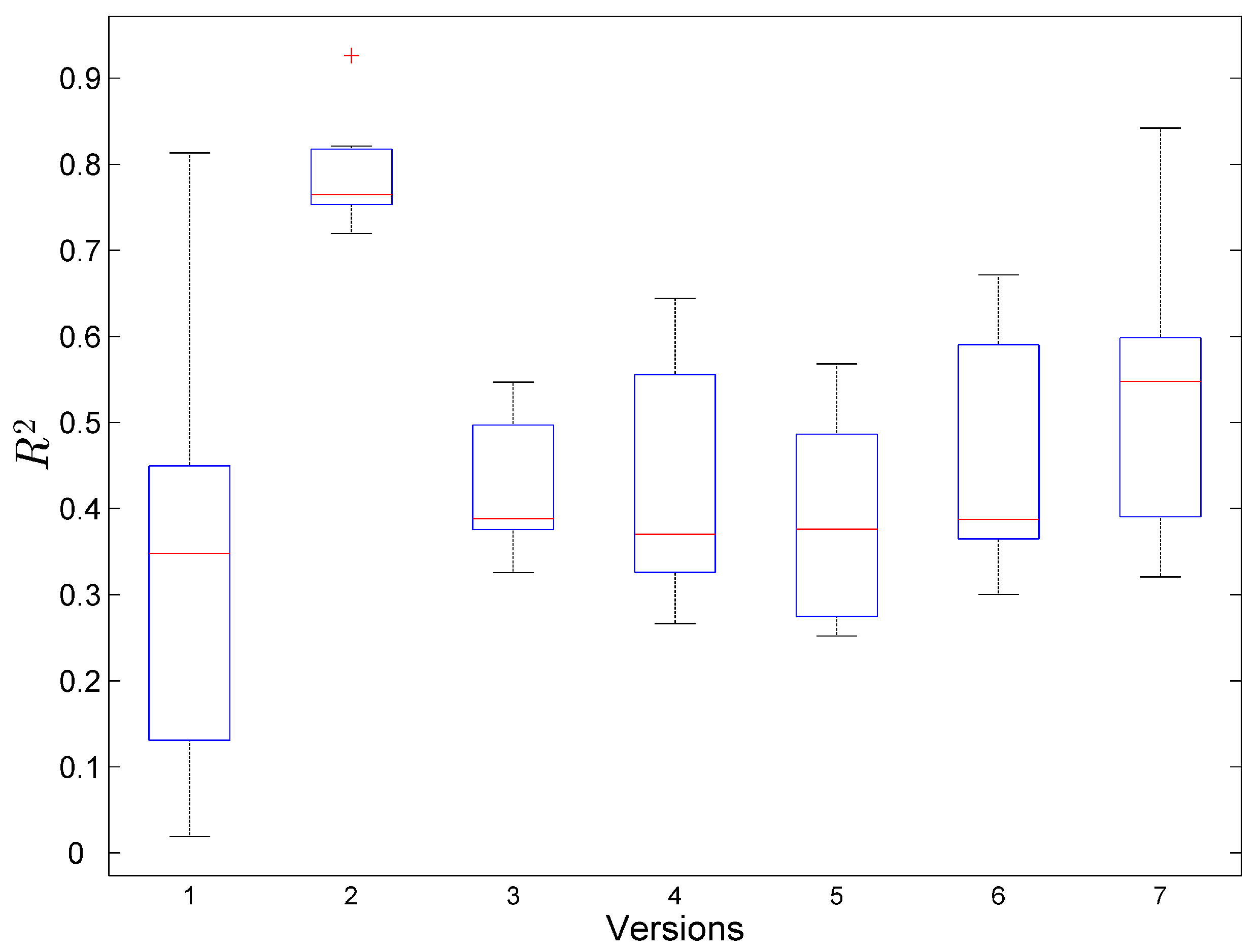
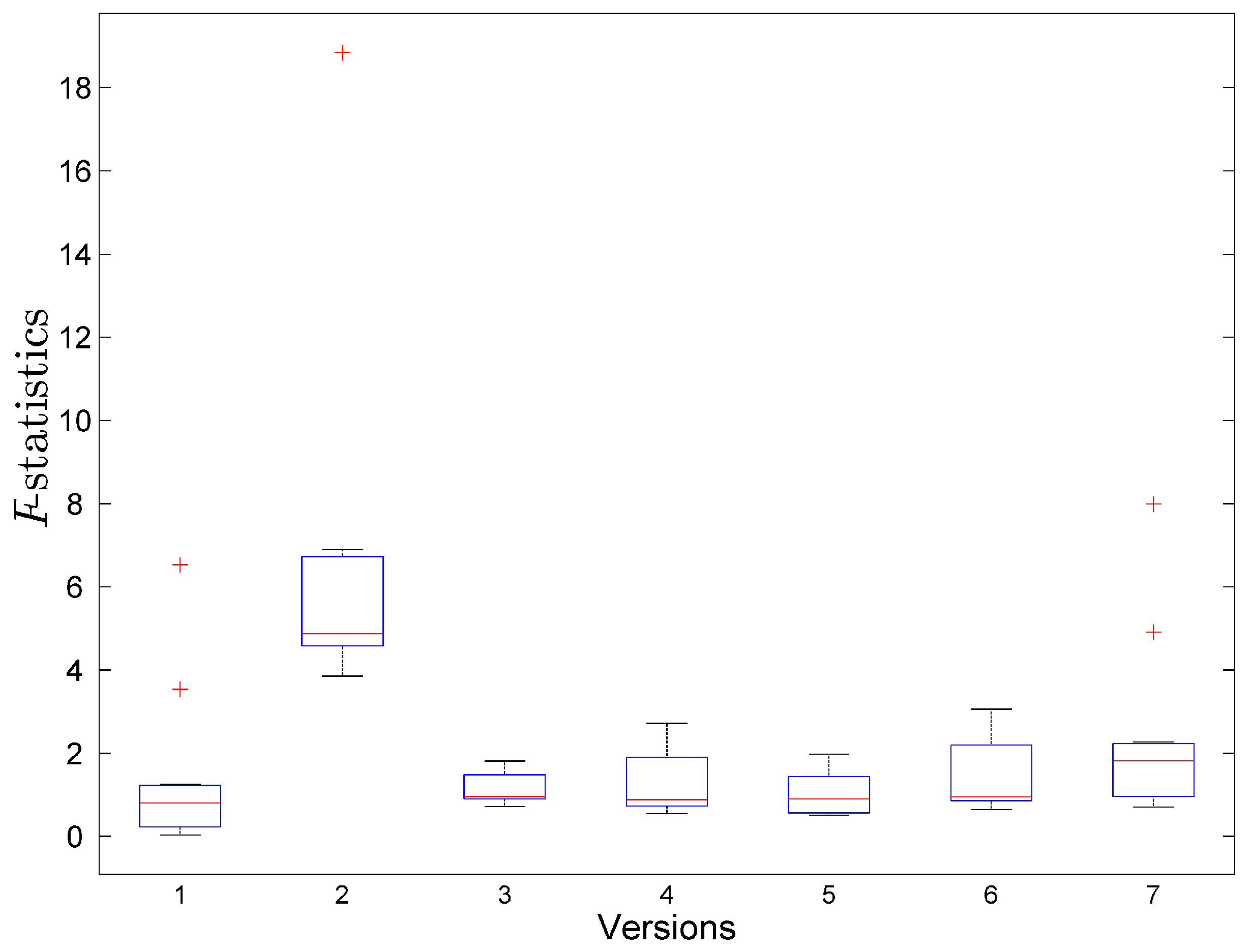
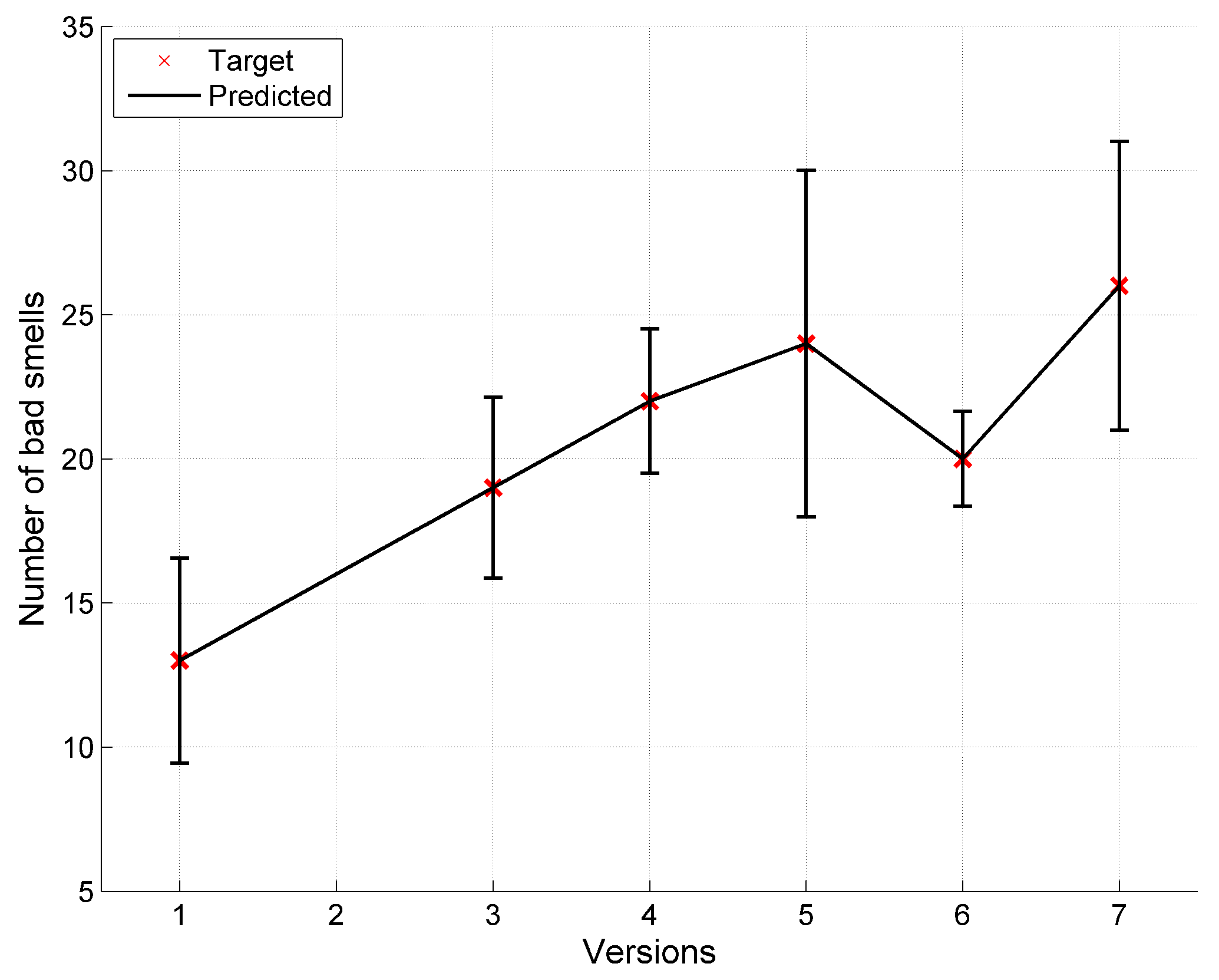
6. Result and Discussion
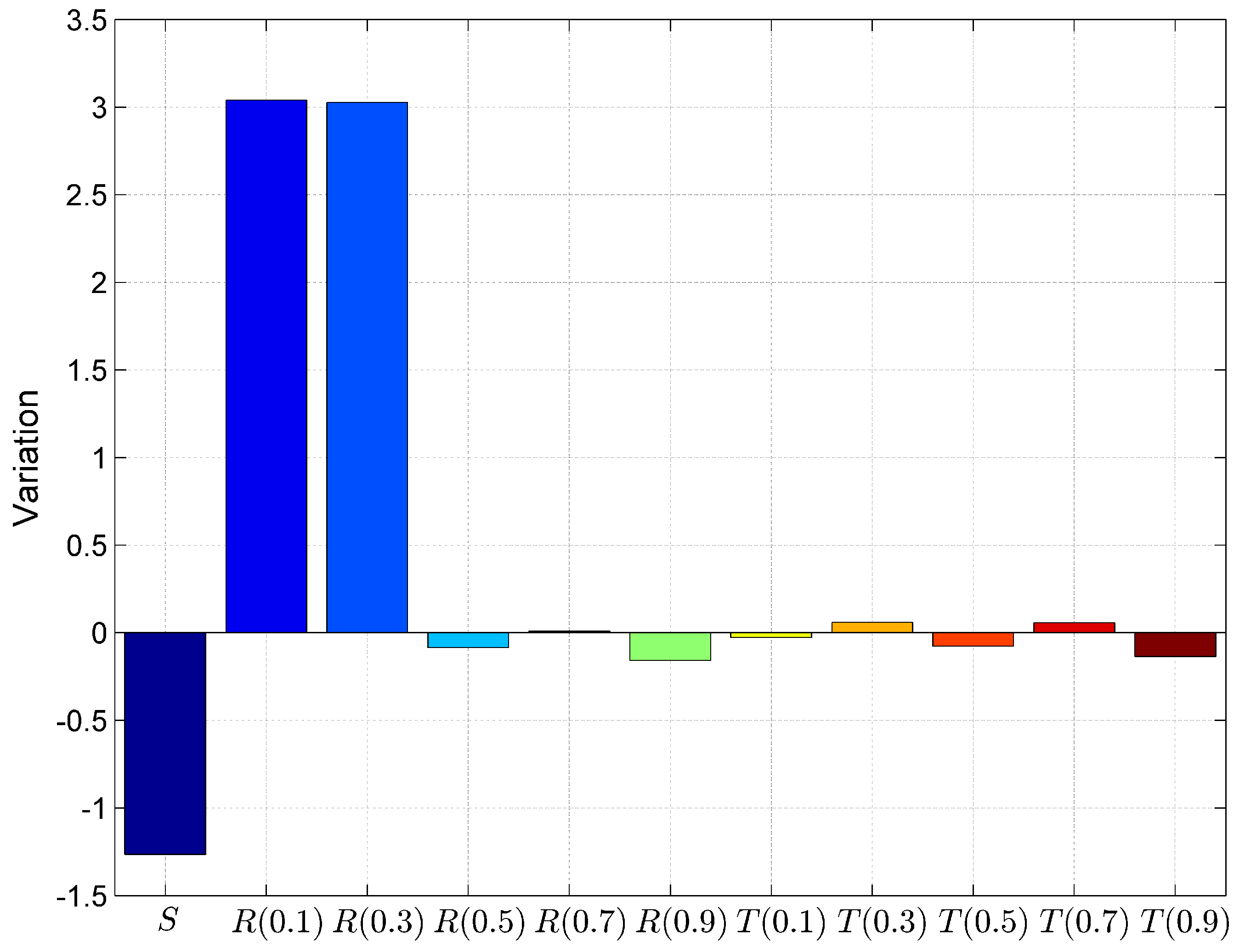
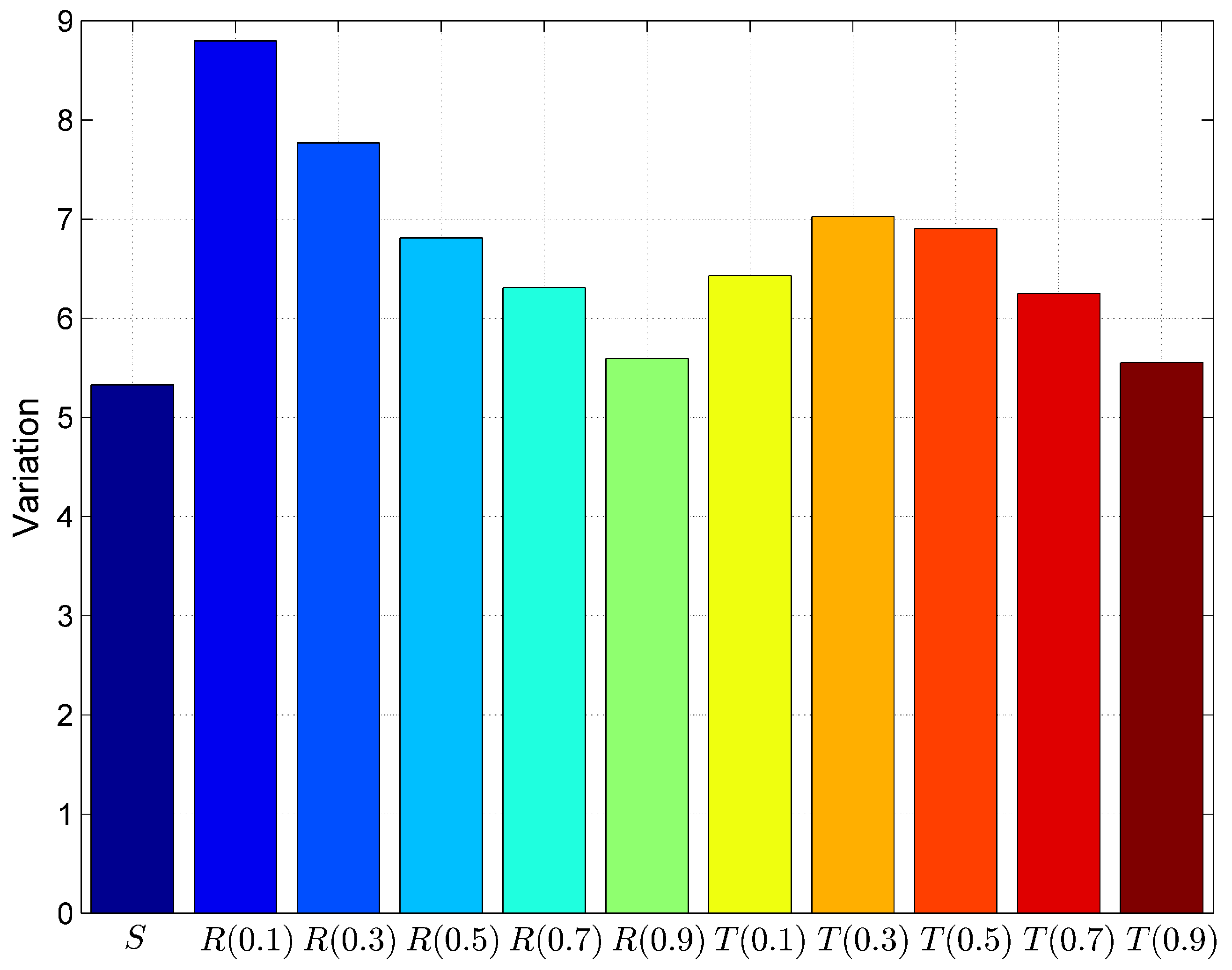
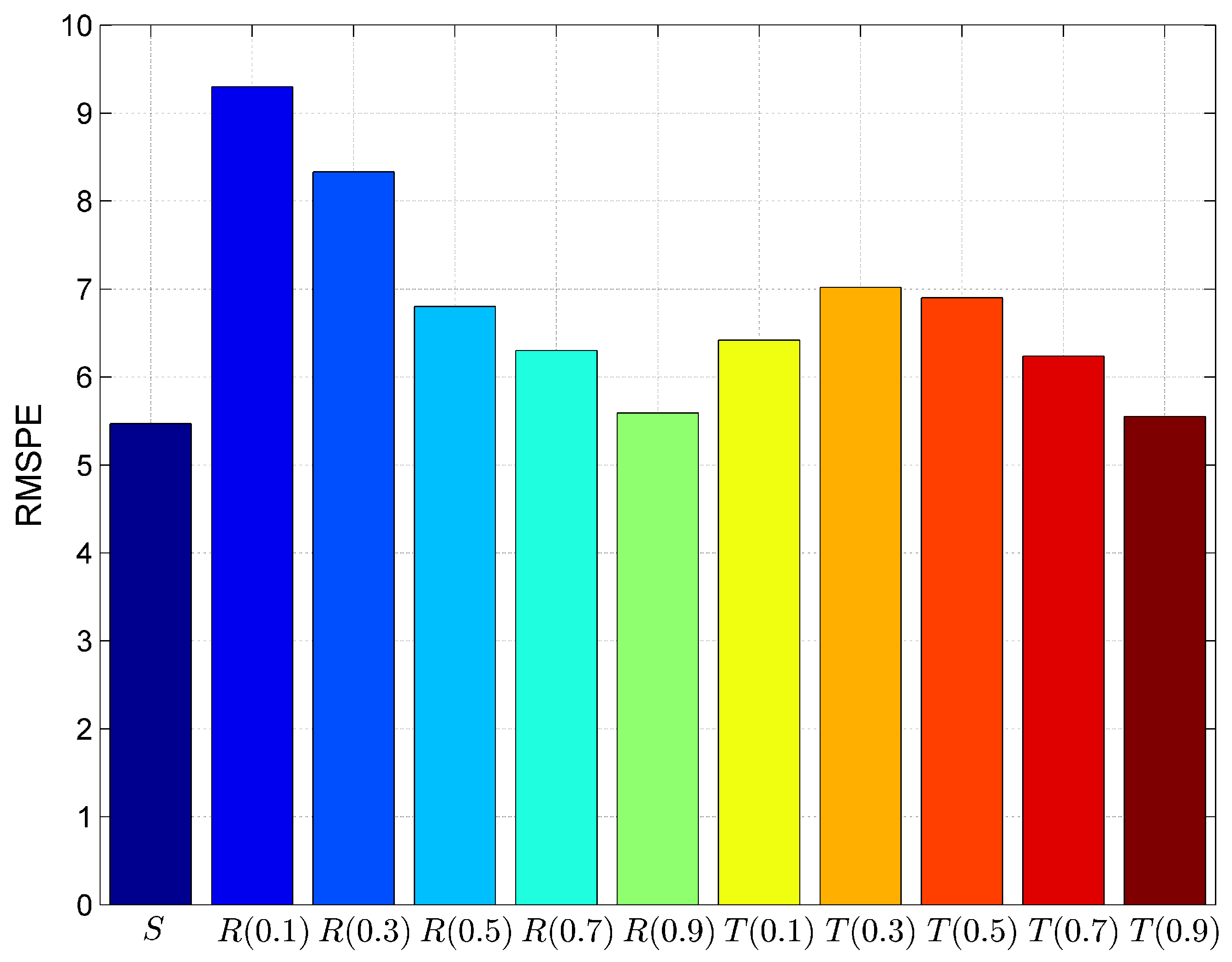
6.1. Result
6.2. Discussion
7. Application and Limitation
Threats to Validity
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lehman, M.M. Programs, Life Cycles, and Laws of Software Evolution. Proc. IEEE 1980, 68, 1060–1076. [Google Scholar] [CrossRef]
- Cesar Brandao Gomes da Silva, A.; de Figueiredo Carneiro, G.; Brito e Abreu, F.; Pessoa Monteiro, M. Frequent Releases in Open Source Software: A Systematic Review. Information 2017, 8, 109. [Google Scholar] [CrossRef]
- Parikh, G. The Guide to Software Maintenance; Winthrop: Cambridge, MA, USA, 1982. [Google Scholar]
- Yau, S.S.; Tsai, J.J.P. A survey of software design techniques. IEEE Trans. Softw. Eng. 1986, SE-12, 713–721. [Google Scholar] [CrossRef]
- International Organization for Standardization (ISO). Quality—Vocabulary; ISO 8402; International Organization for Standardization (ISO): Geneva, Switzerland, 1986. [Google Scholar]
- Zhang, M.; Hall, T.; Baddoo, N. Code bad smells: A review of current knowledge. J. Softw. Maint. Evolut. Res. Prac. 2011, 23, 179–202. [Google Scholar] [CrossRef]
- Tufano, M.; Palomba, F.; Bavota, G.; Oliveto, R.; Di Penta, M.; De Lucia, A.; Poshyvanyk, D. When and why your code starts to smell bad. In Proceedings of the 37th International Conference on Software Engineering-Volume 1, Florence, Italy, 16–24 May 2015; pp. 403–414. [Google Scholar]
- Rani, A.; Chhabra, J.K. Evolution of code smells over multiple versions of softwares: An empirical investigation. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 1093–1098. [Google Scholar]
- Garousi, V.; Küçük, B. Smells in software test code: A survey of knowledge in industry and academia. J. Syst. Softw. 2018, 138, 52–81. [Google Scholar] [CrossRef]
- Sharma, T.; Fragkoulis, M.; Spinellis, D. House of Cards: Code Smells in Open-Source C# Repositories. In Proceedings of the 2017 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Toronto, ON, Canada, 8–9 September 2017; pp. 424–429. [Google Scholar]
- Misra, S.; Adewumi, A.; Fernandez-Sanz, L.; Damasevicius, R. A Suite of Object Oriented Cognitive Complexity Metrics. IEEE Access 2018, 6, 8782–8796. [Google Scholar] [CrossRef]
- Maneerat, N.; Muenchaisri, P. Bad-smell prediction from software design model using machine learning techniques. In Proceedings of the Eighth International Joint Conference on Computer Science and Software Engineering (JCSSE), Nakhon Pathom, Thailand, 11–13 May 2011; pp. 331–336. [Google Scholar]
- Gupta, A.; Suri, B.; Misra, S. A systematic literature review: Code bad smells in Java source code. In Proceedings of the International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017; pp. 665–682. [Google Scholar]
- Hozano, M.; Garcia, A.; Fonseca, B.; Costa, E. Are you smelling it? Investigating how similar developers detect code smells. Inf. Softw. Technol. 2018, 93, 130–146. [Google Scholar] [CrossRef]
- Damasevicius, R. On The Human, Organizational, and Technical Aspects of Software Development and Analysis. In Information Systems Development; Papadopoulos, G., Wojtkowski, W., Wojtkowski, G., Wrycza, S., Zupancic, J., Eds.; Springer: Boston, MA, USA, 2009; pp. 11–19. [Google Scholar]
- Song, K.Y.; Chang, I.H.; Pham, H. A Software Reliability Model with a Weibull Fault Detection Rate Function Subject to Operating Environments. Appl. Sci. 2017, 7, 983. [Google Scholar] [CrossRef]
- Fowler, M.; Beck, K.; Brant, J.; Opdyke, W.; Roberts, D. Refactoring: Improving the Design of Existing Code; Addison-Wesley: Boston, MA, USA, 1999. [Google Scholar]
- Mäntylä, M.V.; Lassenius, C. Subjective evaluation of software evolvability using code smells: An empirical study. Empir. Softw. Eng. 2006, 11, 395–431. [Google Scholar] [CrossRef]
- Tufano, M.; Palomba, F.; Bavota, G.; Oliveto, R.; Di Penta, M.; De Lucia, A.; Poshyvanyk, D. When and why your code starts to smell bad (and whether the smells go away). IEEE Trans. Softw. Eng. 2017, 43, 1063–1088. [Google Scholar] [CrossRef]
- Chatzigeorgiou, A.; Manakos, A. Investigating the evolution of code smells in object-oriented systems. Innov. Syst. Softw. Eng. 2014, 10, 3–18. [Google Scholar] [CrossRef]
- Zhang, M.; Baddoo, N.; Wernick, P.; Hall, T. Improving the precision of fowler’s definitions of bad smells. In Proceedings of the 32nd Annual IEEE Software Engineering Workshop, SEW’08, Kassandra, Greece, 15–16 October 2008; pp. 161–166. [Google Scholar]
- Van Emden, E.; Moonen, L. Java quality assurance by detecting code smells. In Proceedings of the Ninth Working Conference on Reverse Engineering, Richmond, VA, USA, 29 November 2002; pp. 97–106. [Google Scholar]
- Moha, N.; Guéhéneuc, Y.-G.; Le Meur, A.-F.; Duchien, L.; Tiberghien, A. From a domain analysis to the specification and detection of code and design smells. Form. Asp. Computing 2010, 22, 345–361. [Google Scholar] [CrossRef]
- Moha, N.; Guéhéneuc, Y.-G.; Le Meur, A.-F.; Duchien, L. A domain analysis to specify design defects and generate detection algorithms. In Fundamental Approaches to Software Engineering; Fiadeiro, J.L., Inverardi, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 276–291. [Google Scholar]
- Fontana, F.A.; Mariani, E.; Morniroli, A.; Sormani, R.; Tonello, A. An experience report on using code smells detection tools. In Proceedings of the 2011 IEEE Fourth International Conference on Software Testing, Verification and Validation Workshops, Berlin, Germany, 21–25 March 2011; pp. 450–457. [Google Scholar]
- Fontana, F.A.; Mäntylä, M.V.; Zanoni, M.; Marino, A. Comparing and experimenting machine learning techniques for code smell detection. Empir. Softw. Eng. 2016, 21, 1143–1191. [Google Scholar] [CrossRef]
- Dexun, J.; Peijun, M.; Xiaohong, S.; Tiantian, W. Detecting bad smells with weight based distance metrics theory. In Proceedings of the 2012 Second International Conference on Instrumentation, Measurement, Computer, Communication and Control, Harbin, China, 8–10 December 2012; pp. 299–304. [Google Scholar]
- Liu, H.; Ma, Z.; Shao, W.; Niu, Z. Schedule of bad smell detection and resolution: A new way to save effort. IEEE Trans. Softw. Eng. 2012, 38, 220–235. [Google Scholar] [CrossRef]
- Palomba, F.; Bavota, G.; di Penta, M.; Oliveto, R.; de Lucia, A.; Poshyvanyk, D. Detecting bad smells in source code using change history information. In Proceedings of the 2013 28th IEEE/ACM International Conference on Automated Software Engineering (ASE), Silicon Valley, CA, USA, 11–15 November 2013; pp. 268–278. [Google Scholar]
- Hassaine, S.; Khomh, F.; Guéhéneuc, Y.-G.; Hamel, S. IDS: An immune-inspired approach for the detection of software design smells. In Proceedings of the 2010 Seventh International Conference on the Quality of Information and Communications Technology, Porto, Portugal, 29 September–2 October 2010; pp. 343–348. [Google Scholar]
- Czibula, G.; Marian, Z.; Czibula, I.G. Detecting software design defects using relational association rule mining. Knowl. Inf. Syst. 2015, 42, 545–577. [Google Scholar] [CrossRef]
- Mahouachi, R.; Kessentini, M.; Ghedira, K. A new design defects classification: Marrying detection and correction. In Fundamental Approaches to Software Engineering; de Lara, J., Zisman, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 455–470. [Google Scholar]
- Boussaa, M.; Kessentini, W.; Kessentini, M.; Bechikh, S.; Chikha, S.B. Competitive coevolutionary code-smells detection. In Search Based Software Engineering; Ruhe, G., Zhang, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 50–65. [Google Scholar]
- Ouni, A.; Kessentini, M.; Bechikh, S.; Sahraoui, H. Prioritizing code-smells correction tasks using chemical reaction optimization. Softw. Q. J. 2015, 23, 323–361. [Google Scholar] [CrossRef]
- Kessentini, M.; Mahaouachi, R.; Ghedira, K. What you like in design use to correct bad-smells. Softw. Q. J. 2013, 21, 551–571. [Google Scholar] [CrossRef]
- Kessentini, M.; Sahraoui, H.; Boukadoum, M.; Wimmer, M. Search-based design defects detection by example. In Fundamental Approaches to Software Engineering; Giannakopoulou, D., Orejas, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 401–415. [Google Scholar]
- Kessentini, W.; Kessentini, M.; Sahraoui, H.; Bechikh, S.; Ouni, A. A cooperative parallel search-based software engineering approach for code-smells detection. IEEE Trans. Softw. Eng. 2014, 40, 841–861. [Google Scholar] [CrossRef]
- Yamashita, A.; Counsell, S. Code smells as system-level indicators of maintainability: An empirical study. J. Syst. Softw. 2013, 86, 2639–2653. [Google Scholar] [CrossRef]
- Yamashita, A.; Moonen, L. To what extent can maintenance problems be predicted by code smell detection?–An empirical study. Inf. Softw. Technol. 2013, 55, 2223–2242. [Google Scholar] [CrossRef]
- Yamashita, A.; Moonen, L. Exploring the impact of inter-smell relations on software maintainability: An empirical study. In Proceedings of the 2013 International Conference on Software Engineering, San Francisco, CA, USA, 18–26 May 2013; pp. 682–691. [Google Scholar]
- Yamashita, A. Assessing the capability of code smells to explain maintenance problems: an empirical study combining quantitative and qualitative data. Empir. Softw. Eng. 2014, 19, 1111–1143. [Google Scholar] [CrossRef]
- Khomh, F.; Di Penta, M.; Gueheneuc, Y.G. An exploratory study of the impact of code smells on software change-proneness. In Proceedings of the 16th Working Conference on Reverse Engineering, WCRE’09, Lille, France, 13–16 October 2009; pp. 75–84. [Google Scholar]
- Gupta, A.; Suri, B. A survey on code clone, its behavior and applications. In Networking Communication and Data Knowledge Engineering; ICRACCCS-2016; Lecture Notes on Data Engineering and Communications Technologies; Springer: Berlin/Heidelberg, Germany, 2016; Volume 4, pp. 27–39. [Google Scholar]
- Holschuh, T.; Pauser, M.; Herzig, K.; Zimmermann, T.; Premraj, R.; Zeller, A. Predicting defects in sap java code: An experience report. In Proceedings of the 31st International Conference on Software Engineering, ICSE-Companion, Vancouver, BC, Canada, 16–24 May 2009; pp. 172–181. [Google Scholar]
- Taba, S.E.S.; Khomh, F.; Zou, Y.; Hassan, A.E.; Nagappan, M. Predicting Bugs Using Antipatterns. In Proceedings of the 2013 IEEE International Conference on Software Maintenance (ICSM ’13), Eindhoven, The Netherlands, 22–28 September 2013; pp. 270–279. [Google Scholar]
- Codabux, Z.; Sultana, K.Z.; Williams, B.J. The Relationship Between Code Smells and Traceable Patterns—Are They Measuring the Same Thing? Int. J. Soft. Eng. Knowl. Eng. 2007, 27, 1529. [Google Scholar] [CrossRef]
- Zhu, M.; Zhang, X.; Pham, H. A comparison analysis of environmental factors affecting software reliability. J. Syst. Softw. 2005, 109, 150–160. [Google Scholar] [CrossRef]
- Amarjeet; Chhabra, J.K. Robustness in search-based software remodularization. In Proceedings of the 2017 International Conference on Infocom Technologies and Unmanned Systems (Trends and Future Directions) (ICTUS), Dubai, UAE, 18–20 December 2017; pp. 611–615. [Google Scholar]
- Bansal, A. Empirical analysis of search based algorithms to identify change prone classes of open source software. Compu. Lang. Syst. Struct. 2017, 47, 211–231. [Google Scholar] [CrossRef]
- Kaur, K.; Kaur, P. Evaluation of sampling techniques in software fault prediction using metrics and code smells. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1377–1387. [Google Scholar]
- Hassan, A.E. Predicting faults using the complexity of code changes. In Proceedings of the 31st International Conference on Software Engineering, Washington, WA, USA, 16–24 May 2009; pp. 78–88. [Google Scholar]
- Singh, V.B.; Chaturvedi, K.K. Entropy based bug prediction using support vector regression. In Proceedings of the 12th International Conference on Intelligent Systems Design and Applications (ISDA), Kochi, India, 27–29 November 2012; pp. 746–751. [Google Scholar]
- Chaturvedi, K.K.; Kapur, P.K.; Anand, S.; Singh, V.B. Predicting software change complexity using entropy based measures. In Proceedings of the 6th International Conference on Quality, Reliability, Infocomm Technology and Industrial Technology Management (ICQRITITM 2012), Delhi, India, 23–25 November 2012; pp. 26–28. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; The Regents of the University of California: Berkeley, CA, USA, 1961. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Coifman, R.R.; Wickerhauser, M.V. Entropy-based algorithms for best basis selection. IEEE Trans. Inf. Theory 1992, 38, 713–718. [Google Scholar] [CrossRef]
- Stockl, D.; Dewitte, K.; Thienpont, L.M. Validity of linear regression in method comparison studies: Is it limited by the statistical model or the quality of the analytical input data? J. Clin. Chem. 1998, 44, 2340–2346. [Google Scholar]
- Bewick, V.; Cheek, L.; Ball, J. Statistics Review 7: Correlation and regression. J. Crit. Care 2003, 7, 451–459. [Google Scholar] [CrossRef] [PubMed]
- Feldt, R.; Magazinius, A. Validity Threats in Empirical Software Engineering Research-An Initial Survey. In Proceedings of the 22nd International Conference on Software Engineering & Knowledge Engineering (SEKE’2010), California, CA, USA, 1–3 July 2010; pp. 374–379. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bad Smell Observations with Software Classes | Bad Smell Detection | Mathematical Model | Entropy Based Approach | Industrial Application | |
|---|---|---|---|---|---|
| Proposed Approach | Yes | Yes | Yes | Yes | Yes |
| Tufano et al. [7,19] | No | Yes | No | No | Yes |
| Maneerat et al. [12] | No | Yes | No | No | No |
| Bansal [49] | No | No | No | No | No |
| Zhu et al. [47] | No | No | Yes | No | No |
| Amarjeet et al. [48] | No | No | No | No | No |
| Holschuh [44] | No | Yes | No | No | Yes |
| Czibula et al. [31] | Yes | Yes | No | No | No |
| Chaturvedi et al. [53] | No | No | Yes | Yes | No |
| Singh et al. [52] | No | No | Yes | Yes | No |
| Class | Version 1 | Version 2 | Version 3 |
|---|---|---|---|
| C1 | * | * | * |
| C2 | * | - | * |
| C3 | ** | ** | - |
| C4 | * | ** | * |
| s. no | Name | Description |
|---|---|---|
| 1 | Empty Catch Block | When the catch block is left blank in the catch statement. |
| 2 | Dummy Handler | Dummy handler is only used for viewing the exception but it will not handle the exception. |
| 3 | Nested Try Statements | When one or more try statements are contained in the try statement. |
| 4 | Unprotected Main | Outer exception will not be handled in the main program; it can only be handled in a subprogram or a function. |
| 5 | Careless Cleanup | The exception resource can be interrupted by another exception. |
| 6 | Exception thrown in the finally block | How to handle the exception thrown inside the finally block of another try catch statement. |
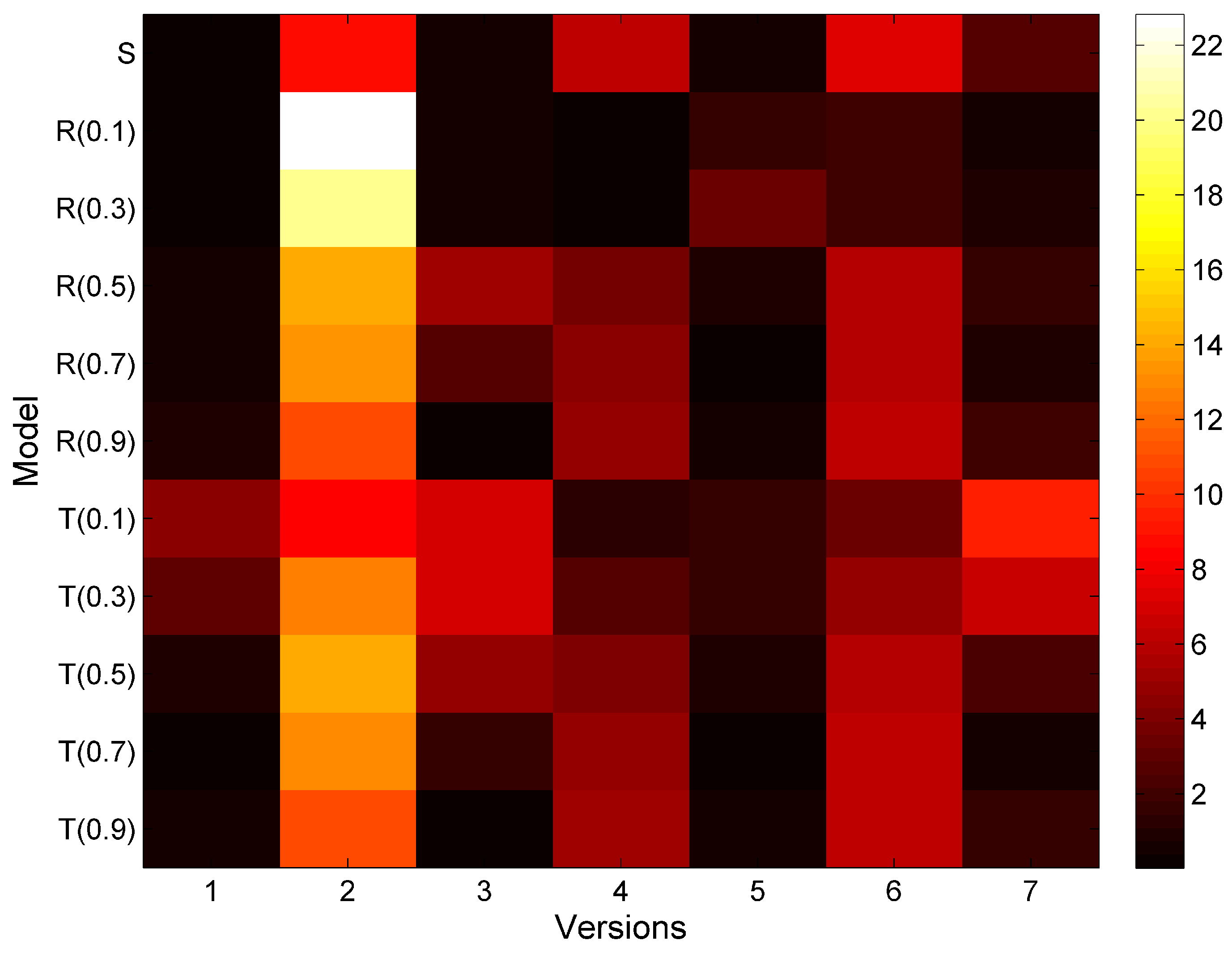
| Class Name | Bad Smells In Each Version of the Software | ||||||
|---|---|---|---|---|---|---|---|
| ver1 | ver2 | ver3 | ver4 | ver5 | ver6 | ver7 | |
| CacheControlUtil | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| AbstractExtensionFactory | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| CompressionUtil | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| MimeTypeHelper | 0 | 6 | 0 | 6 | 6 | 6 | 4 |
| ServiceUtil | 5 | 15 | 1 | 0 | 0 | 0 | 14 |
| UrlEncoding | 0 | 3 | 1 | 1 | 1 | 1 | 0 |
| DHEnc | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| Security Base | 0 | 1 | 4 | 4 | 4 | 0 | 0 |
| URITemplates | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| ThreadHelper | 0 | 2 | 2 | 2 | 2 | 2 | 2 |
| FOMWriter | 0 | 2 | 2 | 0 | 2 | 2 | 0 |
| SimpleAdapter | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| BaseResponseContext | 0 | 2 | 2 | 2 | 2 | 2 | 0 |
| Test | 6 | 1 | 0 | 0 | 0 | 0 | 0 |
| XsltExample | 1 | 0 | 0 | 0 | 0 | 0 | 2 |
| AbderaResult | 1 | 0 | 0 | 0 | 0 | 0 | 2 |
| Enc | 0 | 1 | 1 | 1 | 1 | 1 | 0 |
| SimpleCache Key | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| Escaping | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
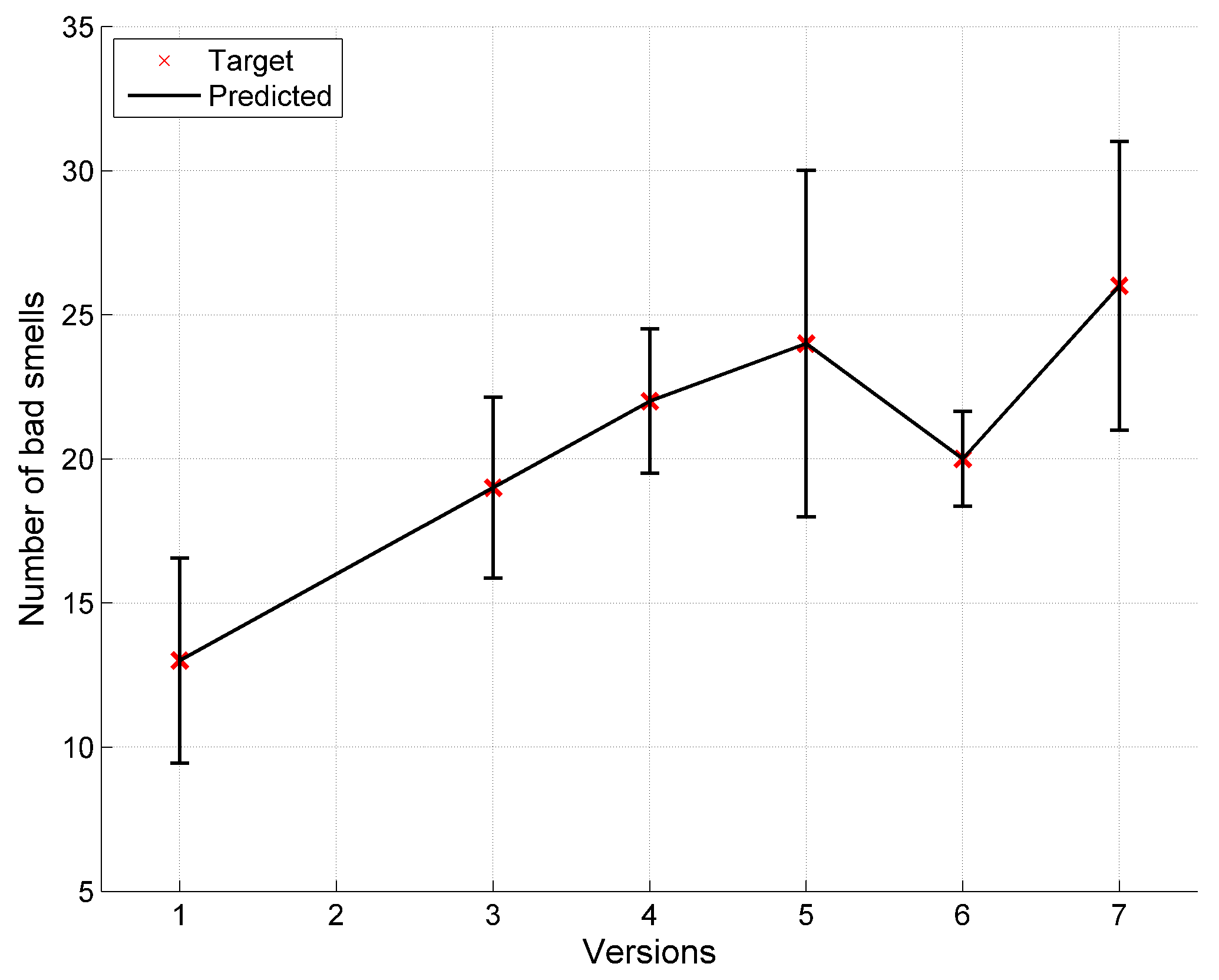
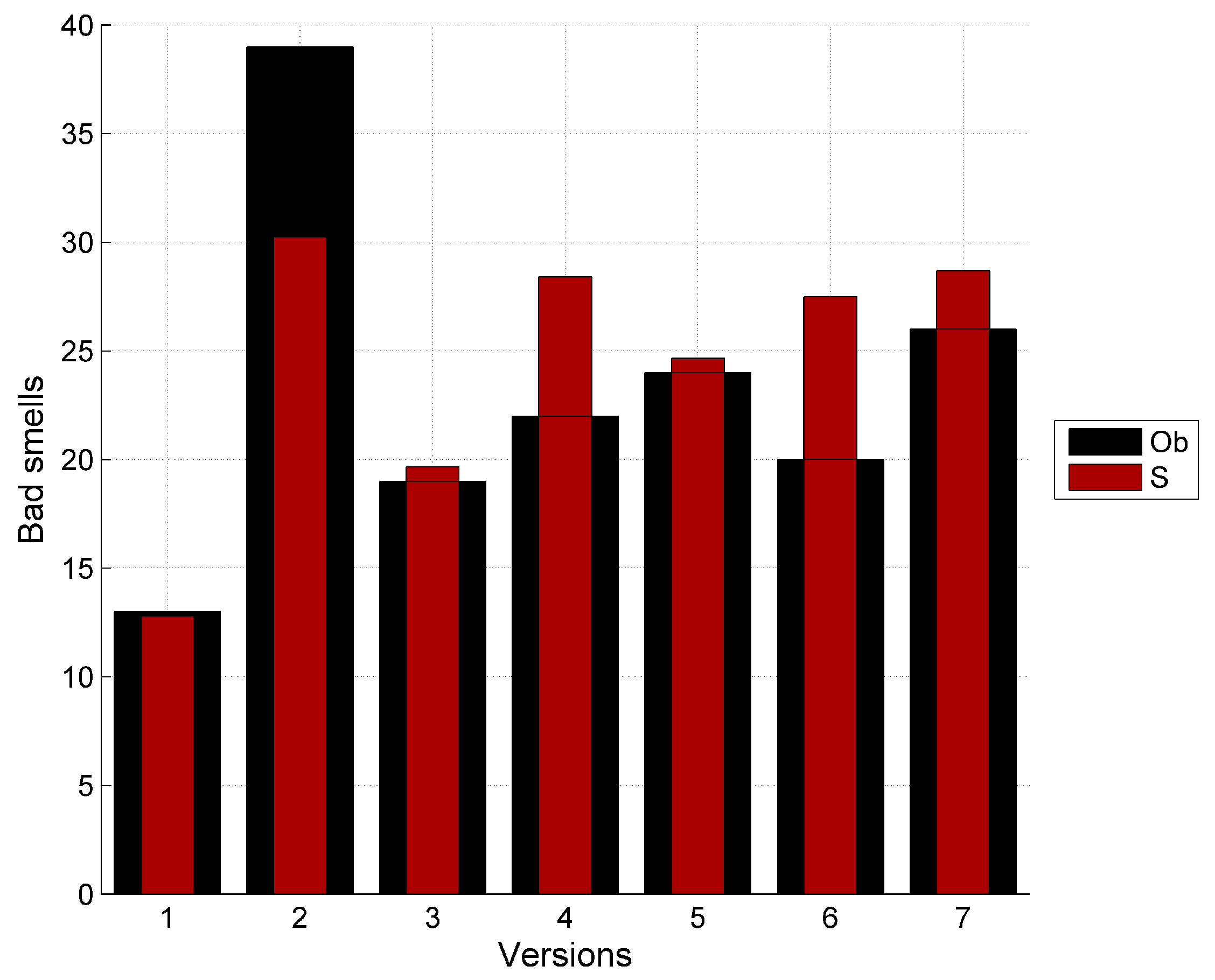
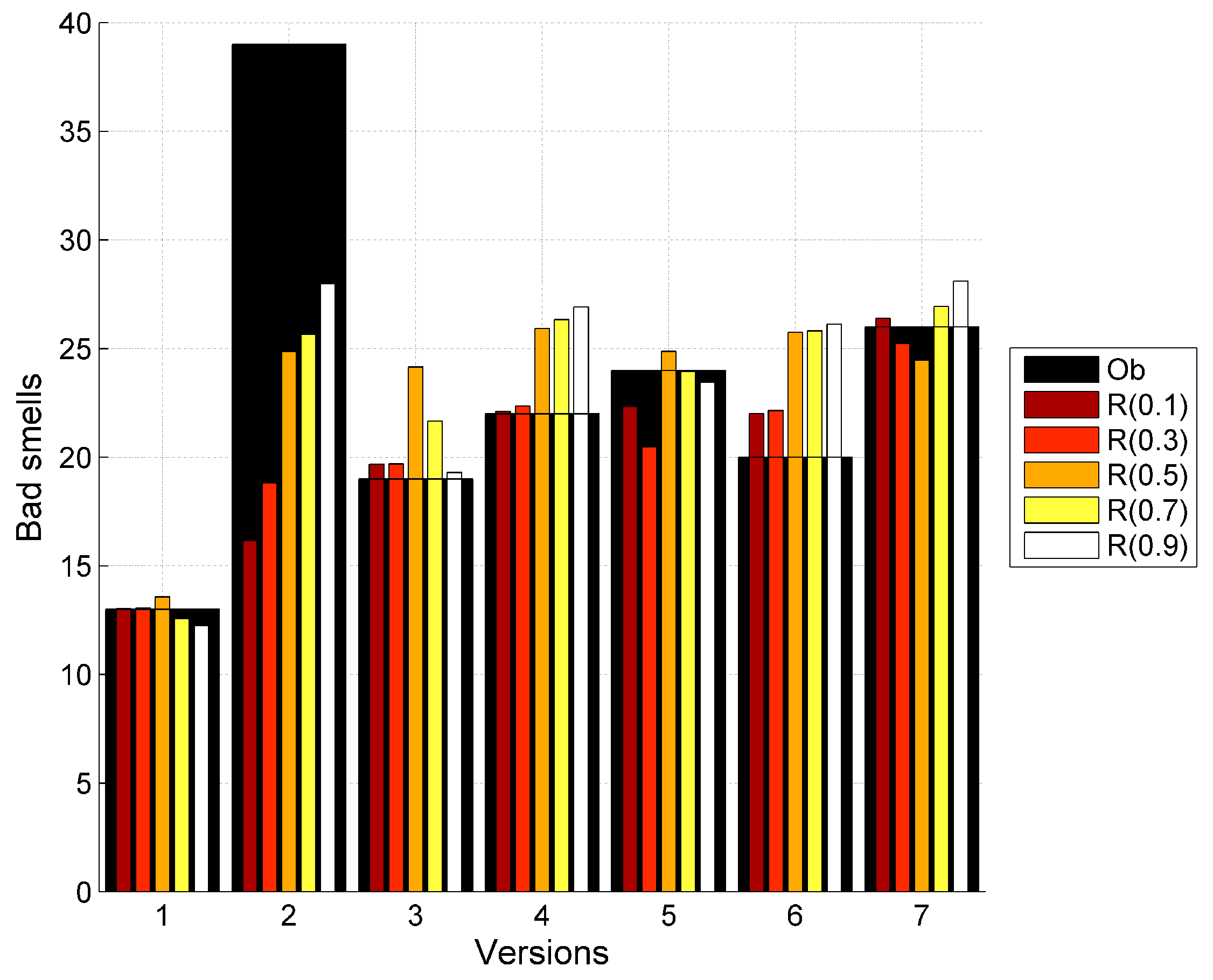
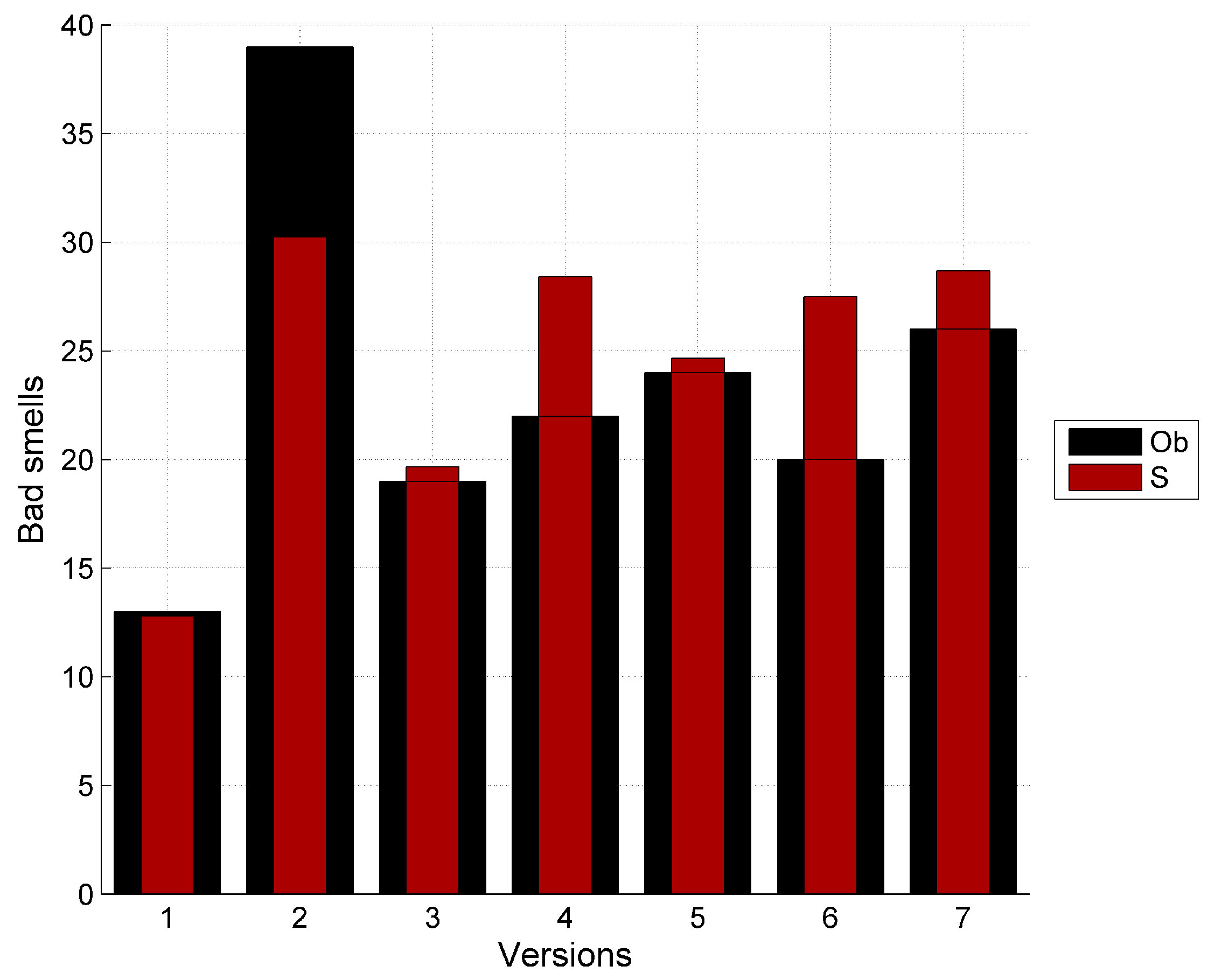
| Total | 13 | 39 | 19 | 22 | 24 | 20 | 26 |
| S | ) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1.61 | 1.95 | 1.86 | 1.78 | 1.71 | 1.64 | 2.65 | 2.10 | 1.71 | 1.42 | 1.21 |
| 3.11 | 3.84 | 3.7 | 3.54 | 3.37 | 3.2 | 11.09 | 7.16 | 4.82 | 3.38 | 2.48 |
| 3.51 | 3.68 | 3.65 | 3.61 | 3.57 | 3.53 | 9.95 | 6.96 | 4.99 | 3.67 | 2.77 |
| 3.20 | 3.55 | 3.48 | 3.41 | 3.33 | 3.25 | 9.08 | 6.31 | 4.51 | 3.33 | 2.53 |
| 3.35 | 3.54 | 3.61 | 3.54 | 3.46 | 3.39 | 9.85 | 6.78 | 4.81 | 3.519 | 2.65 |
| 3.24 | 3.55 | 3.49 | 3.43 | 3.36 | 3.28 | 9.11 | 6.36 | 4.57 | 3.37 | 2.56 |
| 2.11 | 2.74 | 2.60 | 2.46 | 2.32 | 2.18 | 5.038 | 3.63 | 2.70 | 2.069 | 1.63 |
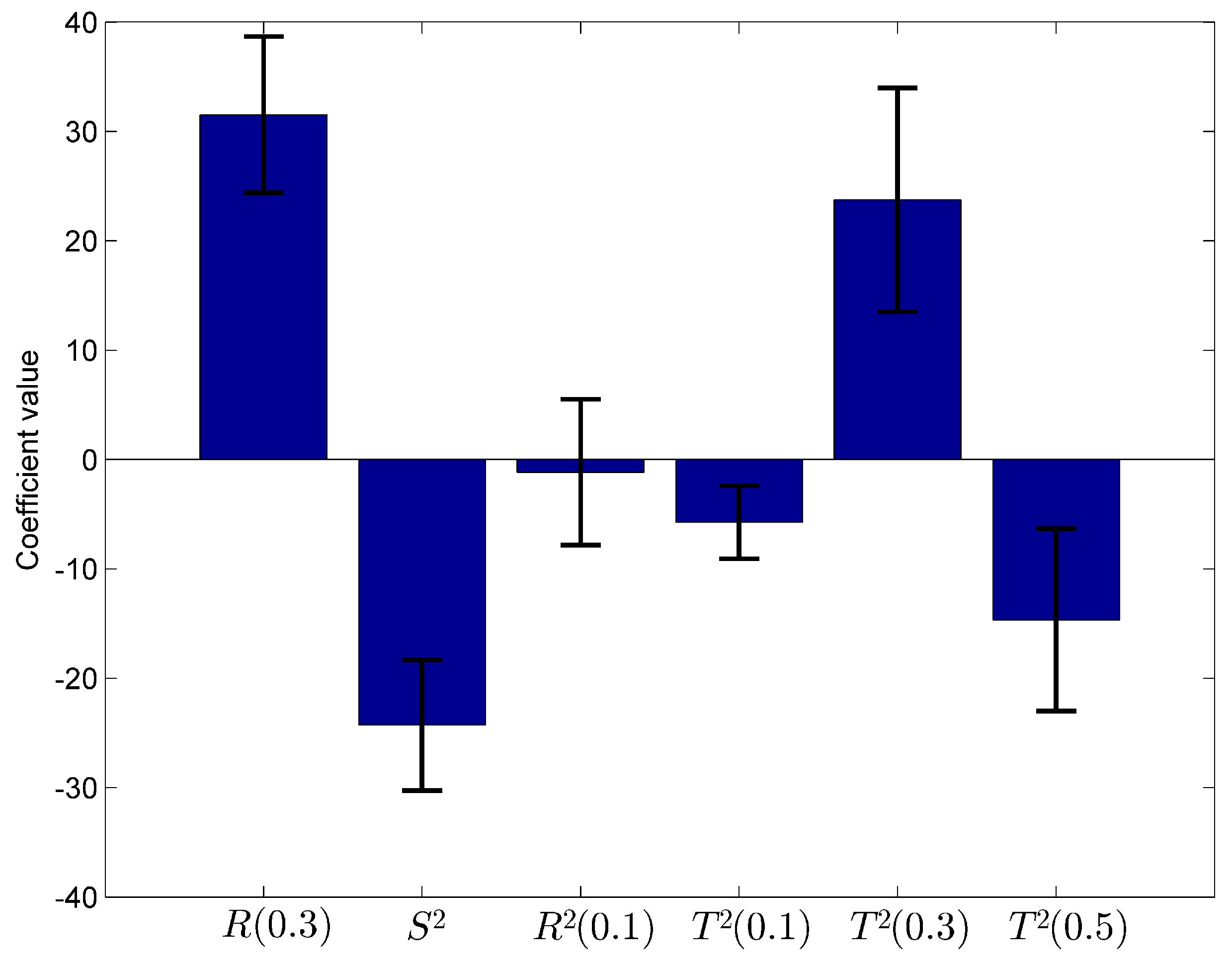
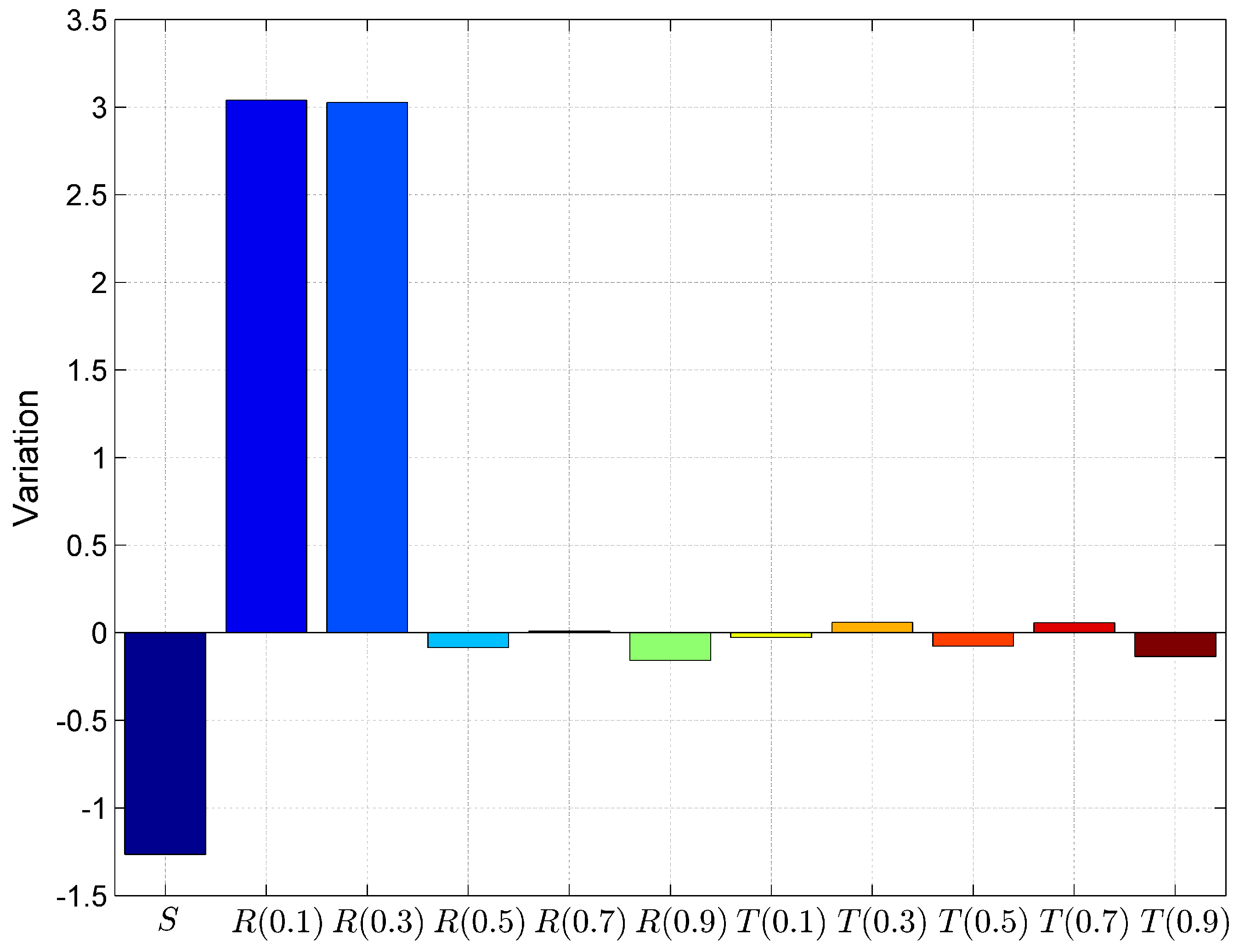
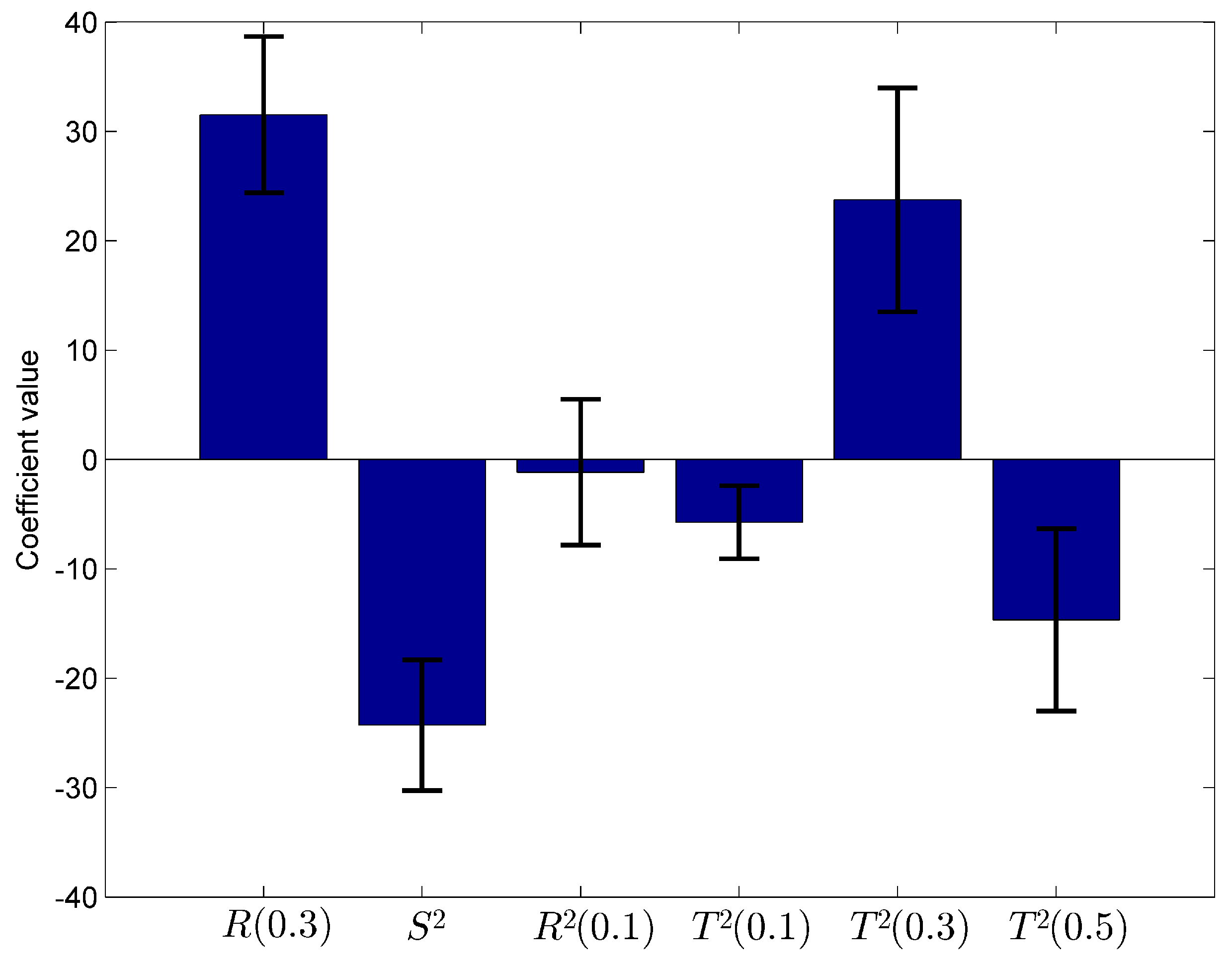
| Dependent Variable | Coefficient | Std. Deviation of Coefficient |
|---|---|---|
| R(0.3) | 31.534 | 7.268 |
| −24.284 | 6.169 | |
| (0.1) | −1.155 | 6.83 |
| (0.1) | −5.728 | 3.323 |
| (0.3) | 23.751 | 10.283 |
| (0.5) | −14.649 | 8.498 |
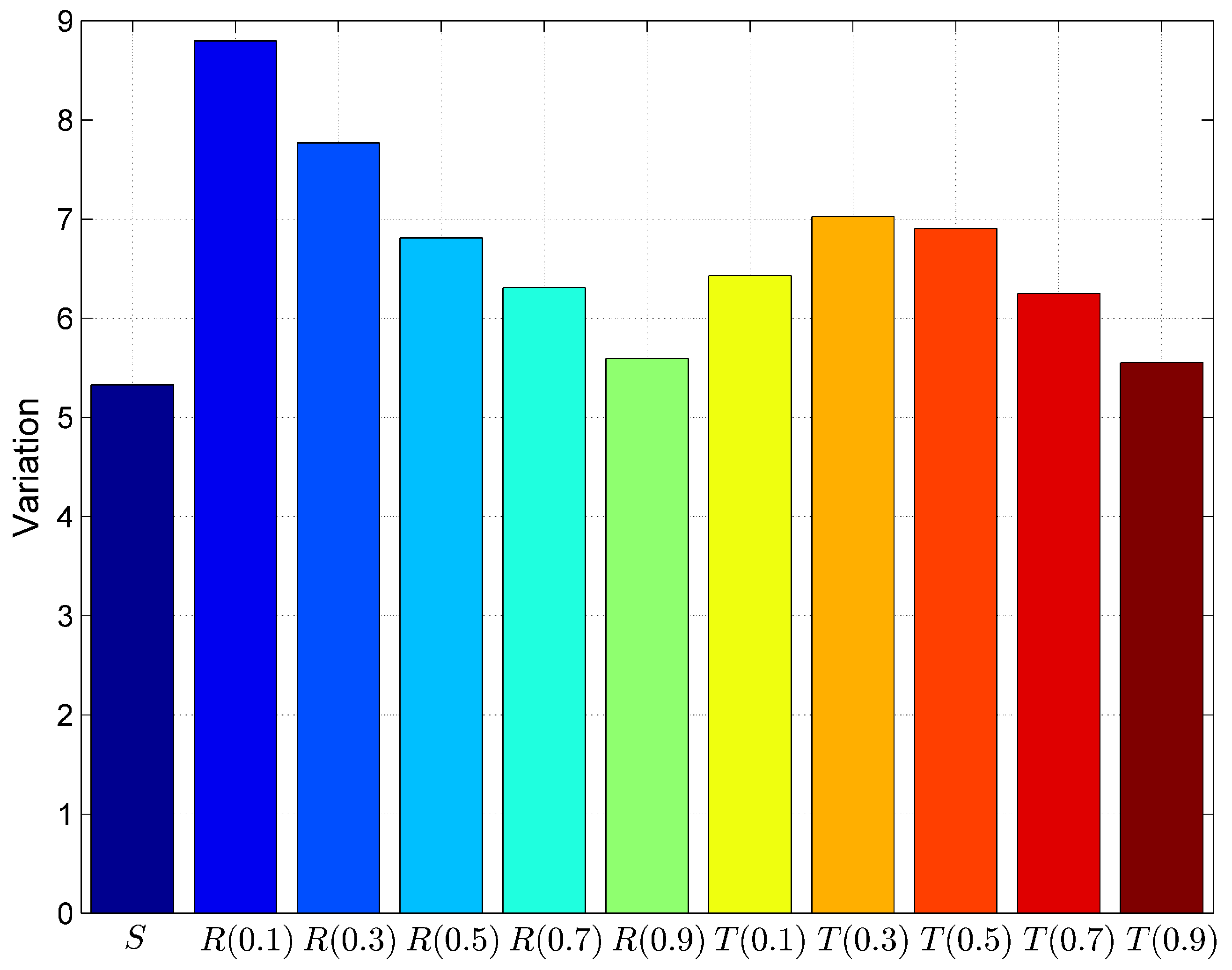
| S | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 12.81 | 13.02 | 13.06 | 13.57 | 12.57 | 12.23 | 17.39 | 15.99 | 14.07 | 12.66 | 12.27 |
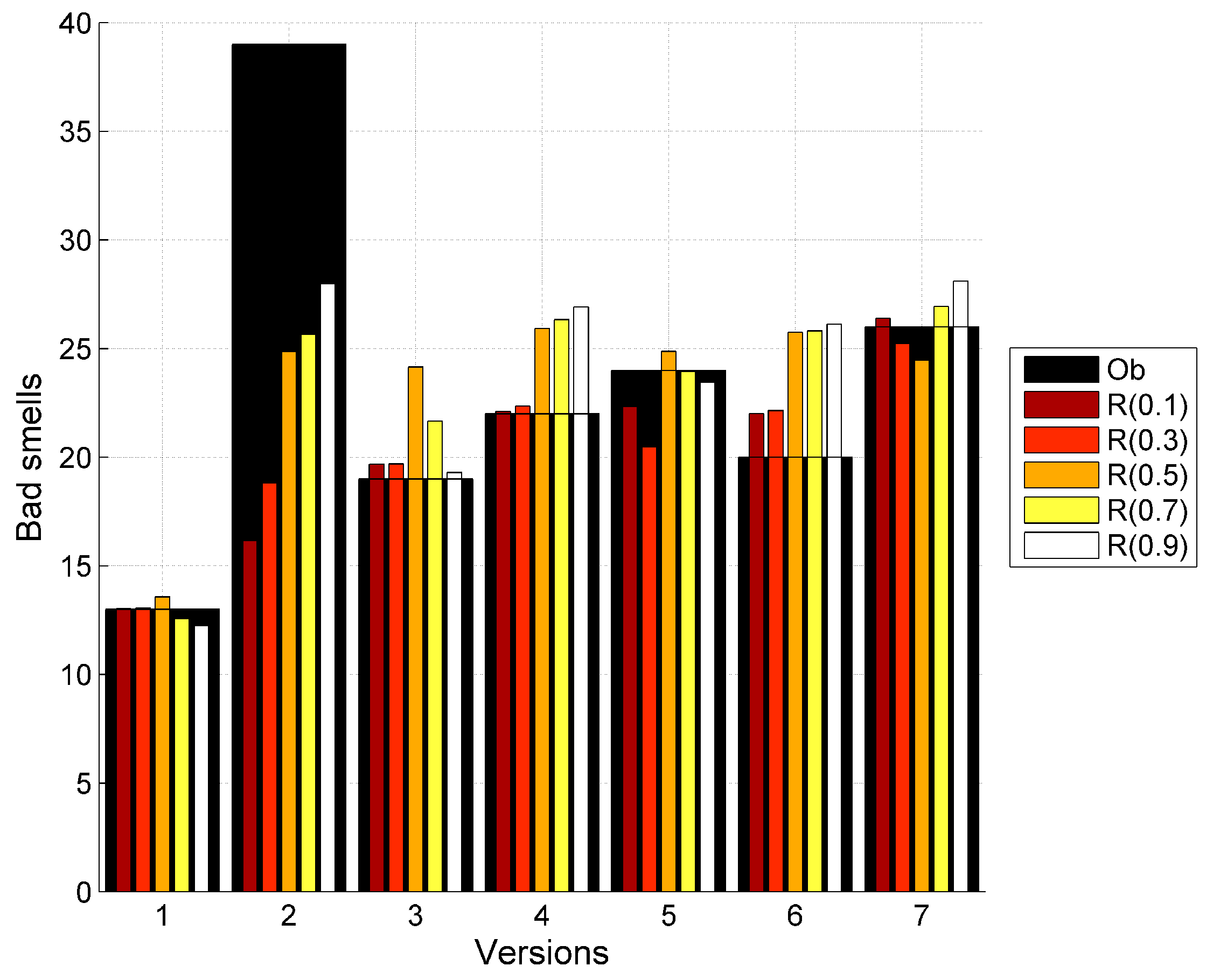
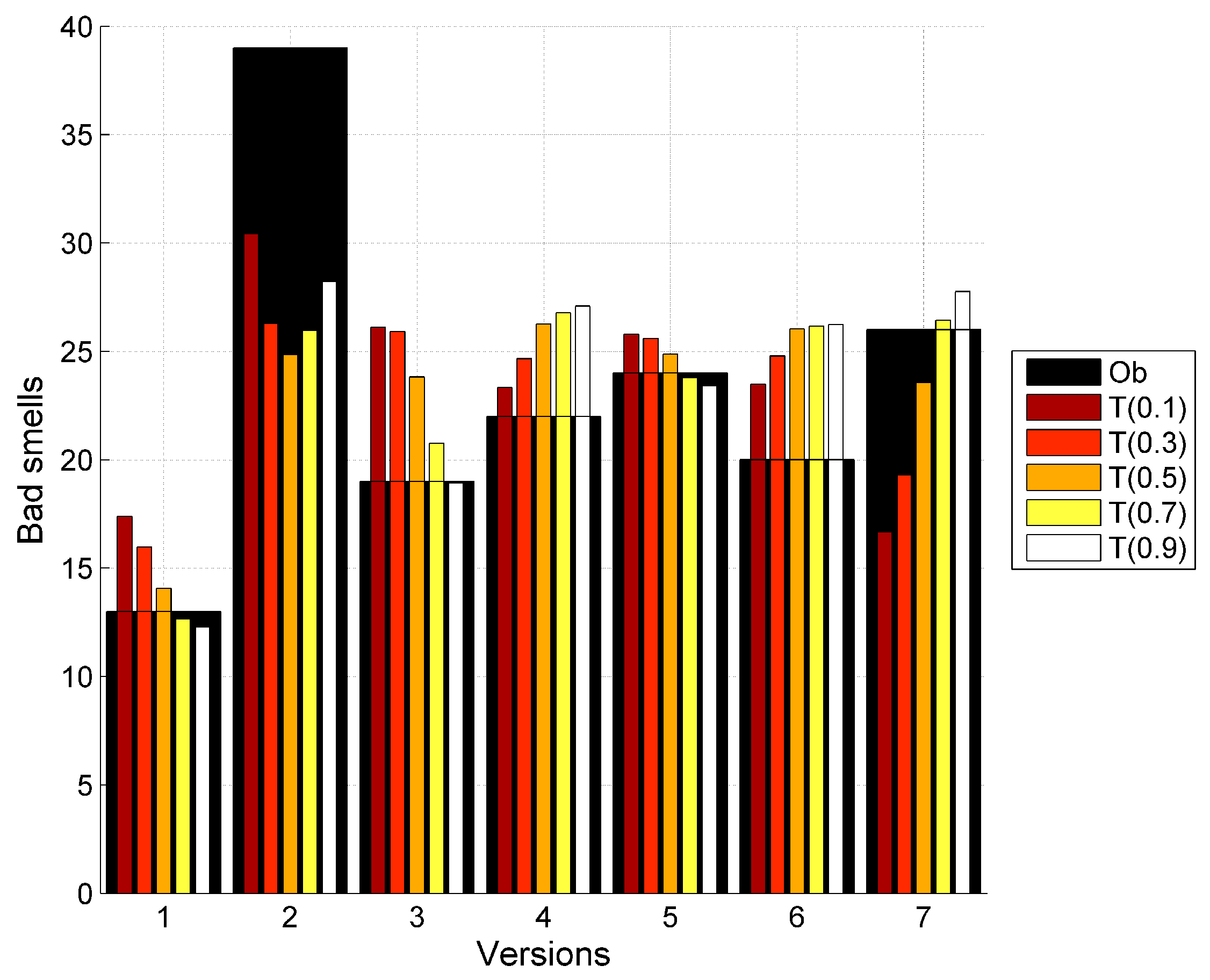
| 39 | 30.24 | 16.16 | 18.81 | 24.86 | 25.65 | 28.0 | 30.42 | 26.3 | 24.86 | 25.97 | 28.23 |
| 19 | 19.66 | 19.68 | 19.70 | 24.15 | 21.67 | 19.30 | 26.12 | 25.92 | 23.82 | 20.77 | 18.93 |
| 22 | 28.4 | 22.11 | 22.37 | 25.92 | 26.33 | 26.92 | 23.35 | 24.67 | 26.27 | 26.8 | 27.10 |
| 24 | 24.65 | 22.33 | 20.47 | 24.88 | 23.94 | 23.44 | 25.79 | 25.59 | 24.89 | 23.79 | 23.42 |
| 20 | 27.49 | 22.01 | 22.15 | 25.74 | 25.82 | 26.11 | 23.50 | 24.79 | 26.05 | 26.17 | 26.25 |
| 26 | 28.69 | 26.39 | 25.23 | 24.47 | 26.94 | 28.10 | 16.66 | 19.3 | 23.57 | 26.44 | 27.77 |
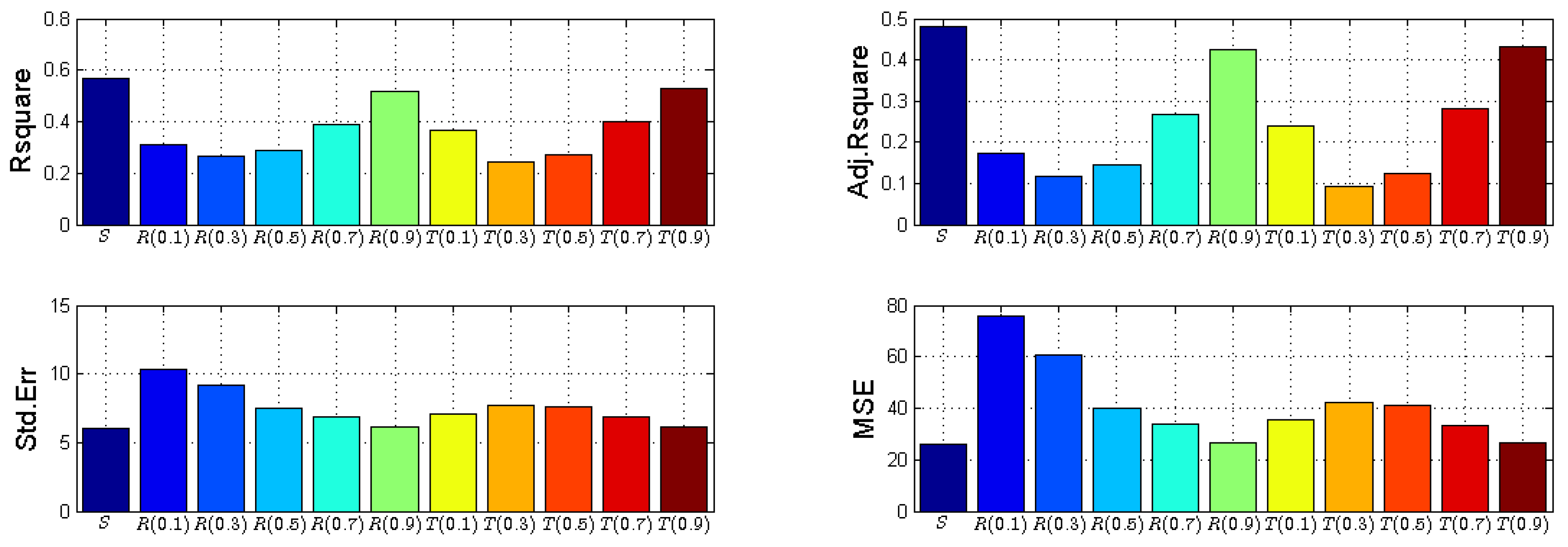
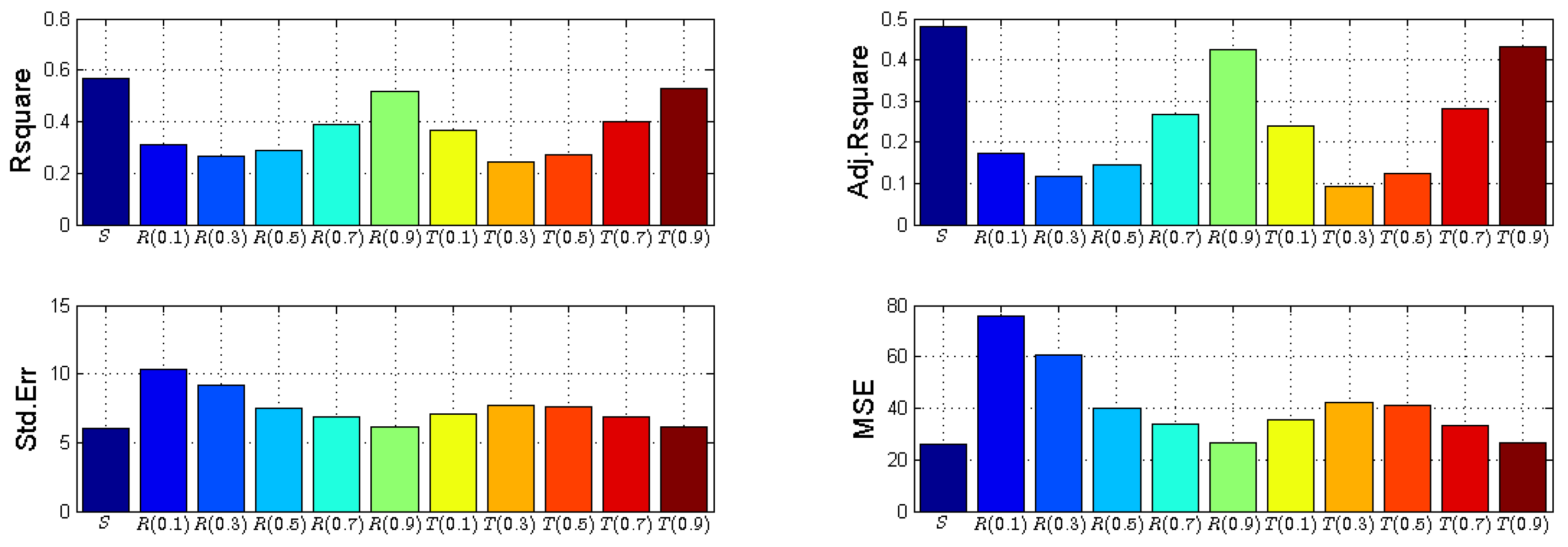
| Entropy | Parameter () | Rsquare | Adj. Rsquare | Std. Err | MSE |
|---|---|---|---|---|---|
| Shannon | - | 0.567 | 0.4804 | 6.0261 | 25.939 |
| Rényi | 0.1 | 0.312 | 0.1744 | 10.2862 | 75.5764 |
| 0.3 | 0.264 | 0.1168 | 9.2305 | 60.8594 | |
| 0.5 | 0.289 | 0.1468 | 7.4598 | 39.7493 | |
| 0.7 | 0.39 | 0.268 | 6.9112 | 34.1185 | |
| 0.9 | 0.52 | 0.424 | 6.131 | 26.8495 | |
| Tsallis | 0.1 | 0.367 | 0.2404 | 7.0405 | 35.4062 |
| 0.3 | 0.244 | 0.0928 | 7.693 | 42.2734 | |
| 0.5 | 0.27 | 0.124 | 7.5623 | 40.8495 | |
| 0.7 | 0.4 | 0.28 | 6.8458 | 33.4757 | |
| 0.9 | 0.527 | 0.4324 | 6.0847 | 26.4462 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gupta, A.; Suri, B.; Kumar, V.; Misra, S.; Blažauskas, T.; Damaševičius, R. Software Code Smell Prediction Model Using Shannon, Rényi and Tsallis Entropies. Entropy 2018, 20, 372. https://doi.org/10.3390/e20050372
Gupta A, Suri B, Kumar V, Misra S, Blažauskas T, Damaševičius R. Software Code Smell Prediction Model Using Shannon, Rényi and Tsallis Entropies. Entropy. 2018; 20(5):372. https://doi.org/10.3390/e20050372
Chicago/Turabian StyleGupta, Aakanshi, Bharti Suri, Vijay Kumar, Sanjay Misra, Tomas Blažauskas, and Robertas Damaševičius. 2018. "Software Code Smell Prediction Model Using Shannon, Rényi and Tsallis Entropies" Entropy 20, no. 5: 372. https://doi.org/10.3390/e20050372
APA StyleGupta, A., Suri, B., Kumar, V., Misra, S., Blažauskas, T., & Damaševičius, R. (2018). Software Code Smell Prediction Model Using Shannon, Rényi and Tsallis Entropies. Entropy, 20(5), 372. https://doi.org/10.3390/e20050372